
Task Allocation of Multiple Unmanned Aerial Vehicles Based on Deep Transfer Reinforcement Learning


Abstract
:1. Introduction
2. Background
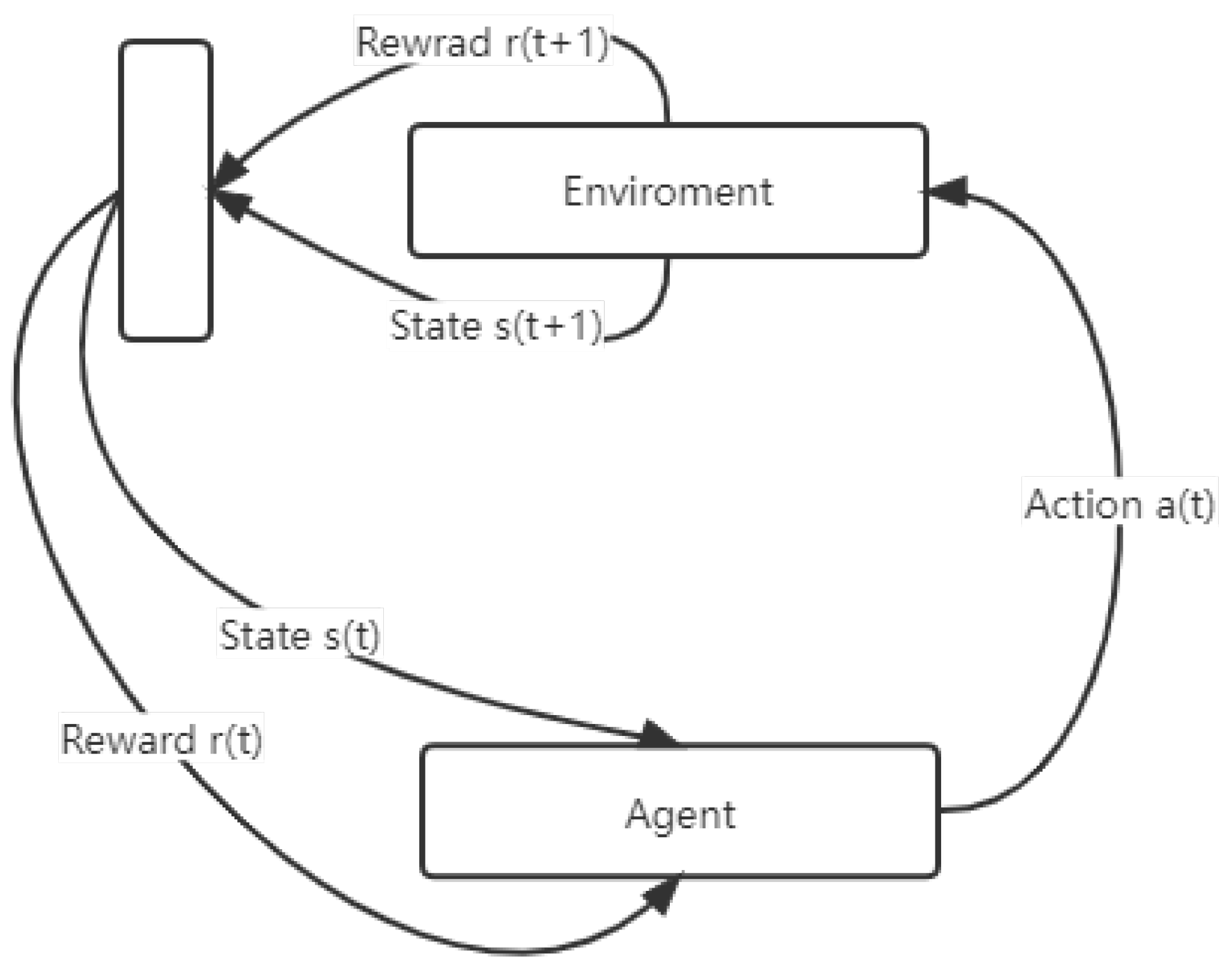
2.1. Reinforcement Learning
2.2. QMIX Algorithm
- Agent network: each agent has to learn an independent value function . The network structure of the agent adopts the DRQN network structure.
- Hybrid network: This part adopts a fully connected network structure, with of each agent as input, and takes the joint action value function as the output.
- Hyperparameter network: This part is mainly responsible for generating the weights of the hybrid network.
2.3. Transfer Learning
- Instance-based transfer learning: Find data in the source domain that are similar to the target domain, adjust the data, and use them for training in the target domain.
- Feature-based transfer learning method: The source domain and the target domain have some similar features. After feature transformation, the source domain and the target domain have the same data distribution.
- Model-based transfer learning method: The target domain and the source domain share the parameters of the model, that is, the model trained with a large amount of data in the source domain is directly applied to the target domain.
- Relation-based transfer learning method: When the target domain is similar to the source domain, their internal connections are also similar. This method transfers the relationship between data in the source domain to the target domain.
3. Problem Description
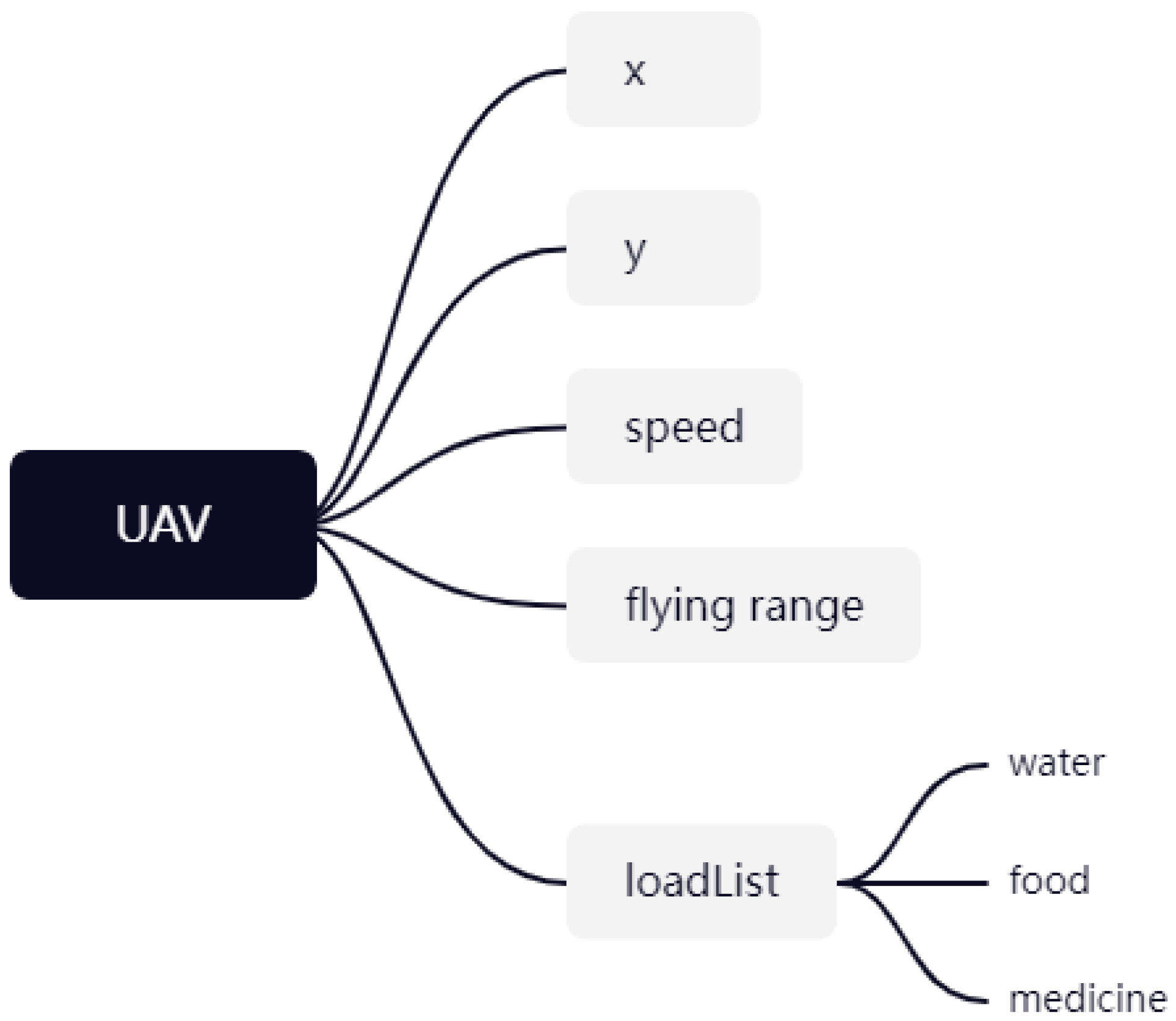
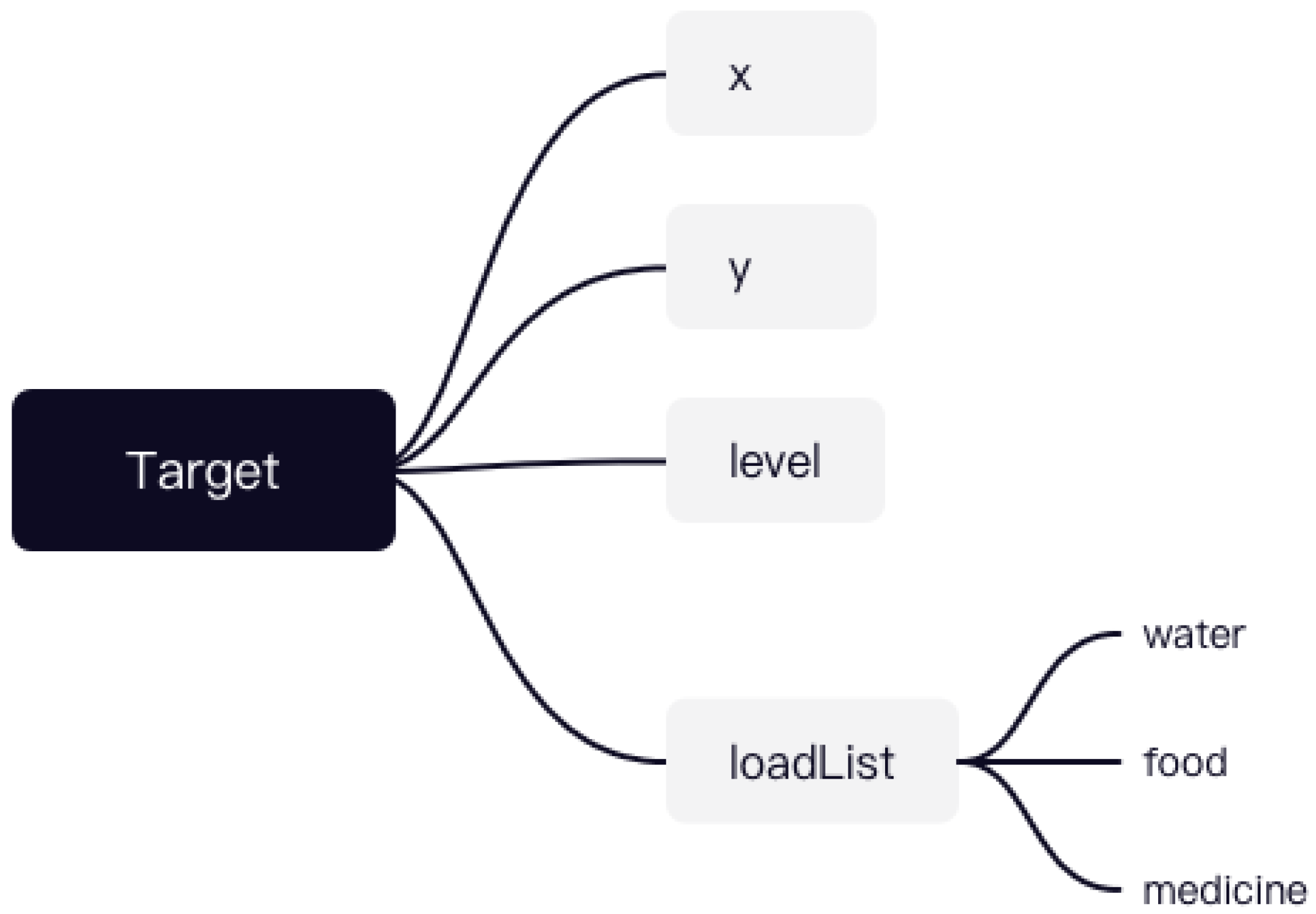
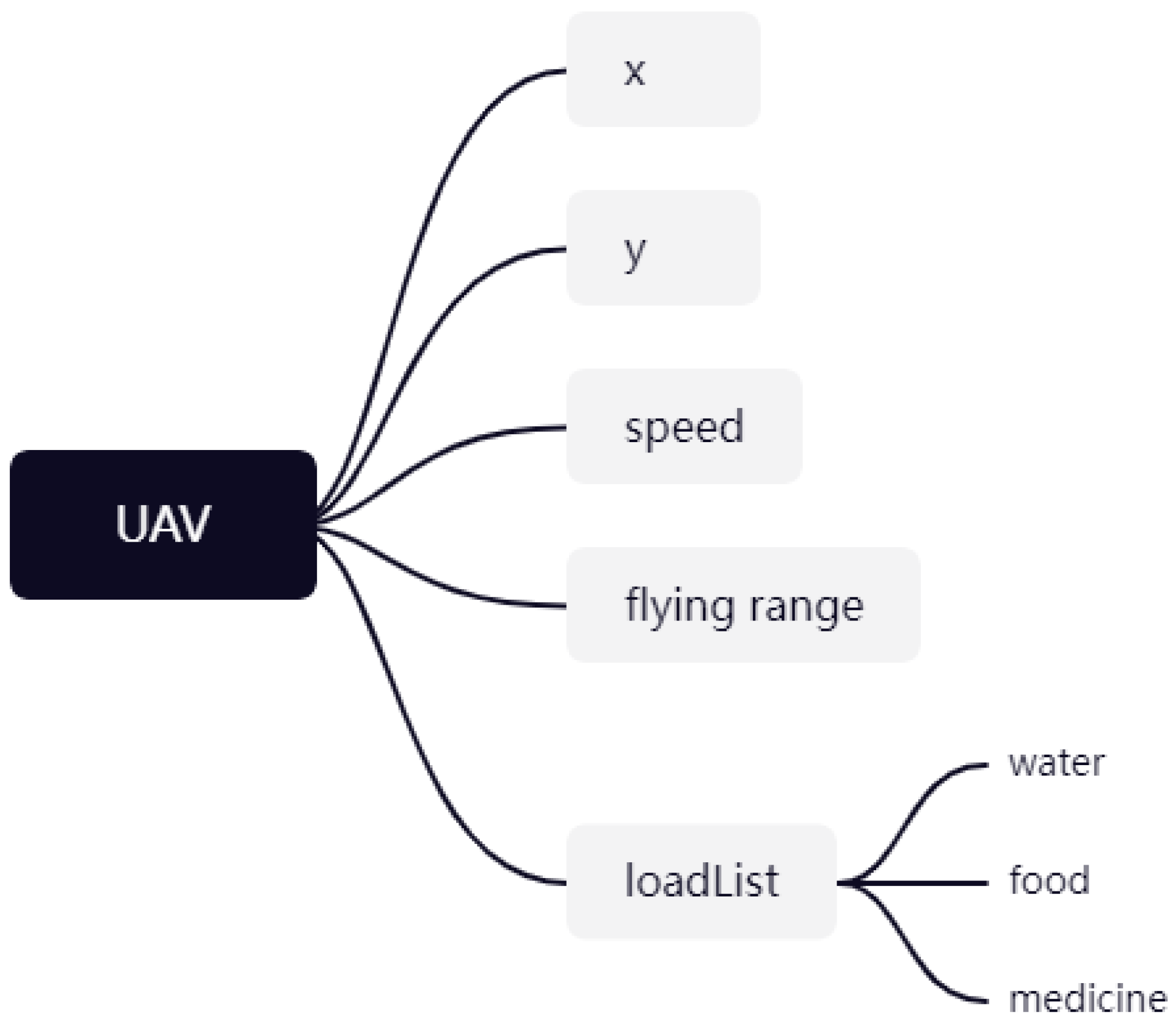
3.1. Simulation Environment Modeling
3.2. MDP Model of Task Allocation
3.2.1. State Space
3.2.2. Observation Space
3.2.3. Action Space
3.2.4. Reward Function
4. Task Assignment Algorithm of Deep Transfer Reinforcement Learning Algorithm Based on QMIX
4.1. DQN-Based Task Assignment Method
4.2. Task Allocation Algorithm Based on QMIX
4.3. Deep Transfer Reinforcement Learning Algorithm Based on QMIX
| Algorithm 1 Task allocation algorithm based on QMIX. |
| Input: UAV swarm information, target point information |
| Output: Agent Network and Mixing Network network parameters |
| 1: Initialize network parameters, data storage unit D, capacity M, total number of iteration rounds T, target network parameter update frequency p |
| 2: whiledo |
| 3: Simulation environment, UAV cluster information, target point information restoration |
| 4: while do |
| 5: Obtain the current mission state S, the observed value O of each UAV and the feasible action A of each UAV from the environment |
| 6: Each drone obtains the Q value of each action taken in the current state through eval netwrok |
| 7: Choose an action based on the resulting Q value |
| 8: Get reward R from the environment based on the actions of all drones in the current state |
| 9: Store , the observed value of each UAV O, the action taken by each UAV A, the feasible action of each UAV U, the reward R, and whether the assigned task is completed , into the data storage unit D |
| 10: if then |
| 11: Randomly sample some data from D |
| 12: Update the network parameters according to the loss function
|
| 13: if then |
| 14: Update the parameters of the target network |
| Algorithm 2 Deep transfer reinforcement learning algorithm based on QMIX. |
| Input: UAV swarm information, target point information, strategy library and its corresponding source task information |
| Output: Task assignment results |
| 1: whiledo |
| 2: Simulation environment, UAV cluster information, target point information restoration |
| 3: Calculate the sum total of the squared differences between the input information and the information corresponding to the ith source task |
| 4: if then |
| 5: |
| 6: |
| 7: Copy the network parameters of the i source task to the network of the new task |
| 8: Execute Algorithm 1, but do not need to initialize the network parameters |
5. Algorithm Verification and Analysis
5.1. Experimental Setup
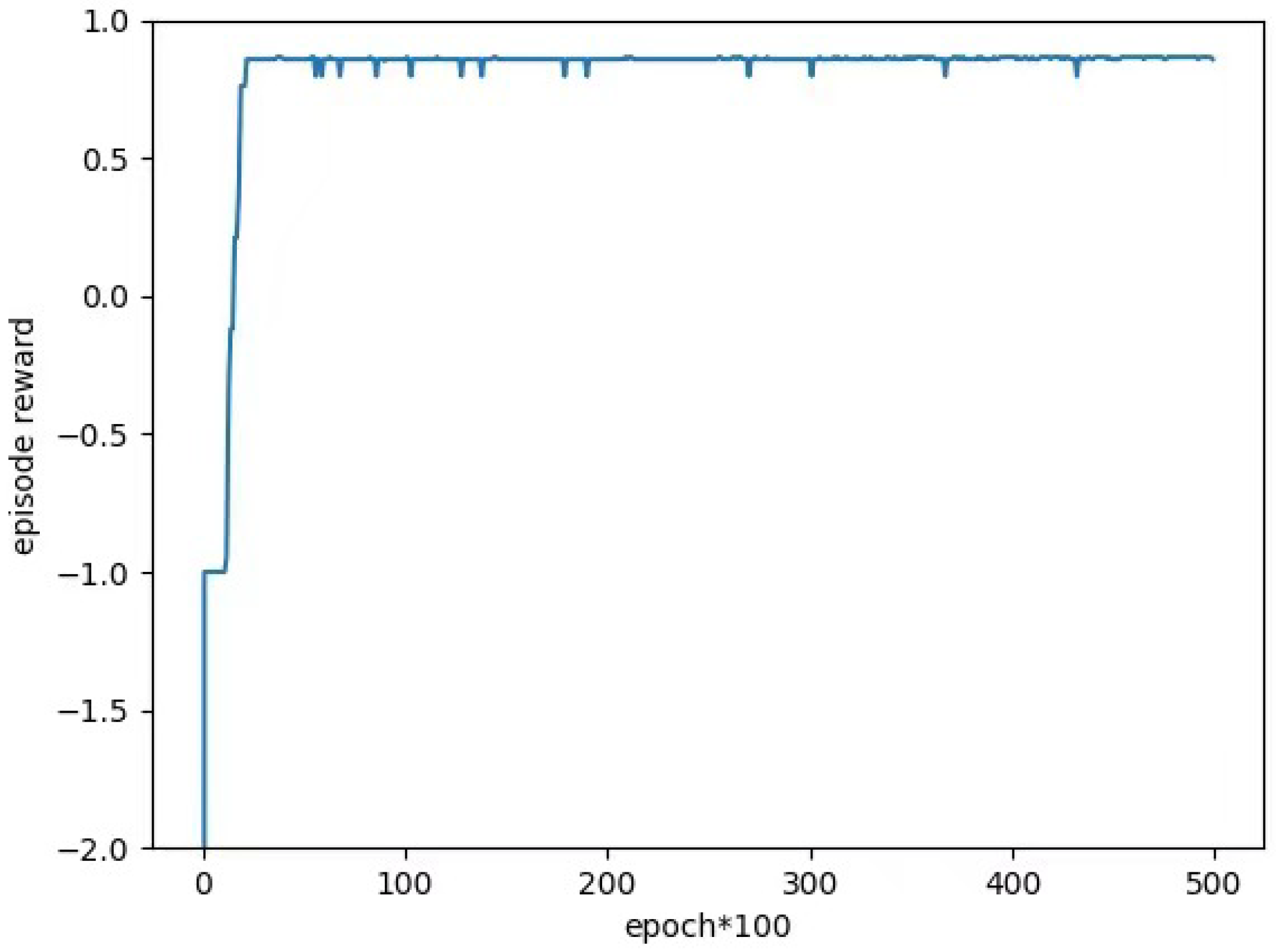
5.2. Experimental Process
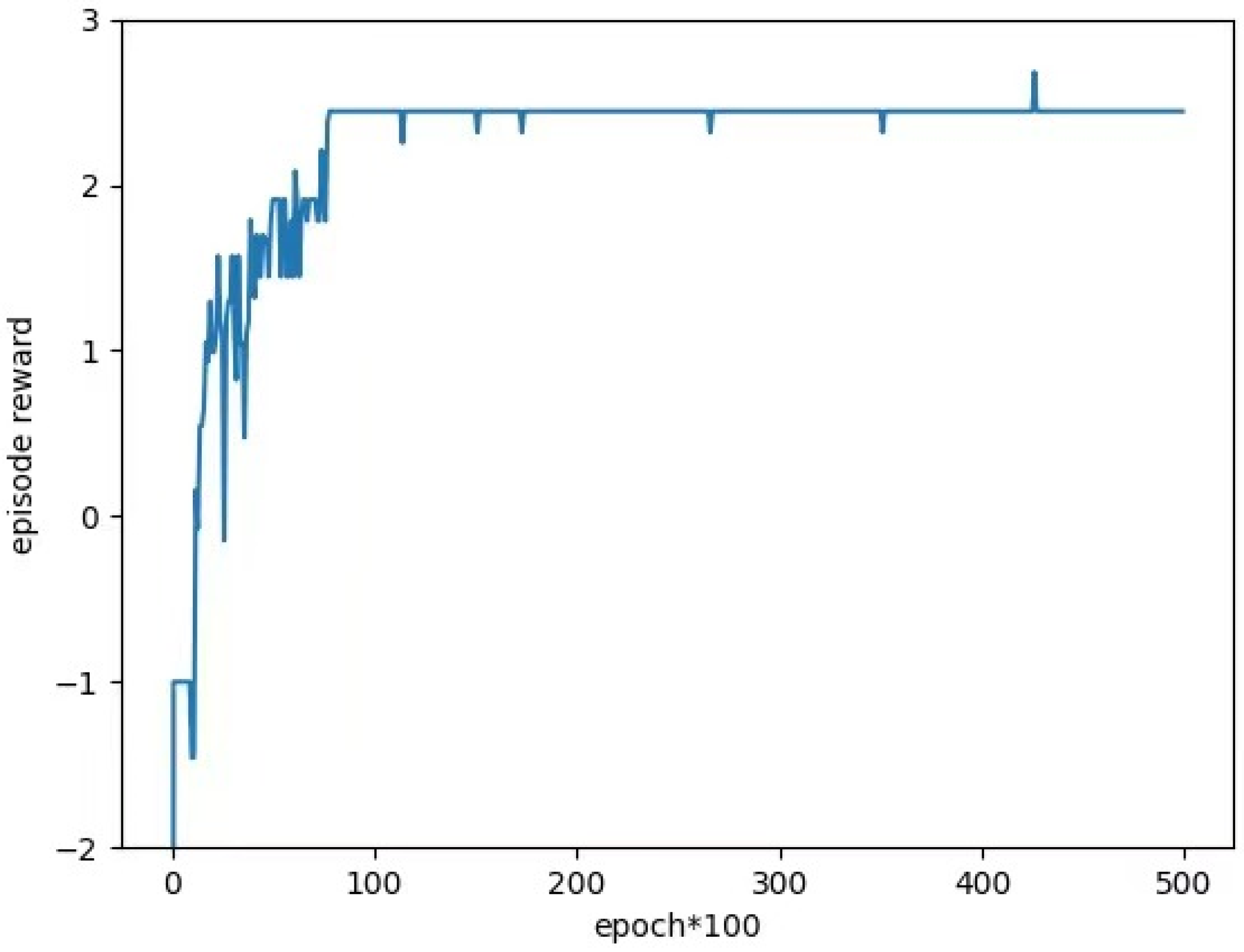
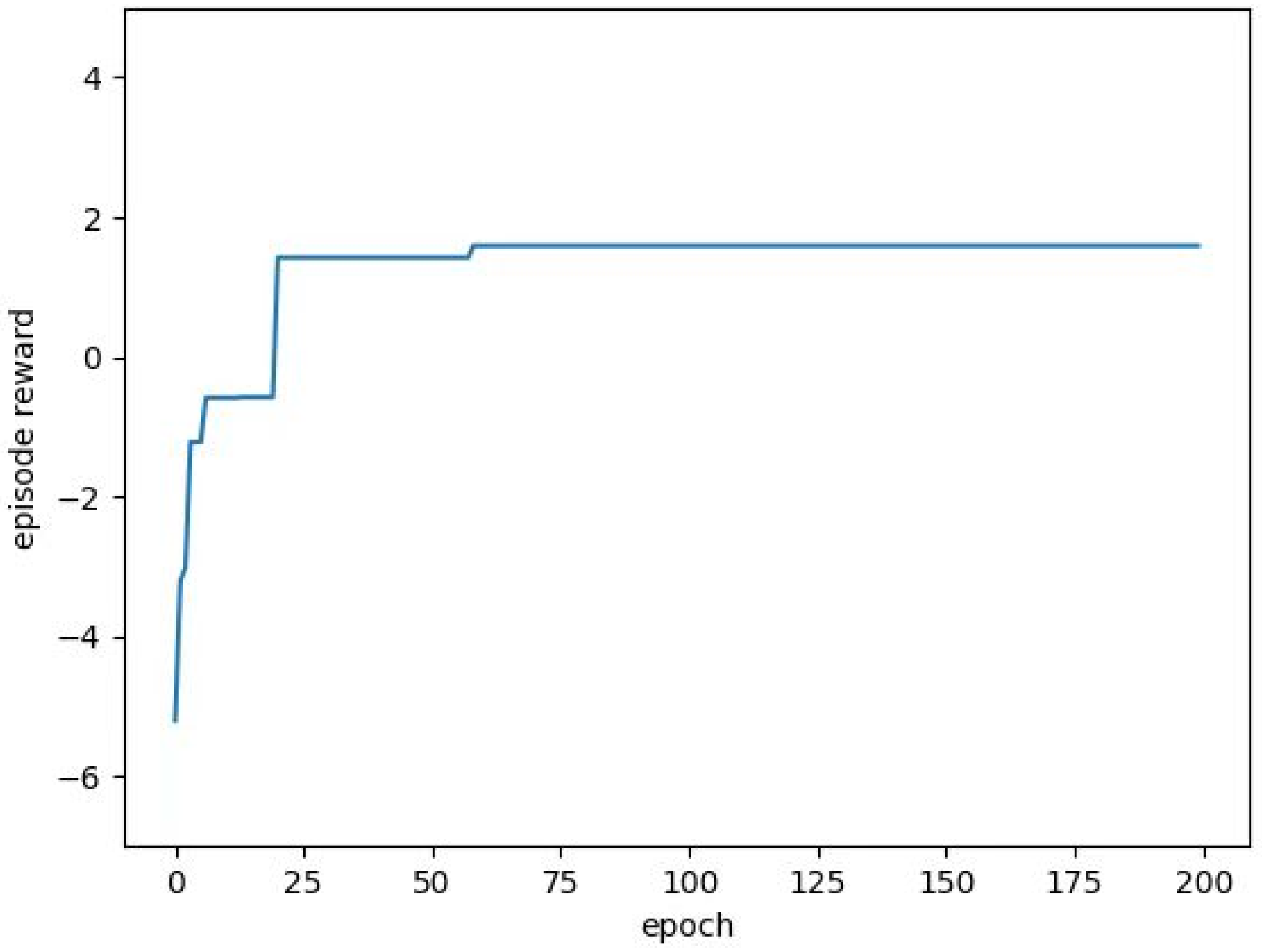
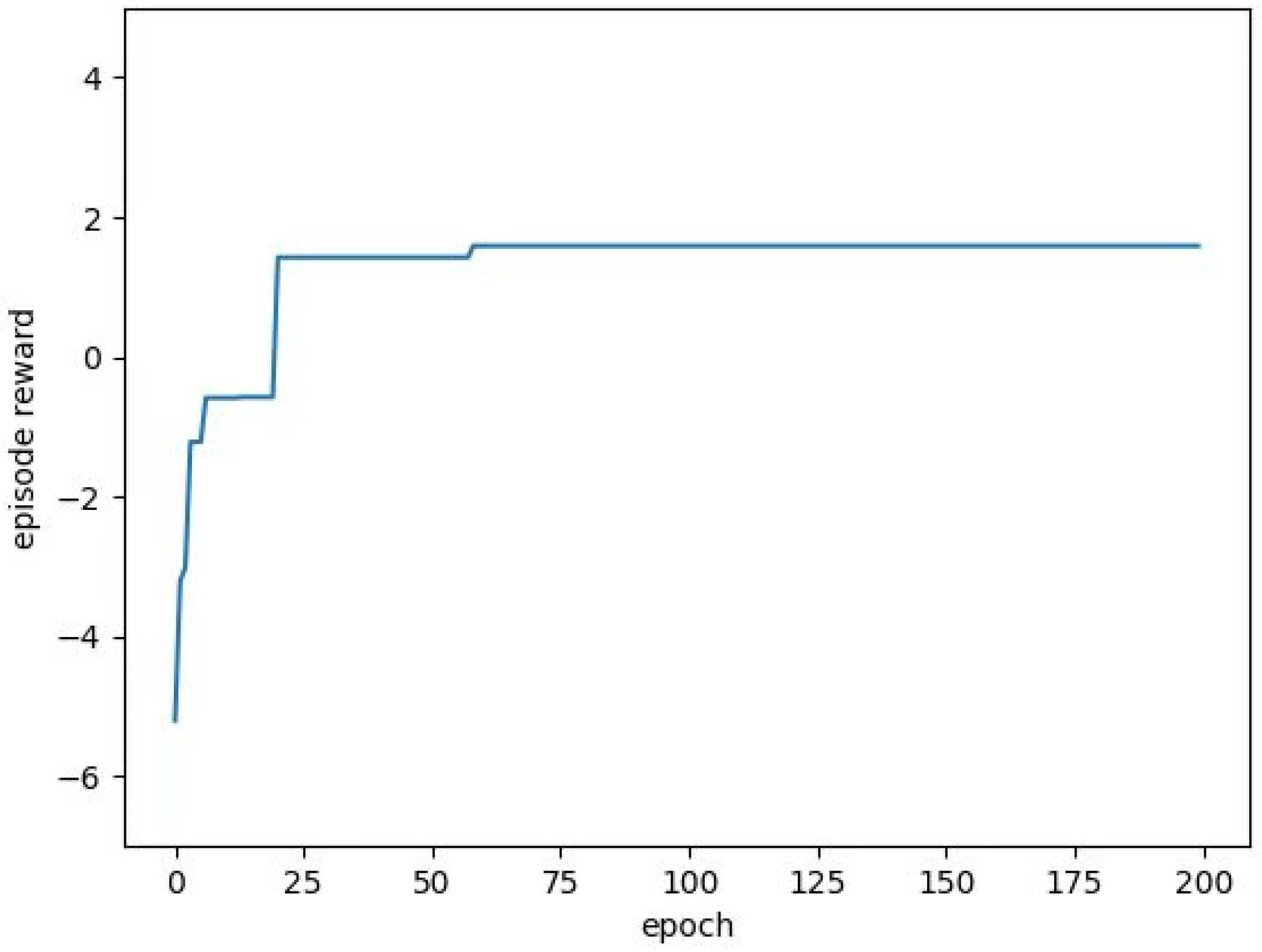
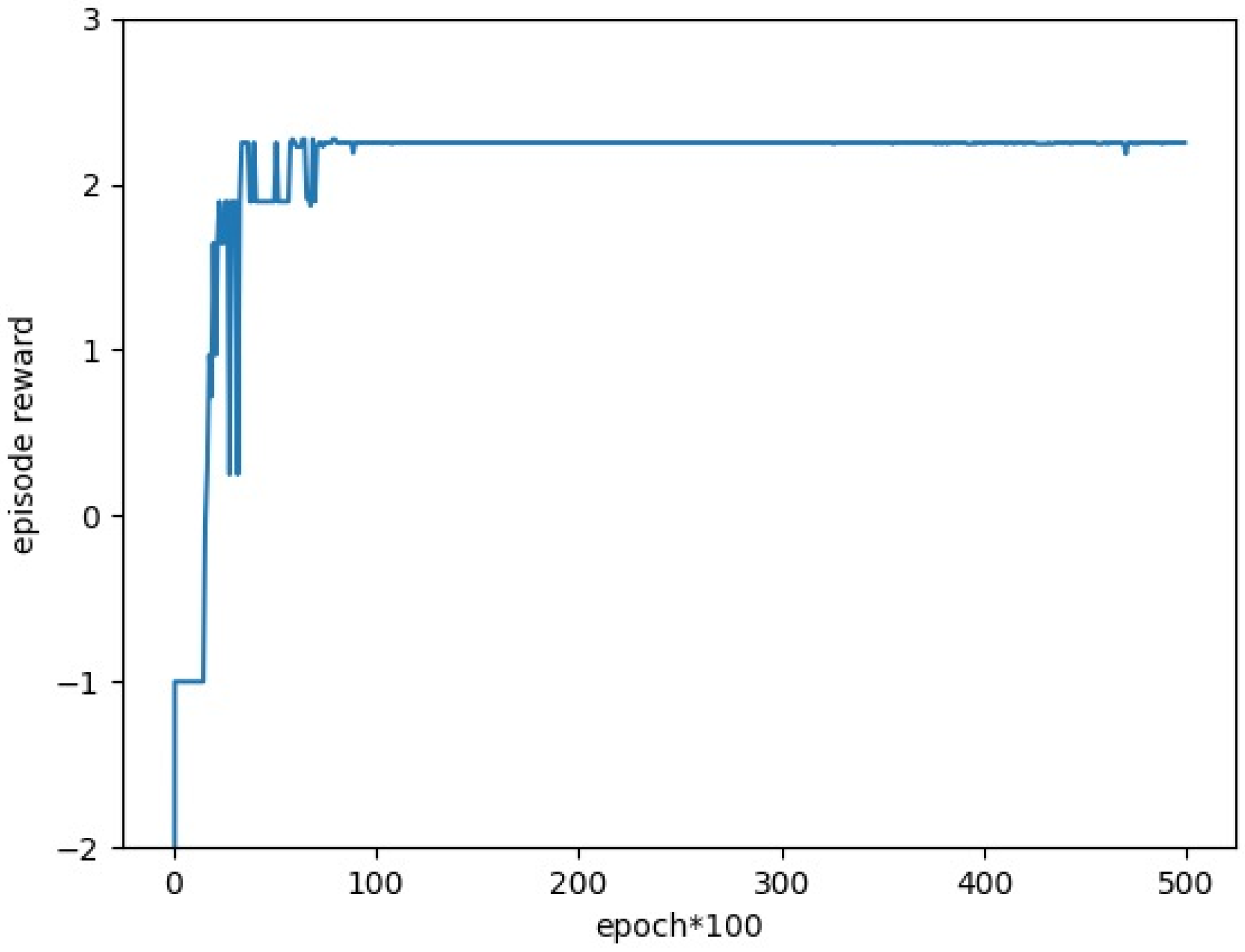
5.2.1. Task Allocation Based on QMIX Algorithm
5.2.2. Task Assignment Based on Genetic Algorithm
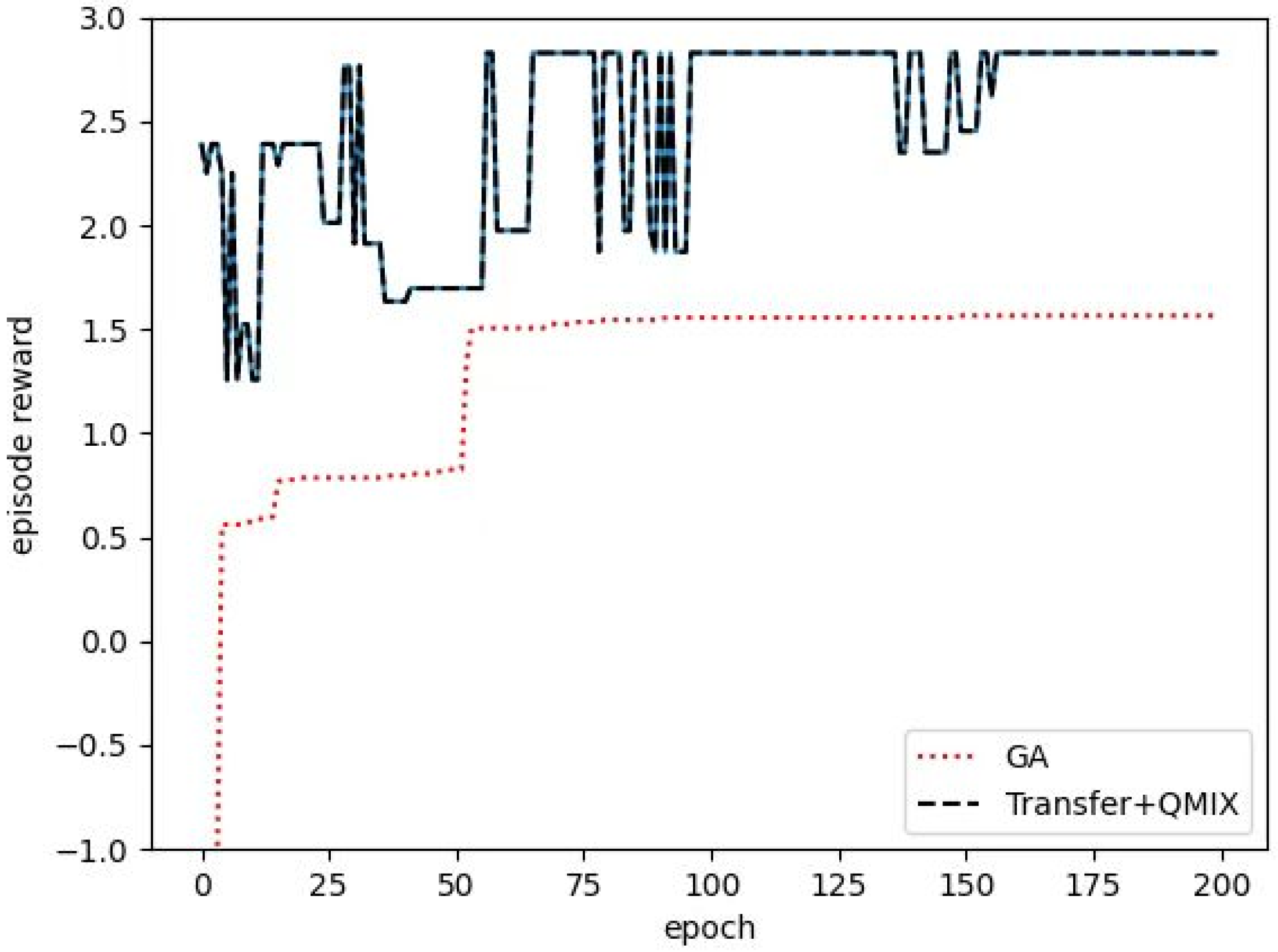
5.2.3. Deep Transfer Reinforcement Learning Algorithm Based on QMIX
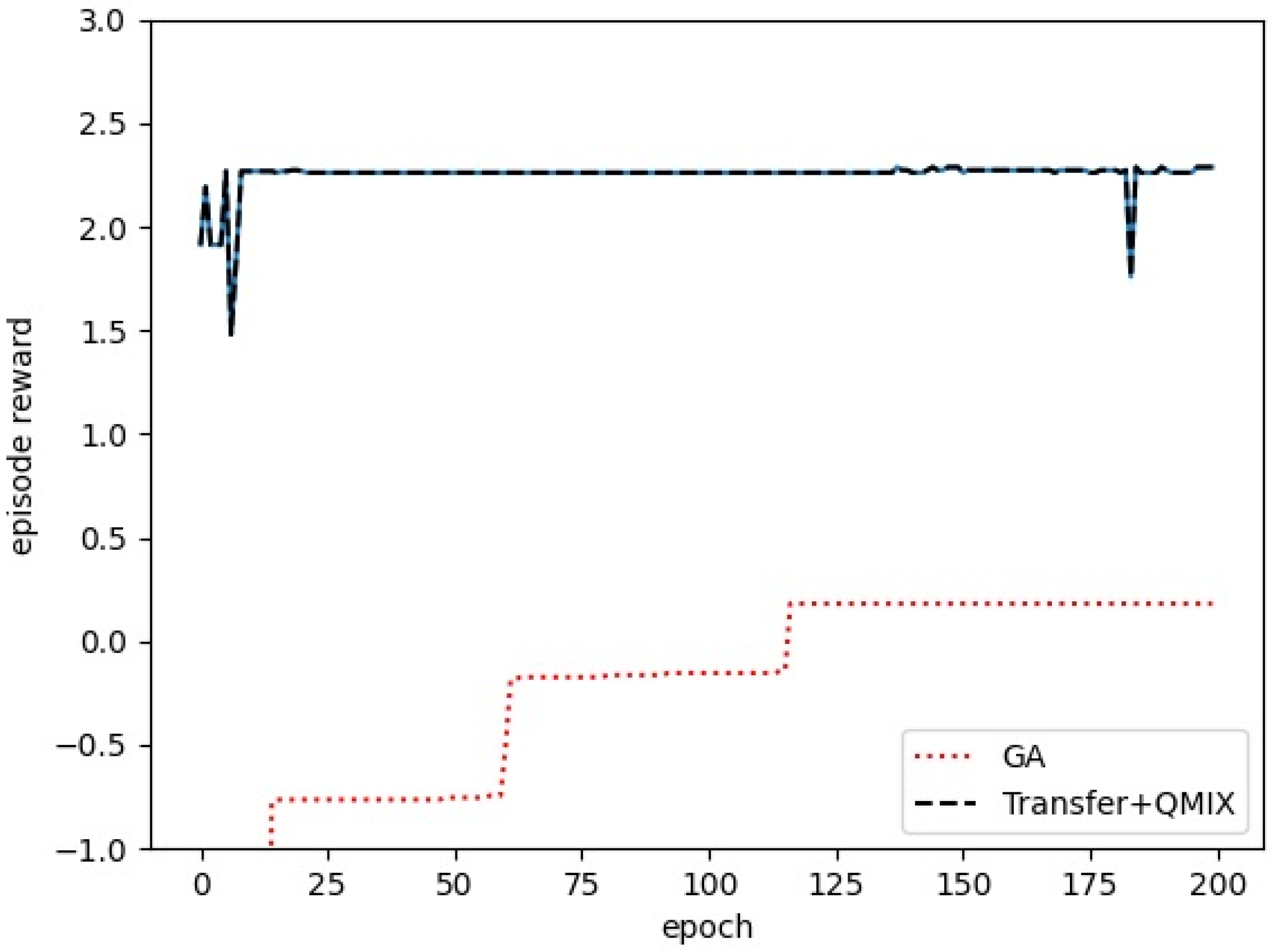
5.2.4. Universal Verification
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Aldao, E.; González-deSantos, L.M.; Michinel, H.; González-Jorge, H. UAV Obstacle Avoidance Algorithm to Navigate in Dynamic Building Environments. Drones 2022, 6, 16. [Google Scholar] [CrossRef]
- Zimroz, P.; Trybała, P.; Wróblewski, A.; Góralczyk, M.; Szrek, J.; Wójcik, A.; Zimroz, R. Application of UAV in search and rescue actions in underground mine—A specific sound detection in noisy acoustic signal. Energies 2021, 14, 3725. [Google Scholar] [CrossRef]
- Steenbeek, A.; Nex, F. CNN-Based Dense Monocular Visual SLAM for Real-Time UAV Exploration in Emergency Conditions. Drones 2021, 6, 79. [Google Scholar] [CrossRef]
- Zhang, R.; Feng, Y.; Yang, Y. Hybrid particle swarm optimization algorithm for cooperative task allocation of multiple UAVs. J. Aeronaut. 2022, 1–15. [Google Scholar]
- Peng, Y.; Duan, H.; Zhang, D.; Wei, C. Dynamic task allocation of UAV cluster imitating gray wolf cooperative predation behavior. Control Theory Appl. 2021, 38, 1855–1862. [Google Scholar]
- Yang, H.; Wang, Q. Multi AUV task allocation method based on dynamic ant colony labor division model. Control. Decis.-Mak. 2021, 36, 1911–1919. [Google Scholar]
- Qin, B.; Zhang, D.; Tang, S.; Wang, M. Distributed Grouping Cooperative Dynamic Task Assignment Method of UAV Swarm. Appl. Sci. 2022, 12, 2865. [Google Scholar] [CrossRef]
- Jiang, S. Research and Simulation of Multi UAV Mission Planning Algorithm in Dynamic Environment; University of Electronic Science and Technology: Chengdu, China, 2021. [Google Scholar]
- Li, Y.; Hu, J. Application and Prospect of reinforcement learning in the field of unmanned vehicles. Inf. Control 2022, 51, 129–141. [Google Scholar]
- Xiang, X.; Yan, C.; Wang, C.; Yin, D. Coordinated control method of fixed wing UAV formation based on deep reinforcement learning. J. Aeronaut. 2021, 42, 420–433. [Google Scholar]
- Huang, H.; Yang, Y.; Wang, H.; Ding, Z.; Sari, H.; Adachi, F. Deep reinforcement learning for UAV navigation through massive MIMO technique. IEEE Trans. Veh. Technol. 2019, 69, 1117–1121. [Google Scholar] [CrossRef] [Green Version]
- Akhloufi, M.A.; Arola, S.; Bonnet, A. Drones Chasing Drones: Reinforcement Learning and Deep Search Area Proposal. Drones 2019, 3, 58. [Google Scholar] [CrossRef] [Green Version]
- Tang, Y.; Tang, X.; Li, C.; Li, X. Dynamic task allocation of multiple unmanned aerial vehicles based on deep reinforcement learning. J. Guangxi Norm. Univ. (Nat. Sci. Ed.) 2021, 39, 63–71. [Google Scholar]
- Zhu, P.; Fang, X. Multi-UAV Cooperative Task As-signment Based on Half Random Q-Learning. Symmetry 2021, 13, 2417. [Google Scholar] [CrossRef]
- Ding, C.; Zheng, Z. A Reinforcement Learning Approach Based on Automatic Policy Amendment for Multi-AUV Task Allocation in Ocean Current. Drones 2022, 6, 141. [Google Scholar] [CrossRef]
- Hu, P.; Pan, Q.; Wu, S.; Ma, J.; Guo, Y. Multi agent system cooperative formation obstacle avoidance and collision avoidance control based on transfer reinforcement learning. In Proceedings of the 2021 China Automation Conference, Zhanjiang, China, 5–7 November 2021. [Google Scholar]
- Shi, H.; Li, J.; Mao, J.; Hwang, K.S. Lateral transfer learning for multiagent reinforcement learning. IEEE Trans. Cybern. 2021. [Google Scholar] [CrossRef] [PubMed]
- Zhuang, F.; Qi, Z.; Duan, K.; Xi, D.; Zhu, Y.; Zhu, H.; Xiong, H.; He, Q. A comprehensive survey on transfer learning. Proc. IEEE 2020, 109, 43–76. [Google Scholar] [CrossRef]
- Rashid, T.; Samvelyan, M.; Schroeder, C.; Farquhar, G.; Foerster, J.; Whiteson, S. Qmix: Monotonic value function factorisation for deep mul-ti-agent reinforcement learning. Int. Conf. Mach. Learn. 2018. Available online: https://arxiv.org/abs/2003.08839 (accessed on 27 July 2022).
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing atari with deep reinforcement learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Value |
|---|---|
| seed | 123 |
| n_epochs | 50,000 |
| evaluate_per_epoch | 100 |
| batch_size | 32 |
| buffer_size | 100 |
| update_target_params | 200 |
| drqn_hidden_dim | 64 |
| qmix_hidden_dim | 32 |
| Name | Value |
|---|---|
| seed | 123 |
| num_total | 30 |
| iteration | 200 |
| max_step | 5 |
| Name | Value |
|---|---|
| seed | 123 |
| n_epochs | 200 |
| evaluate_per_epoch | 1 |
| batch_size | 32 |
| buffer_size | 100 |
| update_target_params | 200 |
| drqn_hidden_dim | 64 |
| qmix_hidden_dim | 32 |
| Algorithm | Running Time/s |
|---|---|
| Genetic algorithm | 6 |
| QMIX algorithm | 120 |
| Algorithm in this paper | 8 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yin, Y.; Guo, Y.; Su, Q.; Wang, Z. Task Allocation of Multiple Unmanned Aerial Vehicles Based on Deep Transfer Reinforcement Learning. Drones 2022, 6, 215. https://doi.org/10.3390/drones6080215
Yin Y, Guo Y, Su Q, Wang Z. Task Allocation of Multiple Unmanned Aerial Vehicles Based on Deep Transfer Reinforcement Learning. Drones. 2022; 6(8):215. https://doi.org/10.3390/drones6080215
Chicago/Turabian StyleYin, Yongfeng, Yang Guo, Qingran Su, and Zhetao Wang. 2022. "Task Allocation of Multiple Unmanned Aerial Vehicles Based on Deep Transfer Reinforcement Learning" Drones 6, no. 8: 215. https://doi.org/10.3390/drones6080215
APA StyleYin, Y., Guo, Y., Su, Q., & Wang, Z. (2022). Task Allocation of Multiple Unmanned Aerial Vehicles Based on Deep Transfer Reinforcement Learning. Drones, 6(8), 215. https://doi.org/10.3390/drones6080215