Figure 1.
Ground Truth and Bounding Box.
Figure 1.
Ground Truth and Bounding Box.
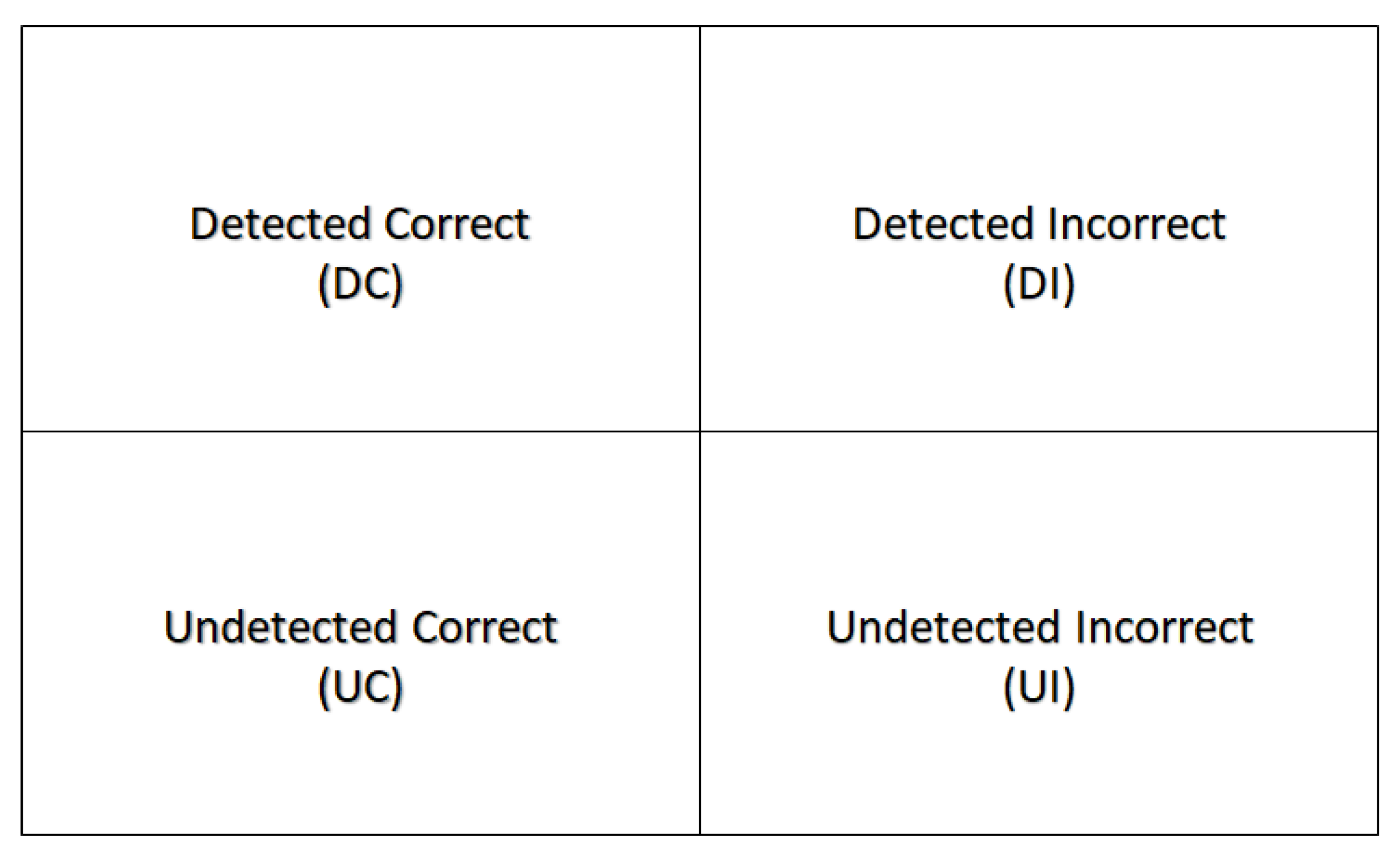
Figure 2.
Classification of Items in a Detection.
Figure 2.
Classification of Items in a Detection.
Figure 3.
Pinhole camera model.
Figure 3.
Pinhole camera model.
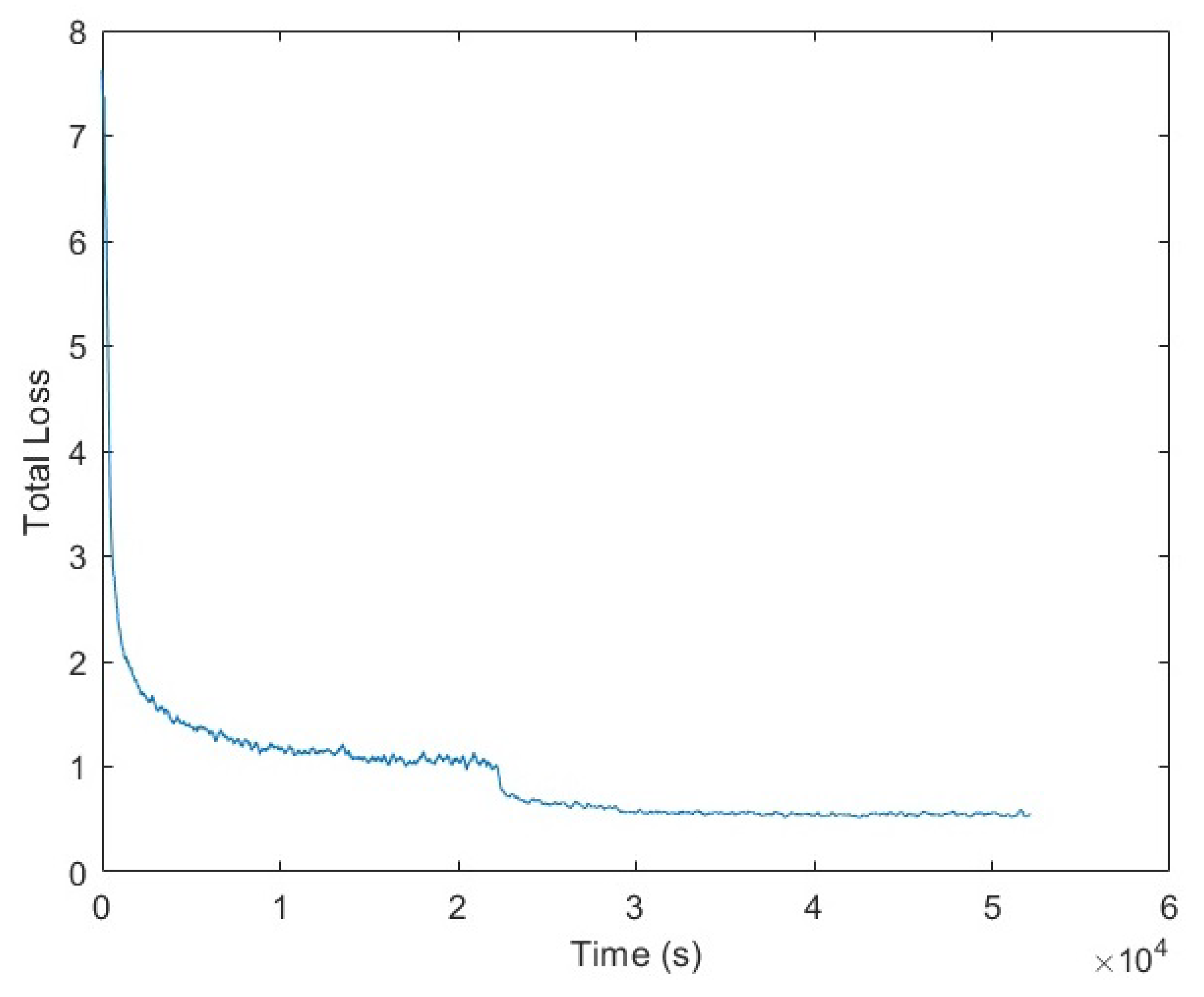
Figure 4.
SSD MobileNet v1 Total Loss.
Figure 4.
SSD MobileNet v1 Total Loss.
Figure 5.
YOLO v2 Total Loss.
Figure 5.
YOLO v2 Total Loss.
Figure 6.
White curtain backdrop: unrectified (left), rectified (right).
Figure 6.
White curtain backdrop: unrectified (left), rectified (right).
Figure 7.
Complex scene backdrop: unrectified (left), rectified (right).
Figure 7.
Complex scene backdrop: unrectified (left), rectified (right).
Figure 8.
Body-fixed frames defined within the Vicon motion capture system.
Figure 8.
Body-fixed frames defined within the Vicon motion capture system.
Figure 9.
Relative depth estimation: Vicon versus camera-based calculations.
Figure 9.
Relative depth estimation: Vicon versus camera-based calculations.
Figure 10.
Examples of Accurate Bounding Box.
Figure 10.
Examples of Accurate Bounding Box.
Figure 11.
Examples of Loose Bounding Box.
Figure 11.
Examples of Loose Bounding Box.
Figure 12.
Examples of Wrong Bounding Box.
Figure 12.
Examples of Wrong Bounding Box.
Table 1.
Processing Computer Specifications.
Table 1.
Processing Computer Specifications.
| Component | Specification |
|---|
| CPU | Intel I7-8700K @ 3.70 GHz |
| RAM | 32 GB DDR4-2666 MHz |
| GPU | Nvidia GTX 1080 Ti |
| Storage | 2TB HDD 7200 rpm |
Table 2.
TensorFlow Object Detection API Training Settings.
Table 2.
TensorFlow Object Detection API Training Settings.
| API Name | Steps | Batch Size | Training Time (h) | Converged Total Loss |
|---|
| SSD MobileNet v1 | 200 k | 42 | 37.67 | 2.00 |
| SSD Inception v2 | 200 k | 24 | 21.43 | 2.00 |
| Faster RCNN Inception v2 | 200 k | 1 | 5.6 | 0.05 |
Table 3.
Darknet Object Detection API Training Settings.
Table 3.
Darknet Object Detection API Training Settings.
| API Name | Steps | Batch Size | Sub Division | Training Time (h) | Converged Total Loss |
|---|
| YOLO v2 | 45000 | 64 | 8 | 14.5 | 0.55 |
| Tiny YOLO | 40200 | 64 | 4 | 9.33 | 0.93 |
Table 4.
Object Detection Systems Speed Comparison.
Table 4.
Object Detection Systems Speed Comparison.
| Object Detection API | Speed in Linux (fps) | Speed in ROS (fps) |
|---|
| SSD MobileNet v1 | 188.35 | 2.72 |
| SSD Inception v2 | 107.32 | 1.98 |
| Faster RCNN v2 | 21.25 | 1.97 |
| YOLO v2 | 71.11 | 67.30 |
| Tiny YOLO | 140.51 | 73.80 |
Table 5.
Difference of TensorFlow Detection Results on Rectified and Unrectified Videos.
Table 5.
Difference of TensorFlow Detection Results on Rectified and Unrectified Videos.
| API | x (%) | y (%) | z (%) | Avg. (%) |
|---|
| SSD MobileNet v1 | 6.21 | 18.42 | 72.11 | 36.30 |
| SSD Inception v2 | 3.85 | 25.74 | 73.59 | 35.70 |
| Faster RCNN Inception v2 | 127 | 14.95 | 56.08 | 68.24 |
Table 6.
Difference of YOLO v2 Performance for Rectified (R) and Unrectified (U) images in Training (T) and Video (V).
Table 6.
Difference of YOLO v2 Performance for Rectified (R) and Unrectified (U) images in Training (T) and Video (V).
| Setup | x (%) | y (%) | z (%) | Avg. (%) |
|---|
| UT/UV vs. UT/RV | 3.92 | 18.83 | 40.45 | 24.8 |
| RT/ UV vs. RT/RV | 16.51 | 28.68 | 4.61 | 15.09 |
| UT/UV vs. RT/RV | −1.90 | 18.05 | 3.06 | 6.40 |
Table 7.
RMS Errors for side and height flights over white background, UT/UV setup.
Table 7.
RMS Errors for side and height flights over white background, UT/UV setup.
| Detection System | x (cm) | y (cm) | z (cm) | Avg. (cm) |
|---|
| SSD MobileNet v1 | 12.08 | 9.84 | 37.21 | 19.71 |
| SSD Inception v2 | 11.43 | 8.00 | 23.57 | 14.33 |
| Faster RCNN Inception v2 | 11.33 | 7.76 | 19.96 | 13.02 |
| YOLO v2 | 12.37 | 6.48 | 19.35 | 12.73 |
Table 8.
RMS Errors for side and height flights over white background, RT/RV setup.
Table 8.
RMS Errors for side and height flights over white background, RT/RV setup.
| Detection System | x (cm) | y (cm) | z (cm) | Avg. (cm) |
|---|
| YOLO v2 | 11.84 | 7.06 | 20.82 | 13.24 |
| Tiny YOLO | 13.18 | 5.64 | 32.19 | 17.00 |
Table 9.
RMS Errors for side and height flights over complex background, UT/UV setup.
Table 9.
RMS Errors for side and height flights over complex background, UT/UV setup.
| Detection System | x (cm) | y (cm) | z (cm) | Avg. (cm) |
|---|
| SSD MobileNet v1 | 11.69 | 15.93 | 18.88 | 15.50 |
| SSD Inception v2 | 10.62 | 14.70 | 8.58 | 11.30 |
| Faster RCNN Inception v2 | 16.81 | 9.14 | 32.41 | 19.45 |
| YOLO v2 | 15.01 | 11.39 | 40.19 | 22.20 |
Table 10.
RMS Errors for side and height flights over complex background, RT/RV setup.
Table 10.
RMS Errors for side and height flights over complex background, RT/RV setup.
| Detection System | x (cm) | y (cm) | z (cm) | Avg. (cm) |
|---|
| YOLO v2 | 47.72 | 19.82 | 37.53 | 35.02 |
| Tiny YOLO | 14.96 | 10.15 | 44.15 | 23.09 |
Table 11.
RMS Errors for depth flights over white background, UT/UV setup.
Table 11.
RMS Errors for depth flights over white background, UT/UV setup.
| Detection System | x (cm) | y (cm) | z (cm) | Avg. (cm) |
|---|
| SSD MobileNet v1 | 12.86 | 6.86 | 30.44 | 16.72 |
| SSD Inception v2 | 12.52 | 4.78 | 21.02 | 12.77 |
| Faster RCNN Inception v2 | 11.61 | 5.42 | 17.23 | 11.42 |
| YOLO v2 | 12.45 | 4.28 | 17.25 | 11.33 |
Table 12.
RMS Errors for depth flights over white background, RT/RV setup.
Table 12.
RMS Errors for depth flights over white background, RT/RV setup.
| Detection System | x (cm) | y (cm) | z (cm) | Avg. (cm) |
|---|
| YOLO v2 | 12.04 | 4.95 | 18.89 | 11.96 |
| Tiny YOLO | 11.80 | 3.75 | 20.27 | 11.94 |
Table 13.
RMS Errors for depth flights over complex background, UT/UV setup.
Table 13.
RMS Errors for depth flights over complex background, UT/UV setup.
| Detection System | x (cm) | y (cm) | z (cm) | Avg. (cm) |
|---|
| SSD MobileNet v1 | 7.65 | 16.18 | 22.70 | 15.51 |
| SSD Inception v2 | 7.50 | 13.10 | 17.15 | 12.58 |
| Faster RCNN Inception v2 | 11.33 | 7.21 | 25.69 | 14.75 |
| YOLO v2 | 15.17 | 10.20 | 37.67 | 21.01 |
Table 14.
RMS Errors for depth flights over complex background, RT/RV setup.
Table 14.
RMS Errors for depth flights over complex background, RT/RV setup.
| Detection System | x (cm) | y (cm) | z (cm) | Avg. (cm) |
|---|
| YOLO v2 | 39.73 | 24.05 | 41.10 | 34.96 |
| Tiny YOLO | 15.04 | 12.23 | 59.65 | 29.98 |
Table 15.
RMS Errors for rotation flights over white background, UT/UV setup.
Table 15.
RMS Errors for rotation flights over white background, UT/UV setup.
| Detection System | x (cm) | y (cm) | z (cm) | Avg. (cm) |
|---|
| SSD MobileNet v1 | 16.38 | 7.02 | 31.43 | 18.28 |
| SSD Inception v2 | 16.49 | 5.21 | 20.28 | 14.00 |
| Faster RCNN Inception v2 | 15.31 | 4.92 | 19.13 | 13.12 |
| YOLO v2 | 15.57 | 4.31 | 18.87 | 12.92 |
Table 16.
RMS Errors for rotation flights over white background, RT/RV setup.
Table 16.
RMS Errors for rotation flights over white background, RT/RV setup.
| Detection System | x (cm) | y (cm) | z (cm) | Avg. (cm) |
|---|
| YOLO v2 | 15.88 | 4.70 | 16.91 | 12.50 |
| Tiny YOLO | 17.15 | 4.08 | 26.44 | 15.89 |
Table 17.
RMS Errors for rotation flights over complex background, UT/UV setup.
Table 17.
RMS Errors for rotation flights over complex background, UT/UV setup.
| Detection System | x (cm) | y (cm) | z (cm) | Avg. (cm) |
|---|
| SSD MobileNet v1 | 14.62 | 14.96 | 15.22 | 14.93 |
| SSD Inception v2 | 13.70 | 11.96 | 19.45 | 15.04 |
| Faster RCNN Inception v2 | 18.90 | 7.01 | 33.84 | 19.91 |
| YOLO v2 | 20.84 | 9.35 | 37.28 | 22.49 |
Table 18.
RMS Errors for rotation flights over complex background, RT/RV setup.
Table 18.
RMS Errors for rotation flights over complex background, RT/RV setup.
| Detection System | x (cm) | y (cm) | z (cm) | Avg. (cm) |
|---|
| YOLO v2 | 34.52 | 11.80 | 37.80 | 28.04 |
| Tiny YOLO | 20.74 | 9.20 | 39.02 | 22.99 |
Table 19.
RMS Errors for trajectory flights over white background, UT/UV setup.
Table 19.
RMS Errors for trajectory flights over white background, UT/UV setup.
| Detection System | x (cm) | y (cm) | z (cm) | Avg. (cm) |
|---|
| SSD MobileNet v1 | 14.69 | 5.67 | 28.91 | 16.42 |
| SSD Inception v2 | 13.78 | 5.12 | 21.68 | 13.53 |
| Faster RCNN Inception v2 | 13.76 | 5.94 | 18.35 | 12.68 |
| YOLO v2 | 14.79 | 3.92 | 15.00 | 11.24 |
Table 20.
RMS Errors for trajectory flights over white background, RT/RV setup.
Table 20.
RMS Errors for trajectory flights over white background, RT/RV setup.
| Detection System | x (cm) | y (cm) | z (cm) | Avg. (cm) |
|---|
| YOLO v2 | 14.46 | 5.43 | 14.96 | 11.62 |
| Tiny YOLO | 14.74 | 3.42 | 19.32 | 12.49 |
Table 21.
RMS Errors for trajectory flights over complex background, UT/UV setup.
Table 21.
RMS Errors for trajectory flights over complex background, UT/UV setup.
| Detection System | x (cm) | y (cm) | z (cm) | Avg. (cm) |
|---|
| SSD MobileNet v1 | 13.62 | 16.51 | 18.92 | 16.35 |
| SSD Inception v2 | 13.18 | 19.17 | 30.49 | 20.95 |
| Faster RCNN Inception v2 | 17.68 | 7.75 | 34.25 | 19.89 |
| YOLO v2 | 15.89 | 7.06 | 52.38 | 25.11 |
Table 22.
RMS Errors for trajectory flights over complex background, RT/RV setup.
Table 22.
RMS Errors for trajectory flights over complex background, RT/RV setup.
| Detection System | x (cm) | y (cm) | z (cm) | Avg. (cm) |
|---|
| YOLO v2 | 44.59 | 29.99 | 44.68 | 39.75 |
| Tiny YOLO | 17.42 | 10.42 | 50.31 | 26.05 |
Table 23.
Average of RMS Errors for Flights, UT/UV Setup.
Table 23.
Average of RMS Errors for Flights, UT/UV Setup.
| Detection System | Simple BG RMSE Avg. (cm) | Complex BG RMSE Avg. (cm) |
|---|
| SSD MobileNet v1 | 17.78 | 15.57 |
| SSD Inception v2 | 13.66 | 14.97 |
| Faster RCNN Inception v2 | 12.56 | 18.50 |
| YOLO v2 | 12.50 | 22.70 |
Table 24.
Average of RMS Errors for Flights, RT/RV Setup.
Table 24.
Average of RMS Errors for Flights, RT/RV Setup.
| Detection System | Simple BG RMSE Avg. (cm) | Complex BG RMSE Avg. (cm) |
|---|
| YOLO v2 | 12.33 | 34.44 |
| Tiny YOLO | 14.33 | 25.27 |
Table 25.
mAP for Side and Height flights, UT/UV Setup.
Table 25.
mAP for Side and Height flights, UT/UV Setup.
| Object Detection System | Simple BG | Complex BG |
|---|
| SSD MobileNet v1 | 0.8442 | 0.8226 |
| SSD Inception v2 | 0.8045 | 0.7259 |
| Faster RCNN Inception v2 | 1.0000 | 0.9555 |
| YOLO v2 | 1.0000 | 0.5151 |
Table 26.
mAP for Side and Height flights, RT/RV Setup.
Table 26.
mAP for Side and Height flights, RT/RV Setup.
| Object Detection System | Simple BG | Complex BG |
|---|
| YOLO v2 | 1.0000 | 0.9525 |
| Tiny YOLO | 0.5559 | 0.7097 |
Table 27.
mAP for Depth flights, UT/UV Setup.
Table 27.
mAP for Depth flights, UT/UV Setup.
| Object Detection System | Simple BG | Complex BG |
|---|
| SSD MobileNet v1 | 0.9277 | 0.6229 |
| SSD Inception v2 | 0.6485 | 0.5726 |
| Faster RCNN Inception v2 | 1.0000 | 0.9739 |
| YOLO v2 | 0.9945 | 0.6578 |
Table 28.
mAP for Depth flights, RT/RV Setup.
Table 28.
mAP for Depth flights, RT/RV Setup.
| Object Detection System | Simple BG | Complex BG |
|---|
| YOLO v2 | 1.0000 | 0.9738 |
| Tiny YOLO | 0.3933 | 0.8603 |
Table 29.
mAP for Rotation flights, UT/UV Setup.
Table 29.
mAP for Rotation flights, UT/UV Setup.
| Object Detection System | Simple BG | Complex BG |
|---|
| SSD MobileNet v1 | 0.9130 | 0.9353 |
| SSD Inception v2 | 0.8477 | 0.8160 |
| Faster RCNN Inception v2 | 1.0000 | 0.9810 |
| YOLO v2 | 1.0000 | 0.4610 |
Table 30.
mAP for Rotation flights, RT/RV Setup.
Table 30.
mAP for Rotation flights, RT/RV Setup.
| Object Detection System | Simple BG | Complex BG |
|---|
| YOLO v2 | 1.0000 | 0.9726 |
| Tiny YOLO | 0.7626 | 0.8270 |
Table 31.
mAP for Trajectory flights, UT/UV Setup.
Table 31.
mAP for Trajectory flights, UT/UV Setup.
| Object Detection System | Simple BG | Complex BG |
|---|
| SSD MobileNet v1 | 0.7921 | 0.8088 |
| SSD Inception v2 | 0.9040 | 0.9137 |
| Faster RCNN Inception v2 | 1.0000 | 0.9520 |
| YOLO v2 | 0.9992 | 0.4643 |
Table 32.
mAP for Trajectory flights, RT/RV Setup.
Table 32.
mAP for Trajectory flights, RT/RV Setup.
| Object Detection System | Simple BG | Complex BG |
|---|
| YOLO v2 | 1.0000 | 0.9302 |
| Tiny YOLO | 0.7034 | 0.7274 |
Table 33.
Average mAP, UT/UV Setup.
Table 33.
Average mAP, UT/UV Setup.
| Object Detection System | Simple BG | Complex BG |
|---|
| SSD MobileNet v1 | 0.8693 | 0.7974 |
| SSD Inception v2 | 0.8012 | 0.7571 |
| Faster RCNN Inception v2 | 1.0000 | 0.9656 |
| YOLO v2 | 0.9984 | 0.5246 |
Table 34.
Average mAP, RT/RV Setup.
Table 34.
Average mAP, RT/RV Setup.
| Object Detection System | Simple BG | Complex BG |
|---|
| YOLO v2 | 1.0000 | 0.9573 |
| Tiny YOLO | 0.6038 | 0.7811 |
Table 35.
Object Detection System Scores over White Background: Efficiency (E), Accuracy (A), Consistency (C).
Table 35.
Object Detection System Scores over White Background: Efficiency (E), Accuracy (A), Consistency (C).
| Object Detection API | E | A | C | Total |
|---|
| SSD MobileNet v1 | 0.54 | 16.29 | 34.77 | 51.61 |
| SSD Inception v2 | 0.40 | 21.79 | 32.05 | 54.23 |
| Faster RCNN v2 | 0.39 | 23.25 | 40.00 | 63.65 |
| YOLO v2 | 13.46 | 23.33 | 39.94 | 76.73 |
| Tiny YOLO | 14.76 | 20.63 | 24.11 | 59.50 |
Table 36.
Object Detection System Scores over Complex Background: Efficiency (E), Accuracy (A), Consistency (C).
Table 36.
Object Detection System Scores over Complex Background: Efficiency (E), Accuracy (A), Consistency (C).
| Object Detection API | E | A | C | Total |
|---|
| SSD MobileNet v1 | 0.54 | 19.24 | 31.90 | 51.68 |
| SSD Inception v2 | 0.40 | 20.04 | 30.28 | 50.72 |
| Faster RCNN v2 | 0.39 | 15.33 | 38.62 | 54.35 |
| YOLO v2 | 13.46 | 9.73 | 20.98 | 44.18 |
| Tiny YOLO | 14.76 | 17.79 | 17.12 | 49.68 |















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}