
Advancing Human Understanding with Deep Learning Go AI Engines †



{kind=link}
Abstract
:1. Introduction
1.1. The Black-Box Nature of Deep Learning AIs
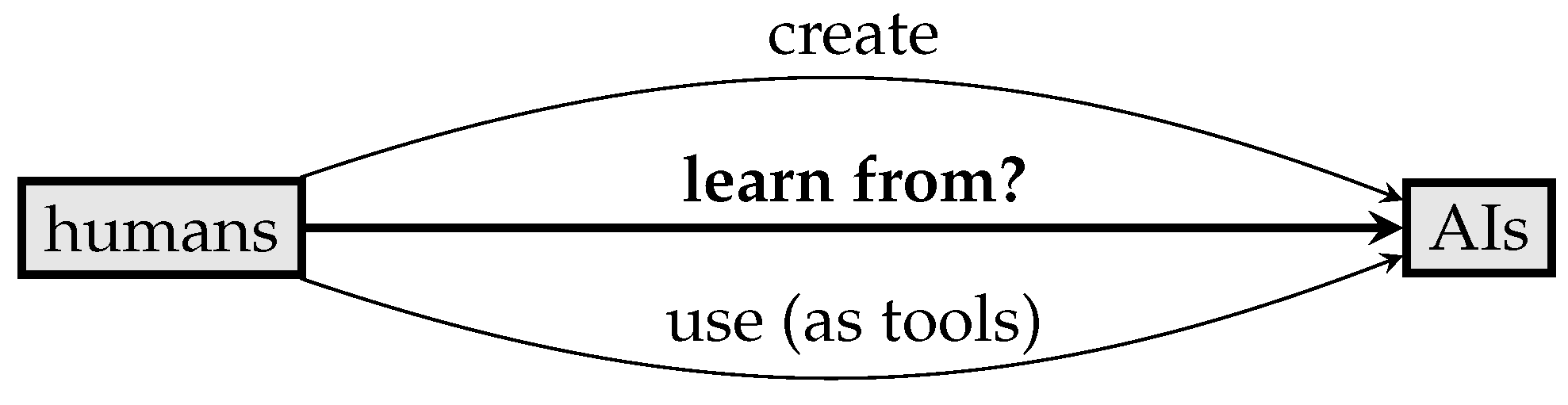
How can we learn from AIs?, i.e., How can we understand a complex problem domain better with access to high-quality statistical patterns?
1.2. AIs and Humans
1.3. AIs and the Go Community
2. Possible Solutions for the Black-Box Problem
- Internal analysis of the neural networks—intelligible intelligence: In deep learning AI systems, unlike in the brain, we have complete access to the whole neural network, down to single neurons. We can uncover the abstract hierarchical representation of Go knowledge inside the network by using feature visualization used for image recognition networks [11]. However, we know that neural networks may or may not have comprehensible representations. The space of possible Go-playing neural networks may have a vanishingly small fraction in human-accessible formats. Despite the difficulties, this work is underway now for chess [12].
- Improve our learning methods: Learning the game at the professional level proceeds from intuitive understanding to explicit verbalizations. In the case of Go, strategic plans are explanations for what is happening on the board. Therefore, the methods of scientific knowledge creation do apply here. Go AIs are inexhaustible sources of experiments providing high-quality statistical data. Growing Go knowledge can be faster by formulating plans when choosing moves rather than just looking up the best move recommended by the AIs.
3. The Requirements of the Teaching–Learning Situation
- The teacher should know more—otherwise, what can we learn?
- The teacher should be able to explain.
- The student should be able to comprehend.
- The AI knows more, as it has superhuman playing strength. This statement might be challenged by a standard argument that neural networks do not ‘know’ anything since they are just big tables of numbers, and the AIs’ thinking is just matrix multiplication. Be it a simple mechanism, its winning record neutralizes ontological complaints.
- The AI does not explain. It only gives probabilities and score estimates.
- How can a student then achieve understanding? It is up to the student to actively create situations where learning is possible.
4. Acting as a Scientist
- Science
- We create explanations and test them by observations, experiments.
- Go
- We create plans based on judgments of the current board position. They are verified or falsified by the opponent, or by the analyzing AI.
5. Game Review as Storytelling
6. Discussion
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Deutsch, D. The Beginning of Infinit: Explanations That Transform the World; Penguin Publishing Group: New York, NY, USA, 2011. [Google Scholar]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep Learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Sutton, R.; Barto, A. Reinforcement Learning: An Introduction, 2nd ed.; Adaptive Computation and Machine Learning Series; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Silver, D.; Schrittwieser, J.; Simonyan, K.; Antonoglou, I.; Huang, A.; Guez, A.; Hubert, T.; Baker, L.; Lai, M.; Bolton, A.; et al. Mastering the game of Go without human knowledge. Nature 2017, 550, 354–359. [Google Scholar] [CrossRef] [PubMed]
- Silver, D.; Hubert, T.; Schrittwieser, J.; Antonoglou, I.; Lai, M.; Guez, A.; Lanctot, M.; Sifre, L.; Kumaran, D.; Graepel, T.; et al. A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play. Science 2018, 362, 1140–1144. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pearl, J.; Mackenzie, D. The Book of Why: The New Science of Cause and Effect; Penguin Books: London, UK, 2018. [Google Scholar]
- Tegmark, M. Life 3.0: Being Human in the Age of Artificial Intelligence; Knopf Doubleday Publishing Group: New York, NY, USA, 2017. [Google Scholar]
- Malone, T. Superminds: The Surprising Power of People and Computers Thinking Together; Little, Brown: Boston, MA, USA, 2018. [Google Scholar]
- Kasparov, G. Deep Thinking: Where Machine Intelligence Ends and Human Creativity Begins; Millennium Series; Hodder & Stoughton: London, UK, 2017. [Google Scholar]
- Egri-Nagy, A.; Törmänen, A. The Game Is Not over Yet—Go in the Post-AlphaGo Era. Philosophies 2020, 5, 37. [Google Scholar] [CrossRef]
- Olah, C.; Mordvintsev, A.; Schubert, L. Feature Visualization. Distill 2017, 2, e7. [Google Scholar] [CrossRef]
- McGrath, T.; Kapishnikov, A.; Tomašev, N.; Pearce, A.; Hassabis, D.; Kim, B.; Paquet, U.; Kramnik, V. Acquisition of Chess Knowledge in AlphaZero. arXiv 2021, arXiv:cs.AI/2111.09259. [Google Scholar]
- Godfrey-Smith, P. Theory and Reality: An Introduction to the Philosophy of Science; Science and Its Conceptual Foundations Series; University of Chicago Press: Chicago, IL, USA, 2009. [Google Scholar]
- Popper, K.; Popper, K. The Logic of Scientific Discovery; ISSR Library, Routledge: London, UK, 2002. [Google Scholar]
- Cron, L. Wired for Story: The Writer’s Guide to Using Brain Science to Hook Readers from the Very First Sentence; Clarkson Potter/Ten Speed: New York, NY, USA, 2012. [Google Scholar]
- Gottschall, J. The Storytelling Animal: How Stories Make Us Human; Houghton Mifflin Harcourt: Boston, MA, USA, 2013. [Google Scholar]
- Storr, W. The Science of Storytelling: Why Stories Make Us Human and How to Tell Them Better; ABRAMS: New York, NY, USA, 2020. [Google Scholar]
- Marletto, C. The Science of Can and Can’t: A Physicist’s Journey Through the Land of Counterfactuals; Penguin Books, Limited: London, UK, 2021. [Google Scholar]
- Davies, A.; Veličković, P.; Buesing, L.; Blackwell, S.; Zheng, D.; Tomašev, N.; Tanburn, R.; Battaglia, P.; Blundell, C.; Juhász, A.; et al. Advancing mathematics by guiding human intuition with AI. Nature 2021, 600, 70–74. [Google Scholar] [CrossRef] [PubMed]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Egri-Nagy, A.; Törmänen, A. Advancing Human Understanding with Deep Learning Go AI Engines. Proceedings 2022, 81, 22. https://doi.org/10.3390/proceedings2022081022
Egri-Nagy A, Törmänen A. Advancing Human Understanding with Deep Learning Go AI Engines. Proceedings. 2022; 81(1):22. https://doi.org/10.3390/proceedings2022081022
Chicago/Turabian StyleEgri-Nagy, Attila, and Antti Törmänen. 2022. "Advancing Human Understanding with Deep Learning Go AI Engines" Proceedings 81, no. 1: 22. https://doi.org/10.3390/proceedings2022081022
APA StyleEgri-Nagy, A., & Törmänen, A. (2022). Advancing Human Understanding with Deep Learning Go AI Engines. Proceedings, 81(1), 22. https://doi.org/10.3390/proceedings2022081022