Using Entropy to Forecast Bitcoin’s Daily Conditional Value at Risk †




Abstract
:1. Introduction
2. Methodology
2.1. Entropy of Symbolic Intraday Logreturns
2.2. Entropy and Daily VaR and CVaR
2.3. Forecasting Model for Daily VaR and CVaR
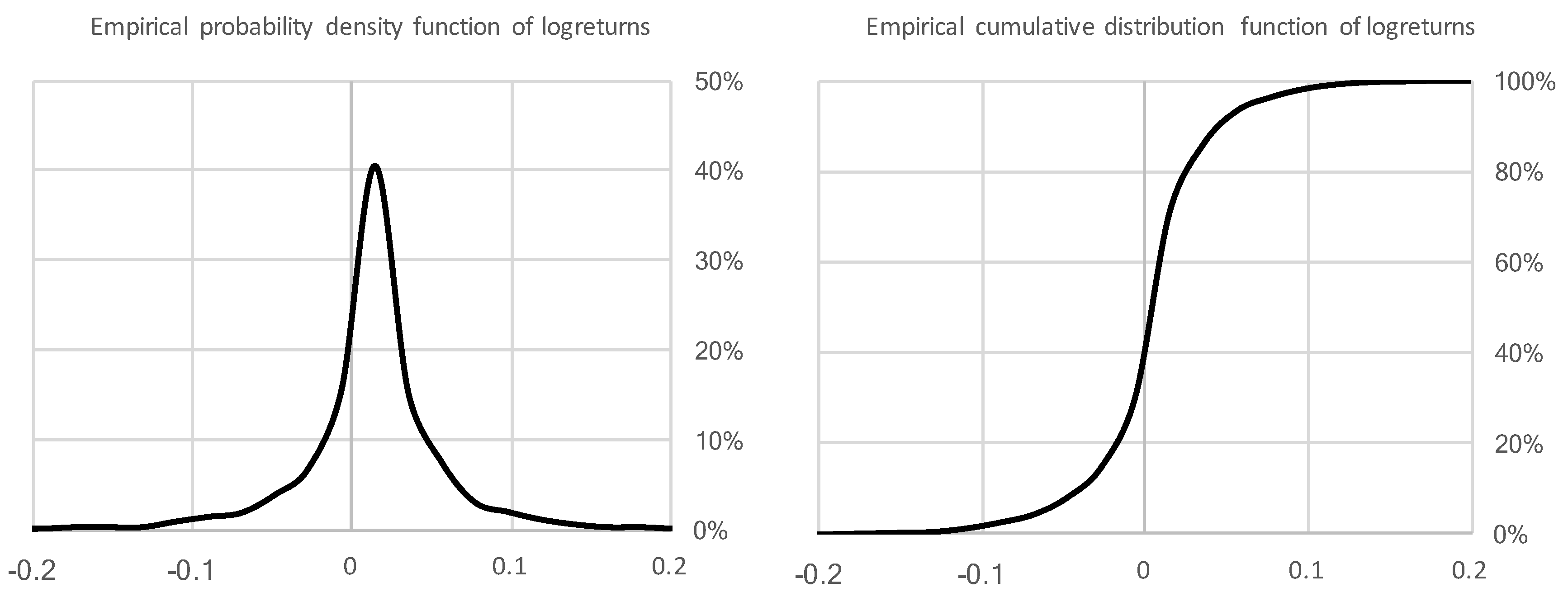
3. Empirical Study
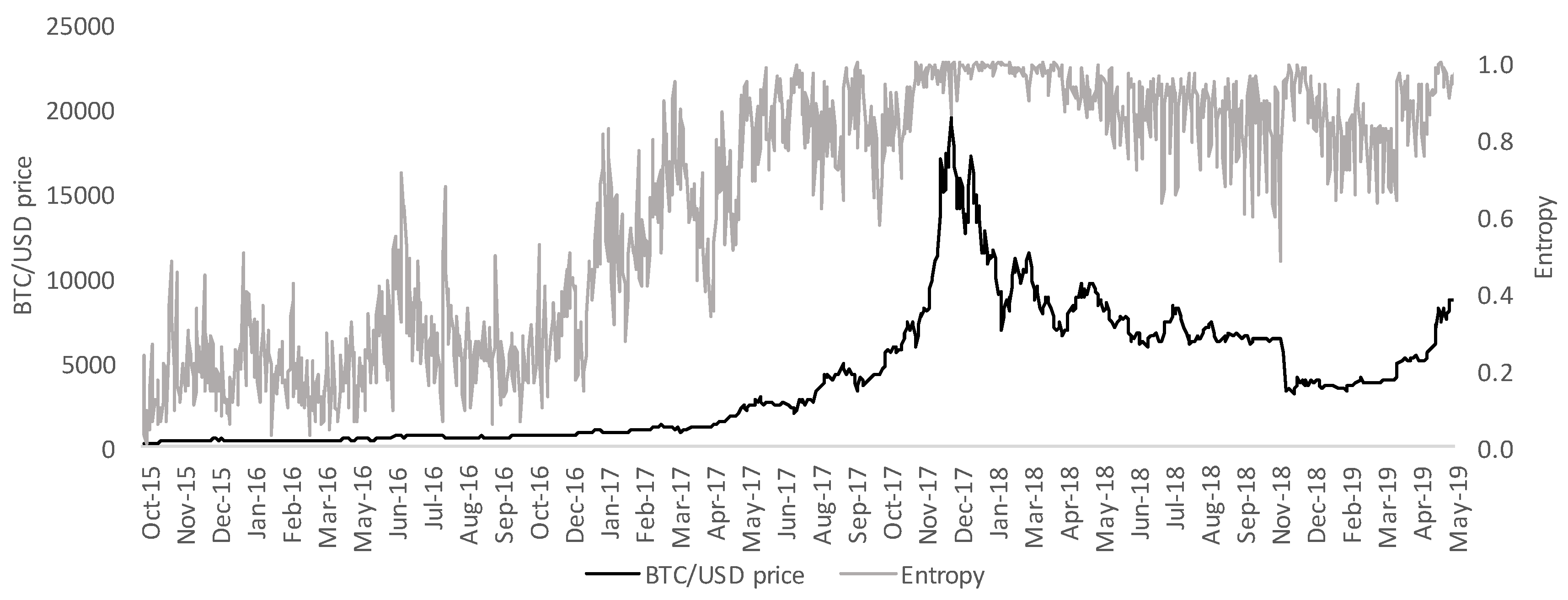
3.1. Bitcoin
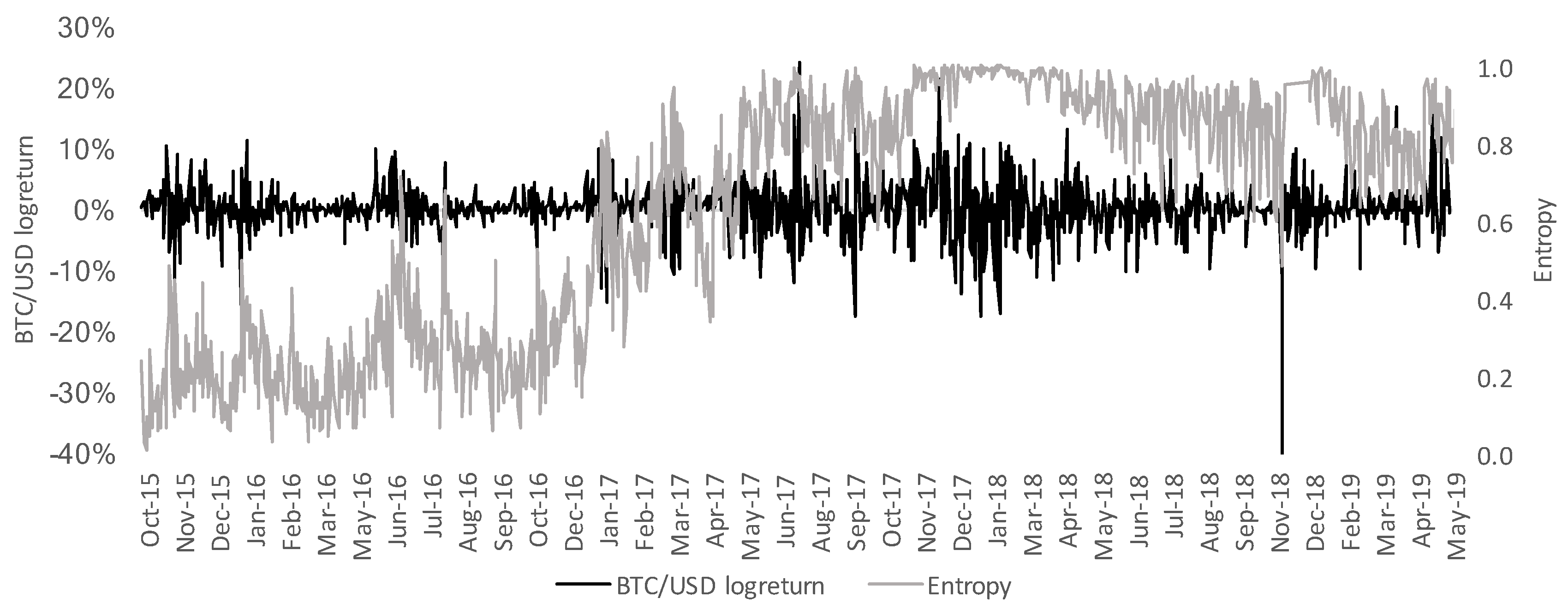
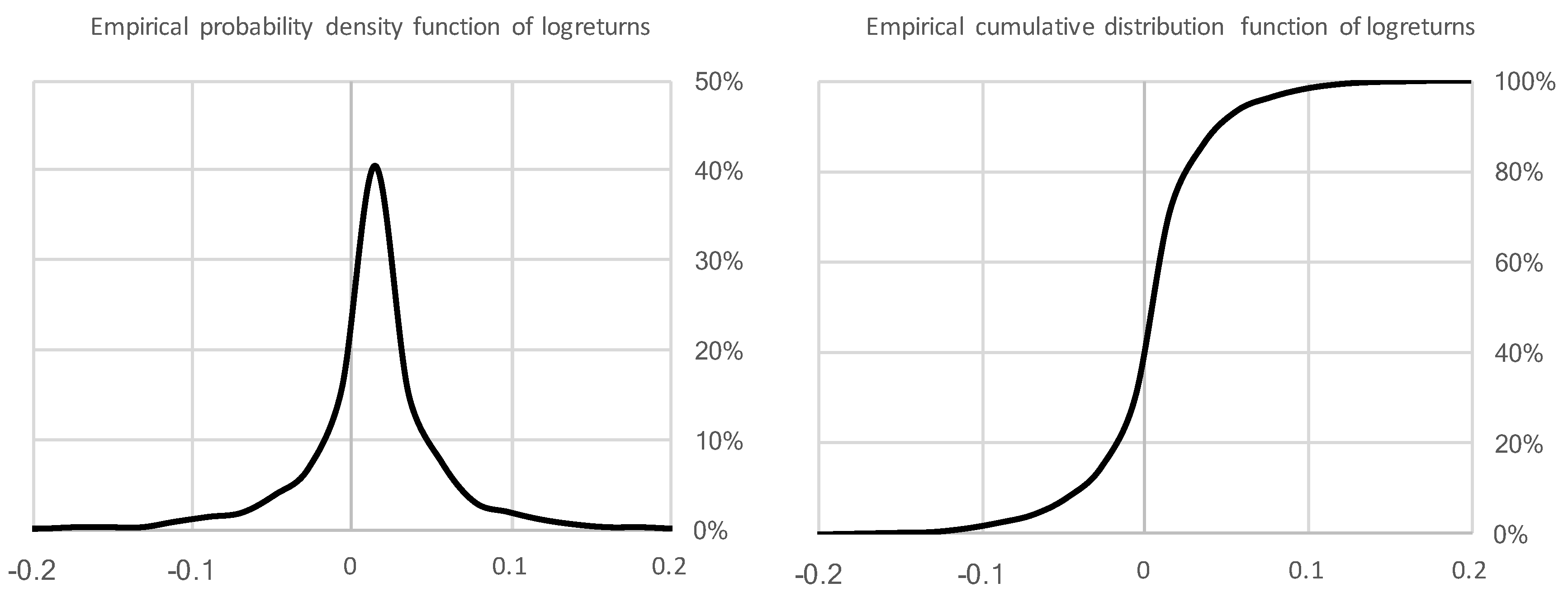
3.2. Entropy and Daily CVaR
3.3. Forecasting Daily CVaR
4. Conclusions
Author Contributions
Acknowledgments
Conflicts of Interest
Abbreviations
| CVaR | Conditional Value at Risk |
| GARCH | Generalized Autoregressive Conditional Heteroskedasticity |
| MAE | Mean Absolute Error |
| RMSE | Root Mean Squared Error |
| STSA | Symbolic Time Series Analysis |
| VaR | Value at Risk |
References
- Rockafellar, R.T.; Uryasev, S.P. Optimization of conditional value-at-risk. J. Risk 2000, 2, 21–42. [Google Scholar] [CrossRef]
- Love, R.F.; Morris, J.G.; Wesolowsky, G.O. Facilities Location: Models & Methods; NY: North-Holland, The Netherlands, 1988. [Google Scholar]
- Sarykalin, S.; Serraino, G.; Uryasev, S.P. Value-at-risk vs. conditional value-at-risk in risk management and optimization. Tutorials Oper. Res. 2008, 270–294. [Google Scholar] [CrossRef]
- Yamai, Y.; Yoshiba, T. Comparative analyses of expected shortfall and value-at-risk: their validity under market stress. Monet. Econ. Stud. 2002, 20, 181–237. [Google Scholar]
- Rockafellar, R.T.; Uryasev, S.P. Conditional value-at-risk for general loss distributions. J. Bank. Financ. 2002, 26, 1443–1471. [Google Scholar] [CrossRef]
- Philippatos, G.C.; Wilson, C. Entropy, market risk and the selection of efficient portfolios. Appl. Econ. 1972, 4, 209–220. [Google Scholar] [CrossRef]
- Ebrahimi, N.; Maasoumi, E.; Soofi, E.S. Ordering univariate distributions by entropy and variance. J. Econ. 1999, 90, 317–336. [Google Scholar] [CrossRef]
- Dionisio, A.; Menezes, R.; Mendes, D.A. An econophysics approach to analyze uncertainty in financial markets: an application to the Portuguese stock market. Eur. Phys. J. B 2006, 50, 161–164. [Google Scholar] [CrossRef]
- Pele, D.T.; Lazar, E.; Dufour, A. Information entropy and measures of market risk. Entropy 2017, 19, 226. [Google Scholar] [CrossRef]
- Billio, M.; Casarin, R.; Costola, M.; Pasqualini, A. An entropy-based early warning indicator for systemic risk. J. Int. Financ. Mark. Inst. Money 2016, 45, 42–59. [Google Scholar] [CrossRef]
- Pele, D.T.; Mazurencu-Marinescu-Pele, M. Using high-frequency entropy to forecast bitcoins daily value at risk. Entropy 2019, 21, 102. [Google Scholar] [CrossRef] [PubMed]
- Zhang, W.; Wang, P.; Li, X.; Shen, D. Some stylized facts of the cryptocurrency market. Appl. Econ. 2018, 50, 5950–5965. [Google Scholar] [CrossRef]
- Hu, A.; Parlour, C.A.; Rajan, U. Cryptocurrencies: stylized facts on a new investible instrument. Work. Pap. 2018. [Google Scholar] [CrossRef]
- Saa, O.T.; Stern, J.M. Auditable Blockchain Randomization Tool. arXiv 2019, arXiv:1904.09500. [Google Scholar]
- Colucci, S. On Estimating Bitcoin Value at Risk: A Comparative Analysis. Work. Pap. 2018. [Google Scholar] [CrossRef]
- Daw, C.; Finney, C.; Tracy, E. A review of symbolic analysis of experimental data. Rev. Sci. Instrum. 2003, 74, 915–930. [Google Scholar] [CrossRef]
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Koenker, R.; Bassett, G. Regression quantiles. Econometrica 1978, 46, 33–50. [Google Scholar] [CrossRef]
- Feng, W.; Wang, Y.; Zhang, Z. Can cryptocurrencies be a safe haven: A tail risk perspective analysis. Appl. Econ. 2018, 50, 4745–4762. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
| Parameter | Estimation | p-Value | Standard Error |
|---|---|---|---|
| 0.006 | 0.000 | 0.005 | |
| 0.032 | 0.000 | 0.008 | |
| 0.132 |
| Parameter | Estimation | p-Value | Standard Error |
|---|---|---|---|
| −9.133 | 0.002 | 1.316 | |
| 8.253 | 0.001 | 3.488 |
| Parameter | Estimation | p-Value | Standard Error |
|---|---|---|---|
| −6.961 | 0.001 | 0.592 | |
| 7.800 | 0.001 | 1.605 |
| Model | MAE | RMSE |
|---|---|---|
| Forecasting using entropy | 5.26 × 10 | 7.28 × 10 |
| Forecasting using historical CVaR | 3.56 × 10 | 4.52 × 10 |
| Model | MAE | RMSE |
|---|---|---|
| Forecasting using entropy | 1.04 × 10 | 5.42 × 10 |
| Forecasting using historical CVaR | 3.16 × 10 | 1.51 × 10 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Takada, H.H.; Azevedo, S.X.; Stern, J.M.; Ribeiro, C.O. Using Entropy to Forecast Bitcoin’s Daily Conditional Value at Risk. Proceedings 2019, 33, 7. https://doi.org/10.3390/proceedings2019033007
Takada HH, Azevedo SX, Stern JM, Ribeiro CO. Using Entropy to Forecast Bitcoin’s Daily Conditional Value at Risk. Proceedings. 2019; 33(1):7. https://doi.org/10.3390/proceedings2019033007
Chicago/Turabian StyleTakada, Hellinton H., Sylvio X. Azevedo, Julio M. Stern, and Celma O. Ribeiro. 2019. "Using Entropy to Forecast Bitcoin’s Daily Conditional Value at Risk" Proceedings 33, no. 1: 7. https://doi.org/10.3390/proceedings2019033007
APA StyleTakada, H. H., Azevedo, S. X., Stern, J. M., & Ribeiro, C. O. (2019). Using Entropy to Forecast Bitcoin’s Daily Conditional Value at Risk. Proceedings, 33(1), 7. https://doi.org/10.3390/proceedings2019033007