A New Approach to the Formant Measuring Problem †


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- Ability to derive error bars on the formant frequencies, bandwidths and peak amplitudes.
- Elimination of windowing and averaging procedures. A typical method to measure formants in a SSV is to slide over the signal with a tapering window, estimate the formant frequency, bandwidth and peak amplitude in each window, and then to average these estimates over the windows [9]. In our approach, the pitch-synchronous nature of the model eliminates any windowing procedure (and thus various user-made choices) by making use of the pitch period as a natural time scale [12]. In addition, the formant frequencies and bandwidths are estimated simultaneously in each period, which can be understood as a generalized averaging operation over pitch periods ([11] Section 7.5).
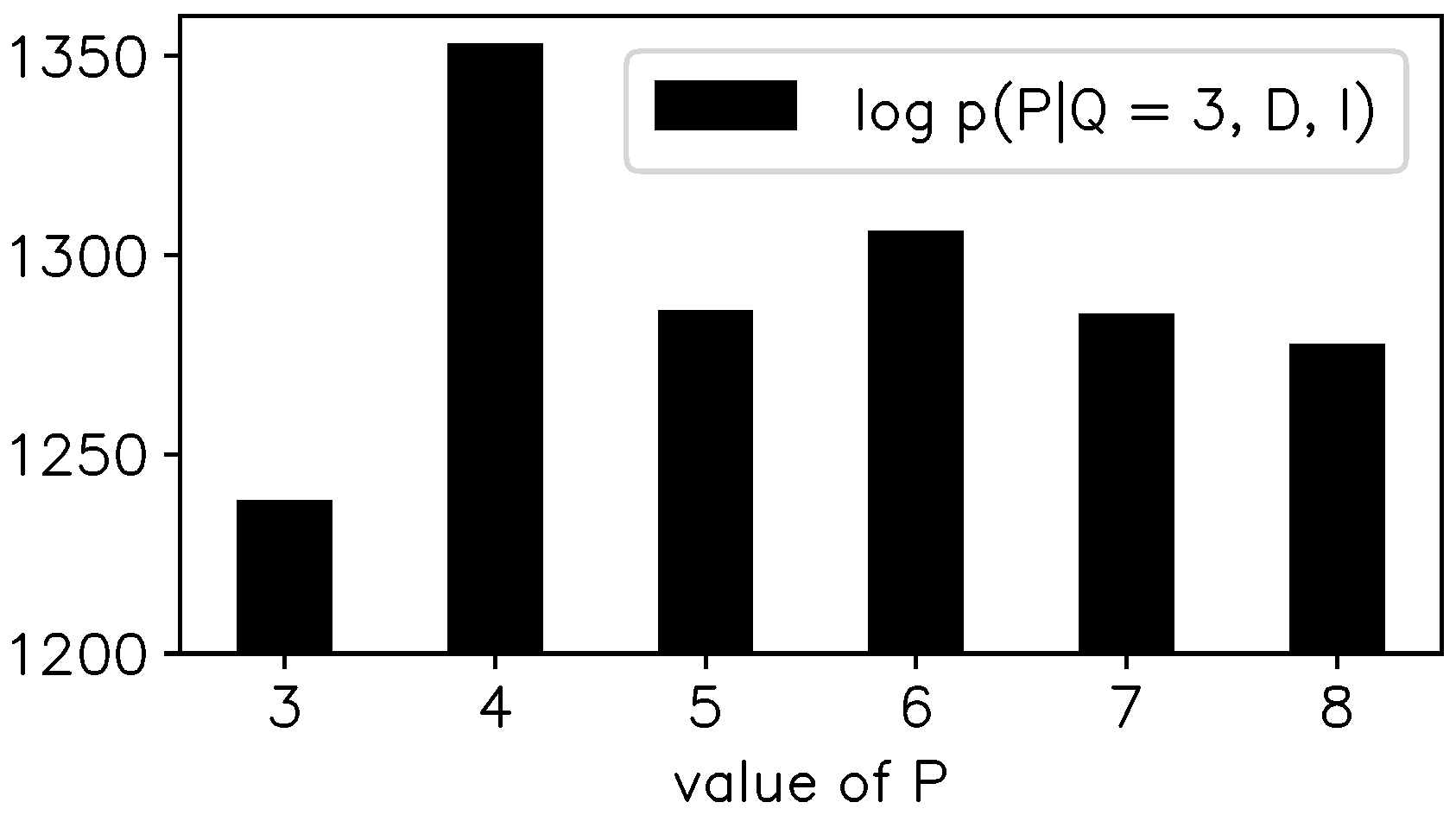
- “Automatic” model order determination. This is done by inferring the most probable model order given the SSV (and the model). This can be contrasted with traditional LPC analysis, where the number of poles must be decided by the user on the basis of several well-established guidelines, but where the final judgment ultimately remains qualitative. However, in the current approach, the proposed model (including the prior pdfs) is still too simple to guarantee satisfactory model order determination in all cases.
- Limited applicability: we only model SSVs, though possible extensions are discussed in the conclusion of the paper.
- Though the inference algorithm described below is efficient and relatively fast compared to typical problems in numerical Bayesian inference, it is still much slower than LPC analysis. For example, all calculations for the SSV [ɛ] discussed below took about half a minute.
2. SSV Model
2.1. Individual Pitch Periods
2.2. Multiple Pitch Periods: SSV
2.3. Estimation
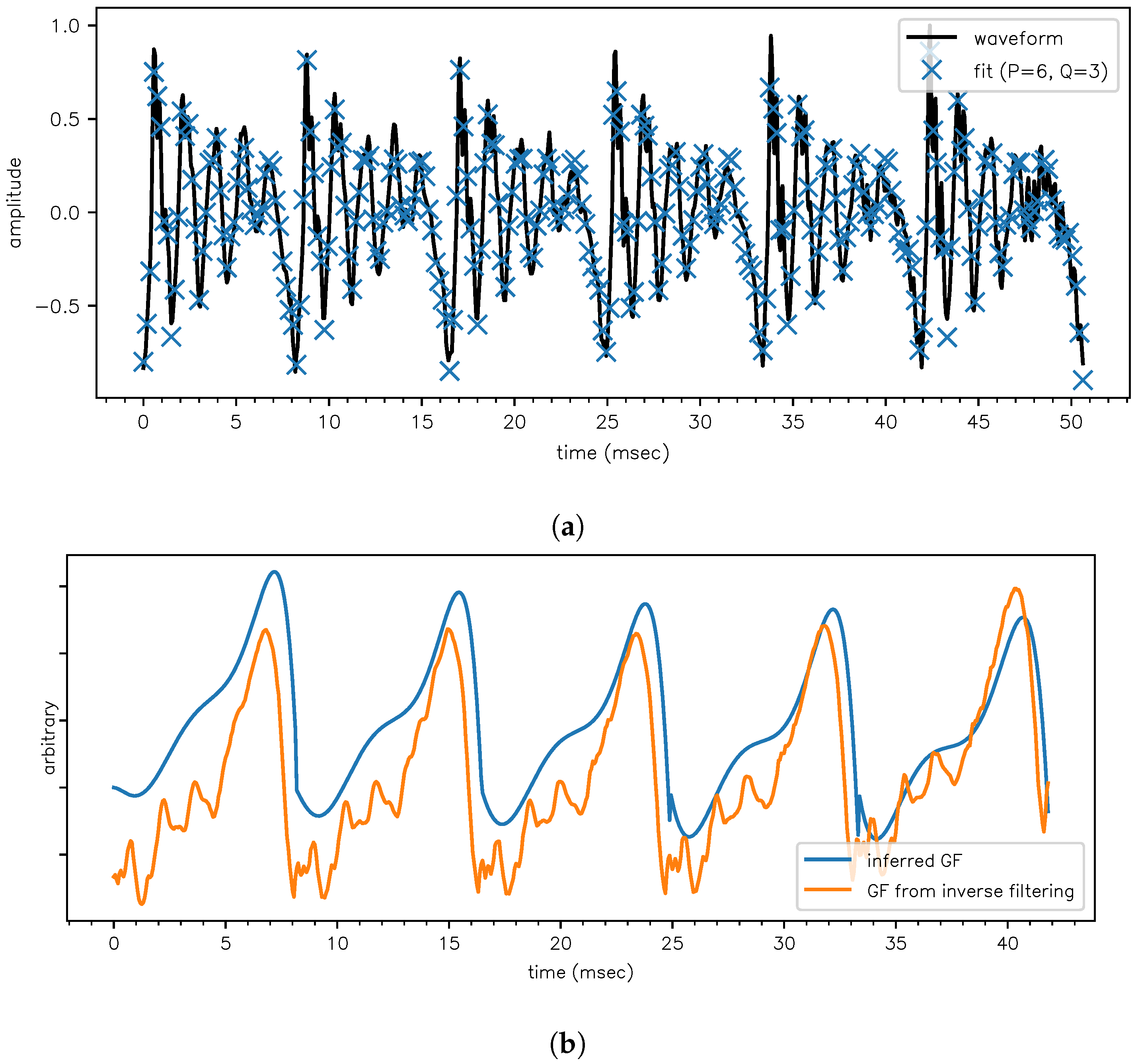
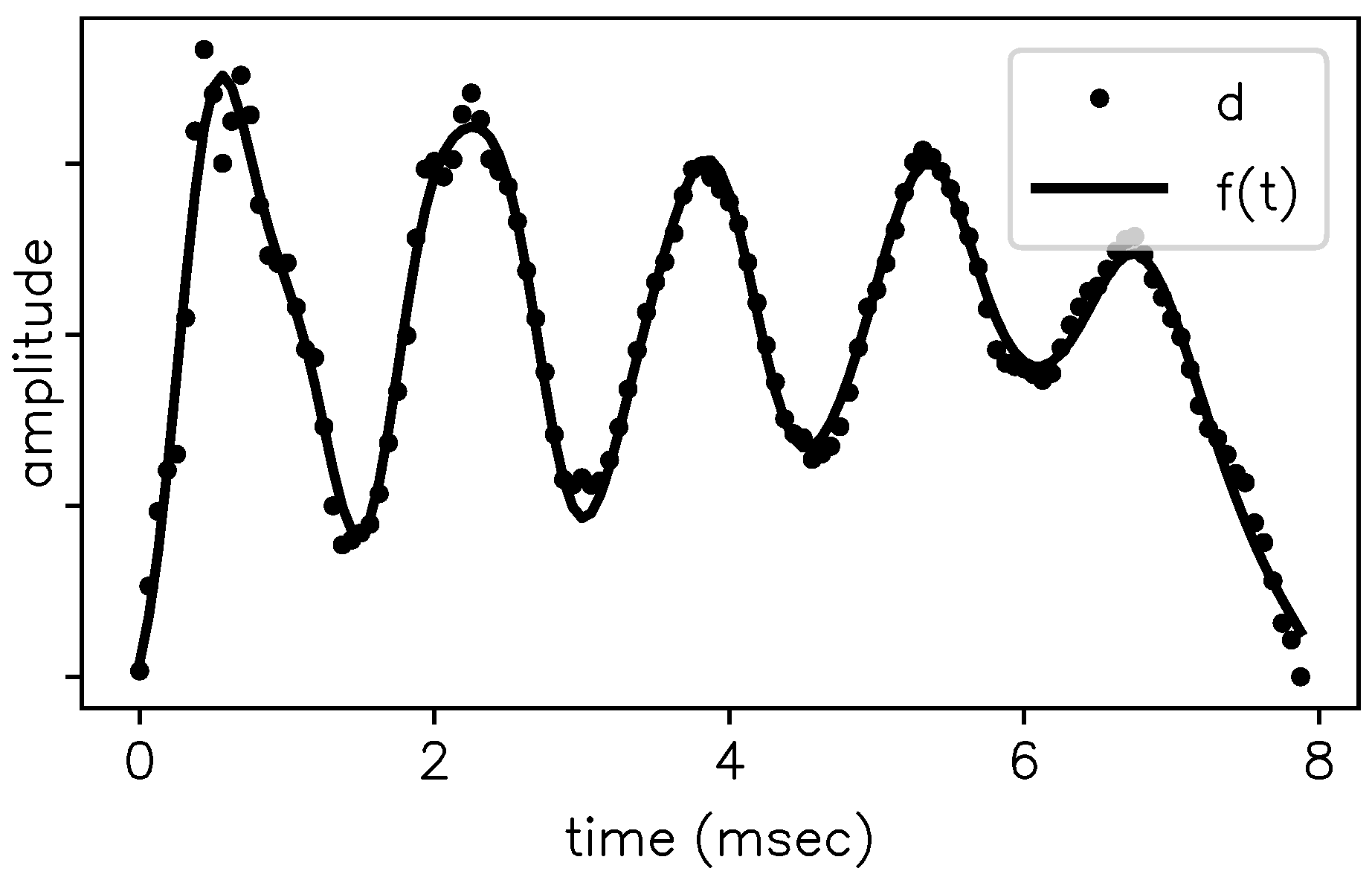
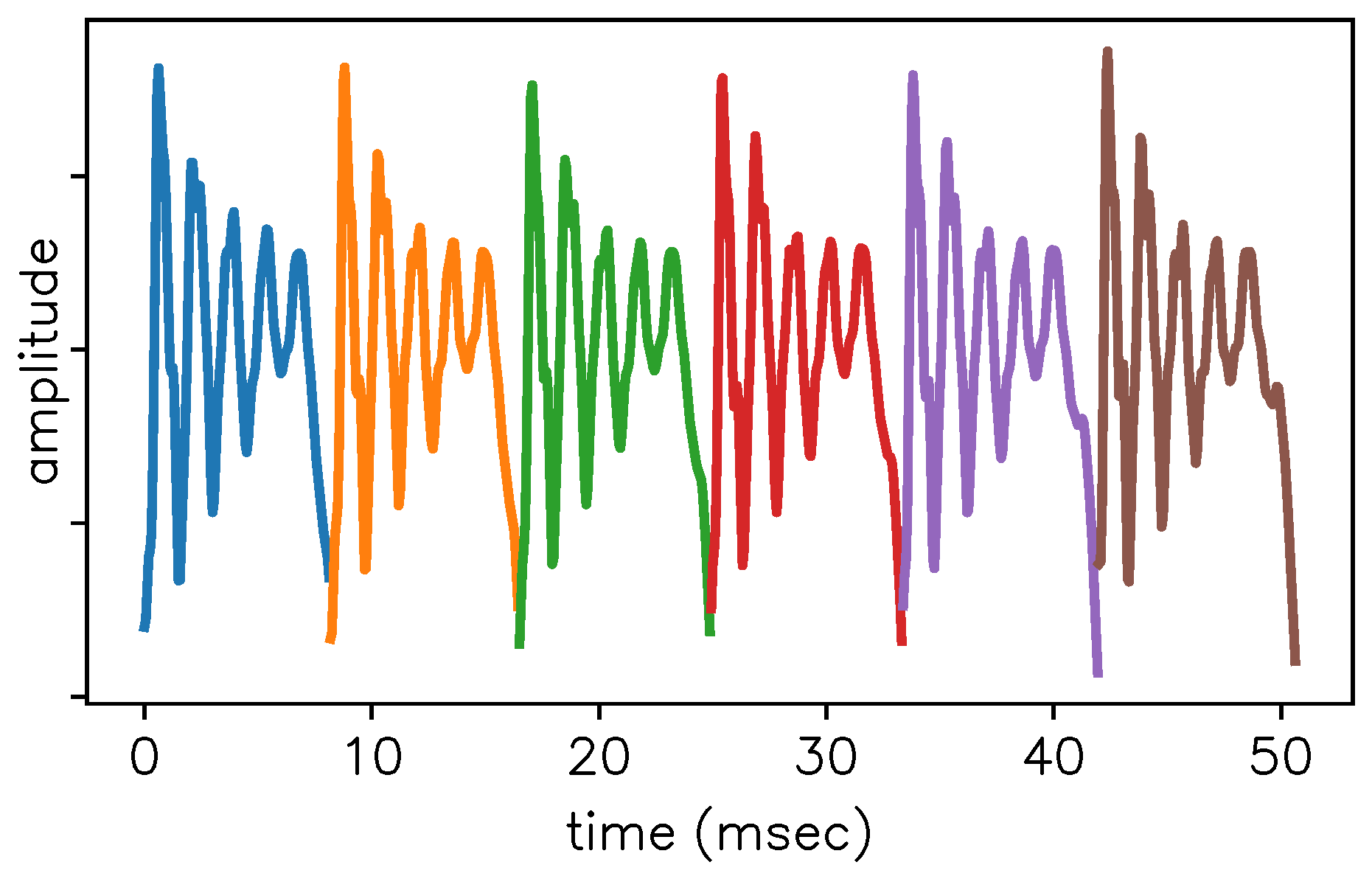
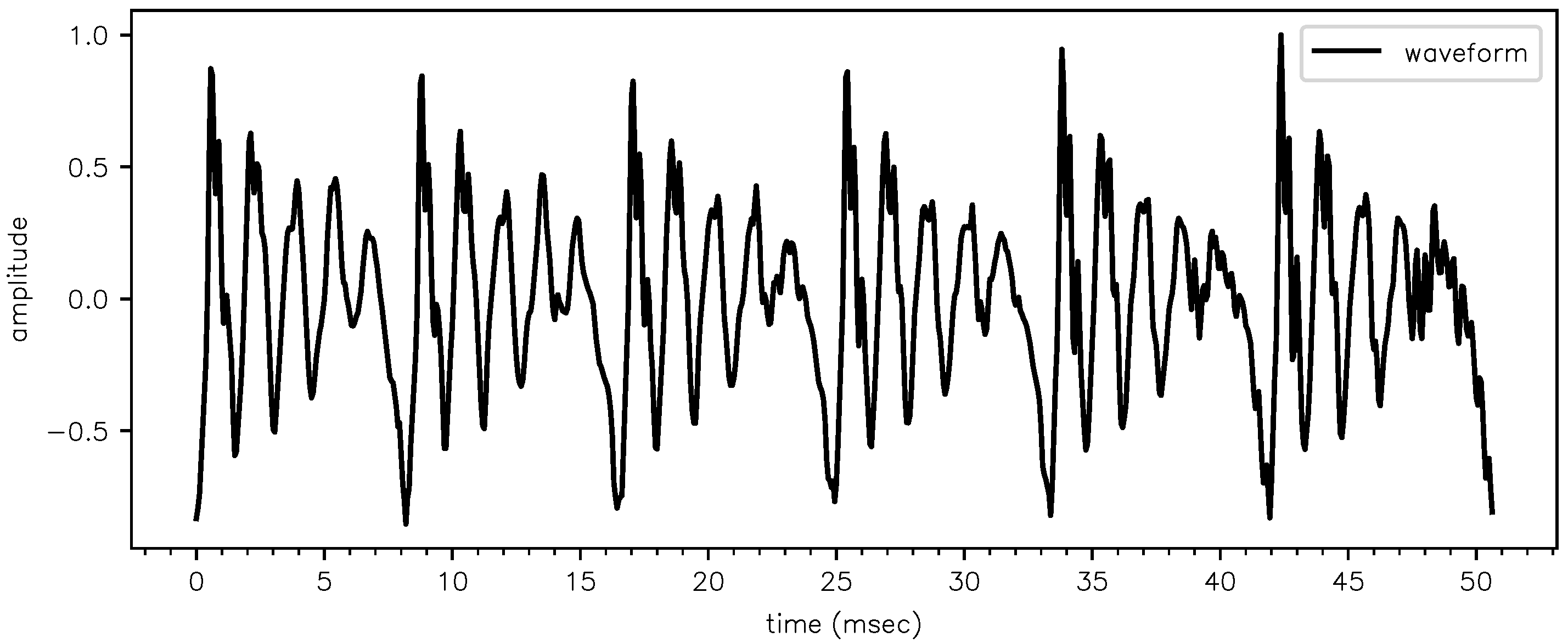
3. Application on a Steady-State Portion of [ɛ]
- (F1)est = 658 ± 2 Hz at −2.0 ± 0.1 dB/ms
- (F2)est = 1463 ± 10 Hz at −2.9 ± 0.5 dB/ms
- (F3)est = 2660 ± 10 Hz at −3.0 ± 0.7 dB/ms
- (F1)LPC = 670 Hz
- (F2)LPC = 1491 Hz
- (F3)LPC = 2771 Hz
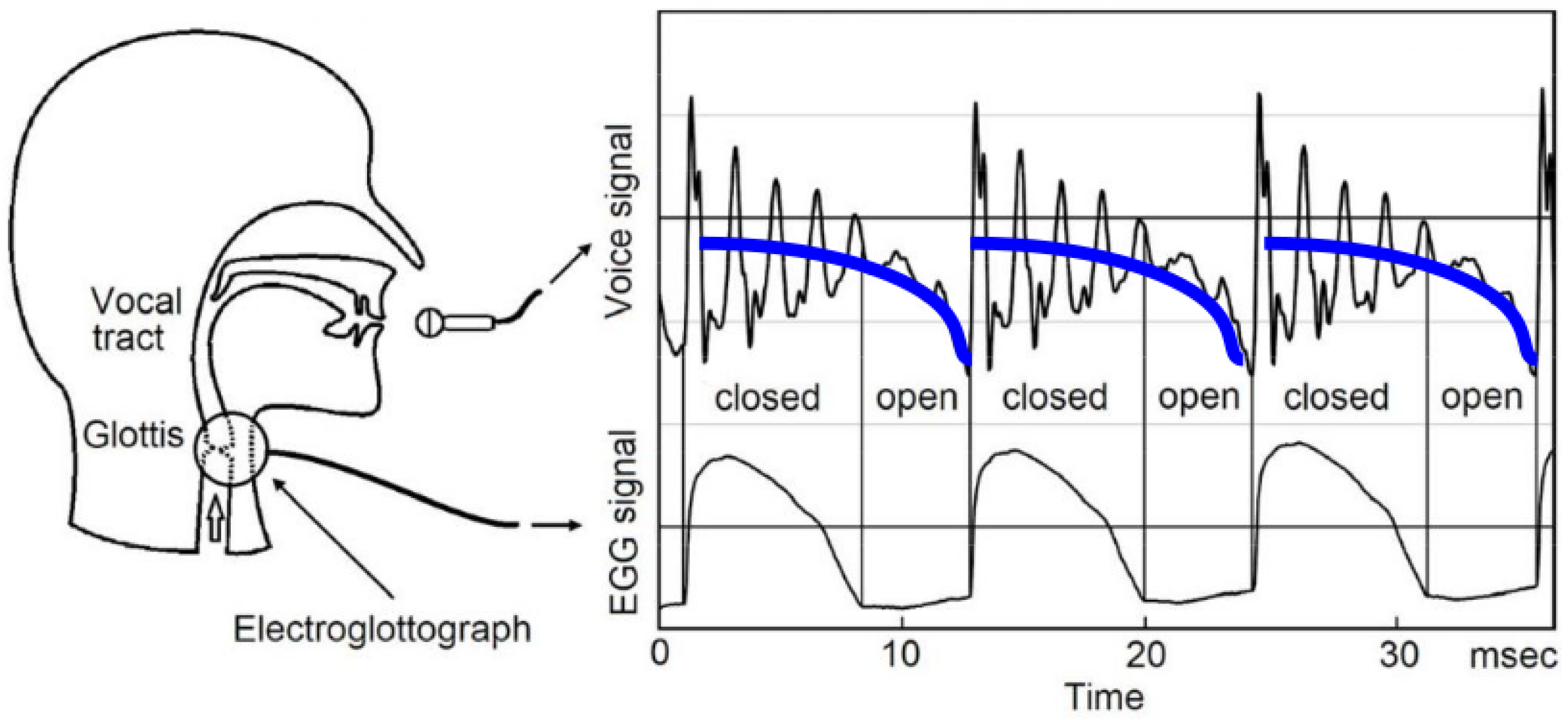
4. Conclusions
4.1. Possible Extensions
Author Contributions
Funding
Conflicts of Interest
References
- Fant, G. Acoustic Theory of Speech Production; Mouton: Den Haag, The Netherlands, 1960. [Google Scholar]
- Hermann, L. Phonophotographische Untersuchungen. Pflügers Arch. Eur. J. Physiol. 1889, 45, 582–592. [Google Scholar] [CrossRef]
- Fulop, S.A. Speech Spectrum Analysis; Signals and Communication Technology; Springer: Berlin, Germany, 2011; OCLC: 746243279. [Google Scholar]
- Kent, R.D.; Vorperian, H.K. Static Measurements of Vowel Formant Frequencies and Bandwidths: A Review. J. Commun. Disord. 2018, 74, 74–97. [Google Scholar] [CrossRef] [PubMed]
- Maurer, D. Acoustics of the Vowel; Peter Lang: Bern, Switzerland, 2016. [Google Scholar]
- Harrison, P. Making Accurate Formant Measurements: An Empirical Investigation of the Influence of the Measurement Tool, Analysis Settings and Speaker on Formant Measurements. Ph.D. Thesis, University of York, York, UK, 2013. [Google Scholar]
- Vallabha, G.K.; Tuller, B. Systematic Errors in the Formant Analysis of Steady-State Vowels. Speech Commun. 2002, 38, 141–160. [Google Scholar] [CrossRef]
- Peterson, G.E.; Barney, H.L. Control Methods Used in a Study of the Vowels. J. Acoust. Soc. Am. 1952, 24, 175–184. [Google Scholar] [CrossRef]
- Rabiner, L.R.; Schafer, R.W. Introduction to Digital Speech Processing. Found. Trends Signal Process. 2007, 1, 1–194. [Google Scholar] [CrossRef]
- Jaynes, E.T. Bayesian Spectrum and Chirp Analysis; Springer: Dordrecht, The Netherlands, 1987; pp. 1–29. [Google Scholar]
- Bretthorst, G.L. Bayesian Spectrum Analysis and Parameter Estimation; Springer Science & Business Media: Berlin, Germany, 1988. [Google Scholar]
- Chen, C.J.; Miller, D.A. Pitch-Synchronous Analysis of Human Voice. J. Voice 2019. [Google Scholar] [CrossRef] [PubMed]
- Boersma, P. Should Jitter Be Measured by Peak Picking or by Waveform Matching. Folia Phoniatr. Et Logop. 2009, 61, 305–308. [Google Scholar] [CrossRef] [PubMed]
- Wise, J.; Caprio, J.; Parks, T. Maximum likelihood pitch estimation. IEEE Trans. Acoust. Speech Signal Process. 1976, 24, 418–423. [Google Scholar] [CrossRef]
- Ladefoged, P. Elements of Acoustic Phonetics; University of Chicago Press: Chicago, IL, USA, 1996. [Google Scholar]
- Miller, D.G.; Schutte, H.K. Characteristic Patterns of Sub-and Supraglottal Pressure Variations within the Glottal Cycle. In Proceedings of the Transcripts of the Thirteenth Symposium on Care of the Professional Voice, New York, NY, USA; 1984; pp. 70–75. [Google Scholar]
- Doval, B.; D’Alessandro, C.; Henrich, N. The Spectrum of Glottal Flow Models. Acta Acust. United Acust. 2006, 92, 1026–1046. [Google Scholar]
- Ó Ruanaidh, J.J.K.; Fitzgerald, W.J. Numerical Bayesian Methods Applied to Signal Processing; Statistics and Computing; Springer New York: New York, NY, USA, 1996. [Google Scholar] [CrossRef]
- Fitzgerald, P.; Godsill, S.J.; Kokaram, A.C. Bayesian Methods in Signal and Image. Bayesian Stat. 1999, 6, 239–254. [Google Scholar]
- Bretthorst, G.L. Bayesian Spectrum Analysis on Quadrature NMR Data with Noise Correlations. In Maximum Entropy and Bayesian Methods; Springer: Berlin, Germany, 1989; pp. 261–273. [Google Scholar]
- Press, W.H.; Teukolsky, S.A.; Vetterling, W.T.; Flannery, B.P. Numerical Recipes in C: The Art of Scientific Computing, 2nd Ed. ed; Cambridge University Press: New York, NY, USA, 1992. [Google Scholar]
- Kominek, J.; Black, A.W. The CMU Arctic speech databases. In Proceedings of the Fifth ISCA Workshop on Speech Synthesis, Pittsburgh, PA, USA, June 14-16, 2004. [Google Scholar]
- Boersma, P.; Weenink, D.J.M. Praat, a system for doing phonetics by computer. Glot Int. 2002, 5, 341–345. [Google Scholar]
- Sanchez, J. Application of Classical, Bayesian and Maximum Entropy Spectrum Analysis to Nonstationary Time Series Data. In Maximum Entropy and Bayesian Methods; Springer: Berlin, Germany, 1989; pp. 309–319. [Google Scholar]
- Alku, P. Glottal Inverse Filtering Analysis of Human Voice Production—A Review of Estimation and Parameterization Methods of the Glottal Excitation and Their Applications. Sadhana 2011, 36, 623–650. [Google Scholar] [CrossRef]
- Rabiner, L.R.; Juang, B.H.; Rutledge, J.C. Fundamentals of Speech Recognition; PTR Prentice Hall: Englewood Cliffs, NJ, USA, 1993; Volume 14. [Google Scholar]
- Becker, T.; Jessen, M.; Grigoras, C. Forensic Speaker Verification Using Formant Features and Gaussian Mixture Models. In Proceedings of the Ninth Annual Conference of the International Speech Communication Association, Brisbane, Australia, September 22-26, 2008. [Google Scholar]
- Ng, A.K.; Koh, T.S.; Baey, E.; Lee, T.H.; Abeyratne, U.R.; Puvanendran, K. Could Formant Frequencies of Snore Signals Be an Alternative Means for the Diagnosis of Obstructive Sleep Apnea? Sleep Med. 2008, 9, 894–898. [Google Scholar] [CrossRef] [PubMed]
- Bonastre, J.F.; Kahn, J.; Rossato, S.; Ajili, M. Forensic Speaker Recognition: Mirages and Reality. S. Fuchs/D 2015, 255. [Google Scholar] [CrossRef]
- Nolan, F. Speaker Identification Evidence: Its Forms, Limitations, and Roles. In Proceedings of the Conference “Law and Language: Prospect and Retrospect”, Levi, Finnish, Lapland, 2001; pp. 1–19. [Google Scholar]
- Sivia, D.; Skilling, J. Data Analysis: A Bayesian Tutorial; OUP: Oxford, UK, 2006. [Google Scholar]
- Chen, C.J. Elements of Human Voice; World Scientific: Singapore, 2016. [Google Scholar]
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Van Soom, M.; de Boer, B. A New Approach to the Formant Measuring Problem. Proceedings 2019, 33, 29. https://doi.org/10.3390/proceedings2019033029
Van Soom M, de Boer B. A New Approach to the Formant Measuring Problem. Proceedings. 2019; 33(1):29. https://doi.org/10.3390/proceedings2019033029
Chicago/Turabian StyleVan Soom, Marnix, and Bart de Boer. 2019. "A New Approach to the Formant Measuring Problem" Proceedings 33, no. 1: 29. https://doi.org/10.3390/proceedings2019033029
APA StyleVan Soom, M., & de Boer, B. (2019). A New Approach to the Formant Measuring Problem. Proceedings, 33(1), 29. https://doi.org/10.3390/proceedings2019033029