1. Introduction
Nested_fit is a general purpose parallelized data analysis code for the evaluation of
Bayesian evidence and parameter probability distributions for given data sets and modeling function. The computation of the Bayesian evidence is based on the nested sampling algorithm [
1,
2,
3], for the integration of the likelihood function over the parameter space. This integration is obtained reducing the
J-dimensional volume (where
J is the number of parameters) in a one-dimensional integral by a clever exploration of the parameter space. In
Nested_fit, this exploration is obtained with a search algorithm for new parameter values called
lawn mower robot, which has been initially developed by L. Simons [
4] and modified here for a better exploration of multimodal problems.
Nested_fit has been developed over the past years to analyze several sets of experimental data from, mainly, atomic physics experiments. For this reason, it has some special feature well adapted to the analysis of atomic spectra as specific line profiles, possibility to study correlated spectra at the same time, eg. background and signal-plus-background spectra, and with a likelihood function built considering a Poisson statistics per each channel, well adapted to low-statistics data.
In the next section we will describe the general structure and feautres of
Nested_fit. In
Section 3 we shortly introduce the basic concepts of Bayesian model comparison and the nested sampling method. The specific algorithm for the parameter space exploration for the nested sampling is presented in details in
Section 4. An example of application of
Nested_fit is presented in
Section 5 for the analysis of single two-body electron capture ion decay. A conclusive section will end the article, where recent application of
Nested_fit to different atomic physics analysis are mentioned.
2. General Structure of the Program
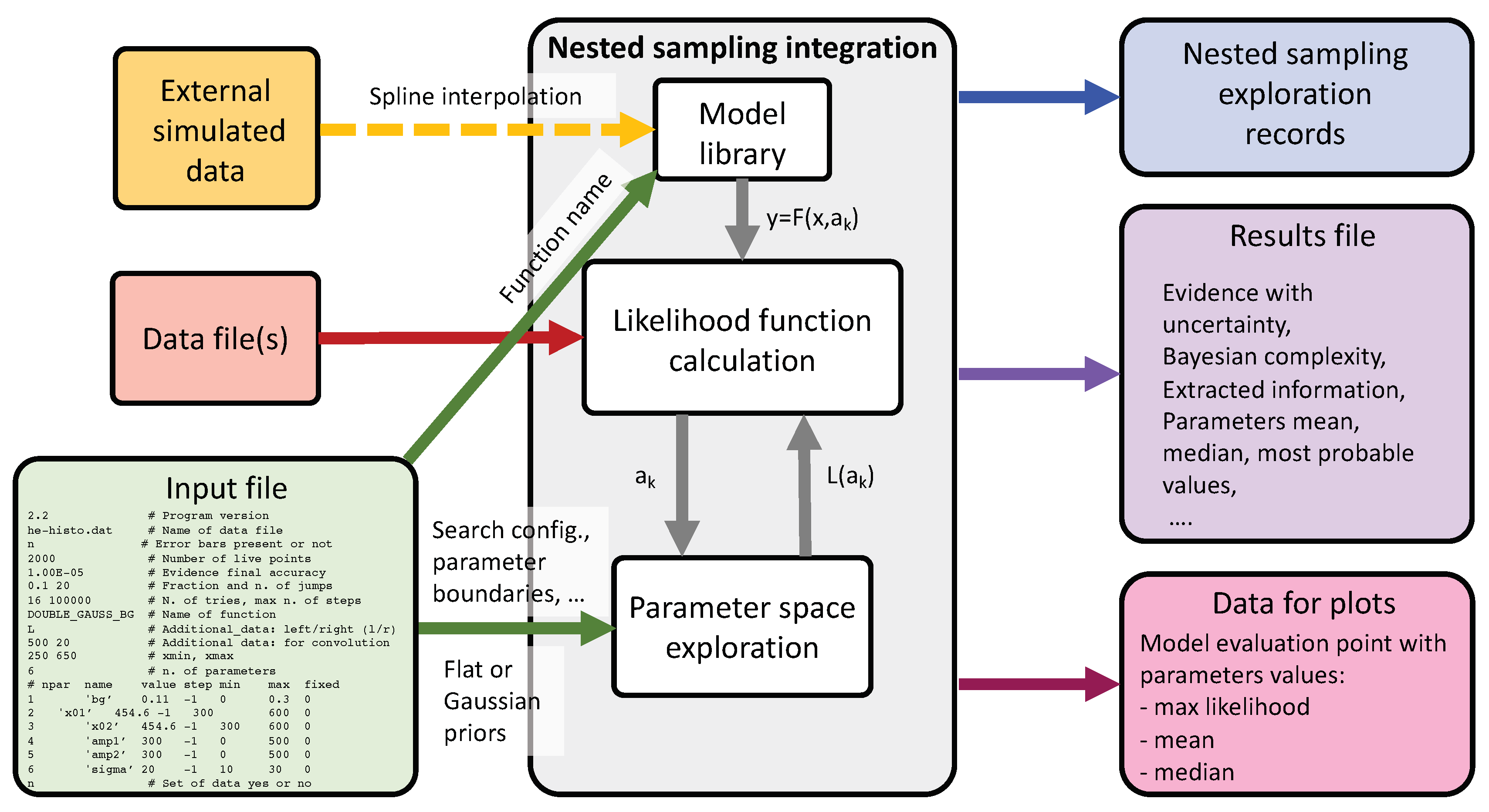
The general structure of the program is represented in
Figure 1. The main input files are two: the file
nf_input.dat, where all computation input parameters are included, and the data file, which name is indicated in the parameter input file. The function name in the input file indicates the model to be used for the calculation of the likelihood function. Several functions are already defined in the function library for modelling spectral lines: Gaussian, Log-normal, Lorentzian, Voigt (Gaussian and Lorentzian convolution), Gaussian convoluted with an exponential (for asymmetric peaks), etc. Additional functions can be easily defined by the users in the dedicated routine (
USERFNC). Differently from the version presented in Ref. [
5] (V. 0.7), in the new version discussed here (V. 2.2) non-analytical or simulated profile models can be implemented. In this case, one or more additional files have to be provided by the users. These external data, which can have some noise like the case of simulated data, are interpolated by B-splines using FITPACK routines [
6]. The B-spline parameters are stored and used as profile/model with the total amplitude and a possible offset as free parameters. An additional feature of this new program version, is the possibility to analyze data with error bars. This option has to be indicated in the input file.
Several data sets can be analyzed at the same time by selecting the option “set of data: YES”. This is particularly important for the correct study of physically correlated spectra at the same time, e.g., background and signal-plus-background spectra. This is done using a global user-defined function with common parameters of specific models for each spectrum. In the case of multiple data files, the program read an additional input parameter file nf_input_set.dat for the additional datafile names to analyze and data ranges to consider.
The exploration of the parameter space and the corresponding evaluation of the likelihood function is done implementing the nested sampling algorithm [
1,
2,
3]. If the data are in the format
, a Poisson distribution for each channel is assumed for the likelihood function. If the data has error bars
, a Gaussian distribution is assumed (new feature in V. 2.2).
The main analysis results are summarized in the output file nf_output_res.dat . Here the details of the computation (n. of live points, n. of trials, n. of total iteration) can be found as well as the final evidence value and its uncertainty , the parameter values corresponding to the maximum of the likelihood function, the mean, the median, the standard deviation and the confidence intervals (68%, 95% and 99%) of the posterior probability distribution of each parameter. The information gain and the Bayesian complexity are also provided in the output.
Data for plots and for further analyses are provided in the files nf_output_data_*.dat. These files contain the original input data together with the model function values corresponding to the parameters with the highest likelihood function value (nf_output_data_max.dat) or the parameter mean value (nf_output_data_mean.dat) or median value (nf_output_data_median.dat) with the corresponding residuals and error bars. Additional nf_output_fit_*.dat files contain a model evaluation with higher density than the original data for graphical presentation purpose.
The step-by-step details of the nested sampling exploration are provided in the file
nf_output_points.dat that contains the live points used during the parameter space exploration, their associated likelihood values and posterior probabilities. From this file, the different parameter probability distributions and joint probabilities can be built from the marginalization of the unretained parameters. For this purpose, a special dedicated Phython library
Nested_res has been developed. Additional informations can be found in Ref. [
5].
3. Implementation of the Nested Sampling for the Evidence Calculation
For a given data set(s)
and model(s)
, the Bayesian evidence
is extracted for the evaluation of the probability to the different models them-selves:
where
is the prior probability of each model (assumed constant if not specific preferences for the model is present) and
I indicates the background information. The Bayesian evidence is the integral value of the likelihood function over the entire parameter space defined by the priors
:
where
J is the number of the parameters of the considered model, and where we explicitly show the dependency of likelihood function
on the model
.
The calculation of the Bayesian evidence is made with the nested sampling, similarly to other available codes [
2,
7,
8,
9,
10]. Nested sampling allows for reducing the above integral in the one-dimensional integral
where
X is defined by the relation
Equation (
3) can be numerically calculated using the rectangle integration method subdividing the
interval in
segments with an ensemble
of
M ordered points
. We have then
where
and
. The evaluation of
is obtained by the exploration of the likelihood function with a Monte Carlo sampling via a subsequence of steps. For this, we use a collection of
K parameter values
that we call
live points. More details on the nested sampling algorithm and its implementation can be found in Refs. [
1,
2,
3,
7,
8,
9,
10]. The specific implementation of nested sampling in
Nested_fit is presented in details in Ref. [
5].
The bottleneck of the nested sampling algorithm is the search of new points within the
J-dimensional volume defined by
. Different methods are commonly employed to accomplish this difficult task. One efficient method is the ellipsoidal nested sampling [
7]. It is based on the approximation of the iso-likelihood contour defined by
by a
J-dimensional ellipsoid calculated from the covariance matrix of the live points. The new point is then selected within the ellipsoidal volume (with an enlargement factor selected by the user). This method, well adapted for unimodal posterior distribution has also been extended to multimodal problems [
8,
9], i.e., with the presence of distinguished regions of the parameter space with high values of the likelihood function. Other search algorithms are based on Markov chain Monte Carlo (MCMC) methods [
10] and the recent
Galilean Monte Carlo [
11,
12], particularly adapted to explore the regions close to the boundary of
volumes.
Nested_fit program is based on an improved version of the
lawn mower robot method, originally developed by L. Simons [
4] and presented in details in the next section.
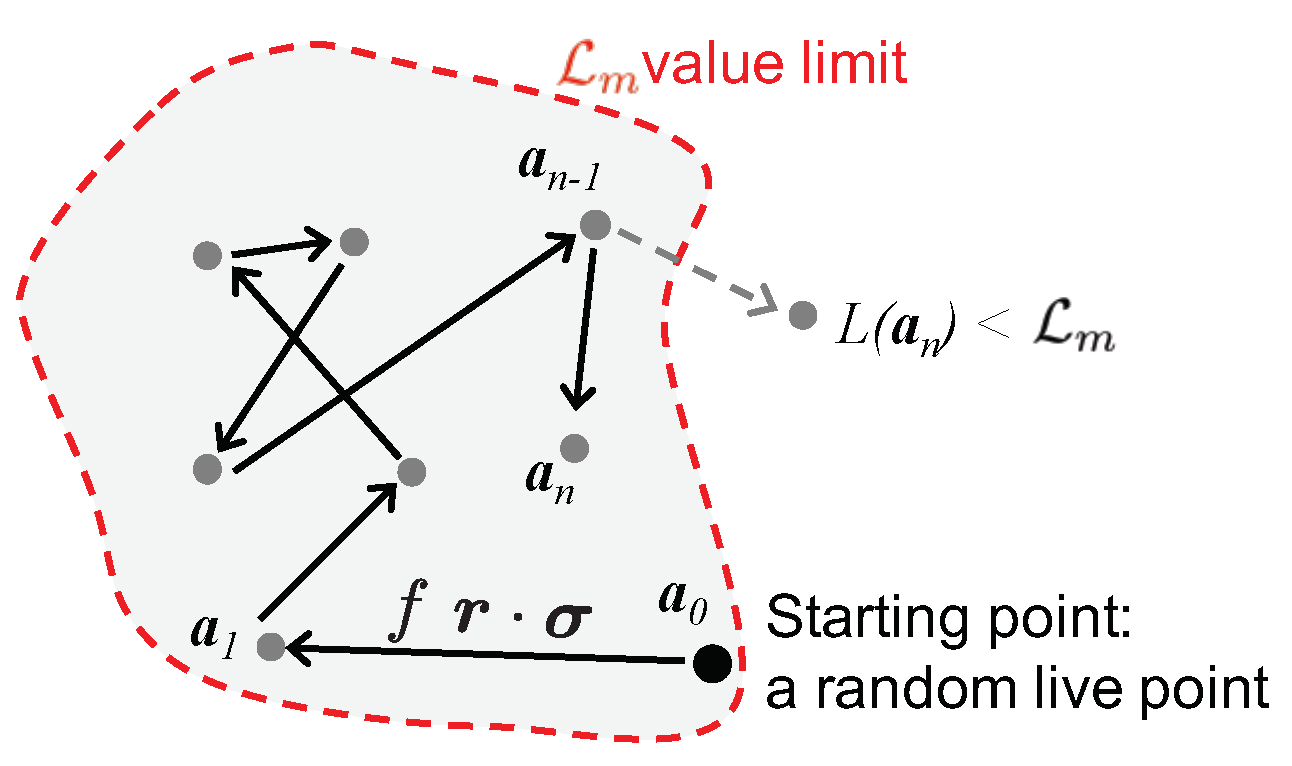
4. The Lawn Mower Robot Search Algorithm
A schematic view of the improved
lawn mower robot algorithm is represented in
Figure 2. To cancel the correlation between the starting point and the final point, a series of
N jumps are made in this volume. The different stages of the algorithm are
- 1.
Choose randomly a starting point from the available live points as starting point of the Markov chain where n is the number of the jump. The number of tries (see below) is set to zero.
- 2.
From the values , find a new parameter sets where each parameter is calculated by , where is the standard deviation of the live points of the nested sampling computation step relative to the parameter, is a sorted random number and f is a factor defined by the user.
- (a)
If and , go to the beginning of step 2 with an increment of the jump number .
- (b)
If and , is new live point to be included in the new set .
- (c)
If and and the number of tries is less than the maximum allowed number , go back to beginning of step 2 with an increment of the number of tries .
- (d)
If and and a new parameter set has to be selected. Instead than choosing one of the existing live points, is built from distinct components from different live points: where k is randomly chosen between 1 and K for each j. Then and go to the beginning of step 2.
Step 2c, the main improvement of the original lawn mower robot algorithm, makes the algorithm well adapted to problems with multimodal parameter distributions allowing easy jump between high-likelihood regions. The value of is fixed in the code ( = 10,000 in the present version). The other parameters can be provided by the input file.
5. An Application to Low-Statistics Data
To show the capabilities of
Nested_fit, we present in this section its implementation on a particular critical case corresponding to a debated experiment. In 2008 it was observed an unexpected modulation in the two-body electron capture decay of single H-like
Pm ions to the stable
Nd bare nucleus, with a monochromatic electron-neutrino emission [
13]. The same modulation frequency, but with much smaller amplitude, was found in 2010 data [
14] but not in the latest campaign in 2014 [
15] where much more events have been recorded.
The unstable ions are produced by collision with a solid target and then injected in a storage ring where they are cooled down. In the storage ring, the decay time of single ions is measured from changes of the Schottky noise frequency induced by the ion revolution. The H-like
Pm ion and
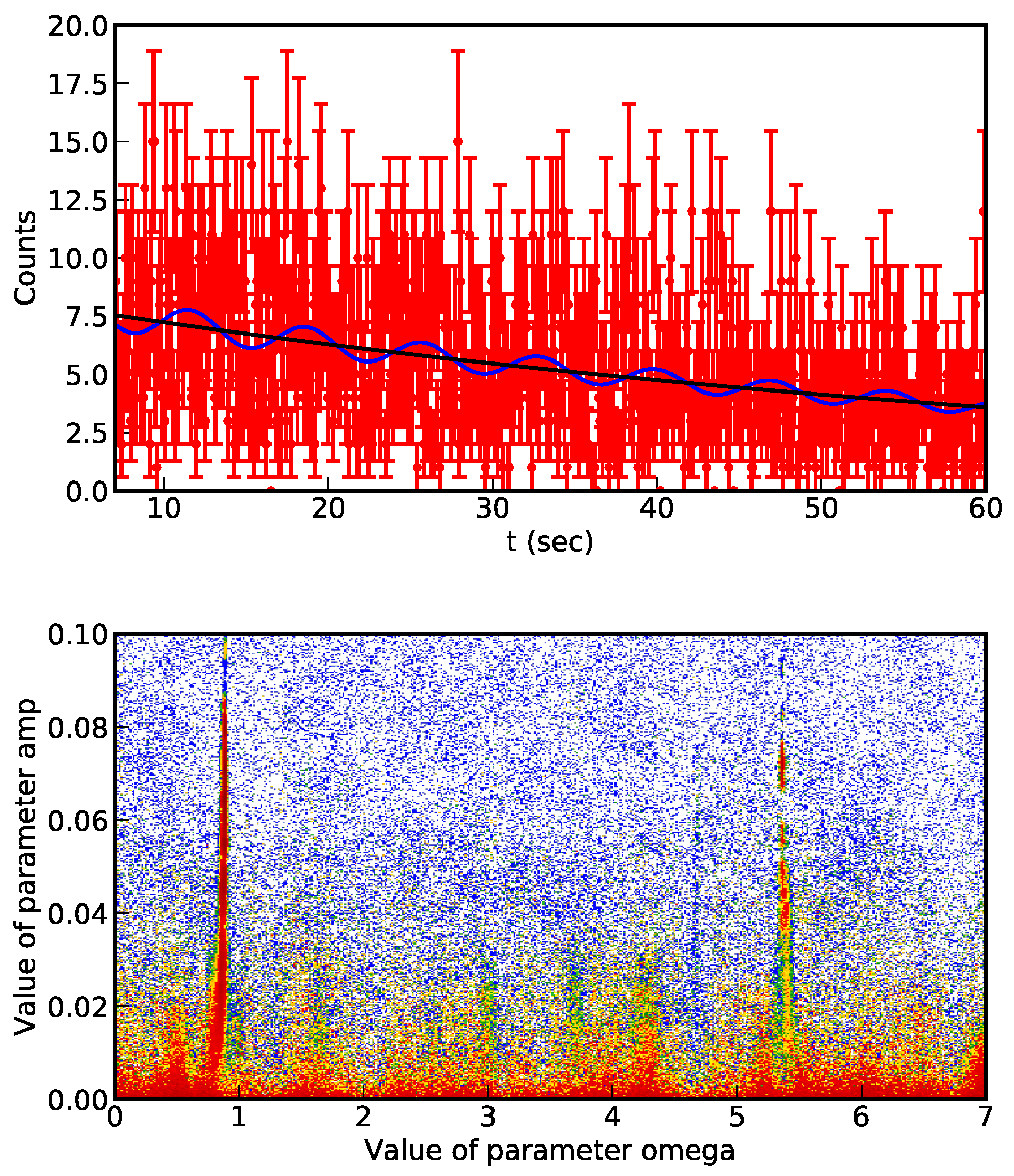
Nd bare nucleus masses correspond in fact to different revolution frequencies. From the accumulated data of single decay events, the decay probability per unit of time can be measured. An example of the data collected in 2010 is presented in
Figure 3 (up).
The observed modulation of the expected exponential decay has not yet a clear explanation. A possible connection with neutrino masses differences is speculated in the literature. The determination of the presence or not of a modulation is a perfect case for implementing Bayesian model comparison with Nested_fit.
When a possible modulation of the exponential decay is assumed, the likelihood function corresponding to 2010 data presents several maxima. This reflect the periodicity nature of the considered function, which can manifest itself via different harmonics, and the low number of available counts per channel. The difficulties to deal with these multiple likelihood maxima pushed in fact the creation of the improved lawn mower robot algorithm.
In
Figure 3 (top) we present the collected data together with the exponential and modulated exponential functions corresponding to the most probable parameter set. The output result from
Nested_fit are presented in
Table 1 where model 1 and 2 represent the absence of presence of modulation. For each model, values of the evidence, Bayesian complexity and extracted information are provided, as well as model probabilities. The uncertainty of the probabilities is related to the uncertainty of the evidence. As example of probability distribution, we present in
Figure 3 (bottom) the joint probability of the amplitude
a and pulsation
of the modulation in model 2. The 2D histogram (obtained with Python
nested_res.py library that accompany
Nested_fit program) is constructed by marginalization on the other parameters. As it can be seen, different maxima are visible, which make difficult the convergence of the nested sampling method. The improved
lawn mower robot algorithm can deal with this kind of situation, even if the computation time is sometime long (several days in a single CPU).
As it can be observed, the assigned probability to each model are similar and the confidential intervals for the parameter relative to the modulation model are very large. These two aspects reflect the difficulty to treat this problem where the acquired data are not sufficient to provide a marked preference for one model with or without modulation (see Ref. [
15] for a more extended discussion). Even if apparently unsatisfying, this result avoid however possible over-interpretation of the data commonly encountered when classical methods are employed, as recently discussed in Ref. [
16] in the context of nuclear physics.
6. Conclusions
We presented here the program
Nested_fit, a general purpose parallelized data analysis code for the evaluation of Bayesian evidence and other statistically relevant outputs. It uses the nested sampling method with the implementation of the improved lawn mower robot algorithm for the evaluation of the Bayesian evidence.
Nested_fit has been developed over the past years for the analysis of several sets of atomic experimental data that strongly contribute to the code evolution. We would like to mention in particular the analysis of low-statistics X-ray spectra of He-like uranium [
5,
17], X-ray spectra of pionic atoms [
18,
19], electron photoemission spectra from nano-particles [
20,
21], single-ion decay spectra [
15] and response function of crystal X-ray spectrometers (in progress).
Compared to the version reported in Ref. [
5], the presented version (V. 2.2) shows additional important features: i) the possibility to interpolate and use computed or simulated external profiles and ii) the implementation of Gaussian likelihood function for data with error bars.
Future developments of
Nested_fit will be focussed on the implementation of new exploration methods for the live point evolution of the nested sampling [
8,
9,
11,
12]. More precisely, the main goal is the improvement the efficiency for the exploration of the parameter space where the likelihood function presents several local maxima.
Funding
This research received no external funding.
Acknowledgments
The author thanks the Alexander von Humboldt Foundation that provide the financing to attend the MaxEnt2019 conference. Moreover, the author would like to express once again his deep gratitude to Leopold M. Simons who introduced the author to the Bayesian data analysis and without whom this work could not have been started. The development of this program would not be possible without the close interactions and discussions with many collaborators that the author would like to thank as well: N. Winckler, R. Grisenti, A. Lévy, D. Gotta, Y. Litvinov, J. Machado, N. Paul and all members of the Pionic Hydrogen, FOCAL and GSI Oscillation collaborations and the ASUR group at INSP.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Skilling, J. Nested Sampling. AIP Conf. Proc. 2004, 735, 395–405. [Google Scholar]
- Sivia, D.S.; Skilling, J. Data Analysis: A Bayesian Tutorial, 2nd ed.; Oxford University Press: Oxford, UK, 2006. [Google Scholar]
- Skilling, J. Nested sampling for general Bayesian computation. Bayesian Anal. 2006, 1, 833–859. [Google Scholar] [CrossRef]
- Theisen, M. Analyse der Linienform von Röntgenübergängen nach der Bayesmethode. Master Thesis, Faculty of Mathematics, Computer Science and Natural Sciences, RWTH Aachen University, Aachen, Germany, 2013. [Google Scholar]
- Trassinelli, M. Bayesian data analysis tools for atomic physics. Nucl. Instrum. Methods B 2017, 408, 301–312. [Google Scholar] [CrossRef]
- Dierckx, P. Curve and Surface Fitting with Splines; Oxford University Press: Oxford, UK, 1995. [Google Scholar]
- Mukherjee, P.; Parkinson, D.; Liddle, A.R. A Nested Sampling Algorithm for Cosmological Model Selection. Astrophys. J. Lett. 2006, 638, L51. [Google Scholar] [CrossRef]
- Feroz, F.; Hobson, M.P. Multimodal nested sampling: An efficient and robust alternative to Markov Chain Monte Carlo methods for astronomical data analyses. Mon. Not. R. Astron. Soc. 2008, 384, 449–463. [Google Scholar] [CrossRef]
- Feroz, F.; Hobson, M.P.; Bridges, M. MultiNest: An efficient and robust Bayesian inference tool for cosmology and particle physics. Mon. Not. R. Astron. Soc. 2009, 398, 1601–1614. [Google Scholar] [CrossRef]
- Veitch, J.; Vecchio, A. Bayesian coherent analysis of in-spiral gravitational wave signals with a detector network. Phys. Rev. D 2010, 81, 062003. [Google Scholar] [CrossRef]
- Skilling, J. Bayesian computation in big spaces-nested sampling and Galilean Monte Carlo. AIP Conf. Proc. 2012, 1443, 145–156. [Google Scholar]
- Feroz, F.; Skilling, J. Exploring multi-modal distributions with nested sampling. AIP Conf. Proc. 2013, 1553, 106–113. [Google Scholar]
- Litvinov, Y.A.; Bosch, F.; Winckler, N.; Boutin, D.; Essel, H.G.; Faestermann, T.; Geissel, H.; Hess, S.; Kienle, P.; Knöbel, R.; et al. Observation of non-exponential orbital electron capture decays of hydrogen-like 140Pr and 142Pm ions. Phys. Lett. B 2008, 664, 162–168. [Google Scholar] [CrossRef]
- Kienle, P.; Bosch, F.; Bühler, P.; Faestermann, T.; Litvinov, Y.A.; Winckler, N.; Sanjari, M.; Shubina, D.; Atanasov, D.; Geissel, H.; et al. High-resolution measurement of the time-modulated orbital electron capture and of the decay of hydrogen-like 142Pm60+ ions. Phys. Lett. B 2013, 726, 638–645. [Google Scholar] [CrossRef]
- Ozturk, F.C.; Akkus, B.; Atanasov, D.; Beyer, H.; Bosch, F.; Boutin, D.; Brandau, C.; Bühler, P.; Cakirli, R.B.; Chen, R.J.; et al. Recision Test of Purely Exponential Electron Capture Decay of Hydrogen-Like 142 Pm Ions. arXiv 2019, preprint. arXiv:1907.06920. [Google Scholar]
- King, G.; Lovell, A.; Neufcourt, L.; Nunes, F. Direct Comparison between Bayesian and Frequentist Uncertainty Quantification for Nuclear Reactions. Phys. Rev. Lett. 2019, 122, 232502. [Google Scholar] [CrossRef] [PubMed]
- Trassinelli, M.; Kumar, A.; Beyer, H.F.; Indelicato, P.; Märtin, R.; Reuschl, R.; Stöhlker, T. Doppler-tuned Bragg spectroscopy of excited levels in He-like uranium: A discussion of the uncertainty contributions. J. Phys. CS 2009, 163, 012026. [Google Scholar] [CrossRef]
- Trassinelli, M.; Anagnostopoulos, D.F.; Borchert, G.; Dax, A.; Egger, J.P.; Gotta, D.; Hennebach, M.; Indelicato, P.; Liu, Y.W.; Manil, B.; et al. Measurement of the charged pion mass using X-ray spectroscopy of exotic atoms. Phys. Lett. B 2016, 759, 583–588. [Google Scholar] [CrossRef]
- Trassinelli, M.; Anagnostopoulos, D.; Borchert, G.; Dax, A.; Egger, J.P.; Gotta, D.; Hennebach, M.; Indelicato, P.; Liu, Y.W.; Manil, B.; et al. Measurement of the charged pion mass using a low-density target of light atoms. EPJ Web Conf. 2016, 130, 01022. [Google Scholar] [CrossRef]
- Papagiannouli, I.; Patanen, M.; Blanchet, V.; Bozek, J.D.; de Anda Villa, M.; Huttula, M.; Kokkonen, E.; Lamour, E.; Mevel, E.; Pelimanni, E.; et al. Depth Profiling of the Chemical Composition of Free-Standing Carbon Dots Using X-ray Photoelectron Spectroscopy. J. Phys. Chem. A 2018, 122, 14889–14897. [Google Scholar] [CrossRef]
- Villa, M.D.A.; Gaudin, J.; Amans, D.; Boudjada, F.; Bozek, J.; Grisenti, R.E.; Lamour, E.; Laurens, G.; Macé, S.; Nicolas, C.; et al. Assessing the surface oxidation state of free-standing gold nanoparticles produced by laser ablation. Langmuir 2019. submitted. [Google Scholar]
| Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2019 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).



{kind=link}
{kind=link}
{kind=link}