Multimodal Sensor Data Fusion for Activity Recognition Using Filtered Classifier †




Abstract
:1. Introduction
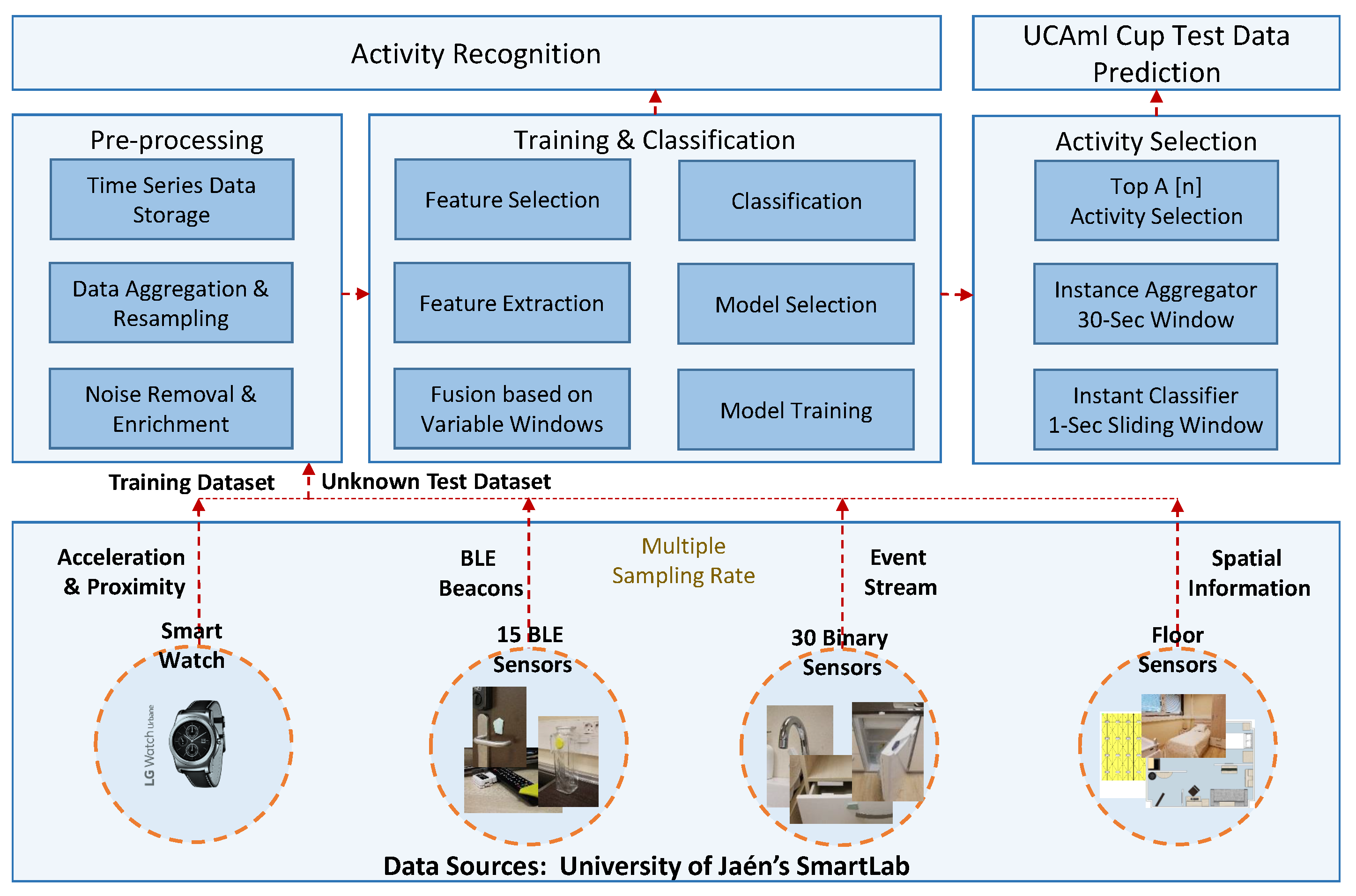
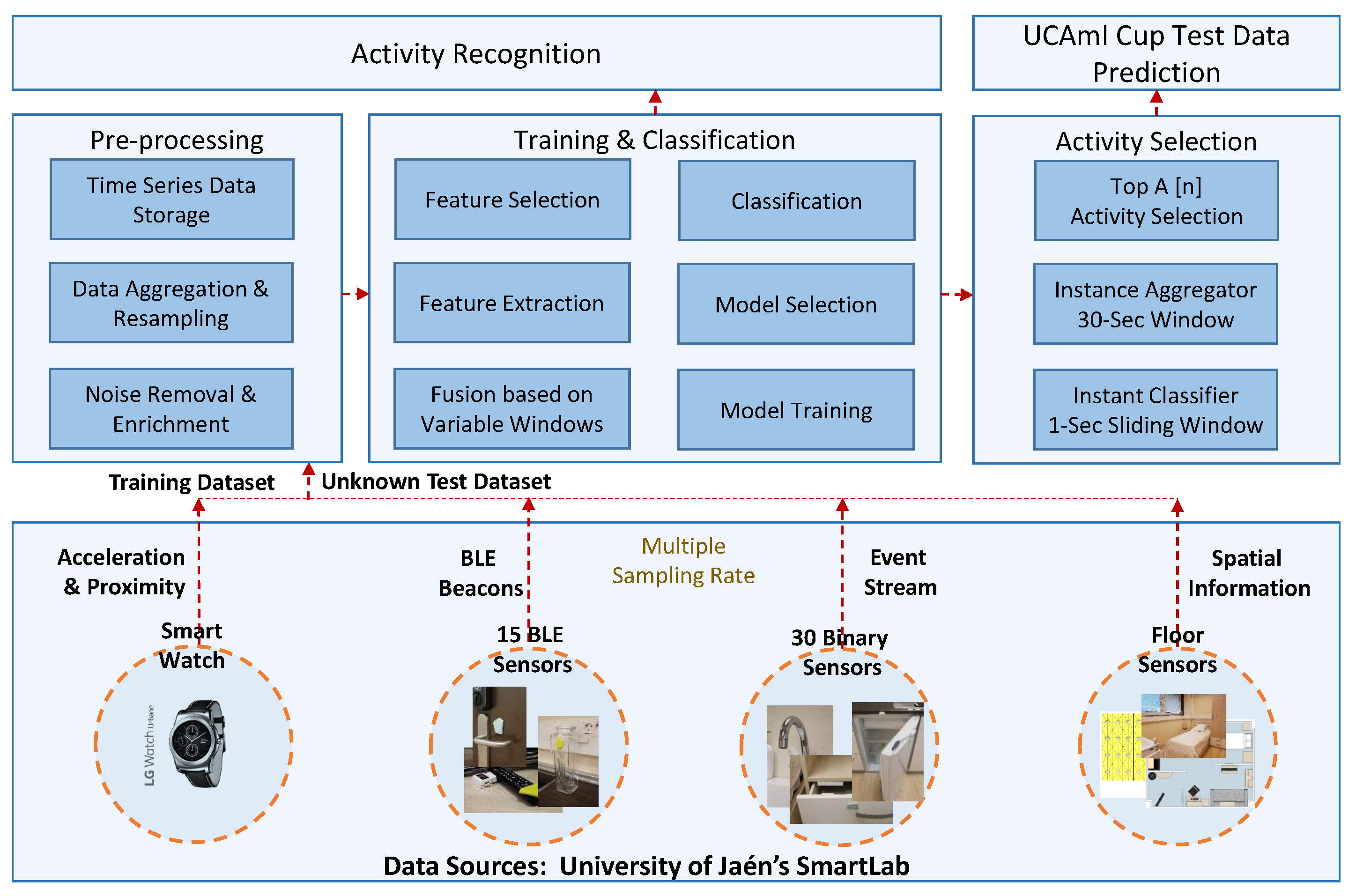
2. Methodology
2.1. Dataset Description
2.1.1. Binary Sensor Event Streams
2.1.2. Spatial Data
2.1.3. Proximity Data and Bluetooth Beacons
2.1.4. Acceleration Data
2.2. UCAmI Cup Challenge Design
Main Tasks
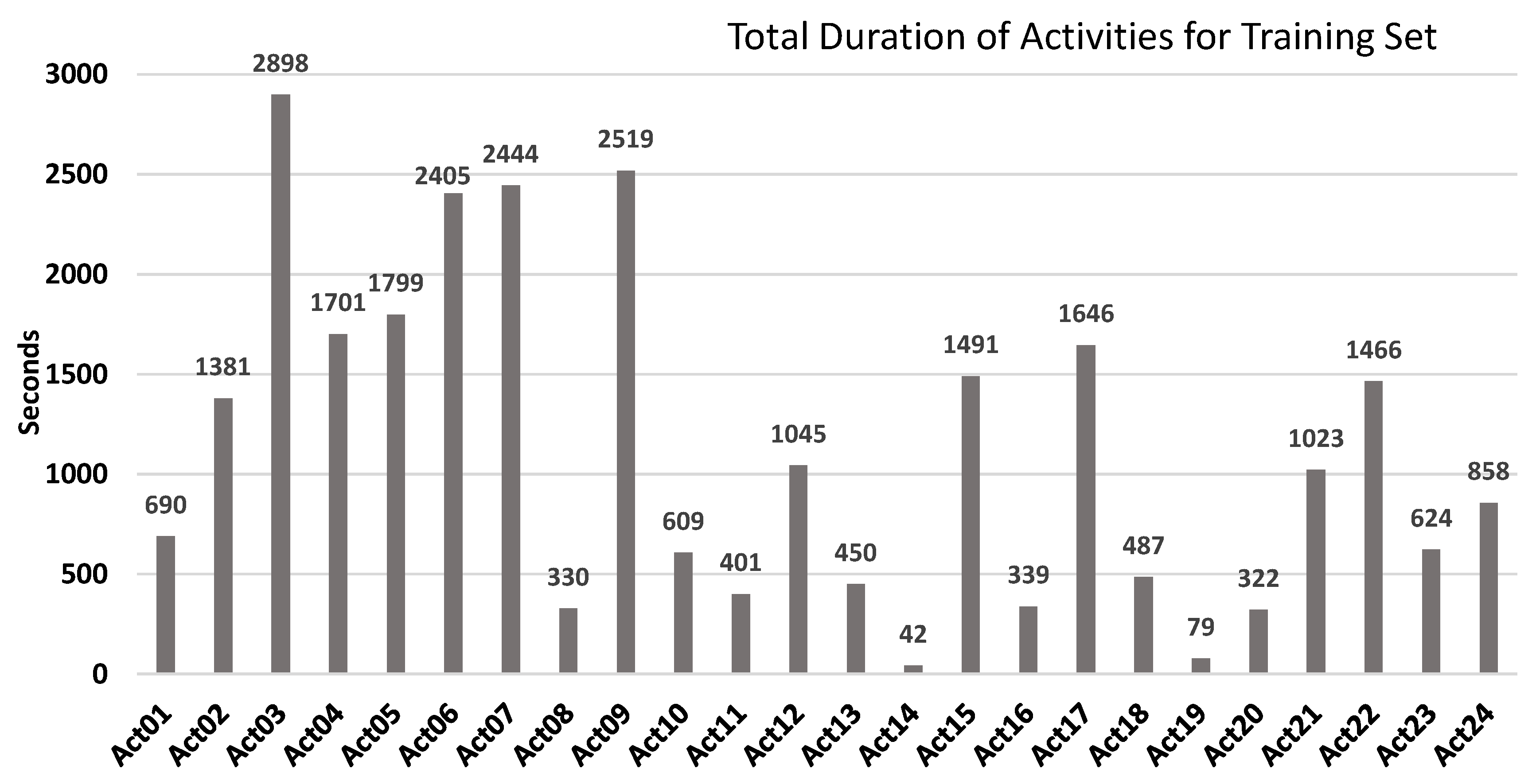
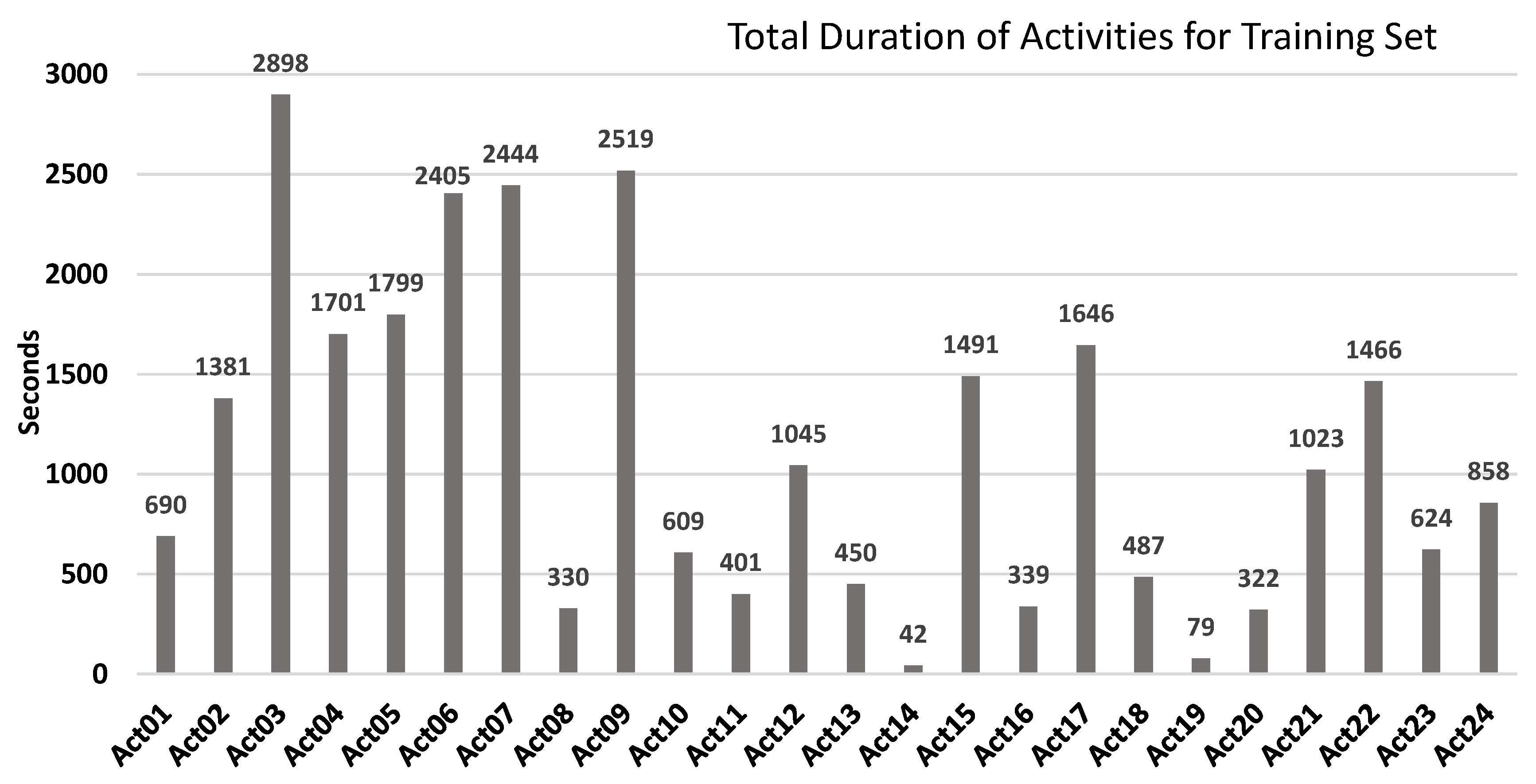
- Labelled training dataset with seven days of recordings that contained 169 instances followed by different daily life routines.
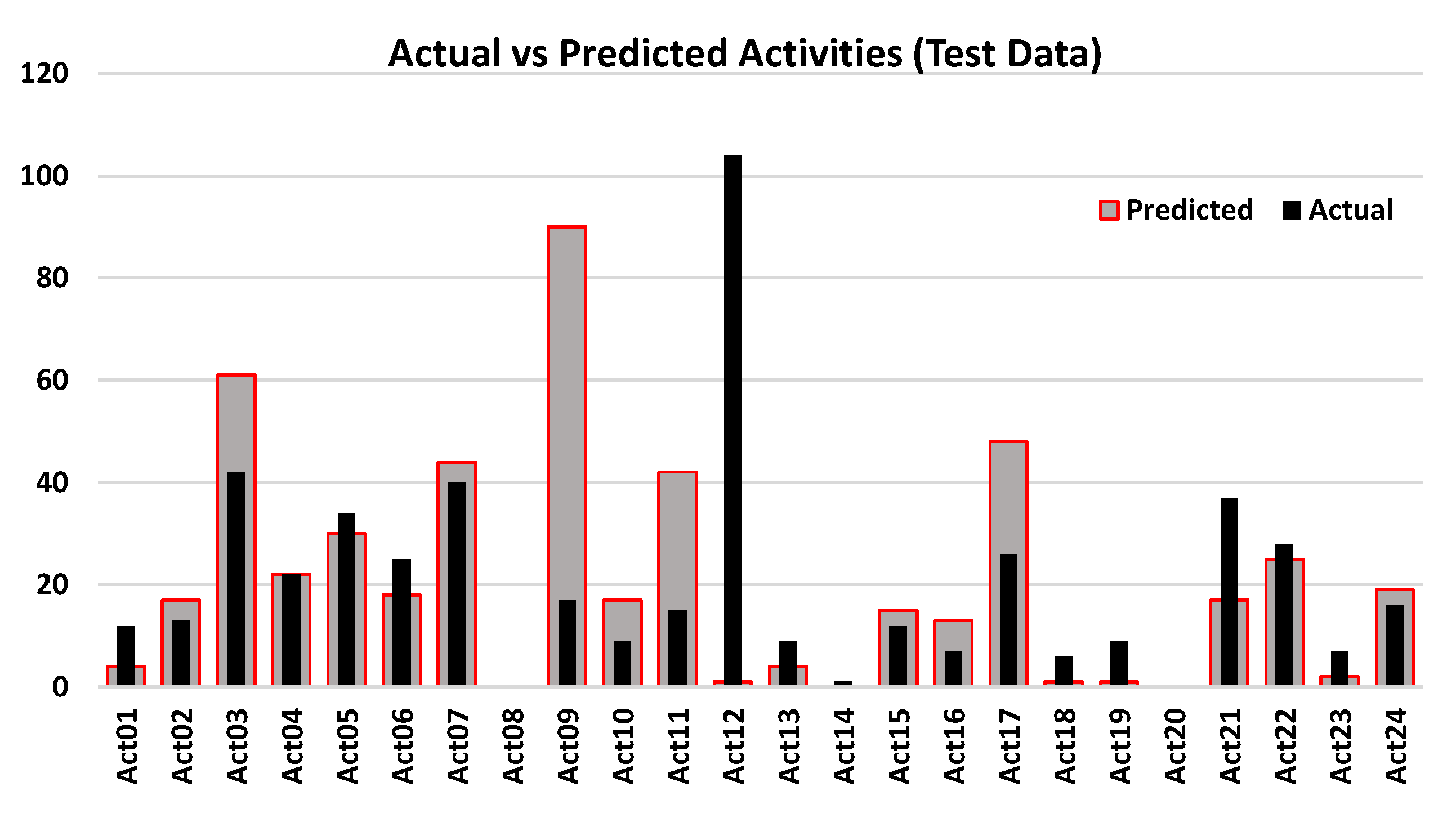
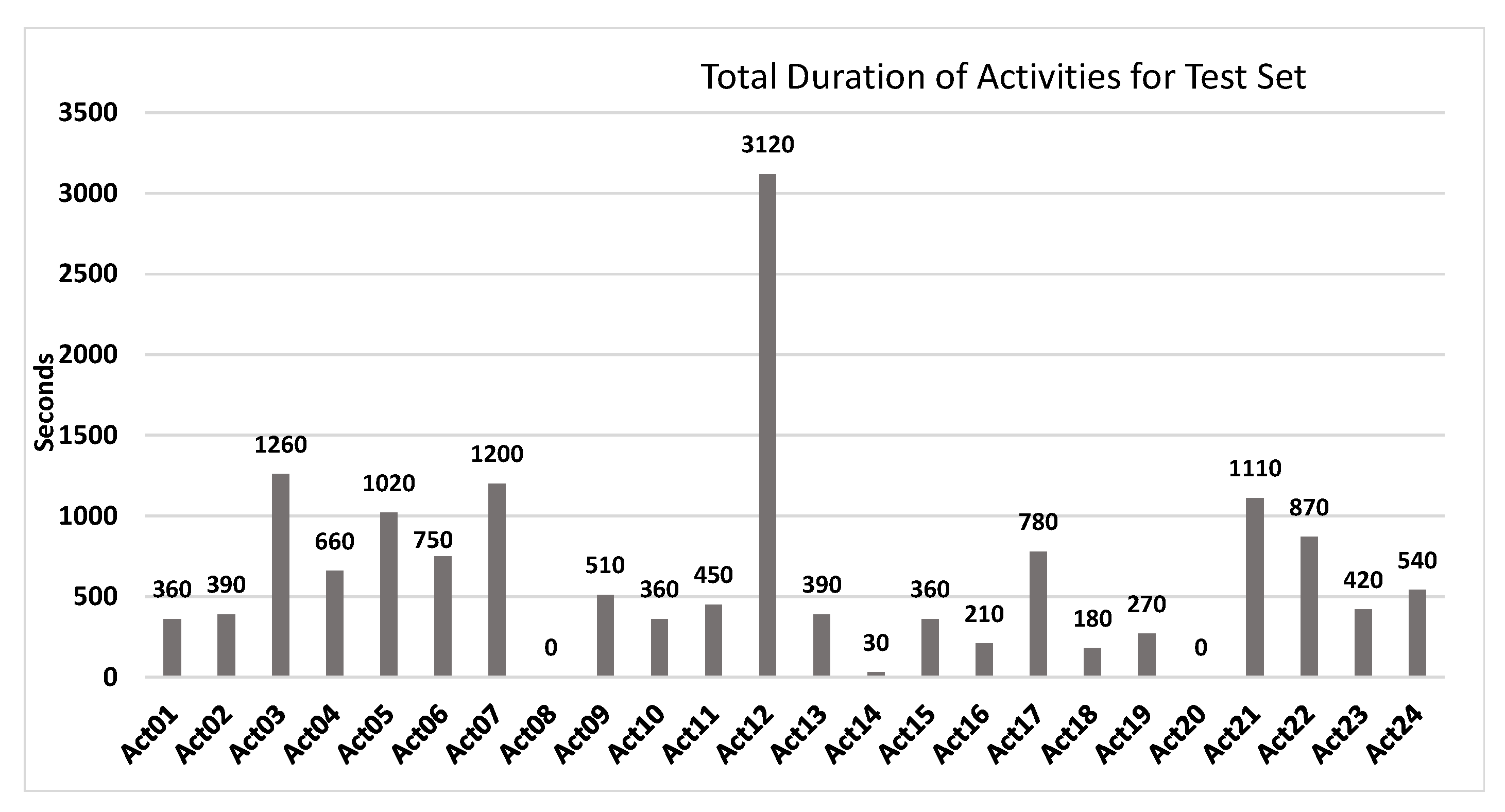
- Unlabelled test dataset with three days of recordings that contained 77 instances obtained by following a set of daily life routines.
2.3. Activity Recognition Methods
2.3.1. Data Alignment & Mapping
2.3.2. Data Preprocessing
2.3.3. Experimental Implementation
| Algorithm 1: Data alignment and re-sampling algorithm for UJAmI Smart Lab dataset (D) |
 |
2.3.4. Classification
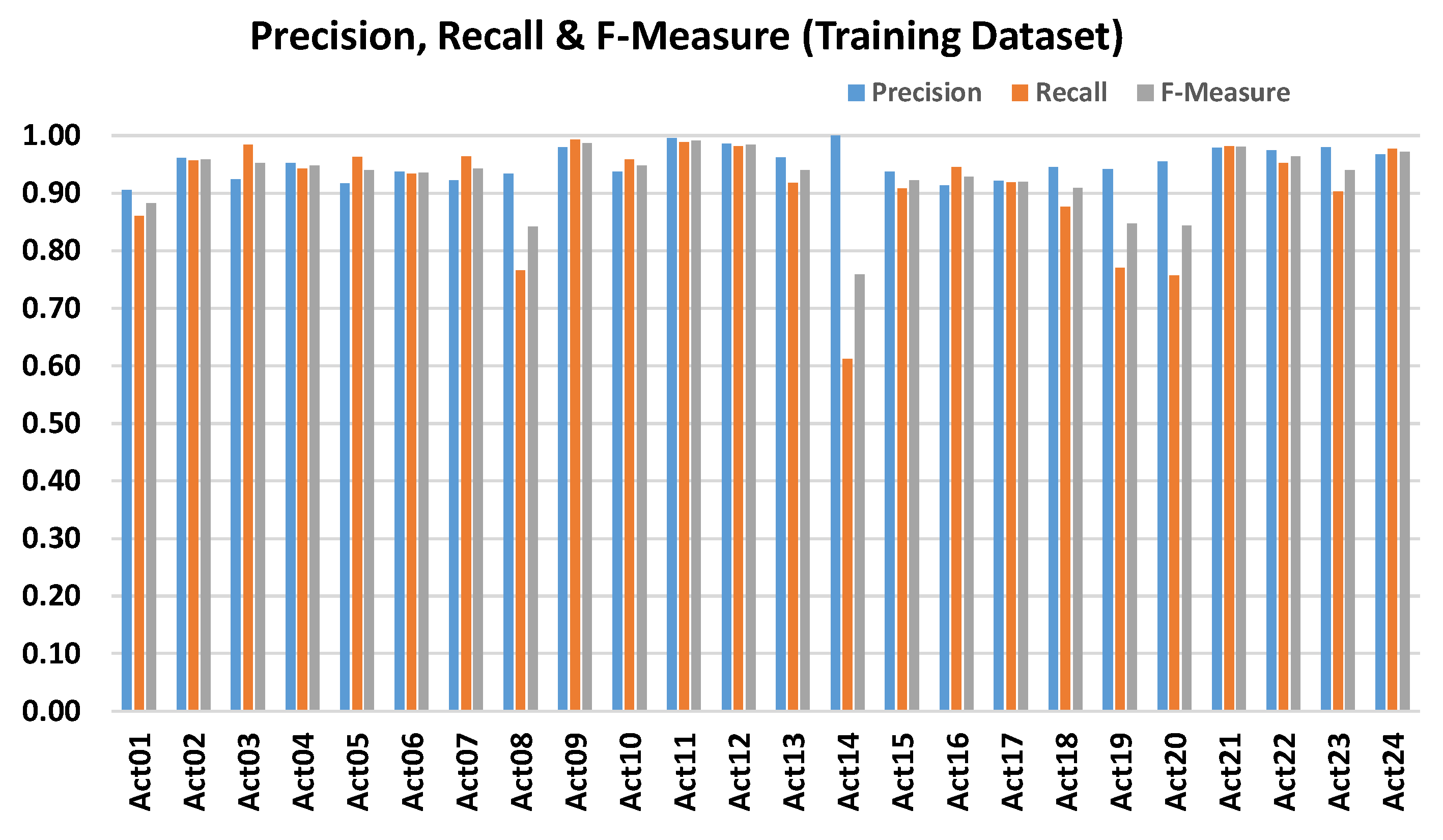
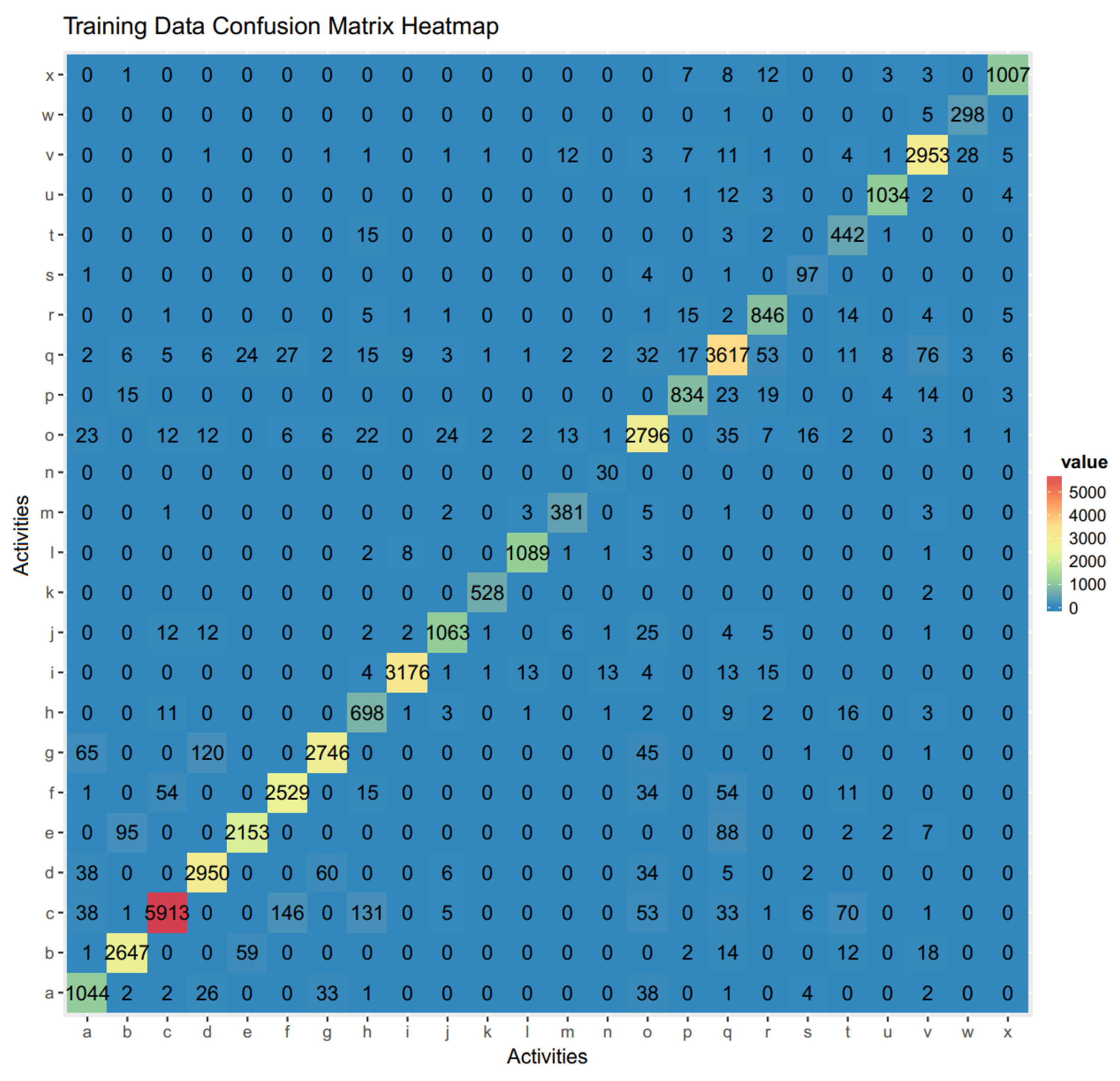
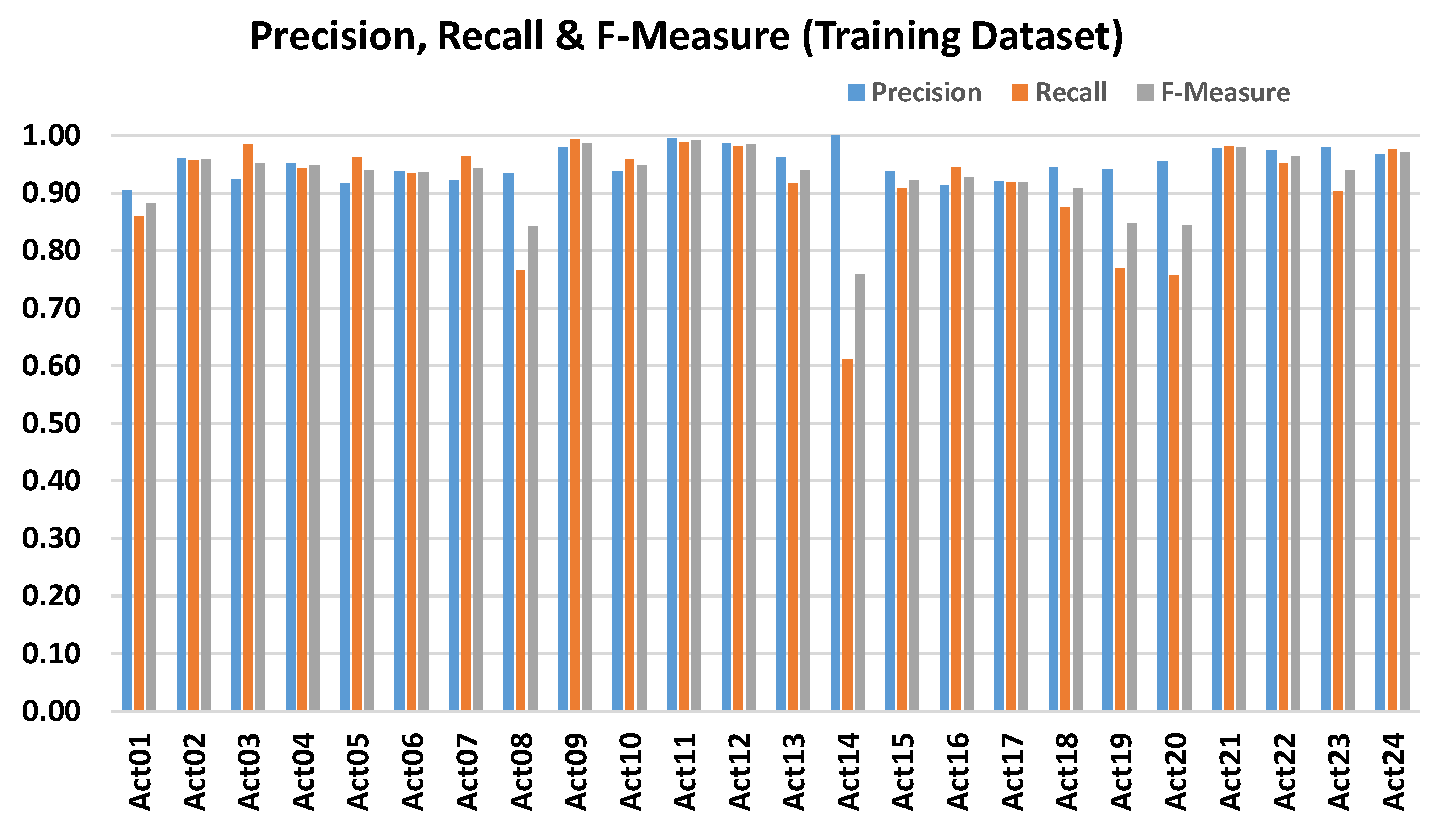
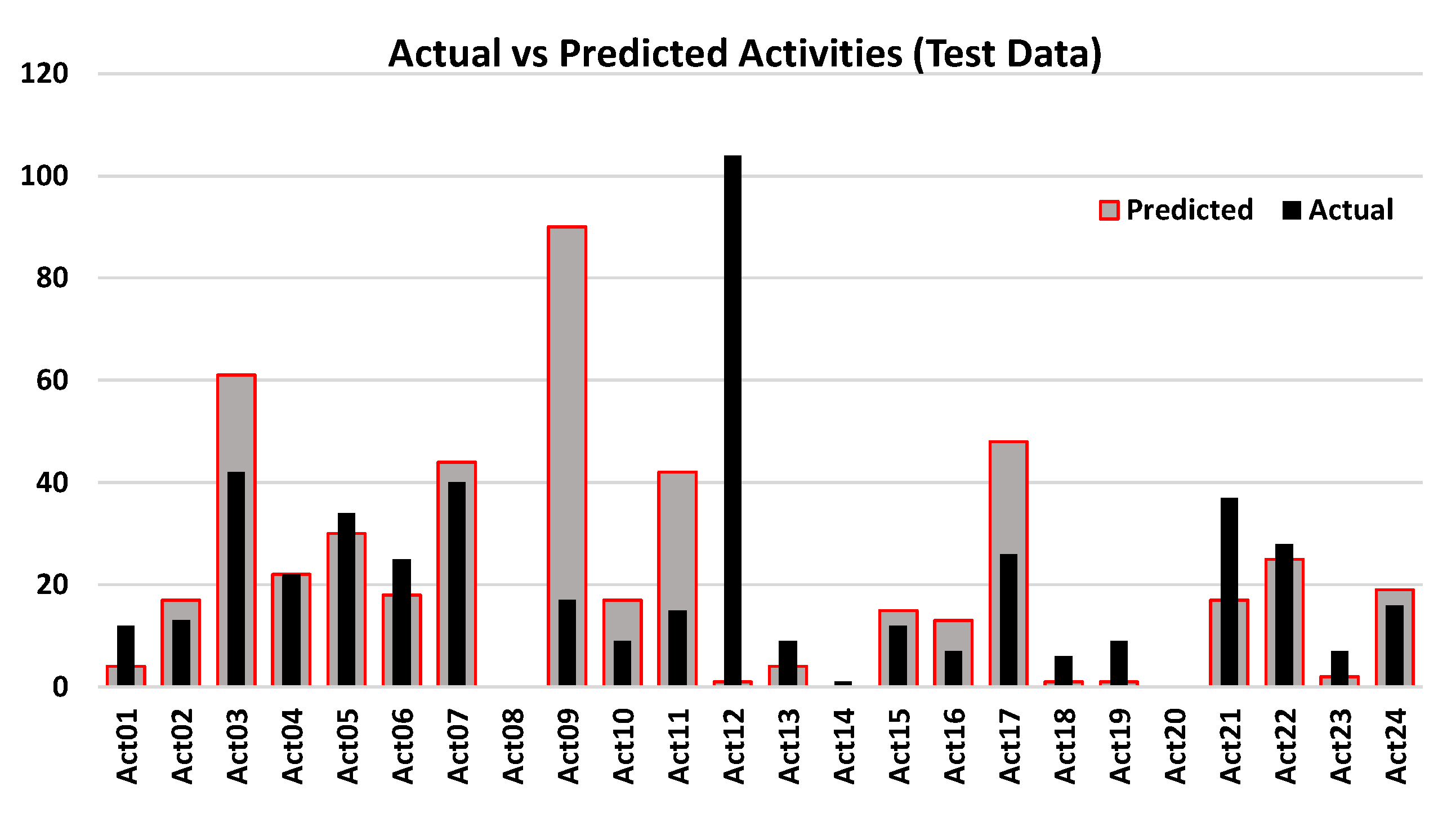
3. Results and Discussion
Performance Evaluation
4. Conclusions and Future Work
Author Contributions
Acknowledgments
Conflicts of Interest
Abbreviations
| ADL | Activities of Daily Living |
| AR | Activity Recognition |
| UJAmI | University of Jaén Ambient Intelligence |
| ML | Machine-Learned |
References
- Chen, J.; Zhang, Q. Distinct Sampling on Streaming Data with Near-Duplicates. In Proceedings of the 35th ACM SIGMOD-SIGACT-SIGAI Symposium on Principles of Database Systems, Houston, TX, USA, 10–15 June 2018; pp. 369–382. [Google Scholar]
- Espinilla, M.; Medina, J.; Hallberg, J.; Nugent, C. A new approach based on temporal sub-windows for online sensor-based activity recognition. J. Ambient Intell. Humaniz. Comput. 2018, 1–13. [Google Scholar] [CrossRef]
- Fahim, M.; Baker, T.; Khattak, A.M.; Shah, B.; Aleem, S.; Chow, F. Context Mining of Sedentary Behaviour for Promoting Self-Awareness Using a Smartphone. Sensors 2018, 18, 874. [Google Scholar] [CrossRef] [PubMed]
- Song, G.; Qu, W.; Liu, X.; Wang, X. Approximate Calculation of Window Aggregate Functions via Global Random Sample. Data Sci. Eng. 2018, 3, 40–51. [Google Scholar] [CrossRef]
- Haas, P.J. Data-stream sampling: Basic techniques and results. In Data Stream Management; Springer: Berlin, Germany, 2016; pp. 13–44. [Google Scholar]
- Yamansavaşçılar, B.; Güvensan, M.A. Activity recognition on smartphones: Efficient sampling rates and window sizes. In Proceedings of the 2016 IEEE International Conference on IEEE Pervasive Computing and Communication Workshops (PerCom Workshops), Sydney, Australia, 14–18 March 2016; pp. 1–6. [Google Scholar]
- Braverman, V.; Ostrovsky, R.; Zaniolo, C. Optimal sampling from sliding windows. J. Comput. Syst. Sci. 2012, 78, 260–272. [Google Scholar] [CrossRef]
- Wu, K.L.; Xia, Y. Adaptive Sampling Schemes for Clustering Streaming Graphs. U.S. Patent 9,886,521, 6 February 2018. [Google Scholar]
- Hentschel, B.; Haas, P.J.; Tian, Y. Temporally-Biased Sampling for Online Model Management. arXiv 2018, arXiv:1801.09709. [Google Scholar] [CrossRef]
- Gravina, R.; Alinia, P.; Ghasemzadeh, H.; Fortino, G. Multi-sensor fusion in body sensor networks: State-of-the-art and research challenges. Inf. Fusion 2017, 35, 68–80. [Google Scholar] [CrossRef]
- Tschumitschew, K.; Klawonn, F. Effects of drift and noise on the optimal sliding window size for data stream regression models. Commun. Stat.-Theory Methods 2017, 46, 5109–5132. [Google Scholar] [CrossRef]
- Krishnan, N.C.; Cook, D.J. Activity recognition on streaming sensor data. Pervasive Mob. Comput. 2014, 10, 138–154. [Google Scholar] [CrossRef] [PubMed]
- Figo, D.; Diniz, P.C.; Ferreira, D.R.; Cardoso, J.M. Preprocessing techniques for context recognition from accelerometer data. Pers. Ubiquitous Comput. 2010, 14, 645–662. [Google Scholar] [CrossRef]
- Razzaq, M.A.; Villalonga, C.; Lee, S.; Akhtar, U.; Ali, M.; Kim, E.S.; Khattak, A.M.; Seung, H.; Hur, T.; Bang, J.; et al. mlCAF: Multi-Level Cross-Domain Semantic Context Fusioning for Behavior Identification. Sensors 2017, 17, 2433. [Google Scholar] [CrossRef] [PubMed]
- Banos, O.; Galvez, J.M.; Damas, M.; Pomares, H.; Rojas, I. Window size impact in human activity recognition. Sensors 2014, 14, 6474–6499. [Google Scholar] [CrossRef] [PubMed]
- Lai, X.; Liu, Q.; Wei, X.; Wang, W.; Zhou, G.; Han, G. A survey of body sensor networks. Sensors 2013, 13, 5406–5447. [Google Scholar] [CrossRef] [PubMed]
- UJAmI. Available online: http://ceatic.ujaen.es/ujami/sites/default/files/2018-07/UCAmI20Cup.zip (accessed on 11 September 2018).
- UCAmI Cup 2018. Available online: http://mamilab.esi.uclm.es/ucami2018/UCAmICup.html (accessed on 11 September 2018).
- Bulling, A.; Blanke, U.; Schiele, B. A tutorial on human activity recognition using body-worn inertial sensors. ACM Comput. Surv. (CSUR) 2014, 46, 33. [Google Scholar] [CrossRef]
- Yang, J.; Nguyen, M.N.; San, P.P.; Li, X.; Krishnaswamy, S. Deep Convolutional Neural Networks on Multichannel Time Series for Human Activity Recognition. In Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence (IJCAI 2015), Buenos Aires, Argentina, 25–31 July 2015; Volume 15, pp. 3995–4001. [Google Scholar]
- Dernbach, S.; Das, B.; Krishnan, N.C.; Thomas, B.L.; Cook, D.J. Simple and complex activity recognition through smart phones. In Proceedings of the 2012 8th International Conference on Intelligent Environments (IE), Guanajuato, Mexico, 26–29 June 2012; pp. 214–221. [Google Scholar]
- Python. Available online: https://www.python.org/ (accessed on 11 September 2018).
- MySQL. Available online: https://www.mysql.com/ (accessed on 11 September 2018).
- Weka. Available online: https://www.cs.waikato.ac.nz/ml/weka/ (accessed on 11 September 2018).
- Walton, E.; Casey, C.; Mitsch, J.; Vázquez-Diosdado, J.A.; Yan, J.; Dottorini, T.; Ellis, K.A.; Winterlich, A.; Kaler, J. Evaluation of sampling frequency, window size and sensor position for classification of sheep behaviour. R. Soc. Open Sci. 2018, 5, 171442. [Google Scholar] [CrossRef] [PubMed]
- Van der Gaag, M.; Hoffman, T.; Remijsen, M.; Hijman, R.; de Haan, L.; van Meijel, B.; van Harten, P.N.; Valmaggia, L.; De Hert, M.; Cuijpers, A.; et al. The five-factor model of the Positive and Negative Syndrome Scale II: A ten-fold cross-validation of a revised model. Schizophr. R. 2006, 85, 280–287. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ID | Activity Name | ID | Activity Name | ID | Activity Name |
|---|---|---|---|---|---|
| Act01 | Take medication | Act09 | Watch TV | Act17 | Brush teeth |
| Act02 | Prepare breakfast | Act10 | Enter the SmartLab | Act18 | Use the toilet |
| Act03 | Prepare lunch | Act11 | Play a videogame | Act19 | Wash dishes |
| Act04 | Prepare dinner | Act12 | Relax on the sofa | Act20 | Put washing into the washing machine |
| Act05 | Breakfast | Act13 | Leave the SmarLab | Act21 | Work at the table |
| Act06 | Lunch | Act14 | Visit in the SmartLab | Act22 | Dressing |
| Act07 | Dinner | Act15 | Put waste in the bin | Act23 | Go to the bed |
| Act08 | Eat a snack | Act16 | Wash hands | Act24 | Wake up |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Razzaq, M.A.; Cleland, I.; Nugent, C.; Lee, S. Multimodal Sensor Data Fusion for Activity Recognition Using Filtered Classifier. Proceedings 2018, 2, 1262. https://doi.org/10.3390/proceedings2191262
Razzaq MA, Cleland I, Nugent C, Lee S. Multimodal Sensor Data Fusion for Activity Recognition Using Filtered Classifier. Proceedings. 2018; 2(19):1262. https://doi.org/10.3390/proceedings2191262
Chicago/Turabian StyleRazzaq, Muhammad Asif, Ian Cleland, Chris Nugent, and Sungyoung Lee. 2018. "Multimodal Sensor Data Fusion for Activity Recognition Using Filtered Classifier" Proceedings 2, no. 19: 1262. https://doi.org/10.3390/proceedings2191262
APA StyleRazzaq, M. A., Cleland, I., Nugent, C., & Lee, S. (2018). Multimodal Sensor Data Fusion for Activity Recognition Using Filtered Classifier. Proceedings, 2(19), 1262. https://doi.org/10.3390/proceedings2191262