Abstract
Ground-Penetrating Radar is a non-destructive tool for detecting subsurface structures. However, traditional image interpretation is often limited by medium complexity and noise. To improve detection efficiency and accuracy, this study combines deep learning techniques to develop an automatic embankment cavity identification system based on the YOLOv10 model. The research first constructs a training dataset containing GPR images of embankment cavities and expands the dataset through data augmentation strategies to enhance model adaptability. Subsequently, cross-validation is employed to fine-tune the hyperparameters of the YOLOv10 model, seeking optimal performance. The experimental results demonstrate that the YOLOv10 model successfully identifies cavities in radar images, achieving accuracy rates of nearly 90% and 97%. This study proves the potential of deep learning in GPR image analysis, effectively improving detection efficiency, accuracy, and automation levels, providing more reliable technical support for embankment safety inspection.
1. Research Motivation and Objectives
Ground-Penetrating Radar is a non-destructive testing technique used to detect subsurface targets such as underground structures, pipelines, and cavities. Although GPR has clear advantages in detecting buried objects, challenges remain in processing and analyzing radar images due to the complexity of subsurface media and interference from noise. The interpretation process is often labor-intensive and involves several pre-processing steps, including filtering and background removal. Moreover, the interpretation heavily relies on engineers’ experience to visually inspect anomalies within the radar images and make judgments based on professional knowledge. This manual approach not only increases the time required for interpretation but also introduces subjectivity, as results may vary depending on individual expertise. Consequently, this affects detection accuracy and leads to low operational efficiency and inconsistency in identification outcomes. This study explores the integration of Ground-Penetrating Radar (GPR) with the YOLOv10 object detection algorithm in deep learning to develop a technique for the automatic identification of embankment cavities. The primary goal is to enhance the accuracy and operational stability of image interpretation through automation. The research encompasses the optimization of the model training process, the construction and annotation of GPR image datasets, and the integration of image processing and detection models to establish a complete automated workflow. By training on a large volume of image data and fine-tuning model parameters, the system aims to improve the accuracy and generalizability of cavity feature recognition. Simultaneously, it reduces the time required for analysis and minimizes reliance on manual interpretation, thereby enhancing inspection efficiency and consistency.
2. Materials and Methods
In this study, a dataset of Ground-Penetrating Radar (GPR) images depicting embankment cavities and pipelines was first collected and established. Data augmentation techniques such as image rotation and mirroring were applied to expand the dataset and enhance model adaptability. After image annotation using LabelImg, multiple hyperparameter experiments were conducted with the YOLOv10 model, adjusting training parameters such as batch size, epochs, and input image size (imgsz) to improve performance. Cross-validation was used to evaluate the model’s effectiveness, and the optimal parameter configuration was selected as the baseline for subsequent recognition tasks. In addition, the YOLOv4 model was adopted as a benchmark for comparative analysis. Model performance was assessed through multiple metrics, including accuracy, recall, and F1-score, to examine the impact of different training volumes and preprocessing strategies.
Given that the primary detection targets—subsurface cavities—often exhibit vague boundary features in radar images, traditional evaluation using the mean Average Precision (mAP) metric based on bounding box overlap may be overly stringent. To address this, the YOLO model’s prediction results were exported into MATLAB R2024b, where evaluations were recalculated based on the actual physical dimensions represented in radar images. This approach offers a more application-relevant assessment of model performance, as illustrated in Figure 1.
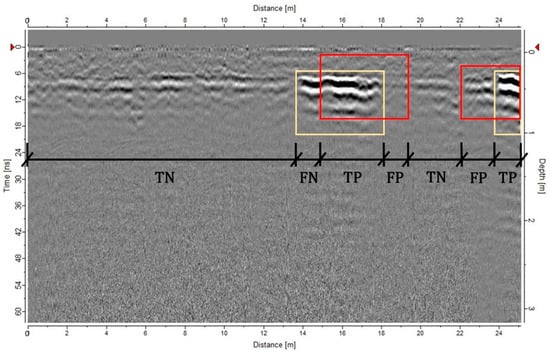
Figure 1.
Standard for calculating metrics based on radar image length (yellow box: ground truth; red box: model prediction).
3. Testing Results Analysis
3.1. The Impact of Training Epochs on Model Performance
This study investigates the impact of training epochs—one of the key hyperparameters in the YOLOv10 model—on detection performance for various types of Ground-Penetrating Radar (GPR) images. The model was trained using epoch values of 50, 150, and 300, and evaluated under different image complexity levels (clearly visible targets, recognizable targets, and complex images). The goal was to assess the trade-off between accuracy and computational efficiency. As shown in Table 1 and Figure 2, increasing the number of epochs from 50 to 150 led to significant improvements in Accuracy, Precision, Recall, and F1-score, with the most notable gains observed in Recall and F1-score. Specifically, the F1-score for clearly visible images improved from 72% to 95%, while recognizable images saw an increase from 89% to 93%. However, further increasing the epoch count to 300 yielded only marginal performance gains while significantly increasing training time and computational resource consumption. Considering both model accuracy and computational cost, the results indicate that an epoch setting of 150 provides an optimal balance between training efficiency and detection performance. This configuration demonstrates sufficient flexibility to meet detection requirements under varying GPR image conditions.

Table 1.
Test results of different Epoch hyperparameters across image categories.
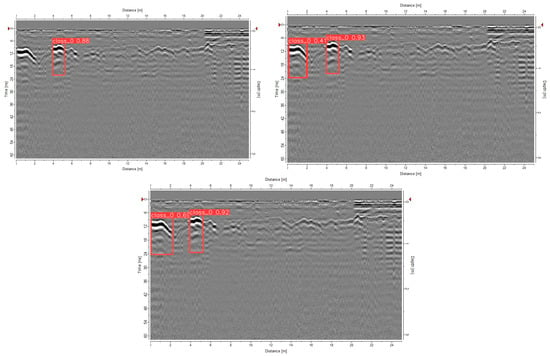
Figure 2.
Test results for different Epoch hyperparameters (Hyperparameter epoch = 50, 150, 300).
3.2. Analysis of the Impact of Training Data Volume on Model Performance
This study investigates the impact of training dataset size on the detection performance of the YOLOv10 model for Ground-Penetrating Radar images. With all hyperparameters held constant, the model was trained using datasets ranging from 100 to 1268 images. The corresponding variations in Accuracy, Precision, Recall, and F1-score were observed. As shown in Table 2 and Figure 3, the overall detection performance improved significantly with increasing training data volume. When trained with only 100 images, the model failed to effectively learn representative features, resulting in an Accuracy of merely 20% and an F1-score of 33%, indicating evident underfitting. As the training set increased to 500 images, performance improved substantially. However, when further expanded to 750 images, although Accuracy continued to rise, Precision declined and the F1-score fluctuated, suggesting the presence of over-detection—more predicted bounding boxes accompanied by a higher false positive rate, reducing the matching accuracy. Upon increasing the dataset to 1002 and 1268 images, the model’s performance stabilized, and all metrics approached saturation, indicating that the model had effectively learned and recognized anomaly patterns within GPR images. Overall, the results reveal a strong positive correlation between training data volume and model performance. Increasing the quantity of representative training data significantly enhances model learning stability and detection accuracy, while reducing misclassification rates. Thus, a sufficient and well-annotated dataset is essential for improving the recognition capability of radar images.
Table 2.
Evaluation results for different numbers of training samples.
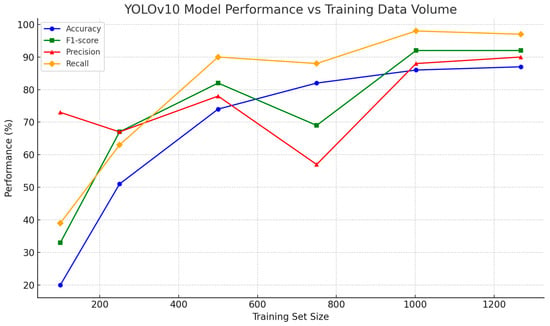
Figure 3.
Performance metrics trends under different training data sizes.
4. Conclusions
This study conducted a comprehensive series of hyperparameter adjustments and training strategy optimizations for the YOLOv10 model, aiming to enhance its performance in detecting voids and pipelines within Ground-Penetrating Radar (GPR) images. Initially, key hyperparameters of the model were systematically tuned to identify the most suitable configuration for void feature detection. After optimization, YOLOv10 was compared with the conventional YOLOv4 architecture under identical dataset conditions to evaluate performance differences. The results demonstrated that YOLOv10 achieved an accuracy of 97% to 99% in void detection, indicating high sensitivity and stability toward such anomalies. In pipeline detection, the model also achieved approximately 90% precision, confirming its robustness in multi-object detection. Additionally, the study examined the effect of training data volume on model performance and found a positive correlation: increasing the number of training samples led to improvements in both accuracy and stability. In conclusion, the experimental results affirm that the YOLOv10 model holds strong potential in the automated identification of voids and pipelines in GPR imagery. It not only improves detection efficiency but also serves as a valuable tool to assist professionals in preliminary interpretation, laying a solid foundation for future integration into automated analysis workflows.
Author Contributions
Conceptualization, K.-T.H. and Y.-W.W.; Methodology, Y.-W.W.; Software, Y.-W.W.; Validation, Y.-W.W.; Formal analysis, Y.-W.W.; Investigation, Y.-W.W.; Resources, K.-T.H.; Data curation, Y.-W.W.; Writing—original draft preparation, Y.-W.W.; Writing—review and editing, K.-T.H.; Visualization, K.-T.H.; Supervision, K.-T.H.; Project administration, K.-T.H.; Funding acquisition, K.-T.H. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data that support the findings of this study are available from the corresponding author upon reasonable request.
Conflicts of Interest
The authors declare no conflict of interest.
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).