Cognitive Computing Architectures for Machine (Deep) Learning at Scale †

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
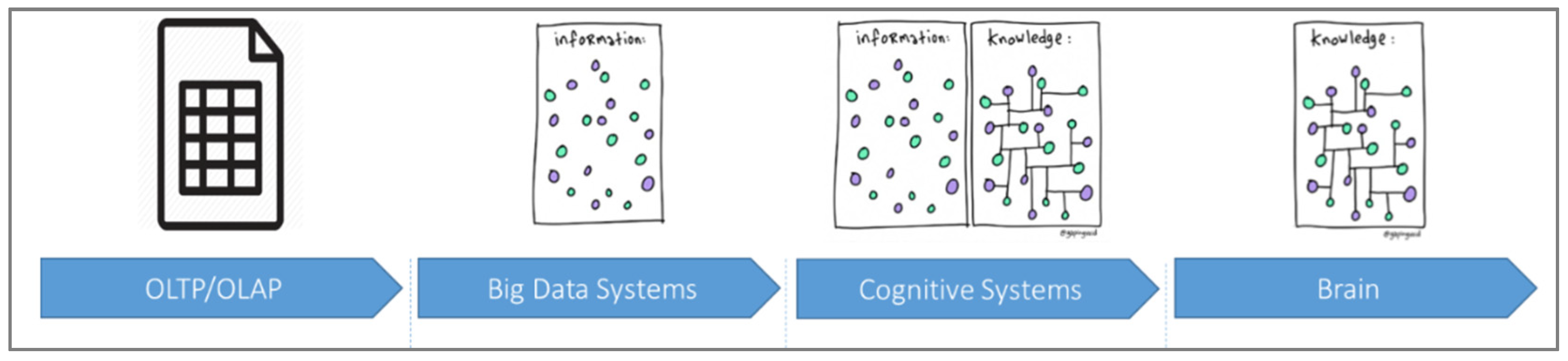
:1. Introduction
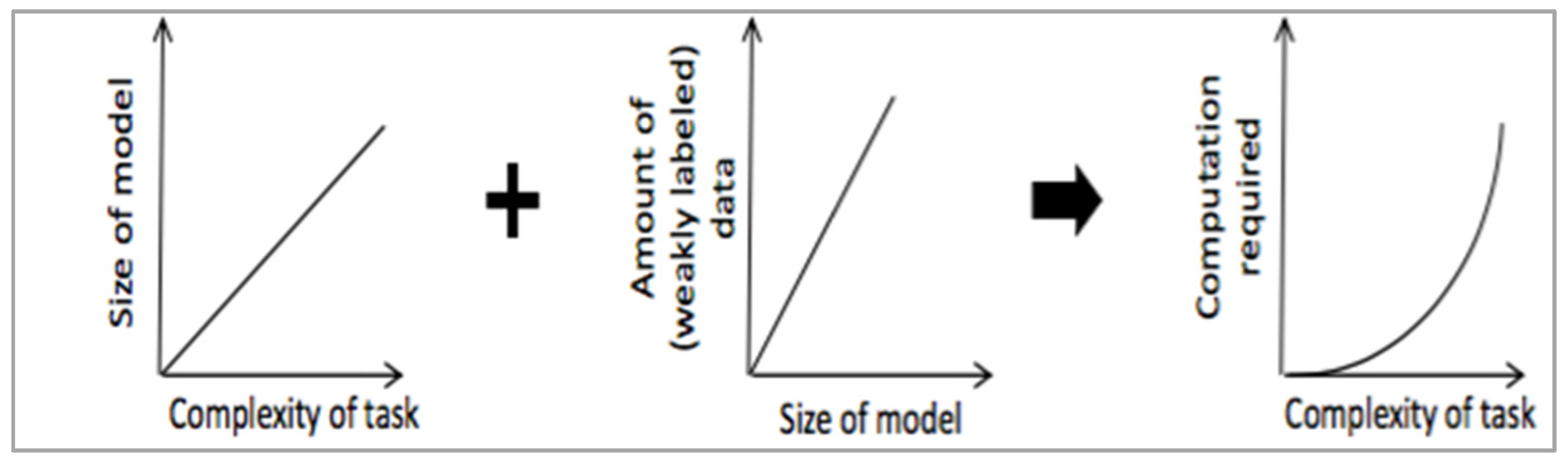
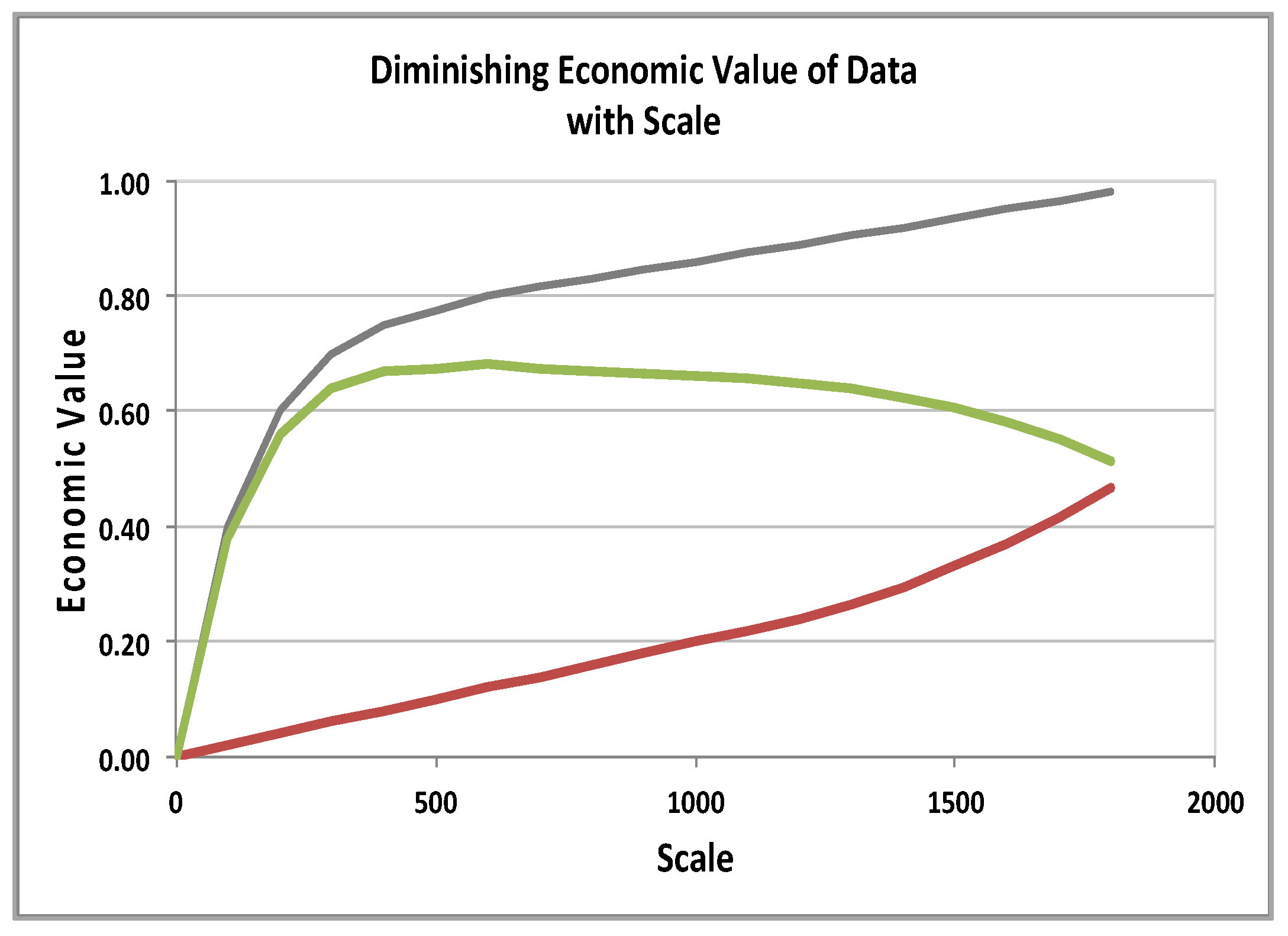
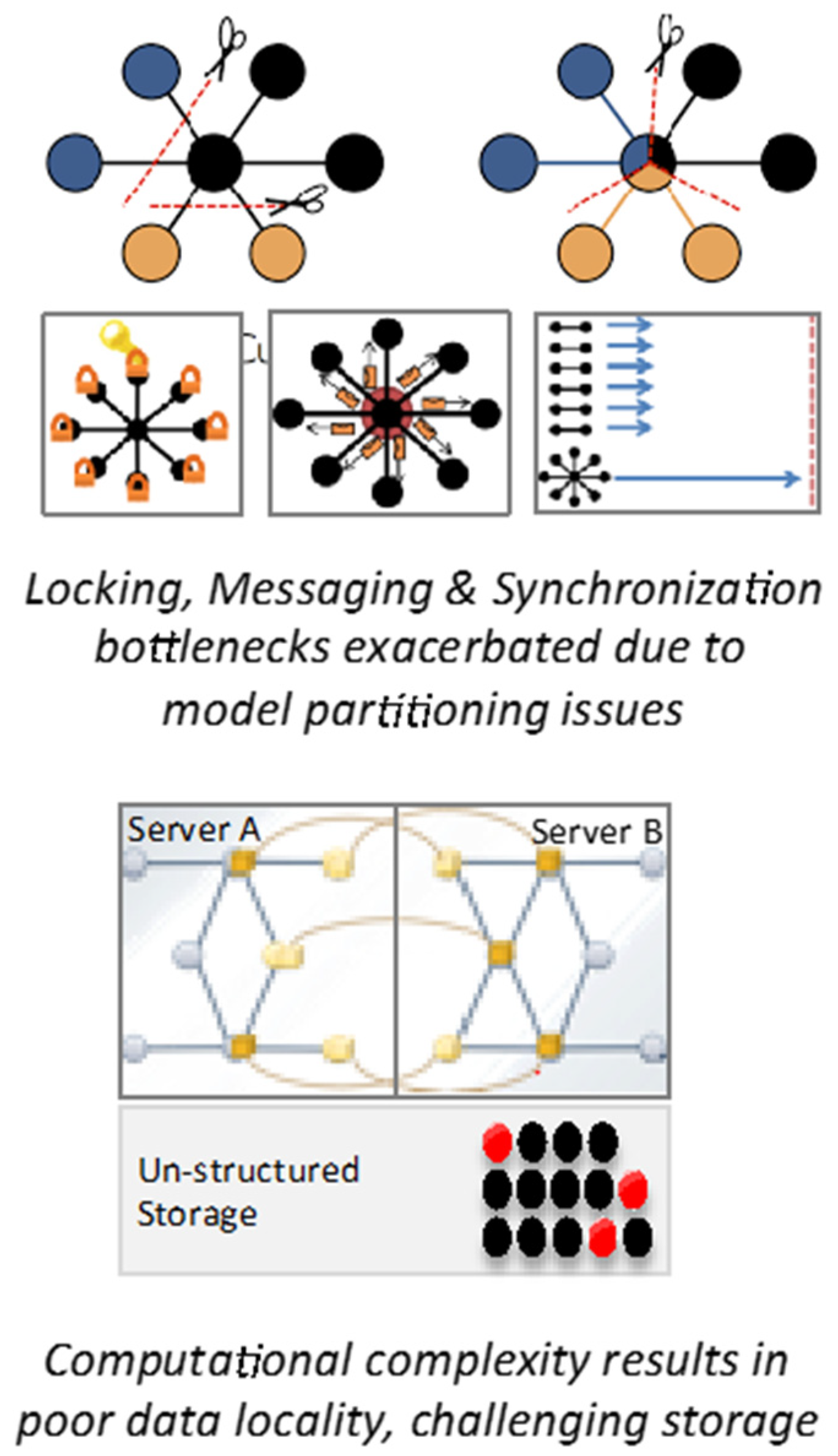
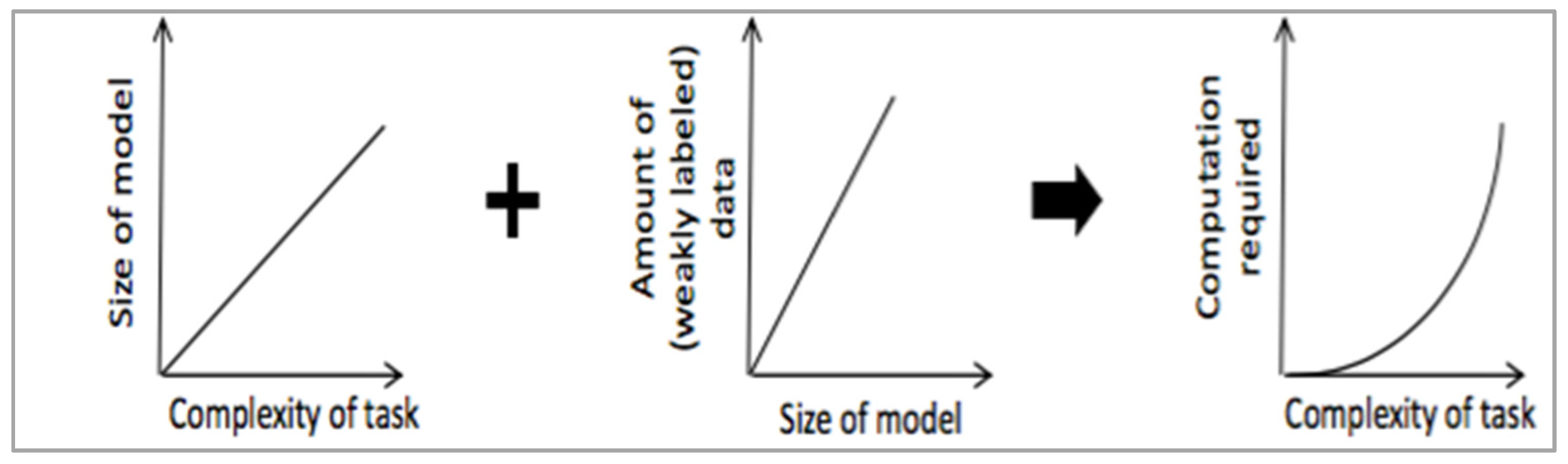
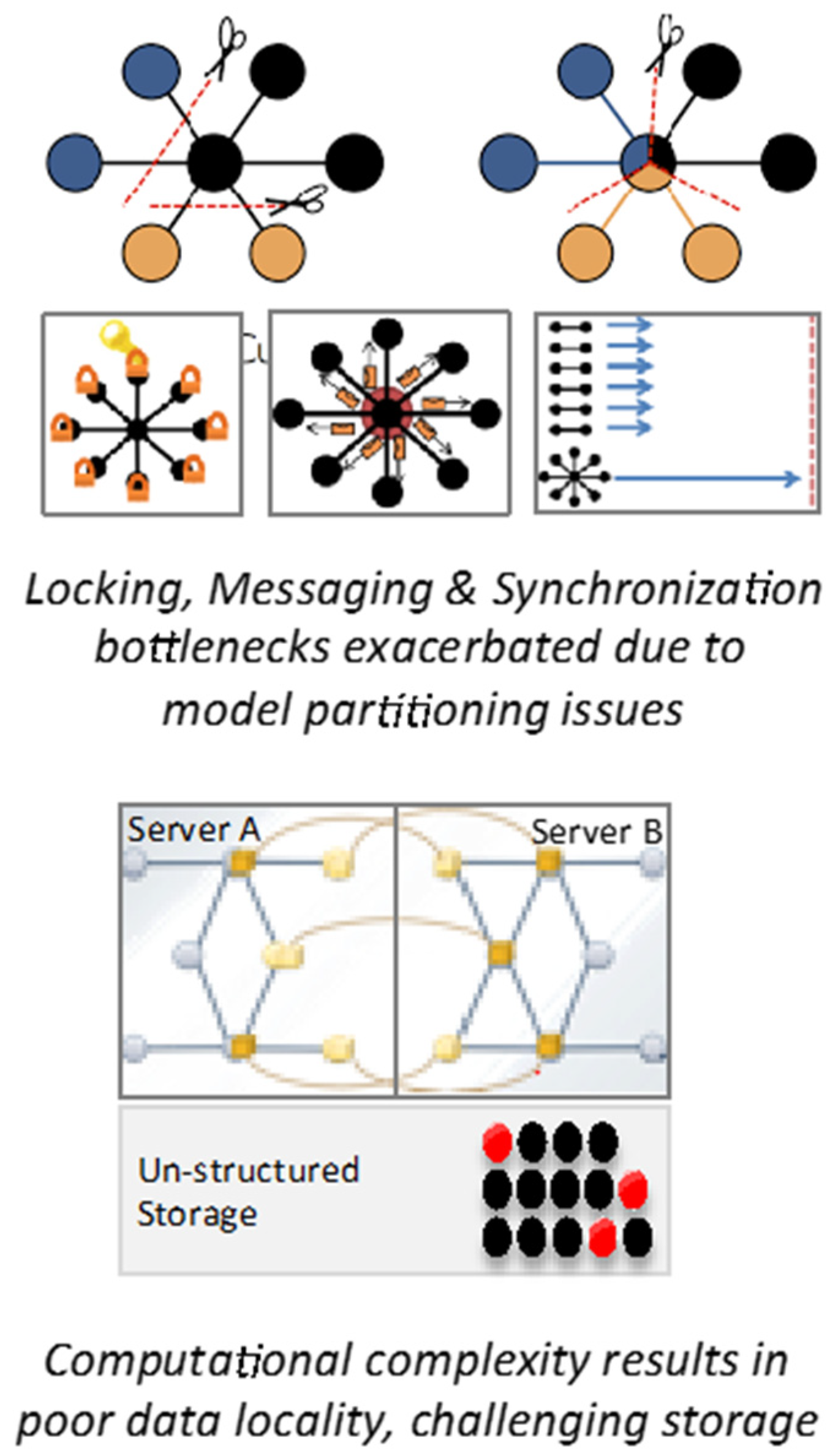
2. Challenges with Machine Learning
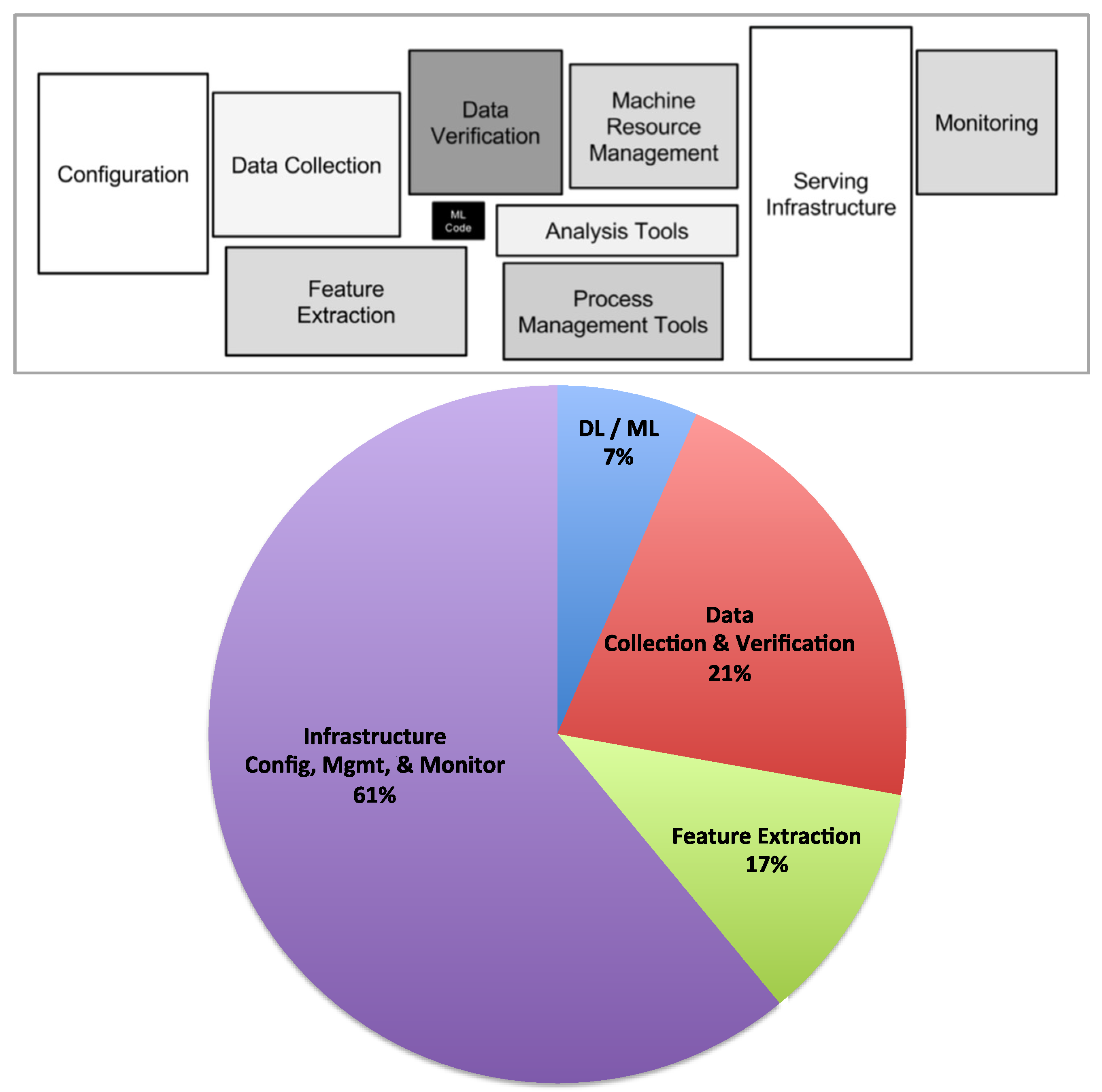
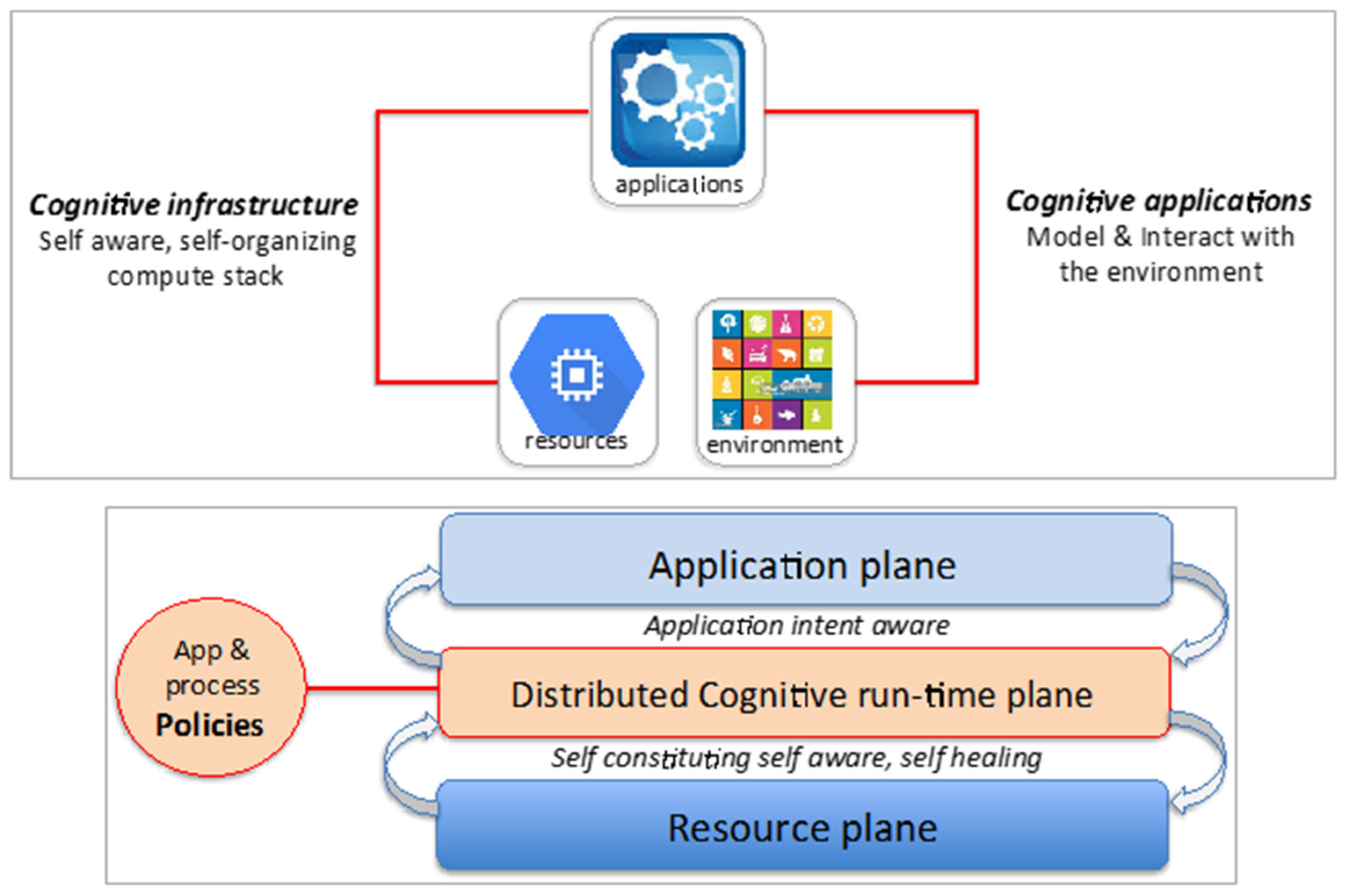
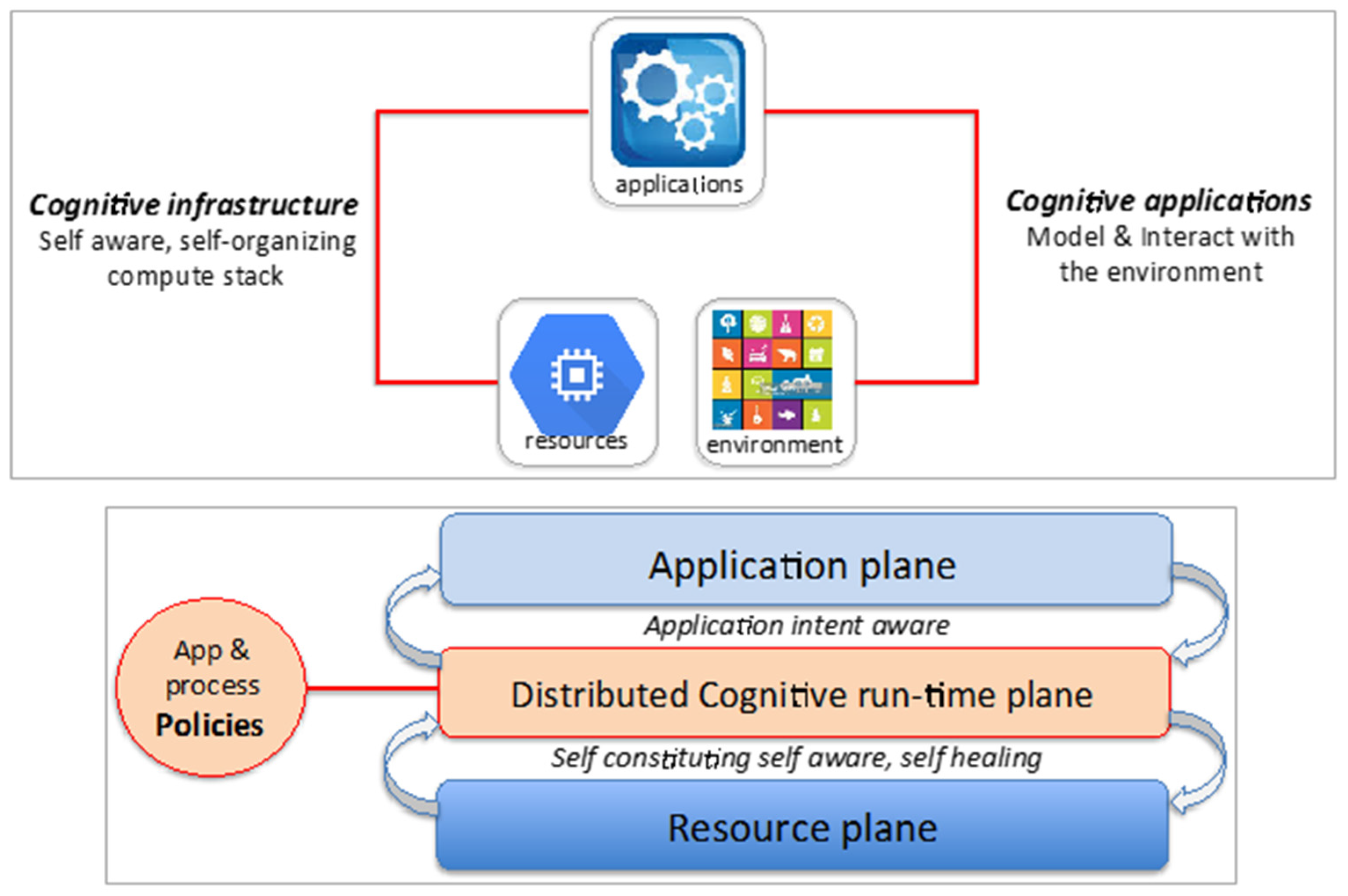
3. Cognitive Computing Stack
- Separation of Concerns and Information hiding: Infrastructure and process optimization concerns are separated from application logic to hide complexity that allows domain experts to re-focus on ML/DL breakthroughs.
- Autonomic scaling: Provides features that economize scaling, and allow applications to achieve high performance without human engineering. It extracts the best performance of many-core systems, while optimizing for reliability and data movement—the primary impediments in designing scale-out DL/ML systems.
- Ability to handle complexity with scale: The system can accumulate knowledge and act on it to adaptively tune its behavior to robustly achieve desired goals within the performance, power, and resilience envelopes specified in the policy framework.
- Computation resiliency and trusted results: Improve the resiliency of data, applications, software, and hardware systems, as well as the trustworthiness of the results produced through in-situ fault detection, fault prediction and trust verification mechanisms.
Conflicts of Interest
References
- Storage Implications of Cognitive Computing. Available online: http://www.snia.org/sites/default/files/DSI/2016/presentations/gen_sessions/BalintFleischer-JianLI_Storage_Implications_Cognitive_Computing_1-04.pdf (accessed on 6 July 2017).
- Liu, Y.; Gadepalli, K.; Norouzi, M.; Dahl, G.E.; Kohlberger, T.; Boyko, A.; Venugopalan, S.; Timofeev, A.; Nelson, P.Q.; Corrado, G.S.; et al. Detecting Cancer Metastases on Gigapixel Pathology Images. arXiv 2017, arXiv:1703.02442. [Google Scholar]
- A Neural Network for Machine Translation, at Production Scale. Available online: https://research.googleblog.com/2016/09/a-neural-network-for-machine.html (accessed on 6 July 2017).
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Chilimbi, T.M.; Suzue, Y.; Apacible, J.; Kalyanaraman, K. Project Adam: Building an Efficient and Scalable Deep Learning Training System. In Proceedings of the 11th Usenix Conference on Operating Systems Design and Implementatio (OSDI), Broomfield, CO, USA, 6–8 October 2014; Volume 14. [Google Scholar]
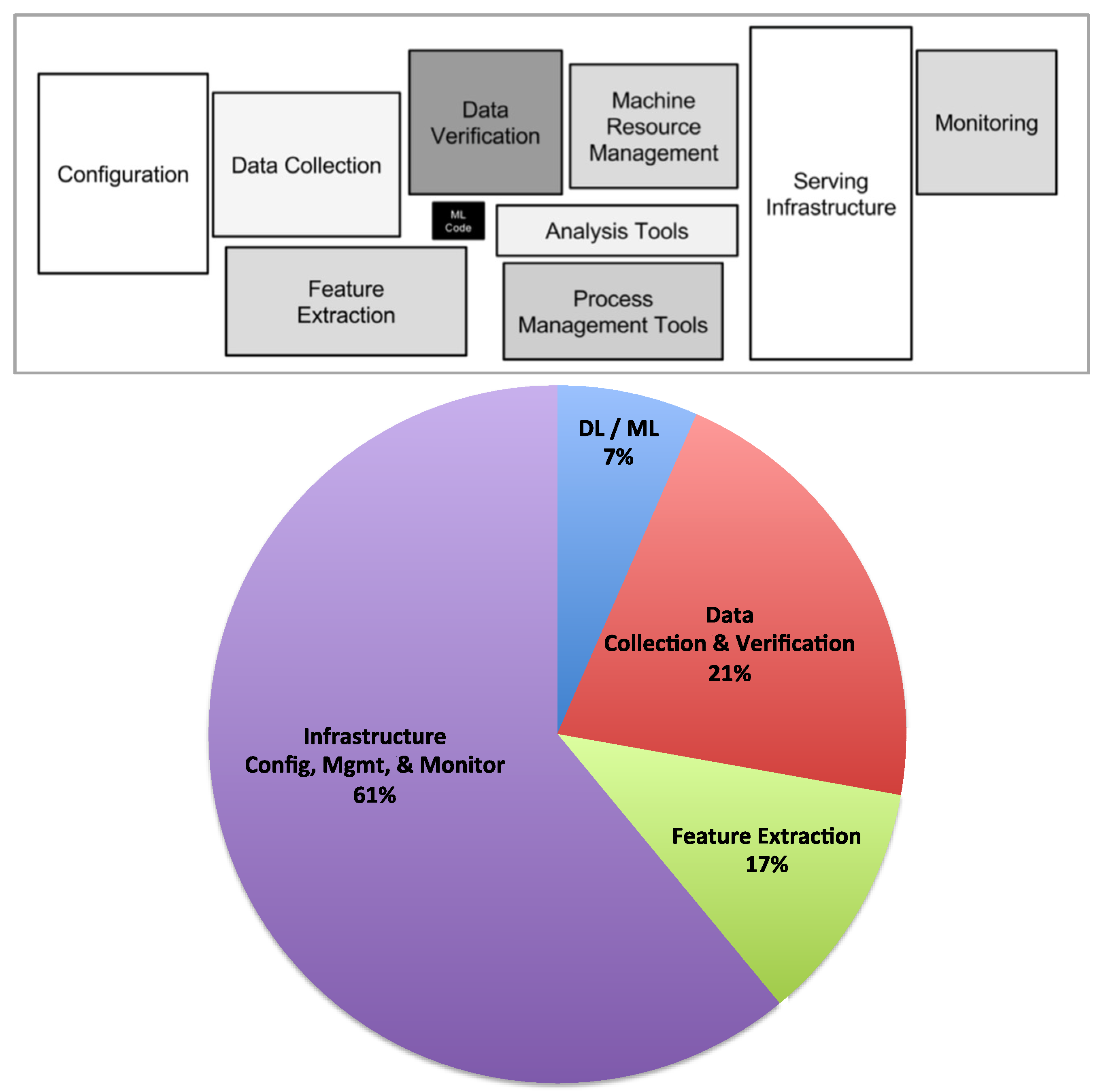
- Sculley, D.; Hold, G.; Golovin, D.; Davydov, E.; Phillips, H.; Ebner, D.; Chaudhary, V.; Young, M.; Crespo, J.F.; Dennison, D. ; Crespo, J.F.; Dennison, D. Hidden technical debt in machine learning systems. In Proceedings of the 28th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; pp. 2503–2511. [Google Scholar]
- Palkar, S.; Thomas, J.J.; Shanbhag, A.; Narayanan, D.; Pirk, H.; Schwarzkopf, M.; Amarasinghe, S.; Zaharia, M. Weld: A common runtime for high performance data analytics. In Proceedings of the Conference on Innovative Data Systems Research (CIDR), Chaminade, CA, USA, 8–11 January 2017. [Google Scholar]
- Keuper, J.; Preundt, F.-J. Distributed training of deep neural networks: Theoretical and practical limits of parallel scalability. In Proceedings of the Workshop on Machine Learning in High Performance Computing Environments, Salt Lake City, UT, USA, 13–18 November 2016. [Google Scholar]
- Mikkilineni, R.; Comparini, A.; Morana, G. The Turing O-Machine and the DIME Network Architecture: Injecting the Architectural Resiliency into Distributed Computing. In Proceedings of the Turing-100—The Alan Turing Centenary, Manchester, UK, 22–25 June 2012. [Google Scholar]
- Rockville, M.D. Machine Learning and Understanding for Intelligent Extreme Scale Scientific Computing and Discovery; DOE Workshop Report; Workshop Organizing Committee: Rockville, MD, USA, 2015. [Google Scholar]
- Dr. Rao Mikkilineni, Available online:. Available online: https://www.linkedin.com/in/raomikkilineni/ (accessed on 6 July 2017).




Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2017 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mittal, S. Cognitive Computing Architectures for Machine (Deep) Learning at Scale. Proceedings 2017, 1, 186. https://doi.org/10.3390/IS4SI-2017-04025
Mittal S. Cognitive Computing Architectures for Machine (Deep) Learning at Scale. Proceedings. 2017; 1(3):186. https://doi.org/10.3390/IS4SI-2017-04025
Chicago/Turabian StyleMittal, Samir. 2017. "Cognitive Computing Architectures for Machine (Deep) Learning at Scale" Proceedings 1, no. 3: 186. https://doi.org/10.3390/IS4SI-2017-04025
APA StyleMittal, S. (2017). Cognitive Computing Architectures for Machine (Deep) Learning at Scale. Proceedings, 1(3), 186. https://doi.org/10.3390/IS4SI-2017-04025