
Lessons Learned from Implementing Light Field Camera Animation: Implications, Limitations, Potentials, and Future Research Efforts



Abstract
1. Introduction
2. Materials and Methods
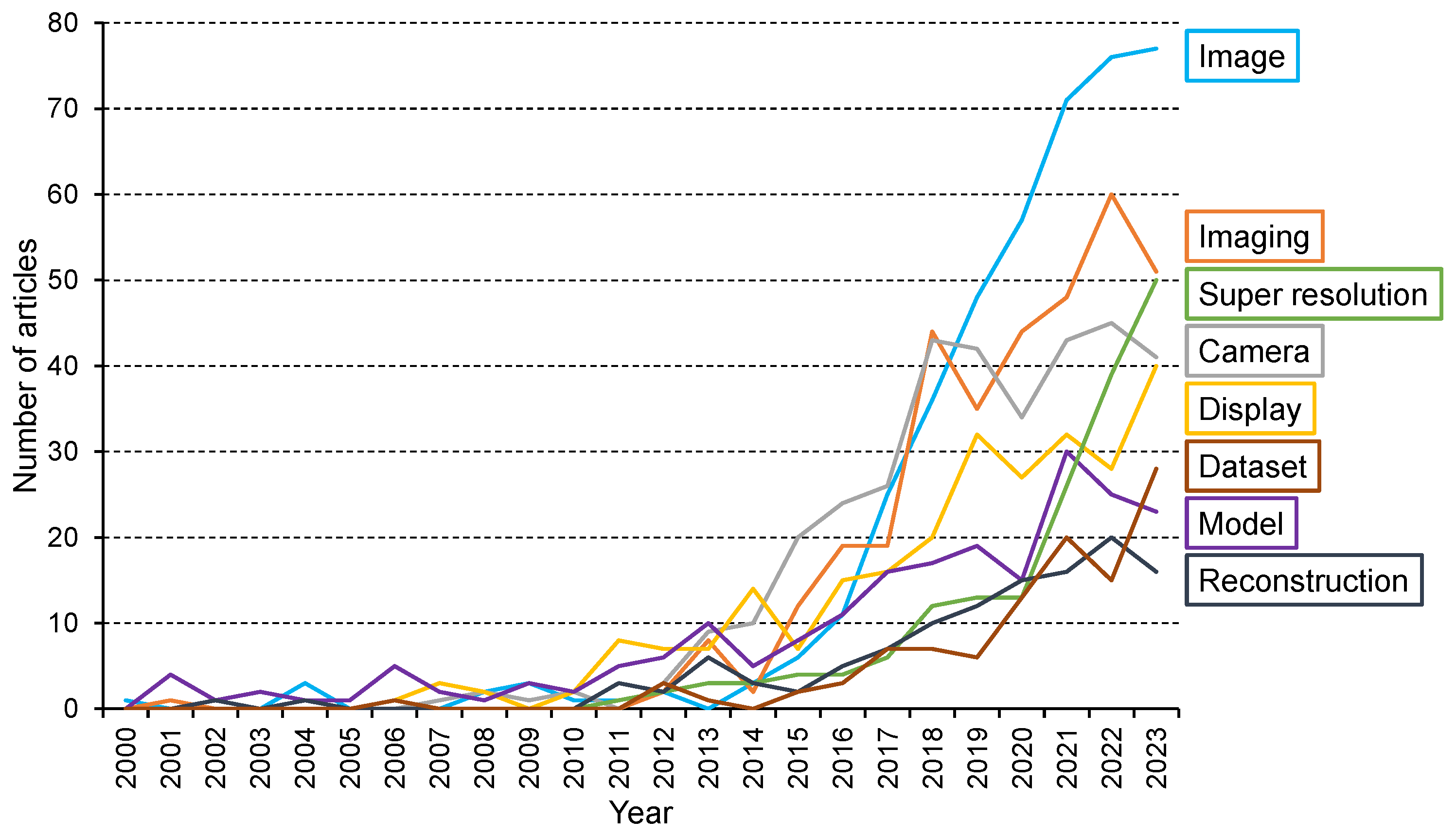
3. Analysis of Research Trends and Topics
4. Related Work
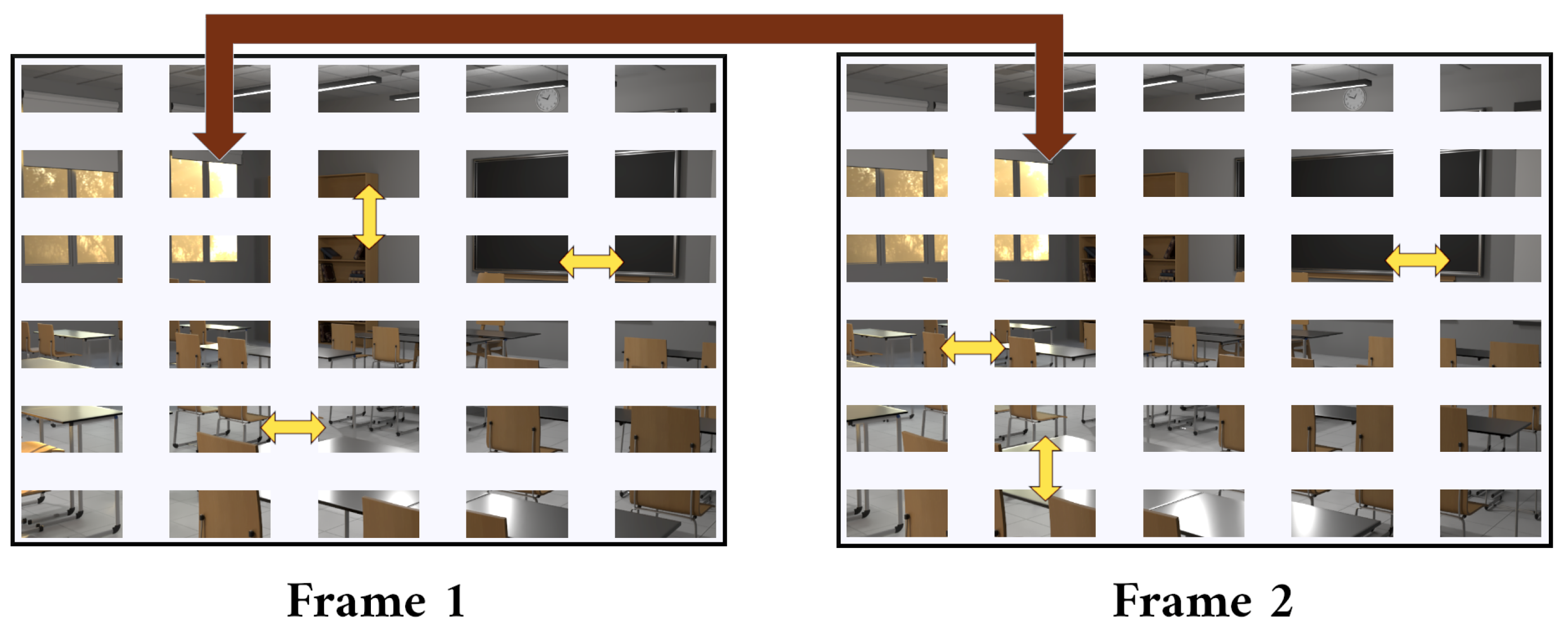
5. Implementing Light Field Camera Animation
6. Implications
6.1. Use Cases
6.2. Visual Content
6.3. Quality Assessment
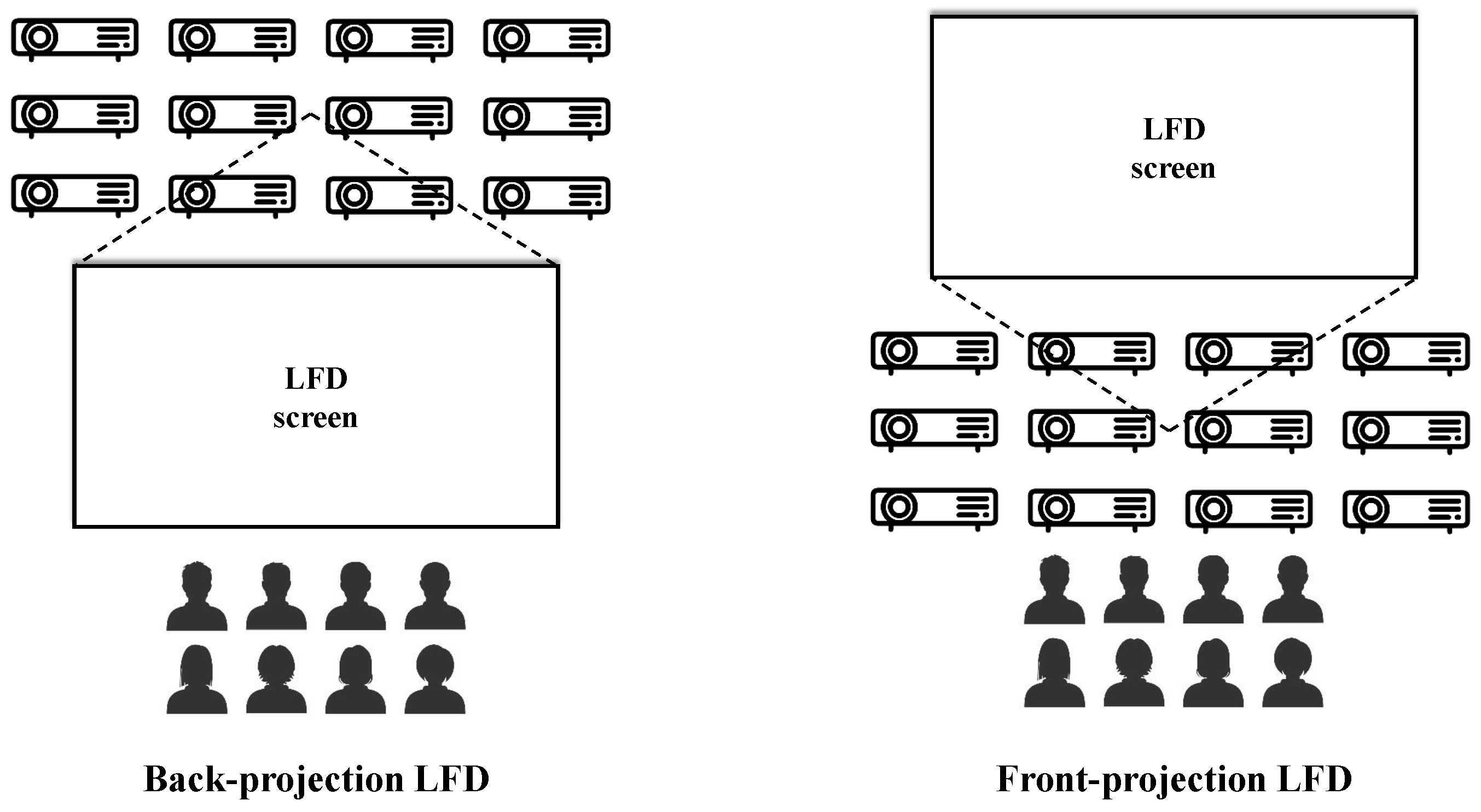
6.4. Capture and Display Hardware
7. Limitations
7.1. Use Cases
7.2. Visual Content
7.3. Quality Assessment
7.4. Capture and Display Hardware
8. Potentials
8.1. Use Cases
8.2. Visual Content
8.3. Quality Assessment
8.4. Capture and Display Hardware
9. Future Research Efforts
9.1. Use Cases
9.2. Visual Content
9.3. Quality Assessment
9.4. Capture and Display Hardware

| LFD | Angular Resolution | FOV | Screen Dimensions | Maximum Viewing Distance for Super Resolution |
|---|---|---|---|---|
| Lume Pad 2 [207] | 12.4” | 4.21 cm | ||
| HoloVizio 80WLT [208] | 30” | 45.83 cm | ||
| HoloVizio 640RC [62] | 72” | 57.29 cm | ||
| Looking Glass Portrait [209] | 7.9” | 79.03 cm | ||
| Looking Glass Go [210] | overall / optimal | 60” | 79.03 cm | |
| Looking Glass 65” [211] | 65” | 86.48 cm | ||
| Looking Glass 32” Spatial Display [212] | 32” | 86.48 cm | ||
| Looking Glass 16” Spatial Display [213] | overall / optimal | 16” | 86.48 cm | |
| HoloVizio 722RC [214] | 72” | 91.67 cm | ||
| HoloVizio C80 [206] | 140” | 91.67 cm |
10. Limitations of the Work
11. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| AFR | Adaptive feature remixing |
| CNN | Convolutional neural network |
| CTU | Coding tree unit |
| EPI | Epipolar plane image |
| FOV | Field of view |
| FP | Full parallax |
| HCI | Human–computer interaction |
| HOP | Horizontal-only parallax |
| HLRA | Homography-based low-rank approximation |
| HVS | Human visual system |
| GAN | Generative adversarial network |
| LF | Light field |
| LFCNN | Light field convolution neural network |
| LFD | Light field display |
| LF-DFnet | Light field—deformable convolution network |
| LF-IINet | Light field—intra–inter view interaction network |
| MPI | Multiplane image |
| MPR | Multiplanar reformations |
| POV | Point of view |
| QoE | Quality of experience |
| ROI | Region of interest |
| SAI | Sub-aperture images |
| SADN | Spatial-angular-decorrelated network |
| VVA | Valid viewing area |
References
- Guindy, M.; Barsi, A.; Kara, P.A.; Balogh, T.; Simon, A. Realistic physical camera motion for light field visualization. In Proceedings of the Holography: Advances and Modern Trends VII, Online, 19–29 April 2021; SPIE: Bellingham, WA, USA, 2021; Volume 11774, pp. 70–77. [Google Scholar]
- Guindy, M.; Kara, P.A.; Balogh, T.; Simon, A. Perceptual preference for 3D interactions and realistic physical camera motions on light field displays. In Proceedings of the Virtual, Augmented, and Mixed Reality (XR) Technology for Multi-Domain Operations III, Orlando, FL, USA, 3–7 April 2022; SPIE: Bellingham, WA, USA, 2022; Volume 12125, pp. 156–164. [Google Scholar]
- Guindy, M.; Barsi, A.; Kara, P.A.; Adhikarla, V.K.; Balogh, T.; Simon, A. Camera animation for immersive light field imaging. Electronics 2022, 11, 2689. [Google Scholar] [CrossRef]
- Gershun, A. The light field. J. Math. Phys. 1939, 18, 51–151. [Google Scholar] [CrossRef]
- da Vinci, L. The Notebooks of Leonardo da Vinci; Richter, J.P., Ed.; Courier Corporation: Chelmsford, MA, USA, 1970; Volume 2. [Google Scholar]
- Faraday, M. LIV. Thoughts on ray-vibrations. Lond. Edinb. Dublin Philos. Mag. J. Sci. 1846, 28, 345–350. [Google Scholar] [CrossRef]
- Ives, F.E. Parallax Stereogram and Process of Making Same. US725567A, 14 April 1903. [Google Scholar]
- Lippmann, G. Epreuves reversibles donnant la sensation du relief. J. Phys. Theor. Appl. 1908, 7, 821–825. [Google Scholar] [CrossRef]
- Levoy, M.; Hanrahan, P. Light field rendering. In Proceedings of the 23rd Annual Conference on Computer Graphics and Interactive Techniques, New Orleans, LA, USA, 4–9 August 1996; pp. 31–42. [Google Scholar]
- Balram, N.; Tošić, I. Light-field imaging and display systems. Inf. Disp. 2016, 32, 6–13. [Google Scholar] [CrossRef]
- Wetzstein, G. Computational Plenoptic Image Acquisition and Display. Ph.D. Thesis, University of British Columbia, Vancouver, BC, Canada, 2011. [Google Scholar]
- Wu, G.; Masia, B.; Jarabo, A.; Zhang, Y.; Wang, L.; Dai, Q.; Chai, T.; Liu, Y. Light field image processing: An overview. IEEE J. Sel. Top. Signal Process. 2017, 11, 926–954. [Google Scholar] [CrossRef]
- McMillan, L.; Bishop, G. Plenoptic modeling: An image-based rendering system. In Proceedings of the 22nd Annual Conference on Computer Graphics and Interactive Techniques, Los Angeles, CA, USA, 6–11 August 1995; pp. 39–46. [Google Scholar]
- Shum, H.Y.; Kang, S.B.; Chan, S.C. Survey of image-based representations and compression techniques. IEEE Trans. Circuits Syst. Video Technol. 2003, 13, 1020–1037. [Google Scholar] [CrossRef]
- Adelson, E.H.; Bergen, J.R. The Plenoptic Function and the Elements of Early Vision; Vision and Modeling Group, Media Laboratory, Massachusetts Institute of Technology: Cambridge, MA, USA, 1991; Volume 2. [Google Scholar]
- McMillan, L.; Bishop, G. Plenoptic modeling: An image-based rendering system. In Seminal Graphics Papers: Pushing the Boundaries; Association for Computing Machinery: New York, NY, USA, 2023; Volume 2, pp. 433–440. [Google Scholar]
- Ng, R.; Levoy, M.; Brédif, M.; Duval, G.; Horowitz, M.; Hanrahan, P. Light Field Photography with a Hand-Held Plenoptic Camera; Technical Report; Stanford University: Stanford, CA, USA, 2024; Available online: https://hci.stanford.edu/cstr/reports/2005-02.pdf (accessed on 26 July 2024).
- IJsselsteijn, W.A.; Seuntiëns, P.J.; Meesters, L.M. Human factors of 3D displays. In 3D Videocommunication: Algorithms, Concepts and Real-Time Systems in Human Centred Communication; Wiley Library: Hoboken, NJ, USA, 2005; pp. 217–233. [Google Scholar]
- Kara, P.A.; Tamboli, R.R.; Cserkaszky, A.; Barsi, A.; Simon, A.; Kusz, A.; Bokor, L.; Martini, M.G. Objective and subjective assessment of binocular disparity for projection-based light field displays. In Proceedings of the 2019 International Conference on 3D Immersion (IC3D), Brussels, Belgium, 11 December 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–8. [Google Scholar]
- Guindy, M.; Adhikarla, V.K.; Kara, P.A.; Balogh, T.; Simon, A. CLASSROOM: Synthetic high dynamic range light field dataset. In Proceedings of the Applications of Digital Image Processing XLV, San Diego, CA, USA, 22–24 August 2022; SPIE: Bellingham, WA, USA, 2022; Volume 12226, pp. 153–162. [Google Scholar]
- Sung, K.; Shirley, P.; Baer, S. Essentials of Interactive Computer Graphics: Concepts and Implementation; CRC Press: Boca Raton, FL, USA, 2008. [Google Scholar]
- Darukumalli, S.; Kara, P.A.; Barsi, A.; Martini, M.G.; Balogh, T. Subjective quality assessment of zooming levels and image reconstructions based on region of interest for light field displays. In Proceedings of the 2016 International Conference on 3D Imaging (IC3D), Liege, Belgium, 13–14 December 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1–6. [Google Scholar]
- Darukumalli, S.; Kara, P.A.; Barsi, A.; Martini, M.G.; Balogh, T.; Chehaibi, A. Performance comparison of subjective assessment methodologies for light field displays. In Proceedings of the 2016 IEEE International Symposium on Signal Processing and Information Technology (ISSPIT), Limassol, Cyprus, 12–14 December 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 28–33. [Google Scholar]
- Magnor, M.; Girod, B. Data compression for light-field rendering. IEEE Trans. Circuits Syst. Video Technol. 2000, 10, 338–343. [Google Scholar] [CrossRef]
- Girod, B.; Chang, C.L.; Ramanathan, P.; Zhu, X. Light field compression using disparity-compensated lifting. In Proceedings of the 2003 IEEE International Conference on Acoustics, Speech, and Signal Processing, 2003, Proceedings, (ICASSP’03), Hong Kong, China, 6–10 April 2003; Volume 4, pp. IV–760. [Google Scholar]
- Jagmohan, A.; Sehgal, A.; Ahuja, N. Compression of lightfield rendered images using coset codes. In Proceedings of the The Thrity-Seventh Asilomar Conference on Signals, Systems & Computers, Pacific Grove, CA, USA, 9–12 November 2003; IEEE: Piscataway, NJ, USA, 2003; Volume 1, pp. 830–834. [Google Scholar]
- Chen, W.C.; Bouguet, J.Y.; Chu, M.H.; Grzeszczuk, R. Light field mapping: Efficient representation and hardware rendering of surface light fields. ACM Trans. Graph. (TOG) 2002, 21, 447–456. [Google Scholar] [CrossRef]
- Zhu, X.; Aaron, A.; Girod, B. Distributed compression for large camera arrays. In Proceedings of the IEEE Workshop on Statistical Signal Processing, St. Louis, MO, USA, 28 September–1 October 2003; IEEE: Piscataway, NJ, USA, 2003; pp. 30–33. [Google Scholar]
- Li, Y.; Sjöström, M.; Olsson, R.; Jennehag, U. Efficient intra prediction scheme for light field image compression. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 539–543. [Google Scholar]
- Li, Y.; Sjöström, M.; Olsson, R.; Jennehag, U. Scalable coding of plenoptic images by using a sparse set and disparities. IEEE Trans. Image Process. 2015, 25, 80–91. [Google Scholar] [CrossRef]
- Perra, C. Lossless plenoptic image compression using adaptive block differential prediction. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), South Brisbane, Australia, 19–24 April 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 1231–1234. [Google Scholar]
- Li, Y.; Olsson, R.; Sjöström, M. Compression of unfocused plenoptic images using a displacement intra prediction. In Proceedings of the 2016 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), Seattle, WA, USA, 11–15 July 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1–4. [Google Scholar]
- Conti, C.; Nunes, P.; Soares, L.D. HEVC-based light field image coding with bi-predicted self-similarity compensation. In Proceedings of the 2016 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), Seattle, WA, USA, 11–15 July 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1–4. [Google Scholar]
- Monteiro, R.; Lucas, L.; Conti, C.; Nunes, P.; Rodrigues, N.; Faria, S.; Pagliari, C.; Da Silva, E.; Soares, L. Light field HEVC-based image coding using locally linear embedding and self-similarity compensated prediction. In Proceedings of the 2016 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), Seattle, WA, USA, 11–15 July 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1–4. [Google Scholar]
- Liu, D.; Wang, L.; Li, L.; Xiong, Z.; Wu, F.; Zeng, W. Pseudo-sequence-based light field image compression. In Proceedings of the 2016 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), Seattle, WA, USA, 11–15 July 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1–4. [Google Scholar]
- Jiang, X.; Le Pendu, M.; Farrugia, R.A.; Guillemot, C. Light field compression with homography-based low-rank approximation. IEEE J. Sel. Top. Signal Process. 2017, 11, 1132–1145. [Google Scholar] [CrossRef]
- Chen, J.; Hou, J.; Chau, L.P. Light field compression with disparity-guided sparse coding based on structural key views. IEEE Trans. Image Process. 2017, 27, 314–324. [Google Scholar] [CrossRef] [PubMed]
- Zhao, Z.; Wang, S.; Jia, C.; Zhang, X.; Ma, S.; Yang, J. Light field image compression based on deep learning. In Proceedings of the 2018 IEEE International conference on multimedia and expo (ICME), San Diego, CA, USA, 23–27 July 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–6. [Google Scholar]
- Dib, E.; Le Pendu, M.; Guillemot, C. Light field compression using Fourier disparity layers. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 3751–3755. [Google Scholar]
- Huang, X.; An, P.; Chen, Y.; Liu, D.; Shen, L. Low bitrate light field compression with geometry and content consistency. IEEE Trans. Multimed. 2020, 24, 152–165. [Google Scholar] [CrossRef]
- Chen, Y.; An, P.; Huang, X.; Yang, C.; Liu, D.; Wu, Q. Light field compression using global multiplane representation and two-step prediction. IEEE Signal Process. Lett. 2020, 27, 1135–1139. [Google Scholar] [CrossRef]
- Liu, D.; Huang, X.; Zhan, W.; Ai, L.; Zheng, X.; Cheng, S. View synthesis-based light field image compression using a generative adversarial network. Inf. Sci. 2021, 545, 118–131. [Google Scholar] [CrossRef]
- Tong, K.; Jin, X.; Wang, C.; Jiang, F. SADN: Learned light field image compression with spatial-angular decorrelation. In Proceedings of the ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1870–1874. [Google Scholar]
- Jin, P.; Jiang, G.; Chen, Y.; Jiang, Z.; Yu, M. Perceptual Light Field Image Coding with CTU Level Bit Allocation. In Proceedings of the International Conference on Computer Analysis of Images and Patterns, Limassol, Cyprus, 25–28 September 2023; Springer: Berlin/Heidelberg, Germany, 2023; pp. 255–264. [Google Scholar]
- Kawakami, M.; Tsutake, C.; Takahashi, K.; Fujii, T. Compressing Light Field as Multiplane Image. ITE Trans. Media Technol. Appl. 2023, 11, 27–33. [Google Scholar] [CrossRef]
- Shi, J.; Xu, Y.; Guillemot, C. Learning Kernel-Modulated Neural Representation for Efficient Light Field Compression. arXiv 2023, arXiv:2307.06143. [Google Scholar] [CrossRef]
- Magnor, M.A.; Endmann, A.; Girod, B. Progressive Compression and Rendering of Light Fields. In Proceedings of the VMV, Saarbrücken, Germany, 22–24 November 2000; Citeseer: Princeton, NJ, USA, 2000; pp. 199–204. [Google Scholar]
- Aggoun, A. A 3D DCT compression algorithm for omnidirectional integral images. In Proceedings of the 2006 IEEE International Conference on Acoustics Speech and Signal Processing Proceedings, Toulouse, France, 14–19 May 2006; IEEE: Piscataway, NJ, USA, 2006; Volume 2. [Google Scholar]
- Dong, X.; Qionghan, D.; Wenli, X. Data compression of light field using wavelet packet. In Proceedings of the 2004 IEEE International Conference on Multimedia and Expo (ICME) (IEEE Cat. No. 04TH8763), Taipei, Taiwan, 27–30 June 2004; IEEE: Piscataway, NJ, USA, 2004; Volume 2, pp. 1071–1074. [Google Scholar]
- Chang, C.L.; Zhu, X.; Ramanathan, P.; Girod, B. Light field compression using disparity-compensated lifting and shape adaptation. IEEE Trans. Image Process. 2006, 15, 793–806. [Google Scholar] [CrossRef]
- Aggoun, A. Compression of 3D integral images using 3D wavelet transform. J. Disp. Technol. 2011, 7, 586–592. [Google Scholar] [CrossRef]
- Kundu, S. Light field compression using homography and 2D warping. In Proceedings of the 2012 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Kyoto, Japan, 25–30 March 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 1349–1352. [Google Scholar]
- Conti, C.; Kovács, P.T.; Balogh, T.; Nunes, P.; Soares, L.D. Light-field video coding using geometry-based disparity compensation. In Proceedings of the 2014 3DTV-Conference: The True Vision-Capture, Transmission and Display of 3D Video (3DTV-CON), Budapest, Hungary, 2–4 July 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 1–4. [Google Scholar]
- Jin, X.; Han, H.; Dai, Q. Image reshaping for efficient compression of plenoptic content. IEEE J. Sel. Top. Signal Process. 2017, 11, 1173–1186. [Google Scholar] [CrossRef]
- Dai, F.; Zhang, J.; Ma, Y.; Zhang, Y. Lenselet image compression scheme based on subaperture images streaming. In Proceedings of the 2015 IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 4733–4737. [Google Scholar]
- Vieira, A.; Duarte, H.; Perra, C.; Tavora, L.; Assuncao, P. Data formats for high efficiency coding of Lytro-Illum light fields. In Proceedings of the 2015 International Conference on Image Processing Theory, Tools and Applications (IPTA), Orleans, France, 10–13 November 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 494–497. [Google Scholar]
- Li, L.; Li, Z.; Li, B.; Liu, D.; Li, H. Pseudo-sequence-based 2-D hierarchical coding structure for light-field image compression. IEEE J. Sel. Top. Signal Process. 2017, 11, 1107–1119. [Google Scholar] [CrossRef]
- Shao, J.; Bai, E.; Jiang, X.; Wu, Y. Light-Field Image Compression Based on a Two-Dimensional Prediction Coding Structure. Information 2024, 15, 339. [Google Scholar] [CrossRef]
- Kara, P.A.; Tamboli, R.R.; Shafiee, E.; Martini, M.G.; Simon, A.; Guindy, M. Beyond perceptual thresholds and personal preference: Towards novel research questions and methodologies of quality of experience studies on light field visualization. Electronics 2022, 11, 953. [Google Scholar] [CrossRef]
- IEEE P3333.1.4-2022; Recommended Practice for the Quality Assessment of Light Field Imaging. IEEE Standards Association: Piscataway, NJ, USA, 2023. Available online: https://standards.ieee.org/ieee/3333.1.4/10873/ (accessed on 26 July 2024).
- Balogh, T. The holovizio system. In Proceedings of the Stereoscopic Displays and Virtual Reality Systems XIII, San Jose, CA, USA, 15–19 January 2006; SPIE: Bellingham, WA, USA, 2006; Volume 6055, pp. 279–290. [Google Scholar]
- Balogh, T.; Kovács, P.T.; Barsi, A. Holovizio 3D display system. In Proceedings of the 2007 3DTV Conference, Kos, Greece, 7–9 May 2007; IEEE: Piscataway, NJ, USA, 2007; pp. 1–4. [Google Scholar]
- Megyesi, Z.; Barsi, A.; Balogh, T. 3D Video Visualization on the Holovizio System. In Proceedings of the 2008 3DTV Conference: The True Vision-Capture, Transmission and Display of 3D Video, Istanbul, Turkey, 28–30 May 2008; IEEE: Piscataway, NJ, USA, 2008; pp. 269–272. [Google Scholar]
- Balogh, T.; Kovács, P. Holovizio: The next generation of 3D oil & gas visualization. In Proceedings of the 70th EAGE Conference and Exhibition-Workshops and Fieldtrips, Rome, Italy, 9–12 June 2008; European Association of Geoscientists & Engineers: Utrecht, The Netherlands, 2008. [Google Scholar]
- Balogh, T.; Kovács, P.T.; Dobrányi, Z.; Barsi, A.; Megyesi, Z.; Gaál, Z.; Balogh, G. The Holovizio system—New opportunity offered by 3D displays. In Proceedings of the TMCE, Kusadasi, Turkey, 21–25 April 2008; pp. 79–89. [Google Scholar]
- Balogh, T.; Kovács, P.T. Real-time 3D light field transmission. In Proceedings of the Real-Time Image and Video Processing, Brussels, Belgium, 16 April 2010; SPIE: Bellingham, WA, USA, 2010; Volume 7724, pp. 53–59. [Google Scholar]
- Balogh, T.; Nagy, Z.; Kovács, P.T.; Adhikarla, V.K. Natural 3D content on glasses-free light-field 3D cinema. In Proceedings of the Stereoscopic Displays and Applications XXIV, Burlingame, CA, USA, 3–7 February 2013; SPIE: Bellingham, WA, USA, 2013; Volume 8648, pp. 103–110. [Google Scholar]
- Kovács, P.T.; Balogh, T. 3D light-field display technologies. In Emerging Technologies for 3D Video: Creation, Coding, Transmission and Rendering; Wiley Library: Hoboken, NJ, USA, 2013; pp. 336–345. [Google Scholar]
- Kara, P.A.; Cserkaszky, A.; Darukumalli, S.; Barsi, A.; Martini, M.G. On the edge of the seat: Reduced angular resolution of a light field cinema with fixed observer positions. In Proceedings of the 2017 Ninth International Conference on Quality of Multimedia Experience (QoMEX), Erfurt, Germany, 31 May–2 June 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–6. [Google Scholar]
- Cserkaszky, A.; Kara, P.A.; Tamboli, R.R.; Barsi, A.; Martini, M.G.; Bokor, L.; Balogh, T. Angularly continuous light-field format: Concept, implementation, and evaluation. J. Soc. Inf. Disp. 2019, 27, 442–461. [Google Scholar] [CrossRef]
- Tamboli, R.; Vupparaboina, K.K.; Ready, J.; Jana, S.; Channappayya, S. A subjective evaluation of true 3D images. In Proceedings of the 2014 International Conference on 3D Imaging (IC3D), Liege, Belgium, 9–10 December 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 1–8. [Google Scholar]
- Tamboli, R.R.; Appina, B.; Channappayya, S.; Jana, S. Super-multiview content with high angular resolution: 3D quality assessment on horizontal-parallax lightfield display. Signal Process. Image Commun. 2016, 47, 42–55. [Google Scholar] [CrossRef]
- Tamboli, R.R.; Appina, B.; Channappayya, S.S.; Jana, S. Achieving high angular resolution via view synthesis: Quality assessment of 3D content on super multiview lightfield display. In Proceedings of the 2017 International Conference on 3D Immersion (IC3D), Brussels, Belgium, 11–12 December 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–8. [Google Scholar]
- Ahar, A.; Chlipala, M.; Birnbaum, T.; Zaperty, W.; Symeonidou, A.; Kozacki, T.; Kujawinska, M.; Schelkens, P. Suitability analysis of holographic vs light field and 2D displays for subjective quality assessment of Fourier holograms. Opt. Express 2020, 28, 37069–37091. [Google Scholar] [CrossRef] [PubMed]
- Dricot, A.; Jung, J.; Cagnazzo, M.; Pesquet, B.; Dufaux, F.; Kovács, P.T.; Adhikarla, V.K. Subjective evaluation of Super Multi-View compressed contents on high-end light-field 3D displays. Signal Process. Image Commun. 2015, 39, 369–385. [Google Scholar] [CrossRef]
- Cserkaszky, A.; Barsi, A.; Kara, P.A.; Martini, M.G. To interpolate or not to interpolate: Subjective assessment of interpolation performance on a light field display. In Proceedings of the 2017 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), Hong Kong, China, 10–14 July 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 55–60. [Google Scholar]
- Kovács, P.T.; Lackner, K.; Barsi, A.; Balázs, Á.; Boev, A.; Bregović, R.; Gotchev, A. Measurement of perceived spatial resolution in 3D light-field displays. In Proceedings of the 2014 IEEE International Conference on Image Processing (ICIP), Paris, France, 27–30 October 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 768–772. [Google Scholar]
- Kovács, P.T.; Bregović, R.; Boev, A.; Barsi, A.; Gotchev, A. Quantifying spatial and angular resolution of light-field 3-D displays. IEEE J. Sel. Top. Signal Process. 2017, 11, 1213–1222. [Google Scholar] [CrossRef]
- Kara, P.A.; Guindy, M.; Xinyu, Q.; Szakal, V.A.; Balogh, T.; Simon, A. The effect of angular resolution and 3D rendering on the perceived quality of the industrial use cases of light field visualization. In Proceedings of the 2022 16th International Conference on Signal-Image Technology & Internet-Based Systems (SITIS), Dijon, France, 19–21 October 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 600–607. [Google Scholar]
- Tamboli, R.R.; Kara, P.A.; Cserkaszky, A.; Barsi, A.; Martini, M.G.; Jana, S. Canonical 3D object orientation for interactive light-field visualization. In Proceedings of the Applications of Digital Image Processing XLI, San Diego, CA, USA, 19–23 August 2018; SPIE: Bellingham, WA, USA, 2018; Volume 10752, pp. 77–83. [Google Scholar]
- Adhikarla, V.K.; Jakus, G.; Sodnik, J. Design and evaluation of freehand gesture interaction for light field display. In Proceedings of the Human-Computer Interaction: Interaction Technologies: 17th International Conference, HCI International 2015, Los Angeles, CA, USA, 2–7 August 2015; Proceedings, Part II 17. Springer: Berlin/Heidelberg, Germany, 2015; pp. 54–65. [Google Scholar]
- Adhikarla, V.K.; Sodnik, J.; Szolgay, P.; Jakus, G. Exploring direct 3D interaction for full horizontal parallax light field displays using leap motion controller. Sensors 2015, 15, 8642–8663. [Google Scholar] [CrossRef]
- Zhang, X.; Braley, S.; Rubens, C.; Merritt, T.; Vertegaal, R. LightBee: A self-levitating light field display for hologrammatic telepresence. In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems, Glasgow, Scotland, UK, 4–9 May 2019; pp. 1–10. [Google Scholar]
- Cserkaszky, A.; Barsi, A.; Nagy, Z.; Puhr, G.; Balogh, T.; Kara, P.A. Real-time light-field 3D telepresence. In Proceedings of the 2018 7th European Workshop on Visual Information Processing (EUVIP), Tampere, Finland, 26–28 November 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–5. [Google Scholar]
- Shafiee, E.; Martini, M.G. Datasets for the quality assessment of light field imaging: Comparison and future directions. IEEE Access 2023, 11, 15014–15029. [Google Scholar] [CrossRef]
- Vaish, V.; Adams, A. The (New) Stanford Light Field Archive; Computer Graphics Laboratory, Stanford University: Stanford, CA, USA, 2008; Volume 6, p. 3. [Google Scholar]
- Rerabek, M.; Yuan, L.; Authier, L.A.; Ebrahimi, T. [ISO/IEC JTC 1/SC 29/WG1 Contribution] EPFL Light-Field Image Dataset 2015. p. 3. Available online: https://www.epfl.ch/labs/mmspg/downloads/epfl-light-field-image-dataset/ (accessed on 26 July 2024).
- Shekhar, S.; Kunz Beigpour, S.; Ziegler, M.; Chwesiuk, M.; Paleń, D.; Myszkowski, K.; Keinert, J.; Mantiuk, R.; Didyk, P. Light-field intrinsic dataset. In Proceedings of the British Machine Vision Conference 2018 (BMVC). British Machine Vision Association, Newcastle, UK, 3–6 September 2018. [Google Scholar]
- Tamboli, R.R.; Reddy, M.S.; Kara, P.A.; Martini, M.G.; Channappayya, S.S.; Jana, S. A high-angular-resolution turntable data-set for experiments on light field visualization quality. In Proceedings of the 2018 Tenth International Conference on Quality of Multimedia Experience (QoMEX), Cagliari, Italy, 29 May–1 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–3. [Google Scholar]
- Ellahi, W.; Vigier, T.; Le Callet, P. Analysis of public light field datasets for visual quality assessment and new challenges. In Proceedings of the European Light Field Imaging Workshop, Borovets, Bulgaria, 4–6 June 2019. [Google Scholar]
- Static Planar Light-Field Test Dataset. Available online: https://www.iis.fraunhofer.de/en/ff/amm/dl/lightfielddataset.html (accessed on 26 July 2024).
- Guillo, L.; Jiang, X.; Lafruit, G.; Guillemot, C. ISO/IEC JTC1/SC29/WG1 & WG11; Light Field Video Dataset Captured by a R8 Raytrix Camera (with Disparity Maps); International Organisation for Standardisation: Geneva, Switzerland, 2018; Available online: http://clim.inria.fr/Datasets/RaytrixR8Dataset-5x5/index.html (accessed on 26 July 2024).
- Dansereau, D.G.; Girod, B.; Wetzstein, G. LiFF: Light field features in scale and depth. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 8042–8051. [Google Scholar]
- Moreschini, S.; Gama, F.; Bregovic, R.; Gotchev, A. CIVIT datasets: Horizontal-parallax-only densely-sampled light-fields. In Proceedings of the European Light Field Imaging Workshop, Borovets, Bulgaria, 4–6 June 2019; Volume 6, pp. 1–4. [Google Scholar]
- Zakeri, F.S.; Durmush, A.; Ziegler, M.; Bätz, M.; Keinert, J. Non-planar inside-out dense light-field dataset and reconstruction pipeline. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1059–1063. [Google Scholar]
- Gul, M.S.K.; Wolf, T.; Bätz, M.; Ziegler, M.; Keinert, J. A high-resolution high dynamic range light-field dataset with an application to view synthesis and tone-mapping. In Proceedings of the 2020 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), London, UK, 6–10 July 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–6. [Google Scholar]
- Yue, D.; Gul, M.S.K.; Bätz, M.; Keinert, J.; Mantiuk, R. A benchmark of light field view interpolation methods. In Proceedings of the 2020 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), London, UK, 6–10 July 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–6. [Google Scholar]
- Rerabek, M.; Ebrahimi, T. New light field image dataset. In Proceedings of the 8th International Conference on Quality of Multimedia Experience (QoMEX), Lisbon, Portugal, 6–8 June 2016. [Google Scholar]
- Wanner, S.; Meister, S.; Goldluecke, B. Datasets and benchmarks for densely sampled 4D light fields. In Proceedings of the VMV, Saarbrücken, Germany, 3–6 September 2013; Volume 13, pp. 225–226. [Google Scholar]
- Mousnier, A.; Vural, E.; Guillemot, C. Partial light field tomographic reconstruction from a fixed-camera focal stack. arXiv 2015, arXiv:1503.01903. [Google Scholar]
- Honauer, K.; Johannsen, O.; Kondermann, D.; Goldluecke, B. A dataset and evaluation methodology for depth estimation on 4D light fields. In Proceedings of the Computer Vision–ACCV 2016: 13th Asian Conference on Computer Vision, Taipei, Taiwan, 20–24 November 2016; Revised Selected Papers, Part III 13. Springer: Berlin/Heidelberg, Germany, 2017; pp. 19–34. [Google Scholar]
- Sabater, N.; Boisson, G.; Vandame, B.; Kerbiriou, P.; Babon, F.; Hog, M.; Gendrot, R.; Langlois, T.; Bureller, O.; Schubert, A.; et al. Dataset and pipeline for multi-view light-field video. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 30–40. [Google Scholar]
- Ahmad, W.; Palmieri, L.; Koch, R.; Sjöström, M. Matching light field datasets from plenoptic cameras 1.0 and 2.0. In Proceedings of the 2018-3DTV-Conference: The True Vision-Capture, Transmission and Display of 3D Video (3DTV-CON), Helsinki, Finland, 3–5 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–4. [Google Scholar]
- Kim, C.; Zimmer, H.; Pritch, Y.; Sorkine-Hornung, A.; Gross, M.H. Scene reconstruction from high spatio-angular resolution light fields. ACM Trans. Graph. 2013, 32, 1–12. [Google Scholar] [CrossRef]
- Hu, X.; Wang, C.; Pan, Y.; Liu, Y.; Wang, Y.; Liu, Y.; Zhang, L.; Shirmohammadi, S. 4DLFVD: A 4D light field video dataset. In Proceedings of the 12th ACM Multimedia Systems Conference, Istanbul, Turkey, 28 September–1 October 2021; pp. 287–292. [Google Scholar]
- Srinivasan, P.P.; Wang, T.; Sreelal, A.; Ramamoorthi, R.; Ng, R. Learning to synthesize a 4D RGBD light field from a single image. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2243–2251. [Google Scholar]
- Wang, T.C.; Zhu, J.Y.; Hiroaki, E.; Chandraker, M.; Efros, A.A.; Ramamoorthi, R. A 4D light-field dataset and CNN architectures for material recognition. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part III 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 121–138. [Google Scholar]
- The Plenoptic 2.0 Toolbox: Benchmarking of Depth Estimation Methods for MLA-Based Focused Plenoptic Cameras. Available online: https://zenodo.org/records/3558284#.YeXpMHrP2Hs (accessed on 26 July 2024).
- Kiran Adhikarla, V.; Vinkler, M.; Sumin, D.; Mantiuk, R.K.; Myszkowski, K.; Seidel, H.P.; Didyk, P. Towards a quality metric for dense light fields. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 58–67. [Google Scholar]
- Viola, I.; Ebrahimi, T. VALID: Visual quality assessment for light field images dataset. In Proceedings of the 2018 Tenth International Conference on Quality of Multimedia Experience (QoMEX), Cagliari, Italy, 29 May–1 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–3. [Google Scholar]
- Shi, L.; Zhao, S.; Zhou, W.; Chen, Z. Perceptual evaluation of light field image. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 41–45. [Google Scholar]
- Schambach, M.; Heizmann, M. A Multispectral Light Field Dataset for Light Field Deep Learning. IEEE Access 2020, 8, 193492–193502. [Google Scholar] [CrossRef]
- Zizien, A.; Fliegel, K. LFDD: Light field image dataset for performance evaluation of objective quality metrics. In Proceedings of the Applications of Digital Image Processing XLIII, Online, CA, USA, 24 August–4 September 2020; SPIE: Bellingham, WA, USA, 2020; Volume 11510, pp. 671–683. [Google Scholar]
- Paudyal, P.; Battisti, F.; Sjöström, M.; Olsson, R.; Carli, M. Towards the perceptual quality evaluation of compressed light field images. IEEE Trans. Broadcast. 2017, 63, 507–522. [Google Scholar] [CrossRef]
- Shan, L.; An, P.; Liu, D.; Ma, R. Subjective evaluation of light field images for quality assessment database. In Proceedings of the Digital TV and Wireless Multimedia Communication: 14th International Forum, IFTC 2017, Shanghai, China, 8–9 November 2017; Revised Selected Papers 14. Springer: Berlin/Heidelberg, Germany, 2018; pp. 267–276. [Google Scholar]
- Nava, F.P.; Luke, J. Simultaneous estimation of super-resolved depth and all-in-focus images from a plenoptic camera. In Proceedings of the 2009 3DTV Conference: The True Vision-Capture, Transmission and Display of 3D Video, Potsdam, Germany, 4–6 May 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 1–4. [Google Scholar]
- Lim, J.; Ok, H.; Park, B.; Kang, J.; Lee, S. Improving the spatail resolution based on 4D light field data. In Proceedings of the 2009 16th IEEE International Conference on Image Processing (ICIP), Cairo, Egypt, 7–10 November 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 1173–1176. [Google Scholar]
- Georgiev, T.; Chunev, G.; Lumsdaine, A. Superresolution with the focused plenoptic camera. In Proceedings of the Computational Imaging IX, San Francisco, CA, USA, 23–27 January 2011; SPIE: Bellingham, WA, USA, 2011; Volume 7873, pp. 232–244. [Google Scholar]
- Liang, C.K.; Ramamoorthi, R. A light transport framework for lenslet light field cameras. ACM Trans. Graph. (TOG) 2015, 34, 1–19. [Google Scholar] [CrossRef]
- Bishop, T.E.; Favaro, P. The light field camera: Extended depth of field, aliasing, and superresolution. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 34, 972–986. [Google Scholar] [CrossRef] [PubMed]
- Mitra, K.; Veeraraghavan, A. Light field denoising, light field superresolution and stereo camera based refocussing using a GMM light field patch prior. In Proceedings of the 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Providence, RI, USA, 16–21 June 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 22–28. [Google Scholar]
- Wanner, S.; Goldluecke, B. Variational light field analysis for disparity estimation and super-resolution. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 36, 606–619. [Google Scholar] [CrossRef] [PubMed]
- Rossi, M.; Frossard, P. Graph-based light field super-resolution. In Proceedings of the 2017 IEEE 19th International Workshop on Multimedia Signal Processing (MMSP), Luton, UK, 16–18 October 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–6. [Google Scholar]
- Rossi, M.; El Gheche, M.; Frossard, P. A nonsmooth graph-based approach to light field super-resolution. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 2590–2594. [Google Scholar]
- Alain, M.; Smolic, A. Light field super-resolution via LFBM5D sparse coding. In Proceedings of the 2018 25th IEEE international conference on image processing (ICIP), Athens, Greece, 7–10 October 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 2501–2505. [Google Scholar]
- Farag, S.; Velisavljevic, V. A novel disparity-assisted block matching-based approach for super-resolution of light field images. In Proceedings of the 2018-3DTV-Conference: The True Vision-Capture, Transmission and Display of 3D Video (3DTV-CON), Helsinki, Finland, 3–5 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–4. [Google Scholar]
- Fan, H.; Liu, D.; Xiong, Z.; Wu, F. Two-stage convolutional neural network for light field super-resolution. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1167–1171. [Google Scholar]
- Wang, Y.; Liu, F.; Zhang, K.; Hou, G.; Sun, Z.; Tan, T. LFNet: A novel bidirectional recurrent convolutional neural network for light-field image super-resolution. IEEE Trans. Image Process. 2018, 27, 4274–4286. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Yang, J.; Wang, L.; Ying, X.; Wu, T.; An, W.; Guo, Y. Light field image super-resolution using deformable convolution. IEEE Trans. Image Process. 2020, 30, 1057–1071. [Google Scholar] [CrossRef]
- Zhang, S.; Lin, Y.; Sheng, H. Residual networks for light field image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 11046–11055. [Google Scholar]
- Farrugia, R.A.; Guillemot, C. Light field super-resolution using a low-rank prior and deep convolutional neural networks. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 42, 1162–1175. [Google Scholar] [CrossRef]
- Liu, G.; Yue, H.; Wu, J.; Yang, J. Intra-inter view interaction network for light field image super-resolution. IEEE Trans. Multimed. 2021, 25, 256–266. [Google Scholar] [CrossRef]
- Mo, Y.; Wang, Y.; Xiao, C.; Yang, J.; An, W. Dense dual-attention network for light field image super-resolution. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 4431–4443. [Google Scholar] [CrossRef]
- Zhang, S.; Chang, S.; Lin, Y. End-to-end light field spatial super-resolution network using multiple epipolar geometry. IEEE Trans. Image Process. 2021, 30, 5956–5968. [Google Scholar] [CrossRef] [PubMed]
- Van Duong, V.; Huu, T.N.; Yim, J.; Jeon, B. Light field image super-resolution network via joint spatial-angular and epipolar information. IEEE Trans. Comput. Imaging 2023, 9, 350–366. [Google Scholar] [CrossRef]
- Yoon, Y.; Jeon, H.G.; Yoo, D.; Lee, J.Y.; Kweon, I.S. Light-field image super-resolution using convolutional neural network. IEEE Signal Process. Lett. 2017, 24, 848–852. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, L.; Yang, J.; An, W.; Yu, J.; Guo, Y. Spatial-angular interaction for light field image super-resolution. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XXIII 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 290–308. [Google Scholar]
- Ko, K.; Koh, Y.J.; Chang, S.; Kim, C.S. Light field super-resolution via adaptive feature remixing. IEEE Trans. Image Process. 2021, 30, 4114–4128. [Google Scholar] [CrossRef] [PubMed]
- Brown, B. Cinematography: Theory and Practice: Image Making for Cinematographers and Directors; Taylor & Francis: Milton Park, Oxfordshire, 2016. [Google Scholar]
- Schell, J. The Art of Game Design: A Book of Lenses; CRC Press: Boca Raton, FL, USA, 2008. [Google Scholar]
- Callenbach, E. The Five C’s of Cinematography: Motion Picture Filming Techniques Simplified by Joseph V. Mascelli; Silman-James Press: West Hollywood, CA, USA, 1966. [Google Scholar]
- Kara, P.A.; Barsi, A.; Tamboli, R.R.; Guindy, M.; Martini, M.G.; Balogh, T.; Simon, A. Recommendations on the viewing distance of light field displays. In Proceedings of the Digital Optical Technologies 2021, Online Only, Germany, 21–26 June 2021; SPIE: Bellingham, WA, USA, 2021; Volume 11788, pp. 166–179. [Google Scholar]
- Kara, P.A.; Simon, A. The Good News, the Bad News, and the Ugly Truth: A Review on the 3D Interaction of Light Field Displays. Multimodal Technol. Interact. 2023, 7, 45. [Google Scholar] [CrossRef]
- Guindy, M.; Barsi, A.; Kara, P.A.; Balogh, T.; Simon, A. Interaction methods for light field displays by means of a theater model environment. In Proceedings of the Holography: Advances and Modern Trends VII, Online Only, Czech Republic, 19–29 April 2021; SPIE: Bellingham, WA, USA, 2021; Volume 11774, pp. 109–118. [Google Scholar]
- iMARE CULTURE. 2020. Available online: https://imareculture.eu/ (accessed on 26 July 2024).
- Rotter, P. Why did the 3D revolution fail?: The present and future of stereoscopy [commentary]. IEEE Technol. Soc. Mag. 2017, 36, 81–85. [Google Scholar] [CrossRef]
- Pei, Z.; Li, Y.; Ma, M.; Li, J.; Leng, C.; Zhang, X.; Zhang, Y. Occluded-object 3D reconstruction using camera array synthetic aperture imaging. Sensors 2019, 19, 607. [Google Scholar] [CrossRef] [PubMed]
- Xu, Y.; Maeno, K.; Nagahara, H.; Taniguchi, R.i. Camera array calibration for light field acquisition. Front. Comput. Sci. 2015, 9, 691–702. [Google Scholar] [CrossRef]
- Goldlücke, B.; Klehm, O.; Wanner, S.; Eisemann, E.; Cameras, P. Digital Representations of the Real World: How to Capture, Model, and Render Visual Reality; CRC Press: Boca Raton, FL, USA, 2015; pp. 67–79. Available online: http://www.crcpress.com/product/isbn/9781482243819 (accessed on 26 July 2024).
- Cserkaszky, A.; Kara, P.A.; Tamboli, R.R.; Barsi, A.; Martini, M.G.; Balogh, T. Light-field capture and display systems: Limitations, challenges, and potentials. In Proceedings of the Novel Optical Systems Design and Optimization XXI, International Society for Optics and Photonics, San Diego, CA, USA, 19–23 August 2018. [Google Scholar]
- Yang, J.C.; Everett, M.; Buehler, C.; McMillan, L. A real-time distributed light field camera. Render. Tech. 2002, 2002, 2. [Google Scholar]
- Popovic, V.; Afshari, H.; Schmid, A.; Leblebici, Y. Real-time implementation of Gaussian image blending in a spherical light field camera. In Proceedings of the 2013 IEEE international conference on industrial technology (ICIT), Cape Town, Western Cape, South Africa, 25–28 February 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 1173–1178. [Google Scholar]
- Gortler, S.J.; Grzeszczuk, R.; Szeliski, R.; Cohen, M.F. The lumigraph. In Proceedings of the 23rd Annual Conference on Computer Graphics and Interactive Techniques, New York, NY, USA, 4–9 August 1996; SIGGRAPH’96. pp. 43–54. [Google Scholar]
- Taguchi, Y.; Agrawal, A.; Ramalingam, S.; Veeraraghavan, A. Axial light field for curved mirrors: Reflect your perspective, widen your view. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 499–506. [Google Scholar]
- Liang, C.K.; Lin, T.H.; Wong, B.Y.; Liu, C.; Chen, H.H. Programmable aperture photography: Multiplexed light field acquisition. In ACM Siggraph 2008 Papers; ACM, Inc.: New York, NY, USA, 2008; pp. 1–10. [Google Scholar]
- Adelson, E.H.; Wang, J.Y. Single lens stereo with a plenoptic camera. IEEE Trans. Pattern Anal. Mach. Intell. 1992, 14, 99–106. [Google Scholar] [CrossRef]
- Okano, F.; Arai, J.; Hoshino, H.; Yuyama, I. Three-dimensional video system based on integral photography. Opt. Eng. 1999, 38, 1072–1077. [Google Scholar] [CrossRef]
- Ihrke, I.; Stich, T.; Gottschlich, H.; Magnor, M.; Seidel, H.P. Fast incident light field acquisition and rendering. J. WSCG 2008, 16, 25–32. [Google Scholar]
- Zhang, C.; Chen, T. Light field capturing with lensless cameras. In Proceedings of the IEEE International Conference on Image Processing, Genoa, Italy, 11–14 September 2005; IEEE: Piscataway, NJ, USA, 2005; Volume 3. [Google Scholar]
- Georgeiv, T.; Zheng, K.C.; Curless, B.; Salesin, D.; Nayar, S.; Intwala, C. Spatio-Angular Resolution Tradeoffs in Integral Photography. In Symposium on Rendering; Akenine-Moeller, T., Heidrich, W., Eds.; The Eurographics Association: London, UK, 2006. [Google Scholar]
- Ueda, K.; Koike, T.; Takahashi, K.; Naemura, T. Adaptive integral photography imaging with variable-focus lens array. In Proceedings of the Stereoscopic Displays and Applications XIX, San Jose, CA, USA, 27–31 January 2008; SPIE: Bellingham, WA, USA, 2008; Volume 6803, pp. 443–451. [Google Scholar]
- Ueda, K.; Lee, D.; Koike, T.; Takahashi, K.; Naemura, T. Multi-focal compound eye: Liquid lens array for computational photography. In Proceedings of the ACM SIGGRAPH 2008 New Tech Demos, New York, NY, USA, 11–15 August 2008. SIGGRAPH’08. [Google Scholar]
- Unger, J.; Wenger, A.; Hawkins, T.; Gardner, A.; Debevec, P.E. Capturing and Rendering with Incident Light Fields. Render. Tech. 2003, 2003, 1–10. [Google Scholar]
- Levoy, M.; Chen, B.; Vaish, V.; Horowitz, M.; McDowall, I.; Bolas, M. Synthetic aperture confocal imaging. ACM Trans. Graph. (ToG) 2004, 23, 825–834. [Google Scholar] [CrossRef]
- Lanman, D.; Crispell, D.; Wachs, M.; Taubin, G. Spherical catadioptric arrays: Construction, multi-view geometry, and calibration. In Proceedings of the Third International Symposium on 3D Data Processing, Visualization, and Transmission (3DPVT’06), Chapel Hill, NC, USA, 14–16 June 2006; IEEE: Piscataway, NJ, USA, 2006; pp. 81–88. [Google Scholar]
- Taguchi, Y.; Agrawal, A.; Veeraraghavan, A.; Ramalingam, S.; Raskar, R. Axial-cones: Modeling spherical catadioptric cameras for wide-angle light field rendering. ACM Trans. Graph. 2010, 29, 172. [Google Scholar] [CrossRef]
- Ogata, S.; Ishida, J.; Sasano, T. Optical sensor array in an artificial compound eye. Opt. Eng. 1994, 33, 3649–3655. [Google Scholar]
- Tanida, J.; Kumagai, T.; Yamada, K.; Miyatake, S.; Ishida, K.; Morimoto, T.; Kondou, N.; Miyazaki, D.; Ichioka, Y. Thin observation module by bound optics (TOMBO): Concept and experimental verification. Appl. Opt. 2001, 40, 1806–1813. [Google Scholar] [CrossRef]
- Tanida, J.; Shogenji, R.; Kitamura, Y.; Yamada, K.; Miyamoto, M.; Miyatake, S. Color imaging with an integrated compound imaging system. Opt. Express 2003, 11, 2109–2117. [Google Scholar] [CrossRef]
- Hiura, S.; Mohan, A.; Raskar, R. Krill-eye: Superposition compound eye for wide-angle imaging via grin lenses. IPSJ Trans. Comput. Vis. Appl. 2010, 2, 186–199. [Google Scholar] [CrossRef]
- Yang, J.; Lee, C.; Isaksen, A.; McMillan, L. A Low-Cost Portable Light Field Capture Device. In Proceedings of the Siggraph Conference Abstracts and Applications, New Orleans, LA, USA, 23–28 July 2000. [Google Scholar]
- Raytrix: 3D Light Field Vision. Available online: https://raytrix.de/ (accessed on 26 July 2024).
- Veeraraghavan, A.; Raskar, R.; Agrawal, A.; Mohan, A.; Tumblin, J. Dappled photography: Mask enhanced cameras for heterodyned light fields and coded aperture refocusing. ACM Trans. Graph. 2007, 26, 69. [Google Scholar] [CrossRef]
- Hahne, C.; Aggoun, A.; Velisavljevic, V.; Fiebig, S.; Pesch, M. Baseline and triangulation geometry in a standard plenoptic camera. Int. J. Comput. Vis. 2018, 126, 21–35. [Google Scholar] [CrossRef]
- Georgiev, T.; Intwala, C. Light Field Camera Design for Integral View Photography, Adobe System. 2006. Available online: https://www.tgeorgiev.net/IntegralView.pdf (accessed on 26 July 2024).
- Jeon, H.G.; Park, J.; Choe, G.; Park, J.; Bok, Y.; Tai, Y.W.; So Kweon, I. Accurate depth map estimation from a lenslet light field camera. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1547–1555. [Google Scholar]
- Kara, P.A.; Kovacs, P.T.; Vagharshakyan, S.; Martini, M.G.; Barsi, A.; Balogh, T.; Chuchvara, A.; Chehaibi, A. The effect of light field reconstruction and angular resolution reduction on the quality of experience. In Proceedings of the 2016 12th International Conference on Signal-Image Technology & Internet-Based Systems (SITIS), Naples, Italy, 28 November–1 December 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 781–786. [Google Scholar]
- Höhne, K.H.; Fuchs, H.; Pizer, S.M. 3D Imaging in Medicine: Algorithms, Systems, Applications; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012; Volume 60. [Google Scholar]
- Chan, S.; Conti, F.; Salisbury, K.; Blevins, N.H. Virtual reality simulation in neurosurgery: Technologies and evolution. Neurosurgery 2013, 72, 154–164. [Google Scholar] [CrossRef]
- Ferroli, P.; Tringali, G.; Acerbi, F.; Schiariti, M.; Broggi, M.; Aquino, D.; Broggi, G. Advanced 3-dimensional planning in neurosurgery. Neurosurgery 2013, 72, 54–62. [Google Scholar] [CrossRef]
- Langdon, W.B.; Modat, M.; Petke, J.; Harman, M. Improving 3D medical image registration CUDA software with genetic programming. In Proceedings of the 2014 Annual Conference on Genetic and Evolutionary Computation, Vancouver, BC, Canada, 12–16 July 2014; pp. 951–958. [Google Scholar]
- Cserkaszky, A.; Kara, P.A.; Barsi, A.; Martini, M.G. The potential synergies of visual scene reconstruction and medical image reconstruction. In Proceedings of the Novel Optical Systems Design and Optimization XXI, San Diego, CA, USA, 19–23 August 2018; SPIE: Bellingham, WA, USA, 2018; Volume 10746, pp. 19–25. [Google Scholar]
- Robinson, M.S.; Brylow, S.; Tschimmel, M.; Humm, D.; Lawrence, S.; Thomas, P.; Denevi, B.W.; Bowman-Cisneros, E.; Zerr, J.; Ravine, M.; et al. Lunar reconnaissance orbiter camera (LROC) instrument overview. Space Sci. Rev. 2010, 150, 81–124. [Google Scholar] [CrossRef]
- Yan, Z.; Wang, C.; Yan, Z.; Wang, F. Research Summary on Light Field Display Technology Based on Projection. In Proceedings of the 2020 International Conference on Machine Learning and Computer Application, Shangri-La, China, 11–13 September 2020; IOP Publishing: Bristol, UK, 2020; Volume 1682. [Google Scholar]
- Diewald, S.; Möller, A.; Roalter, L.; Kranz, M. DriveAssist—A V2X-Based Driver Assistance System for Android. In Mensch & Computer 2012—Workshopband: Interaktiv Informiert–Allgegenwärtig und Allumfassend!? Oldenbourg Verlag: Munich, Germany, 2012. [Google Scholar]
- Olaverri-Monreal, C.; Jizba, T. Human factors in the design of human–machine interaction: An overview emphasizing V2X communication. IEEE Trans. Intell. Veh. 2016, 1, 302–313. [Google Scholar] [CrossRef]
- Xu, T.; Jiang, R.; Wen, C.; Liu, M.; Zhou, J. A hybrid model for lane change prediction with V2X-based driver assistance. Phys. A Stat. Mech. Its Appl. 2019, 534, 122033. [Google Scholar] [CrossRef]
- Hirai, T.; Murase, T. Performance evaluations of PC5-based cellular-V2X mode 4 for feasibility analysis of driver assistance systems with crash warning. Sensors 2020, 20, 2950. [Google Scholar] [CrossRef] [PubMed]
- Kara, P.A.; Wippelhauser, A.; Balogh, T.; Bokor, L. How I met your V2X sensor data: Analysis of projection-based light field visualization for vehicle-to-everything communication protocols and use cases. Sensors 2023, 23, 1284. [Google Scholar] [CrossRef]
- Kara, P.A.; Tamboli, R.R.; Adhikarla, V.K.; Balogh, T.; Guindy, M.; Simon, A. Connected without disconnection: Overview of light field metaverse applications and their quality of experience. Displays 2023, 78, 102430. [Google Scholar] [CrossRef]
- Kara, P.A.; Cserkaszky, A.; Martini, M.G.; Barsi, A.; Bokor, L.; Balogh, T. Evaluation of the concept of dynamic adaptive streaming of light field video. IEEE Trans. Broadcast. 2018, 64, 407–421. [Google Scholar] [CrossRef]
- Kara, P.A.; Tamboli, R.R.; Cserkaszky, A.; Martini, M.G.; Barsi, A.; Bokor, L. The viewing conditions of light-field video for subjective quality assessment. In Proceedings of the 2018 International Conference on 3D Immersion (IC3D), Brussels, Belgium, 5 December 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–8. [Google Scholar]
- Kovács, P.T.; Boev, A.; Bregovic, R.; Gotchev, A. Quality Measurement Of 3D Light-Field Displays. In Proceedings of the Eight International Workshop on Video Processing and Quality Metrics for Consumer Electronics, VPQM-2014, Chandler, AZ, USA, 30–31 January 2014; Available online: https://researchportal.tuni.fi/fi/publications/quality-measurement-of-3d-light-field-displays (accessed on 26 July 2024).
- Turing, A.M. Computing machinery and intelligence. Mind 1950, 59, 433–460. [Google Scholar] [CrossRef]
- Banks, M.S.; Hoffman, D.M.; Kim, J.; Wetzstein, G. 3D Displays. Annu. Rev. Vis. Sci. 2016, 2, 397–435. [Google Scholar] [CrossRef]
- Hamilton, M.; Wells, N.; Soares, A. On Requirements for Field of Light Displays to Pass the Visual Turing Test. In Proceedings of the 2022 IEEE International Symposium on Multimedia (ISM), Naples, Italy, 5–7 December 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 86–87. [Google Scholar]
- Hopper, D.G. 1000 X difference between current displays and capability of human visual system: Payoff potential for affordable defense systems. In Proceedings of the Cockpit Displays VII: Displays for Defense Applications, Orlando, FL, USA, 24–28 April 2000; SPIE: Bellingham, WA, USA, 2000; Volume 4022, pp. 378–389. [Google Scholar]
- Curry, D.G.; Martinsen, G.L.; Hopper, D.G. Capability of the human visual system. Cockpit Displays X 2003, 5080, 58–69. [Google Scholar]
- Ellis, C. The pupillary light reflex in normal subjects. Br. J. Ophthalmol. 1981, 65, 754–759. [Google Scholar] [CrossRef] [PubMed]
- Walker, H.K.; Hall, W.D.; Hurst, J.W. Clinical Methods: The History, Physical, and Laboratory Examinations; Butterworth-Heinemann: Oxford, UK, 1990; Available online: https://www.acpjournals.org/doi/10.7326/0003-4819-113-7-563_2 (accessed on 26 July 2024).
- Atchison, D.A.; Markwell, E.L.; Kasthurirangan, S.; Pope, J.M.; Smith, G.; Swann, P.G. Age-related changes in optical and biometric characteristics of emmetropic eyes. J. Vis. 2008, 8, 29. [Google Scholar] [CrossRef] [PubMed]
- Bradley, M.M.; Miccoli, L.; Escrig, M.A.; Lang, P.J. The pupil as a measure of emotional arousal and autonomic activation. Psychophysiology 2008, 45, 602–607. [Google Scholar] [CrossRef] [PubMed]
- Sluka, T.; Kvasov, A.; Kubes, T. Digital Light-Field. 2021. Available online: https://creal.com/app/uploads/2022/04/CREAL-White-Paper-Digital-Light-field.pdf (accessed on 26 July 2024).
- ELF-SR1 Spatial Reality Display - Sony Pro. Available online: https://pro.sony/ue_US/products/spatial-reality-displays/elf-sr1#TEME502131AllYouNeedIsYourEyes-elf-sr1 (accessed on 26 July 2024).
- ELF-SR2 Spatial Reality Display - Sony Pro. Available online: https://pro.sony/ue_US/products/spatial-reality-displays/elf-sr2 (accessed on 26 July 2024).
- HoloVizio C80 Glasses-Free 3D Cinema System. Available online: https://holografika.com/c80-glasses-free-3d-cinema/ (accessed on 26 July 2024).
- Lume Pad 2. Available online: https://www.leiainc.com/lume-pad-2 (accessed on 26 July 2024).
- HoloVizio 80WLT Full-Angle 3D Displaying. Available online: https://holografika.com/80wlt/ (accessed on 26 July 2024).
- Looking Glass Portrait. Available online: https://lookingglassfactory.com/looking-glass-portrait (accessed on 26 July 2024).
- Looking Glass Go. Available online: https://lookingglassfactory.com/looking-glass-go (accessed on 26 July 2024).
- Looking Glass 65”. Available online: https://lookingglassfactory.com/looking-glass-65 (accessed on 26 July 2024).
- Looking Glass 32” Spatial Display. Available online: https://lookingglassfactory.com/looking-glass-32 (accessed on 26 July 2024).
- Looking Glass 16” Spatial Display. Available online: https://lookingglassfactory.com/16-spatial-oled (accessed on 26 July 2024).
- HoloVizio 722RC Large-Scale 3D Displaying. Available online: https://holografika.com/722rc/ (accessed on 26 July 2024).
- Yeung, H.W.F.; Hou, J.; Chen, X.; Chen, J.; Chen, Z.; Chung, Y.Y. Light field spatial super-resolution using deep efficient spatial-angular separable convolution. IEEE Trans. Image Process. 2018, 28, 2319–2330. [Google Scholar] [CrossRef]
- Farrugia, R.A.; Galea, C.; Guillemot, C. Super resolution of light field images using linear subspace projection of patch-volumes. IEEE J. Sel. Top. Signal Process. 2017, 11, 1058–1071. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}



| LF Compression Technique | Citations | Type of Compression |
|---|---|---|
| Disparity compensation for compressing synthetic 4D LFs | [24,25,26] | lossy |
| Approximation through factorization | [27] | lossy |
| Geometry estimation using Wyner–Ziv coding | [28] | lossy |
| Compression methods for LF images captured by hand-held devices | [29,30,32,33,34,35] [31] | lossy lossless |
| Homography-based low-rank approximation | [36] | lossy |
| Disparity-guided sparse coding | [37] | lossy |
| Deep-learning-based assessment of the intrinsic similarities between LF images | [38] | lossy |
| Fourier disparity layer representation | [39] | lossy |
| Low-bitrate LF compression based on structural consistency | [40] | lossy |
| Disparity-based global representation prediction | [41] | lossy |
| Compression by means of a generative adversarial network | [42] | lossy |
| Spatial-angular-decorrelated network | [43] | lossy |
| Bit allocation based on a coding tree unit | [44] | lossy |
| Compressed representation via multiplane images comprised of semi-transparent stacked images | [45] | lossy |
| Neural-network-based compression by using the visual aspects of sub-aperture images, incorporating descriptive and modulatory kernels | [46] | lossless |
| Transform coding | [47,48,49,50,51] | lossy |
| Predictive coding | [35,52,53,54] | lossy |
| Pseudo-sequence coding methods | [55,56,57] | lossy |
| 2D prediction coding framework | [58] | lossy |
| LF Dataset Type | Definition | Data Capture Methods | Examples |
|---|---|---|---|
| Content-only | Contains the LF contents only | - Lenslet camera | [86,87,88,89,90,91] |
| - Single-lens camera | [90,92,93,94,95,96] | ||
| - Array of cameras | [90,97] | ||
| - Virtual camera | [94,96,98] | ||
| Task-based | Includes additional | - Lenslet camera | [99,100,101,102,103] |
| information on the task for | - Single-lens camera | [104,105] | |
| which the dataset was created | - Array of cameras | [106] | |
| - Virtual camera | [103,104,107,108] | ||
| QoE | Contains subjective ratings | -Lenslet camera | [109,110,111,112,113] |
| that were acquired through | - Single-lens camera | [72,114] | |
| extensive testing with | - Virtual camera | [113,115] | |
| numerous test participants |
| LF Acquisition Type | Definition | Acquisition Methods | Examples |
|---|---|---|---|
| Multiple sensors | Camera arrays for wide-baseline capture | - Linear camera setup | [66] |
| - Arc camera setup | [84] | ||
| - 2D grid camera setup | [151] | ||
| - Spherical camera setup | [152] | ||
| Temporal multiplexing | Uses a single camera instead of multiple cameras for wide-baseline capture | - Camera on turntable or rotating camera while reorienting | [9,153,154] |
| - Programmable aperture photography | [155] | ||
| - Extension of integral photography | [17,156,157] | ||
| - Rotation of a planar mirror | [158] | ||
| - Lensless LF camera | [159] | ||
| Spatial and frequency multiplexing | Uses a single camera to create LF images by means of spatial or frequency multiplexing | - Parallax barriers | [7] |
| - Integral photography | [8] | ||
| - External lens arrays | [160,161,162] | ||
| - Array of planar, tilted mirrors or mirrored spheres | [163,164,165,166] | ||
| - Lens arrays and a single sensor in related compound imaging systems | [167,168,169,170] | ||
| - Combining a lens array and a flatbed scanner in a lenslet-based architecture | [171] | ||
| - Plenoptic cameras | [156,172] | ||
| - Frequency multiplexing | [173] |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guindy, M.; Kara, P.A. Lessons Learned from Implementing Light Field Camera Animation: Implications, Limitations, Potentials, and Future Research Efforts. Multimodal Technol. Interact. 2024, 8, 68. https://doi.org/10.3390/mti8080068
Guindy M, Kara PA. Lessons Learned from Implementing Light Field Camera Animation: Implications, Limitations, Potentials, and Future Research Efforts. Multimodal Technologies and Interaction. 2024; 8(8):68. https://doi.org/10.3390/mti8080068
Chicago/Turabian StyleGuindy, Mary, and Peter A. Kara. 2024. "Lessons Learned from Implementing Light Field Camera Animation: Implications, Limitations, Potentials, and Future Research Efforts" Multimodal Technologies and Interaction 8, no. 8: 68. https://doi.org/10.3390/mti8080068
APA StyleGuindy, M., & Kara, P. A. (2024). Lessons Learned from Implementing Light Field Camera Animation: Implications, Limitations, Potentials, and Future Research Efforts. Multimodal Technologies and Interaction, 8(8), 68. https://doi.org/10.3390/mti8080068