
The Value of Open Data in HCI: A Case Report from Mobile Text Entry Research


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Related Work
2.1. Gaze Data Use in Text Entry Studies
2.2. Open Data Practices in HCI
2.3. Case-Study Research
3. Motivation and Materials
3.1. Motivation
3.2. Materials
4. Engagement with an Unfamiliar Open Dataset
4.1. Identifying and Addressing Data Quality Issues
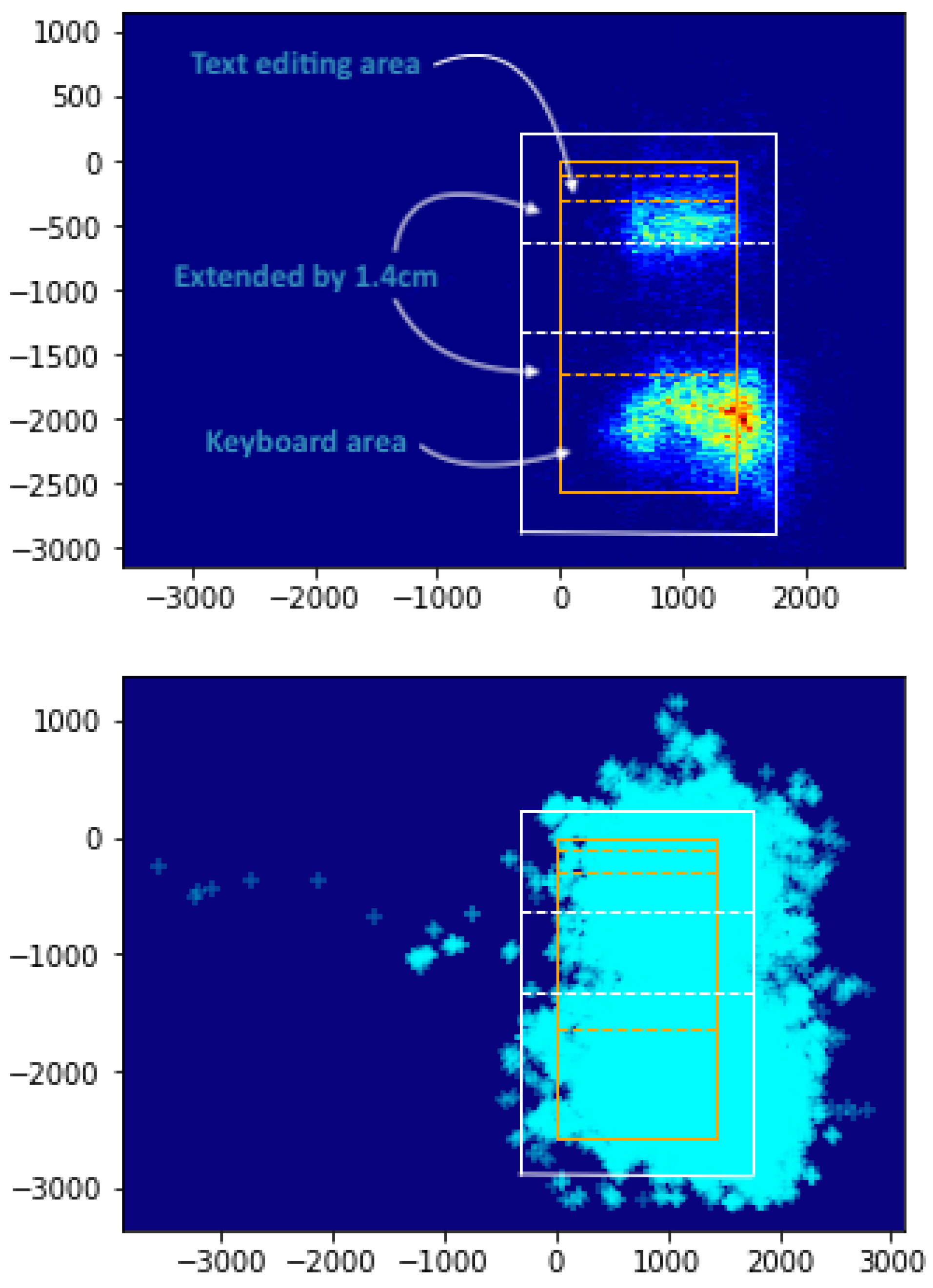
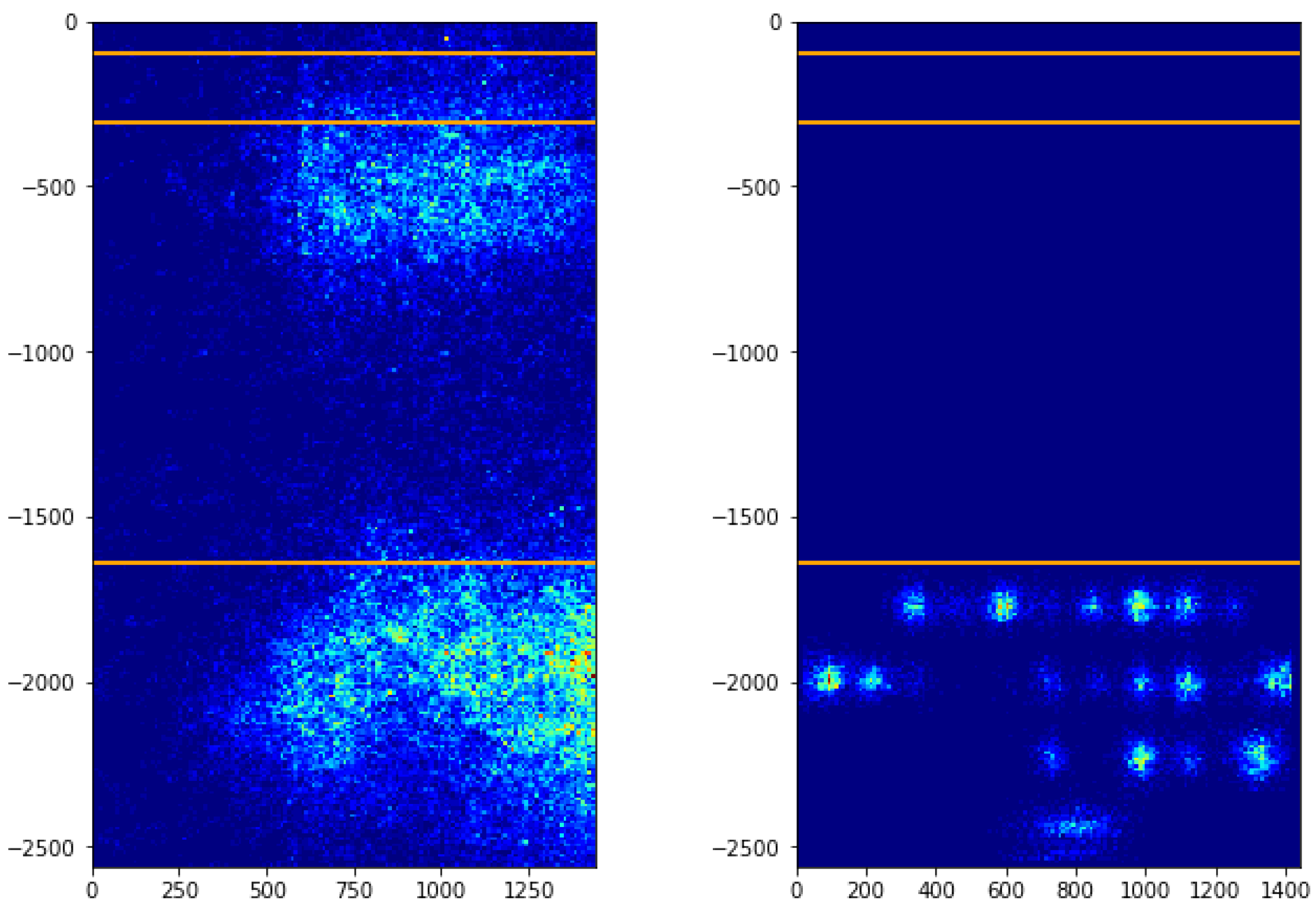
4.1.1. Keyboard Area Gazes
4.1.2. Text Editing Area Gazes
5. Replication of Results
5.1. Identifying Attention Shifts
5.2. Quantifying Gaze Shifts
5.2.1. Threshold-Based Gaze Shift Identification
5.2.2. Cluster-Based Gaze Shift Identification
| Algorithm 1: Cluster-based gaze shift detection algorithm. |
 |
5.3. Replicating Study Results
5.3.1. Frequency of Gaze Shifting per Sentence
5.3.2. Gaze Ratio on Keyboard
5.3.3. Correlation of Gaze Shifts and Errors in a Sentence
6. Discussion
6.1. Technical Contribution
6.2. Applying Open Data Recommendations from Other Domains to HCI
- “Treat datasets as guilty until proven innocent”. As the initial exploration of the data revealed, the inaccuracies of the equipment (eye tracker) and participant physical positioning made the raw data unsuitable for use as-is. The dataset paper made reference to these issues, but the extent to which they affect the produced data could not have been communicated strongly enough without visualisation. Further, it turned out that the data was not, in any way, sanitised prior to release, and that the lack of promised (but not delivered) processing code made it difficult to determine which, if any, pre-processing needs were needed prior to use. Without this initial exploration, it would have been impossible to identify the rectification steps that needed to be taken.
- “Identify the assumptions underlying a dataset in writing”. As alluded in Jiang et al.’s paper, though not in an overly overt manner, significant decisions needed to be made in order to decide how to treat data, by exclusion or transformation, and on how the concept of an “upwards gaze” could be quantifiably defined. In order to remove the “guilty” label from the data and the way we treated it, careful justification at every decision point needed to be made, based on statistical data exploration and/or other literature. The preceding account is reflective of this process, which was required in order to get to a stage where data could be actually used.
- “Conduct independent peer reviews and checks during and after dataset development”. Whilst I am not the creator of the dataset, I was indeed the creator of modifications posed on it. The rationality of the decisions made on how the dataset should be modified were checked with peers who provided good insights and confirmation that they were reasonable.
- “Evaluate datasets against experience and judgment”. Work on this dataset began by using it “as-is”, perhaps because the data came from a reputable research lab, the paper was published in a highly competitive conference, or because the endeavour started with an exciting idea about how to meet the original aim. The key take-away here is that open datasets are a “wild west”. Peer-review ensures that published papers meet certain quality standards, but the quality of accompanying datasets or code is not reviewed. Given the significant effort required to properly prepare both datasets and accompanying analysis code, and that there is currently next to no benefit for the authors for ensuring this effort is taken, one should err on the side of caution.
- “Use visualization tools”. Visualisation tools proved to be immensely helpful for understanding the underlying problems with the data, the extent of their effect, and for de-obfuscating the original authors’ assumptions as were presented in the paper. The fact that only two-dimensional data (screen coordinates, or time and vertical coordinate) were needed for the analyses in this paper, significantly contributed to the importance of visualisation in helping to understand the data. More complex datasets might require the co-analysis of k-dimensional data, which can be hard to visualise, unless reduced in dimensionality with techniques such as PCA or tSNE.
- “Perform sensitivity studies of dataset parameters”. When considering inclusion criteria or transformations to be applied on the original data, it is important to assess, at every step, how the relevant parameters affect the outcome, both in terms of data preservation, and correspondence of data with expected phenomena. The goal should be to minimise data loss, with the assumption that while noise is definitely present in any information signal, the majority of what was captured should be useful information, particularly if it was captured by equipment or methods which are known to be largely reliable under ideal conditions. Simply discarding large volumes of data may lead to future problems in the analysis, such as, in our case, data gaps in the gaze series.
- “Understand the assumptions and limitations of datasets rather than using them as black boxes”. It is important to have a working knowledge of the methods and equipment used to generate the dataset. First-hand experience is ideally needed, but might be unavailable, particularly for equipment which is uncommonly accessible to researchers. To mitigate the lack of first-hand experience, related work using similar equipment should be sought in literature, and this might be helpful in understanding how data generated from such equipment could suffer from problems.
6.3. Making HCI Datasets Useful, Usable and Used
- Dataset requirement specification. HCI researchers who wish to share their data with the community may already be considering questions such as "What properties should the dataset have?" or "Who will it be used by?" when preparing a data release. To improve decisions at this point, I argue that materials released with published papers should be treated as preliminary releases. A formal consultation period in which interested parties could contact them as potential stakeholders should be specified, either as part of the repository infrastructure, or as a promise to the community, in the accompanying paper. It is impossible to foresee all requirements, hence the need for a maintenance stage, but some issues could be easily picked up by experienced community members. For example, while Jiang et al. include a file with the coordinates of each key’s center, the actual dimensions of each key are missing, therefore it is impossible to know if a gaze fell on a particular key area at, or near, the time of touch. Additionally information such as keyboard area size, coordinates of the text editing area, coordinates of the extended device area, font sizes etc., which were not present and had to be estimated from proxy sources (e.g., the paper’s accompanying video), could have been included as requirements.
- Dataset design. Researchers might address here issues on the operationalisation of the dataset requirements, including questions about data packaging and formats, user anonymity, ethics board approval or lack of human or material resources. The HCI community could help by identifying expert peers who might help with such work. Taking action at this step should address most of the data sharing barriers identified in [25]. As an example, Jiang et al.’s release could have included not just the raw data, but the “cleaned up” versions used in their own analyses, or other data aggregates which might be useful in order to reproduce the paper’s results, assuming that code for this work would not be provided.
- Dataset implementation. Recipients of the dataset might find themselves asking questions on the design of the dataset, which might well be answered in the accompanying paper (e.g., "How were the data design decisions taken?" or "Why were they done this way?") and not as part of accompanying dataset descriptors. Thus, paper authors should be mindful that such questions might arise during use of their dataset, and pre-emptively work to address them while writing the paper (or, post- peer review). Alternatively, such questions and answers could be enumerated in readme files alongside the data, since often papers are tight for space. Associate chairs, editors and reviewers for such papers should make explicit comment on whether they feel the paper contains enough clarity on how data was pre-processed and sanitised prior to use. In papers such as Jiang et al’s., implementation accounts are limited to readme files which contain brief data descriptors, but more detail about how data was generated, kept, or why it is missing, as seen in our own exploration, would be useful in guiding further work.
- Dataset testing. Authors might be reluctant to release all the source code for analysing the dataset, as after all properly formatting and commenting code, which is often developed in a “hacky” way for the purposes of a publication, is a significant effort. However, releasing even parts of the processing code, perhaps just enough so that another researcher can verify at least one or some of the findings, could go a long way towards helping the reproduction of the results, or further investigation of the data. We argue that a minimal set of processing code should be mandatorily included with any dataset. Paper chairs or ACs should check that these are readily available to the general public at the time of submission of the camera-ready paper. As noted, it was with some disappointment that we discovered that processing code was not available for Jiang et al.’s paper, even though it was promised in the paper itself.
- Dataset maintenance. Other questions, particularly those relating to data maintenance, probably go largely unanswered after publication. Ideally, datasets should be immutable, but errors could be discovered by others at any time. Data providers should have a way to incorporate these into the publicly released dataset (e.g., through versioning), as well as to coalesce data processing code or other related materials that the community might offer, alongside their own. A data maintenance plan is important as contact authors are often doctoral students whose academic emails may cease to work after graduation. Replication of the original datasets by other researchers could increase availability and integrity of the data, but ideally the publishing organisations (professional societies and journals) and/or host institutions or companies, should facilitate dataset archival and maintenance as part of services they already offer to authors. With reference to Jiang et al.’s material, the primary author seems to have dropped off the academic radar, so to speak. Open releases should have a clearly labelled contact person and contact details, with at least one alternative contact. Given the release of the data in a static website at the University of Aalto, there is no possibility for versioning, issue reporting or addition of third-party material and resources by other researchers. In this sense, a release through repositiories such as GitHub, Zenodo or OSF would help in alleviating such problems.
6.4. Implications for the HCI Community
6.5. Implications for the Mobile Text Entry Community
- The target metrics used (e.g., WPM, KSPC, error rates) are common across most papers, and the data needed to derive these is more or less the same (keystroke data). It is plausibly feasible to derive a commonly agreed specification on the format which every text-entry prototype should produce its keystroke data in. Researchers could undertake the responsibility to ensure adherence to this data standard with any prototype they produce.
- Metadata that describe the experiments could also easily be standardised. Most text-entry research uses the transcription task as its de-facto tool, therefore participant descriptions, condition descriptions, phrasesets and other aspects of experiment design can be standardised.
- There already exist a range of experimental tools which could help towards the reduction of time needed to adhere to such standards. For example, WebTEM [51] provides a web-based interface in which to run keyboard-independent transcription task experiments in lab experiments, negating the need for applications to do their own logging. For field experiments, Wildkey [3] and ResearchIME [52] are two examples of privacy-preserving smartphone keyboards that could be commonly used. All are maintened by highly active members of the community, who could adapt their code to adhere to these standards.
- A repository for the registration and archival of experiment data can be easily and quickly developed without formal support from a professional society or publisher. In fact, such a system could be community-administered and self-hosting could attract submissions from authors who publish with other reputable conferences or journals outside leading outlets for related scientific research.
7. Conclusions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Jiang, X.; Li, Y.; Jokinen, J.P.; Hirvola, V.B.; Oulasvirta, A.; Ren, X. How We Type: Eye and Finger Movement Strategies in Mobile Typing. In Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems, Honolulu, HI, USA, 25–30 April 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 1–14. [Google Scholar]
- Yi, X.; Wang, C.; Bi, X.; Shi, Y. PalmBoard: Leveraging Implicit Touch Pressure in Statistical Decoding for Indirect Text Entry. In Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems, Honolulu, HI, USA, 25–30 April 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 1–13. [Google Scholar]
- Rodrigues, A.; Santos, A.R.; Montague, K.; Nicolau, H.; Guerreiro, T. WildKey: A Privacy-Aware Keyboard Toolkit for Data Collection In-The-Wild. In Adjunct Proceedings of the 2021 ACM International Joint Conference on Pervasive and Ubiquitous Computing and Proceedings of the 2021 ACM International Symposium on Wearable Computers; Association for Computing Machinery: New York, NY, USA, 2021; pp. 542–545. [Google Scholar]
- Arif, A.S.; Stuerzlinger, W. Analysis of Text Entry Performance Metrics. In Proceedings of the 2009 IEEE Toronto International Conference Science and Technology for Humanity (TIC-STH), Toronto, ON, Canada, 26–27 September 2009; pp. 100–105. [Google Scholar] [CrossRef]
- Banovic, N.; Sethapakdi, T.; Hari, Y.; Dey, A.K.; Mankoff, J. The Limits of Expert Text Entry Speed on Mobile Keyboards with Autocorrect. In Proceedings of the 21st International Conference on Human-Computer Interaction with Mobile Devices and Services, MobileHCI’19, New York, NY, USA, 1–4 October 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 1–12. [Google Scholar] [CrossRef]
- Komninos, A.; Dunlop, M.; Katsaris, K.; Garofalakis, J. A Glimpse of Mobile Text Entry Errors and Corrective Behaviour in the Wild. In Proceedings of the 20th International Conference on Human-Computer Interaction with Mobile Devices and Services Adjunct, MobileHCI’18, Barcelona, Spain, 3–6 September 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 221–228. [Google Scholar] [CrossRef]
- Palin, K.; Feit, A.M.; Kim, S.; Kristensson, P.O.; Oulasvirta, A. How Do People Type on Mobile Devices? Observations from a Study with 37,000 Volunteers. In Proceedings of the 21st International Conference on Human-Computer Interaction with Mobile Devices and Services, MobileHCI’19, New York, NY, USA, 1–4 October 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 1–12. [Google Scholar] [CrossRef]
- Alharbi, O.; Stuerzlinger, W.; Putze, F. The Effects of Predictive Features of Mobile Keyboards on Text Entry Speed and Errors. Proc. ACM Hum. Interact. 2020, 4, 183:1–183:16. [Google Scholar] [CrossRef]
- Papoutsaki, A.; Gokaslan, A.; Tompkin, J.; He, Y.; Huang, J. The Eye of the Typer: A Benchmark and Analysis of Gaze Behavior during Typing. In Proceedings of the 2018 ACM Symposium on Eye Tracking Research & Applications, ETRA’18, Warsaw, Poland, 14–17 June 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 1–9. [Google Scholar] [CrossRef]
- Feit, A.M.; Weir, D.; Oulasvirta, A. How We Type: Movement Strategies and Performance in Everyday Typing. In Proceedings of the 2016 CHI Conference on Human Factors in Computing Systems, CHI ’16, San Jose, CA, USA, 7–12 May 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 4262–4273. [Google Scholar] [CrossRef]
- Wang, J.; Fu, E.Y.; Ngai, G.; Leong, H.V. Investigating Differences in Gaze and Typing Behavior Across Age Groups and Writing Genres. In Proceedings of the 2019 IEEE 43rd Annual Computer Software and Applications Conference (COMPSAC), Milwaukee, WI, USA, 15–19 July 2019; Volume 1, pp. 622–629. [Google Scholar] [CrossRef]
- Wang, J.; Fu, E.Y.; Ngai, G.; Leong, H.V. Investigating Differences in Gaze and Typing Behavior Across Writing Genres. Int. J. Hum. Comput. Interact. 2021, 38, 541–561. [Google Scholar] [CrossRef]
- Al-Khalifa, H.S.; Al-Mohsin, M.; Al-Twaim, M.; Al-Razgan, M.S. Soft Keyboard UX Evaluation: An Eye Tracking Study. In Proceedings of the 6th International Conference on Management of Emergent Digital EcoSystems, MEDES ’14, Buraidah Al Qassim, Saudi Arabia, 15–17 September 2014; Association for Computing Machinery: New York, NY, USA, 2014; pp. 78–84. [Google Scholar] [CrossRef]
- Valliappan, N.; Dai, N.; Steinberg, E.; He, J.; Rogers, K.; Ramachandran, V.; Xu, P.; Shojaeizadeh, M.; Guo, L.; Kohlhoff, K.; et al. Accelerating Eye Movement Research via Accurate and Affordable Smartphone Eye Tracking. Nat. Commun. 2020, 11, 4553. [Google Scholar] [CrossRef]
- Kim, H.; Yi, S.; Yoon, S.Y. Exploring Touch Feedback Display of Virtual Keyboards for Reduced Eye Movements. Displays 2019, 56, 38–48. [Google Scholar] [CrossRef]
- Putze, F.; Ihrig, T.; Schultz, T.; Stuerzlinger, W. Platform for Studying Self-Repairing Auto-Corrections in Mobile Text Entry Based on Brain Activity, Gaze, and Context. In Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems, Honolulu, HI, USA, 25–30 April 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 1–13. [Google Scholar]
- Pasquetto, I.V.; Sands, A.E.; Darch, P.T.; Borgman, C.L. Open Data in Scientific Settings: From Policy to Practice. In Proceedings of the 2016 CHI Conference on Human Factors in Computing Systems, CHI’16, San Jose, CA, USA, 7–12 May 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 1585–1596. [Google Scholar] [CrossRef]
- Kay, M.; Haroz, S.; Guha, S.; Dragicevic, P. Special Interest Group on Transparent Statistics in HCI. In Proceedings of the 2016 CHI Conference Extended Abstracts on Human Factors in Computing Systems, CHI EA’16, San Jose, CA, USA, 7–12 May 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 1081–1084. [Google Scholar] [CrossRef]
- Chuang, L.L.; Pfeil, U. Transparency and Openness Promotion Guidelines for HCI. In Proceedings of the Extended Abstracts of the 2018 CHI Conference on Human Factors in Computing Systems, CHI EA’18, Montreal, QC, Canada, 21–26 April 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 1–4. [Google Scholar] [CrossRef]
- Echtler, F.; Häußler, M. Open Source, Open Science, and the Replication Crisis in HCI. In Proceedings of the Extended Abstracts of the 2018 CHI Conference on Human Factors in Computing Systems, CHI EA’18, Montreal, QC, Canada, 21–26 April 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 1–8. [Google Scholar] [CrossRef]
- Banovic, N. To Replicate or Not to Replicate? Getmobile Mob. Comput. Commun. 2016, 19, 23–27. [Google Scholar] [CrossRef]
- Hornbæk, K.; Sander, S.S.; Bargas-Avila, J.A.; Grue Simonsen, J. Is Once Enough?On the Extent and Content of Replications in Human-Computer Interaction. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, CHI’14, Toronto, ON, Canada, 26 April–1 May 2014; Association for Computing Machinery: New York, NY, USA, 2014; pp. 3523–3532. [Google Scholar] [CrossRef]
- Wilson, M.L.L.; Resnick, P.; Coyle, D.; Chi, E.H. RepliCHI: The Workshop. In Proceedings of the CHI ’13 Extended Abstracts on Human Factors in Computing Systems, CHI EA’13, Paris, France, 27 April–2 May 2013; Association for Computing Machinery: New York, NY, USA, 2013; pp. 3159–3162. [Google Scholar] [CrossRef]
- Cockburn, A.; Gutwin, C.; Dix, A. HARK No More: On the Preregistration of CHI Experiments. In Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems, Montreal, QC, Canada, 21–26 April 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 1–12. [Google Scholar]
- Wacharamanotham, C.; Eisenring, L.; Haroz, S.; Echtler, F. Transparency of CHI Research Artifacts: Results of a Self-Reported Survey. In Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems, Honolulu, HI, USA, 25–30 April 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 1–14. [Google Scholar]
- Cockburn, A.; Dragicevic, P.; Besançon, L.; Gutwin, C. Threats of a Replication Crisis in Empirical Computer Science. Commun. ACM 2020, 63, 70–79. [Google Scholar] [CrossRef]
- Ballou, N.; Warriar, V.R.; Deterding, S. Are You Open? A Content Analysis of Transparency and Openness Guidelines in HCI Journals. In Proceedings of the 2021 CHI Conference on Human Factors in Computing Systems, CHI’21, Yokohama, Japan, 8–13 May 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 1–10. [Google Scholar] [CrossRef]
- Feger, S.S.; Dallmeier-Tiessen, S.; Woźniak, P.W.; Schmidt, A. The Role of HCI in Reproducible Science: Understanding, Supporting and Motivating Core Practices. In Proceedings of the Extended Abstracts of the 2019 CHI Conference on Human Factors in Computing Systems, CHI EA’19, Glasgow, UK, 4–9 May 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Feger, S.S.; Woźniak, P.W.; Niess, J.; Schmidt, A. Tailored Science Badges: Enabling New Forms of Research Interaction. In Proceedings of the Designing Interactive Systems Conference 2021, DIS’21, Virtual Event, 28 June–2 July 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 576–588. [Google Scholar] [CrossRef]
- Jiao, C.; Li, K.; Fang, Z. Data Sharing Practices across Knowledge Domains: A Dynamic Examination of Data Availability Statements in PLOS ONE Publications. J. Inf. Sci. 2022. [Google Scholar] [CrossRef]
- Tedersoo, L.; Küngas, R.; Oras, E.; Köster, K.; Eenmaa, H.; Leijen, Ä.; Pedaste, M.; Raju, M.; Astapova, A.; Lukner, H.; et al. Data Sharing Practices and Data Availability upon Request Differ across Scientific Disciplines. Sci. Data 2021, 8, 192. [Google Scholar] [CrossRef] [PubMed]
- Rouder, J.N. The What, Why, and How of Born-Open Data. Behav. Res. Methods 2016, 48, 1062–1069. [Google Scholar] [CrossRef] [PubMed]
- Hutchinson, B.; Smart, A.; Hanna, A.; Denton, E.; Greer, C.; Kjartansson, O.; Barnes, P.; Mitchell, M. Towards Accountability for Machine Learning Datasets: Practices from Software Engineering and Infrastructure. In Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, FAccT’21, Toronto, ON, Canada, 3–10 March 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 560–575. [Google Scholar] [CrossRef]
- Feger, S.S.; Wozniak, P.W.; Lischke, L.; Schmidt, A. ‘Yes, I Comply!’: Motivations and Practices around Research Data Management and Reuse across Scientific Fields. Proc. ACM -Hum. Interact. 2020, 4, 141:1–141:26. [Google Scholar] [CrossRef]
- Vertesi, J.; Dourish, P. The Value of Data: Considering the Context of Production in Data Economies. In Proceedings of the ACM 2011 Conference on Computer Supported Cooperative Work, CSCW ’11, Hangzhou, China, 19–23 March 2011; Association for Computing Machinery: New York, NY, USA, 2011; pp. 533–542. [Google Scholar] [CrossRef]
- Kjeldskov, J.; Paay, J. A Longitudinal Review of Mobile HCI Research Methods. In Proceedings of the 14th International Conference on Human-computer Interaction with Mobile Devices and Services, MobileHCI’12, San Francsico, CA, USA, 21–24 September 2012; Association for Computing Machinery: New York, NY, USA, 2012; pp. 69–78. [Google Scholar] [CrossRef]
- Nachtigall, T.; Tetteroo, D.; Markopoulos, P. A Five-Year Review of Methods, Purposes and Domains of the International Symposium on Wearable Computing. In Proceedings of the 2018 ACM International Symposium on Wearable Computers, ISWC’18, Singapore, 8–12 October 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 48–55. [Google Scholar] [CrossRef]
- Caine, K. Local Standards for Sample Size at CHI. In Proceedings of the 2016 CHI Conference on Human Factors in Computing Systems, CHI’16, San Jose, CA, USA, 7–12 May 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 981–992. [Google Scholar] [CrossRef]
- Dragicevic, P. Fair Statistical Communication in HCI. In Modern Statistical Methods for HCI; Robertson, J., Kaptein, M., Eds.; Human–Computer Interaction Series; Springer International Publishing: Cham, Switzerland, 2016; pp. 291–330. [Google Scholar] [CrossRef]
- Kay, M.; Haroz, S.; Guha, S.; Dragicevic, P.; Wacharamanotham, C. Moving Transparent Statistics Forward at CHI. In Proceedings of the 2017 CHI Conference Extended Abstracts on Human Factors in Computing Systems, Denver, CO, USA, 6–11 May 2017. [Google Scholar]
- Crowe, S.; Cresswell, K.; Robertson, A.; Huby, G.; Avery, A.; Sheikh, A. The Case Study Approach. BMC Med. Res. Methodol. 2011, 11, 100. [Google Scholar] [CrossRef] [PubMed]
- Stake, R.E. The Art of Case Study Research; SAGE: Newcastle upon Tyne, UK, 1995. [Google Scholar]
- Flyvbjerg, B. Five Misunderstandings About Case-Study Research. Qual. Inq. 2006, 12, 219–245. [Google Scholar] [CrossRef]
- Hammersley, M.; Foster, P.; Gomm, R. Case Study and Generalisation; Sage: London, UK, 2000; pp. 98–115. [Google Scholar]
- Steinberg, P.F. Can We Generalize from Case Studies? Glob. Environ. Politics 2015, 15, 152–175. [Google Scholar] [CrossRef]
- Tsang, E.W. Generalizing from Research Findings: The Merits of Case Studies. Int. J. Manag. Rev. 2014, 16, 369–383. [Google Scholar] [CrossRef]
- Anderson, C.; Hübener, I.; Seipp, A.K.; Ohly, S.; David, K.; Pejovic, V. A Survey of Attention Management Systems in Ubiquitous Computing Environments. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2018, 2, 58:1–58:27. [Google Scholar] [CrossRef]
- Komninos, A.; Nicol, E.; Dunlop, M.D. Designed with Older Adults to SupportBetter Error Correction in SmartPhone Text Entry: The MaxieKeyboard. In Proceedings of the 17th International Conference on Human-Computer Interaction with Mobile Devices and Services Adjunct, MobileHCI’15, Copenhagen, Denmark, 24–27 August 2015; Association for Computing Machinery: New York, NY, USA, 2015; pp. 797–802. [Google Scholar] [CrossRef]
- Shah, S.; Jain, A. Impact of the COVID-19 Pandemic on User Experience (UX) Research. In Proceedings of the HCI International 2021—Posters; Stephanidis, C., Antona, M., Ntoa, S., Eds.; Springer International Publishing: Cham, Switzerland, 2021; Communications in Computer and Information Science; pp. 599–607. [Google Scholar] [CrossRef]
- Alvi, I.A. Engineers Need to Get Real, But Can’t: The Role of Models. In Proceedings of the Structures Congress, Pittsburgh, PA, USA, 2–4 May 2013; pp. 916–927. [Google Scholar] [CrossRef]
- Arif, A.S.; Mazalek, A. WebTEM: A Web Application to Record Text Entry Metrics. In Proceedings of the 2016 ACM International Conference on Interactive Surfaces and Spaces, ISS ’16, Niagara Falls, ON, Canada, 6–9 November 2016; Association for Computing Machinery: New York, NY, USA, 2016; pp. 415–420. [Google Scholar] [CrossRef]
- Buschek, D.; Bisinger, B.; Alt, F. ResearchIME: A Mobile Keyboard Application for Studying Free Typing Behaviour in the Wild. In Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems, Montreal, QC, Canada, 21–26 April 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 1–14. [Google Scholar]












Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Komninos, A. The Value of Open Data in HCI: A Case Report from Mobile Text Entry Research. Multimodal Technol. Interact. 2022, 6, 71. https://doi.org/10.3390/mti6090071
Komninos A. The Value of Open Data in HCI: A Case Report from Mobile Text Entry Research. Multimodal Technologies and Interaction. 2022; 6(9):71. https://doi.org/10.3390/mti6090071
Chicago/Turabian StyleKomninos, Andreas. 2022. "The Value of Open Data in HCI: A Case Report from Mobile Text Entry Research" Multimodal Technologies and Interaction 6, no. 9: 71. https://doi.org/10.3390/mti6090071
APA StyleKomninos, A. (2022). The Value of Open Data in HCI: A Case Report from Mobile Text Entry Research. Multimodal Technologies and Interaction, 6(9), 71. https://doi.org/10.3390/mti6090071