
User Authentication Recognition Process Using Long Short-Term Memory Model






Abstract
1. Introduction
2. Materials
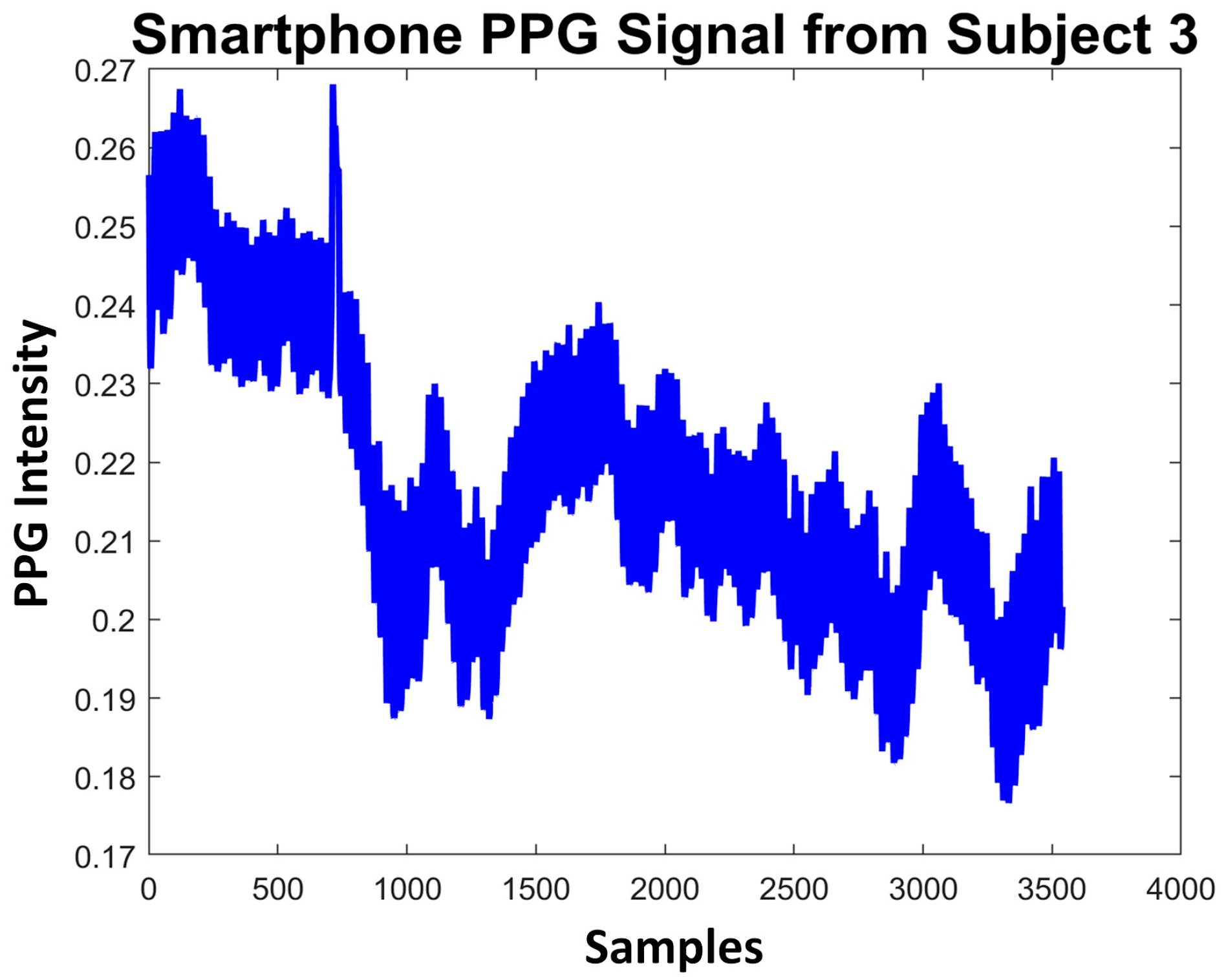
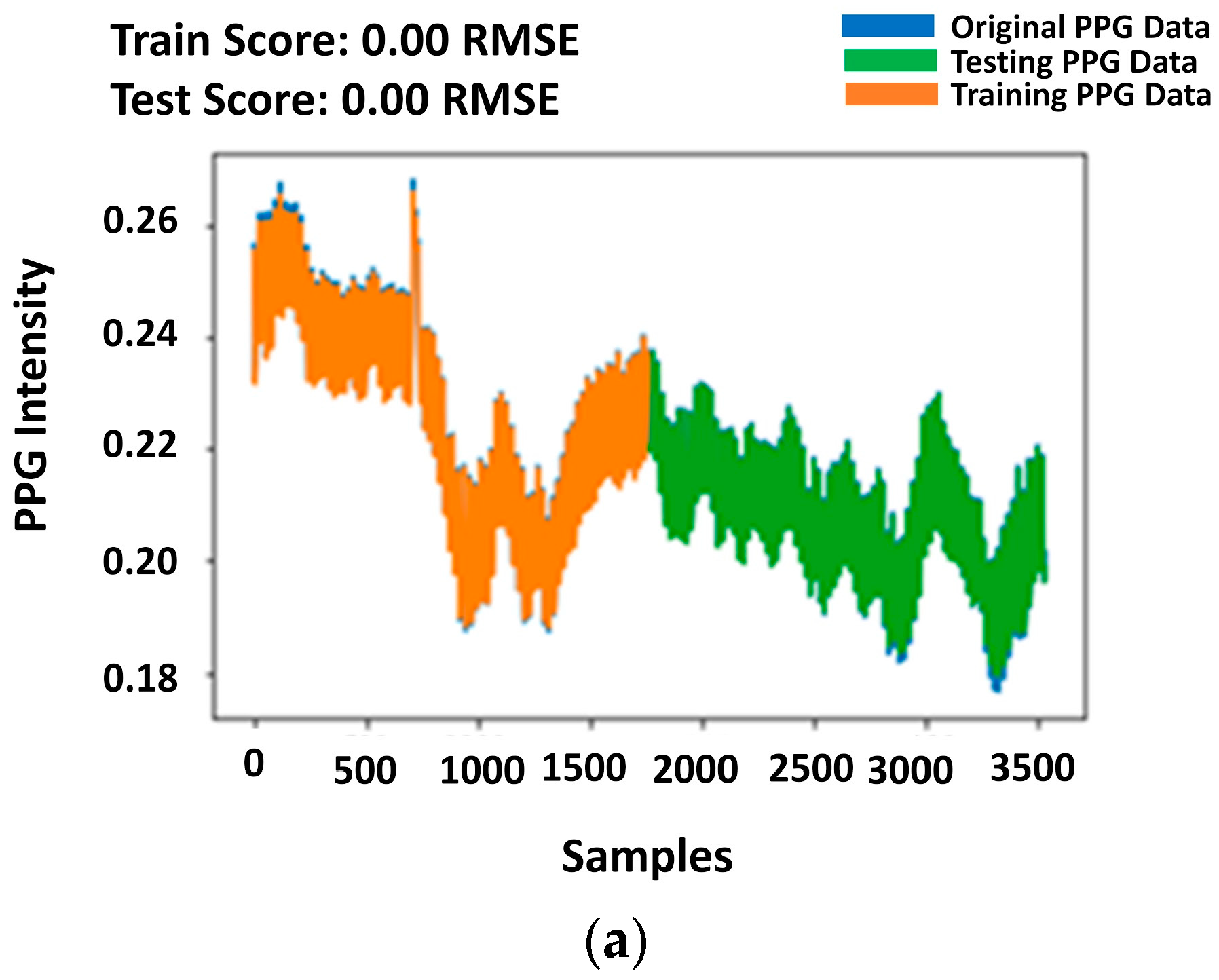
2.1. Smartphone PPG Signal Dataset
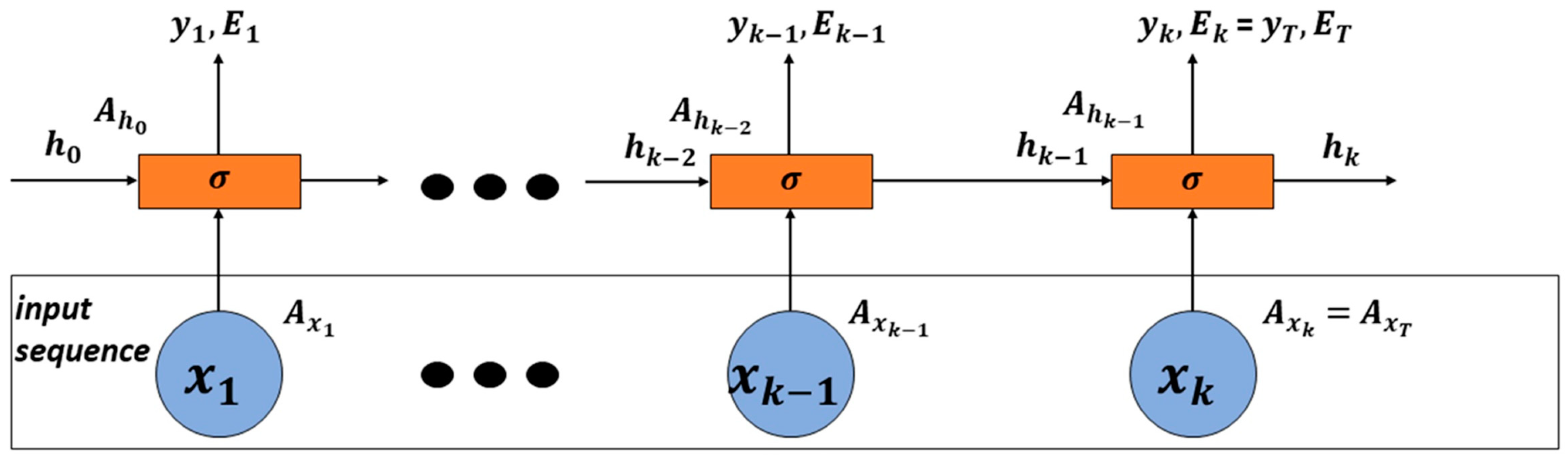
2.2. RNN
3. Methods
3.1. LSTM Memory Cell
- Input gate () controls the input activation of new information to the memory cell.
- Output gate () controls the output flow.
- Forget gate () controls when to forget the internal state information.
- Input modulation gate () controls the main input to the memory cell.
- Internal state () controls the internal recurrence of the memory cell.
- Hidden state () controls the information from the previous data sample within the context window:
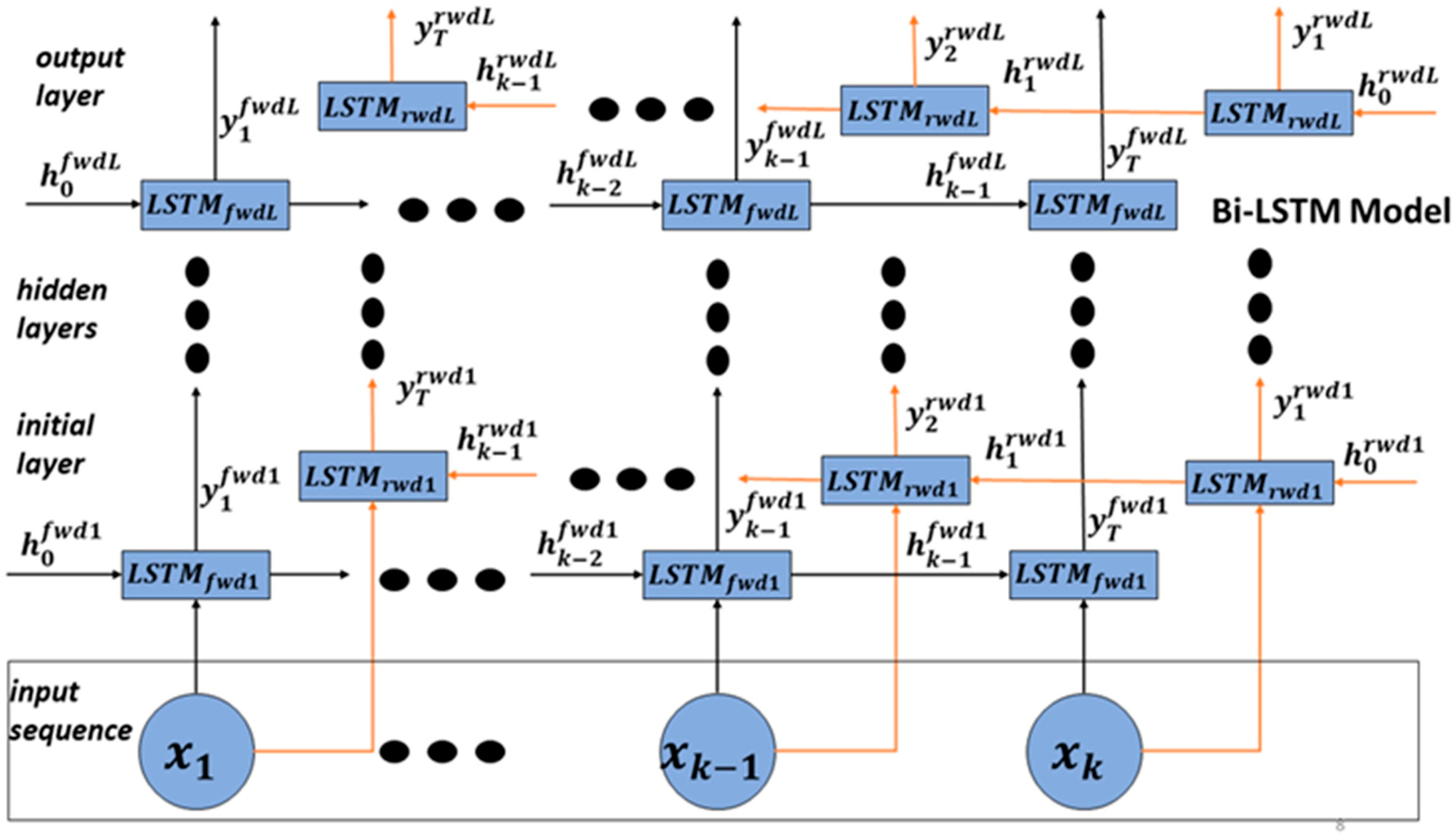
3.2. LSTM vs. Bi-LSTM
3.3. Optimization of Hyperparameters of LSTM
- Learning rate: The learning rate parameter has a strong influence on how quickly or slowly the model can converge to a local maximum. If it is too large, it can cause a quick convergence to a suboptimal solution. On the other hand, if it is too small, it may reach the solution slowly. ADAM optimizer is an adaptive learning rate operator [44]. The optimizer tends to be influenced by the learning rate hyperparameter, which means that it is an important input for the optimization.
- Batch sizes: An input dataset is initially divided into many batches, depending on the batch size, and fed into a neural network. A batch size creates a subset of the training set that is used to evaluate the gradient of the loss function and update the weights.
- Number of epochs: The number of epochs represents the total number of iterations by which the data run through the selected optimizer.
4. Results and Discussion
4.1. LSTM Regression Performance
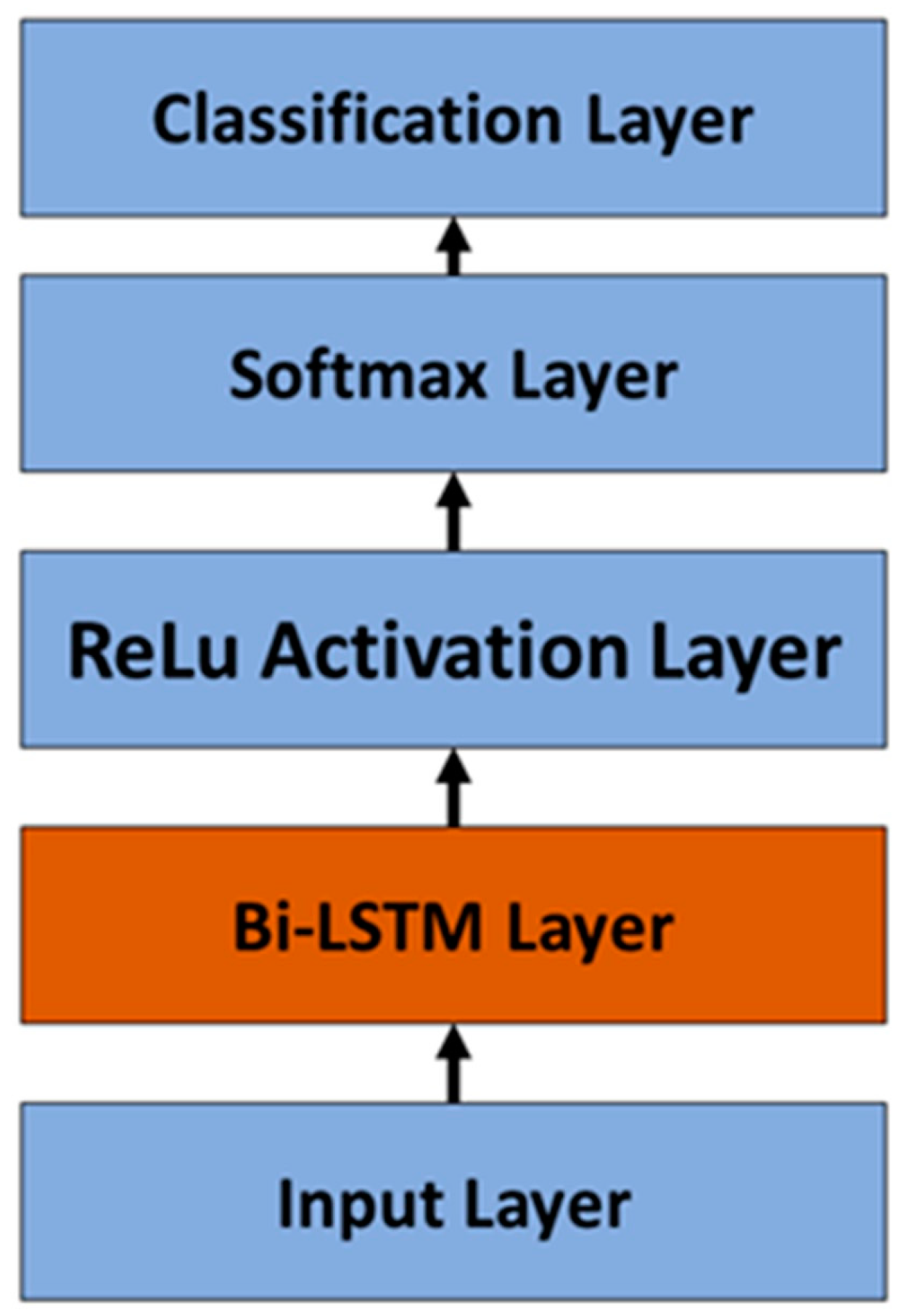
4.2. LSTM Classification Performance
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Tabei, F.; Kumar, R.; Phan, T.N.; McManus, D.D.; Chong, J. A Novel Personalized Motion and Noise Artifact (MNA) Detection Method for Smartphone Photoplethysmograph (PPG) Signals. IEEE Access 2018, 6, 60498–60512. [Google Scholar] [CrossRef]
- Abay, T.Y.; Kyriacou, P.A. Photoplethysmography for blood volumes and oxygenation changes during intermittent vascular occlusions. J. Clin. Monit. Comput. 2018, 8, 447–455. [Google Scholar] [CrossRef] [PubMed]
- Tabei, F.; Gresham, J.M.; Askarian, B.; Jung, K.; Chong, J. Cuff-Less Blood Pressure Monitoring System Using Smartphones. IEEE Access 2020, 8, 11534–11545. [Google Scholar] [CrossRef]
- Shoushan, M.M.; Reyes, B.A.; Rodriguez, A.R.M.; Chong, J. Contactless Monitoring of Heart Rate Variability during Respiratory Maneuvers. IEEE Sens. J. 2022, 22, 14563–14573. [Google Scholar] [CrossRef]
- Ayesha, A.H.; Qiao, D.; Zulkernine, F. Heart Rate Monitoring Using PPG with Smartphone Camera. In Proceedings of the 2021 IEEE International Conference on Bioinformatics and Biomedicine, Houston, TX, USA, 9–12 December 2021; pp. 2985–2991. [Google Scholar]
- Lamonaca, F.; Carni, D.L.; Grimaldi, D.; Nastro, A.; Riccio, M.; Spagnolo, V. Blood oxygen saturation measurement by smartphone camera. In Proceedings of the 2015 IEEE International Symposium on Meical Measurements and Applications, Turin, Italy, 7–9 May 2015; pp. 359–364. [Google Scholar]
- Plaza, J.L.; Nam, Y.; Chon, K.; Lasaosa, P.L.; Herrando, E.G. Respiratory rate derived from smartphone-camera-acquired pulse photoplethysmographic signals. Physiol. Meas. 2015, 36, 2317–2333. [Google Scholar]
- Buriro, A. Behavioral Biometrics for Smartphone User Authentication. Ph.D. Thesis, University of Trento, Trento, Italy, 2017. [Google Scholar]
- Abuhamad, M.; Abusnaina, A.; Nyang, D.; Mohaisen, D. Sensor-Based Continuous Authentication of Smartphones’ Users Using Behavioral Biometrics: A Contemporary Survey. IEEE Internet Things J. 2021, 8, 65–84. [Google Scholar] [CrossRef]
- Ortiz, B.L.; Chong, J.; Gupta, V.; Shoushan, M.; Jung, K.; Dallas, T. A Biometric Authentication Technique Using Smartphone Fingertip Photoplethysmography Signals. IEEE Sens. J. 2022, 22, 14237–14249. [Google Scholar] [CrossRef]
- Wang, S.; Adams, C.; Broadbent, A. Password authentication schemes on a quantum computer. In Proceedings of the 2021 IEEE International Conference on Quantum Computing and Engineering (QCE), Broomfield, CO, USA, 17–22 October 2021; pp. 346–350. [Google Scholar]
- Manasseh, T. An Enhanced Password-Username Authentication System Using Cryptographic Hashing and Recognition Based Graphical Password. IOSR J. Comput. Eng. 2016, 18, 54–58. [Google Scholar]
- Vikas, B.O. Authentication Scheme for Passwords using Color and Text. IJSRSET 2015, 1, 316–323. [Google Scholar]
- Ju, S.; Seo, H.; Han, S.; Ryou, J.; Kwak, J. A Study on User Authentication Methodology Using Numeric Password and Fingerprint Biometric Information. BioMed Res. Int. 2013, 1–7. [Google Scholar] [CrossRef]
- Raza, M.; Iqbal, M.; Sharif, M.; Haider, W. A Survey of Password Attacks and Comparative Analysis on Methods for Secure Authentication. World Appl. Sci. J. 2012, 19, 439–444. [Google Scholar]
- Sreelekshmi, S.; Shabanam, T.S.; Nair, P.P.; George, N.; Saji, S. RFID based Smart Card for Campus Automation. Int. J. Eng. Res. Technol. 2021, 9, 38–40. [Google Scholar]
- Singh, P.K.; Kumar, N.; Gupta, B.K. Smart Card ID: An Evolving and Viable Technology. Int. J. Adv. Comput. Sci. Appl. 2018, 9, 115–124. [Google Scholar]
- Henniger, O.; Franke, K. Biometric user authentication on smart cards by means of handwritten signatures. Lect. Notes Comput. Sci. 2004, 547–554. [Google Scholar] [CrossRef]
- Singh, A.K.; Solanki, A.; Nayyar, A.; Qureshi, B. Elliptic Curve Signcryption-Based Mutual Authentication Protocol for Smart Cards. Appl. Sci. 2019, 10, 8291. [Google Scholar] [CrossRef]
- Mainenti, D. User Perceptions of Apple’s Face ID. In Information Science, Human Computer Interaction (DIS805); 2017; Available online: https://www.researchgate.net/profile/David-Mainenti/publication/321795099_User_Perceptions_of_Apple’s_Face_ID/links/5a31f871458515afb6d97834/User-Perceptions-of-Apples-Face-ID.pdf (accessed on 25 November 2022).
- Cappallo, S.; Mensink, T.; Snoek, C.G. Latent factors of visual popularity prediction. In Proceedings of the 5th ACM on International Conference on Multimedia Retrieval, Shanghai, China, 23–26 June 2015; pp. 23–26. [Google Scholar]
- Alvappillai, A.; Barrina, P.N. Face Recognition Using Machine Learning; University California San Diego: La Jolla, CA, USA, 2017; pp. 1–6. [Google Scholar]
- Dospinescu, O.; Lîsîi, I. The recognition of fingerprints on mobile applications—An android case study. J. East. Eur. Res. Bus. Econ. 2016, 1–11. [Google Scholar] [CrossRef]
- Chowdhury, A.M.M.; Imtiaz, M.H. Contactless Fingerprint Recognition Using Deep Learning—A Systematic Review. J. Cybersecur. Priv. 2022, 2, 714–730. [Google Scholar] [CrossRef]
- Yang, W.; Wang, S.; Hu, J.; Zheng, G.; Valli, C. Security and Accuracy of Fingerprint-Based Biometrics: A Review. Symmetry 2019, 11, 141. [Google Scholar] [CrossRef]
- Tang, K.; Liu, A.; Li, P.; Chen, X. A Novel Fingerprint Sensing Technology Based on Electrostatic Imaging. Sensors 2018, 18, 3050. [Google Scholar] [CrossRef]
- Bhattacharyya, D.; Ranjan, R.; Alisherov, F.; Choi, M. Biometric authentication: A review. Int. J. u-e-Serv. Sci. Technol. 2009, 2, 13–28. [Google Scholar]
- Schroff, F.; Kalenichenko, D.; Philbin, J. FaceNet: A unified embedding for face recognition and clustering. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar]
- Smartphone User Statistics. Smartphone Statistics for 2022|Facinating Mobile Phone Stats. Available online: https://www.ukwebhostreview.com/smartphone-statistics (accessed on 9 October 2022).
- Apple Backs Finisar with $390 Million for Face ID Technology. Available online: https://www.mercurynews.com/2017/12/13/apple-backs-finisar-with-390-million-for-face-id-technology/ (accessed on 9 October 2022).
- Zhang, X.; Qin, Z.; Lyu, Y. Biometric authentication via finger photoplethysmogram. In Proceedings of the 2018 2nd International Conference on Computer Science and Artificial Intelligence, Shenzhen, China, 8–10 December 2018; pp. 263–267. [Google Scholar]
- Kavsaoğlu, A.R.; Polat, K.; Bozkurt, M.R. A novel feature ranking algorithm for biometric recognition with PPG signals. Comput. Biol. Med. 2014, 49, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Lovisotto, G.; Turner, H.; Eberz, S.; Martinovic, I. Seeing red: PPG biometrics using smartphone cameras. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 16–18 June 2020; pp. 818–819. [Google Scholar]
- Cherrat, E.M.; Alaoui, R.; Bouzahir, H. Convolutional neural networks approach for multimodal biometric identification system using the fusion of fingerprint, finger-vein and face images. PeerJ Comput. Sci. 2020, 6, 248. [Google Scholar] [CrossRef] [PubMed]
- Gupta, V. Voice disorder detection using long short term memory (lstm) model. arXiv 2018, arXiv:1812.01779. [Google Scholar]
- Kim, B.H.; Pyun, J.Y. ECG identification for personal authentication using LSTM-based deep recurrent neural networks. Sensors 2020, 20, 3069. [Google Scholar] [CrossRef] [PubMed]
- iPhone, X. Available online: https://support.apple.com/kb/sp770?locale=en_US (accessed on 21 September 2021).
- Ekiz, D.; Can, Y.S.; Dardagan, Y.C.; Aydar, F.; Kose, R.D.; Ersoy, C. End-to-end deep multi-modal physiological authentication with smartbands. IEEE Sens. J. 2021, 21, 14977–14986. [Google Scholar] [CrossRef]
- Elsayed, I.E. Adaptive Signal Processing—Recurrent Neural Networks; Mansoura University: Mansoura, Egypt; Available online: https://www.academia.edu/50985677/Recurrent_Neural_Networks (accessed on 9 October 2022).
- Grosse, R. Lecture 15: Exploding and Vanishing Gradients; The University of Toronto Department of Computer Science, University of Toronto: Toronto, ON, Canada, 2017. [Google Scholar]
- Mattheakis, M.; Protopapas, P. Recurrent neural networks: Exploding vanishing gradients & reservoir computing. In Advanced Topics in Data Science; Harvard Press: Cambridge, MA, USA, 2019. [Google Scholar]
- Neural Network (2): RNN and Problems of Exploding/Vanishing Gradient. Available online: https://liyanxu.blog/2018/11/01/rnn-exploding-vanishing-gradient/ (accessed on 9 October 2022).
- How LSTM Networks Solve the Problem of Vanishing Gradients. Available online: https://medium.datadriveninvestor.com/how-do-lstm-networks-solve-the-problem-of-vanishing-gradients-a6784971a577 (accessed on 9 October 2022).
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; pp. 301–302. [Google Scholar]
- Huenerfauth, M.; van Rossum, G.; Muller, R.P. Introduction to Python. Available online: https://m2siame.univ-tlse3.fr/_media/rpi/g2ebi_python_tutorial.pdf (accessed on 25 November 2022).
- Welcome to Google Colab. Available online: https://colab.research.google.com/ (accessed on 9 October 2022).
- Loss Function in Machine Learning. Available online: https://medium.com/swlh/cross-entropy-loss-in-pytorch-c010faf97bab (accessed on 9 October 2022).













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number of Subjects | Epochs | Learning Rate | Batch Sizes | Hidden Units |
|---|---|---|---|---|
| 5 | 60 | 0.01 | 150 | 100 |
| 10 | 150 | 0.001 | 150 | 100 |
| 20 | 150 | 0.001 | 150 | 250 |
| 30 | 500 | 0.001 | 150 | 250 |
| Number of Subjects | Accuracy | F1 Score | Recall | Precision |
|---|---|---|---|---|
| 5 | 90.9% | 94.8% | 96.8% | 92.8% |
| 10 | 90.6% | 94.9% | 99.7% | 90.7% |
| 20 | 95.1% | 97.3% | 99.9% | 95.2% |
| 30 | 96.7% | 98.0% | 100% | 97.0% |
| Epochs | Testing Accuracy | Testing Losses |
|---|---|---|
| 10 | 96.6% | 0.15 |
| 50 | 96.7% | 0.12 |
| 200 | 96.5% | 0.09 |
| 500 | 97.6% | 0.07 |
| 1000 | 95.5% | 0.67 |
| Batch Sizes | Testing Accuracy | Testing Losses |
|---|---|---|
| 32 | 96.7% | 0.09 |
| 64 | 96.5% | 0.10 |
| 150 | 96.7% | 0.12 |
| 256 | 96.6% | 0.015 |
| Learning Rates | Testing Accuracy | Testing Losses |
|---|---|---|
| 0.001 | 96.7% | 0.12 |
| 0.005 | 96.6% | 0.09 |
| 0.01 | 96.7% | 0.10 |
| 0.05 | 96.6% | 0.15 |
| 0.1 | 96.7% | 0.15 |
| Performance Metric | Percentage |
|---|---|
| Accuracy | 96.7% |
| Precision | 97.0% |
| Recall | 100% |
| F1 Score | 98.0% |
| FAR | 0.03% |
| FRR | 0.00% |
| EER | 0.03% |
| Architecture | Training Accuracy | Testing Accuracy |
|---|---|---|
| LSTM baseline model | 93.2% | 59.1% |
| UA-based Bi-LSTM model | 93.0% | 95.0% |
| Architecture | Training Accuracy | Testing Accuracy |
|---|---|---|
| LSTM baseline model | 96.3% | 96.3% |
| UA-based Bi-LSTM model | 96.7% | 96.7% |
| Authors | Year | UA-Type System | Authentication Technique | Advantages | Challenges |
|---|---|---|---|---|---|
| Tivkaa et al. [11] | 2021 | Non- biometric | Password | Online password guessing attacks. | Proof of concept (No implemented). Online UA solution. |
| Sherry et al. [12] | 2016 | Non- biometric | Password | Two-steps online login attempts. | Online UA system. System unable to learn from previous attacks. |
| Sreelekshmi et al. [16] | 2021 | Non- biometric | RFID/ smart cards | UA RFID-based school access system | Facility access application. Hardware implementation. Inconstant UA solution. |
| Mainenti et al. [20] | 2017 | Biometric | Facial | Apple’s face ID system. Wearable device UA system. External sensor. | Privacy issues. External artifacts affect the UA process. Inconstant UA recognition. Face orientation is limited. Expensive. |
| Yang et al. [25] | 2019 | Biometric | Fingerprint | Contactless fingerprint UA system. | external hardware required. High-complexity design. High cost. |
| Our Proposed Method | 2022 | Biometric | Fingertip | Contactless fingertip UA system. Physiology exclusive data. No additional hardware. | More testing in different authentication scenarios. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ortiz, B.L.; Gupta, V.; Chong, J.W.; Jung, K.; Dallas, T. User Authentication Recognition Process Using Long Short-Term Memory Model. Multimodal Technol. Interact. 2022, 6, 107. https://doi.org/10.3390/mti6120107
Ortiz BL, Gupta V, Chong JW, Jung K, Dallas T. User Authentication Recognition Process Using Long Short-Term Memory Model. Multimodal Technologies and Interaction. 2022; 6(12):107. https://doi.org/10.3390/mti6120107
Chicago/Turabian StyleOrtiz, Bengie L., Vibhuti Gupta, Jo Woon Chong, Kwanghee Jung, and Tim Dallas. 2022. "User Authentication Recognition Process Using Long Short-Term Memory Model" Multimodal Technologies and Interaction 6, no. 12: 107. https://doi.org/10.3390/mti6120107
APA StyleOrtiz, B. L., Gupta, V., Chong, J. W., Jung, K., & Dallas, T. (2022). User Authentication Recognition Process Using Long Short-Term Memory Model. Multimodal Technologies and Interaction, 6(12), 107. https://doi.org/10.3390/mti6120107