Multimodal Observation and Classification of People Engaged in Problem Solving: Application to Chess Players

Abstract
:1. Introduction
2. State-of-the-Art
- Can our experimental set up be used to capture reliable recordings for such study?
- Can we detect when chess players are challenged beyond their abilities from such measurements and what are the most relevant features?
3. Experiments
3.1. Materials and Participants
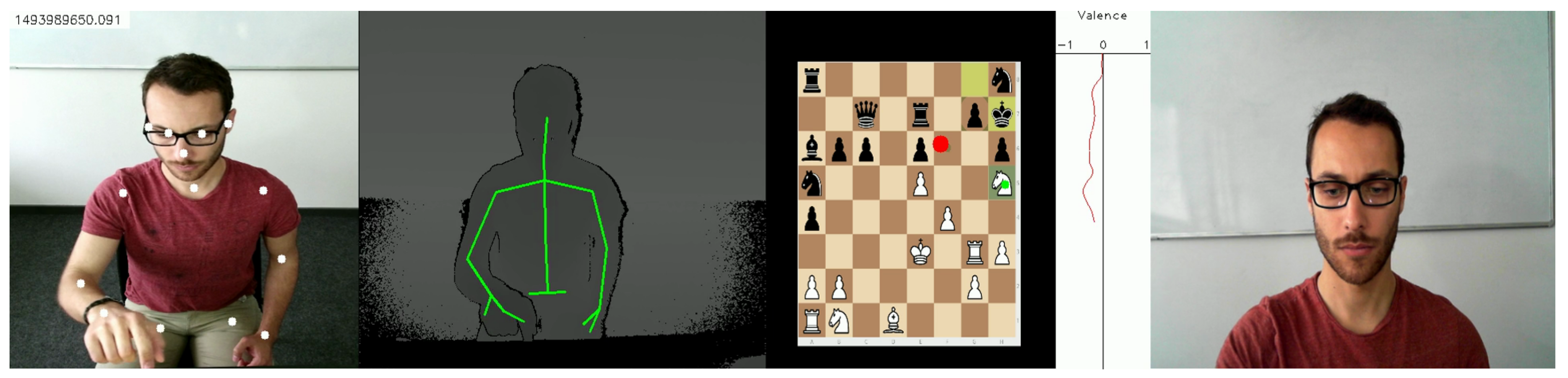
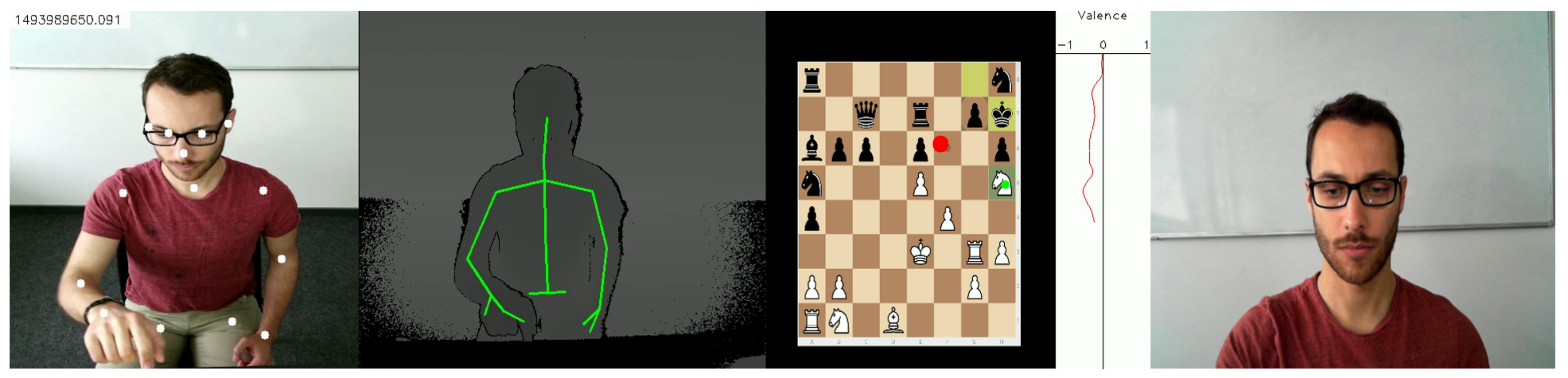
3.1.1. Experimental Setup
3.1.2. Participants
3.2. Methods
3.2.1. Chess Tasks
3.2.2. Procedure
3.3. Analysis
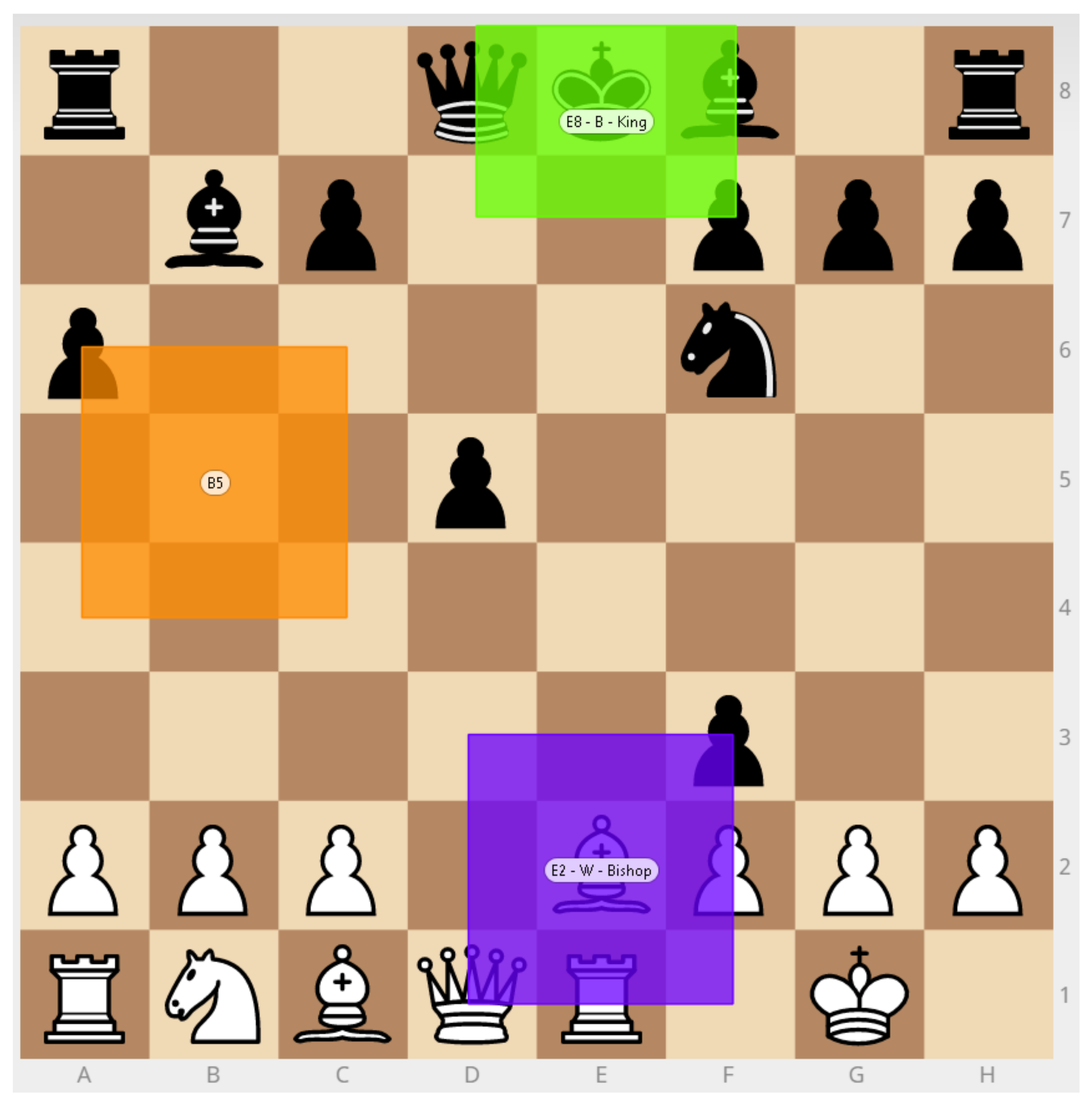
3.3.1. Eye-Gaze
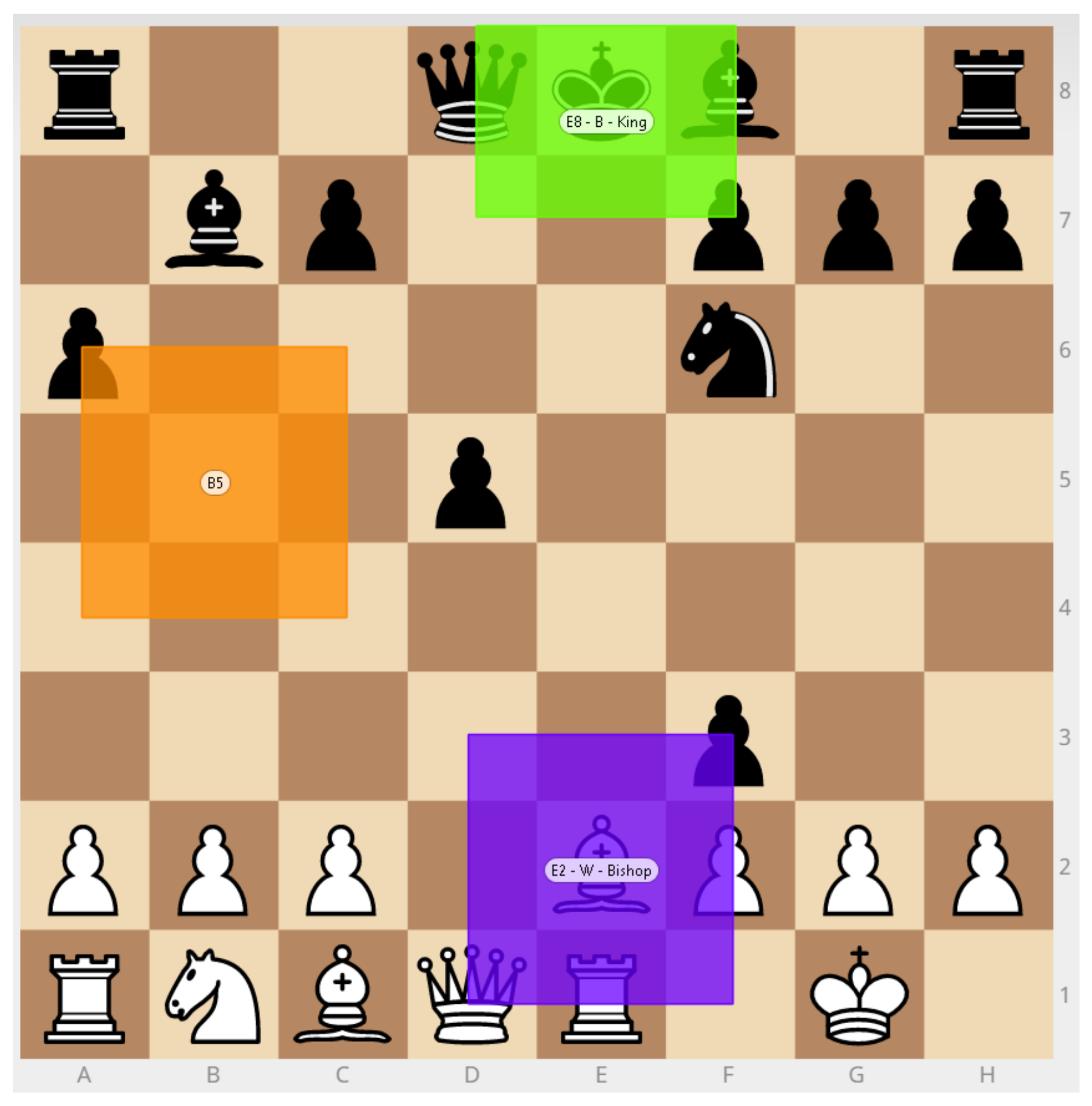
- What pieces received the most focus of attention from participants?
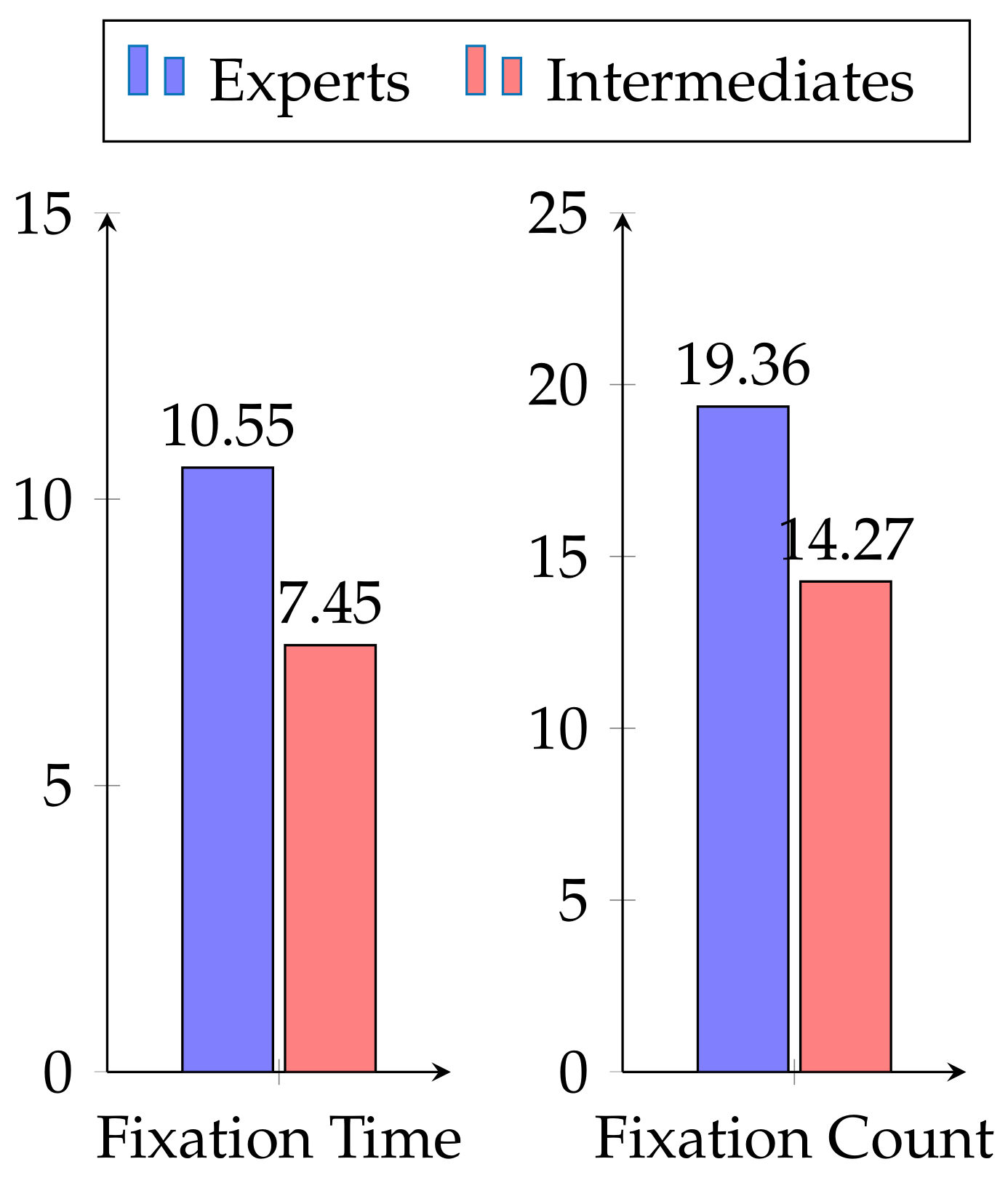
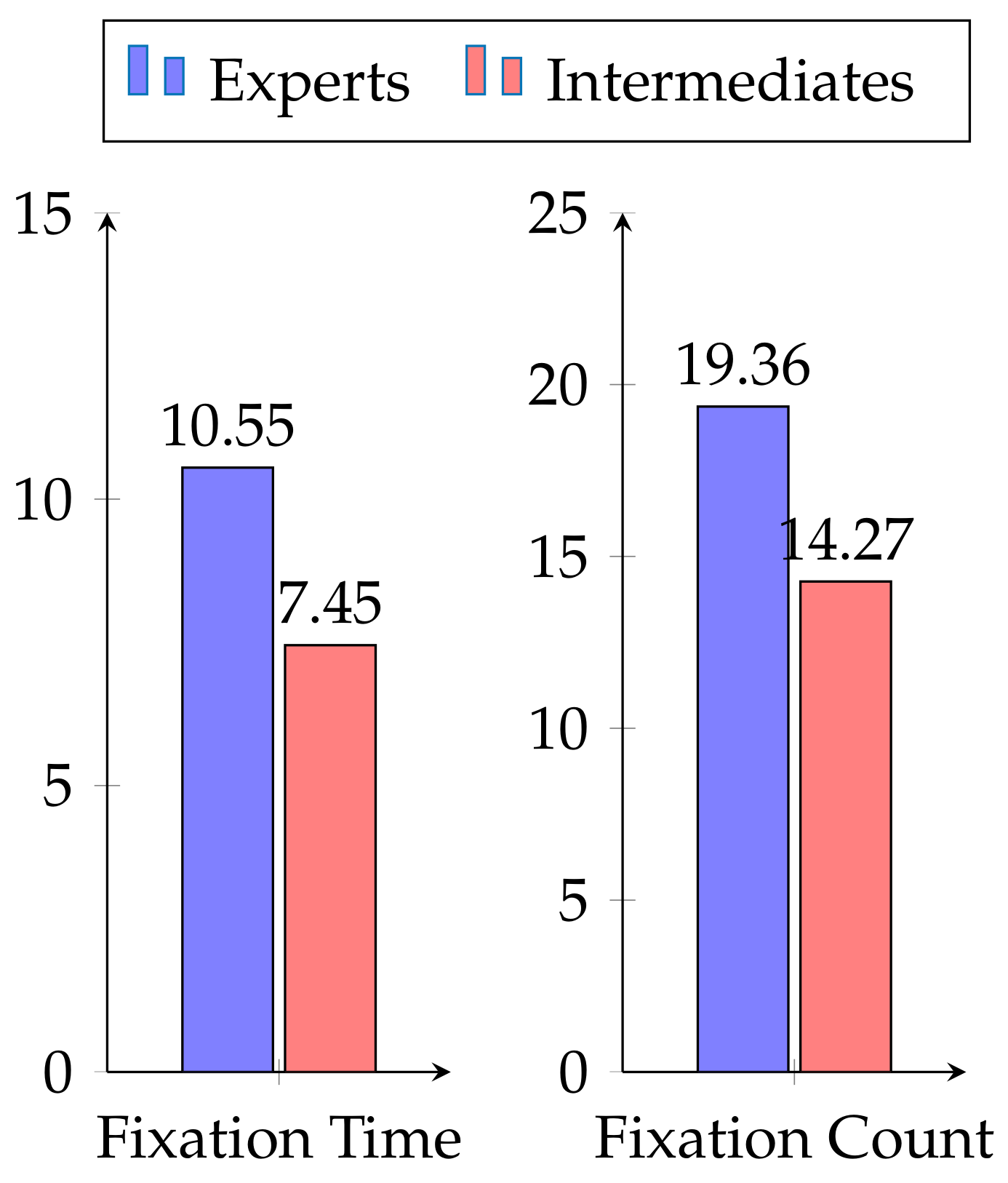
- Is there significant difference in gaze movements between novices and experts?
3.3.2. Facial Emotions
- Valence: intensity of positive emotions (Happy) minus intensity of negatives emotions (sadness, anger, fear and disgust);
- Arousal: computed accordingly to activation intensities of the 20 Action Units.
3.3.3. Body Posture
4. Results
4.1. Unimodal Analysis
4.1.1. Eye-Gaze
- The orientation phase: participants scan the board to grasp information about piece’s organization;
- The exploration phase: participants consider variations (moves) from the current configuration;
- The investigation phase: participants analyze in depth the two most probable candidates from phase 2;
- The proof phase: participants confirm the validity of their choice.
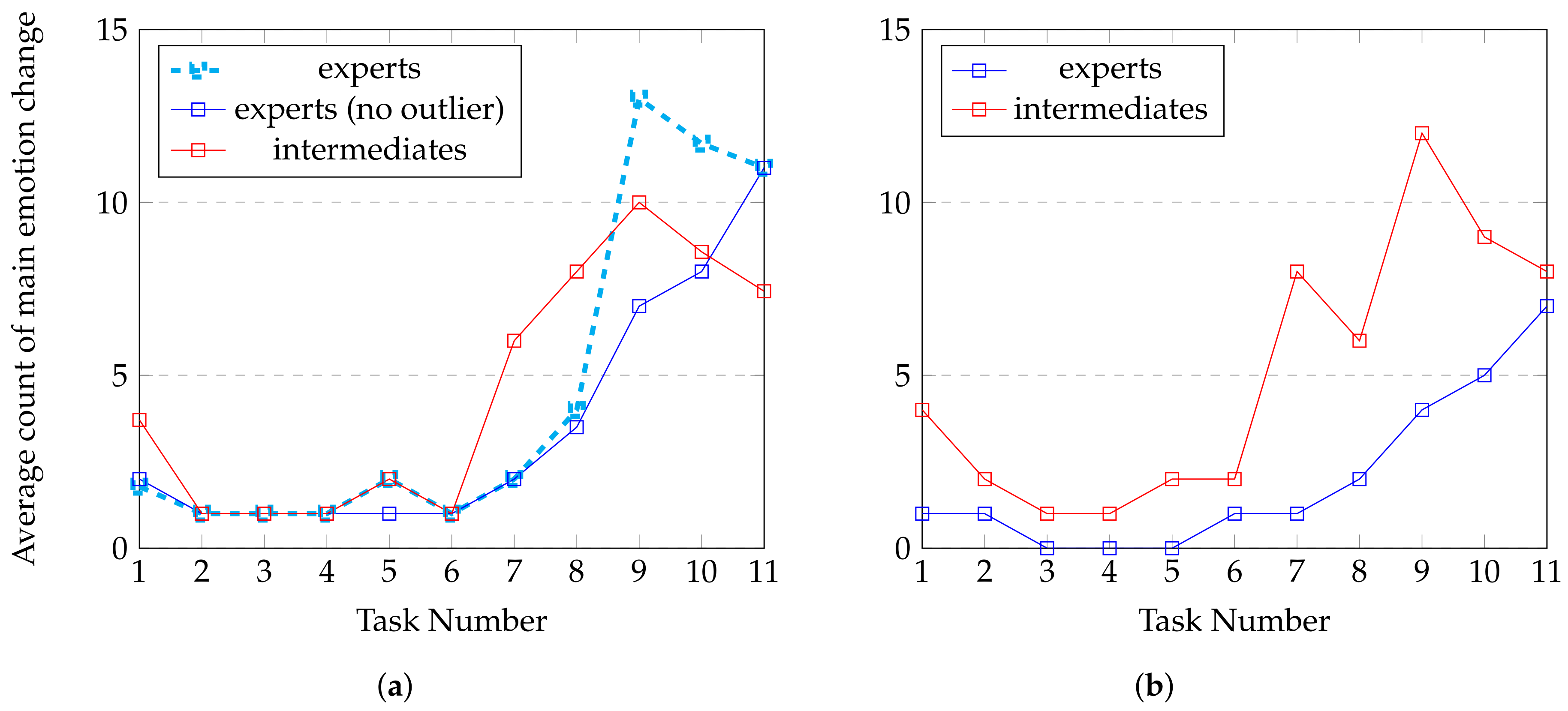
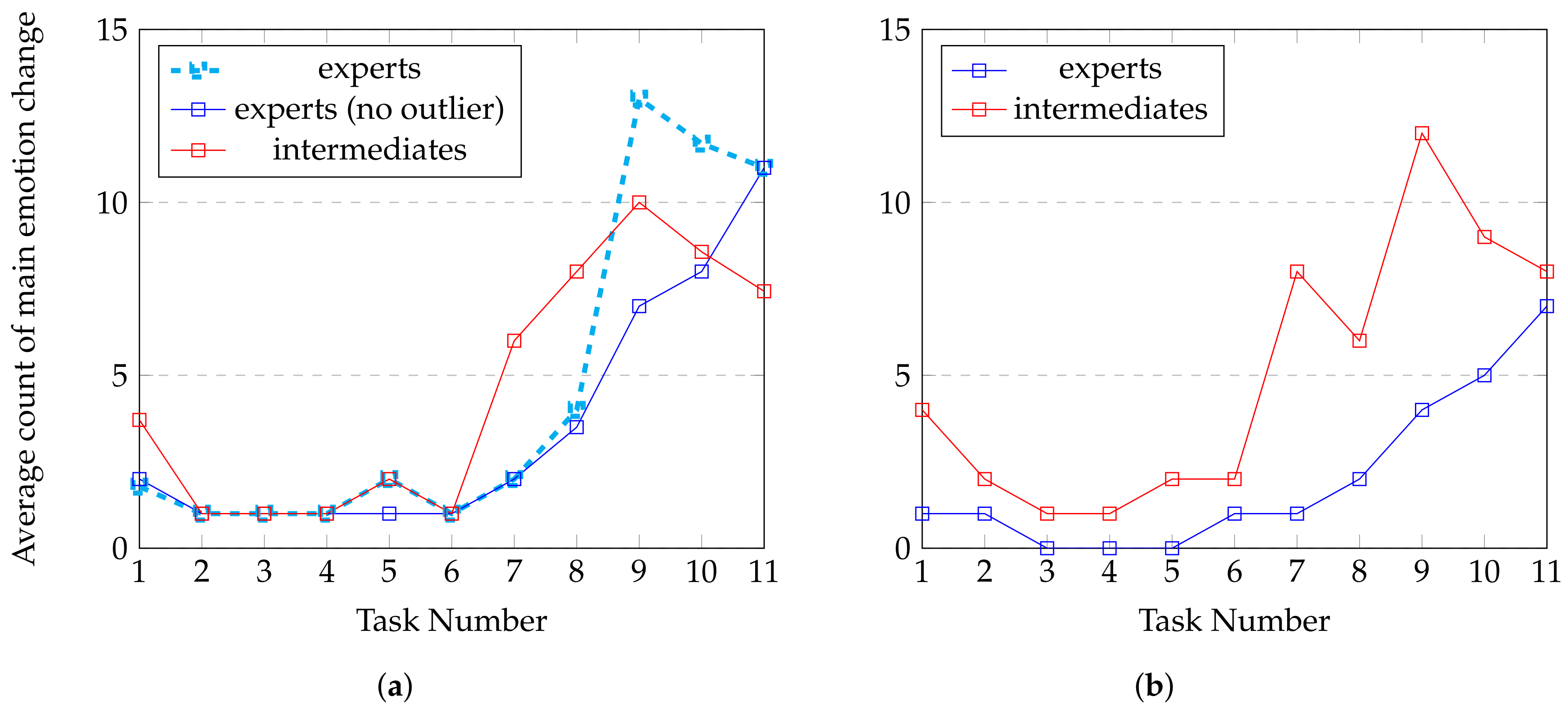
4.1.2. Emotions
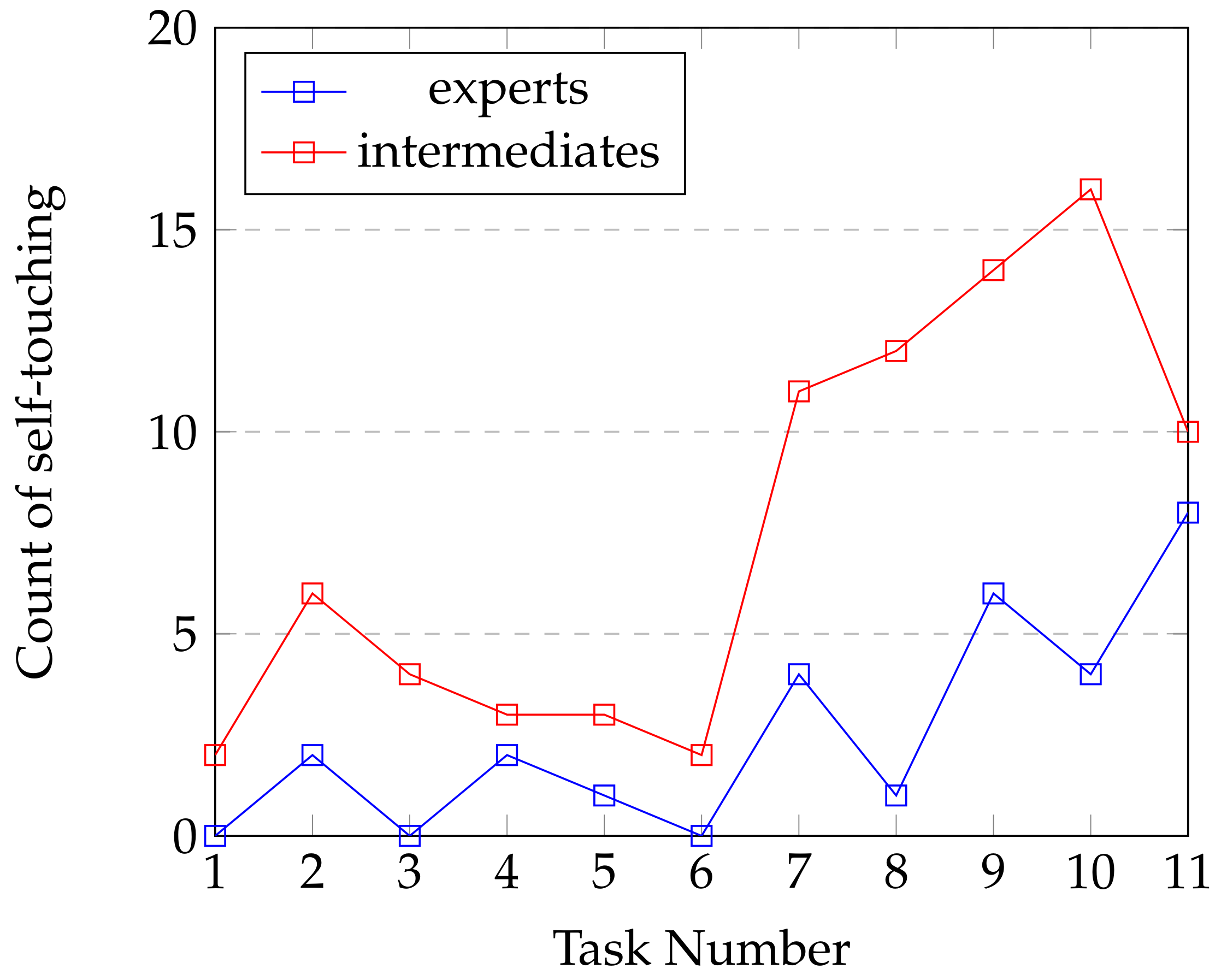
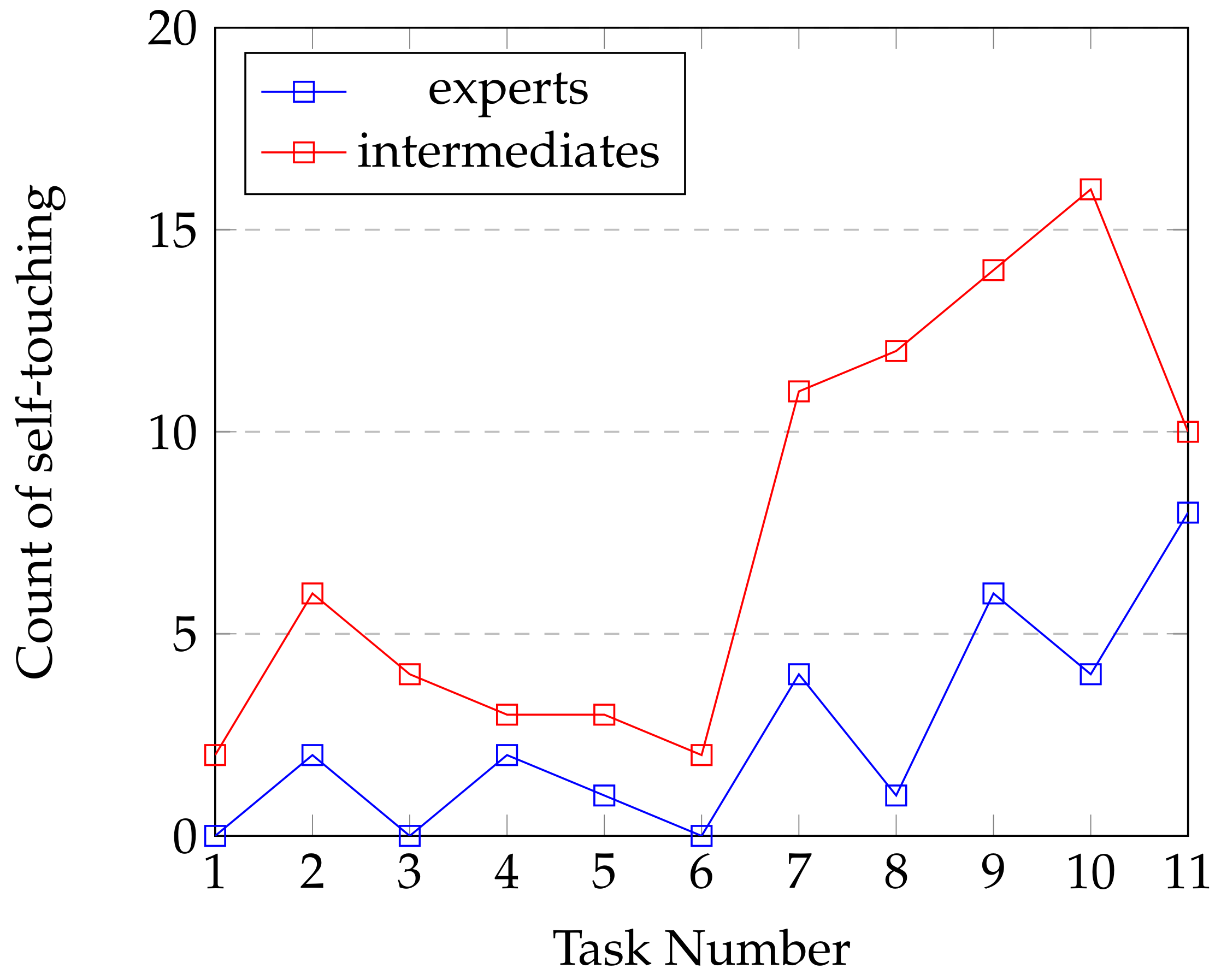
4.1.3. Body Posture
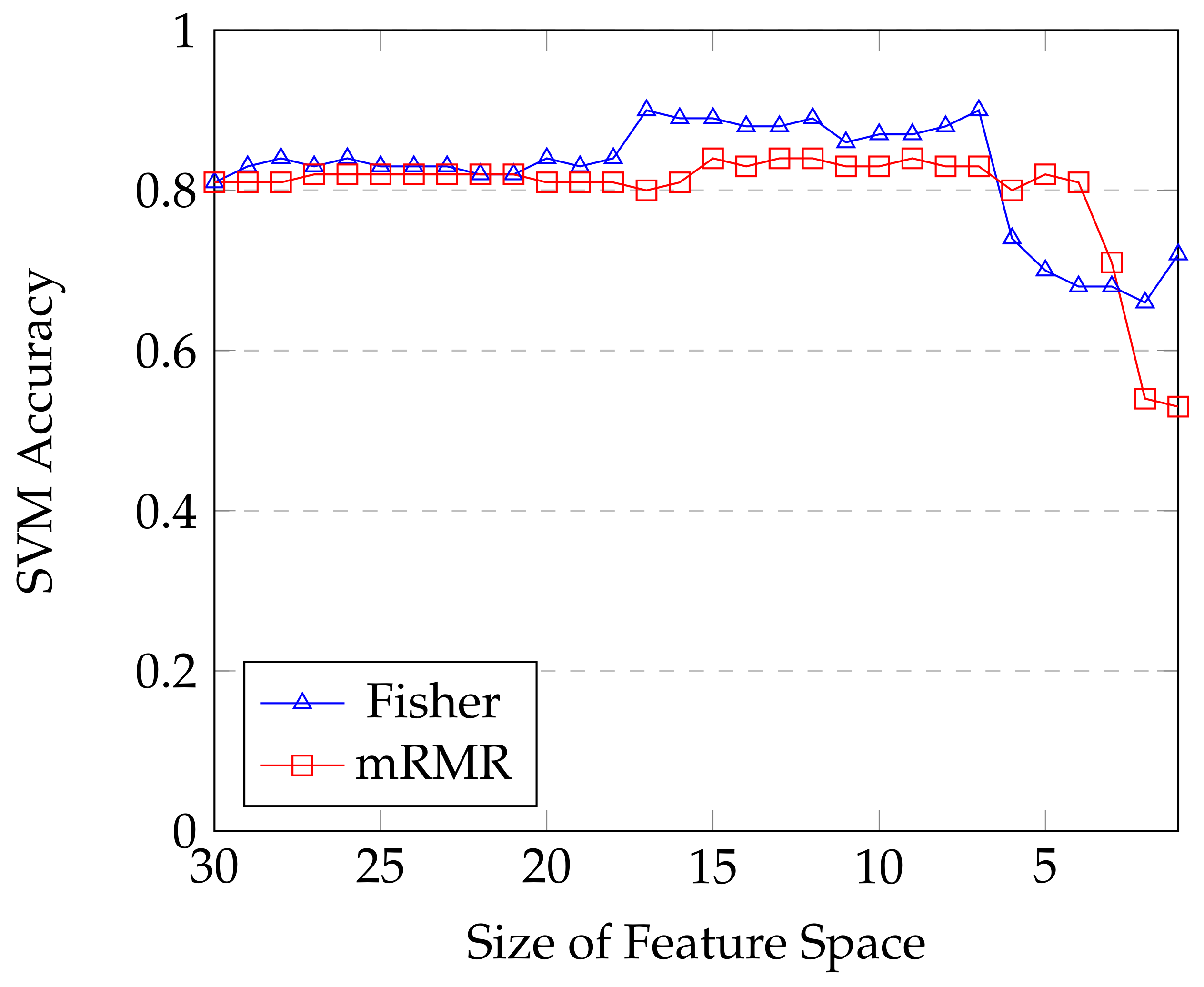
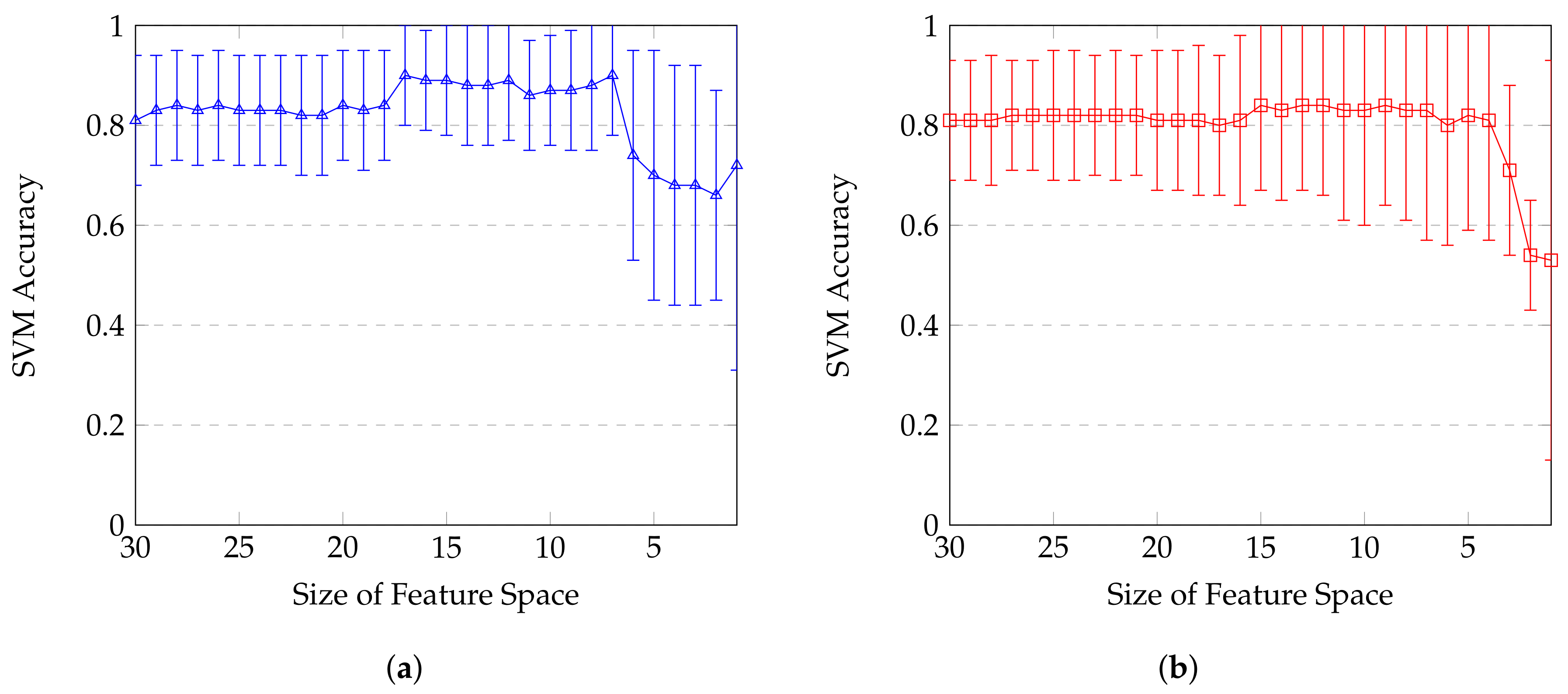
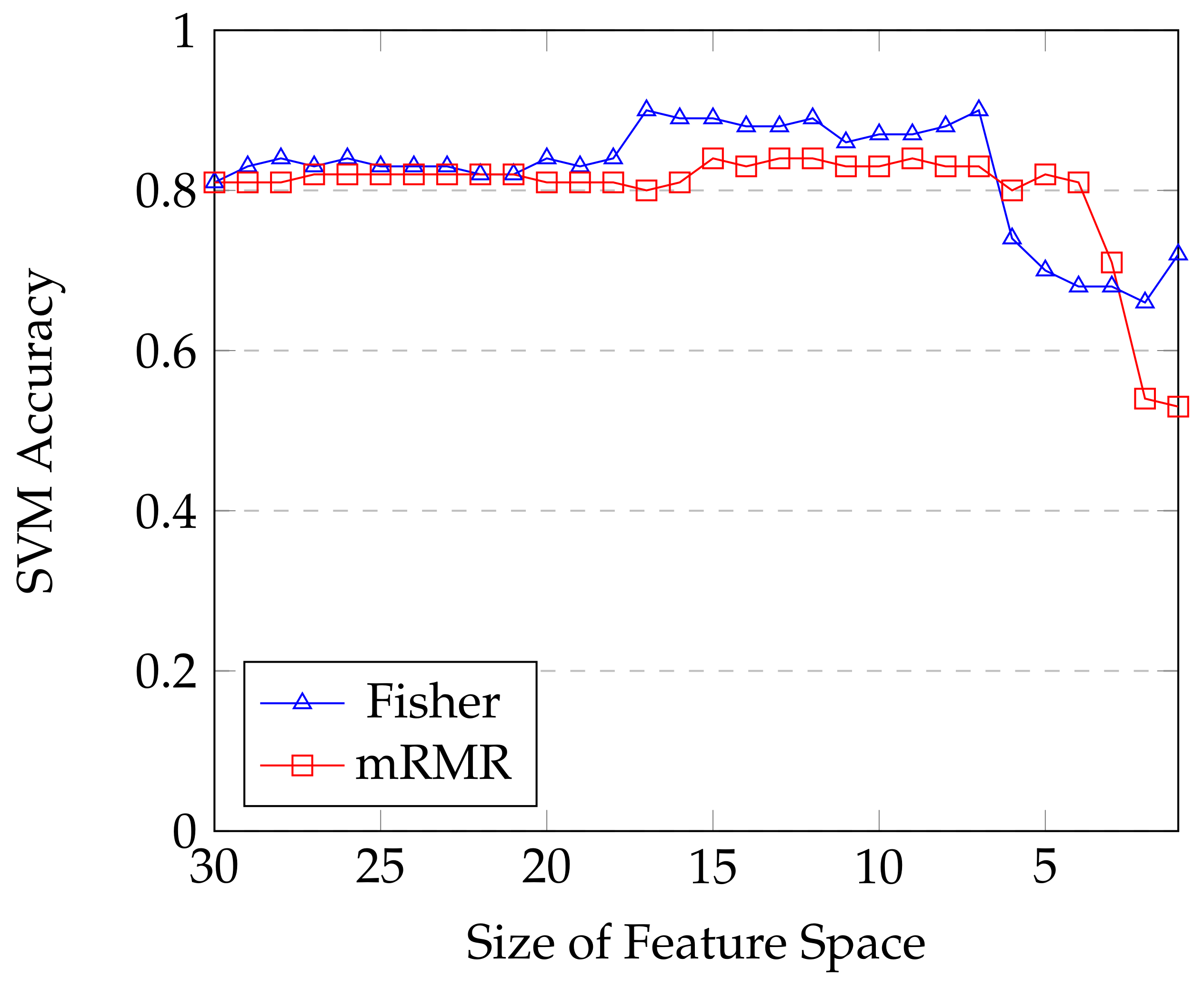
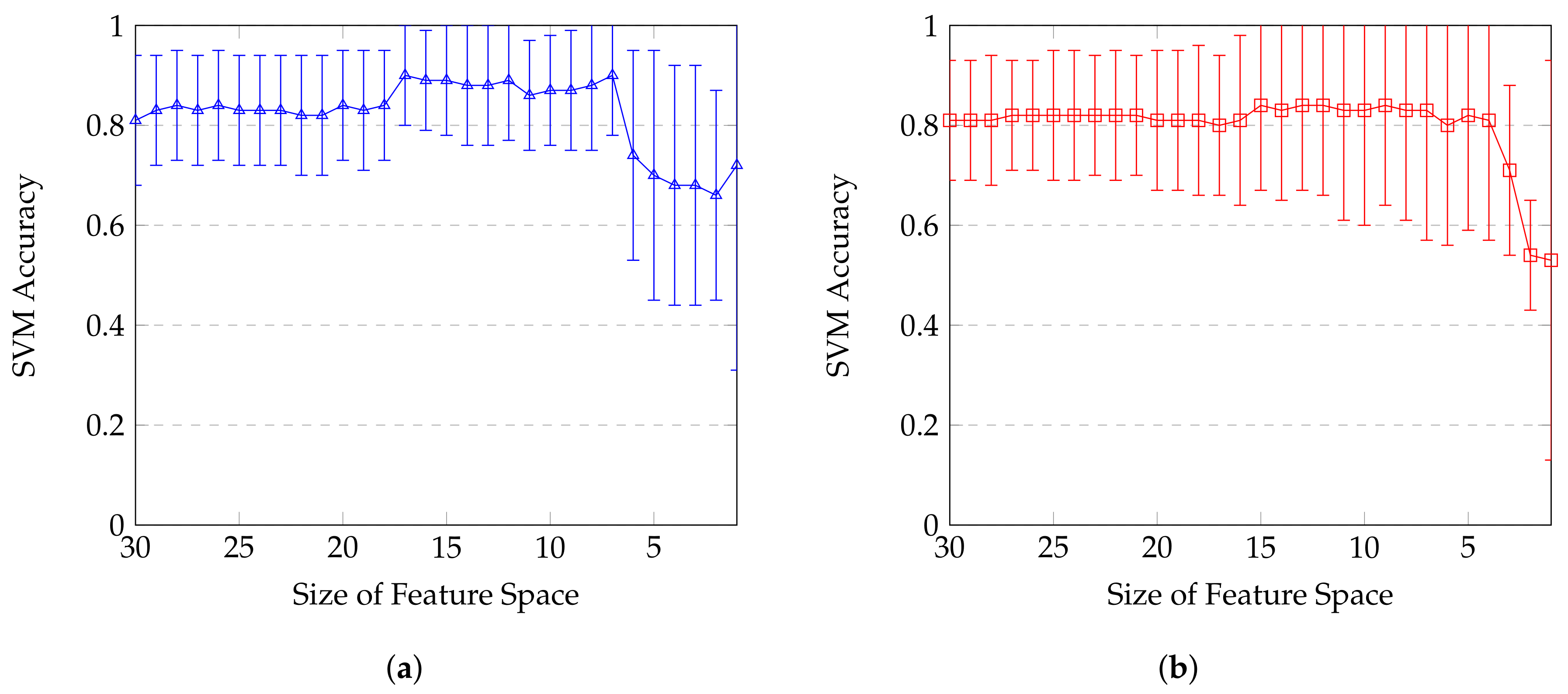
4.2. Statistical Classification and Features Selection
5. Discussion
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- El Kaliouby, R.; Robinson, P. Real-time inference of complex mental states from facial expressions and head gestures. In Real-Time Vision for Human-Computer Interaction; Springer: Berlin, Germany, 2005; pp. 181–200. [Google Scholar]
- Baltrušaitis, T.; McDuff, D.; Banda, N.; Mahmoud, M.; El Kaliouby, R.; Robinson, P.; Picard, R. Real-time inference of mental states from facial expressions and upper body gestures. In Proceedings of the 2011 IEEE International Conference on Automatic Face & Gesture Recognition and Workshops (FG 2011), Santa Barbara, CA, USA, 21–25 March 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 909–914. [Google Scholar]
- Charness, N.; Reingold, E.M.; Pomplun, M.; Stampe, D.M. The perceptual aspect of skilled performance in chess: Evidence from eye movements. Mem. Cogn. 2001, 29, 1146–1152. [Google Scholar] [CrossRef]
- Reingold, E.M.; Charness, N. Perception in chess: Evidence from eye movements. In Cognitive Processes in Eye Guidance; University of Oxford: Oxford, UK, 2005; pp. 325–354. [Google Scholar]
- Baltrušaitis, T.; Robinson, P.; Morency, L.P. OpenFace: An open source facial behavior analysis toolkit. In Proceedings of the 2016 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Placid, NY, USA, 7–10 March 2016; pp. 1–10. [Google Scholar]
- Cao, Z.; Simon, T.; Wei, S.E.; Sheikh, Y. Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields. arXiv, 2017; arXiv:1611.08050. [Google Scholar]
- Simon, T.; Joo, H.; Matthews, I.; Sheikh, Y. Hand Keypoint Detection in Single Images using Multiview Bootstrapping. arXiv, 2017; arXiv:1704.07809. [Google Scholar]
- Wei, S.E.; Ramakrishna, V.; Kanade, T.; Sheikh, Y. Convolutional pose machines. arXiv, 2016; arXiv:1602.00134. [Google Scholar]
- Kahneman, D. Thinking, Fast and Slow; Macmillan Publishers: Basingstoke, UK, 2011. [Google Scholar]
- Ekman, P.; Friesen, W.V. Nonverbal leakage and clues to deception. Psychiatry 1969, 32, 88–106. [Google Scholar] [CrossRef] [PubMed]
- Poh, M.Z.; McDuff, D.J.; Picard, R.W. Advancements in noncontact, multiparameter physiological measurements using a webcam. IEEE Trans. Biomed. Eng. 2011, 58, 7–11. [Google Scholar] [CrossRef] [PubMed]
- Shotton, J.; Sharp, T.; Kipman, A.; Fitzgibbon, A.; Finocchio, M.; Blake, A.; Cook, M.; Moore, R. Real-time human pose recognition in parts from single depth images. Commun. ACM 2013, 56, 116–124. [Google Scholar] [CrossRef]
- Stiefelhagen, R.; Yang, J.; Waibel, A. A model-based gaze tracking system. Int. J. Artif. Intell.Tools 1997, 6, 193–209. [Google Scholar] [CrossRef]
- Paletta, L.; Dini, A.; Murko, C.; Yahyanejad, S.; Schwarz, M.; Lodron, G.; Ladstätter, S.; Paar, G.; Velik, R. Towards Real-time Probabilistic Evaluation of Situation Awareness from Human Gaze in Human-Robot Interaction. In Proceedings of the Companion of the 2017 ACM/IEEE International Conference on Human-Robot Interaction, Vienna, Austria, 6–9 March 2017; ACM: New York, NY, USA, 2017; pp. 247–248. [Google Scholar]
- D’orazio, T.; Leo, M.; Distante, A. Eye detection in face images for a driver vigilance system. In Proceedings of the 2004 IEEE Intelligent Vehicles Symposium, Parma, Italy, 14–17 June 2004; IEEE: Piscataway, NJ, USA, 2004; pp. 95–98. [Google Scholar]
- Giraud, T.; Soury, M.; Hua, J.; Delaborde, A.; Tahon, M.; Jauregui, D.A.G.; Eyharabide, V.; Filaire, E.; Le Scanff, C.; Devillers, L.; et al. Multimodal Expressions of Stress during a Public Speaking Task: Collection, Annotation and Global Analyses. In Proceedings of the 2013 Humaine Association Conference on Affective Computing and Intelligent Interaction (ACII), Geneva, Switzerland, 2–5 September 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 417–422. [Google Scholar]
- Abadi, M.K.; Staiano, J.; Cappelletti, A.; Zancanaro, M.; Sebe, N. Multimodal engagement classification for affective cinema. In Proceedings of the 2013 Humaine Association Conference on Affective Computing and Intelligent Interaction (ACII), Geneva, Switzerland, 2–5 September 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 411–416. [Google Scholar]
- Portaz, M.; Garcia, M.; Barbulescu, A.; Begault, A.; Boissieux, L.; Cani, M.P.; Ronfard, R.; Vaufreydaz, D. Figurines, a multimodal framework for tangible storytelling. In Proceedings of the WOCCI 2017—6th Workshop on Child Computer Interaction at ICMI 2017—19th ACM International Conference on Multi-modal Interaction, Glasgow, UK, 13–17 November 2017. [Google Scholar]
- Vaufreydaz, D.; Nègre, A. MobileRGBD, An Open Benchmark Corpus for mobile RGB-D Related Algorithms. In Proceedings of the 13th International Conference on Control, Automation, Robotics and Vision, Singapore, 10–12 December 2014. [Google Scholar]
- Holmqvist, K.; Nyström, M.; Andersson, R.; Dewhurst, R.; Jarodzka, H.; Van de Weijer, J. Eye Tracking: A Comprehensive Guide to Methods and Measures; OUP Oxford: Oxford, UK, 2011. [Google Scholar]
- Poole, A.; Ball, L.J. Eye tracking in HCI and usability research. Encycl. Hum. Comput. Interact. 2006, 1, 211–219. [Google Scholar]
- Ehmke, C.; Wilson, S. Identifying web usability problems from eye-tracking data. In Proceedings of the 21st British HCI Group Annual Conference on People and Computers: HCI… but Not As We Know It, University of Lancaster, Lancaster, UK, 3–7 September 2007; Volume 1, pp. 119–128. [Google Scholar]
- Den Uyl, M.; Van Kuilenburg, H. The FaceReader: Online facial expression recognition. In Proceedings of the Measuring Behavior, 2005, Wageningen, The Netherlands, 30 August–2 September 2005; Volume 30, pp. 589–590. [Google Scholar]
- Langner, O.; Dotsch, R.; Bijlstra, G.; Wigboldus, D.H.; Hawk, S.T.; Van Knippenberg, A. Presentation and validation of the Radboud Faces Database. Cogn. Emot. 2010, 24, 1377–1388. [Google Scholar] [CrossRef]
- Goeleven, E.; De Raedt, R.; Leyman, L.; Verschuere, B. The Karolinska directed emotional faces: A validation study. Cogn. Emot. 2008, 22, 1094–1118. [Google Scholar] [CrossRef]
- Bijlstra, G.; Dotsch, R. FaceReader 4 emotion classification performance on images from the Radboud Faces Database. 2015. Available online: http://gijsbijlstra.nl/wp-content/uploads/2012/02/TechnicalReport_FR4_RaFD.pdf (accessed on 2 March 2018).
- Anzalone, S.M.; Boucenna, S.; Ivaldi, S.; Chetouani, M. Evaluating the engagement with social robots. Int. J. Soc. Robot. 2015, 7, 465–478. [Google Scholar] [CrossRef]
- Harrigan, J.A. Self-touching as an indicator of underlying affect and language processes. Soc. Sci. Med. 1985, 20, 1161–1168. [Google Scholar] [CrossRef]
- Johal, W.; Pellier, D.; Adam, C.; Fiorino, H.; Pesty, S. A cognitive and affective architecture for social human-robot interaction. In Proceedings of the Tenth Annual ACM/IEEE International Conference on Human-Robot Interaction Extended Abstracts, Portland, OR, USA, 2–5 March 2015; ACM: New York, NY, USA, 2015; pp. 71–72. [Google Scholar]
- Aigrain, J.; Spodenkiewicz, M.; Dubuisson, S.; Detyniecki, M.; Cohen, D.; Chetouani, M. Multimodal stress detection from multiple assessments. IEEE Trans. Affect. Comput. 2016, PP, 1. [Google Scholar] [CrossRef]
- De Groot, A.D. Thought and Choice in Chess; Walter de Gruyter GmbH & Co KG: Berlin, Germany, 1978. [Google Scholar]
- Peng, H.; Long, F.; Ding, C. Feature selection based on mutual information criteria of max-dependency, max-relevance, and min-redundancy. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1226–1238. [Google Scholar] [CrossRef] [PubMed]
- Vaufreydaz, D.; Johal, W.; Combe, C. Starting engagement detection towards a companion robot using multimodal features. arXiv, 2015; arXiv:1503.03732. [Google Scholar]
- Duda, R.O.; Hart, P.E.; Stork, D.G. Pattern Classification; Wiley: New York, NY, USA, 1973; Volume 2. [Google Scholar]
- Li, J.; Cheng, K.; Wang, S.; Morstatter, F.; Robert, T.; Tang, J.; Liu, H. Feature Selection: A Data Perspective. arXiv, 2016; arXiv:1601.07996. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Features | Modality | Sensor |
|---|---|---|
| Fixation Duration | Eye-Gaze | Tobii Bar |
| Fixation Count | ||
| Visit Count | ||
| 7 Basics Emotions | Emotion | Webcam |
| Valence | ||
| Arousal | ||
| Heart Rate | ||
| Agitation (X, Y, Z) | Body | Kinect |
| Volume | ||
| Self-Touch |
| Task 1 | Task 2 | Task 3 | Task 4 | Task 5 | Task 6 | Task 7 | Task 8 | Task 9 | Task 10 | Task 11 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Difficulty of the task | Easy | Easy | Easy | Easy | Easy | Easy | Medium | Medium | Hard | Hard | Hard |
| Number of moves required to complete the task | 1 | 1 | 1 | 1 | 2 | 2 | 3 | 3 | 4 | 5 | 6 |
| Number of experts who pass the task (/9) | 9 | 8 | 8 | 9 | 9 | 9 | 9 | 8 | 8 | 4 | 1 |
| Number of intermediates who pass the task (/14) | 13 | 9 | 12 | 8 | 12 | 13 | 7 | 6 | 3 | 2 | 0 |
| Modality | Features | Data Type | Statistical Transformation | Number of Features |
|---|---|---|---|---|
| Gaze | Fixation | Discrete | Duration-Count | 2 |
| Visit | Discrete | Count | 1 | |
| Emotion | 7 Basics Emotions | Continuous | Mean - Var - Std | 21 |
| Valence | Continuous | Mean - Var - Std | 3 | |
| Arousal | Continuous | Mean - Var - Std | 3 | |
| Heart Rate | Continuous | Mean - Var - Std | 3 | |
| Body | Agitation (X, Y, Z) | Continuous | Mean-Var-Std | 9 |
| Volume | Continuous | Mean-Var-Std | 3 | |
| Self-Touch | Discrete | Duration-Count | 2 |
| Modalities | G | B | E | G + B | G + E | B + E | G + B + E |
| Number of Features | 3 | 14 | 30 | 17 | 33 | 44 | 47 |
| Accuracy Score | |||||||
| Standard Deviation |
| mRMR Ranking Order | Feature | Modality | Description |
|---|---|---|---|
| 1 | Y_Agitation_var | Body | Variation of agitation on Y axis |
| 2 | Disgusted_std | Emotion | Standard Deviation of the detected basic emotion: Disgusted |
| 3 | Fixation_Duration | Gaze | Average Fixation Duration on AOI |
| 4 | Valence_mean | Emotion | Mean of the computed Valence |
| 5 | Volume_var | Body | Variance of the body volume |
| 6 | HeartRate_std | Emotion | Standard Deviation of Heart Rate |
| 7 | Angry_var | Emotion | Variance of the detected basic emotion: Angry |
| 8 | SelfTouches_Count | Body | Average number of self-touches |
| 9 | Scared_var | Emotion | Variance of the detected basic emotion: Scared |
| 10 | Angry_mean | Emotion | Mean of the detected basic emotion: Angry |
| 11 | Fixation_Count | Gaze | Average Number of Fixation on AOI |
| 12 | X_Agitation_std | Body | Standard Deviation of agitation on X axis |
| 13 | Happy_mean | Emotion | Mean of the detected basic emotion: Happy |
| 14 | Disgusted_var | Emotion | Variation of the detected basic emotion: Disgusted |
| 15 | Volume_std | Body | Standard Deviation of the body volume |
| 16 | HeartRate_mean | Emotion | Mean of Heart Rate |
| 17 | Sad_std | Emotion | Standard Deviation of the detected basic emotion: Sad |
| 18 | Arousal_mean | Emotion | Mean of the computed arousal |
| 19 | SelfTouches_Duration | Body | Average duration of self-touches |
| 20 | Neutral_var | Emotion | Variation of the detected basic emotion: Neutral |
| Fisher Ranking Order | Feature | Modality | Description |
|---|---|---|---|
| 1 | Valence_mean | Emotion | Mean of the computed Valence |
| 2 | Y_Agitation_var | Body | Variation of agitation on Y axis |
| 3 | Z_Agitation_var | Body | Variation of agitation on Z axis |
| 4 | Y_Agitation_std | Body | Standard Deviation of agitation on Y axis |
| 5 | X_Agitation_var | Body | Variation of agitation on X axis |
| 6 | Angry_mean | Emotion | Mean of the detected basic emotion: Angry |
| 7 | Z_Agitation_std | Body | Standard Deviation of agitation on Z axis |
| 8 | X_Agitation_std | Body | Standard Deviation of agitation on X axis |
| 9 | Volume_mean | Body | Mean of the body volume |
| 10 | HeartRate_mean | Emotion | Mean of Heart Rate |
| 11 | Disgusted_std | Emotion | Standard Deviation of the detected basic emotion: Disgusted |
| 12 | Angry_var | Emotion | Variance of the detected basic emotion: Angry |
| 13 | Sad_mean | Emotion | Mean of the detected basic emotion: Sad |
| 14 | Fixation_Duration | Gaze | Average Fixation Duration on AOI |
| 15 | X_Agitation_mean | Body | Mean of agitation on X axis |
| 16 | Y_Agitation_mean | Body | Mean of agitation on Y axis |
| 17 | Z_Agitation_mean | Body | Mean of agitation on Z axis |
| 18 | Disgusted_var | Emotion | Variance of the detected basic emotion: Disgusted |
| 19 | Volume_std | Body | Standard Deviation of the body volume |
| 20 | SelfTouches_Count | Body | Average number of self-touches |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guntz, T.; Balzarini, R.; Vaufreydaz, D.; Crowley, J. Multimodal Observation and Classification of People Engaged in Problem Solving: Application to Chess Players. Multimodal Technol. Interact. 2018, 2, 11. https://doi.org/10.3390/mti2020011
Guntz T, Balzarini R, Vaufreydaz D, Crowley J. Multimodal Observation and Classification of People Engaged in Problem Solving: Application to Chess Players. Multimodal Technologies and Interaction. 2018; 2(2):11. https://doi.org/10.3390/mti2020011
Chicago/Turabian StyleGuntz, Thomas, Raffaella Balzarini, Dominique Vaufreydaz, and James Crowley. 2018. "Multimodal Observation and Classification of People Engaged in Problem Solving: Application to Chess Players" Multimodal Technologies and Interaction 2, no. 2: 11. https://doi.org/10.3390/mti2020011
APA StyleGuntz, T., Balzarini, R., Vaufreydaz, D., & Crowley, J. (2018). Multimodal Observation and Classification of People Engaged in Problem Solving: Application to Chess Players. Multimodal Technologies and Interaction, 2(2), 11. https://doi.org/10.3390/mti2020011