1. Introduction
Among stream-cipher systems, the ’synchronized binary-additive stream cipher’ (S-BASC) is the canonical example. In the S-BASC, a sequence of pseudo-random bits (’keystream’) is generated by an algorithm acting on a finite-state machine (’keystream generator’ or KSG) and then combined with the plaintext via bit-wise modulo-2 addition. The starting state of this KSG includes a secret key and often a randomizing initial value (IV; such as a nonce or frame number). To ensure full mixing of this initial state, the system may also require some number of KSG iterations before encryption begins (’warm-up’).
Besides the synchronous (S-BASC) mode, stream-cipher systems can also utilize other modes, including a recently-described one called PudgyTurtle [
1]. This mode operates on small groups of bits (’symbols’) instead of individual bits and has the unusual property that the encryption requires an uncertain amount of keystreams: each plaintext symbol is
encoded using a variable-length section of keystream, and then each codeword is
enciphered by XOR’ing it to a separate, fixed-length section of keystream.
Some cryptanalytic techniques against stream ciphers target specific features of a particular KSG (e.g., distinguishing and correlation attacks) [
2,
3,
4], while others are generic methods that work against any system (e.g., brute-force and time-memory tradeoff attacks) [
5,
6,
7,
8,
9]. Here, we discuss another generic approach called the ’bit-flipping attack’ (BFA), in which the opponent perturbs the ciphertext so that it will be decrypted into something other than intended. The BFA takes advantage of
malleability—a major weakness of S-BASC systems which allows for the alteration of the ciphertext in ways undetectable by the receiver.
The BFA has two variations (
nonselective and
tailored), whose essential difference is the requirement for known plaintext. During a nonselective BFA, the attacker adds random bits to the ciphertext, thus making the decryption unrecognizable and rendering the channel useless. This variation is mentioned here only for completeness and is more suitably discussed in the context of jamming in communications theory or denial-of-service attacks in network security theory [
10,
11]. During a tailored BFA, known plaintext
is used to craft one or more bit-flips that will produce some desired decryption
. Let ⊕ represent modulo-2 addition (XOR), and let
and
represent sections of ciphertext and keystream corresponding to
. The opponent intercepts
and then transmits the modified ciphertext
. Since XOR is an involution, decryption of this ’flipped’ ciphertext will produce
Standard defenses against bit-flipping include authenticated encryption and the message-authentication code (MAC)—a keyed hash of the plaintext which allows the recipient to detect tampering and reject nonauthentic ciphertexts (Chapter 4 [
12]). Another strategy against bit-flipping is to use an encryption mode. In 2001, for example, Golić noted that stream-cipher modes with an ’inifite memory’ have
“an inherent potential that can be used for message integrity purposes” [
13]. Modes that incorporate ciphertext feedback, for instance, could propagate the effects of changing even one ciphertext-bit, thereby making it difficult to tailor a BFA.
Although the connection between encryption modes and integrity pointed out by Golić has been reported in the literature for decades, little has been written about the actual details of using stream-cipher modes for this purpose and nothing at all about PudgyTurtle in this context. The primary goal of this paper is to explore the behavior of this new encryption mode against a BFA. We demonstrate that PudgyTurtle mode creates uncertainty about where exactly the decrypted text will start showing the effects of bit-flipping, how long these effects will persist, what the distribution of decrypted symbols will be, and whether or not length will be preserved. We emphasize that despite these interesting (and sometimes unique) features, PudgyTurtle provides only partial protection against bit-flipping. It reduces, but does not completely eliminate, ciphertext malleability.
The other contribution of this manuscript is to provide a flexible implementation of PudgyTurtle mode. To date, analysis of PudgyTurtle has focused on one particular version with nibble-sized (4-bit) input and byte-sized (8-bit) output. To study bit-flipping more broadly, however, we introduce a ’generalized’ PudgyTurtle (denoted as PT[]) which allows for variably sized symbols.
Our main results are as follows: (1) PudgyTurtle mode can be generalized, and its performance predicted; (2) the outcomes of all bit-flipping attacks against PudgyTurtle include an element of uncertainty; (3) some bit-flipping attacks against PudgyTurtle are rejected by the decryption algorithm, with a probability depending on the position of the flipped bit relative to its underlying codeword; (4) bit-flipping attacks can produce effects ranging from altering one symbol all the way to an ’avalanche’; (5) knowing in advance exactly how a BFA will alter the decrypted text is difficult, but generic statistical predictions are possible; and (6) some bit-flipping attacks may increase the length of decrypted text relative to the original plaintext.
After discussing notation (
Section 2) and methods (
Section 3), we review stream-cipher encryption modes (
Section 4). Next, we present and analyze the generalized formulation of PudgyTurtle (
Section 5) and use this more-flexible implementation to explore PudgyTurtle mode’s behavior during bit-flipping attacks, including a (hypothetical) electronic banking fraud scheme (
Section 6 and
Section 7).
2. Notation
2.1. Numbers
Hexadecimal values are prefixed by 0x, and binary values are subscripted by 2 (e.g., 254 can be written as 0xFE or 11111110).
2.2. Functions and Operators
Operators include ⊕ for XOR (modulo-2 addition), ⊗ for AND (bitwise multiplication), ≫ for right-shift; ‖ for concatenation, () for the floor (ceiling) of real-valued u, and for the Hamming weight (i.e., number of 1 bits) in binary vector V. The Hamming distance (ℓ1-norm) between binary vectors V and is .
2.3. Symbols and Sequences
PudgyTurtle mode operates on small groups of bits (’symbols’, denoted by uppercase letters) rather than individual bits (lowercase letters). Let
represent
j-th bit of binary sequence
B, where
. The
i-th (nonoverlapping)
s-bit symbol within this sequence is
where
, and
. For convenience,
can be dropped in favor of the simpler notations
and
whenever the number of bits per symbol is unambiguous or irrelevant to the context.
X, Y, and K stand for plaintext, ciphertext, and keystream, respectively. Symbols with primes are ’known’ (e.g., the known plaintext and its corresponding ciphertext are represented by and ). Symbols with asterisks occur during bit-flipping attacks (e.g., is the modified ciphertext that has been subjected to bit-flipping, and is the decryption of this ’flipped’ ciphertext).
2.4. Keystream Generator
PudgyTurtle is cipher agnostic: it takes bits from a ’black-box’ KSG operating on an n-bit state S. The t-th keystream bit is , where is the output function, the state-update function, , and initial state contains the secret key and IV.
3. Methods
In the experiments described below, the plaintext source (unless otherwise specified) is an 800,000-bit ASCII-encoded English-language text. Encryption is done via one of two ’toy’ ciphers: (1) RC4 with a 40-bit key and (2) a simple, maximal-period 24-bit NLFSR with primitive polynomial
[
14]. We emphasize that these KSGs are chosen for simplicity and used for illustrative purposes only. Neither is intended as a practically secure stream-cipher, either with or without PudgyTurtle.
We study the simplest attack, in which a single ciphertext bit is flipped (), this modified ciphertext is decrypted (), and this decryption is then compared to the original plaintext ( vs. X). Measured outcomes include the following:
is the fraction of attacks for which the ciphertext is rejected. Rejection (described in detail later) occurs if bit-flipping produces an invalid codeword during decryption;
is the frequency distribution of values taken by all the decrypted symbols;
is the frequency distribution of values taken by the i-th decrypted symbol;
Hd is the Hamming distance between the i-th original plaintext bit and i-th bit in the decryption of ;
is the normalized Hamming distance between the original plaintext and decrypted (flipped) ciphertext:
4. Stream-Cipher Modes
Here, we briefly review PudgyTurtle mode and also discuss stream-cipher modes in general.
4.1. Pudgy Turtle Mode
In one implementation of PudgyTurtle, the plaintext is broken into 4-bit groups (’nibbles’), each of which is encrypted in four steps. First, an 8-bit mask is created by concatenating two nibbles of keystream. Next, keystream nibbles are generated until one of them matches the plaintext nibble—either exactly or to within a one-bit tolerance. This step produces two important quantities: the ’failure counter’ (the number of keystream nibbles that failed to match the plaintext nibble) and the ’discrepancy code’ (a number describing the relationship between the two matching symbols: 0 for an exact match or 1–4 to indicate the mismatched bit’s position). This match is then encoded by concatenating the failure counter (taken as a 5-bit number) and the discrepancy code (taken as a 3-bit number), and the resulting codeword is enciphered by XOR’ing it with the mask.
There is one important question: What happens if so many failures (>32) occur during plaintext-to-keystream matching that their number can no longer be described with five bits? Whenever such an overflow event occurs, a special codeword is enciphered by XOR’ing it with the current mask and then inserting it into the ciphertext. After this, a new mask is created; the failure counter is reset to zero, and attempts to match the current plaintext nibble continue.
This special ’all-1’ codeword, 0xFF, comes from concatenating the maximum failure counter ( = 31 = 11111) with one particular discrepancy code (111) reserved for overflows. Note that the maximum failure counter alone does not always indicate an overflow (e.g., an exact match between a plaintext nibble and the 32 nd keystream nibble would produce codeword 11111‖000 = 0xF8, not the overflow codeword).
Decryption is a straightforward reversal of this procedure. First, a mask is built by concatenating two keystream nibbles. Next, the mask is XOR’ed with the current 8-bit ciphertext byte to unmask (decipher) the underlying codeword. This codeword is split into its failure counter (upper 5 bits) and discrepancy code (lower 3 bits). A number of keystream nibbles are generated (specifically, one more than the failure counter), the last one of which matches the plaintext nibble to within a bit. The discrepancy code is then used to ’reverse engineer’ (decode) this keystream nibble back into the correct plaintext nibble; the result is output, and decryption of the next ciphertext byte commences.
If an overflow is detected during decryption (i.e., when unmasking produces the special all-1 codeword 0xFF), then no decrypted symbol is output. Instead, 32 keystream nibbles are generated and discarded, a new mask is built, the next ciphertext byte is unmasked, and decryption continues as decsribed above.
4.2. Classical Modes: Synchronous and Asynchronous
A ’general binary stream cipher’ operating without delay has state-update and encryption equations
where KEY is the initial KSG-state (
). Stream ciphers are classically described as having two encryption modes:
synchronous (S-BASC) and
asynchronous [
15,
16]. In the synchronous mode, the state-update function operates independently of plaintext or ciphertext:
. In the asynchronous mode, this no longer holds. Golić further subclassified asynchronous systems into those with finite and infinite memory [
13]. For the finite-memory type, designated as ’self-synchronizing stream ciphers’, the KSG state itself includes feedback from
n previous ciphertext bits:
=
,
and …,
. For the infinite-memory type, designated as ’stream cipher with memory’,
operates not only on
but also on
.
More recently, Hamann, Krause, and Meier proposed
FP(1)-mode, which has been instantiated in the lightweight stream cipher LIZARD [
17,
18].
FP(1)-mode—designed for packet-based operations in which each key/IV only generates a limited amount of keystream—consists of three phases: key loading (creating a KSG state from the secret key and IV), key-mixing (repeatedly iterating this KSG-state while feeding back its nominal output), and key hardening (XOR’ing this mixed KSG-state with the secret-key).
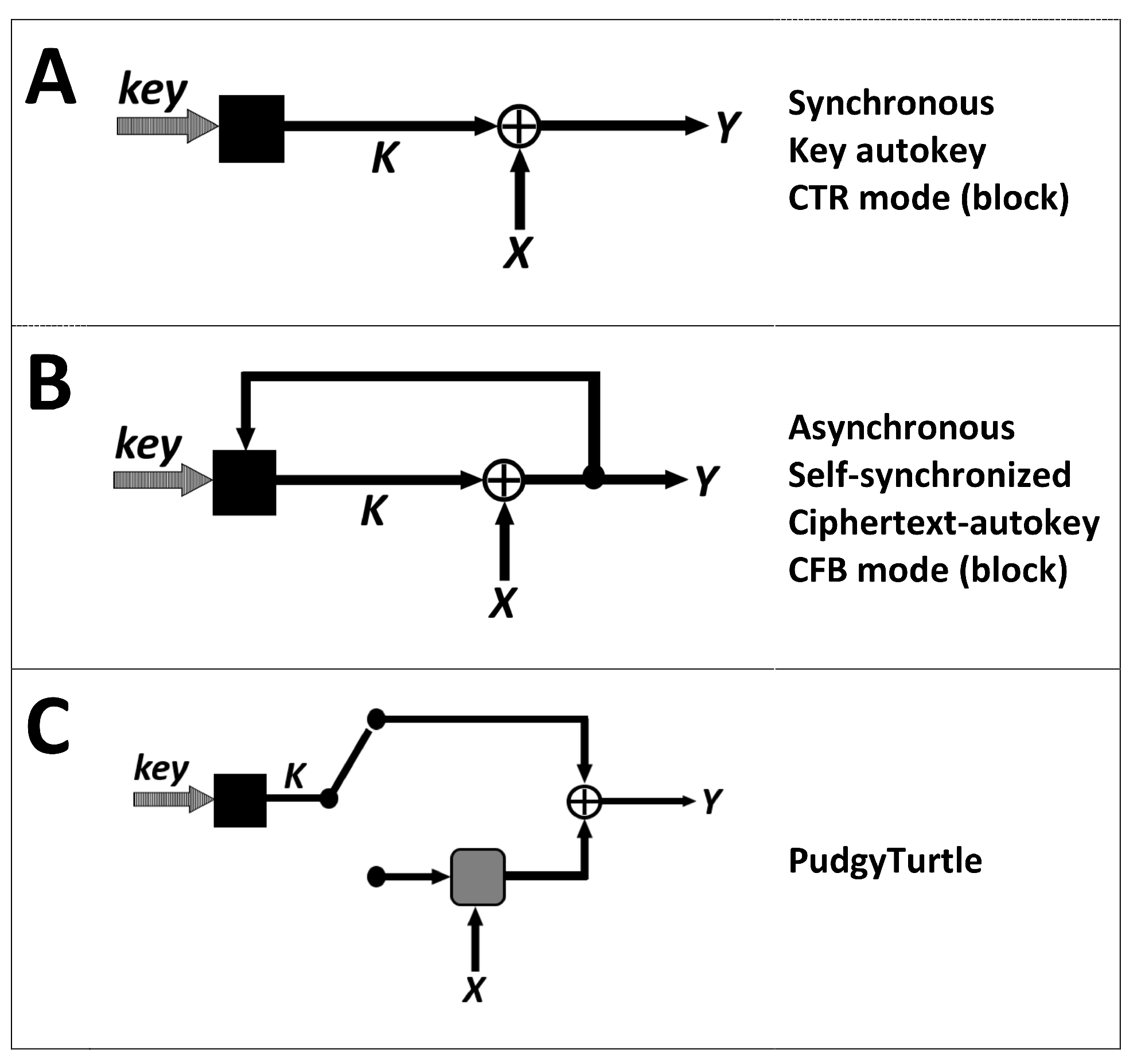
Synchronous mode, asynchronous mode, and PudgyTurtle mode are illustrated in
Figure 1. Here, ’key’ is the initial KSG state (secret-key ± IV), black boxes represent the KSG, and the gray box stands for PudgyTurtle’s error-correcting code (ECC).
Figure 1A illustrates synchronous (S-BASC) mode, also called ’memoryless’ and ’key-autokey’. This mode is used in numerous stream-cipher systems and by block ciphers operating in CTR (counter) mode.
Figure 1B depicts the asynchronous mode (e.g., finite-memory type), also called ’ciphertext-autokey’ and ’self-synchronizing’. Here, the KSG state incorporates some number of previous ciphertext bit(s). Errors from a flipped ciphertext bit ’wash out’ after
n KSG updates (where
n is the KSG-state size), thereby resynchronizing the system. Asynchronous modes are used by the stream-ciphers SAVILLE (an older Suite-A system jointly designed by NSA and GCHQ) [
19], PKZIP [
20,
21], Hiji-bij-bij [
22], WAKE [
23], the T-function system of Klimov and Shamir [
24], and by block ciphers in the CFB (cipher feedback) mode.
Figure 1C shows PudgyTurtle mode. As suggested by the toggle-switch selector, this mode uses different segments of keystream for different purposes. Some keystream is used to encode a multi-bit plaintext symbol (when the toggle is ’down’), and another section of keystream is XOR’d to this codeword to encipher it (when the toggle is ’up’). PudgyTurtle shares some features with the synchronous mode (keystream can be generated in advance) and others with asynchronous mode (memory), but it also has unique features (the amount of keystream required to encrypt each plaintext symbol varies,
X and
K are not combined by a simple XOR, and ’memory’ is not due to feedback from
Y to the KSG state but rather due to an iterative encoding process between
X and
K).
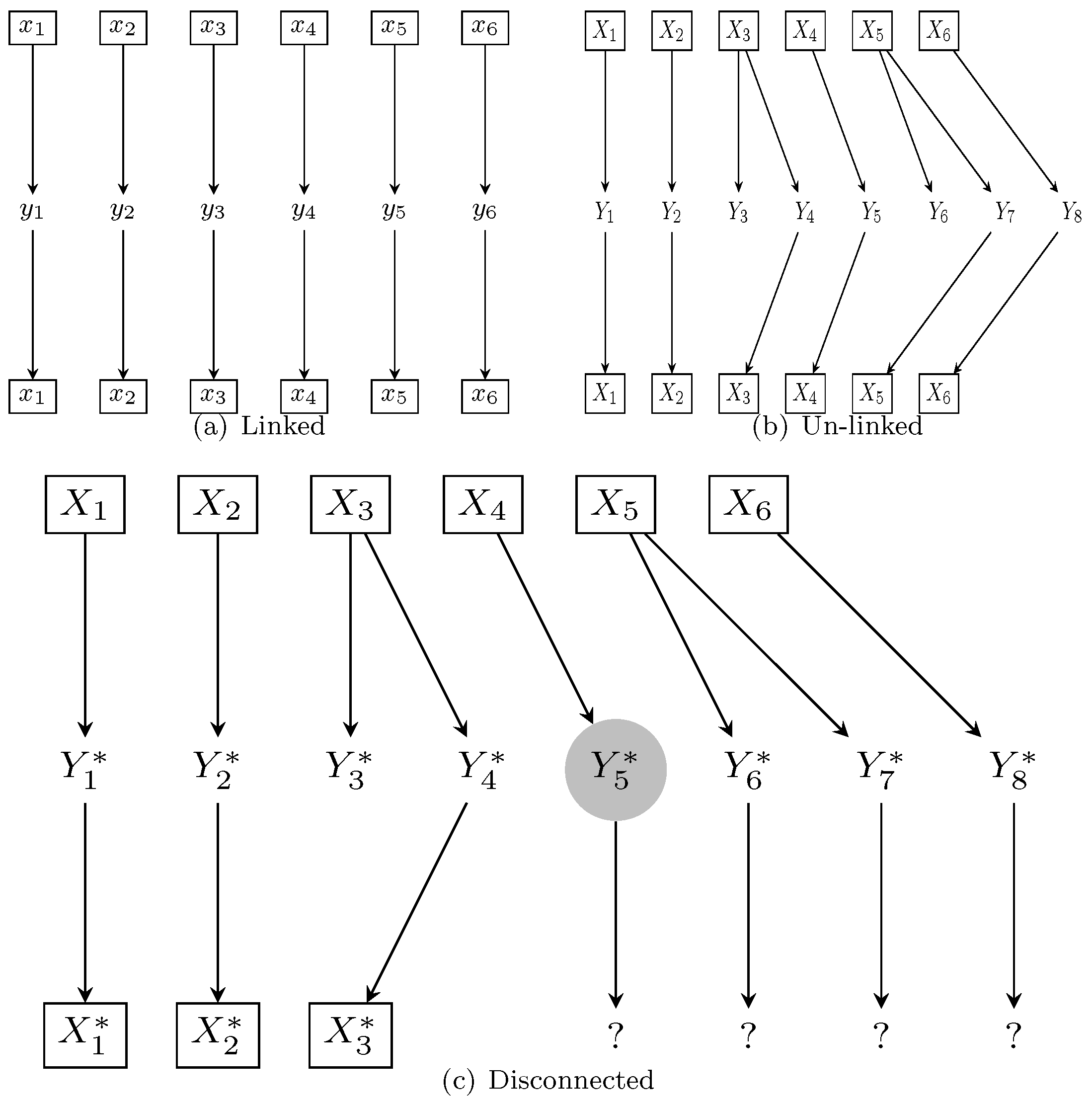
4.3. Synchronization, Linkage, and Connection
Some new terminology is helpful to describe the relationships between plaintext, keystream, and ciphertext in PudgyTurtle mode. Synchronized is reserved for describing encryption modes themselves, not the sequences upon which they operate. Linkage is a low-level concept describing the mathematical relationship between plaintext, keystream, and ciphertext symbol indices. Connection is a high-level concept emphasizing that unambiguous decryption can be possible even for sequences that are not linked. During normal PudgyTurtle operation, X, Y, and K are unlinked but connected. A BFA, however, may cause disconnection as well.
In more detail,
linked describes two sequences whose identically indexed elements are functionally related.
Figure 2a shows that during typical stream-cipher encryption,
X,
K, and
Y are linked:
is a function of
and
. Even with asynchronous modes, where
may be a more complex function of previous ciphertext or plaintext bits, linkage is maintained. With PudgyTurtle mode, however, these sequences become unlinked (
Figure 2b):
is now a function of
and
—the first bit of the relevant section of keystream. Overflows cause the
j to drift ahead of
i, and the uncertainty of each plaintext-to-keystream match causes
t to drift ahead of both
j and
i. Despite being unlinked, however, the sequences remain connected, and so decryption is still possible.
During a bit-flipping attack, however,
Y and
K may
disconnect.
Figure 2c shows what happens when a flipped bit within the fifth ciphertext symbol (gray circle) causes
to be unmasked into a new, incorrect codeword whose failure counter differs from what is should be. Now, decryption no longer works: the PudgyTurtle algorithm ’thinks’ that the wrong keystream symbol should be used to decrypt
into
. Disconnection affects not only this symbol but also triggers an avalanche effect: all subsequent ciphertext symbols will be unmasked into seemingly random values (?-symbols) rather than into correct codewords.
5. Generalized PudgyTurtle
To study bit-flipping attacks most broadly, it would be useful for PudgyTurtle to allow input and output symbols of many sizes—not just nibble-sized input and byte-sized output. Toward this end, we introduce the ’generalized’ PudgyTurtle implementation PT[]. Here, s is the size (in bits) of each plaintext symbol, f is the size of each failure counter, d is the size of each discrepancy code, and is the size of each codeword, mask, and ciphertext-symbol. In this notation, the original implementation was PT[4,5,3], which encrypted a 4-bit plaintext symbol into 8-bit ciphertext symbols.
5.1. Match Function
PudgyTurtle requires matching (to within a 1-bit tolerance) some
s-bit plaintext symbol
to some
s-bit keystream symbol
. The details of this match are captured by a (0–
s)-valued discrepancy code
D, which can be expressed as the output of a
match function,
:
:
For example, if the 5-bit plaintext and keystream symbols match everywhere except their fourth bit, then , , and so . If, on the other hand, these two symbols match exactly, then D would be = 0. Notice that is simply a ’place holder’ for when and differ by >1 bit—this value will not become part of any discrepancy code.
5.2. Encryption
To encrypt the s-bit plaintext symbol into the c-bit ciphertext-symbol with keystream starting at bit , the following steps are taken:
MASK
Create a mask of c keystream bits: ;
Update t, the new ’current’ keystream bit: .
MATCH Starting from , generate successive s-bit keystream symbols , until either
- (a)
One of these keystream symbols, designated as , matches exactly or differs from it by a single bit. In either case, proceed to Step 3;
or …
- (b)
keystream symbols have failed to match. If this overflow event happens
- •
Output the c-bit ciphertext-symbol ;
- •
Update the index of : ;
- •
Update the ciphertext-symbol index: ;
- •
Return to Step 1.
ENCODE Make a c-bit codeword, , where failure-counter F (the number of s-bit keystream symbols just tested against that failed to match) is represented by f bits, and discrepancy code is represented by d bits.
ENCIPHER
UPDATE
- •
Update the keystream-bit index: ;
- •
Update the plaintext-symbol index: ;
- •
Update the ciphertext-symbol index: ;
- •
Return to Step 1.
For example, consider encoding a plaintext-to-keystream match using PT[4,5,3], which has 4-bit symbols (s = 4), 5-bit failure counters (f = 5), and 3-bit discrepancy codes (d = 3), and produces 8-bit codewords (c = 5+3 = 8). Suppose plaintext-symbol matches the tenth keystream symbol against which it is tested everywhere except its high-order bit. Then = 10, and so = = , and D would be = 4. The resulting codeword would be C = () = 01001100 = 01001100 = 0x4C, and thus the final ciphertext symbol would be 0x4C XOR’d with its corresponding 8-bit mask.
5.3. Decryption
To decrypt the c-bit ciphertext symbol into using keystream starting at bit , the following occurs:
MASK
DECIPHERUnmask the ciphertext symbol to reveal its underlying codeword .
OVERFLOW? If C is the ’all-1’ overflow codeword, then
Generate and discard (s-bit sized) keystream symbols;
Update the keystream bit-index: ;
Update the ciphertext symbol index: ;
Return to Step 1.
UNPACK If C was not the overflow codeword, then split it into two components: extract failure-counter F from its f highest-order bits and discrepancy-code D from its d lowest-order bits: , and .
VALIDATE If , then halt the decryption and return ⊥.
DECODE Use F and D to ’reverse engineer’ the original plaintext-to-keystream match:
Generate () s-bit keystream symbols ;
Recover the plaintext symbol from
by inverting the discrepancy-code:
UPDATE
Output ;
Update the index of : ;
Update the ciphertext-symbol index: ;
Update the decrypted-symbol index: ;
Return to Step 1.
The VALIDATE step may seem redundant: at this point in the algorithm, discrepancy codes should always be in range (i.e., since the codeword is not an overflow, D should be between 0 and s). However, this step is made explicit because ciphertexts that have been subjected to bit-flipping attacks may produce invalid discrepancy codes at this point. In such cases, the ciphertext is rejected and no decryption is returned.
As an example (again using PT[4,5,3]), suppose that ciphertext Y = 0xAB is deciphered by mask M = 0xE7, producing the codeword C = (0xAB⊕0xE7) = 0x4C. Since this is not the overflow codeword (i.e., ), we proceed with the unpacking step: 0x4C = 01001100 = = () = (). The validation step succeeds because the discrepancy code is within range (i.e., D is not ). Next, since , we must generate ten new (4-bit) keystream symbols to reach the one that matched the current plaintext symbol. Since D = 4, the plaintext symbol must have differed from in its fourth (high-order) bit: that is, . Thus, the decrypted symbol is = .
5.4. Indexing
For a stream-cipher in synchronous mode, indexing is trivial: for all i. For PudgyTurtle mode, this is not the case: it can be challenging to cross-index sequences or even to unambiguously index one sequence that may be split into different-sized symbols (e.g., s-bit and c-bit symbols within K).
Regarding
X and
Y, although the symbol size for each sequence differs (i.e.,
s-bit groups for the plaintext, and
c-bit groups for the ciphertext), this size remains fixed throughout encryption. Thus, both sequences can be indexed continuously:
Because of overflows, may exceed , causing these two sequences to become unlinked: no longer represents an encrypted version of but rather of where . This issue is easily understood and just requires careful description of exactly what ’i’ in (or ’j’ in ) means in a specific context.
Keystream indexing is more difficult because PudgyTurtle uses different-sized symbols within K for different tasks (i.e., c-bit symbols for masks, and s-bit symbols to match the plaintext). For PT[4,5,3], it so happens that the each 8-bit mask is exactly twice the length of each 4-bit keystream (or plaintext) symbol. Thus, making a mask means ’concatenating two keystream symbols’, a coincidence which allows continuous indexing of the entire keystream as 4-bit symbols.
For PT[
] however, the mask is not necessarily a concatenation of some whole number of
s-bit symbols, nor is the index of the keystream bit at which matching begins necessarily a multiple of
s. Thus, instead of indexing the entire keystream, only shorter keystream subsequences
are indexed, where
and simplified notation
is used instead of
. Each subsequence falls in between two masks. Assuming that the relevant section of keystream starts at
, then
can be expressed in a precise but awkward way as follows:
However, since t depends on the outcomes of all previous plaintext-to-keystream matches, each bit’s index above becomes a history-dependent function of the plaintext and the secret key.
5.5. Bit Padding
In PT[], the plaintext and ciphertext symbol lengths may not split evenly into groups of 8 bits. Thus, bit padding (specifically, Method #2 of ISO/IEC 9191-1) is employed so that input and output can be stored and displayed as bytes. In this padding technique, a single bit is appended to the original data, followed by zero or more 0 bits to achieve a context-specific total length. Bit padding during encryption is conducted in two steps:
First, the plaintext is bit-padded to make a whole number of s-bit symbols;
Next, the ciphertext is bit-padded to make a whole number of 8-bit bytes.
During decryption, an initial layer of bit-padding is removed from the ciphertext to obtain a whole number of c-bit symbols. After decryption into s-bit plaintext symbols, another layer of bit-padding is removed to obtain a whole number of 8-bit bytes.
5.6. PT[] Performance
PudgyTurtle produces a bandwidth expansion called the ciphertext expansion factor (CEF) and also uses more keystream bits than plaintext bits (keystream expansion factor or KEF). CEF consumes memory, and KEF expends time. Since previous work described these measures only for PT[4,5,3], here we examine CEF and KEF for the generalized implementation and compare predictions to observed data.
Overflows
For PT[4,5,3], overflows are infrequent (one per ∼80,000 bytes). For PT[], overflows can be more common, even occurring several times in a row. To describe this clearly, some new terminology is useful:
An overflow means that attempts to match a plaintext symbol to successive keystream symbols have all failed;
An overflow event is the occurrence of one or more overflows during encryption of a single plaintext symbol;
The order of an overflow event is the number of overflows it contains: 1-order refers to a single overflow, 2-order refers to a double overflow, and so on. The case of ’no overflows’ can also be formally described as a 0-order event. Note that for PT[4,5,3], all overflow events observed thus far are 1-order, so the total number of overflows equals the number of overflow events. When higher-order events occur, however, the number of overflows exceeds the number of events.
During plaintext-to-keystream matching, the chance of an exact match or one-bit mismatch between any two
s-bit symbols is
In addition, the probability of a successful match after
m failures is
. Let discrete random variable
represent the
order of an overflow event. The probability of no overflows (i.e., a successful plaintext-to-keystream match within
attempts) is
The probability of any overflows (i.e., an overflow event of order ≥1) is
where the probability of each
j-order event above is
Figure 3 shows the observed (•) and predicted (∘) overflow-event probabilities plotted against
. This X-axis parameter was chosen because overflows occur more often when symbols become bigger and/or fewer failures are allowed (larger
). The observed probabilities are from 121 different PT[
] implementations, obtained by systematically varying
s and
f between 4 and 14, and – since the discrepancy-code does not affect
– setting
d to the smallest value provides a sufficient number of codewords (i.e.,
). For each implementation, the plaintext was encrypted using a randomly keyed 24-bit NLFSR. Observed data (•) came from dividing the actual number of overflow events by the number of plaintext symbols. Predicted probabilities (∘) came from substituting each
s and
f into (
1). Notice that predictions are very similar to the observed data and that overflows increase with
as anticipated. When
,
reaches a floor value, and when
, overflows become common enough to dominate the behavior of PudgyTurtle mode.
5.7. Expansion Factors
Since overflows were uncommon for PT[4,5,3], their effects on CEF and KEF can be ignored. For PT[], however, new expressions for these expansion factors are required to properly account for overflows.
Observations. Data were obtained from 1859 different PT[
] implementations, in which
s,
f, and
d all ranged between 4 and 16. For each implementation, the same plaintext was encrypted using an NLFSR with a unique, randomly chosen key. CEF and KEF were then calculated as
and
respectively, and plotted in
Figure 4.
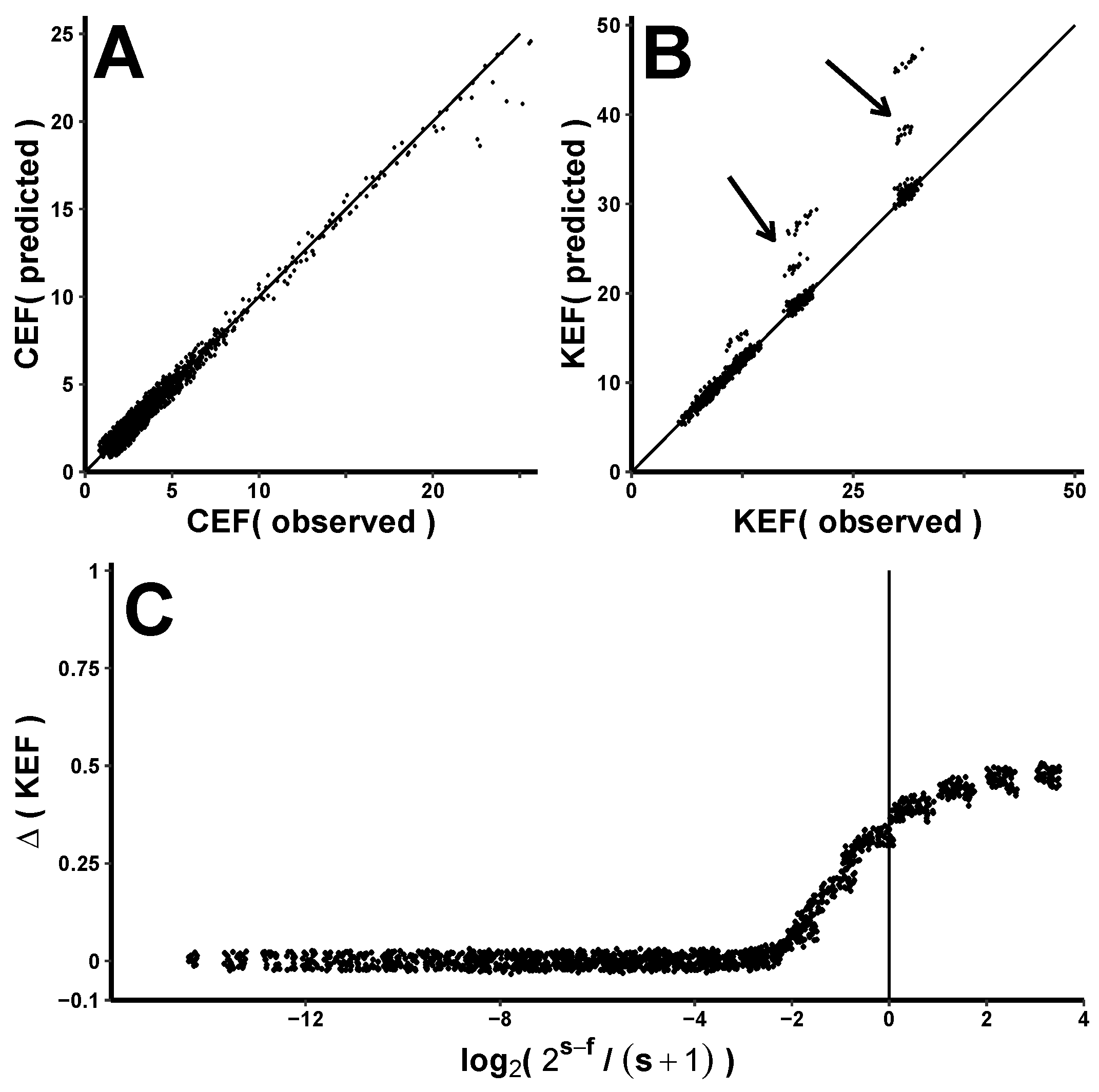
Figure 4A plots CEF against
—again using this X-axis parameter since ’more overflows’ obviously also implies ’more ciphertext’. Interestingly, the CEF curve is U-shaped, with a minimum when
. Above this, CEF increases because of more overflows (i.e., larger
s and/or smaller
f reduce the likelihood of each plaintext-to-keystream match). Below this, CEF increases not because of overflows but because of arithmetic: traveling leftward along the X-axis makes
s smaller,
f larger, or both, which in turn makes
—a major determinant of CEF—bigger (see ’Predictions’ below). This local minimum can be better appreciated in
Figure 4B, which is a close-up of
. This graph also includes lines fitted to discrepancy-code sizes
d = 4 and 12. These lines suggest that for a given
ratio, increasing
d increases CEF—again illustrating its dependence on
.
KEF depends strongly upon
s, as shown in
Figure 4C. Once
s exceeds ∼10, keystream expansion is in the hundreds, and encryption takes noticeably longer.
Figure 4D provides a close-up view of KEF values for
, along with lines fitted to codeword lengths
c = 10 and 15. These lines suggest that changing
c (which could be done by altering
f,
d, or both) affects KEF less than does changing
s.
Figure 4.
Observed expansion factors. CEF and KEF for >1800 NLFSR encryptions of the same plaintext, each using a unique secret key and a different PudgyTurtle implementation. Panel (A) depicts CEF as a function of . Panel (B) shows a close-up of this data for , along with fitted curves for d = 4 and 12. Notice that CEF is minimized when and increases with d for a given . Panel (C) illustrates KEF as a function of s. Panel (D) provides a close-up view of KEF when . The fitted lines here for codeword-sizes c = 10 and 15 (where ) suggest that PudgyTurtle’s other two parameters have relatively less impact on KEF than does s. Abbreviations: CEF—ciphertext expansion factor; KEF—keystream expansion factor; NLFSR—nonlinear feedback shift register; s—plaintext-symbol size; f—failure-counter size; d—discrepancy-code size.
Figure 4.
Observed expansion factors. CEF and KEF for >1800 NLFSR encryptions of the same plaintext, each using a unique secret key and a different PudgyTurtle implementation. Panel (A) depicts CEF as a function of . Panel (B) shows a close-up of this data for , along with fitted curves for d = 4 and 12. Notice that CEF is minimized when and increases with d for a given . Panel (C) illustrates KEF as a function of s. Panel (D) provides a close-up view of KEF when . The fitted lines here for codeword-sizes c = 10 and 15 (where ) suggest that PudgyTurtle’s other two parameters have relatively less impact on KEF than does s. Abbreviations: CEF—ciphertext expansion factor; KEF—keystream expansion factor; NLFSR—nonlinear feedback shift register; s—plaintext-symbol size; f—failure-counter size; d—discrepancy-code size.
5.7.1. Predicted CEF
Regarding bandwidth (ciphertext) expansion, recall that CEF was 2 for PT[4,5,3] when overflows were ignored. This value was obtained by dividing the size of each ciphertext symbol (c = 5 + 3 = 8 bits) by the length of each plaintext symbol (s = 4 bits). Thus, without overflows, it would be expected that CEF = for PT[].
The total number of overflows is the number of overflow events (
) multiplied by the typical number of overflows per event. With this latter quantity, the expected value of random variable
O, is
Since each overflow adds one more
c-bit symbol to the ciphertext, all the overflows together will add
more bits in total. Thus, a more accurate prediction of ciphertext expansion would be
where
.
With
above as an infinite sum, how many of its terms should be used when calculating CEF? Recall that
, the probability of an overflow event in Equation (
1) can be calculated two different ways. One way (the complement of the no-overflow probability) yields its definitive ’true’ value. The other way approximates
with an infinite sum. We first determine how many terms are required to make this summation converge to within 10
of the true
and then use this same number of terms to calculate
in Equation (
2) as well.
5.7.2. Predicted KEF
Regarding keystream expansion, recall that KEF was 5.2 for PT[4,5,3] when overflows were ignored. This value was obtained by adding the number of keystream symbols per mask (2, the number of 4-bit nibbles in an 8-bit mask) to the average number of keystream symbols required for a successful plaintext-to-keystream match (16/5 = 3.2, the mean of a geometric distribution with = 5/16). Thus, without overflows, it might be expected that KEF = for PT[].
To account for overflows, consider the keystream as being composed of two (noncontiguous) parts:
includes all the bits consumed by overflow events and
includes all the bits consumed by successful (nonoverflow) plaintext-to-keystream matches. Thus, KEF =
. To determine
, note that each overflow consumes one
c-bit mask plus
symbols or
keystream bits total. This number, multiplied by the total number of overflows, will equal
:
To determine
, let
represent the average number of keystream symbols required for a match. The amount of keystream needed to represent all the matches will be
Combining these two quantities and using
as mentioned earlier, we acquire the new expression for KEF as follows:
Before examining the accuracy of this formula, however, one point must be addressed. In theory, the average number of keystream symbols needed for a successful plaintext-to-keystream match is
. However, in practice,
since an overflow is triggered after
failures. Thus, if
, KEF predicted by Equation (
4) will exceed the observed KEF.
Figure 5 illustrates the accuracy of CEF and KEF predictions according to the above data from 1859 different PT[
] implementations. Panel A plots the predicted (Y-axis) vs. the observed (X-axis) CEF for values < 25. As expected, points generally fall along the identity line. Panel B is a similar plot for KEF values < 50. Most points fall along the identity, but some predictions overestimate the observed data (arrows above the identity line). These prediction errors should be minimal when
is small compared to
and become increasingly obvious as
gets larger and eventually surpasses
. Panel C shows the relative error (i.e.,
= (KEF
− KEF
)/KEF
plotted against a dimensionless parameter
When , their ratio is 1, and this parameter is zero (vertical line at X = 0). Negative X values represent predictions when is small compared to , and positive X values represent predictions in the converse situation. As expected, the error in predicting KEF is small when and becomes substantial when . A transition zone of increasingly inaccurate predictions extends 1–2 log-units from the vertical line.
6. PudgyTurtle and Bit-Flipping Attacks
We investigate the simplest possible BFA, in which one ciphertext bit is flipped, the modified ciphertext () is decrypted, and this decryption () is compared against the original plaintext (X). Insight into how this mode behaves during such attacks is gained by varying the PudgyTurtle implementation parameters s, f, and d, and by changing the position of the flipped bit (within Y as a whole and within any given c-bit symbol).
6.1. Rejected Ciphertexts
One important concept is that a flipped ciphertext bit may produce an
invalid discrepancy-code during decryption. When this occurs, the ciphertext will be rejected: the decryption algorithm halts at Step #5 (VALIDATE) and returns ⊥. For instance, PT[4,5,3] has
possible discrepancy codes, but only six are actually assigned:
| | | | | | | |
| Valid (to encode plaintext- | NOT | NOT | Valid (to encode |
| to-keystream matches) | valid | valid | overflows) |
Flipping a bit could cause the new ciphertext symbol to be ’unmasked’ into an invalid codeword containing D = 101 or 110 (both invalid) or containing D = 111 (valid) paired with a failure counter . In all, PT[4,5,3] has 95 invalid (8-bit) codewords, with 32 ending in 101, 32 ending in 110, and 31 more ending in 111 but not beginning with 11111—none of which would allow to be converted back into a plaintext-symbol.
6.2. Two Categories of Tailored BFA
Each ciphertext symbol is created by XOR’ing a codeword to a same-sized mask of keystream. In turn, each codeword is a failure counter concatenated with a discrepancy code (
), including the special overflow case, where
F and
D are both ’all-1’. Symbolizing bit #
u of ciphertext-symbol #
j as
,
Let denote the bit within that is flipped during an attack. Depending upon its position, there are two categories of BFAs:
These two kinds of attacks have qualitatively different effects. During a FLIP-F attack, the keystream and ciphertext usually become disconnected, causing an avalanche effect: many bits of and X will differ. In contrast, during a FLIP-D attack, the keystream and ciphertext usually remain connected: only a few bits of and X will differ. Here, ’avalanche’ means simply that flipping one ciphertext bit changes about half of the decrypted bits. We do not claim that a ’strict avalanche criterion’ (SAC) is satisfied since this requires formal statistical testing of all input/output bit combinations. The reason for not using SAC is that avalanches often contain invalid discrepancy codes. In such cases, decryption returns ⊥, and no data are available for statistical inference.
6.3. Localizing the Effect of a Flipped Bit
Encryption modes can affect the number and position of bits in that differ from their corresponding bits in X. For synchronous mode, flipping affects only . For asyn- chronous/self-synchronizing mode, flipping affects the decryption starting , and these changes persist for n bits (i.e., the KSG size). For PudgyTurtle mode, flipping can lead to variability in both the starting point and duration of these changes.
To begin studying these positional effects, a 256-bit message (extracted from the longer ASCII English plaintext) was encrypted under PT[8,4,4] using RC4 and a randomly generated key. One ciphertext bit (specifically one of the eight bits between
and
) was then flipped. The result was decrypted, and the first and last bit index where
and
X differed was tabulated. Enough secret keys were chosen to produce 100 ’successful’ attacks against each of the eight bit positions (i.e., 27,749 total attacks to obtain 800 that were not rejected).
Figure 6A illustrates the
first bit index at which
and
X differed (Y-axis) for each flipped ciphertext bit on the X-axis.
Figure 6B, organized similarly, shows the
last bit index at which the decryption and original plaintext differed.
These results emphasize that PudgyTurtle mode makes it harder to predict the effect of flipping even a single ciphertext bit: the bit position at which changes in
are first observed (
Figure 6A) varies considerably as does the total number of affected bits (
Figure 6B). The attacker can guess
on average where and how many bits of
might change but would find it hard to know the
exact effects of flipping a particular ciphertext bit. PudgyTurtle also affects qualitative attack outcomes. For example, flipping some ciphertext bits (#129 through #133) can affect the whole decryption—as shown in Panel B by the points scattered near bit #256 on the Y-axis—while flipping other bits (#128, #134, or #135), only affects a limited segment of the decryption—typically not much beyond bit #100.
6.4. Positional Effects within a Codeword
The position of the flipped bit within a codeword (FLIP-F vs. FLIP-D) also affects the outcome of a BFA. Compared to flipping a discrepancy-code bit, flipping a failure-counter bit more often triggers an avalanche, increasing the chance of an invalid discrepancy code and leading to higher . In one example using PT[6,5,3] and RC4 key 0x1122334455, we observed the rejection rate for eighty BFAs (produced by flipping each bit from the first ten ciphertext symbols). Overall 63.8% of BFAs were rejected, but the flipped bit’s position had a substantial effect: 96% of FLIP-F attacks were rejected, compared to only 10% of the FLIP-D attacks.
This suggests that for a given plaintext symbol size
s, changing
f and
d while keeping codeword length
c fixed should influence
predictably: larger
d means more ’unassigned’ discrepancy codes, creating more opportunities for invalid discrepancy codes to inadvertently appear during a BFA, ending with a higher rejection rate. This was confirmed using the same protocol as above, but using PT[6,5,
d] with
d = 3, 4, 5, and 6.
Figure 7 shows that
does not change much among FLIP-F attacks (dotted line), which are rejected with high probability. Most of the variation in
occurs during FLIP-D attacks (dashed line), for which rejections rise from 10% with the lowest
d-value to 56.7% with the highest
d-value. Overall, the rejection rate was in the 65–75% range (solid line).
Is this result somehow specific to PT[6,5,d] or does it generalize to other PudgyTurtle implementations? This was tested using the same RC4 key and again by flipping each bit within the first ten ciphertext-symbols. This time, however, all legal PT[] implementations with s, f, and d∈ {4, 5, 6, 7, 8} were used, producing a total of 15,000 separate BFAs. Overall 79.32 ± 4.57% (mean ± s.d.) of ciphertexts were rejected. Among FLIP-F attacks, more were rejected more reliably (99.72 ± 1.33%) than among FLIP-D attacks (57.25 ± 13.33%). Together, these observations illustrate how the BFA outcome is affected by the relative position of the flipped bit within any c-bit ciphertext symbol and by the system parameters themselves.
6.5. Predicting
Since is consistently high for FLIP-F attacks, a more interesting question is whether it can be predicted for FLIP-D attacks. With two examples, we demonstrate that specific attacks can be analyzed individually, but there does not appear to be an all-purpose predictive formula.
These examples use PT[8,5,4] and a 24-bit NLFSR, with 1000 unique, randomly chosen secret keys. For each encryption, attacks were performed against bit , , , and (the ciphertext bits associated with the first discrepancy-code). Although all of these attacks are FLIP-D, their effects on differ. Just over half (56%) of the attacks against bit were rejected, but only about one-third (36%) of attacks against the other three ciphertext bits were rejected.
Table 1 illustrates how these four attacks affect discrepancy codes. Columns 1 and 2 list the original discrepancy code (
D) in decimal and binary. Of
= 16 possible values, one (
D = 1111
) is for overflows, nine others (
D = 0 through 8) describe plaintext-to-keystream matches, and the remaining six (gray background) are unassigned and would not occur during encryption. Columns #3–6 show the new discrepancy codes (
) after flipping ciphertext bits #6, 7, 8, and 9 respectively. Again, the gray background means that
is invalid, and ’-’ stands for discrepancy codes that could not be produced during a BFA (i.e., because the original
D from which
is derived would never occur). One entry in this table deserves special mention. In Column 3 (Flip
), the parentheses around
=
1111 mean that this all-1 discrepancy code only produces a valid codeword when paired with the all-1 failure counter
F =
11111. In this case, the resulting codeword is decodable as ’overflow’. If
=
1111 is paired with any other failure counter, however, the resulting codeword will be invalid, and the attack will be rejected.
To predict
, our analysis assumes that
D = 1111
= 15 is identical to an overflow event, and so
= 0.3181 from (
1). Additionally, we assume that all (
) = 9 valid nonoverflow discrepancy codes are uniformly distributed with probability
—unlike failure counters, which are geometrically distributed. Since probabilities sum to unity,
. Another useful probability (used shortly) is
, the failure counter that can occur either as part of an ’all-1’ overflow codeword (when paired with
D =
1111) or as part of a codeword representing a successful plaintext-to-keystream match to
(when paired with
). Thus,
, where
is the usual probability of a successful plaintext-to-keystream match.
Consider first the FLIP-D attack against bit
, shown in Column 3 of
Table 1. The original codeword in
Y can contain any of ten discrepancy-codes (
D = 0–8 and 15), while the new codeword in
can contain only four (
= 0, 7, 8, and 15). Thus,
Three of these new discrepancy codes (
= 0, 7, or 8) would cause a codeword to be decoded as ’successful plaintext-to-keystream match’. The remaining one (
= 15) would cause a codeword to be decoded as ’overflow’ (when paired with failure counter
F =
11111) or as ’invalid’ (when paired with any other failure counter).
Table 1.
FLIP-D attacks against the first ciphertext symbol. For PT[8,5,4], this table shows possible outcomes of flipping each ciphertext bit corresponding to the first discrepancy code (, , , and ). Columns 1 and 2 show the original discrepancy code (D) in decimal and binary; and Columns 3, 4, 5, and 6 show the new discrepancy codes () produced by flipping the first, second, third, and fourth bit of D, respectively. Gray indicates invalid codes, and ’-’ indicates codes that would not occur. One special case (parentheses: eighth row, third column) occurs when the first bit of D = 0111 is flipped, producing = 1111. The new codeword () is only valid if the failure counter happens to be F = 11111. In this case, the codeword represents an incorrect but valid ’overflow’; otherwise, the attack will be rejected. FLIP-D attacks behave differently depending upon which bit is flipped (e.g., flipping produces four possible ’s and allows for overflows, while attacks against , , and produce eight ’s but no overflows).
Table 1.
FLIP-D attacks against the first ciphertext symbol. For PT[8,5,4], this table shows possible outcomes of flipping each ciphertext bit corresponding to the first discrepancy code (, , , and ). Columns 1 and 2 show the original discrepancy code (D) in decimal and binary; and Columns 3, 4, 5, and 6 show the new discrepancy codes () produced by flipping the first, second, third, and fourth bit of D, respectively. Gray indicates invalid codes, and ’-’ indicates codes that would not occur. One special case (parentheses: eighth row, third column) occurs when the first bit of D = 0111 is flipped, producing = 1111. The new codeword () is only valid if the failure counter happens to be F = 11111. In this case, the codeword represents an incorrect but valid ’overflow’; otherwise, the attack will be rejected. FLIP-D attacks behave differently depending upon which bit is flipped (e.g., flipping produces four possible ’s and allows for overflows, while attacks against , , and produce eight ’s but no overflows).
| Original | Flip | Flip | Flip | Flip |
|---|
| | | | |
| 0 | 0000 | 1000 | 0100 | 0010 | 0001 |
| 1 | 0001 | 1001 | 0101 | 0011 | 0000 |
| 2 | 0010 | 1010 | 0110 | 0000 | 0011 |
| 3 | 0011 | 1011 | 0111 | 0001 | 0010 |
| 4 | 0100 | 1100 | 0000 | 0110 | 0101 |
| 5 | 0101 | 1101 | 0001 | 0111 | 0100 |
| 6 | 0110 | 1110 | 0010 | 0100 | 0111 |
| 7 | 0111 | (1111) | 0011 | 0101 | 0110 |
| 8 | 1000 | 0000 | 1100 | 1010 | 1001 |
| 9 | 1001 | - | - | - | - |
| 10 | 1010 | - | - | - | - |
| 11 | 1011 | - | - | - | - |
| 12 | 1100 | - | - | - | - |
| 13 | 1101 | - | - | - | - |
| 14 | 1110 | - | - | - | - |
| 15 | 1111 | 0111 | 1011 | 1101 | 1110 |
The probability that this BFA will
not be rejected is the sum of the four values above,
, which is similar to the observed value of 48.5%. The probability that the attack will be rejected is
which is again similar to the observed value of 51.5%.
FLIP-D attacks against
,
, and
all behave similarly to one another but differently from the attack against
. As a specific example, consider the attack against
. Applying the same reasoning to the last Column of
Table 1,
and
Again, both predictions are similar to the observed values of 59.2% accepted and 40.8% rejected.
These two examples (BFAs against and ) show the mechanistic steps involved in calculating . While a similar approach can be applied to any FLIP-D attack against any PT[], the details matter: there is no all-purpose formula, and the ultimate probability of interest depends on various inter-relationships between the position of the flipped bit within a c-bit codeword and the system parameters s, f, and d.
6.6. Decrypted Symbol Frequencies
How exactly will the decrypted bits change? In other words, how does the distribution of decrypted symbols compare to that of the original plaintext ? Since most FLIP-F attacks will be rejected, again, it is easier to explore this question using FLIP-D attacks. In this section, we present two experiments: one examines the entire decryption, while the other is limited to one decrypted symbol .
EXPERIMENT 1. A 16-byte test pattern was encrypted with RC4 under 100 different secret keys. PudgyTurtle implementation, PT[8,4,4], was chosen to make each decrypted symbol one byte (s = 8 bits), so that its value can be plotted on a 16 × 16 grid with the Y (or X)-axis as its high (or low)-order nibble. The plaintext X = 0x00112233 44556677 8899AABB CCDDEEFF was chosen to visually stand out on this grid as a diagonal line running from lower left (0,0) to upper right (0xF,0xF). For each ciphertext, every possible FLIP-D attack was carried out (i.e., flipping bits – within , flipping bits – within , and so on). For each attack, was decrypted, and the identity of each decrypted byte tabulated.
Figure 8 shows a ’heat map’ histogram of the observed distribution
. Bytes matching the original plaintext are set off as white squares surrounded by dotted lines. On this diagonal (lower left to upper right), white is for visualization only—not for representation of any particular probability. For the off-diagonal squares, byte frequencies are represented via a normalized gray scale, where light gray stands for a frequency of ∼0.05%, and the black for ∼1.19%. (Note: a frequency of 0.4% would be expected for 250 uniformly distributed bytes.) Notice that the histogram does not appear to be completely uniform (e.g., the 4 × 4 squares in the upper left and lower right seem less common than do other similarly sized areas). What is more important than these details, however, is the fact that every off-diagonal cell is shaded to at least some degree: although the original plaintext distribution
contained only sixteen bytes,
contains all 2
= 256 possible bytes.
EXPERIMENT 2. A more granular view can be obtained by focusing on the distribution of one decrypted symbol rather than all of This experiment examines the distribution of the first decrypted byte in response to FLIP-D attacks against bits within the first ciphertext symbol. One subtle point is the following: if happens to decrypt as an overflow, then actually corresponds to a decrypted version of , not of .
The plaintext (whose first byte is
=
0x20) was encrypted using PT[8,5,4] and the 24-bit NLFSR. For each encryption, one ciphertext bit (either
,
,
, or
) was flipped. Then, 4000 randomly selected keys were used, producing 1000 unique FLIP-D attacks against each of these four ciphertext bits. For each FLIP-D attack, the identity of decrypted symbol
was tabulated. This process resulted in four empirical
distributions, which were plotted as 16 × 16 heat maps.
Figure 9 shows this data, with panels A, B, C, and D representing
during attacks against bits #6, #7, #8, and #9, respectively.
These results hint at the difficulty of predicting the identity of the first decrypted byte even after changing just one bit of the first ciphertext symbol. For example, there is an obvious qualitative difference between
Figure 9A and the other three distributions: the former is spread fairly evenly over most of its domain but has a single peak (
), while the latter consist of four equiprobable values, which are assigned to different bytes in each case.
6.6.1. Attacks against Bit : Qualitative Aspects
Here, we explain the qualitative (distribution shape) differences among these FLIP-D attack outcomes, starting with the attack against bit
. In this case, the first discrepancy code (
) was observed to take only four different values:
0000 = 0,
0111 = 7,
1000 = 8,
1111 = 15. At first, this seems at odds with
Figure 9A. How can an attack produce only four discrepancy codes, and yet
can still take so many (∼180) different identities? The table below shows each of these new discrepancy codes being decrypted into
. Columns 1 and 2 are the original (
and flipped (
) codewords. Column 3 gives the expression used during decryption to obtain
, and Column 4 evaluates this expression. Note that if
=
0111 is changed to
=
1111, and the resulting codeword (
) will only be valid if
happens to be
11111 = 31—the ’all-1’ failure counter associated with overflows (symbolized by
in the last row of Column 2).
| Original | Flip | First Decrypted Symbol () |
| | Expression | Value |
| | | 0xA0 |
| 31 | 31 | | any byte |
| | | 0xA0 |
| | | any byte |
The most common decrypted symbol during this attack is = 0xA0. Row 1 shows how becomes 0xA0 when = 1000 = 8 (i.e., when matches keystream symbol everywhere except bit #8). In the absence of a bit-flipping attack, the first decrypted symbol ’should’ therefore be , which means that should be . A FLIP-D attack against changes the discrepancy code from = 1000 to = 0000 while leaving failure counter unchanged. Thus, the first decrypted symbol in becomes = .
Row 3 shows how becomes 0xA0 when = 0000 = 0 (i.e., when matches exactly—meaning that = 0x20). Here, the FLIP-D attack changes the discrepancy code from = 0 to = 1000 = 8 without affecting the failure counter. Thus, when is decrypted, its first symbol will be , which again equals 0xA0.
Besides 0xA0, the other values of appear to be scattered uniformly, as suggested by Rows 2 and 4 of the above table. In Row 2, an overflow occurs when encrypting the first plaintext symbol, and so decryption of the resulting ’all-1’ codeword () = () would not produce any output. The FLIP-D attack, however, changes the discrepancy code from 1111 to 0111, without changing . Since this new discrepancy code means ’a match everywhere except bit #7’, decryption now produces , which can take any value since, by definition, the keystream is pseudo-random.
Row 4 shows the other way in which can be decrypted into an arbitrary byte: the attack changes = 0111 into = 1111. The original codeword () would have been interpreted as ’ matched everywhere except bit #7’ and would have produced a decrypted symbol accordingly. The new codeword () will only be valid if is also all 1’s, in which case this new codeword will be interpreted as ’overflow’. Therefore, no decrypted symbol will be output, and the first symbol in the decrypted text () will actually be a decryption of the second ciphertext symbol and not the first ciphertext-symbol. Since the second failure counter and discrepancy code are unrelated to , the decryption can produce any value for . (This assumes of course, that does not also decrypt as an overflow. If it does, the same argument applies but with the third failure-counter and discrepancy-code rather than the second, and so on.)
6.6.2. Attacks against Bit : Quantitative Aspects
This explains the qualitative appearance of
for the attack against bit
(i.e.,
0xA0 is relatively common but any byte is possible). Regarding the actual probabilities, 557 of these attacks were rejected and 443 led to successful decryptions. Among these,
was observed to be
0xA0 33.18% of the time (147/443) and to take all other values 66.82% of the time (296/443). To help explain these values, Columns 1 and 2 of the table below show the values of and observed frequencies (out of 1000) of the first discrepancy code,
; Columns 3 and 4 show the values and observed frequencies (out of 443) of the new code
during the attack; and Column 5 gives the predicted frequencies (see below), assuming that
—the relative frequency of overflow to nonoverflow discrepancy-codes—remains fixed, where
= 0.318144 from Equation (
1).
| Original | FlipAttack |
| #/1000 | | #/443 | Predicted |
| 0000 | 0.079 | 1000 | 0.178330 | 0.161019 |
| 0001 | 0.085 | - | 0 | - |
| 0010 | 0.080 | - | 0 | - |
| 0011 | 0.078 | - | 0 | - |
| 0100 | 0.078 | - | 0 | - |
| 0101 | 0.073 | - | 0 | - |
| 0110 | 0.068 | - | 0 | - |
| 0111 | 0.097 | 1111 | 0.004515 | 0.001801 |
| 1000 | 0.066 | 0000 | 0.148984 | 0.161019 |
| 1111 | 0.296 | 0111 | 0.668172 | 0.676162 |
=
0000 and
1000 should occur with equal probability, which we denote as
.
=
0111 arises from the original discrepancy code for an overflow,
=
1111, and thus has probability
. Since the original discrepancy-code probabilities sum to unity,
, and so
= 4.199268. Finally,
=
1111 can only be observed within an ’all-1’ overflow codeword (i.e., when failure counter
=
11111 = 31); otherwise, the attack would be rejected. Thus,
. Since the probability of these different
values must sum to one,
from which we obtain
and the other predicted probabilities in the last column of the table above.
6.6.3. Attacks on Bits , , and
FLIP-D attacks against bits , , and behave similarly to each other but differently than from the attack against . Rather than a large number of possible values, each of these other three FLIP-D attacks produces only four values. Interestingly, however, each of these three attacks can involve eight (not four) ’flipped’ discrepancy codes. In the attack against , a smaller number of discrepancy codes (4) lead to many values. Here, the opposite pattern is observed: a larger number of discrepancy codes (eight) lead to a smaller number (four) of values. Why does this occur?
Consider as an example the 1000 attacks against bit
, of which 638 succeeded and 362 were rejected. The observed frequencies of the original and ’flipped’ discrepancy codes (along with predicted values for the latter) are shown below:
| Original | FlipAttack |
| #/1000 | | #/638 | Predicted |
| 0000 | 0.079 | 0001 | 0.133 | 1/8 |
| 0001 | 0.085 | 0000 | 0.123 | 1/8 |
| 0010 | 0.080 | 0011 | 0.122 | 1/8 |
| 0011 | 0.078 | 0010 | 0.125 | 1/8 |
| 0100 | 0.078 | 0101 | 0.114 | 1/8 |
| 0101 | 0.073 | 0100 | 0.122 | 1/8 |
| 0110 | 0.068 | 0111 | 0.152 | 1/8 |
| 0111 | 0.097 | 0110 | 0.107 | 1/8 |
| 1000 | 0.066 | 1001 | 0 | - |
| 1111 | 0.296 | 1110 | 0 | - |
= 0–8 each occur with probability . Although 1000 and 1111 are legal values for , flipping the last bit of either will make it invalid (gray background). Thus, the ’flipped’ discrepancy code can take eight possible values, each of which is observed to occur near its expected frequency of .
The eight corresponding values can be paired into four ’dyads’, in which one member becomes the other when is flipped, but both cause to be decrypted into the same value. For example, discrepancy codes 4 and 5 are a dyad: flipping the final bit of 4 yields 5, and flipping the final bit of 5 yields 4. When the original discrepancy code is = 5, the first plaintext symbol and its matching the keystream symbol must have differed in their fifth bit. Thus, = = 0x20⊕0x10 = 0x30. During the FLIP-D attack, however, = 5 becomes its dyadic partner = 4. Under this new (incorrect) discrepancy code, will be decrypted into = 0x38. Had the original discrepancy code been = 4 (i.e., the dyadic partner of = 5), then by the same reasoning would be 0x20⊕00001000 = 0x28. The bit-flip attack would alter this discrepancy code to = 5, leading to the (incorrect) decryption = 0x38. Thus, both and produce the same decrypted symbol, = 0x38.
In a similar manner, the other three dyads for the attack against (0 and 1, 2 and 3, 6 and 7) will produce the other three observed values of . The probability of each value of is the sum of the probabilities of its corresponding dyad, which is just = 25%. (The same argument applies also for attacks against bits and —only differing in the details of which discrepancy-codes are paired into which dyads.)
To summarize, we have shown how can span the entire domain of 256 possible bytes, even though the original X had only sixteen unique bytes. We have also discussed how flipping different bits within one discrepancy code (e.g., vs. , , or ) can produce qualitatively and quantitatively different distributions for the corresponding decrypted symbol.
6.7. Reconnection
One seemingly anomalous finding must still be explained. FLIP-F attacks should trigger an avalanche and therefore be rejected—especially for a lengthy plaintext like 800,000-bit message used here. However,
Figure 7 shows that
some (<1%) FLIP-F attacks are not. This is not due to mere statistical chance but rather due to a specific phenomenon called
reconnection.
Recall that during normal PudgyTurtle decryption, Y and K are unlinked but connected. During a FLIP-D attack, and K usually stay connected: is still the appropriate keystream symbol to use for decryption (although the altered value of D will cause to be reverse-engineered into the wrong plaintext symbol). During a FLIP-F attack, however, and K usually disconnect: is no longer the correct keystream symbol for reverse-engineering since by definition the failure counter F is wrong. Disconnection then causes each subsequent ciphertext symbol to be ’unmasked’ into an effectively random value rather than the appropriate codeword, producing an arbitrary decryption with a high probability of being rejected. If rejection does not occur, it is likely that K and have reconnected. This occurs by chance if the running total of keystream symbols consumed while decrypting up to some point coincides with the running total of keystream symbols that would have been consumed decrypting Y up to that same point.
To illustrate reconnection, consider an example using PT[8,5,4] and a randomly keyed 24-bit NLFSR, in which 1000 FLIP-F attacks are mounted against bit #1 (the first failure-counter bit). To better visualize the raw data, the plaintext is a 32768-bit message containing a simple repeating 16-byte test pattern. As expected, most attacks were rejected (990/1000), but a few (0.1%) led to successful decryptions. The partial hex dump of one such decryption (secret key
0x5A286F) is shown below, along with the original plaintext:
| X (original) | 00112233 44556677 8899AABB CCDDEEFF 00112233... |
| (BFA) | A4480333 44556677 8899AABB CCDDEEFF 00112233... |
The first three decrypted bytes differ from the original plaintext, but all remaining bytes are identical. The cartoon below compares the failure counters during decryption of the original and ’flipped’ ciphertexts. Column 1 shows the index of the symbol being decrypted. Failure counters are shown for decryption of each symbol in
Y (Column 2) and
(Column 4). Running totals (∑) of the required number of keystream symbols for plaintext-to-keystream matching which are given for
Y (Column 3) and
(Column 5). (Recall that for failure counter
, an overflow or successful plaintext-to-keystream match consumes
keystream symbols). The running-total does not include the keystream involved in constructing each mask. Including this data would not change the results but would require keeping a running total of
keystream
bits for each entry, rather than of
keystream
symbols.)
| Reconnection during a FLIP-F Attack |
| | Original () | | Flipped () |
| | | ∑ | | | ∑ |
| 1 | 13 | 14 | | 29 | 30 |
| 2 | 23 | 38 | | 14 | 45 |
| 3 | 25 | | | 18 | |
| 4 | 21 | 86 | | 21 | 86 |
| 5 | 21 | 108 | | 21 | 108 |
| ⋮ | | ⋮ | | | ⋮ |
The running-totals match after decryption of the third symbol (∑ = 64, circled). Thus, , and may differ from , , and , but will be the same thereafter. During this FLIP-F attack, disconnects from K immediately (during decryption of ), but then—due to a coincidence of running-totals—reconnects after decryption of the third ciphertext symbol. Decrypting either Y or up to this point would require 64 keystream symbols.
It would seem that the attacker could leverage this behavior to their advantage by tailoring a BFA to affect only a certain segment of plaintext, but reconnection is an uncertain prospect. Although it is easy to visualize after the fact (given
Y,
, and
K), it is difficult to know in advance whether or not it will occur, and—if it does—where exactly it will happen. Moreover, BFAs in this paper are limited to flipping only one bit. For attacks involving multiple bit flipping, the chance of maintaining a reconnected state for the entire remaining
would diminish. Both of these factors make it harder for an attacker to exploit a reconnection (also see
Section 7).
6.8. Symbol Insertion
Bit-flipping attacks against PudgyTurtle can also produce an unusual behavior called symbol insertion, in which the decryption contains an ’extra’ symbol. This violation of length preservation appears to be unique to PudgyTurtle and would not occur during bit-flipping attacks against other stream-cipher encryption modes.
The root cause of symbol insertion is overflows: when a flipped bit changes an overflow symbol into a valid nonoverflow codeword, a new decrypted symbol is produced rather than the ’no output’ that would otherwise have occurred. Flipping bit while using PT[4,5,3], for instance, might change an overflow codeword (11111111) into 11111011. The former would not produce any decrypted symbol, but the latter—which PudgyTurtle would interpret as “ matched the plaintext-symbol everywhere except bit #3”—would produce the ’extra’ decrypted symbol .
Data from
Section 6.7 also provide an example of symbol insertion. Hex dumps from this attack (with secret key
0x9D5EA3) are as follows:
| X (original) | 00112233 44556677 8899AABB CCDDEEFF 00112233... |
| (BFA) | D7201722 33445566 778899AA BBCCDDEE FF001122... |
After its third byte,
is immediately recognizable as
X shifted rightward by one byte. The failure counters and running totals for this attack are presented below.
| Symbol Insertion during a FLIP-F Attack |
| | Original () | | Flipped () |
| | | ∑ | | | ∑ |
| 1 | 15 | 16 | | 31 | 32 |
| 2 | (31) | 48 | | 24 | 57 |
| 3 | 17 | | | 8 | |
| 4 | 16 | 83 | | 16 | 83 |
| 5 | 19 | 103 | | 19 | 103 |
| ⋮ | | ⋮ | | | ⋮ |
is normally decrypted as an overflow—indicated by parenthesis around its associated failure counter (F = 31 in Row 2)—and therefore has no corresponding output symbol. Thus, and together only yield one decrypted symbol. On the other hand, during the bit-flip attack, no longer decrypts as an overflow, and so and together produce two decrypted symbols: now contains one more symbol than did the original plaintext (To be clear, the first failure counter during the bit-flip attack ( = 31, Row 1, Column 4) is the same value that occurs during an overflow. However, the discrepancy code paired with is not 1111, and so the resulting codeword of () is not interpreted as an overflow but rather as a plaintext-to-keystream match between and . This numerical coincidence has nothing to do with reconnection or symbol insertion). Reconnection occurs after the third ciphertext symbol (identical running-totals ), and thus the remainder of is decrypted correctly, but each symbol’s position is shifted one s-bit (8-bit) symbol rightward compared to X.
Illustrated differently, the decryption of the original (unmodified) ciphertext—including the
-overflow—is as follows:
| | | | | … |
| ↓ | ↓ | ↓ | ↓ | ↓ | |
| | | | | … |
| 0x00 | | 0x11 | 0x22 | 0x33 | … |
Meanwhile, the decryption of the flipped ciphertext is as follows:
| | | | | … |
| ↓ | ↓ | ↓ | ↓ | ↓ | |
| | | | | … |
| 0xD7 | 0x20 | 0x17 | 0x22 | 0x33 | … |
correctly decrypts to
0x22, for example, but this byte is now the
fourth decrypted symbol, not the third.
Another clue about symbol-insertion comes from the normalized Hamming distance. For this attack, = 46.9%. This value seems odd: although is nearly 50%, the decryption is not ’random-looking’ at all but quite recognizable as a shifted version of the original test pattern.
When comparing a message to a shifted version of itself, the normalized Hamming distance may take a recognizable value. With natural languages, this value is known (e.g., for a one-byte shifted version of our ASCII-encoded English plaintext source, it would be ≈ 36.2%), and for study purposes, it could even be manipulated with specially designed plaintexts (e.g., would be ’1’ for the plaintext 0xFF00FF00… shifted by one byte, etc.). For a 1-byte shift and this particular test pattern, just happens to be nearly 50%—the same value expected during an avalanche.
The original intuition about FLIP-F attacks triggering avalanches, altering many bits of and being rejected, is sound. However, among the few FLIP-F attacks that are not rejected, reconnection and sometimes symbol insertion will be observed. A rejected ciphertext should have , but in practice, there may not be any data to analyze. With reconnection, reflects the number of bits over which disconnection persists. With symbol insertion, may take a recognizable value for a certain plaintext (or class of plaintexts).
7. Robbing the Bank
This section discusses a bit-flip attack against a hypothetical banking transaction. The goal of this exercise is to change a very simple 15-byte plaintext (“DEPOSIT:$500.00”) into a new message specifying a larger deposit. The decryption must match the original format except that it may contain up to 4 digits before the decimal point—thus allowing the attacker to take advantage of potentially inserting an ’extra’ decrypted symbol to deposit more than $999.99.
To preview the results, most attacks fail. Among successful attacks, only a few decryptions are ’meaningful’: most violate pre-specified formatting guidelines. Among meaningful decryptions, the deposited amount is unpredictable: it may be less than, greater than, or exactly equal to $500. Among successful deposits >$500, the profit varies over a ten-fold range. Although PudgyTurtle does not completely prevent successful attacks, it adds significant uncertainty about which bit should be flipped to make a profit.
This experiment uses PT[8,4,4] and RC4 with 1000 randomly chosen 40-bit secret keys. For each key, attacks were performed against ciphertext symbols starting with (the first one that might represent an encrypted digit—assuming no overflows) and ending with the penultimate ciphertext symbol, . For each ciphertext-symbol, all eight of its bits were flipped in succession, resulting in 223,272 individual bit-flip attacks in total. Each attack was categorized into one of four outcomes:
REJECT: decryption returned ⊥ due to an invalid discrepancy-code.
NONSENSE: decryption occurred, but was not meaningful. The bank itself (not the decryption algorithm) would likely reject these transactions for being ill-formatted. Meaningful decryptions were required to contain the string “DEPOSIT:$” followed by 1–4 decimal digits, a decimal point, and two more digits. Nonsense decryptions included things like “DEPzSIT:$100.00” (mis-spelling), “DEPOSIT:$50a.00” (nondigital value), “DEPOSIT:$500+00” (no decimal point), “DEPOSIT:$.05” (too few digits before the decimal point), and “DEPOSIT:$500.1” (too few digits after the decimal point). Leading zeros (e.g., “DEPOSIT:$0010.00”) and null transactions (e.g., “DEPOSIT:$000.00”), however, were accepted.
LOSS: a meaningful decryption specified a deposit ≤$500.00. A $500.00 deposit exactly also counted as a ’LOSS’ due to the uncompensated time and effort required to mount the attack
GAIN: a meaningful decryption produced a deposit >$500.00.
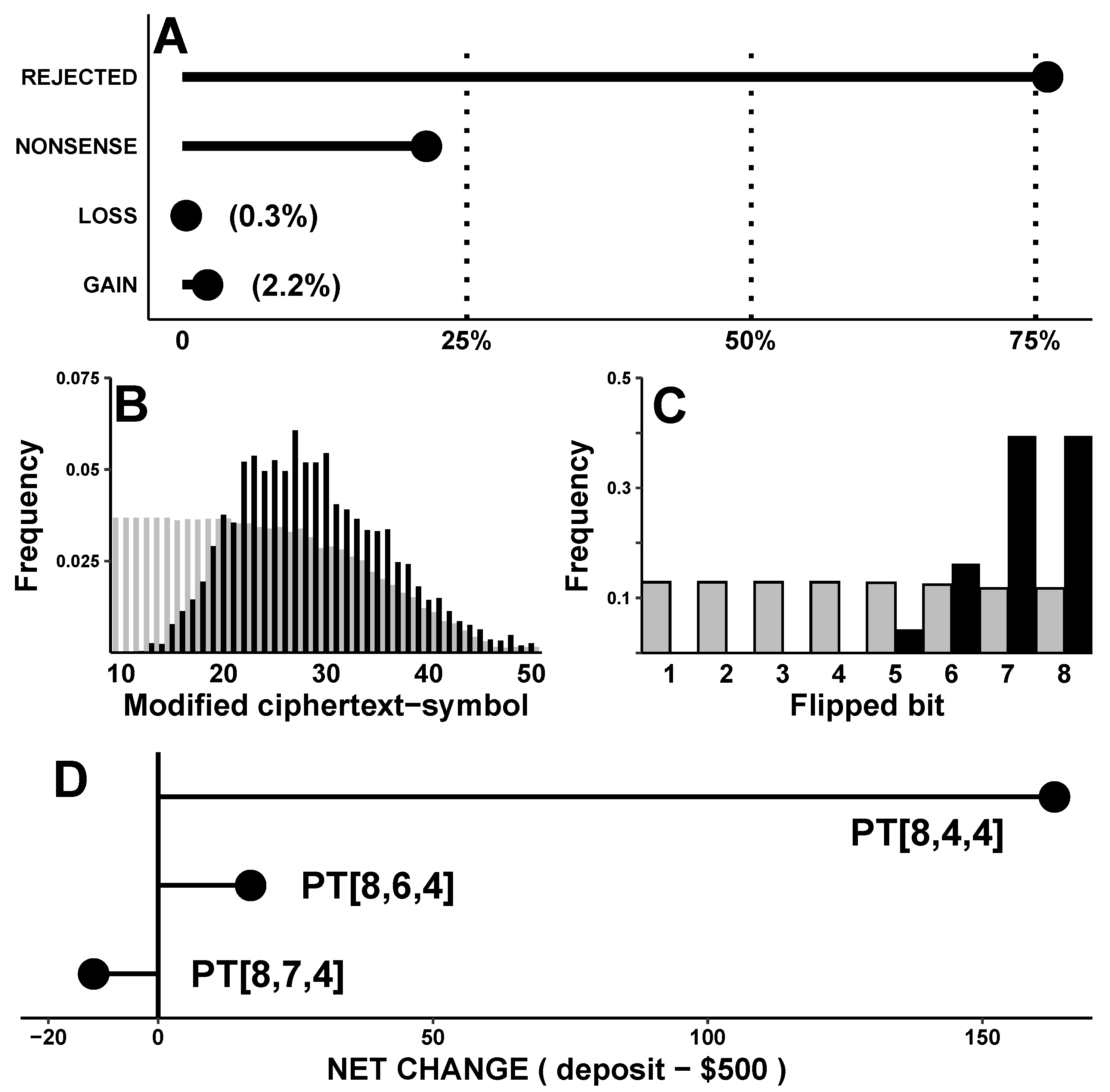
Figure 10A shows that valid decryptions were rare: about three-quarters of BFAs were rejected (76.1%), and most others decrypted into nonsense (21.4%).
Meaningful decryptions—by which we mean those that were not rejected and decrypted into something besides nonsense—occurred only ≈2.5% (5604/223272) of the time. The ultimate goal of this exercise (GAIN) was even less common—although gains did constitute a majority of meaningful decryptions (4667/5604 = 87%, but only 4667/223272 = 2.1% of all attacks).
Can the attacker predict which bit to target in order to have the bank accept the transaction? The results suggest not.
Figure 10B shows histograms of which ciphertext symbol contained the flipped bit, both for meaningful decryptions (black bars,
▪) and for rejected attacks or nonsense decryptions (gray bars,
![Cryptography 07 00025 i001]()
). Although these two histograms have different shapes, they overlap significantly. Thus, targeting symbols that occur early or late in the ciphertext is suboptimal: these symbols coincide with low-probability tails of the black (’meaningful’) histogram. Yet, targeting the remaining ciphertext symbols near the peak of the black curve is also not ideal: their positions fall along the plateau of the gray (’nonsense/rejected’) histogram. Therefore, such attacks are equally likely to fail as attacks against early ciphertext symbols.
Figure 10C shows similar information about which bit (within any 8-bit ciphertext-symbol) was flipped. While FLIP-D attacks against the two final bits of any codeword seems like the best strategy, such attacks still have a similar probability of REJECTED/NONSENSE outcomes as do attacks against the other six bits.
So far, GAIN and LOSS have been lumped together as ’meaningful’ decryptions. However, it is not clear how certain the attacker be about the actual dollar amount of the final result or which bit should be flipped to turn a profit. After all, decrypted deposits varied widely—from $0.00 to $9500.00. If we define the net change as a ’decrypted deposit’ minus $500.00, then its average would $163.12—reflecting an average LOSS of −$272.25 and an average GAIN of $227.00.
Higher profits occur among decryptions with an extra symbol (i.e., changing the dollar amount before the decimal point from a 3-digit to a 4-digit value). Since symbol insertion occurs when an overflow codeword is changed into something else, extra digits should be more common when overflows are more common, and vice-versa. The attack so far has only involved a single PudgyTurtle implementation (PT[8,4,4]) with a substantial overflow rate of . Would ’robbing the bank’ be less profitable in situations with fewer overflows?
To test this, another set of bank robberies was attempted against implementations with larger failure counters (
f = 6 and 7) and therefore fewer overflows (i.e.,
= 10.12% for PT[8,6,4] and 1.02% for PT[8,7,4]). The rest of the protocol was identical to the one above, but this time only 100 keys were used. For each implementation, the net change was averaged over all meaningful decryptions. As illustrated in
Figure 10D, overflows indeed affected the profit margin. When overflows were most likely (PT[8,4,4]), the average net change was a GAIN of
$163; when overflows were somewhat less likely (PT[8,6,4]), the net-change was a GAIN of only
$16; and when overflows were rare (PT[8,7,4]), the net change was a LOSS of
$11.
This analysis adds little to what the bank robber could simply have assumed from the outset: the best strategy is a FLIP-D attack against some ciphertext symbol ’in the middle’ that probably represents an encrypted plaintext digit. While these observations can be taken as limited conclusions for a 1-bit attack against one particular plaintext and PudgyTurtle implementation, a broader interpretation is also possible: predicting the actual results of bit-flipping attacks in the presence of PudgyTurtle is difficult. The ultimate outcome depends on factors controlled by the attacker (i.e., which bits(s) are flipped) and by the sender/receiver (i.e., implementation parameters s, f, and d) but also has some inherent uncertainty due to the stochastic nature of PudgyTurtle mode’s plaintext-to-keystream matching process.
8. Discussion
This manuscript has explored how the stream-cipher encryption mode PudgyTurtle affects ciphertext malleability in the context of bit-flipping attacks. In these attacks, the opponent captures the ciphertext, alters one or more bits, and then retransmits this modified ciphertext. Here, we investigated only the simplest attack: flipping a single bit.
PudgyTurtle’s plaintext-to-keystream matching process implements a nonsystematic, 1-bit error-correcting code, transforming an
s bit input into a
bit output. Many other stream-ciphers also utilize error-correcting codes, such as the ’noisy keystream encryption’ (NKE) model of Kara and Erguler [
25,
26] and several variants of the ’learning parity with noise’ (LPN) problem [
27] including LPN-C by Gilbert and colleagues [
28], a matrix-based system by Applebaum [
29], and a homophonic system by Mihaljevic and Imai [
30]. In these examples, the plaintext is typically encoded with an error-correcting code, and then the codewords are purposely mixed with noise as well as keystream. This ’encode before enciphering’ idea has been analyzed in depth by Bellare and Rogaway [
31] and even relates in some ways back to Shannon’s observations about how easy it would be to encipher a perfectly- ncoded (i.e., zero redundancy) artificial language [
32]. What differentiates PudgyTurtle mode from these other systems is that the underlying motivation for the ECC is not to combat
external noise but rather to describe the match (to within a 1-bit tolerance) between each plaintext symbol and some keystream symbol. Essentially, the keystream functions as an ’internal’ noise source, against which each plaintext symbol is compared. The stochastic nature of each plaintext-to-keystream match introduces history (feedback) into the encryption process, thereby adding qualitative and quantitative uncertainty to the outcome of bit-flipping attacks.
Good protection against bit-flipping can be provided by authenticated encryption modes (Chapter 4 [
33]) or message-authentication codes (Section 18.14 [
34]). However, these authentication strategies themselves may be vulnerable. The MAC, for instance, has security issues including attacks based on replay, length-extension, padding, variable key lengths, collisions of suffix-based constructions, and side channels (timing of string comparisons) [
35,
36,
37], (Chapter 7 [
38]), (Chapter 4 [
12]), (Chapter 3 [
33]). Therefore these methods may necessitate yet another layer of complexity (e.g., sharing another [authentication] key, including a counter or nonce, lengthening the authentication tag size above some threshold, and so on).
Another protection against bit-flipping is to use a stream-cipher encryption mode other than synchronous (S-BASC). These modes enhance message integrity to some degree, and thus offer limited defense against bit-flipping—although not the full protection afforded by a MAC. Taking the ’effect’ of a one-bit BFA to mean the point at which begins to diverge from X and the number of bits over which this continues, we can say, for example, that against S-BASC mode, the effect is immediate and short lived (one bit). Against the asynchronous/self-synchronizing mode, the effect is also immediate, but persists for n bits (the size of the KSG inner state). Against PudgyTurtle mode, the effect has a variable starting point and duration. This unpredictability is because PudgyTurtle includes uncertainty about how much keystream will be required to encrypt each plaintext symbol.
This paper first introduced a ’generalized’ PudgyTurtle implementation (PT[
]) which allows variably sized input and output symbols. This implementation takes
s-bit plaintext symbols as input and produces
c-bit ciphertext symbols as output, where
,
f is the failure-counter size, and
d the discrepancy-code size. In previous research using one particular implementation (PT[4,5,3]), overflows were rare, its bandwidth expansion was ∼2, and its keystream expansion was ∼5.2. For generalized PudgyTurtle, overflows can be more common (even occurring as multioverflow events) and scales with
, bandwidth expansion scales with
, and keystream expansion with
s. Many (
) combinations can achieve both adequate speed and compactness (i.e., keystream expansion <5–10, and bandwidth expansion <2–3), with Equations (
1), (
3), and (
4) predicting the performance of any proposed PT[
] implementation.
Next, this paper explored the several ways in which PudgyTurtle mode affects message integrity during single-bit bit-flipping attacks:
The attacker may be able to predict the effects of a BFA (i.e., the first and last affected bits) on average, but not exactly.
The decryption algorithm itself rejects attacks that produce an invalid codeword. Each codeword is the concatenation of an f-bit failure counter and a d-bit discrepancy code (). In PudgyTurtle, all failure counters are possible, but only () discrepancy codes are needed—not all of them. A BFA may produce one of these unassigned discrepancy codes or may lead to an incorrect pairing of the ’all-1’ discrepancy code (associated with overflows) with an F that is not all 1’s. Either way, the resulting codeword will be invalid.
Depending upon which bit within a c-bit ciphertext-symbol is flipped, attacks can be grouped into those that alter a failure counter (FLIP-F) and those that alter a discrepancy code (FLIP-D). Rejections are more likely during FLIP-F attacks than FLIP-D attacks. When a failure counter is altered, the keystream and ciphertext become disconnected, after which the decryption algorithm returns seemingly random outcomes. When a discrepancy-code is altered, in contrast, the keystream and ciphertext remain connected: except for one affected ciphertext-symbol, decryption proceeds normally, affecting only a few bits overall.
Flipping even a single ciphertext-bit can change the distribution of decrypted symbols substantially compared to the original plaintext, altering its domain (all vs. just a few s-bit symbols) and shape (uniform vs. peaked). These distributions can be computed on a case-by-case basis but may not be amenable to a generalized formula.
Avalanches sometimes self-terminate. If the keystream and ciphertext ’reconnect’, the attack will not be rejected. Reconnection happens when the running-total number of keystream symbols used to decrypt the modified ciphertext coincidentally equals what it would have been for the original ciphertext. The length of disconnected ciphertext and the position at which reconnection happens are both uncertain, however, due to the statistical nature of each plaintext-to-keystream match.
A new symbol is sometimes inserted into the decryption during a BFA. This occurs when a ciphertext symbol that should have been unmasked as an overflow (and therefore not trigger any output) is instead unmasked as a codeword that specifies a plaintext-to-keystream match (and therefore does trigger the output of a decrypted symbol). Symbol insertion also involves uncertainty with respect to its location and identity.
Together, these effects of PudgyTurtle mode make it harder for an attacker to tailor the correct set of bit flips to achieve a desired outcome and increase the likelihood that the modified ciphertext will be rejected. In the final section of this paper, we attacked a hypothetical bank transaction with the goal of depositing more than the specified amount of money. The results of this experiment confirmed all of these observations: most attacks were rejected by the decryption algorithm itself; most attacks that were decrypted contained obvious formatting errors which would not have been accepted by the bank; the content of the remaining decryptions (∼2% of all attacks) was uncertain: losses could occur as well as gains, and even among attacks resulting in a net gain, the actual profit could vary substantially.
One limitation of this manuscript is only including BFAs in which a single bit was flipped. This simple case made it easier to interpret the effects of bit-position on attack outcomes but artificially limited the power of each attack. However, some of the observed effects may be even less likely if multiple bit flips are allowed. Reconnections, for example would likely be shorter if multiple bit-flips caused disconnection at many points. Another limitation is the toy ciphers used in our experiments: a 40-bit RC4 and a simple 24-stage NLFSR. While neither of these is appropriate for secure systems, both can nevertheless generate sufficiently random keystream for the purposes of this study. Potentially, however, subtle bit correlations could have influenced some of our results (e.g., attacks targeting , the outcomes of which rely more heavily on early keystream). To reduce this effect, we chose KSG starting states at random and when feasible used a different one for each bit-flip attack.
The extent to which various stream-cipher modes increase the work effort and decrease the success-rate of bit-flipping attacks remains an open question. PudgyTurtle mode by itself should not be relied upon to prevent such attacks. Future research, however, may focus on improving its effectiveness in this regard. For example, as probabilistic encryption (such as the ’noisy keystream’ [
25,
26]) could in theory render tailored bit-flipping infeasible, could PudgyTurtle also be modified to achieve randomized encryption?


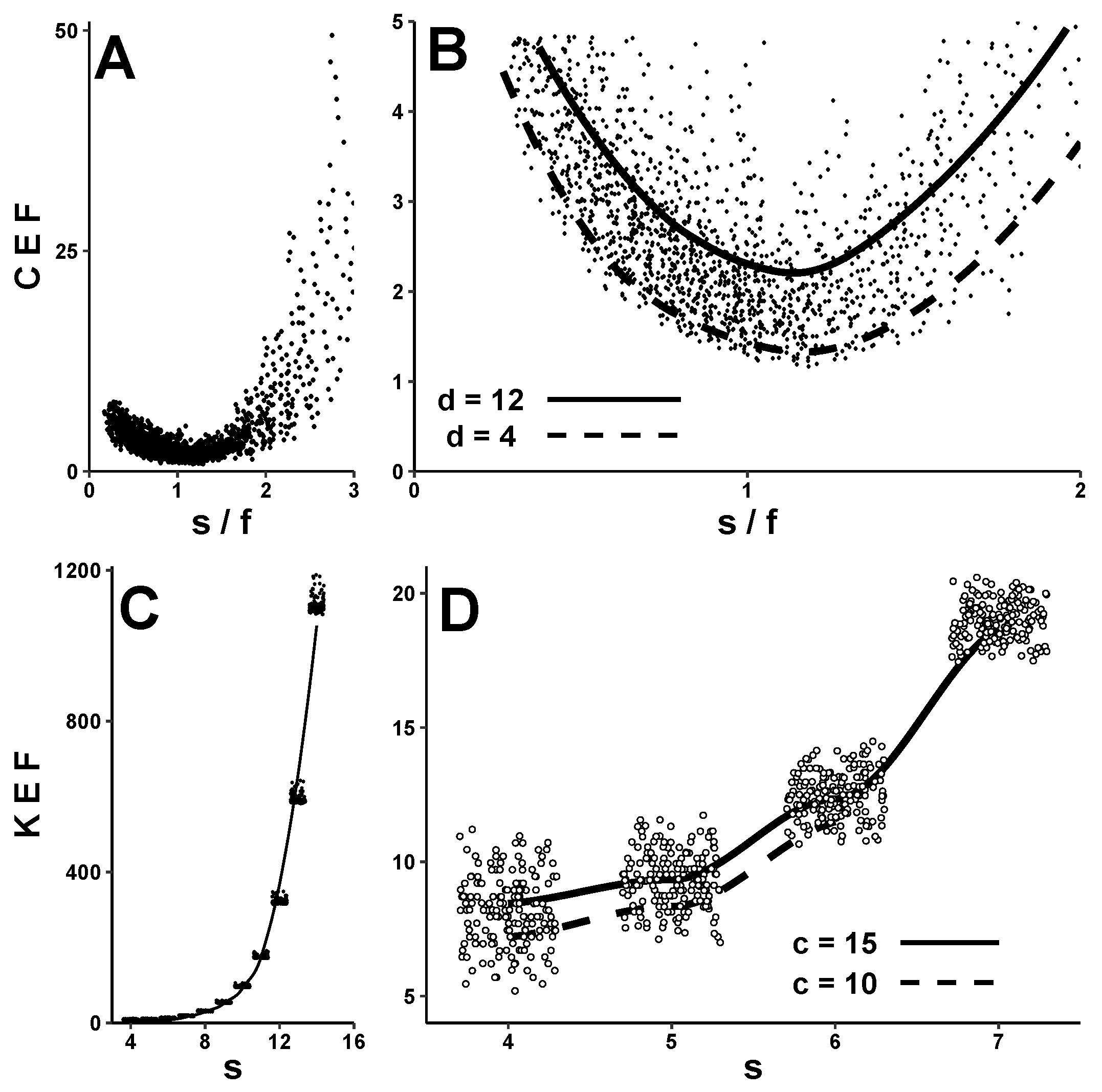

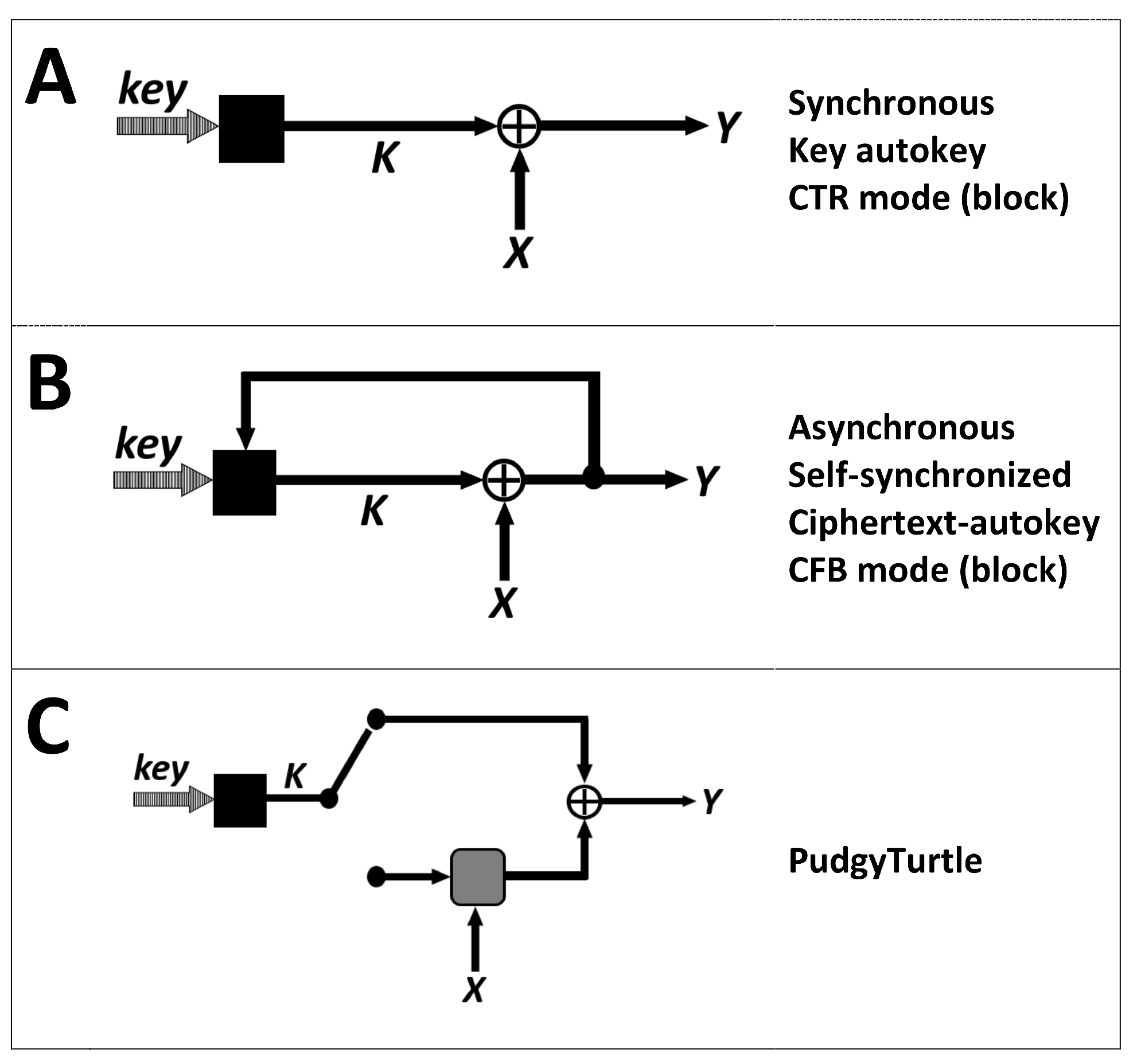{kind=link}
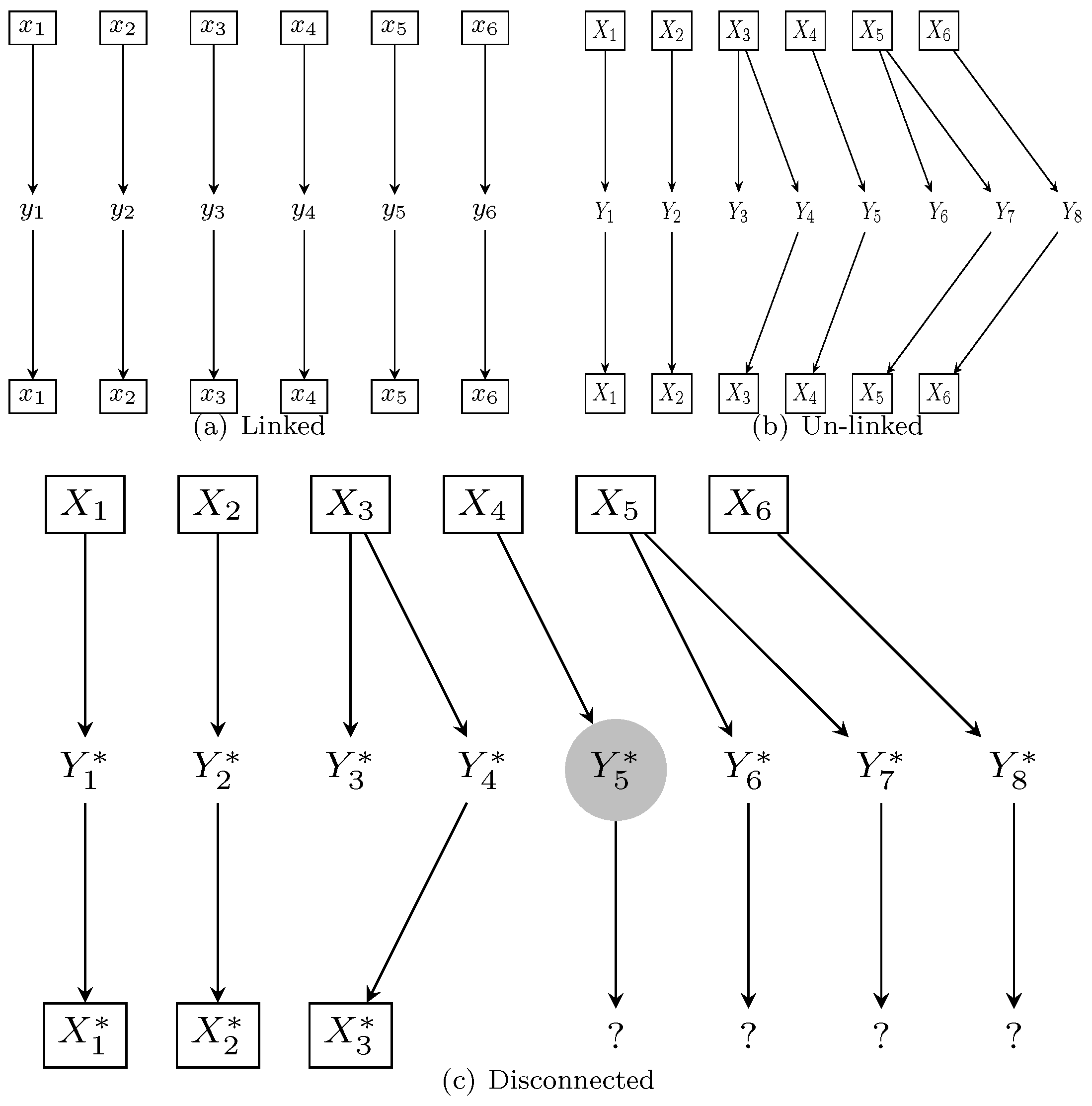{kind=link}
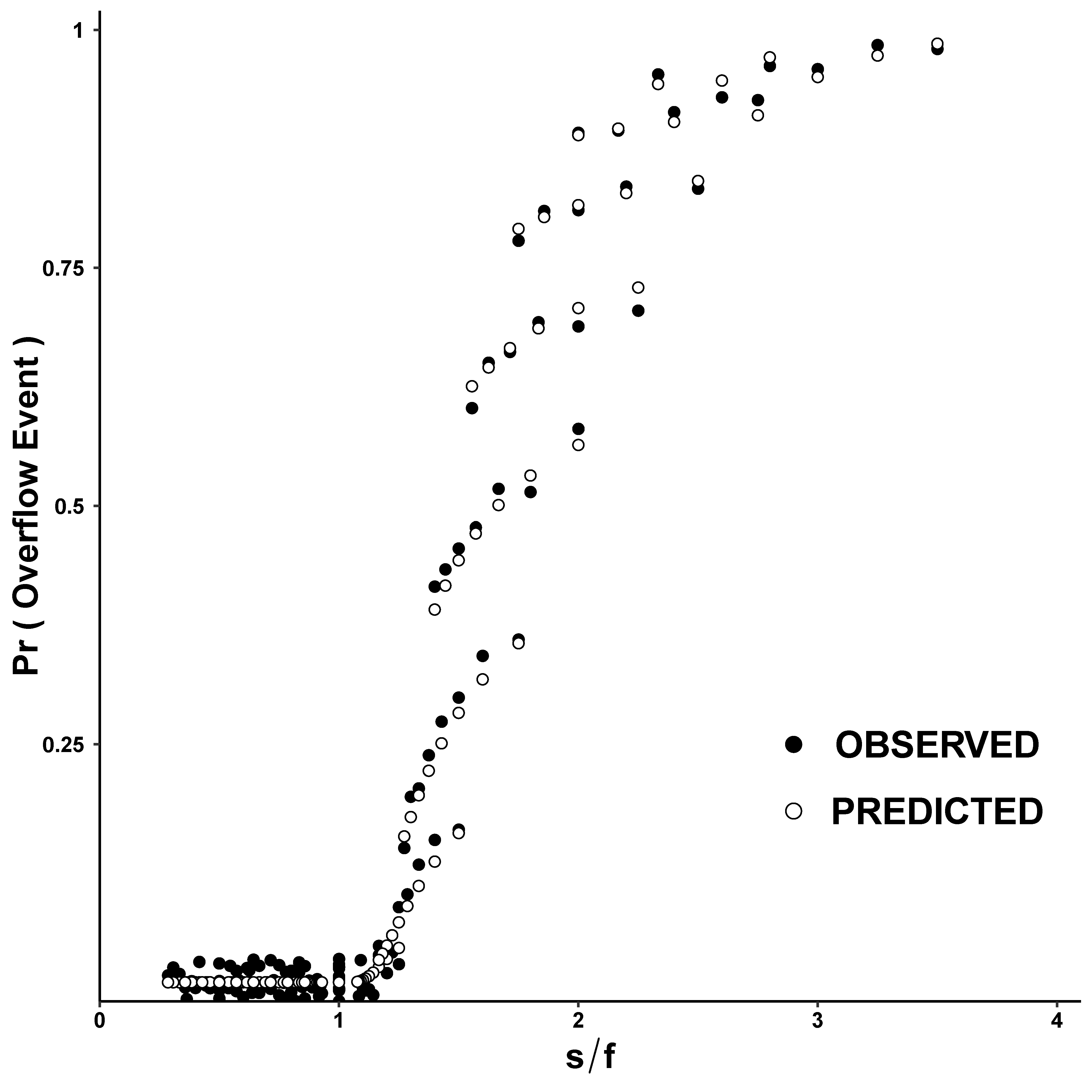{kind=link}
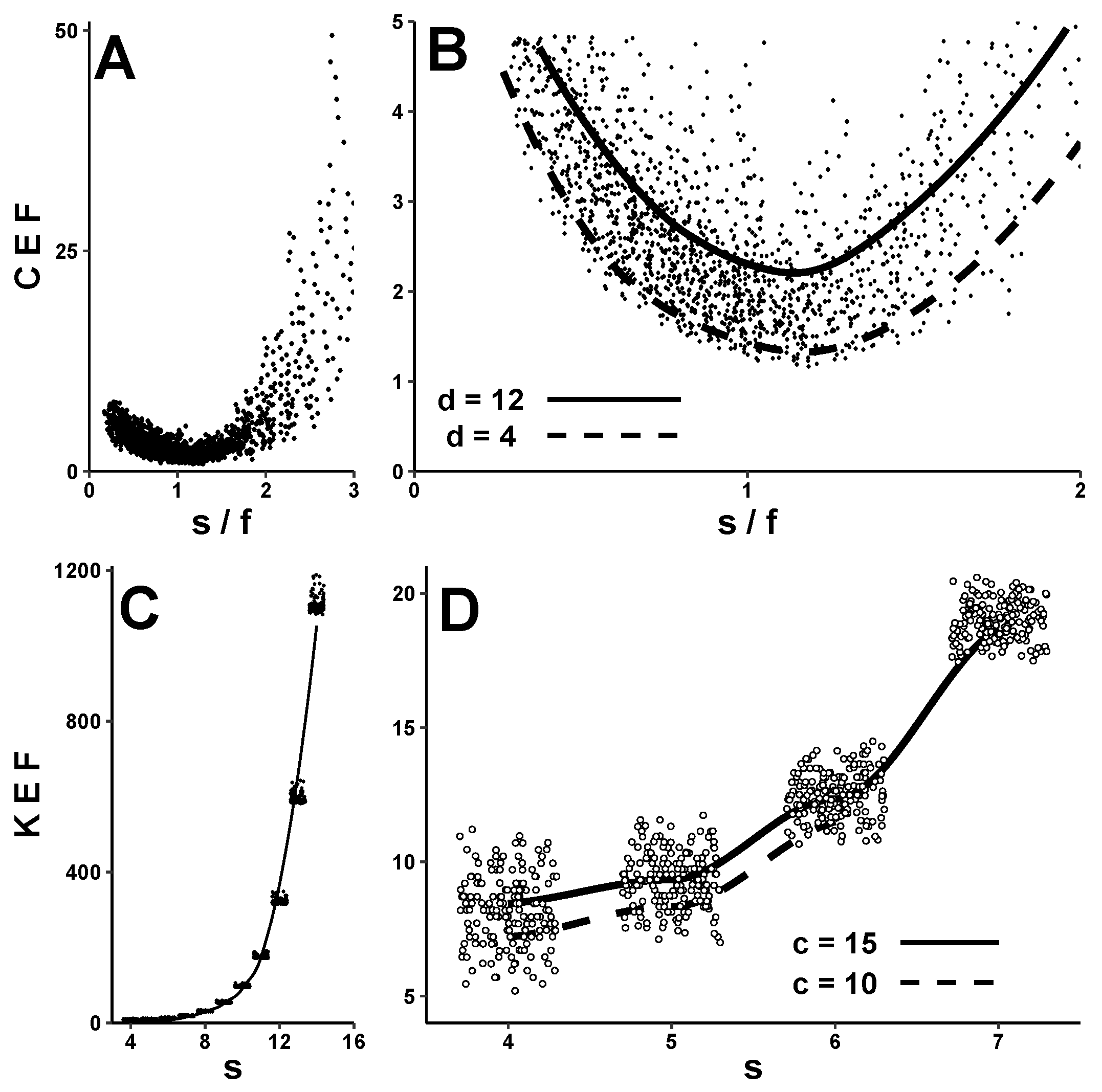{kind=link}
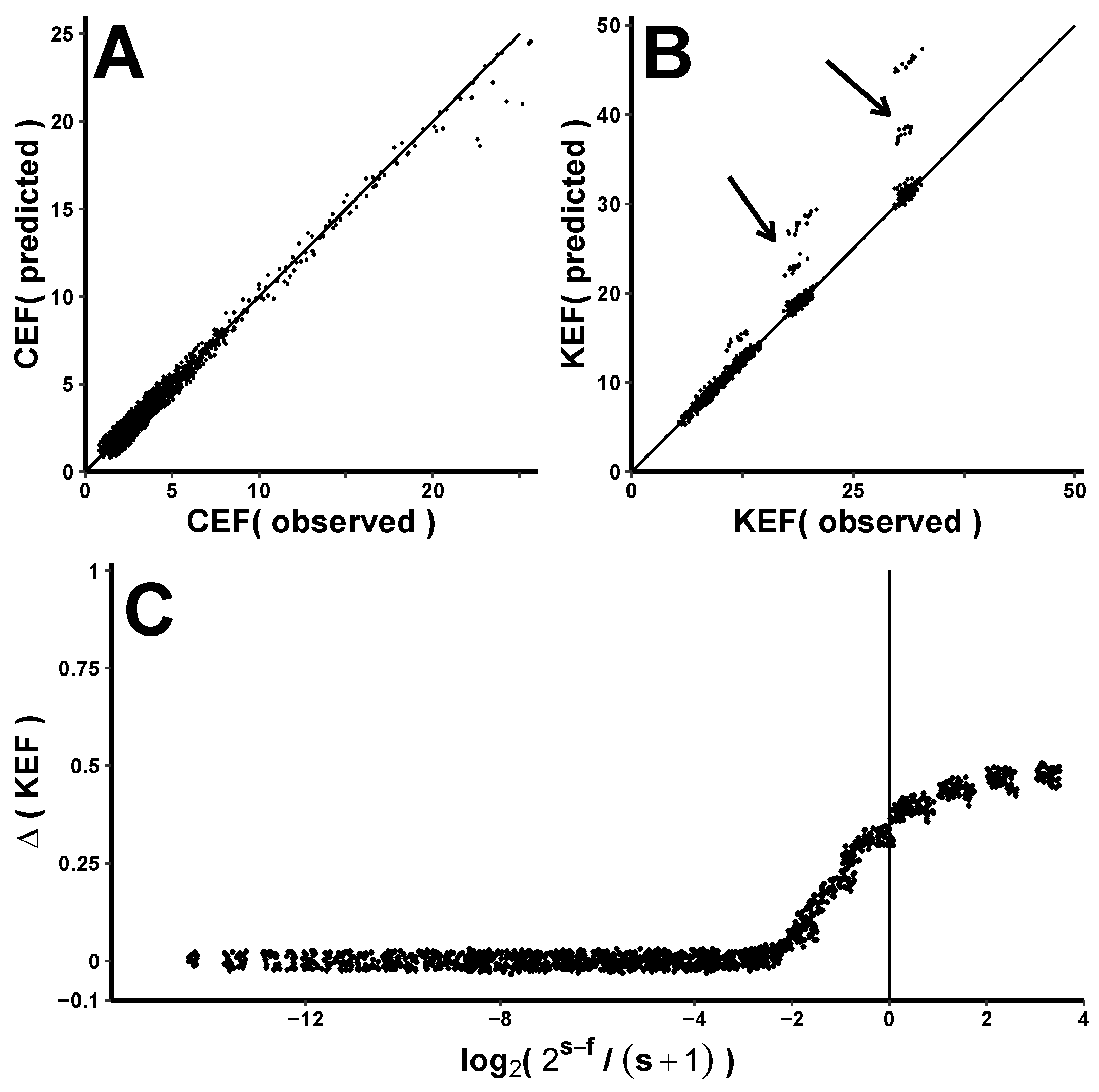{kind=link}
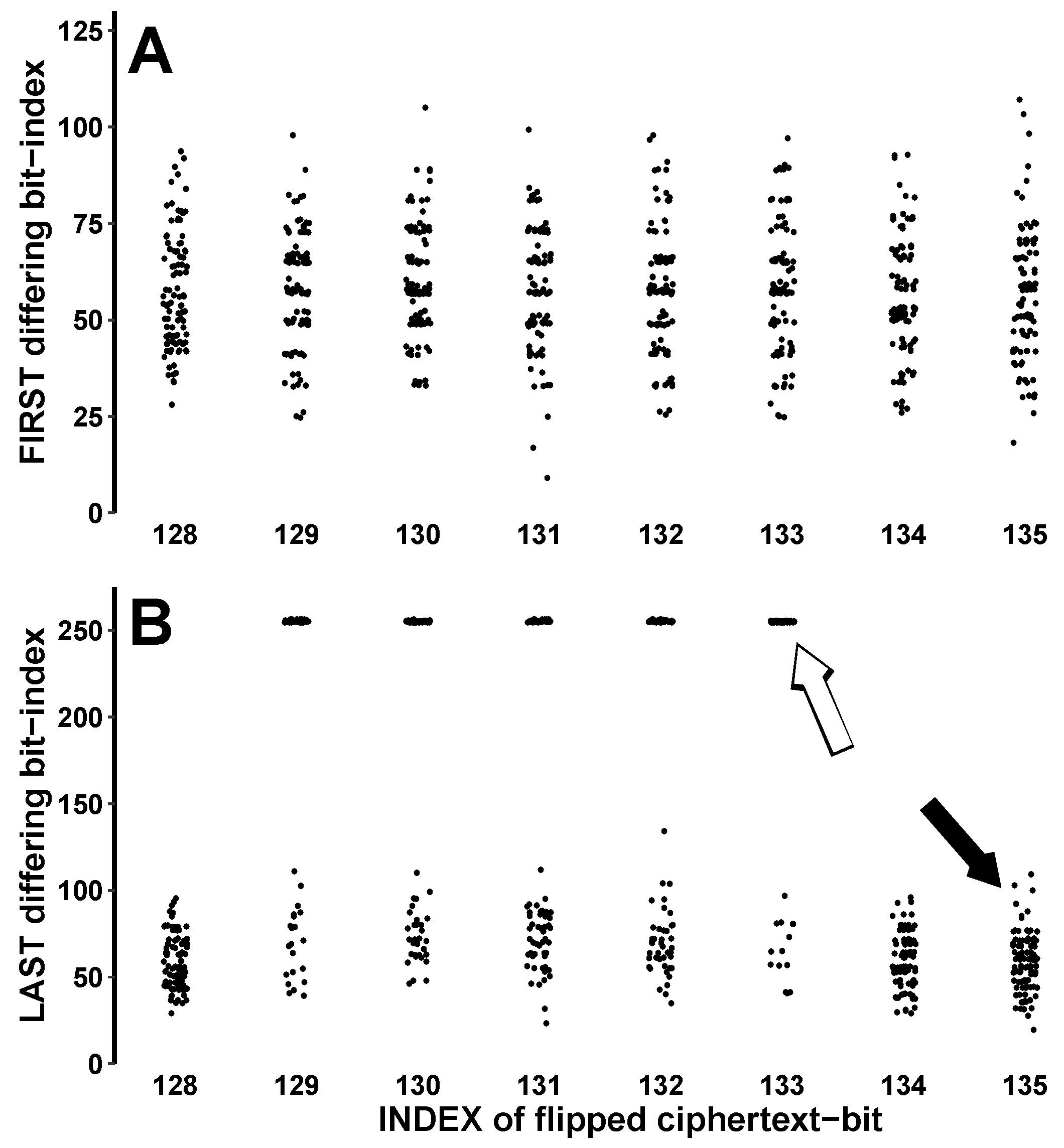{kind=link}
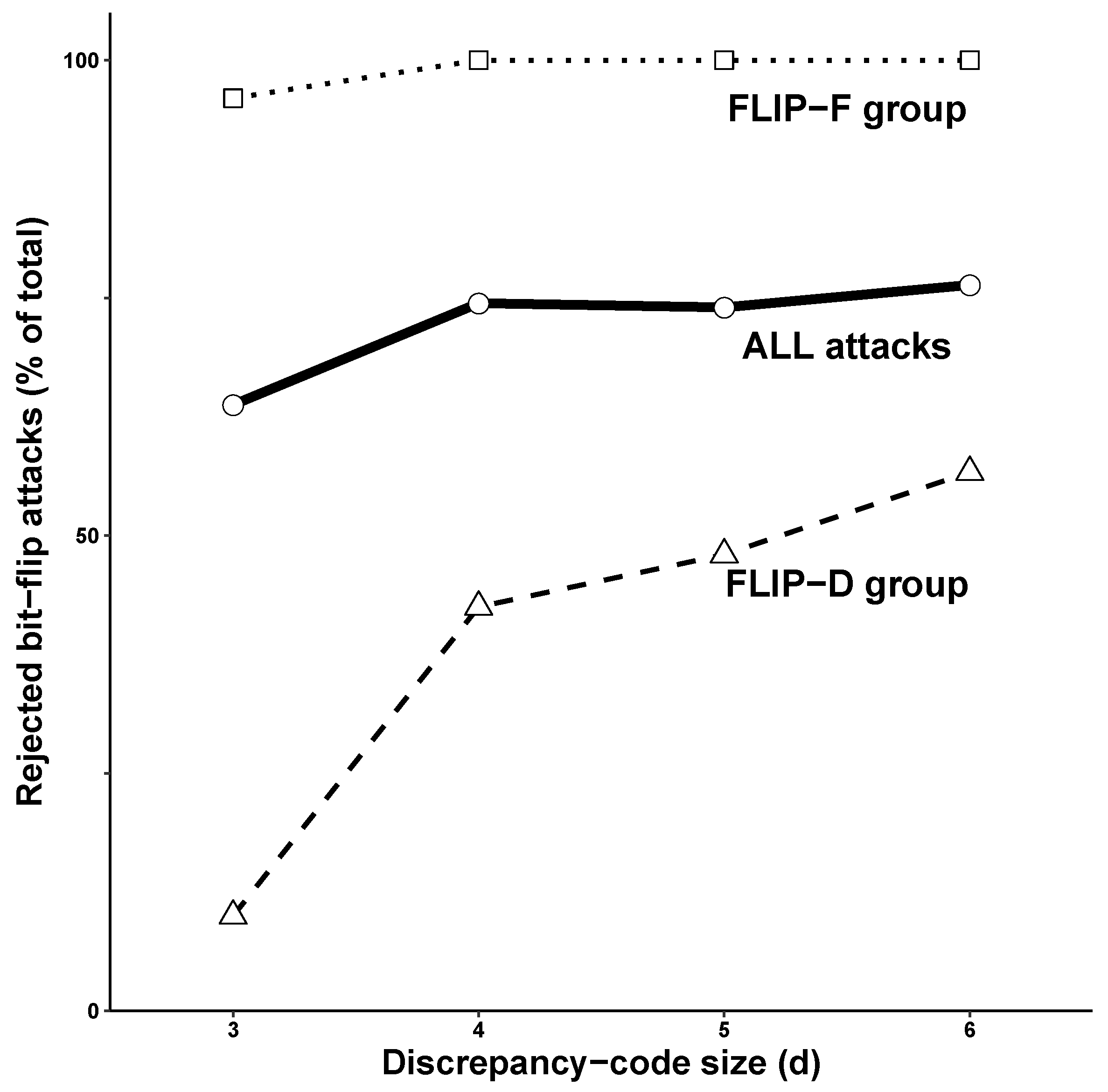{kind=link}
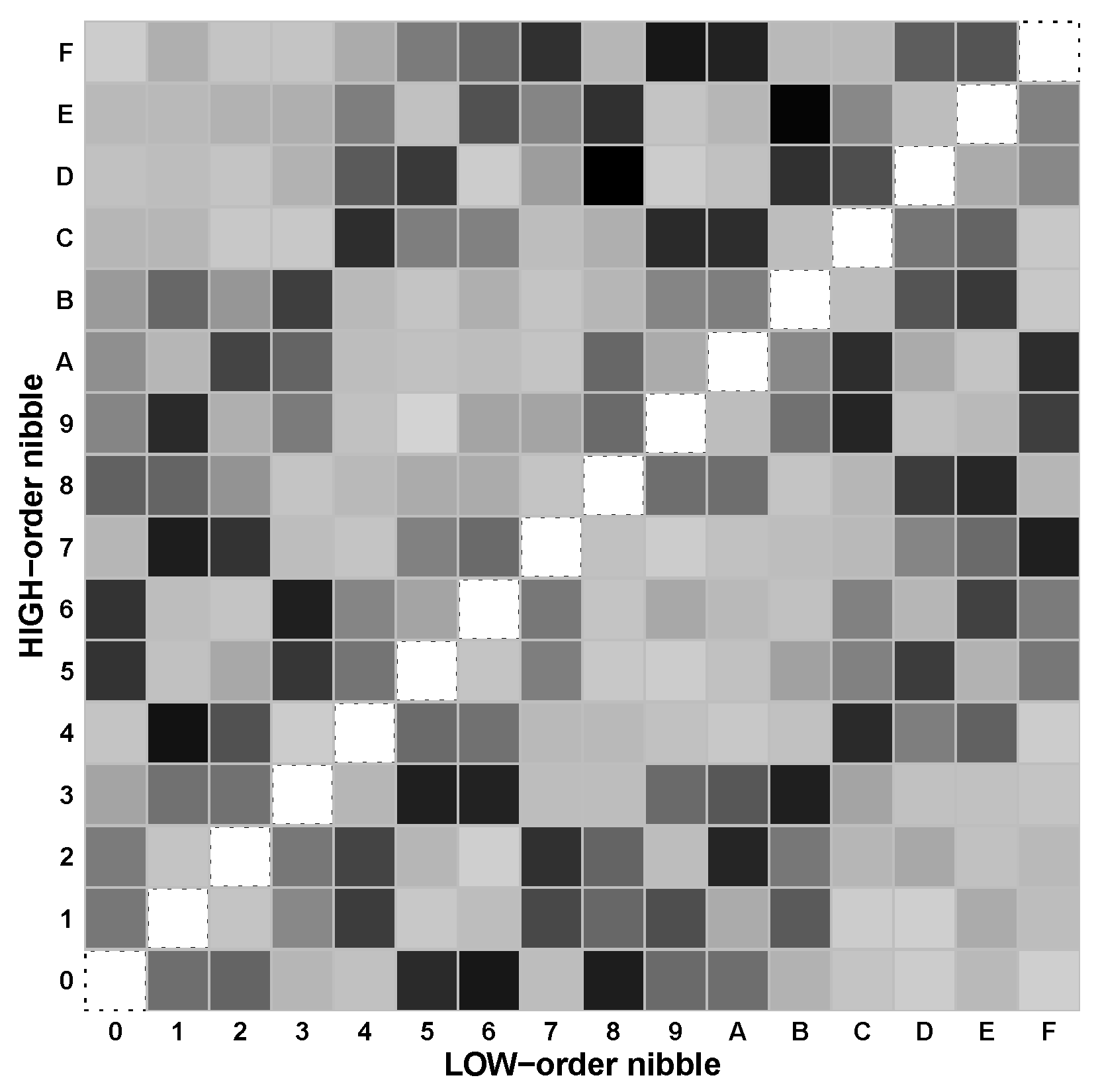{kind=link}
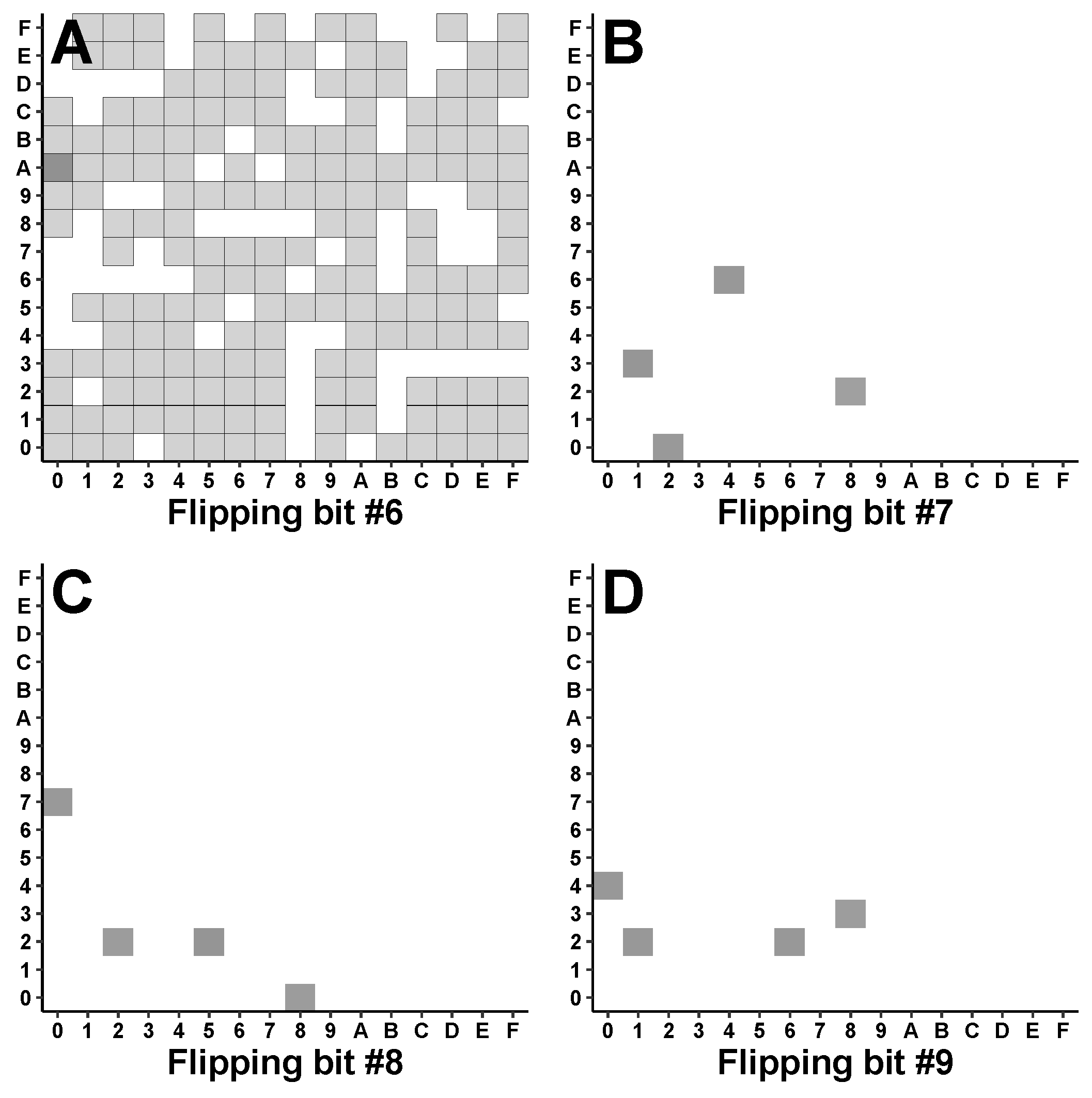{kind=link}
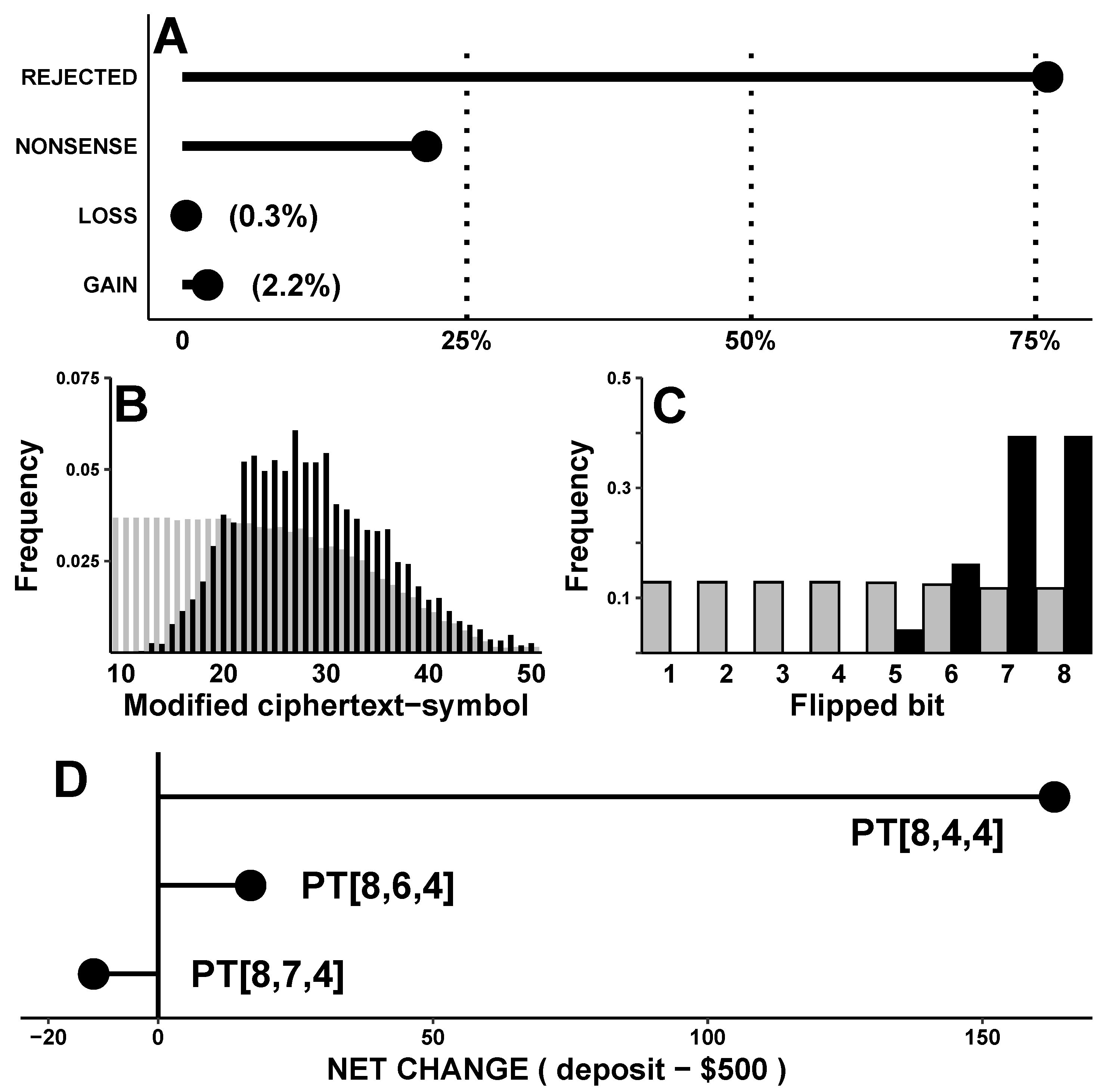{kind=link}
 ). Although these two histograms have different shapes, they overlap significantly. Thus, targeting symbols that occur early or late in the ciphertext is suboptimal: these symbols coincide with low-probability tails of the black (’meaningful’) histogram. Yet, targeting the remaining ciphertext symbols near the peak of the black curve is also not ideal: their positions fall along the plateau of the gray (’nonsense/rejected’) histogram. Therefore, such attacks are equally likely to fail as attacks against early ciphertext symbols.
). Although these two histograms have different shapes, they overlap significantly. Thus, targeting symbols that occur early or late in the ciphertext is suboptimal: these symbols coincide with low-probability tails of the black (’meaningful’) histogram. Yet, targeting the remaining ciphertext symbols near the peak of the black curve is also not ideal: their positions fall along the plateau of the gray (’nonsense/rejected’) histogram. Therefore, such attacks are equally likely to fail as attacks against early ciphertext symbols.