On the Design and Analysis of a Biometric Authentication System Using Keystroke Dynamics



Abstract
:1. Introduction
- (1)
- The development of a biometric-based multifactor user authentication scheme, which expolits keystrock dynamics;
- (2)
- The design and implementation of a hardware prototype of the proposed system;
- (3)
- The evaluation of the usability of the proposed system through a feasbility study, which is based on training data from 32 users.
2. Related Work
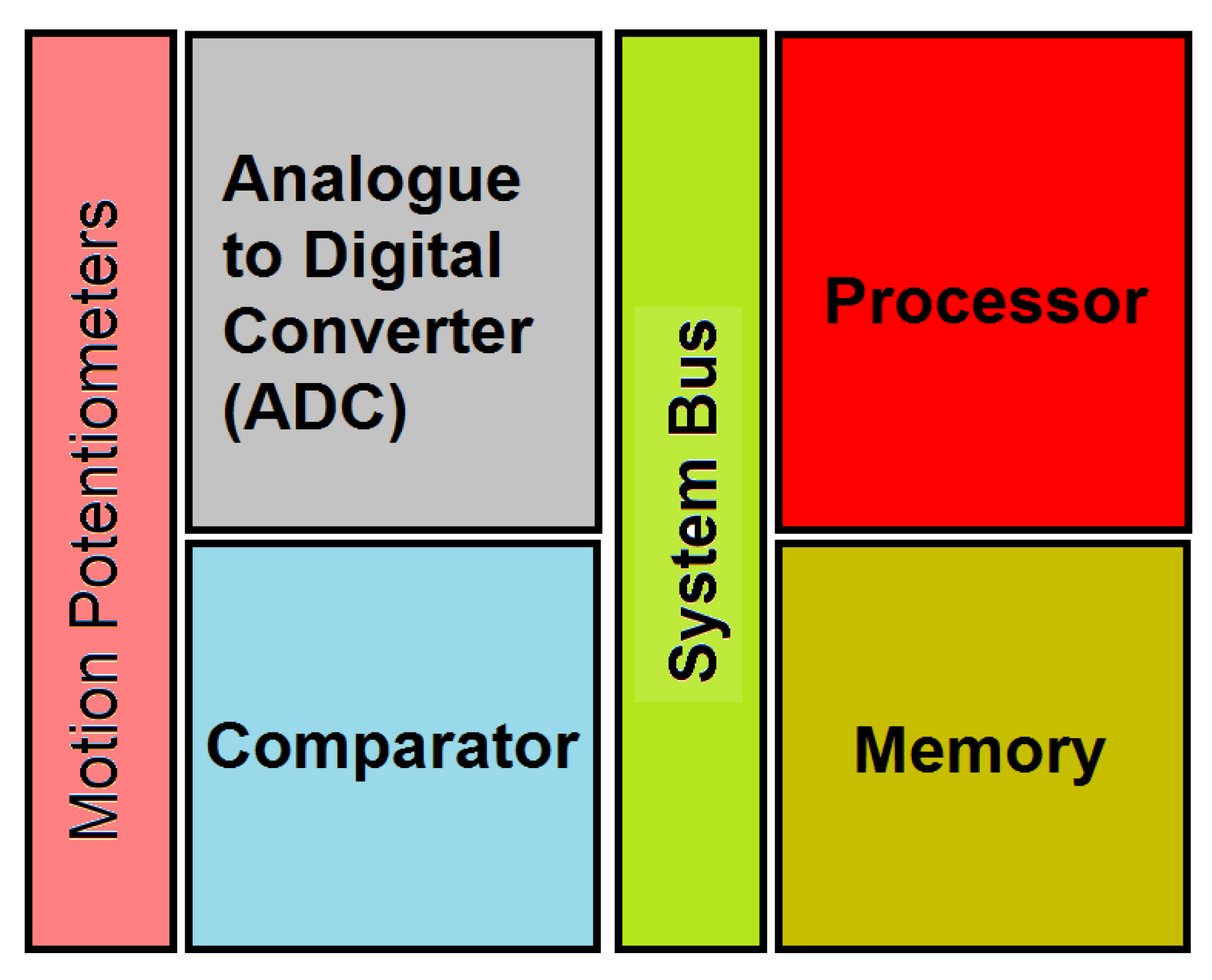
3. Proposed System Architecture
4. Implementation
4.1. Key Pad
4.2. The Analogue to Digital Converter
4.3. The Comparator Block
4.4. The Software Part
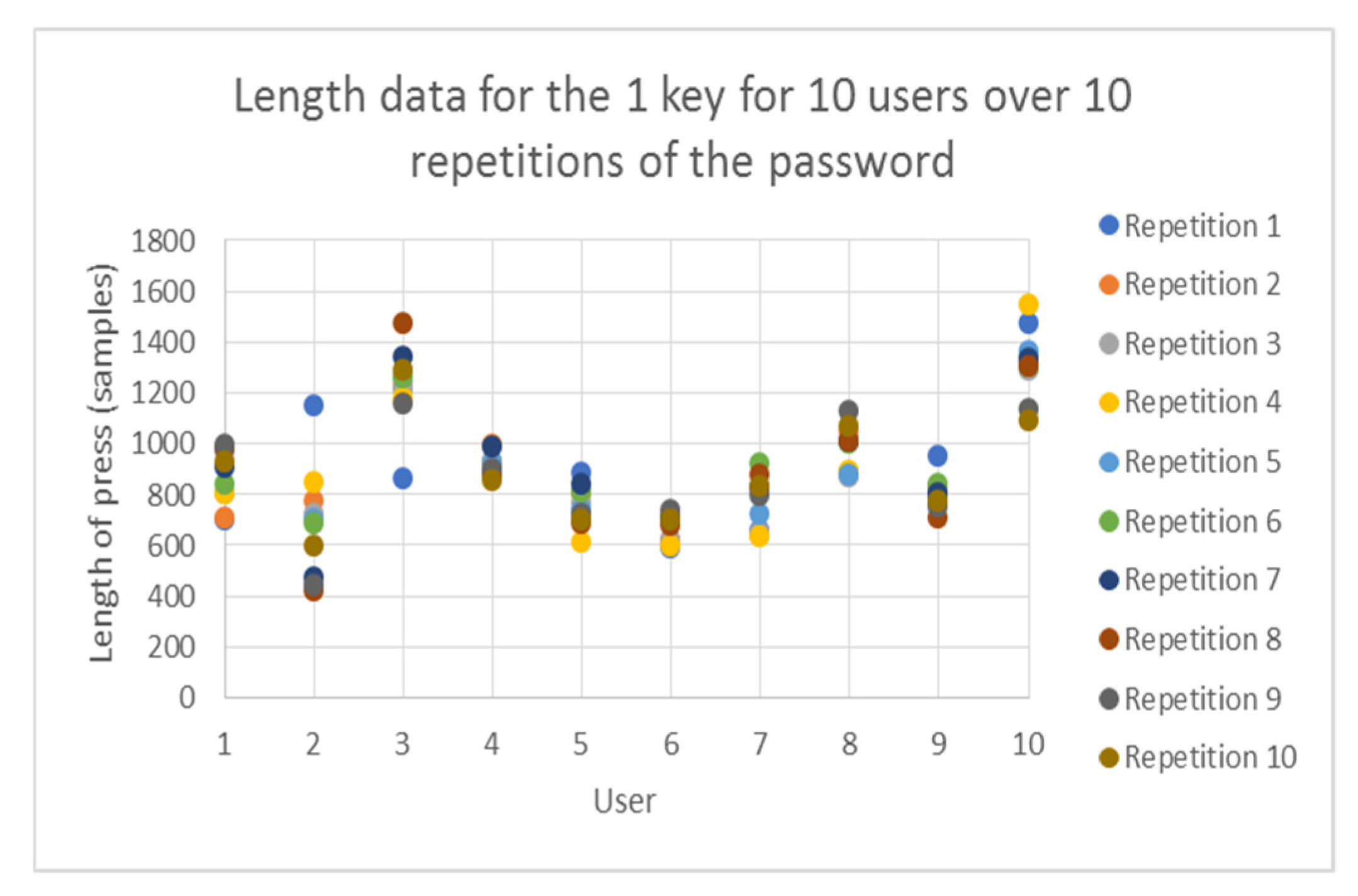
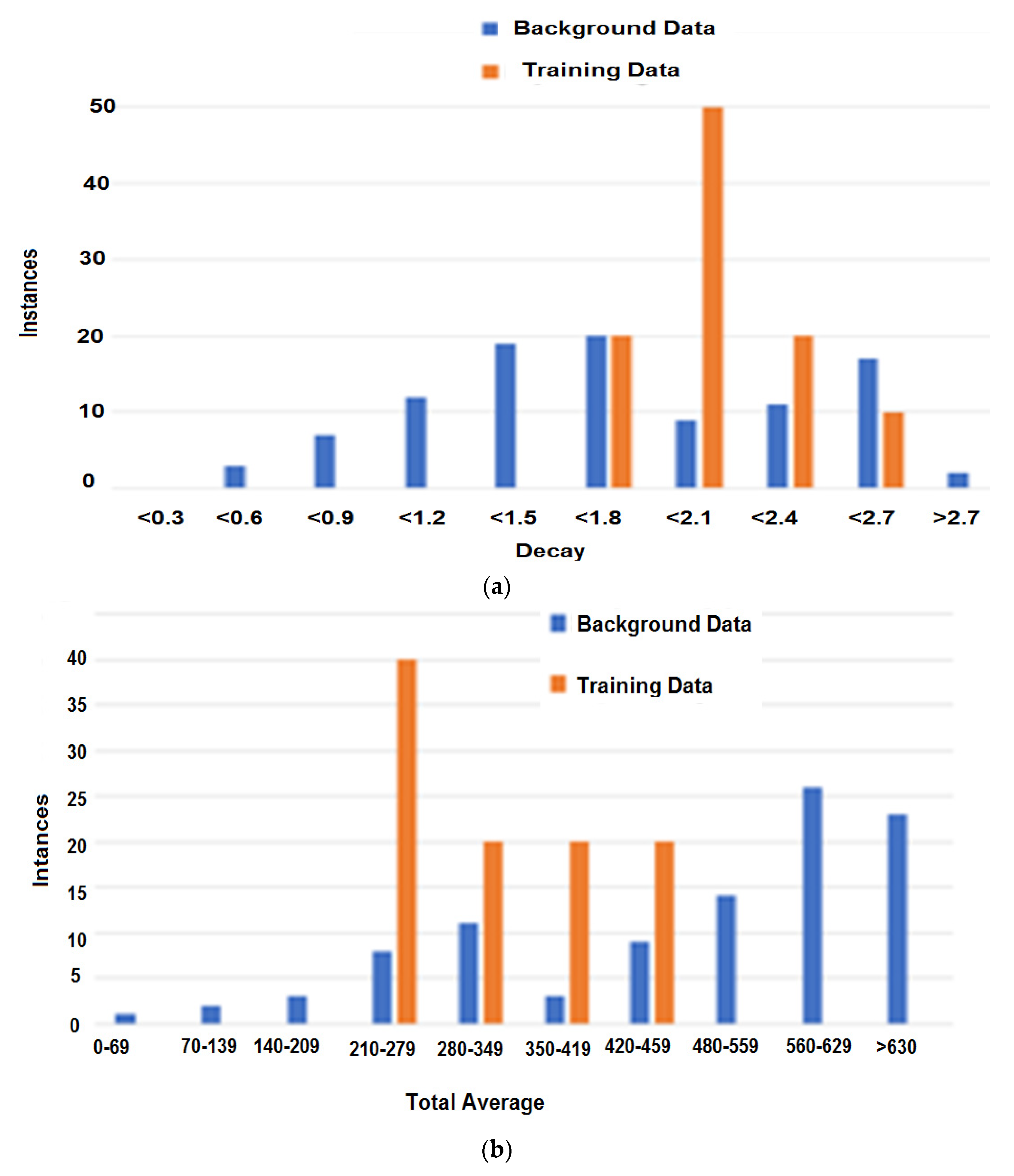
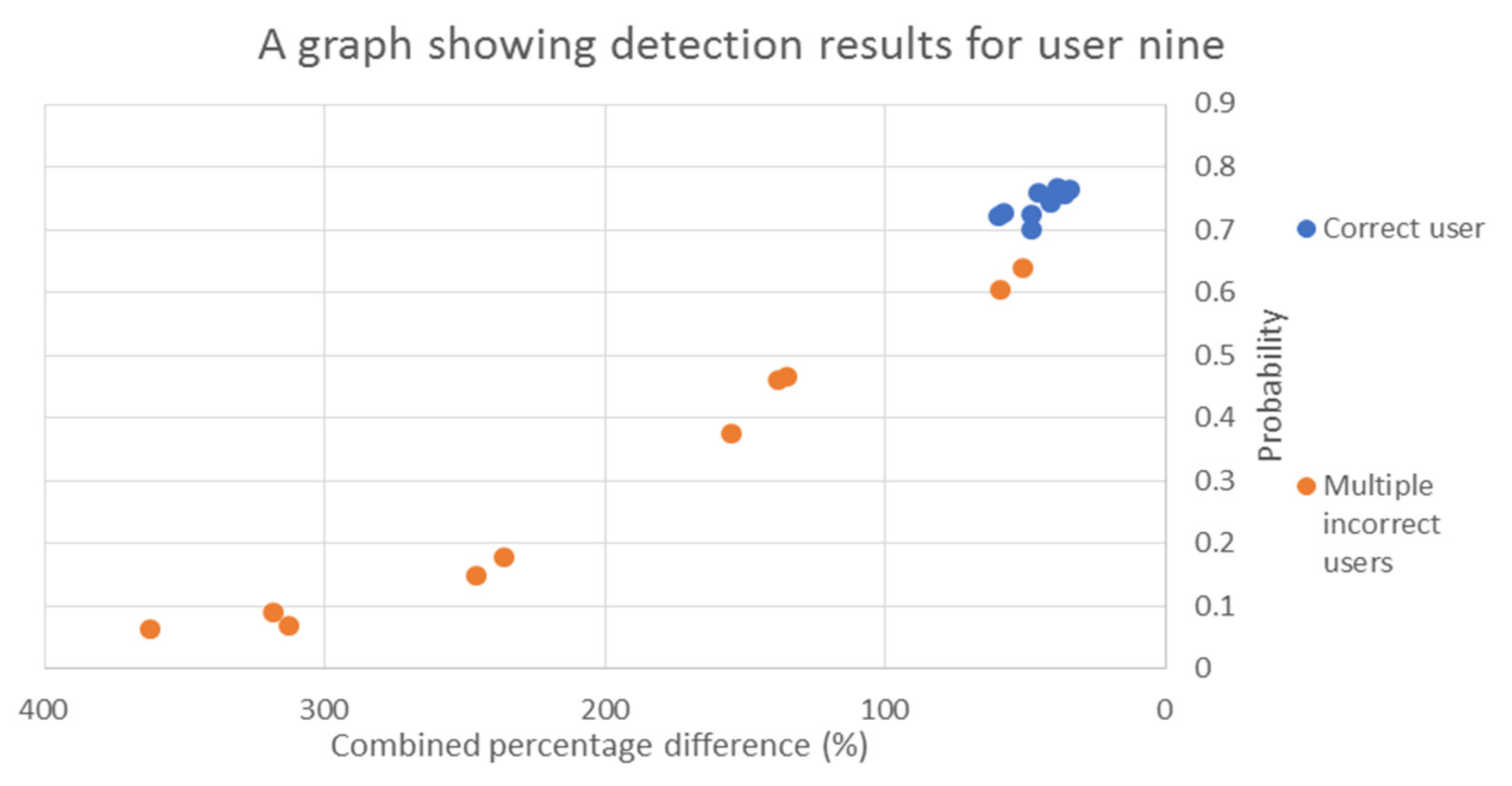
5. Evaluation
5.1. Survey
5.2. Results
5.3. Comparison with Existing Techniques
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Tian, Z.; Qiao, H.; Tian, J.; Zhu, H.; Li, X. An Automated Brute Force Method Based on Webpage Static Analysis. In Proceedings of the 2018 10th International Conference on Measuring Technology and Mechatronics Automation (ICMTMA), Changsha, China, 10–11 February 2018; pp. 100–103. [Google Scholar]
- Crocker, P.; Querido, P. Two Factor Encryption in Cloud Storage Providers Using Hardware Tokens. In Proceedings of the 2015 IEEE Globecom Workshops (GC Wkshps), San Diego, CA, USA, 6–10 December 2015; pp. 1–6. [Google Scholar]
- Nobayashi, D.; Nakamura, Y.; Ikenaga, T.; Hori, Y. Development of Single Sign-On System with Hardware Token and Key Management Server. In Proceedings of the 2007 Second International Conference on Systems and Networks Communications (ICSNC 2007), Cap Esterel, France, 25–31 August 2007; p. 73. [Google Scholar]
- Halak, B. Physically Unclonable Functions: From Basic Design Principles to Advanced Hardware Security Applications; Springer International Publishing: New York, NY, USA, 2018. [Google Scholar]
- Yilmaz, Y.; Gunn, S.R.; Halak, B. Lightweight PUF-Based Authentication Protocol for IoT Devices. In Proceedings of the 2018 IEEE 3rd International Verification and Security Workshop (IVSW), Costa Brava, Spain, 2–4 July 2018; pp. 38–43. [Google Scholar]
- Su, H.; Zwolinski, M.; Halak, B. A Machine Learning Attacks Resistant Two Stage Physical Unclonable Functions Design. In Proceedings of the 2018 IEEE 3rd International Verification and Security Workshop (IVSW), Costa Brava, Spain, 2–4 July 2018; pp. 52–55. [Google Scholar]
- Mispan, M.S.; Su, H.; Zwolinski, M.; Halak, B. Cost-efficient design for modeling attacks resistant PUFs. In Proceedings of the 2018 Design, Automation & Test in Europe Conference & Exhibition (DATE), Dresden, Germany, 19–23 March 2018; pp. 467–472. [Google Scholar]
- Halak, B. Security Attacks on Physically Unclonable Functions and Possible Countermeasures. In Physically Unclonable Functions: From Basic Design Principles to Advanced Hardware Security Applications; Springer International Publishing: Cham, Switzerland, 2018; pp. 131–182. [Google Scholar]
- Halak, B. Hardware-Based Security Applications of Physically Unclonable Functions. In Physically Unclonable Functions: From Basic Design Principles to Advanced Hardware Security Applications; Halak, B., Ed.; Springer International Publishing: Cham, Switzerland, 2018; pp. 183–227. [Google Scholar]
- Marasco, E.; Feldman, A.; Romine, K.R. Enhancing Optical Cross-Sensor Fingerprint Matching Using Local Textural Features. In Proceedings of the 2018 IEEE Winter Applications of Computer Vision Workshops (WACVW), Lake Tahoe, NV, USA, 15 March 2018; pp. 37–43. [Google Scholar]
- Haware, S.; Barhatte, A. Retina based biometric identification using SURF and ORB feature descriptors. In Proceedings of the 2017 International conference on Microelectronic Devices, Circuits and Systems (ICMDCS), Vellore, India, 10–12 August 2017; pp. 1–6. [Google Scholar]
- Epp, C.; Lippold, M.; Mandryk, R.L. Identifying emotional states using keystroke dynamics. In Proceedings of the Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, CHI 2011, Vancouver, BC, Canada, 7–12 May 2011; pp. 715–724. [Google Scholar]
- Crawford, H. Keystroke dynamics: Characteristics and opportunities. In Proceedings of the 2010 Eighth International Conference on Privacy, Security and Trust, Ottawa, ON, Canada, 17–19 August 2010; pp. 205–212. [Google Scholar]
- Maiorana, E.; Campisi, P.; González-Carballo, N.; Neri, A. Keystroke dynamics authentication for mobile phones. In Proceedings of the 2011 ACM Symposium on Applied Computing (SAC), TaiChung, Taiwan, 21–24 March 2011. [Google Scholar]
- Anusas-Amornkul, T.; Wangsuk, K. A comparison of keystroke dynamics techniques for user authentication. In Proceedings of the 2015 International Computer Science and Engineering Conference (ICSEC), Zhengzhou, China, 19 July 2015; pp. 1–5. [Google Scholar]
- Araujo, L.; Sucupira, L.; Lizarraga, M.; Ling, L.; Yabu-Uti, J. User authentication through typing biometrics features. IEEE Trans. Signal Process. 2005, 53, 851–855. [Google Scholar] [CrossRef]
- Darabseh, A.; Namin, A.S. On Accuracy of Classification-Based Keystroke Dynamics for Continuous User Authentication. In Proceedings of the 2015 International Conference on Cyberworlds (CW), Visby, Sweden, 7–9 October 2015; pp. 321–324. [Google Scholar]
- Ahmed, A.A.; Traore, I. Biometric Recognition Based on Free-Text Keystroke Dynamics. IEEE Trans. Cybern. 2013, 44, 458–472. [Google Scholar] [CrossRef] [PubMed]
- Roth, J.; Liu, X.; Ross, A.; Metaxas, D. Investigating the Discriminative Power of Keystroke Sound. IEEE Trans. Inf. Forensics Secur. 2015, 10, 333–345. [Google Scholar] [CrossRef]
- Zhou, Q.; Yang, Y.; Hong, F.; Feng, Y.; Guo, Z. User Identification and Authentication Using Keystroke Dynamics with Acoustic Signal. In Proceedings of the 2016 12th International Conference on Mobile Ad-Hoc and Sensor Networks (MSN), Hefei, China, 16–18 December 2016; pp. 445–449. [Google Scholar]
- Teh, P.S.; Yue, S.; Teoh, A.B.J. Improving keystroke dynamics authentication system via multiple feature fusion scheme. In Proceedings of the 2012 International Conference on Cyber Security, Cyber Warfare and Digital Forensic (CyberSec), Kuala Lumpur, Malaysia, 26–28 June 2012; pp. 277–282. [Google Scholar]
- Sulavko, A.; Eremenko, A.V.; Fedotov, A.A. Users’ identification through keystroke dynamics based on vibration parameters and keyboard pressure. In Proceedings of the 2017 Dynamics of Systems, Mechanisms and Machines (Dynamics), Omsk, Russia, 14–16 November 2017; pp. 1–7. [Google Scholar]
- Sulong, A.; Siddiqi, M.U. Intelligent keystroke pressure-based typing biometrics authentication system using radial basis function network. In Proceedings of the 2011 IEEE 7th International Colloquium on Signal Processing and Its Applications, Kuala Lumpur, Malaysia, 6–8 March 2009; pp. 151–155. [Google Scholar]
- Leberknight, C.S.; Widmeyer, G.R.; Recce, M.L. An Investigation into the Efficacy of Keystroke Analysis for Perimeter Defense and Facility Access. In Proceedings of the 2008 IEEE Conference on Technologies for Homeland Security, Waltham, MA, USA, 12–13 May 2008; pp. 345–350. [Google Scholar]
- Loh, S.X.C.; Ow-Yong, H.Y.; Lim, H.Y.; Lai, W.K.; Lim, L.L. Fuzzy inference for user identification of pressure-based keystroke biometrics. In Proceedings of the 2017 IEEE 15th Student Conference on Research and Development (SCOReD), Putrajaya, Malaysia, 13–14 December 2017; pp. 77–82. [Google Scholar]
- Grabham, N.; White, N. Use of a Novel Keypad Biometric for Enhanced User Identity Verification. In Proceedings of the 2008 IEEE Instrumentation and Measurement Technology Conference, Victoria, BC, Canada, 12–15 May 2008; pp. 12–16. [Google Scholar]
- Bleha, S.; Slivinsky, C.; Hussien, B. Computer-access security systems using keystroke dynamics. IEEE Trans. Pattern Anal. Mach. Intell. 1990, 12, 1217–1222. [Google Scholar] [CrossRef]
- Cho, S.; Han, C.; Han, D.H.; Kim, H.-I. Web-Based Keystroke Dynamics Identity Verification Using Neural Network. J. Organ. Comput. Electron. Commer. 2000, 10, 295–307. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| User No. | Probability | Percentage Difference | ||
|---|---|---|---|---|
| FAR | FRR | FAR | FRR | |
| 1 | 0.00% | 0.00% | 0.00% | 0.00% |
| 2 | 10.00% | 10.00% | 10.00% | 40.00% |
| 3 | 0.00% | 0.00% | 0.00% | 0.00% |
| 4 | 10.00% | 10.00% | 10.00% | 20.00% |
| 5 | 10.00% | 10.00% | 30.00% | 0.00% |
| 6 | 0.00% | 0.00% | 0.00% | 0.00% |
| 7 | 30.00% | 0.00% | 10.00% | 0.00% |
| 8 | 0.00% | 0.00% | 30.00% | 0.00% |
| 9 | 0.00% | 0.00% | 10.00% | 10.00% |
| 10 | 0.00% | 0.00% | 0.00% | 0.00% |
| Average | 6.00% | 3.00% | 10.00% | 7.00% |
| User Authentication Technique | Measured Data | Error Rates |
|---|---|---|
| Bleha et al. [27] | Keyboard timing data | False Acceptance Rate (FAR) 0.5%, False Rejection Rate (FRR) 3.1% |
| Anusas-amornkul and Wangsuk [15] | Keyboard timing data | Equal Error Rate (EER) 4–12% |
| Araujo et al. [16] | Keyboard timing data | FAR 1.89%, FRR 1.45% |
| Darabseh and Namin [17] | Continuous authentication | Around 20% error rate |
| Ahmed and Traore [18] | Continuous authentication | Around 2% error rate |
| Roth et al. [19] | Keystroke sounds | Around 11% error rate |
| Zhou et al. [20] | Keystroke sounds | FAR 11%, FRR 12% |
| Sulong et al. [23] | Keyboard pressure/displacement | FAR 1.67%, FRR 0% |
| Sulavko et al. [22] | Keyboard pressure/displacement | 0.6% error rate |
| Loh et al. [25] | Number pad pressure/displacement | 60% error rate |
| Grabham and White [26] | Number pad pressure/displacement | EER 10% |
| This study | Number pad pressure/displacement | 4.5% average error rate |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cockell, R.; Halak, B. On the Design and Analysis of a Biometric Authentication System Using Keystroke Dynamics. Cryptography 2020, 4, 12. https://doi.org/10.3390/cryptography4020012
Cockell R, Halak B. On the Design and Analysis of a Biometric Authentication System Using Keystroke Dynamics. Cryptography. 2020; 4(2):12. https://doi.org/10.3390/cryptography4020012
Chicago/Turabian StyleCockell, Robert, and Basel Halak. 2020. "On the Design and Analysis of a Biometric Authentication System Using Keystroke Dynamics" Cryptography 4, no. 2: 12. https://doi.org/10.3390/cryptography4020012
APA StyleCockell, R., & Halak, B. (2020). On the Design and Analysis of a Biometric Authentication System Using Keystroke Dynamics. Cryptography, 4(2), 12. https://doi.org/10.3390/cryptography4020012