Abstract
The need for non-interactive human recognition systems to ensure safe isolation between users and biometric equipment has been exposed by the COVID-19 pandemic. This study introduces a novel Multi-Scaled Deep Convolutional Structure for Punctilious Human Gait Authentication (MSDCS-PHGA). The proposed MSDCS-PHGA involves segmenting, preprocessing, and resizing silhouette images into three scales. Gait features are extracted from these multi-scale images using custom convolutional layers and fused to form an integrated feature set. This multi-scaled deep convolutional approach demonstrates its efficacy in gait recognition by significantly enhancing accuracy. The proposed convolutional neural network (CNN) architecture is assessed using three benchmark datasets: CASIA, OU-ISIR, and OU-MVLP. Moreover, the proposed model is evaluated against other pre-trained models using key performance metrics such as precision, accuracy, sensitivity, specificity, and training time. The results indicate that the proposed deep CNN model outperforms existing models focused on human gait. Notably, it achieves an accuracy of approximately 99.9% for both the CASIA and OU-ISIR datasets and 99.8% for the OU-MVLP dataset while maintaining a minimal training time of around 3 min.
1. Introduction
Over recent decades, research in biometric identification has progressively advanced, focusing on non-contact methods [1]. Biometrics, which identify individuals based on biological and behavioral traits [2], encompass various forms, including fingerprint [3], DNA [4], facial recognition [5], iris scanning [6], and gait recognition [7]. Gait recognition has been a prominent method in the growing demand for intelligent and secure monitoring, demonstrated most notably during the COVID-19 epidemic [8]. Gait recognition is distinguished among biometric systems due to its inherent non-contact nature. This characteristic allows the identification process to be conducted from a distance without requiring the subject’s direct interaction with the biometric capturing device. The non-invasive and hygienic nature of gait recognition is particularly advantageous, as highlighted during scenarios such as the COVID-19 pandemic. This capability to operate effectively without physical contact places gait recognition in a unique position compared to other biometric methods that necessitate proximity or direct interaction [9]. It is also resilient to attempts at disguise or concealment. It functions well with low-resolution images, making it versatile for various security contexts, such as shopping centers, healthcare facilities, financial institutions, airports, and military installations.
The gait identification models are essential in biometric identification via analyzing walking patterns. There are two main types: Model-Based, focusing on body part analysis such as joints, and Model-Free, which uses binary isolated images or gait energy images (GEIs). These models contribute uniquely to recognizing and understanding individual gait patterns, each with distinct methodologies and applications.
The Model-Based gait recognition approach involves analyzing body parts, such as a participant’s joints, to develop a gait recognition algorithm. High-quality input frames are crucial for their effectiveness, typically necessitating a multi-camera setup for capturing detailed gait sequences [10]. Model-Based algorithms are versatile, handling variations like changes in clothing or the presence of carried objects. However, challenges in task recognition and the high cost of participant modeling limit its practical popularity [11].
Model-Free gait recognition is an appearance-based method that utilizes binary isolated images for gait recognition. It is notably applied in two ways: (i) using human gait silhouette images for datasets like CASIA and OU-ISIR and (ii) employing gait energy images (GEIs) for the OU-MVLP dataset [11]. The GEI approach is preferred for its low computational cost and high recognition rate, achieved by aligning and averaging silhouettes and comparing successive GEIs. Alternatively, the silhouette-based method inputs silhouette images directly into deep convolutional neural networks (CNNs) for feature extraction. Compared to GEI, this method further improves recognition by leveraging the advanced capabilities of CNNs [12].
When it comes to the difficulties of gait identification, deep convolutional neural network (CNN) methods have proven to be beneficial. Additionally, deep learning-based gait authentication has applications in human psychology, such as analyzing emotional patterns through point-light displays [13].
This study introduces a new approach to human gait authentication: the Multi-Scaled Deep Convolutional Structure for Punctilious Gait Analysis (MSDCS-PHGA). This study’s primary contributions include the following:
- Introducing a novel technique for extracting and resizing gait images into three scales;
- Developing a deep CNN algorithm specifically tailored for efficient gait feature extraction;
- An innovative approach for the fusion of features extracted at multiple scales enhances the robustness of gait recognition;
- Implementing a fine-tuned multilayer perceptron (MLP) for feature recognition;
- Developing an optimized convolutional neural network (CNN) model;
- Conducting a comprehensive comparative analysis with leading traditional CNN algorithms demonstrates that the suggested model is more accurate and efficient than state-of-the-art gait recognition technology.
2. Related Works
This section presents an overview of current developments in gait recognition, exploring approaches ranging from traditional models to advanced CNN techniques. It highlights the progression of gait recognition technology, detailing methods that enhance accuracy and expand applications.
Altilio et al. [14] presented a reliable monitoring scheme to automatically record and classify patient movements based on machine learning classification methods. The largest accuracy value scored 91% in affordable and residence-based rehabilitation methods from Probabilistic Neural Networks (PNNs). Using the suggested deep convolutional neural network (DCNN), Saleh et al. [15] presented a person recognition algorithm. Once Image Augmentation (IA) had been applied to the identical data, its performance indicators were compared. The trial outcomes scored 96% with IA compared to 82% without IA. Liao et al. [11] introduced a gait authentication model named PoseGait, which utilizes spatiotemporal information extracted from poses to improve gait identification rates. This study demonstrated that the suggested system has a more reliable performance.
Moreover, Liao et al. [16] have developed a new Dense-vision GAN (DV-GAN) model that addresses the problem of large-angle intervals in vision synthesis by utilizing view space covering. The modeling procedure of DV-GAN enhanced the discriminative performance of synthesized gait images. Subsequently, the characteristics of the model will enhance the gait recognition model.
Elharrouss et al. [17] introduced a gait identification model that utilizes a deep CNN to estimate and recognize the angle of the gait. The proposed model scored more than 98% recognition accuracy for three gait datasets. Zou et al. [18] developed a gait authentication technique based on a hybrid deep neural network combining a recurrent neural network (RNN) and a CNN. This model has trained two datasets collected by smartphones from 118 subjects in the wild. The experimental results achieved more than 93% in-person identification accuracy. Wu et al. [19] presented the gait recognition system by extracting discriminative features from video sequences’ temporal and spatial domains. The proposed method has identified the correlation between video frames and the temporal variation in a specific region. The findings have demonstrated a significant enhancement in gait identification. Guo et al. [20] employed the Gabor Filter technique to extract gait features from gait energy images. Subsequently, they utilized Linear Discriminant Analysis (LDA) to address the issue of feature size. The gait features were ultimately categorized using the Particle Swarm Optimization Algorithm (PSA). The results indicate that the suggested recognition algorithm achieves flawless performance metrics in cross-view gait recognition.
Aybuke et al. [21] tested ten standard machine learning algorithms on the data gait called (HugaDB) of 18 individuals. The empirical findings demonstrated superior performance in the IB1, Bayesian Net, and Random Forest (RF) algorithms. Zhang et al. [22] have presented a novel recognition algorithm called Joint Unique-gait and Cross-gait Network (JUCNet) to improve the gait recognition performance. Extensive tests revealed that the proposed method outperformed all other studies. M. Sivarathinabala and S. Abirami [23] extracted static and dynamic features from CMU motion capture and the TUMIIT KGP gait database and then applied feature fusion between both. Finally, the experimented result scored 97% efficiency when the fused features were recognized based on the support vector machine model.
Saleem et al. [24] employed deep learning techniques to identify the CASIA-B gait database. A comprehensive framework was implemented to incorporate feature extraction, selection, and classification of the fused features utilizing various methodologies. The gait features have been derived from the enhanced data using pre-trained models, specifically Inception-ResNet-V2 and NASNet Mobile. By employing the modified mean absolute deviation extended serial fusion (MDeSF) method, the amalgamation of the most optimal characteristics yielded an experimental outcome with an accuracy of 89%. Shiqi et al. [25] proposed a model called GaitGANv2 using generative adversarial networks (GANs). The presented algorithm varies from classic GAN in that GaitGANv2 has two discriminators rather than one. GaitGANv2 has attained state-of-the-art performance, according to experimental results.
E. Anbalagan et al. [26] proposed a gait recognition model by extracting features from a gray-level co-occurrence matrix (GLCM) from the preprocessed images. Then, the Long Short-Term Memory (LSTM), multilayer perceptron (MLP), and deep neural networks (DNNs) were classified as images from the extracted features. Finally, the experimental results scored a 96% accuracy with a 0.04% error value.
In recent advancements in gait recognition, self-supervised learning techniques have emerged as powerful tools for extracting meaningful representations from unlabeled data. Specifically, self-supervised contrastive learning has been effectively utilized to learn invariant gait representations, which are crucial for predicting the freezing of gait events in patients with Parkinson’s disease [27]. This approach leverages time series acceleration data to generate robust, class-specific gait representations without the reliance on labeled datasets. By employing contrastive learning, the model captures essential gait features and patterns, enhancing the prediction accuracy and generalizability across various gait analysis tasks.
Contrastive learning’s effectiveness extends beyond traditional gait recognition, contributing significantly to biosignal analysis and computer vision. The self-supervised nature of this learning paradigm allows for more efficient model training and adaptation in scenarios where labeled data are scarce or unavailable, thereby improving the robustness of gait recognition systems.
This contrasts with supervised learning approaches where models are trained with labeled data, such as using artificial neural networks (ANNs) to enhance the accuracy of estimations made by robot-mounted 3D cameras in human gait analysis [28]. While supervised methods rely on high-quality, labeled datasets to achieve high accuracy, self-supervised methods like contrastive learning offer a viable alternative for improving system performance in less constrained environments.
Wang et al. [29] presented a gait identification model by a convolutional LSTM approach called Conv-LSTM. They took a few steps to execute the gait recognition procedure. Firstly, they extracted silhouette images from video frames to create gait energy images (GEIs) from them and then enlarged their volume to relieve the gait cycle’s limitation. Later on, they experimented with examining one subject’s cross-covariance. Finally, they accomplish gait recognition by creating a Conv-LSTM model. The experimental results scored 93% and 95% accuracy on CASIA-B and OU-ISIR, respectively. Zhao et al. [30] addressed the issue of multiview gait identification, specifically the lack of consistency across different viewing angles, by introducing a spiderweb graph neural network (SpiderNet). This network connects a single view and other view angles concurrently. Their suggested methodology was implemented on three datasets called CASIA-B, OU-MVLP, and SDUgait and scored an accuracy of 98%, 96%, and 98%, respectively.
Each of these studies contributes to the evolving landscape of gait recognition technology. Table 1 illustrates a comparative study of the various state-of-the-art techniques for gait recognition. In the field of gait recognition, despite advancements using deep learning techniques, several research gaps remain that need addressing to enhance the robustness and applicability of these systems in real-world conditions:

Table 1.
Comparison between the various state-of-the-art techniques for gait recognition.
- Real-World Data Application: There is a lack of models rigorously tested on diverse, real-world datasets. Improvements are needed for systems to perform well in various environmental and situational contexts;
- Viewing Angle Variability: Many models struggle with large variations in viewing angles. Enhanced view synthesis methods could help improve recognition accuracy in practical settings;
- Dataset Quality: Enhancements in data segmentation and dataset quality are necessary to improve model training outcomes and recognition accuracy;
- System Complexity and Accuracy: Some innovative models exhibit low accuracy due to their complexity. Simplifying these models while maintaining or improving accuracy is crucial;
- Cross-View Recognition: Improved techniques for cross-view gait recognition are needed to ensure consistent performance across different viewing angles.
Addressing these gaps involves developing more adaptable models and constructing datasets that better mirror the complexity of everyday scenarios.
3. Convolutional Neural Network Models (CNNs)
Convolutional neural networks (CNNs) are a class of multilayer artificial neural networks or deep learning (DL) architecture that draws inspiration from the visual systems of real creatures [35]. Recently, CNNs have gained popularity in image processing as they improve performance without extracting features from segmented pictures [36]. These networks are utilized in various fields, such as visual tasks, natural language processing, image identification, and classification [37]. A typical convolutional neural network (CNN) comprises layers that perform linear and nonlinear operations, which are acquired jointly [38]. The essential components of a convolutional neural network (CNN) consist of convolution layers, which extract features; pooling layers, which perform down-sampling operations on the feature maps; and fully linked layers at the end to flatten these maps [39]. Other CNN designs are available, including LeNet, AlexNet, VGG, Inception, ResNet, and Xception [35]. Although each model has a distinct structure, they share foundational elements.
4. Methodology
This section introduces the proposed CNN models for gait recognition, beginning with the proposed CNN model, which intends to improve gait recognition. The model also seeks to expand the scope of gait applications, such as tracking the spread of COVID-19 [15], rather than other widely used biometrics, like fingerprints, faces, iris, and DNA. The section also covers the CASIA gait [40], OU-ISIR [41], and OU-MVLP [33,42] datasets used for pre-training these models. Moreover, it outlines the preprocessing techniques to enhance image quality and prepare the data for effective analysis.
The conceptual design of the proposed Multi-Scaled Deep Convolutional Structure for Punctilious Human Gait Authentication (MSDCS-PHGA) is foundational to understanding the innovative approach this study introduces to gait recognition. The MSDCS-PHGA architecture is engineered to efficiently process and analyze human gait data captured in silhouette form. The gait authentication approach, detailed in Figure 1, employs CNNs to process silhouette images at three scale resolutions: 50 × 50, 100 × 100, and 150 × 150 pixels. Each set of images undergoes processing by a dedicated CNN, with the resulting features fused for classification by a fully connected network comprising an input layer, a dense hidden layer, and an output layer with four neurons.
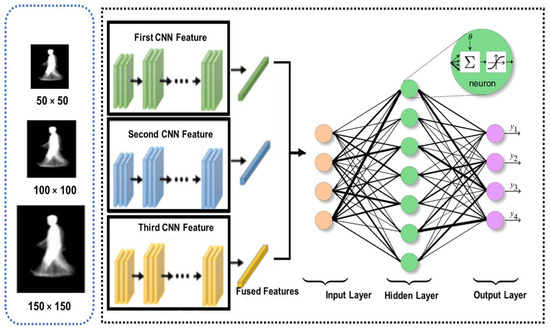
Figure 1.
Gait recognition approach components.
Figure 1 illustrates the detailed workflow of MSDCS-PHGA, showing the process from image capture to final gait authentication. Each component of the conceptual design is mapped to its operational counterpart in the system architecture, providing a clear visualization of the method’s functionality. It consists of three core components: multi-scale image processing, feature extraction through convolutional layers, and feature fusion for final gait classification as follows:
- Multi-Scale Image Processing: To accommodate variations in distance and perspective that naturally occur in gait data, silhouette images are segmented, preprocessed, and resized into three distinct scales: 50 × 50, 100 × 100, and 150 × 150 pixels. This scaling ensures that the network learns to recognize features across different resolutions, enhancing its ability to generalize across diverse real-world conditions;
- Feature Extraction: Each scaled image is processed by a custom-designed convolutional neural network (CNN). These networks are tailored to extract spatial hierarchies of features from simple edges to more complex gait patterns. The architecture of each CNN layer is specifically optimized to maximize the extraction of discriminative features from the gait data, which is crucial for the subsequent classification accuracy;
- Feature Fusion: After feature extraction, a fusion mechanism is employed to integrate the features from all scales into a coherent feature set. This integrated set harnesses the complementary information available across different scales, significantly boosting the robustness and accuracy of the gait recognition process.
The MSDCS-PHGA is grounded in the theory that a deeper analysis of spatial features at multiple scales can substantially improve gait recognition accuracy. By harnessing multi-scale data, the model effectively captures a more comprehensive range of biomechanical and behavioral gait dynamics, often lost in single-scale approaches. The proposed design integrates seamlessly with existing biometric systems, enhancing reliability without requiring extensive modifications. It is compatible with standard image capture devices and can be easily implemented alongside existing security protocols, significantly improving non-intrusive biometric authentication.
4.1. The Proposed Procedures for Gait Recognition
In this study, all algorithms for gait recognition follow a comprehensive five-step procedure. Each stage of this procedure is crucial, contributing significantly to the overall effectiveness of the process. Step 1 involves preprocessing and segmenting all gait datasets, where silhouettes and gait energy images (GEIs) are extracted as the primary data forms, per the guidelines in reference [43]. This step ensures that the data are refined and suitable for detailed analysis. The second step is dedicated to extracting distinct gait features from these prepared multi-scale gait images, capturing the unique aspects of individual gaits.
In Step 3, the focus is on concatenating and fusing the extracted features from the multi-scale images, creating a comprehensive and robust feature set to address variations in gait patterns effectively. Step 4 involves training and testing deep learning modules, encompassing a range of traditional and traditional algorithms proposed in this research. This phase aligns them with the latest advances in gait recognition technology.
The final step, Step 5, is the computation and analysis of key performance metrics such as precision, F-score, recall, False Negative Rate, and training time, providing a quantitative assessment of the algorithms’ effectiveness. The procedural intricacies of these steps are systematically outlined in Algorithm 1. To complement the textual explanation, Figure 2 visually illustrates the main steps of the proposed model’s flowchart [44]. Figure 3 provides an illustrative example of a gait energy image (GEI) for an individual, showcasing the data analyzed.
| Algorithm 1: Gait Authentication Model | ||
| Input: Isolated Gait Dataset (I). | ||
| Output: Identified gait Images. | ||
| //Read the Isolated Gait dataset (ROI) | ||
| 1. | I ← read(ROI) | |
| // Normalize all isolated images (I) | ||
| 2. | N ← normalize(I) | |
| //Split images (I) for training, testing, and validation by (Train_test_split) | ||
| 3. | train_X, test_X, valid_X, train_y, test_y, valid_y ← split(N) | |
| //Training and testing Algorithms | ||
| 4. | M ← [ABDGNet, LeNet, AlexNet, VGG, Inception, ResNet50, Xception] | |
| //Extract Features from three models. | ||
| 5. | Foreach model m in M | |
| 6. | F ← extract(m, train_X, test_X, valid_X) // Extract Features | |
| 7. | Ffused ← concatenate(F) | |
| 8. | mFused ← train(Ffused, train_y) //Apply Concatenation Feature Fusion | |
| 9. | Summary ← mFused //Train the Fused Model Layers | |
| 10. | mCompiled ← compile(mFused) //Summary of the Fused Model | |
| 11. | epochs ← 30 | |
| 12. | batch_size ← 32 | |
| 13. | ver ← 2 | |
| 14. | mFit ← fit(mCompiled, train_X, train_y, epochs, batch_size, ver) | |
| 15. | plot(mFit) | |
| 16. | ConfMatrix ← calculate(mFit, test_X, test_y) | |
| 17. | plot(ConfMatrix) | |
| 18. | Store ← (mFused) //Store the Model | |
| 19. | End For | |
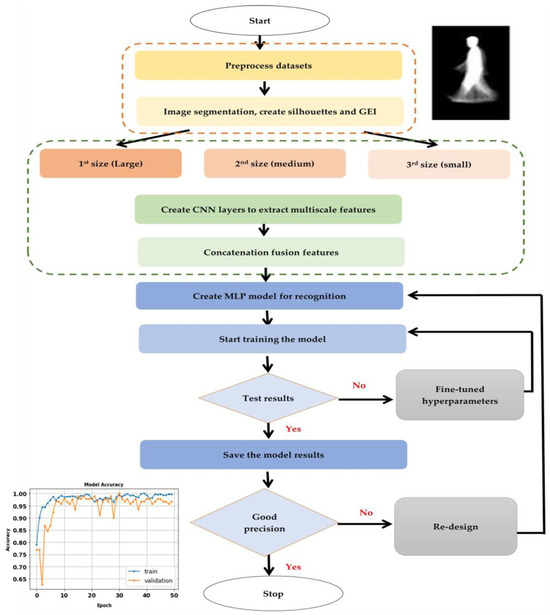
Figure 2.
The proposed model flowchart.
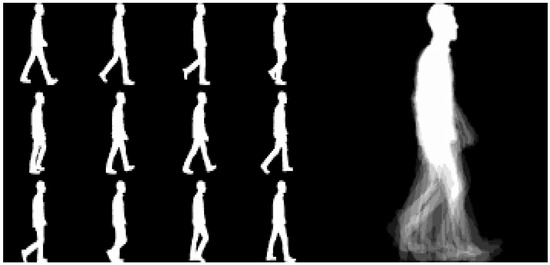
Figure 3.
Gait energy image (GEI) for one person.
4.2. Dataset Description
CASIA gait datasets [40] were created by the Institute of Automation Chinese Academy of Sciences and included four gait datasets: A, B, C, and D. Moreover, the Institute of Scientific and Industrial Research (ISIR) has presented OU-ISIR, which contained three gait datasets: A, B, and OU-MVLP. The proposed approach is applied to CASIA, OU-ISIR, and OU-MVLP gait datasets, which included different categories for study. The total number of images in the three applied datasets is around 20 K, where each one is different owing to several view angles, speeds, and clothing variations. Table 2 shows the gait dataset description, and Figure 4 depicts a selection of the applied datasets.
Table 2.
Gait data description.

Figure 4.
Sample of class label for (a) CASIA (A), (b) CASIA (B), (c) CASIA (C), (d) OU-ISIR (A), (e) OU-ISIR (B), and (f) OU-MVLP datasets.
4.2.1. CASIA
Dataset A has taken from 20 persons. Each individual has 12 image patterns, and every four contains three directions to the image surface, which are 0°, 45°, and 90°. Each sequence has a unique length depending on the walker’s speed, but it must range between 37 and 27. This dataset contains 19,139 images in a size of 2.2 GB [20,31]. Dataset B is a large multi-view gait dataset created in January 2005. It was collected from 124 participants, and the gait data were collected from 11 different view angles, ranging from 0° to 180° divided by 18° with three different variations: walking manner, carrying, and clothing condition changes [45,46]. Dataset C was created in August 2005 with an infrared camera. It collected 153 participants in four walking conditions (slow walking, normal walking with or without the bag, and fast walking). These videos were all taken at night [31].
In this study, we prioritized the privacy of participants. To comply with ethical standards, we anonymized the images by cropping out the faces of individuals. This modification made post-experimentation does not impact the scientific validity of the results, as it solely involves the facial regions, leaving the key aspects of gait analysis intact. This step ensures participant confidentiality while maintaining the integrity of our research findings.
4.2.2. OU-ISIR
The OU-ISIR dataset was created in March 2007 [41], which contains 4007 subjects (1872 females and 2135 males) with ages varying from 1 to 94 years. It was gathered from treadmill subjects surrounded by 25 cameras at 60 frames per second, 640 by 480 pixels [32]. The OU-ISIR dataset contains two subsets: 9 speed variations between 2 and 10 km/h in OU-ISIR (A) and garment variations up to 32 combinations in OU-ISIR (B) datasets [41].
4.2.3. OU-MVLP
The Multi-view Large Population Dataset (OU-MVLP) was created in Feb. 2018 [42] and collected from 10,307 subjects (5114 males and 5193 females) with different ages from 2 to 87 years old. This dataset contains 14 view angles spanning from 0° to 90° and 180° to 270°, taken by seven cameras (Cam1–7) mounted at 15-degree azimuth angles along a quarter of a circle whose center coincides with the walking course’s center.
4.3. Preprocessing Dataset
Image preprocessing procedures are used to improve the image quality. Preprocessing aims to reduce noise, remove distortion, and eventually suppress or highlight other attributes essential for subsequent processing, such as segmentation and recognition. Firstly, the gait dataset images were scaled down to three different sizes: 150 × 150, 100 × 100, and 50 × 50, then converted to gray-scaled images to reduce the computational time. In addition, subtract each gait image from its background to obtain isolated images and apply histogram equalization to contrast the resulting image, which is expressed by Equation (1) [47]:
The segmented images are then converted to binary images by the Otsu threshold approach [48], which maximizes the between-class variance, as computed by Equations (2) and (3):
where are referred to as the probabilities of the foreground and background parts. Also, , and are represented as the mean of the gray level of the foreground, background, and entire gray-level image, respectively.
Finally, the binary images are passed through the morphological operations of dilation and filling to remove the impurities from the isolated binary images using a disk Structure Element (SE) with a radius of 1. In addition, all isolated images have normalized for enhancing images by creating a new range from an existing one [49]. The dilation of an image A (set) by structuring element B is defined as Equation (4) [50]:
The filling operation has been predicated on filling the entire region with ‘black’ beginning at any point within the boundary, which is computed by Equation (5) [51]:
where = P, B is the Structure Element (SE), and Ac is the complement of set A. Figure 5 refers to the proposed gait preprocessing procedures applied in the proposed study. Figure 6 depicts a sample of the preprocessed datasets.
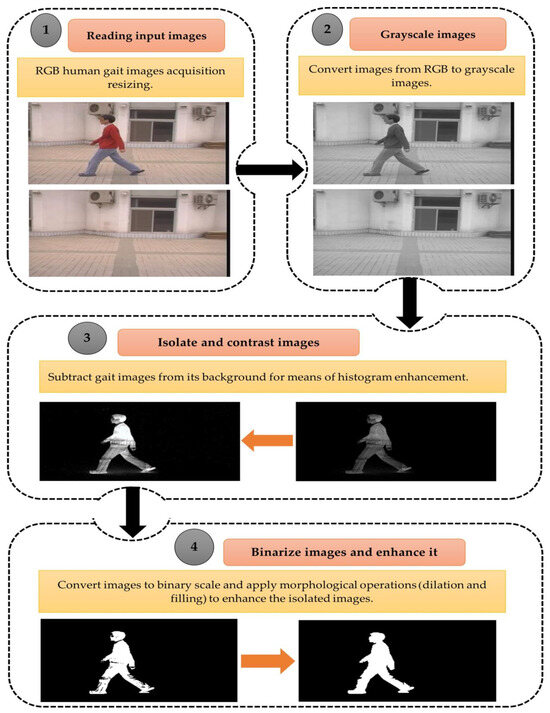
Figure 5.
Gait dataset preprocessing steps.

Figure 6.
Sample of the preprocessed (a) CASIA (A), (b) CASIA (B), (c) CASIA (C), (d) OU-ISIR-A, (e) OU-ISIR-B, and (f) OU-MVLP gait datasets.
The dataset can be normalized by a predefined boundary, which can be calculated by Equation (6) [49]:
contains Min–Max normalized data one when predefined boundaries are [C, D] and A is the main data range. Algorithm 2 presents the main preprocessing procedures of the gait images.
| Algorithm 2: Preprocessing Steps | ||
| Input: RGB gait dataset (D) and Background images (DBack). | ||
| Output: binary isolated gait dataset images (I). | ||
| 1. | Procedure Generate Isolated Gait Dataset (D, DBack): | |
| // Resize all images to three sizes (150, 100, and 50) | ||
| 2. | DResized←resize(D, [150, 100, 50]) | |
| // Apply Rgb2gray image conversion | ||
| 3. | DGS←grayScale(DResized) | |
| // Apply subtraction between grayscale gait and background | ||
| 4. | I←DGS – DBack | |
| // Apply histogram equalization | ||
| 5. | IEqualized←histogramEqualization(I) | |
| // Apply the image Thresholding procedure | ||
| 6. | IThreshold←OtsuThresholding(IEqualized) | |
| // Construct a Structuring Element with disk radius = 1 | ||
| 7. | SE←CreateStructuringElement (radius = 1) | |
| // Dilate image | ||
| 8. | IDilated←DilateImage(IThreshold, SE) | |
| // Fill the holes | ||
| 9. | IFilled←fillHoles(IDilated, threshold = t) | |
| // Remove all connected components less than t | ||
| 10. | I←RemoveSmallComponents(IFilled, threshold = t) | |
| 11. | ReturnI | |
| 12. | End Procedure | |
4.4. The Structure of the Proposed CNN Model
After processing and isolating the images from the gait datasets, a novel deep convolutional neural network, Appearance-Based Deep Gait Network (ABDGNet), is constructed for gait image recognition. The architecture of ABDGNet is meticulously designed and consists of four convolutional layers. Following each convolutional layer is a max pooling layer with a 2 × 2 mask size.
The first two convolutional layers are equipped with 32 filters, each 3 × 3 in size, with a stride of 1, and employ the ReLU activation function for nonlinear processing. The subsequent two layers are more complex, each containing 64 filters of 3 × 3 in size, but with a stride of 2, and also utilize the ReLU activation function.
The ReLU classifier carries out the classification in ABDGNet, the output of which is computed using Equation (7) [52]:
In the subsequent stages, the output is flattened to transition from convolutional to fully connected layers. The network includes three dense layers with 1024, 512, and 256 depths, respectively. After the multi-scale features are concatenated, they pass through another dense layer with a depth of 100, followed by a SoftMax layer for final classification, as defined by Equation (8):
where is the weight matrix of the output layer and is the bias of the output layer. The output of each layer can be calculated by Equations (9) and (10) [53].
Or
N is the input size, F refers to the filter number, P is the padding size, and S is the stride value. Equation (9) computes the output layer with padding value, and Equation (10) computes the output in case of zero padding. Figure 7 presents the overall architecture of ABDGNet. Figure 8 illustrates the detailed layers of ABDGNet using the CASIA dataset as a sample.
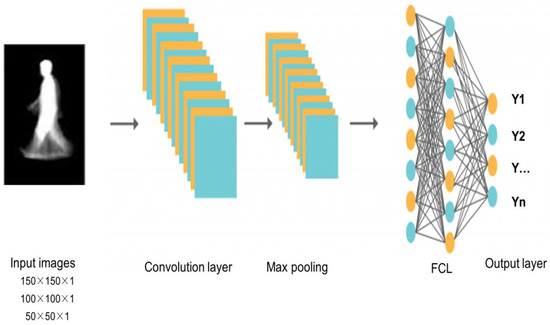
Figure 7.
The ABDGNet architecture.

Figure 8.
The ABDGNet layers using CASIA dataset.
4.5. Performance Evaluation
The performance metrics of the model are thoroughly evaluated using data from the confusion matrix. Essential parameters derived from the confusion matrix include the true positive value (TP), the true negative value (TN), the false positive value (FP), and the false negative value (FN). Figure 9 illustrates a sample confusion matrix for the proposed system using the CASIA-B dataset. The model’s performance metrics evaluation encompasses accuracy, sensitivity, specificity, precision, false discovery rate, F1-score, training time, and recall rate (R) [47]. The accuracy of ABDGNet is calculated using Equation (11) [54]:
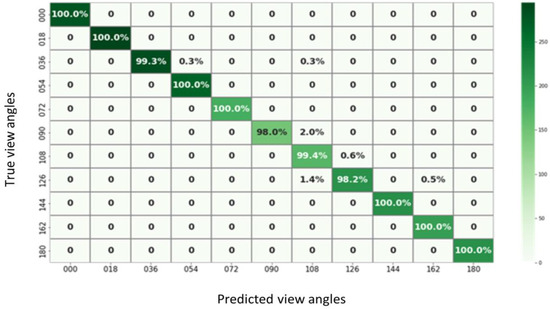
Figure 9.
The ABDGNet confusion matrix.
The sensitivity or True Positive Rate (TPR) and the specificity or True Negative Rate (TNR) can be calculated by Equations (12) and (13):
The precision and recall values can be calculated by Equations (14) and (15) [55]:
F-score can measure a harmonic mean of precision and recall, which can be computed by Equation (16):
The false discovery rate (FDR) quantifies the proportion of unnecessary alerts, which can be calculated by Equation (17):
The False Negative Rate (FNR) can be calculated by Equation (18):
5. Results and Discussion
This section explores the gait recognition efficiency of the ABDGNet model and compares it with popular traditional CNN algorithms applied to various gait datasets, including LeNet, AlexNet, VggNet, Inception, Resnet50, Xception, and ABDGNet. The performance of each algorithm is analyzed in detail. These algorithms, with their predefined layers and parameters, utilize the settings shown in Table 3 for the ABDGNet model. Key evaluation metrics such as accuracy, sensitivity, specificity, recall, F-score, training time, and FNR are used to assess the quality of the traditional algorithms and to facilitate a comparison with the proposed algorithm.
Table 3.
Parameter settings for ABDGNet model.
To evaluate the proposed models, we used the following approaches. Firstly, all datasets used were split by (the train-test-split) model into three parts: train, test, and validation set, with a percentage of 70:15:15%, respectively.
Then, the proposed framework was compiled and fitted according to the number of the fine-tunned hyperparameters, which are listed in Table 4; a learning rate of 0.0005 to determine the step size for updates; the number of epochs, indicating model stability; a batch size set to 32, specifying the number of samples processed simultaneously; and a momentum factor of 0.5, used for calculating adaptive learning rates and maintaining a decaying average of past gradients. All tests were conducted on a PC with Microsoft Windows 10, a 7-core processor running at 4.0 GHz, 12 GB of RAM, and an NVidia Tesla 16 GB GPU.
Table 4.
Parameter settings for traditional pre-trained models.
5.1. LeNet
The performance of the LeNet algorithm was determined by training all tested gait datasets. The algorithm was trained using the following parameters: 32 × 32 image size, 30 epochs, and batch size 32. Table 5 details the results of the LeNet evaluation metrics. Figure 10 illustrates the precision curves for various classes. LeNet’s accuracy was estimated to be approximately 92.6%, with a total runtime of nearly 1 min and 39 s. Additionally, Figure 11 displays the LeNet model’s loss and accuracy curves.
Table 5.
LeNet evaluation results on key performance metrics.
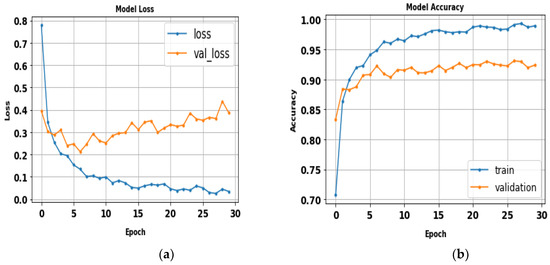
Figure 10.
(a) Loss curve; (b) accuracy curve of LeNet.
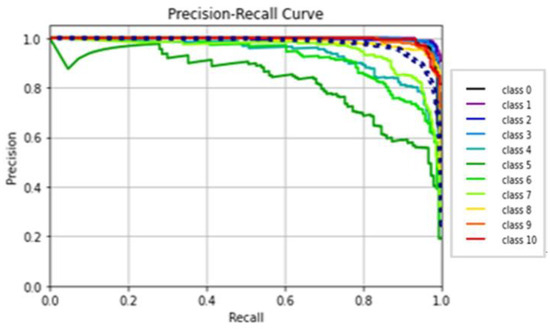
Figure 11.
Classes’ precision–recall curves of LeNet.
5.2. AlexNet
The AlexNet model was tested by using gait datasets to evaluate its performance. Training and fitting the model was applied using the following parameters: 227 × 227 image size, 30 epochs, and batch size 32. Table 6 illustrates the evaluation metrics results of AlexNet. Figure 12 shows the AlexNet model loss and accuracy curves, which achieved a 99.1% accuracy value in a total training time of 4 min 26 s. Figure 13 shows precision–recall curves.
Table 6.
AlexNet evaluation results on key performance metrics.
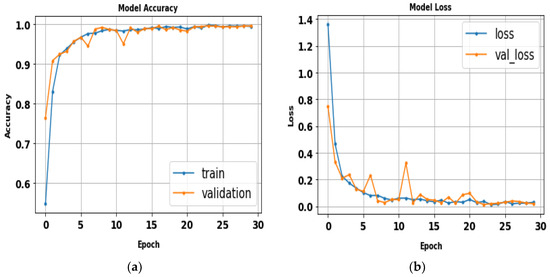
Figure 12.
(a) Loss curve; (b) accuracy curve of AlexNet.
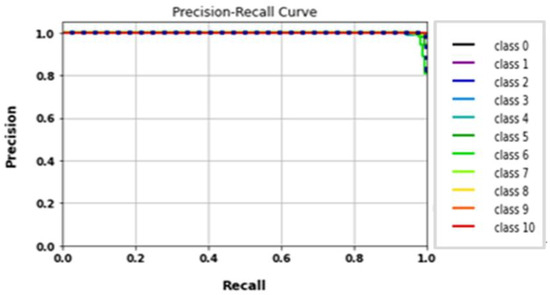
Figure 13.
Classes’ precision–recall curves of AlexNet.
5.3. VggNet
Training all tested gait datasets determined the competence of VGG modules (VGG16 and VGG19). Using an image size of 224 × 224, 30 epochs, and a batch size of 32, two VGG models were built. Although both architectures produced similar performance outcomes, one took less time to run than the other; Table 7 shows the performance results of VggNet. The loss and accuracy curves of the VggNet model, which achieved 98.7% accuracy in approximately 41 min and 26 s, are shown in Figure 14. Figure 15 displays the VggNet model’s precision–recall curves.
Table 7.
The VggNet evaluation metrics results.
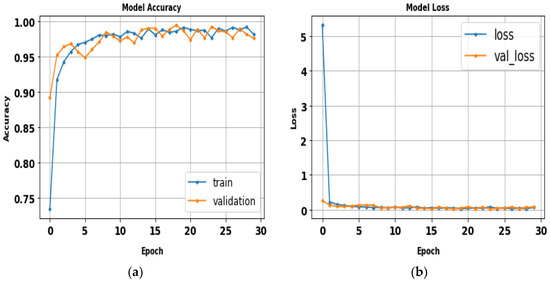
Figure 14.
(a) Loss curve; (b) accuracy curve of VggNet.
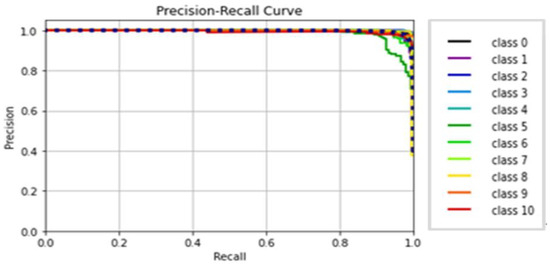
Figure 15.
Classes’ precision–recall curves of VggNet.
5.4. Inception-v3
The Inception model was trained on gait datasets with specific parameters: 224 × 224 RGB image size, 30 epochs, and batch size 32. Table 8 shows the model’s evaluation metrics. Figure 16 displays the loss and accuracy curves of the Inception model, which achieved 96.8% accuracy in 37 min and 36 s. The precision–recall curves for various classes are depicted in Figure 17.
Table 8.
Performance evaluation metrics for the Inception model.
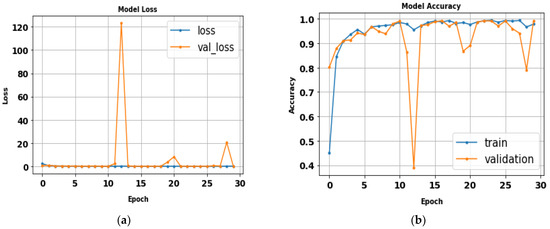
Figure 16.
(a) Loss curve; (b) accuracy curve of Inception-v3 model.
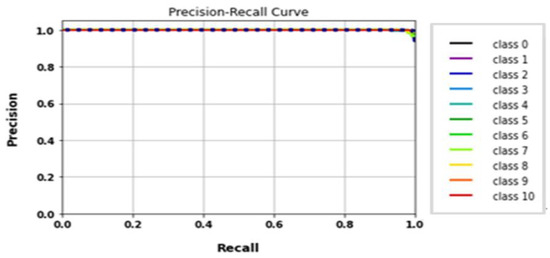
Figure 17.
Classes’ precision–recall curves of Inception model.
5.5. Resnet
The performance of the ResNet50 model was established by training all tested gait datasets. Fitting the model was developed using the following parameters: 224 × 224 RGB image size, 30 epochs, and batch size 32. Table 9 displays ResNet50 evaluation metrics results. ResNet accuracy was around 98.7%, with a total training time of nearly 46 min and 17 s. Figure 18 illustrates the classes’ precision–recall curves of ResNet. Figure 19 shows the loss and accuracy curves.
Table 9.
Performance evaluation metrics for the ResNet50 model.
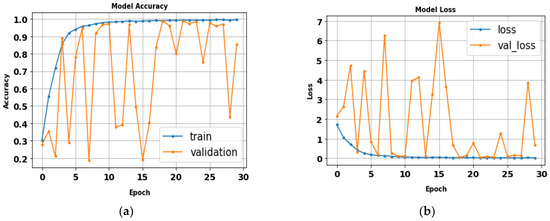
Figure 18.
(a) Loss curve; (b) accuracy curve of ResNet model.
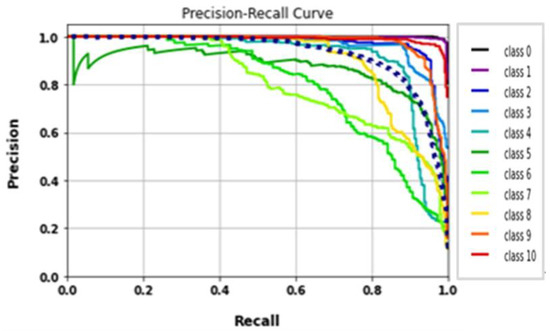
Figure 19.
Classes’ precision–recall curves of ResNet model.
5.6. Xception
After fitting the Xception model, all tested gait datasets’ performance metrics were evaluated using 224 × 224 RGB image size, 30 epochs, and a batch size of 32. Table 10 displays the evaluation metrics results of the Xception model. Figure 20 illustrates the Xception model loss and accuracy curves. The Xception model achieved an accuracy of 96.4% in approximately one and a half hours. Class precision curves for the Xception model are depicted in Figure 21.
Table 10.
Performance evaluation metrics for the Xception model.
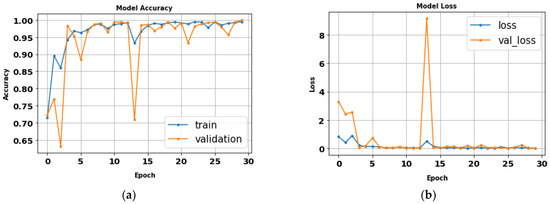
Figure 20.
(a) Loss curve; (b) accuracy curve of Xception model.
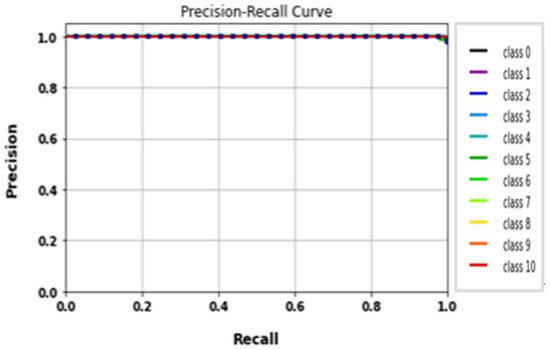
Figure 21.
Classes’ precision–recall curves of Xception model.
The performance results of the traditional CNN indicate that gait recognition values range between 92 and 99%, albeit with high running times. ABDGNet was also applied to the same dataset, aiming to enhance these performance metrics.
5.7. The Proposed CNN (ABDGNet)
The proposed CNN model (ABDGNet) was compared to several traditional CNN and existing models using three publicly available gait datasets: CASIA, OU-ISIR, and OU-MVLP. It achieved high accuracy rates, reaching 99.9% for CASIA-(B) and OU-ISIR and 99.7% for OU-MVLP in a relatively short training time, as shown in Table 11. Figure 22 displays the loss and accuracy curves of various applied datasets.
Table 11.
The proposed (ABDGNet) performance results.
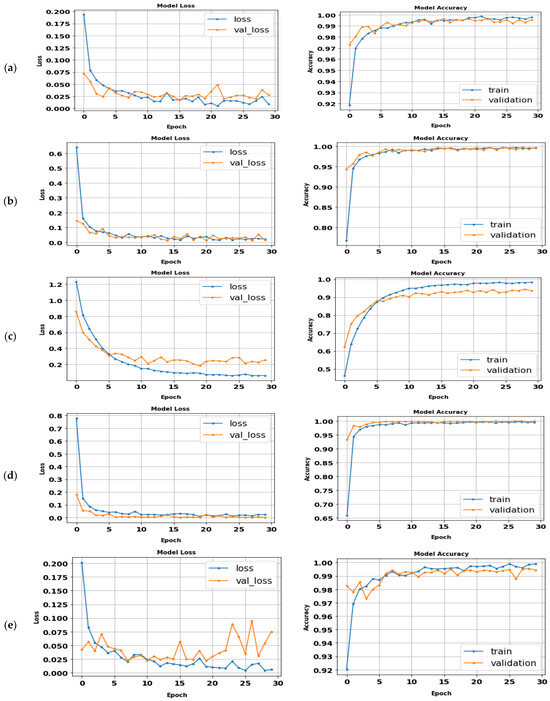
Figure 22.
The ABDGNet loss and accuracy curves for (a) CASIA (A), (b) CASIA (B), (c) OU-ISIR-A, (d) OU-ISIR-B, and (e) OU-MVLP.
5.8. Evaluation of CASIA
The proposed gait recognition model was evaluated using the CASIA dataset according to the optimal parameters listed in Table 3. The comparison between the CASIA-B dataset and the traditional CNN was conducted, as detailed in Table 12 and Table 13. It was then extended with four existing models, including [11,56,57], as illustrated in Table 14. The average value of results [54] was calculated according to Equation (19):
Table 12.
Classes’ precision of all implemented algorithms.
Table 13.
Performance results.
Table 14.
Detailed analysis of view angles used in various studies on the CASIA dataset.
The results indicated the effectiveness of the proposed model. Table 13 highlights that the proposed model outperformed the traditional CNN models in accuracy and training time, achieving 99.9% accuracy within three minutes. Figure 23 complements this by showing the training times for all traditional CNNs. Furthermore, Table 12’s data reveal the superior performance of the proposed model over other existing approaches, achieving a 100% recognition rate across all angles. Notably, for angles within the range of 36°, 108°, and 180°, the model maintained a high recognition rate of 99.0%.
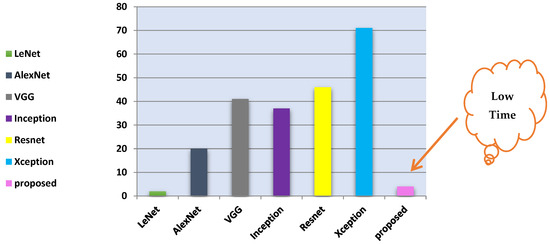
Figure 23.
Comparison of training time for various CNN models.
5.9. Evaluation of OU-ISIR
The proposed ABDGNet model was also evaluated using the OU-ISIR dataset, following the same optimal parameters. According to Table 15, ABDGNet, when benchmarked against existing models such as those in references [19,22], showcased superior performance. It achieved a notable 99.9% accuracy in gait recognition within approximately three minutes. This result places ABDGNet ahead of current state-of-the-art models in the field.
Table 15.
Accuracy comparison of different gait recognition methods on the OU-ISIR dataset.
5.10. Evaluation of OU-MVLP
The evaluation of ABDGNet using the OU-MVLP dataset, which comprises data from 14 different view angles, confirms the model’s effectiveness. Adhering to optimal parameters, ABDGNet’s performance was compared with methods from references [17,58,59], as detailed in Table 16. This comparison reveals that ABDGNet surpasses the existing models, achieving a remarkable recognition accuracy of 99.8% in a notably short time frame of approximately three minutes.
Table 16.
Performance comparison of various models across different view angles on the OU-MVLP dataset.
The research findings are divided into two phases. In the first phase, a comparative analysis was conducted between the proposed convolutional neural network (CNN) model and traditional CNNs. Table 13 summarizes the results, showing that ABDGNet achieved precision and accuracy of 99.6% and 99.9%, respectively, within 3 min and 25 s. Figure 23 illustrates the training times for traditional CNN models and the proposed ABDGNet. The proposed model achieved the highest precision of 99.6% and an accuracy of 99.9%, all within a brief training duration of only 3 min and 25 s.
Multi-scale image processing has demonstrated its pivotal role in enhancing gait recognition accuracy by accommodating variations in distance and perspective, which are natural in gait data. Furthermore, utilizing multi-scale approaches instead of a single one can improve the feature representation, resulting in better differentiation between various classes and enhancing object localization within an image. In our analysis, when the model applied a single-scale approach with image sizes of 50 × 50, 100 × 100, and 150 × 150 pixels, it achieved accuracy values of 98.5%, 98.8%, and 99.0%, respectively. In contrast, the multi-scale approach consistently showed superior performance, with accuracy rates reaching 99.9% for the CASIA dataset and 99.8% for the OU-MVLP dataset.
This enhancement is attributable to the multi-scale approach’s capacity to capture and integrate features across different resolutions, thereby improving the model’s robustness and adaptability to varying real-world conditions. The superior performance of the multi-scale approach underscores its effectiveness in handling the inherent variability in gait patterns more efficiently than the single-scale approach.
Furthermore, a detailed comparative study incorporating other recent gait recognition studies using CNN algorithms, such as ABDGNet, is presented in Table 17. The comparative results reinforce the superior accuracy and efficiency of the proposed multi-scale approach over other contemporary methods. ABDGNet’s performance metrics stand out in this comparison, highlighting its superiority over other CNN-based gait recognition methods.
Table 17.
Comparative analysis of the ABDGNET model with contemporary gait recognition studies.
6. Conclusions
This paper introduced ABDGNet, an advanced deep learning model that targets improvements in gait recognition. Utilizing a specialized CNN architecture, ABDGNet carefully processes, segments, and enhances gait images, effectively handling multiple scales of input data. An in-depth comparative analysis against traditional CNN models, based on essential performance metrics, has confirmed the enhanced capability of ABDGNet. Notably, the model demonstrates outstanding performance with an accuracy of 99.9%, a precision of 99.6%, a recall of 100%, a specificity of 99.0%, and a remarkably low False Negative Rate of 0.36. In addition to its precision, ABDGNet distinguishes itself with its efficient processing, evidenced by reduced training times compared to its counterparts. These findings underscore ABDGNet’s substantial advancements in speed and accuracy, indicating a significant leap forward in gait recognition technology. The study’s results advocate for ABDGNet as a robust and reliable solution, offering considerable promise for future surveillance and biometric authentication applications.
Author Contributions
Conceptualization, R.N.Y. and M.M.A.; methodology, M.M.A. and A.E.E.R.; software, R.N.Y., M.M.A. and A.E.E.R.; validation, M.B., M.A.E.; and W.M.B.; formal analysis, M.B., M.A.E.; and W.M.B.; investigation, R.N.Y. and; A.E.E.R. resources, A.E.E.R., W.M.B. and M.M.A.; data curation, R.N.Y. and W.M.B.; writing—original draft preparation, R.N.Y., A.E.E.R. and M.M.A.; writing—review and editing, M.B., M.A.E.; and W.M.B.; visualization, A.E.E.R. and W.M.B.; supervision, M.A.E.; project administration, M.A.E.; funding acquisition, W.M.B. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Deputyship for Research & Innovation, Ministry of Education in Saudi Arabia, through project number 445-9-728.
Institutional Review Board Statement
Not applicable.
Data Availability Statement
Data are available upon request. The preprocessing steps of our study Python code in GitHub at the following link: https://github.com/remooooooooooo/preprocessing-steps/blob/main/python (accessed on 20 April 2024).
Acknowledgments
The authors extend their appreciation to the Deputyship for Research & Innovation, Ministry of Education in Saudi Arabia, for funding this research work through project number 445-9-728.
Conflicts of Interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
References
- Okano, T.; Izumi, S.; Kawaguchi, H.; Yoshimoto, M. Non-contact biometric identification and authentication using microwave Doppler sensor. In Proceedings of the 2017 IEEE Biomedical Circuits and Systems Conference (BioCAS), Turin, Italy, 19–21 October 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–4. [Google Scholar]
- Dadakhanov, S. Analyze and Development System with Multiple Biometric Identification. arXiv 2020, arXiv:2004.04911. [Google Scholar]
- Krish, R.P.; Fierrez, J.; Ramos, D.; Alonso-Fernandez, F.; Bigun, J. Improving automated latent fingerprint identification using extended minutia types. Inf. Fusion 2019, 50, 9–19. [Google Scholar] [CrossRef]
- Huang, Q.; Duan, B.; Qu, Z.; Fan, S.; Xia, B. The DNA Recognition Motif of GapR Has an Intrinsic DNA Binding Preference towards AT-rich DNA. Molecules 2021, 26, 5776. [Google Scholar] [CrossRef]
- Kortli, Y.; Jridi, M.; Al Falou, A.; Atri, M. Face recognition systems: A survey. Sensors 2020, 20, 342. [Google Scholar] [CrossRef] [PubMed]
- Khanam, R.; Haseen, Z.; Rahman, N.; Singh, J. Performance analysis of iris recognition system. In Data and Communication Networks; Springer: Cham, Switzerland, 2019; pp. 159–171. [Google Scholar]
- Zhang, Z.; Tran, L.; Yin, X.; Atoum, Y.; Liu, X.; Wan, J.; Wang, N. Gait recognition via disentangled representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4710–4719. [Google Scholar]
- Tariq, W.; Othman, M.L.; Akhtar, S.; Tariq, F. Gait Feature Based on Human Identification & Classification by Using Artificial Neural Network and Project Management Approaches for Its Implementation. Int. J. Eng. Technol. 2019, 8, 133–137. [Google Scholar]
- Yamada, H.; Ahn, J.; Mozos, O.M.; Iwashita, Y.; Kurazume, R. Gait-based person identification using 3D LiDAR and long short-term memory deep networks. Adv. Robot. 2020, 34, 1201–1211. [Google Scholar] [CrossRef]
- Kumar, M.; Singh, N.; Kumar, R.; Goel, S.; Kumar, K. Gait recognition based on vision systems: A systematic survey. J. Vis. Commun. Image Represent. 2021, 75, 103052. [Google Scholar] [CrossRef]
- Liao, R.; Yu, S.; An, W.; Huang, Y. A model-based gait recognition method with body pose and human prior knowledge. Pattern Recognit. 2020, 98, 107069. [Google Scholar] [CrossRef]
- Wu, Z.; Huang, Y.; Wang, L.; Wang, X.; Tan, T. A comprehensive study on cross-view gait based human identification with deep cnns. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 209–226. [Google Scholar] [CrossRef]
- Bukhari, M.; Bajwa, K.B.; Gillani, S.; Maqsood, M.; Durrani, M.Y.; Mehmood, I.; Ugail, H.; Rho, S. An efficient gait recognition method for known and unknown covariate conditions. IEEE Access 2020, 9, 6465–6477. [Google Scholar] [CrossRef]
- Altilio, R.; Rossetti, A.; Fang, Q.; Gu, X.; Panella, M. A comparison of machine learning classifiers for smartphone-based gait analysis. Med. Biol. Eng. Comput. 2021, 59, 535–546. [Google Scholar] [CrossRef]
- Saleh, A.M.; Hamoud, T. Analysis and best parameters selection for person recognition based on gait model using CNN algorithm and image augmentation. J. Big Data 2021, 8, 1–20. [Google Scholar] [CrossRef]
- Liao, R.; An, W.; Li, Z.; Bhattacharyya, S.S. A novel view synthesis approach based on view space covering for gait recognition. Neurocomputing 2021, 453, 13–25. [Google Scholar] [CrossRef]
- Elharrouss, O.; Almaadeed, N.; Al-Maadeed, S.; Bouridane, A. Gait recognition for person re-identification. J. Supercomput. 2021, 77, 3653–3672. [Google Scholar] [CrossRef]
- Zou, Q.; Wang, Y.; Wang, Q.; Zhao, Y.; Li, Q. Deep learning-based gait recognition using smartphones in the wild. IEEE Trans. Inf. Forensics Secur. 2020, 15, 3197–3212. [Google Scholar] [CrossRef]
- Wu, X.; An, W.; Yu, S.; Guo, W.; García, E.B. Spatial-temporal graph attention network for video-based gait recognition. In Proceedings of the Asian Conference on Pattern Recognition, Auckland, New Zealand, 26–29 November 2019; Springer: Cham, Switzerland, 2019; pp. 274–286. [Google Scholar]
- Guo, H.; Li, B.; Zhang, Y.; Zhang, Y.; Li, W.; Qiao, F.; Rong, X.; Zhou, S. Gait recognition based on the feature extraction of Gabor filter and linear discriminant analysis and improved local coupled extreme learning machine. Math. Probl. Eng. 2020, 2020, 5393058. [Google Scholar] [CrossRef]
- Kececi, A.; Yildirak, A.; Ozyazici, K.; Ayluctarhan, G.; Agbulut, O.; Zincir, I. Implementation of machine learning algorithms for gait recognition. Eng. Sci. Technol. Int. J. 2020, 23, 931–937. [Google Scholar] [CrossRef]
- Zhang, K.; Luo, W.; Ma, L.; Liu, W.; Li, H. Learning joint gait representation via quintuplet loss minimization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4700–4709. [Google Scholar]
- Sivarathinabala, M.; Abirami, S. AGRS: Automated gait recognition system in smart environment. J. Intell. Fuzzy Syst. 2019, 36, 2511–2525. [Google Scholar] [CrossRef]
- Saleem, F.; Khan, M.A.; Alhaisoni, M.; Tariq, U.; Armghan, A.; Alenezi, F.; Choi, J.-I.; Kadry, S. Human gait recognition: A single stream optimal deep learning features fusion. Sensors 2021, 21, 7584. [Google Scholar] [CrossRef]
- Yu, S.; Chen, H.; Garcia Reyes, E.B.; Poh, N. Gaitgan: Invariant gait feature extraction using generative adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 30–37. [Google Scholar]
- Anbalagan, E.; Anbhazhagan, S.M. Deep learning model using ensemble based approach for walking activity recognition and gait event prediction with grey level co-occurrence matrix. Expert Syst. Appl. 2023, 227, 120337. [Google Scholar] [CrossRef]
- Xia, Y.; Sun, H.; Zhang, B.; Xu, Y.; Ye, Q. Prediction of freezing of gait based on self-supervised pretraining via contrastive learning. Biomed. Signal Process. Control 2024, 89, 105765. [Google Scholar] [CrossRef]
- Guffanti, D.; Brunete, A.; Hernando, M.; Álvarez, D.; Rueda, J.; Navarro, E. Supervised learning for improving the accuracy of robot-mounted 3D camera applied to human gait analysis. Heliyon 2024, 10, e26227. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Yan, W.Q. Human gait recognition based on frame-by-frame gait energy images and convolutional long short-term memory. Int. J. Neural Syst. 2020, 30, 1950027. [Google Scholar] [CrossRef] [PubMed]
- Zhao, A.; Li, J.; Ahmed, M. Spidernet: A spiderweb graph neural network for multi-view gait recognition. Knowl.-Based Syst. 2020, 206, 106273. [Google Scholar] [CrossRef]
- CASIA Gait Dataset. Available online: http://www.cbsr.ia.ac.cn/users/szheng/?page_id=71 (accessed on 1 May 2023).
- OU-ISIR Dataset. Available online: http://www.am.sanken.osaka-u.ac.jp/BiometricDB/GaitTM.html (accessed on 10 May 2023).
- Takemura, N.; Makihara, Y.; Muramatsu, D.; Echigo, T.; Yagi, Y. Multi-view large population gait dataset and its performance evaluation for cross-view gait recognition. IPSJ Trans. Comput. Vis. Appl. 2018, 10, 4. [Google Scholar] [CrossRef]
- Makihara, Y.; Suzuki, A.; Muramatsu, D.; Li, X.; Yagi, Y. Joint intensity and spatial metric learning for robust gait recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5705–5715. [Google Scholar]
- Ghosh, A.; Sufian, A.; Sultana, F.; Chakrabarti, A.; De, D. Fundamental concepts of convolutional neural network. In Recent Trends and Advances in Artificial Intelligence and Internet of Things; Springer: Cham, Switzerland, 2020; pp. 519–567. [Google Scholar]
- Cheng, G.; Guo, W. Rock images classification by using deep convolution neural network. J. Phys. Conf. Ser. 2017, 887, 012089. [Google Scholar] [CrossRef]
- Condori, R.H.M.; Romualdo, L.M.; Bruno, O.M.; de Cerqueira Luz, P.H. Comparison between traditional texture methods and deep learning descriptors for detection of nitrogen deficiency in maize crops. In Proceedings of the 2017 Workshop of Computer Vision (WVC), Natal, Brazil, 30 October–1 November 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 7–12. [Google Scholar]
- Elmahdy, M.S.; Abdeldayem, S.S.; Yassine, I.A. Low quality dermal image classification using transfer learning. In Proceedings of the 2017 IEEE EMBS International Conference on Biomedical & Health Informatics (BHI), Orland, FL, USA, 16–19 February 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 373–376. [Google Scholar]
- Yamashita, R.; Nishio, M.; Do, R.K.G.; Togashi, K. Convolutional neural networks: An overview and application in radiology. Insights Into Imaging 2018, 9, 611–629. [Google Scholar] [CrossRef] [PubMed]
- Rao, P.S.; Sahu, G.; Parida, P. Methods for Automatic Gait Recognition: A Review. In Proceedings of the International Conference on Innovations in Bio-Inspired Computing and Applications, Gunupur, India, 16–18 December 2019; Springer: Cham, Switzerland, 2019; pp. 57–65. [Google Scholar]
- Makihara, Y.; Mannami, H.; Tsuji, A.; Hossain, M.A.; Sugiura, K.; Mori, A.; Yagi, Y. The OU-ISIR gait database comprising the treadmill dataset. IPSJ Trans. Comput. Vis. Appl. 2012, 4, 53–62. [Google Scholar] [CrossRef]
- Xu, C.; Makihara, Y.; Liao, R.; Niitsuma, H.; Li, X.; Yagi, Y.; Lu, J. Real-time gait-based age estimation and gender classification from a single image. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Virtual, 5–9 January 2021; pp. 3460–3470. [Google Scholar]
- Li, Z.; Xiong, J.; Ye, X. A new gait energy image based on mask processing for pedestrian gait recognition. In Proceedings of the 2019 International Conference on Image and Video Processing, and Artificial Intelligence, Shanghai, China, 23–25 August 2019; International Society for Optics and Photonics: Bellingham, WA, USA, 2019; p. 113212A. [Google Scholar]
- Connie, T.; Goh, M.K.O.; Teoh, A.B.J. Human gait recognition using localized Grassmann mean representatives with partial least squares regression. Multimed. Tools Appl. 2018, 77, 28457–28482. [Google Scholar] [CrossRef]
- Zheng, S.; Zhang, J.; Huang, K.; He, R.; Tan, T. Robust view transformation model for gait recognition. In Proceedings of the 2011 18th IEEE International Conference on Image Processing, Brussels, Belgium, 11–14 September 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 2073–2076. [Google Scholar]
- He, R.; Tan, T.; Wang, L. Robust recovery of corrupted low-rankmatrix by implicit regularizers. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 36, 770–783. [Google Scholar] [CrossRef]
- Xie, Y.; Ning, L.; Wang, M.; Li, C. Image enhancement based on histogram equalization. J. Phys. Conf. Ser. 2019, 1314, 012161. [Google Scholar] [CrossRef]
- Yang, P.; Song, W.; Zhao, X.; Zheng, R.; Qingge, L. An improved Otsu threshold segmentation algorithm. Int. J. Comput. Sci. Eng. 2020, 22, 146–153. [Google Scholar] [CrossRef]
- Donon, Y.; Kupriyanov, A.; Paringer, R. Image normalization for Blurred Image Matching. CEUR Workshop Proc. 2020, 127–131. [Google Scholar]
- Raju, S.; Rajan, E. Skin Texture Analysis Using Morphological Dilation and Erosion. Int. J. Pure Appl. Math 2018, 118, 205–223. [Google Scholar]
- Švábek, D. Comparison of morphological face filling in image with human-made fill. AIP Conf. Proc. 2018, 2040, 030009. [Google Scholar]
- Agarap, A.F. Deep learning using rectified linear units (relu). arXiv 2018, arXiv:1803.08375. [Google Scholar]
- Jie, H.J.; Wanda, P. RunPool: A dynamic pooling layer for convolution neural network. Int. J. Comput. Intell. Syst. 2020, 13, 66–76. [Google Scholar] [CrossRef]
- Yousif, B.B.; Ata, M.M.; Fawzy, N.; Obaya, M. Toward an optimized neutrosophic k-means with genetic algorithm for automatic vehicle license plate recognition (ONKM-AVLPR). IEEE Access 2020, 8, 49285–49312. [Google Scholar] [CrossRef]
- Francies, M.L.; Ata, M.M.; Mohamed, M.A. A robust multiclass 3D object recognition based on modern YOLO deep learning algorithms. Concurr. Comput. Pract. Exp. 2021, 36, e6517. [Google Scholar] [CrossRef]
- Zhang, Z.; Tran, L.; Liu, F.; Liu, X. On learning disentangled representations for gait recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 345–360. [Google Scholar] [CrossRef]
- Ben, X.; Zhang, P.; Lai, Z.; Yan, R.; Zhai, X.; Meng, W. A general tensor representation framework for cross-view gait recognition. Pattern Recognit. 2019, 90, 87–98. [Google Scholar] [CrossRef]
- Carley, C.; Ristani, E.; Tomasi, C. Person re-identification from gait using an autocorrelation network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Chao, H.; He, Y.; Zhang, J.; Feng, J. Gaitset: Regarding gait as a set for cross-view gait recognition. Proc. AAAI Conf. Artif. Intell. 2019, 33, 8126–8133. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).