


Gender-Driven English Speech Emotion Recognition with Genetic Algorithm


Abstract
1. Introduction
- Propose a novel speech gender–emotion recognition model.
- Extract various features from speech for gender and emotion recognition.
- Utilize a genetic algorithm for high-dimensional feature selection for fast emotion recognition, in which the algorithm is improved through feature evaluation, the selection of parents, crossover, and mutation.
- Validate the performance of the proposed algorithm on four English datasets.
2. Related Works
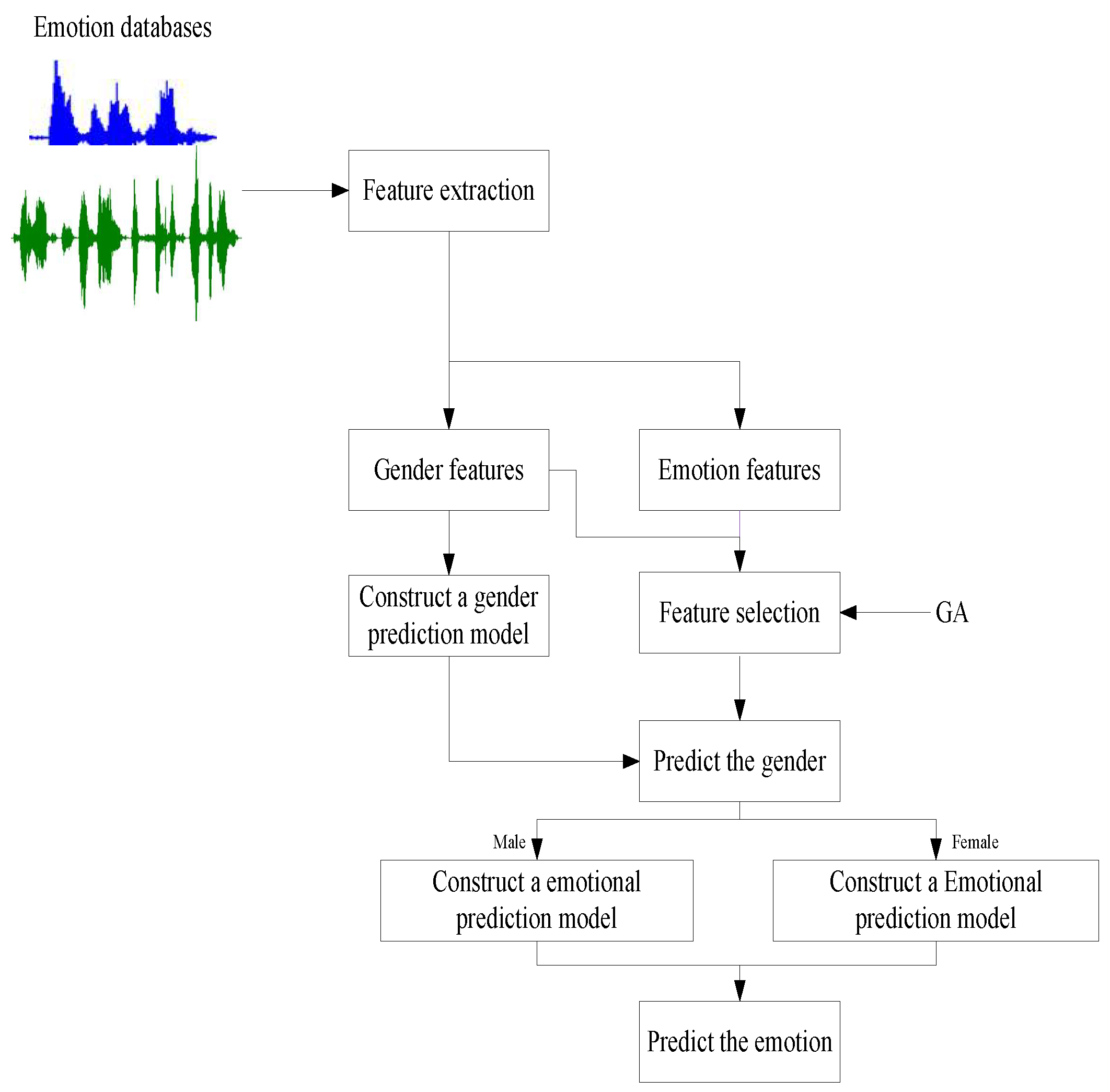
3. Materials and Methods
3.1. Emotional Databases
- 1
- CREMA-D
- 2
- EmergencyCalls
- 3
- IEMOCAP-S1
- 4
- RAVDESS
3.2. Feature Extraction
3.3. Improved Genetic Algorithm
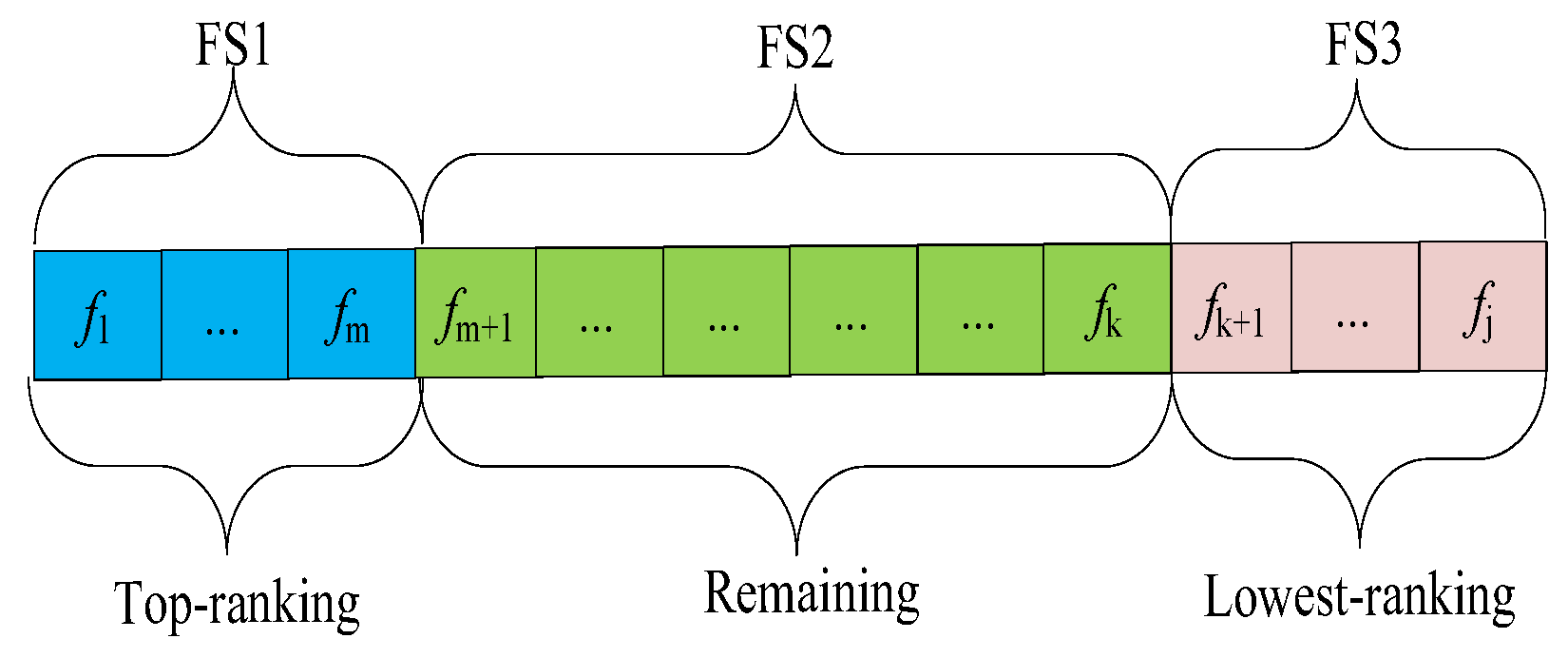
3.3.1. Feature Evaluation
3.3.2. The Selection of Parents
| Algorithm 1: The selection of parents |
 |
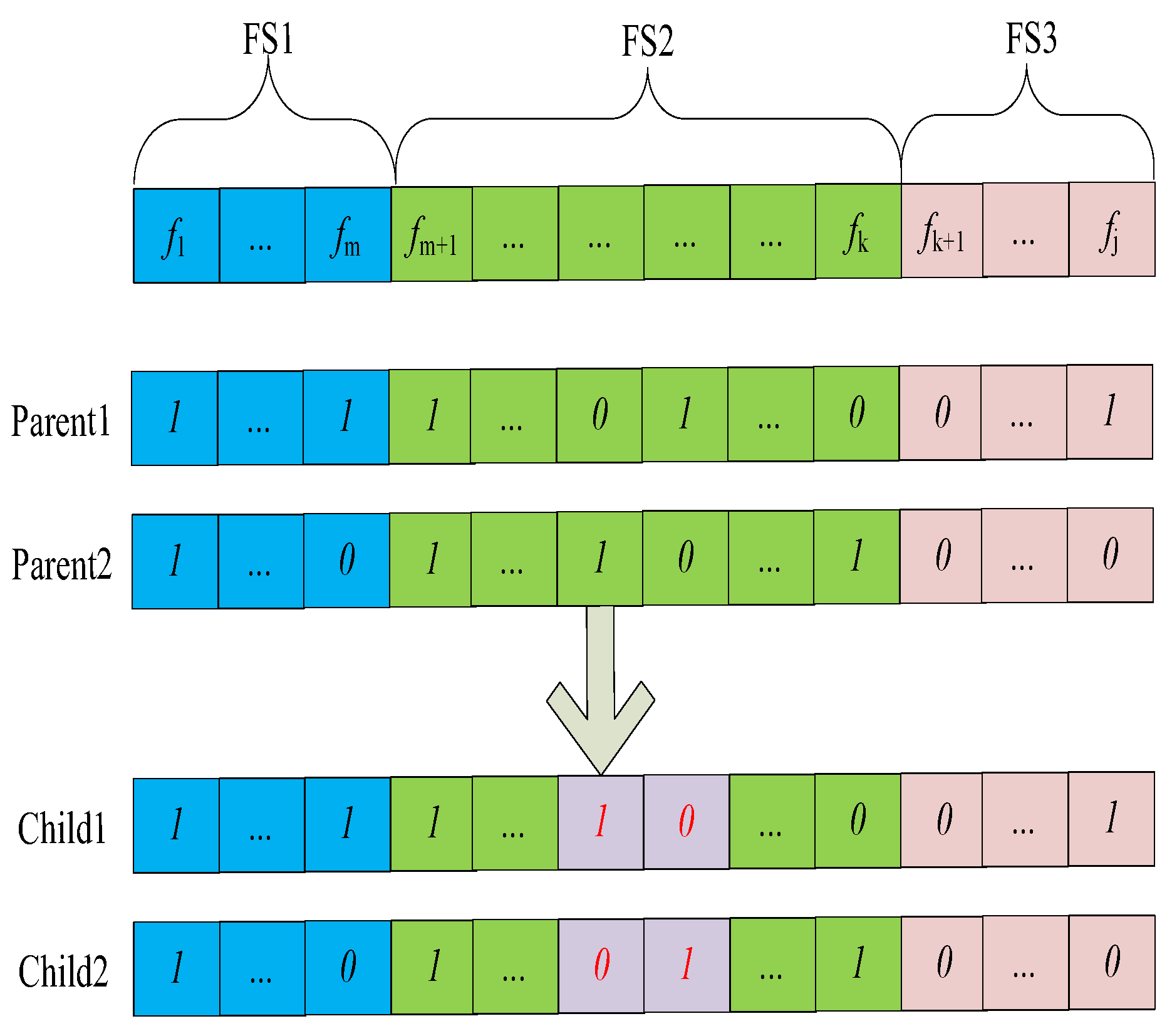
3.3.3. Crossover and Mutation
| Algorithm 2: Mutation |
 |
4. Experimental Results and Analysis
4.1. Objective Function
4.2. Experimental Analysis
4.3. Discussion
- (1)
- In CREMA-D, the second derivative of PCM, and the variances in logMelFreqBand[6] and logMelFreqBand_FDE[2] are the features with the most differences. Variance is an extremely influential statistical characteristic, and logMelFreqBand[0–7] stand out as the most important emotion features.
- (2)
- In EmergencyCalls, the first derivative of logMelFreqBand_FDE[0] appears more frequently than the other features. Similarly to for CREMA-D, variance plays a significant role, and MFCC_FDE[0,2,3,5,6], logMelFreqBand[4,5,6], and logMelFreqBand_FDE[0,1,2,3,6] are identified as emotion features that exhibit gender differences.
- (3)
- In RAVDESS, the first derivative of MFCC_FDE[12] and the quartile1 of PCM_FDE appear with a higher frequency. Mean and variance are the most important statistical characteristics, while MFCC[0,1,5,12], MFCC_FDE[0,10,11,12,14], PCM, jitterLocal, and jitterDDP are gender-difference features.
- (4)
- In IEMOCAP-S1, the first derivative of logMelFreqBand_FDE[0], and the variances in logMelFreqBand[4,5] are features with distinct gender-related variations. Similarly to the previous datasets, variance maintains its importance. Notably, logMelFreqBand[0,1,2,7], MFCC[0,4,5], and their corresponding FDEs play influential roles in capturing gender-related emotional features.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Bhushan, B. Optimal Feature Learning for Speech Emotion Recognition—A DeepNet Approach. In Proceedings of the 2023 International Conference on Data Science and Network Security (ICDSNS), Tiptur, India, 28–29 July 2023; IEEE: New York, NY, USA, 2023; pp. 1–6. [Google Scholar]
- Wani, T.M.; Gunawan, T.S.; Qadri, S.A.A.; Kartiwi, M.; Ambikairajah, E. A comprehensive review of speech emotion recognition systems. IEEE Access 2021, 9, 47795–47814. [Google Scholar] [CrossRef]
- Donuk, K. CREMA-D: Improving Accuracy with BPSO-Based Feature Selection for Emotion Recognition Using Speech. J. Soft Comput. Artif. Intell. 2022, 3, 51–57. [Google Scholar] [CrossRef]
- Fahad, M.S.; Ranjan, A.; Yadav, J.; Deepak, A. A survey of speech emotion recognition in natural environment. Digit. Signal Process. 2021, 110, 102951. [Google Scholar] [CrossRef]
- Akçay, M.B.; Oğuz, K. Speech emotion recognition: Emotional models, databases, features, preprocessing methods, supporting modalities, and classifiers. Speech Commun. 2020, 116, 56–76. [Google Scholar] [CrossRef]
- Issa, D.; Demirci, M.F.; Yazici, A. Speech emotion recognition with deep convolutional neural networks. Biomed. Signal Process. Control 2020, 59, 101894. [Google Scholar] [CrossRef]
- Hu, G.; Zhong, J.; Wang, X.; Wei, G. Multi-strategy assisted chaotic coot-inspired optimization algorithm for medical feature selection: A cervical cancer behavior risk study. Comput. Biol. Med. 2022, 151, 106239. [Google Scholar] [CrossRef] [PubMed]
- Barrera-García, J.; Cisternas-Caneo, F.; Crawford, B.; Gómez Sánchez, M.; Soto, R. Feature Selection Problem and Metaheuristics: A Systematic Literature Review about Its Formulation, Evaluation and Applications. Biomimetics 2023, 9, 9. [Google Scholar] [CrossRef] [PubMed]
- Hu, P.; Pan, J.S.; Chu, S.C.; Sun, C. Multi-surrogate assisted binary particle swarm optimization algorithm and its application for feature selection. Appl. Soft Comput. 2022, 121, 108736. [Google Scholar] [CrossRef]
- Jia, H.; Rao, H.; Wen, C.; Mirjalili, S. Crayfish optimization algorithm. Artif. Intell. Rev. 2023, 56, 1919–1979. [Google Scholar] [CrossRef]
- Jia, H.; Peng, X.; Lang, C. Remora optimization algorithm. Expert Syst. Appl. 2021, 185, 115665. [Google Scholar] [CrossRef]
- Hu, G.; Zhong, J.; Zhao, C.; Wei, G.; Chang, C.T. LCAHA: A hybrid artificial hummingbird algorithm with multi-strategy for engineering applications. Comput. Methods Appl. Mech. Eng. 2023, 415, 116238. [Google Scholar] [CrossRef]
- Zhao, W.; Wang, L.; Zhang, Z.; Fan, H.; Zhang, J.; Mirjalili, S.; Khodadadi, N.; Cao, Q. Electric eel foraging optimization: A new bio-inspired optimizer for engineering applications. Expert Syst. Appl. 2024, 238, 122200. [Google Scholar] [CrossRef]
- Wu, D.; Jia, H.; Abualigah, L.; Xing, Z.; Zheng, R.; Wang, H.; Altalhi, M. Enhance teaching-learning-based optimization for tsallis-entropy-based feature selection classification approach. Processes 2022, 10, 360. [Google Scholar] [CrossRef]
- Lu, J.; Su, X.; Zhong, J.; Hu, G. Multi-objective shape optimization of developable Bézier-like surfaces using non-dominated sorting genetic algorithm. Mech. Ind. 2023, 24, 38. [Google Scholar] [CrossRef]
- Gao, Y.; Gao, L.; Liu, Y.; Wu, M.; Zhang, Z. Assessment of water resources carrying capacity using chaotic particle swarm genetic algorithm. J. Am. Water Resour. Assoc. 2024, 60, 667–686. [Google Scholar] [CrossRef]
- Pan, J.S.; Hu, P.; Snášel, V.; Chu, S.C. A survey on binary metaheuristic algorithms and their engineering applications. Artif. Intell. Rev. 2022, 56, 6101–6167. [Google Scholar] [CrossRef] [PubMed]
- Yue, L.; Hu, P.; Chu, S.C.; Pan, J.S. Genetic Algorithm for High-Dimensional Emotion Recognition from Speech Signals. Electronics 2023, 12, 4779. [Google Scholar] [CrossRef]
- Zhou, J.; Hua, Z. A correlation guided genetic algorithm and its application to feature selection. Appl. Soft Comput. 2022, 123, 108964. [Google Scholar] [CrossRef]
- Song, H.; Wang, J.; Song, L.; Zhang, H.; Bei, J.; Ni, J.; Ye, B. Improvement and application of hybrid real-coded genetic algorithm. Appl. Intell. 2022, 52, 17410–17448. [Google Scholar] [CrossRef]
- Li, J.; Li, L. A hybrid genetic algorithm based on information entropy and game theory. IEEE Access 2020, 8, 36602–36611. [Google Scholar]
- Yan, C.; Li, M.X.; Liu, W. Application of Improved Genetic Algorithm in Function Optimization. J. Inf. Sci. Eng. 2019, 35, 1299. [Google Scholar]
- Harifi, S.; Mohamaddoust, R. Zigzag mutation: A new mutation operator to improve the genetic algorithm. Multimed. Tools Appl. 2023, 82, 1–22. [Google Scholar] [CrossRef]
- Dorea, C.C.; Guerra, J.A., Jr.; Morgado, R.; Pereira, A.G. Multistage markov chain modeling of the genetic algorithm and convergence results. Numer. Funct. Anal. Optim. 2010, 31, 164–171. [Google Scholar] [CrossRef]
- Li, J.-H.; Li, M. An analysis on convergence and convergence rate estimate of elitist genetic algorithms in noisy environments. Optik 2013, 124, 6780–6785. [Google Scholar]
- Peng, Y.; Luo, X.; Wei, W. A new fuzzy adaptive simulated annealing genetic algorithm and its convergence analysis and convergence rate estimation. Int. J. Control Autom. Syst. 2014, 12, 670–679. [Google Scholar] [CrossRef]
- Bisio, I.; Delfino, A.; Lavagetto, F.; Marchese, M.; Sciarrone, A. Gender-driven emotion recognition through speech signals for ambient intelligence applications. IEEE Trans. Emerg. Top. Comput. 2013, 1, 244–257. [Google Scholar] [CrossRef]
- Bhattacharya, P.; Gupta, R.K.; Yang, Y. Exploring the contextual factors affecting multimodal emotion recognition in videos. IEEE Trans. Affect. Comput. 2021, 14, 1547–1557. [Google Scholar] [CrossRef]
- Zaman, S.R.; Sadekeen, D.; Alfaz, M.A.; Shahriyar, R. One source to detect them all: Gender, age, and emotion detection from voice. In Proceedings of the 2021 IEEE 45th Annual Computers, Software, and Applications Conference (COMPSAC), Madrid, Spain, 12–16 July 2021; IEEE: New York, NY, USA, 2021; pp. 338–343. [Google Scholar]
- Verma, D.; Mukhopadhyay, D.; Mark, E. Role of gender influence in vocal Hindi conversations: A study on speech emotion recognition. In Proceedings of the 2016 International Conference on Computing Communication Control and Automation (ICCUBEA), Pune, India, 12–13 August 2016; IEEE: New York, NY, USA, 2016; pp. 1–6. [Google Scholar]
- Bandela, S.R.; Siva Priyanka, S.; Sunil Kumar, K.; Vijay Bhaskar Reddy, Y.; Berhanu, A.A. Stressed Speech Emotion Recognition Using Teager Energy and Spectral Feature Fusion with Feature Optimization. Comput. Intell. Neurosci. 2023, 2023, 5765760. [Google Scholar] [CrossRef] [PubMed]
- Rituerto-González, E.; Mínguez-Sánchez, A.; Gallardo-Antolín, A.; Peláez-Moreno, C. Data augmentation for speaker identification under stress conditions to combat gender-based violence. Appl. Sci. 2019, 9, 2298. [Google Scholar] [CrossRef]
- Kaggle. Speech Emotion Recognition for Emergency Calls. Available online: https://www.kaggle.com/datasets/anuvagoyal/speech-emotion-recognition-for-emergency-calls (accessed on 12 June 2024).
- Busso, C.; Bulut, M.; Lee, C.C.; Kazemzadeh, A.; Mower, E.; Kim, S.; Chang, J.N.; Lee, S.; Narayanan, S.S. IEMOCAP: Interactive emotional dyadic motion capture database. Lang. Resour. Eval. 2008, 42, 335–359. [Google Scholar] [CrossRef]
- Bajaj, A.; Jha, A.; Vashisth, L.; Tripathi, K. Comparative Wavelet and MFCC Speech Emotion Recognition Experiments on the RAVDESS Dataset. Math. Stat. Eng. Appl. 2022, 71, 1288–1293. [Google Scholar]
- Mengash, H.A.; Alruwais, N.; Kouki, F.; Singla, C.; Abd Elhameed, E.S.; Mahmud, A. Archimedes Optimization Algorithm-Based Feature Selection with Hybrid Deep-Learning-Based Churn Prediction in Telecom Industries. Biomimetics 2023, 9, 1. [Google Scholar] [CrossRef] [PubMed]
- Yao, L.; Yang, J.; Yuan, P.; Li, G.; Lu, Y.; Zhang, T. Multi-Strategy Improved Sand Cat Swarm Optimization: Global Optimization and Feature Selection. Biomimetics 2023, 8, 492. [Google Scholar] [CrossRef] [PubMed]
- Sun, L.; Li, Q.; Fu, S.; Li, P. Speech emotion recognition based on genetic algorithm–decision tree fusion of deep and acoustic features. ETRI J. 2022, 44, 462–475. [Google Scholar] [CrossRef]
- Yogesh, C.; Hariharan, M.; Ngadiran, R.; Adom, A.H.; Yaacob, S.; Polat, K. Hybrid BBO_PSO and higher order spectral features for emotion and stress recognition from natural speech. Appl. Soft Comput. 2017, 56, 217–232. [Google Scholar]
- Garain, A.; Ray, B.; Giampaolo, F.; Velasquez, J.D.; Singh, P.K.; Sarkar, R. GRaNN: Feature selection with golden ratio-aided neural network for emotion, gender and speaker identification from voice signals. Neural Comput. Appl. 2022, 34, 14463–14486. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Description | Features |
|---|---|---|
| Gender | Pitch | max, min, median, mean, variance and derivatives |
| Emotion | PCM loudness | max, min, median, mean, variance and derivatives |
| MFCC [0–14] | max, min, median, mean, variance, derivatives, and their corresponding first-order delta coefficients (FDE) of smooth low-level descriptors | |
| log Mel Freq. Band [0–7] | skewness, kurtosis, max, min, median, mean, variance, derivatives, and FDE | |
| LSP Frequency [0–7] | max, min, median, mean, variance, derivatives, and FDE | |
| F0 by Sub-Harmonic Sum | lin. regression error Q/A-, max, min, median, mean, variance, derivatives, and FDE | |
| F0 Envelope quartile | quartile—1/2/3, max, min, median, mean, variance, derivatives, and FDE | |
| Voicing Probability | quartile range—2-1/3-2/3-1, max, min, median, mean, variance, derivatives, and FDE | |
| Jitter local | percentile 1/99, max, min, median, mean, variance, derivatives, and FDE | |
| Jitter DDP | percentile range 99-1, max, min, median, mean, variance, derivatives, and FDE | |
| Shimmer local | up-level time—75/90, max, min, median, mean, variance, derivatives, and FDE |
| Algorithms | Main Parameters |
|---|---|
| GA | pC = 1; mu = 0.02; |
| IGA | mu = 0.02; |
| BBO_PSO | pMutation = 0.1; KeepRate = 0.2; |
| MA | mu = 0.01; DANCE = 5; fl = 1 |
| Datasets | MA | BBO_PSO | GA | IGA |
|---|---|---|---|---|
| CREMA-D | 0.6890 | 0.6181 | 0.5923 | 0.6569 |
| EmergencyCalls | 0.6703 | 0.6077 | 0.6400 | 0.7471 |
| IEMOCAP-S1 | 0.5671 | 0.4819 | 0.4928 | 0.6023 |
| RAVDESS | 0.6821 | 0.6532 | 0.5852 | 0.6838 |
| >/≈/< | 1/1/2 | 0/0/4 | 0/0/4 | 3/0/0 |
| Rank | 1.75 | 3.75 | 3.25 | 1.25 |
| p-Value | 0.0169 |
| Dataset | MA | BBO_PSO | GA | IGA | ||||
|---|---|---|---|---|---|---|---|---|
| Length | Time | Length | Time | Length | Time | Length | Time | |
| CREMA-D | 317.4 | 40,543.1062 | 253.6 | 48,106.5402 | 461.1 | 20,755.5475 | 197.2 | 12,860.7447 |
| EmergencyCalls | 318.4 | 1433.4570 | 240.8 | 932.8905 | 482.65 | 706.4227 | 197.65 | 577.1138 |
| IEMOCAP-S1 | 318.35 | 9930.3462 | 243.65 | 9985.9357 | 485.9 | 5127.9112 | 188.75 | 3476.7207 |
| RAVDESS | 319.95 | 8491.6366 | 245.45 | 6492.9197 | 492.3 | 4143.9636 | 193.5 | 2612.5911 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yue, L.; Hu, P.; Zhu, J. Gender-Driven English Speech Emotion Recognition with Genetic Algorithm. Biomimetics 2024, 9, 360. https://doi.org/10.3390/biomimetics9060360
Yue L, Hu P, Zhu J. Gender-Driven English Speech Emotion Recognition with Genetic Algorithm. Biomimetics. 2024; 9(6):360. https://doi.org/10.3390/biomimetics9060360
Chicago/Turabian StyleYue, Liya, Pei Hu, and Jiulong Zhu. 2024. "Gender-Driven English Speech Emotion Recognition with Genetic Algorithm" Biomimetics 9, no. 6: 360. https://doi.org/10.3390/biomimetics9060360
APA StyleYue, L., Hu, P., & Zhu, J. (2024). Gender-Driven English Speech Emotion Recognition with Genetic Algorithm. Biomimetics, 9(6), 360. https://doi.org/10.3390/biomimetics9060360