Abstract
Population-based metaheuristics can be seen as a set of agents that smartly explore the space of solutions of a given optimization problem. These agents are commonly governed by movement operators that decide how the exploration is driven. Although metaheuristics have successfully been used for more than 20 years, performing rapid and high-quality parameter control is still a main concern. For instance, deciding the proper population size yielding a good balance between quality of results and computing time is constantly a hard task, even more so in the presence of an unexplored optimization problem. In this paper, we propose a self-adaptive strategy based on the on-line population balance, which aims for improvements in the performance and search process on population-based algorithms. The design behind the proposed approach relies on three different components. Firstly, an optimization-based component which defines all metaheuristic tasks related to carry out the resolution of the optimization problems. Secondly, a learning-based component focused on transforming dynamic data into knowledge in order to influence the search in the solution space. Thirdly, a probabilistic-based selector component is designed to dynamically adjust the population. We illustrate an extensive experimental process on large instance sets from three well-known discrete optimization problems: Manufacturing Cell Design Problem, Set covering Problem, and Multidimensional Knapsack Problem. The proposed approach is able to compete against classic, autonomous, as well as IRace-tuned metaheuristics, yielding interesting results and potential future work regarding dynamically adjusting the number of solutions interacting on different times within the search process.
MSC:
68T05; 68T02; 68R05
1. Introduction
Metaheuristics (MH) correspond to a heterogeneous family of algorithms, and multiple classifications have been proposed, such as single-solution, population-based, and nature-inspired []. In addition, it is well-known that the tuning of their key components, such as movement operators, stochastic elements, and parameters, can be the objective of multiple improvements in order to achieve a better performance. In this regard, dynamically adjusting parameters such as the population size is an important topic to the scientific community, which focuses its research on the employment of population-based approaches in order to solve hard optimization problems. This parameter can be considered as one of the most transversal issues to be defined on population-based algorithms. Nevertheless, it can be illustrated that this issue can be the most difficult parameter to settle on MH []. Moreover, the real impact behind the number of agents has been rarely addressed and proved to depend on several scenarios []: for instance, variants designed to perform in a particular study case, approaches designed to perform on a specific application, and approaches designed to tackle high-dimensional problems. Thus, in order to improve the arduous task in controlling this parameter, we propose a novel self-adaptive strategy, which aims to dynamically balance the amount of agents by analyzing the dynamic data generated on run-time solving different discrete optimization problems. In the literature, this kind of strategy has developed a solid foot in the optimization field, and in particular on evolutionary algorithms, where the generalized ideas include convergence optimization, global search improvements, and high affinity on parallelism, among others [,,,]. For instance, it is well-known that the harmony search algorithm has drawbacks such as falling in local optima and premature convergence. However, these issues have been tackled by improvements on its internal components, data management, tuning parameters, and search process [,,]. The real well-known issue which exists to this day concerns the proposition of tailored/fitted solutions focused to perform under certain conditions, constrained to a defined environment, tackling a clear objective, and a specific problem or even specific instances within a problem []. Moreover, in the literature there exist a wide number of proposed MH. However, a recurrent scenario is that most advances and improvements proposed in the state-of-the-art are focused on well-known algorithms, such as the works regarding the population size and other parameters in Particle Swarm Optimization (PSO) [,,]. In this context, the proposed approach, named Learning-based Linear Population (LBLP), aims for an improvement in the performance achieved by a pure population-based algorithm thanks to the influence given by the incorporation of a learning-based component balancing the agents on run-time. In addition, the interaction between MH and Machine Learning (ML) has attracted massive attention from the scientific community given the great results yielded on their respective fields [,,,,].
The design proposed in this work includes the definition of three components which are mainly based on ideas and techniques from the optimization and ML fields []. In this context, the first component focuses on the management of major issues concerning population-based related tasks, such as generation of the initial population, intensification, diversification, and binarization. In this first attempt, we employ the Spotted Hyena Optimizer (SHO) algorithm [], which has proved to be a good option solving optimization problems [,,,,,]. Regarding the second component, the main objective is the management of the dynamic data generated. This component includes two major tasks, which are the management of the data-structures behind LBLP and the management of the learning-based method. The learning process is carried out by a statistical modeling method ruled by the means of multiple linear regression. In this context, the process in control of the population size will be influenced by the knowledge generated through this process. The third proposed component concerns the management of parameters and agents used by LBLP while carrying out the solving process. In this regard, three major tasks are performed through the search process, the selection mechanism, control of probabilities, and increase/decrease of solutions within the population. The objective behind the selection mechanism includes the proper choice of a population size to perform for a certain amount of iterations on run-time. The design behind the mechanism follows a Monte Carlo simulation strategy. The second task concerns the control of parameters such as the probabilities employed. In addition, the third task carries out the generation-increase and the removal of solutions.
In order to test the performance and prove the viability or our proposed hybrid approach, we solve three well-known optimization problems, named the Manufacturing cell design problem (MCDP) [], the Set covering problem (SCP) [], and the Multidimensional knapsack problem (MKP) []. The illustrated comparison is carried out in a three-step experimentation phase. Firstly, we carry out a performance comparison against reported results yielded by competitive state-of-the-art algorithms. Secondly, we compare against a pure implementation of SHO assisted by IRace, which is a well-known parameter tuning method []. Thirdly, we compare the results obtained by the pure implementation of SHO vs. our proposed hybrid. Finally, we illustrate the interesting experimental results and discussion, where the proposed LBLP achieves good performance, proving to be a good and competitive option to tackle hard optimization problems.
The main contributions and strong points in the proposal can be described as follows.
- Robust self-adaptive hybrid approach capable of tackling hard optimization problems;
- Online-tuning/Control of a key issue in population-based approaches: Adapting population size on run-time;
- The hybrid approach successfully solved multiple hard optimization problems: In the experimentation phase, great results were achieved solving the MCDP, SCP, and MKP by employing an unique set of configuration values;
- Scalability in the first component designed: This work proved great adaptability given to the employed population-based algorithm. This allows the incorporation of several movement operators from different population-based algorithms in order to be instantiated by the approach to perform (parallel approach);
- Scalability in the third designed component: This work demonstrated significant benefits derived from the dynamic data generated through the search. The proposed design allows for the incorporation of different techniques, such as multiple supervised and deep learning methods.
The rest of this paper is organized as follows. The related work is introduced in Section 2. In Section 3 we illustrate the proper background in order to fully understand the proposed work and optimization problems solved. The proposed hybrid approach is explained in Section 4. Section 5 illustrates the experimental results. Finally, we conclude and suggest some lines of future research in Section 6.
2. Related Work
The proposed self-adaptive strategy has been designed by the interaction of multiple components from the optimization and machine learning field. In the literature, this kind of proposal has been known as hybrid approaches, which aims to incorporate knowledge from data and experience to the search process while solving a given problem. This line of investigation has received noteworthy attention from the scientific community and multiple taxonomies have been reported [,].
Preliminary works concerning machine learning at the service of optimization methods has been a trendy approach in recent years. In Ref. [], a hybrid approach conformed by TS and Support Vector Machine (SVM) was proposed. The objective was to design an approach capable of tackling hard combinatorial optimization problems, such as Knapsack Problem (KP), Set Covering Problem (SCP), and the Traveling Salesman Problem (TSP). The proposed hybrid defined decision rules from a corpus of solutions generated in a random fashion, which were used to predict high quality solutions for a given instance and lead the search. However, the complexity behind the designed approach is a key factor and authors highlight the arduous and time consuming tasks, such as the knowledge needed to build the corpus, and the extraction of the classification rules. In addition, more recent hybrids that integrate self-adaptive strategies in their process have been receiving significant attention given the achieved results. In Ref. [], an ensemble learning model focused on detecting fake news was proposed. This hybrid includes off-line process and online process. The authors proposed the incorporation of a self-adaptive harmony search at the off-line process in order to modify the weight of four defined training models based on different CNN versions. However, the issues persist to this end, such as computation complexity, resources, and solutions being tailored for an specific objective.
The objective behind the proposed approach concerns the improvement in the performance of a pure population-based algorithm based on the proper control of parameters []. This work gives emphasis on the population size value, which is well-known for being a key parameter defined by all swarm-based approaches. In this regard, similar objectives can be observed in Refs. [,], where the authors proposed two hybrids that follow the same objective. The approaches employ Autonomous Search (AS) to assist the MH Human Behavior-Based Optimizer (HBBO) and SHO, respectively. AS is described as a reactive process that lets the solvers automatically reconfigure their parameters in order to improve when poor performances are detected. Nevertheless, data-driven hybrids that follow an equal objective are scarce. Currently, the body research related to this work focuses on classification, clustering, and data mining techniques. In this context, the authors in Ref. [] proposed a hybrid framework based on the Co-evolutionary Genetic Algorithm (CGA) supported by machine learning. They employed inductive learning methods from a group of elite populations in order to influence the population with lower fitness. Their objective was to achieve a constant evolution of agents with low performance through the search. The learning process was carried out by the C4.5 and CN2 algorithms in order to perform the classification. Regarding data mining-based approaches, in Ref. [], a hybrid version of ant colony optimization that incorporates a data mining module to guide the search process was proposed. Regarding the usage of clustering-based methods, Streichert et al. [] proposed the clustering-based nitching method. The main objective behind the proposed approach was to identify multiple global and local optima in a multimodal search space. The model is employed over well-known evolutionary algorithms, and the aim of the model was the preservation of diversity using a multi population approach.
The proposed hybrid brings inspiration from multiple ideas described as follows. Firstly, we propose a hybrid approach that is capable of solving different optimization problems. In addition, the main objective concerns the design of a self-adaptive strategy in order to dynamically adjust and control a key parameter such as the population size on population-based approaches. In this regard, we detected a scarce number of illustrated works that focus their efforts on this issue. In the literature, the objective of most proposed works concern the tuning of parameters. The values are adjusted before the execution of the algorithm, usually through a number of previous runs. However, the proposed work adjusts the parameter values on-the-fly. In this context, a control method chooses a set of values for the optimization algorithm to perform in a given amount of time. The performance achieved is properly measured. Thus, the control method is able to know how good that choice was. These steps are repeated, and the aim is to maximize the chances of success by making the best decisions in the optimization process. On the other hand, although there is a clear presence of well-known learning-based methods such as clustering and classification, regression analysis is hardly employed, leaving out highly potential models that can tackle the presented issue. Lastly, we highlight the promising results obtained by solving three different hard optimization problems, which are illustrated in Section 5. In this regard, most proposed approaches in the literature are problem-oriented. Nevertheless, one of our objectives is for the proposed approach to be nature-friendly for the given problem. Thus, with the presented results a promising contribution to the field is illustrated.
3. Background
In this section, we review essential topics needed in order to fully understand the proposed hybrid. Firstly, the main features of population-based methods are presented, followed by the description of the employed SHO algorithm. Secondly, the detailed description of the proposed problems solved in this work are illustrated.
3.1. Metaheuristics
The MHs can be described as general-purpose methods that have great capabilities to tackle optimization problems []. This heterogeneous family of algorithms has been the focus of several works as a consequence of their attractive features such as the capability to tackle hard optimization problems in a finite computational time, achieving close-to-optimal solutions []. In the literature, subgroups from this family have been identified thanks to different criteria given the features of the proposed algorithms. Firstly, single solution algorithms were designed to carry out the transformation of a single solution during the search. Well-known examples are the local search [], simulated annealing [], etc. On the other hand, population-based algorithms focus on the transformation of multiple solutions during the search. In this context, all the agents/solutions in the population interact between them and evolve. Well-known algorithms are the shuffle frog leaping algorithm [], ant colony optimization [], gray wolf optimizer [], and so on. Another big family of proposed algorithms consist of nature-inspired approaches. They are born as metaphors that define their behaviors on the basis of nature. For instance, the genetic algorithm [], memetic algorithm [], and differential evolution []. Additionally, an inverse phenomena can be described for non-natural algorithms, such as imperialist competitive algorithm [], and several subgroups of algorithms designed from multiple fields, such as music, physics, and so on. However, all the proposed algorithms in this heterogeneous family share between them equal concepts in their design, such as ideas, components, parameters, and so on.
3.1.1. Spotted Hyena Optimizer
In this work, we employ the SHO algorithm, which is a population-based MH that follows clustering ideas in their performance and has proved to be a good option for solving optimization problems. The main concept behind this algorithm is the social relationship between spotted hyenas and their collaborative behavior, which was originally designed to optimize constraint and unconstrained design problems. Regarding the description and equations of the movement operators, at the beginning, encircling prey is applied. The objective is to update the position of each agent towards the current best candidate solution in the population. In order to carry out the perturbation on each agent, we employ Equations (1) and (2). In (1), is the distance between the current agent (P) and the actual best agent in the population (). In addition, in Equation (2), we compute the update of the current agent. In both equations, B and E correspond to co-efficient vectors; they are computed as illustrated in Equations (3) and (4), where and are random [0, 1] vectors.
The second movement employed is named hunting. The main objective is to influence the decision regarding the next position of each agent and the main idea is to compose a cluster towards the current best agent. In order to carry out this movement, we employ Equations (6)–(8). In (6) and (7), represents the distance, represents the actual best agent in the population, and the current agent being updated. Equation (7) illustrates the data-structure that contains the population clustered, where N indicates the number of agents.
Attacking the prey is illustrated as the third movement employed. This operator concerns the exploitation of the search space. In (9), each agent belonging to the cluster , generated in (8), will be updated.
The fourth movement concerns the performance of a passive exploration. The proposed SHO performs with B and E as co-efficient with random values to force the agents to move far away from the actual best agent in the population. This mechanism improves the global search of the approach. Additionally, SHO was initially designed to work on a continuous space. In order to tackle the MCDP, SCP, and MKP, a transformation of domain is needed and this process is illustrated in the next subsection.
3.1.2. Domain Transfer
In the literature, continuous population-based MH have proved to be very effective in tackling several high complex optimization problems []. Currently, the increment in complexity of binary modern industrial problems have pushed new challenges to the scientific community, which have ended up proposing continuous methods as potential options to tackle this domain. For instance, Binary Bat Algorithm [], PSO [], Binary Salp Swarm Algorithm [], Binary Dragonfly [], and Binary Magnetic Optimization Algorithm [], among others [,,]. In order to carry out the transformation, binarization strategies have been proposed []. In this regard, a well-known employed strategy concerns the Two-step binarization scheme, which as the name implies, is composed of a two step process where transformation and binarization is performed. Firstly, transfer functions were introduced to the field in Ref. [] with the aim to give a probability between 0 and 1 employing low computational resources. Thus, transfer functions, illustrated in Table 1, are applied to the values generated by the movement operator from the continuous MH. This process achieves these values to be in the range between 0 and 1. Secondly, the application of binarization is carried out, which focuses on the value discretization applied to the output values from the first step. This process decides for a binary value (0 or 1) to be selected. In this regard, classic methods have been described as follows:

Table 1.
Transfer function.
- Standard: If the condition is satisfied, standard method returns 1, otherwise returns 0.
- Complement: If the condition is satisfied, standard method returns the complement value.
- Static probability: A probability is generated and evaluated with a transfer function.
- Elitist Discretization: Method Elitist Roulette, also known as Monte Carlo, consists of selecting randomly among the best individuals of the population, with a probability proportional to its fitness.
In this work, the two-step strategy employed consists of the transfer function and the elitist discretization.
3.2. Optimization Problems
In this subsection we illustrate a detailed explanation of the three optimization problems tackled by our proposed LBLP.
3.2.1. Manufacturing Cell Design Problem
The Manufacturing Cell Design Problem (MCDP) [] is a classical optimization problem that finds application in lines of manufacture. In this regard, the MCDP consists of organizing a manufacturing plant or facility into a set of cells, each of them made up of different machines meant to process different parts of a product that have similar characteristics. The main objective is to minimize the movement and exchange of material between cells in order to reduce the production costs and increase productivity. The optimization model is stated as follows. Let:
- M—the number of machines;
- P—the number of parts;
- C—the number of cells;
- i—the index of machines (i = 1, …, M);
- j—the index of parts (j = 1, …, P);
- k—the index of cells (k = 1, …, C);
- —the binary machine-part incidence matrix M × P;
- —the maximum number of machines per cell. We selected as the objective function to minimize the number of times that a given part must be processed by a machine that does not belong to the cell that the part has been assigned to. Let:
The problem is represented by the following mathematical model:
Subject to
In this work, we solved a set of 35 instances from different authors. Each instance has its own configuration, the amounts of machines goes from 5 to 40, parts goes from 7 to 100, and so on. For this experiment, the instances tested have been executed 30 times.
3.2.2. Set Covering Problem
The set covering problem (SCP) is one of the well-known Karp’s 21 NP-complete problems, where the goal is to find a subset of columns in a 1-0 matrix so that they cover all the rows of the matrix at a minimum cost. Several applications of the SCP can be seen in the real world, for instance, bus crew scheduling [], location of emergency facilities [], and vehicle routing []. The formal definition is presented as follows. Let m × n be a binary matrix A = () and a positive n-dimensional vector C = (), where each element of C gives the cost of selecting the column j of matrix A. If is equal to 1, then it means that the row i is covered by column j, otherwise it is not. The goal of the SCP is to find a minimum cost of columns in A such that each row in A is covered by at least one column. A mathematical definition of the SCP can be expressed as follows:
where is 1 if column j is in the solution, otherwise it is 0. The constraint ensures that each row i is covered by at least one column. In this work, we solved 65 different instances, which have been organized into 11 sets extracted from the Beasley’s ORlibrary. The employed instances were pre-processed in order to reduce the size and complexity. In this context, multiple pre-processing methods have been proposed in the literature for the SCP []. In this work, we used two of them, which have proved to be the most effective: Column Domination (CD) and Column Inclusion (CI). Firstly, the definition of CD concerns a set of rows being covered by another column and <. We then say that column j is dominated by , and column j is removed from the solution. Second, in CI, the process is described as when a row is covered by only one column after the CD is applied. This means that there is no better column to cover those rows, and therefore this column must be included in the optimal solution. For this experiment, the test instances have been executed 30 times.
3.2.3. Multidimensional Knapsack Problem
Multidimensional Knapsack Problem (MKP) is NP-hard and can be considered as the generalized form of the classic Knapsack Problem (KP). The goal of MKP is to search for a subset of given objects that maximize the total profit while satisfying all constraints on resources. In addition, the KP is a widely-used problem with real-world applications in diverse fields including cryptography, allocation problems, scheduling, and production [,]. The model can be stated as follows.
where n is the number of items and m is the number of knapsack constraints with capacities . Each item j requires units of resource consumption in the ith knapsack and yields units of profit upon inclusion. The goal is to find a subset of items that yields maximum profit without exceeding the resource capacities. In this work, we solved 6 different set instances from the Beasley’s ORlibrary. The details concerning the solved benchmark is illustrated in Table 2.
Table 2.
Configuration details from MKP instances employed in this work.
4. Proposed Hybrid Approach
In this section we describe the details concerning the proposed hybrid: the main ideas, motivations, and design. Firstly, a general description of the process carried out is presented. In Section 4.2 we describe a more detailed methodology behind LBLP. Section 4.3, describes the main ideas, objectives, and techniques employed in the design of the proposed components. Finally, Section 4.4 illustrates the proposed algorithms.
4.1. General Description
The proposed LBLP follows a population-based solving strategy, which concerns multiple agents evolving in the solution space, intensification and diversification are performed, and the process is terminated when a threshold defined as an amount of iteration is met. Dynamically the adjusting parameters, especially population size, is an important topic that continues to be of growing interest to the natural computation community. In Ref. [], the authors carried out a complete analysis of different implementations of PSO in order to define the perfect number of agents to perform. However, they highlighted that the same configuration will not necessarily fit each optimization problem or even each instance of the same problem. In this proposal we employ a population-based algorithm and consequently improve the performance by modifying the population size on run-time. This proposed modification is designed by the means of a learning component based on regression, which transforms all the yielded results employing different population sizes during solving time. Thus, the modifications are managed based on the possible best performance that can be achieved by employing a certain size as a population value. In this context, this whole process is governed by two parameters that are used as thresholds in order to carry out different tasks for LBLP: (1) The instance for a new population size to perform and (2) the instance when the knowledge needs to be generated. The first threshold is named , which decides when the selection process will be carried out. This process will be selecting a suitable population size to perform. The second proposed parameter is named , which manages when the regression analysis needs to be performed. The steps comprehending the proposed LBLP are described as follows:
- Step 1:
- Set the initial parameters for the population-based algorithm and the regression analysis.
- Step 2:
- Select the initial population size to perform.
- Step 3:
- Generate initial population.
- Step 4:
- while the termination criteria is not met.
- Step 4.1:
- Carry out intensification and diversification on the population.
- Step 4.2:
- Management of dynamic data generated.
- Step 4.3:
- Check if amount of iteration has been met.
- Step 4.3.1:
- Perform regression analysis.
- Step 4.3.2:
- Management knowledge generated.
- Step 4.4:
- Check if amount of iteration has been met.
- Step 4.4.1:
- Perform the selection mechanism.
- Step 4.4.2:
- Perform the balance of population.
- Step 4.5:
- Update the population-based algorithm’s parameters.
4.2. Methodology
The proposed LBLP defines four different population sizes as schemes to be selected to perform during the search. The initial probability given to each scheme to be selected is equally defined. For instance, if we configure four different size values, their initial probability to be picked corresponds to 0.25. Thus, at iteration 1, the selection mechanism (given by the Roulette selector component) will be choosing a scheme, and this selected value is the one to be performed in the next iterations. In addition, in each iteration, the component managing the movement operators (given by the Driver component) will be sequentially carrying out diversification and intensification within the agents on the search space. This process generates dynamic data on each iteration that is sorted and stored, and this recollected data will be processed when the threshold is met, where regression is applied and knowledge is generated. This learning process concerns the results yielded by the regression and the value interpretations, where the scheme with the best computed forecasting fitness value is selected and rewarded as the winner. In this regard, if this probability is selected it will be boosted by the model.
4.3. LBLP Components
In this subsection, we present a detailed explanation and definition of each component proposed in our first attempt designing LBLP.
4.3.1. Component 1: The Driver
The solving strategy employed by the proposed hybrid follows a population-based design. This component brings inspiration from the optimization field in order to search in the solution space of a given problem. The objective behind this component includes the generation of initial/new population (solutions), intensification, diversification, and binarization. In this first attempt proposing LBLP, we employ SHO mostly because it can be identified as a modern MH, outside of the well-known PSO, differential evolution, and genetic algorithms. In addition, the selection was based on the expertise of the research team. Nevertheless, in future upgrades, the incorporation of several algorithms smartly-selected to perform on run-time will be considered. Regarding the domain transfer process, the driver will be carrying the two-step strategy over the solutions generated. The strategy performed was function and the elitist discretization, which has already been proved to perform.
4.3.2. Component 2: Regression Model
This component is the key factor in LBLP. It concerns the analysis, storage, and decision making over the dynamic data generated. In this regard, while a scheme is performing, the regression model will be storing and indexing their respective fitness values achieved. Concerning the data-structure employed, in this work they were designed as vectors, but a more generalized description is presented as follows.
where stores the fitness values reached by the agents of each scheme performed. concerns the data-structure with the probabilities for each scheme to be selected. represents the data-structure which stores the corresponding solutions for each regression analysis carried out. The data-structure concerns the ranking for each scheme regarding the best values reached. In addition, d represents the number of schemes designed to be employed by LBLP. Regarding the regression analysis, it is carried out by the means of linear regression, where the fitted function is of the form:
where y corresponds to the dependent variable, which is the fitness and value to predict. x represents the independent variable, which corresponds to the scheme performed. In this simple linear regression model, we present the close relationship between the performance and population size, which is employed through search. Regarding our proposed learning-model, we define four fitted functions for each scheme defined in this work, and they are represented as follows.
In order to solve these functions, we employ the least squares method which is a well-known approach used in the regression field. The outputs of the mentioned analysis goes to , where in order to select the winner scheme the model takes the following decision:
where the probabilities concerning each scheme, stored in , will be updated taking in consideration Equation (15) and . Thus, this process will be addressed by the selection of the best prognostic regarding fitness defined by the four linear models, and the best result will be given “priority”. A practical example can be described as follows: At the beginning, in each iteration, the approach will select a scheme using a probabilistic roulette. For a four-way scheme, the initial probabilities for each scheme to be selected was in a 25%–25%–25%–25% ratio. Additionally, the regression model is always storing and sorting the fitness values and agents on run-time. When the threshold is met, Equation (15) analyses the prognostic achieved and gives the winning scheme a higher probability to be chosen. For instance, we designed a ratio of 55%–15%–15%–15%.
4.3.3. Component 3: Roulette Selector
The idea associated behind this component corresponds to a roulette system, where the main objective concerns the probabilistic selection mechanism behind the agents performing on run-time. In this work, a 4-way scheme defining 4 different population sizes (20, 30, 40, and 50 agents) is employed. In the literature, the perfect number of agents to be employed has been an everlasting discussion within the scientific community. In this context, in Ref. [], the reasoning for the selection goes after the complexity such as the high-dimensional or unimodal problems, a designed topology of the proposed approach, and for approaches tackling very large tasks. Thus, the definition of this parameter value concerns an adjusting-testing process. In this work we follow the first standard recommendation given by the authors, which is between 20 and 50 agents. In future upgrades to be proposed for LBLP, new configuration will be employed.
Regarding the selection mechanism, the schemes are placed and selected by their assigned probabilities. The initial probability of each scheme to be selected is defined as follows.
where N corresponds to the number of schemes designed for the approach. Thus, in a 4-way scheme they are described as follows.
The probabilities for each scheme will be modified by the regression model after the corresponding analysis on the dynamic data generated is carried out on run-time.
4.4. Proposed Algorithm
In this section, we illustrate a detailed description of the proposed Algorithm 1.
| Algorithm 1 Proposed LBLP |
|
5. Experimental Results
In this section, we describe the experimentation process carried out to evaluate the performance of our proposed LBLP. In this context, a two-step experimentation phase was designed in order to test the competitiveness. Firstly, we compare against state-of-the-art algorithms solving the MCDP, SCP, and MKP. In the second step, we compare the results obtained by our LBLP against implementations based in SHO + IRace, and classic SHO. Additionally, the results are evaluated using the relative percentage deviation (). The quantifies the deviation of the best value obtained by the approach from for each instance. The configuration employed is illustrated in Table 3, and we highlight the good performance achieved.
Table 3.
The second experimentation phase’s configuration parameters for LBLP, Classic SHO, and Classic SHO + IRace.
5.1. First Experimentation Phase
As mentioned before, this subsection illustrates a detailed comparison and discussion of the performance achieved by LBLP against reported data from state-of-the-art algorithms for each problem.
5.1.1. Manufacturing Cell Design Problem
In this comparison, we employ the reported results illustrated by Binary Cat Swarm Optimization (BCSO) [], Egyptian Vulture Optimization Algorithm (EVOA), and the Modified Binary Firefly Algorithm (MBFA) []. In order to have a deeper sample of algorithms related to the proposed work, we also include a Human Behavior-Based Algorithm supported by Autonomous Search approach [], which focuses on the control of the population size on run-time. In addition, to compare and understand the results, we highlighted in bold the best result for each instance when the optimum is met.
Table 4 illustrates the comparison of the reported results, and the description is as follows. The first column ID represents the identifier assigned to each instance. The depicts the global optimum or best value known for the given instance. Column Best, Mean, and are the given values for best value reached, the mean value of 30 executions, and the relative percentage deviation correspondingly for each approach. Regarding the performance comparison, the lead is clearly dominated by BCSO and the proposed LBLP. Analyzing the values reported in column Best, BCSO gets all 35 best values known, in comparison to 25 values for LBLP. In addition, concerning the median values for column Best in all the instances, LBLP can be placed in second place with 35.14 and the algorithm with the best performance reported is BCSO, which has a median value of 34.51. In this regard, far behind follows MBFA, EVOA, and HBBO-AS which computed 42.54, 50.83, and 55.03 respectively. On the other hand, concerning the median value for column Mean, the proposed LBLP gets first place with 36.00 against a 36.61 reached by BCSO. This can be interpreted as being more robust and consistent in the reported performance. Moreover, we highlight that in several results, the proposed LBLP remains close to the best values known for those instances, which gives room for future improvements. Thus, the overall observations can be described as follows. LBLP does not fall behind against state-of-the-art algorithms specially designed to tackle the MCDP. In addition, the proposed approach achieved better results than HBBO-AS, which can be interpreted as how a population-based approach makes great profit due to the adaptability given by statistical modeling methods.
Table 4.
Computational results achieved by LBLP and state-of-the-art approaches solving the MCDP.
5.1.2. Set Covering Problem
In this comparison, we made use of the reported results illustrated by binary cat swarm optimization (BCSO) [], binary firefly optimization (BFO) [], binary shuffled frog leaping algorithm (BSFLA) [], binary artificial bee colony (BABC) [], and binary electromagnetism-like algorithm (BELA) []. In addition, we highlighted in bold the best result for each instance when the optimum is met.
Table 5 illustrates the comparison of results achieved by LBLP against the state-of-the-art algorithms specially designed to tackle the SCP; the description is as follows. The column ID represents the identifier assigned to each instance. The depicts the global optimum or best value known for the given instance. Column Best, Mean, and are the given values for the best value reached, the mean value of 30 executions, and the relative percentage deviation correspondingly for each approach. Regarding the performance comparison, between the six approaches the lead is carried by LBLP. In this regard, a closer observation to the median values can be interpreted as follows. The proposed approach achieved the smallest value for column Best and Mean with 197.31 and 199.75, correspondingly. Moreover, the overall performance in the hardest sets of instances, such as groups F, G, and H, is pretty good as we analyzed the RPD values in comparison to BCSO and BELA. We highlight that in several results the proposed LBLP remains close to the best values known for those instances, encouraging us to continue working and further improve our method.
Table 5.
Computational results achieved by LBLP and state-of-the-art approaches solving the SCP.
5.1.3. Multidimensional Knapsack Problem
Regarding the MKP, the state-of-the-art algorithms employed include the filter-and-fan heuristic (F& F) [], Binary version of the PSO algorithm (3R-BPSO) [], and a hybrid quantum particle swarm optimization (QPSO) algorithm []. These approaches were defined in the literature as specifically designed methods to effectively tackle the MKP, and a certain degree of adaptability was designed into their search process on run-time. For instance, the 3R-BPSO algorithm employs three repair operators in order to fix infeasible solutions generated on run-time. In addition, if the results of an algorithm for a set of benchmark instances are not available, the algorithm will be ignored in the comparative study, for instance, 3R-BPSO in mknapcb2 and mknapcb5. In order to compare and understand the results, we highlighted in bold the best result for each instance when the optimum is met.
Table 6 illustrates the reported performance by the state-of-the-art approaches vs. LBLP. The column ID represents the identifier assigned to each instance. The depicts the global optimum or best value known for the given instance. Column Best, Mean, and are the given values for the best value reached, the mean value of 30 executions, and the relative percentage deviation correspondingly for each approach. Regarding the performance comparison, QPSO and LBLP lead the ranking by the reported performance. The QPSO approach reported a total of 21 best known values and LBLP reached 20 optimum values out of 30. However, observing the median values for column best, the proposed LBLP falls behind even against F & F with a 67,179.10 vs. 67,438.93. In this context, this issue can be clearly observed by the RPD values, instances mknapcb2 and mknapcb5 computed 1.47% and 3.13%, respectively, for tests 5.250.04 and 10.250.04. Thus, there exists a considerable distance between the performance for those instances where the best values known is not reached by LBLP. Nevertheless, in this first attempt, LBLP proved to be a competitive approach capable of tackling multiple optimization problems. In addition, this issue encouraged us to further improve and take profit from multiple mechanisms and heuristics to be employed in the design.
Table 6.
Computational results achieved by LBLP and state-of-the-art approaches solving the MKP.
5.1.4. Overall Performance in This Phase
In this first experimentation phase, LBLP was compared against state-of-the-art approaches specially designed to tackle the MCDP, SCP, and MKP. In this context, the proposed hybrid demonstrated a competitive performance for the three different problems tested. Regarding the MCDP, LBLP achieved 25 best values known out of a total of 35, achieving second place overall; see Figure 1. Regarding the SCP, LBLP achieved 39 best values known out of 65, achieving first place; see Figure 2. In addition, it is well-known that optimization methods such as MH are designed to perform in certain environments. Thus, there exists a certain degree of uncertainty when employing such methods to tackle different types of optimization problems. For instance, we can observe the polarized performance reported by BCSO solving the MCDP and SCP. In this regard, this is one of the strong points of our proposition, as the optimization problem to be tackled is not an issue given the adaptability of our proposed LBLP. Regarding the MKP, the proposed LBLP reached second place with 20 best values known out of 30; see Figure 3. Regarding the overall performance, LBLP proved to be competitive. However, we observed an inconsistent performance solving the MKP when the optimum value was not reached. This issue can be interpreted as a consequence of LBLP not taking enough profit from the population size vs. the diversification/intensification relationship and the frequency on which knowledge is opportunely generated. In this first attempt designing LBLP, the approach works with static values for and . In this context, a first improvement can be described as the incorporation of a new learning-based component managing the values for and on demand. The objective will be to achieve higher adaptability, giving the decision to auto-assign thresholds to perform the scheme-selection mechanism and the regression analysis.
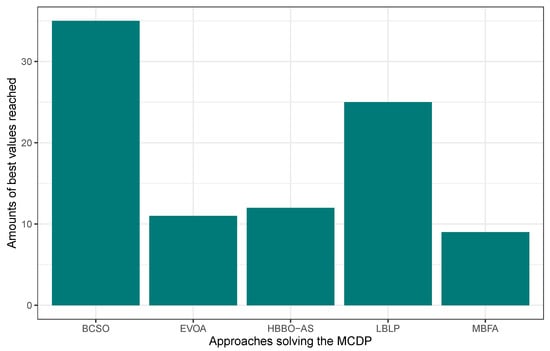
Figure 1.
Performance comparison between state-of-the-art approaches vs. LBLP tackling the MCDP.
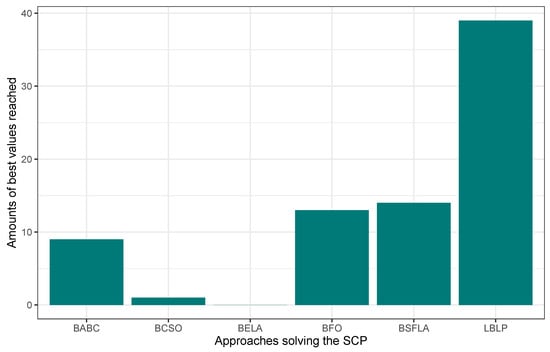
Figure 2.
Performance comparison between state-of-the-art approaches vs. LBLP tackling the SCP.
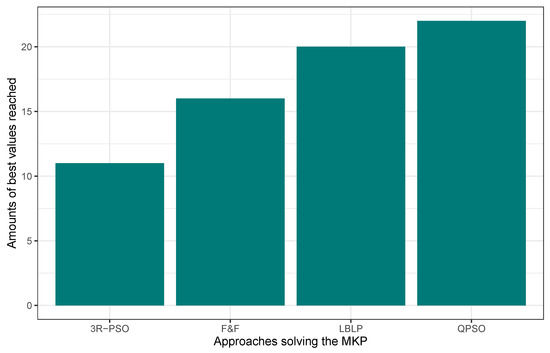
Figure 3.
Performance comparison between state-of-the-art approaches vs. LBLP tackling the MKP.
5.2. Second Experimentation Phase
In this subsection, we take a closer look at the performance achieved by classic and hybrid approaches. We compare and discuss implementations based on the classic SHO, classic SHO assisted by IRace, and the proposed LBLP. In addition, in order to further demonstrate the improvement given by hybrids in optimization tools, the Wilcoxon’s signed rank (Mann and Whitney 1947) test is carried out. We highlight the improvements, shortcomings, complexity, and robustness observed through the comparison.
5.2.1. Manufacturing Cell Design Problem
In this experimentation, Table 7 illustrates the comparison of results obtained by Classic SHO, Classic SHO assisted by IRace, and LBLP. In addition, in Table 8, a comparison against a hybrid approach is presented. This hybrid was proposed by Soto et al. in Ref. [] and includes an approach based on the interaction between the population-based human behavior-based algorithm supported by autonomous search algorithm and autonomous search (HBBO-AS), which focuses on the modification of the population. The table description is as follows: column ID represents the identifier for each instance; the depicts the global optimum or best value known for the given instance; column Best, Worst, Mean, and are the given values for best value reached, the worst value reached, the mean value of 30 executions, and the relative percentage deviation correspondingly for each approach. In order to compare and understand the results, we highlighted in bold the best result for each instance when the optimum is met.
Table 7.
Computational results achieved by LBLP, Classic SHO, and Classic SHO + IRace solving the MCDP.
Table 8.
Computational results achieved by LBLP and HBBO + AS solving the MCDP.
Regarding the overall performance of approaches related to SHO, LBLP takes the lead and Classic SHO goes in last place. If we observe the median values, LBLP obtained 35.14 in comparison to 36.09 achieved by Classic SHO, and 35.43 by Classic SHO + IRace for column best. However, Classic SHO + Irace seems to be more consistent as we observed columns Worst and Mean, where 36.37 and 35.90 were the median values achieved against 37.54 and 36.00 reached by LBLP. Nevertheless, the achieved performance can be expressed as hybrid approaches being more competitive than their respective classic algorithms. LBLP demonstrated to be a good option tackling the MCDP and rooms for improvements were observed. In order to further demonstrate the performance by hybrids solving the MCDP, a statistical analysis is carried out. Table 9 illustrates a matrix that comprehends the resulting p-values after applying the well-known Average Wilcoxon–Mann–Whitney test for all the instances corresponding to the MCDP. Thus, a p-value less than 0.05 means that the difference is statistically significant, so the comparison of their averages is valid, such as LBLP vs. SHO. Concerning the comparison between LBLP and HBBO-AS, the approach led by autonomous search falls clearly behind on all the columns presented. However, new ideas and future interaction between optimization tools are highlighted. For instance, regarding performance metrics, the main job carried out by AS was to detect low performance or repetitive values/patterns on the solution. In this context, new components based on deep learning would clearly be effective at tackling this task.
Table 9.
Average Wilcoxon–Mann–Whitney test for MCDP.
5.2.2. Set Covering Problem
In this subsection, the results obtained by the three implementations are illustrated in Table 10. The description of the table is as follows: column ID represents the identifier assigned to each instance; depicts the global optimum or best value known for the given instance; column Best, Mean, and are the given values for best value reached, the mean value of 30 executions, and the relative percentage deviation correspondingly for each approach. In order to compare and understand the results, we highlighted in bold the best result for each instance when the optimum is met.
Table 10.
Computational results achieved by LBLP, Classic SHO, and Classic SHO + IRace solving the SCP.
Regarding the best values achieved, LBLP leads with 39 followed by 23 achieved by Classic SHO + IRace, and Classic SHO with 18. This is confirmed by the median values in column best and RPD, where LBLP achieved 197.31 and 1.09, Classic SHO computed 199.89 and 2.24, and Classic SHO + IRace obtained 197.95 and 1.42. Moreover, we highlight that even in the instances where the best values are not met, LBLP stays close to the reported values and this can be corroborated by the small RPD values computed. On the other hand, two interesting phenomenons can be observed in this test. Firstly, the hybridized implementation outperforms the classic approach. In addition, the LBLP median values for column mean can be interpreted as a degree of deficit in robustness. In order to tackle this issue, new improvements will be performed over the regression model and configuration parameters. Nevertheless, LBLP reached most values known and proved to be a competitive option tackling the SCP, which has multiple opportunities to evolve and improve in future works. In order to further demonstrate the performance by hybrids solving the SCP, a statistical analysis is carried out. Table 11 illustrates a matrix that comprehends the resulting p-values after applying the well-known Average Wilcoxon–Mann–Whitney test for all the instances corresponding to the SCP. Thus, a p-value less than 0.05 means that the difference is statistically significant, so the comparison of their averages is valid, such as LBLP vs. SHO.
Table 11.
Average Wilcoxon-Mann-Whitney test for SCP.
5.2.3. Multidimensional Knapsack Problem
In this subsection, the results obtained tackling the MKP are compared and discussed. In Table 12, we illustrate the comparison of results obtained by the three implementation works. In addition, Table 13 illustrates a comparison between the proposed LBLP and LMBP, which is a hybrid architecture based on population algorithm assisted by multiple regression models []. The table description is as follows: column ID represents the identifier assigned to each instance; depicts the global optimum or best value known for the given instance; Column Best, Worst, Mean, and are the given values for the best value reached, the worst value reached, the mean value of 30 executions, and the relative percentage deviation correspondingly for each approach. In order to compare and understand the results, we highlighted in bold the best result for each instance when the optimum is met.
Table 12.
Computational results achieved by LBLP, Classic SHO, and Classic SHO + IRace solving the MKP.
Table 13.
Computational results achieved by LBLP, and LMPB solving the MKP.
Regarding the best values concerning Table 12, the implementation employing IRace leads the overall performance with median values for column Best of 67,268, followed by LBLP with 67,179, and 66,730 for classic SHO. In addition, this is corroborated by the median values computed for column RPD, and IRace achieved 0.27 against a 0.35 for the proposed hybrid. However, the phenomenon observed in this test differs completely in comparison to the ones reported in the previous subsections. The median values reported for column Mean illustrates good robustness in the overall performance of LBLP. On the other hand, the bad results illustrated by Classic SHO + IRace can be interpreted as an inconsistency in the performance and as being trapped in local optima in multiple MKP instances. In order to further demonstrate the performance by hybrids solving the MKP, a statistical analysis is carried out. Table 14 illustrates a matrix that comprehends the resulting p-values after applying the well-known Average Wilcoxon–Mann–Whitney test for all the instances corresponding to the MKP. Thus, a p-value less than 0.05 means that the difference is statistically significant, so the comparison of their averages is valid, such as LBLP vs. SHO. Regarding results in Table 13, an equal competition is observed, and LMPB is capable of achieving better values for solving instances where LBLP falls behind. Nevertheless, it is interesting to consider designing a more complete or complex learning-based component. We observed that there is no certainty in achieving a good performance with a sole technique solving all the instances. Thus, a proper answer to this issue could be presented by the design of different learning techniques.
Table 14.
Average Wilcoxon-Mann-Whitney test for MKP.
5.2.4. Overall Performance in This Phase
In this second experimentation phase, the proposed LBLP was compared against the Classic SHO and Classic SHO + IRace solving the MCDP, SCP, and MKP. The objective was to verify the improvements blending a learning-based method in the search process of a population-based strategy. In this regard, the proposed LBLP achieved good results solving the optimization problems. Figure 4, Figure 5 and Figure 6 illustrate a performance overview, which ended up corroborating the idea of profiting over dynamic data generated. On the other hand, the good performance demonstrated by Classic SHO + IRace is to be expected. IRace is an off-line method that specializes in the tuning of parameters. Regarding the complexity, users need a certain degree of expertise in R, as the scripts configuration process can be an arduous task, and the implemented optimization tool can be enhanced by IRace. Regarding the proposed approach, LBLP requires the configuration of a scheme, , and . In addition, the implementation comprehends a population-based algorithm and well-known statistical modeling methods.
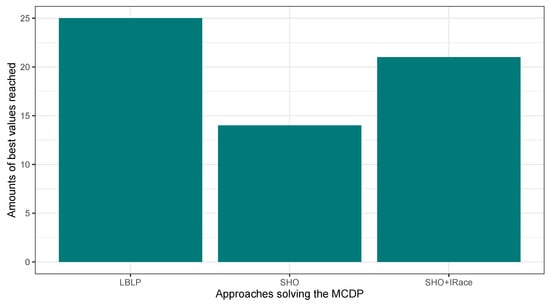
Figure 4.
Performance comparison between SHO, SHO assisted by IRace, and LBLP tackling the MCDP.
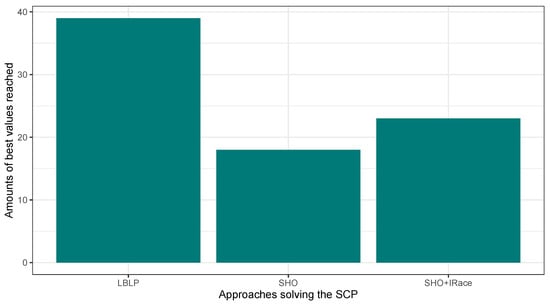
Figure 5.
Performance comparison between SHO, SHO assisted by IRace, and LBLP tackling the SCP.
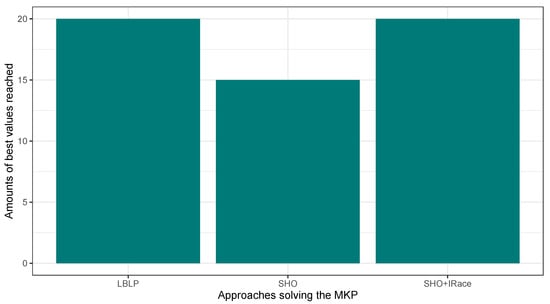
Figure 6.
Performance comparison between SHO, SHO assisted by IRace, and LBLP tackling the MKP.
Regarding the observed phenomenons, while solving the MCDP and SCP, LBLP achieved a considerable amount of best values for the column Best but falls behind for the column Mean. Nonetheless, this situation completely changed while solving the MKP. The interpretation can be described in two ways: LBLP asking for a faster response in the learning process and a more detailed configuration of the parameters. Firstly, the parameters proposed in this work are static through the search. This issue was already addressed in Section 5.1.4. Nevertheless, multiple and unexpected events may present themselves while the search is being carried out. Thus, in order for LBLP to answer properly, the first improvement needs to be done over and , which controls the scheme selection and the generation of knowledge. On the other hand, concerning the proposed scheme, 4 different values were employed that completely differ from the static values employed by Classic SHO + IRace, such as 41 and 33. In this regard, multiple options as schemes will be added and tested. For instance, 20 different schemes from 20 to 40 agents. Lastly, a more complex scenario can be designed for a further detailed mechanism to be employed by the learning model. The objective is for each defined scheme to implement different and values in order to increment the adaptiveness of LBLP.
6. Conclusions
In this work, a hybrid self-adaptive approach has been proposed in order to solve hard discrete optimization problems. The main objective was to improve the performance by transforming a general component that exists on all population-based algorithms—the population size. The proposed strategy focuses on the dynamic update of this parameter in order to give high adaptive capacities to the agents, which is governed by a learning-based component that takes profits from their dynamic data generated on run-time. Interesting facts concerning the design are described as follows. As the complexity of the learning component is not high as the statistical modeling methods employed are well-known, the main issue is the novelty in the designed mechanism taking profit of the technique. In this context, movement operators from SHO and linear regression are classic means in their respective fields to solve multiple problems. On the other hand, general complications and drawbacks can be described as follows: computational time incremented, increment of complexity based on the scalability in the designed architecture, and increment at the complexity based on the wide spectrum of optimization problems to be tackled.
Regarding the experimentation carried out, LBLP proved to be a good option in comparison to state-of-the-art methods. We solved three well-known different hard optimization problems: the MCDP, SCP, and MKP, employing a unique configuration set of parameter values for the LBLP. In this context, the first phase helped us to measure at which point LBLP was a viable optimization tool in comparison to already reported approaches. The second phase was meant to highlight the improvements achieved regarding the performance between a pure population-based algorithm vs. the incorporation of a low-level learning-based component of the design. In addition, the competitiveness against reported successful hybrids and parameter-tuned versions of the employed algorithms was highlighted. This is an interesting observation, mainly because of the limitations behind the proposed approach, which concerns the algorithms selected. For instance, if we observe the linear regression, the main drawback is the inclusion of a unique performance metric as an independent variable in the model. In this regard, there are several metrics that exist in the literature and can have different weights during the search, such as bad solutions, percentage of unfeasible solutions, diversity, and amount of feasible solutions generated, among others. Nevertheless, the overall good performance and the given rooms for improvement brings motivation to further exploit this research field. In addition, this work contributed with scientific evidence of hybridized strategies outperforming their classic algorithm, proving to be profitable approaches solving hard optimization problems.
Regarding the phenomenon described in the experimentation phases, future considerations and improvements were discussed. In this regard, two improvements are under consideration: (1) dynamically adjusting values for and and (2) multiple and larger ranges for population size values. On the other hand, the well-known drawback generally associated with on-line data-driven methods are the amount, profit, and quality of the data given to the model to properly and timely learn on run-time. Thus, as there is no guarantee for the performance achieved by different learning techniques, it is a major issue to carry out an extensive experimental process employing state-of-the-art regression-based methods. However, this consideration can end up on a considerable increment on solving time in comparison to the ones reported in this work. Thus, the incorporation of an optimizer regarding the computational resources employed on run-time will be a key factor for future proposals.
Author Contributions
Formal analysis, E.V., J.P. and R.S.; investigation, E.V., J.P., J.L.-R., R.S. and B.C.; resource, R.S.; software, E.V., C.L. and J.P.; validation, B.C. and E.-G.T.; writing—original draft, E.V., C.L., R.S. and B.C.; writing—review and editing, E.V., J.L.-R., C.L. and R.S. All authors have read and agreed to the published version of the manuscript.
Funding
Ricardo Soto is supported by Grant CONICYT/FONDECYT/REGULAR/1190129. Broderick Crawford is supported by Grant ANID/FONDECYT/REGULAR/1210810, and Emanuel Vega is supported by National Agency for Research and Development (ANID)/Scholarship Program/DOCTORADO NACIONAL/2020-21202527. Javier Peña is supported by National Agency for Research and Development (ANID)/Scholarship Program/DOCTORADO NACIONAL/2022-21220879.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
No new data were created or analyzed in this study. Data sharing is not applicable to this article.
Conflicts of Interest
The authors declare no conflict of interest. The founding sponsors had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript, and in the decision to publish the results.
References
- Talbi, E.G. Metaheuristics: From Design to Implementation; John Wiley & Sons: Hoboken, NJ, USA, 2009. [Google Scholar]
- Del Ser, J.; Osaba, E.; Molina, D.; Yang, X.S.; Salcedo-Sanz, S.; Camacho, D.; Das, S.; Suganthan, P.N.; Coello, C.A.; Herrera, F. Bio-inspired computation: Where we stand and what’s next. Swarm Evol. Comput. 2019, 48, 220–250. [Google Scholar] [CrossRef]
- Piotrowski, A.P.; Napiorkowski, J.J.; Piotrowska, A.E. Population size in particle swarm optimization. Swarm Evol. Comput. 2020, 58, 100718. [Google Scholar] [CrossRef]
- Hansen, N.; Müller, S.D.; Koumoutsakos, P. Reducing the time complexity of the derandomized evolution strategy with covariance matrix adaptation (CMA-ES). Evol. Comput. 2003, 11, 1–18. [Google Scholar] [CrossRef]
- Hansen, N.; Auger, A. CMA-ES: Evolution strategies and covariance matrix adaptation. In Proceedings of the 13th Annual Conference Companion on Genetic and Evolutionary Computation, Dublin, Ireland, 12–16 July 2011; pp. 991–1010. [Google Scholar]
- Sarker, R.; Kamruzzaman, J.; Newton, C. Evolutionary optimization (EvOpt): A brief review and analysis. Int. J. Comput. Intell. Appl. 2003, 3, 311–330. [Google Scholar] [CrossRef]
- Hansen, N.; Ostermeier, A. Completely derandomized self-adaptation in evolution strategies. Evol. Comput. 2001, 9, 159–195. [Google Scholar] [CrossRef] [PubMed]
- Gupta, S. Enhanced harmony search algorithm with non-linear control parameters for global optimization and engineering design problems. Eng. Comput. 2022, 38 (Suppl. 4), 3539–3562. [Google Scholar] [CrossRef]
- Huang, Y.F.; Chen, P.H. Fake news detection using an ensemble learning model based on self-adaptive harmony search algorithms. Expert Syst. Appl. 2020, 159, 113584. [Google Scholar] [CrossRef]
- Kulluk, S.; Ozbakir, L.; Baykasoglu, A. Self-adaptive global best harmony search algorithm for training neural networks. Procedia Comput. Sci. 2011, 3, 282–286. [Google Scholar] [CrossRef]
- Banks, A.; Vincent, J.; Anyakoha, C. A review of particle swarm optimization. Part I: Background and development. Nat. Comput. 2007, 6, 467–484. [Google Scholar] [CrossRef]
- Cheng, S.; Lu, H.; Lei, X.; Shi, Y. A quarter century of particle swarm optimization. Complex Intell. Syst. 2018, 4, 227–239. [Google Scholar] [CrossRef]
- Wang, D.; Tan, D.; Liu, L. Particle swarm optimization algorithm: An overview. Soft Comput. 2018, 22, 387–408. [Google Scholar] [CrossRef]
- Song, H.; Triguero, I.; Özcan, E. A review on the self and dual interactions between machine learning and optimisation. Prog. Artif. Intell. 2019, 8, 143–165. [Google Scholar] [CrossRef]
- Karimi-Mamaghan, M.; Mohammadi, M.; Meyer, P.; Karimi-Mamaghan, A.M.; Talbi, E.G. Machine learning at the service of meta-heuristics for solving combinatorial optimization problems: A state-of-the-art. Eur. J. Oper. Res. 2022, 296, 393–422. [Google Scholar] [CrossRef]
- Talbi, E.G. Machine learning into metaheuristics: A survey and taxonomy. Acm Comput. Surv. (CSUR) 2021, 54, 1–32. [Google Scholar] [CrossRef]
- Birattari, M.; Kacprzyk, J. Tuning Metaheuristics: A Machine Learning Perspective (Vol. 197); Springer: Berlin, Germany, 2009. [Google Scholar]
- Talbi, E.G. Combining metaheuristics with mathematical programming, constraint programming and machine learning. Ann. Oper. Res. 2016, 240, 171–215. [Google Scholar] [CrossRef]
- Calvet, L.; de Armas, J.; Masip, D.; Juan, A.A. Learnheuristics: Hybridizing metaheuristics with machine learning for optimization with dynamic inputs. Open Math. 2017, 15, 261–280. [Google Scholar] [CrossRef]
- Dhiman, G.; Kumar, V. Spotted hyena optimizer: A novel bio-inspired based metaheuristic technique for engineering applications. Adv. Eng. Software 2017, 114, 48–70. [Google Scholar] [CrossRef]
- Luo, Q.; Li, J.; Zhou, Y.; Liao, L. Using spotted hyena optimizer for training feedforward neural networks. Cogn. Syst. Res. 2021, 65, 1–16. [Google Scholar] [CrossRef]
- Soto, R.; Crawford, B.; Vega, E.; Gómez, A.; Gómez-Pulido, J.A. Solving the Set Covering Problem Using Spotted Hyena Optimizer and Autonomous Search. In Advances and Trends in Artificial Intelligence; Wotawa, F., Friedrich, G., Pill, I., Koitz-Hristov, R., Ali, M., Eds.; From Theory to Practice. IEA/AIE 2019. Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2019; Volume 11606. [Google Scholar]
- Ghafori, S.; Gharehchopogh, F.S. Advances in spotted hyena optimizer: A comprehensive survey. Arch. Comput. Methods Eng. 2022, 29, 1569–1590. [Google Scholar] [CrossRef]
- Dhiman, G.; Kaur, A. Spotted hyena optimizer for solving engineering design problems. In Proceedings of the 2017 International Conference on Machine Learning and Data Science (MLDS), Noida, India, 14–15 December 2017; IEEE: Piscataway, NJ, USA; pp. 114–119. [Google Scholar]
- Dhiman, G.; Kumar, V. Spotted hyena optimizer for solving complex and non-linear constrained engineering problems. In Harmony Search and Nature Inspired Optimization Algorithms: Theory and Applications, ICHSA 2018; Springer: Singapore, 2019; pp. 857–867. [Google Scholar]
- Dhiman, G.; Kaur, A. A hybrid algorithm based on particle swarm and spotted hyena optimizer for global optimization. In Soft Computing for Problem Solving: SocProS 2017; Springer: Singapore, 2019; Volume 1, pp. 599–615. [Google Scholar]
- Mahdavi, I.; Paydar, M.M.; Solimanpur, M.; Heidarzade, A. Genetic algorithm approach for solving a cell formation problem in cellular manufacturing. Expert Syst. Appl. 2009, 36, 6598–6604. [Google Scholar] [CrossRef]
- Beasley, J.E. An algorithm for set covering problem. Eur. J. Oper. Res. 1987, 31, 85–93. [Google Scholar] [CrossRef]
- Fréville, A. The multidimensional 0–1 knapsack problem: An overview. Eur. J. Oper. Res. 2004, 155, 1–21. [Google Scholar] [CrossRef]
- Lopez-Ibanez, M.; Dubois-Lacoste, J.; Caceres, L.P.; Birattari, M.; Stutzle, T. The irace package: Iterated racing for automatic algorithm configuration. Oper. Res. Perspect. 2016, 3, 43–58. [Google Scholar]
- Talbi, E.-G. A taxonomy of hybrid metaheuristics. J. Heuristics 2002, 8, 541–564. [Google Scholar] [CrossRef]
- Zennaki, M.; Ech-Cherif, A. A new machine learning based approach for tuning metaheuristics for the solution of hard combinatorial optimization problems. J. Appl. Sci. 2010, 10, 1991–2000. [Google Scholar] [CrossRef]
- de Lacerda, M.G.P.; de Araujo Pessoa, L.F.; de Lima Neto, F.B.; Ludermir, T.B.; Kuchen, H. A systematic literature review on general parameter control for evolutionary and swarm-based algorithms. Swarm Evol. Comput. 2021, 60, 100777. [Google Scholar] [CrossRef]
- Soto, R.; Crawford, B.; González, F.; Vega, E.; Castro, C.; Paredes, F. Solving the Manufacturing Cell Design Problem Using Human Behavior-Based Algorithm Supported by Autonomous Search. IEEE Access 2019, 7, 132228–132239. [Google Scholar] [CrossRef]
- Handa, H.; Baba, M.; Horiuchi, T.; Katai, O. A novel hybrid framework of coevolutionary GA and machine learning. Int. J. Comput. Intell. Appl. 2002, 2, 33–52. [Google Scholar] [CrossRef]
- Adak, Z.; Demiriz, A. Hybridization of population-based ant colony optimization via data mining. Intell. Data Anal. 2020, 24, 291–307. [Google Scholar] [CrossRef]
- Streichert, F.; Stein, G.; Ulmer, H.; Zell, A. A clustering based niching method for evolutionary algorithms. In Genetic and Evolutionary Computation Conference; Springer: Berlin/Heidelberg, Germany, 2003; pp. 644–645. [Google Scholar]
- Sörensen, K.; Glover, F. Metaheuristics. Encycl. Oper. Res. Manag. Sci. 2013, 62, 960–970. [Google Scholar]
- Gogna, A.; Tayal, A. Metaheuristics: Review and application. J. Exp. Theor. Artif. Intell. 2013, 25, 503–526. [Google Scholar] [CrossRef]
- Crama, Y.; Kolen, A.W.; Pesch, E.J. Local search in combinatorial optimization. Artif. Neural Networks 1995, 931, 157–174. [Google Scholar]
- Kirkpatrick, S. Optimization by simulated annealing: Quantitative studies. J. Stat. Physics 1984, 34, 975–986. [Google Scholar] [CrossRef]
- Eusuff, M.; Lansey, K.; Pasha, F. Shuffled frog-leaping algorithm: A memetic meta-heuristic for discrete optimization. Eng. Optim. 2006, 38, 129–154. [Google Scholar] [CrossRef]
- Dorigo, M.; Birattari, M.; Stutzle, T. Ant colony optimization. IEEE Comput. Intell. Mag. 2006, 1, 28–39. [Google Scholar] [CrossRef]
- Mirjalili, S.; Mirjalili, S.M.; Lewis, A. Grey wolf optimizer. Adv. Eng. Software 2014, 69, 46–61. [Google Scholar] [CrossRef]
- Holland, J.H. Adaptation in Natural and Artificial Systems: An Introductory Analysis with Applications to Biology, Control, and Artificial Intelligence; MIT Press: Cambridge, MA, USA, 1992. [Google Scholar]
- Moscato, P. On evolution, search, optimization, genetic algorithms and martial arts: Towards memetic algorithms. Caltech Concurr. Comput. Program C3p Rep. 1989, 826, 1989. [Google Scholar]
- Storn, R.; Price, K. Differential evolution—A simple and efficient heuristic for global optimization over continuous spaces. J. Glob. Optim. 1997, 11, 341–359. [Google Scholar] [CrossRef]
- Atashpaz-Gargari, E.; Lucas, C. Imperialist competitive algorithm: An algorithm for optimization inspired by imperialistic competition. In Proceedings of the 2007 IEEE Congress on Evolutionary Computation, Singapore, 25–28 September 2007; IEEE: Piscataway, NJ, USA; pp. 4661–4667. [Google Scholar]
- Cuevas, E.; Fausto, F.; González, A. New Advancements in Swarm Algorithms: Operators and Applications; Springer International Publishing: Berlin/Heidelberg, Germany, 2020. [Google Scholar]
- Mirjalili, S.; Mirjalili, S.M.; Yang, X.S. Binary bat algorithm. Neural Comput. Appl. 2014, 25, 663–681. [Google Scholar] [CrossRef]
- Mirjalili, S.; Lewis, A. S-shaped versus v-shaped transfer functions for binary particle swarm optimization. Swarm Evol. Comput. 2013, 9, 1–14. [Google Scholar] [CrossRef]
- Faris, H.; Mafarja, M.M.; Heidari, A.A.; Aljarah, I.; Ala’M, A.Z.; Mirjalili, S.; Fujita, H. An efficient binary salp swarm algorithm with crossover scheme for feature selection problems. Knowl.-Based Syst. 2018, 154, 43–67. [Google Scholar] [CrossRef]
- Mafarja, M.; Aljarah, I.; Heidari, A.A.; Faris, H.; Fournier-Viger, P.; Li, X.; Mirjalili, S. Binary dragonfly optimization for feature selection using time-varying transfer functions. Knowl.-Based Syst. 2018, 161, 185–204. [Google Scholar] [CrossRef]
- Mirjalili, S.; Hashim, S.Z.M. BMOA: Binary magnetic optimization algorithm. Int. J. Mach. Learn. Comput. 2012, 2, 204. [Google Scholar] [CrossRef]
- Valenzuela, M.; Pinto, H.; Moraga, P.; Altimiras, F.; Villavicencio, G. A percentile methodology applied to Binarization of swarm intelligence metaheuristics. J. Inf. Syst. Eng. Manag. 2019, 4, em0104. [Google Scholar] [CrossRef] [PubMed]
- Gölcük, İ.; Ozsoydan, F.B.; Durmaz, E.D. Analysis of Different Binarization Techniques within Whale Optimization Algorithm. In Proceedings of the 2019 Innovations in Intelligent Systems and Applications Conference (ASYU), Izmir, Turkey, 31 October–2 November 2019; IEEE: Piscataway, NJ, USA; pp. 1–5. [Google Scholar]
- Slezkin, A.O.; Hodashinsky, I.A.; Shelupanov, A.A. Binarization of the Swallow swarm optimization for feature selection. Program. Comput. Softw. 2021, 47, 374–388. [Google Scholar] [CrossRef]
- Kennedy, J.; Eberhart, R.C. A discrete binary version of the particle swarm algorithm. In Proceedings of the 1997 IEEE International Conference on Systems, Man, and Cybernetics. Computational Cybernetics and Simulation, Orlando, FL, USA, 12–15 October 1997; IEEE: Piscataway, NJ, USA; Volume 5, pp. 4104–4108. [Google Scholar]
- Boctor, F.F. A Jinear formulation of the machine-part cell formation problem. Int. J. Prod. Res. 1991, 29, 343–356. [Google Scholar] [CrossRef]
- Smith, B. Impacs—A bus crew scheduling system using integer programming. Math Program 1988, 42, 181–187. [Google Scholar] [CrossRef]
- Toregas, C.; Swain, R.; Revelle, C.; Bergman, L. The location of emergency service facilities. Oper. Res. 1971, 19, 1363–1373. [Google Scholar] [CrossRef]
- Foster, B.; Ryan, D. An integer programming approach to the vehicle scheduling problem. Oper. Res. Q 1976, 27, 367–384. [Google Scholar] [CrossRef]
- Fisher, M.; Kedia, P. Optimal solution of set covering/partitioning problems using dual heuristics. Manag. Sci. 1990, 36, 674–688. [Google Scholar] [CrossRef]
- Pisinger, D. The quadratic knapsack problem—A survey. Discret. Appl. Math. 2007, 155, 623–648. [Google Scholar] [CrossRef]
- Horowitz, E.; Sahni, S. Computing partitions with applications to the knapsack problem. J. ACM (JACM) 1974, 21, 277–292. [Google Scholar] [CrossRef]
- Soto, R.; Crawford, B.; Toledo, A.; Fuente-Mella, H.; Castro, C.; Paredes, F.; Olivares, R. Solving the Manufacturing Cell Design Problem through Binary Cat Swarm Optimization with Dynamic Mixture Ratios. Comput. Intell. Neurosci. 2019, 2019, 4787856. [Google Scholar] [CrossRef] [PubMed]
- Almonacid, B.; Aspee, F.; Soto, R.; Crawford, B.; Lama, J. Solving the Manufacturing Cell Design Problem using the Modified Binary Firefly Algorithm and the Egyptian Vulture Optimization Algorithm. IET Softw. 2016, 11, 105–115. [Google Scholar] [CrossRef]
- Crawford, B.; Soto, R.; Berros, N.; Johnson, F.; Paredes, F.; Castro, C.; Norero, E. A binary cat swarm optimization algorithm for the non-unicost set covering problem. Math Probl. Eng. 2014, 2015, 578541. [Google Scholar] [CrossRef]
- Crawford, B.; Soto, R.; Olivares-Suarez, M.; Paredes, F. A binary firefly algorithm for the set covering problem. In 3rd Computer Science On-Line Conference 2014 (CSOC 2014); Advances in intelligent systems and computing; Springer: Cham, Switzerland, 2014; Volume 285, pp. 65–73. [Google Scholar]
- Crawford, B.; Soto, R.; Pena, C.; Palma, W.; Johnson, F.; Paredes, F. Solving the set covering problem with a shuffled frog leaping algorithm. In Proceedings of the 7th Asian Conference, ACIIDS 2015, Bali, Indonesia, 23–25 March 2015; Proceedings, Part II. Lecture Notes in Computer Science. Springer: Cham, Switzerland, 2015; Volume 9012, pp. 41–50. [Google Scholar]
- Cuesta, R.; Crawford, B.; Soto, R.; Paredes, F. An artificial bee colony algorithm for the set covering problem, In 3rd Computer Science On-Line Conference 2014 (CSOC 2014); Advances in Intelligent Systems and Computing; Springer: Cham, Switzerland, 2014; Volume 285, pp. 53–63. [Google Scholar]
- Soto, R.; Crawford, B.; Munoz, A.; Johnson, F.; Paredes, F. Preprocessing, repairing and transfer functions can help binary electromagnetism-like algorithms. In Artificial Intelligence Perspectives and Applications; Advances in Intelligent Systems and Computing; Springer: Cham, Switzerland, 2015; Volume 347, pp. 89–97. [Google Scholar]
- Khemakhem, M.; Haddar, B.; Chebil, K.; Hanafi, S. A Filter-and-Fan Metaheuristic for the 0-1 Multidimensional Knapsack Problem. Int. J. Appl. Metaheuristic Comput. (IJAMC) 2012, 3, 43–63. [Google Scholar] [CrossRef]
- Chih, M. Three pseudo-utility ratio-inspired particle swarm optimization with local search for multidimensional knapsack problem. Swarm Evol. Comput. 2018, 39, 279–296. [Google Scholar] [CrossRef]
- Haddar, B.; Khemakhem, M.; Hanafi, S.; Wilbaut, C. A hybrid quantum particle swarm optimization for the multidimensional knapsack problem. Eng. Appl. Artif. Intell. 2016, 55, 1–13. [Google Scholar] [CrossRef]
- Vega, E.; Soto, R.; Contreras, P.; Crawford, B.; Peña, J.; Castro, C. Combining a Population-Based Approach with Multiple Linear Models for Continuous and Discrete Optimization Problems. Mathematics 2022, 10, 2920. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).