
Competitive Perceptrons: The Relevance of Modeling New Bioinspired Properties Such as Intrinsic Plasticity, Metaplasticity, and Lateral Inhibition of Rate-Coding Artificial Neurons


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Materials and Methods
2.1. Plasticity and Learning
2.2. Long-Term Potentiation and Depression
2.3. Metaplasticity
“A learning procedure that induces greater modifications in the artificial synaptic weights W with less frequent patterns as they produce less prior firing than frequent patterns” [13].
2.4. Intrinsic Plasticity
2.5. Competitive Learning by Lateral Inhibition
3. Results
3.1. Brief Description of the KLN
3.2. Lateral Inhibition
- (a)
- Each neuron laterally inhibits its neighbors.
- (b)
- Each activation function has steep slopes.
- (c)
- Intrinsic plasticity regulates neurons’ activations.
- (d)
- The presynaptic rule is used for learning synaptic weights. The most activated neuron emerges from the internal dynamics of the network in which each neuron acts without any kind of external supervision.
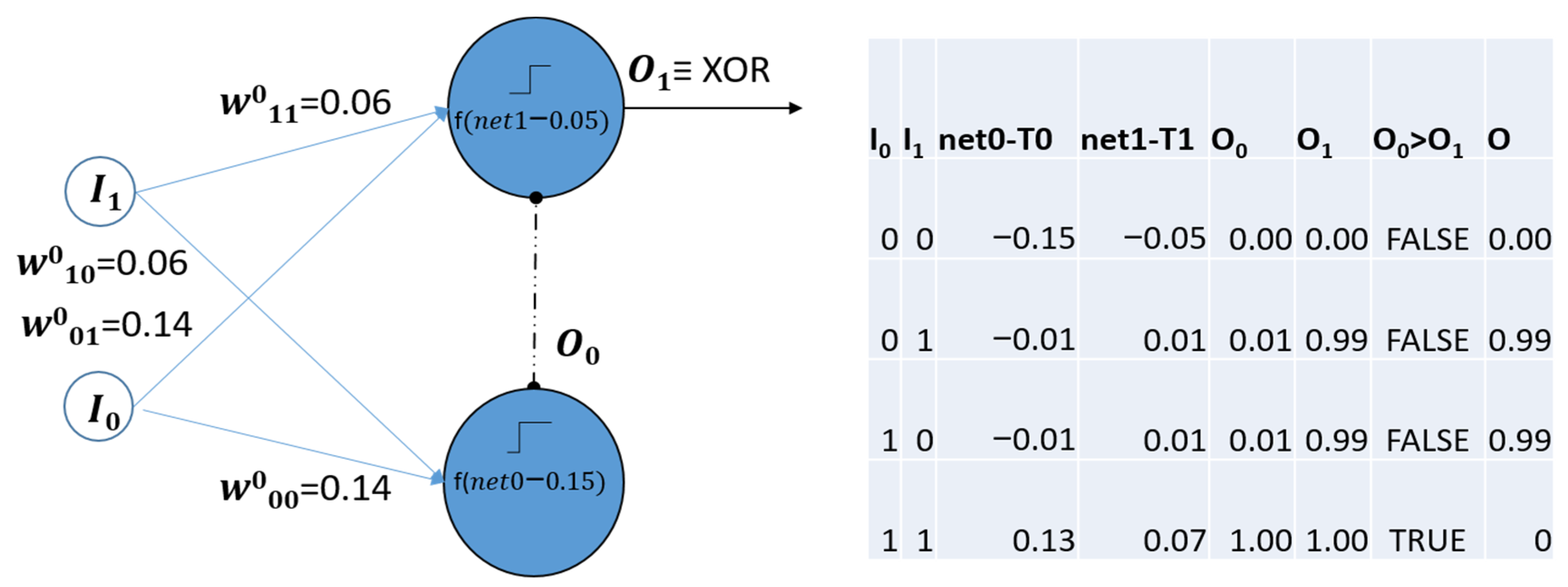
3.3. The Competitive Perceptron
“…a single layer perceptron with normalized inputs, lateral inhibition in the processing neurons and trained by the presynaptic rule.” [19].
3.4. Limitations of This Study
3.5. Future Research
4. Discussion
5. Conclusions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Fombellida, J.; Martín-Rubio, I.; Torres-Alegre, S.; Andina, D. Tackling business intelligence with bioinspired deep learning. Neural Comput. Appl. 2020, 32, 13195–13202. [Google Scholar] [CrossRef]
- Hinton, G.E. The Next Generation of Neural Networks. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information (SIGIR ‘20), Virtual Event, China, 25–30 July 2020; p. 1. [Google Scholar] [CrossRef]
- Ramón y Cajal, S. Histologie du Système Nerveux de L’homme & des Vertébrés: Cervelet, Cerveau Moyen, Rétine, Couche Optique, Corps Strié, Écorce Cérébrale Générale & Régionale, Grand Sympathique; 1911; Volume 2, A. Maloine; Available online: https://www.biodiversitylibrary.org/bibliography/48637 (accessed on 21 November 2023).
- McCulloch, W.S.; Pitts, W.A. A logical calculus of the ideas immanent in nervous activity. Bull. Math. Biophys. 1943, 5, 115–133. [Google Scholar] [CrossRef]
- Hebb, D.O. The Organization of Behavior, 1st ed.; John Wiley & Sons. Inc.: New York, NY, USA, 1949; Available online: https://pure.mpg.de/rest/items/item_2346268_3/component/file_2346267/content (accessed on 30 June 2023).
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. Available online: http://www.cs.toronto.edu/~hinton/absps/naturebp.pdf (accessed on 30 June 2023). [CrossRef]
- Cybenko, G. Approximation by Superposition of Sigmoidal Function. Math. Control Signal Syst. 1989, 2, 303–314. [Google Scholar] [CrossRef]
- Ruck, D.W.; Rogers, S.K.; Kabrisky, M.; Oxley, M.E.; Suter, B.W. The multilayer perceptron as an approximation to a Bayes optimal discriminant function. IEEE Trans. Neural Netw. 1990, 1, 296–298. [Google Scholar] [CrossRef]
- Grossberg, S. A Path Toward Explainable AI and Autonomous Adaptive Intelligence: Deep Learning, Adaptive Resonance, and Models of Perception, Emotion, and Action. Front. Neurorobot. 2020, 14, 1–36. [Google Scholar] [CrossRef] [PubMed]
- Bienenstock, E.L.; Cooper, L.N.; Munro, P.W. Theory for the development of neuron selectivity: Orientation specificity and binocular interaction in visual cortex. J. Neurosci. 1982, 2, 32–48. [Google Scholar] [CrossRef]
- Abraham, W.C.; Jones, O.D.; Glanzman, D.L. Is plasticity of synapses the mechanism of long-term memory storage? NPJ Sci. Learn. 2019, 4, 1–10. [Google Scholar] [CrossRef]
- Abraham, W.C.; Bear, M.F. Metaplasticity: The plasticity of synaptic plasticity. Trends Neurosci. 1996, 19, 126–130. [Google Scholar] [CrossRef]
- Andina, D.; Álvarez-Vellisco, A.; Jevtic, A.; Fombellida, J. Metaplasticity can Improve Artificial Neural Networks Learning. Intell. Autom. Soft Comput. 2019, 15, 683–696. [Google Scholar]
- Abraham, W.C. Metaplasticity: Key Element in Memory and Learning? Am. Physiol. Soc. 1999, 14, 85. [Google Scholar] [CrossRef] [PubMed]
- Marcano-Cedeño, A.; Quintanilla-Domínguez, J.; Andina, D. WBCD breast cancer database classification applying artificial metaplasticity neural network. Expert Syst. Appl. 2011, 38, 9573–9579. [Google Scholar] [CrossRef]
- Marcano-Cedeño, A.; Marin-De-La-Barcena, A.; Jiménez-Trillo, J.; Piñuela, J.A. Artificial metaplasticity neural network applied to credit scoring. Int. J. Neural Syst. 2011, 21, 311–317. [Google Scholar] [CrossRef] [PubMed]
- Marcano-Cedeño, A.; Quintanilla-Domínguez, J.; Andina, D. Wood defects classification using artificial metaplasticity neural network. In Proceedings of the 35th Annual Conference of IEEE Industrial Electronics, Porto, Portugal, 3–5 November 2009; pp. 3422–3427. [Google Scholar] [CrossRef]
- Marcano-Cedeño, A.; Quintanilla-Domínguez, J.; Cortina-Januchs, M.G. Feature selection using sequential forward selection and classification applying artificial metaplasticity neural network. In Proceedings of the IECON 2010—36th Annual Conference on IEEE Industrial Electronics Society, Glendale, AZ, USA, 7–10 November 2010. [Google Scholar] [CrossRef]
- Peláez, F.J.R.; Aguiar-Furucho, M.A.; Andina, D. Intrinsic plasticity for natural competition in koniocortex-like neural networks. Int. J. Neural Syst. 2015, 26, 1650040. [Google Scholar] [CrossRef]
- Grossberg, S. Adaptive pattern classification and universal recoding: I. Parallel development and coding of neural feature detectors. Biol. Cybern. 1976, 23, 121–134. [Google Scholar] [CrossRef]
- Minai, A.A. Covariance learning of correlated patterns in competitive networks. Neural Comput. 1997, 9, 667–681. [Google Scholar] [CrossRef]
- Peláez, F.J.R.; Simoes, G. Computational model of synaptic metaplasticity. In Proceedings of the International Joint Conference of Neural Networks, Washington, DC, USA, 10–16 July 1999. [Google Scholar] [CrossRef]
- Singh, N.; Bartol, T.; Levine, H.; Sejnowski, T.; Nadkarni, S. Presynaptic endoplasmic reticulum regulates short-term plasticity in hippocampal synapses. Commun. Biol. 2021, 4, 1–13. [Google Scholar] [CrossRef]
- Miller, K.D.; Pinto, D.J.; Simons, D.J. Processing in layer IV of neocortical circuit: New insights from visual and somatosensory cortex. Curr. Opin. Neurobiol. 2001, 11, 488–497. [Google Scholar] [CrossRef]
- Fombellida, J.; Peláez, F.J.R.; Andina, D. Koniocortex-Like Network Unsupervised Learning Surpasses Supervised Results on WBCD Breast Cancer Database. In Biomedical Applications Based on Natural and Artificial Computing; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2017; Volume 10338, pp. 32–41. [Google Scholar] [CrossRef]
- Fombellida, J.; Andina, D. Koniocortex-Like Network Application to Business Intelligence. In Proceedings of the 2018 World Automation Congress (WAC), Stevenson, WA, USA, 3–6 June 2018. [Google Scholar] [CrossRef]
- Fombellida, J.; Martín-Rubio, I.; Romera-Zarza, A.; Andina, D. KLN, a new biological koniocortex based unsupervised neural network: Competitive results on credit scoring. Nat. Comput. 2019, 18, 265–273. [Google Scholar] [CrossRef]
- Torres-Alegre, S.; Benachib, Y.; Ferrández-Vicente, J.M.; Andina, D. Application of Koniocortex-Like Networks to Cardiac Arrhythmias Classification. In From Bioinspired Systems and Biomedical Applications to Machine Learning; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2019; Volume 11487, pp. 264–273. [Google Scholar] [CrossRef]
- Torres-Alegre, S.; Fombellida, J.; Piñuela izquierdo, J.A.; Andinak, D. AMSOM: Artificial metaplasticity in SOM neural networks—Application to MIT-BIH arrhythmias database. Neural Comput. Appl. 2020, 32, 13213–13220. [Google Scholar] [CrossRef]
- Vives-Boix, V.; Ruiz-Fernández, D. Fundamentals of artificial metaplasticity in radial basis function networks for breast cancer classification. Neural Comput. Appl. 2021, 33, 12869–12880. [Google Scholar] [CrossRef]
- Vives-Boix, V.; Ruiz-Fernández, D. Diabetic retinopathy detection through convolutional neural networks with synaptic metaplasticity. Comput. Methods Programs Biomed. 2021, 206, 106094. [Google Scholar] [CrossRef] [PubMed]
- Xu, Q.; Wang, Y.; Chen, B.; Li, Z.; Wang, N. Firing pattern in a memristive Hodgkin–Huxley circuit: Numerical simulation and analog circuit validation. Chaos Solitons Fractals 2023, 172, 113627. [Google Scholar] [CrossRef]
- Sun, J.; Wang, Y.; Liu, P.; Wen, S.; Wang, Y. Memristor-Based Neural Network Circuit With Multimode Generalization and Differentiation on Pavlov Associative Memory. IEEE Trans. Cybern. 2023, 53, 3351–3362. [Google Scholar] [CrossRef]
- Schmidgall, S.; Achterberg, J.; Miconi, T.; Kirsch, L.; Ziaei, R.; Hajiseyedrazi, S.P.; Eshraghian, J. Brain-inspired learning in artificial neural networks: A review. arXiv 2023, arXiv:2305.11252. [Google Scholar] [CrossRef]






Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Andina, D. Competitive Perceptrons: The Relevance of Modeling New Bioinspired Properties Such as Intrinsic Plasticity, Metaplasticity, and Lateral Inhibition of Rate-Coding Artificial Neurons. Biomimetics 2023, 8, 564. https://doi.org/10.3390/biomimetics8080564
Andina D. Competitive Perceptrons: The Relevance of Modeling New Bioinspired Properties Such as Intrinsic Plasticity, Metaplasticity, and Lateral Inhibition of Rate-Coding Artificial Neurons. Biomimetics. 2023; 8(8):564. https://doi.org/10.3390/biomimetics8080564
Chicago/Turabian StyleAndina, Diego. 2023. "Competitive Perceptrons: The Relevance of Modeling New Bioinspired Properties Such as Intrinsic Plasticity, Metaplasticity, and Lateral Inhibition of Rate-Coding Artificial Neurons" Biomimetics 8, no. 8: 564. https://doi.org/10.3390/biomimetics8080564
APA StyleAndina, D. (2023). Competitive Perceptrons: The Relevance of Modeling New Bioinspired Properties Such as Intrinsic Plasticity, Metaplasticity, and Lateral Inhibition of Rate-Coding Artificial Neurons. Biomimetics, 8(8), 564. https://doi.org/10.3390/biomimetics8080564