An Evaluation Methodology for Interactive Reinforcement Learning with Simulated Users




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
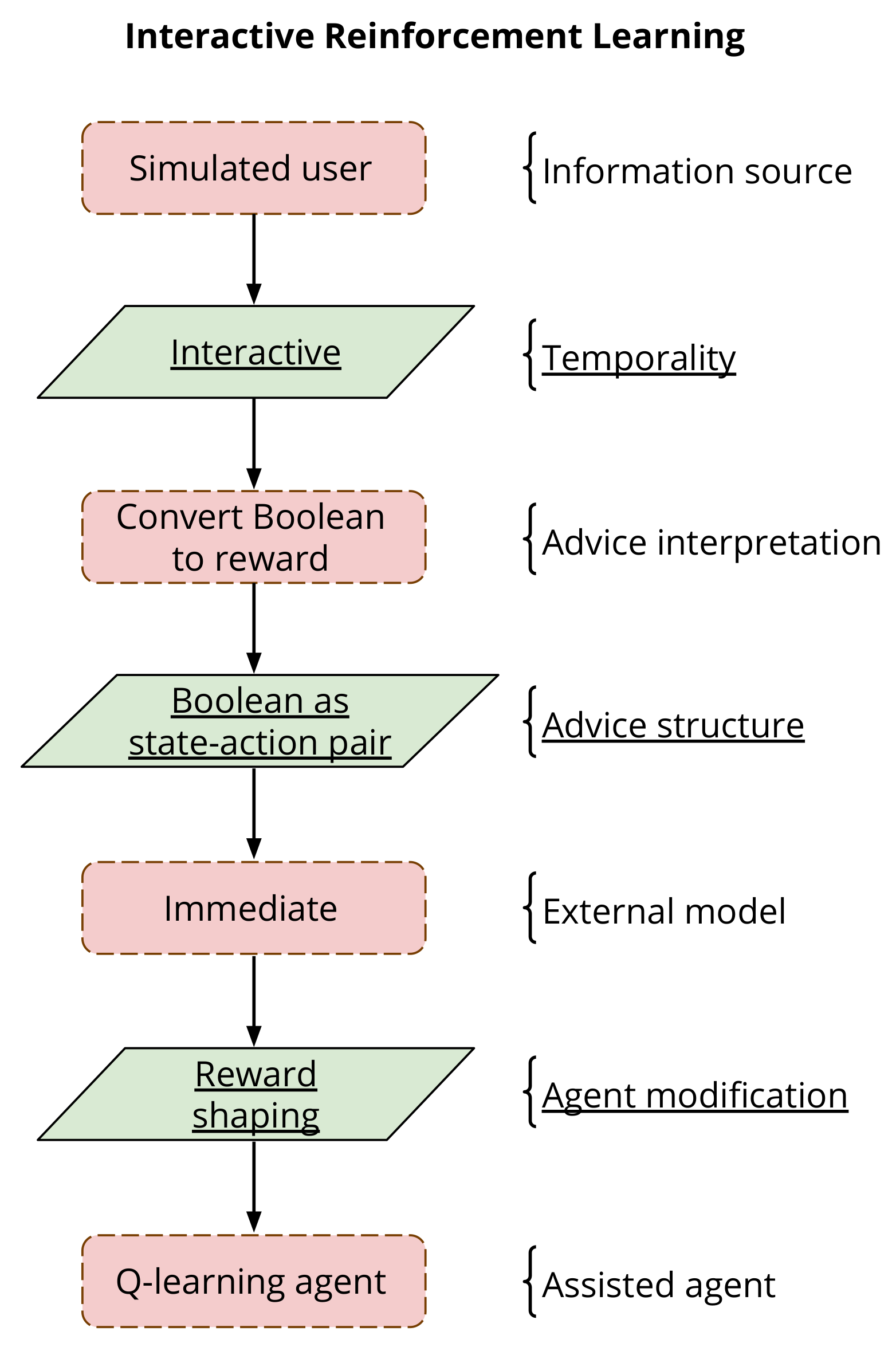
2. Human-Sourced Information
2.1. Characteristics of Human Interactions
- Accuracy: it is a measure of how appropriate information is to the current situation. An information source may be inaccurate due to confusion, poor knowledge, noise, or intentional maliciousness.
- Availability: the information source may not be available all the time or may not respond in the time provided.
- Concept drift: the intentions of the agent and the intentions of the information source may shift over time, such that each time is attempting to work towards a different goal or with a different understanding of the environment.
- Reward bias: advisors may have different teaching styles and prefer to give positive or negative feedback. We classify this as positive reward bias and negative reward bias respectively.
- Cognitive bias: it refers to an advisor’s preconceived thoughts about the nature of the agent and the knowledge they have available to advise the agent in decision making. Advisors are likely to provide advice related to the areas of the domain that they know about and neglect the areas where they know little.
- Knowledge level: an advisor may have little information about all aspects of a problem (breadth), or expert information about a single aspect (depth). Knowledge level may also change over time as the advisor observes the dynamics of the agent or environment.
- Latency: it is a measure of the time taken to retrieve information from the information source. If the latency is too high, then the information may be applied to the wrong state.
2.2. Problems with Human Testing
3. Simulated Users
3.1. Applications of Simulated Users
3.2. Evaluation Principles
- Principle of consistency: states that simulated users should not take actions or provide information that the intended user would not. This principle is constrained to the context of the system being developed and the experimental parameters being tested.
- Principle of completeness: states that simulated users should produce every possible action that the intended user may take. The more complete the action range of the simulated user is the more exhaustive and accurate the evaluation can be.
- Principle of variation: states that simulated users should behave like the users they are modelled from, while not replicating average behaviour completely. To effectively replicate a real user, simulated users must produce outliers and perform unintended actions that, while unlikely, real users may perform.
3.3. Representing Human-Sourced Information
- Probabilistic model: it uses a data-driven approach for representing the intended user of the system [44,45]. The simulated user’s behaviour is defined by probable action choices, probabilities determined by observations of real user behaviour. For example, if users were observed to take action A in 40% of cases, and action B in the remaining, then this would be replicated in the simulated user.
- Heuristic model: it is a deterministic approach for representing the behaviour of a simulated user. Among the most common methods for representing information deterministically are hierarchical patterns [46] and rule sets [47]. Heuristic models are simple to create and maintain, and require little effort to modify. This approach works well when there is little information known about the intended user, but that information is thought to be accurate and reliable.
- Stochastic model: it is an approach used to simulate processes that fluctuate over time, often within a boundary. While it may appear to be like the probabilistic model, stochastic models have a random probability distribution. Examples of stochastic processes include speech and audio signals, data such as temperature and pressure, and medical signals such as EEG and EKG [48]. This approach to modelling is useful for representing complex data and simulating indeterminacy from the intended user.
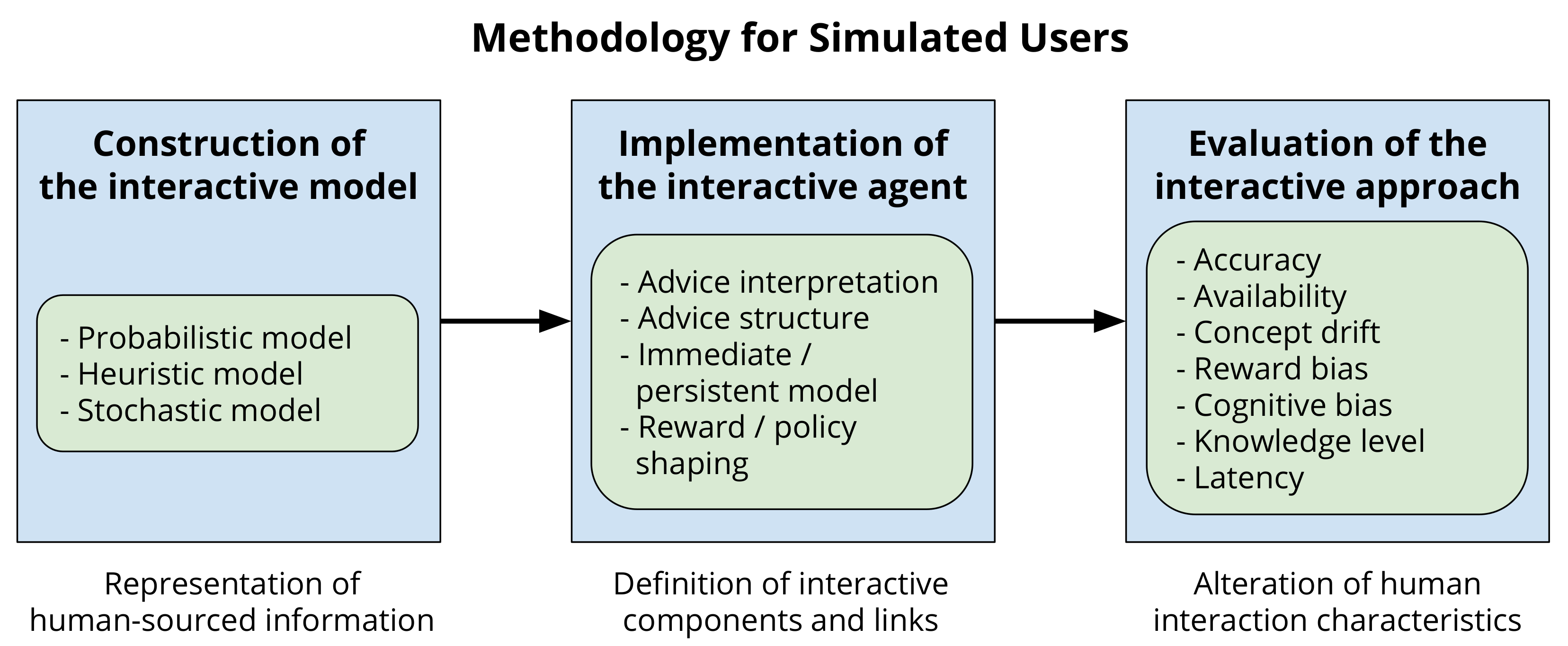
4. Evaluative Methodology Using Simulated Users in Interactive Reinforcement Learning
Proposed Methodology
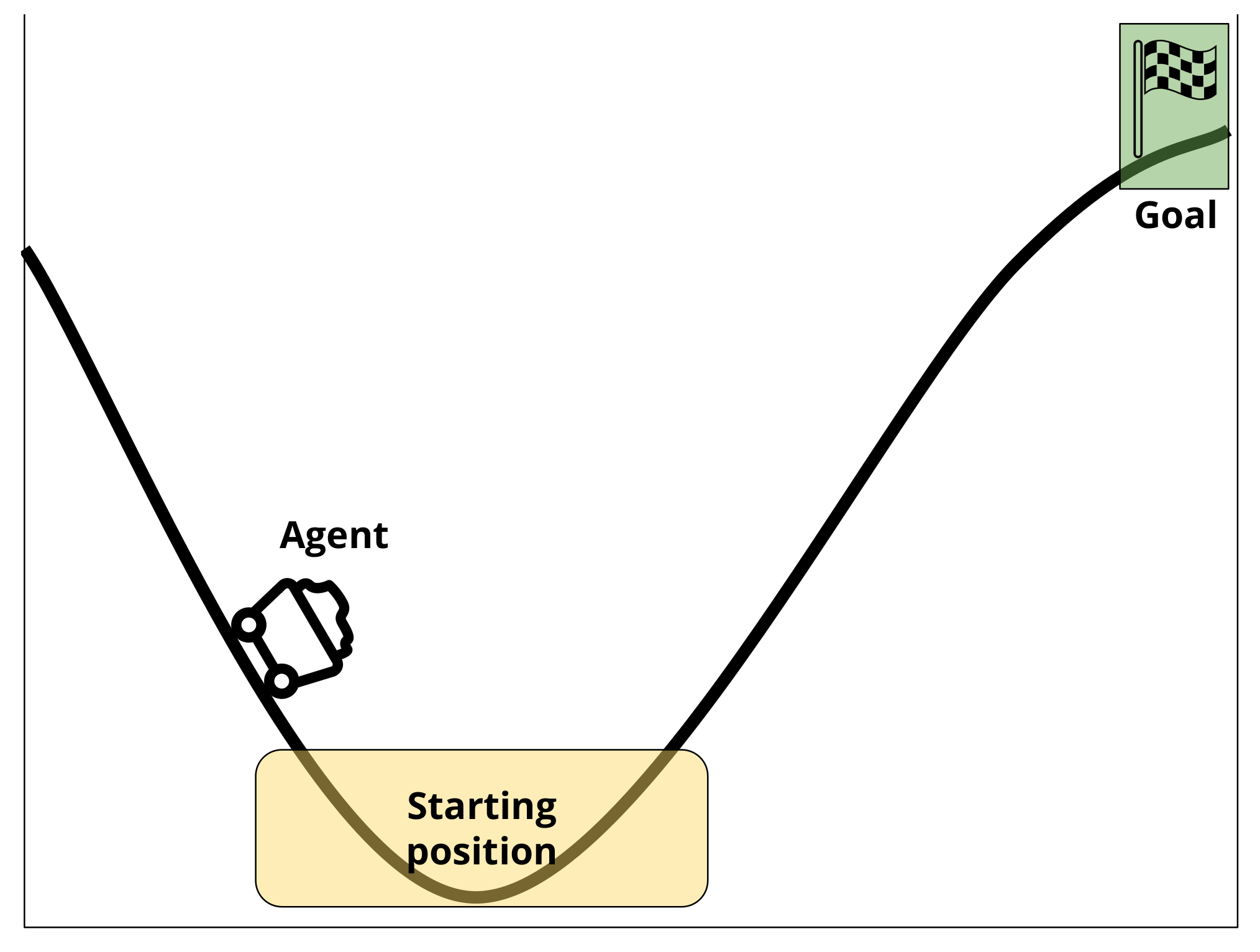
5. Illustrative Experiment
5.1. Experimental Set-Up
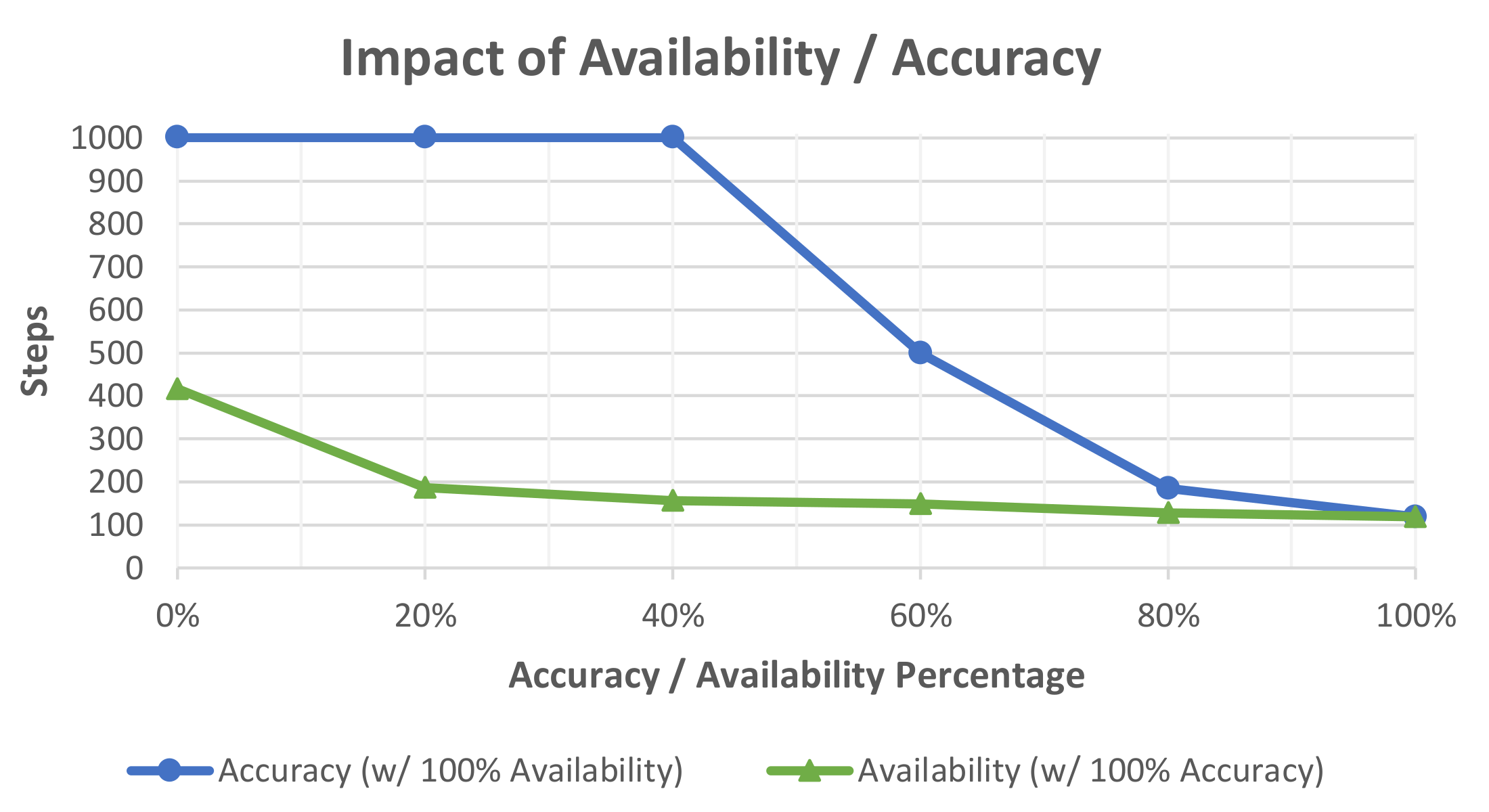
5.2. Results
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Cruz, F.; Wüppen, P.; Fazrie, A.; Weber, C.; Wermter, S. Action selection methods in a robotic reinforcement learning scenario. In Proceedings of the 2018 IEEE Latin American Conference on Computational Intelligence (LA-CCI), Guadalajara, Mexico, 7–9 November 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 13–18. [Google Scholar]
- Littman, M.L. Markov games as a framework for multi-agent reinforcement learning. In Proceedings of the International Conference on Machine Learning ICML, New Brunswick, NJ, USA, 10–13 July 1994; Volume 157, pp. 157–163. [Google Scholar]
- Tesauro, G. TD-Gammon, a self-teaching backgammon program, achieves master-level play. Neural Comput. 1994, 6, 215–219. [Google Scholar] [CrossRef]
- Cruz, F.; Magg, S.; Weber, C.; Wermter, S. Improving reinforcement learning with interactive feedback and affordances. In Proceedings of the Joint IEEE International Conference on Development and Learning and on Epigenetic Robotics ICDL-EpiRob, Genoa, Italy, 13–16 October 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 165–170. [Google Scholar]
- Ayala, A.; Henríquez, C.; Cruz, F. Reinforcement learning using continuous states and interactive feedback. In Proceedings of the International Conference on Applications of Intelligent Systems, Las Palmas, Spain, 7–12 January 2019; pp. 1–5. [Google Scholar]
- Kaelbling, L.P.; Littman, M.L.; Moore, A.W. Reinforcement learning: A survey. J. Artif. Intell. Res. 1996, 4, 237–285. [Google Scholar] [CrossRef]
- Bignold, A.; Cruz, F.; Taylor, M.E.; Brys, T.; Dazeley, R.; Vamplew, P.; Foale, C. A Conceptual Framework for Externally-influenced Agents: An Assisted Reinforcement Learning Review. arXiv 2020, arXiv:2007.01544. [Google Scholar]
- Bignold, A.; Cruz, F.; Dazeley, R.; Vamplew, P.; Foale, C. Human Engagement Providing Evaluative and Informative Advice for Interactive Reinforcement Learning. arXiv 2020, arXiv:2009.09575. [Google Scholar]
- Amershi, S.; Cakmak, M.; Knox, W.B.; Kulesza, T. Power to the people: The role of humans in interactive machine learning. AI Mag. 2014, 35, 105–120. [Google Scholar] [CrossRef]
- Griffith, S.; Subramanian, K.; Scholz, J.; Isbell, C.; Thomaz, A.L. Policy shaping: Integrating human feedback with reinforcement learning. In Advances in Neural Information Processing Systems; Georgia Institute of Technology: Atlanta, GA, USA, 2013; pp. 2625–2633. [Google Scholar]
- Moreira, I.; Rivas, J.; Cruz, F.; Dazeley, R.; Ayala, A.; Fernandes, B. Deep Reinforcement Learning with Interactive Feedback in a Human-Robot Environment. Appl. Sci. 2020, 10, 5574. [Google Scholar] [CrossRef]
- Millán-Arias, C.; Fernandes, B.; Cruz, F.; Dazeley, R.; Fernandes, S. A robust approach for continuous interactive reinforcement learning. In Proceedings of the 8th International Conference on Human-Agent Interaction, Sydney, NSW, Australia, 10–13 November 2020; pp. 278–280. [Google Scholar]
- Cruz, F.; Parisi, G.I.; Wermter, S. Multi-modal feedback for affordance-driven interactive reinforcement learning. In Proceedings of the International Joint Conference on Neural Networks IJCNN, Rio de Janeiro, Brazil, 8–13 July 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 5515–5522. [Google Scholar]
- Millán, C.; Fernandes, B.; Cruz, F. Human feedback in continuous actor-critic reinforcement learning. In Proceedings of the European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning ESANN, Bruges, Belgium, 24–26 April 2019; pp. 661–666. [Google Scholar]
- Cruz, F.; Magg, S.; Nagai, Y.; Wermter, S. Improving interactive reinforcement learning: What makes a good teacher? Connect. Sci. 2018, 30, 306–325. [Google Scholar] [CrossRef]
- Schatzmann, J.; Weilhammer, K.; Stuttle, M.; Young, S. A survey of statistical user simulation techniques for reinforcement learning of dialogue management strategies. Knowl. Eng. Rev. 2006, 21, 97–126. [Google Scholar] [CrossRef]
- Compton, P. Simulating expertise. In Proceedings of the 6th Pacific Knowledge Acquisition Workshop; Citeseer: Sydney, NSW, Australia, 2000; pp. 51–70. [Google Scholar]
- Roveda, L.; Maskani, J.; Franceschi, P.; Abdi, A.; Braghin, F.; Tosatti, L.M.; Pedrocchi, N. Model-based reinforcement learning variable impedance control for human-robot collaboration. J. Intell. Robot. Syst. 2020, 1–17. [Google Scholar] [CrossRef]
- Roveda, L.; Magni, M.; Cantoni, M.; Piga, D.; Bucca, G. Human-robot collaboration in sensorless assembly task learning enhanced by uncertainties adaptation via Bayesian Optimization. Robot. Auton. Syst. 2020, 136, 103711. [Google Scholar] [CrossRef]
- Shahid, A.A.; Roveda, L.; Piga, D.; Braghin, F. Learning continuous control actions for robotic grasping with reinforcement learning. In Proceedings of the 2020 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Toronto, ON, Canada, 11–14 October 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 4066–4072. [Google Scholar]
- Cruz, F.; Parisi, G.I.; Wermter, S. Learning contextual affordances with an associative neural architecture. In Proceedings of the European Symposium on Artificial Neural Network, Computational Intelligence and Machine Learning ESANN, Bruges, Belgium, 27–29 April 2016; UCLouvain: Ottignies-Louvain-la-Neuv, Belgium, 2016; pp. 665–670. [Google Scholar]
- Cruz, F.; Dazeley, R.; Vamplew, P. Memory-based explainable reinforcement learning. In Proceedings of the Australasian Joint Conference on Artificial Intelligence, Adelaide, Australia, 2–5 December 2019; Springer: Cham, Switzerland, 2019; pp. 66–77. [Google Scholar]
- Cruz, F.; Dazeley, R.; Vamplew, P. Explainable robotic systems: Interpreting outcome-focused actions in a reinforcement learning scenario. arXiv 2020, arXiv:2006.13615. [Google Scholar]
- Barros, P.; Tanevska, A.; Sciutti, A. Learning from Learners: Adapting Reinforcement Learning Agents to be Competitive in a Card Game. arXiv 2020, arXiv:2004.04000. [Google Scholar]
- Cruz, F.; Acuña, G.; Cubillos, F.; Moreno, V.; Bassi, D. Indirect training of grey-box models: Application to a bioprocess. In Proceedings of the International Symposium on Neural Networks, Nanjing, China, 3–7 June 2007; Springer: Berlin/Heidelberg, Germany, 2007; pp. 391–397. [Google Scholar]
- Churamani, N.; Cruz, F.; Griffiths, S.; Barros, P. iCub: Learning emotion expressions using human reward. arXiv 2020, arXiv:2003.13483. [Google Scholar]
- Cruz, F.; Wüppen, P.; Magg, S.; Fazrie, A.; Wermter, S. Agent-advising approaches in an interactive reinforcement learning scenario. In Proceedings of the Joint IEEE International Conference on Development and Learning and Epigenetic Robotics ICDL-EpiRob, Lisbon, Portugal, 18–21 September 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 209–214. [Google Scholar]
- Brys, T.; Harutyunyan, A.; Suay, H.B.; Chernova, S.; Taylor, M.E.; Nowé, A. Reinforcement learning from demonstration through shaping. In Proceedings of the International Joint Conference on Artificial Intelligence (IJCAI), Buenos Aires, Argentina, 25–31 July 2015; p. 26. [Google Scholar]
- Thomaz, A.L.; Breazeal, C. Asymmetric interpretations of positive and negative human feedback for a social learning agent. In Proceedings of the 16th IEEE International Symposium on Robot and Human Interactive Communication, Jeju, Korea, 26–29 August 2007; IEEE: Piscataway, NJ, USA, 2007; pp. 720–725. [Google Scholar]
- Knox, W.B.; Stone, P. Reinforcement learning from human reward: Discounting in episodic tasks. In Proceedings of the 2012 IEEE RO-MAN: 21st IEEE International Symposium on Robot and Human Interactive Communication, Paris, France, 9–13 September 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 878–885. [Google Scholar]
- Cao, T.M.; Compton, P. A simulation framework for knowledge acquisition evaluation. In Proceedings of the Twenty-eighth Australasian Conference on Computer Science-Volume 38; Australian Computer Society, Inc.: Sydney, NSW, Australia, 2005; pp. 353–360. [Google Scholar]
- Compton, P.; Preston, P.; Kang, B. The Use of Simulated Experts in Evaluating Knowledge Acquisition; University of Calgary: Calgary, AB, Canada, 1995. [Google Scholar]
- Schatztnann, J.; Stuttle, M.N.; Weilhammer, K.; Young, S. Effects of the user model on simulation-based learning of dialogue strategies. In Proceedings of the IEEE Workshop on Automatic Speech Recognition and Understanding, San Juan, Puerto Rico, 27 November–1 December 2005; IEEE: Piscataway, NJ, USA, 2005; pp. 220–225. [Google Scholar]
- Dazeley, R.; Kang, B.H. Weighted MCRDR: Deriving information about relationships between classifications in MCRDR. In Proceedings of the Australasian Joint Conference on Artificial Intelligence, Perth, WA, Australia, 3–5 December 2003; Springer: Berlin/Heidelberg, Germany, 2003; pp. 245–255. [Google Scholar]
- Dazeley, R.; Kang, B.H. Detecting the knowledge frontier: An error predicting knowledge based system. In Proceedings of the Pacific Knowledge Acquisition Workshop, Auckland, New Zealand, 9–13 August 2004. [Google Scholar]
- Kang, B.H.; Preston, P.; Compton, P. Simulated expert evaluation of multiple classification ripple down rules. In Proceedings of the 11th Workshop on Knowledge Acquisition, Modeling and Management, Banff, AB, Canada, 18–23 April 1998. [Google Scholar]
- Papaioannou, I.; Lemon, O. Combining chat and task-based multimodal dialogue for more engaging HRI: A scalable method using reinforcement learning. In Proceedings of the Companion of the 2017 ACM/IEEE International Conference on Human-Robot Interaction, Vienna, Austria, 6–9 March 2017; ACM: New York, NY, USA, 2017; pp. 365–366. [Google Scholar]
- Georgila, K.; Henderson, J.; Lemon, O. User simulation for spoken dialogue systems: Learning and evaluation. In Proceedings of the Ninth International Conference on Spoken Language Processing, Pittsburgh, PA, USA, 17–21 September 2006. [Google Scholar]
- Scheffler, K.; Young, S. Automatic learning of dialogue strategy using dialogue simulation and reinforcement learning. In Proceedings of the Second International Conference on Human Language Technology Research, San Diego, CA, USA, 24–27 March 2002; Morgan Kaufmann Publishers Inc.: Burlington, MA, USA, 2002; pp. 12–19. [Google Scholar]
- Misu, T.; Georgila, K.; Leuski, A.; Traum, D. Reinforcement learning of question-answering dialogue policies for virtual museum guides. In Proceedings of the 13th Annual Meeting of the Special Interest Group on Discourse and Dialogue, Seoul, Korea, 5–6 July 2012; Association for Computational Linguistics: Stroudsburg, PA, USA, 2012; pp. 84–93. [Google Scholar]
- Georgila, K.; Henderson, J.; Lemon, O. Learning user simulations for information state update dialogue systems. In Proceedings of the Ninth European Conference on Speech Communication and Technology, Lisbon, Portugal, 4–8 September 2005. [Google Scholar]
- Rieser, V.; Lemon, O. Cluster-based user simulations for learning dialogue strategies. In Proceedings of the Ninth International Conference on Spoken Language Processing, Pittsburgh, PA, USA, 17–21 September 2006. [Google Scholar]
- Hofmann, K.; Schuth, A.; Whiteson, S.; de Rijke, M. Reusing historical interaction data for faster online learning to rank for IR. In Proceedings of the Sixth ACM International Conference on Web Search and Data Mining, Rome, Italy, 4–8 February 2013; ACM: New York NY, USA, 2013; pp. 183–192. [Google Scholar]
- Scheffler, K.; Young, S. Corpus-based dialogue simulation for automatic strategy learning and evaluation. In Proceedings of the NAACL Workshop on Adaptation in Dialogue Systems, Pittsburgh, PA, USA, 2–7 June 2001; pp. 64–70. [Google Scholar]
- Cuayáhuitl, H.; Renals, S.; Lemon, O.; Shimodaira, H. Reinforcement learning of dialogue strategies with hierarchical abstract machines. In Proceedings of the 2006 IEEE Spoken Language Technology Workshop, Palm Beach, Aruba, 10–13 December 2006; IEEE: Piscataway, NJ, USA, 2006; pp. 182–185. [Google Scholar]
- Celiberto, L.A., Jr.; Ribeiro, C.H.; Costa, A.H.; Bianchi, R.A. Heuristic reinforcement learning applied to robocup simulation agents. In RoboCup 2007: Robot Soccer World Cup XI; Springer: Berlin/Heidelberg, Germany, 2007; pp. 220–227. [Google Scholar]
- Liang, X.; Balasingham, I.; Byun, S.S. A reinforcement learning based routing protocol with QoS support for biomedical sensor networks. In Proceedings of the 2008 First International Symposium on Applied Sciences on Biomedical and Communication Technologies, Aalborg, Denmark, 25–28 October 2008; IEEE: Piscataway, NJ, USA, 2008; pp. 1–5. [Google Scholar]
- López-Cózar, R.; Callejas, Z.; McTear, M. Testing the performance of spoken dialogue systems by means of an artificially simulated user. Artif. Intell. Rev. 2006, 26, 291–323. [Google Scholar] [CrossRef]
- Bignold, A.; Cruz, F.; Dazeley, R.; Vamplew, P.; Foale, C. Persistent Rule-based Interactive Reinforcement Learning. arXiv 2021, arXiv:2102.02441. [Google Scholar]
- Knox, W.B.; Stone, P. TAMER: Training an agent manually via evaluative reinforcement. In Proceedings of the 2008 7th IEEE International Conference on Development and Learning, Monterey, CA, USA, 9–12 August 2008; IEEE: Piscataway, NJ, USA, 2008; pp. 292–297. [Google Scholar]
- Vamplew, P.; Issabekov, R.; Dazeley, R.; Foale, C.; Berry, A.; Moore, T.; Creighton, D. Steering approaches to Pareto-optimal multiobjective reinforcement learning. Neurocomputing 2017, 263, 26–38. [Google Scholar] [CrossRef][Green Version]
- Thomaz, A.L.; Breazeal, C. Reinforcement Learning with Human Teachers: Evidence of Feedback and Guidance with Implications for Learning Performance; AAAI: Boston, MA, USA, 2006; Volume 6, pp. 1000–1005. [Google Scholar]
- Thomaz, A.L.; Hoffman, G.; Breazeal, C. Reinforcement learning with human teachers: Understanding how people want to teach robots. In Proceedings of the ROMAN 2006-The 15th IEEE International Symposium on Robot and Human Interactive Communication, Hatfield, UK, 6–8 September 2006; IEEE: Piscataway, NJ, USA, 2006; pp. 352–357. [Google Scholar]
- Taylor, M.E.; Carboni, N.; Fachantidis, A.; Vlahavas, I.; Torrey, L. Reinforcement learning agents providing advice in complex video games. Connect. Sci. 2014, 26, 45–63. [Google Scholar] [CrossRef]






Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bignold, A.; Cruz, F.; Dazeley, R.; Vamplew, P.; Foale, C. An Evaluation Methodology for Interactive Reinforcement Learning with Simulated Users. Biomimetics 2021, 6, 13. https://doi.org/10.3390/biomimetics6010013
Bignold A, Cruz F, Dazeley R, Vamplew P, Foale C. An Evaluation Methodology for Interactive Reinforcement Learning with Simulated Users. Biomimetics. 2021; 6(1):13. https://doi.org/10.3390/biomimetics6010013
Chicago/Turabian StyleBignold, Adam, Francisco Cruz, Richard Dazeley, Peter Vamplew, and Cameron Foale. 2021. "An Evaluation Methodology for Interactive Reinforcement Learning with Simulated Users" Biomimetics 6, no. 1: 13. https://doi.org/10.3390/biomimetics6010013
APA StyleBignold, A., Cruz, F., Dazeley, R., Vamplew, P., & Foale, C. (2021). An Evaluation Methodology for Interactive Reinforcement Learning with Simulated Users. Biomimetics, 6(1), 13. https://doi.org/10.3390/biomimetics6010013