Abstract
In recent years, the rapid advancement of deep learning techniques has significantly propelled the development of face forgery methods, drawing considerable attention to face forgery detection. However, existing detection methods still struggle with generalization across different datasets and forgery techniques. In this work, we address this challenge by leveraging both local texture cues and global frequency domain information in a complementary manner to enhance the robustness of face forgery detection. Specifically, we introduce a local texture mining and enhancement module. The input image is segmented into patches and a subset is strategically masked, then texture enhanced. This joint masking and enhancement strategy forces the model to focus on generalizable localized texture traces, mitigates overfitting to specific identity features and enabling the model to capture more meaningful subtle traces of forgery. Additionally, we extract multi-scale frequency domain features from the face image using wavelet transform, thereby preserving various frequency domain characteristics of the image. And we propose an innovative frequency-domain processing strategy to adjust the contributions of different frequency-domain components through frequency-domain selection and dynamic weighting. This Facilitates the model’s ability to uncover frequency-domain inconsistencies across various global frequency layers. Furthermore, we propose an integrated framework that combines these two feature modalities, enhanced with spatial attention and channel attention mechanisms, to foster a synergistic effect. Extensive experiments conducted on several benchmark datasets demonstrate that the proposed technique demonstrates superior performance and generalization capabilities compared to existing methods.
1. Introduction
The rapid advancement of deep learning has significantly contributed to the evolution of face forgery technology. Modern face forgery methods are capable of generating highly realistic counterfeit face images, with the development of Generative Adversarial Networks (GANs) [1,2,3] and autoencoders [4,5] lowering the technical threshold for such forgeries. These advancements enable the batch generation of forged images, improving their quality to the point where they are often indistinguishable from genuine faces to the naked eye. As a result, the risk of misuse of face forgery has escalated, raising significant concerns about security. Consequently, the need for robust face forgery detection techniques has garnered substantial attention from both the research community and industry, aiming to address the security challenges posed by the widespread abuse of face forgery technologies.
Face forgery detection involves distinguishing between real and fake facial images, where objective differences exist between the two. Current detection methods aim to learn these differences by training models on real and fake image datasets. Convolutional neural networks (CNNs) have become the predominant approach for face forgery detection, as illustrated in Figure 1. This figure shows the heat map of the region of interest generated by an EfficientNet [6] model applied to the FF++ [7] dataset of the NT [8] forgery method on a forged image. From the heatmap, we observe that the EfficientNet model exhibits two key limitations: firstly, it tends to focus too heavily on local regions, potentially overlooking other important forgery cues; secondly, the model fails to precisely locate the discrepancies between real and fake images. For example, the NT forgery method in the figure only alters the mouth region of the face, yet the model does not focus on this localized forgery. In fact, for some forged images, the model’s attention is mistakenly directed to non-facial regions. These issues underscore a fundamental challenge of CNN-based approaches, where misalignment in feature attention and the overfitting to localized patterns hinder the model’s ability to generalize across domains. Although CNNs achieve high performance within a dataset domain, they often struggle to maintain this effectiveness in cross-domain settings, leading to significant performance degradation. To address these challenges, we proposes a solution that enhances both the extraction of forged features and the global modeling capability of CNNs.

Figure 1.
Example of Grad-Cam [9] of CNN network attention to face forgery. The CNN network is an EfficientNet [6]. The color shade reflects the attention level, the darker red gets more attention. The fake image is derived from the NT method in the FF++ dataset, and only the mouth region of the face is faked. The red box in the fake images plot roughly marks the faked region.
Early approaches to face forgery detection primarily relied on classification-based neural networks [6,10,11], where CNNs were trained to perform binary classification between real and forged images. Methods such as CapsuleNet [12] and MesoNet [13] introduced modifications to CNN architectures to enhance feature extraction. However, approaches that solely rely on CNNs often difficult to generalize when faced with previously unseen datasets or novel forgery techniques. To address this limitation, some methods [14,15,16] have explored physiological facial features, such as mouth movement during speech or blinking frequency, leveraging inter-frame variations in videos to detect forgeries. While effective in certain cases, these methods are limited by their dependence on specific facial gestures and motion cues, limiting their applicability to various types of forged media. Some studies focus on improving model learning by enhancing dataset diversity. Some methods [17,18,19] construct synthetic forgery images to enrich the variety of manipulated images or constrain the range of differences between real and fake images, allowing models to learn subtle and precise forgery patterns. However, these approaches demand substantial computational resources for data preprocessing. Moreover, the model’s performance remains highly dependent on the chosen forgery construction technique, making it challenging to adapt when confronted with unseen and more complex forgery datasets. Several image processing based techniques [20,21,22] have been proposed to improve detection. For instance, RFM [20] mitigates model sensitivity by masking specific regions, while DCL [21] leverages a combination of data processing techniques to construct contrastive learning models, demonstrating some improvement in cross-domain generalization. Recent work has also explored forgery detection across different domains. For example, GFF [23] employs Spatial Rich Model (SRM) [24] to extract high-frequency residual noise from images, while FreqNet [25] utilizes Fourier transform to detect inconsistencies in the frequency domain. These methods help mitigate overfitting to color information and expand the learnable feature space, thereby improving model robustness against diverse forgery techniques, but still underutilized features of different domains.
Drawing inspiration from biomimetic principles, we perform feature extraction and processing on forged images to achieve face forgery detection. First, inspired by the biological visual system’s response to and processing of image information at different spatial frequencies, we propose a comprehensive approach that utilizes both RGB color images and frequency-domain images for local and global image processing. This is further enhanced by wavelet decomposition for frequency-domain image processing, simulating the multi-scale characteristics of visual processing. Second, employing a CNN as the backbone network, whose architecture is inspired by the hierarchical and locally connected manner in which the animal visual cortex processes information, enables effective feature extraction and processing. Finally, referencing the human attentional processes of selective focus and information integration, we incorporate spatial and channel attention within the CNN. This promotes the synergistic utilization of features from multi-scale image inputs, thereby enhancing the model’s cross-scale modeling capability.
Inspired by the hierarchical information processing mechanisms of biological visual system, we use a CNN backbone. To enhance face forgery detection capabilities and mitigate the inherent limitations of CNN-based approaches, we introduce a novel framework that integrates advanced feature mining techniques with an optimized network architecture. Our goal is to improve CNNs’ ability to effectively extract forgery cues while addressing their tendency to focus excessively on localized regions. In the face forgery clues extraction stage, we extract local texture features and global frequency domain information. To prevent overfitting to high-level facial semantics, we propose a Local Texture Mining and Enhancement (LTME) module. This module extracts local texture information in segmented regions and selectively masks certain texture components to disrupt high-level semantic coherence. Consequently, LTME forces the model to focus on fine-grained forgery traces. Additionally, a texture enhancement submodule further amplifies these local features, guiding the model toward more precise forgery detection. For frequency domain feature extraction, the Global Frequency Feature Filtering Extraction (GFE) module leverages wavelet-based multi-layer frequency decomposition, inspired by the multi-scale information processing of biological vision systems. GFE strategically filters out low-frequency components that resemble the original image while preserving crucial global frequency information. This selective filtering reduces the model’s reliance on high-level semantic information that is independent of forgery artifacts, thereby improving its generalization ability. Following extraction, both local texture features and global frequency features are fed into the backbone network. To further enhance non-local modeling capability and effectively integrate local and global information, we propose a Local-Global Feature Enhancement (LGFE) module, drawing inspiration from biological attention processes. LGFE utilizes spatial and channel attention mechanisms to simulate the selective focusing and information integration processes of biological attention. Facilitating information exchange between local and global representations, thereby improving the model’s ability to capture forgery patterns across different scales and contexts.
Our contributions are summarized as follows:
- We propose a local texture mining and enhancement module (LTME) to extract forgery clues from local texture features and a global frequency feature filtering extraction module (GFE) to capture forgery cues from the frequency domain. These modules work together to reduce the influence of high-level semantic facial features, offering new approaches for detecting manipulation cues in face forgery images from both local and global perspectives.
- We propose a local and global feature enhancement module (LGFE) that enhances the model’s ability to synergistically exploit both local and global features. By employing spatial and channel attention mechanisms, the LGFE improves the model’s global perception and its capacity for non-local modeling.
- We conduct extensive ablation studies to validate the effectiveness of the proposed modules. In-domain comparison experiments and cross-domain experiments validate the model. Experimental results show that our method has high generalization ability while maintaining the highest accuracy.
2. Related Work
2.1. Conventional Face Forgery Detection
Early face forgery detection methods [6,10,12,13,26] simply regarded face forgery detection as a binary classification problem, using classification models to distinguish between real and face forgery images. However, these models were not specifically optimized for the unique characteristics of face forgery tasks. Due to the inherent limitations of convolutional neural networks (CNNs), such methods often overfit to local discrepancies within face forgery images, or even mistakenly focus on non-facial regions. While these approaches tend to perform well on in-domain datasets, they exhibit significant performance degradation when tested across domains. To address these limitations, several works have introduced more specialized methods [12,13,27]. For instance, Multitask Learning [27] employed a multi-task framework, utilizing an encoder-decoder architecture. The encoder performs binary classification, while a Y-decoder is used for region segmentation and input reconstruction, enabling simultaneous detection of forgeries and localization of manipulated regions. Nguyen et al. [12] propose Capsule Networks for face forgery detection. This method achieves comparable performance to traditional CNNs but with fewer parameters, making it more efficient. Furthermore, some studies [15,16,28] have explored biometric inconsistencies as clues for detecting face forgeries. For example, Agarwal et al. [28] detected video forgeries by analyzing the mouth shape during speech, while Yang et al. [15] exploited unnatural head poses as indicators of forgery in multimedia. Despite their success, these methods are constrained by the reliance on specific facial cues, limiting their generalizability to other types of face manipulations.
2.2. Uncovering Hidden Forgery Clues
To improve the generalization capability of face forgery detection models, recent studies [18,19,23,29,30,31] have focused on uncovering forgery traces that exhibit more robust and universal performance across various datasets. Some methods [17,18,19] rely on dataset processing techniques to self-construct forgery traces, enabling the model to learn a broader range of forgery types. For instance, SBI [19] segments the face from a single original image and reassembles it to create a forged image. Chen et al. [17] propose using generative adversary networks (GANs) [1] to perform forgery construction within a restricted region of the face. However, these methods often require significant computational resources for data pre-processing, and the effectiveness of forgery detection is heavily dependent on the specific dataset processing technique employed. Recent works [25,32,33] have sought to identify hidden, generic forgery cues across various domains of an image, such as the frequency domain or fine-grained texture features. Several studies have contributed to uncovering these subtle forgery patterns. For example, Sun et al. [21] used comparative learning between real and forged images to capture incongruent features. Zhu et al. [32] decomposed faces into 3D models and employed a dual-stream structure to highlight face details. Additionally, Luo et al. [23] and Fei et al. [34] utilized Spatial Rich Models (SRM) [24] filters to generate high-frequency noise modalities from RGB images. These noise features were then integrated into a dual-stream network to enhance the detection of forgery cues.
3. Proposed Method
The overall architecture of the model is shown in Figure 2. The input color image is first processed in two ways to be used for local texture feature mining and global frequency domain feature mining respectively. For local texture feature extraction, we propose the local texture mining and enhancement module (LTME), which first divides the input image into patches, then masks a subset of these patches, and then re-combines these patches randomly as the input, and enhances the retained local information with features through the texture enhancement module. To extract global forgery traces, we propose the global frequency feature filtering extraction module (GFE), which applies a Discrete Wavelet Transform (DWT) to decompose the image into four distinct frequency components through two levels of wavelet decomposition. We remove the features most similar to the original image whose two decompositions are both low frequency, and retain the other global frequency domain features. Local and global features are feature extracted through the backbone network (EfficientNet [6]), and the local and global feature enhancement module (LGFE) is designed to enhance synergistic utilization of the two features in the model. The LTME, GFE, and LGFE modules are described in detail next.
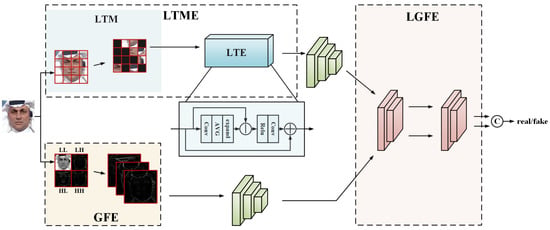
Figure 2.
Overview of the proposed model. The LTME module consists of the LTM module and the LTE module, which are responsible for local texture feature mining and local texture feature enhancement, respectively. The green module is backbone, and we use EfficientNet-B4. The initial layer of backbone is processed and inserted into the LTM module for feature enhancement. The GFE module uses the wavelet transform for frequency domain feature extraction and rejects LL frequency features.
3.1. Local Texture Mining and Enhancement Module
We avoid the learning of face identity information by the model by segmenting the face image into patches. As shown in Figure 2. Specifically, for any input image X, we first segment it into patches, to conveniently match the model input resolution, we set r = 4. After segmentation, a random portion of the patches are masked, considering that there exists a region in the outermost part of the image that is not the location of the face, and contains less information than the central region of the patch, we mask the outer patches and the inner patches with different ratios. We randomly select outer patches mask, and then mask the four corners of the outer patch. And in the inner layer patches are randomly selected for masking. That is, at least half of the outer patch is masked and half of the inner patch is masked. Finally, these patches are reorganized into in random order. Through the blocking and masking method, on the one hand, it destroys the overall structure of the face, avoids the influence of the high-level semantic information of the face (e.g., gender, appearance information) on the learning of the forged features, and highlights the local texture information of the face. On the other hand, it helps the model to avoid overfitting. After that, is input into the backbone, and we perform local texture enhancement after the initial layer of the backbone to enhance the low-level semantic texture features that are not yet abstracted by the backbone.
The process of local texture enhancement is shown in Figure 2 LTE. We first extract the feature from the initial layer output of the backbone by a set of convolutions, and then perform an average pooling operation to capture the smoothed representation of the context to obtain the average feature , after which we perform a bilinear interpolation process to adjust the scale of the average feature to the same scale as that of the feature before the average pooling, so that it can be used for subsequent operations. We subtract the two sets of features to obtain the salient texture residual information of the features, the process is as follows
Then the original features are augmented using the salient texture residual information, which is first processed using a bn layer and an activation function relu processing, and then the salient texture residual information is superimposed on the original features
The feature that finalizes the enhancement of the extracted texture is obtained, and the feature is used to lose back into the backbone to continue the feature extraction.
3.2. Global Frequency Feature Filtering Extraction Module
Methods of mining frequency domain information in image processing are diverse, such as mining image high-frequency residuals using a SRM [24], transforming frequency domain information using Fourier transform, and discrete wavelet transform [35,36]. Many face forgery detection methods try to mine image frequency domain modalities in the hope of finding traces of forgery hidden under the colors. From the perspective of avoiding model fitting to high-level semantic features of the face, we propose a global frequency feature filtering extraction module (GFE) based on discrete wavelet transform, which extracts global frequency domain features while extracting multiple frequency domain scale features through wavelet decomposition and excludes low-frequency features with high similarity to color images, so that the model focuses on finding more generalized features of the forged traces rather than the identity information of the face.
We perform frequency domain feature extraction on the input image by means of a 2d discrete wavelet transform, as in Figure 3. Specifically, the image is decomposed by two wavelet filters using the Mallat algorithm [36]. For the four types of components obtained by decomposition: low frequency component (LL), horizontal detail coefficient (LH), vertical detail coefficient (HL), diagonal detail coefficient (HH). We do not use the low frequency component (LL) with the most face identity information. The 2d discrete wavelet transform performs two low pass filters on the image to obtain the LL image, which removes a large amount of high-frequency information and outputs low-frequency information. This LL image only loses the high frequency details compared with the original image, and has small differences with the original RGB image. To avoid feature duplication mining of frequency domain information and RGB texture information, we choose to use the rest of non-low-frequency components LH, HL and HH. For these components, we do not reconstruct the image together but reconstruct them into three image feature outputs respectively. And by dynamically assigning weights for feature fusion, the three frequency domain feature weights are adaptively weighted during training. Specifically, the feature importance is captured by global average pooling of the three image feature outputs, and then adaptive adjustment is achieved by dynamically generating weights for each sample through a layer of fully connected layers. We restrict the weights to a minimum value of 0.2, and use the softmax function to ensure that the sum of the weights is 1.
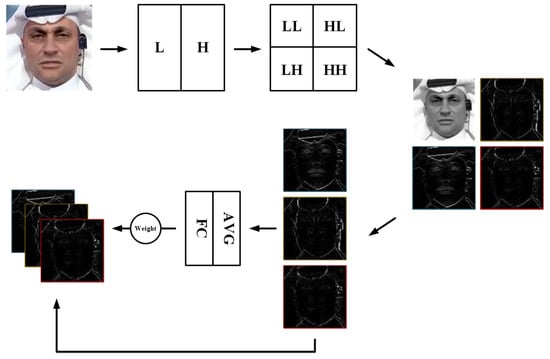
Figure 3.
Illustration of GFE. The images are 2D discrete wavelet transformed and dynamically combined after removing LL.
3.3. Local and Global Feature Enhancement Module
In order to make good use of local and global features, we design a local and global feature enhancement module (LGFE) to model the similarity of the two types of features and share feature weights to improve the synergy of the two types of features. The designed local and global feature sharing module is shown in Figure 4. The module consists of two primary parts. Spatial domain part models the interaction between local texture features and global frequency domain features through the cross-utilization of spatial attention. Channel domain part realizes the modeling of the relationship between the two types of feature maps through the sharing of weights by channel attention. By jointly leveraging spatial and channel-based feature interactions, the LGFE module enhances the model’s ability to synergistically utilize local and global features, thereby significantly improving the overall detection performance.
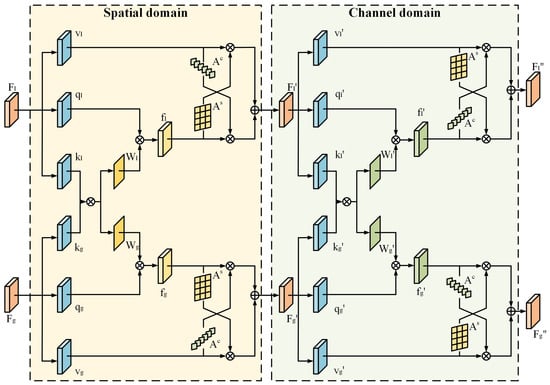
Figure 4.
Illustration of LGFE. Enhancement and sharing of local and global features in the spatial and channel domains.
Specifically, the features extracted from the backbone are used as the initial inputs to the local and global feature sharing module, such that the local features are denoted as and the global features are denoted as , and the subscripts represent the two types of local and global features, respectively. The feature sharing enhancement is first performed from spatial domain by extracting the Query component, Key component and Value component from each of the two features: , , and , , , where , the parameter r is a scalar used for dimensionality reduction of the channel to reduce the number of parameters and to improve the computational efficiency.The extraction of Key component is realized by two layers of convolution, the first layer of convolution with convolution kernel size of , which carries out the extraction independently, and the second layer of convolution with convolution kernel size of , and unlike the previous layer, this layer of convolution is shared for use during the extraction of both features, projecting the feature maps of both features into the same vector space. In addition, only one layer of convolution is used for Query component and Value component extraction. After that, the H and W in the Key component are spread out, at which point , and then the relevance weights of the two sets of Key components are computed by matrix multiplication, and the corresponding feature’s corresponding spatial relevance attentional weights are generated by the softmax function. spatial correlation attention weight , the process is as follows:
The spatial correlation attention weights are matrix multiplied with the previously extracted Query component to obtain the spatially enhanced features and . This spatially enhanced feature is then subjected to mutual enhancement operation with the previously extracted Value component , specifically, the spatial attention map is extracted from the spatially enhanced feature by two-layer convolution, and the spatial attention map is extracted from the spatially enhanced feature by global average pooling and two-layer convolution to extract the channel attention map from the Value component for cross-enhancement, i.e., using the spatial attention map for the Value component and the channel attention map for the spatially enhanced feature. The feature is then summed with the value component feature and channel merged by convolution to complete the spatial domain feature enhancement, and the output features and are used as inputs for the subsequent shared enhancement of the channel domain features.
For channel enhancement, the local feature and global feature are also extracted with Query component, Key component and Value component to obtain , , , where component extraction operation is consistent with the component extraction operation for spatial domain. After that, the H and W in the Key components are also flatten, at which point , and then the correlation weights of the two sets of Key components are computed by matrix multiplication, and the corresponding channel correlation attentional weights for the corresponding features are generated by softmax function. The channel correlation attention weights of the features are generated by softmax function, which is the same as the component extraction operation of spatial domain, except that the order of the matrices is switched when matrix multiplication is used to extract the correlation weights . Then the channel correlation attention weights are matrix multiplied with the Query components to obtain the channel enhancement features and , and then mutual enhancement operation is performed. Then, the channel attention map is extracted from the channel enhancement features, and the spatial attention map is extracted from the Value component, and the two cross-enhancements are performed. Finally, the enhanced features are summed to obtain the features and that complete the enhancement of the local and global feature sharing modules.
3.4. Feature Fusion and Loss Function
We perform a connected combination of local and global features. Specifically, features extracted from the local stream and the global stream are first concatenated along the channel dimension. This concatenated feature map, encompassing both fine-grained details and holistic context, is then processed by a convolution. The fused feature is subsequently passed through a ReLU activation function for non-linearity. This resulting fused feature vector, representing the combined local and global evidence, forms the input to the final classification stage. For the final classification decision, the fused feature vector is fed into a fully connected layer. This layer maps the high-dimensional fused features to a lower-dimensional space corresponding to the real or fake classes. Regarding the loss function, we use the cross-entropy loss function to minimize the discrepancy between the predicted probabilities and the ground-truth labels.
4. Experiments
4.1. Experimental Settings
4.1.1. Datasets
To evaluate the effectiveness of our proposed method, we conduct experiments on three widely used benchmark datasets: FaceForensics++ (FF++) [7], Celeb-DF [37], and DeepFake Detection Challenge (DFDC) [38]. FaceForensics++ (FF++) is a widely adopted dataset that includes four types of face forgery techniques: Deepfakes (DF) [39], Face2Face (F2F) [40], FaceSwap (FS) [41], and NeuralTextures (NT) [8]. These methods can be categorized into two groups: Deep learning-based approaches, including Deepfakes and NeuralTextures, and Computer graphics-based methods, including Face2Face and FaceSwap. The dataset comprises 1000 real YouTube videos, each subjected to the four forgery techniques, producing a total of 4000 manipulated videos. FF++ provides videos at three resolution levels: raw, c23, and c40, with c23 being the most representative of real-world forgeries. In our experiments, we use the c23 version by default. Celeb-DF consists of 590 real videos collected from YouTube and 5639 high-quality Deepfake videos generated using an advanced Deepfake algorithm. It is available in two versions: Celeb-DFv1 and Celeb-DFv2, with Celeb-DFv2 being an improved and expanded version of v1. For our experiments, we use the Celeb-DFv2 dataset. DeepFake Detection Challenge (DFDC) is a large-scale Deepfake detection dataset introduced by Facebook (Meta). It includes videos manipulated using multiple, unknown forgery methods, making it a challenging benchmark for evaluating the generalization capability of forgery detection models.
4.1.2. Evaluation Metrics
Following previous work, we employ two primary evaluation metrics: Accuracy (ACC) and Area Under the Receiver Operating Characteristic Curve (AUC). Accuracy (ACC) measures the proportion of correctly classified instances out of the total dataset, providing an overall assessment of the model’s correctness. Area Under the Curve (AUC), derived from the Receiver Operating Characteristic (ROC) curve, evaluates the classifier’s ability to distinguish between real and forged images. AUC represents the probability that the model ranks a randomly chosen positive instance higher than a randomly chosen negative instance. A higher AUC value indicates superior model performance, as it signifies better discrimination capability between genuine and forged samples.
4.1.3. Implementation Details
We use EfficientNet-b4(Eff-b4) [6] as the backbone, which is initialized using the pre-training weights of ImageNet, and the input images are resized to match the backbone specification. To maintain consistency, this paper follows the FF++ dataset’s settings for face extraction methods and dataset partitioning, and 30 frames of face images are extracted for each video. The model is trained using stochastic gradient descent optimizer, with the initial learning rate set to and weight decay set to . For the training parameters, the batch size is set to 32 and epoch to 15.
4.2. Comparison with Previous Methods
4.2.1. In-Domain Evaluation
We conducted in-domain performance tests on the c23 compression version of the FF++ dataset and the Celeb-DF dataset. The FF++ (c23) version has the closest level of compression to the fake images that exist in real life. the Celeb-DF dataset has a high degree of realism that is indistinguishable by the human eye. As shown in Table 1, even though the existing methods have achieved high levels in the in-domain tests, our method achieves better results on both datasets. There is a 0.6% acc performance improvement and 0.35% auc performance improvement on the FF++ dataset. On Celeb-DF, a performance improvement of 0.09% in acc and a high level of auc are achieved. The GocNet [33], CLG [42], and PEL [29] methods in the table also extract the modalities of the images and construct network architectures with two branches, but the modalities are extracted differently from our method. GocNet labels residual traces by gradient operator, CLG extracts high-frequency features by SRM [24] filter, and PEL performs image processing using a discrete cosine transform. Compared with these similar methods, our method also shows superior performance, indicating that our feature extraction from the combination of local texture and global frequency domains can better utilize the characteristics of the two-branch network and synergize well to improve forgery detection.

Table 1.
In-domain performances on FF++ and Celeb-DF.
4.2.2. Cross-Domain Evaluation
To evaluate the generalization capability of our model, we set up two types of experiments. The first experiment involves training the model on a specific dataset and then testing it on other datasets to assess its ability to generalize across different datasets. The second experiment focuses on training the model on a dataset with a specific forgery method and subsequently testing its ability to detect authentic samples from datasets generated using other forgery methods. This setup allows us to evaluate the model’s performance in handling unknown forgery methods and its robustness in cross-method detection. The details of these experiments are as follows.
To evaluate the performance of the proposed method on unseen data, we trained our model on two compression degree versions, c23 and c40, of the FF++ dataset, and tested it on the Celeb-DF and DFDC datasets to assess its generalization performance across different datasets. These three datasets differ in terms of forgery methods and content characteristics, providing a robust evaluation of the generalizability of the method. As shown in Table 2, our method achieves excellent results on both the Celeb-DF and DFDC datasets across both compression levels (c23 and c40). The table indicates the specific compression degree version of the FF++ dataset used for training and records the backbone network utilized by each method, ensuring a comprehensive and fair comparison. From the table, we observe that our method performs optimally on the DFDC. For the Celeb-DF dataset, our method performs best in the FF++ (c23)-based training method, achieving a performance improvement of 0.24%, and also achieves good performance in the FF++ (c40)-based training method. These results demonstrate that our modal processing and feature extraction method excels at recognizing forged features and performs well in cross-dataset scenarios, highlighting its robustness and generalization ability for face forgery detection in previously unseen datasets.
Table 2.
Cross-domain evaluations on Celeb-DF and DFDC.
To evaluate the performance of our method under unknown forgery generation techniques, we selected DeepFake (DF), a forgery method based on self-encoders, and Face2Face (F2F), a forgery method based on computer graphics, from the FF++ dataset for training. We then conducted generalization tests on each forgery method within the FF++ dataset. The results are presented in Table 3. For comparison, GFF [23] utilizes SRM filters to mine high-frequency noise features and constructs a two-stream network, while DCL [21] employs extensive data augmentation operations, including random patching. Both methods use EfficientNet-b4 as the backbone network. Compared to these approaches, our method outperforms most in various aspects. Specifically, the DF-trained network achieves a performance improvement on NT, and demonstrates comparable performance on F2F, with a slight decrease in performance on FS. Additionally, the model trained using F2F shows and improvements on FS and NT, respectively, while maintaining competitive performance on DF, which highlights the effectiveness of our approach in extracting forgery features across different forgery methods. Overall, our method demonstrates superior generalization ability in scenarios involving unknown forgery generation techniques, outperforming other state-of-the-art feature mining methods in detecting face forgeries.
Table 3.
Cross-domain evaluations on FF++.
4.3. Ablation Study
We conducted a series of ablation experiments to assess the effectiveness of the individual components of our proposed method. These experiments primarily focus on two key aspects: modality extraction method and module architecture. For the feature extraction of different modalities, we performed ablation comparisons between our proposed local texture mining module (LTM) and other spatial domain processing techniques to evaluate the contribution of our approach to feature extraction in the spatial domain, and We compared our global frequency feature filtering extraction module (GFE) with other standard frequency domain information extraction techniques to examine the advantages of our approach in capturing high-frequency inconsistencies. For the module architecture, ablation experiments are carried out on the local texture enhancement module (LTE) as well as the LGFE module’s components that constitute the interactive utilization of local and global feature weights.
4.3.1. Modality
As shown in Table 4, we constructed a variant network by employing different feature extraction methods to validate the effectiveness of our proposed localized texture extraction method (LTM) and global frequency feature filtering extraction module (GFE). Specifically, we replaced the spatial-domain and frequency-domain extraction methods to assess their individual contributions. In the frequency domain variant, we utilized commonly used methods, such as the SRM-based frequency domain residual extraction and the discrete wavelet transform (DWT), which share similarities with our approach. The other components of the model remained unchanged. The results show that our GFE module provides significant performance improvements, achieving and higher performance compared to the SRM and DWT methods, respectively. In the spatial domain variant, we tested different methods for processing color images, including an unprocessed RGB, as well as an approach involving only patching and random reorganization. The results highlight that our proposed LTM approach brings a substantial performance boost, particularly when compared to the unprocessed RGB. This demonstrates the effectiveness of our method in extracting masked face identity information and improving the model’s performance.
Table 4.
Ablation study of feature extraction strategy.
4.3.2. Components
In the ablation experiments on the components within our model, we primarily focused on the local texture enhancement (LTE) module and the components of the local and global feature enhancement (LGFE) module. We constructed various model variants, as shown in Table 5. The results indicate that the best performance is achieved when all modules are incorporated. In (a1), high in-domain performance occurs, but the generalization is poor, possibly due to overfitting of the FF++ forgery feature. (a4) and (a5), which use only single-class attention enhancement, perform worse in both in-domain and generalization performance relative to our joint use of spatial and channel attention enhancement, suggesting that our approach is superior in exploiting the synergistic performance of the local texture and global frequency features. In addition, the generalization performance of (a4) shows some degradation relative to (a2), and the spatial enhancement reinforces the overfitting of the forged feature in the domain, which affects the generalization performance. These results highlight the effectiveness of texture enhancement and demonstrate that the weight sharing mechanism at both the spatial and channel levels between local and global features enables these two types of features to complement each other effectively. This synergy significantly improves the overall performance of the model.
Table 5.
Ablation study of different components. “✔” indicates the component is contained. FF++ is an in-domain test with ACC. Celeb-DF is a generalizability test with AUC.
4.4. Visualization
To explore the regions of interest identified by our proposed method, we utilized Grad-CAM [9] to generate heat maps, as shown in Figure 5. The heat map employs warm colors to indicate regions with high interest, where the intensity of the color corresponds to the level of attention the model places on those regions. The heat map is generated from forged images, with the corresponding real image from the neighboring frame provided in the first row for comparison. It is noteworthy that the NT forgery method is applied solely to the mouth region of the face. In the baseline Eff-b4 network, both the baseline and our method perform real or fake classification; however, the baseline primarily focuses on localized information, with some attention directed at non-forged areas or even non-facial regions. In contrast, our method successfully identifies forgery cues, with the region of interest typically centered on the forged areas within the face. This visualization underscores the effectiveness of our approach in extracting common forgery traces. It highlights the positive impact of our feature extraction method, which advances the semantic suppression of facial features, allowing the model to better capture forgery cues. Additionally, the synergistic use of local and global information enhances the model’s ability to accurately differentiate between real and fake images over a broader range.
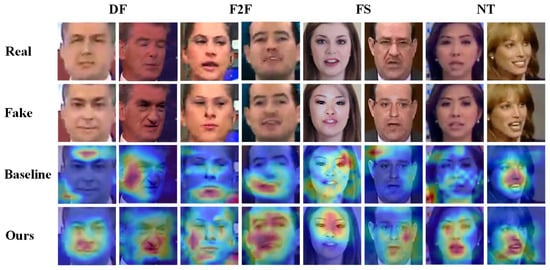
Figure 5.
Examples of Grad-CAM [9] visualization face forgery detection. Warmer colors indicate higher model focus. The face forgery image is manufactured by NT [8], and NT performed mouth action forgery.
5. Conclusions
In this work, we introduce a novel face forgery detection method that effectively mines forgery cues from both the color and frequency domains. We address the CNN’s excessive local attention to the non-forged parts of the face forgery image, and propose to perform local texture feature mining in the color domain and low-frequency filtering in the frequency domain to avoid the model’s overfitting to the non-forged semantics of the image, and to achieve the effective mining of the forged inconsistent cues. We perform spatial and channel attention sharing and enhancement between the RGB and frequency domains to establish the global attention of the model and realize the synergistic exploitation of the two types of features. Several experiments validate the effectiveness of our approach.
Author Contributions
Funding acquisition, X.J. and Q.J.; Methodology, Y.K.; Resources, X.J.; Supervision, X.J. and Q.J.; Validation, X.J.; Writing—original draft, Y.K.; Writing—review and editing, X.J., Y.X., Y.Z., M.L.M.K., Q.J. and W.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China (Nos. 62261060 and 12202377), Basic Research Project of Yunnan Province (Nos. 202301AW070007, 202301AT070407, 202301AU070210, and 202401AT070470), Major Scientific and Technological Project of Yunnan Province (No. 202202AD080002), Yunnan Province Expert Workstations (202305AF150078), and Xingdian Talent Project in Yunnan Province of China.
Institutional Review Board Statement
Data used are from publicly available datasets.
Data Availability Statement
Data availability online: https://github.com/ondyari/FaceForensics (accessed on 31 July 2022), https://github.com/yuezunli/celeb-deepfakeforensics (accessed on 5 December 2022) and https://www.kaggle.com/c/deepfake-detection-challenge/data (accessed on 5 December 2022).
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.C.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the Advances in Neural Information Processing Systems 27: Annual Conference on Neural Information Processing Systems 2014, Montreal, QC, Canada, 8–13 December 2014; Ghahramani, Z., Welling, M., Cortes, C., Lawrence, N.D., Weinberger, K.Q., Eds.; 2014; pp. 2672–2680. [Google Scholar]
- Karras, T.; Laine, S.; Aila, T. A Style-Based Generator Architecture for Generative Adversarial Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, 16–20 June 2019; Computer Vision Foundation/IEEE: New York, NY, USA, 2019; pp. 4401–4410. [Google Scholar]
- Zhu, J.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks. In Proceedings of the IEEE International Conference on Computer Vision, ICCV 2017, Venice, Italy, 22–29 October 2017; IEEE Computer Society: Los Alamitos, CA, USA, 2017; pp. 2242–2251. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-Encoding Variational Bayes. In Proceedings of the 2nd International Conference on Learning Representations, ICLR 2014, Banff, AB, Canada, 14–16 April 2014; Conference Track Proceedings. Bengio, Y., LeCun, Y., Eds.; 2014. [Google Scholar]
- Cho, K.; van Merrienboer, B.; Gülçehre, Ç.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, EMNLP 2014, Doha, Qatar, 25–29 October 2014; A meeting of SIGDAT, a Special Interest Group of the ACL. Moschitti, A., Pang, B., Daelemans, W., Eds.; ACL: Stroudsburg, PA, USA, 2014; pp. 1724–1734. [Google Scholar]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. In Proceedings of the 36th International Conference on Machine Learning, ICML 2019, Long Beach, CA, USA, 9–15 June 2019; Proceedings of Machine Learning Research. Chaudhuri, K., Salakhutdinov, R., Eds.; PMLR: New York, NY, USA, 2019; Volume 97, pp. 6105–6114. [Google Scholar]
- Rössler, A.; Cozzolino, D.; Verdoliva, L.; Riess, C.; Thies, J.; Nießner, M. FaceForensics++: Learning to Detect Manipulated Facial Images. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, ICCV 2019, Seoul, Republic of Korea, 27 October–2 November 2019; IEEE: New York, NY, USA, 2019; pp. 1–11. [Google Scholar]
- Thies, J.; Zollhöfer, M.; Nießner, M. Deferred neural rendering: Image synthesis using neural textures. ACM Trans. Graph. (TOG) 2019, 38, 1–12. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. In Proceedings of the IEEE International Conference on Computer Vision, ICCV 2017, Venice, Italy, 22–29 October 2017; IEEE Computer Society: Los Alamitos, CA, USA, 2017; pp. 618–626. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, 27–30 June 2016; IEEE Computer Society: Los Alamitos, CA, USA, 2016; pp. 770–778. [Google Scholar]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; IEEE Computer Society: Los Alamitos, CA, USA, 2017; pp. 1800–1807. [Google Scholar]
- Nguyen, H.H.; Yamagishi, J.; Echizen, I. Use of a Capsule Network to Detect Fake Images and Videos. arXiv 2019, arXiv:1910.12467. [Google Scholar] [CrossRef]
- Afchar, D.; Nozick, V.; Yamagishi, J.; Echizen, I. MesoNet: A Compact Facial Video Forgery Detection Network. In Proceedings of the 2018 IEEE International Workshop on Information Forensics and Security, WIFS 2018, Hong Kong, China, 11–13 December 2018; IEEE: New York, NY, USA, 2018; pp. 1–7. [Google Scholar]
- Wang, T.; Mallya, A.; Liu, M. One-Shot Free-View Neural Talking-Head Synthesis for Video Conferencing. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, Virtual, 19–25 June 2021; Computer Vision Foundation/IEEE: New York, NY, USA, 2021; pp. 10039–10049. [Google Scholar]
- Yang, X.; Li, Y.; Lyu, S. Exposing Deep Fakes Using Inconsistent Head Poses. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP 2019, Brighton, UK, 12–17 May 2019; IEEE: New York, NY, USA, 2019; pp. 8261–8265. [Google Scholar]
- Li, Y.; Chang, M.; Lyu, S. In Ictu Oculi: Exposing AI Created Fake Videos by Detecting Eye Blinking. In Proceedings of the 2018 IEEE International Workshop on Information Forensics and Security, WIFS 2018, Hong Kong, China, 11–13 December 2018; IEEE: New York, NY, USA, 2018; pp. 1–7. [Google Scholar]
- Chen, L.; Zhang, Y.; Song, Y.; Liu, L.; Wang, J. Self-supervised Learning of Adversarial Example: Towards Good Generalizations for Deepfake Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, 18–24 June 2022; IEEE: New York, NY, USA, 2022; pp. 18689–18698. [Google Scholar]
- Dong, X.; Bao, J.; Chen, D.; Zhang, T.; Zhang, W.; Yu, N.; Chen, D.; Wen, F.; Guo, B. Protecting Celebrities from DeepFake with Identity Consistency Transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, 18–24 June 2022; IEEE: New York, NY, USA, 2022; pp. 9458–9468. [Google Scholar]
- Shiohara, K.; Yamasaki, T. Detecting Deepfakes with Self-Blended Images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, 18–24 June 2022; IEEE: New York, NY, USA, 2022; pp. 18699–18708. [Google Scholar]
- Wang, C.; Deng, W. Representative Forgery Mining for Fake Face Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, Virtual, 19–25 June 2021; Computer Vision Foundation/IEEE: New York, NY, USA, 2021; pp. 14923–14932. [Google Scholar]
- Sun, K.; Yao, T.; Chen, S.; Ding, S.; Li, J.; Ji, R. Dual contrastive learning for general face forgery detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 22 February–1 March 2022; AAAI Press: Washington, DC, USA, 2022; Volume 36, pp. 2316–2324. [Google Scholar]
- Chen, X.; Tao, H.; Zhou, H.; Zhou, P.; Deng, Y. Hierarchical and progressive learning with key point sensitive loss for sonar image classification. Multimed. Syst. 2024, 30, 380. [Google Scholar] [CrossRef]
- Luo, Y.; Zhang, Y.; Yan, J.; Liu, W. Generalizing Face Forgery Detection With High-Frequency Features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, Virtual, 19–25 June 2021; Computer Vision Foundation/IEEE: New York, NY, USA, 2021; pp. 16317–16326. [Google Scholar]
- Fridrich, J.J.; Kodovský, J. Rich Models for Steganalysis of Digital Images. IEEE Trans. Inf. Forensics Secur. 2012, 7, 868–882. [Google Scholar] [CrossRef]
- Tan, C.; Zhao, Y.; Wei, S.; Gu, G.; Liu, P.; Wei, Y. Frequency-Aware Deepfake Detection: Improving Generalizability through Frequency Space Domain Learning. In Proceedings of the Thirty-Eighth AAAI Conference on Artificial Intelligence, AAAI 2024, Thirty-Sixth Conference on Innovative Applications of Artificial Intelligence, IAAI 2024, Fourteenth Symposium on Educational Advances in Artificial Intelligence, EAAI 2024, Vancouver, BC, Canada, 20–27 February 2024; Wooldridge, M.J., Dy, J.G., Natarajan, S., Eds.; AAAI Press: Washington, DC, USA, 2024; pp. 5052–5060. [Google Scholar]
- Zhao, H.; Zhou, W.; Chen, D.; Wei, T.; Zhang, W.; Yu, N. Multi-Attentional Deepfake Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, Virtual, 19–25 June 2021; Computer Vision Foundation/IEEE: New York, NY, USA, 2021; pp. 2185–2194. [Google Scholar]
- Nguyen, H.H.; Fang, F.; Yamagishi, J.; Echizen, I. Multi-task Learning for Detecting and Segmenting Manipulated Facial Images and Videos. In Proceedings of the 10th IEEE International Conference on Biometrics Theory, Applications and Systems, BTAS 2019, Tampa, FL, USA, 23–26 September 2019; IEEE: New York, NY, USA, 2019; pp. 1–8. [Google Scholar]
- Agarwal, S.; Farid, H.; Fried, O.; Agrawala, M. Detecting Deep-Fake Videos from Phoneme-Viseme Mismatches. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR Workshops 2020, Seattle, WA, USA, 14–19 June 2020; Computer Vision Foundation/IEEE: New York, NY, USA, 2020; pp. 2814–2822. [Google Scholar]
- Gu, Q.; Chen, S.; Yao, T.; Chen, Y.; Ding, S.; Yi, R. Exploiting Fine-Grained Face Forgery Clues via Progressive Enhancement Learning. In Proceedings of the Thirty-Sixth AAAI Conference on Artificial Intelligence, AAAI 2022, Thirty-Fourth Conference on Innovative Applications of Artificial Intelligence, IAAI 2022, the Twelveth Symposium on Educational Advances in Artificial Intelligence, EAAI 2022, Virtual Event, 22 February–1 March 2022; AAAI Press: Washington, DC, USA, 2022; pp. 735–743. [Google Scholar]
- Yang, J.; Li, A.; Xiao, S.; Lu, W.; Gao, X. MTD-Net: Learning to Detect Deepfakes Images by Multi-Scale Texture Difference. IEEE Trans. Inf. Forensics Secur. 2021, 16, 4234–4245. [Google Scholar] [CrossRef]
- Yang, G.; Wei, A.; Fang, X.; Zhang, J. FDS_2D: Rethinking magnitude-phase features for DeepFake detection. Multimed. Syst. 2023, 29, 2399–2413. [Google Scholar] [CrossRef]
- Zhu, X.; Wang, H.; Fei, H.; Lei, Z.; Li, S.Z. Face Forgery Detection by 3D Decomposition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, Virtual, 19–25 June 2021; Computer Vision Foundation/IEEE: New York, NY, USA, 2021; pp. 2929–2939. [Google Scholar]
- Guo, Z.; Yang, G.; Zhang, D.; Xia, M. Rethinking gradient operator for exposing AI-enabled face forgeries. Expert Syst. Appl. 2023, 215, 119361. [Google Scholar] [CrossRef]
- Fei, J.; Dai, Y.; Yu, P.; Shen, T.; Xia, Z.; Weng, J. Learning Second Order Local Anomaly for General Face Forgery Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, 18–24 June 2022; IEEE: New York, NY, USA, 2022; pp. 20238–20248. [Google Scholar]
- Brewster, M.E. An Introduction to Wavelets (Charles K. Chui). SIAM Rev. 1993, 35, 312–313. [Google Scholar] [CrossRef]
- Mallat, S. A Theory for Multiresolution Signal Decomposition: The Wavelet Representation. IEEE Trans. Pattern Anal. Mach. Intell. 1989, 11, 674–693. [Google Scholar] [CrossRef]
- Li, Y.; Yang, X.; Sun, P.; Qi, H.; Lyu, S. Celeb-DF: A Large-Scale Challenging Dataset for DeepFake Forensics. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, WA, USA, 13–19 June 2020; Computer Vision Foundation/IEEE: New York, NY, USA, 2020; pp. 3204–3213. [Google Scholar]
- Dolhansky, B.; Howes, R.; Pflaum, B.; Baram, N.; Canton-Ferrer, C. The Deepfake Detection Challenge (DFDC) Preview Dataset. arXiv 2019, arXiv:1910.08854. [Google Scholar] [CrossRef]
- Deepfakes. 2018. Available online: https://github.com/deepfakes/faceswap (accessed on 29 October 2018).
- Thies, J.; Zollhofer, M.; Stamminger, M.; Theobalt, C.; Nießner, M. Face2face: Real-time face capture and reenactment of rgb videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2387–2395. [Google Scholar]
- Kowalski, M. Faceswap. 2018. Available online: https://github.com/marekkowalski/faceswap (accessed on 1 August 2020).
- Dong, F.; Zou, X.; Wang, J.; Liu, X. Contrastive learning-based general Deepfake detection with multi-scale RGB frequency clues. J. King Saud Univ.—Comput. Inf. Sci. 2023, 35, 90–99. [Google Scholar] [CrossRef]
- Qian, Y.; Yin, G.; Sheng, L.; Chen, Z.; Shao, J. Thinking in Frequency: Face Forgery Detection by Mining Frequency-Aware Clues. In Proceedings of the Computer Vision—ECCV 2020—16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XII; Lecture Notes in Computer Science. Vedaldi, A., Bischof, H., Brox, T., Frahm, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2020; Volume 12357, pp. 86–103. [Google Scholar]
- Zi, B.; Chang, M.; Chen, J.; Ma, X.; Jiang, Y. WildDeepfake: A Challenging Real-World Dataset for Deepfake Detection. In Proceedings of the MM ’20: The 28th ACM International Conference on Multimedia, Virtual Event/Seattle, WA, USA, 12–16 October 2020; Chen, C.W., Cucchiara, R., Hua, X., Qi, G., Ricci, E., Zhang, Z., Zimmermann, R., Eds.; ACM: New York, NY, USA, 2020; pp. 2382–2390. [Google Scholar]
- Cao, J.; Ma, C.; Yao, T.; Chen, S.; Ding, S.; Yang, X. End-to-End Reconstruction-Classification Learning for Face Forgery Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, 18–24 June 2022; IEEE: New York, NY, USA, 2022; pp. 4103–4112. [Google Scholar]
- Ahmed, A.H.; Hamzah, L.; Raed, K.; Saeed, A. FSBI: Deepfake detection with frequency enhanced self-blended images. Image Vis. Comput. 2025, 154, 105418. [Google Scholar] [CrossRef]
- Yin, Z.; Wang, J.; Xiao, Y.; Zhao, H.; Li, T.; Zhou, W.; Liu, A.; Liu, X. Improving Deepfake Detection Generalization by Invariant Risk Minimization. IEEE Trans. Multimed. 2024, 26, 6785–6798. [Google Scholar] [CrossRef]
- Masi, I.; Killekar, A.; Mascarenhas, R.M.; Gurudatt, S.P.; AbdAlmageed, W. Two-Branch Recurrent Network for Isolating Deepfakes in Videos. In Proceedings of the Computer Vision—ECCV 2020—16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part VII; Lecture Notes in Computer Science. Vedaldi, A., Bischof, H., Brox, T., Frahm, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2020; Volume 12352, pp. 667–684. [Google Scholar]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; IEEE Computer Society: Los Alamitos, CA, USA, 2017; pp. 2261–2269. [Google Scholar]
- Li, L.; Bao, J.; Zhang, T.; Yang, H.; Chen, D.; Wen, F.; Guo, B. Face X-Ray for More General Face Forgery Detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, WA, USA, 13–19 June 2020; Computer Vision Foundation/IEEE: New York, NY, USA, 2020; pp. 5000–5009. [Google Scholar]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep High-Resolution Representation Learning for Human Pose Estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, 16–20 June 2019; Computer Vision Foundation/IEEE: New York, NY, USA, 2019; pp. 5693–5703. [Google Scholar]
- Lin, L.; He, X.; Ju, Y.; Wang, X.; Ding, F.; Hu, S. Preserving Fairness Generalization in Deepfake Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, 16–22 June 2024; IEEE: New York, NY, USA, 2024; pp. 16815–16825. [Google Scholar]
- Zhang, Y.; Lin, W.; Xu, J.; Xu, W.; Xu, Y. MLPN: Multi-Scale Laplacian Pyramid Network for deepfake detection and localization. J. Inf. Secur. Appl. 2025, 89, 103965. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).