Abstract
Despite spiking neural networks (SNNs) inherently exceling at processing time series due to their rich spatio-temporal information and efficient event-driven computing, the challenge of extracting complex correlations between variables in multivariate time series (MTS) remains to be addressed. This paper proposes a reinforced, event-driven, and attention-based convolution SNN model (REAT-CSNN) with three novel features. First, a joint Gramian Angular Field and Rate (GAFR) coding scheme is proposed to convert MTS into spike images, preserving the inherent features in MTS, such as the temporal patterns and spatio-temporal correlations between time series. Second, an advanced LIF-pooling strategy is developed, which is then theoretically and empirically proved to be effective in preserving more features from the regions of interest in spike images than average-pooling strategies. Third, a convolutional block attention mechanism (CBAM) is redesigned to support spike-based input, enhancing event-driven characteristics in weighting operations while maintaining outstanding capability to capture the information encoded in spike images. Experiments on multiple MTS data sets, such as stocks and PM2.5 data sets, demonstrate that our model rivals, and even surpasses, some CNN- and RNN-based techniques, with up to 3% better performance, while consuming significantly less energy.
1. Introduction
Spiking neural networks (SNNs) are directly inspired by the information encoding mechanisms of biological neural systems, which rely on discrete spiking signals to transmit dynamic spatio-temporal information [1,2,3]. The design of their spiking neurons mimics the biological process of membrane potential accumulation and spiking emission, thereby achieving an event-driven characteristic similar to that of biological brains. This biomimetic property enhances the robustness of the model in complex environments, provides theoretical support for developing novel neuromorphic computing architectures, and it has led to SNNs being recognized as the third generation of neural networks [4,5].
Research on SNNs has revealed that they have a performance comparable to that of conventional artificial neural networks (ANN) while being more energy-efficient [6,7,8,9], particularly in image analysis tasks [10,11,12,13]. However, there has been relatively little prior work on SNNs in relation to MTS analysis, which is essential in our daily lives but limited by energy expenditure, such as portable medical devices for healthcare that monitor various physical signs [14,15,16,17].
Recently, SNN-based solutions to univariate time series (UTS) analysis have been of interest to researchers [18]. To this end, advanced techniques from conventional ANN models, such as convolution neural networks (CNN) and recurrent neural networks (RNN), have been incorporated into the architecture design of SNN models [19,20,21,22,23]. For example, spike-based memory cells have been proposed by mimicking gate mechanisms in long-short-term memory (LSTM) and gated recurring unit (GRU) setups, which have the ability to analyze temporal patterns in UTS [21,24,25,26]. Convolution layers have also been introduced in SNNs [27], taking advantage of the ability of convolutional kernels to extract temporal patterns in a time series matrix.
Unfortunately, it is still difficult to use the SNN-based approaches mentioned earlier to analyze multivariate time series (MTS). This is mainly attributed to the complex spatio-temporal correlations posed by the high-dimensional nature of MTS [28,29]. Motivated by the convolution SNN (CSNN) architecture proposed by Gautam et al. [27], our aim is to develop a variant of CSNN to address the MTS prediction issue by overcoming the following challenges.
First, existing encoding schemes have a limited ability to accurately represent knowledge that corresponds to different classes of characteristics in MTS [30]. It further results in the performance bottleneck of existing SNN-based methods [31]. To solve this problem, Long et al. [32] employed the non-subsampled shearlet transform (NSST) technique. However, the state of a neuron was denoted as a real value, rather than as a spike.
Second, neither max-pooling nor average-pooling is effective enough to reduce the dimension while still preserving features of spike images, as they differ from regular images [33,34,35]. More precisely, max-pooling can lead to an overload of spike activation, further resulting in more energy consumption, while average polling has difficulty in threshold configuration, which can cause information loss.
Third, the spike-based memory cell has the weakness of hardly achieving the energy-efficient sparse firing regime [36] or losing the nugget of information [37]. The transformation of MTS into spike images in convolution-based SNN increases the dimension of the data, resulting in the discontinuity and randomness of the feature distribution in high-dimensional, spike-based images. Although attention mechanisms are potential solutions, most of them are implemented based on real values rather than spikes, which violates the integrated event-driven nature of SNNs.
In an effort to deal with the above problems, this paper presents a reinforced, event-driven, and attention-based convolution SNN model (REAT-CSNN), which integrates an effective spike-encoding scheme and a novel pooling strategy. A variant of the attention mechanism is developed to deal with the critical spaito-temporal correlations from spike images, which have high dimensions due to the encoding. More precisely, the main contributions are as follows.
- By incorporating the advantages of Gramian Angular Field (GAF) and rate encoding techniques, the proposed spike-encoding strategy allows for an effective representation of the knowledge with respect to temporal patterns and variable dependencies in MTS.
- The proposed Leaky-Integrate-and-Fire (LIF)-based pooling strategy has been theoretically and experimentally proven to be effective in extracting more features from the regions of interest in a spike image than average-pooling strategies.
- The redesigned Spike-based Convolutional Block Attention Mechanism (SCBAM) strengthens its event-driven characteristics in weighting operations while still having the outstanding capability to capture the spatio-temporal correlations encoded in the spike images.
- By performing experiments on multiple MTS data sets, the results show that the performance of our model rivals, and even surpasses, some CNN-, RNN-, and SNN-based techniques, with up to better performance but with less energy consumption.
2. Related Work
As of late, the progress of deep learning techniques has prompted the development of models for MTS prediction. These techniques improve prediction performance by capturing the multifaceted nature of nonlinearity, nonstationarity, and spatio-temporal correlation between MTS. In the following, we diagram a portion of the latest and typical methods in MTS prediction methods from the point of view of ANN-based models and SNN-based models.
2.1. ANN-Based Models
ANN-based models can be divided into two categories: Euclidean space-based models, such as CNN and RNN; and graph-structure-based models, such as graph neural network (GNN) [38,39,40]. CNNs are commonly used for the analysis of two-dimensional (2D) images. To apply CNNs to time series analysis, existing models attempt to represent MTS as a multidimensional tensor from temporal and spatial dimensions so that convolutional kernels can be used to extract temporal patterns and dependencies. For example, Chen et al. [38] modeled MTS in a traffic network as a 3D volume and then used spatio-temporal kernels in different layers to capture temporal and spatial correlations. Wang et al. [39] modeled MTS as a 2D volume but employed multiple CNNs to address the issue of periodic MTS prediction, and they automatically extracted correlations between different variables from a global perspective. Moreover, 2D volume was also used in [40] with a proposed attention module to learn the representation of spatio-temporal relationships.
Compared to CNN-based models, RNN and the corresponding variants, such as LSTM and GRU [41,42,43,44], are used more frequently in MTS analysis because of their ability to exhibit temporal dynamic behavior in a textual sequence, which has the same 1D structure as time series. One challenge in RNN-based methods is how to use historical information effectively in forecasting future time series. To address this, attention mechanisms are often used. For example, both Qin et al. [41] and Liu et al. [42] developed a dual-stage, attention-based RNN to capture long-term temporal dependencies and to select relevant MTS for predictions. The difference was due to the fact that the former study aimed at single-step prediction, whereas the latter study focused on multiple-step prediction. Similarly, a dual-stage attention mechanism was also employed in the GRU for the MTS prediction developed by Tan et al. [45]. Additionally, the combination of CNN and RNN models has become a popular approach for MTS prediction, such as the Conv-LSTM network model proposed by Xiao et al. [43] and the temporal self-attention-based Conv-LSTM proposed by Fu et al. [44], which benefit from integrating dependencies between time series in CNN and exploring long-term temporal correlation in RNN.
Rather than ANN-based models, GNNs allow for the input of graph structures, which can be used to represent the implicit and explicit correlations between MTS, such as the relationships between the stakeholders of a certain stock. This provides GNNs with the capability to explore the dependencies between time series in depth. For example, Chen et al. [46] proposed a dual CNN and GNN model for stock prediction, which captures spatial and temporal correlations across time series. To further enhance the GNN’s capacity to remember significant features in time series, Rao et al. [37] combined GNN with LSTM. The GNN was used to balance the contribution of the external features of other time series on the target time series, while two parallel LSTMs were used to learn the temporal patterns and MTS dependencies in the long-term history.
2.2. SNN-Based Models
As SNN techniques matured, increasing attention has been drawn to solving time series problems using SNN-based approaches. To improve the practicability of these methods, much effort has been dedicated to the development of the spike encoding scheme and the extraction of time series patterns.
The spike encoding scheme allows time series to be represented as spike trains while preserving important information that could be beneficial for accurate analysis. Sharma et al. [20] proposed a continuous firing temporal coding scheme to represent the temporal correlations in a high-dimensional chaotic time series of electricity prices. However, this encoding scheme is only applicable to univariate time series, which restricts its capacity to capture the spatio-temporal correlation in MTS. To address this issue, Long et al. [32] proposed a NSST technique, which enables MTS to be processed in the NSST domain. This makes the SNN model particularly advantageous for capturing the nonlinearity and non-stationarity in MTS, as well as the dependence between time series. Unfortunately, NSST denotes the state of a neuron as a real number, rather than as a spike. Thus, it violates the event-driven nature of SNN.
Regarding pattern extraction, existing studies can be divided into two categories based on the kernel architecture used in SNN models, which are RNN-based or CNN-based. For RNN-based models, Liu et al. [21] developed an SNN by replicating the recurrent structure of RNNs. More precisely, they proposed two gate mechanisms, namely the reset gate and the consumption gate. Similarly, Wachirawit et al. [24] also developed a gated SNN. They managed to solve the issue of non-differentiability for the surrogate derivative and decreased the gap between the derivative of the activation function of the spiking neurons. Yan et al. [47] designed a quantum-inspired SNN that combined a quantum particle swarm optimization algorithm and a Kalman filtering technique to smooth and denoise the original time series data.
Examining the remarkable achievements of SNNs in image analysis, an alternative approach transformed the multivariate time series into matrices, referred to as spike images. This allows models, such as CSNN proposed by Gautam et al. [27], to be used in time series analysis. Powered by convolutional kernels, the features extracted from the spike images correspond to the temporal patterns and dependencies between time series. However, spike images are not the same as practical images, making it difficult to accurately retain useful features without losing information. We propose a novel pooling strategy, in conjunction with a spike-based attention module, to further enhance the feature exploration capacity of CSNN, thereby improving the prediction accuracy.
The success of SNN techniques promotes its practical application in time series analysis. For instance, David et al. [14] presented a novel SNN model for forecasting financial time series, which was capable of recognizing nonstationarity in financial data. Macikag et al. [48] developed a clustering-based ensemble model to predict air pollution, which combined multiple evolving SNNs to analyze a different set of time series related to different air pollution indicators. Capizzi et al. [49] applied an SNN-based method to efficiently and inexpensively capture the temporal dynamics of the chemical processes that occur in the digestor.
Despite the encouraging outcomes of the SNN-based approaches mentioned above, they focus mainly on univariate time series. There are still difficulties to be tackled when dealing with MTS issues, such as spikes encoding, event-driven architecture design, and spatio-temporal extraction, which are the main causes of the considerable gap between SNN and traditional ANN in MTS analysis.
3. Preliminary Work
3.1. GAF
Gramian Angular Field (GAF) [50] is a technique that can encode a time series in an image while preserving the temporal correlations between time series. Mathematically, we define a time series with observations in the historical T steps by . First, we rescale as with the normalized method in (1) so that falls in the range of :
Next, the in the polar coordinate system is expressed as in the equation in (2), where the radius is calculated with time step , and the angular cosine is calculated with :
GAF can generate two types of images using the equations of the Gramian angular summation field (GASF) and the Gramian angular difference field (GADF). The major difference between GASF and GADF depends on the conversion of trigonometric functions, where GASF is based on cosine functions and GADF is based on sine functions. In this paper, we employed and defined GASF as follows:
3.2. Rate Coding
Rate coding schemes are broadly classified into three categories, including count coding, density coding, and population coding. The proposed SNN model depends on the count rate coding, which has been widely used in SNN [30] to solve image analysis problems.
Typically, the first phase of count rate coding is to duplicate an image K times. Thus, we have . In the second phase, K spike images are generated, denoted by , where has the same size as I. Each pixel in is a spike with the value 0 or 1, and they are estimated based on a specific probability distribution that is parameterized with the intensity of the pixel located in the same position in . For example, Saunders [10] utilized the Poisson distribution with a mean event rate equal to the firing rate that is scaled by the intensity of the pixel.
3.3. LIF
The Leaky Integrate-and-Fire (LIF) model is a popularly used SNN model to analyze the behavior of a nervous system. Unlike the conventional artificial neural network, a LIF model consists of multiple layers of LIF neurons. Suppose that the j-th LIF neuron in the l-th layer receives the spike from the i-th neuron in the previous layer at the time step t, which is denoted by . Furthermore, is modulated with weight and then integrated into , which behaves like a leaky integrator and decays exponentially according to a constant . Mathematically, we can estimate by the following:
where is the number of neurons in the layer , is a constant coefficient, and is the current at the time step .
The dynamic of leads to the variation of the membrane potential , which can be described as follows:
where is the time constant of the membrane potential, and represents the resting potential. As shown in Formula (6), is reset to once it exceeds the membrane potential threshold with the corresponding output . Otherwise, .
Since it is extremely expensive to estimate through (5), an approximation of is received using the following iterative expression:
3.4. CBAM
Given an intermediate feature map , the Convolutional Block Attention Module (CBAM) [51] obtains the local interest region of , which is denoted by , through a channel attention module (CAM) and a spatial attention module (SAM). More precisely, the architecture of is modeled as
where is a multiple-layer perceptron, denotes average-pooling, denotes the max-pooling, and denotes the sigmoid function. Subsequently, is operated on the output of the CAM, , which is expressed as
where represents the convolution operation. is obtained as follows:
where ⊗ is the element-wise multiplication.
4. Methodology
We modeled a MTS prediction problem as . More precisely, denotes the MTS in historical T time steps. is expressed by , where N denotes the multivariate dimensions. Our objective was to develop a SNN model , named REAT-CSNN, which can predict MTS in the next time step with . For better clarity, the frequently used abbreviations in this paper are listed in the Abbreviations section.
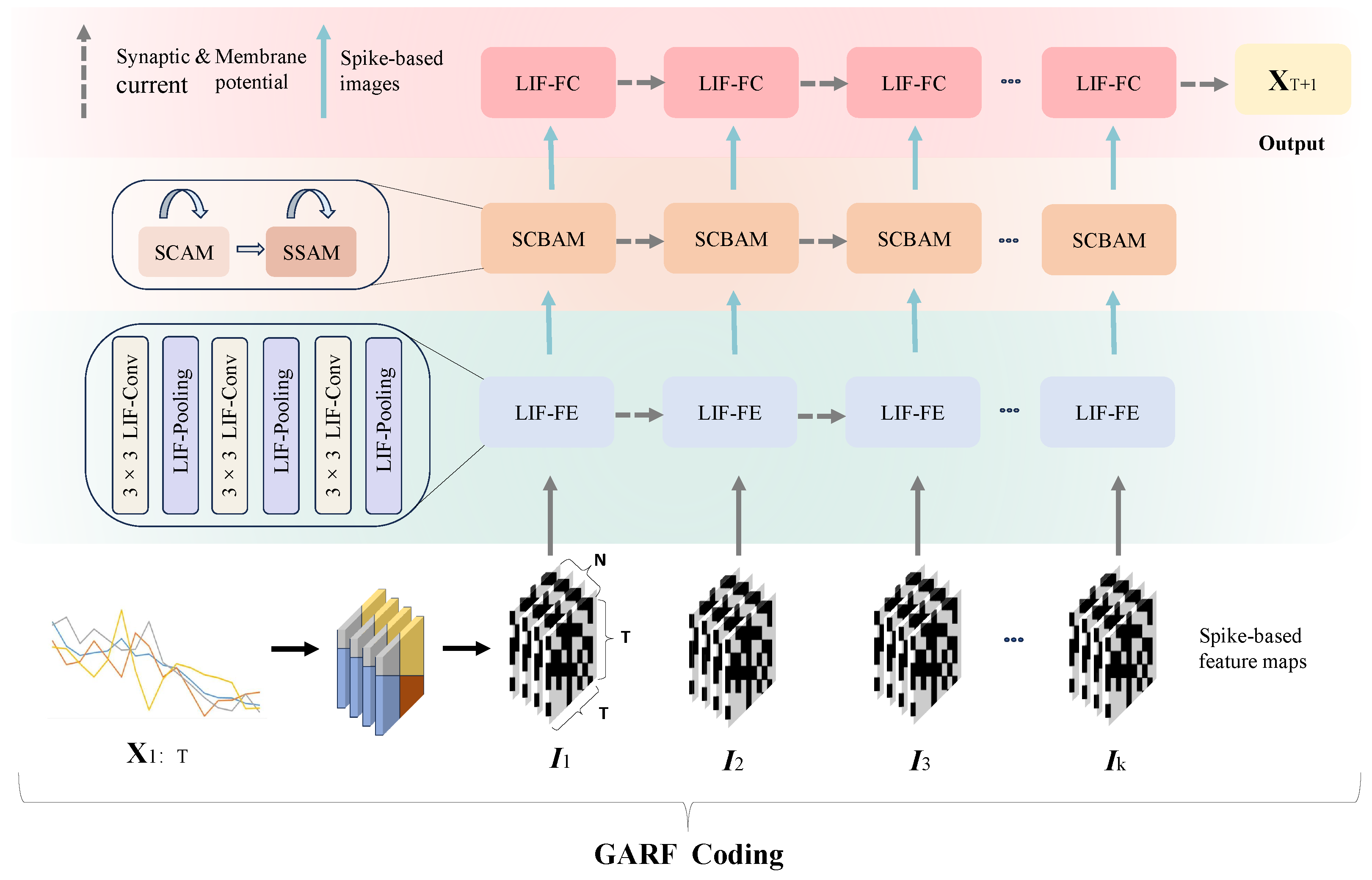
The architecture of REAT-CSNN is shown in Figure 1. is first converted to the multichannel spike image series with the proposed Gramian Angular Field Rate coding (GAFR coding) algorithm, which is illustrated in Section 4.1. is a three-dimensional image, in which both the width and height are equal to T, and the channel size is N.
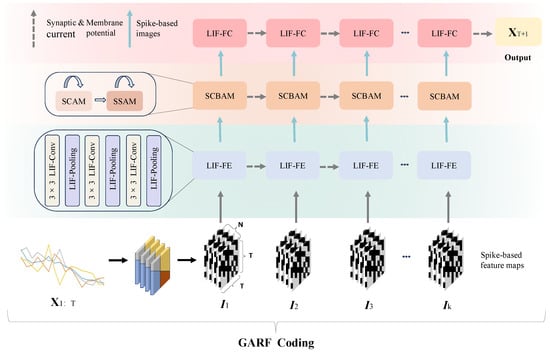
Figure 1.
The architecture of REAT-CSNN.
is then transmitted to the LIF-based feature extraction module (LIF-FE) that includes LIF-based convolution (LIF-Conv) and LIF-pooling layers, with the objective of extracting and shrinking the representation of the features. It is worth mentioning that we have altered the pooling strategy used in the existing CSNN model so that the input from different pixels within a patch is taken into account when creating spike-based feature maps. More information can be found in Section 4.2.
Due to the growth of the data dimension caused by GAFR coding, it can be difficult for conventional Convolutional Spiking Neural Network (CSNN) [23] to accurately identify the relevant and important features in spike image sequences. To this end, an improved Convolutional Block Attention Mechanism (CBAM) is used by assigning its ability to cope with spikes. The biologically plausible characteristic of REAT-CSNN is further enhanced by the Spike-based Spatial Attention Module (SSAM). This module is essential to locate the critical features in the spatial dimension of , which correspond to the temporal patterns, such as tendency and periodicity, in a time series. Furthermore, the Spike-based Channel Attention Module (SCAM) is used to identify the critical features in the channel dimension of . This module acts as a filter to focus on the important spatio-temporal correlations in MTS, which are discussed further in Section 4.3.
Lastly, a fully LIF-based connection layer is stacked, giving the final output of the forecast result in the next single time step .
4.1. GAFR Coding
Recently, SNN-based approaches have achieved promising results in computer vision tasks. Since excitatory neurons in SNN models only have the ability to deal with spike information, neural coding schemes are usually used to convert pixels in an image into spikes before feeding the image into SNN models. Considering the maturity of these image-driven SNN-based methods, a barrier to applying these approaches in MTS analysis is how to effectively transfer MTS into images while simultaneously maintaining critical knowledge such as the spatio-temporal correlations between time series. A popular approach is to transform into an image of size . This image can then be converted into a spike image using temporal or rate coding. However, this is not an accessible method as temporal coding or rate coding has drawbacks, such as high latency, information loss, and data distortion, which limits the ability to represent all of the patterns and dependencies in MTS.
In this paper, inspired by the fact that GAF is a useful technique for transferring time series into images, such that a CNN model can be used for time series analysis, we combined GAF and rate coding to create an integrated coding scheme called GAFR coding. This scheme takes advantage of both GAF and rate coding as GAF has been demonstrated to maintain the temporal information of time series, while rate coding is more effective than temporal coding in preserving the original features of images.
The GAFR coding scheme consists of two steps. First, is transformed into GAF data with multiple channels, where each time series is treated as a channel. In this case, the MTS is converted into a multi-channel image. Second, the obtained multi-channel image data are encoded using rate coding to enable spike-based computation. Each pixel value of the image data is represented as the firing rate of a spiking neuron in the spike-based computation.
4.2. LIF-Pooling
In CNN, a pooling layer is used to compress a set of pixels into a compact representation. The pooling operation has the benefit of reducing the feature dimension so that the size of the model parameters can be decreased. Meanwhile, it generalizes the features extracted by convolutional filters with little information lost since the features in a patch are usually correlated.
The situation differs from that above when employing the pooling operation on spike images. To begin with, either the input or output from the medium layers of an CSNN model is an image in which the intensity of each pixel is a binary value. In this case, suppose a max-pooling is used, then the output is always 1 if there exists at least one active spike in a patch. It not only aggravates energy consumption, but also makes inefficient event-driven triggering more likely, further resulting in more time being required for model learning. In addition, the temporal correlation over different time lags is encoded in each pixel in the spike image, leading to the features independently distributed in each pixel. Therefore, it easily filters out critical spikes after the max-pooling operation. Unfortunately, although average-pooling can alleviate the issue caused by max-pooling by leveraging the information from all of the pixels in a patch, a threshold has to be used to control the output to be a binary value, and such a threshold is an empirical value that is hard to precisely set.
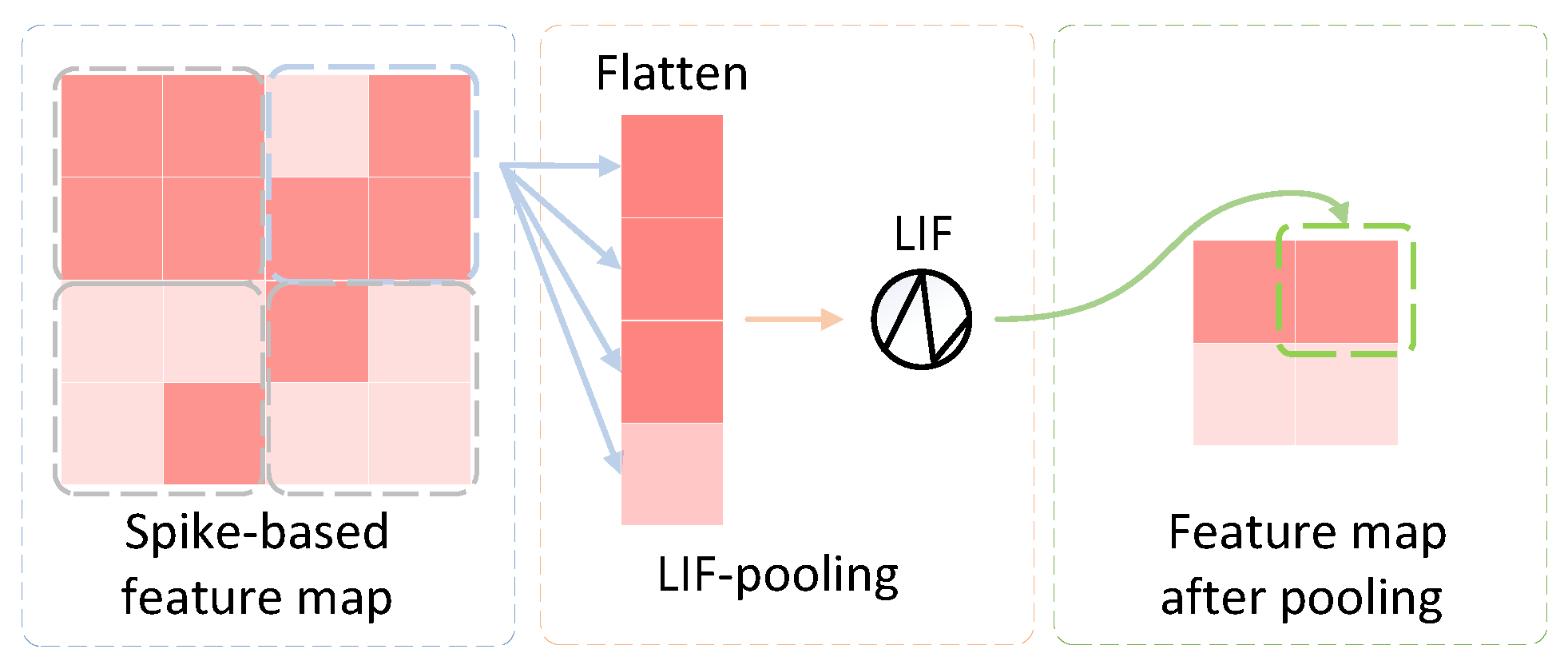
Inspired by LIF-based convolution, we developed an event-driven pooling mechanism. As shown in Figure 2, the block in the middle of the figure refers to the proposed LIF-pooling module, which consists of two components. In the first component, each patch is flattened as a one-dimensional tensor. Each tensor is fed to the second component that plays the same function as an LIF neuron that has an output estimated based on Formula (6).
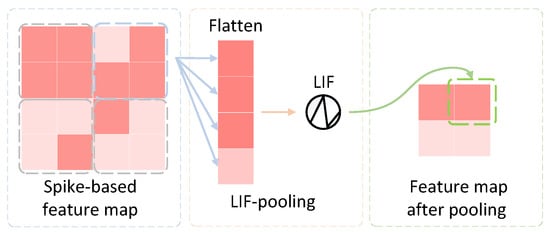
Figure 2.
The principle of LIF-pooling.
Given an intermediate spike-based feature image , the number of spikes activated after the LIF-based pooling with the membrane potential threshold in a region of interest is denoted by , and the number of spikes after average-pooling with the configured threshold is represented by . This leads to the following theorem:
Theorem 1.
when is equal to the size of a patch and .
Proof.
We divided into a set of patches P, where each patch has equal size. We estimated as follows:
where is estimated based on with Formulas (5) and (6). In average-pooling, given a patch p, we first calculated the sum of intensities in p with
where S is the size of p. Suppose , then we substitute (13) into (5) and is rewritten as
Taking into account that , , and , we have . Given , it is reasonable to believe that many more spikes will be activated after LIF-based pooling compared to average-pooling. We have the following three cases:
- Case 1: ,
- Case 2: ,
- Case 3: .
Accordingly, there should be at least one patch in which one of the above three cases is satisfied. Therefore, is proven. □
The theorem suggests that the risk of data loss when using average-pooling in a region of interest of a spike feature map can be reduced via using LIF-pooling under certain conditions. Additionally, it provides us with a guide to configure the thresholds ( and ) used in LIF-pooling. The effectiveness of how well the information is preserved after applying our proposed pooling mechanism is visualized in Section 5.4.1.
4.3. SCBAM
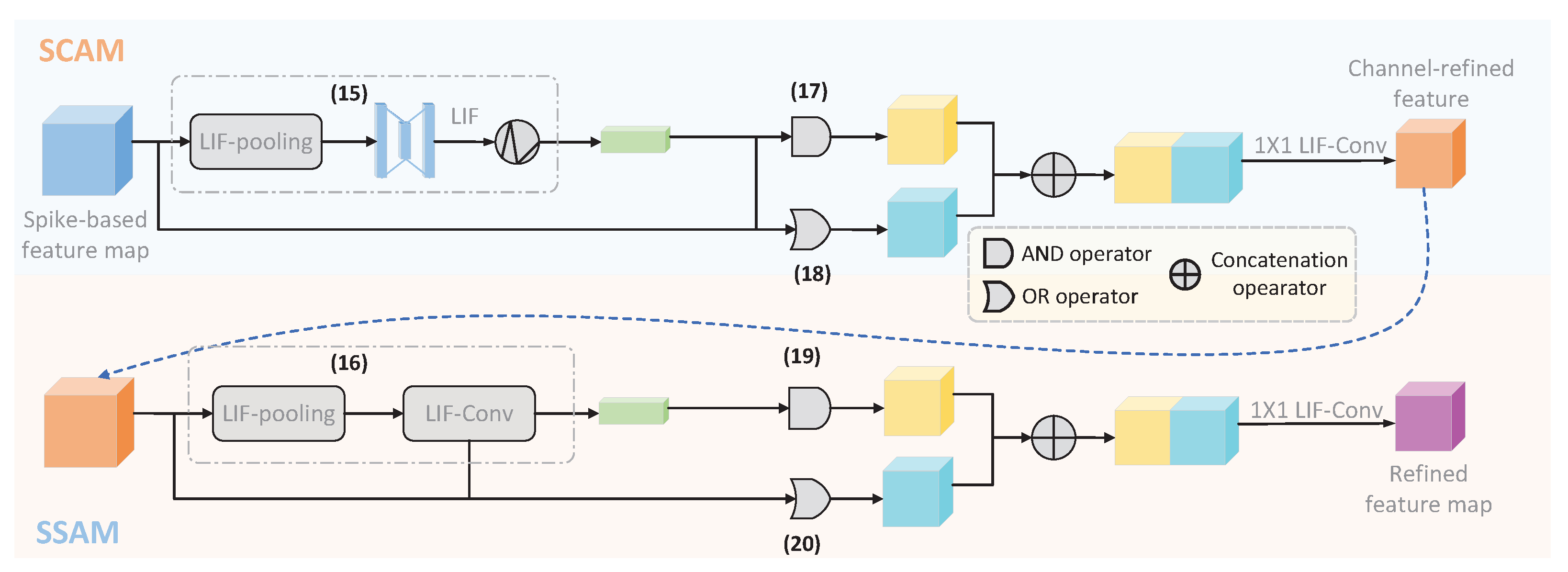
The proposed Spike-based Convolutional Block Attention Mechanism (SCBAM) is a variant of CBAM developed by Woo et al. [51]. Similarly to CBAM, SCBAM also consists of two modules, namely SCAM and SSAM, and it is implemented in spatial and channel dimensions, respectively. The major difference between SCBAM and CBAM is that SCBAM enables CBAM to operate on the intermediate spike-based feature map with the output in the format of a spike rather than real numbers. Therefore, the information propagated through all layers of the REAT-CSNN model is spike-based. Furthermore, the experimental results show that SCBAM performs similarly to CBAM. To better illustrate, we take SCAM as an example, which is shown in Figure 3. More precisely, to enhance the event-driven capability of SCBAM, we implement SCAM and SSAM in a sequence of discrete time windows. In each time window , SCAM and SSAM are performed according to the definition in Formulas (8) and (9):
where , , and in (8) are replaced by and the LIF-pooling () developed in Section 4.2, and the in (9) is replaced by .
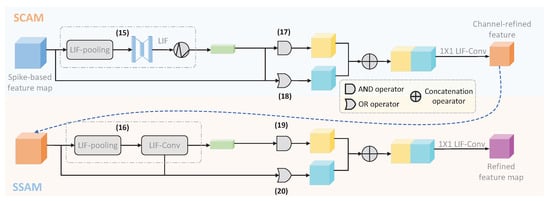
Figure 3.
The process of SCBAM in one time step.
Unfortunately, the above modification is not powerful enough to guarantee that SCBAM is completely implemented on the spikes because of the existence of weighted sum operations. To this end, we perform the AND (∪) and OR (∩) operations instead of the weighted sum operations as follows:
Hereafter, we concatenate and with
and reduce the dimension of using one-dimensional convolution.
5. Experimental Results and Analysis
5.1. Tasks and Data Sets
We evaluate the performance of the proposed REAT-CSNN model by applying it in a variety of MTS prediction tasks, which are briefly introduced as follows. All datasets are available via https://github.com/Yongsheng124/REAT-CSNN (accessed on 13 March 2025).
- Stock prediction: We predict the direction of stock prices by taking into account the correlation between different stocks. For example, the stocks in the same sector, such as banking or healthcare, are likely to move in the same direction and react to the market in a similar way. To this end, we collected data from five gaming companies (Activision, Blizzard, Electronic Arts, Nintendo, and Tencent) over a period of 3094 days, from 4 January 2010 to 4 April 2022. The data set includes the daily date, opening price, closing price, the highest price, the lowest price, and the transaction volume, totaling 15,470 records. To standardize the prediction across all five companies, we normalized each feature in the data set. Specifically, our prediction objective was to use the all of the features from the first nine time steps to forecast the closing price at the tenth time step.
- PM2.5 prediction: We predict the rise and fall of PM2.5 levels in Beijing using the PM2.5 data [52] provided by the US Embassy in Beijing from 1 January 2010 to 31 December 2014, which consists of 43,824 records. This data set includes 12 features such as the year, month, day, hour, dew point, temperature, PM2.5 concentration, wind direction, air pressure, wind speed, snowfall, and precipitation. For convenience, we integrate year, month, day, and hour into a time feature, and, for missing values, we delete the entire record. Similarly, we use data from every nine time steps to predict the PM2.5 concentration for the next time step.
- Air quality prediction: We predicted the rise and fall of concentration to monitor air quality using the data set collected by the air quality chemical multisensor device deployed on highly polluted roads in an Italian city from March 2004 to February 2005 [53]. This data set contains information on the average hourly concentrations of five types of polluting gases, including , hydrocarbons, benzene, and nitrogen oxides. The data set has 9358 observations, including 15 features such as time, temperature, relative humidity, absolute humidity, and polluting gas concentration. Moreover, we directly delete records with missing values.
- Air pollution prediction: We predict the rise and fall of concentration to track air pollution using the gas turbine and the emission data set. This data set contains 36,722 observations collected by 11 sensors located in northwest Turkey. The data span a period of 5 years, from 1 January 2011 to 31 December 2015, with a sampling frequency of one hour. Each record includes ambient temperature, air pressure, humidity, air filter difference pressure, gas turbine exhaust pressure, turbine inlet temperature, turbine after temperature, compressor discharge pressure, turbine energy yield, concentration, and concentration, totaling 11 features. It is worth noting that each observation does not provide the time feature, and it still contains the inherent time feature because it is strictly sorted by time. As above, we delete those records with missing values.
5.2. Experimental Setting
The data set is split into three sections: 80% for training, 10% for validation, and 10% for testing. All data records are normalized to a range of 0 to 1. Data cleaning is used to process missing or noisy data points, and we use features from nine time steps to predict the rise and fall of the target feature for the next time step. In addition, to minimize the impact of randomness, we conducted each experiment 10 times with different random seeds, assuming the results followed a standard normal distribution, and we then calculated the mean and standard deviation to report the model’s final result as .
We used RNN-based and GNN-based approaches, which have been widely used for MTS prediction, as baselines. Furthermore, we compared our method with another SNN model, namely Long-Short-Term Memory SNN (LSNN). The details of these baselines are as follows.
- RNN: A neural network with memory ability, allowing the network to capture temporal correlations in the sequence. We used a simple one-layer RNN model.
- LSTM: A variant of RNN that introduces a gating mechanism with the advantage of handling long-term dependencies. In this paper, we used a simple one-layer LSTM model.
- GRU: Another variant of RNN, which has a higher computational efficiency than LSTM. Similar to RNN and LSTM, we used a one-layer GRU model.
- GCN [54]: Operates directly on graph-structure-based data that are built on the basis of the relationships between stocks.
- LSNN [55]: Integrates a neuronal adaptation mechanism into the recurrent SNN (RSNN) model with the function of capturing dynamic processes on large time scales, including the excitability and inhibition of neurons, spike frequency, spike time interval, etc.
We used Adam as the optimizer for REAT-CSNN, with a mean squared error (MSE) loss function and a batch size of 20. The learning rate was set to . To control variables, we used the same hyperparameters for all other benchmark models and conducted 10 experiments in the same environment. We evaluated the performance of the model by measuring the single-step prediction accuracy that is calculated by
where is the result predicted for time series n at the time step , and if , or 0 otherwise. All models were run on Pytorch 1.10.2, and the hardware used was an Intel(R) Platinum 8255C CPU (2.50 GHz), 40G memory, and an RTX2080Ti (the code is available via https://github.com/1422819414/REAT-CSNN (accessed on 13 March 2025)).
5.3. Results
The results in Table 1 demonstrate that REAT-CSNN performed better on all tasks, apart from the prediction of air pollution. Our model surpasses LSNN with an improvement of up to in PM2.5 prediction. Additionally, our model performs better than typical ANN- and graph-based MTS predictive methods. Compared to LSTM and GRU, the better performance achieved by our proposed model in different tasks indicates that the event-driven architecture of REAT-CSNN has the capacity to capture long- and short-term patterns in MTS. In particular, under a comparable parameter scale, the performance gap between our model and RNN can reach almost in stock prediction. In PM2.5 and air quality prediction, our model outperforms RNN with an improvement of and , respectively. Furthermore, the smaller variance suggests that our model has a more stable performance than RNN.

Table 1.
The accuracy of MTS prediction on multiple data sets.
It is noteworthy that REAT-CSNN outperformed GCN in stock prediction. As previously mentioned, GCN has a higher predictive accuracy than other ANN-based approaches due to its ability to capture explicit and implicit relationships between stakeholders in a stock, which enhances the predictive accuracy. Notably, our model outperformed GCN, improving by , with only 1/5 of the number of parameters. This demonstrates that our proposed model has a similar capability to GCN in capturing deep spatio-temporal correlations between stocks. However, REAT-CSNN does not require any prior knowledge to construct the graph that is used in GMN-based methods.
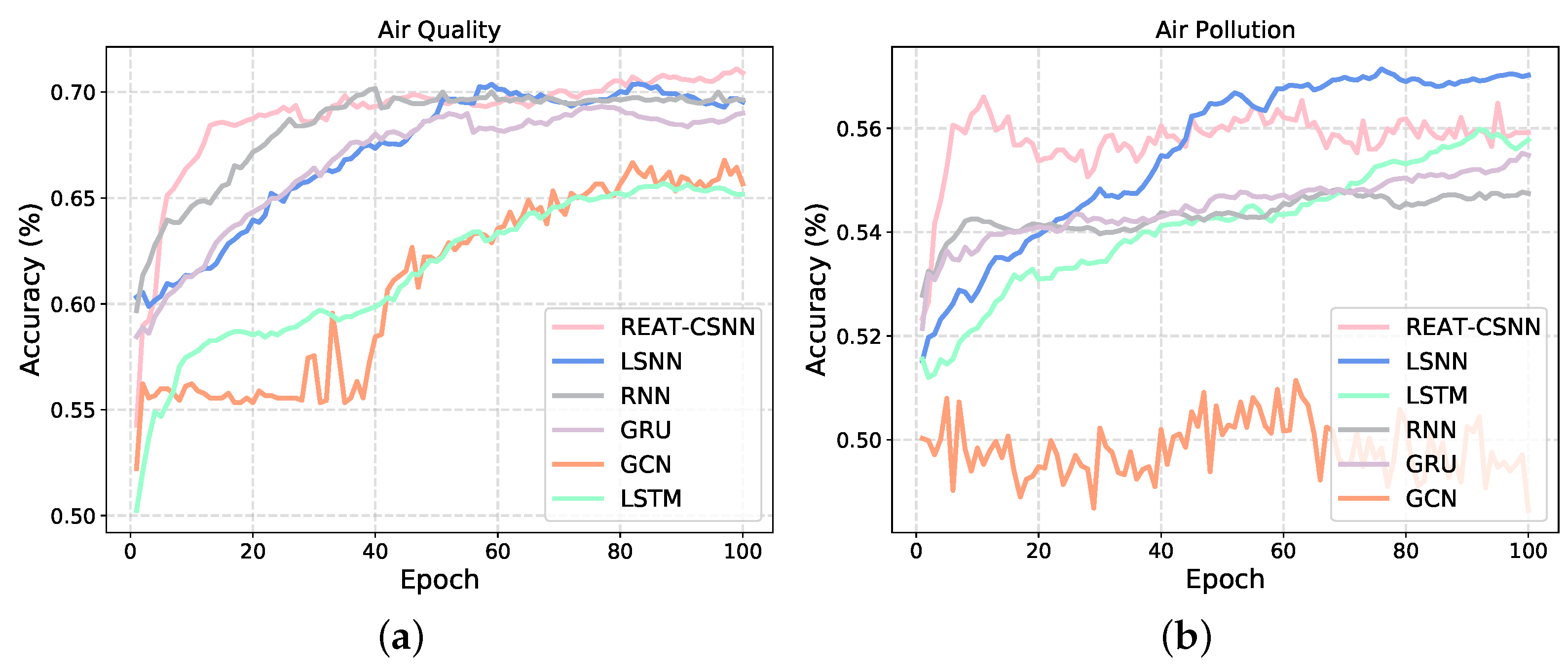
Figure 4 shows the changes in the test set accuracy during the training process of each model. It can be seen that, when facing the air quality data set with a not strong non-linear complexity between variables, our model has an advantage. However, REAT-CSNN is slightly inferior to LSNN in terms of air pollution prediction. This is mainly due to the fact that the convolution operation and SCABM component do not have as much of an impact as they do in other MTS prediction tasks since the data collected from different detectors have a weak spatio-temporal correlation due to the large physical distance. Therefore, our proposed model is more suitable for MTS where variables interact simply directly and exhibit minor nonlinear relationships. Although convolution and SCBAM enhances the ability to capture complex nonlinear relationships to some extent, it still cannot compensate for the structural differences compared to RNN-based methods. Similarly, as depicted in Figure 4b, the accuracy of GCN in dealing with air pollution prediction keeps oscillating around 0.5 and basically fails to train. This indicates that convolution-based methods find it difficult to extract overly complex, high-dimensional, and spatio-temporal relationships. Furthermore, it is reasonable to believe that REAT-CSNN is comparable to ANN- and GNN-based methods in terms of MTS prediction, particularly when there is a strong spatio-temporal correlation between time series variables but with a lower energy requirement (see Section 5.5).
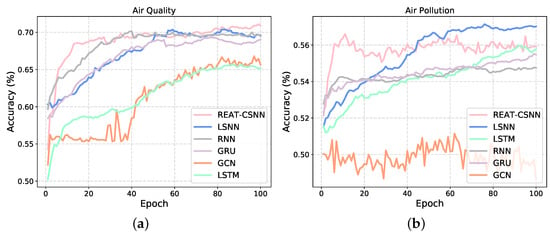
Figure 4.
The training process of REAR-CSNN and other models on different data sets. (a) On the air quality data set. (b) On the air pollution data set.
5.4. Ablation
We evaluated the effectiveness of the proposed LIF-pooling and SCABM through ablation tests. More precisely, to test the effectiveness of the LIF-pooling strategy, we first carried out an ablation test on the stock prediction task, the results of which are shown in Figure 5. These results demonstrate the difference between average-pooling (where the threshold is 0.5) and LIF-pooling. Then, we conducted a comparison between the max-pooling and LIF-pooling strategies, as shown in Table 2, to further illustrate the power of LIF-pooling. Furthermore, two sets of ablation tests are given in Table 2, which were performed on PM2.5 and stock data sets, respectively. The tests were designed to assess the effect of different attention modules on the model’s performance by implementing the following configurations:
- REAT-CSNN without any attention modules;
- REAT-CSNN when only considering SSAM;
- REAT-CSNN when only considering SCAM;
- REAT-CSNN by switching the implementation orders of SSAM and SCAM in SCBAM.
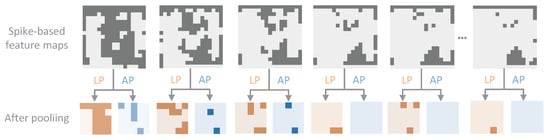
Figure 5.
Comparison between LIF-pooling (LP) and average-pooling (AP).
Figure 5.
Comparison between LIF-pooling (LP) and average-pooling (AP).
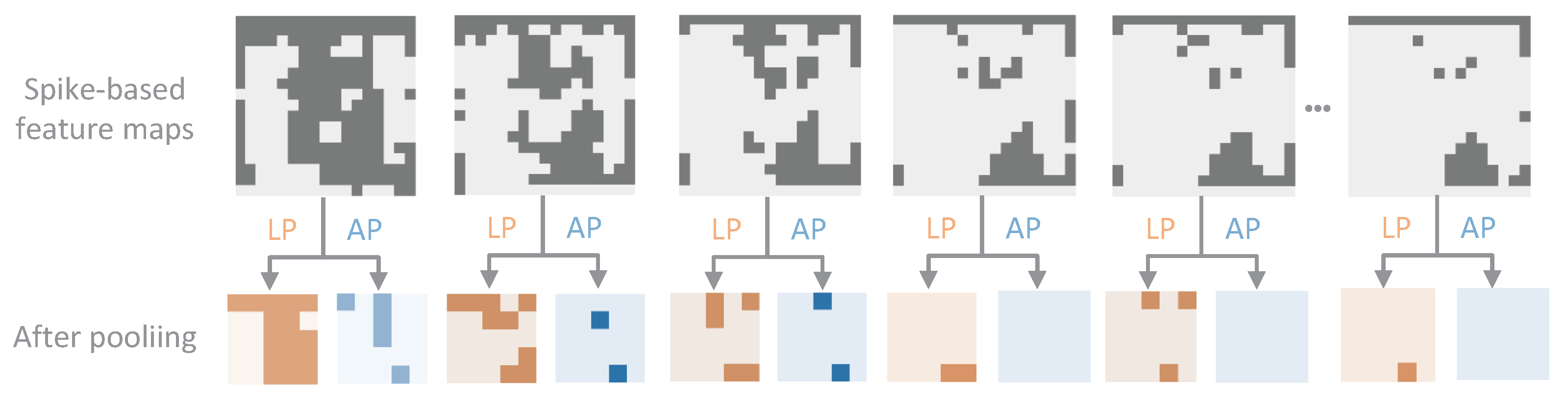
Table 2.
Ablative analysis on the max-pooling and attention modules.
Table 2.
Ablative analysis on the max-pooling and attention modules.
| Attention Module | Stock | PM2.5 | |||
|---|---|---|---|---|---|
| SCAM | SSAM | Max-Pooling | LIF-Pooling | Max-Pooling | LIF-Pooling |
| ✗ | ✗ | ||||
| ✗ | ✓ | ||||
| ✓ | ✗ | ||||
| ✓ | ✓ | ||||
5.4.1. Pooling Strategy
As shown in Figure 5, we chose six regions from the spike-based feature maps produced by different LIF-Conv layers. We visualize each feature map by representing the activated spikes in deep gray and the non-active spikes in light gray. The orange and blue feature maps are the results of applying LIF-pooling and average-pooling to the selected feature maps, respectively. It is evident that LIF-pooling (orange) preserves much more information than average-pooling (blue). This is in agreement with the analysis provided in Theorem 1. Examining the results of REAT-CSNN in Table 2, which is when max-pooling and LIF-pooling were employed, it is clear that LIF-pooling was highly successful in enhancing the prediction accuracy in the two data sets. This verifies that the proposed LIF-pooling mechanism is much more effective than the max-pooling operation.
In addition to the observation mentioned above, our experimental results with max-pooling reveal some interesting findings. Surprisingly, the prediction accuracy of our model with an attention mechanism does not improve when max-pooling is used. In fact, the accuracy of the model even decreased in some cases. For example, the average accuracy of stock prediction with max-pooling and without attention modules is , which is slightly higher than the obtained when using the SCAM and SSAM modules. Similar results were observed in the PM2.5 prediction. As discussed in Section 4.2, having too much information does not necessarily mean that more precise features are extracted. Therefore, although max-pooling assigns a value of 1 to any element in a patch of the spike feature map, which results in too much information being retained, it makes it difficult for the attention mechanism to assign the correct weights to the truly important features. The results obtained from REAT-CSNN with the application of LIF-pooling are distinct from those of the above (in the second and last columns). The attention mechanism is capable of increasing the accuracy of the prediction.
5.4.2. Attention Modules
From an application point of view, SCAM and SSAM play different roles in predicting MTS. Notably, SCAM had the most significant improvement in stock prediction, suggesting that channel attention is more critical than spatial attention for accurate stock prediction as it can detect and pinpoint the essential spatio-temporal correlation between time series variables. On the other hand, both modules have a clear improvement in the accuracy of PM2.5 prediction. There is only a minor variation (of and ) when the two modules were exchanged in the REAT-CSNN model. These results demonstrate that the proposed attention modules are successful in improving the forecasting performance in MTS tasks.
5.5. Energy Efficiency
Low energy consumption is the most notable characteristic of SNN-based models. To this end, we estimate the energy consumption of our proposed model with the aforementioned baselines. In our model, most of the energy consumption occurs in LIF-based convolution layers and LIF-based FC layers. Unlike traditional CNNs, where the computational complexity of a convolution heavily depends on the number of Multiplication and Addition Computing (MAC) operations [56], LIF-Cov is composed of several Addition Computing (AC) operations due to its event-driven activation nature. Therefore, we estimate the energy consumption at each LIF-Cov layer () as follows:
where is the channel size of the input; k is the kernel size; is the channel size of the output; W and H represent the width and height of the feature map, respectively; and is the energy consumption of a unit AC operation. More specifically, pJ when AC is operated on 32-bit floating numbers, and pJ when AC is operated on 32-bit integers [56]. The energy consumption at each LIF-FC layer () is estimated as follows:
where and are the number of input and output neurons, respectively. Based on and , we can further estimate the energy consumption of REAT-CSNN and LSNN, which are denoted by and .
The energy consumption of RNN, LSTM, and GRU is denoted by , , and , which is based mainly on the energy consumption in each recurrent layer, denoted by and estimated as
In (25), and are the dimensions of the input layer and the hidden layer; is the number of non-linear blocks with for RNN, for LSTM, and for GRU; and is the energy consumption of a unit MAC operation, which is equal to 4.6 pJ when MAC is operated on 32-bit floating numbers and 3.2 pJ when MAC is operated on 32-bit integers.
The energy consumption of GCN () is estimated as
where is the number of vertices, is the number of edges, and is the feature dimension at each vertex.
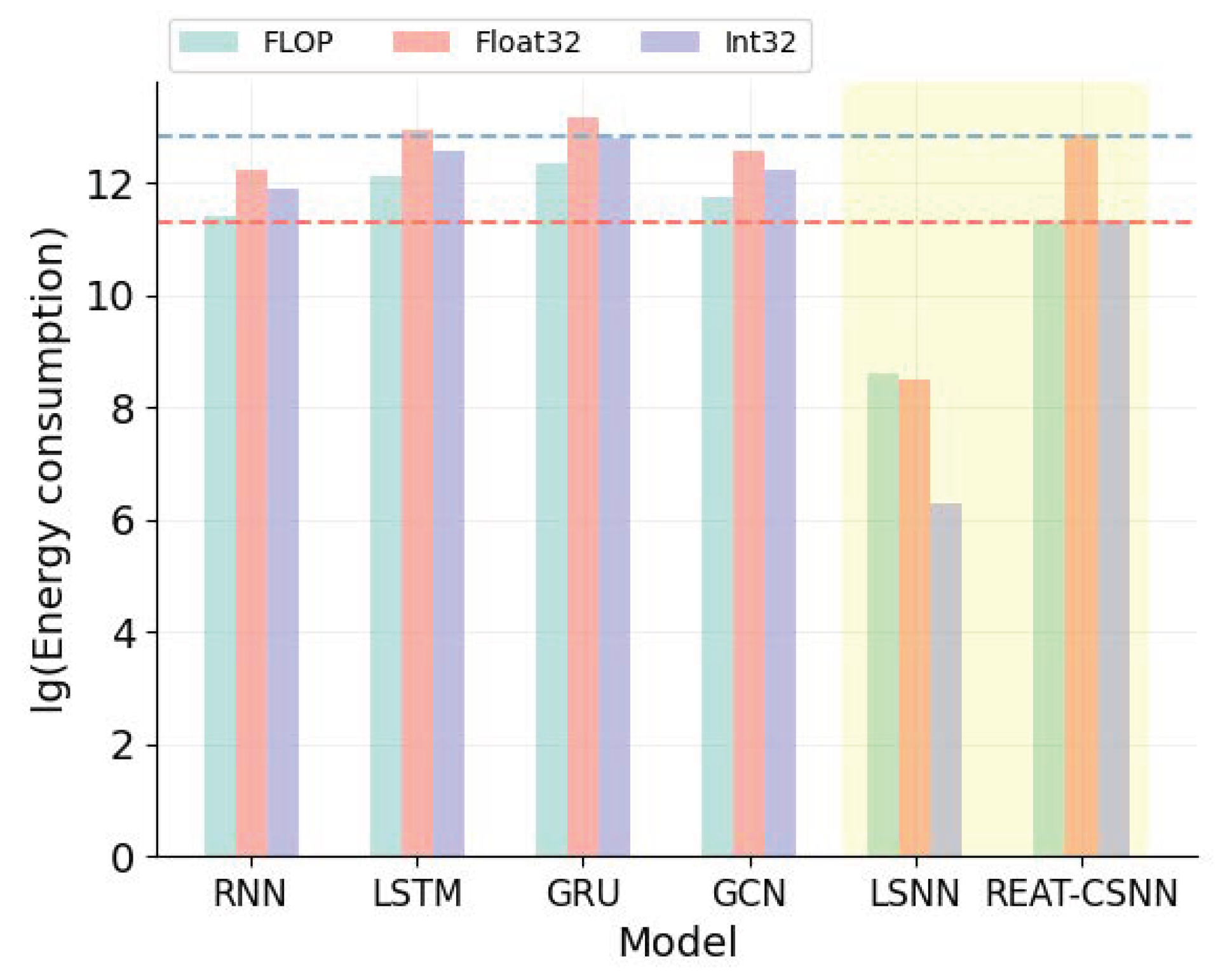
Table 3 presents the energy consumption of different models from the perspectives of floating point operations per second (FLOP), operations on 32-bit floating numbers (Float32), and operations on 32-bit integers (Int32). It is evident that our model has significantly lower energy consumption than traditional deep learning models, particularly for GRU and LSTM. As illustrated in Figure 6, the decrease in energy consumption is up to two orders of magnitude less than the LSTM, GRU, and GCN operated on FLOP and Int32. However, the lowest energy consumption is from the LSNN. This is because REAT-CSNN has more components, such as the attention mechanism, which are designed to improve prediction accuracy.
Table 3.
Energy consumption analysis.
Figure 6.
Energy consumption analysis.
6. Conclusions
We developed a REAT-CSNN model that utilizes a GAFR coding scheme, a LIF-pooling strategy, and a SCBAM to improve the accuracy of MTS prediction. This model is more biologically plausible as it enables all components to be implemented on the basis of spikes instead of real numbers. Additionally, it has a strong capability in exploring and capturing the spatio-temporal correlations in MTS. In the future, we will attempt to expand our work to real-world scenarios by taking into account the dynamics of spatio-temporal correlations. In addition, the model will be tested on SNN-enabled hardware.
Author Contributions
Conceptualization, Y.L. and P.D.; methodology, Y.L.; programming, X.G. and Y.H.; validation, Y.L. and X.G.; formal analysis, Y.L. and W.Y.; writing—Y.L. and P.D.; writing—review and editing, B.Z. and P.D.; supervision, B.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the project “Research on efficient supply and demand optimization of ride-hailing under multimodal scene changes in intelligent transportation systems”, which was authorized by the Natural Science Foundation of Liaoning Province with grant number 02110076523001.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data are contained within the article.
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
| Content | Significance |
| CSNN | Convolution Spiking Neural Network |
| GAFR | Gramian Angular Field Rate |
| LIF | Leaky-Integrate-and-Fire |
| LIF-pooling | LIF-based Pooling |
| LIF-Conv | LIF-based Convolution |
| MTS | Multivariate Time Series |
| REAT-CSNN | Reinforced Event-driven Attention CSNN |
| SCBAM | Spike-based Convolutional Block Attention Mechanism |
| SSAM | Spike-based Spatial Attention Module |
| SCAM | Spike-based Channel Attention Module |
References
- Wu, Y.; Zhao, R.; Zhu, J.; Chen, F.; Xu, M.; Li, G.; Song, S.; Deng, L.; Wang, G.; Zheng, H.; et al. Brain-inspired global-local learning incorporated with neuromorphic computing. Nat. Commun. 2022, 13, 65. [Google Scholar] [CrossRef] [PubMed]
- Xu, M.; Liu, F.; Hu, Y.; Li, H.; Wei, Y.; Zhong, S.; Pei, J.; Deng, L. Adaptive synaptic scaling in spiking networks for continual learning and enhanced robustness. IEEE Trans. Neural Netw. Learn. Syst. 2024, 36, 5151–5165. [Google Scholar] [CrossRef] [PubMed]
- Xu, M.; Zheng, H.; Pei, J.; Deng, L. A unified structured framework for AGI: Bridging cognition and neuromorphic computing. In International Conference on Artificial General Intelligence; Springer: Cham, Switzerland, 2023; pp. 345–356. [Google Scholar]
- Maass, W. Networks of spiking neurons: The third generation of neural network models. Neural Netw. 1997, 10, 1659–1671. [Google Scholar] [CrossRef]
- Ghosh-Dastidar, S.; Adeli, H. Third generation neural networks: Spiking neural networks. In Advances in Computational Intelligence; Springer: Berlin/Heidelberg, Germany, 2009; pp. 167–178. [Google Scholar]
- Yamazaki, K.; Vo-Ho, V.K.; Bulsara, D.; Le, N. Spiking neural networks and their applications: A Review. Brain Sci. 2022, 12, 863. [Google Scholar] [CrossRef]
- Zhang, T.; Jia, S.; Cheng, X.; Xu, B. Tuning Convolutional Spiking Neural Network With Biologically Plausible Reward Propagation. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 7621–7631. [Google Scholar] [CrossRef]
- Zhang, A.; Li, X.; Gao, Y.; Niu, Y. Event-Driven Intrinsic Plasticity for Spiking Convolutional Neural Networks. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 1986–1995. [Google Scholar] [CrossRef]
- Islam, R.; Majurski, P.; Kwon, J.; Tummala, S.R.S.K. Exploring High-Level Neural Networks Architectures for Efficient Spiking Neural Networks Implementation. In Proceedings of the 2023 3rd International Conference on Robotics, Electrical and Signal Processing Techniques (ICREST), Dhaka, Bangladesh, 7–8 January 2023; pp. 212–216. [Google Scholar] [CrossRef]
- Saunders, D.J.; Siegelmann, H.T.; Kozma, R.; Ruszinkó, M. Stdp learning of image patches with convolutional spiking neural networks. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–7. [Google Scholar]
- Fei, X.; Jianping, L.; Jie, T.; Guangshuo, W. Image Recognition Algorithm Based on Spiking Neural Network. In Proceedings of the 2022 19th International Computer Conference on Wavelet Active Media Technology and Information Processing (ICCWAMTIP), Chengdu, China, 16–18 December 2022; pp. 1–5. [Google Scholar] [CrossRef]
- Zhou, R. A Method of Converting ANN to SNN for Image Classification. In Proceedings of the 2023 IEEE 3rd International Conference on Electronic Technology, Communication and Information (ICETCI), Changchun, China, 26–28 May 2023; pp. 819–822. [Google Scholar] [CrossRef]
- Li, J.; Hu, W.; Yuan, Y.; Huo, H.; Fang, T. Bio-inspired deep spiking neural network for image classification. In Proceedings of the Neural Information Processing: 24th International Conference, ICONIP 2017, Guangzhou, China, 14–18 November 2017; Proceedings, Part II 24. Springer: Berlin/Heidelberg, Germany, 2017; pp. 294–304. [Google Scholar]
- Reid, D.; Hussain, A.J.; Tawfik, H. Financial time series prediction using spiking neural networks. PLoS ONE 2014, 9, e103656. [Google Scholar] [CrossRef]
- Kasabov, N.; Capecci, E. Spiking neural network methodology for modelling, classification and understanding of EEG spatio-temporal data measuring cognitive processes. Inf. Sci. 2015, 294, 565–575. [Google Scholar] [CrossRef]
- Xing, Y.; Zhang, L.; Hou, Z.; Li, X.; Shi, Y.; Yuan, Y.; Zhang, F.; Liang, S.; Li, Z.; Yan, L. Accurate ECG classification based on spiking neural network and attentional mechanism for real-time implementation on personal portable devices. Electronics 2022, 11, 1889. [Google Scholar] [CrossRef]
- Maji, P.; Patra, R.; Dhibar, K.; Mondal, H.K. SNN Based Neuromorphic Computing Towards Healthcare Applications. In Internet of Things. Advances in Information and Communication Technology, Proceedings of the 6th IFIP International Cross-Domain Conference, IFIPIoT 2023, Denton, TX, USA, 2–3 November 2023; Springer: Cham, Switzerland, 2023; pp. 261–271. [Google Scholar]
- Gaurav, R.; Stewart, T.C.; Yi, Y. Reservoir based spiking models for univariate Time Series Classification. Front. Comput. Neurosci. 2023, 17, 1148284. [Google Scholar] [CrossRef]
- Fang, H.; Shrestha, A.; Qiu, Q. Multivariate time series classification using spiking neural networks. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–7. [Google Scholar]
- Sharma, V.; Srinivasan, D. A spiking neural network based on temporal encoding for electricity price time series forecasting in deregulated markets. In Proceedings of the The 2010 international joint conference on neural networks (IJCNN), Barcelona, Spain, 18–23 July 2010; pp. 1–8. [Google Scholar]
- Liu, Q.; Long, L.; Peng, H.; Wang, J.; Yang, Q.; Song, X.; Riscos-Núñez, A.; Pérez-Jiménez, M.J. Gated spiking neural P systems for time series forecasting. IEEE Trans. Neural Netw. Learn. Syst. 2021, 34, 6227–6236. [Google Scholar] [CrossRef] [PubMed]
- Fukumori, K.; Yoshida, N.; Sugano, H.; Nakajima, M.; Tanaka, T. Epileptic Spike Detection by Recurrent Neural Networks with Self-Attention Mechanism. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022; pp. 1406–1410. [Google Scholar] [CrossRef]
- Samadzadeh, A.; Far, F.S.T.; Javadi, A.; Nickabadi, A.; Chehreghani, M.H. Convolutional spiking neural networks for spatio-temporal feature extraction. Neural Process. Lett. 2023, 55, 6979–6995. [Google Scholar] [CrossRef]
- Ponghiran, W.; Roy, K. Spiking neural networks with improved inherent recurrence dynamics for sequential learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Online, 22 February–1 March 2022; Volume 36, pp. 8001–8008. [Google Scholar]
- Elsayed, N.; Maida, A.S.; Bayoumi, M. Gated Recurrent Neural Networks Empirical Utilization for Time Series Classification. In Proceedings of the 2019 International Conference on Internet of Things (iThings) and IEEE Green Computing and Communications (GreenCom) and IEEE Cyber, Physical and Social Computing (CPSCom) and IEEE Smart Data (SmartData), Atlanta, GA, USA, 14–17 July 2019; pp. 1207–1210. [Google Scholar] [CrossRef]
- Xia, M.; Shao, H.; Ma, X.; de Silva, C.W. A stacked GRU-RNN-based approach for predicting renewable energy and electricity load for smart grid operation. IEEE Trans. Ind. Inform. 2021, 17, 7050–7059. [Google Scholar] [CrossRef]
- Gautam, A.; Singh, V. CLR-based deep convolutional spiking neural network with validation based stopping for time series classification. Appl. Intell. 2020, 50, 830–848. [Google Scholar] [CrossRef]
- Shih, S.Y.; Sun, F.K.; Lee, H.y. Temporal pattern attention for multivariate time series forecasting. Mach. Learn. 2019, 108, 1421–1441. [Google Scholar] [CrossRef]
- Choi, Y.; Lim, H.; Choi, H.; Kim, I.J. GAN-Based Anomaly Detection and Localization of Multivariate Time Series Data for Power Plant. In Proceedings of the 2020 IEEE International Conference on Big Data and Smart Computing (BigComp), Pusan, Republic of Korea, 19–22 February 2020; pp. 71–74. [Google Scholar] [CrossRef]
- Auge, D.; Hille, J.; Mueller, E.; Knoll, A. A survey of encoding techniques for signal processing in spiking neural networks. Neural Process. Lett. 2021, 53, 4693–4710. [Google Scholar] [CrossRef]
- George, A.M.; Dey, S.; Banerjee, D.; Mukherjee, A.; Suri, M. Online time-series forecasting using spiking reservoir. Neurocomputing 2023, 518, 82–94. [Google Scholar] [CrossRef]
- Long, L.; Liu, Q.; Peng, H.; Wang, J.; Yang, Q. Multivariate time series forecasting method based on nonlinear spiking neural P systems and non-subsampled shearlet transform. Neural Netw. 2022, 152, 300–310. [Google Scholar] [CrossRef]
- Guarda, L.; Tapia, J.E.; Droguett, E.L.; Ramos, M. A novel Capsule Neural Network based model for drowsiness detection using electroencephalography signals. Expert Syst. Appl. 2022, 201, 116977. [Google Scholar] [CrossRef]
- Jiang, P.; Zou, C. Convolution neural network with multiple pooling strategies for speech emotion recognition. In Proceedings of the 2022 6th International Symposium on Computer Science and Intelligent Control (ISCSIC), Beijing, China, 11–13 November 2022; pp. 89–92. [Google Scholar] [CrossRef]
- More, Y.; Dumbre, K.; Shiragapur, B. Horizontal Max Pooling a Novel Approach for Noise Reduction in Max Pooling for Better Feature Detect. In Proceedings of the 2023 International Conference on Emerging Smart Computing and Informatics (ESCI), Pune, India, 1–3 March 2023; pp. 1–5. [Google Scholar] [CrossRef]
- Gong, P.; Wang, P.; Zhou, Y.; Zhang, D. A Spiking Neural Network With Adaptive Graph Convolution and LSTM for EEG-Based Brain-Computer Interfaces. IEEE Trans. Neural Syst. Rehabil. Eng. 2023, 31, 1440–1450. [Google Scholar] [CrossRef]
- Rao, A.; Plank, P.; Wild, A.; Maass, W. A long short-term memory for AI applications in spike-based neuromorphic hardware. Nat. Mach. Intell. 2022, 4, 467–479. [Google Scholar] [CrossRef]
- Chen, C.; Li, K.; Teo, S.G.; Chen, G.; Zou, X.; Yang, X.; Vijay, R.C.; Feng, J.; Zeng, Z. Exploiting spatio-temporal correlations with multiple 3d convolutional neural networks for citywide vehicle flow prediction. In Proceedings of the 2018 IEEE International Conference on Data Mining (ICDM), Singapore, 17–20 November 2018; pp. 893–898. [Google Scholar]
- Wang, K.; Li, K.; Zhou, L.; Hu, Y.; Cheng, Z.; Liu, J.; Chen, C. Multiple convolutional neural networks for multivariate time series prediction. Neurocomputing 2019, 360, 107–119. [Google Scholar] [CrossRef]
- Zhang, J.; Dai, Q. MrCAN: Multi-relations aware convolutional attention network for multivariate time series forecasting. Inf. Sci. 2023, 643, 119277. [Google Scholar] [CrossRef]
- Qin, Y.; Song, D.; Chen, H.; Cheng, W.; Jiang, G.; Cottrell, G. A dual-stage attention-based recurrent neural network for time series prediction. arXiv 2017, arXiv:1704.02971. [Google Scholar]
- Liu, Y.; Gong, C.; Yang, L.; Chen, Y. DSTP-RNN: A dual-stage two-phase attention-based recurrent neural network for long-term and multivariate time series prediction. Expert Syst. Appl. 2020, 143, 113082. [Google Scholar] [CrossRef]
- Xiao, Y.; Yin, H.; Zhang, Y.; Qi, H.; Zhang, Y.; Liu, Z. A dual-stage attention-based Conv-LSTM network for spatio-temporal correlation and multivariate time series prediction. Int. J. Intell. Syst. 2021, 36, 2036–2057. [Google Scholar] [CrossRef]
- Fu, E.; Zhang, Y.; Yang, F.; Wang, S. Temporal self-attention-based Conv-LSTM network for multivariate time series prediction. Neurocomputing 2022, 501, 162–173. [Google Scholar] [CrossRef]
- Tan, Q.; Ye, M.; Yang, B.; Liu, S.; Ma, A.J.; Yip, T.C.F.; Wong, G.L.H.; Yuen, P. Data-gru: Dual-attention time-aware gated recurrent unit for irregular multivariate time series. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 930–937. [Google Scholar]
- Chen, W.; Jiang, M.; Zhang, W.G.; Chen, Z. A novel graph convolutional feature based convolutional neural network for stock trend prediction. Inf. Sci. 2021, 556, 67–94. [Google Scholar] [CrossRef]
- Yan, F.; Liu, W.; Dong, F.; Hirota, K. A quantum-inspired online spiking neural network for time-series predictions. Nonlinear Dyn. 2023, 111, 15201–15213. [Google Scholar] [CrossRef]
- Maciąg, P.S.; Kasabov, N.; Kryszkiewicz, M.; Bembenik, R. Air pollution prediction with clustering-based ensemble of evolving spiking neural networks and a case study for London area. Environ. Model. Softw. 2019, 118, 262–280. [Google Scholar] [CrossRef]
- Capizzi, G.; Sciuto, G.L.; Napoli, C.; Woźniak, M.; Susi, G. A spiking neural network-based long-term prediction system for biogas production. Neural Netw. 2020, 129, 271–279. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Oates, T. Imaging time-series to improve classification and imputation. arXiv 2015, arXiv:1506.00327. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Chen, S. Beijing PM2.5 Data. UCI Machine Learning Repository. 2017. Available online: https://archive.ics.uci.edu/dataset/381/beijing+pm2+5+data (accessed on 12 March 2025).
- Vito, S. Air Quality. UCI Machine Learning Repository. 2016. Available online: https://archive.ics.uci.edu/dataset/360/air+quality (accessed on 12 March 2025).
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Bellec, G.; Salaj, D.; Subramoney, A.; Legenstein, R.; Maass, W. Long short-term memory and learning-to-learn in networks of spiking neurons. Adv. Neural Inf. Process. Syst. 2018, 31, 795–805. [Google Scholar]
- Kim, S.; Park, S.; Na, B.; Yoon, S. Spiking-yolo: Spiking neural network for energy-efficient object detection. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 11270–11277. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).