1. Introduction
Atrial fibrillation (AF) is the most common type of sustained arrhythmia [
1]. It is defined and characterized by extremely rapid and uncoordinated atrial activities [
2]. Atrial fibrillation can significantly increase the risk of developing other high-risk cardiovascular diseases, including stroke [
3], systemic embolism [
4], vascular dementia [
4], heart failure [
5], myocardial infarction [
6], and sudden cardiac death [
7]. Atrial fibrillation usually affects the elderly and initially presents as paroxysmal. Without intervention, paroxysmal AF tends to progress to persistent and permanent AF [
2]. Currently, the electrocardiogram (ECG) is the most commonly used monitoring technique for detecting and quantifying the electrical activities of the heart [
8]. The occurrence of arrhythmia is usually manifested as the change in ECG morphology and rhythm. For example, the common characteristics of AF on the ECG include irregular RR intervals, the disappearance of P waves, and the appearance of f waves [
9]. According to diagnostic conventions, a fibrillation episode lasting at least 30 s can be diagnosed as clinical AF [
10]. However, the recognized complexity of ECG is much higher than that of ordinary images, which makes the diagnosis process time-consuming and error-prone. In addition, the quality of ECG diagnosis depends on the professional level of cardiologists, and it may even require multiple experts to resolve differences in decision making. As a result, most of the ECG data collected in the medical field have not been systematically organized and diagnosed. Therefore, it is of great significance to develop efficient and reliable automated detection methods to analyze and interpret ECG recordings.
So far, deep learning (DL) technology has made remarkable progress in the field of automated AF detection. Among them, supervised learning methods dominate current research. Representative deep learning network models include CNN [
11,
12,
13], LSTM [
14,
15,
16,
17], Transformer [
18,
19], the fusion of multiple networks [
20,
21], etc. These methods have demonstrated excellent performance in multi-lead and single-lead AF detection. Some studies [
22] have shown that DL has the potential to reach or even exceed the proficiency level of cardiologists in arrhythmia detection. However, for AF detection, the good generalization performance of supervised learning models depends on a large amount of high-quality annotated ECG data, which is always difficult to obtain. Therefore, it poses a serious problem for AF detection: the AF detection methods based on supervised learning are prone to overfitting in the case of limited annotated data, thus limiting their generalizability.
Considering that multiple instances sharing the same label should share some consistent representations of data that can be learned by the network, AF detection methods based on contrastive learning (CL) [
23] attempt to learn this data consistency from unlabeled data to alleviate overfitting, thereby mitigating the impact of limited labeled data and reducing the dependence on labeled data. As a mainstream technique of self-supervised learning (SSL), CL includes two processes: the pre-training task and the downstream task. Among them, the pre-training task usually takes unlabeled data as input, while the labeled data are used for the downstream task. The core idea of this method is to encourage the model to distinguish similar and different data without labels so that the model maps similar samples from the same class closer in the high-dimensional feature space while separating samples from different classes, thus providing meaningful representations for fine-tuning with labeled data in the downstream task and generating more accurate predictions. Specifically, mainstream CL methods bring the representations of positive sample pairs composed of target samples and similar (positive) samples closer in the embedding space while pushing the representations of negative sample pairs composed of target samples and dissimilar (negative) samples farther apart. Therefore, in CL, the selection of positive sample pairs and the design of the corresponding contrastive loss function have received great attention from researchers.
In the field of computer vision, numerous effective CL frameworks such as SimCLR [
24], MoCo [
25], BYOL [
26] widely apply data augmentation to generate positive samples. Among them, SimCLR and its improved versions [
27] are the most commonly used frameworks. They take the target sample and the augmented sample as a positive pair, and they regard the target sample and other samples as negative pairs. In the field of time series, some studies attempt to implement augmentation techniques applicable to time series data, such as DTW data augmentation proposed by TimeCLR [
28] and random cropping and timestamp masking proposed by TS2Vec [
29].
Unlike image data and traditional time series data, there are inherent connections in multiple attribute dimensions among different ECG samples. The data consistency resulting from these internal connections may be beneficial to downstream tasks and can serve as a basis for the selection of positive samples other than data augmentation. For example, TNC [
30] conducts subject consistency by taking the time-neighboring samples of the same subject as positive pairs. The CLOCS [
31] method further takes into account the samples of different leads and the samples of the same subject to achieve contrastive learning at the channel consistency and subject consistency.
However, despite the certain degree of progress made in the CL methods for ECG, the following problems still exist, which may lead to suboptimal performance in the AF detection task. Firstly, existing CL-based studies usually randomly select negative samples from training data, which means that negative samples may be selected from the samples of the same category as the target sample, resulting in a decline in the quality of representation. Secondly, the downstream task is not used to guide the entire process of positive sample selection in the pre-training task, including data augmentation and the inherent connections of ECG data. Some augmentation methods are unable to generate hard samples with sufficient differences for the downstream task, which is not conducive to learning distinguishable features. Some inherent connections of ECG data are unstable. For example, the paroxysmal nature of AF may cause the ECG data of the same subject to come from multiple distributions, making it impossible for CL to capture the subject consistency. In addition, existing deep learning usually uses data with similar distributions during the training and testing processes, which may exhibit instability in real-world scenarios. The cross-dataset testing method, which evaluates the performance on external datasets that are significantly different from the training data, is becoming an important solution to effectively address this problem.
To address the above issues, we propose a multi-level and multiple contrast learning (MLMCL) solution for AF detection using single-lead ECGs. This method introduces semi-supervised pre-training, which uses both labeled and unlabeled data during the pre-training stage. It constructs robust representations by selecting negative samples based on labels to prevent the decline in representation quality caused by randomly selecting negative samples. To fully tap into the full potential of ECG data, MLMCL performs multiple contrastive learning on the multi-level feature representations extracted by the encoder, which systematically mine the temporal consistency, channel consistency, and label consistency. Among them, the temporal contrastive learning focuses on the representative morphology at a single timestamp, the channel contrastive learning focuses on the invariant information across leads, and the label contrastive learning focuses on the information retained across subjects. In addition, by leveraging the ECG knowledge in the AF-related medical domain, we propose using vertical flipping and T-wave masking to achieve diagnostic region augmentation and non-diagnostic region augmentation, respectively, which together form the domain knowledge augmentation to generate hard samples. We apply MLMCL on the basis of domain knowledge augmentation to learn the generalizable feature representations in ECG, maximizing the potential of both labeled and unlabeled data and reducing the dependence on labeled data. Finally, we conduct pre-training under the cross-dataset testing setting. After obtaining the ECG representations, the model is fine-tuned for AF detection on the labeled dataset. The cross-dataset testing evaluation is carried through linear probing and full fine-tuning to ensure its robustness. Our contributions are as follows:
This paper proposes a semi-supervised contrastive learning framework that uses both labeled and unlabeled data during the pre-training stage to construct robust representations by selecting negative samples based on labels.
For AF detection, an MLMCL contrastive learning method is proposed. It performs multiple contrastive learning to extract the temporal consistency, channel consistency, and label consistency on multi-level feature representations, thereby learning generalizable representations.
By utilizing the knowledge in the AF diagnosis domain, a domain knowledge augmentation combining diagnostic region augmentation and non-diagnostic region augmentation is proposed for generating hard samples to learn distinguishable features.
The proposed method outperforms existing methods under the cross-dataset testing mode, and the external tests on multiple datasets demonstrate the generalizability of the proposed method.
The remaining parts of this study are arranged as follows.
Section 2 introduces the related work.
Section 3 outlines the methods used in this study.
Section 4 presents the datasets, experiments, and results.
Section 5 summarizes this study.
2. Related Works
The essence of CL is to mine the common patterns of similar data. According to the requirements of downstream tasks, CL-based methods usually select positive and negative sample pairs in a customized manner. They learn data consistency by maximizing the similarity of the representations of positive sample pairs while minimizing the similarity of the representations of negative sample pairs. Selecting appropriate positive samples is crucial for ensuring the performance of downstream tasks [
32]. For example, the SimCLR proposed by Chen et al. [
24] defines positive samples as the augmented views of the target sample and directly regards the views from other samples in the current batch as negative samples. Tian et al. [
33] use different modal views of the same sample as positive sample pairs. The way of selecting positive samples determines the semantic information of the learned representations. Therefore, it is important to develop a selection strategy of positive sample applicable to ECG.
The CL methods in the ECG field have been studied for extracting effective ECG representations. Some studies directly transfer CL methods from other fields to the ECG field. For example, Mehari et al. [
34] directly compared instance-based CL methods (SimCLR, BYOL, and SwAV) and latent forecasting methods (CPC) to demonstrate the feasibility of learning useful representations from 12-lead ECG data through self-supervised learning. Soltanieh et al. [
35] used multiple different augmentations and parameters to evaluate the effectiveness of the ECG representations of three contrastive learning methods (SimCRL, BYOL, and SwAV) on out-of-distribution datasets. Zhang et al. [
36] adopted a contrastive learning method that manipulates temporal–spatial reverse augmentation to learn ECG representations and explored the impact of different combinations of horizontal flipping (temporal reverse) and vertical flipping (space reverse) in the pre-training stage on the downstream AF detection task. Although these methods have shown improvements over the fully supervised baseline, their selection of positive samples largely depends on data augmentation methods. More ECG contrastive learning methods construct positive samples by combining the data consistencies of the ECG inherent attributes. Such consistencies take various attribute dimensions, and each will be considered in turn, including the consistency of the time, subject, channel, rhythm, morphology, and label.
Temporal Consistency: Temporal consistency, also known as contextual consistency, encourages the feature representations at the same timestamp in different augmented views to be similar. TS2vec [
29] proposes contextual consistency in the time dimension of sample representations. It regards the representations of the same timestamp in two augmented views as positive pairs and the representations of different timestamps as negative pairs, focusing on the representative morphology at a single timestamp in the sample.
Subject Consistency: The ECG data of the same subject usually maintains a highly identical pattern within a short period of time, which is the prerequisite for subject consistency. Cheng et al. [
37] incorporated a subject-aware condition into the SSL framework to promote the extraction of subject invariance through contrastive loss and adversarial training. Lan et al. [
38] proposed an intra-inter subject self-supervised learning (ISL) model for arrhythmia diagnosis. The inter-subject SSL maximizes the subject consistency between different augmented views of the same subject and minimizes the similarity between different subjects to learn the unique representations of differences between different subjects. However, when the ECG data of the same patient comes from multiple distributions, the assumed prerequisite of subject consistency is not satisfied.
Channel Consistency: Different leads data of ECG share the same rhythmic characteristics and represent the same cardiac activity with different waveform morphologies. Channel consistency encourages the learning of invariance across leads, especially rhythmic invariance. Liu et al. [
39] proposed a dense lead contrast (DLC) method, which explores the intra-lead and inter-lead invariance through contrastive learning between different leads. In the follow-up work, Liu et al. further [
40] proposed a direct lead assignment (DLA) contrastive learning method. In pre-training, DLA simultaneously focuses on the global ECG representation and lead-specific features by performing contrastive learning between multi-lead and single-lead representations, thus improving the quality of single-lead representation. Some studies focused on both the subject consistency and channel consistency of ECG data, such as the 3KG method proposed by Gopal et al. [
41] and the CLOCS method proposed by Kiyasseh et al. [
31].
Rhythmic Consistency and Morphological Consistency: Liu et al. [
42] proposed a morphology–rhythm contrast (MRC) learning framework. MRC performs dual contrastive learning through random beat selection (morphological view) and 0–1 pulse generation (rhythm view), thereby unifying the morphological and rhythmic features. Zhu et al. [
43] designed pre-training tasks for intra-period and inter-period representation learning to capture the stable morphological features of a single period and the rhythmic features of multiple periods, respectively. The morphological consistency adopted by these methods [
42,
43] is a kind of subsequence consistency, which encourages the representation of the time series to be closer to its sampled subsequence. However, the representation of single-period subsequence features usually cannot reflect the overall morphological features. Due to the loss of information, subsequence consistency may not be applicable to ECG data.
Label Consistency: The label consistency representation is the goal of downstream tasks. Incorporating label information into contrastive learning can provide good initialization parameters for downstream tasks. The supervised CL proposed by Khosla et al. [
44] extended CL from the self-supervised domain to the full-supervised domain. The proposed supervised contrastive loss function (SupCon), by introducing label information, makes samples belonging to the same class cluster more closely in the embedding space, while samples of different classes are pushed away from each other. On this basis, Le et al. [
45] applied supervised contrastive learning to the classification of multi-lead ECG arrhythmias.
The above studies have demonstrated that using CL methods for ECG representation learning can achieve performance comparable to or even surpassing that of fully supervised methods. Summarizing the current research, existing methods mainly consider the consistency of attributes such as the time, channel, subject, rhythm, morphology (subsequence), and label of the ECG. However, existing studies usually only consider one or two attribute consistencies of ECG data and overlook the degree of matching of these strategies with the downstream task data, such as subsequence consistency. Few studies have proposed customized data augmentation methods for downstream tasks. Additionally, existing methods usually only use unlabeled data or only use labeled data for pre-training. These limitations result in the inability of existing methods to fully tap into the full potential of ECG data. To overcome these limitations, we develop a CL method for AF detection by leveraging the ECG data consistencies of multiple attribute dimensions such as time, channel, and label, as well as AF domain knowledge augmentation methods. We do not specifically implement rhythm consistency, since it has already been achieved in channel consistency and diagnostic region augmentation. Due to the presence of a large number of paroxysmal samples in AF records, which may cause the data of the same subject to have different distributions, we abandon the subject consistency strategy in AF detection.
3. Method
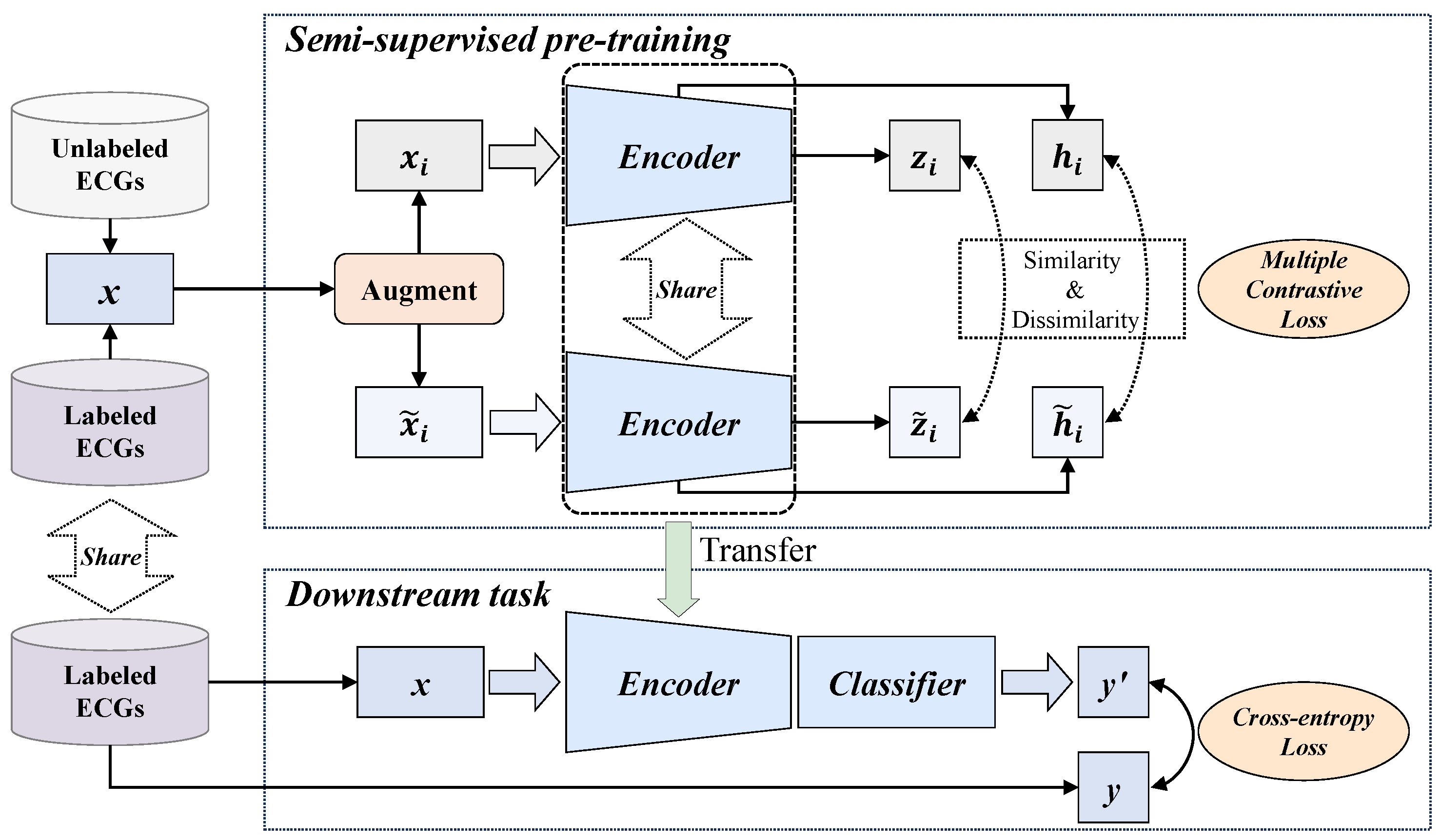
The overall process of the proposed MLMCL algorithm is shown in
Figure 1, which includes two parts: the semi-supervised pre-training task and the downstream task. In the pre-training part, multiple contrast learning is performed on multi-level representations of labeled and unlabeled data, aiming to learn the general representations of single-lead ECGs. The downstream task is the AF detection in single-lead ECG. The MLMCL method contains three key components: domain knowledge augmentation, a multi-level encoder, and multiple contrastive losses. The following provides a more detailed description from three aspects: data augmentation, contrastive learning pre-training, and the downstream task.
3.1. Domain Knowledge Augmentation
Data augmentation is a crucial part for the success of CL methods. It does not need to utilize the inherent connections (such as label categories) of different sample data to obtain similar positive samples. Instead, it only needs to directly transform a single sample to generate similar views. When the data augmentation transformation operators are applied to each ECG instance, the guarantee for extracting efficient representations is to maintain the invariance of important information in the ECG records. However, sometimes series data augmentation methods produce less difference between the augmented sample and the original ECG sample, making it impossible to generate reliable “hard” samples to help the model locate the key invariant features related to downstream tasks.
In ECG, arrhythmia may change the ECG rhythm and the morphology of specific regions, and each type of arrhythmia has distinguishable characteristic patterns. We attempted to utilize the medical domain knowledge of ECG diagnosis to address the issue of hard sample generation [
46]. The proposed domain knowledge augmentation is a method that combines diagnostic region augmentation and non-diagnostic region augmentation. Both the diagnostic and non-diagnostic region augmentation modify the signal values in the corresponding regions to generate “hard” samples for achieving robust learning. The aim is to transform the waveform of the diagnostic/non-diagnostic regions to a large extent so that it is distinguishable from the original sample and other ECG categories, thereby explicitly guiding the model to learn distinguishable features.
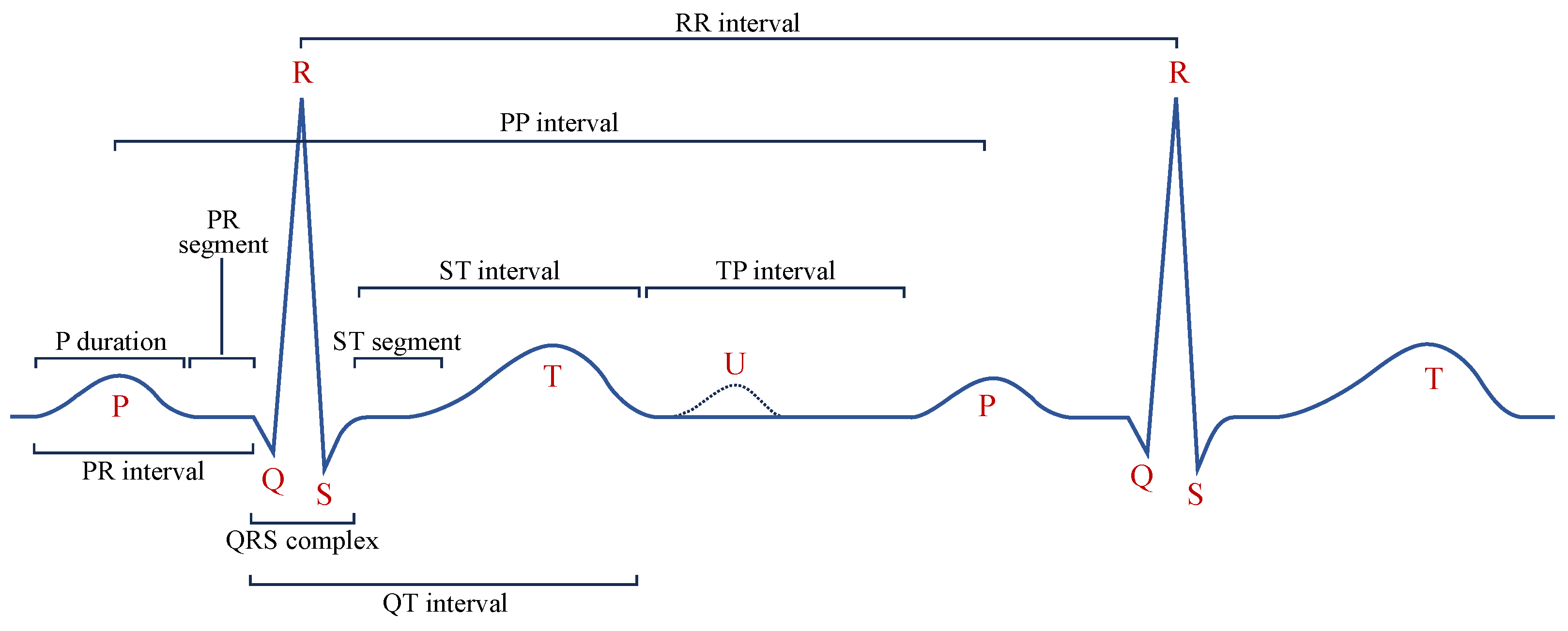
Diagnostic Region Augmentation: As shown in
Figure 2, the key diagnostic regions of AF lie in the P-wave and QRS-wave regions. Considering that the positive and negative morphologies of P wave/QRS wave are symmetrical in the vertical direction, we thus adopt vertical flipping for diagnostic region augmentation. Vertical flipping will create a sufficiently large difference between the original ECG sample and the augmented sample, without causing confusion between the P wave and f wave. The vertical flipping augmentation of the raw ECG signal
can be represented as
.
Non-Diagnostic Region Augmentation: For the non-diagnostic regions of AF, considering that the morphology and position of the T wave are not the key factors for diagnosing AF, we adopt the method of T-wave masking to reduce the interference of the T-wave part on the extraction of diagnostic features, making the model focus more on the diagnostic regions such as the P wave and QRS wave. T-wave masking sets the specific ST interval in the single-lead ECG signal to a fixed value. Specifically, its implementation includes two steps. First, the QRS-wave region of each heartbeat needs to be identified on the entire ECG record, since the QRS wave is the most distinctive wave region and is widely used as a reference for locating other characteristic wave regions. Second, the c% number of the ST intervals in the single-lead ECG sample are set to a fixed value. Usually, the T wave appears within the range of 300 ms after the R wave. Considering that the duration of the QRS wave is usually 80 ms to 100 ms, we achieved T-wave masking by setting the region from 50 ms to 300 ms after the R wave to a fixed value. In the experiments, a typical value for the masking parameter is .
Typically, contrastive learning methods use two augmented variants with different strengths to improve the robustness of the learned representations [
47]. In this paper, the weak augmented variant directly uses the pre-processed data without transforming the original ECG sample, since the ECG samples are not augmented in the downstream task. The strong augmented variant adopts the domain knowledge augmentation strategy to generate “hard” samples. A typical implementation of domain knowledge augmentation is shown in
Figure 3. In fact, we applied diagnostic region augmentation on top of non-diagnostic region augmentation with a 50% probability to achieve domain knowledge enhancement. Given a raw single-lead ECG sample
, augmentation produces two views that can be represented as
and
, respectively. These views are passed to the encoder to extract their high-dimensional latent representations.
3.2. Multi-Level Multiple Contrastive Learning Pre-Training
The proposed MLMCL is a semi-supervised contrastive learning method for single-lead ECGs, which can learn ECG representations from both labeled and unlabeled data simultaneously. Each single-lead ECG is regarded as single-channel 1D data with a sequence length of . Given a labeled dataset that contains M instance/label pairs and an unlabeled dataset that contains N instances, the goal of the MLMCL pre-training is to learn an encoder to extract effective representations relevant to the downstream task from each .
During the pre-training stage, two augmented copies of the same sample are fed into a multi-level encoder to obtain the intermediate hidden representations and the output encoder representations, and data consistency in multiple attribute dimensions on the multi-layer representations is encouraged. The temporal contrastive loss is calculated on the hidden representations, and the channel contrastive loss and label contrastive loss are calculated on the encoder representations. By utilizing the inherent data consistency in multiple dimensions through contrastive learning, the encoder is optimized with multiple contrastive losses to help learn a representation that is both representative and generalizable.
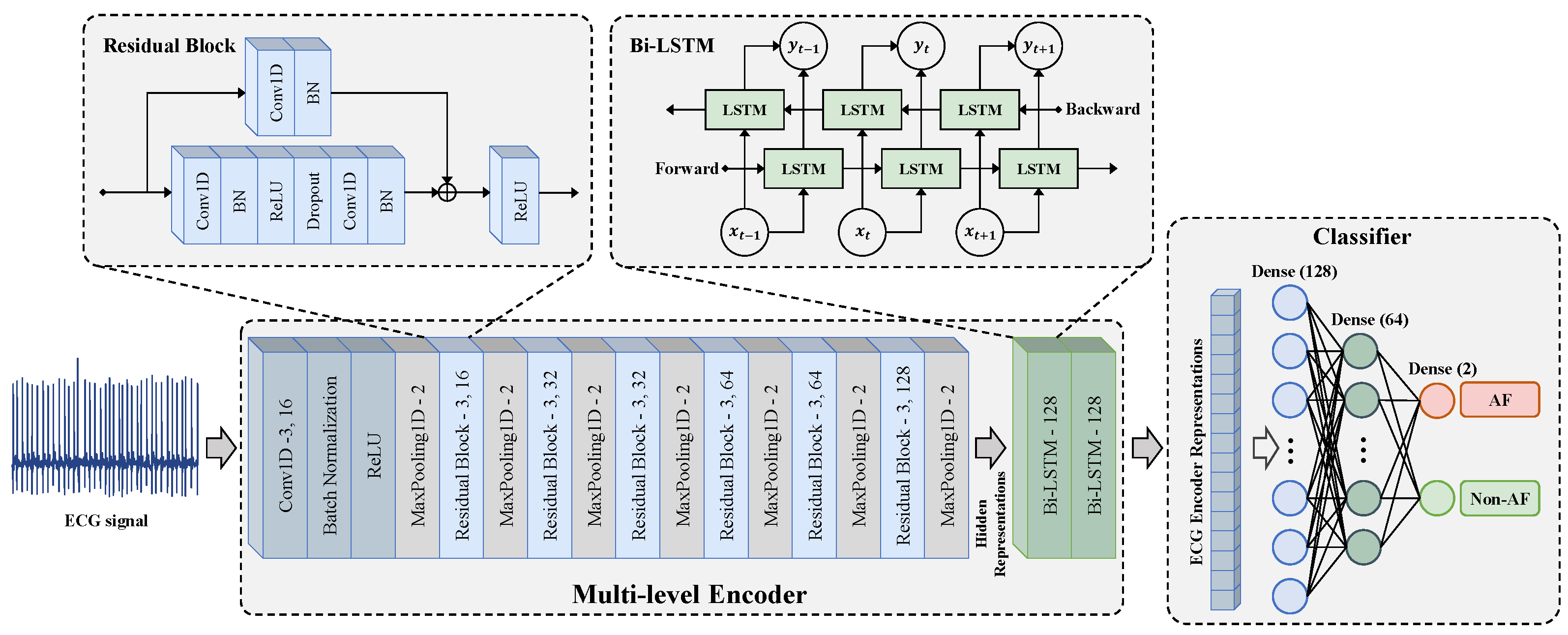
As shown in
Figure 4, the multi-level encoder consists of two parts, including a convolutional feature extraction network
and a temporal–spatial feature fusion network
. The convolutional feature extraction network adopts a residual block design. It extracts the context representation of each sample through one input convolutional layer and six residual blocks. It maps
to a high-dimensional latent space to obtain the hidden representation
. The hidden representation
contains
T representation vectors in the time dimension. The feature vector
at the
t-th timestamp is a representation vector with
dimensions and is used to calculate the temporal contrastive loss.
The temporal–spatial feature fusion network is constructed using the Bidirectional Long Short-Term Memory Network (Bi-LSTM) to extract the temporal-spatial features of ECG. The learns from the hidden representation to obtain the representation , which also contains T representation vectors in the time dimension. Since the output of the last time step of the LSTM network integrates the temporal–spatial information of in order to reduce the amount of computation, the output of the last time step is taken as the output encoder representation. The output of the encoder is normalized onto the unit hypersphere in , which makes it possible to use the inner product to measure the distance in the latent space.
Unlike the models with the SimCLR architecture, we adopted a projector-free design. The experimental results (
Section 4.4.3) show that our method did not lead to a performance decline without using a projector. In fact, the absence of an additional projector could further reduce the pre-training parameters and time consumption.
3.2.1. Temporal Contrastive Learning
Contrastive learning generally assumes that the representation of an augmented sample will carry information similar to that of the corresponding original sample. Analogously, their representation vectors at the same timestamp will also carry similar context information, especially for high-dimensional latent representations extracted by convolutional networks because of the same receptive field and the same network parameters. In order to learn discriminative representations that change over time, we chose to learn temporal consistency. For two augmentations of the same sample, representation vectors with the same timestamp are regarded as positive pairs, and representation vectors from different timestamps are treated as negative pairs [
29]. Temporal contrastive learning helps the encoder focus on the representative features at a single timestamp. Since temporal consistency does not rely on labels, temporal contrastive learning was performed on both labeled and unlabeled data.
For a given ECG sample
and its augmentation
, the convolutional feature extraction network in the encoder extracts their respective hidden representations as
and
, respectively. To capture the temporal consistency, the positive pair is
, and the negative pairs are
and
. In practice, the contrastive loss is calculated within a mini-batch of data. In a batch with
B raw ECG samples, the temporal contrastive loss [
29] is defined as
where
is an indicator function, which equals 1 when the condition
is satisfied and equals 0 otherwise. The function
is the exponential function and the function
is the natural logarithm function. The symbol
is a scalar temperature parameter used to adjust the slope of the loss function. The symbol ⊙ represents the inner product operation and is used to calculate the cosine similarity between two vectors. The cosine similarity of vectors
and
is defined as
.
3.2.2. Channel Contrastive Learning
The 12 lead signals in the same ECG can be thought of as natural augmentation of each other [
31], since multiple lead ECG signals collected simultaneously will reflect the same cardiac activity, and they are associated with the same class. Although some arrhythmias affect specific parts of the heart so that they can only be detected by a few leads, the irregular rhythm of AF is special and can be observed in all leads. Minimizing the inter-lead differences helps to discover the rhythm invariance among the leads [
48]. Therefore, we utilize the invariance of different leads for channel contrastive learning.
For a given ECG sample
, its time-aligned sample of other leads can be represented as
. The samples
and
are input into the encoder to obtain their respective encoder representations
and
. To capture the channel consistency, the encoder representation
should be close to
, and conversely, away from the representation
and
of any other different samples. Specifically, the positive pair is
, and the negative pairs are
and
. In a batch with
B initial ECG samples, the channel contrastive loss [
39] is defined as
where the indicator function
equals 1 when the condition
is satisfied and equals 0 otherwise.
3.2.3. Label Contrastive Learning
In self-supervised contrastive learning, the negative samples of the target sample are composed of samples randomly selected from the mini-batch data. When multiple negative samples and the target sample have the same label, the contrastive loss may push samples of the same class further apart. For downstream supervised tasks, this may lead to a decline in the quality of the representation. Therefore, label consistency was introduced to solve this problem. Label consistency is beneficial for learning domain-adaptive representations of certain diseases across patients or even datasets because it indicates that samples with the same label should exhibit shared patterns even if they are collected from different subjects in different ways. Here, we adopted semi-supervised learning in pre-training to introduce labeled data and label contrastive loss.
In a batch with
B initial ECG samples, the positive samples of the target sample
will be generalized to any number of samples
that have the same label as the target sample. Different from the self-supervised contrastive loss, the label contrastive loss contrasts the set of all samples with the same class label with the remaining samples of other classes in the batch. The calculation formula of label contrastive loss [
44] is as follows:
In the formula, is the set of indices in the batch index that do not include i, is the set of sample indices in the batch that have the same label as sample i, and is the number of its elements.
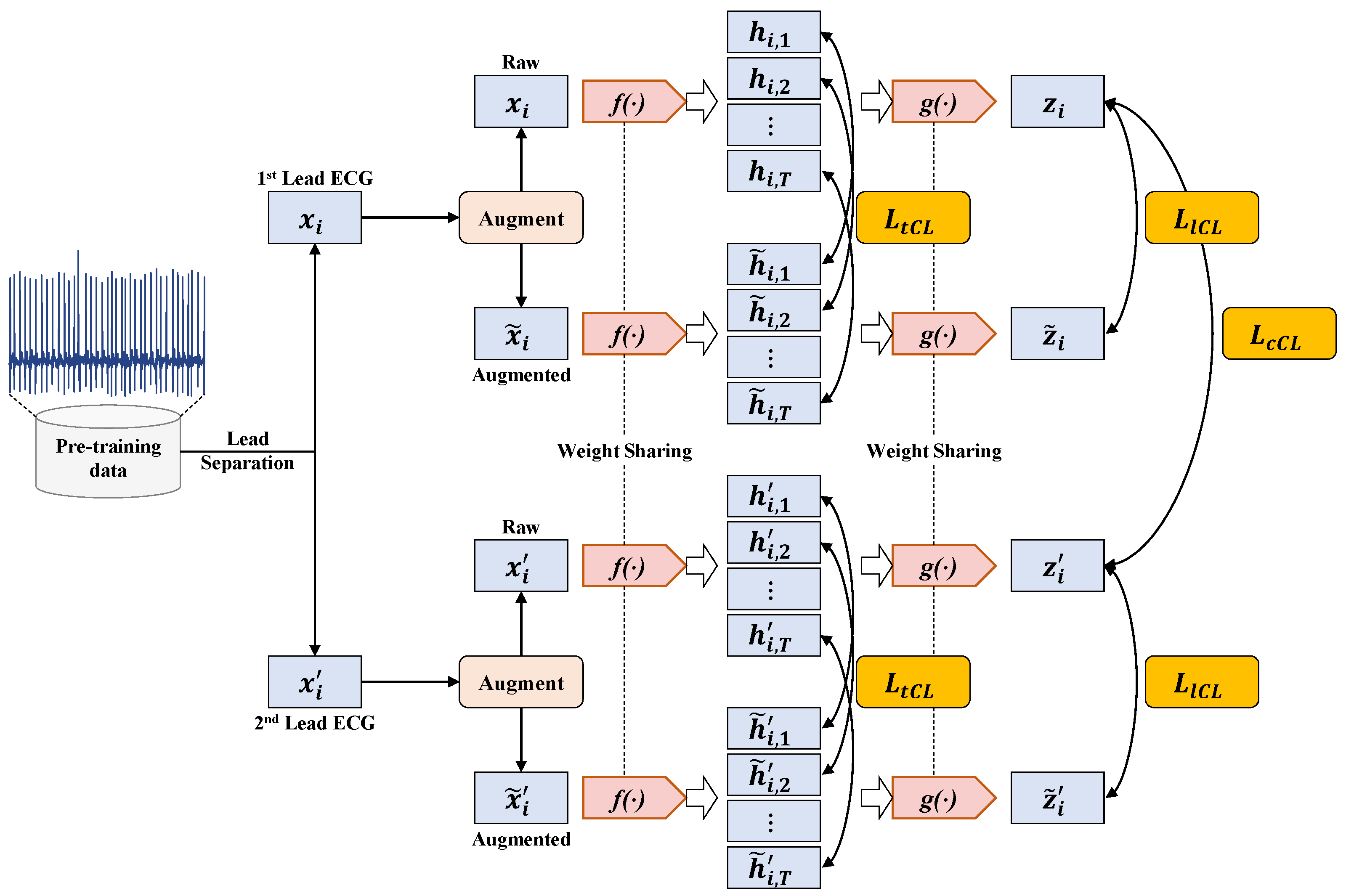
3.2.4. Multiple Contrastive Loss
The calculation process of the multiple contrastive loss used in MLMCL is shown as
Figure 5. The multiple contrastive loss
consists of three loss terms. The temporal contrastive loss and the label contrastive loss help to learn robust representations that are invariant to transformations, while the channel contrastive loss encourages the encoder to learn lead-invariant representations. To sum up, the multiple contrastive loss of the MLMCL method is as follows:
where
are hyperparameters that adjust the scale of each loss and satisfy
. For the labeled dataset, three contrastive losses were adopted. For the unlabeled data, only temporal contrastive loss and channel contrastive loss were adopted, that is,
was set to 0.
3.3. Fine-Tuning for AF Detection Task
After the MLMCL pre-training is completed, the encoder composed of the convolutional feature extraction network
and the temporal–spatial feature fusion network
are passed to the downstream AF detection task as a feature extractor. During fine-tuning, in order to use the pre-trained encoder for classification, the encoder is fine-tuned and a classifier is trained. The classifier is usually designed as a multi-layer perceptron (MLP) with a hidden layer, and ReLU is the activation function used between each fully connected layer. As shown in
Figure 4, the classifier used in the downstream task was designed with three fully connected layers, and a batch normalization layer was added before the activation function to stabilize the training. The cross-entropy loss was used for the supervised training of AF detection:
Among them,
C is the number of categories,
is the
i-th element of the true label
, and
is the
i-th element of the prediction result
.



 ,
, 




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}