1. Introduction
Classification is a supervised technique of categorizing a given set of data into classes using one or more variables. Classification models are predictive methods that assign predefined categories to cases based on the characteristics of these cases. These methods are widely used in all areas of science, medicine, engineering, and biomedical-related or science-related fields. Over the years, classification methods have progressed meaningfully, observing the expansion of Bayesian classification [
1], decision trees, and support vector machines [
2]. Cluster analysis is another machine learning (ML) method used to identify subgroups in a given dataset, especially datasets with high dimensionality. There are numerous algorithms for clustering that use different similarity measures [
3].
Classification techniques, which have the capacity to handle large datasets, play an important role in almost every field. These models find applications in a wide range of fields including spam detection algorithms [
4], bank loan decisions with different levels of risk of default, sentiment analysis, fraud detection systems, and medical diagnosis. By accurately categorizing data, these models help businesses make informed decisions, identify patterns, and gain valuable insights for improved decision-making processes.
An Artificial Neural Network (ANN) is a machine learning method using the concept of a human neuron. It is a computational method that imitates the way biological neurons work [
5]. RF is a group of decision trees in which each tree is trained with a specific random noise. The random aspect of RF reduces the risk of overfitting and improves overall model classification. It also ensures high predictive precision and flexibility [
6].
Logistic regression (LR) and probit analysis (PA) are classification algorithms that can be used to predict categorical outcome variables using a set of independent variables. The LR assumes that the error terms have a logistic probability distribution, but PA assumes that the error term follows a normal probability distribution [
7].
A comparative study of random forest, logistic regression, and neural networks used accuracy and computational efficiency as a tool for their performance in classification [
8]. In an earthquake-induced landslide study, RF and ANN models were assessed using accuracy, AUC, precision, specificity, and recall ratio [
9]. ML metrics were used to evaluate the model performance of RF and LR [
10]. A systematic review measured the overall performance of LR and an ANN [
11].
ML techniques were used to assess and examine subjects with post-traumatic stress disorder (PTSD) and acute stress disorder (ASD) [
12]. A comprehensive systematic review on mental health patients was performed using ML techniques for analyzing bipolar disorder patients [
13]. He et al. studied the estimation of depression relating to deep neural networks and Ramos-Lima researched the application of ML techniques in assessing subjects with PTSD and ASD [
12,
14]. Tabatabai et al. used the binary Hyperbolastic regression of type II to study the role of a patient-centered communication scale on the patient satisfaction of healthcare providers in the USA [
15]. In addition, the risk assessment of death classification during the COVID 19 alpha, delta, and omicron periods was evaluated using the Hyperbolastic regression of type I [
16].
This paper introduces a new classification method called Taba regression that will enable the user to classify binary, multinomial, and ordinal categorical data. The performance of this method, with respect to ML metrics, was evaluated using liver cirrhosis data in comparison with LR, PA, an ANN, and RF.
2. Materials and Methods
2.1. Taba Probability Distribution
For the random variable
X,
. The standard Taba CDF is defined as
The Taba CDF can be used as an activation function in a neural network. The inverse of the standard Taba distribution function is given by
The probability density function for the Taba distribution is given by
Figure 1 shows the CDF of logistic (
), probit (
), negative log-log (
), complementary log-log (
), Hyperbolastic II (
), and Taba (
), and
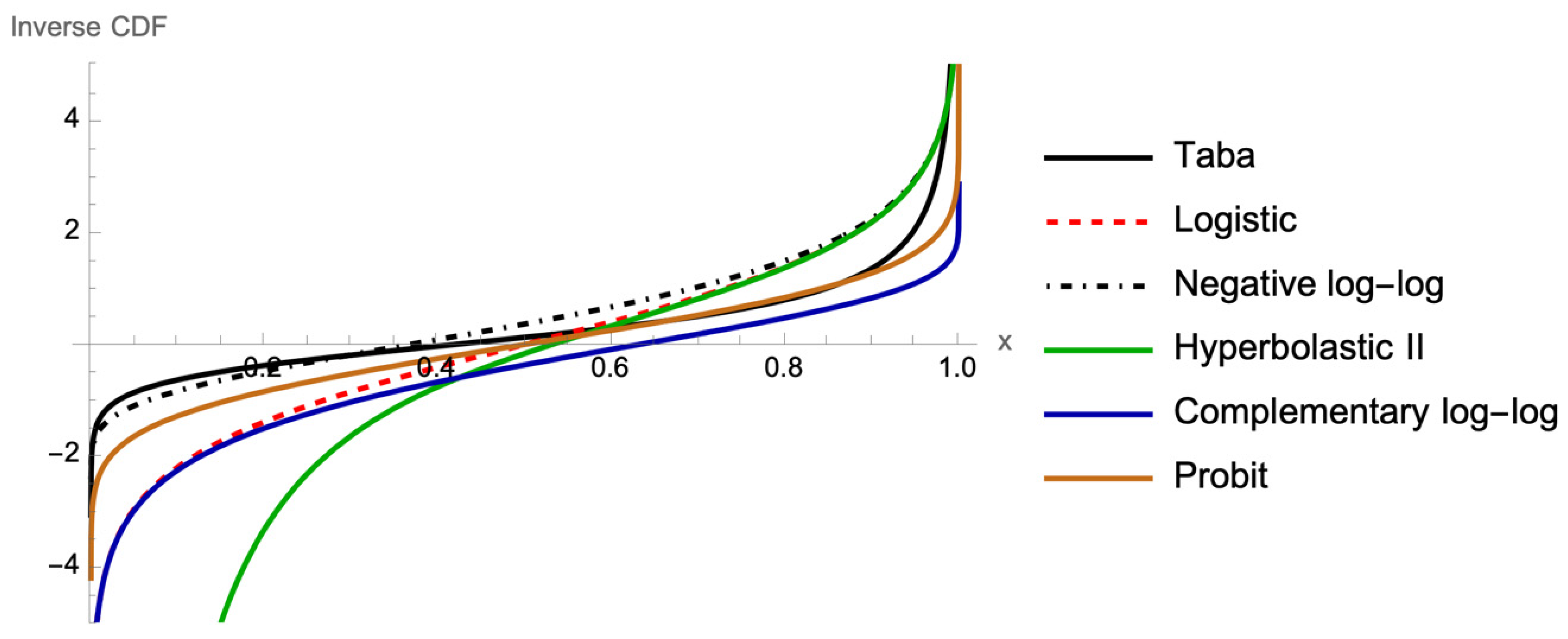
Figure 2 illustrates the corresponding graphs of the inverse CDF, or link functions, which are functions of probabilities that result in a linear model in the parameters.
2.2. Taba Regression
The Taba regression is a classification model that utilizes Taba probability distribution to model a binary (dichotomous), multinomial (nominal multiclass), or ordinal (ordinal multiclass) outcome variable. Taba regression is an ML classification method, which is a supervised learning technique. It is used for predicting the categorical dependent variable utilizing a given set of explanatory variables.
2.2.1. Binary Taba Regression
For the binary variable
, let success be defined as
and failure as
, then the success probability of a sample of size
as a function of parameter vector
is defined as
where
and
represents the number of explanatory variables. Now consider the model
where
are independent random variables with expected value
and
are independent Bernoulli variables with a mean
and variance
.
For simple binary Taba regression with only one explanatory variable, the function (1) reduces to
or equivalently
where
and
are location and scale parameters with
and
.
For binary Taba regression, the odds of success are:
The purpose of binary Taba regression is to predict a binary outcome by means of a single independent variable (simple binary Taba regression) or a set of independent variables (multiple binary Taba regression). In general, binary classification models are routinely used in many areas including medical, public health, dental, biomedical, machine learning, social, behavioral, and engineering sciences.
Assumptions of Binary Taba Regression
Similar to other binary classification methods, the following assumptions must be satisfied:
Each observation must be independent of one another.
The dependent variable must be binary.
Absence of multicollinearity among independent variables.
Linear relationship between explanatory variables and hyperbolic sine of log odds.
There should be no strong outliers, high leverage values, or influential observations in the dataset.
Parameter Estimation for Binary Taba Regression
Because Taba regression predicts probabilities, we can estimate weight parameters using likelihood function. For each training datapoint, we have a vector of features, , and an observed class, . The probability of that class was either , if , or , if .
The likelihood function for binary Taba regression is equal to
The estimate of the weight parameter vector
can be found by maximizing the log-likelihood function of the form
The estimated variance–covariance matrix for a weight parameter vector is calculated using the inverse of the estimated Fisher’s Information matrix, from which the test statistics are derived.
2.2.2. Multinomial Taba Regression
The multinomial Taba regression is used when the dependent variable is a nominal categorical with more than two levels and there is no natural order. In this model, the explanatory variables can be categorical or continuous.
Assumptions of Multinomial Taba Regression
Similar to other multinomial models, multinomial Taba regression must satisfy the following:
Observations are assumed to be independent.
Outcome categories are assumed to be mutually exclusive and collectively exhaustive.
No severe outliers, high leverage values, or highly influential observation in the dataset.
Lack of multicollinearity between independent variables.
Linear relationship between independent variables and the hyperbolic sine of log odds of success
2.2.3. Ordinal Taba Regression
Ordinal Taba regression, or Taba proportional odds regression, is used to classify an ordinal outcome variable using a set of explanatory variables. Level rankings of the outcome variable categories do not imply equal distances between them.
Assumptions of Ordinal Taba Regression
Similar to the proportional odds model assumptions, Taba ordinal regression must satisfy the following:
The dependent variable must be measured on an ordinal level.
No independent variable has an unequal effect on a specific level of the ordinal categorical dependent variable.
The predictor variables must be independent.
To test the validity of the proportional odds model, the score test can be used. The Brant and Wolfe–Gould tests for proportional odds are appropriate when the sample size is small [
1,
2]. The proportional odds assumption needs to be tested prior to its usage [
17,
18].
Parameter Estimation for Ordinal Taba Regression
For the
k-category ordinal outcome, the cumulative probability for the
ith response belongs to the category less than or equal to
j and is given by
and for
and
. The
is the ordinal log-odds of falling into or below category
against falling above it and is equal to
where
For parameter vectors
let
denote the probability
then we have
or equivalently
The likelihood function for ordinal Taba regression is
and the log-likelihood is
The estimate of parameter vectors
can be obtained by maximizing the log-likelihood function
3. Results
3.1. Analysis of Liver Cirrhosis Data
Cirrhosis results from extended liver damage, causing massive scarring, most likely due to hepatitis or chronic alcohol consumption. The data used here are from a Mayo Clinic study on Primary Biliary Cirrhosis (PBC) of the liver carried out from 1974 to 1984. During this period, 424 PBC patients referred to the Mayo Clinic qualified for the randomized placebo-controlled trial testing the drug D-penicillamine. The Cirrhosis Patient Survival Prediction data were obtained from the UC Irvine repository. Only 312 patients participated in the trial [
19,
20].
Table 1 shows the demographic and clinical characteristics of the patients. A total of 40.1% died of cirrhosis; 50.6% had received the drug D-Penicillamine and 49.1% were given a placebo; 7.7% had ascites, 51.3% had hepatomegaly, and 28.8% had spiders.
The mean age for patients was 18,269.44 days, with a standard deviation of 3864.805 days. The age range was from 9598 to 28,650 days. The mean bilirubin level was 3.256 mg/dL, with a standard deviation of 4.530 mg/dL. Albumin had a mean level of 3.52 mg/dL and a standard deviation of 0.41989 mg/dL. The mean cholesterol level was 368.75 mg/dL, with a standard deviation of 233.063 mg/dL, and copper had a mean level of 97.04 μg/dL, with a standard deviation of 86.019 μg/dL. Alkaline phosphatase had a mean level of 1982.66 IU/L and a standard deviation of 2140.389 IU/L, as shown in
Table 2.
3.1.1. Analysis of Cirrhosis Using an ANN
To predict death status for cirrhosis, an ANN was created through Multi-Layer Perceptron with a hyperbolic tangent as a hidden layer activation function and softmax as an outer layer activation function, as well as cross-entropy as the error function. The standardized method was used for the rescaling of continuous variables, and 72.4% (226 datapoints) of the dataset was used for training and the remaining 27.6% (86 datapoints) was used for testing purposes. The number of hidden layers was one, the number of units in the hidden layer was four (excluding the bias unit), and the activation function for the hidden layer was a hyperbolic tangent. For the output layer, the number of units was two, the activation function was softmax, and the error function was cross-entropy. IBM SPSS software version 29 was used to analyze the data using the ANN method.
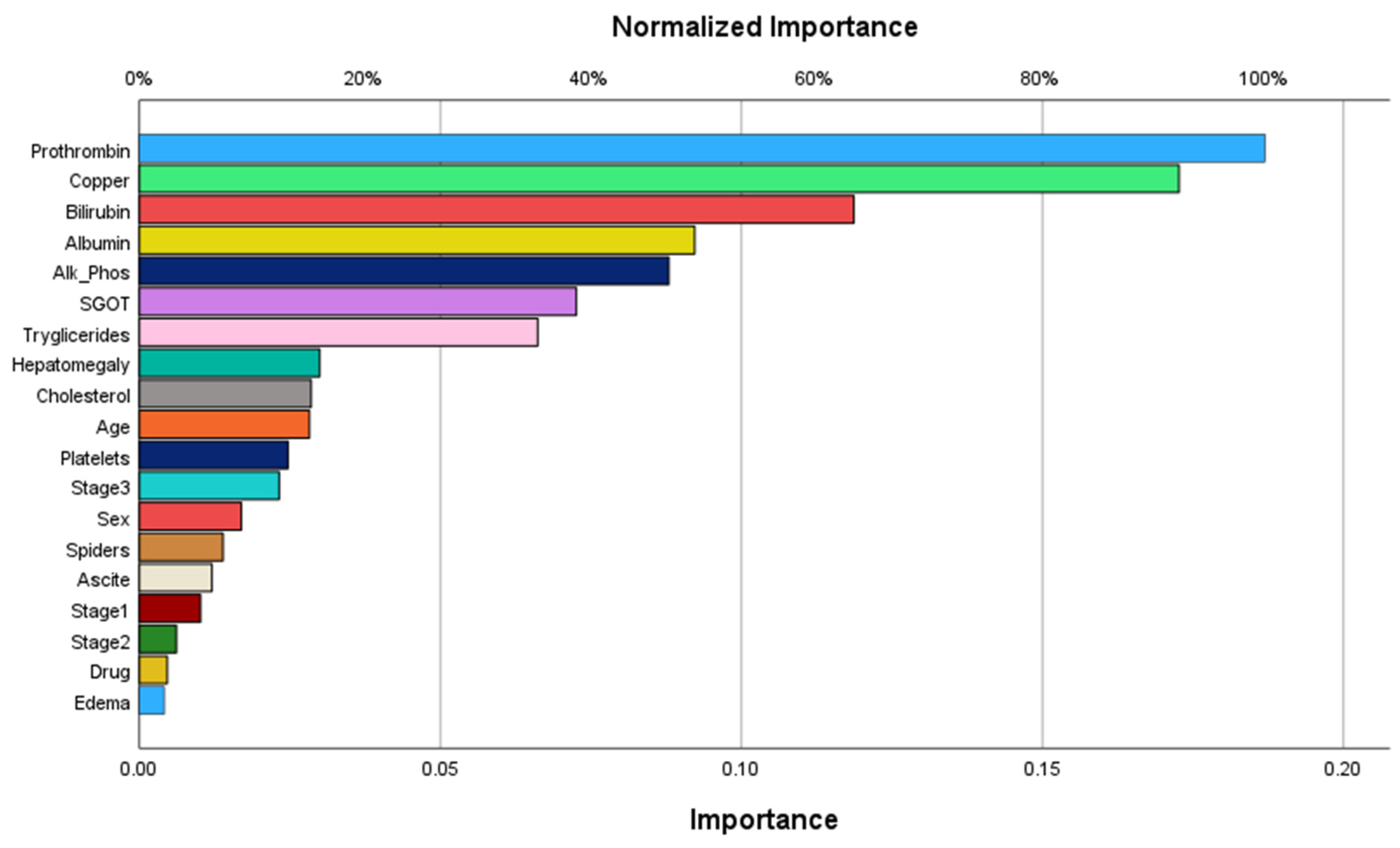
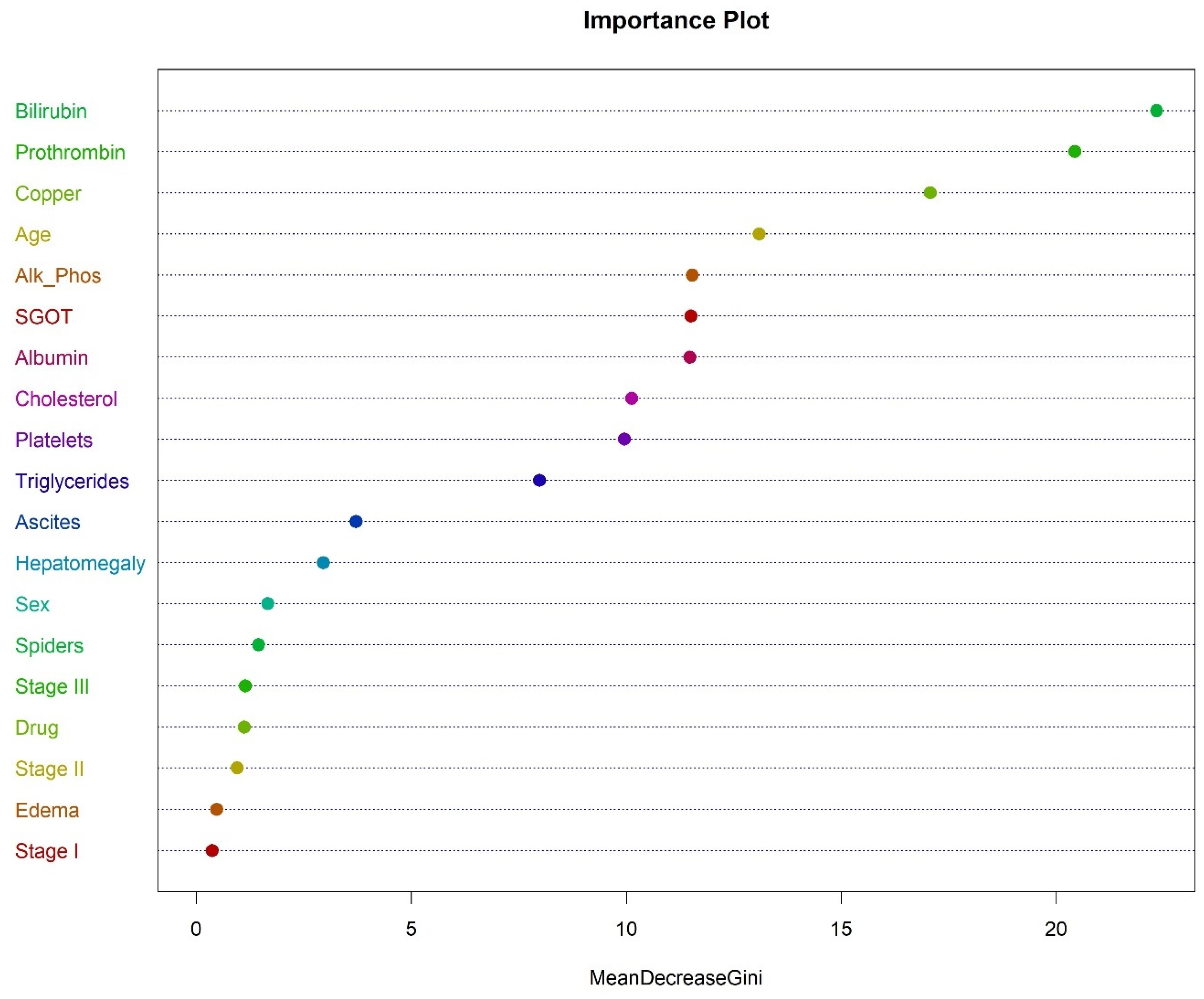
The order of importance of predictor variables according to the ANN is shown in
Figure 3, and the importance and normalized importance values are given in
Table 3.
The most important variable identified by the ANN was prothrombin, followed by copper, bilirubin, albumin, alkaline phosphatase, and SGGT. The least important variable was edema.
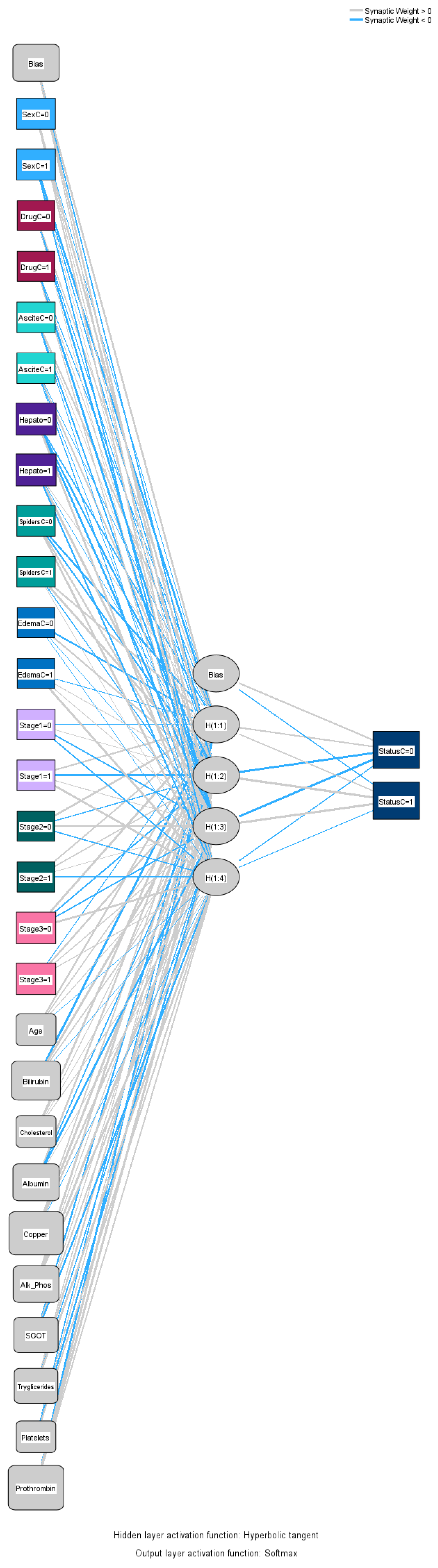
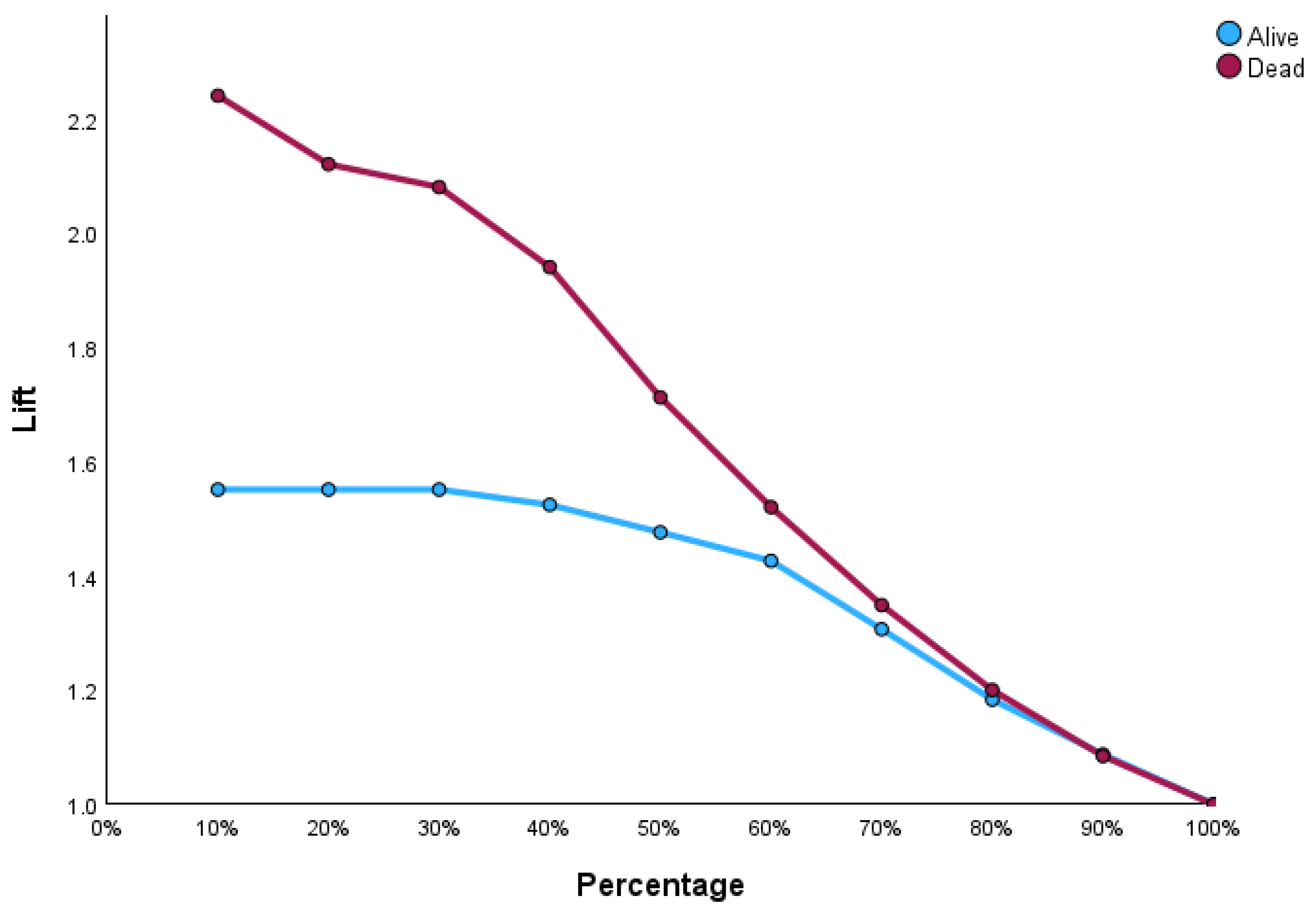
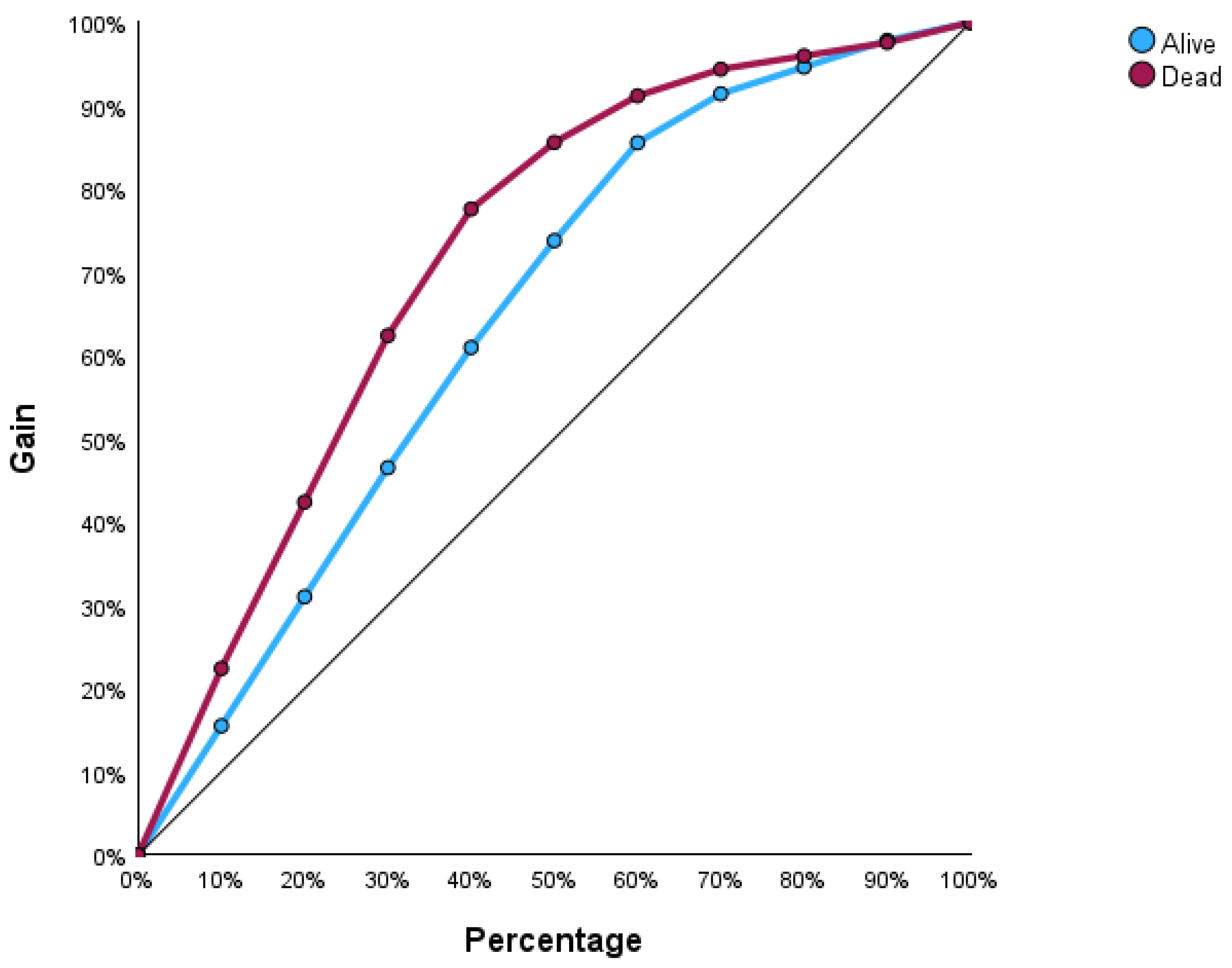
Figure 4 illustrates the input–output relations with hidden multilayers, which performs all the calculations to find hidden features and patterns. To assess the performance of the ANN, we will use lift and gain diagrams. A lift diagram displays the predictive ability of a binary ANN classification model. It measures how effectively the ANN identifies positive instances compared to a baseline of random selection. Furthermore, it indicates how much better one can expect to do with the predictive model compared to without a model.
Figure 5 shows the lift curve. For the first 10% of the data, the lift is approximately 2.25, meaning that selecting 10% of the observations with the highest predicted values using the ANN model results in 2.25 more deaths than if that 10% were selected at random.
The gain at a given decile level is the ratio of cumulative number of deaths up to that decile to the total number of deaths in the entire dataset. For instance, we can identify and target approximately 23% of patients who died as a result of cirrhosis by sampling only 10% of those patients, as shown in
Figure 6.
It was found that in the testing stage the accuracy of the ANN was 80.2%. The true positive rate (TPR), which is also known as recall, was 74.2%. The precision (PRE) of the ANN was 71.9%, with an F-score (FS) of 73.0%. The area under this curve (AUC) was found to be 0.871 for both the training and testing sets. The AUC sums up how well a model can produce relative scores to discriminate between positive or negative instances across all classification thresholds. The AUC ranges from 0 to 1, where 1 indicates a perfect model and 0.5 shows random guessing. The calculated metrics for each ML classification method are shown in
Table 4.
3.1.2. Analysis of Cirrhosis Using LR
For the LR, the model accuracy was 82.1%. The TPR was 72.8%. The precision was 80.5% with an FS of 76.5%. The AUC was found to be 0.898. The value of -2log-likelihood for LR was 255.884 and the Akaike Information Criterion (AIC), which is a measure of model quality, was 295.884. The Bayesian Information Criterion (BIC), which is a criterion for model quality, was 370.7440638. Significant variables were prothrombin (p-value < 0.001), age (p-value = 0.002), alkaline phosphatase (p-value = 0.004), and SGOT (p-value = 0.037).
3.1.3. Analysis of Cirrhosis Using PA
The accuracy of the PA model was 81.7%, with a TPR value of 70.4%. The precision was 81.5% with an FS of 75.5%. The ROC curve for PA has an AUC value of 0.896. The value of -2log-likelihood for LR was 260.274 and the AIC was 300.273. The BIC was 375.134. Significant variables were prothrombin (p-value < 0.001), age (p-value = 0.003), alkaline phosphatase (p-value = 0.003), and SGOT (p-value = 0.045). Significant variables were prothrombin (p-value < 0.001), age (p-value = 0.003), alkaline phosphatase (p-value = 0.003), and SGOT (p-value = 0.045).
3.1.4. Analysis of Cirrhosis Using Random Forest
To perform the random forest analysis for cirrhosis data, the R package randomForest was used. Breiman’s random forest algorithm was used for classification [
21,
22]. The accuracy of random forest in classifying cirrhosis death was 79.2%. The recall was 72.0% and the precision was 75.0%. The FS for the random forest was 73.5%, with an AUC value of 0.852.
The most important variable in classifying the death due to cirrhosis was bilirubin, followed by prothrombin, copper, age, alkaline phosphatase, and SGOT, as shown in
Figure 7.
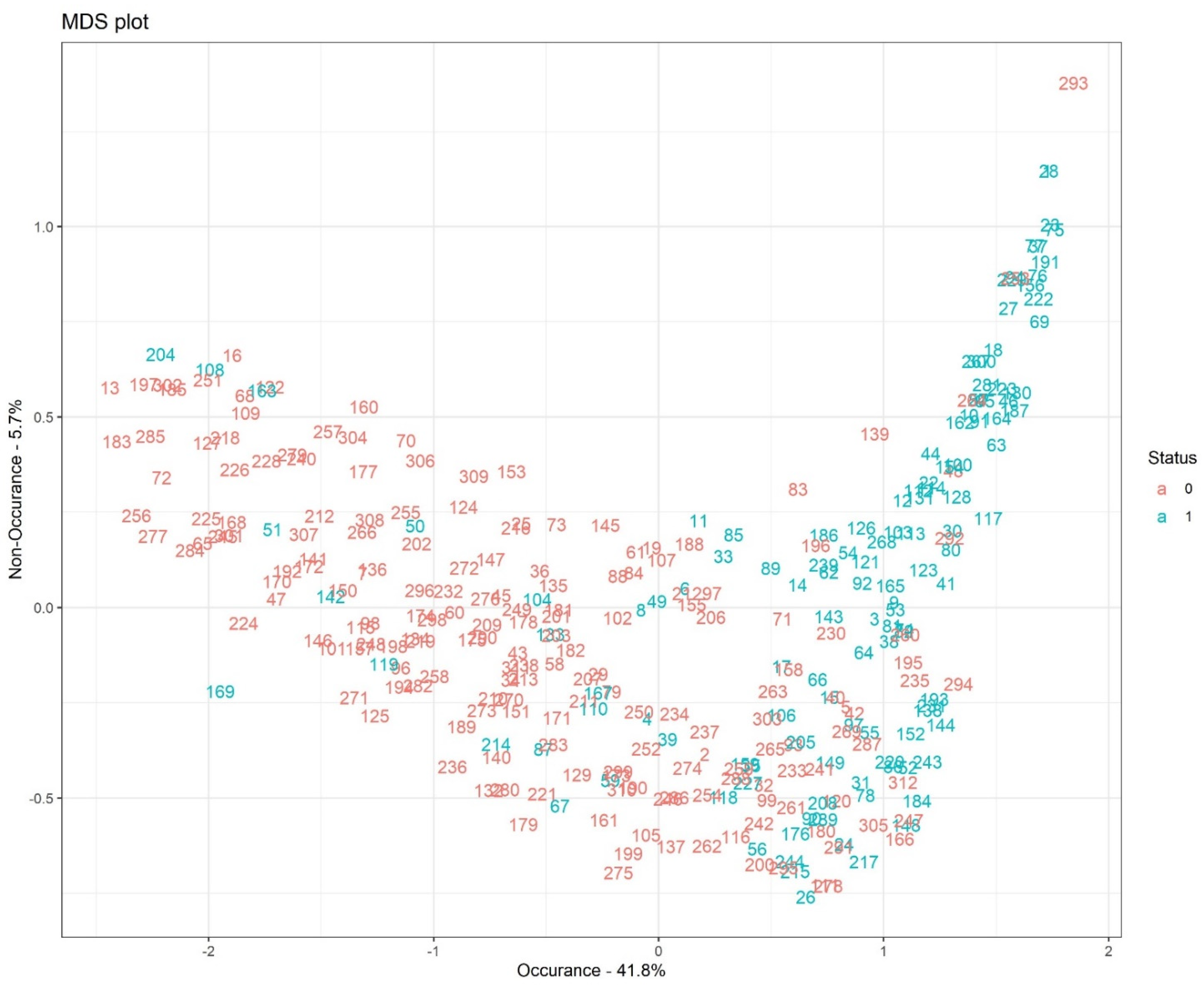
Figure 8 illustrates the multidimensional scaling (MDS) plot based on proximity measures across observations with 41.8% occurrence and 5.7% non-occurrence rates. The MDS plot shows a pictorial visualization of the level of similarity of individual cases, coded here as 1 (dead) and 0 (alive) in our dataset.
Figure 9 shows the error plot, which gives a visualization of the “Out-of-Bag (OOB) error”. It is a way to estimate random forest’s prediction error by using datapoints that were not used in the training stage for each individual tree within the forest.
3.1.5. Analysis of Cirrhosis Using Taba Regression
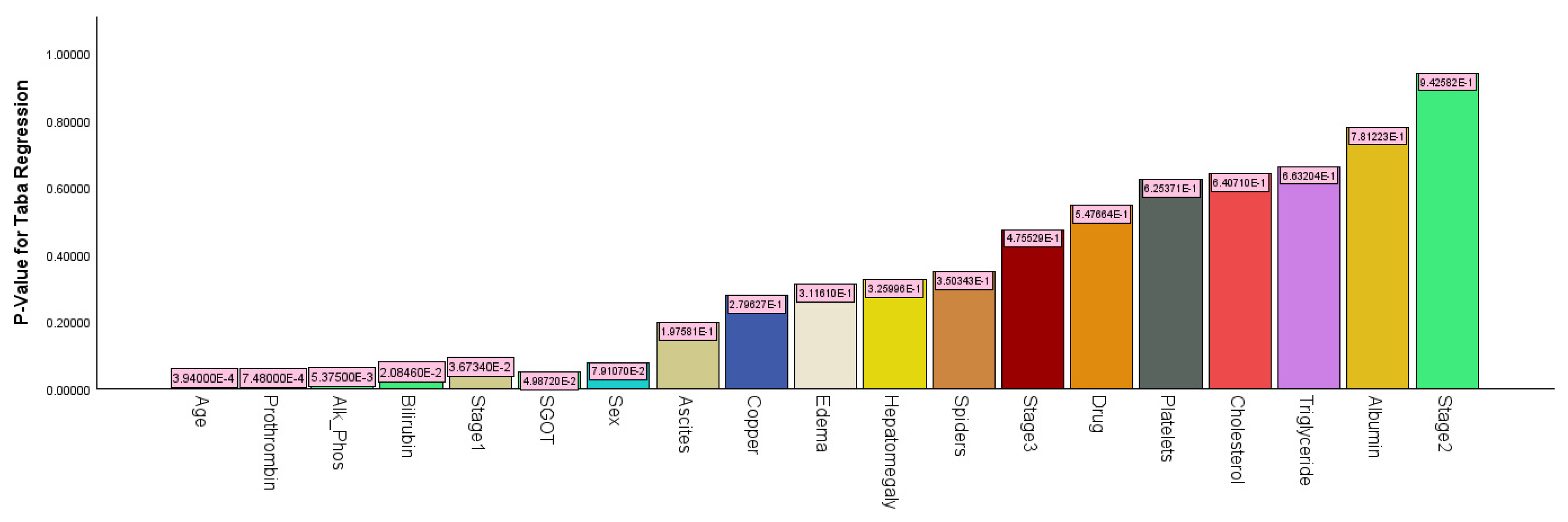
An analysis of cirrhosis data using Taba regression resulted in a recall of 76.0% and a precision of 79.2%. The accuracy was 82.4%, with an FS of 0.775 and an AUC value of 0.902. The -2log-likelihood for binary Taba regression was 244.884, with an AIC value of 284.584 and a BIC value of 359.444. As shown in
Figure 10, the most significant predictor variable was age (
p-value < 0.001), followed by prothrombin (
p-value < 0.001), alkaline phosphatase (
p-value = 0.021), stage 1 (
p-value = 0.037), and SGOT (
p-value =0.050).
Table 5 gives the parameter estimates for binary Taba regression.
4. Discussion
The performance of any given classification method differs wildly depending on the nature of the dataset. Selecting a model to implement for a particular application on the basis of performance measures still remains a major topic of discussion in classification. In the cirrhosis dataset, the standard measures of classification considered in this paper, such as recall, precision, F-score, and AUC, showed that Taba performs extremely well in comparison to four other popular ML classification methods. These measures offer intuition into the model performance as well as help in finding the most appropriate model for the analysis of the dataset under consideration. Taba regression performed better, with higher overall accuracy, TPR, FS, and AUC value compared to the other methods considered in this study.
ANNs and RF necessitate more computational tools and data to perform well. For instance, RF builds multiple decision trees and combines their results, which requires significant computational resources. This collective approach makes it slower than Taba regression. Training an RF model can take a long time, which may not be ideal for real-world applications. This computational intensity can also lead to high memory usage and stress systems with limited resources.
Taba regression uses less processing power and memory, has computational efficiency in that it is faster to train, has fewer parameters to tune, is less prone to overfitting, and has the flexibility to handle binary, multinomial, and ordinal categorical outcome variables. These characteristics allow Taba regression to work well with smaller datasets or when the data have high variance, noise, or influential observations in the explanatory variables. Unlike ANNs and RF, Taba regression outputs probabilities, which helps in understanding the relationship between the outcome and explanatory variable(s) and the confidence level of predictions. Taba regression is easy to understand, implement, and interpret, making it a desirable method when analyzing data.
5. Conclusions
A new classification method for the analysis of binary, multinomial, and ordinal outcome was introduced. Taba regression performed best with regard to accuracy, recall, FS, and AUC when compared with the other four models considered in this paper. The results indicate that Taba regression is a competitive ML method when compared with ANNs, RF, LR, and PA in classifying death status using liver cirrhosis data. Based on the performance of Taba regression, we hope researchers will consider using this model as a classification model when analyzing their data. In the future, we plan to (1) develop an R program capable of performing all necessary computations for binary, multinomial, and ordinal Taba regressions, (2) evaluate the performance of multinomial and ordinal Taba regressions in comparison with other ML methods using biomedical or public health data, and (3) evaluate the robustness of these ML techniques under deterministic and random noise for small, medium, and large datasets. Our data reveal that Taba achieves high accuracy with respect to ML metrics and offers a practical and accessible solution for tackling classification problems, effectively balancing interpretability and accuracy in classification tasks.
Author Contributions
Conceptualization, M.T.; methodology, M.T.; software, M.T., and D.W.; validation, M.T., D.W., C.-K.C., K.P.S., and T.L.W.; formal analysis, M.T., and D.W.; investigation, M.T., D.W., C.-K.C., K.P.S., and T.L.W.; resources, M.T., and D.W.; data curation, M.T., and D.W.; writing—original draft preparation, M.T.; writing—review and editing, M.T., D.W., C.-K.C., K.P.S., and T.L.W.; visualization, M.T., and D.W.; supervision, M.T.; project administration, M.T.; funding acquisition, M.T. All authors have read and agreed to the published version of the manuscript.
Funding
This research was partly supported by Meharry Medical College RCMI (NIH grant MD007586) and the Tennessee Center for Aids Research (P30 AI110527).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Acknowledgments
Not applicable.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Du, C.-J.; Sun, D.-W. Object Classification Methods. In Computer Vision Technology for Food Quality Evaluation; Elsevier: New York, NY, USA, 2008; pp. 81–107. ISBN 978-0-12-373642-0. [Google Scholar]
- Somvanshi, M.; Chavan, P.; Tambade, S.; Shinde, S.V. A Review of Machine Learning Techniques Using Decision Tree and Support Vector Machine. In Proceedings of the 2016 International Conference on Computing Communication Control and Automation (ICCUBEA), Pune, India, 12–13 August 2016; pp. 1–7. [Google Scholar]
- Tabatabai, M.; Bailey, S.; Bursac, Z.; Tabatabai, H.; Wilus, D.; Singh, K.P. An Introduction to New Robust Linear and Monotonic Correlation Coefficients. BMC Bioinform. 2021, 22, 170. [Google Scholar] [CrossRef]
- Kontsewaya, Y.; Antonov, E.; Artamonov, A. Evaluating the Effectiveness of Machine Learning Methods for Spam Detection. Procedia Comput. Sci. 2021, 190, 479–486. [Google Scholar] [CrossRef]
- Han, S.-H.; Kim, K.W.; Kim, S.; Youn, Y.C. Artificial Neural Network: Understanding the Basic Concepts without Mathematics. Dement Neurocognitive Disord 2018, 17, 83. [Google Scholar] [CrossRef]
- Aria, M.; Cuccurullo, C.; Gnasso, A. A Comparison among Interpretative Proposals for Random Forests. Mach. Learn. Appl. 2021, 6, 100094. [Google Scholar] [CrossRef]
- Mohammad, T.; Li, H.; Eby, W.; Kengwoung-Keumo, J.; Manne, U.; Bae, S.; Fouad, M.; Singh, K.P. Robust Logistic and Probit Methods for Binary and Multinomial Regression. J. Biom. Biostat. 2014, 5, 202. [Google Scholar] [CrossRef]
- Reznychenko, T.; Uglickich, E.; Nagy, I. Accuracy Comparison of Logistic Regression, Random Forest, and Neural Networks Applied to Real MaaS Data. In Proceedings of the 2024 Smart City Symposium Prague (SCSP), Prague, Czech Republic, 23 May 2024; pp. 1–5. [Google Scholar]
- Kamal, M.; Zhang, B.; Cao, J.; Zhang, X.; Chang, J. Comparative Study of Artificial Neural Network and Random Forest Model for Susceptibility Assessment of Landslides Induced by Earthquake in the Western Sichuan Plateau, China. Sustainability 2022, 14, 13739. [Google Scholar] [CrossRef]
- Health Informatics Department; College of Public Health and Health Informatics; King Saud Bin Abdulaziz University for Health Sciences (KSAU-HS); King Abdullah International Medical Research Center (KAIMRC); Ministry of National Guard Health Affairs; Riyadh, K.S.A.; Daghistani, T.; Alshammari, R. Comparison of Statistical Logistic Regression and RandomForest Machine Learning Techniques in Predicting Diabetes. JAIT 2020, 11, 78–83. [Google Scholar] [CrossRef]
- Issitt, R.W.; Cortina-Borja, M.; Bryant, W.; Bowyer, S.; Taylor, A.M.; Sebire, N. Classification Performance of Neural Networks Versus Logistic Regression Models: Evidence From Healthcare Practice. Cureus 2022, 14, e22443. [Google Scholar] [CrossRef] [PubMed]
- Ramos-Lima, L.F.; Waikamp, V.; Antonelli-Salgado, T.; Passos, I.C.; Freitas, L.H.M. The Use of Machine Learning Techniques in Trauma-Related Disorders: A Systematic Review. J. Psychiatr. Res. 2020, 121, 159–172. [Google Scholar] [CrossRef] [PubMed]
- Librenza-Garcia, D.; Kotzian, B.J.; Yang, J.; Mwangi, B.; Cao, B.; Pereira Lima, L.N.; Bermudez, M.B.; Boeira, M.V.; Kapczinski, F.; Passos, I.C. The Impact of Machine Learning Techniques in the Study of Bipolar Disorder: A Systematic Review. Neurosci. Biobehav. Rev. 2017, 80, 538–554. [Google Scholar] [CrossRef] [PubMed]
- He, L.; Niu, M.; Tiwari, P.; Marttinen, P.; Su, R.; Jiang, J.; Guo, C.; Wang, H.; Ding, S.; Wang, Z.; et al. Deep Learning for Depression Recognition with Audiovisual Cues: A Review. Inf. Fusion 2022, 80, 56–86. [Google Scholar] [CrossRef]
- Tabatabai, M.A.; Matthews-Juarez, P.; Bahri, N.; Cooper, R.; Alcendor, D.; Ramesh, A.; Wilus, D.; Singh, K.; Juarez, P. The Role of Patient-Centered Communication Scale in Patients’ Satisfaction of Healthcare Providers before and during the COVID-19 Pandemic. Patient Exp. J. 2023, 10, 113–123. [Google Scholar] [CrossRef]
- Tabatabai, M.; Juarez, P.D.; Matthews-Juarez, P.; Wilus, D.M.; Ramesh, A.; Alcendor, D.J.; Tabatabai, N.; Singh, K.P. An Analysis of COVID-19 Mortality During the Dominancy of Alpha, Delta, and Omicron in the USA. J. Prim. Care Community Health 2023, 14, 215013192311701. [Google Scholar] [CrossRef]
- Brant, R. Assessing Proportionality in the Proportional Odds Model for Ordinal Logistic Regression. Biometrics 1990, 46, 1171. [Google Scholar] [CrossRef]
- Wolfe, R.; Gould, W. An Approximate Likelihood-Ratio Test for Ordinal Response Models. Stata Tech. Bull. 1998, 7, 76. [Google Scholar]
- Fleming, T.R.; Harrington, D.P. Counting Processes and Survival Analysis; John Wiley & Sons: Hoboken, NJ, USA, 2013; Volume 625. [Google Scholar]
- Markelle Kelly, Rachel Longjohn, Kolby Nottingham, The UCI Machine Learning Repository. Available online: https://archive.ics.uci.edu (accessed on 22 March 2023).
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Breiman, L.; Cutler, A.; Liaw, A.; Wiener, M. randomForest: Breiman and Cutlers Random Forests for Classification and Regression. R News 2002, 2, 18–22. [Google Scholar]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}