1. Introduction
Sleep is a crucial biological process. Transient sleep pattern changes and disorders, such as acute sleep deprivation, sleep breathing disorders, narcolepsy, periodic limb movement syndrome, REM sleep disorder, and parasomnias, have been reported to have a significant impact on people’s health, sometimes even leading to lethal consequences [
1,
2]. Consequently, monitoring sleep is considered as a task with clinical significance and practical prospects.
The development of sensor technologies has made it possible to extend the range of sleep monitoring from professional clinical environment to daily home-monitoring scenarios. To establish long term health monitoring and conduct data analysis, human identification of the acquired signals plays a crucial and prerequisite role, and has recently become a prominent requirement along with the growing application of intelligent healthcare devices in daily life. Inaccurate identification may cause failure in health monitoring and disease warning, and affects the trustworthiness of the technologies to be applied in the real world.
Vision-based solutions such as videos and pictures have been widely used for human identification. Although effective, such surveillance systems have their limitations. They are sensitive to environment light condition changes, and are intrusive methods where privacy issues could be aroused [
3,
4].
Various studies have chosen radar signals as a non-contact source for vital biometric extraction, motion monitoring, and pose estimation [
5,
6,
7,
8,
9,
10,
11], which suggests that, from radar data, we can acquire highly personal information, which is potentially promising for human identification. Some groups [
12,
13,
14] have shown that with machine learning techniques, the features of motions such as walking and running can be promising for trajectory identification and tracking. The radar signals of different participants showed a distinguishable feature difference in range-Doppler (RD)/range-Doppler-azimuth (RDA) map and micro-Doppler (
) signature, which can be recognized by machine learning techniques. However, such features may not be feasible during stationary scenarios such as resting and sleeping. To stress such limitations, some groups used radar to acquire heart motion [
15,
16] or respiratory pattern [
17,
18] for human identification. However, there were certain constraints on the data acquisition setups. The data sets were usually acquired in the seated position. Or, laser positioning was introduced to ensure the precise position of the antenna. Such ideal acquisition conditions may not be achievable during actual home-monitoring scenarios. When the acquired heart motion signal sequences are mixed with noise and random body movements, the feature signatures in Short Time Fourier Transform (STFT) images or the single beat segments may not be as obvious as described in the literature. In this work, we will explore a solution of a time series classification problem for radar signal sequences, and discuss the factors which may affect the accuracy of the classification in details.
When discussing the human identification problem from radar data, most of the studies tend to evaluate the performance of the proposed methods using the close set classification accuracy with labeled data. However, in practice, the radar signal sequences acquired from actual scenarios are quite different from the data for training. Such unknown sequences cannot be recognized by the model and therefore not correctly labeled, causing confusion and a potential data safety hazard. To tackle this issue, a more robust scheme should be proposed to detect and identify such data properly.
One intuitive solution is to assign the unknowns an additional label, turning the unknown detection problem into a classification problem so that supervised learning methods can be applied. Such methodologies have their limits. The features of the unknown samples cannot be exhaustively numerated; therefore, open set recognition methods are studied. Traditional machine learning methods [
19,
20,
21,
22,
23] such as SVM, sparse representation, and nearest neighbor have been proposed to be utilized in this area. However, such methods suffered from the common limitation, and the necessity of carefully selected features. Deep learning-based methods have shown powerful potential in self-adaptive feature extraction and recognition. Open Max [
24,
25] was proposed to modify the softmax layer in the deep learning model, which used Weibull-based calibration to weight the classification scores and add a new score for the unknown class. Generative and adversarial methods [
26,
27,
28], auto-encoder and its variants [
29,
30] were also reported to model the features of the unlabeled data. Besides such general methods, there were also schemes specially designed for open set recognition [
31,
32]. These methods usually required specifically designed network structures or learning schemes, and were primarily focused on nature images. As far as we know, until now, the open set recognition problem, especially on radar signal data, is still a challenging task which has not been sufficiently studied.
In this paper, we propose a deep learning-based scheme for open set human identification from radar signals, and consider human identification as a classification problem. The radar signal sequences are preprocessed and divided into fixed length samples for training. We represent each radar signal sample as a point in the proposed feature space, so that the samples from unknown sequences can be distinguished from those from the labeled sequences.
The rest of this paper is organized as follows. In
Section 2, we explain the details of the proposed identification scheme. In
Section 3, we discuss the performance of the proposed method by comparing with state of the art methods. In
Section 4, we discuss the implementation in detail and the robustness performance. And the conclusion is in
Section 5.
2. Materials and Methods
2.1. Identification Scheme
In this section, we will describe our proposed human identification scheme in detail. The overall structure of the scheme is briefly illustrated in
Figure 1.
The training process is illustrated with the blue lines. The radar sequences are processed and divided into sample sets which will be described in detail in
Section 2.2, and fed into deep convolution network for close set classification. Along with the probability distribution vector, we also extract the input to the last Dense N layer as interested feature vectors, and generate a Principal Component Space (PCS). Each radar sequence will be represented as a point cloud in this space. When a new unlabeled sequence is acquired, the labeling process follows the red lines. The sequence is preprocessed and fed into the trained network to extract the feature vectors. The feature vectors are then projected into PCS to generate the point cloud representation. We compare the features of the point cloud of the unlabeled sequence with those of the labeled sequences, and decide whether it is an unknown sequence. If the features of the unlabeled sequence agrees with one of the training sequences, the Dense N and softmax layer gives out the probability distribution and the corresponding label is assigned as a normal classification network. Otherwise, one category of the training sequences is replaced with the unknown sequence, then the network is retrained and PCS is updated. Repeating such cycles with acquired sequences, the network can be gradually customized by the user data.
2.2. Data Processing and Data Set Composition
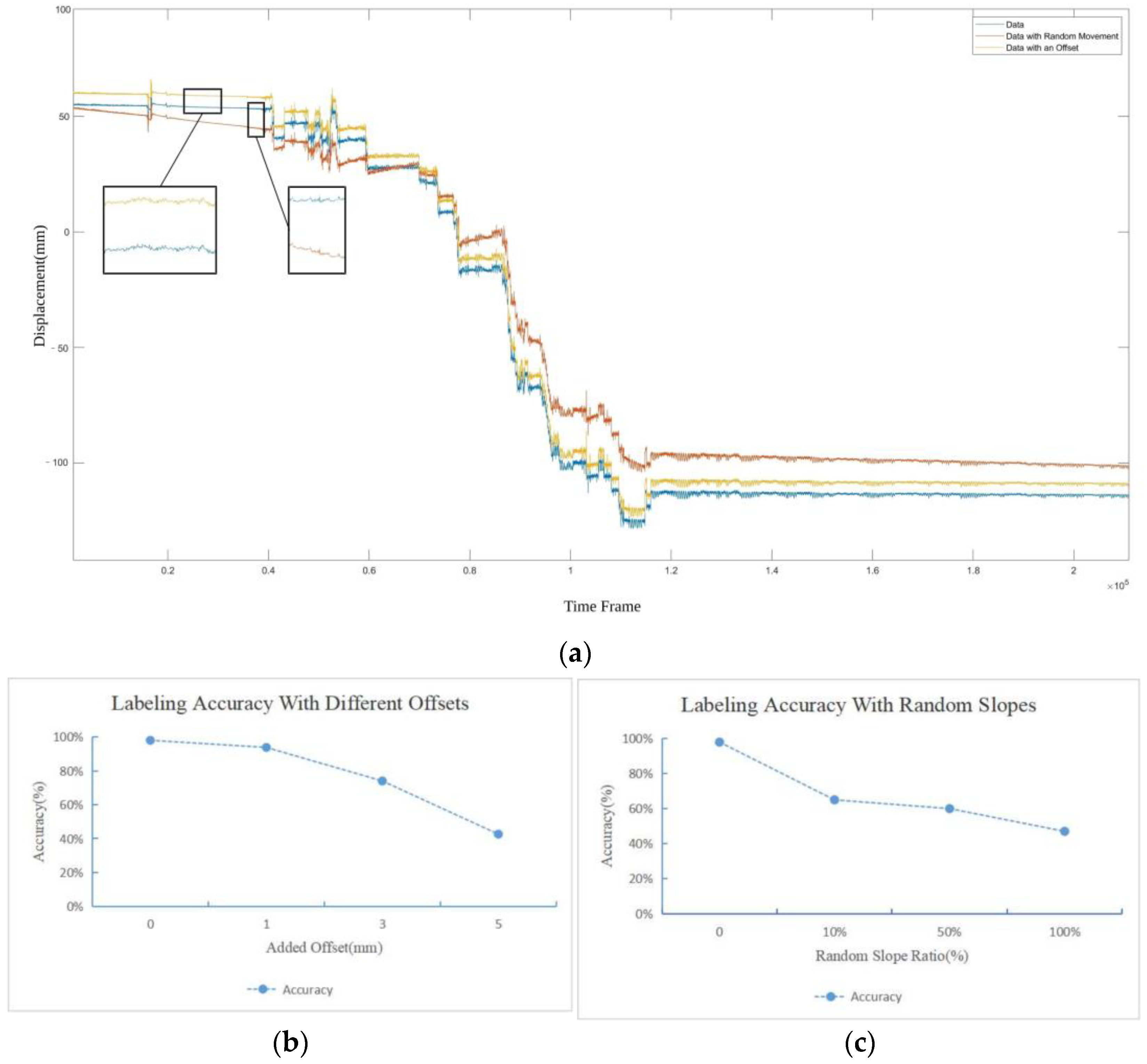
A typical radar signal sequence is shown in
Figure 2a, which is a time sequence showing the obstacle movement relative to the radar device. Each sequence records the movement of the human body continuously in a time period about several tens of minutes. An id is assigned to each sequence to distinguish different person in the acquisition procedure.
We can see that the sequence contains static baseline shift, representing the distance between person and the radar, and linear slopes which suggest position change process of human body relative to the device during data acquisition. It also contains small periodical fluctuations representing the unconscious movement of the human body, such as respiration and heartbeat. We introduce a PELT [
33]-based change point detection method to divide the sequence into segments according to the change points of slopes, and apply a linear fitting for each segment which is then subtracted from the original sequence to eliminate the large linear components. A typical result is shown in
Figure 2a, and detailed comparisons of sequences before and after the baseline shift and slope suppression are provided in
Figure 2b,c. The impact of changes in the data acquisition environment is suppressed, and only the relatively weak motion is left, which represents the signature of the detected person.
After the preprocessing step, the sequence shows approximately periodical fluctuations without baseline shift and large scale slopes, representing a learnable mixed pattern of respiration and heartbeat. To form the data sets, we divide the preprocessed sequences into fixed-length samples, and assign each sample a label by the id of the corresponding sequence. The length of the samples should be properly chosen. A too small sample length may not cover a complete period of the sequences, undermining the integrity of the signal features, while a too long sample length will require more GPU memory, and may affect real time performance. A trade off should be made between accuracy and efficiency, and the choice of sample length will be discussed in
Section 4.1.
2.3. Deep Learning Model Summary
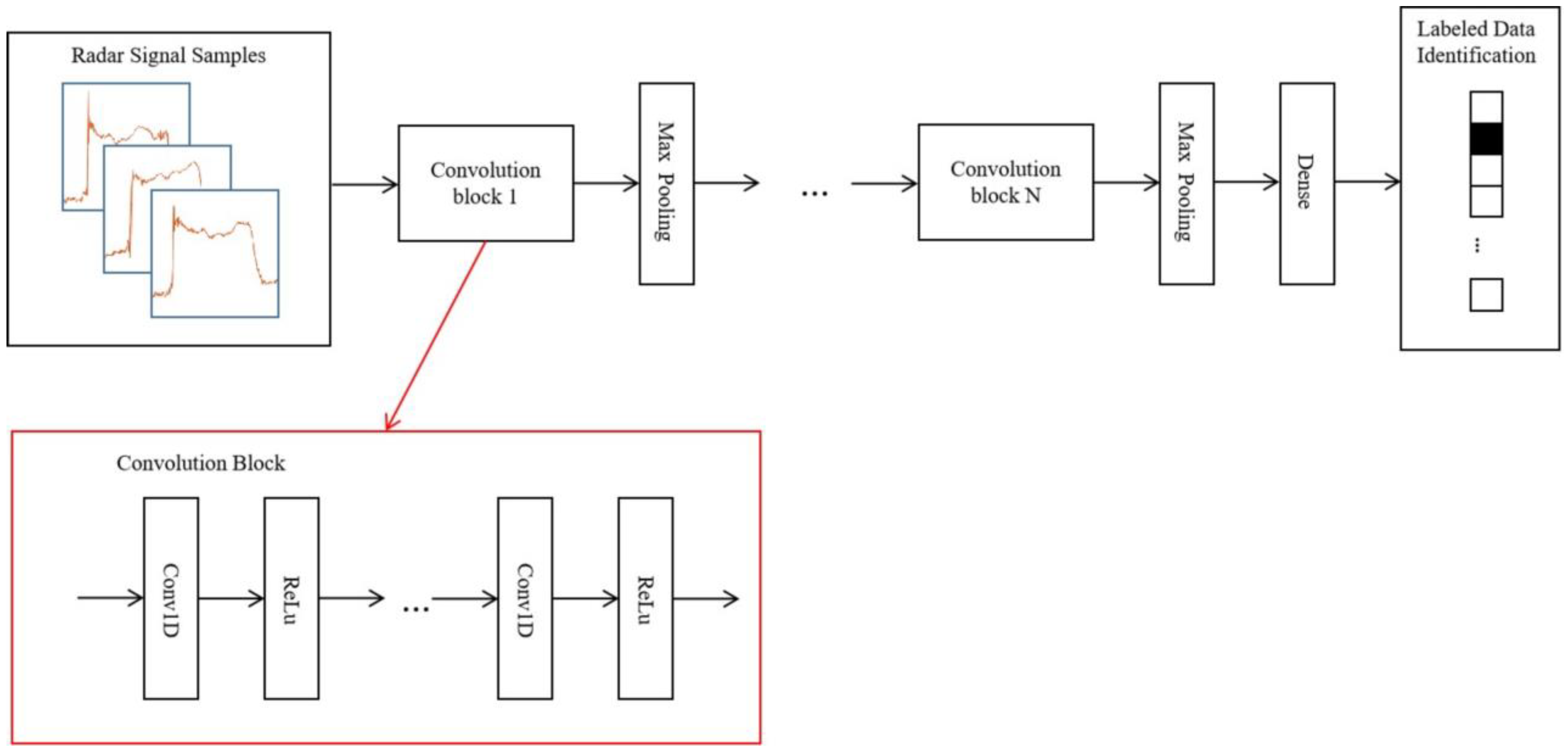
The details of the convolution neural network in
Figure 1 is shown in
Figure 3. The network is composed of 3 sequential convolution blocks, each containing 2 repeated one-dimensional convolution layers followed by a ReLu activation layer. Between convolution blocks, max pooling layers are used for down sampling. As the depth of the blocks increases, we gradually increase the number of convolution layer channels in the blocks, and decrease the size of the convolution kernel. The numbers of filters of the repeated convolution layer in each block are 32, 64, and 128, respectively. The kernel sizes in each block are 7, 5, and 3, respectively. The number of strides is 1. The kernel size of the max pooling layer is 3. A dense 128 layer is used to generate the classification probability distribution from the features extracted by convolution blocks.
2.4. Unknown Detection and Principal Component Representation
We utilize the features extracted by the close set classification network as a criterion for unknown sample detection.
After the close set classification training is completed, the samples in the training data sets are fed into the network. The input tensors to the last dense layer are extracted to form the key feature sets where , , and is the number of the persons in the training data sets. is the size of the training data set with label , is the size of the features.
We apply PCA to the key feature sets, and obtain the principal components
where
, which forms the basis of a space describing the key feature sets, which we define as PCS. An arbitrary feature
of the sample
in the training data sets can be represented as a d-dimension point in PCS
, where
We cluster the points by their respective label, and calculate the mean and standard variance , which describe the statistics index of the labeled data sets in PCS representation. For an unlabeled sequence, we follow the same procedure, and feed an arbitrary sample to the network to generate the feature . We describe the feature as a point in PCS as according to Equation (1). If does not follow the PCS statistics index of any labeled data sets, we mark the sample as an unknown sample. Otherwise, the dense N and softmax layer continues to give out the probability distribution and one-hot vector as the normal classification network does.
The advantage of the proposed unknown detection method is that it makes full use of the byproduct of the classification network. The unknown sample detection and normal sample labeling are completed simultaneously, requiring no additional specifically designed network structures or extra learning schemes to capture the feature difference between the unknown and the labeled data.
3. Experiment and Results
3.1. Experiment Setup and Implementation Details
The data we used to test the proposed method in this paper come from two sources.
The first source is the public Schellenberg data set [
34] of clinically recorded data which contains vital signs measured through radar and the synchronized reference sensor. The radar system used in this data set is based on Six-Port technology and operates at 24 GHz in the Industrial Scientific Medical (ISM) frequency band. It monitored 30 healthy volunteers in the following scenarios: Resting, Valsalva Maneuver (VM), Apnea, and Tilt Table Up and Down. For each volunteer, each scenario was measured for about 10 min. A positioning laser is used to align the antenna with the interested region. Meanwhile, a Task Force Monitor (TFM) is used as the reference device to measure the electrocardiogram, impedance cardiogram, and non-invasive continuous blood pressure. An image cited from the literature [
31] shows the data acquisition setup in
Figure 4a. In this study, we are primarily interested in the human identification in stationary states; therefore, we randomly selected 10 sequences of the cardiac radar data in the resting scenario from this public data set for subsequent experiments.
The second source is an experimentally acquired data set in our lab with a millimeter wave radar operated in Frequency Modulated Continuous Wave (FMCW) mode. The device working parameters are listed in
Table 1. The radar device is placed on the nightstand table, with a tilted downward position, which ensured the torso is in the boresight of the radar. Currently, there is no specific orientation and position requirements of the device. We will investigate the influence of device position and orientation in our future work. We monitored the radar signal data of four volunteers in a sleeping state. The volunteers are asked to remain in a stationary supine posture, for about 40 min. In this experiment, no laser positioning is used. Informed consent was obtained from all the volunteers. The experimental procedure for data acquisition and utilization in this research has been approved by the ethics committee of Shenzhen Institute of Advanced Technology, Chinese Academy of Sciences. The committee reference number is SIAT-IRB-231011-H0675. This data set simulates a daily home-monitoring scenario, where the ideal data acquisition setup of the Schellenberg data set is not applicable.
Figure 4b shows a typical data acquisition environment setup.
The proposed deep learning method is implemented with PyTorch on an NVIDIA GeForce RTX 3060 GPU. We choose the Adam optimizer to minimize the cross entropy. We introduce a learning rate decay schedule; the learning rate is reduced by 0.5 times when the metric stops improving.
3.2. Identification Accuracy
To test the performance of the proposed human identification network, we randomly select 20% samples from each sequence to form a test subset, and use the remaining samples to train the deep learning model with a validation split ratio of 0.1. Then, we have the training, validation, testing distribution to be 72:8:20. For the public data set, we randomly choose the data of 10 volunteers. When we choose the sample length of 2 s, the number of total samples of each volunteer is 300, as a typical sequence is about 10 min long. For experimentally acquired data sets, the data of four volunteers are used. Similarly, the number of total samples of each volunteer is set to 1000. We evaluate the classification accuracy by the confusion matrices, and compare the performance of our proposed network with state-of-the-art deep learning techniques.
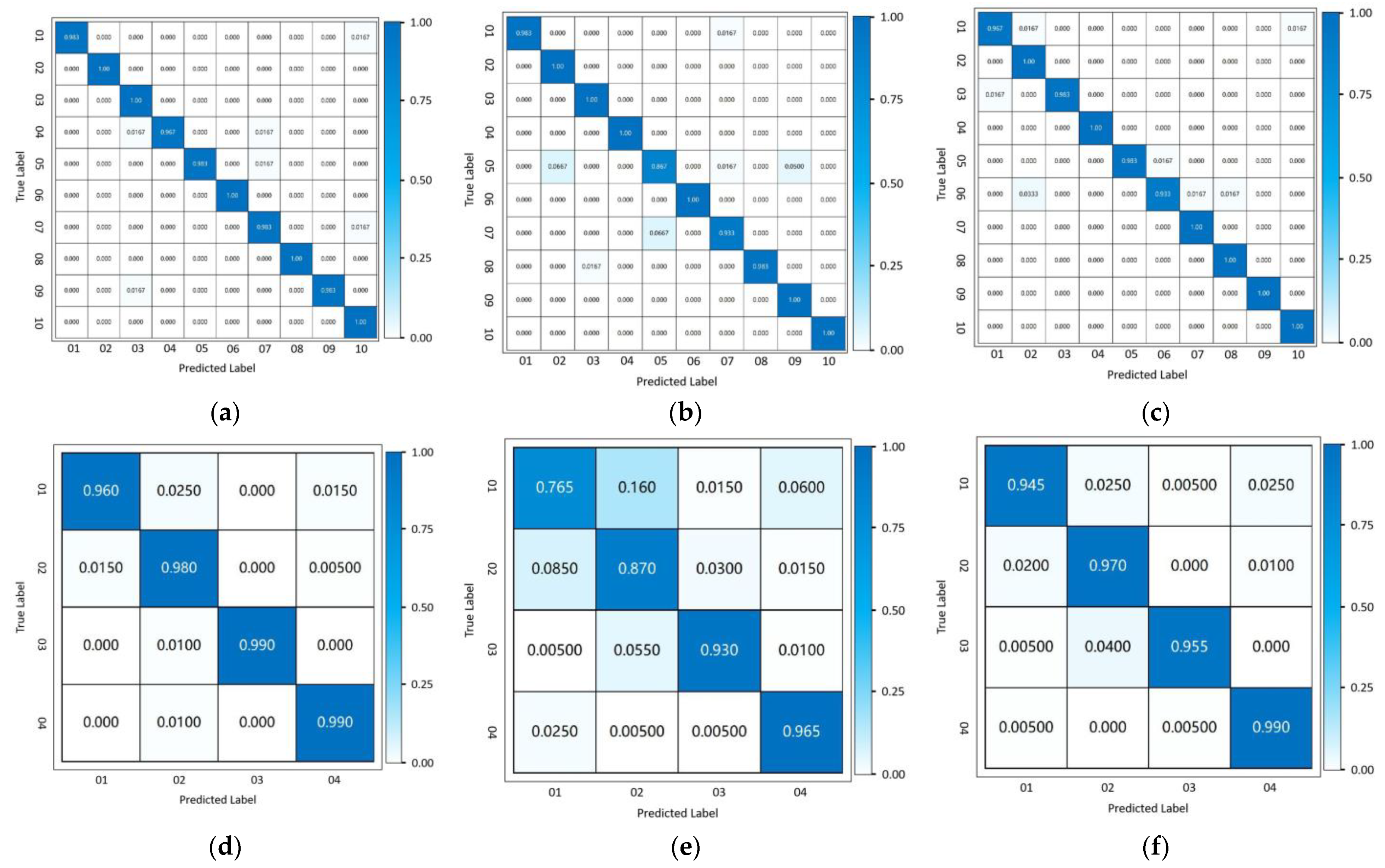
We show the identification accuracy of our proposed method by the typical confusion matrices shown in
Figure 5. For the public data set and the experimentally acquired data set, the average labeling accuracy reaches 98.2% and 96.8%, respectively.
We also compare the proposed method with other machine learning techniques, such as the LSTM-based classification network and Inception Network specially designed for time sequence classification tasks as proposed in [
35]. The Inception Network applies multiple filters with varying length simultaneously to the input time series, which can automatically capture the features from both long and short time series. For the public data set, the LSTM classification network achieves 97.6% labeling accuracy, and the Inception Network achieves 97.5% labeling accuracy, respectively. For the experimentally acquired data set, the LSTM achieves 90.2% labeling accuracy and the Inception Network achieves 96.5% labeling accuracy, respectively. We also show typical result confusion matrices in
Figure 5.
For the public data set, the labeling accuracy of the three methods is of the same level. For the experimentally acquired data set, since the data acquisition conditions are not as ideal as the public data set, the labeling accuracy of the LSTM classification network falls significantly, while the labeling accuracy of the two convolution-based methods (our proposed method and Inception Network) is affected less. Therefore, we conclude that the labeling accuracy of our proposed method outperforms the LSTM-based classification method, and achieves an equivalent level of accuracy with the Inception Network. However, the parameter size of our proposed method is obviously smaller than the Inception Network with less calculation time, as shown in
Figure 6. We can also see that although, when dealing with more complex data with less obvious periodical patterns, the performance of LSTM classification network is lower as compared with convolution-based methods, the parameter size is also significantly smaller with a higher calculation efficiency, which suggests potential advantages in scenarios with high real-time requirements.
3.3. Unknown Sequence Detection Accuracy
To test the detection of unknown samples, we randomly select one sequence as the unknown sequence, and use the remaining sequences as labeled sequences to generate the labeled data sets to train the network and generate the PCS representation. The training data set, validation data set and the test subset are split with the same ratio (72:8:20) as the close set human identification problem mentioned in
Section 3.2. The samples of the unknown sequences and the test subset are mixed to form the unknown test sample set, so that we can evaluate how our proposed unknown detection method works while preserving the feature recognition of the labeled sequences. When the training process completed, we feed the unknown test sample set to the network, express the samples as points in the PCS representation, and assign the “unknown” or “labeled” label according to the criterion described in
Section 2.4.
To examine how the unknown samples can be distinguished from the labeled data, under the principal component representation, we define four statuses to describe the unknown detection result. If an arbitrary sample from the unknown sequence is detected as ‘unknown’, it is defined as True Positive (
TP); otherwise, it is defined as False Negative (
FN). If an arbitrary sample from the labeled sequences is detected as ‘labeled’, it is defined as True Negative (
TN); otherwise, it is defined as False Positive (
FP). The metrics to evaluate the unknown detection accuracy are given as follows:
The accuracy shows the general labeling accuracy of the entire unknown test data set. The precision evaluates, among all the samples detected as “unknown”, how many of them are actually from the unknown sequence, and how many of them are falsely marked “unknown” ones. A higher precision shows better ability to distinguish the feature difference between unknown and labeled sequences. The recall evaluates how many of the actual unknown samples are accurately detected. A higher recall shows better ability to detect the unknown sequences. The FPR evaluates how many of the labeled samples are inaccurately marked as unknown samples. A smaller FPR shows better ability to recognize the labeled sequences. The F1 score is used to balance the precision and recall when the class distribution is unbalanced.
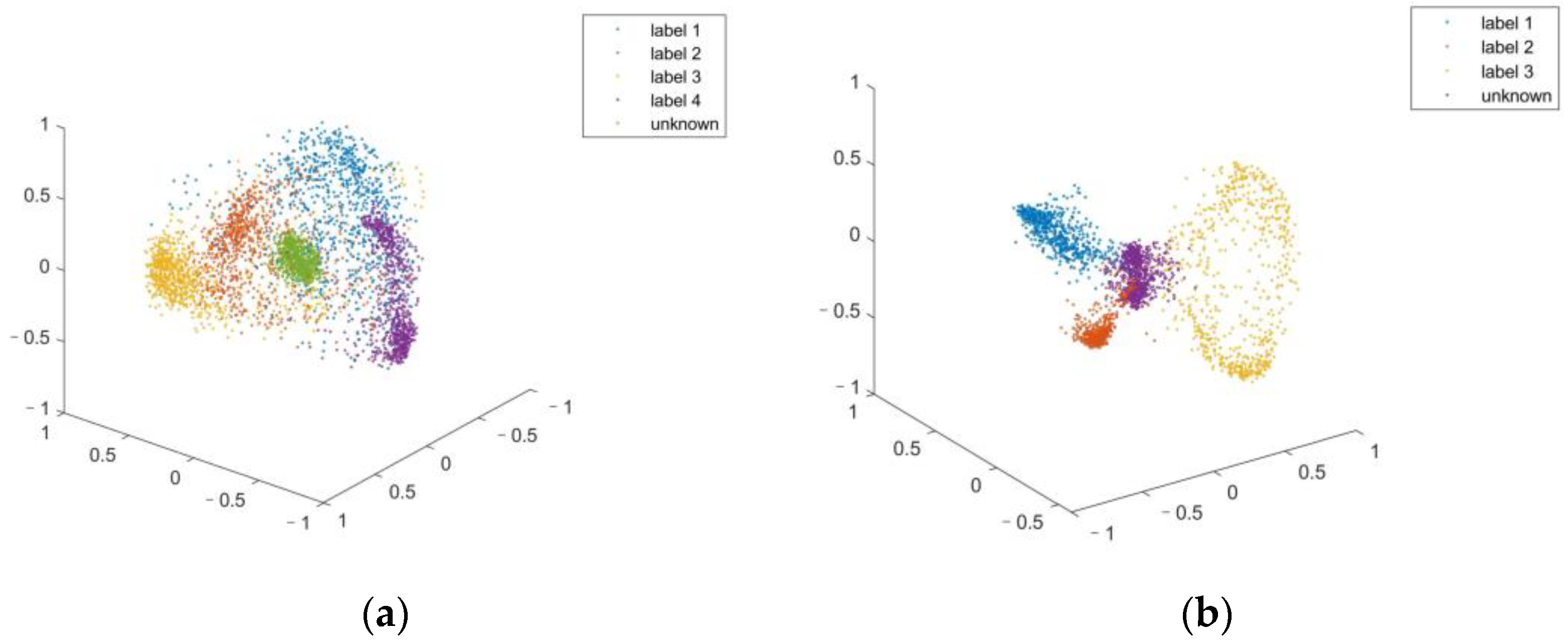
For visualization purposes, we use the first three principal components to show the feature distribution of the labeled and unknown samples in
Figure 7. It can be seen that although only 85% of the total variance is utilized, the distribution of the point clouds still shows an apparent difference in the PCS.
The accuracy of the unknown data detection is shown in
Table 2. We report the recall to be about 100%, which suggests almost all the unknown samples are correctly marked. A very small FPR and high precision suggests that there is very little part of the labeled samples inaccurately marked as unknown. Since the sample set is generated from a continuous time sequence, occasional sample detection error can be filtered out in time domain; therefore, it will not affect the final decision of unknown data detection. In the future, we will explore a detailed motion-tracking and time domain-filtering scheme to further improve the robustness of unknown detection scheme.
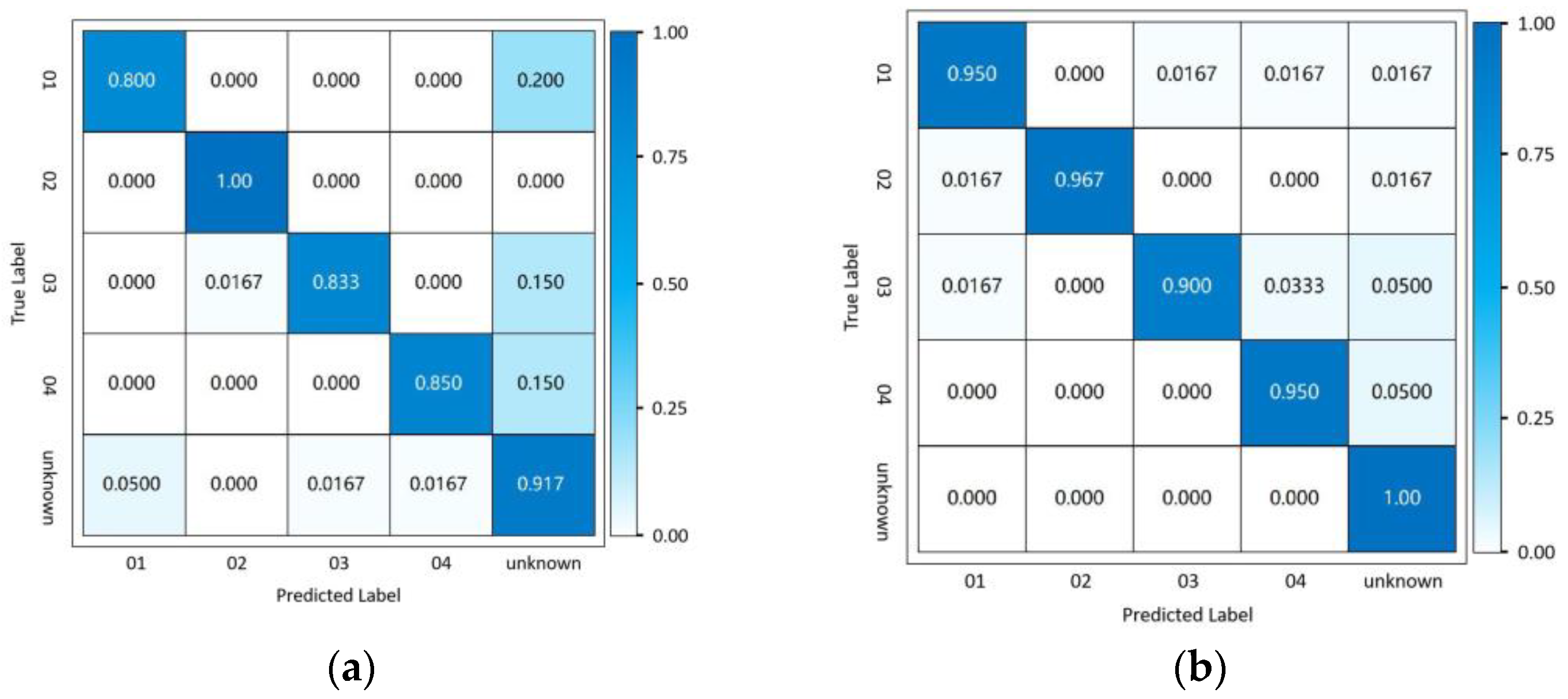
We compare our method with the widely applied open set recognition method—OpenMax. OpenMax is based on the Extreme Value Theory to incorporate likelihood of the recognition system failure, by fitting a Weibull distribution to the samples of each known class, and to correct the known class score and calculate an unknown class score by the probability of classification failure. When the maximum classification probability is obtained in the unknown class or the maximum classification probability is less than a certain threshold, the unknown class is recognized. As a widely applied open set recognition method, OpenMax is an extension of the existing classification network, and does not require extra specifically designed network structures or additional learning schemes.
We report that the detection rate of unknown samples by OpenMax is around 90%, but we also notice that this method affects the accuracy of close-set human identification. The average identification accuracy falls to around 87.0%.
The correction procedure of OpenMax changes the information extracted from the deep learning model; therefore, the identification accuracy might be affected. OpenMax does not improve the feature representation, and the fitting criterion is a handcrafted function which is not involved in the training; therefore, it might not always fit the right distribution of the feature space. Therefore, it may be more difficult to distinguish the unknown samples from the labeled ones when the features are more complicated. Meanwhile, our proposed method utilizes the features extracted by the network to generate the Principal Component Space. When the features are mapped into the generated space, the difference of distributions is improved, while the information extracted by the network is maintained.
Therefore, we conclude that although OpenMax has been proved promising for natural images, when applied to a time series such as the radar sequences, the performance may not be as accurate and robust.
Figure 8 shows a typical confusion matrix comparison.
5. Conclusions
In this paper, we propose a novel deep learning-based scheme for human identification using radar sequences. In addition to employing traditional close-set classification methods, we extract input tensors to the final dense-N layer as a feature of interest, introducing a Principal Component Space presentation. In the Principal Component Space, the radar sequence features can be represented as point clouds, and the feature difference among labeled sequences and the unknown sequence can be distinguished.
We use the public Schellenberg data set and a data set experimentally acquired in our lab to validate our proposed method. We compared our proposed method with state-of-the-art deep learning methods. Compared with LSTM network, our proposed approach demonstrates superior accuracy and robustness. Compared with the Inception Network, another convolution based state-of-the-art method, our proposed approach achieved an equivalent level of accuracy with less computation time and fewer parameters. This suggests that our proposed approach outperforms the state-of-the-art time series classification techniques in performance and efficiency, as well as notable robustness under different experiment conditions.
The proposed unknown detection scheme enhanced the feature representation of the samples, and is proved be more effective than the traditional open set classification methods such as OpenMax in distinguishing the unknown samples from the labeled ones in the time series classification problem. An additional advantage of our proposed method is that the classification and unknown detection are completed simultaneously, requiring no additional specific network structures or learning schemes.
The proposed method exhibits promising potential for future applications of non-contact sleep monitoring using millimeter wave radar.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}