

Self-FI: Self-Supervised Learning for Disease Diagnosis in Fundus Images


 , , ,
, , ,
Abstract
:
1. Introduction
- We demonstrate that our self-supervised learning method outperforms conventional supervised learning in UFI classification, achieving unrivaled results with an AUC score of 86.96. This underlines the potential of self-supervised learning as an effective instrument for medical image analysis, especially in contexts where labeled data are either scarce or prohibitively expensive to procure.
- We propose a novel contrastive learning technique that employs a new loss function, thereby enhancing the quality of the learned representations. Our approach draws upon both intra- and inter-image correlations to derive a feature space that is optimally suited for UFI classification. We substantiate the effectiveness of our method through a series of experiments and validations, including an examination of learned feature maps and an assessment of different hyperparameters.
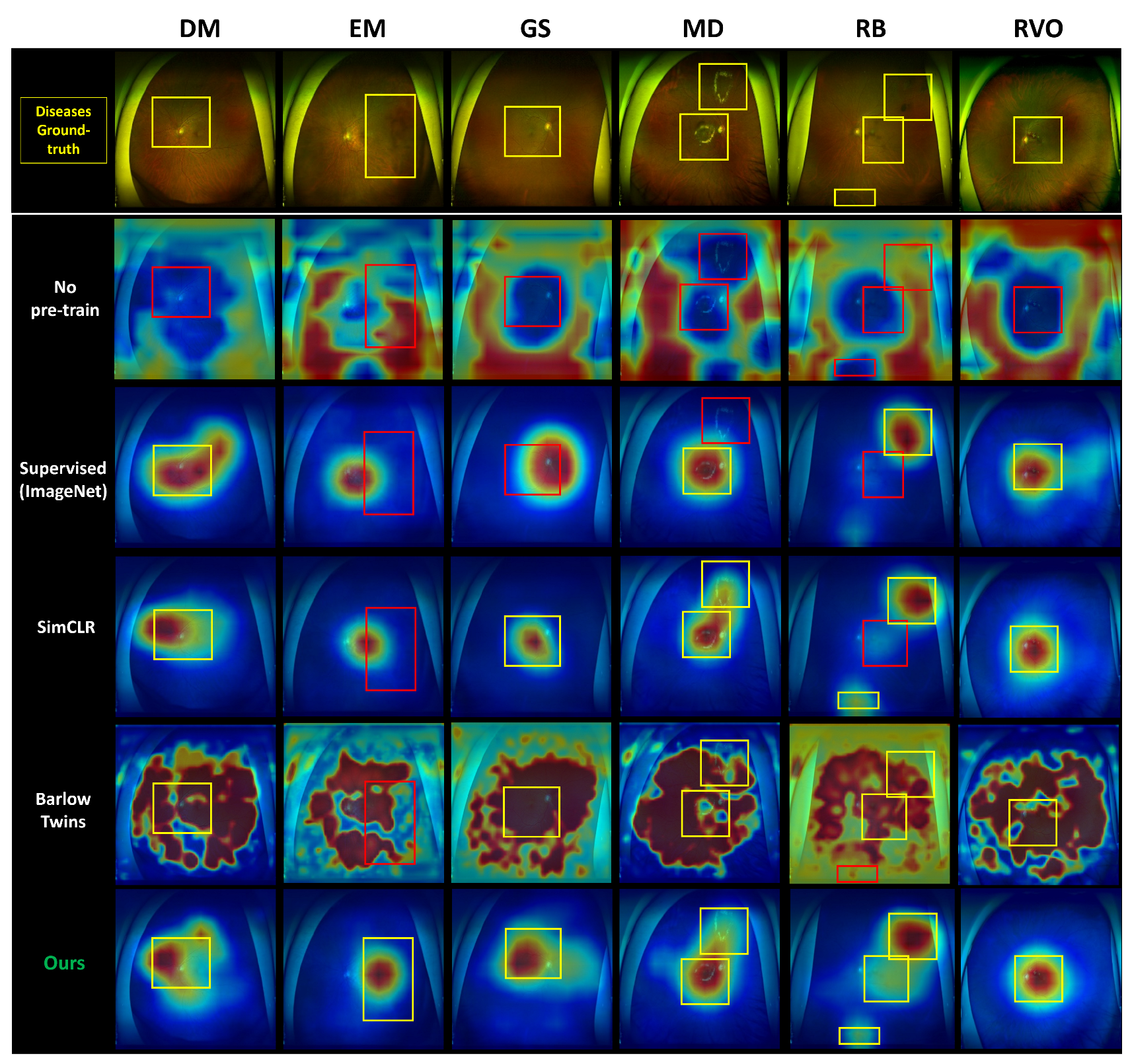
- We offer comprehensive heatmaps of our models for each of the six diseases encompassed in our dataset using GradCAM [23]. This provides an in-depth insight into the model’s focus on each disease. We validate our model by juxtaposing it against a range of other methodologies, including supervised learning and transfer learning from preexisting models. Our proposed model outperforms these comparative methods, emphasizing the crucial role of self-supervised learning in medical image analysis.
- Our work signifies a significant leap forward in the application of self-supervised learning for disease diagnosis in retinal fundus images. By harnessing the capabilities of contrastive learning and our innovative loss function, we demonstrate the feasibility of achieving state-of-the-art results with a limited quantity of labeled data. Our approach presents a novel pathway for medical practitioners to diagnose patients efficiently and accurately, thereby enhancing patient outcomes and the overall quality of care.
2. Materials and Methods
2.1. Dataset
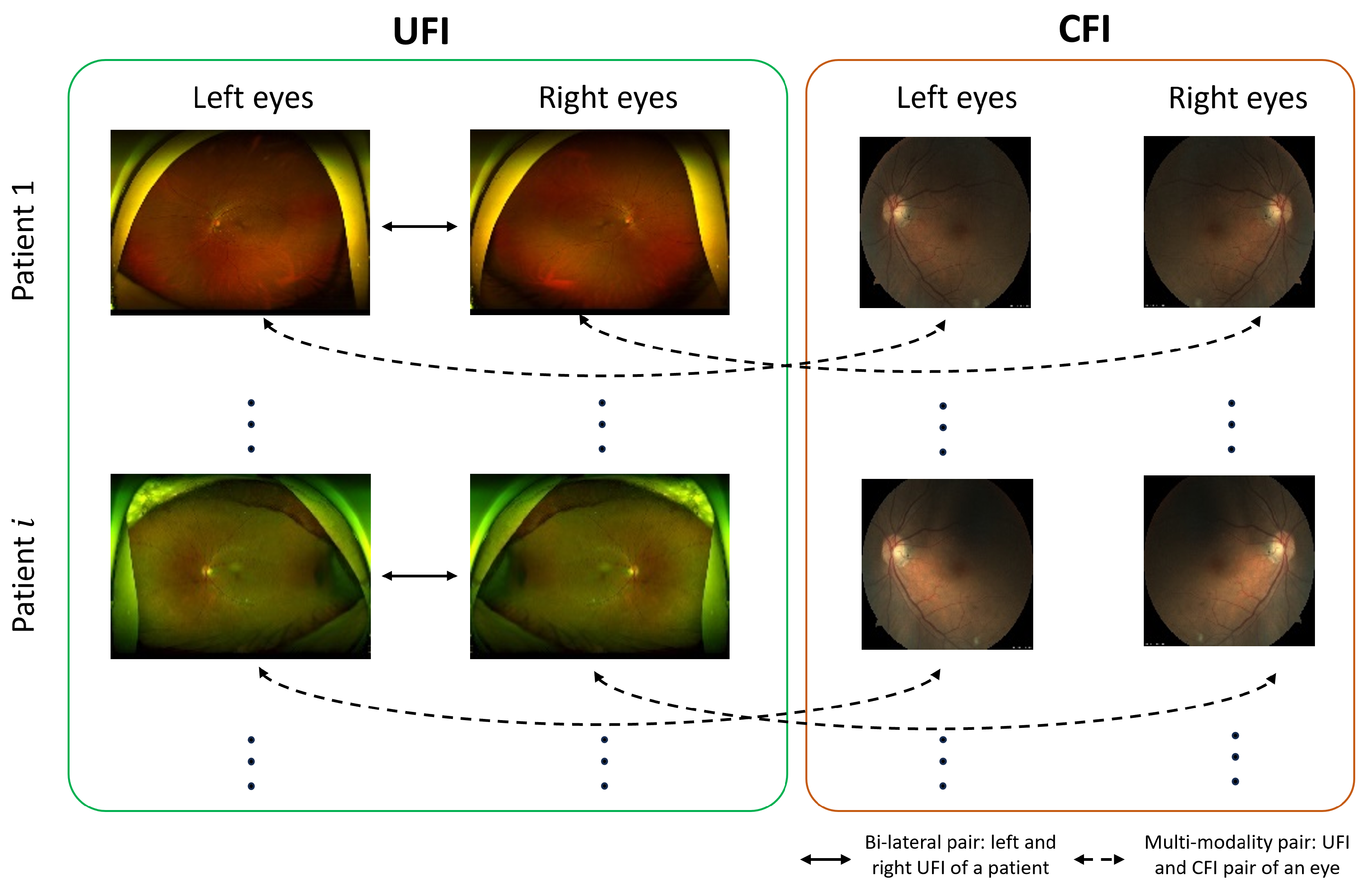
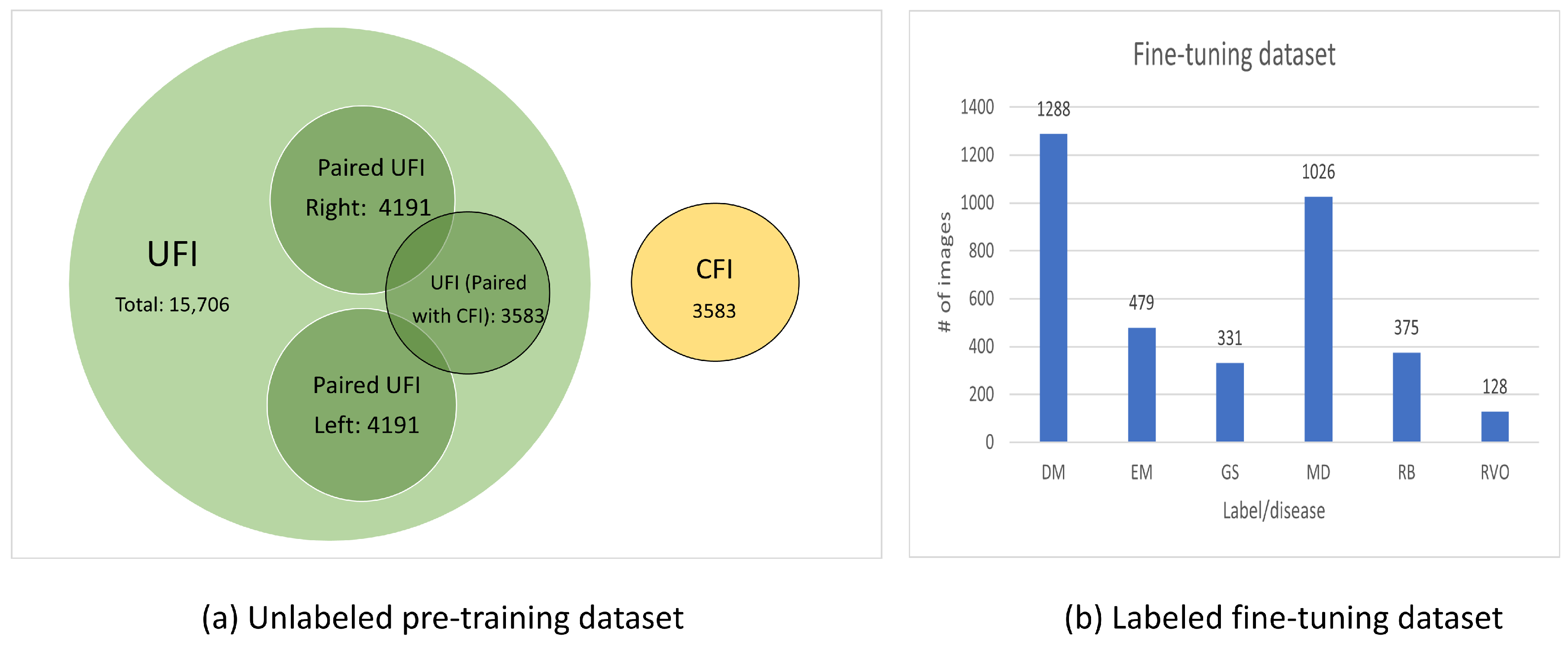
- UFI unlabeled: The UFI unlabeled subset is a diverse collection of 15,706 ultra-wide-field fundus images, including UFI images from UFI Left–Right and UFI–CFI Pair. Without any specific annotations, these images span across a variety of eye conditions and also include images of healthy eyes. This collection is an invaluable asset for self-supervised and unsupervised learning approaches.
- UFI Left–Right: Comprising 8382 fundus images of various eye conditions and healthy eyes, the UFI Left–Right pair dataset is specifically assembled to assist tasks that require data in pairs, such as stereo image matching. Each image in this set has a corresponding left and right pair.
- UFI–CFI: The UFI–CFI pair subset consists of 7166 fundus images, incorporating both ultra-wide-field fundus images (UFI) and conventional fundus images (CFI). Created to explore the benefits of multi-modality pre-training through self-supervised learning, this set spans across all diseases and healthy eye conditions, thereby serving as a rich resource for disease diagnostic research.
- UFI Labeled: The UFI labeled subset is a curated collection of ultra-wide-field fundus images, annotated by a team of experienced ophthalmologists, and consists a total of 3285 images. Primarily intended for supervised learning approaches that require labeled data for training, these annotations offer vital details about the presence and severity of various eye diseases, including diabetic retinopathy, age-related macular degeneration, and glaucoma.
2.2. Methodology
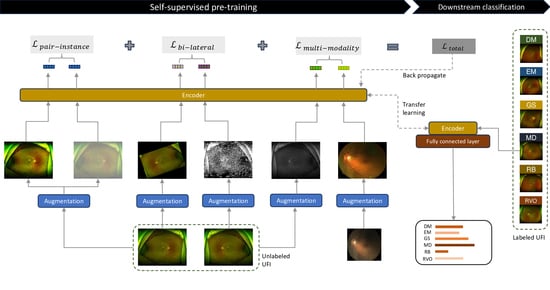
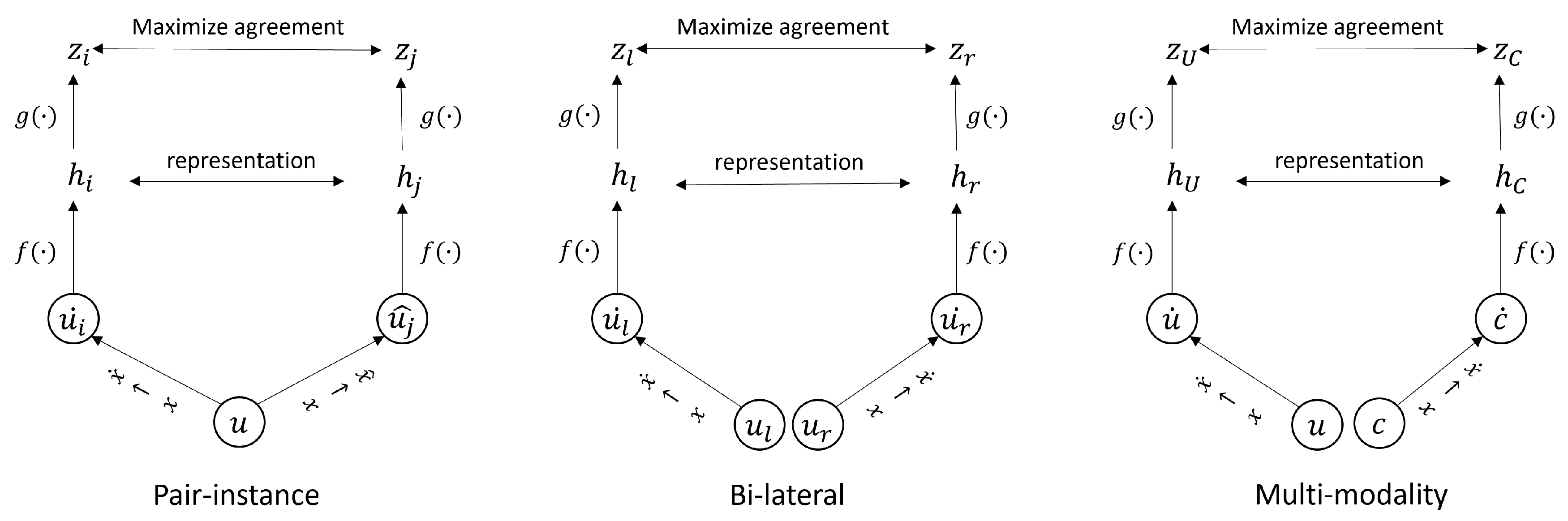
2.2.1. Pair-Instance Pre-Training
2.2.2. Bi-Lateral Pre-Training
2.2.3. Multi-Modality Pre-Training
2.2.4. Self-FI: Self-Supervised Learning Model on Retinal Fundus Images for Disease Diagnosis
| Algorithm 1: Proposed contrastive learning methods. |
 |
2.3. Implementation Settings
2.4. Measurements Metrics
3. Results
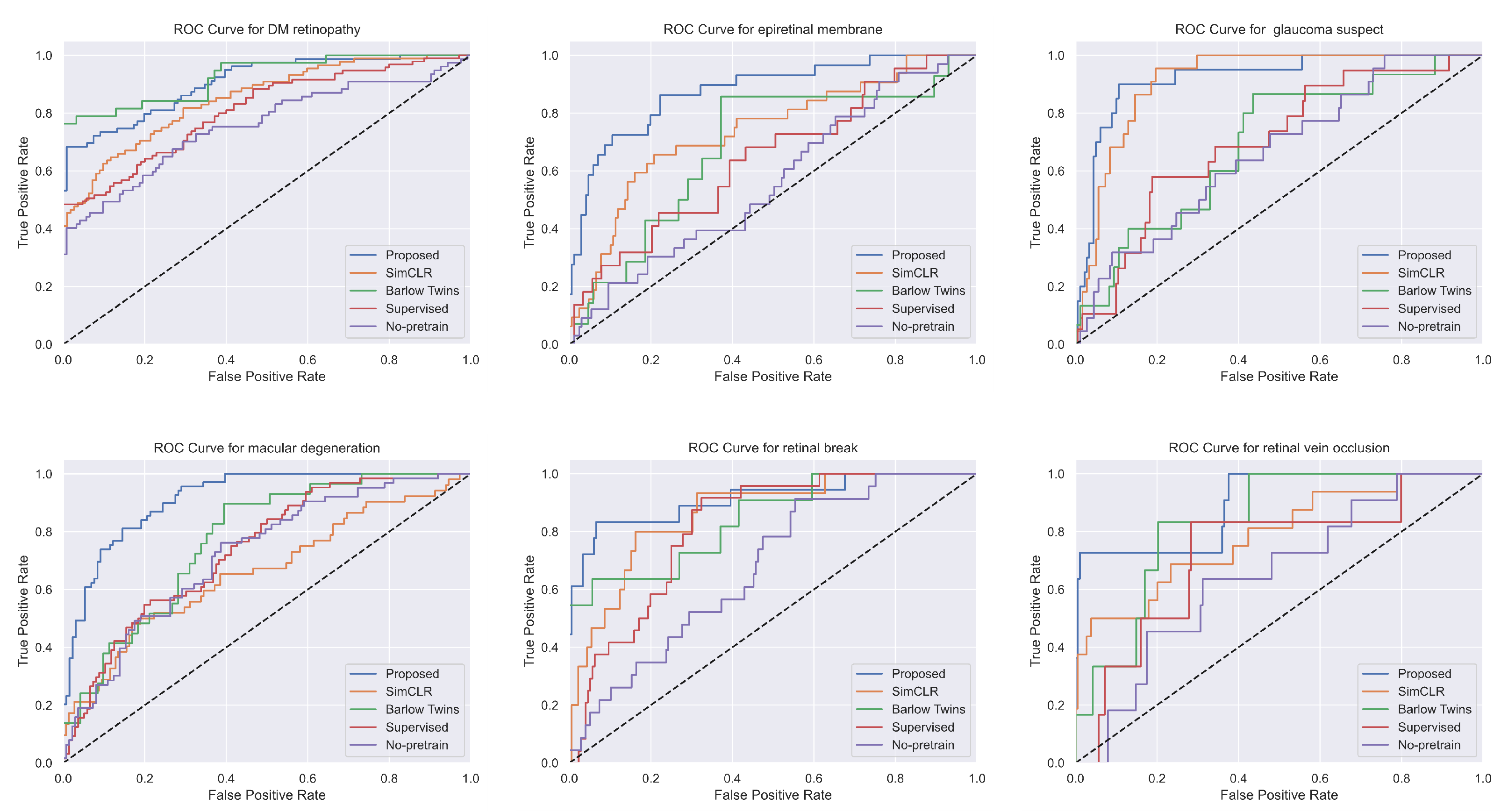
3.1. Comparison with Other Methods
3.2. Ablation Study
3.3. Contribution of Each Pairing Method on the Improvement of the Performance
4. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Sun, C.; Shrivastava, A.; Singh, S.; Gupta, A. Revisiting unreasonable effectiveness of data in deep learning era. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 843–852. [Google Scholar]
- Chartrand, G.; Cheng, P.M.; Vorontsov, E.; Drozdzal, M.; Turcotte, S.; Pal, C.J.; Kadoury, S.; Tang, A. Deep learning: A primer for radiologists. Radiographics 2017, 37, 2113–2131. [Google Scholar] [CrossRef] [PubMed]
- Jing, L.; Tian, Y. Self-supervised visual feature learning with deep neural networks: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 4037–4058. [Google Scholar] [CrossRef] [PubMed]
- Zhu, J.; Li, Y.; Ding, L.; Zhou, S.K. Aggregative Self-supervised Feature Learning from Limited Medical Images. In Medical Image Computing and Computer Assisted Intervention—MICCAI 2022, Proceedings of the 25th International Conference, Singapore, 18–22 September 2022; Proceedings, Part VIII; Springer Nature: Cham, Switzerland, 2006; pp. 57–66. [Google Scholar]
- Koohbanani, N.A.; Unnikrishnan, B.; Khurram, S.A.; Krishnaswamy, P.; Rajpoot, N. Self-path: Self-supervision for classification of pathology images with limited annotations. IEEE Trans. Med. Imaging 2021, 40, 2845–2856. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 9729–9738. [Google Scholar]
- Xu, J. A review of self-supervised learning methods in the field of medical image analysis. Int. J. Image, Graph. Signal Process. (IJIGSP) 2021, 13, 33–46. [Google Scholar] [CrossRef]
- Ahn, S.; Pham, Q.T.; Shin, J.; Song, S.J. Future image synthesis for diabetic retinopathy based on the lesion occurrence probability. Electronics 2021, 10, 726. [Google Scholar] [CrossRef]
- Lee, J.; Lee, J.; Cho, S.; Song, J.; Lee, M.; Kim, S.H.; Lee, J.Y.; Shin, D.H.; Kim, J.M.; Bae, J.H.; et al. Development of decision support software for deep learning-based automated retinal disease screening using relatively limited fundus photograph data. Electronics 2021, 10, 163. [Google Scholar] [CrossRef]
- Tan, C.S.; Chew, M.C.; van Hemert, J.; Singer, M.A.; Bell, D.; Sadda, S.R. Measuring the precise area of peripheral retinal non-perfusion using ultra-widefield imaging and its correlation with the ischaemic index. Br. J. Ophthalmol. 2016, 100, 235–239. [Google Scholar] [CrossRef] [PubMed]
- Witmer, M.T.; Parlitsis, G.; Patel, S.; Kiss, S. Comparison of ultra-widefield fluorescein angiography with the Heidelberg Spectralis® noncontact ultra-widefield module versus the Optos® Optomap®. Clin. Ophthalmol. 2013, 7, 389–394. [Google Scholar] [CrossRef] [PubMed]
- Silva, P.S.; Cavallerano, J.D.; Haddad, N.M.; Kwak, H.; Dyer, K.H.; Omar, A.F.; Shikari, H.; Aiello, L.M.; Sun, J.K.; Aiello, L.P. Peripheral lesions identified on ultrawide field imaging predict increased risk of diabetic retinopathy progression over 4 years. Ophthalmology 2015, 122, 949–956. [Google Scholar] [CrossRef] [PubMed]
- Ting, D.S.W.; Pasquale, L.R.; Peng, L.; Campbell, J.P.; Lee, A.Y.; Raman, R.; Tan, G.S.W.; Schmetterer, L.; Keane, P.A.; Wong, T.Y. Artificial intelligence and deep learning in ophthalmology. Br. J. Ophthalmol. 2019, 103, 167–175. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Q.; Zou, H.; Wang, Z. Long-Tailed Multi-label Retinal Diseases Recognition via Relational Learning and Knowledge Distillation. In Medical Image Computing and Computer Assisted Intervention—MICCAI 2022, Proceedings of the 25th International Conference, Singapore, 18–22 September 2022; Proceedings, Part II; Springer Nature: Cham, Switzerland, 2022; pp. 709–718. [Google Scholar]
- Zhuang, F.; Qi, Z.; Duan, K.; Xi, D.; Zhu, Y.; Zhu, H.; He, Q. A comprehensive survey on transfer learning. Proc. IEEE 2019, 109, 43–76. [Google Scholar] [CrossRef]
- Oord, A.V.D.; Li, Y.; Vinyals, O. Representation learning with contrastive predictive coding. arXiv 2018, arXiv:1807.03748. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. In Proceedings of the 37th International Conference on Machine Learning, Virtual, 13–18 July 2020. [Google Scholar]
- Cubuk, E.D.; Zoph, B.; Mane, D.; Vasudevan, V.; Le, Q.V. Autoaugment: Learning augmentation strategies from data. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 113–123. [Google Scholar]
- Jiang, Z.; Zhang, H.; Wang, Y.; Ko, S.B. Retinal blood vessel segmentation using fully convolutional network with transfer learning. Comput. Med. Imaging Graph. 2018, 68, 1–15. [Google Scholar] [CrossRef] [PubMed]
- Mahapatra, D.; Ge, Z. Training data independent image registration with gans using transfer learning and segmentation information. In Proceedings of the IEEE 16th International Symposium on Biomedical Imaging (ISBI 2019), Venice, Italy, 8–11 April 2019; pp. 709–713. [Google Scholar]
- Oh, K.; Kang, H.M.; Leem, D.; Lee, H.; Seo, K.Y.; Yoon, S. Early detection of diabetic retinopathy based on deep learning and ultra-wide-field fundus images. Sci. Rep. 2021, 11, 1897. [Google Scholar] [CrossRef] [PubMed]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Chintala, S. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Nice, France, 2019; Volume 32, pp. 8024–8035. Available online: http://papers.neurips.cc/paper/9015-pytorch-an-imperative-style-high-performance-deep-learning-library.pdf (accessed on 13 August 2023).
- Zbontar, J.; Jing, L.; Misra, I.; LeCun, Y.; Deny, S. Barlow twins: Self-supervised learning via redundancy reduction. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 12310–12320. [Google Scholar]
- Sadda, S.R.; Wu, Z.; Walsh, A.C.; Richine, L.; Dougall, J.; Cortez, R.; LaBree, L.D. Errors in retinal thickness measurements obtained by optical coherence tomography. Ophthalmology 2006, 113, 285–293. [Google Scholar] [CrossRef] [PubMed]
- DeBuc, D.C. A review on the structural and functional characterization of the retina with optical coherence tomography. Eye Contact Lens Sci. Clin. Pract. 2012, 38, 272. [Google Scholar]
- Ritchie, M.D.; Holzinger, E.R.; Li, R.; Pendergrass, S.A.; Kim, D. Methods of integrating data to uncover genotype—Phenotype interactions. Nat. Rev. Genet. 2015, 16, 85–97. [Google Scholar] [CrossRef] [PubMed]
- Shen, D.; Wu, G.; Suk, H.I. Deep learning in medical image analysis. Annu. Rev. Biomed. Eng. 2017, 19, 221–248. [Google Scholar] [CrossRef] [PubMed]
- Tajbakhsh, N.; Shin, J.Y.; Gurudu, S.R.; Hurst, R.T.; Kendall, C.B.; Gotway, M.B.; Liang, J. Convolutional neural networks for medical image analysis: Full training or fine tuning? IEEE Trans. Med. Imaging 2016, 35, 1299–1312. [Google Scholar] [CrossRef] [PubMed]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | AUC Score | Accuracy | F1 Score | Precision | Recall |
|---|---|---|---|---|---|
| No pre-train | 72.95 | 84.21 | 28.29 | 39.47 | 48.29 |
| Supervised (ImageNet) | 84.57 | 87.67 | 57.11 | 67.03 | 61.22 |
| SimCLR [18] | 85.09 | 88.25 | 57.42 | 67.70 | 64.18 |
| Barlow Twins [26] | 85.47 | 89.46 | 40.14 | 55.93 | 53.69 |
| Ours | 86.96 | 89.50 | 62.51 | 71.80 | 64.54 |
| Methods | DM | EM | GS | MD | RB | RVO |
|---|---|---|---|---|---|---|
| No pre-train | 74.39 | 54.24 | 84.48 | 72.47 | 68.42 | 64.75 |
| Supervised (ImageNet) | 91.16 | 57.56 | 83.31 | 84.62 | 92.66 | 90.05 |
| SimCLR [18] | 90.31 | 79.48 | 86.19 | 84.63 | 92.77 | 66.68 |
| Barlow Twins [26] | 95.65 | 64.52 | 83.17 | 86.79 | 85.45 | 83.93 |
| Ours | 93.36 | 84.73 | 97.29 | 87.39 | 93.08 | 69.49 |
| Method | AUC Score | Accuracy | F1 Score | Precision | Recall |
|---|---|---|---|---|---|
| Pair-instance | 85.09 | 88.25 | 57.42 | 67.70 | 64.18 |
| Bi-lateral | 85.47 | 88.13 | 57.16 | 63.18 | 63.93 |
| Multi-modality | 85.90 | 89.13 | 61.54 | 67.99 | 64.19 |
| Ours | 86.96 | 89.50 | 62.51 | 71.80 | 64.54 |
| Pair-Instance | Bi-Lateral | Multi-Modality | AUC Score | Accuracy | F1 Score | Precision | Recall |
|---|---|---|---|---|---|---|---|
| ✓ | ✓ | 86.75 | 88.92 | 59.55 | 68.77 | 62.08 | |
| ✓ | ✓ | 86.55 | 88.71 | 61.19 | 66.46 | 61.99 | |
| ✓ | ✓ | 86.51 | 88.83 | 63.06 | 70.53 | 64.94 | |
| ✓ | ✓ | ✓ | 86.96 | 89.50 | 62.51 | 71.80 | 64.54 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nguyen, T.D.; Le, D.-T.; Bum, J.; Kim, S.; Song, S.J.; Choo, H. Self-FI: Self-Supervised Learning for Disease Diagnosis in Fundus Images. Bioengineering 2023, 10, 1089. https://doi.org/10.3390/bioengineering10091089
Nguyen TD, Le D-T, Bum J, Kim S, Song SJ, Choo H. Self-FI: Self-Supervised Learning for Disease Diagnosis in Fundus Images. Bioengineering. 2023; 10(9):1089. https://doi.org/10.3390/bioengineering10091089
Chicago/Turabian StyleNguyen, Toan Duc, Duc-Tai Le, Junghyun Bum, Seongho Kim, Su Jeong Song, and Hyunseung Choo. 2023. "Self-FI: Self-Supervised Learning for Disease Diagnosis in Fundus Images" Bioengineering 10, no. 9: 1089. https://doi.org/10.3390/bioengineering10091089
APA StyleNguyen, T. D., Le, D.-T., Bum, J., Kim, S., Song, S. J., & Choo, H. (2023). Self-FI: Self-Supervised Learning for Disease Diagnosis in Fundus Images. Bioengineering, 10(9), 1089. https://doi.org/10.3390/bioengineering10091089