
A Recommendation System for Execution Plans Using Machine Learning


Abstract
:1. Introduction
2. Related Work
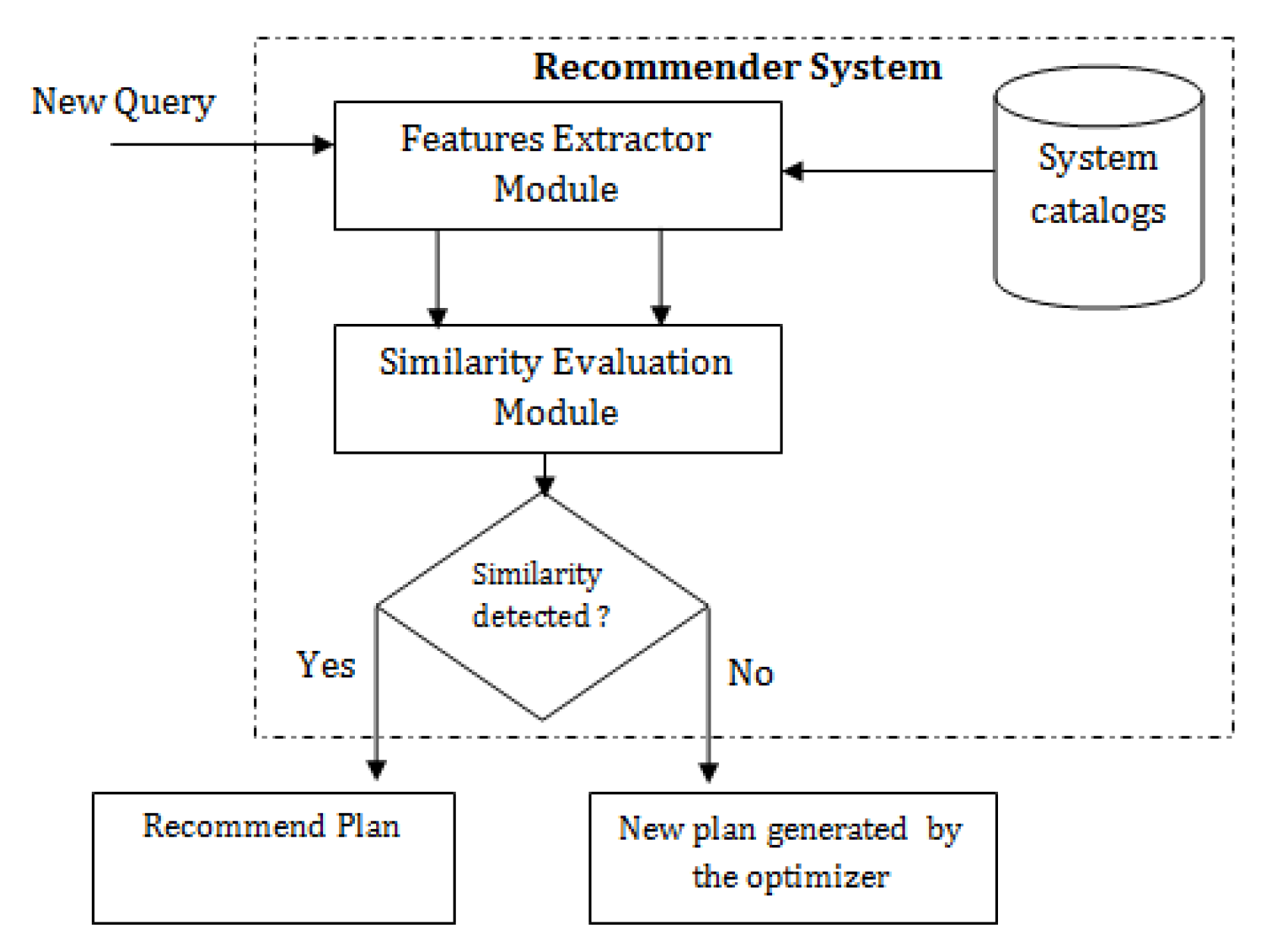
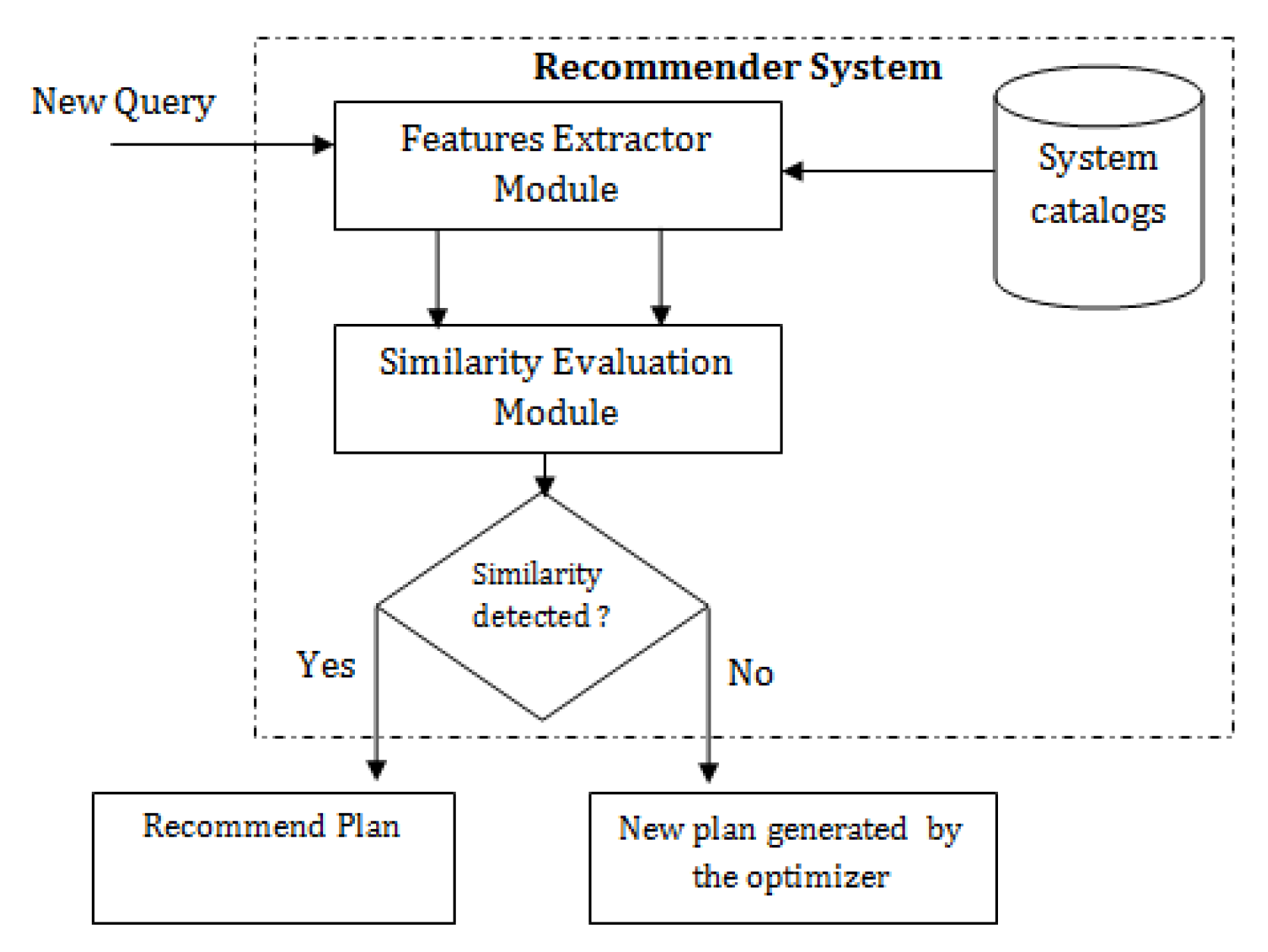
3. Approach to Execution Plan Recommendation
- We firstly propose a textual representation of our data and use it to build the Features Extractor module.
- Secondly, we present a straightforward Similarity Evaluation module that relies only on the comparison of the SQL statements of the queries and studies the pitfalls associated with this method.
- Next, we show how to build an improved Similarity Evaluation module enabled by machine learning techniques. The improved version of the module takes into account the features of the queries’ execution plans.
- We compare three machine learning algorithms and study which one is more accurate in our context.
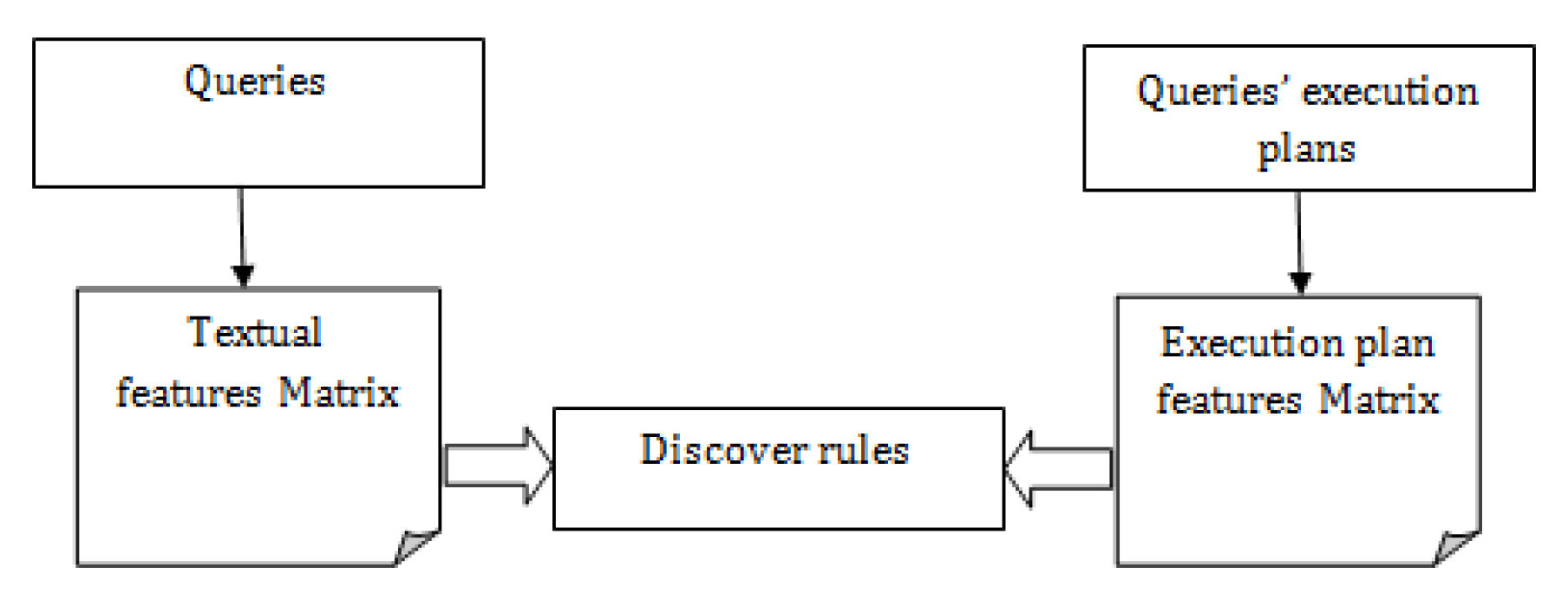
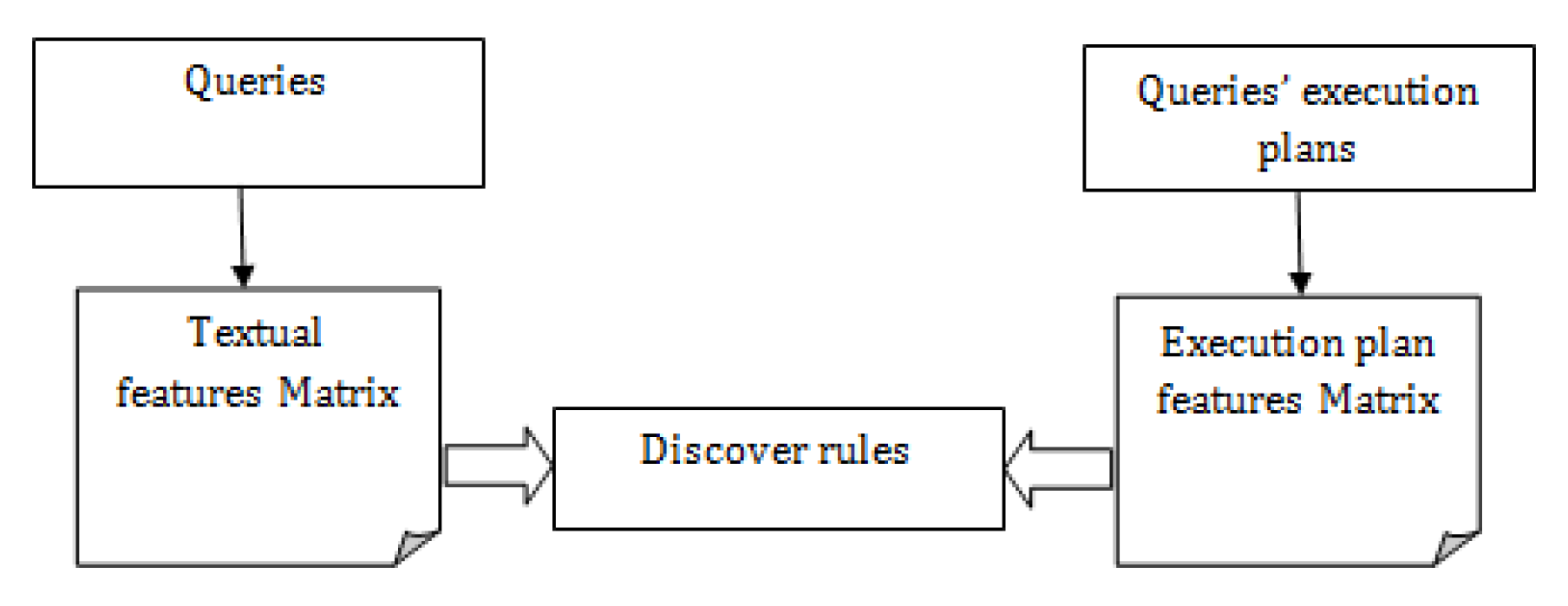
4. Feature Extraction
4.1. Query Features Matrix
4.1.1. Features
Fragments Model
- : SELECT LINE_LEVEL FROM PRODLEVEL WHERE LINE_LEVEL =’RLI9AYC8YAQ4’
- : SELECT ACTVARS.DOLLARSALES FROM ACTVARS,PRODLEVEL
- WHERE ACTVARS.PRODUCT_LEVEL= PRODLEVEL.CODE_LEVEL
- AND PRODLEVEL.LINE_LEVEL =’RLI9AYC8YAQ4’
4.1.2. Weighting Method
TF-IDF
- N: Total Number of Queries in the Database;
- : Frequency of feature f in query q;
- : Number of queries where the feature f appears.
4.2. Execution Plan Features Matrix
5. Straightforward Solution
Limitation
- Judge two queries as not similar, by analyzing their SQL syntax, while their execution plans are actually similar.
- Find that two queries have high similarity measure by comparing their statements, but still their plan are different. This is basically due to the fact that small differences in the SQL statements, that could be ignored in classical text categorization tasks, are very decisive in the process of defining an execution plan.
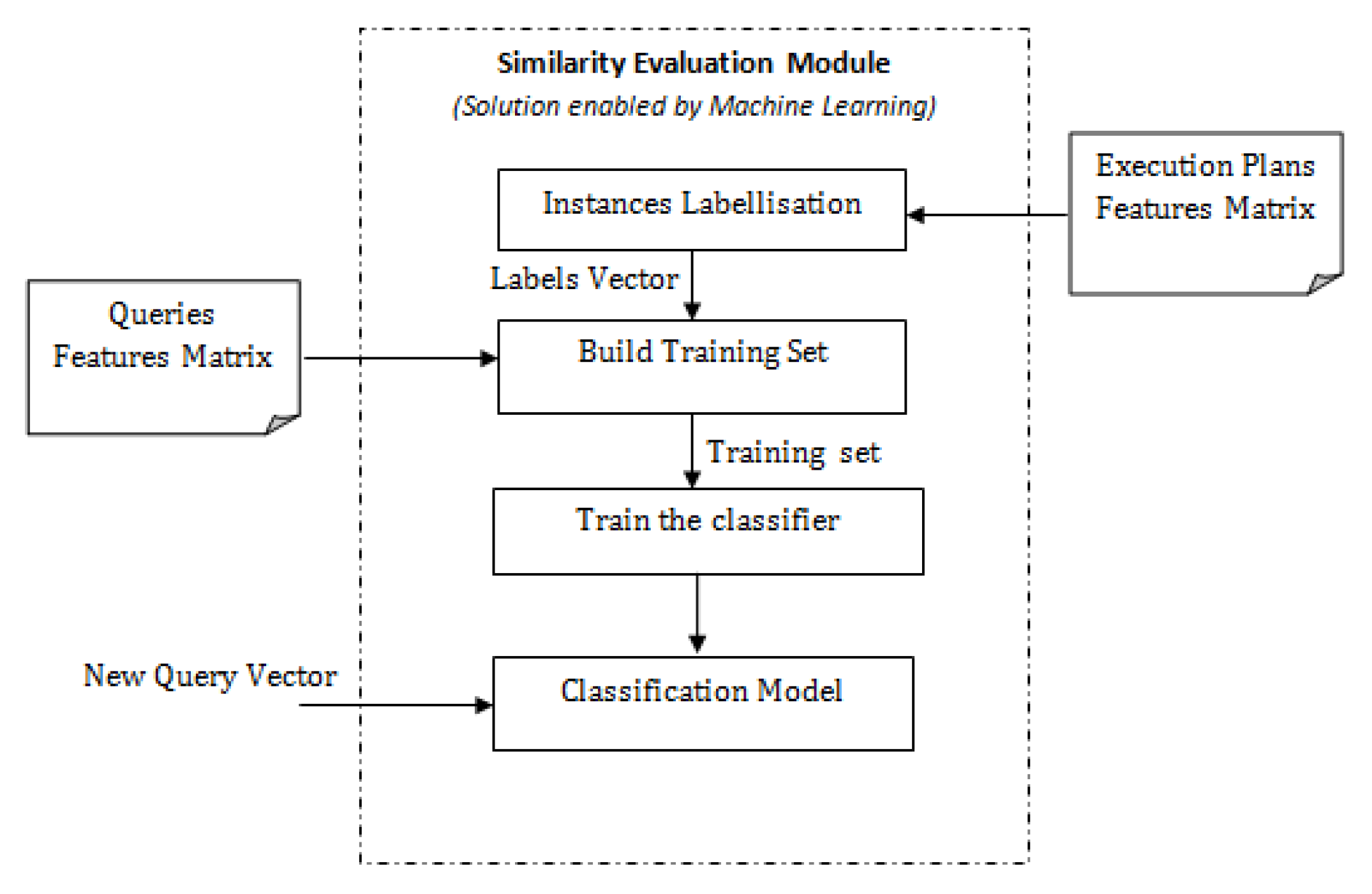
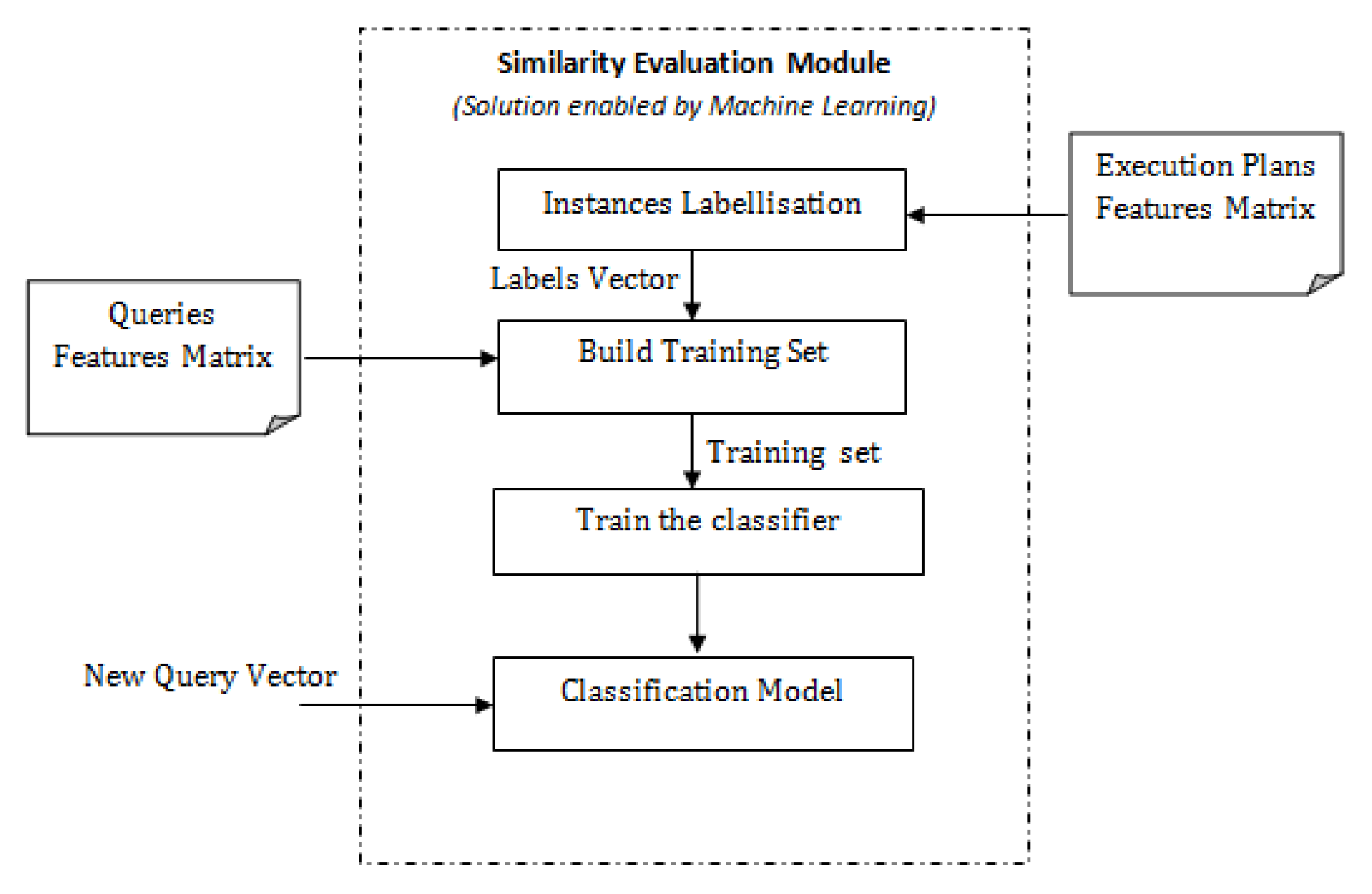
6. Solution Enabled by Machine Learning Techniques
6.1. Evaluating Classification Techniques
6.1.1. Naive Bayes
6.1.2. Support Vector Machines (SVM)
6.2. Evaluating Classification Based on Association Rules
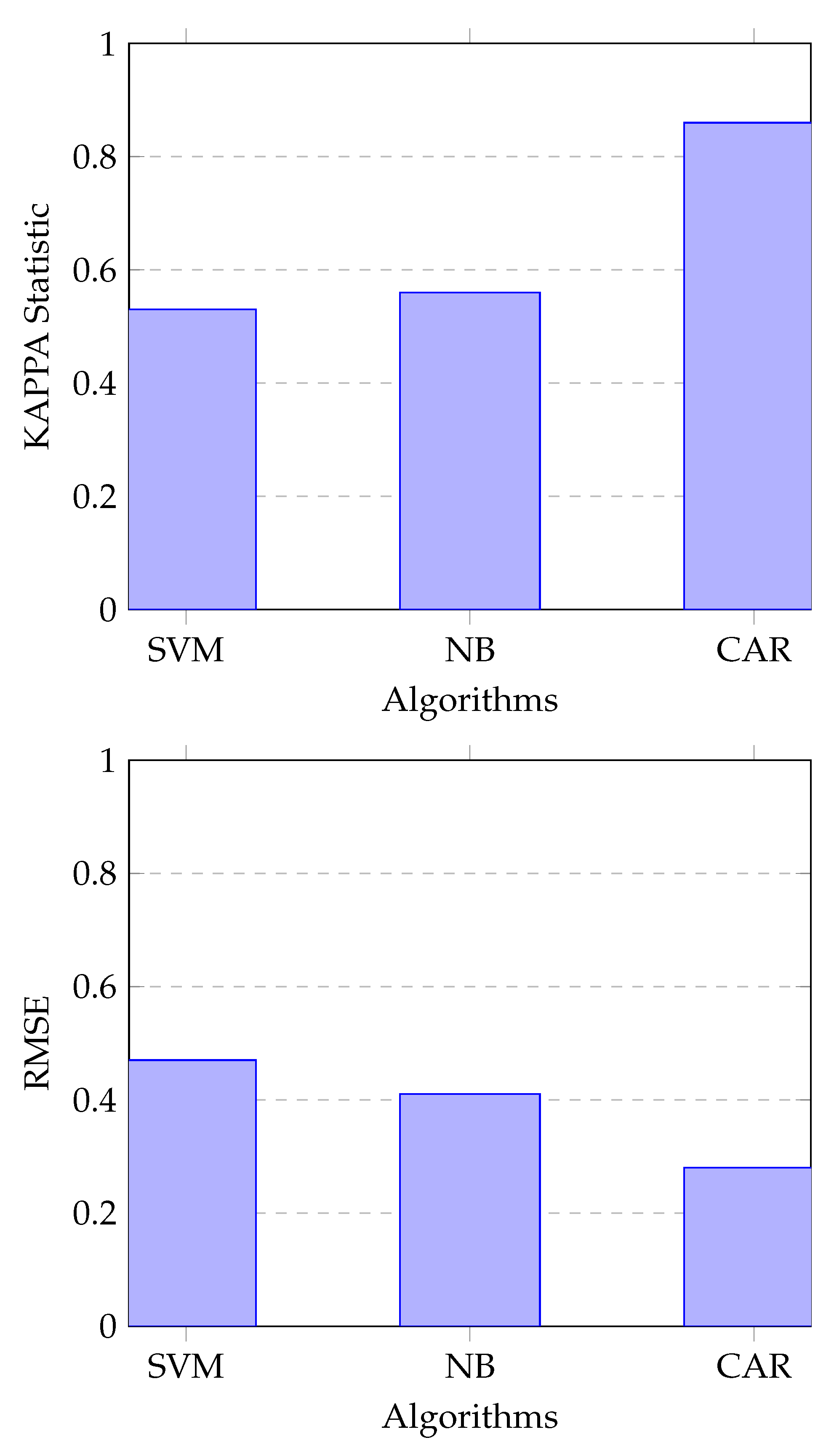
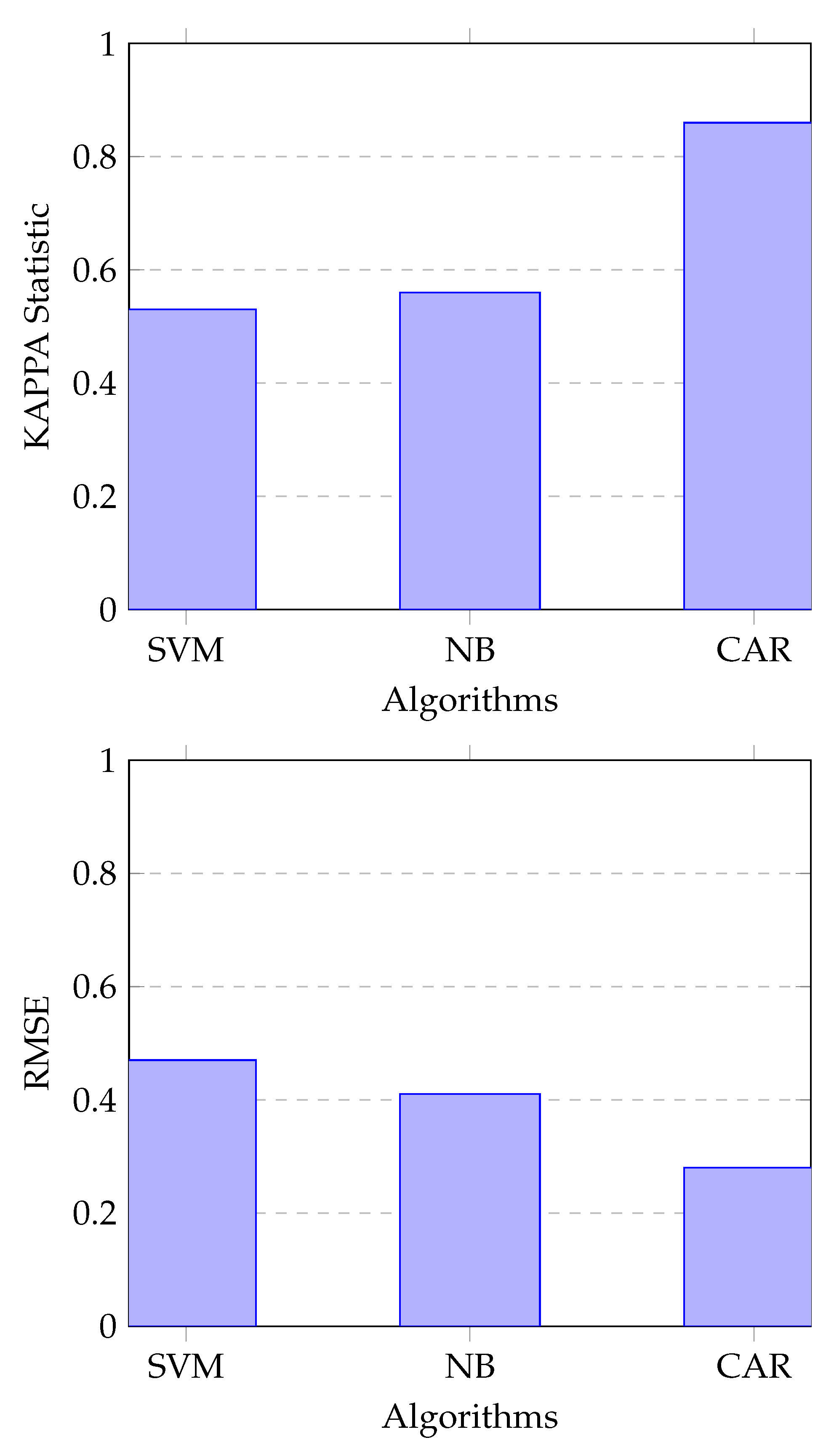
7. Experimentations and Results
7.1. Experimental Set-Up
7.1.1. Data
- Dataset : Contains 1000 simple queries having different execution plans;
- Dataset : Contains 1000 queries containing subqueries.
7.1.2. Models’ Validation
7.1.3. Evaluation Metrics
7.1.4. Tools
7.2. Experimental Results
7.2.1. Experiment 1: Straightforward Solution
- Firstly, we compare our fragments model to a word model (with simple frequency weighting) as we want to identify which one of these two models is more likely to identify queries having similar execution plans;
- Secondly, we test the models with our two datasets: and .
- : SELECT ACTVARS.DOLLARSALES FROM ACTVARS,PRODLEVEL
- WHERE ACTVARS.PRODUCT_LEVEL= PRODLEVEL.CODE_LEVEL
- AND PRODLEVEL.LINE_LEVEL =’RLI9AYC8YAQ4’
- : SELECT CHANNEL_LEVEL,TIME_LEVEL,DOLLARSALES
- FROM ACTVARS,CHANLEVEL WHERE ACTVARS.CHANNEL_LEVEL=
- (SELECT BASE_LEVEL FROM CHANLEVEL WHERE BASE_LEVEL =’C7W3GE3KN9GU’)
- : SELECT * FROM ACTVARS WHERE TIME_LEVEL IN (SELECT MONTH_LEVEL
- FROM TIMELEVEL WHERE MONTH_LEVEL = ’199607’)
- : SELECT ACTVARS.DOLLARSALES FROM ACTVARS,PRODLEVEL
- WHERE ACTVARS.PRODUCT_LEVEL= PRODLEVEL.CODE_LEVEL
- AND PRODLEVEL.LINE_LEVEL = ’ITQS4CE29HQR’
- : SELECT CHANNEL_LEVEL,TIME_LEVEL,DOLLARSALES
- FROM ACTVARS,CHANLEVEL WHERE ACTVARS.CHANNEL_LEVEL=
- (SELECT BASE_LEVEL FROM CHANLEVEL WHERE BASE_LEVEL =’SMYQ2W6NF5X8’)
- : SELECT CHANNEL_LEVEL,TIME_LEVEL,DOLLARSALES
- FROM ACTVARS,CHANLEVEL WHERE CHANLEVEL.BASE_LEVEL=
- (SELECT CHANNEL_LEVEL FROM ACTVARS WHERE CHANNEL_LEVEL =’SMYQ2W6NF5X8’)
- : SELECT * FROM ACTVARS WHERE TIME_LEVEL IN
- (SELECT MONTH_LEVEL FROM TIMELEVEL
- WHERE MONTH_LEVEL = ’199511’)
- : SELECT * FROM ACTVARS WHERE ACTVARS.TIME_LEVEL IN
- (SELECT TIMELEVEL.MONTH_LEVEL FROM TIMELEVEL
- WHERE TIMELEVEL.MONTH_LEVEL = ’199607’)
7.2.2. Experiment 2: Solution Enabled by Machine Learning Techniques
8. Conclusions
Author Contributions
Conflicts of Interest
References
- Wu, W.; Chi, Y.; Hacígümüş, H.; Naughton, J.F. Towards predicting query execution time for concurrent and dynamic database workloads. Proc. VLDB Endow. 2013, 6, 925–936. [Google Scholar] [CrossRef]
- Selinger, P.G.; Astrahan, M.M.; Chamberlin, D.D.; Lorie, R.A.; Price, T.G. Access path selection in a relational database management system. In Proceedings of the 1979 ACM SIGMOD International Conference on the Management of Data, Boston, MA, USA, 30 May–1 June 1979.
- Hasan, R.; Gandon, F. A machine learning approach to SPARQL query performance prediction. In Proceedings of the 2014 IEEE/WIC/ACM International Joint Conferences on Web Intelligence (WI) and Intelligent Agent Technologies (IAT), Warsaw, Poland, 11–14 August 2014; IEEE: Piscataway, NJ, USA, 2014; Volume 1, pp. 266–273. [Google Scholar]
- Gao, L.; Wang, M.; Wang, X.S.; Padmanabhan, S. A learning-based approach to estimate statistics of operators in continuous queries: A case study. In Proceedings of the 8th ACM SIGMOD Workshop on Research Issues in Data Mining and Knowledge Discovery, San Diego, CA, USA, 13 June 2003; ACM: New York, NY, USA, 2003; pp. 66–72. [Google Scholar]
- Gryz, J.; Liang, D. Query selectivity estimation via data mining. In Intelligent Information Processing and Web Mining; Springer: Berlin/Heidelberg, Germany, 2004; pp. 29–38. [Google Scholar]
- Chaudhuri, S.; Ganti, V.; Gravano, L. Selectivity estimation for string predicates: Overcoming the underestimation problem. In Proceedings of the 20th International Conference on Data Engineering, Boston, MA, USA, 30 March–2 April 2004; IEEE: Piscataway, NJ, USA, 2004; pp. 227–238. [Google Scholar]
- Ganapathi, A.; Kuno, H.; Dayal, U.; Wiener, J.L.; Fox, A.; Jordan, M.; Patterson, D. Predicting multiple metrics for queries: Better decisions enabled by machine learning. In Proceedings of the IEEE 25th International Conference on Data Engineering, ICDE’09, Shanghai, China, 29 March–2 April 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 592–603. [Google Scholar]
- Akdere, M.; Çetintemel, U.; Riondato, M.; Upfal, E.; Zdonik, S.B. Learning-based query performance modeling and prediction. In Proceedings of the 2012 IEEE 28th International Conference on Data Engineering (ICDE), Washington, DC, USA, 1–5 April 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 390–401. [Google Scholar]
- Sarda, P.; Haritsa, J.R. Green query optimization: Taming query optimization overheads through plan recycling. In Proceedings of the Thirtieth International Conference on Very Large Data Bases, Toronto, ON, Canada, 31 August–3 September 2004.
- Ghosh, A.; Parikh, J.; Sengar, V.S.; Haritsa, J.R. Plan selection based on query clustering. In Proceedings of the 28th International Conference on Very Large Data Bases, Hong Kong, China, 20–23 August 2002.
- Adomavicius, G.; Tuzhilin, A. Toward the next generation of recommender systems: A survey of the state-of-the-art and possible extensions. IEEE Trans. Knowl. Data Eng. 2005, 17, 734–749. [Google Scholar] [CrossRef]
- Marcel, P.; Negre, E. A Survey of Query Recommendation Techniques for Data Warehouse Exploration; Entrepôts de Données et l’Analyse en ligne—EDA: Clermont-Ferrand, France, 2011; pp. 119–134. [Google Scholar]
- Yao, Q.; An, A.; Huang, X. Finding and analyzing database user sessions. In Database Systems for Advanced Applications; Springer: Berlin/Heidelberg, Germany, 2005; pp. 851–862. [Google Scholar]
- Stefanidis, K.; Drosou, M.; Pitoura, E. You May Also Like results in relational databases. In Proceedings of the International Workshop on Personalized Access, Profile Management and Context Awareness: Databases, Lyon, France, 24–28 August 2009; Volume 9.
- Aligon, J.; Golfarelli, M.; Marcel, P.; Rizzi, S.; Turricchia, E. Mining preferences from OLAP query logs for proactive personalization. In Advances in Databases and Information Systems; Springer: Berlin/Heidelberg, Germany, 1998; pp. 84–79. [Google Scholar]
- Yang, X.; Procopiuc, C.M.; Srivastava, D. Recommending join queries via query log analysis. In Proceedings of the IEEE 25th International Conference on Data Engineering, ICDE’09, Shanghai, China, 29 March–2 April 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 964–975. [Google Scholar]
- Gupta, A.; Mumick, I.S. Materialized Views: Techniques, Implementations, and Applications; MIT Press: Cambridge, MA, USA, 1999. [Google Scholar]
- Chatzopoulou, G.; Eirinaki, M.; Koshy, S.; Mittal, S.; Polyzotis, N.; Varman, J.S.V. The QueRIE system for Personalized Query Recommendations. IEEE Data Eng. Bull. 2011, 34, 55–60. [Google Scholar]
- Lan, M.; Tan, C.L.; Su, J.; Lu, Y. Supervised and traditional term weighting methods for automatic text categorization. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 721–735. [Google Scholar] [CrossRef] [PubMed]
- Aizawa, A. An information-theoretic perspective of tf-idf measures. Inf. Process. Manag. 2003, 39, 45–65. [Google Scholar] [CrossRef]
- Using Explain Plan. Available online: https://docs.oracle.com/cd/B1050101/server.920/a96533/explan.htm (accessed on 10 May 2016).
- Gomaa, W.H.; Fahmy, A.A. A survey of text similarity approaches. Int. J. Comput. Appl. 2013, 68, 13–18. [Google Scholar]
- Friedman, N.; Geiger, D.; Goldszmidt, M. Bayesian network classifiers. Mach. Learn. 1997, 29, 131–163. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Wu, X.; Kumar, V.; Quinlan, J.R.; Ghosh, J.; Yang, Q.; Motoda, H.; McLachlan, G.J.; Ng, A.; Liu, B.; Philip, S.Y.; et al. Top 10 algorithms in data mining. Knowl. Inf. Syst. 2008, 14, 1–37. [Google Scholar] [CrossRef]
- Minh, H.Q.; Niyogi, P.; Yao, Y. Mercers theorem, feature maps, and smoothing. In Learning Theory; Springer: Berlin/Heidelberg, Germany, 2006; pp. 154–168. [Google Scholar]
- Agrawal, R.; Srikant, R. Fast algorithms for mining association rules. In Proceedings of the 20th International Conference on Very Large Data Bases, VLDB, San Francisco, CA, USA, 12 September–15 September 1994; Volume 1215, pp. 487–499.
- Thabtah, F. A review of associative classification mining. Knowl. Eng. Rev. 2007, 22, 37–65. [Google Scholar] [CrossRef]
- Nguyen, L.T.; Nguyen, N.T. Updating mined class association rules for record insertion. Appl. Intell. 2015, 42, 707–721. [Google Scholar] [CrossRef]
- OLAP Council APB-1 OLAP Benchmark Release II. Available online: http://www.olapcouncil.org/research/bmarkly.htm (accessed on 10 May 2016).
- Hall, M.; Frank, E.; Holmes, G.; Pfahringer, B.; Reutemann, P.; Witten, I.H. The WEKA data mining software: An update. ACM SIGKDD Explor. Newsl. 2009, 11, 10–18. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Fragment | Begining | End |
|---|---|---|
| Fragment 1 | Select | From |
| Fragment 2 | From | Where, Group By, Order By |
| Fragment 3 | Where | like, =, Group By, Order By |
| Fragment 4 | = | AND, End of the query |
| Fragment 5 | AND | =, End of the query |
| Fragment 6 | like, Group By, Order By | End of the query |
| Fragments | Model | Model |
|---|---|---|
| Fragment 1 | LINE_LEVEL | ACTVARS.DOLLARSALES |
| Fragment 2 | PRODLEVEL | ACTVARS,PRODLEVEL |
| Fragment 3 | LINE_LEVEL | ACTVARS.PRODUCT_LEVEL |
| Fragment 4 | ’RLI9AYC8YAQ4’ | PRODLEVEL.CODE_LEVEL |
| Fragment 5 | NULL | PRODLEVEL.LINE_LEVEL |
| Fragment 6 | NULL | ’RLI9AYC8YAQ4’ |
| Feature | Description |
|---|---|
| PLAN_HASH_VALUE | A metric that identifies execution plans. |
| COST | Execution cost as estimated by the optimizer. The value of this attribute has no measurement unit. |
| CARDINALITY | Number of rows returned by a query. |
| OPERATION | Defines the operation type (Select, Update, ...). |
| BYTES | Number of needed bytes per query. |
| Table Name | Cardinality | Size (MB) |
|---|---|---|
| ACTVARS | 33,323,400 | 2085 |
| CHANLEVEL | 10 | |
| CUSTLEVEL | 990 | |
| PRODLEVEL | 9900 | |
| TIMELEVEL | 24 |
| Dataset | New Query | Suggested Similar Query | Fragments Model | Words Model |
|---|---|---|---|---|
| 0.98 | 0.93 | |||
| 0.90 | 0.90 | |||
| 0.90 | 0.89 | |||
| 0.97 | 0.92 | |||
| 0.91 | 0.90 | |||
| 0.87 | 0.92 | |||
| 0.33 | 1 | |||
| 0.98 | 0.93 | |||
| 0.85 | 0.95 | |||
| 0.78 | 0.92 |
| Query | Cardinality | Bytes | Plan Hash Value |
|---|---|---|---|
| 196,714 | 9,638,986 | 1,918,545,856 | |
| 196,714 | 9,638,986 | 1,918,545,856 | |
| 688,500 | 42,687,000 | 1,918,545,856 | |
| 688,500 | 42,687,000 | 1,918,545,856 | |
| 81,000 | 2,187,000 | 4,072,885,321 | |
| 81,000 | 2,187,000 | 4,072,885,321 | |
| 81,000 | 7,695,000 | 4,072,885,321 | |
| 79,442 | 1,906,608 | 4,072,885,321 | |
| 65,548 | 1,713,152 | 4,072,885,321 | |
| 4673 | 387,859 | 2,685,087,043 | |
| 4490 | 372,670 | 2,685,087,043 | |
| 4490 | 372,670 | 2,685,087,043 | |
| 68,850 | 3,167,100 | 2,685,087,043 | |
| 68,850 | 3,167,100 | 2,685,087,043 |
| SVM | Naive Bayes | CAR |
|---|---|---|
| 76.55% | 77.95% | 91% |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zahir, J.; El Qadi, A. A Recommendation System for Execution Plans Using Machine Learning. Math. Comput. Appl. 2016, 21, 23. https://doi.org/10.3390/mca21020023
Zahir J, El Qadi A. A Recommendation System for Execution Plans Using Machine Learning. Mathematical and Computational Applications. 2016; 21(2):23. https://doi.org/10.3390/mca21020023
Chicago/Turabian StyleZahir, Jihad, and Abderrahim El Qadi. 2016. "A Recommendation System for Execution Plans Using Machine Learning" Mathematical and Computational Applications 21, no. 2: 23. https://doi.org/10.3390/mca21020023
APA StyleZahir, J., & El Qadi, A. (2016). A Recommendation System for Execution Plans Using Machine Learning. Mathematical and Computational Applications, 21(2), 23. https://doi.org/10.3390/mca21020023