
Predictive Abilities of Bayesian Regularization and Levenberg–Marquardt Algorithms in Artificial Neural Networks: A Comparative Empirical Study on Social Data

Abstract
:1. Introduction
2. Material and Methods
2.1. Data Set (Material)
2.2. Methods
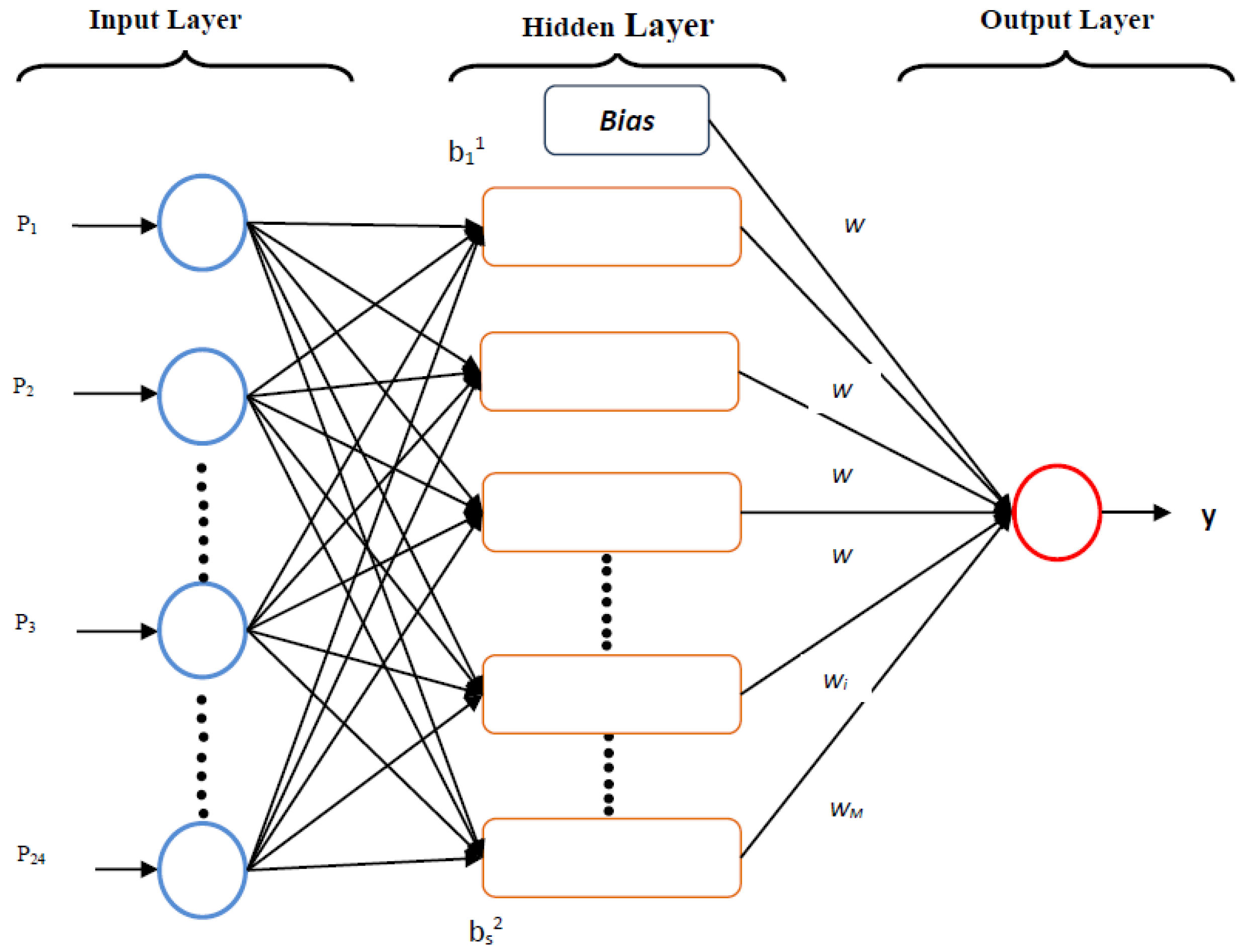
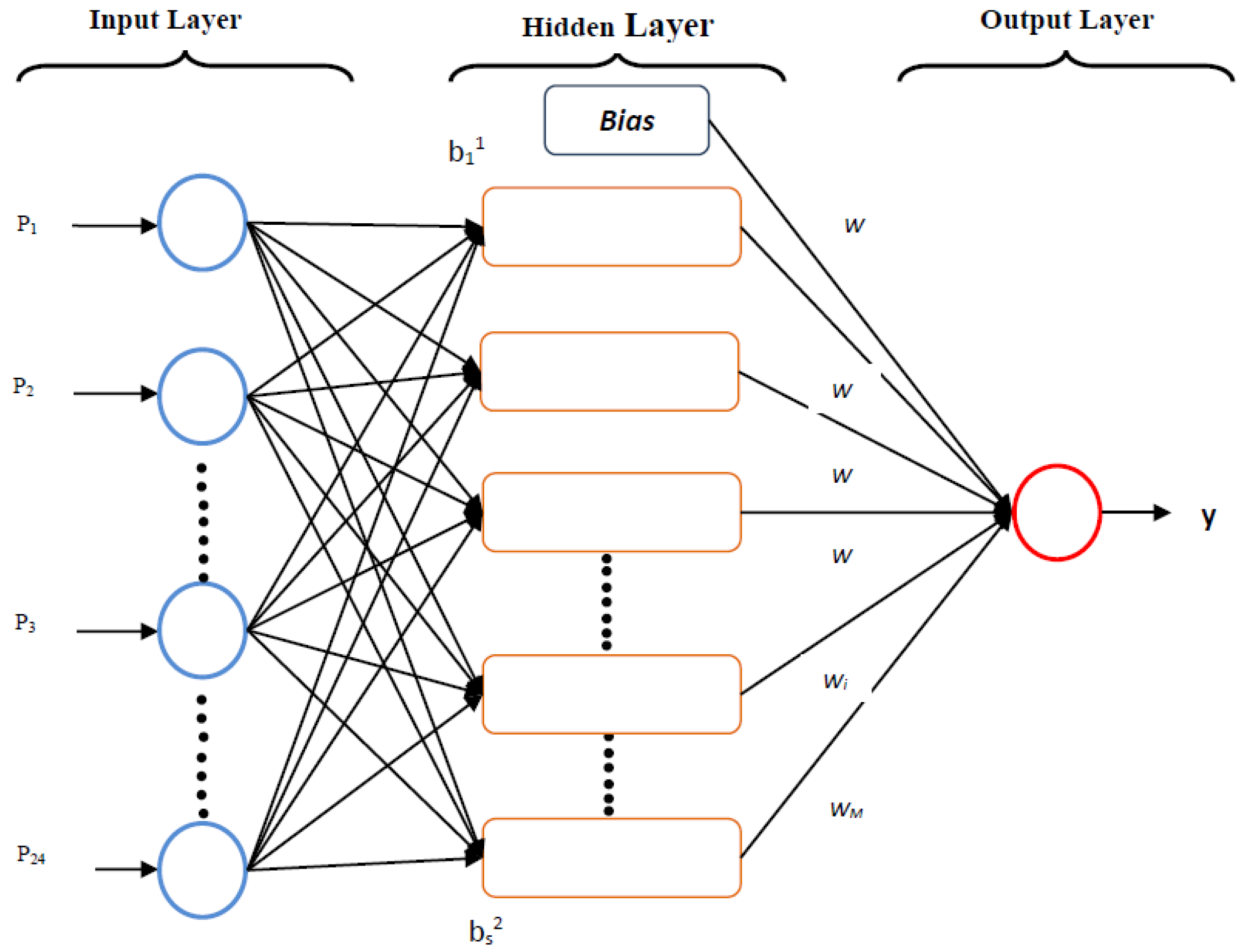
2.2.1. Feed-Forward Neural Networks with Backpropagation Algorithm
- 1
- fhidden layer(.) = linear(.) and foutput layer(.) = linear(.)
- 2
- fhidden layer(.) = tangentsigmoid(.) and foutput layer(.) = linear(.)
2.2.2. Solution to the Overfitting Problem with Bayesian Regularization and Levenberg–Marquardt Neural Networks
2.2.3. Analyses
3. Results and Discussion
4. Conclusions
Conflicts of Interest
References
- Alaniz, A.Y.; Sanchez, E.N.; Loukianov, A.G. Discrete-time adaptive back stepping nonlinear control via high-order neural networks. IEEE Trans. Neural Netw. 2007, 18, 1185–1195. [Google Scholar] [CrossRef] [PubMed]
- Khomfoi, S.; Tolbert, L.M. Fault diagnostic system for a multilevel inverter using a neural network. IEEE Trans Power Electron. 2007, 22, 1062–1069. [Google Scholar] [CrossRef]
- Okut, H.; Gianola, D.; Rosa, G.J.M.; Weigel, K.A. Prediction of body mass index in mice using dense molecular markers and a regularized neural network. Genet. Res. Camb. 2011, 93, 189–201. [Google Scholar] [CrossRef] [PubMed]
- Vigdor, B.; Lerner, B. Accurate and fast off and online fuzzy ARTMAP-based image classification with application to genetic abnormality diagnosis. IEEE Trans. Neural Netw. 2006, 17, 1288–1300. [Google Scholar] [CrossRef] [PubMed]
- Gianola, D.; Okut, H.; Weigel, K.A.; Rosa, G.J.M. Predicting complex quantitative traits with Bayesian neural networks: A case study with Jersey cows and wheat. BMC Genet. 2011, 12, 1–37. [Google Scholar] [CrossRef] [PubMed]
- Moller, F.M. A scaled conjugate gradient algorithm for fast supervised learning. Neural Netw. 1993, 6, 525–533. [Google Scholar] [CrossRef]
- Hagan, M.T.; Menhaj, M.B. Training feedforward networks with the Marquardt algorithm. IEEE Trans. Neural Netw. 1994, 5, 989–993. [Google Scholar] [CrossRef] [PubMed]
- Saini, L.M. Peak load forecasting using Bayesian regularization, Resilient and adaptive backpropagation learning based artificial neural networks. Electr. Power Syst. Res. 2008, 78, 1302–1310. [Google Scholar] [CrossRef]
- Beal, M.; Hagan, M.T.; Demuth, H.B. Neural Network Toolbox™ 6 User’s Guide; The Math Works Inc.: Natick, MA, USA, 2010; pp. 146–175. [Google Scholar]
- Mackay, D.J.C. Bayesian interpolation. Neural Comput. 1992, 4, 415–447. [Google Scholar] [CrossRef]
- Demuth, H.; Beale, M. Neural Network Toolbox User’s Guide Version 4; The Math Works Inc.: Natick, MA, USA, 2000; pp. 5–22. [Google Scholar]
- Bishop, C.M.; Tipping, M.E. A hierarchical latent variable model for data visualization. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 281–293. [Google Scholar] [CrossRef]
- Burden, F.; Winkler, D. Bayesian regularization of neural networks. Methods Mol. Biol. 2008, 458, 25–44. [Google Scholar] [PubMed]
- Marwalla, T. Bayesian training of neural networks using genetic programming. Pattern Recognit. Lett. 2007, 28, 1452–1458. [Google Scholar] [CrossRef]
- Titterington, D.M. Bayesian methods for neural networks and related models. Stat. Sci. 2004, 19, 128–139. [Google Scholar] [CrossRef]
- Felipe, V.P.S.; Okut, H.; Gianola, D.; Silva, M.A.; Rosa, G.J.M. Effect of genotype imputation on genome-enabled prediction of complex traits: an empirical study with mice data. BMC Genet. 2014, 15, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Alados, I.; Mellado, J.A.; Ramos, F.; Alados-Arboledas, L. Estimating UV erythemal irradiance by means of neural networks. Photochem. Photobiol. 2004, 80, 351–358. [Google Scholar] [CrossRef] [PubMed]
- Mackay, J.C.D. Information Theory, Inference and Learning Algorithms; University Press: Cambridge, UK, 2008. [Google Scholar]
- Sorich, M.J.; Miners, J.O.; Ross, A.M.; Winker, D.A.; Burden, F.R.; Smith, P.A. Comparison of linear and nonlinear classification algorithms for the prediction of drug and chemical metabolism by human UDP-Glucuronosyl transferesa isoforms. J. Chem. Inf. Comput. Sci. 2003, 43, 2019–2024. [Google Scholar] [CrossRef] [PubMed]
- Xu, M.; Zengi, G.; Xu, X.; Huang, G.; Jiang, R.; Sun, W. Application of Bayesian regularized BP neural network model for trend analysis. Acidity and chemical composition of precipitation in North. Water Air Soil Pollut. 2006, 172, 167–184. [Google Scholar] [CrossRef]
- Mackay, J.C.D. Comparison of approximate methods for handling hyperparameters. Neural Comput. 1996, 8, 1–35. [Google Scholar] [CrossRef]
- Kelemen, A.; Liang, Y. Statistical advances and challenges for analyzing correlated high dimensional SNP data in genomic study for complex. Dis. Stat. Surv. 2008, 2, 43–60. [Google Scholar]
- Gianola, D.; Manfredi, E.; Simianer, H. On measures of association among genetic variables. Anim. Genet. 2012, 43, 19–35. [Google Scholar] [CrossRef] [PubMed]
- Okut, H.; Wu, X.L.; Rosa, G.J.M.; Bauck, S.; Woodward, B.W.; Schnabel, R.D.; Taylor, J.F.; Gianola, D. Predicting expected progeny difference for marbling score in Angus cattle using artificial neural networks and Bayesian regression models. Genet. Sel. Evolut. 2013, 45, 1–8. [Google Scholar] [CrossRef] [PubMed]
- Foresee, F.D.; Hagan, M.T. Gauss-Newton approximation to Bayesian learning. In Proceedings of the IEEE International Conference on Neural Networks, Houston, TX, USA, 9–12 June 1997; pp. 1930–1935.
- Shaneh, A.; Butler, G. Bayesian Learning for Feed-Forward Neural Network with Application to Proteomic Data: The Glycosylation Sites Detection of The Epidermal Growth Factor-Like Proteins Associated with Cancer as A Case Study. In Advances in Artificial Intelligence; Canadian AI LNAI 4013; Lamontagne, L., Marchand, M., Eds.; Springer-Verleg: Berlin/Heiddelberg, Germany, 2006. [Google Scholar]
- Souza, D.C. Neural Network Learning by the Levenberg–Marquardt Algorithm with Bayesian Regularization. Available online: http://crsouza.blogspot.com/feeds/posts/default/webcite (accessed on 29 July 2015).
- Bui, D.T.; Pradhan, B.; Lofman, O.; Revhaug, I.; Dick, O.B. Landslide susceptibility assessment in the HoaBinh province of Vieatnam: A comparison of the Levenberg–Marqardt and Bayesian regularized neural networks. Geomorphology 2012, 171, 12–29. [Google Scholar]
- Lee, S.; Ryu, J.H.; Won, J.S.; Park, H.J. Determination and application of the weights for landslide susceptibility mapping using an artificial neural network. Eng. Geol. 2004, 71, 289–302. [Google Scholar] [CrossRef]
- Pareek, V.K.; Brungs, M.P.; Adesina, A.A.; Sharma, R. Artificial neural network modeling of a multiphase photo degradation system. J. Photochem. Photobiol. A Chem. 2002, 149, 139–146. [Google Scholar] [CrossRef]
- Bruneau, P.; McElroy, N.R. LogD7.4 modeling using Bayesian regularized neural networks assessment and correction of the errors of prediction. J. Chem. Inf. Model. 2006, 46, 1379–1387. [Google Scholar] [CrossRef] [PubMed]
- Lauret, P.; Fock, F.; Randrianarivony, R.N.; Manicom-Ramsamy, J.F. Bayesian Neural Network approach to short time load forecasting. Energy Convers. Manag. 2008, 5, 1156–1166. [Google Scholar] [CrossRef]
- Ticknor, J.L. A Bayesian regularized artificial neural network for stock market forecasting. Expert Syst. Appl. 2013, 14, 5501–5506. [Google Scholar] [CrossRef]
- Wayg, Y.H.; Li, Y.; Yang, S.L.; Yang, L. An in silico approach for screening flavonoids as P-glycoprotein inhibitors based on a Bayesian regularized neural network. J. Comput. Aided Mol. Des. 2005, 19, 137–147. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
| Cross-Validation (CV) | Sum Square of Errors (SSE) | Effective Number of Parameters | Sum Squared Weights (SSW) | R-Train (Correlation) | R-Test (Correlation) |
|---|---|---|---|---|---|
| 1. sample | 61,372.000 | 22.300 | 0.312 | 0.263 | 0.232 |
| 2. sample | 53,387.000 | 22.200 | 0.332 | 0.261 | 0.236 |
| 3. sample | 55,915.000 | 25.100 | 0.251 | 0.252 | 0.252 |
| 4. sample | 60,031.000 | 22.200 | 0.316 | 0.270 | 0.225 |
| 5. sample | 51,190.000 | 22.100 | 0.329 | 0.261 | 0.243 |
| 6. sample | 53,843.000 | 22.200 | 0.289 | 0.271 | 0.222 |
| 7. sample | 61,012.000 | 21.700 | 0.269 | 0.260 | 0.220 |
| 8. sample | 61,888.000 | 22.200 | 0.283 | 0.278 | 0.217 |
| 9. sample | 55,574.000 | 22.100 | 0.339 | 0.272 | 0.231 |
| 10. sample | 60,606.000 | 22.600 | 0.333 | 0.220 | 0.213 |
| Average of 10 samples | 57,481.800 | 22.470 | 0.305 | 0.261 | 0.229 |
| Architecture | SSE | Effective Number of Parameters | SSW | R-Train (Correlation) | R-Test (Correlation) |
|---|---|---|---|---|---|
| 1 neuron | 57,689.3333 | 22.27 | 0.33118 | 0.2671 | 0.2296 |
| 2 neurons | 57,541.400 | 34.48 | 0.8921 | 0.3044 | 0.2505 |
| 3 neurons | 58,103.300 | 44.68 | 1.6879 | 0.3432 | 0.2385 |
| 4 neurons | 57,127.500 | 62.17 | 2.4836 | 0.3666 | 0.2367 |
| Architecture | SSE | R-Train (Correlation) | R-Test (Correlation) |
|---|---|---|---|
| 1-neuron linear | 57,545.600 | 0.269 | 0.183 |
| 1-neuron non-linear | 58,512.200 | 0.2789 | 0.2047 |
| 2-neuron non-linear | 59,707.700 | 0.355 | 0.203 |
| 3-neuron non-linear | 62,106.200 | 0.3968 | 0.1971 |
| 4-neuron non-linear | 63,180.800 | 0.4446 | 0.1933 |
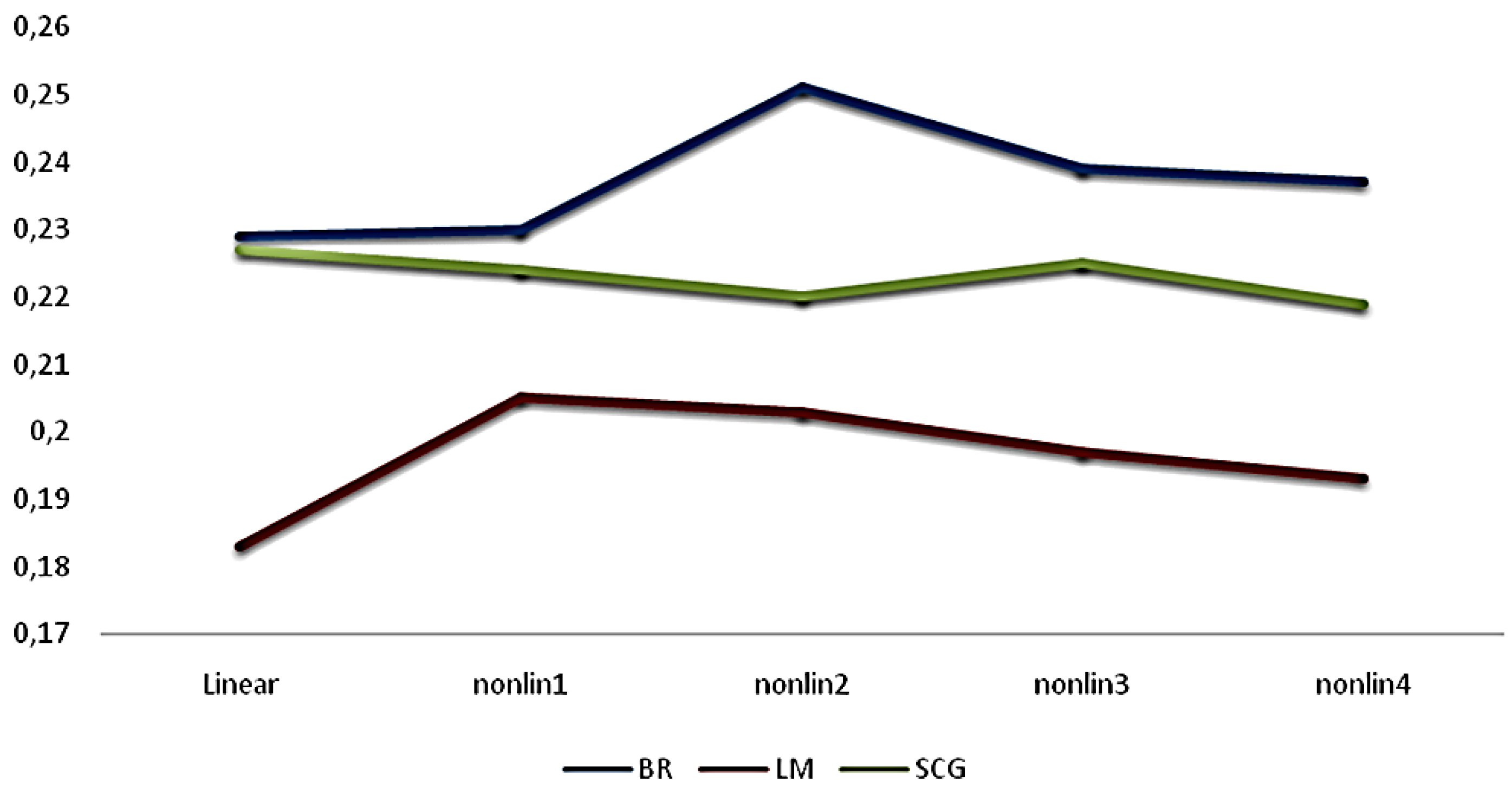
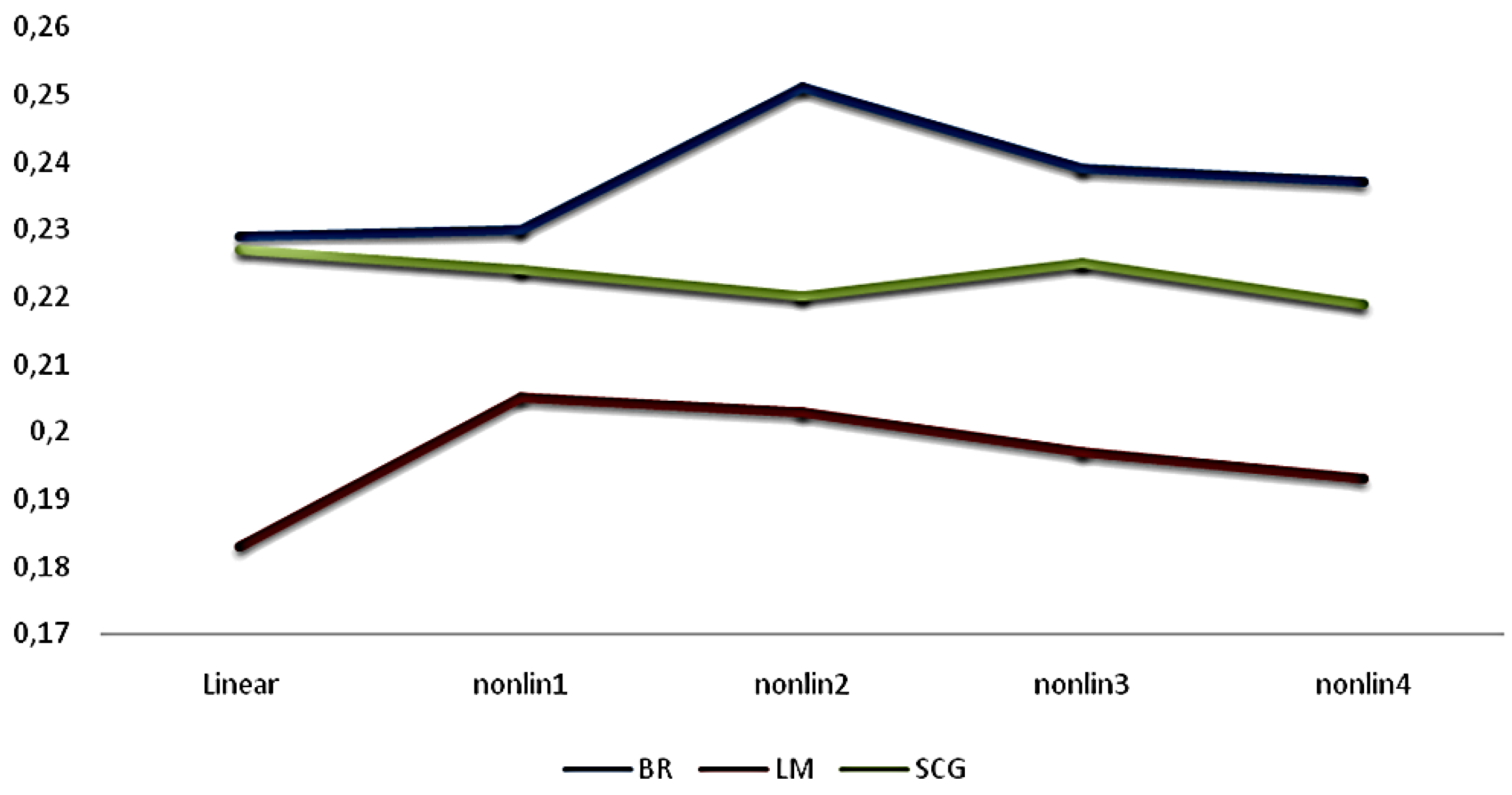
| Training Algorithm | Linear | Nonlinear (One-Neuron) | Nonlinear (Two-Neuron) | Nonlinear (Three-Neuron) | Nonlinear (Four-Neuron) |
|---|---|---|---|---|---|
| BR | 0.229 | 0.23 | 0.251 | 0.239 | 0.237 |
| LM | 0.183 | 0.205 | 0.203 | 0.197 | 0.193 |
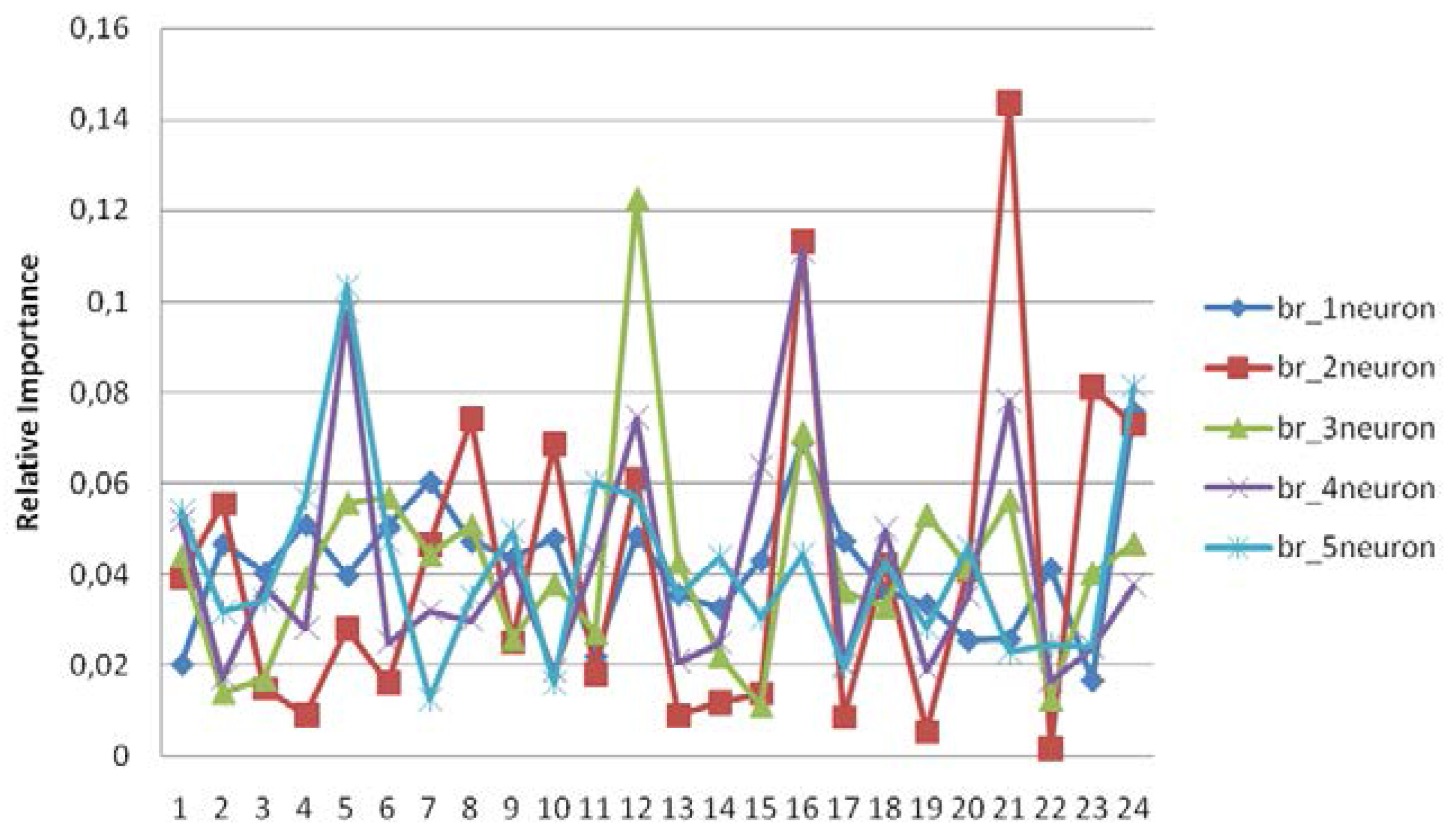
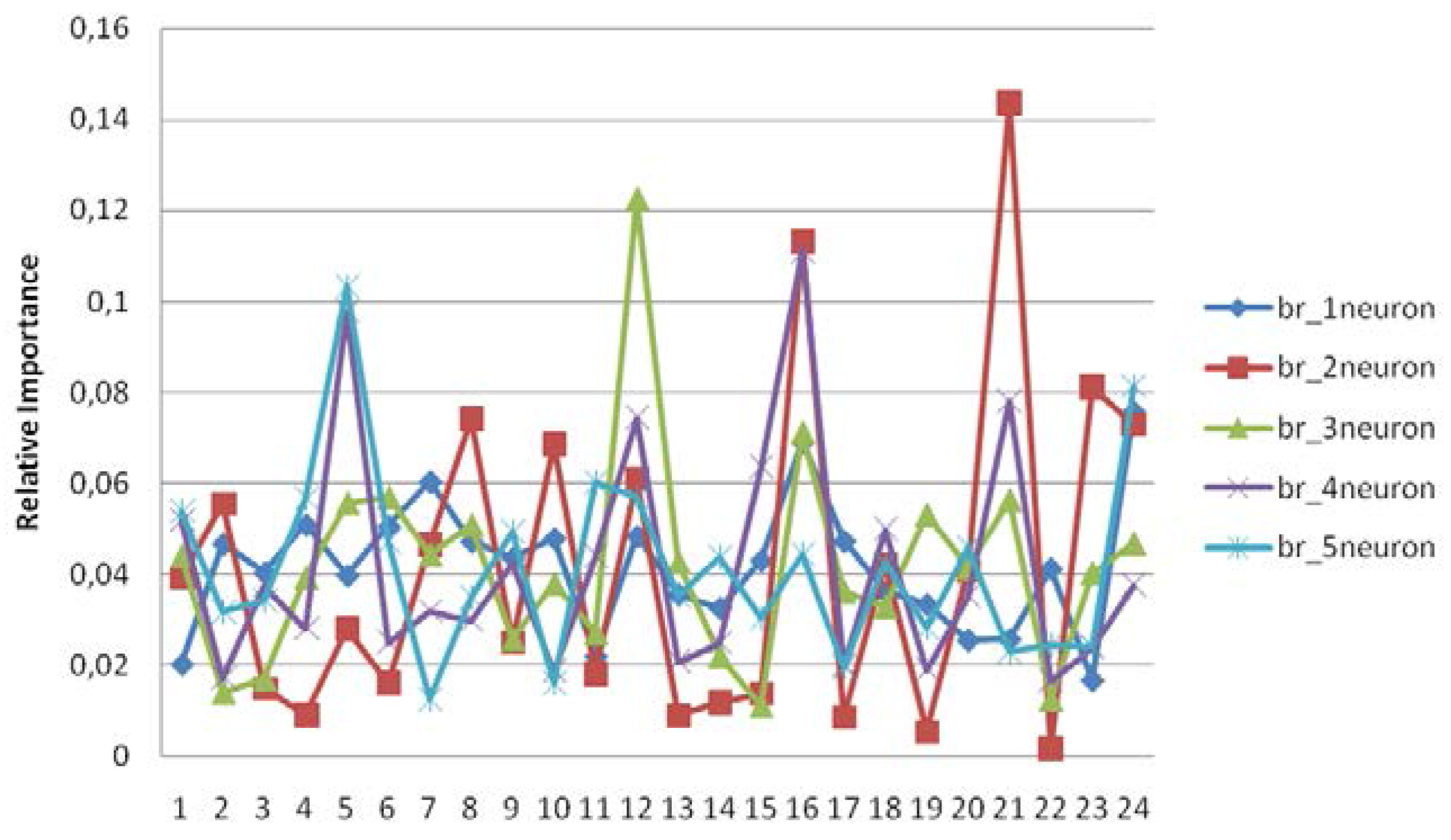
| Predictors | Br_1neur. | Pred. | Br_2neur. | Pred. | Br_3neur. | Pred. | Br_4 neur. | Pred. | Br_5neur. |
|---|---|---|---|---|---|---|---|---|---|
| 24 | 0.075826 | 21 | 0.14369 | 12 | 0.12251 | 16 | 0.1111 | 5 | 0.10333 |
| 16 | 0.069195 | 16 | 0.11314 | 16 | 0.07112 | 5 | 0.09779 | 24 | 0.08138 |
| 7 | 0.060357 | 23 | 0.08125 | 6 | 0.05684 | 21 | 0.07807 | 11 | 0.06017 |
| 4 | 0.050891 | 8 | 0.07418 | 21 | 0.05631 | 12 | 0.07447 | 12 | 0.05692 |
| 6 | 0.050532 | 24 | 0.07294 | 5 | 0.0556 | 15 | 0.06365 | 4 | 0.05661 |
| 12 | 0.048386 | 10 | 0.06862 | 19 | 0.05302 | 1 | 0.05183 | 1 | 0.05389 |
| 10 | 0.047885 | 12 | 0.06106 | 8 | 0.05076 | 18 | 0.04997 | 9 | 0.04936 |
| 17 | 0.047311 | 2 | 0.05554 | 24 | 0.04671 | 11 | 0.04395 | 6 | 0.04713 |
| 8 | 0.047199 | 7 | 0.04651 | 7 | 0.04425 | 9 | 0.04257 | 20 | 0.04578 |
| 2 | 0.046716 | 18 | 0.04221 | 1 | 0.04406 | 3 | 0.03772 | 16 | 0.04452 |
| 9 | 0.043606 | 20 | 0.04074 | 13 | 0.04253 | 24 | 0.0376 | 14 | 0.04377 |
| 15 | 0.043048 | 1 | 0.03932 | 20 | 0.04133 | 20 | 0.03522 | 18 | 0.04253 |
| 22 | 0.041268 | 5 | 0.02792 | 23 | 0.04024 | 7 | 0.03193 | 13 | 0.03518 |
| 3 | 0.040365 | 9 | 0.02497 | 4 | 0.03922 | 8 | 0.02974 | 8 | 0.03504 |
| 5 | 0.039735 | 11 | 0.01811 | 10 | 0.03784 | 4 | 0.02808 | 3 | 0.03427 |
| 18 | 0.036124 | 6 | 0.01616 | 17 | 0.03607 | 6 | 0.02513 | 2 | 0.03183 |
| 13 | 0.035587 | 3 | 0.0148 | 18 | 0.03285 | 14 | 0.02483 | 15 | 0.03038 |
| 19 | 0.033427 | 15 | 0.01372 | 11 | 0.02699 | 23 | 0.02402 | 19 | 0.02815 |
| 14 | 0.032593 | 14 | 0.01176 | 9 | 0.0256 | 13 | 0.02075 | 22 | 0.02449 |
| 21 | 0.025644 | 4 | 0.00903 | 14 | 0.02197 | 17 | 0.02022 | 23 | 0.02403 |
| 20 | 0.025484 | 13 | 0.00885 | 3 | 0.01687 | 19 | 0.019 | 21 | 0.02313 |
| 11 | 0.021935 | 17 | 0.00847 | 2 | 0.01394 | 10 | 0.01868 | 17 | 0.01958 |
| 1 | 0.020202 | 19 | 0.00538 | 22 | 0.01239 | 2 | 0.01712 | 10 | 0.01605 |
| 23 | 0.016684 | 22 | 0.00162 | 15 | 0.01097 | 22 | 0.01656 | 7 | 0.01249 |
© 2016 by the author; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kayri, M. Predictive Abilities of Bayesian Regularization and Levenberg–Marquardt Algorithms in Artificial Neural Networks: A Comparative Empirical Study on Social Data. Math. Comput. Appl. 2016, 21, 20. https://doi.org/10.3390/mca21020020
Kayri M. Predictive Abilities of Bayesian Regularization and Levenberg–Marquardt Algorithms in Artificial Neural Networks: A Comparative Empirical Study on Social Data. Mathematical and Computational Applications. 2016; 21(2):20. https://doi.org/10.3390/mca21020020
Chicago/Turabian StyleKayri, Murat. 2016. "Predictive Abilities of Bayesian Regularization and Levenberg–Marquardt Algorithms in Artificial Neural Networks: A Comparative Empirical Study on Social Data" Mathematical and Computational Applications 21, no. 2: 20. https://doi.org/10.3390/mca21020020
APA StyleKayri, M. (2016). Predictive Abilities of Bayesian Regularization and Levenberg–Marquardt Algorithms in Artificial Neural Networks: A Comparative Empirical Study on Social Data. Mathematical and Computational Applications, 21(2), 20. https://doi.org/10.3390/mca21020020