1. Introduction
In the flexible job shop scheduling problem (FJSP), each operation of a job can be assigned to a different machine, and the processing time on each machine is not necessarily the same [
1]. This flexibility allows companies to respond quickly to order changes, adjust production processes, and adapt better to market demand fluctuations. In most large-scale manufacturing enterprises, the production process necessitates dividing orders into multiple sublots for production. Effective batching strategies optimize resource utilization, reduce production time, and ensure timely product delivery. Additionally, skilled workers are crucial for handling complex tasks and ensuring product quality.
Batch splitting scheduling involves dividing workpieces into sublots and scheduling the most appropriate machines for each sublot [
2]. Based on the number and size of sublots, batch splitting scheduling can be divided into three categories: equal-sized, consistent-sized, and variable-sized batch splitting. In equal-sized batch splitting, each job has the same number of sublots. In consistent-sized batch splitting, the number of sublots for different jobs may vary, but each type of job maintains consistency in every operation. In variable-sized batch splitting, the number and size of sublots can differ for each operation [
3]. This strategy involves a unique batch splitting scheme for each job operation, resulting in a larger search space and increased complexity in solving the scheduling problem. However, compared to equal-sized and consistent-sized strategies, variable-sized batch splitting is better at enhancing machine utilization and processing efficiency due to its flexible sublot division.
In actual production, sublot number and size are constrained by both machine and human resources. If sublots are too large, it leads to excessive working hours for some machines and workers, affecting overall efficiency. If sublots are too small, they must be frequently shifted between workers and machines, making management difficult. A reasonable batch size enhances processing efficiency and distributes workload, thereby reducing worker fatigue. This paper introduces human resource constraints into the production scheduling problem based on variable batch splitting, necessitating the consideration of human resource allocation and efficiency in scheduling optimization when applying the batching strategy.
The remainder of the paper is organized as follows:
Section 2 reviews the pertinent literature and summarizes work related to this research.
Section 3 details the problem studied, outlines assumptions, and develops a mathematical model.
Section 4 introduces a novel two-stage multi-objective evolutionary algorithm that partitions the four subproblems into two parts for independent solving.
Section 5 presents experiments conducted for the problem model and compares the proposed algorithm’s results with other algorithms.
Section 6 provides a summary and outlook.
2. Literature Review
The flexible job shop scheduling problem (FJSP), introduced by Brucker and Schlie in 1990 [
4], has gained significant attention in academic and industrial circles. Swarm Intelligence (SI) and Evolutionary Algorithms (EA) are widely applied in this field [
5].
Batch splitting scheduling has gained significant interest in flexible job shop scheduling. Initial studies focused on equal-sized batch splitting in flow shops. Yoon et al. [
6] proposed a hybrid genetic algorithm integrating linear programming and pairwise swapping, assuming equal-sized sublots and an infinite-capacity buffer. Chao et al. [
7] combined a moving algorithm, net gain, and discrete particle swarm to minimize the total weighted advance and delay objectives. Ventura et al. [
8] addressed the finite buffer flow shop problem with blocking using a novel genetic algorithm. Recent advancements include enhancements to algorithms like ant colony optimization [
9] and grey wolf optimization [
10], all focusing on improving scheduling efficiency in job shop environments.
Consistent-sized batch splitting, which is more aligned with actual production than equal-sized batch splitting, has become the focus of recent research. Zhang et al. [
11] Developed a mixed-integer linear programming model and a collaborative variable neighborhood descent algorithm. Wang et al. [
12] introduced green scheduling and a multi-objective optimization model to minimize completion time and energy consumption using a multi-objective discrete artificial bee colony algorithm. In flexible job shops, Li et al. [
13] proposed a hybrid algorithm combining reinforcement learning and an artificial bee colony algorithm for optimal sublot splitting, thereby reducing maximum completion time. Li et al. [
14] developed a mixed-integer planning model for a flexible assembly job shop with batch splitting using a new bionic algorithm based on the artificial bee colony. Pinar et al. [
15] proposed a constrained planning model incorporating iterative improvement and large-neighborhood search strategies.
Research on variable-sized batch splitting has increased recently. Wang et al. [
16] proposed a two-stage discrete water wave optimization algorithm for a flow shop production system to minimize completion time, with two-wave parallel coding for split and sequential waves. Li et al. [
17] developed a decomposition-based multi-objective evolutionary algorithm for hybrid flow shop scheduling, minimizing average dwell time, final stage energy consumption, and early/late arrival values, with novel mutation, crossover, right-shift strategies, and population initialization. Sanchit et al. [
18] developed a fast linear search algorithm and a branch-and-bound heuristic method for the 1 + m hybrid flow shop problem. Bozek et al. [
19] proposed a two-stage optimization method for flexible job shop scheduling with variable-sized batches. Fatemeh et al. [
20] developed a mixed-integer linear programming model and variable neighborhood search algorithms for parallel assembly phases. Li [
21] proposed a mixed-integer linear programming model and a hyper-heuristic improved genetic algorithm for flexible job shop scheduling with variable-sized splitting, considering constraints like lead time and changeover time. Li et al. [
22] addressed a multi-objective optimization problem considering completion time and total energy consumption using a two-stage multi-objective hybrid algorithm.
Most contemporary manufacturing systems study single resource constraints. However, real production requires considering both machine and human resource constraints. Machines need workers to operate them, and workers have varying skills and efficiencies. These complex workshops with machine and human resource constraints are known as dual-resource constrained (DRC) job shops [
23]. Tao et al. [
24] proposed an adaptive artificial bee colony algorithm for the distributed hybrid flow shop scheduling problem with resource constraints, aiming to minimize completion time. They also studied adaptive perturbation structure and key plant-based local search. He et al. [
25] developed a model for the DRC flexible job shop scheduling problem and an improved African vulture optimization algorithm to optimize completion time and total delay. Gao et al. [
26] proposed a mixed-wash multiswarm micro-migratory bird optimization algorithm for the multi-resource constrained flexible job shop scheduling problem, generating multiple micro-clusters at initialization. Each micro-cluster periodically invokes a stochastic mix-and-shuffle process. Additionally, a diversification control strategy based on life aging is proposed to achieve population diversification. Recent studies have focused on dual- or multiple-resource scheduling problems, emphasizing workers’ abilities and skills. Liu et al. [
27] addressed the complex product assembly line scheduling problem with multi-skilled worker assignment and parallel team scheduling, optimizing for maximum completion time and team workload imbalance. They proposed an integer planning model and a hybrid coding method for worker assignment and task ordering, along with three improvement strategies based on multi-objective evolutionary algorithms. Liu et al. [
28] also considered a hybrid flow shop scheduling problem with multi-skilled workers and fatigue factors by establishing an agent-based simulation system to handle uncertainty in the worker fatigue model. They proposed a novel simulation-based optimization framework combining genetic algorithms and reinforcement learning algorithms. Du et al. [
29] addressed the flexible flow shop scheduling problem with dual-resource constraints, considering machines and heterogeneous workers with different skills and capabilities. Their integer planning model allows for the rational assignment of workers to satisfy fatigue constraints using a genetic algorithm with two novel heuristic decoding methods. Peng et al. [
30] constructed a model for the multi-objective flexible job shop scheduling problem, considering job transportation time, learning effect constraints, and worker efficiency in operating different machines. They developed a hybrid discrete multi-objective imperial competitive algorithm to minimize processing time, energy consumption, and noise.
Currently, there is limited research on batch splitting scheduling in flexible job shops, with most studies focused on job shops, parallel machine shops, and assembly line job shops. Variable-sized batch splitting is more complex than equal-sized and consistent-sized batch splitting, leading to gradual increases in research on variable-sized batch splitting in recent years. Additionally, studies considering workers’ skills and proficiency in flexible job shops remain limited, and few have explored integrating this aspect into batch splitting scheduling research. The flexible job shop variable-sized batch splitting scheduling problem is a highly complex NP-hard problem. Introducing multi-skill and multi-level constraints on workers significantly increases its space and time complexities, making it challenging to model and solve. In this paper, we develop a mixed-integer linear programming model, dividing the problem into four subproblems: sublot splitting, sublot sorting, machine selection, and worker assignment. These subproblems are addressed in two stages. In the first stage, a two-stage multi-objective evolutionary algorithm is proposed to solve sublot sorting, machine selection, and worker allocation. In the second stage, the optimal batch division scheme is optimized and solved.
4. Algorithm Design
4.1. Proposed Two-Stage Multi-Objective Evolutionary Algorithm
The DRCFJSP-VS consists of four subproblems: sublot splitting, sublot sorting, machine selection, and worker assignment. Optimizing these subproblems simultaneously results in a complex problem with a large solution space, making it more challenging to find the optimal solution. Therefore, this paper proposes dividing these four subproblems into two stages and solving them sequentially. The first stage addresses the sublot sorting, machine selection, and worker allocation subproblems, transforming the problem into a dual-resource constrained flexible job shop scheduling problem. This stage focuses on optimizing the allocation of resources to tasks, which simplifies the problem by addressing the most complex constraints first and reducing the solution space for the next stage. The second stage then focuses on batch splitting and optimally solves the batch splitting scheme.
To address the two-stage problems, this paper proposes a two-stage multi-objective evolutionary algorithm (TSMOEA). The differential evolutionary algorithm (DEA) is selected for its advantages, including few parameters, ease of adjustment, and global search capability. In the first stage, an improved multi-objective discrete DEA is used to optimize the dual-resource constrained flexible job shop scheduling problem. In the second stage, an adaptive simulated annealing (SA) algorithm optimizes the variable-sized batch splitting scheduling problem. Given the high coupling between the two phases and the characteristics of simulated annealing—independence from the initial solution, strong global search capability, and the ability to escape local optima—simulated annealing is a more appropriate choice for the second phase of the algorithm. The flowchart of the proposed TSMOEA algorithm is shown in
Figure 1.
The algorithm’s specific process steps are as follows:
Step 1: Initialize the population. Each individual needs to initialize four chromosomes: sublot splitting chromosomes, sublot sorting chromosomes, machine assigning chromosomes, and worker assigning chromosomes.
Step 2: Adaptive crossover and mutation. Three individuals are randomly selected for the sublot sorting, machine assigning, and worker assigning chromosomes. They undergo mutation and crossover using the adaptive mutation and crossover operators designed in this paper to generate a new population, which is then mixed with the old population.
Step 3: Elite selection. Solve the Pareto solutions for the mixed population with respect to the two objectives: minimizing the maximum completion time and minimizing the maximum worker processing time. The elite reserved selection strategy is used to produce sublot sorting, machine assigning, and worker assigning chromosomes for the next generation.
Step 4: Termination condition judgment. The temperature is cooled to check if it falls below the termination threshold. Alternatively, evaluate the Pareto frontier solutions from two consecutive cooling cycles to determine if they match the previous solutions. If one of the termination conditions is met, proceed to Step 8. Otherwise, proceed to Step 5.
Step 5: Generate random perturbation. Apply a random perturbation to the sublot splitting chromosomes, resulting in new sublot splitting chromosomes. Mix the new population with the original population.
Step 6: Accept the new solution or not. Solve the Pareto solutions for the mixed population concerning the two objectives: minimizing the maximum completion time and minimizing the maximum worker processing time. Use the adaptive selection strategy designed in this paper to accept either the new or the original sublot splitting chromosome.
Step 7: Determine the sufficiency of the search. If the search is sufficient, add the optimized sublot splitting chromosomes to the next generation. Otherwise, return to Step 5.
Step 8: Determine the number of iterations. If the number of iterations exceeds the maximum, proceed to Step 9. Otherwise, return to Step 2.
Step 9: Output results. Decode the latest generation population to solve the Pareto solution set. Determine the frontier solutions, identify the optimal individual, and output the maximum completion time and maximum worker processing time for each optimal individual, along with the corresponding sublot splitting, sublot sorting, machine selection, and worker allocation schemes.
4.2. Encoding and Decoding
The DRCFJSP-VS, the subject of this study, comprises four subproblems. The first step is to divide the original lot of the job into sublots for each operation, determining the number and sizes of the sublots. These sublots are then sorted into a logical sequence to serve as the machining sequence while meeting the constraints outlined in
Section 3.3.3. For each sublot, suitable machines and workers are selected separately. In this paper, a four-layer parallel chromosome is used for individual coding. The first chromosome represents the batch division scheme, referred to as the “sublot splitting chromosome”. The second chromosome illustrates the processing order of sublots, designated as the “sublot sorting chromosome”. The third chromosome outlines the selected processing machines for each sublot, referred to as the “machine assigning chromosome”. Finally, the fourth chromosome assigns suitable workers to each sublot, represented by the “worker assigning chromosome”.
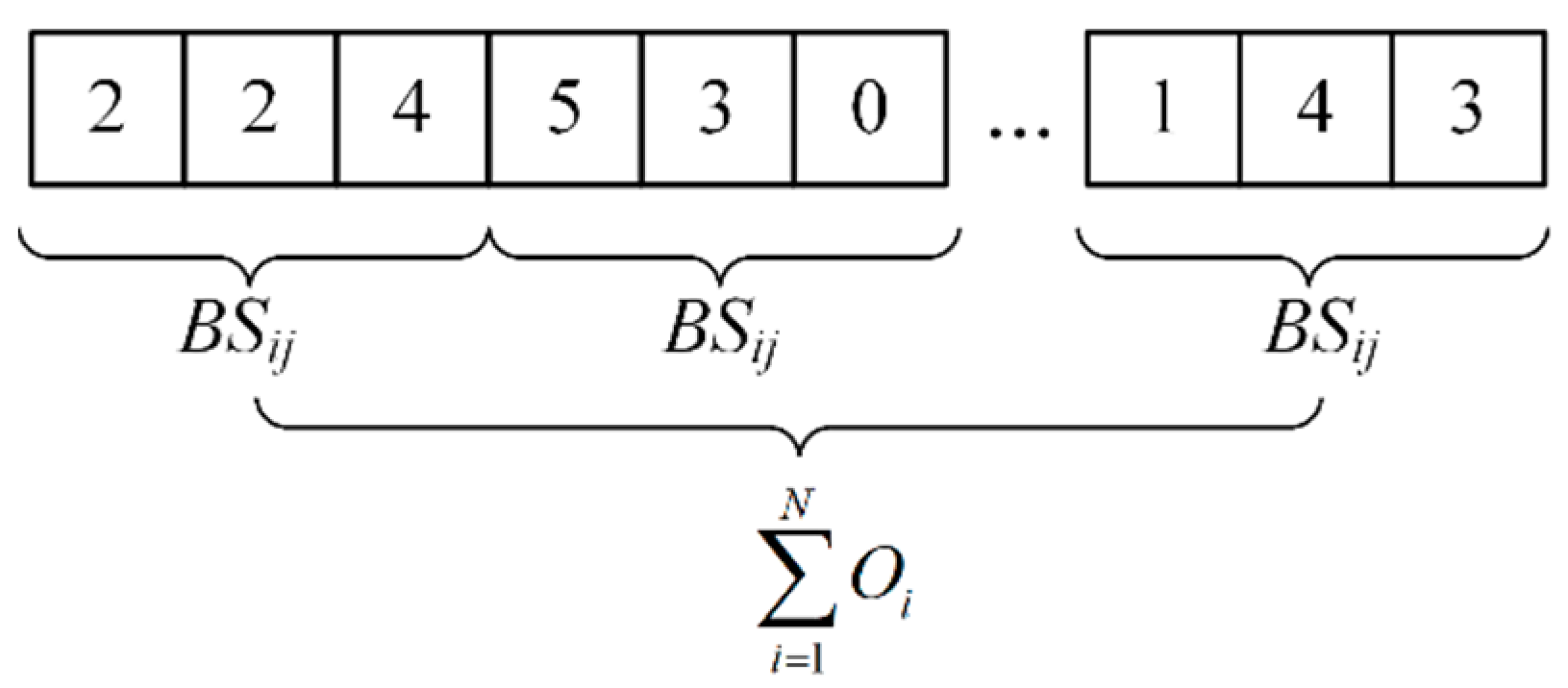
4.2.1. Sublot Splitting Chromosome
The number of sublots,
BSij, into which each operation is divided, as described in
Section 3.3.3, is equal to the sum of the number of machines available for the operation. This is demonstrated by Equation (15).
In this manner, for the
jth process of the job,
i, the number of its sublots expressed on the sublot splitting chromosomes is fixed in length. The sublot splitting chromosome are represented in
Figure 2.
The sublot splitting chromosomes are initially divided into blocks, arranged in the order of jobs and operations. For instance, the first block represents the sublot scheme for the first operation of job 1, while the second block represents the sublot scheme for the second operation of job 1, and so on. The number of genes in each program block represents the maximum number of sublots that can be divided. Each gene represents the size of a sublot. The second block illustrates this. The gene of the second program block is “5/3/0”, indicating that the second operation of job 1 can be divided into three sublots. Since the third sublot is 0, it is divided into two sublots: the first sublot is 5, and the second sublot is 3.
The main advantage of coding the sublot splitting chromosomes in this way is that it ensures that the length of each individual’s chromosomes remains the same during the iterative process. This consistency facilitates mutation, crossover, and decoding operations, and prevents the generation of illegal solutions.
For simplicity and to ensure the quality of the initial solution, this paper adopts an equal-sized batch splitting scheme to initialize the sublot splitting chromosomes. Each operation’s jobs are divided into sublots of equal size.
4.2.2. Sublot Sorting Chromosome
The sublot sorting chromosomes list all sublots for each operation of each job. Their function is to sort these sublots, so the lengths of the sublot sorting chromosomes and the sublot sorting chromosomes should be equal. In this paper, a sequential order of appearance is used to encode the sublot splitting chromosomes.
As illustrated in
Figure 3, the chromosome is comprised of a total of
decimal two-digit numbers. The tens digit of the chromosome indicates the job type to which the current sublots belong. The first digit indicates the number of operations corresponding to the current sublot, and the order of appearance indicates the serial number of the corresponding sublots. For example, the first instance of “21” indicates the first sublot of the first operation of job 2, while the second instance of “21” indicates the second sublot of the first operation of job 2, and so on, until “21” has appeared
BSij times, indicating that all sublots have been sequenced.
It is crucial to recognize that the number representing the next operation can only appear after the number corresponding to the previous operation of each job has been displayed
BSij times. As illustrated in
Figure 3, “22” only appears after three instances of “21”, and “22” for the subsequent operation cannot appear before any instance of “21”. This is consistent with the constraint in
Section 3.3.3, which stipulates that the next operation can only begin once the previous operation of all sublots has been completed.
This two-digit encoding is only suitable for small-scale problems, where both the number of jobs and the number of operations must be less than 10. In contrast, large-scale problems can use four-digit numbers, encoded in the same way. This paper uses two-digit encoding for ease of illustration. Furthermore, the initialization of sublot sorting chromosomes is performed randomly.
4.2.3. Machine Assigning Chromosomes and Worker Assigning Chromosomes
As shown in
Figure 4, machine assigning chromosomes and worker assigning chromosomes are similar in that they are both the same length as sublot sorting chromosomes and sublot splitting chromosomes. Corresponding to the sublot sorting chromosomes, each gene in the machine assigning chromosomes indicates the machine selected for the sublot, and similarly, each gene in the worker assigning chromosomes indicates the worker assigned to the sublot. For example, the first “3” in the machine assigning chromosomes indicates that the sublot selects machine 3 for processing, while the first “1” in the worker assigning chromosomes indicates that the sublot is assigned to worker number 1 for processing. The machine assigning chromosomes and worker assigning chromosomes are initialized in a random manner, taking into account only the processing capacity constraints.
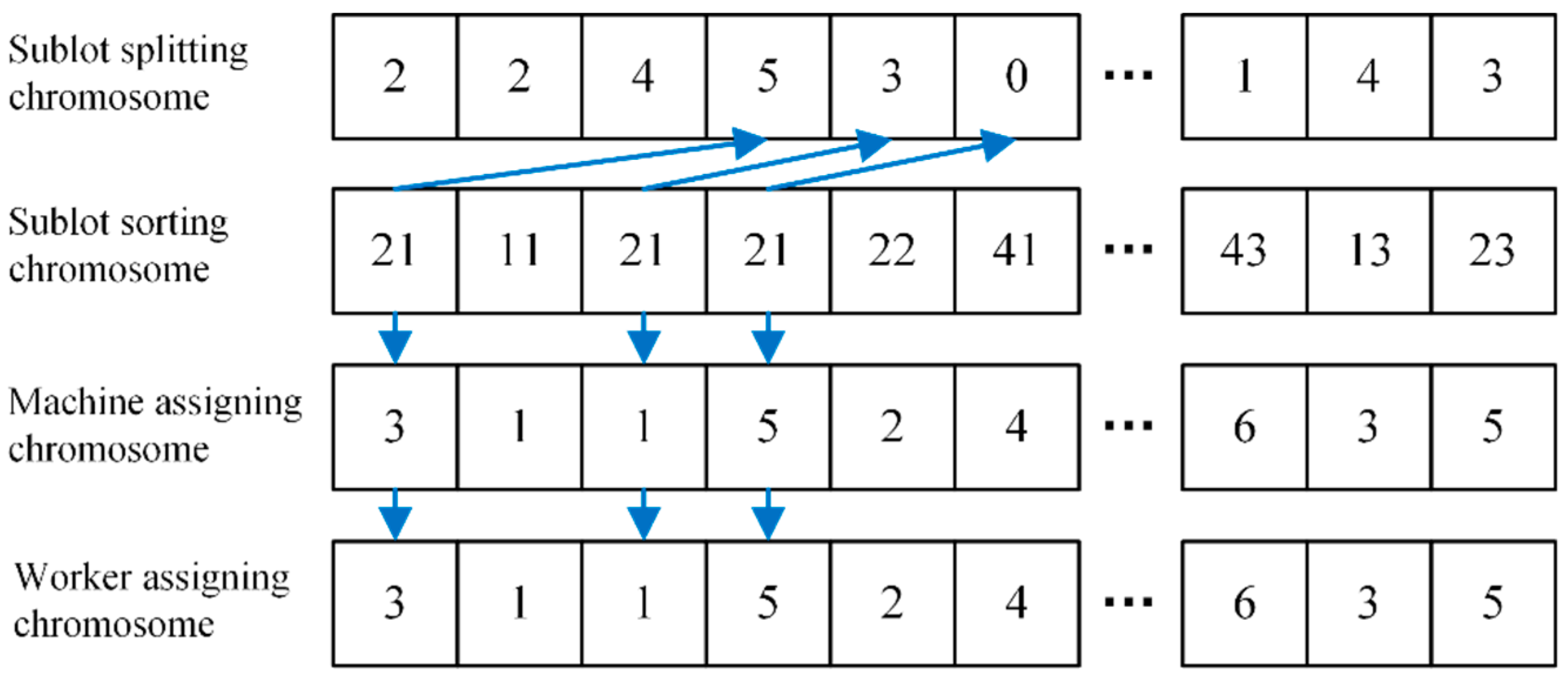
4.2.4. Individual Decoding
An illustration of the decoding process for an individual is shown in
Figure 5. During the decoding process, it is necessary to traverse the sublot sorting chromosome. For example, the decoding process for all sublots of the first operation of job 2 is given in the figure. To illustrate, consider the first instance of the digit “21”. The arrows in the figure indicate how “21” corresponds to the sublot splitting chromosome, machine assigning chromosome, and worker assigning chromosome. This digit is represented by the block “5/3/0” in the sublot splitting chromosome. The first instance of “21” in the figure is therefore “5/3/0”. Decoding the machine assigning-chromosomes and worker assigning chromosomes is relatively simple: directly find the corresponding position of the gene, the selected machine is machine 3, and the assigned worker is worker 3.
The processing time of a sublot can be calculated based on the sublot size, the corresponding operation of the job, and the selected machine and worker. The start time of each sublot is determined by the constraints of the end of the current machining time of the machine and worker and the end time of the machining of all sublots from the previous operation. Subsequently, the end processing time of each sublot can be determined. The maximum sublot end processing time represents the primary objective of the research problem, namely the makespan. The processing time of each sublot is aggregated according to the workers, and the maximum processing time of each worker represents the second objective of the research problem, namely the maximum worker working time.
4.3. First-Stage Discrete Multi-Objective Differential Evolution Algorithm
The conventional differential evolutionary algorithm (DEA) typically follows the following standard process:
- (1)
A random initial population is generated.
- (2)
Mutation of the population.
- (3)
Population crossover.
- (4)
Processing of boundary conditions and selection of an optimal population.
- (5)
Once the predefined termination conditions have been met, the iteration is terminated, and the optimal solution is output.
The mutation and crossover operations typically used in traditional differential evolution algorithms are applied to continuous problems. To effectively address discrete variables and multi-objective optimization challenges, this paper proposes a discrete multi-objective differential evolutionary algorithm. The algorithm considers the characteristics of the discrete problem by appropriately improving the mutation and crossover operations and adopting a Pareto multi-objective optimization strategy to optimize multiple objective functions simultaneously. In this manner, the algorithm can efficiently explore the potential solution space within the discrete search space and identify a set of non-dominated solutions that perform well across multiple objectives.
4.3.1. Adaptive Mutation Operator
The original formula for the adaptive mutation operation in the differential evolutionary algorithm is as follows:
where
denotes the
rth individual of the population in generation
g,
denotes the
rth individual resulting from the mutation in generation
g, and
i = 1, 2, 3, …,
Np,
r1,
r2,
r3 ∈ [1,
Np],
r1 ≠
r2 ≠
r3. In the first stage, adaptive mutation evolution operations are required for sublot sorting chromosomes, machine assigning chromosomes, and worker assigning chromosomes. This formula is more effective when dealing with continuous numerical genes, but not for discrete variables. For the discrete problem, we have improved the original variation operator to suit the problem studied in this paper. For the three discrete variables, sublot sorting chromosomes, machine assigning chromosomes, and worker assigning chromosomes, which are involved in the first stage of this paper, the variation of chromosomes has been improved to a kind of variation based on crossover operation. The specific operation steps are as follows:
- (1)
The Pareto solution set of the population is calculated, and an individual corresponding to a solution in the solution set of the Pareto front is randomly selected as r1.
- (2)
Randomly select two individuals, r2 and r3, from the population that differ from r1, ensuring that r1, r2, r3 ∈ [1, Np], r1 ≠ r2 ≠ r3.
- (3)
The precedence operation crossover (POX) is applied to r1 and r2, resulting in the generation of a new individual, rr.
- (4)
The desired new mutant individual is obtained by crossing the new individual, rr, with r3 for another POX.
The use of POX crossover is straightforward to implement, and it is effective in preserving the structural characteristics of the paternal chromosomes. Furthermore, this approach ensures the rationality of the offspring chromosomes after crossover to meet the operational constraints.
It is acknowledged that using POX crossover may result in individuals becoming too similar. Therefore, this paper proposes an adaptive POX crossover. During the iteration process, the crossover probability is dynamically adjusted based on the number of evolutionary generations to maintain population diversity and improve search efficiency. Specifically, the initial crossover probability is relatively high, promoting individual diversity. Conversely, the crossover probability gradually decreases with more iterations, thereby retaining the genetic information of good solutions. The specific steps of the improved adaptive POX crossover are as follows:
- (1)
The set of jobs is divided into J1 with probability F, while the remainder is J2. The parent chromosomes are designated as p1 and p2, respectively, and the offspring chromosome is designated as cc.
- (2)
The operations of jobs in J1 are copied from p1 to cc, with their positions in cc remaining unchanged.
- (3)
The operations of jobs in J2 are copied from p2 to cc, with the order in cc remaining unchanged. cc represents the resulting individual after POX crossover.
Figure 6 depicts the adaptive POX crossover plot. Pink and blue represent the genes from the p1 and p2 chromosomes that are selected for crossover and transferred to cc, respectively. The arrows indicate the crossover process. In this crossover, p1 represents the superior parent individual whose genes must be retained. The probability of retaining the p1 gene on the parent chromosome, denoted by
F, is given in the following equations:
where
F0 represents the variation operator,
G denotes the maximum number of evolutionary generations, and g denotes the current number of evolutionary generations. At the outset of the algorithm, the adaptive mutation operator is set to 2
F0, which is a high value to maintain individual diversity and prevent premature convergence. As the algorithm progresses, the mutation operator is gradually reduced, and the mutation rate approaches
F0 in the later stages to retain beneficial information, prevent the optimal solution from being destroyed, and increase the probability of finding the global optimum.
4.3.2. Adaptive Crossover Operator and Selection Strategy
In addition to mutation, crossover is also a crucial component of differential evolutionary algorithms. The traditional fixed crossover probability may have limitations in addressing different problems. To address this issue, an adaptive stochastic crossover operator is proposed in this paper, as shown in Equation (19).
This approach ensures that the average value of the crossover operator remains at 0.75. The design of the adaptive crossover operator considers maintaining individual diversity throughout the search process and enhancing global search capability. The enhanced adaptive crossover operator also employs the adaptive POX crossover. However, the probability of retaining the p1 gene of the paternal chromosome was changed from F to CR.
The newly obtained chromosomes from the adaptive crossover serve as the basis for the new sublot sorting chromosomes, machine assigning chromosomes, and worker assigning chromosomes. These chromosomes are then recalculated to reflect the values of the two fitness functions corresponding to the new chromosomes. If the new individual dominates the original individual, the three chromosomes of the individual are updated to reflect the new chromosomes. Otherwise, the original chromosomes are retained. This process follows an elitism procedure, ensuring that the best solutions from the current generation are preserved and passed on to the next generation, thus preventing the loss of high-quality solutions and enhancing the overall performance of the algorithm.
4.3.3. Pseudocode of Discrete Multi-Objective Differential Evolution Algorithm
The specific pseudocode of the proposed first-stage discrete multi-objective differential evolution algorithm is shown in Algorithm 1.
| Algorithm 1. Procedure of discrete multi-objective differential evolution algorithm |
1: For g = 1 to G
2: For each chromosome_type in sublots_sorting_chromosomes, machines_selecting_chromosomes, workers_assigning_chromosomes
3: For each individual i in population
4: Calculate Pareto solution set of the population
5: Select an individual r1 randomly from Pareto solution set
6: Select two different individuals r2 and r3 randomly from the population, ensuring r1 ≠ r2 ≠ r3
7: Perform POX crossover on r1 and r2 to generate a new individual rr
8: Perform POX crossover on rr and r3 to obtain mutant individual
9: Perform adaptive POX crossover as follows:
10: Select jobs into J1 with probability F, remainder into J2
11: Copy jobs from J1 in p1 to cc, maintaining their positions
12: Copy jobs from J2 in p2 to cc, maintaining their order
13: cc = resulting individual after POX crossover
14: Perform enhanced adaptive crossover operation on mutant individual to generate new chromosomes
15: Calculate new fitness values for new chromosomes
16: If new fitness values dominate original fitness values
17: Update individual chromosomes to new chromosomes
18: End If
19: End For
20: End For
21: End For |
4.4. Second-Stage Adaptive Multi-Objective Simulated Annealing Algorithm
In the second stage, iterative optimization is required for the sublot splitting chromosomes to obtain the optimal splitting scheme. In this paper, an adaptive multi-objective simulated annealing algorithm is designed for this subproblem.
4.4.1. Random Disturbance
In the context of simulated annealing iteration, introducing a random perturbation of the chromosome is essential for generating a novel solution. In practical production, machinery processing products often operates on a fixed unit lot, Lp. Consequently, in the design of the perturbation presented in this paper, the unit for perturbation change in sublot splitting chromosomes is also set to Lp. This approach can significantly reduce the search space for sublot splitting chromosomes while simultaneously improving the quality of the solution. The specific method for generating the perturbation is as follows:
- (1)
For each operation divided into multiple sublot sets, randomly select two different sublots, s1 and s2.
- (2)
If rand (0, 1) > PR and the number of sublots of s1 is greater than or equal to Lp, then the number of sublots of s1 should be decreased by Lp, while the number of sublots of s2 should be increased by Lp. Otherwise, no change should be made.
PR is the probability of generating a disturbance for each operation. The value of
Lp is equal to the original lot size of the smallest sublot divided by 100, rounded upward, as illustrated in Equation (20).
This method of generating perturbations not only accelerates the search process by varying the sublot scheme for each operation with a certain probability but also ensures the correctness and reasonableness of the sublot scheme by maintaining a constant sum of sublots for each operation.
4.4.2. Adaptive Acceptance Criterion
The most commonly employed criterion for determining the acceptance or rejection of a novel solution is the Metropolis criterion. If the change in energy (ΔE) is negative, then X′ is accepted as the new current solution X. Otherwise, X′ is accepted as the new current solution X with a probability of exp(−ΔE/T). However, this criterion is only applicable to single-objective optimization problems. For multi-objective problems, some improvement of this acceptance criterion is necessary. The multi-objective Metropolis criterion, as described in this paper, is as follows:
- (1)
Calculate the set of Pareto solutions for the mixed population by adding the individuals generated by the random perturbation to the original population.
- (2)
Calculate the number of newly generated individuals in the Pareto front solution set as NN and the number of individuals in the Pareto front solution set as FN.
Accept the new solution if
NN =
FN; otherwise, accept the new solution with a probability of
MR.
Equation (21) illustrates the value of MR, where the probability of accepting the new solution decreases as the temperature T decreases. The higher the percentage of new individuals in the frontier solution, the higher the probability of accepting the new solution.
4.4.3. Annealing and Termination
In the simulated annealing algorithm, an initial temperature and a termination temperature are set. When the temperature drops below the termination temperature, the simulated annealing algorithm terminates, and no new solutions are searched. In this paper, the following equation is used for the temperature cooling process:
where 0 <
K < 1. This cooling process occurs in the iterative loop of the differential evolution algorithm, meaning that the temperature of the simulated annealing algorithm decreases with each iteration of the differential evolution algorithm. When the temperature is less than the termination temperature, it indicates that the optimal batch scheme has been found. From then on, the batch scheme remains unchanged while only iterations of the differential evolution algorithm continue. Usually, to ensure a thorough search, the initial temperature
T is set higher. To improve search efficiency and reduce solution space complexity, this paper also introduces a new termination strategy. The termination strategy is as follows:
- (1)
Two consecutive temperature drops are performed, each with a number of iterations equal to the Markov chain length L.
- (2)
The simulated annealing algorithm terminates if the number of newly generated individuals, NN, in the Pareto front solution set is zero for each iteration.
The newly implemented termination strategy ensures that the search for a superior batch program is concluded in a timely manner. This not only guarantees the retention of the superior batch program but also reduces unnecessary expenditure of search resources.
4.4.4. Pseudocode of Adaptive Simulated Annealing Algorithm
The specific pseudocode of the proposed second-stage adaptive multi-objective simulated annealing algorithm is shown in Algorithm 2.
| Algorithm 2. Procedure of adaptive simulated annealing algorithm |
1: WHILE T > T_term AND N_iterations < max_iterations AND NOT EarlyTermination DO
2: NN_previous = 0
3: FOR each solution X in population P DO
4: FOR i = 1 TO L DO
5: Generate a random perturbation for X:
6: For each operation divided into multiple sublot sets:
7: Randomly select two different sublots s1, s2.
8: IF rand(0, 1) > PR AND number of sublots of s1 ≥ Lp THEN
9: Decrease the number of sublots of s1 by Lp.
10: Increase the number of sublots of s2 by Lp.
11: Calculate the energy difference ΔE between X and X’ (perturbed solution).
12: IF ΔE < 0 OR (NN = FN) OR (rand(0, 1) < exp(-ΔE/T)) THEN
13: Accept X’ as the new current solution X.
14: Update population P with X’.
15: Update Pareto front solutions.
16: Update NN and FN based on the new solutions in the Pareto front.
17: END IF
18: END FOR
19: END FOR
20: Update temperature T using cooling schedule T = T × K.
21: IF NN > 0 THEN
22: N_iterations = 0
23: ELSE
24: N_iterations = N_iterations + 1
25: END IF
26: IF NN_previous == 0 AND NN == 0 THEN
27: N_consecutive = N_consecutive + 1
28: IF N_consecutive >= 2 THEN
29: EarlyTermination = true
30: END IF
31: ELSE
32: N_consecutive = 0
33: END IF
34: NN_previous = NN
35: END WHILE |
5. Experiments and Analysis
In this paper, we have designed several sets of experiments for the mixed-integer linear programming model and the TSMOEA algorithm proposed for the DRCFJSP-VS problem to verify the reliability of the model and the stability and efficiency of the algorithm, and the designed experiments are all programmed in Python 3.7 and run on a computer with 8 G of RAM and a 2.3 Ghz CPU.
5.1. Validation of the Proposed MILP Model
In order to verify the validity of the proposed mixed-integer linear programming (MILP) model, this paper employs IBM’s CPLEX optimization solver to solve the model. CPLEX, as an industry-leading commercial optimization software, is capable of efficiently dealing with all kinds of linear and integer programming problems due to its excellent performance. The CPLEX solver was employed to obtain optimal or near-optimal solutions to the MILP model, which will serve as important benchmarks for subsequent comparative analyses.
Given the potential difficulties CPLEX may encounter when addressing large-scale problems, a small-scale arithmetic instance drawn from real-world production has been selected for comparative analysis in this paper. The specific data for the arithmetic case are presented in
Table 2 and
Table 3.
Table 2 lists the time required for the jobs to be processed by the selected machine under different operations, as well as the original sublot size of the jobs.
Table 3 reflects the coefficients of the workers’ ability to operate the different machines, with larger coefficients indicating that the worker is less proficient in operating the machine. In the table, “-” indicates that the machine is not able to process the operation or the worker is not able to operate the machine.
The two-stage multi-objective evolutionary algorithm (TSMOEA) proposed in this paper is then applied to the algorithmic example and compared with the solution results from CPLEX. The Pareto front solutions for both are computed and plotted as line graphs for visualization (as shown in
Figure 7). The blue points in the figure represent the Pareto frontier solutions solved by CPLEX, while the orange points represent the frontier solutions solved by TSMOEA. Although the solutions produced by CPLEX exhibit slightly superior performance, the discrepancy between the two is not substantial. This substantiates the MILP model developed in this paper and demonstrates that TSMOEA is comparable to CPLEX in terms of performance on small-scale problems, thereby corroborating its excellent efficacy.
In the context of small-scale problems, CPLEX is unquestionably effective. However, when confronted with large-scale problems, the solution time of CPLEX tends to increase significantly, making it challenging to guarantee the attainment of a global optimal solution. In contrast, the TSMOEA algorithm proposed in this paper is well-suited to address this challenge and offers an efficacious solution for the resolution of large-scale problems.
5.2. Experimental Test Instances
This paper explores the dual-resource constrained flexible job shop scheduling problem with variable sublots (DRCFJSP-VS), an area that remains underexplored. As a result, comprehensive and standardized test instances for direct reference are scarce. To thoroughly evaluate the effectiveness and performance of the proposed algorithm, we have meticulously enhanced and expanded the standardized test instances originally designed by Brandimarte [
31] and Dauzere-Peres et al. [
32]. Specifically, we have constructed 28 new test instances by introducing key parameters such as the original batch size of the job (S_job), the number of workers (N_worker), and the efficiency of workers operating machines (E_worker). These parameters were varied randomly to create a diverse set of scenarios. The details of these arithmetic instances are presented in
Table 4. This curated set of instances provides a robust foundation for our investigation and enables a precise assessment and improvement of the proposed scheduling algorithm.
5.3. Parameter Settings and Design of Experiment
In order to ensure the diversity of the population and adequate search of the algorithm, this paper empirically sets the size of the population, Np, to 100, the number of iterations, G, of the differential evolutionary algorithm to 100, the decay parameter, K, of the temperature to 0.99, and the termination temperature to T0 = 0.001.
In addition, three key parameters must be determined: the variation operator
F0 underlying the differential evolution algorithm, the initial temperature
T for simulated annealing, and the length
L of the Markov chain to be searched for each temperature. The probability of retaining the optimal parent genes is determined by
F0, the probability of the algorithm accepting an inferior solution is determined by
T, and
L ensures that each temperature is adequately searched. Failure to adequately search for the optimal solution will cause the simulated annealing to terminate prematurely, thus missing the optimal solution. In this paper, this is determined using the design of experiment (DOE) method using instance mk02 in 5.2. For each of the three parameters, four parameter levels were selected, as shown in
Table 5.
Based on the number of parameters and the number of levels, an orthogonal test of size
L16(4
3) is selected, as shown in
Table 6. The TSMOEA is run 20 times for each combination of parameter levels, and the average of the IGDs obtained from these 20 runs is taken as the response value (RV) for the current combination.
As illustrated in
Table 7 of the results of orthogonal experiments, the response values of the four tests corresponding to each level of each parameter are averaged (with six decimals retained) and recorded as the average response value for each parameter. The difference between the maximum and minimum values of the average response values for each parameter was calculated as the range, and the ranges were ranked in descending order to indicate the significance of each parameter.
The parameter
F0 has the greatest range, thus exerting the most significant influence on the performance of the algorithm. If
F0 assumes an excessively large value, it will prompt the algorithm to converge prematurely and settle into a local optimum solution. To facilitate analysis, the average response values presented in
Table 7 are plotted as a line graph, as illustrated in
Figure 8.
As illustrated in
Figure 8, the smaller the average response value of each parameter, the more effective the algorithm. Therefore, each parameter of the TSMOEA algorithm proposed in this paper is selected as follows: the base variance factor
F0 = 0.2 for the differential evolution algorithm, the starting temperature
T = 100 for the simulated annealing algorithm, and the length of the Markov chain for each temperature search,
L = 100.
5.4. Comparative Analysis of TSMOEA Variants and Other Algorithms
In order to verify the effectiveness of the improved mutation operator, improved crossover operator, and improved simulated annealing algorithm, this paper introduces additional experiments involving the two-stage multi-objective evolutionary algorithm (TSMOEA) with traditional mutation, TSMOEA with traditional crossover, and TSMOEA with traditional simulated annealing. These experiments aim to evaluate the performance of the proposed improvements. For the traditional mutation operator (TSMOEA-TM), the parameters are set according to common values used in differential evolution: mutation factor (F) = 0.5. For the traditional crossover operator (TSMOEA-TC), the crossover probability (CR) is set to 0.9, which is the probability with which the crossover operation is applied to the individuals. For the traditional simulated annealing (TSMOEA-TSA), the initial temperature (T0) is set to 1000, the cooling rate (K) is set to 0.99, with a maximum of 500 iterations per temperature level, and the stopping criterion is when the temperature drops below a threshold (typically 0.001) or after a fixed number of iterations.
In addition, the TSMOEA proposed in this paper is compared with several widely used algorithms for solving the job shop scheduling problem, including the non-dominated sorting genetic algorithm II (NSGA-II, Fan et al. [
33]), particle swarm optimization (PSO, Zhou et al. [
34]) algorithm, the grey wolf optimizer (GWO, Arani et al. [
35]) algorithm, and the whale optimization algorithm (WOA, Li et al. [
36]). These algorithms are applied to the test instances introduced in
Section 5.2 for comparison. Since none of these algorithms directly address the dual-resource constraints with variable-sized batch splitting and worker capacity, necessary modifications are made by introducing sublot splitting chromosomes and worker assigning chromosomes to adapt these algorithms to the problem at hand. The original parameter settings for each algorithm are adopted as recommended in their respective reference papers.
In order to evaluate the comprehensive performance of the algorithms, two commonly used metrics in multi-objective optimization, Inverted Generational Distance (IGD) and Hypervolume (HV), are selected. The IGD metric measures the minimum Euclidean distance from the true Pareto front to the solution set, focusing on both convergence and distribution, with a smaller IGD value indicating better algorithm performance. The HV metric measures the volume of the region in the objective space enclosed by the set of non-dominated solutions obtained by the algorithm and a reference point. The larger the HV value, the better the comprehensive performance of the algorithm.
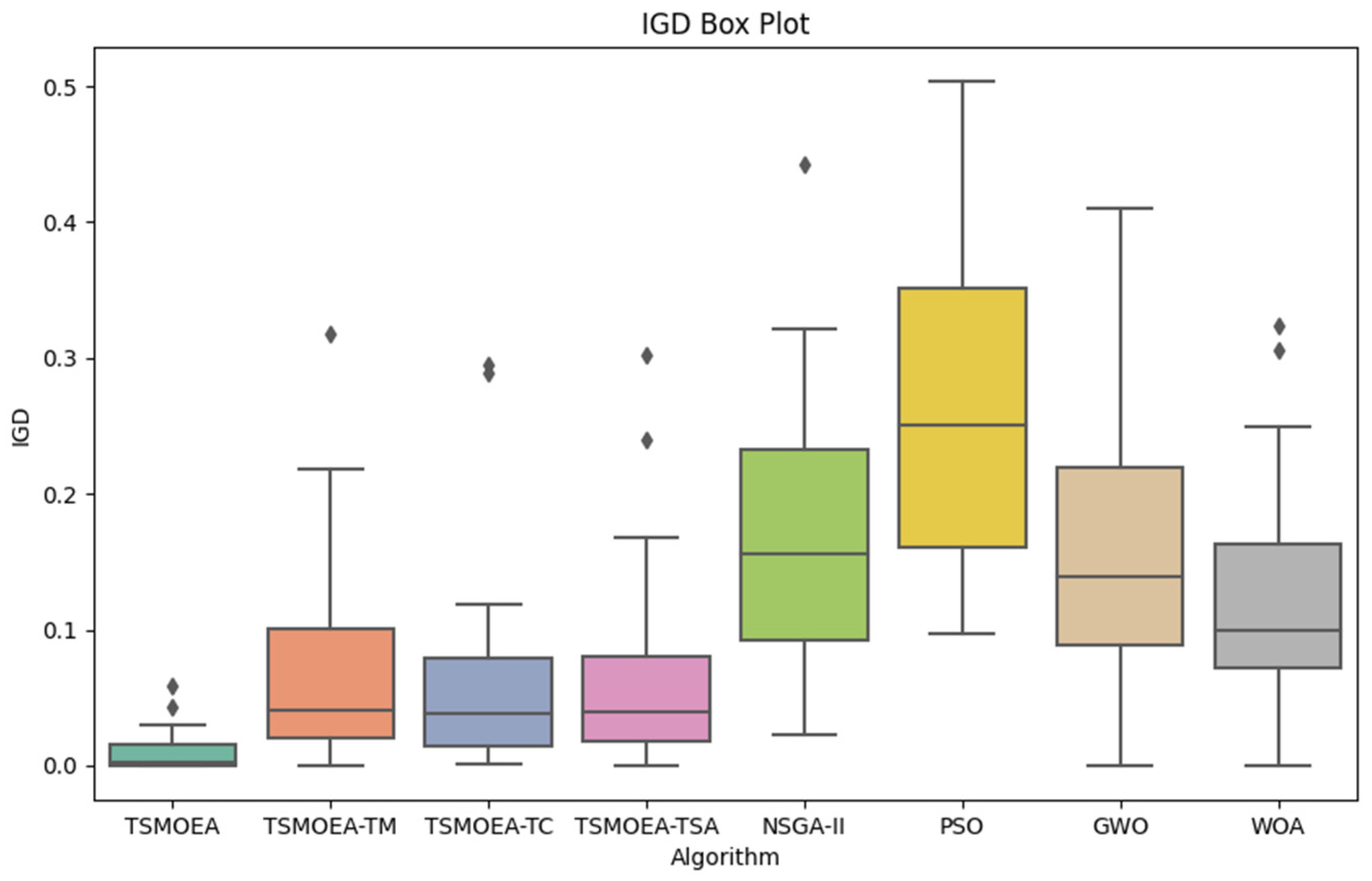
TSMOEA and its variants (TSMOEA-TM, TSMOEA-TC, and TSMOEA-TSA), along with the other four comparison algorithms (NSGA-II, PSO, GWO, and WOA), were each run 20 times on each dataset. The average IGD and HV values obtained from these experiments are recorded in
Table 8.
In order to facilitate the analysis of the stability and efficiency of each algorithm, the data in
Table 8 are plotted as a box plot, as shown in
Figure 9 and
Figure 10.
It can be seen that TSMOEA has the smallest median average IGD value and the smallest lower and upper edges of the box plots, while the median average HV is the largest, and the lower and upper edges of the box plots are the widest. This indicates that TSMOEA outperforms other algorithms in terms of optimality-seeking ability. Notably, the improvements made to the mutation operator, crossover operator, and simulated annealing algorithm contribute significantly to this performance. The adaptive mutation operator helps the algorithm explore a broader search space, while the adaptive crossover operator facilitates better solution combinations. Furthermore, the improved simulated annealing algorithm enhances the algorithm’s ability to escape local optima and reach more optimal solutions. In addition, the IGD and HV box plots of TSMOEA are the shortest, indicating that its solutions are more centralized and that its stability is better than that of other algorithms.
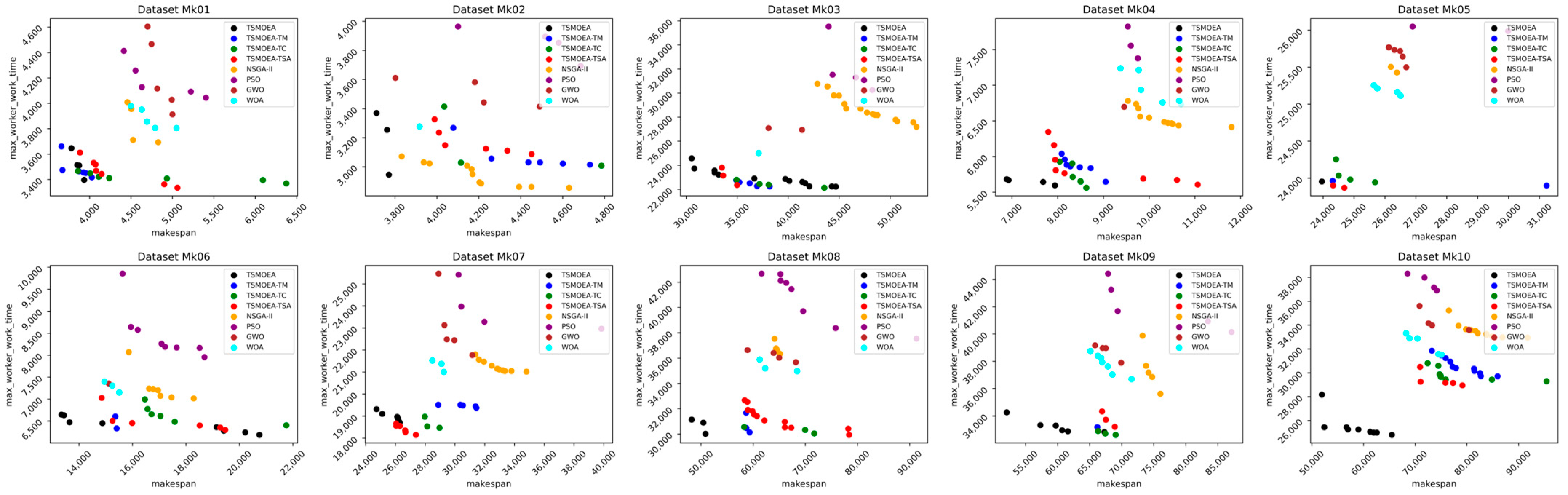
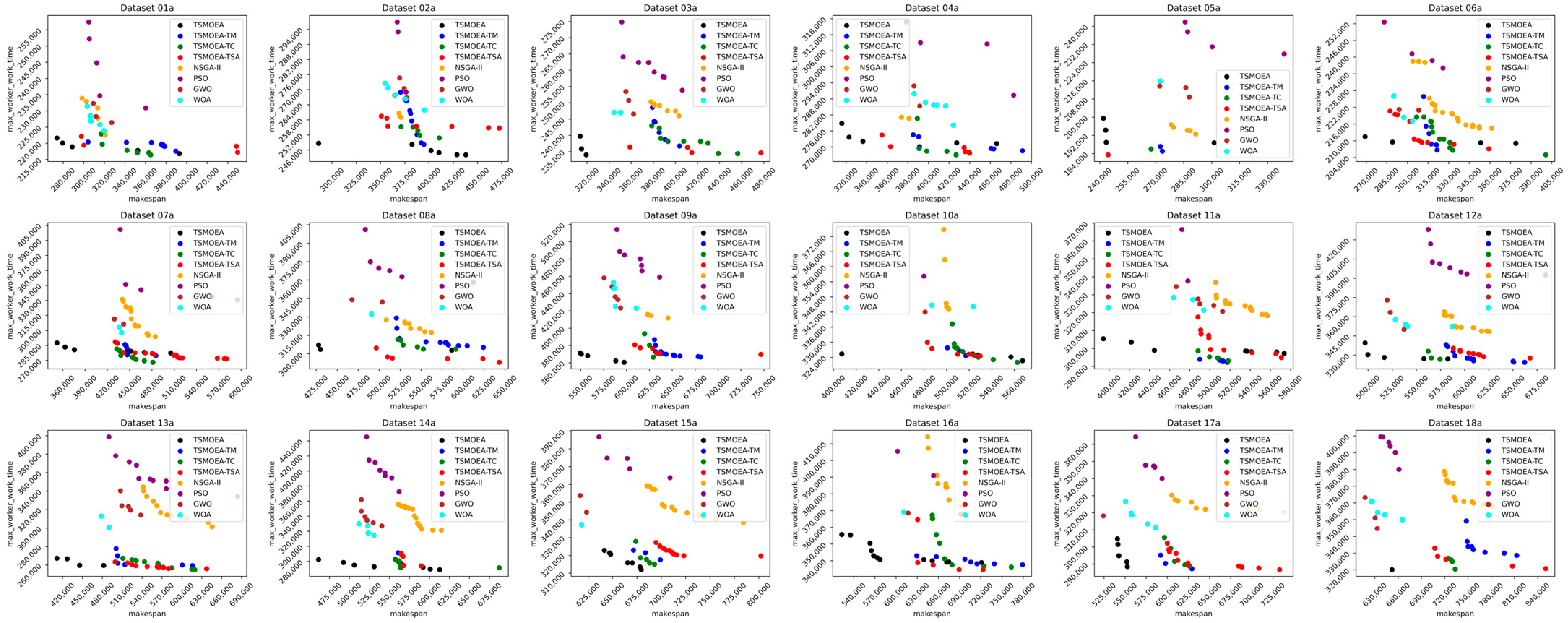
To more clearly compare the effects of the five algorithms on different datasets, scatter plots of the Pareto front solutions obtained by each algorithm are shown in
Figure 11 and
Figure 12.
Overall, the TSMOEA algorithm proposed in this paper exhibited better optimization ability and algorithmic stability in solving the DRCFJSP-VS, effectively solving this problem.
6. Conclusions
In conclusion, this study has made significant progress in addressing the dual-resource constrained flexible job shop scheduling problem with variable sublots (DRCFJSP-VS) by integrating variable sub-batching alongside dual constraints on human and machine resources. The proposed MILP model and two-stage multi-objective evolutionary algorithm (TSMOEA) effectively optimize scheduling under these complex conditions. The TSMOEA incorporates an adaptive mutation operator and adaptive crossover, and it handles dual-resource constraints, which significantly enhance the solution quality for real-world scheduling problems.
However, this study has limitations. It did not consider buffer management between machines, which could lead to blockages. Given that buffer capacity can greatly influence sublot splitting, its inclusion could further improve the robustness of the model. Additionally, unforeseen events, such as worker illness or fatigue, were not incorporated, potentially impacting processing efficiency.
Future research should consider integrating buffer constraints and dynamically adjusting sublot splitting strategies according to buffer capacity. Furthermore, incorporating workers’ adaptability to unforeseen circumstances is essential for improving the practical applicability and flexibility of scheduling solutions, particularly in dynamic environments.


 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}