
A Multigranularity Parallel Pyramidal Transformer Model for Ethylene Production Prediction and Energy Efficiency Optimization


Abstract
1. Introduction
- (1)
- We proposed a novel multigranularity modeling method, named MPPT, which enables more comprehensive feature extraction for industrial process data.
- (2)
- We conducted time-series prediction comparative experiments on an industrial ethylene dataset. The results showed that MPPT achieved the best performance among all comparison models.
- (3)
- Leveraging the prediction accuracy of the MPPT model for ethylene production, we adjusted and optimized the input ratios in ethylene production, achieving energy efficiency optimization in the ethylene production industry.
2. Related Works
2.1. Shallow Neural Networks
2.2. Deep Learning Methods
3. Materials and Methods
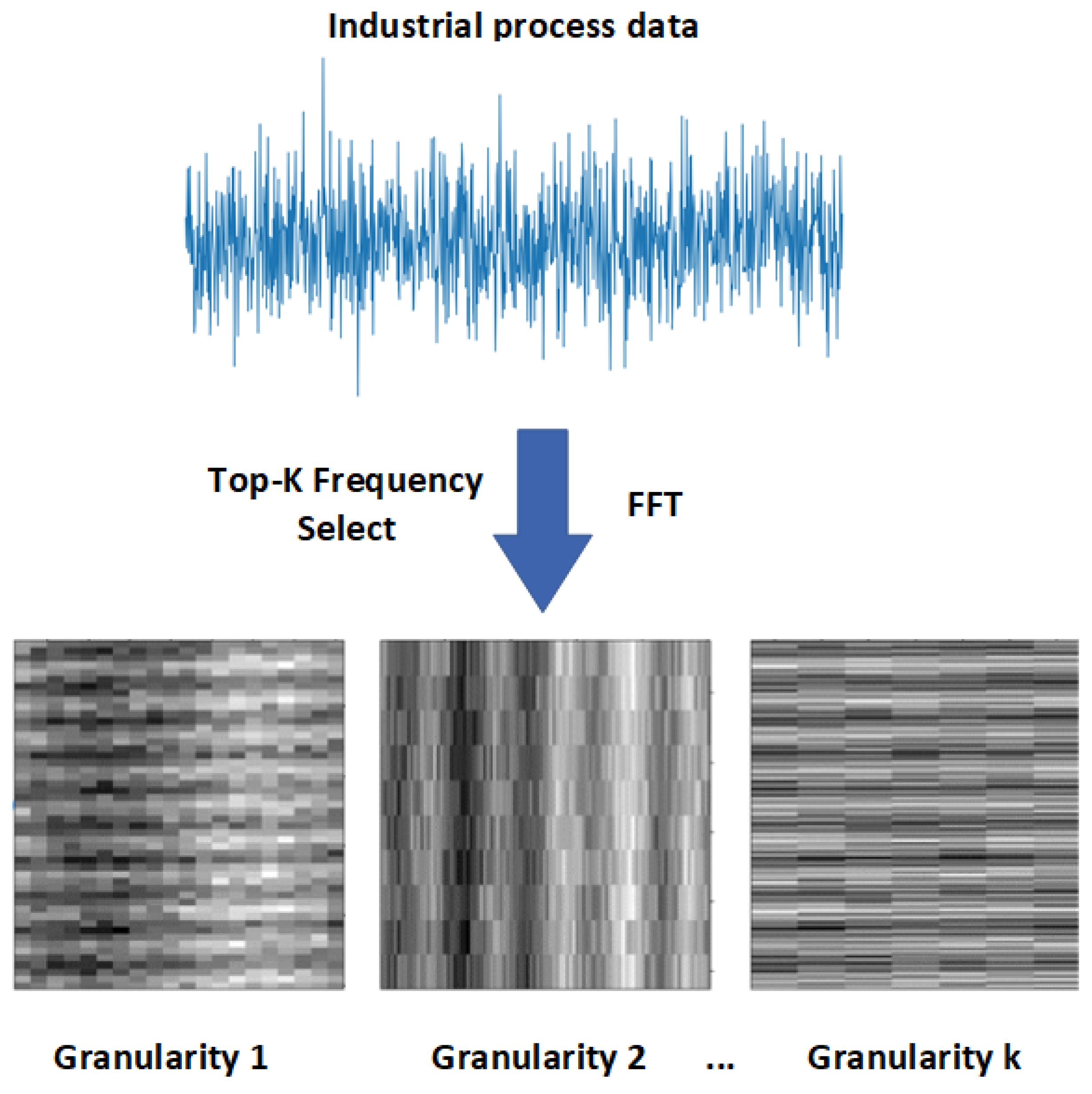
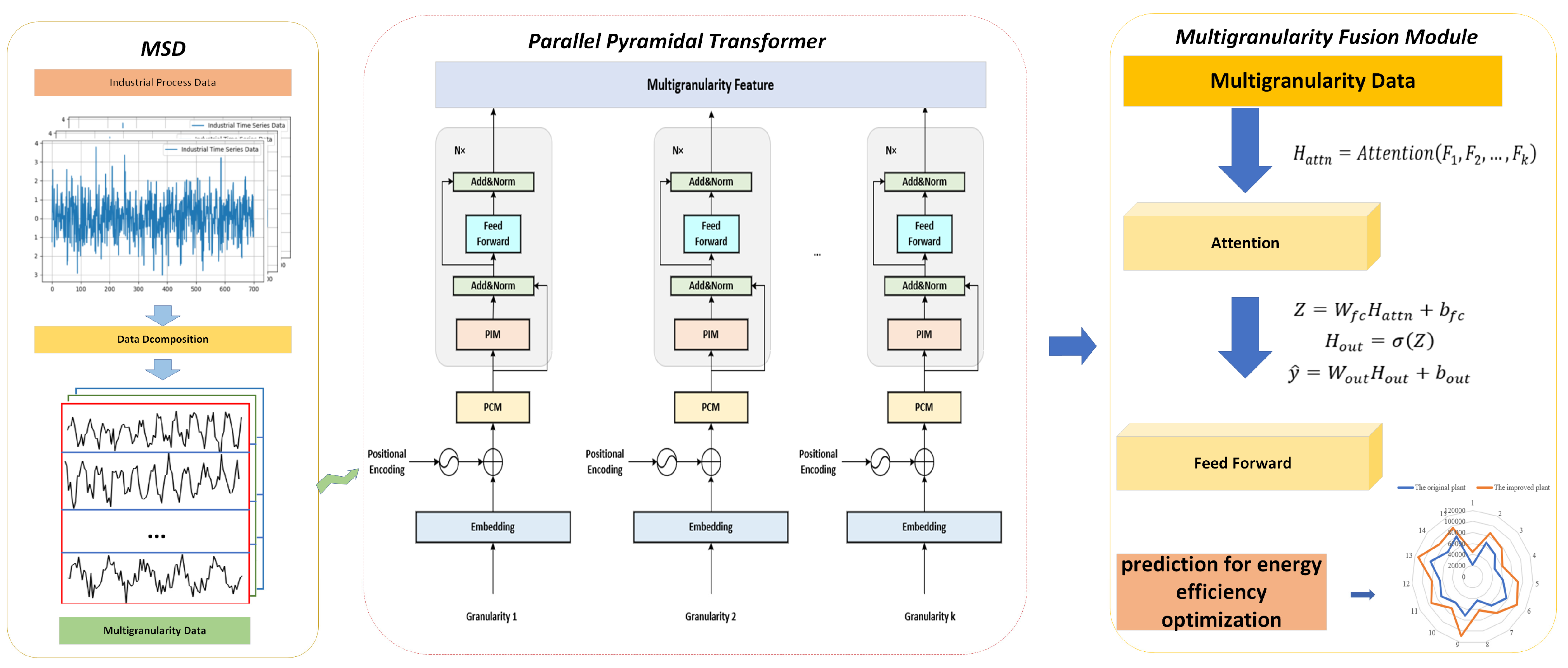
3.1. Multiscale Decomposition Method (MSD)
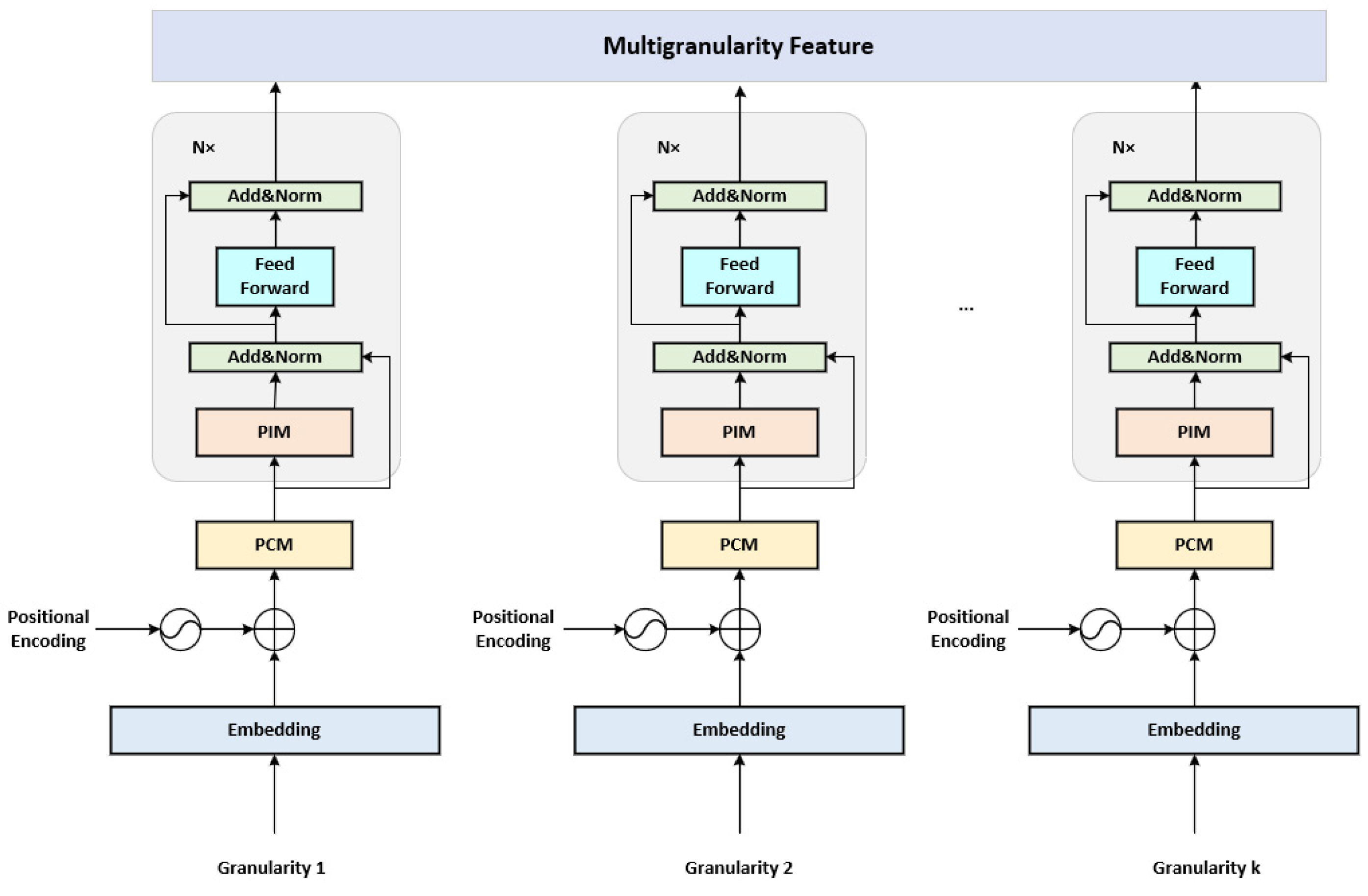
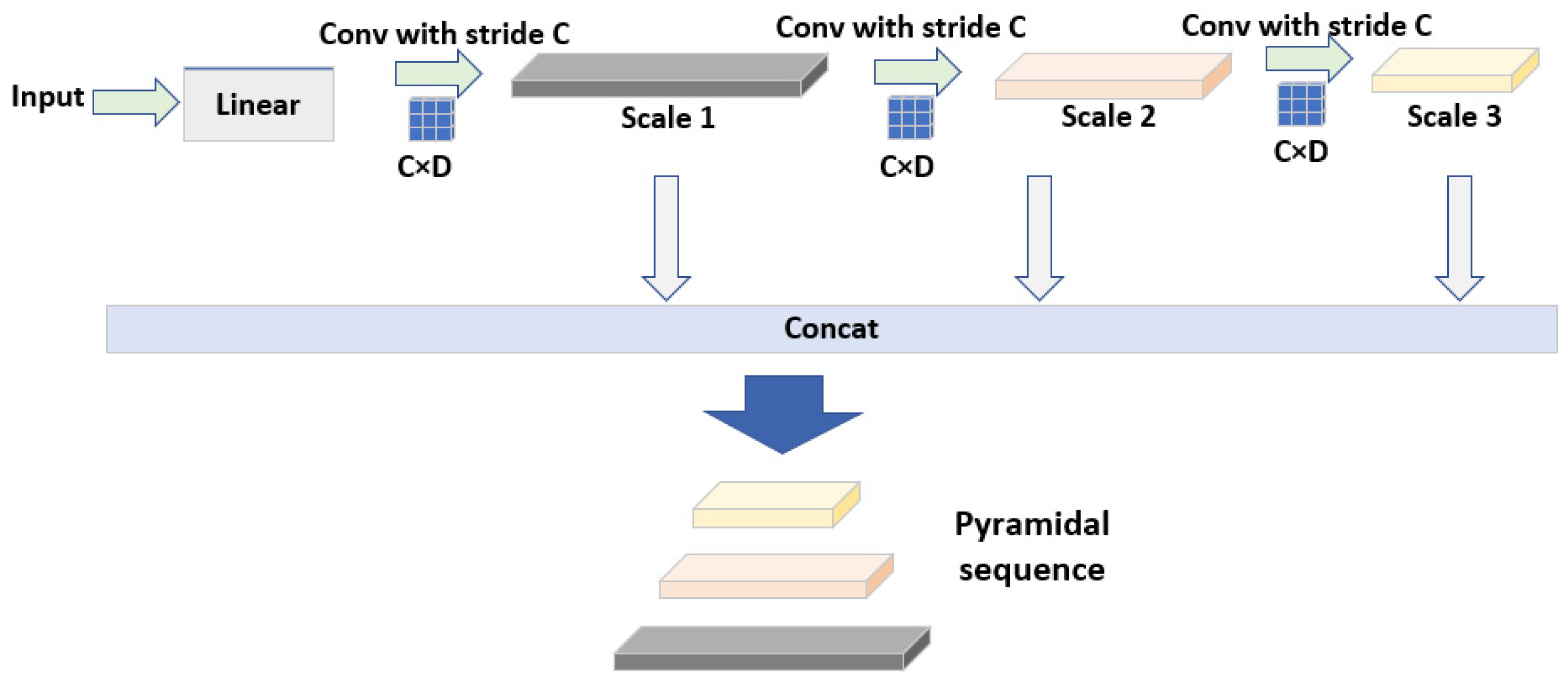
3.2. Parallel Pyramid Transformer (PPT)
3.3. Multigranularity Fusion Module (MF)
3.4. Multigranularity Parallel Pyramid Transformer (MPPT)
4. Experiments and Results
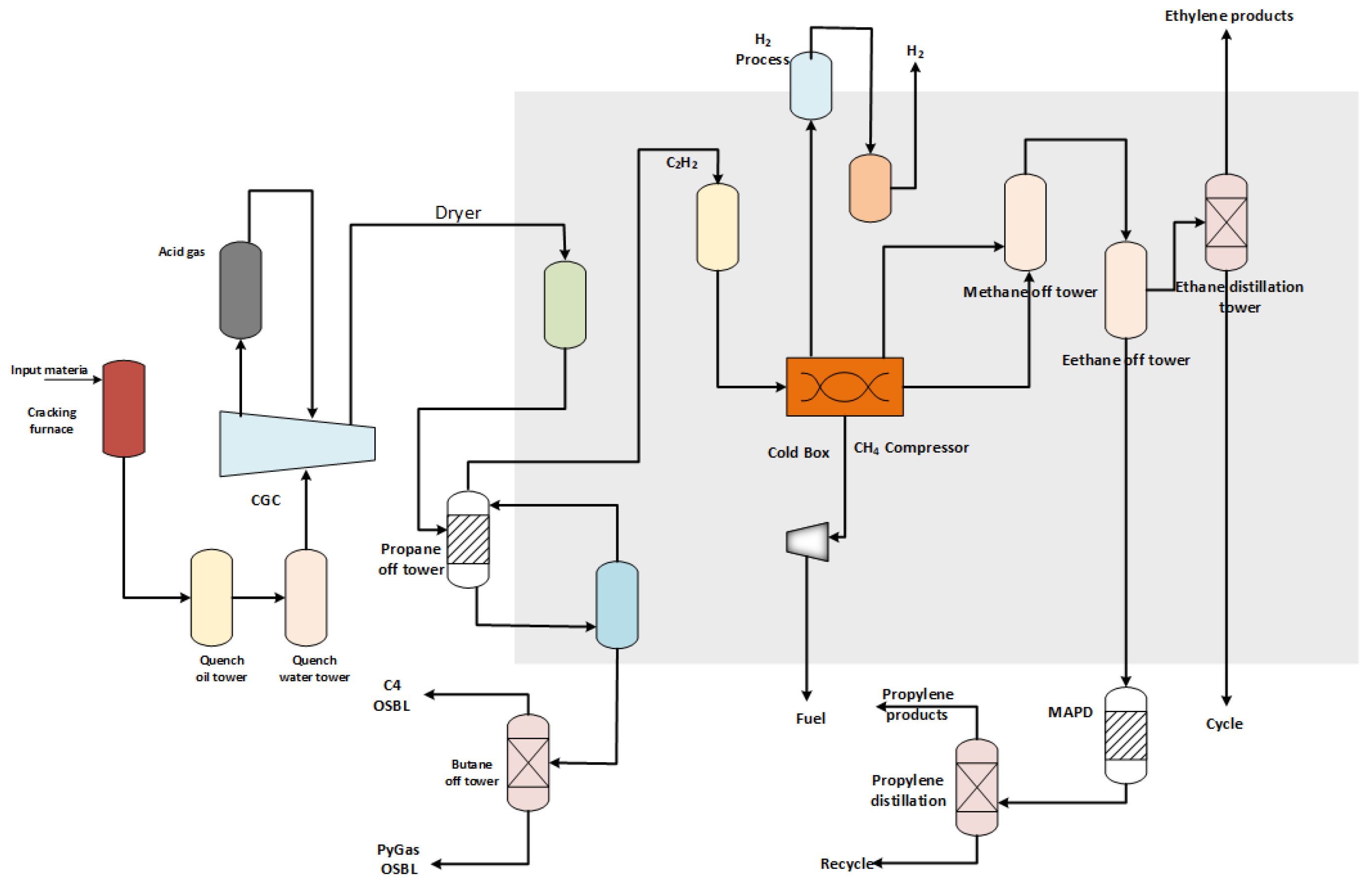
4.1. Ethylene Production Process
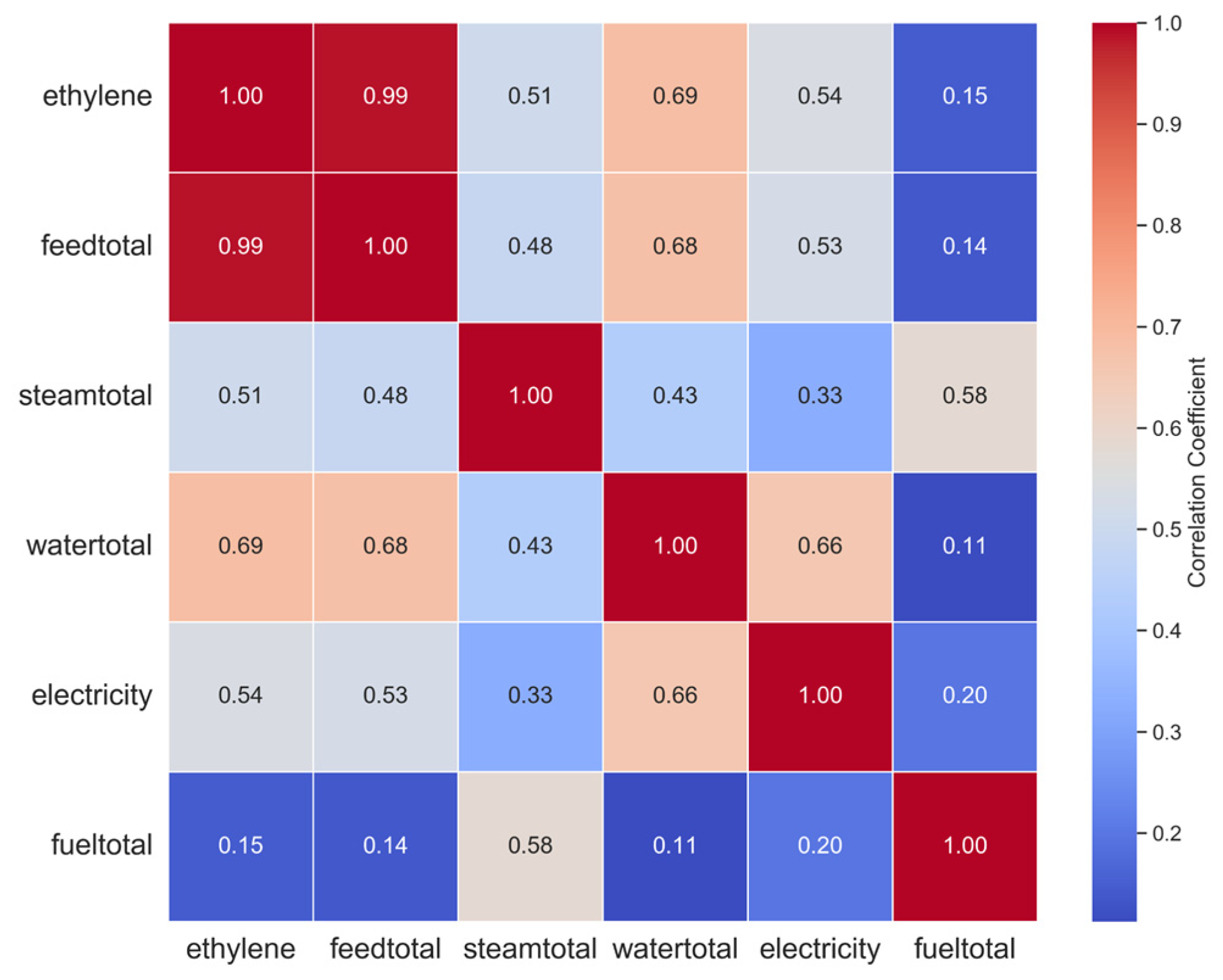
4.2. Analysis of the Ethylene Production Data
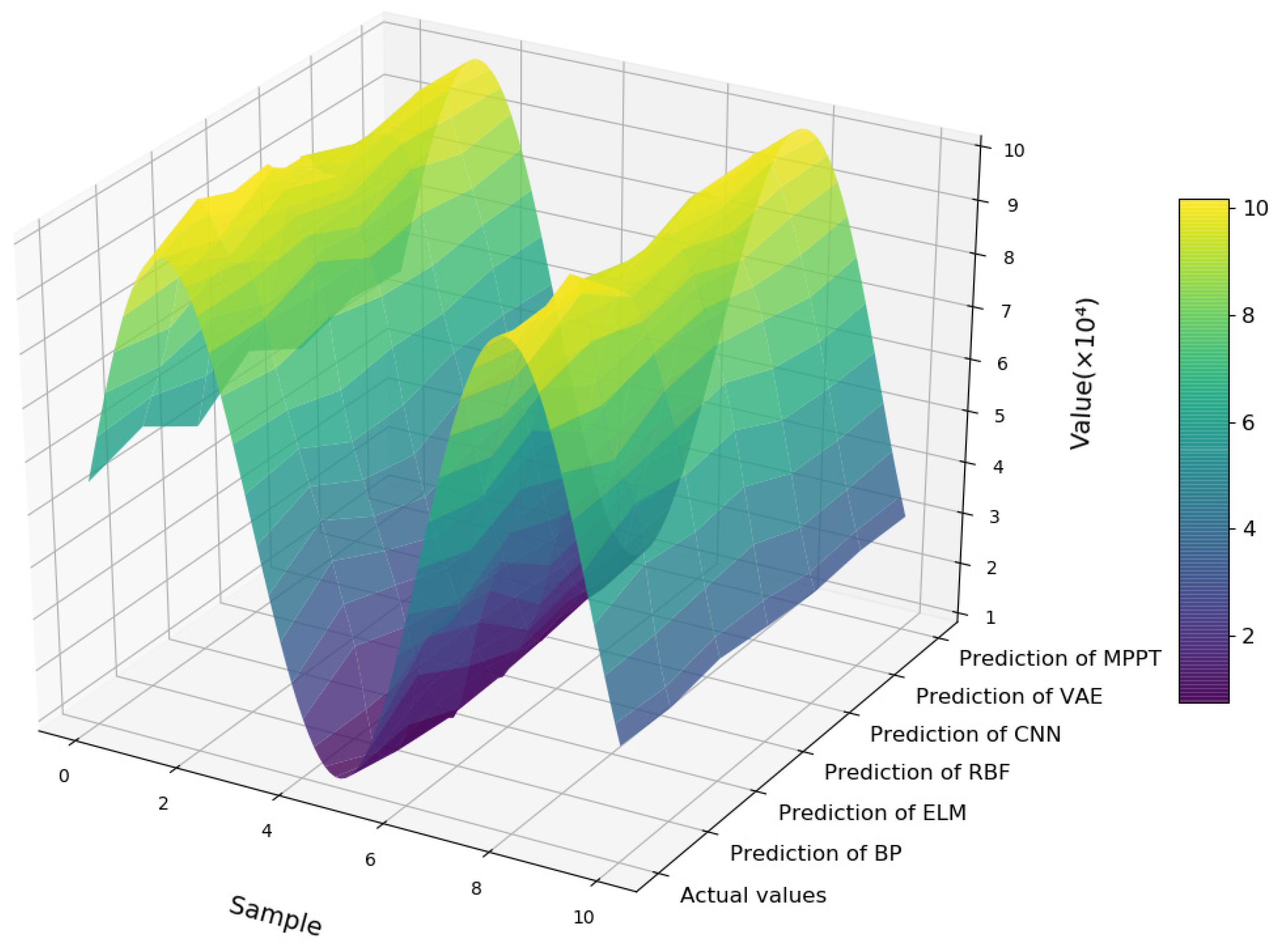
4.3. Case Analysis: Production Prediction and Energy Conservation of Ethylene Production Process
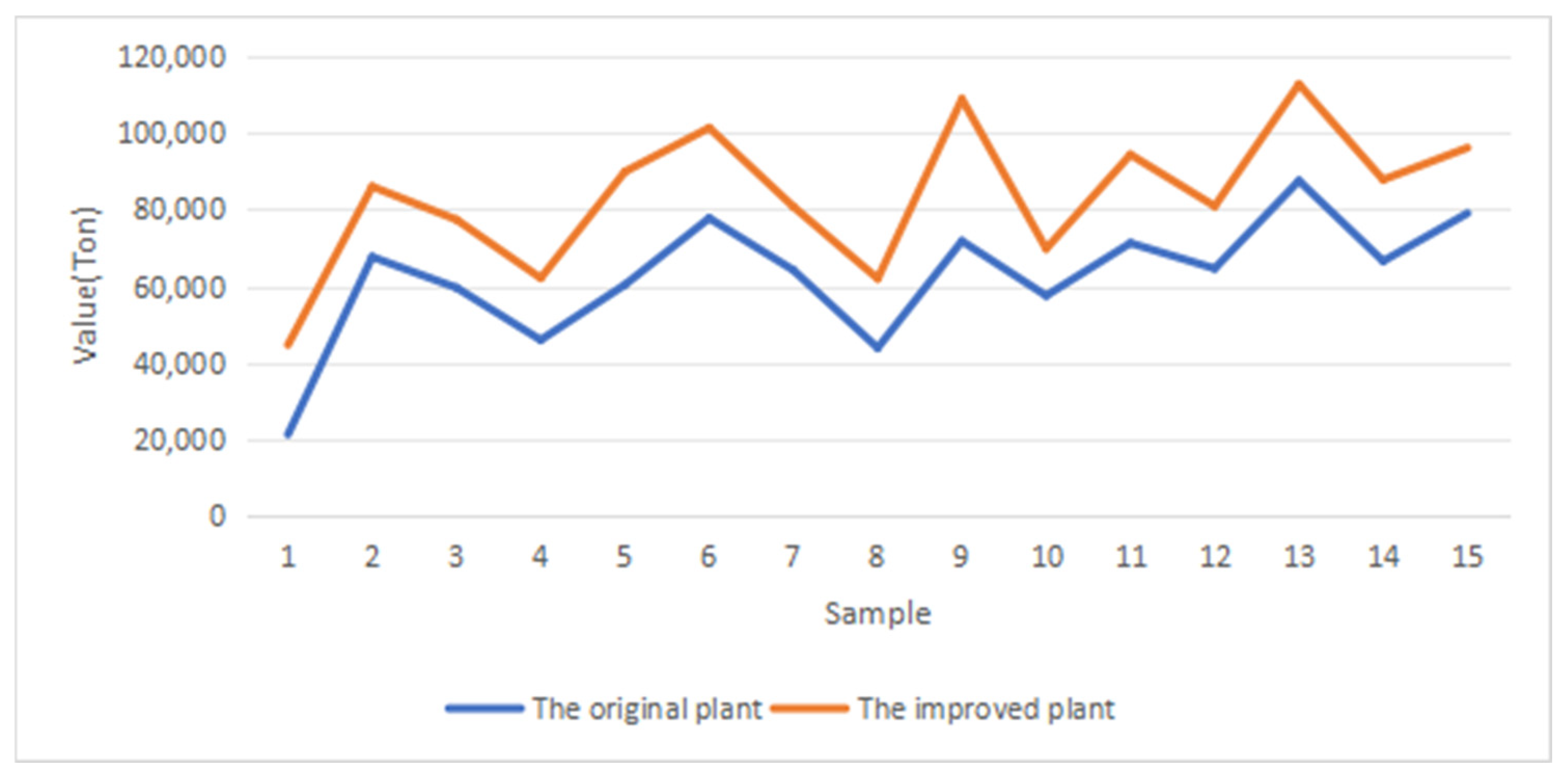
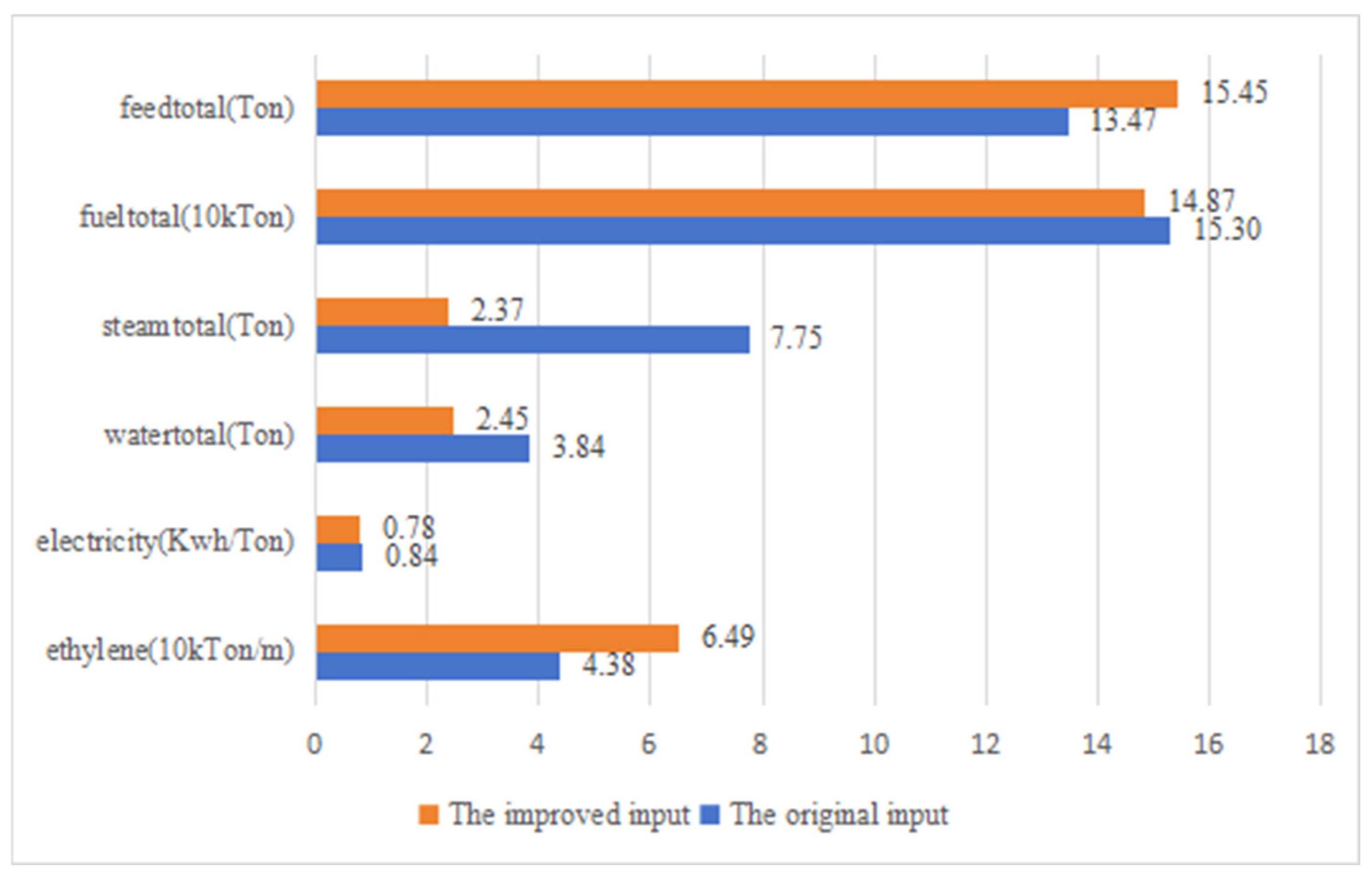
4.4. Energy Efficiency Optimization
5. Discussion
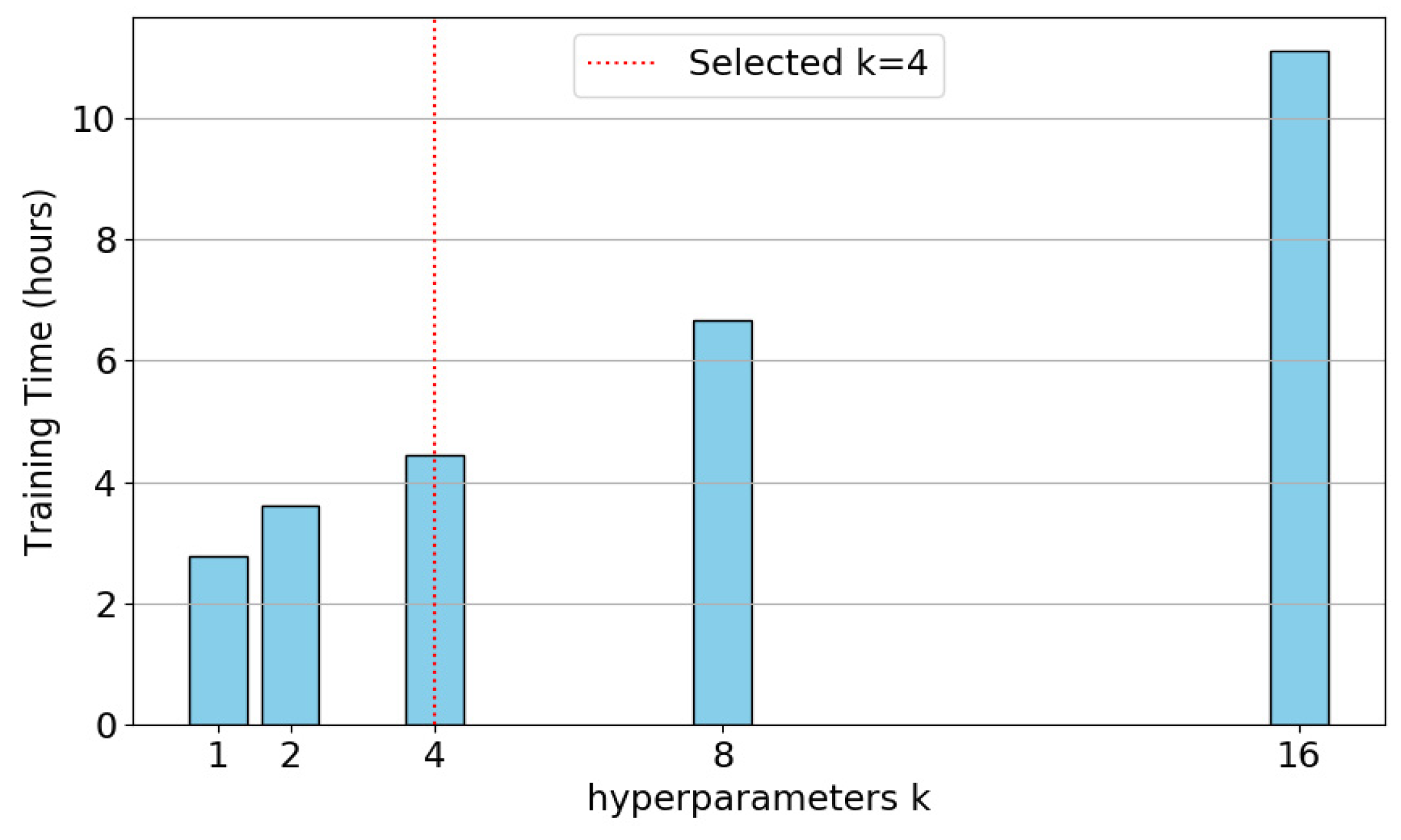
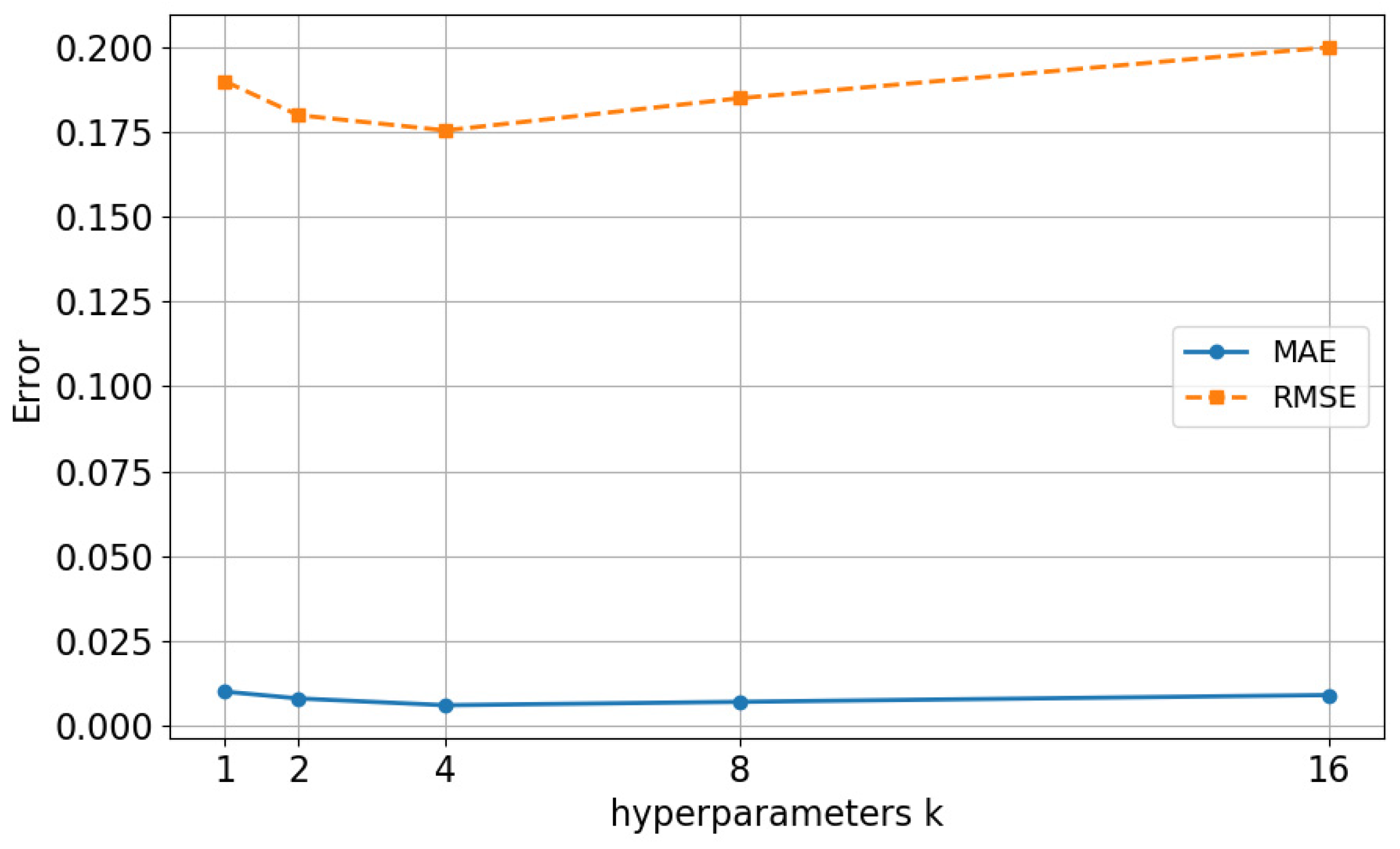
5.1. Limitation Discussion
5.2. Results and Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Tian, C.; Liang, Y.; Lin, Q.; You, D.; Liu, Z. Environmental Pressure Exerted by the Petrochemical Industry and Urban Environmental Resilience: Evidence from Chinese Petrochemical Port Cities. J. Clean. Prod. 2024, 471, 143430. [Google Scholar] [CrossRef]
- Chen, Q.; Lv, M.; Wang, D.; Tang, Z.; Wei, W.; Sun, Y. Eco-Efficiency Assessment for Global Warming Potential of Ethylene Production Processes: A Case Study of China. J. Clean. Prod. 2017, 142, 3109–3116. [Google Scholar] [CrossRef]
- Geng, Z.; Zhang, Y.; Li, C.; Han, Y.; Cui, Y.; Yu, B. Energy Optimization and Prediction Modeling of Petrochemical Industries: An Improved Convolutional Neural Network Based on Cross-Feature. Energy 2020, 194, 116851. [Google Scholar] [CrossRef]
- Li, Q.; Zhang, M.; Shi, X.; Lan, X.; Guo, X.; Guan, Y. An Intelligent Hybrid Feature Subset Selection and Production Pattern Recognition Method for Modeling Ethylene Plant. J. Anal. Appl. Pyrolysis 2021, 160, 105352. [Google Scholar] [CrossRef]
- Wang, Y.; Tang, B.; Tao, W.; Yuan, A.; Li, T.; Liu, Z.; Zhang, F.; Mao, A. Triaxial Compression Strength Prediction of Fissured Rocks in Deep-Buried Coal Mines Based on an Improved Back Propagation Neural Network Model. Processes 2023, 11, 2414. [Google Scholar] [CrossRef]
- Wang, R.; Chen, L.; Huang, Z.; Zhang, W.; Wu, S. A Review on the High-Efficiency Detection and Precision Positioning Technology Application of Agricultural Robots. Processes 2024, 12, 1833. [Google Scholar] [CrossRef]
- Zhang, R.; Wang, Y.; Wang, K.; Zhao, H.; Xu, S.; Mu, L.; Zhou, G. An Evaluating Model for Smart Growth Plan Based on BP Neural Network and Set Pair Analysis. J. Clean. Prod. 2019, 226, 928–939. [Google Scholar] [CrossRef]
- Zhang, M.; Cao, D.; Lan, X.; Shi, X.; Gao, J. An Ensemble-Learning Approach To Predict the Coke Yield of Commercial FCC Unit. Ind. Eng. Chem. Res. 2022, 61, 8422–8431. [Google Scholar] [CrossRef]
- Singh, B. MOWM: Multiple Overlapping Window Method for RBF Based Missing Value Prediction on Big Data. Expert Syst. Appl. 2019, 122, 303–318. [Google Scholar] [CrossRef]
- Wei, L.; Yumin, S. Prediction of Energy Production and Energy Consumption Based on BP Neural Networks. In Proceedings of the 2008 IEEE International Symposium on Knowledge Acquisition and Modeling Workshop, Wuhan, China, 21–22 December 2008; pp. 176–179. [Google Scholar]
- Liang, W.; Wang, G.; Ning, X.; Zhang, J.; Li, Y.; Jiang, C.; Zhang, N. Application of BP Neural Network to the Prediction of Coal Ash Melting Characteristic Temperature. Fuel 2020, 260, 116324. [Google Scholar] [CrossRef]
- Yu, F.; Xu, X. A Short-Term Load Forecasting Model of Natural Gas Based on Optimized Genetic Algorithm and Improved BP Neural Network. Appl. Energy 2014, 134, 102–113. [Google Scholar] [CrossRef]
- Han, Y.; Wu, H.; Jia, M.; Geng, Z.; Zhong, Y. Production Capacity Analysis and Energy Optimization of Complex Petrochemical Industries Using Novel Extreme Learning Machine Integrating Affinity Propagation. Energy Convers. Manag. 2019, 180, 240–249. [Google Scholar] [CrossRef]
- Ji, Y.; Zhang, S.; Yin, Y.; Su, X. Application of the Improved the ELM Algorithm for Prediction of Blast Furnace Gas Utilization Rate. IFAC-Pap. 2018, 51, 59–64. [Google Scholar] [CrossRef]
- Geng, Z.; Qin, L.; Han, Y.; Zhu, Q. Energy Saving and Prediction Modeling of Petrochemical Industries: A Novel ELM Based on FAHP. Energy 2017, 122, 350–362. [Google Scholar] [CrossRef]
- Zhu, Q.-X.; Zhang, X.-H.; Wang, Y.; Xu, Y.; He, Y.-L. A Novel Intelligent Model Integrating PLSR with RBF-Kernel Based Extreme Learning Machine: Application to Modelling Petrochemical Process. IFAC-Pap. 2019, 52, 148–153. [Google Scholar] [CrossRef]
- Han, H.-G.; Chen, Q.; Qiao, J.-F. An Efficient Self-Organizing RBF Neural Network for Water Quality Prediction. Neural Netw. 2011, 24, 717–725. [Google Scholar] [CrossRef]
- Aghbashlo, M.; Hosseinpour, S.; Tabatabaei, M.; Dadak, A.; Younesi, H.; Najafpour, G. Multi-Objective Exergetic Optimization of Continuous Photo-Biohydrogen Production Process Using a Novel Hybrid Fuzzy Clustering-Ranking Approach Coupled with Radial Basis Function (RBF) Neural Network. Int. J. Hydrogen Energy 2016, 41, 18418–18430. [Google Scholar] [CrossRef]
- Li, J.; Zhang, R.; Wang, H.; Xu, Z. Inverse Problem of Permeability Field under Multi-Well Conditions Using TgCNN-Based Surrogate Model. Processes 2024, 12, 1934. [Google Scholar] [CrossRef]
- Yuan, X.; Qi, S.; Wang, Y.; Xia, H. A Dynamic CNN for Nonlinear Dynamic Feature Learning in Soft Sensor Modeling of Industrial Process Data. Control. Eng. Pract. 2020, 104, 104614. [Google Scholar] [CrossRef]
- Shi, X.; Huang, G.; Hao, X.; Yang, Y.; Li, Z. Sliding Window and Dual-Channel CNN (SWDC-CNN): A Novel Method for Synchronous Prediction of Coal and Electricity Consumption in Cement Calcination Process. Appl. Soft Comput. 2022, 129, 109520. [Google Scholar] [CrossRef]
- Han, Y.; Wang, Y.; Chen, Z.; Lu, Y.; Hu, X.; Chen, L.; Geng, Z. Multiscale Variational Autoencoder Regressor for Production Prediction and Energy Saving of Industrial Processes. Chem. Eng. Sci. 2024, 284, 119529. [Google Scholar] [CrossRef]
- Jang, K.; Hong, S.; Kim, M.; Na, J.; Moon, I. Adversarial Autoencoder Based Feature Learning for Fault Detection in Industrial Processes. IEEE Trans. Ind. Inform. 2021, 18, 827–834. [Google Scholar] [CrossRef]
- Laubscher, R.; Rousseau, P. Application of Generative Deep Learning to Predict Temperature, Flow and Species Distributions Using Simulation Data of a Methane Combustor. Int. J. Heat Mass Transf. 2020, 163, 120417. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. In Proceedings of the Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; pp. 6000–6010. [Google Scholar]
- Liu, D.; Wang, Y.; Liu, C.; Yuan, X.; Yang, C.; Gui, W. Data Mode Related Interpretable Transformer Network for Predictive Modeling and Key Sample Analysis in Industrial Processes. IEEE Trans. Ind. Inform. 2022, 19, 9325–9336. [Google Scholar] [CrossRef]
- Han, Y.; Han, L.; Shi, X.; Li, J.; Huang, X.; Hu, X.; Chu, C.; Geng, Z. Novel CNN-Based Transformer Integrating Boruta Algorithm for Production Prediction Modeling and Energy Saving of Industrial Processes. Expert Syst. Appl. 2024, 255, 124447. [Google Scholar] [CrossRef]
- Liu, D.; Wang, Y.; Yuan, X.; Yang, C. Multirate-Former: An Efficient Transformer-Based Hierarchical Network for Multistep Prediction of Multirate Industrial Processes. IEEE Trans. Instrum. Meas. 2024, 73, 1–13. [Google Scholar] [CrossRef]
- Lee, Y.S.; Chen, J. Developing Semi-Supervised Latent Dynamic Variational Autoencoders to Enhance Prediction Performance of Product Quality. Chem. Eng. Sci. 2023, 265, 118192. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Variables | Unit |
|---|---|---|
| Input | Watertotal | ton |
| Steamtotal | ton | |
| Fueltotal | ton | |
| Feedtotal | ton | |
| Electricity | kWh/ton | |
| Output | Ethylene | ton/y |
| Fueltotal (ton) | Electricity (kWh/ton) | Watertotal (ton) | Steamtotal (ton) | Feedtotal (ton) | Ethylene (ton/y) | |
|---|---|---|---|---|---|---|
| Granularity 1 | 1.522 | 2.007 | 1.895 | 1.704 | 1.343 | 1.39 |
| Granularity 2 | 1.819 | 2.397 | 2.621 | 1.927 | 2.397 | 2.061 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lu, B.; Bai, Y.; Zhang, J. A Multigranularity Parallel Pyramidal Transformer Model for Ethylene Production Prediction and Energy Efficiency Optimization. Processes 2025, 13, 104. https://doi.org/10.3390/pr13010104
Lu B, Bai Y, Zhang J. A Multigranularity Parallel Pyramidal Transformer Model for Ethylene Production Prediction and Energy Efficiency Optimization. Processes. 2025; 13(1):104. https://doi.org/10.3390/pr13010104
Chicago/Turabian StyleLu, Biying, Yingliang Bai, and Jing Zhang. 2025. "A Multigranularity Parallel Pyramidal Transformer Model for Ethylene Production Prediction and Energy Efficiency Optimization" Processes 13, no. 1: 104. https://doi.org/10.3390/pr13010104
APA StyleLu, B., Bai, Y., & Zhang, J. (2025). A Multigranularity Parallel Pyramidal Transformer Model for Ethylene Production Prediction and Energy Efficiency Optimization. Processes, 13(1), 104. https://doi.org/10.3390/pr13010104