

Fluent Integration of Laboratory Data into Biocatalytic Process Simulation Using EnzymeML, DWSIM, and Ontologies

 , , , and
, , , and 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Materials and Methods
2.1. Determination of Reaction Kinetics
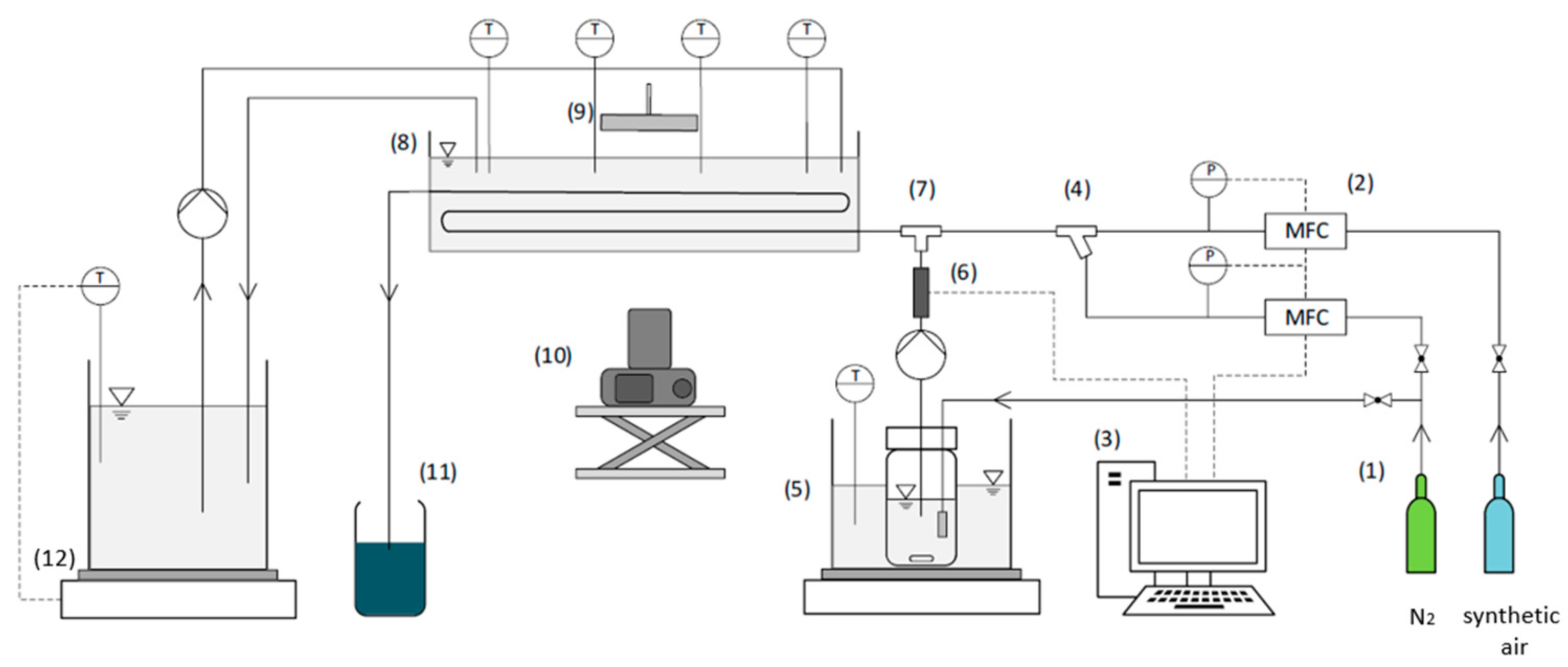
2.2. Tube Reactor Experiments
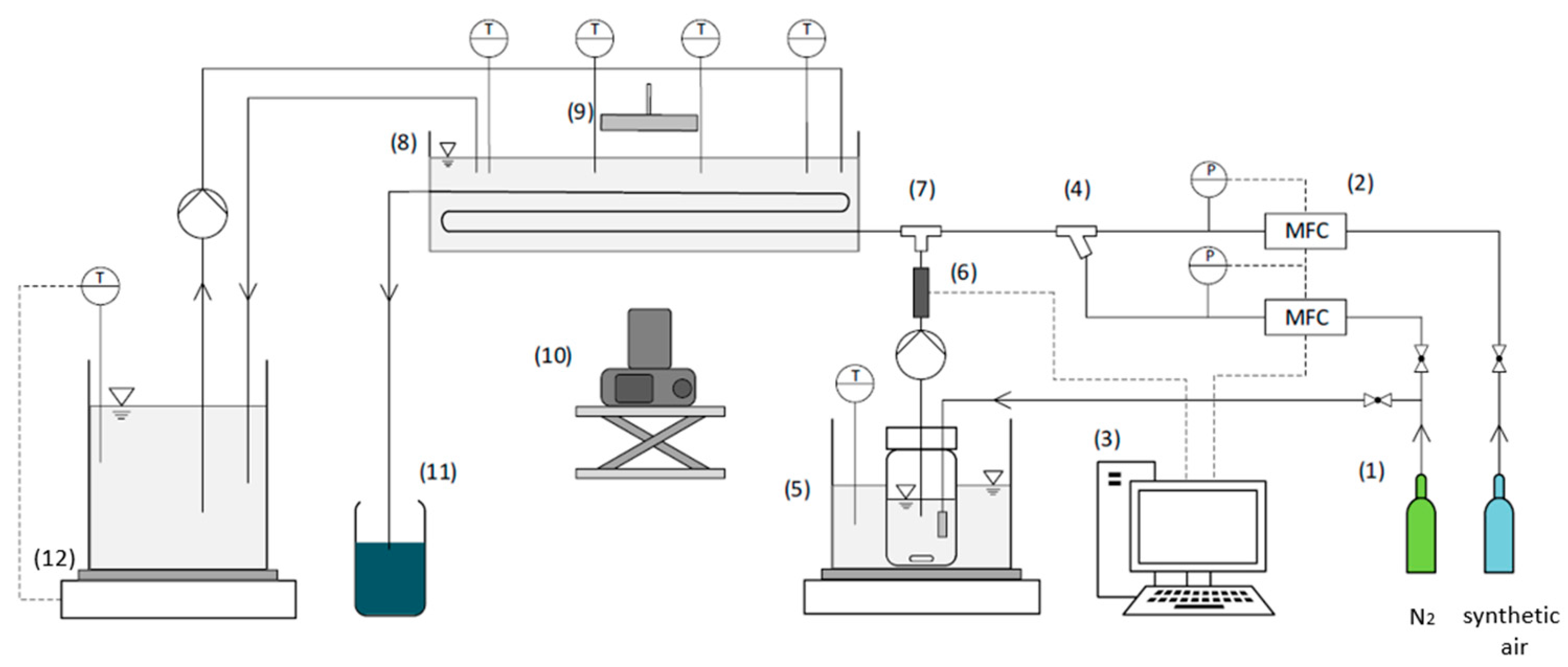
2.2.1. Experimental Setup
2.2.2. Digital Image Processing (DIP)
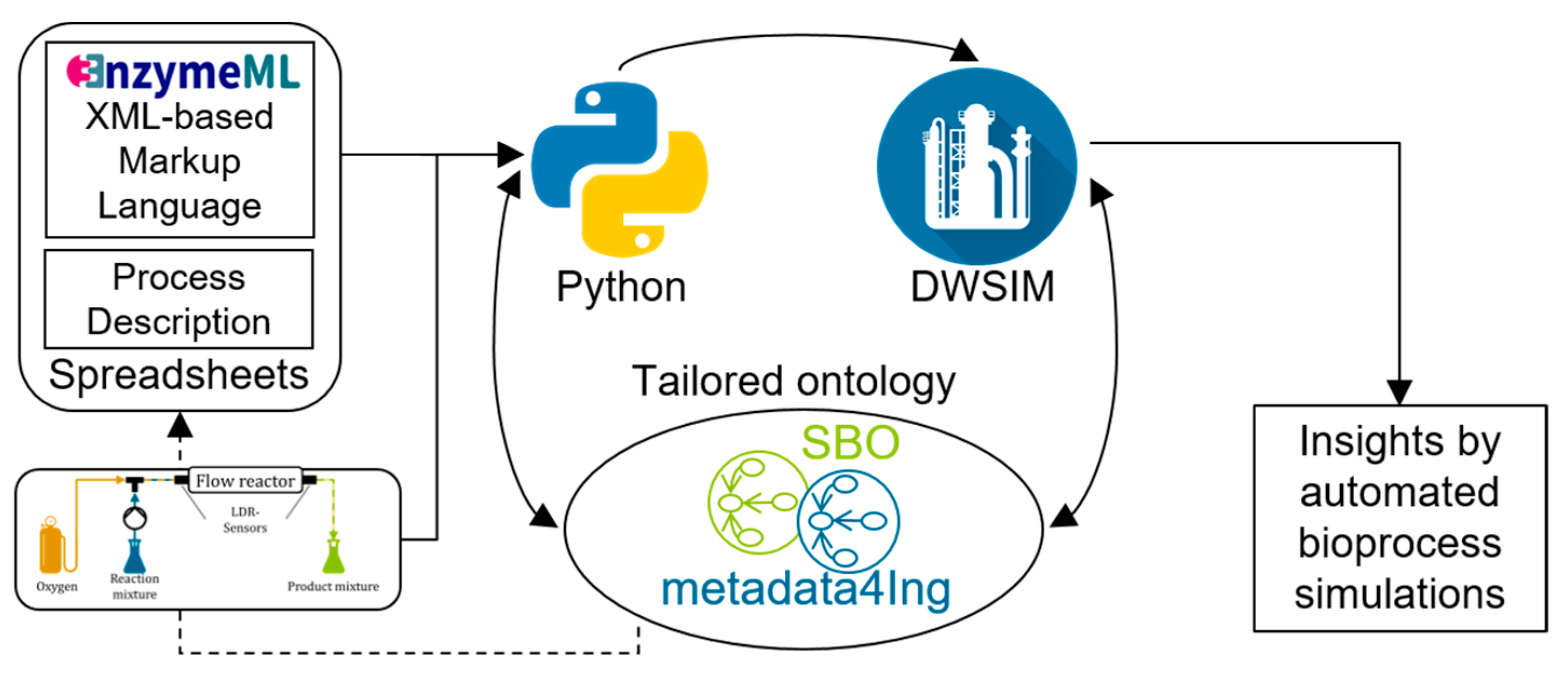
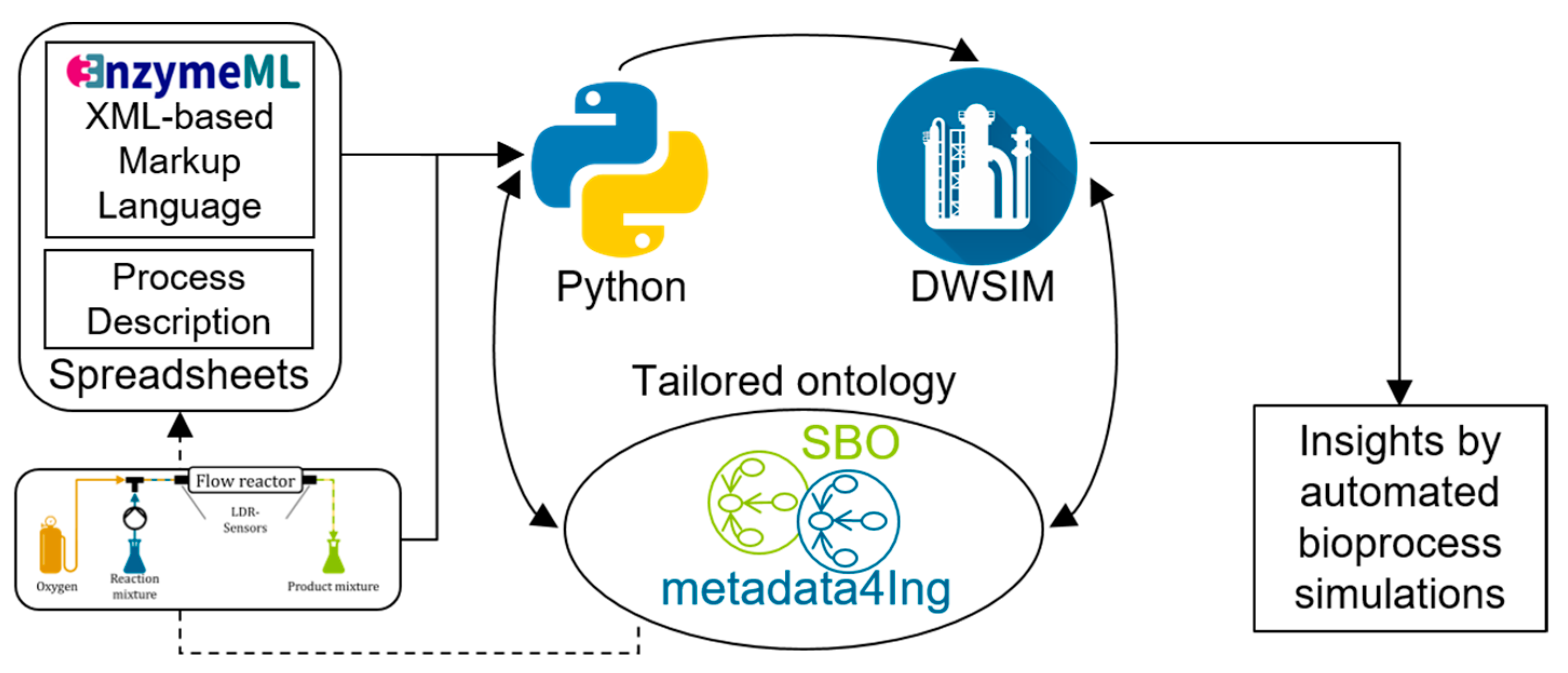
2.3. EnzymeML and MS Excel-Based ELNs
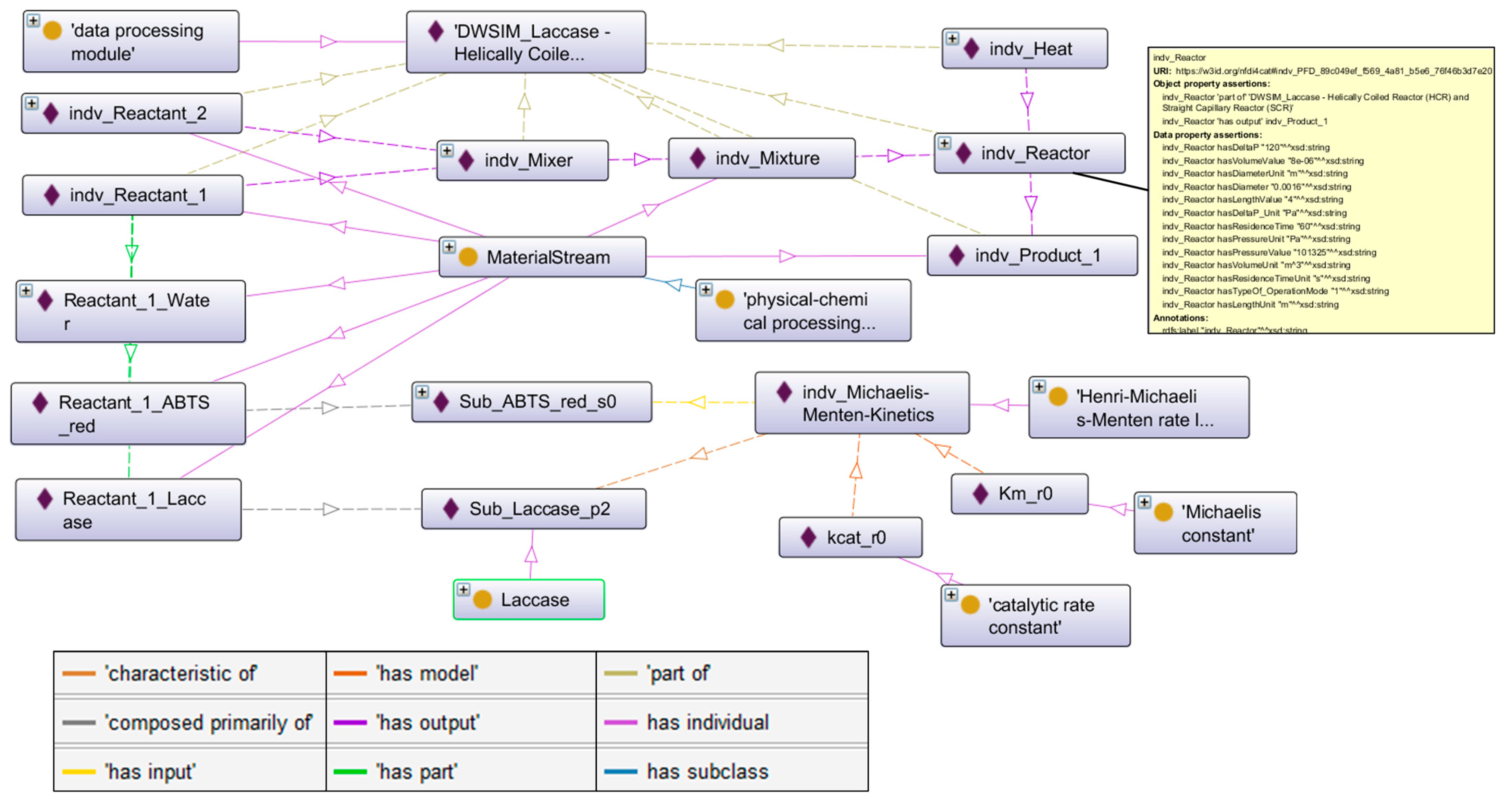
2.4. Ontology Engineering
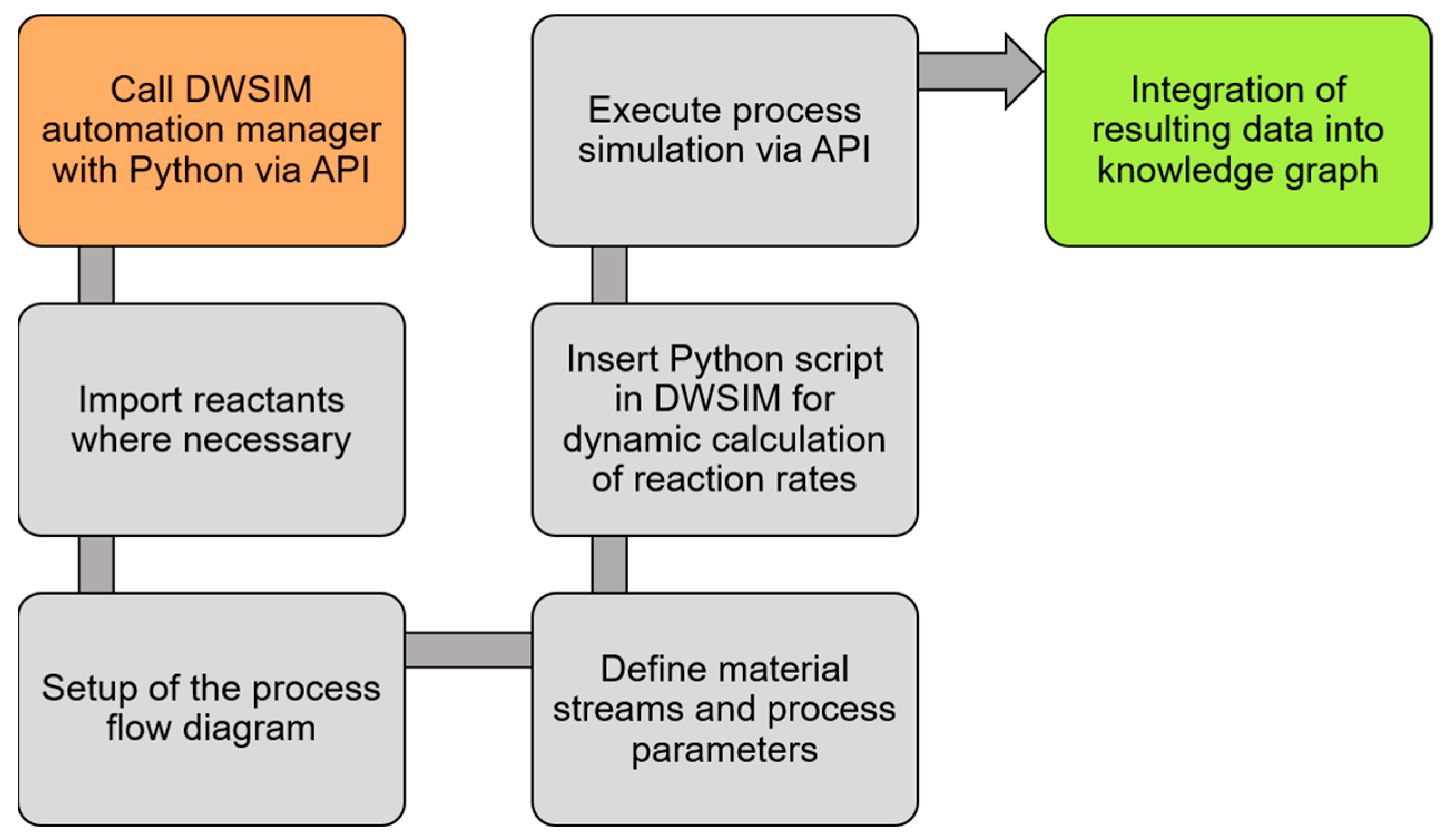
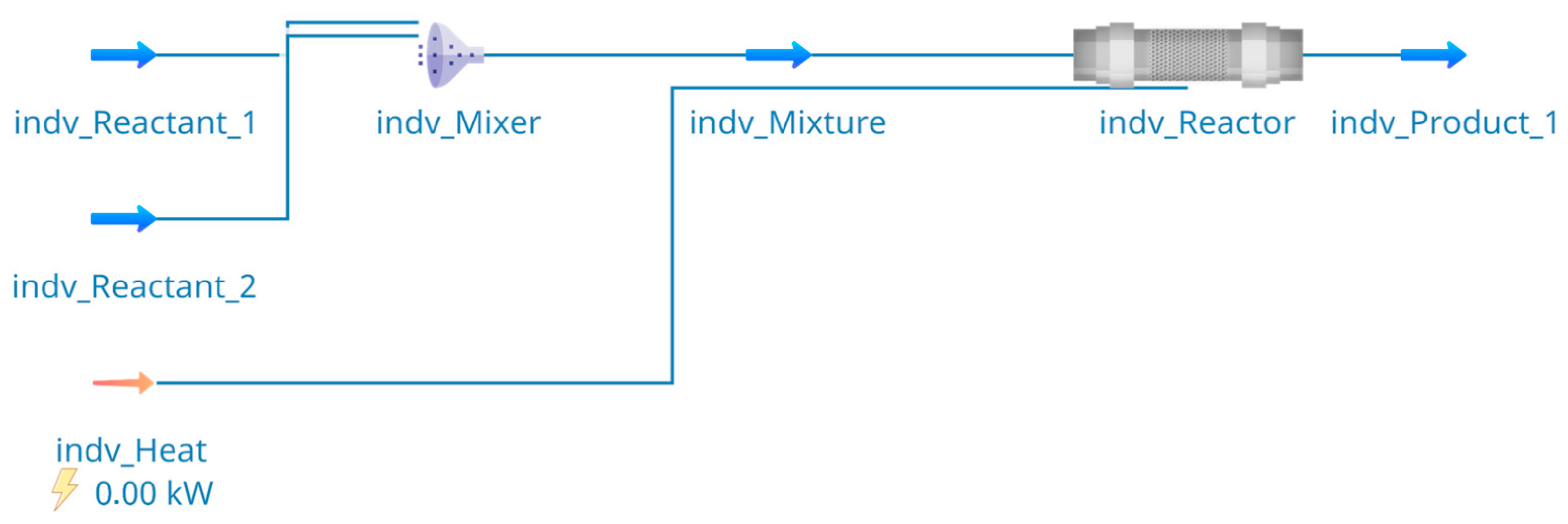
2.5. Process Simulation with DWSIM
3. Results and Discussion
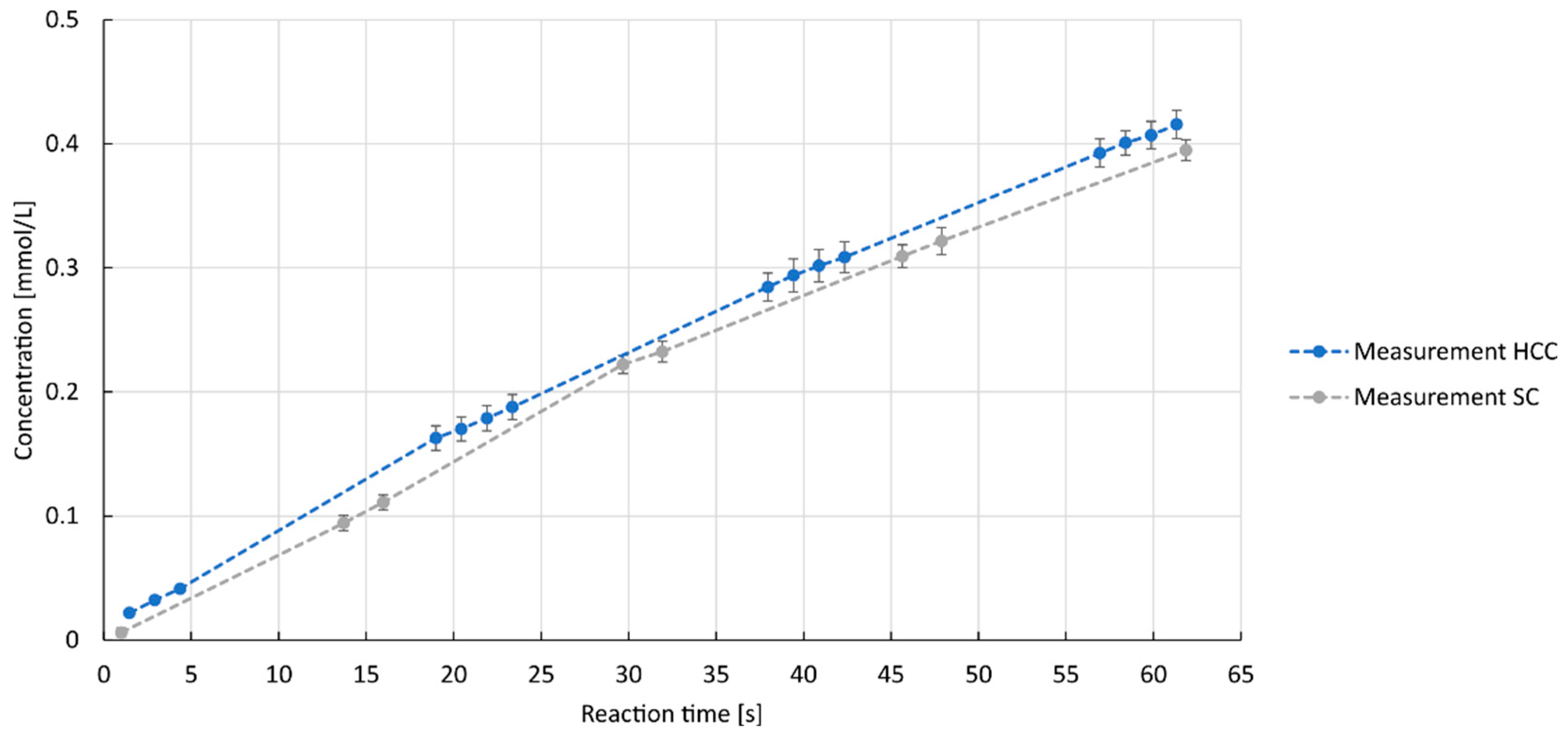
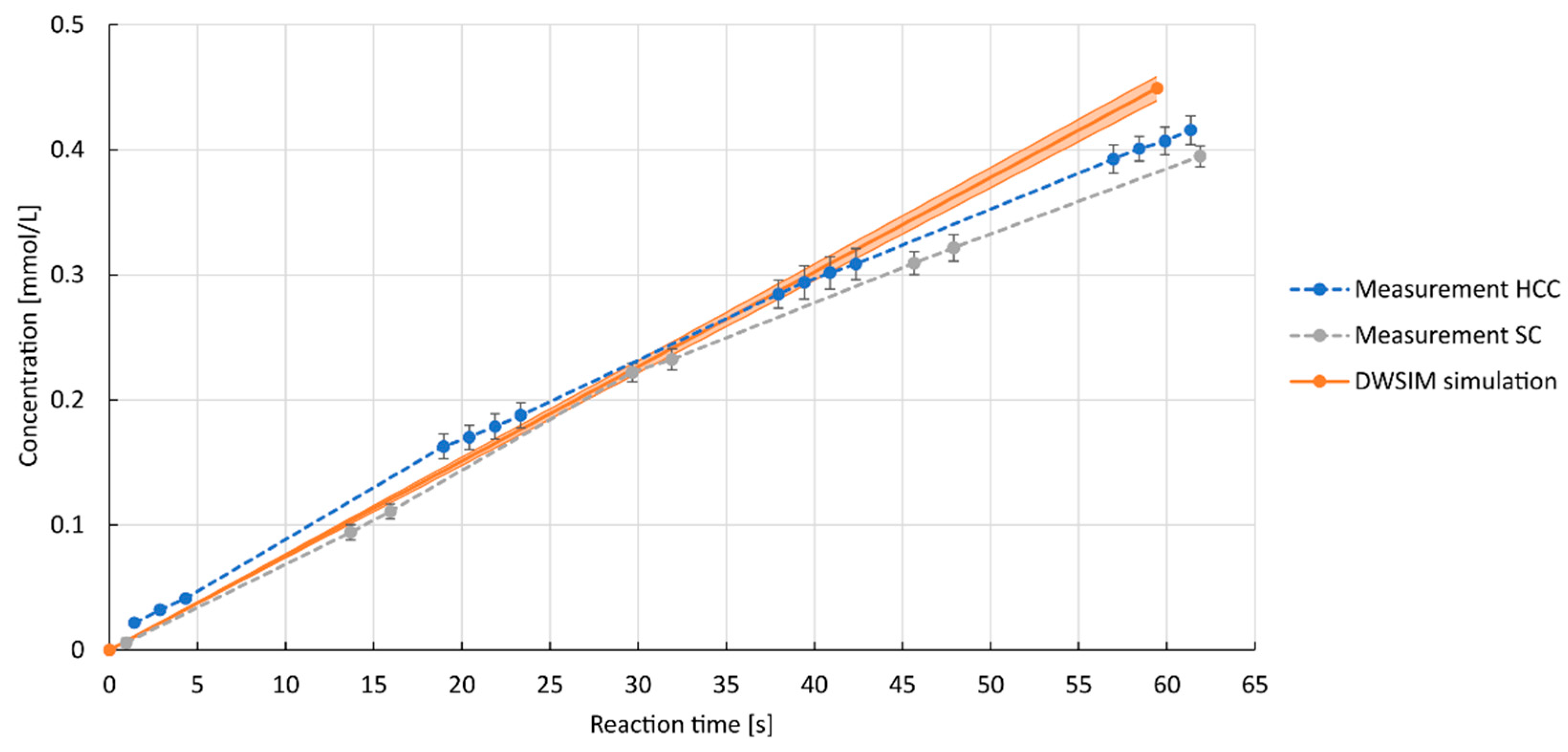
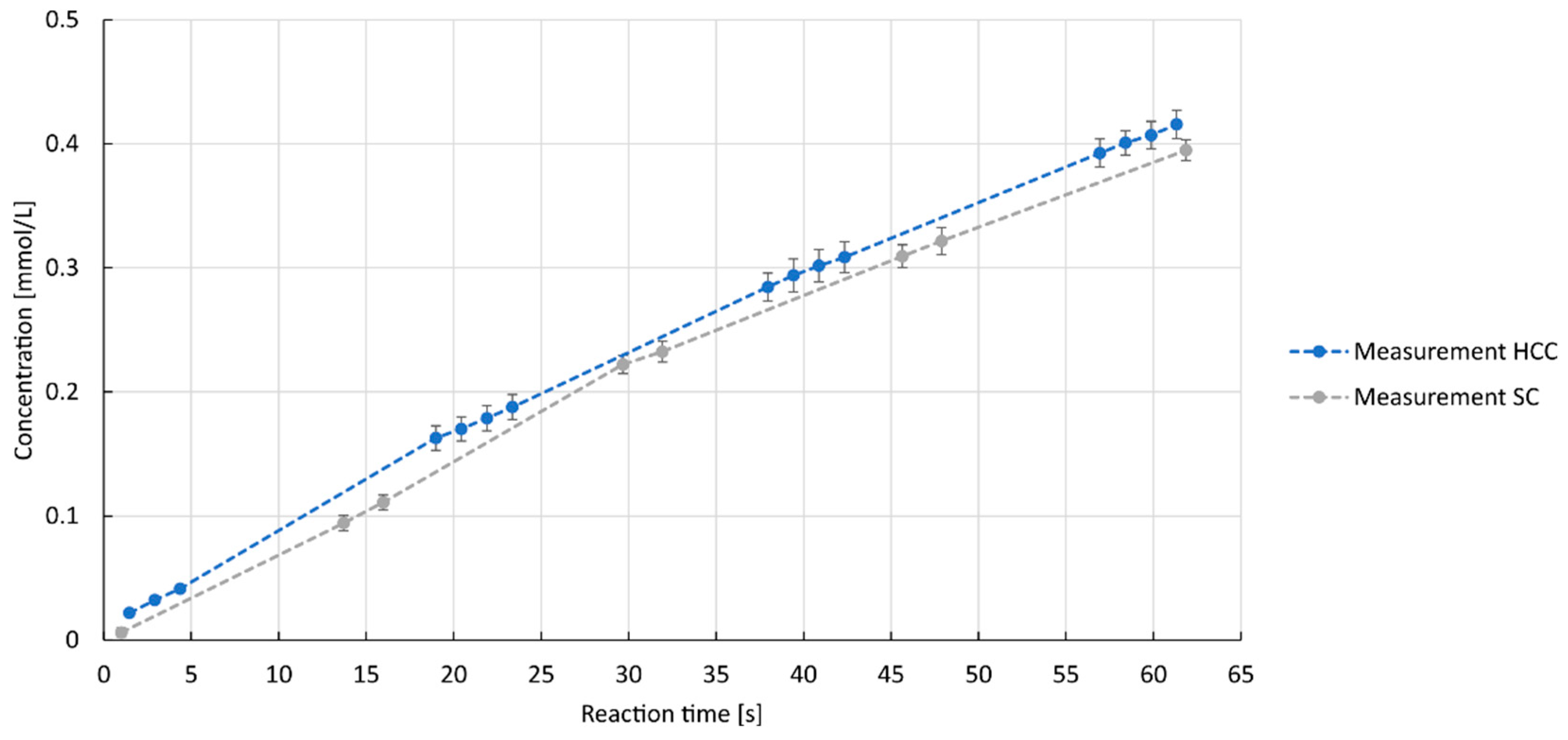
3.1. Experimental Results of Reactor Experiments
3.2. Automated Integration of Laboratory Data in Process Simulations
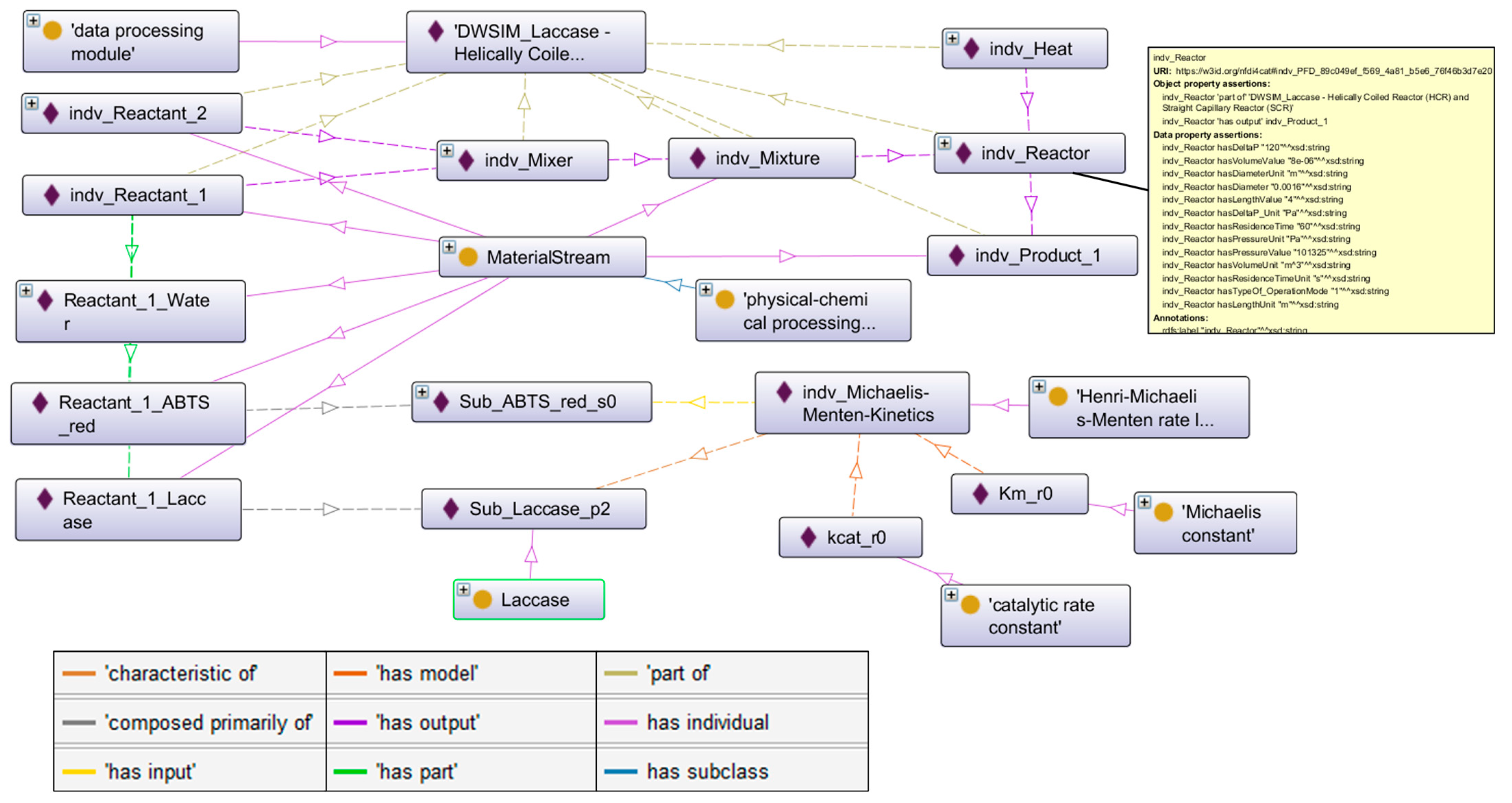
3.2.1. Integration of Experimental Data in the Ontology
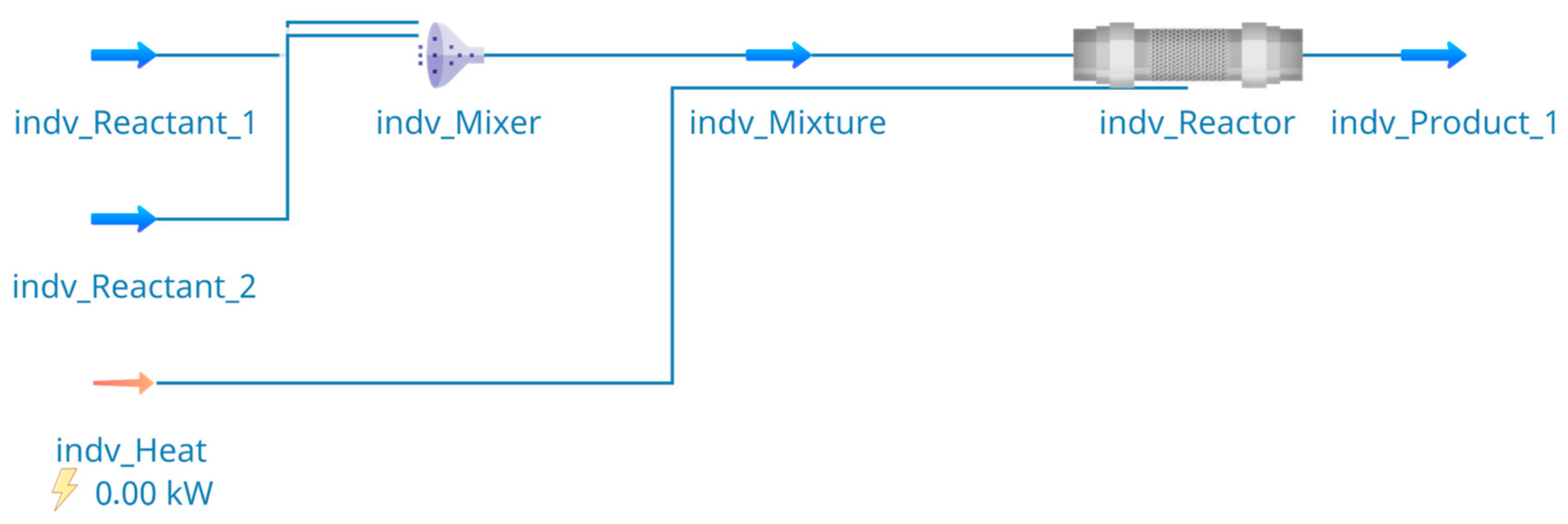
3.2.2. Automated Process Simulation
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wu, S.; Snajdrova, R.; Moore, J.C.; Baldenius, K.; Bornscheuer, U.T. Biocatalysis: Enzymatic Synthesis for Industrial Applications. Angew. Chem. Int. Ed. Engl. 2021, 60, 88–119. [Google Scholar] [CrossRef]
- Rosenthal, K.; Lütz, S. Recent developments and challenges of biocatalytic processes in the pharmaceutical industry. Current Opin. Green Sustain. Chem. 2018, 11, 58–64. [Google Scholar] [CrossRef]
- de Santis, P.; Meyer, L.-E.; Kara, S. The rise of continuous flow biocatalysis—Fundamentals, very recent developments and future perspectives. React. Chem. Eng. 2020, 5, 2155–2184. [Google Scholar] [CrossRef]
- Medeiros, D. DWSIM—Open Source Process Simulator. 2023. Available online: https://dwsim.org/ (accessed on 17 January 2024).
- Wilkinson, M.D.; Dumontier, M.; Jan Aalbersberg, I.J.; Appleton, G.; Axton, M.; Baak, A.; Blomberg, N.; Boiten, J.-W.; da Silva Santos, L.B.; Bourne, P.E.; et al. The FAIR Guiding Principles for scientific data management and stewardship. Sci. Data 2016, 3, 160018. [Google Scholar] [CrossRef]
- Grühn, J.; Behr, A.S.; Eroglu, T.H.; Trögel, V.; Rosenthal, K.; Kockmann, N. From Coiled Flow Inverter to Stirred Tank Reactor—Bioprocess Development and Ontology Design. Chem. Ing. Tech. 2022, 94, 852–863. [Google Scholar] [CrossRef]
- Menke, M.J.; Behr, A.S.; Rosenthal, K.; Linke, D.; Kockmann, N.; Bornscheuer, U.T.; Dörr, M. Development of an Ontology for Biocatalysis. Chem. Ing. Tech. 2022, 94, 1827–1835. [Google Scholar] [CrossRef]
- Lauterbach, S.; Dienhart, H.; Range, J.; Malzacher, S.; Spöring, J.-D.; Rother, D.; Pinto, M.F.; Martins, P.; Lagerman, C.E.; Bommarius, A.S.; et al. EnzymeML: Seamless data flow and modeling of enzymatic data. Nat. Methods 2023, 20, 400–402. [Google Scholar] [CrossRef] [PubMed]
- Range, J.; Halupczok, C.; Lohmann, J.; Swainston, N.; Kettner, C.; Bergmann, F.T.; Weidemann, A.; Wittig, U.; Schnell, S.; Pleiss, J. EnzymeML—A data exchange format for biocatalysis and enzymology. FEBS J. 2022, 289, 5864–5874. [Google Scholar] [CrossRef] [PubMed]
- Juty, N.; Le Novère, N. Systems Biology Ontology. In Encyclopedia of Systems Biology; Dubitzky, W., Wolkenhauer, O., Cho, K.-H., Yokota, H., Eds.; Springer: New York, NY, USA, 2013; p. 2063. [Google Scholar]
- Range, J.; Bergmann, F.; Rohwer, J.; Reisch, A.; Dienhart, H. EnzymeML/PyEnzyme: PyEnzyme 1.1.3. Zenodo. 2022. Available online: https://zenodo.org/records/6457299 (accessed on 23 August 2023).
- Behr, A.S.; Abbaspour, E.; Rosenthal, K.; Pleiss, J.; Kockmann, N. Ontology-Based Laboratory Data Acquisition with EnzymeML for Process Simulation of Biocatalytic Reactors. In Proceedings of the 1st Conference on Research Data Infrastructure, Karlsruhe, Germany, 12–14 September 2023; pp. 398–401. [Google Scholar] [CrossRef]
- Grühn, J.; Vogel, M.; Kockmann, N. Digital Image Processing of Gas-Liquid Reactions in Coiled Capillaries. Chem. Ing. Tech. 2021, 93, 825–829. [Google Scholar] [CrossRef]
- Pleiss, J. Standardized Data, Scalable Documentation, Sustainable Storage—EnzymeML As A Basis For FAIR Data Management in Biocatalysis. ChemCatChem 2021, 13, 3909–3913. [Google Scholar] [CrossRef]
- STRENDA Guideline Level 1A Experimental Conditions; Version 1.8; Beilstein STRENDA Commission: Frankfurt am Main, Germany, 2021.
- Gruber, T.R. A translation approach to portable ontology specifications. Knowl. Acquis. 1993, 5, 199–220. [Google Scholar] [CrossRef]
- Dubitzky, W.; Wolkenhauer, O.; Cho, K.-H.; Yokota, H. (Eds.) Encyclopedia of Systems Biology; Springer: New York, NY, USA, 2013. [Google Scholar]
- Hashibon, A.; Ghedini, E.; Schmitz, G.; Goldbeck, G.; Friis, J. Elemental Multiperspective Material Ontology. EMMC ASBL. Available online: http://emmo.info/emmo (accessed on 4 June 2023).
- Arp, R.; Smith, B.; Spear, A.D. Building Ontologies with Basic Formal Ontology; Massachusetts Institute of Technology: Cambridge, MA, USA, 2015. [Google Scholar]
- Arndt, S.; Farnbacher, B.; Wiljes, C.; Iglezakis, D.; Terzijska, D.; Lanza, G.; Hickmann, J.; Theissen-Lipp, J.; Munke, J.; Windeck, J.; et al. Metadata4Ing: An Ontology for Describing the Generation of Research Data within a Scientific Activity. 2023. Available online: https://zenodo.org/records/10022363 (accessed on 4 November 2023).
- Baldrian, P. Fungal laccases—Occurrence and properties. FEMS Microbiol. Rev. 2006, 30, 215–242. [Google Scholar] [CrossRef] [PubMed]
- Dwivedi, U.N.; Singh, P.; Pandey, V.P.; Kumar, A. Structure–function relationship among bacterial, fungal and plant laccases. J. Mol. Catal. B Enzym. 2011, 68, 117–128. [Google Scholar] [CrossRef]
- Frasconi, M.; Favero, G.; Boer, H.; Koivula, A.; Mazzei, F. Kinetic and biochemical properties of high and low redox potential laccases from fungal and plant origin. Biochim. Biophys. Acta 2010, 1804, 899–908. [Google Scholar] [CrossRef] [PubMed]
- Lorenzo, M.; Moldes, D.; Couto, S.R.; Sanromán, M.A. Inhibition of laccase activity from Trametes versicolor by heavy metals and organic compounds. Chemosphere 2005, 60, 1124–1128. [Google Scholar] [CrossRef] [PubMed]
- Stoilova, I.; Krastanov, A.; Stanchev, V. Properties of crude laccase from Trametes versicolor produced by solid-substrate fermentation. Adv. Biosci. Biotechnol. 2010, 1, 208–215. [Google Scholar] [CrossRef]
- Marques, M.P.; Szita, N. Bioprocess microfluidics: Applying microfluidic devices for bioprocessing. Curr. Opin. Chem. Eng. 2017, 18, 61–68. [Google Scholar] [CrossRef] [PubMed]
- Krühne, U.; Heintz, S.; Ringborg, R.; Rosinha, I.P.; Tufvesson, P.; Gernaey, K.V.; Woodley, J.M. Biocatalytic process development using microfluidic miniaturized systems. Green Process. Synth. 2014, 3, 23–31. [Google Scholar] [CrossRef]
- Kurt, S.K.; Warnebold, F.; Nigam, K.D.; Kockmann, N. Gas-liquid reaction and mass transfer in microstructured coiled flow inverter. Chem. Eng. Sci. 2017, 169, 164–178. [Google Scholar] [CrossRef]
- Jackson, R.; Matentzoglu, N.; Overton, J.A.; Vita, R.; Balhoff, J.P.; Buttigieg, P.L.; Carbon, S.; Courtot, M.; Diehl, A.D.; Dooley, D.M.; et al. OBO Foundry in 2021: Operationalizing open data principles to evaluate ontologies. Database J. Biol. Databases Curation 2021, 2021, baab069. [Google Scholar] [CrossRef]
- Mungall, C.; Matentzoglu, N.; Balhoff, J.; Osumi-Sutherland, D.; Duncan, B.; Gaudet, P.; Tan, S.; Tapley Hoyt, C.; Pilgrim, C.; Overton, J.A.; et al. oborel/obo-Relations: 2023-08-18. Zenodo. 2023. Available online: https://zenodo.org/records/8263469 (accessed on 11 October 2023).
- Musen, M.A. The Protégé Project: A Look Back and a Look Forward. AI Matters 2015, 1, 4–12. [Google Scholar] [CrossRef] [PubMed]


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Behr, A.S.; Surkamp, J.; Abbaspour, E.; Häußler, M.; Lütz, S.; Pleiss, J.; Kockmann, N.; Rosenthal, K. Fluent Integration of Laboratory Data into Biocatalytic Process Simulation Using EnzymeML, DWSIM, and Ontologies. Processes 2024, 12, 597. https://doi.org/10.3390/pr12030597
Behr AS, Surkamp J, Abbaspour E, Häußler M, Lütz S, Pleiss J, Kockmann N, Rosenthal K. Fluent Integration of Laboratory Data into Biocatalytic Process Simulation Using EnzymeML, DWSIM, and Ontologies. Processes. 2024; 12(3):597. https://doi.org/10.3390/pr12030597
Chicago/Turabian StyleBehr, Alexander S., Julia Surkamp, Elnaz Abbaspour, Max Häußler, Stephan Lütz, Jürgen Pleiss, Norbert Kockmann, and Katrin Rosenthal. 2024. "Fluent Integration of Laboratory Data into Biocatalytic Process Simulation Using EnzymeML, DWSIM, and Ontologies" Processes 12, no. 3: 597. https://doi.org/10.3390/pr12030597
APA StyleBehr, A. S., Surkamp, J., Abbaspour, E., Häußler, M., Lütz, S., Pleiss, J., Kockmann, N., & Rosenthal, K. (2024). Fluent Integration of Laboratory Data into Biocatalytic Process Simulation Using EnzymeML, DWSIM, and Ontologies. Processes, 12(3), 597. https://doi.org/10.3390/pr12030597