1. Introduction
Traditional diesel fuel, widely used in transportation, power generation, and industrial applications, has significant negative impacts on climate change and human health due to particulate matter and nitrogen oxide (NOx) emissions [
1]. As traditional fossil fuels become scarce and environmental concerns grow, biodiesel, a sustainable and renewable alternative fuel, has attracted increasing attention. Produced from vegetable oils and animal fats, biodiesel exhibits the characteristics of biodegradability, low toxicity, and lower emissions, mitigating the environmental problems associated with fossil fuels [
2].
In biodiesel production, the final yield is a critical control variable that is intricately coupled with other process variables such as feed flow rate, feed concentration, and feed temperature [
3]. In most industrial processes, the setpoints of crude oil flow rate and catalyst flow rate are adjusted based on existing production and research experience to indirectly track the desired final yield. However, due to the nonlinearity, high latency, and multivariable nature of biodiesel production, empirical settings often fail to maintain a stable yield, leading to product quality degradation and increased production costs. Therefore, in-depth research on this production process and the design of efficient process control strategies are of great significance for improving biodiesel yield, reducing energy consumption, and minimizing waste [
4].
Traditional control methods for biodiesel production, including fuzzy control [
5,
6] and model predictive control (MPC) [
7], have been widely studied. For instance, Manimaran et al. [
8] proposed an MPC-based method for controlling the transesterification process, optimizing controller parameters using genetic algorithms. Gupta et al. [
9] employed a two-layer control framework combining constrained iterative learning control and explicit MPC to address yield fluctuations under disturbances. However, due to the fixed parameters and lack of adaptability, traditional methods struggle to handle the complex and dynamic nature of biodiesel production, limiting the achievable yield. Deep reinforcement learning, capable of learning system dynamics through continuous interaction with the environment and adapting to varying reaction conditions, offers a promising solution for such complex systems.
Mnih et al. [
10] introduced the deep Q-network (DQN) algorithm, which combined deep neural networks with reinforcement learning. By using convolutional neural networks to approximate the Q-function, DQN achieved human-level performance in a variety of Atari games with discrete action spaces. Lillicrap et al. [
11] proposed the deep deterministic policy gradient (DDPG) algorithm, which extended the action space of DQN to continuous domains by incorporating techniques such as experience replay and target Q-networks to enhance stability. Building upon the actor–critic framework, Fujimoto et al. [
12] introduced the twin delayed deep deterministic policy gradient (TD3) algorithm, comprising an actor network, two critic networks, and their respective target networks. The critic networks learn the Q-function, while the actor network updates the policy
under the guidance of the critic. The training process involves optimizing the parameters of the actor, critic, and target networks, with delayed updates for improved stability. Compared to earlier reinforcement learning algorithms, TD3 has demonstrated significant advantages in complex industrial control tasks.
In recent years, deep reinforcement learning algorithms have shown great promise in addressing process control challenges. Powell et al. [
13] proposed a reinforcement learning-based real-time optimization method, embedding optimal decisions in a neural network for steady-state optimization and employing hybrid training to enhance real-time processing capabilities. Peng et al. [
14] combined PID control with the deep deterministic policy gradient (DDPG) algorithm to address the low-power level water level control problem in nuclear power plants, highlighting the feasibility and effectiveness of deep reinforcement learning-based control methods in industrial applications. Panjapornpon et al. [
15] applied a DDPG-based control method to handle pH and liquid level control in a CSTR, demonstrating superior tracking speed and stability compared to traditional controllers. Chowdhury et al. [
16] employed entropy maximization to improve the twin delayed deep deterministic policy gradient (TD3) algorithm for PID tuning, demonstrating its effectiveness in controlling the temperature and feed flow rate of a continuous stirred-tank reactor (CSTR). However, these studies have primarily focused on applying deep reinforcement learning algorithms to simplified chemical processes, while their application to complex processes like biodiesel production remains underexplored. In biodiesel production, the coupling relationships between variables are complex and dynamic, making it challenging for traditional control methods to achieve optimal performance. Deep reinforcement learning algorithms, capable of learning from historical data and system states, can make optimal control decisions, leading to more efficient production.
In this paper, a deep reinforcement learning (TD3) algorithm is proposed for controlling biodiesel production. Firstly, a TD3 algorithm controller was designed based on the dynamic model of biodiesel production. Subsequently, a deep reinforcement learning environment and reward function are constructed using the model and a neural network. After training, an optimized control policy is obtained. Finally, simulation experiments are conducted to compare the tracking performance of the proposed method with traditional control algorithms and other reinforcement learning algorithms.
2. Physical System
To evaluate advanced fault detection and diagnosis methods and control and optimization strategies, the benchmark model BDsim [
17] is employed. The model is capable of the following:
Simulating the impact of critical process variables, including temperature and catalyst flow rate, on product yield. Additionally, the model enables dynamic simulations to validate the performance of the TD3 control algorithm. Biodiesel production, involving the transesterification of oil and methanol, consists of a reactor, separator, washer, and dryer, as illustrated in
Figure 1. The experiment is based on the following assumptions:
- (1)
The raw materials are natural products with constant composition;
- (2)
The catalyst concentration is assumed to be constant throughout the reaction;
- (3)
Any side reactions, such as saponification, are neglected.
Raw materials and methanol are fed into the reactor, where they are thoroughly mixed through agitation. Under specific temperature conditions and in the presence of a basic catalyst, the triglycerides (TG) react with methanol (M) via transesterification to produce fatty acid esters (E) and glycerol (G) as a byproduct. The reaction can be represented as follows:
where TG, DG, MG, M, E, and G represent triglycerides, diglycerides, monoglycerides, methanol, ester, and glycerol, respectively. Due to the incomplete nature of the reaction, the mixture leaving the reactor contains not only the desired products but also a small amount of unreacted materials. Therefore, the mixture must be separated. To facilitate the separation process, the mixture is first cooled in a heat exchanger before entering the separator unit. A gravity settling is then employed to separate the immiscible glycerol (G) and ester (E). In the separator, the mixture separates into two phases: the denser G settles at the bottom as the heavy phase, while the lighter E separates into the upper light phase. The overflowed light phase is collected and sent to a washer, where it is washed with water to remove methanol, catalyst, and other residual impurities. The final product, commercial biodiesel, has a minimum purity of 96.5% [
18].
2.1. Reactor
For the simplicity of the model equations, the set is defined as a collection of chemical species, denoted as
. Starting from the material and energy balances, the differential equations for the reactor can be represented by Equations (1) and (2):
with the total amount of substance inside the reactor given by
where
represents the concentrations of various species in the reactor,
are the flow rates of methanol and oil,
is the reaction rates of the different components,
is the volume of the reactor,
is the reactor temperature,
are the temperatures of methanol and inlet oil, respectively, and
,
are the specific heat capacity and heat of reaction, respectively. The specific values for these parameters can be found in [
18].
Finally, the molar flow rate leaving the reactor unit is obtained by
The numerical values of the parameters are provided in
Appendix A.
2.2. Heat Exchanger
The heat exchanger reduces the temperature of the reaction mixture to the desired separation temperature by releasing energy. Since no reaction occurs within the heat exchanger, the outlet stream has the same composition as the inlet stream, as shown in Equation (3).
represents the heat removed in the heat exchanger.
2.3. Decanter
From the molar mass balance of the light and heavy phases, equations for the compositions of the light- and heavy-phase mixtures in the separator are obtained. The specific expressions are as shown in Equations (4) and (5):
where
represents the concentrations of various species in the light phase,
in the heavy phase,
is the flow rate of the mixture leaving the reactor,
is the molar amount of the mixture, and
is the split fraction, the ratio of the concentration of each substance in the light phase to that before separation. The mixture entering the separator is split asymmetrically. Due to the strong affinity between TG, DG, MG, and esters, all triglycerides are separated into the light phase with a split fraction of
set to 1. Glycerol (G) and part of the methanol (M) are separated into the heavy phase. The overflow of the light phase over the baffle maintains a constant total liquid height
within the separator, where
is the height of the light phase. The height of the light phase is as shown in Equation (6).
The height of the heavy phase,
, is calculated by the following equation (7):
In the equation,
denotes the cross-sectional area of the separator.
Assuming an ideal environment where heat exchange between the mixture inside the separator and the surroundings is negligible, the expression for the separator temperature
is derived based on the energy balance equation, as shown in Equation (8).
2.4. Washer + Dryer
In industrial processes, unpurified biodiesel produced from separation may contain residual methanol, glycerol, and sodium salts. Since these impurities are water soluble, washing and drying steps are employed to remove them, leaving only E and residual TG, DG, and MG. Therefore, the formula for the final yield of biodiesel is as shown in Equation (9):
where
denotes the mole fraction of the mixture,
is the molar mass, and
represents the final yield. Both excessively high and low reaction temperatures can significantly affect the reaction rate and final yield. Therefore, variables
and
are chosen as the controlled variables in this paper. Multiple variables in the reaction process, such as temperature and flow rate, are highly coupled. Considering these interactions, oil temperature
, methanol flow rate
, and oil flow rate
are selected as the manipulated variables.
3. Controller Design
3.1. Markov Decision Process
Reinforcement learning studies the interactions between an agent and an environment, where the agent learns an optimal policy to make sequential decisions and maximize a cumulative reward [
19]. The reinforcement learning problem is typically modeled as a Markov decision process (MDP), defined by a tuple
, where
is the state space,
is the action space,
is the state transition probability, and
is the reward function. At each time step
t, the agent selects an action
in state
according to its policy
and receives a reward
and transitions to a new state
based on the transition probability [
20]. This process continues until the environment terminates, as illustrated in
Figure 2.
The agent’s actions are determined by the policy , where is a probability distribution over the action space. For stochastic policies, defines the probability of selecting action given state .
The value of policy
for the action taken in state S
t is evaluated through the Q-value function
. In Equation (10),
represents the expected cumulative return starting from state
, after executing action
a and then using a specific policy
. This is referred to as the state-action value function. In Equation (11),
represents the expected cumulative return starting from state
while following policy
π, which is referred to as the state value function.
3.2. TD3 Algorithm
Twin delayed deep deterministic policy gradient (TD3) is one of the most advanced reinforcement learning algorithms, addressing the issue of the maximum estimated value in the deep deterministic policy gradient (DDPG). By employing twin critic networks, TD3 effectively mitigates maximization bias, enhancing stability and convergence, especially in continuous action spaces.
To estimate the Q-value of the next state-action pair
, TD3 takes the minimum of the two Q-value estimates as the target value, as shown in Equation (12):
where
is used to measure the discount factor of future rewards. By updating the actor network less frequently than the critic network, TD3 helps to avoid oscillations in complex industrial environments that can arise from frequent updates. A delayed update strategy first updates the critic network multiple times before updating the actor network parameters. This approach effectively avoids the instability of the actor network by assisting in updating the actor network only after the critic network becomes relatively stable [
21]. Network parameters are updated along their gradient to a local maximum to reduce variance. The parameter update formula is as follows:
In the equation,
and
are the parameters of the action network and the evaluation network, respectively, and
is the soft update parameter.
Additionally, DDPG is prone to overfitting the peaks in value estimation. When updating the critic network, the target is susceptible to function approximation errors, leading to increased estimation variance and inaccuracy. TD3 further mitigates this impact by introducing target policy smoothing, a regularization technique that adds noise to reduce the impact of function approximation errors and enhance estimation accuracy, thereby preventing instability caused by drastic input fluctuations in industrial processes.
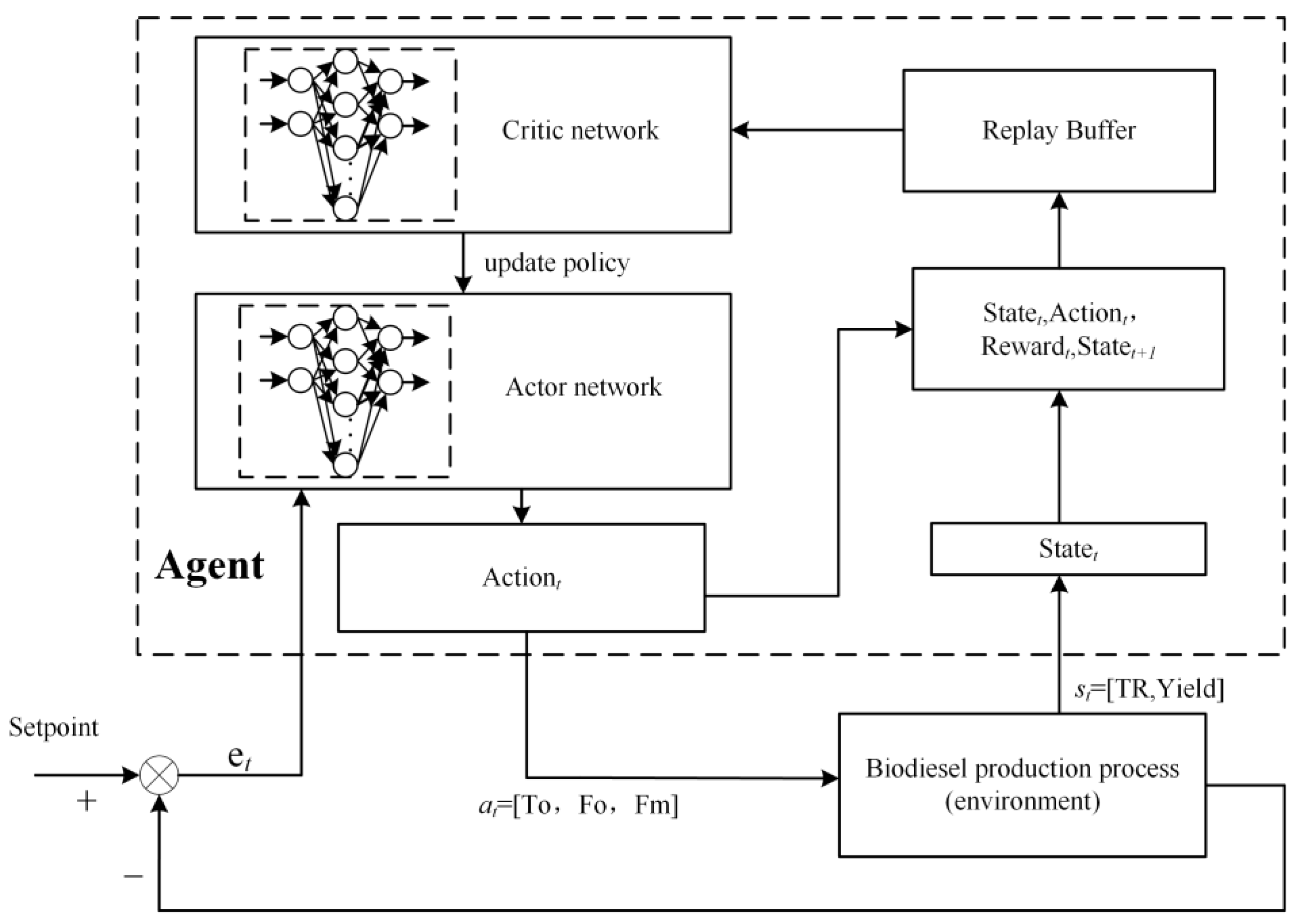
3.3. Control System Framework
In a control system, an agent serves as the controller, while the environment encompasses external factors like industrial processes and sensor data. The objective is to develop an optimal control policy [
22,
23]. As depicted in
Figure 3, the agent interacts with a biodiesel production environment. In deep reinforcement learning, both the state space and action space are pivotal. Unlike traditional supervised learning, the action space in biodiesel production is continuous. The state space is crucial, comprising all potential environmental states.
Table 1 outlines the state space for this specific deep reinforcement learning environment. The input to the state space is a two-dimensional vector
, where
denotes the reactor temperature and
signifies the final yield.
In deep reinforcement learning environments, action spaces are typically categorized into discrete and continuous domains [
24]. Given the nature of biodiesel production processes, the action space for this specific problem is continuous. The specific actions are represented by
, where
correspond to inlet oil temperature, inlet oil flow rate, and inlet alcohol flow rate, respectively. The specific value ranges for these actions are detailed
Table 2.
3.4. Reward Function
In deep reinforcement learning algorithms, designing a reward function that aligns with the actual production process is crucial for guiding the agent to learn quickly and efficiently to achieve control objectives. In biodiesel production, process variables are monitored in real time to obtain dynamic data, which are then fed into the TD3 algorithm. The algorithm evaluates the outcome of the current action using a reward function and generates an optimized control output to adjust parameters such as temperature and flow rate, thereby controlling the production process. The reward function is designed based on the deviation between the current state and the desired value, ensuring that the production process always converges to the setpoint.
The reward function is designed based on the error between the current state and the desired value to regulate the entire production process. To achieve this, the function is divided into three components: a primary reward and two auxiliary rewards. The primary reward is calculated as the error between the value
and the actual process variable
. Specifically, the error is computed as
, set
. An auxiliary reward is provided when both errors are less than a certain threshold. The corresponding reward function is expressed as Equation (14).
In the equation, is the reward scaling factor that guides the agent’s learning direction. represents the error between the current state value and the desired setpoint. is the error threshold for the current state value. is a relatively large reward given when both errors are smaller than their respective thresholds, otherwise, only the smaller reward value will be accepted. When the maximum error threshold is exceeded, the agent will receive a larger penalty.
4. Simulation Experiments and Results
4.1. Experimental Setup
The raw material used in this experiment is palm oil. As the transesterification reaction is highly sensitive to reactor temperature, the primary control objectives are to maintain the reaction temperature and optimize biodiesel yield to ensure complete conversion. The recovered biodiesel product is expected to meet product specifications after methanol recovery.
In this simulation model, feed oil temperature , feed oil flow rate , and methanol flow rate are the manipulated variables (). The heat exchanger and methanol temperature are considered as disturbance variables (). The controlled variables are reactor temperature and yield. The control system is designed to track the setpoints of these variables under fluctuating disturbances , while ensuring that the variables remain within the specified ranges of , . The disturbance variables are defined within the range of , .
Simulations will be conducted to verify the control performance of the TD3 algorithm. The results will be compared with those obtained using traditional PID and NMPC controllers, as well as the DDPG algorithm. For a fair comparison, the hyperparameters of DDPG and TD3 are kept identical, with some key parameters listed in
Table 3.
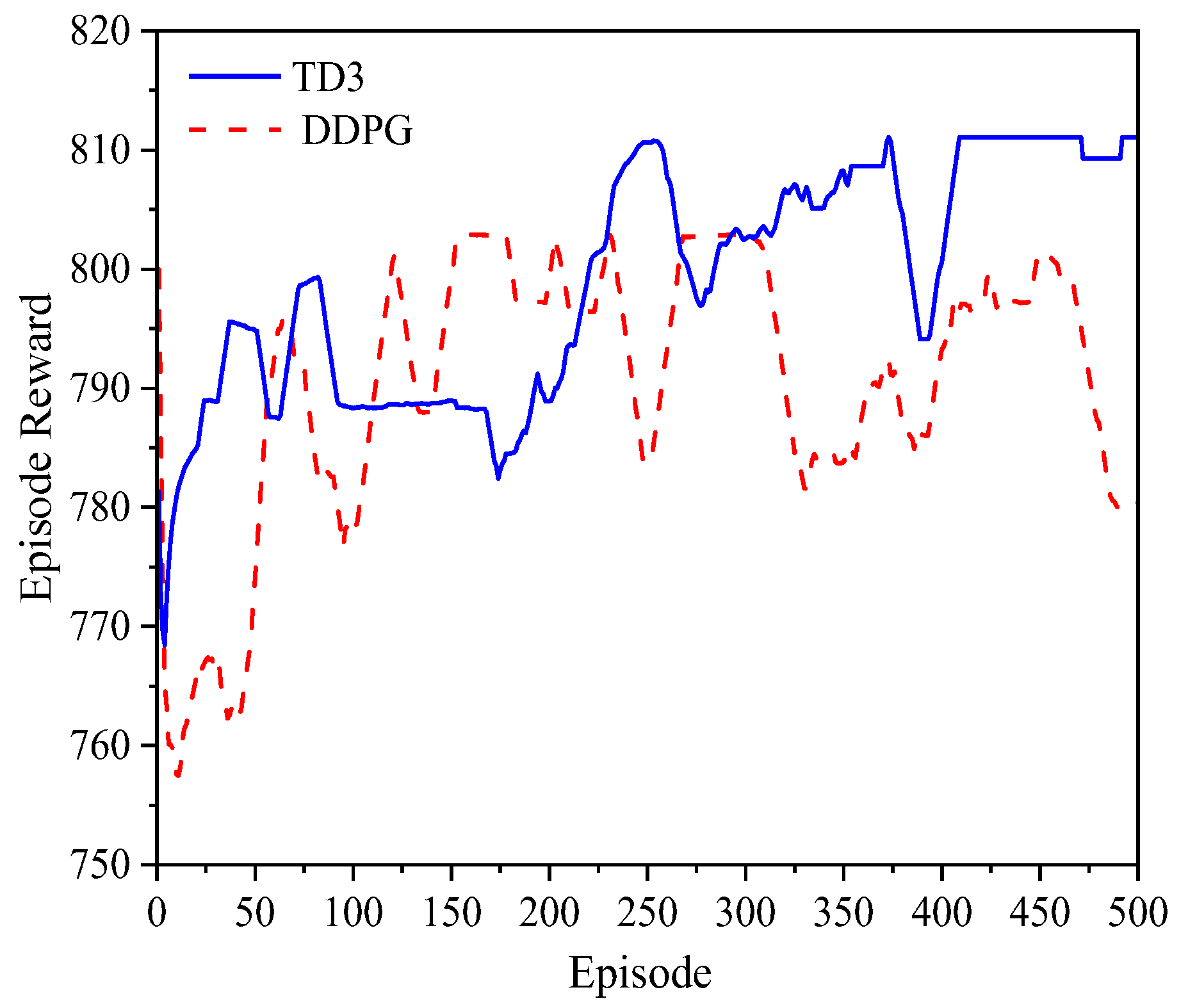
The reward trends for each episode during the training of DDPG and TD3 are shown in
Figure 4. By observing the changes in the reward curves of different deep reinforcement learning algorithms during the agent’s training process, it can be found that TD3 converges the fastest. DDPG reaches the optimal solution 150–200 episodes faster than TD3 and can converge within 150 episodes, indicating a faster training speed compared to TD3. This is because the critic network in TD3 uses a value-based learning method, and during the iterative training of the agent, the approximation error will accumulate continuously, leading to value function underestimation, which in turn causes slow training and the risk of falling into local optima. Using two critic networks to estimate the value of an action simultaneously and taking the average of the outputs of each critic network can improve the accuracy of the action value estimation, mitigating the slow training and conservative policy caused by the accumulation of underestimation.
4.2. Simulation Experiment of Expectation Tracking
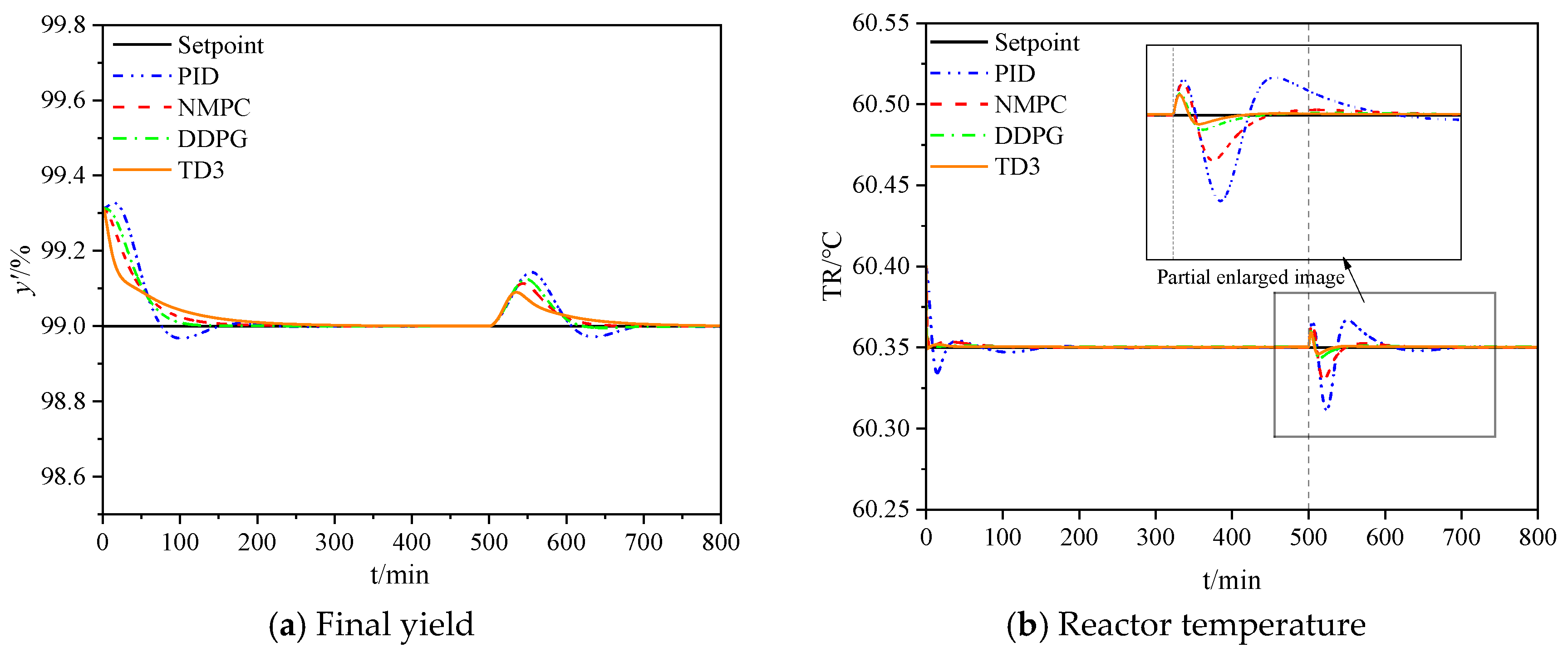
The first set of experiments was designed to evaluate the robustness and dynamic adjustment capability of the control algorithms in a biodiesel production process. The experimental results are shown in
Figure 5.
The results indicate that due to initial process instability, both the yield
(see
Figure 5a) and reactor temperature
(see
Figure 5b) exhibited small fluctuations around the setpoint. However, as the control algorithms took effect, the system gradually stabilized until the yield converged to the setpoint. At 160 minutes, the yield setpoint was changed to 97% (m/m), causing the system to deviate from the steady state. The TD3 algorithm effectively adjusted the control actions based on the new system state, bringing the yield and reactor temperature back to the desired values.
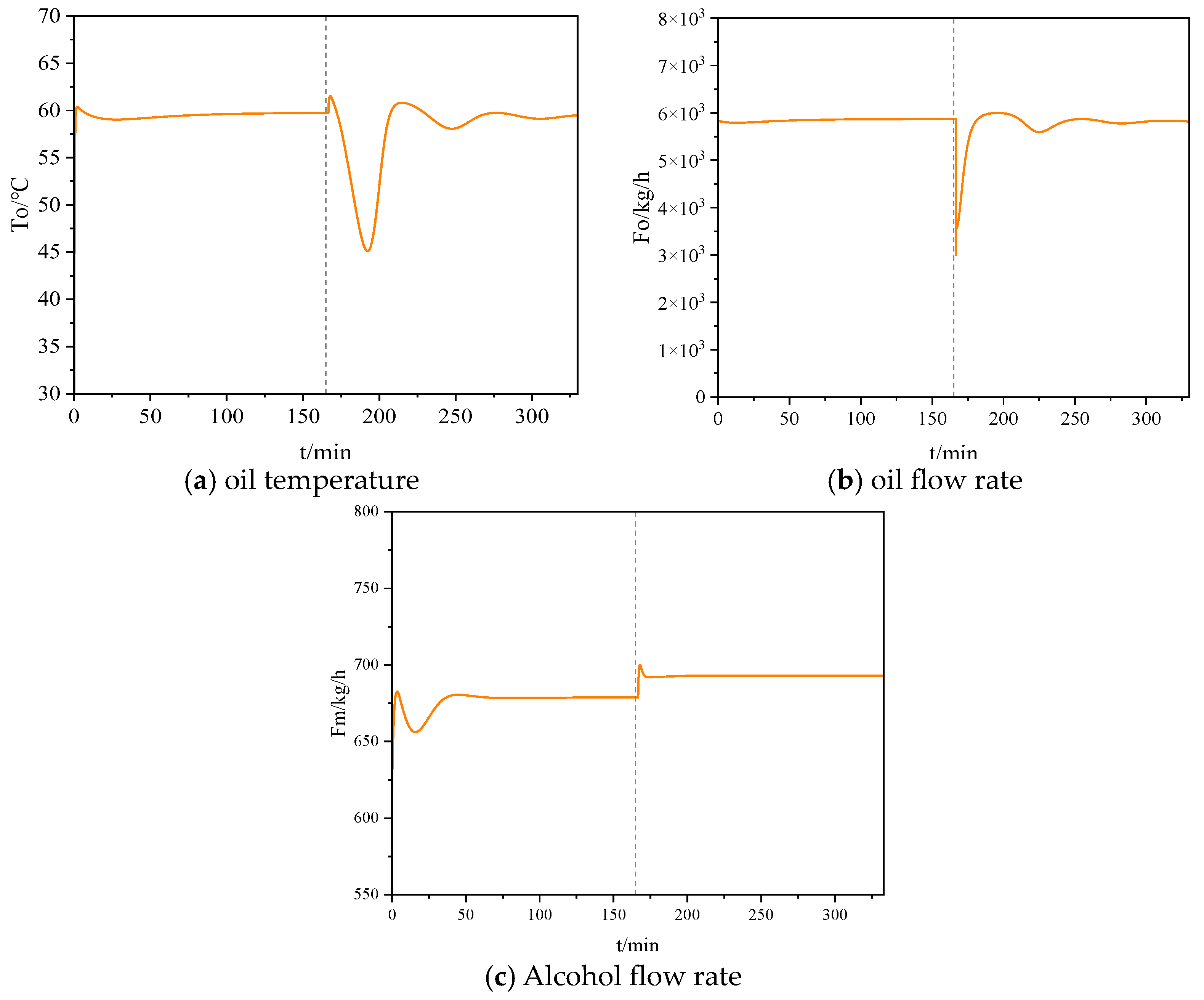
Figure 6 illustrates the variations in inlet oil temperature, alcohol flow rate, and oil flow rate under the TD3 control. To achieve the new yield setpoint, the algorithm reduced the oil flow rate and increased the alcohol flow rate, thereby adjusting the alcohol-to-oil ratio. Moreover, to maintain a suitable reaction temperature, the system controlled the inlet oil temperature to compensate for the temperature fluctuations caused by the introduction of large amounts of cold feedstock.
Comparing the control performance of different algorithms, it is evident that TD3 outperforms both DDPG and traditional control methods in terms of settling time and overshoot. The superior stability of TD3 can be attributed to its rapid convergence capability, which is achieved by employing a dual Q-network and delayed updates, enabling the control system to adapt quickly to environmental changes.
4.3. Simulation Experiment Under Step-Type Noise Input
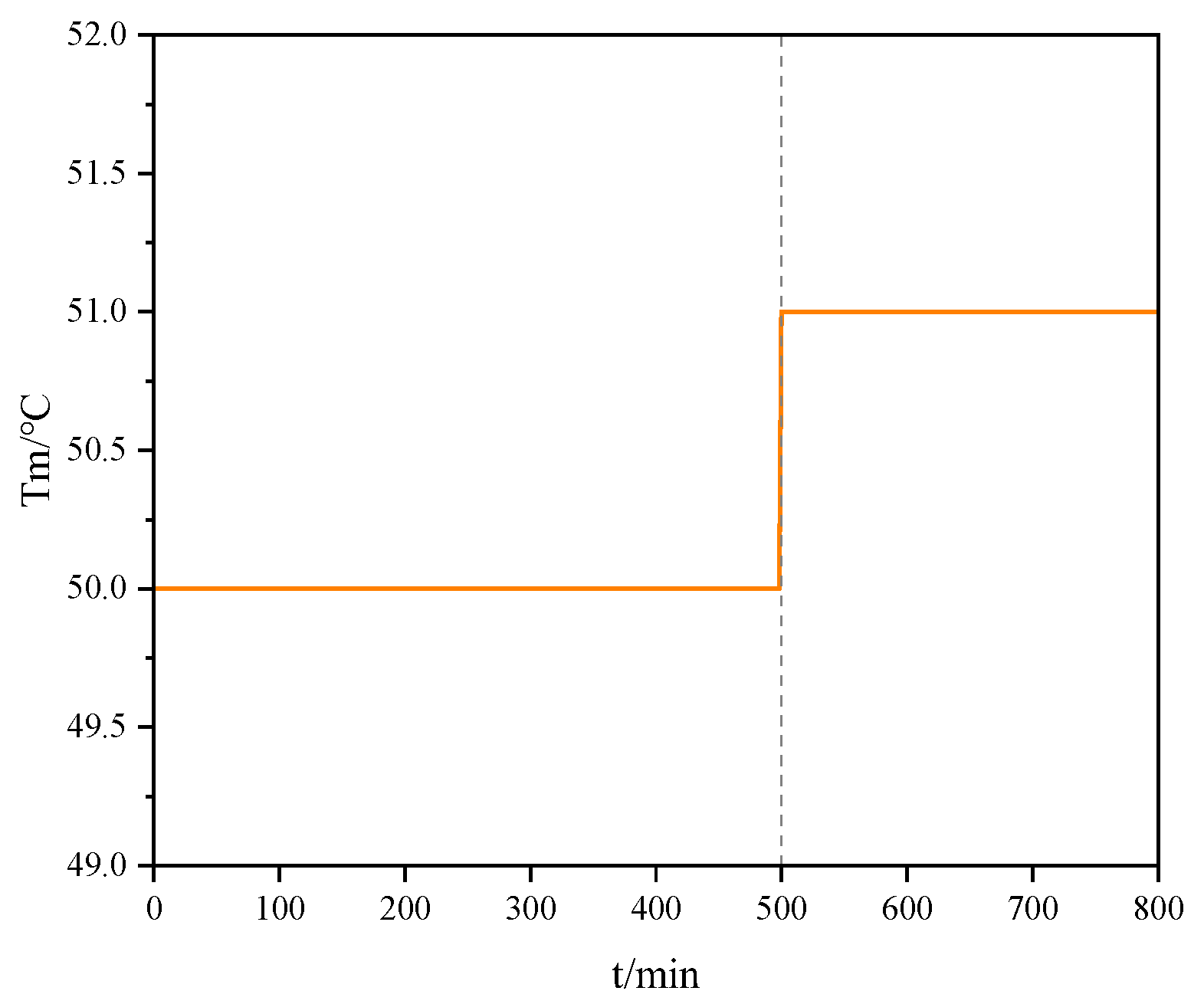
This section experimentally verifies the ability of the production system to reach a stable state rapidly while simultaneously satisfying the imposed upper and lower constraints under significant external disturbances. In the experiment, the alcohol temperature
in the disturbance variable
was kept constant, and a step change was introduced at a specific time. The noise input variation is shown in
Figure 7. Different control algorithms adjusted their inputs based on the changed system state caused by the disturbance, compensating for the noise and returning the reactor temperature to the setpoint.
Under step change conditions, the regulation of final yield
and reactor temperature
by TD3 and other control algorithms is shown in
Figure 8. As shown in
Figure 8a,b, TD3 exhibits the fastest recovery and the smallest fluctuations after disturbances, outperforming other algorithms. The control system, under the corrective action of the controller, gradually converges to a steady state.
Table 4 presents the control performance indices of
and final yield
from
Figure 8a,b. Compared with PID, NMPC, and DDPG, TD3 shows significant advantages in control accuracy and stability. The overall system stability is reflected by MSE and IAE, while control robustness is indicated by MAE. Smaller values of MSE, IAE, and MAE represent better performance. The specific calculation methods for MSE, IAE, and MAE are detailed in
Appendix B.
Among all the evaluated metrics (MSE, MAE, IAE), the TD3 algorithm consistently demonstrated the best performance in both reactor temperature control and yield control. These results indicate that TD3 offers superior control performance when faced with disturbances, effectively reducing errors and enhancing system stability in both temperature and yield control. This highlights the potential of TD3 as a highly efficient control strategy for complex industrial processes such as biodiesel production.
5. Discussion
This study proposes a novel adaptive optimization control method based on the twin delayed deep deterministic policy gradient (TD3) algorithm to address the challenges of multivariable coupling, nonlinearity, and time delay in biodiesel production. By constructing a simplified biodiesel production model and designing a TD3 controller, simulation experiments demonstrated that the TD3-based control strategy can respond quickly, effectively suppressing fluctuations in temperature and yield and ensuring the stable operation of the production system. Compared to other reinforcement learning algorithms and traditional control methods, TD3 exhibits superior stability and a faster response. The introduction of twin critic networks and delayed updates in TD3 significantly enhances the stability and responsiveness of the control policy, showcasing its potential for complex industrial processes. By leveraging experience replay to learn from past interactions, TD3 can adapt to changing environments and explore new control strategies while exploiting existing ones.
While BDsim serves as a convenient benchmark model due to its simplified assumptions, its applicability may be compromised when dealing with highly variable feedstocks such as waste oil. Although TD3’s twin critic network improves convergence, it relies heavily on computational resources and ample interaction data for effective policy learning. To address these limitations, BDsim’s application can be enhanced by incorporating more real-world experimental data and data-driven models. The substantial computational requirements of TD3 can be mitigated by pre-training and transferring the model to target applications.
When applied to real-world production processes, TD3-based control algorithms can dynamically adjust process parameters in real time, enabling more precise control over raw material and catalyst usage, ensuring product quality stability and reducing production costs. In practical chemical reaction processes, a single control strategy is often insufficient. Combining traditional control methods (such as PID control) with reinforcement learning to form a hybrid control strategy can enhance TD3’s performance under con-strained conditions; this hybrid control strategy can be applied to other complex industrial control processes.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}