
HAIPO: Hybrid AI Algorithm-Based Post-Fabrication Optimization for Modern 3D NAND Flash Memory

Abstract
1. Introduction
2. Background
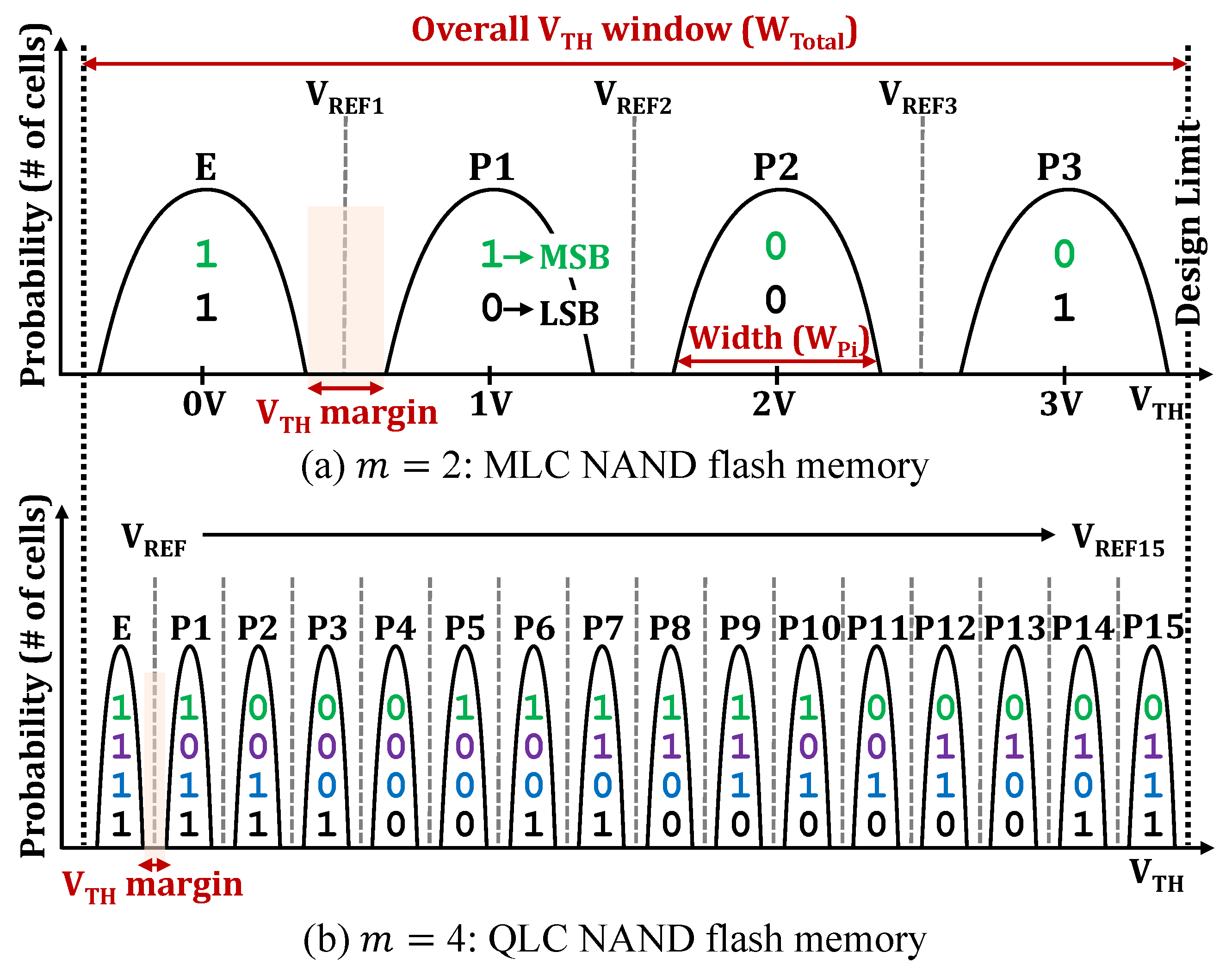
2.1. Overview of NAND Flash Memory
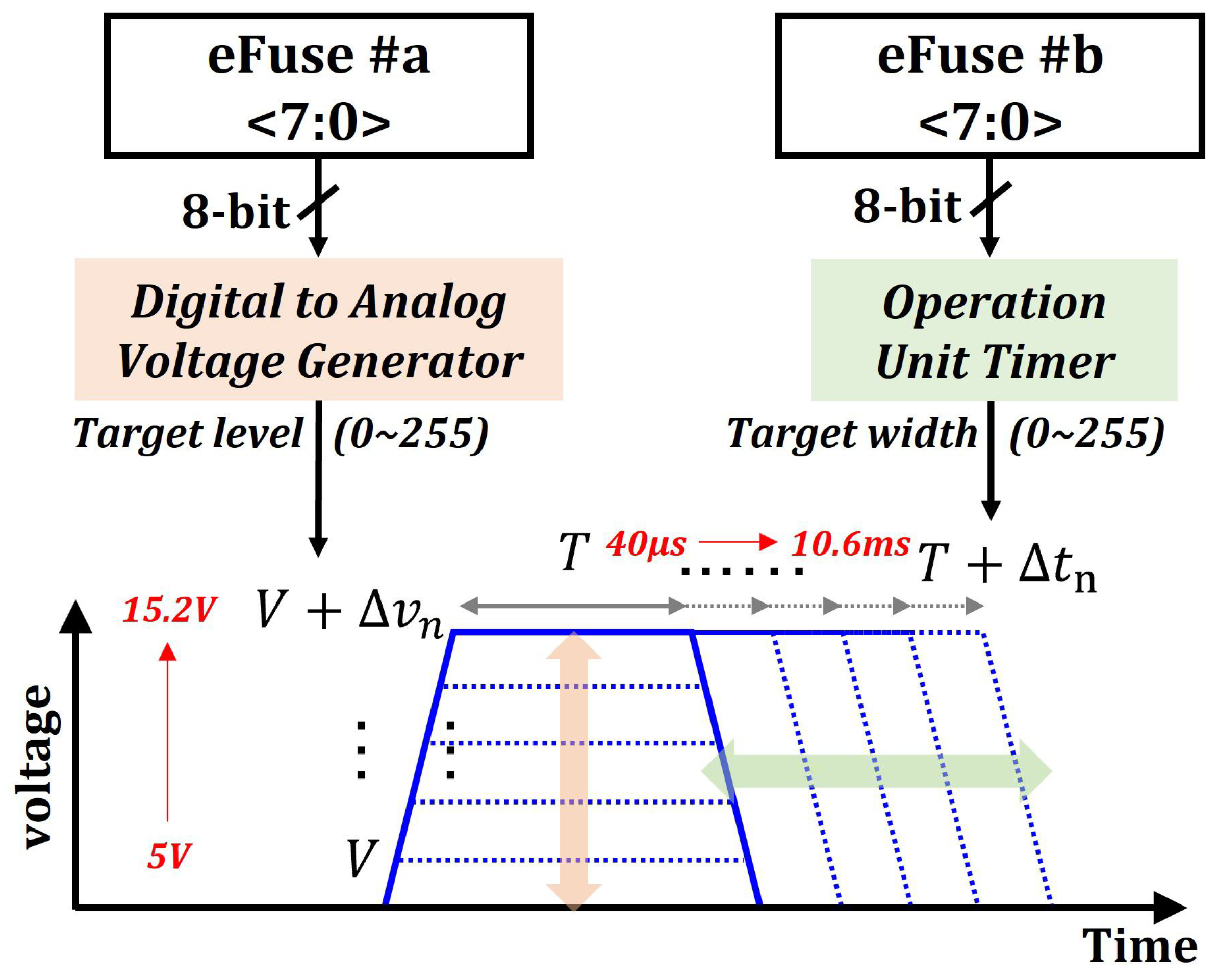
2.2. Tuning NAND Operating Parameter
3. Overview of NAND Post-Fabrication Optimization
3.1. Example of Post-Fabrication Optimization: Program Operation
3.2. Limitation of Conventional Post-Fabrication Optimization
4. HAIPO: Hybrid AI Algorithm-Based Post-Fabrication Optimization
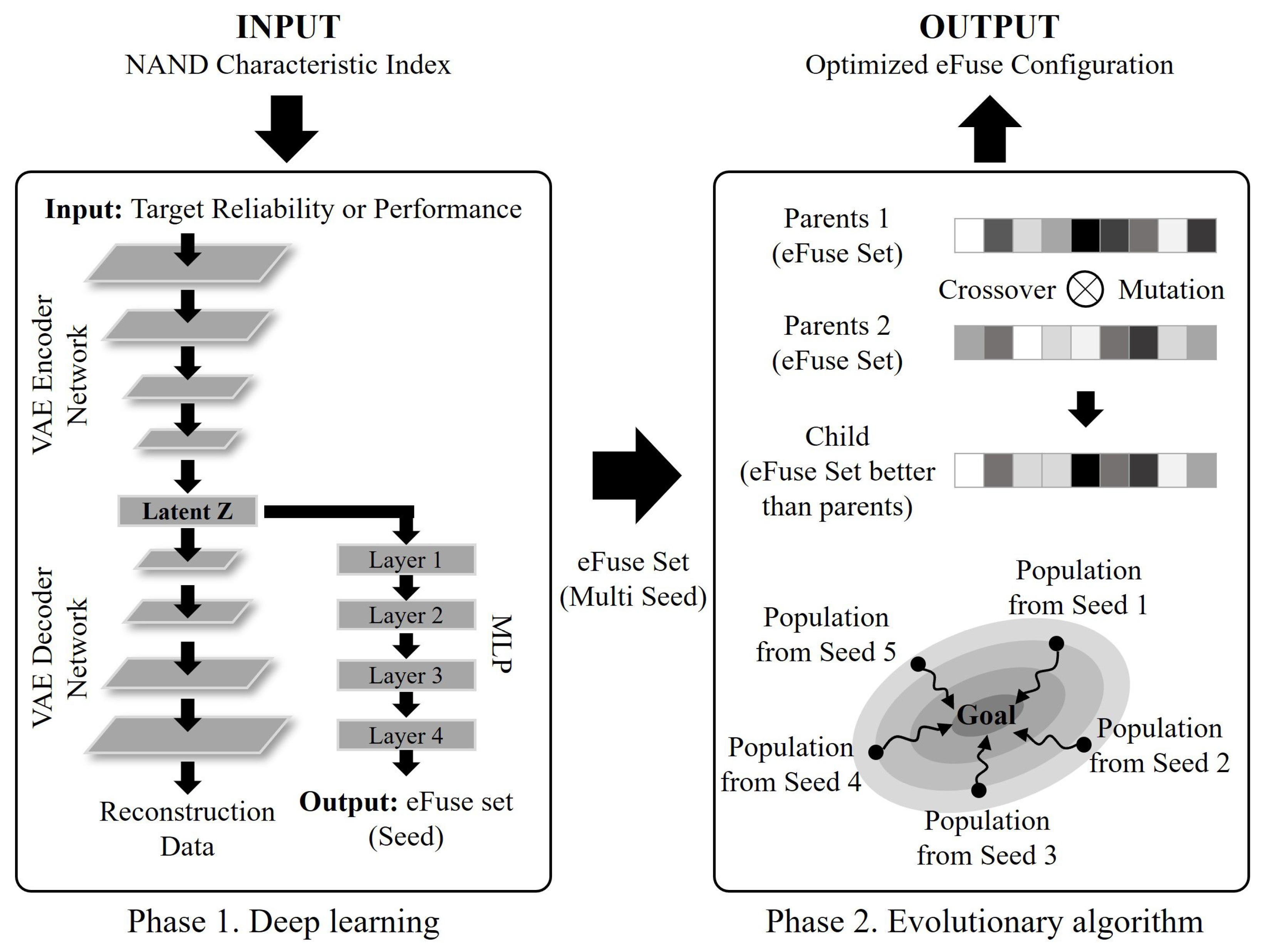
4.1. 2-Phase Framework for a Machine-Learning-Based Optimization, HAIPO(-)
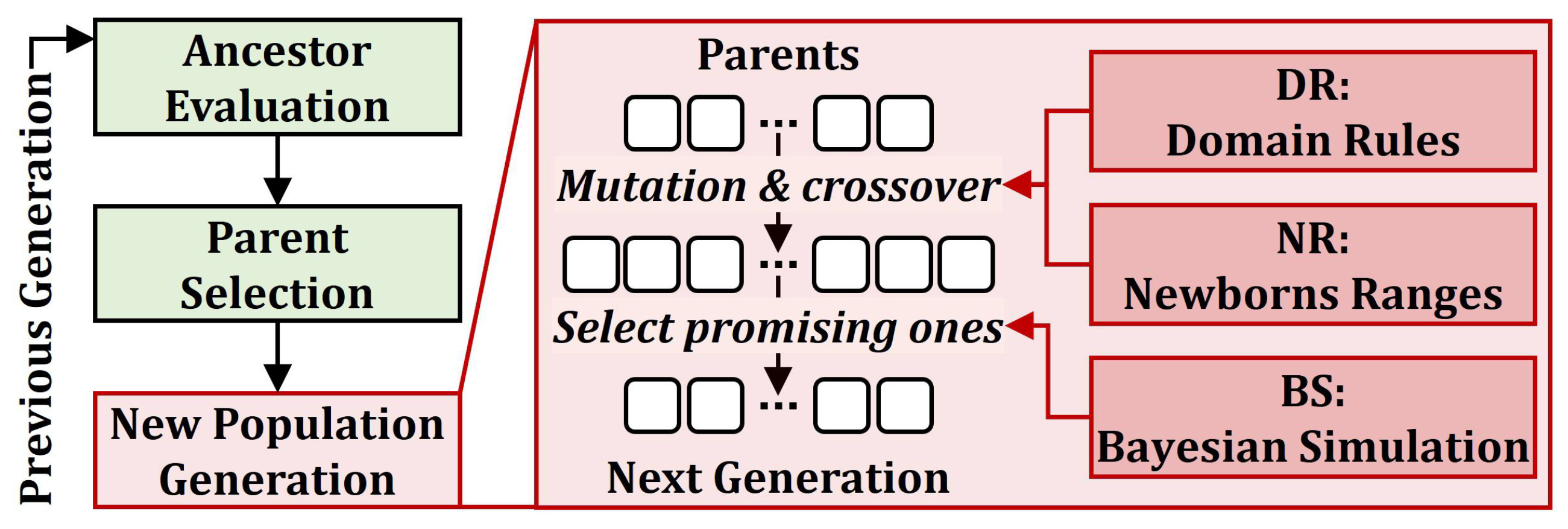
4.2. Rule-Based EA, HAIPO
4.2.1. Ancestor Evaluation and Parent Selection
4.2.2. New Population Generation
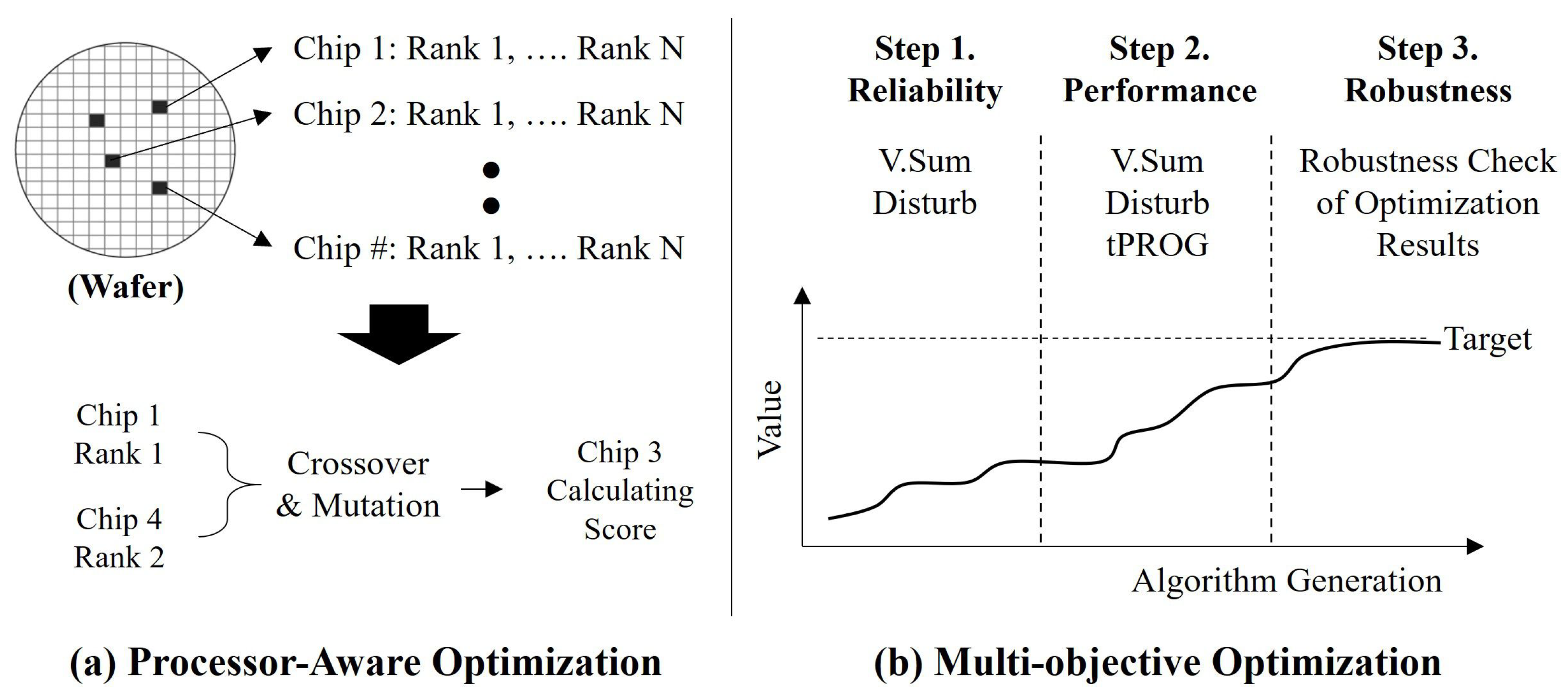
4.3. Additional Optimization Modules: Process-Aware and Multi-Objective Optimization
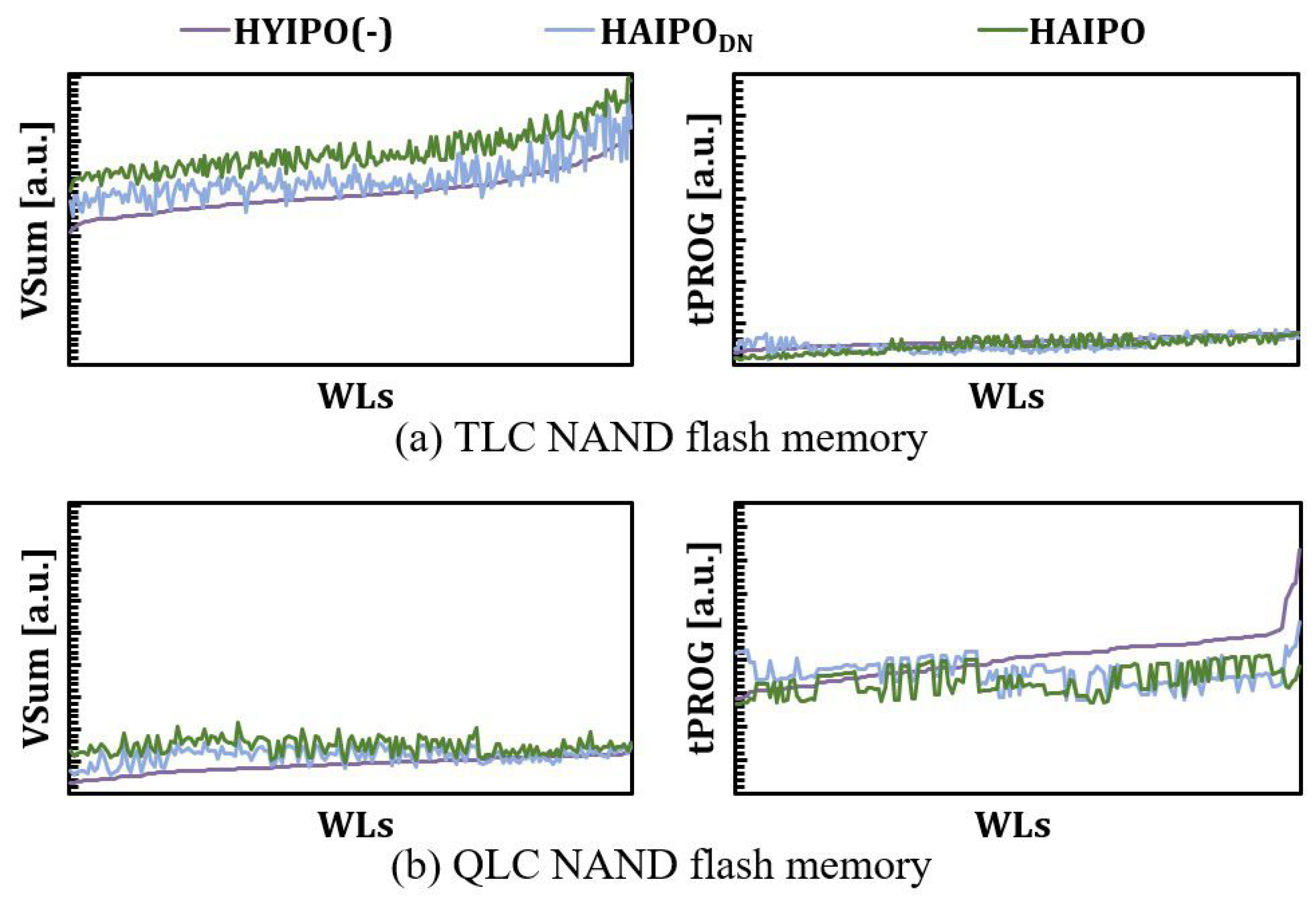
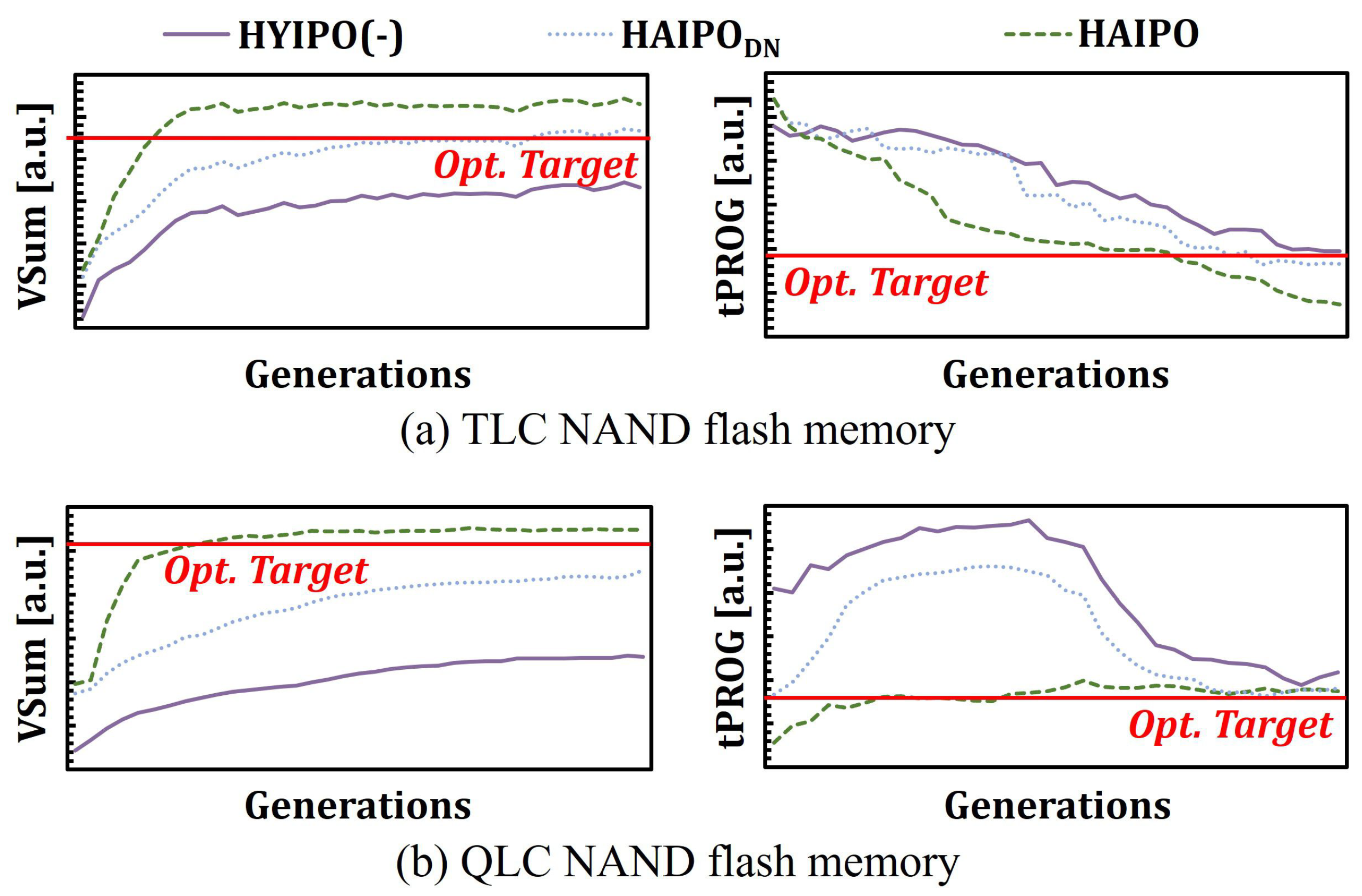
5. Evaluation
6. Related Work
7. Conclusions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Samsung. Samsung Enterprise SSDs. 2023. Available online: https://semiconductor.samsung.com/ssd/enterprise-ssd (accessed on 21 November 2024).
- SK Hynix. SK Hynix Enterprise SSDs. 2023. Available online: https://product.skhynix.com/products/ssd/essd.go (accessed on 21 November 2024).
- Micron. Micron Enterprise SSDs. 2023. Available online: https://www.micron.com/products/ssd/product-lines/9400 (accessed on 21 November 2024).
- Western Digital. Western Digital Data Center SSDs. 2023. Available online: https://github.com/axboe/fio (accessed on 21 November 2024).
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef] [PubMed]
- Whitley, D. A genetic algorithm tutorial. Stat. Comput. 1994, 4, 65–85. [Google Scholar] [CrossRef]
- Maserjian, J.; Zamani, N. Behavior of the Si/SiO2 interface observed by Fowler-Nordheim tunneling. J. Appl. Phys. (JAP) 1982, 53, 559–567. [Google Scholar] [CrossRef]
- Kim, D.; Kim, H.; Yun, S.; Song, Y.; Kim, J.; Joe, S.M.; Kang, K.H.; Jang, J.; Yoon, H.J.; Lee, K.; et al. 13.1 A 1 Tb 4b/cell NAND Flash Memory with tPROG = 2 ms, tR = 110 µs and 1.2 Gb/s High-Speed IO Rate. In Proceedings of the International Solid-State Circuits Conference (ISSCC), San Francisco, CA, USA, 16–20 February 2020. [Google Scholar]
- Kim, M.; Yun, S.W.; Park, J.; Park, H.K.; Lee, J.; Kim, Y.S.; Na, D.; Choi, S.; Song, Y.; Lee, J.; et al. A 1 Tb 3b/Cell 8th-Generation 3D-NAND Flash Memory with 164 MB/s Write Throughput and a 2.4 Gb/s Interface. In Proceedings of the International Solid-State Circuits Conference (ISSCC), San Francisco, CA, USA, 20–26 February 2022. [Google Scholar]
- Cho, J.; Kang, D.C.; Park, J.; Nam, S.-W.; Song, J.-H.; Jung, B.-K.; Lyu, J.; Lee, H.; Kim, W.-T.; Jeon, H.; et al. 512 Gb 3b/Cell 7th-Generation 3D-NAND Flash Memory with 184 MB/s Write Throughput and 2.0 Gb/s Interface. In Proceedings of the International Solid-State Circuits Conference (ISSCC), San Francisco, CA, USA, 13–22 February 2021. [Google Scholar]
- Kanda, K.; Shibata, N.; Hisada, T.; Isobe, K.; Sato, M.; Shimizu, Y.; Shimizu, T.; Sugimoto, T.; Kobayashi, T.; Kanagawa, N.; et al. A 19 nm 112.8 mm2 64 Gb Multi-Level Flash Memory with 400 Mbit/sec/pin 1.8 V Toggle Mode Interface. IEEE J. Solid-State Circuits (JSSC) 2012, 64, 426–428. [Google Scholar] [CrossRef]
- Kim, M.; Chun, M.; Hong, D.; Kim, Y.; Cho, G.; Lee, D.; Kim, J. RealWear: Improving performance and lifetime of SSDs using a NAND aging marker. Perform. Eval. 2021, 48, 120–121. [Google Scholar] [CrossRef]
- Micheloni, R.; Crippa, L.; Marelli, A. Inside NAND Flash Memories; Springer: Dordrecht, The Netherlands, 2010. [Google Scholar] [CrossRef]
- Suh, K.; Suh, B.-H.; Lim, Y.-H.; Kim, J.-K.; Choi, Y.-J.; Koh, Y.-N.; Lee, S.-S.; Kwon, S.-C.; Choi, B.-S.; Choi, J.-H.; et al. A 3.3 V 32 Mb NAND Flash Memory with Incremental Step Pulse Programming Scheme. IEEE J. Solid-State Circuits (JSSC) 1995, 30, 1149–1156. [Google Scholar]
- Kim, M.; Song, Y.; Jung, M.; Kim, J. SARO: A State-Aware Reliability Optimization Technique for High Density NAND Flash Memory. In Proceedings of the Great Lakes Symposium on VLSI (GLSVLSI), Chicago, IL, USA, 23–25 May 2018. [Google Scholar] [CrossRef]
- Jung, S.M.; Jang, J.; Cho, W.; Cho, H.; Jeong, J.; Chang, Y.; Kim, J.; Rah, Y.; Son, Y.; Park, J.; et al. Three dimensionally stacked NAND flash memory technology using stacking single crystal Si layers on ILD and TANOS structure for beyond 30 nm node. In Proceedings of the International Electron Devices Meeting (IEDM), San Francisco, CA, USA, 11–13 December 2006. [Google Scholar]
- Micron. Micron’s 232 Layer NAND Now Shipping: 1Tbit, 6-Plane Dies with 50% More I/O Bandwidth. 2020. Available online: https://www.anandtech.com/show/17509 (accessed on 21 November 2024).
- Jang, J.; Kim, H.-S.; Cho, W.; Cho, H.; Kim, J.; Shim, S.I.; Younggoan; Jeong, J.-H.; Son, B.-K.; Kim, D.W.; et al. Vertical cell array using TCAT (Terabit Cell Array Transistor) technology for ultra high density NAND flash memory. In Proceedings of the Symposium on VLSI Technology, Kyoto, Japan, 15–17 June 2009. [Google Scholar]
- Kim, B.; Seo, G.; Kim, M. Smart Electrical Screening Methodology for Channel Hole Defects of 3D Vertical NAND (VNAND) Flash Memory. Eng 2024, 5, 495–512. [Google Scholar] [CrossRef]
- Robson, N.; Safran, J.; Kothandaraman, C.; Cestero, A.; Chen, X.; Rajeevakumar, R.; Leslie, A.; Moy, D.; Kirihata, T.; Iyer, S. Electrically Programmable Fuse (eFuse): From Memory Redundancy to Autonomic Chips. In Proceedings of the IEEE Custom Integrated Circuits Conference (CICC), San Jose, CA, USA, 16–19 September 2007. [Google Scholar]
- Shim, Y.; Kim, M.; Chun, M.; Park, J.; Kim, Y.; Kim, J. Exploiting Process Similarity of 3D Flash Memory for High Performance SSDs. In Proceedings of the IEEE/ACM International Symposium on Microarchitecture (MICRO), Columbus, OH, USA, 12–16 October 2019. [Google Scholar] [CrossRef]
- JEDEC. JESD218B.02: Solid-State Drive (SSD) Requirements and Endurance Test Method. 2022. Available online: https://www.jedec.org/standards-documents/docs/jesd218b01 (accessed on 21 November 2024).
- Arrhenius, S. Über die Dissociationswärme und den Einfluss der Temperatur auf den Dissociationsgrad der Elektrolyte. Z. Phys. Chem. 1889, 4, 96–116. [Google Scholar] [CrossRef]
- Hou, X.; Shen, L.; Sun, K.; Qiu, G. Deep feature consistent variational autoencoder. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), Santa Rosa, CA, USA, 24–31 March 2017. [Google Scholar] [CrossRef]
- Lim, K.L.; Jiang, X.; Yi, C. Deep clustering with variational autoencoder. IEEE Signal Process. Lett. 2020, 27, 231–235. [Google Scholar] [CrossRef]
- Kim, J.; Lee, J.; Yoo, S. Machine Learning-Based Automatic Generation of eFuse Configuration in NAND Flash Chip. In Proceedings of the IEEE International Test Conference (ITC), Washington, DC, USA, 9–15 November 2019. [Google Scholar] [CrossRef]
- Li, H.; Putra, M.L.; Shi, R.; Lin, X.; Ganger, G.R.; Gunawi, H.S. IODA: A Host/Device Co-Design for Strong Predictability Contract on Modern Flash Storage. In Proceedings of the ACM SIGOPS 28th Symposium on Operating Systems Principles (OSDI), Virtual, 26–29 July 2021. [Google Scholar] [CrossRef]
- Kim, S.; Yang, J.S. Optimized I/O Determinism for Emerging NVM-based NVMe SSD in an Enterprise System. In Proceedings of the Annual Design Automation Conference (DAC), San Francisco, CA, USA, 24–29 June 2018. [Google Scholar] [CrossRef]
- Bongale, P.; Sundaresan, V.; Ghosh, P.; Parekhji, R. A Novel Technique for Interdependent Trim Code Optimization. In Proceedings of the IEEE VLSI Test Symposium (VTS), Las Vegas, NV, USA, 25–27 April 2016. [Google Scholar]
- Xanthopoulos, C.; Ahmadi, A.; Boddikurapati, S.; Nahar, A.; Orr, B.; Makris, Y. Wafer-Level Adaptive Trim Seed Forecasting Based on E-Tests. In Proceedings of the IEEE International Symposium on Circuits and Systems (ISCAS), Baltimore, MD, USA, 28–31 May 2017. [Google Scholar]
- Golonek, T.; Rutkowski, J. Genetic-Algorithm-Based Method for Optimal Analog Test Points Selection. IEEE Trans. Circuits Syst. II Express Briefs (TCAS-II) 2007, 54, 117–121. [Google Scholar] [CrossRef]
- Lin, F.; Cheng, K.T. An Artificial Neural Network Approach for Screening Test Escapes. In Proceedings of the Asia and South Pacific Design Automation Conference (ASP-DAC), Tokyo, Japan, 16–19 January 2017. [Google Scholar]
- Shintani, M.; Inoue, M.; Nakamura, Y. Artificial Neural Network Based Test Escape Screening Using Generative Model. In Proceedings of the IEEE International Test Conference (ITC), Phoenix, AZ, USA, 29 October–1 November 2018. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Sklearn GPR (Gaussian Process Regressor) |
| Kernel | Radial Basis Function Kernel + Constant Kernel |
| Normalization | Standard Scaling |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, M. HAIPO: Hybrid AI Algorithm-Based Post-Fabrication Optimization for Modern 3D NAND Flash Memory. Processes 2024, 12, 2760. https://doi.org/10.3390/pr12122760
Kim M. HAIPO: Hybrid AI Algorithm-Based Post-Fabrication Optimization for Modern 3D NAND Flash Memory. Processes. 2024; 12(12):2760. https://doi.org/10.3390/pr12122760
Chicago/Turabian StyleKim, Myungsuk. 2024. "HAIPO: Hybrid AI Algorithm-Based Post-Fabrication Optimization for Modern 3D NAND Flash Memory" Processes 12, no. 12: 2760. https://doi.org/10.3390/pr12122760
APA StyleKim, M. (2024). HAIPO: Hybrid AI Algorithm-Based Post-Fabrication Optimization for Modern 3D NAND Flash Memory. Processes, 12(12), 2760. https://doi.org/10.3390/pr12122760