

Application of an Improved Link Prediction Algorithm Based on Complex Network in Industrial Structure Adjustment

Abstract
1. Introduction
2. Related Works
3. Improved LP Design in IS Adjustment
3.1. LP Improvement of Complex Network for IS
3.2. IS Adjustment and Optimization Based on the Improved Algorithm
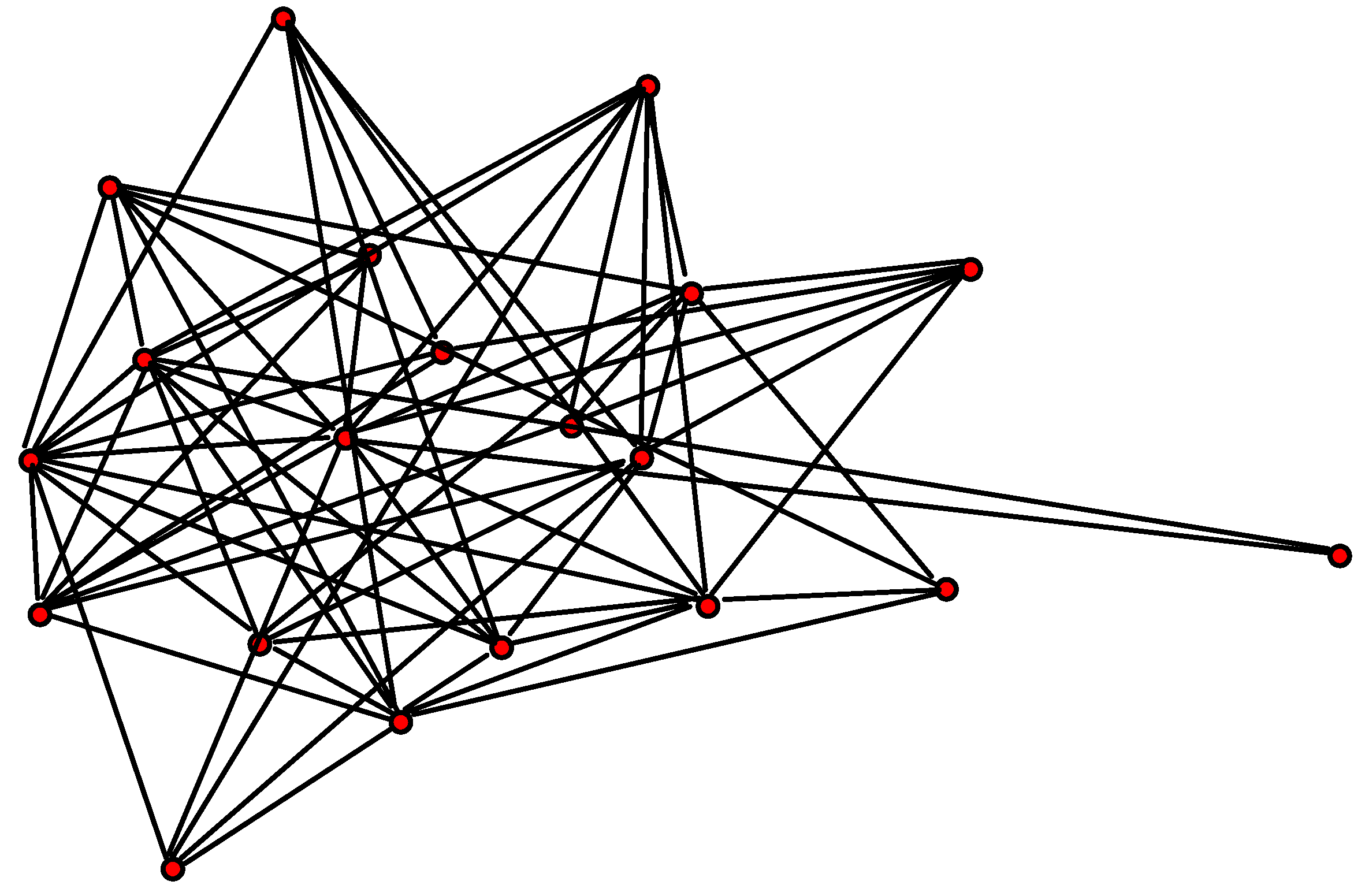
4. LP and IS Adjustment Test Analysis
4.1. LP Test
4.2. IS Adjustment Test
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Li, Q.; Lin, H.; Tan, X.; Du, S. H∞ Consensus for multiagent-based supply chain systems under switching topology and uncertain demands. IEEE Trans. Syst. Man Cybern. Syst. 2020, 50, 4905–4918. [Google Scholar] [CrossRef]
- Wang, L.; Wang, Z.; Ma, Y. Heterogeneous environmental regulation and industrial structure upgrading: Evidence from China. Environ. Sci. Pollut. Res. 2022, 29, 13369–13385. [Google Scholar] [CrossRef]
- Vega-Oliveros, D.A.; Zhao, L.; Rocha, A.; Berton, L. Link Prediction Based on Stochastic Information Diffusion. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 3522–3532. [Google Scholar] [CrossRef] [PubMed]
- Nasiri, E.; Berahmand, K.; Samei, Z.; Li, Y. Impact of Centrality Measures on the Common Neighbors in Link Prediction for Multiplex Networks. Big Data 2022, 10, 138–150. [Google Scholar] [CrossRef]
- Roy, I.; De, A.; Chakrabarti, S. Adversarial Permutation Guided Node Representations for Link Prediction. Proc. Conf. AAAI Artif. Intell. 2021, 35, 9445–9453. [Google Scholar] [CrossRef]
- Ma, W. Dwindling regional environmental pollution through industrial structure adjustment and higher education development. Environ. Sci. Pollut. Res. 2023, 30, 420–433. [Google Scholar] [CrossRef]
- Zhou, B.; Zhou, F.; Zhou, D.; Qiao, J.; Xue, B. Improvement of environmental performance and optimization of industrial structure of the Yangtze River economic belt in China: Going forward together or restraining each other? J. Chin. Gov. 2021, 6, 435–455. [Google Scholar] [CrossRef]
- Zheng, Y.; Peng, J.; Xiao, J.; Su, P.; Li, S. Industrial structure transformation and provincial heterogeneity characteristics evolution of air pollution: Evidence of a threshold effect from China. Atmos. Pollut. Res. 2020, 11, 598–609. [Google Scholar] [CrossRef]
- Huang, W. Research on the Impact of Investment Efficiency of China’s Commercial Economy on Industrial Structure Adjustment Based on Cloud Computing. IEEE Sens. J. 2021, 21, 25525–25531. [Google Scholar] [CrossRef]
- Zang, J.; Wan, L.; Li, Z.; Wang, C.; Wang, S. Does emission trading scheme have spillover effect on industrial structure upgrading? Evidence from the EU based on a PSM-DID approach. Environ. Sci. Pollut. Res. 2020, 27, 12345–12357. [Google Scholar] [CrossRef] [PubMed]
- Shabaz, M.; Garg, U. Predicting future diseases based on existing health status using link prediction. World J. Eng. 2022, 19, 29–32. [Google Scholar] [CrossRef]
- Ghasemian, A.; Hosseinmardi, H.; Galstyan, A.; Airoldi, E.M.; Clauset, A. Stacking models for nearly optimal link prediction in complex networks. Proc. Natl. Acad. Sci. USA 2020, 117, 23393–23400. [Google Scholar] [CrossRef] [PubMed]
- Coşkun, M.; Koyutürk, M. Node similarity-based graph convolution for link prediction in biological networks. Bioinformatics 2021, 37, 4501–4508. [Google Scholar] [CrossRef]
- Chen, J.; Lin, X.; Shi, Z.; Liu, Y. Link Prediction Adversarial Attack Via Iterative Gradient Attack. IEEE Trans. Comput. Soc. Syst. 2020, 7, 1081–1094. [Google Scholar] [CrossRef]
- Kumar, S.; Mallik, A.; Panda, B.S. Link prediction in complex networks using node centrality and light gradient boosting machine. World Wide Web 2022, 25, 2487–2513. [Google Scholar] [CrossRef]
- Breit, A.; Ott, S.; Agibetov, A.; Samwald, M. OpenBioLink: A benchmarking framework for large-scale biomedical link prediction. Bioinformatics 2020, 36, 4097–4098. [Google Scholar] [CrossRef] [PubMed]
- Anand, S.; Rahul; Mallik, A.; Kumar, S. Integrating node centralities, similarity measures, and machine learning classifiers for link prediction. Multimed. Tools Appl. 2022, 81, 38593–38621. [Google Scholar] [CrossRef]
- Ni, Q.; Guo, J.; Wu, W.; Wang, H.; Wu, J. Continuous Influence-Based Community Partition for Social Networks. IEEE Trans. Netw. Sci. Eng. 2022, 9, 1187–1197. [Google Scholar] [CrossRef]
- Ni, Q.; Guo, J.; Wu, W.; Wang, H. Influence-Based Community Partition with Sandwich Method for Social Networks. IEEE Trans. Comput. Soc. Syst. 2023, 10, 819–830. [Google Scholar] [CrossRef]
- Zenggang, X.; Mingyang, Z.; Xuemin, Z.; Sanyuan, Z.; Fang, X.; Xiaochao, Z.; Yunyun, W.; Xiang, L. Social Similarity Routing Algorithm based on Socially Aware Networks in the Big Data Environment. J. Signal Process. Syst. 2022, 94, 1253–1267. [Google Scholar] [CrossRef]
- Gu, W.; Gao, F.; Li, R.; Zhang, J. Learning Universal Network Representation via Link Prediction by Graph Convolutional Neural Network. J. Soc. Comput. 2021, 2, 43–51. [Google Scholar] [CrossRef]
- Manshad, M.K.; Meybodi, M.R.; Salajegheh, A. A new irregular cellular learning automata-based evolutionary computation for time series link prediction in social networks. Appl. Intell. 2021, 51, 71–84. [Google Scholar] [CrossRef]
- Mishra, S.; Singh, S.S.; Kumar, A.; Biswas, B. HOPLP–MUL: Link prediction in multiplex networks based on higher order paths and layer fusion. Appl. Intell. 2023, 53, 3415–3443. [Google Scholar] [CrossRef]
- Tian, J.; Hou, M.; Bian, H.; Li, J. Variable surrogate model-based particle swarm optimization for high-dimensional expensive problems. Complex Intell. Syst. 2022, 1–49. [Google Scholar] [CrossRef]
- Zhou, M.; Jin, H.; Wu, Q.; Xie, H.; Han, Q. Betweenness centrality-based community adaptive network representation for link prediction. Appl. Intell. 2022, 52, 3545–3558. [Google Scholar] [CrossRef]
- Singh, A.K.; Lakshmanan, K. PILHNB: Popularity, interests, location used hidden Naive Bayesian-based model for link prediction in dynamic social networks. Neurocomputing 2021, 461, 562–576. [Google Scholar] [CrossRef]
- Keikha, M.M.; Rahgozar, M.; Asadpour, M. DeepLink: A novel link prediction framework based on deep learning. J. Inf. Sci. 2021, 47, 642–657. [Google Scholar] [CrossRef]
- Li, B.; Tan, Y.; Wu, A.-G.; Duan, G.-R. A Distributionally Robust Optimization Based Method for Stochastic Model Predictive Control. IEEE Trans. Autom. Control 2021, 67, 5762–5776. [Google Scholar] [CrossRef]
- Li, X.; Sun, Y. Application of RBF neural network optimal segmentation algorithm in credit rating. Neural Comput. Appl. 2021, 33, 8227–8235. [Google Scholar] [CrossRef]
- Shengnan, W.; Hongjun, P.; Ruonan, T.; Wenqi, L.; Qi, Y. Network structure’s impacts on link prediction algorithm from meta-analysis perspective. Data Anal. Knowl. Discov. 2021, 5, 102–113. [Google Scholar]
- Zhang, J.; Liu, Y.; Li, Z.; Lu, Y. Forecast-Assisted Service Function Chain Dynamic Deployment for SDN/NFV-Enabled Cloud Management Systems. IEEE Syst. J. 2023, 1–12. [Google Scholar] [CrossRef]
- Fan, H.; Zhang, F.; Wei, Y.; Li, Z.; Zou, C.; Gao, Y.; Dai, Q. Heterogeneous Hypergraph Variational Autoencoder for Link Prediction. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 4125–4138. [Google Scholar] [CrossRef] [PubMed]
- Hu, F.; Qiu, L.; Zhou, H. Medical Device Product Innovation Choices in Asia: An Empirical Analysis Based on Product Space. Front. Public Health 2022, 10, 871575. [Google Scholar] [CrossRef] [PubMed]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Mixing Degree | Check the Accuracy | 0.1 | 0.2 | 0.3 | 0.4 | 0.5 | |||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| True | False | True | False | True | False | True | False | True | False | ||
| 0.1 | 0.563 | / | / | / | / | / | / | / | / | / | / |
| 0.2 | 0.602 | / | / | / | / | / | / | 92% | 8% | 97% | 3% |
| 0.3 | 0.697 | / | / | / | / | 90% | 10% | 95% | 5% | 100% | 0% |
| 0.4 | 0.845 | / | / | 89% | 11% | 92% | 8% | 100% | 0% | 100% | 0% |
| 0.5 | 0.953 | / | / | 92% | 8% | 96% | 4% | 100% | 0% | 100% | 0% |
| Industry 1 | Industry 2 | Similarity |
|---|---|---|
| Chemical products | Wholesale and retail | 1.23 |
| Chemical products | Production and supply of electricity and heat | 1.15 |
| Wholesale and retail | Leasing and business services | 1.11 |
| Chemical products | Leasing and business services | 1.09 |
| Production and supply of electricity and heat | Leasing and business services | 1.05 |
| Production and supply of electricity and heat | Finance | 1.02 |
| Production and supply of electricity and heat | Wholesale and retail | 0.98 |
| Wholesale and retail | Finance | 0.96 |
| Chemical products | Finance | 0.95 |
| Finance | Leasing and business services | 0.92 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, Y.; Zhao, R.; Yin, N. Application of an Improved Link Prediction Algorithm Based on Complex Network in Industrial Structure Adjustment. Processes 2023, 11, 1689. https://doi.org/10.3390/pr11061689
Ma Y, Zhao R, Yin N. Application of an Improved Link Prediction Algorithm Based on Complex Network in Industrial Structure Adjustment. Processes. 2023; 11(6):1689. https://doi.org/10.3390/pr11061689
Chicago/Turabian StyleMa, Yixuan, Rui Zhao, and Nan Yin. 2023. "Application of an Improved Link Prediction Algorithm Based on Complex Network in Industrial Structure Adjustment" Processes 11, no. 6: 1689. https://doi.org/10.3390/pr11061689
APA StyleMa, Y., Zhao, R., & Yin, N. (2023). Application of an Improved Link Prediction Algorithm Based on Complex Network in Industrial Structure Adjustment. Processes, 11(6), 1689. https://doi.org/10.3390/pr11061689