

Research of Carbon Emission Prediction: An Oscillatory Particle Swarm Optimization for Long Short-Term Memory


Abstract
:1. Introduction
2. Related Work
3. Materials and Methods
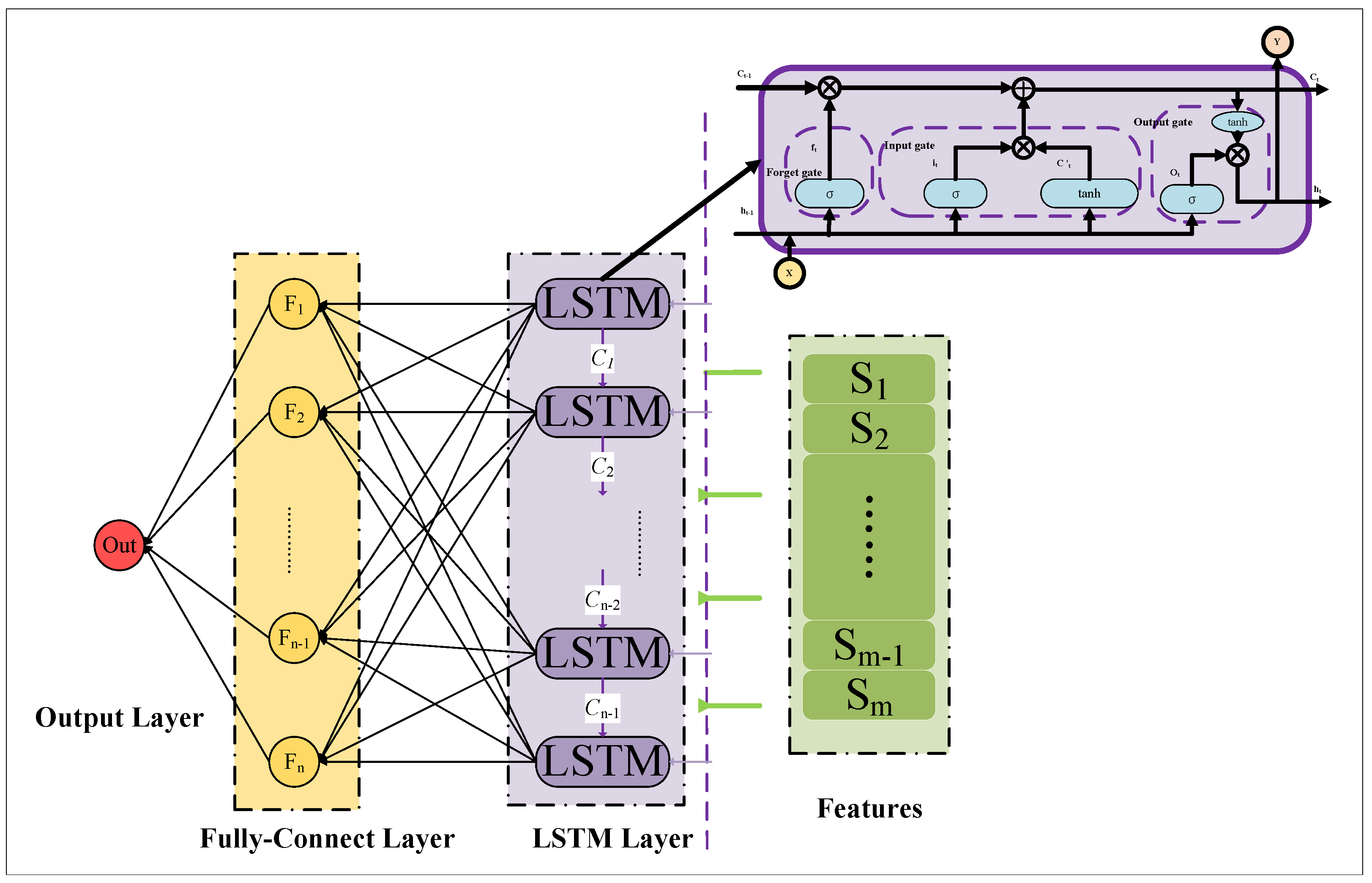
3.1. Long Short-Term Memory
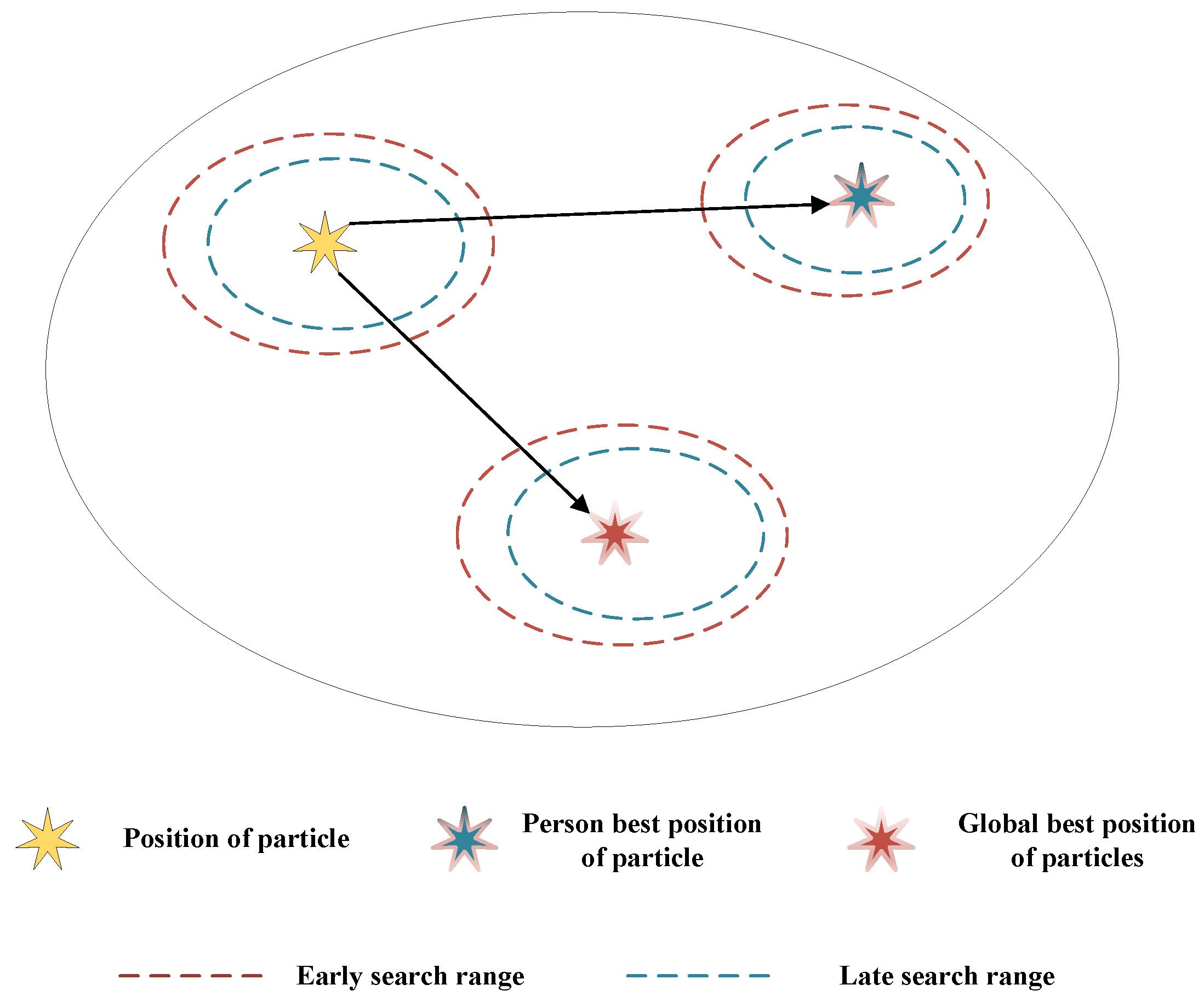
3.2. Oscillatory Particle Swarm Optimization
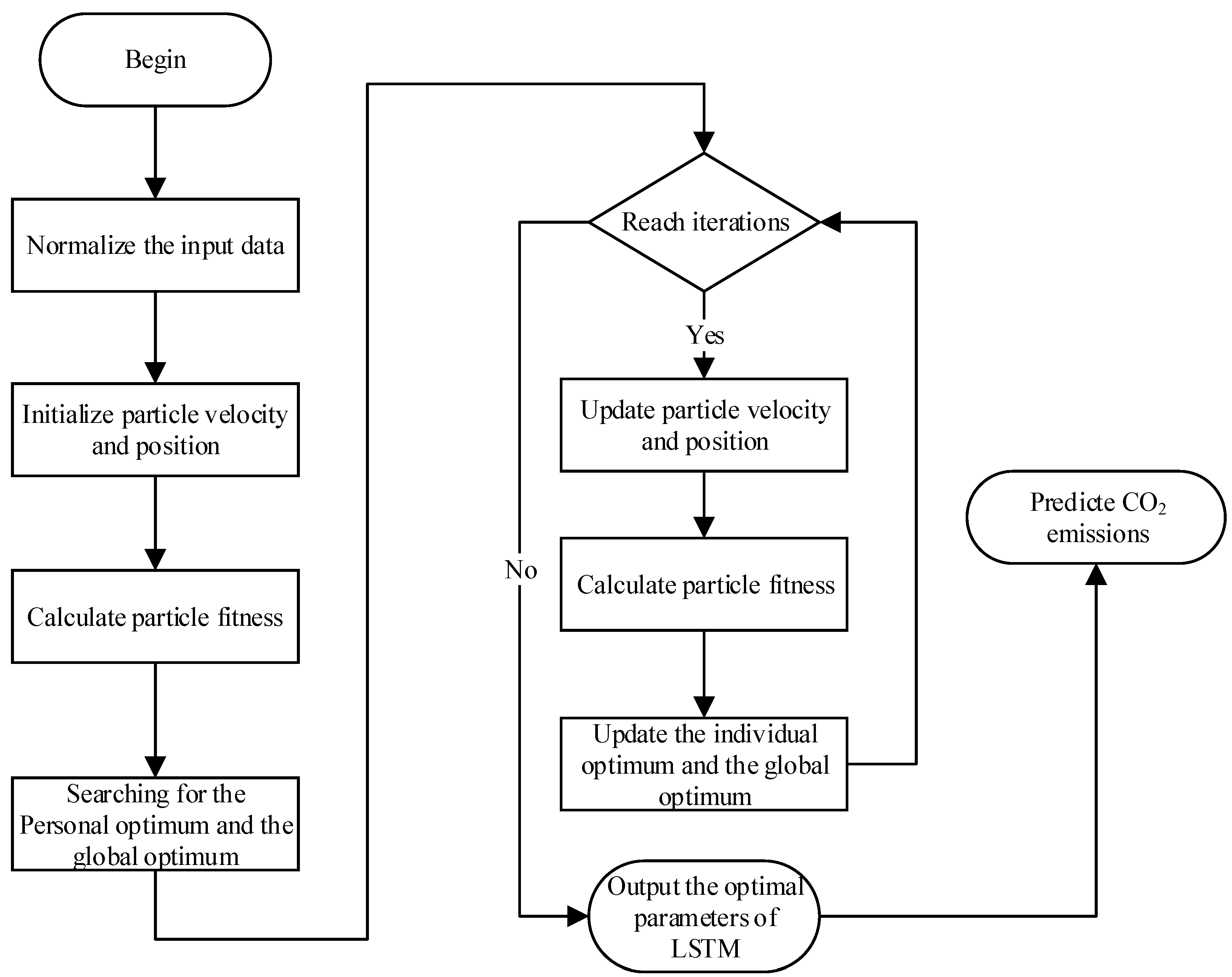
3.3. Framework of OPSO-LSTM Model
- Step 1: Normalize all the data within the range −1 to 1 according to the formula. The normalization formula is shown in Equation (9). The normalization can eliminate the influence of the scale between indicators to solve the comparability between data indicators.where is the output after normalization. and are the minimum and maximum values of the input class of data. X represents the input data.
- Step 2: In the OPSO optimization process, the number of neurons and initial learning rate of LSTM are taken as optimization objects, and the mean square error (MSE) is taken as a fitness function of OPSO. The fitness function of OPSO is as follows:where n is the number of samples. and are the true value and the predicted value, respectively.
- Step 3: The optimal number of neurons and the initial learning rate obtained by searching by OPSO are used as parameters during LSTM training.
4. Experiment and Results
4.1. Data Preparation
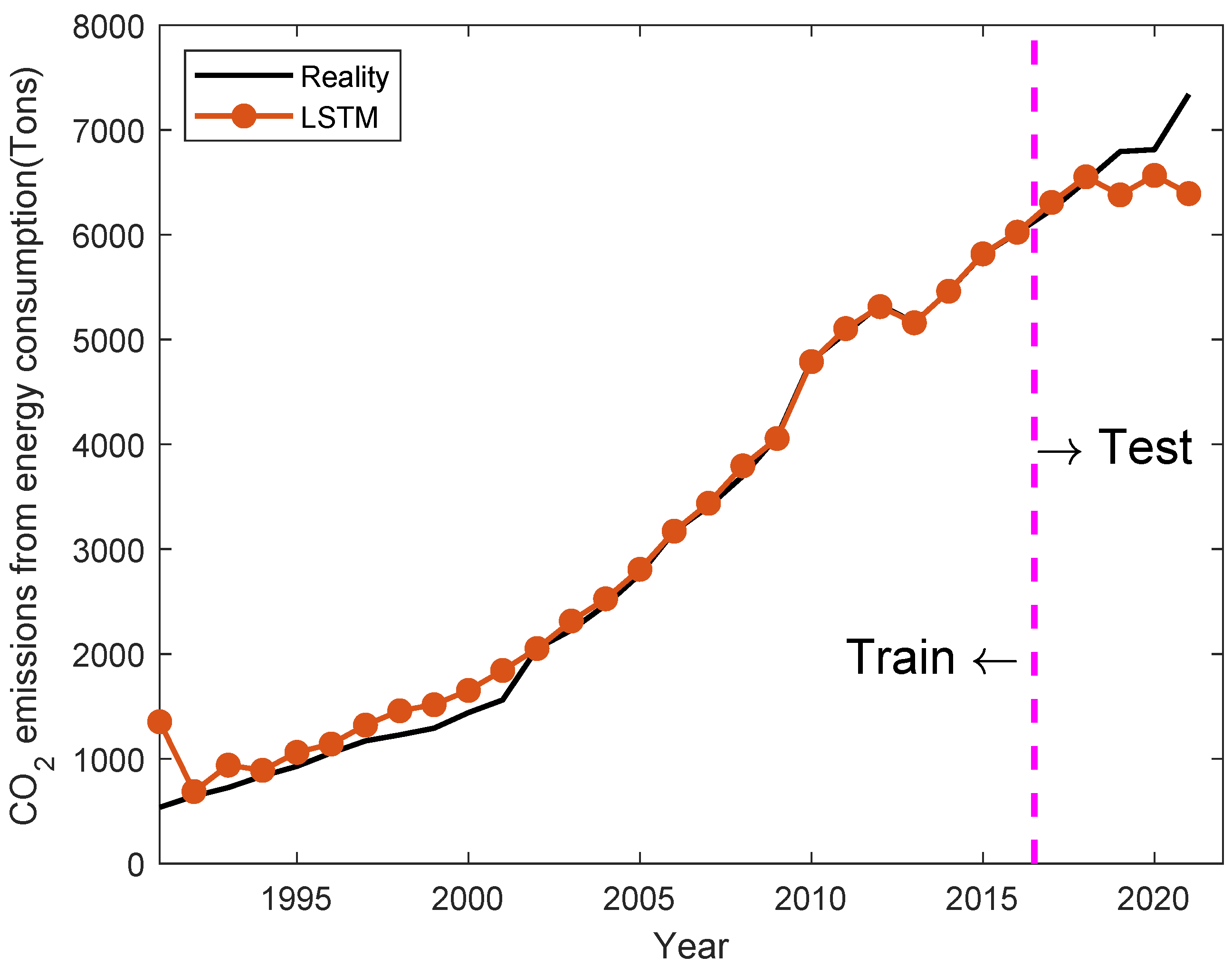
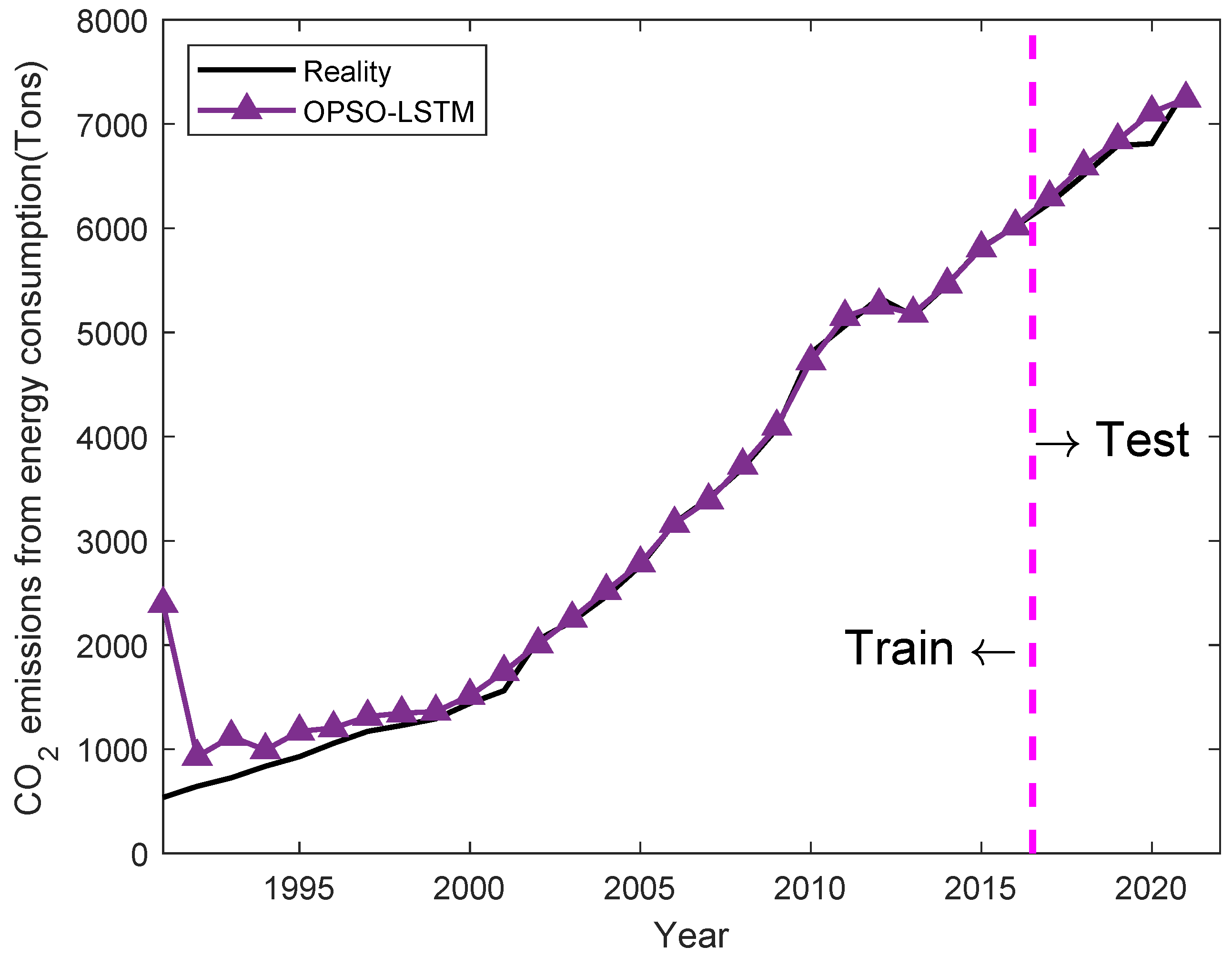
4.2. OPSO-LSTM Forecasting Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Abeydeera, L.H.U.W.; Mesthrige, J.W.; Samarasinghalage, T.I. Global research on carbon emissions: A scientometric review. Sustainability 2019, 11, 3972. [Google Scholar] [CrossRef]
- Wang, X.; Chen, H.; Gan, C.; Lin, H.; Dou, Q.; Tsougenis, E.; Huang, Q.; Cai, M.; Heng, P.A. Weakly Supervised Deep Learning for Whole Slide Lung Cancer Image Analysis. IEEE Trans. Cybern. 2020, 50, 3950–3962. [Google Scholar] [CrossRef] [PubMed]
- Jin, H. Prediction of direct carbon emissions of Chinese provinces using artificial neural networks. PLoS ONE 2021, 16, e0236685. [Google Scholar] [CrossRef]
- Gao, P.; Yue, S.; Chen, H. Carbon emission efficiency of China’s industry sectors: From the perspective of embodied carbon emissions. J. Clean. Prod. 2021, 283, 124655. [Google Scholar] [CrossRef]
- Cai, H.; Wang, Z.; Zhu, Y. Understanding the structure and determinants of intercity carbon emissions association network in China. J. Clean. Prod. 2022, 352, 131535. [Google Scholar] [CrossRef]
- Kılıç, M.; Kuzey, C. The effect of corporate governance on carbon emission disclosures: Evidence from Turkey. Int. J. Clim. Chang. Strateg. Manag. 2019, 11, 35–53. [Google Scholar] [CrossRef]
- Waheed, R.; Sarwar, S.; Wei, C. The survey of economic growth, energy consumption and carbon emission. Energy Rep. 2019, 5, 1103–1115. [Google Scholar] [CrossRef]
- Lee, J.H.; Cho, J.H. Firm-value effects of carbon emissions and carbon disclosures—Evidence from korea. Int. J. Environ. Res. Public Health 2021, 18, 12166. [Google Scholar] [CrossRef]
- Alam, M.S.; Safiullah, M.; Islam, M.S. Cash-rich firms and carbon emissions. Int. Rev. Financ. Anal. 2022, 81, 102106. [Google Scholar] [CrossRef]
- Bai, J.; Chen, Z.; Yan, X.; Zhang, Y. Research on the impact of green finance on carbon emissions: Evidence from China. Econ. Res.-Ekon. Istraz. 2022, 35, 6965–6984. [Google Scholar] [CrossRef]
- Ott, C.; Schiemann, F. The market value of decomposed carbon emissions. J. Bus. Financ. Account. 2023, 50, 3–30. [Google Scholar] [CrossRef]
- Chen, X.; Cheng, F.; Liu, C.; Cheng, L.; Mao, Y. An improved Wolf pack algorithm for optimization problems: Design and evaluation. PLoS ONE 2021, 16, e0254239. [Google Scholar] [CrossRef] [PubMed]
- Mou, X.; Zhang, Y.; Jiang, J.; Sun, H. Achieving Low Carbon Emission for Dynamically Charging Electric Vehicles through Renewable Energy Integration. IEEE Access 2019, 7, 118876–118888. [Google Scholar] [CrossRef]
- Ahvar, E.; Ahvar, S.; Mann, Z.A.; Crespi, N.; Glitho, R.; Garcia-Alfaro, J. DECA: A Dynamic Energy Cost and Carbon Emission-Efficient Application Placement Method for Edge Clouds. IEEE Access 2021, 9, 70192–70213. [Google Scholar] [CrossRef]
- Zhou, F.; Huang, Z.; Zhang, C. Carbon price forecasting based on CEEMDAN and LSTM. Appl. Energy 2022, 311, 118601. [Google Scholar] [CrossRef]
- Kong, F.; Song, J.; Yang, Z. A novel short-term carbon emission prediction model based on secondary decomposition method and long short-term memory network. Environ. Sci. Pollut. Res. 2022, 29, 64983–64998. [Google Scholar] [CrossRef]
- Hu, Y.; Lv, K. Hybrid prediction model for the interindustry carbon emissions transfer network based on the grey model and general vector machine. IEEE Access 2020, 8, 20616–20627. [Google Scholar] [CrossRef]
- Wang, J.; Xie, Y.; Xie, S.; Chen, X. Cooperative particle swarm optimizer with depth first search strategy for global optimization of multimodal functions. Appli. Intell. 2022, 52, 10161–10180. [Google Scholar] [CrossRef]
- Gao, M.; Yang, H.; Xiao, Q.; Goh, M. A novel fractional grey Riccati model for carbon emission prediction. J. Clean. Prod. 2021, 282, 124471. [Google Scholar] [CrossRef]
- Wang, T.; Li, Z.; Geng, X.; Jin, B.; Xu, L. Time Series Prediction of Sea Surface Temperature Based on an Adaptive Graph Learning Neural Model. Future Internet 2022, 14, 171. [Google Scholar] [CrossRef]
- Cai, J.; Ma, X. Carbon emission prediction model of agroforestry ecosystem based on support vector regression machine. Appl. Ecol. Environ. Res. 2019, 17, 6397–6413. [Google Scholar] [CrossRef]
- Kong, F.; Song, J.; Yang, Z. A daily carbon emission prediction model combining two-stage feature selection and optimized extreme learning machine. Environ. Sci. Pollut. Res. 2022, 29, 87983–87997. [Google Scholar] [CrossRef] [PubMed]
- Huang, W.; Dong, S. Improved short-term prediction of significant wave height by decomposing deterministic and stochastic components. Renew. Energy 2021, 177, 743–758. [Google Scholar] [CrossRef]
- Zhao, S.; Patuano, A. International chinese students in the uk: Association between use of green spaces and lower stress levels. Sustainability 2022, 14, 89. [Google Scholar] [CrossRef]
- Lu, X.; Ota, K.; Dong, M.; Yu, C.; Jin, H. Predicting Transportation Carbon Emission with Urban Big Data. IEEE Trans. Sustain. Comput. 2017, 2, 333–344. [Google Scholar] [CrossRef]
- Greff, K.; Srivastava, R.K.; Koutnik, J.; Steunebrink, B.R.; Schmidhuber, J. LSTM: A Search Space Odyssey. IEEE Trans. Neural Netw. Learn. Syst. 2017, 28, 2222–2232. [Google Scholar] [CrossRef] [PubMed]
- Abbasimehr, H.; Shabani, M.; Yousefi, M. An optimized model using LSTM network for demand forecasting. Comput. Ind. Eng. 2020, 143, 106435. [Google Scholar] [CrossRef]
- Zhao, J.; Kou, L.; Wang, H.; He, X.; Xiong, Z.; Liu, C.; Cui, H. Carbon Emission Prediction Model and Analysis in the Yellow River Basin Based on a Machine Learning Method. Sustainability 2022, 14, 6153. [Google Scholar] [CrossRef]
- Guo, J.; Sato, Y. A Pair-wise Bare Bones Particle Swarm Optimization Algorithm for Nonlinear Functions. Int. J. Netw. Distrib. Comput. 2017, 5, 143. [Google Scholar] [CrossRef]
- Tian, H.; Guo, J.; Xiao, H.; Yan, K.; Sato, Y. An electronic transition-based bare bones particle swarm optimization algorithm for high dimensional optimization problems. PLoS ONE 2022, 17, e0271925. [Google Scholar] [CrossRef]
- Guo, X.; He, J.; Wang, B.; Wu, J. Prediction of Sea Surface Temperature by Combining Interdimensional and Self-Attention with Neural Networks. Remote Sens. 2022, 14, 4737. [Google Scholar] [CrossRef]
- Guo, J.; Zhou, G.; Yan, K.; Shi, B.; Di, Y.; Sato, Y. A novel hermit crab optimization algorithm. Sci. Rep. 2023, 13, 9934. [Google Scholar] [CrossRef] [PubMed]
- Xiao, H.; Guo, J.; Shi, B.; Di, Y.; Pan, C.; Yan, K.; Sato, Y. A Twinning Memory Bare-bones Particle Swarm Optimization Algorithm for No-linear Functions. IEEE Access 2022, 11, 25768–25785. [Google Scholar] [CrossRef]
- Li, J.; Tian, Z.; Zhang, G.; Li, W. Multi-AUV Formation Predictive Control Based on CNN-LSTM under Communication Constraints. J. Mar. Sci. Eng. 2023, 11, 873. [Google Scholar] [CrossRef]
- Guo, J.; Sato, Y. A fission-fusion hybrid bare bones particle swarm optimization algorithm for single-objective optimization problems. Appl. Intell. 2019, 49, 3641–3651. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Indicators | GDP | RSCG | PVAFAF | SAC | VBE | RP |
|---|---|---|---|---|---|---|
| Unit | Billion Yuan | Billion Yuan | Billion Yuan | Kha | Ten-Thousand Yuan | Ten-Thousand People |
| 1991 | 120.52 | 41.97 | 78.78 | 829 | 153,000 | 674 |
| 1992 | 184.92 | 55.02 | 87.16 | 868 | 246,000 | 686 |
| 1993 | 260.41 | 72.91 | 120.25 | 884 | 507,000 | 701 |
| 1994 | 331.98 | 95.24 | 169.99 | 844 | 222,300 | 711 |
| 1995 | 363.25 | 110.09 | 202.52 | 870 | 175,900 | 723.79 |
| 1996 | 389.68 | 122.87 | 224.22 | 890.78 | 151,800 | 734.14 |
| 1997 | 411.16 | 135.2 | 234.86 | 914.51 | 279,900 | 743 |
| 1998 | 442.12 | 147.06 | 253.67 | 937.57 | 309,000 | 752.82 |
| 1999 | 476.68 | 160.62 | 279.23 | 931.76 | 333,933.3 | 761.93 |
| 2000 | 526.82 | 176.19 | 311.94 | 906 | 302,139 | 789 |
| 2001 | 579.18 | 192 | 325.13 | 871.73 | 353,452.6 | 795.55 |
| 2002 | 642.74 | 209.91 | 360.2 | 863.34 | 415,089 | 803.13 |
| 2003 | 713.96 | 197.33 | 379.98 | 906.74 | 394,053 | 810.52 |
| 2004 | 802.68 | 245.47 | 438.73 | 826.94 | 585,834 | 817.83 |
| 2005 | 884.87 | 281.58 | 475.88 | 778.06 | 596,925.2 | 828 |
| 2006 | 1027.45 | 326.77 | 492.12 | 699.4 | 649,436 | 835.88 |
| 2007 | 1234 | 387.78 | 547.03 | 757.71 | 821,834 | 845.03 |
| 2008 | 1474.66 | 485.68 | 662.07 | 793.61 | 1,111,836.9 | 854.18 |
| 2009 | 1620.28 | 573 | 700.23 | 800.44 | 1,439,441.5 | 864.07 |
| 2010 | 2020.53 | 698.81 | 813.8 | 786.75 | 1,994,842 | 868.55 |
| 2011 | 2463.84 | 866.92 | 991.53 | 782.4 | 2,554,721.8 | 889.61 |
| 2012 | 2789.38 | 1003.69 | 1067.33 | 786.57 | 2,831,087.1 | 910.43 |
| 2013 | 3115.85 | 1154.87 | 1125.93 | 772.48 | 2,863,073.3 | 920.21 |
| 2014 | 3449.01 | 1298.74 | 1227.14 | 779.4 | 2,763,288.9 | 935.56 |
| 2015 | 3734.19 | 1409.45 | 1294 | 757.5 | 2,786,307.6 | 945.49 |
| 2016 | 4090.2 | 1547.26 | 1433.88 | 731.9 | 3,077,647.7 | 957.48 |
| 2017 | 4497.54 | 1729.44 | 1488.86 | 709.44 | 3,227,630 | 971.5 |
| 2018 | 4910.69 | 1852.68 | 1535.73 | 712.94 | 3,576,139.8 | 982.48 |
| 2019 | 5330.84 | 1951.11 | 1689.4 | 676.24 | 3,659,800.3 | 995.27 |
| 2020 | 5566.24 | 1974.63 | 1821.02 | 676.86 | 3,913,714.1 | 1012.34 |
| 2021 | 6504.05 | 2497.62 | 2014.79 | 684.78 | 4,470,939.5 | 1020.46 |
| Indicators | PT | CV | CVO | RSL | CO2 Emissions from Energy Consumption |
|---|---|---|---|---|---|
| Unit | Ten-Thousand People | Ten-Thousand Tons | Ten-Thousand Units | Yuan | Tons |
| 1991 | 17,133 | 5710.55 | 3.66 | 833 | 536.61 |
| 1992 | 17,708 | 6252.78 | 4.92 | 1019 | 643.74 |
| 1993 | 19,010 | 8612.9 | 6.67 | 1363 | 725.25 |
| 1994 | 18,829 | 8735 | 8.63 | 1673 | 836.13 |
| 1995 | 19,667 | 10,505 | 9.52 | 1993 | 927.99 |
| 1996 | 19,688 | 10,975 | 9.87 | 2337 | 1056.24 |
| 1997 | 21,296 | 11,415.22 | 9.51 | 2432 | 1170.78 |
| 1998 | 21,549 | 11,629.67 | 9.06 | 2552 | 1227.78 |
| 1999 | 22,085 | 11,532.93 | 9.59 | 2729.26 | 1291.8 |
| 2000 | 23,013 | 11,304 | 9.01 | 2903.68 | 1439.85 |
| 2001 | 26,711 | 10,502.26 | 8.28 | 2961.37 | 1561.32 |
| 2002 | 27,992 | 10,497.94 | 10.94 | 3197.75 | 2051.22 |
| 2003 | 28,083 | 11,248.94 | 12.58 | 3275 | 2227.44 |
| 2004 | 31,276 | 11,823.48 | 14.55 | 3620 | 2466.6 |
| 2005 | 32,933 | 13,558.19 | 16.4 | 4145 | 2761.35 |
| 2006 | 36,326 | 16,377.08 | 19.23 | 4736 | 3171 |
| 2007 | 39,451 | 17,343.65 | 22.11 | 5552 | 3405.99 |
| 2008 | 44,186 | 16,847.04 | 25.81 | 6550 | 3697.56 |
| 2009 | 42,232 | 18,417.37 | 30.64 | 6695 | 4075.53 |
| 2010 | 45,718 | 22,481 | 39.24 | 7553 | 4801.86 |
| 2011 | 47,913 | 25,141 | 47.81 | 9237.66 | 5063.94 |
| 2012 | 49,015.38 | 26,906.4 | 55.46 | 10,634.49 | 5331.78 |
| 2013 | 51,000 | 28,833.5 | 64.8 | 11,712 | 5160.99 |
| 2014 | 16,775 | 23,081 | 75.11 | 12,915 | 5459.79 |
| 2015 | 16,284 | 22,330.2 | 83.29 | 17,019.13 | 5813.31 |
| 2016 | 17,092 | 21,828.2 | 96.32 | 18,431 | 6018.36 |
| 2017 | 18,154.57 | 21,397.22 | 113.21 | 20,939 | 6238.68 |
| 2018 | 18,314.17 | 22,093.2 | 126.9 | 22,971 | 6510.69 |
| 2019 | 18,104.85 | 18,552.39 | 137.24 | 19,555 | 6793.17 |
| 2020 | 9735 | 20,737 | 149.05 | 18,972 | 6811.92 |
| 2021 | 11,197 | 28,039 | 168.72 | 22,242 | 7338.57 |
| Parameter | PSO | OPSO |
|---|---|---|
| Populations | 50 | 50 |
| Iterations | 100 | 100 |
| Range of learning rate | [0.001, 0.15] | [0.001, 0.15] |
| Range of neurons | [10, 50] | [10, 50] |
| Year | Reality | LSTM | PSO-LSTM | OPSO-LSTM | |||
|---|---|---|---|---|---|---|---|
| Prediction | Errors | Prediction | Errors | Prediction | Errors | ||
| 2017 | 6238.68 | 6307.6 | 1.10% | 6333.22 | 1.52% | 6296.47 | 0.93% |
| 2018 | 6510.69 | 6552.36 | 0.64% | 6596.39 | 1.32% | 6593.9 | 1.28% |
| 2019 | 6793.17 | 6379.76 | 6.09% | 6701.55 | 1.35% | 6845.27 | 0.77% |
| 2020 | 6811.92 | 6565.77 | 3.61% | 6819.38 | 0.11% | 7112.7 | 4.42% |
| 2021 | 7338.57 | 6391.97 | 12.90% | 6783.3 | 7.57% | 7243.92 | 1.29% |
| Indicators | LSTM | PSO-LSTM | OPSO-LSTM |
|---|---|---|---|
| MAE | 343.349 | 166.917 | 117.708 |
| Difference with OPSO-LSTM | 65.72% | 29.48% | |
| RMSE | 476.243 | 258.090 | 149.939 |
| Difference OPSO-LSTM | 68.52% | 41.90% | |
| MAPE | 0.049 | 0.024 | 0.017 |
| Difference OPSO-LSTM | 65.31% | 29.17% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Y.; Chen, Z.; Li, K.; Shi, T.; Chen, X.; Lei, J.; Wu, T.; Li, Y.; Liu, Q.; Shi, B.; et al. Research of Carbon Emission Prediction: An Oscillatory Particle Swarm Optimization for Long Short-Term Memory. Processes 2023, 11, 3011. https://doi.org/10.3390/pr11103011
Chen Y, Chen Z, Li K, Shi T, Chen X, Lei J, Wu T, Li Y, Liu Q, Shi B, et al. Research of Carbon Emission Prediction: An Oscillatory Particle Swarm Optimization for Long Short-Term Memory. Processes. 2023; 11(10):3011. https://doi.org/10.3390/pr11103011
Chicago/Turabian StyleChen, Yiqing, Zongzhu Chen, Kang Li, Tiezhu Shi, Xiaohua Chen, Jinrui Lei, Tingtian Wu, Yuanling Li, Qian Liu, Binghua Shi, and et al. 2023. "Research of Carbon Emission Prediction: An Oscillatory Particle Swarm Optimization for Long Short-Term Memory" Processes 11, no. 10: 3011. https://doi.org/10.3390/pr11103011
APA StyleChen, Y., Chen, Z., Li, K., Shi, T., Chen, X., Lei, J., Wu, T., Li, Y., Liu, Q., Shi, B., & Guo, J. (2023). Research of Carbon Emission Prediction: An Oscillatory Particle Swarm Optimization for Long Short-Term Memory. Processes, 11(10), 3011. https://doi.org/10.3390/pr11103011