
Optimizing Task Completion Time in Disaster-Affected Regions with the WMDDPG-GSA Algorithm for UAV-Assisted MEC Systems



Abstract
:1. Introduction
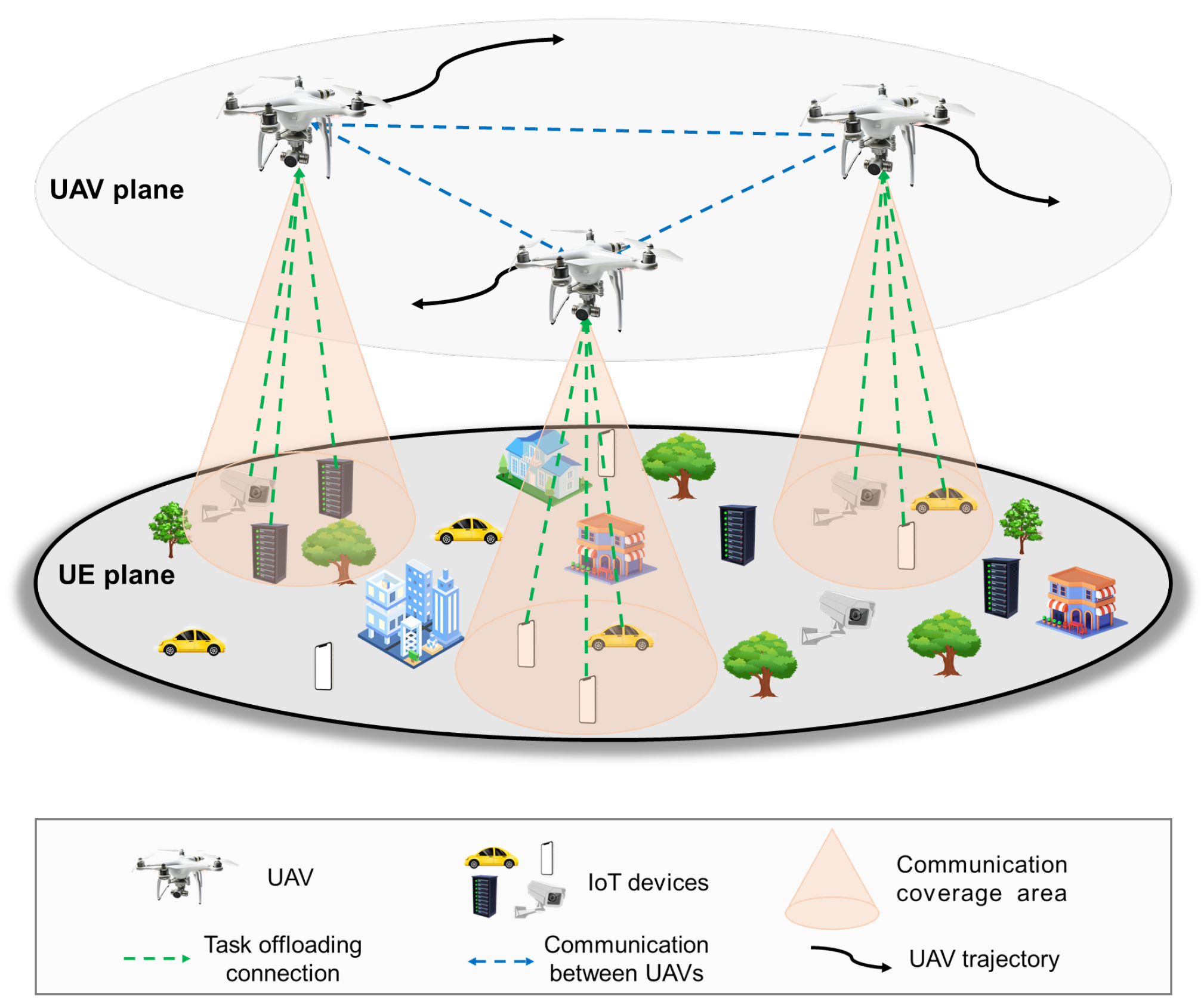
1.1. The UAV-Assisted MEC System
1.2. The Impact of the DFS on the UAV-Assisted MEC System
1.3. UAVs Trajectory Design
1.4. Offloading Strategy
1.5. Contributions and Structure
- This paper presents a UAV-assisted MEC system that models the UAV trajectory as a continuous variable. This approach offers a more accurate representation of the UAV’s behavior and performance during movement.
- In our model, we enable data transmission during UAV movement by considering the impact of the DFS on data transmission. The accurate estimation of the DFS is employed to enhance the precision of data transmission during UAV movement.
- To tackle this highly non-convex problem, we decompose it into two sub-problems in this study. The first sub-problem addresses UAV trajectory planning, for which we propose a Weighted-Strategy-Based Multi-Agent Deep Deterministic Policy Gradient (WMDDPG) algorithm to determine the optimal trajectory. The second sub-problem deals with optimizing the offloading strategy. To overcome the limitations of a greedy algorithm, we introduce an enhanced approach that combines both greedy and simulated annealing (GSA) algorithms.
2. System Model
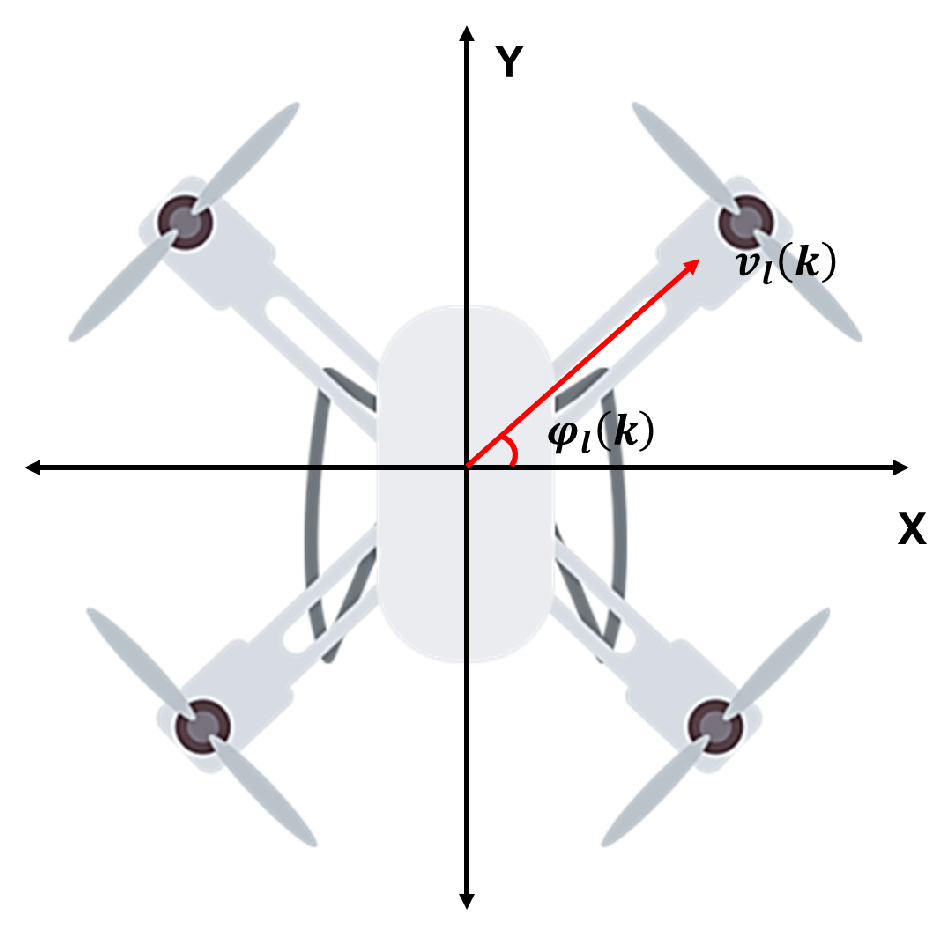
2.1. Motion Model
2.2. Communication Model
2.2.1. Communication between UAVs and UE
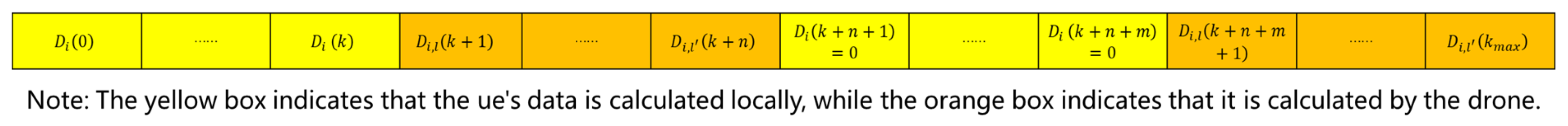
2.2.2. Communication between UAVs
2.2.3. DFS Estimation during UAV Flight
2.3. Computational Model
2.4. Problem Formulation
3. WMDDPG-GSA Algorithm
3.1. Offloading Strategy Algorithm
3.2. UAV Trajectory Algorithm
3.2.1. State Space
3.2.2. Action Space
3.2.3. State Transition Probability
3.2.4. Reward
3.2.5. WMDDPG Algorithm
4. Simulated Result
4.1. Simulation Settings
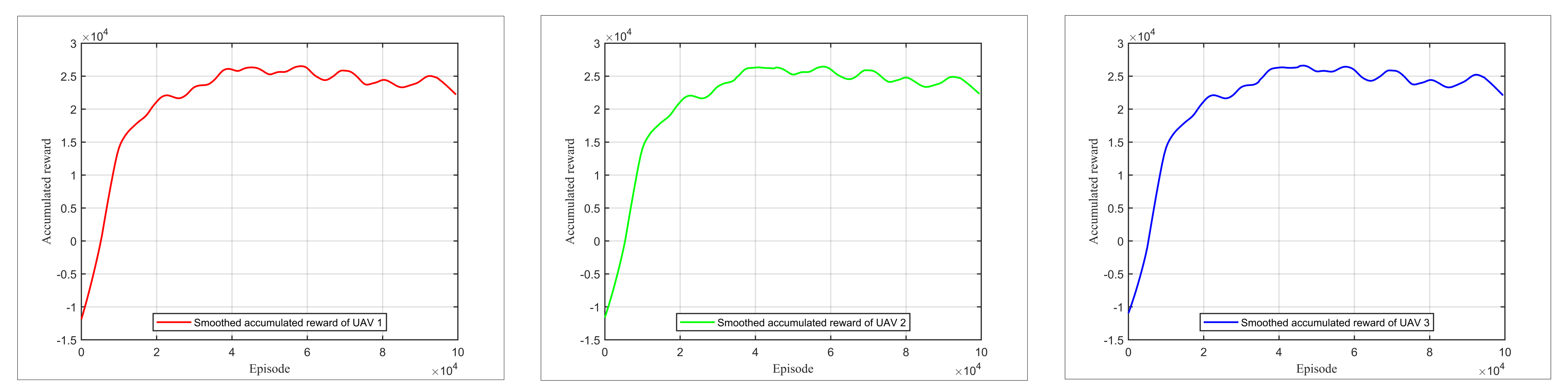
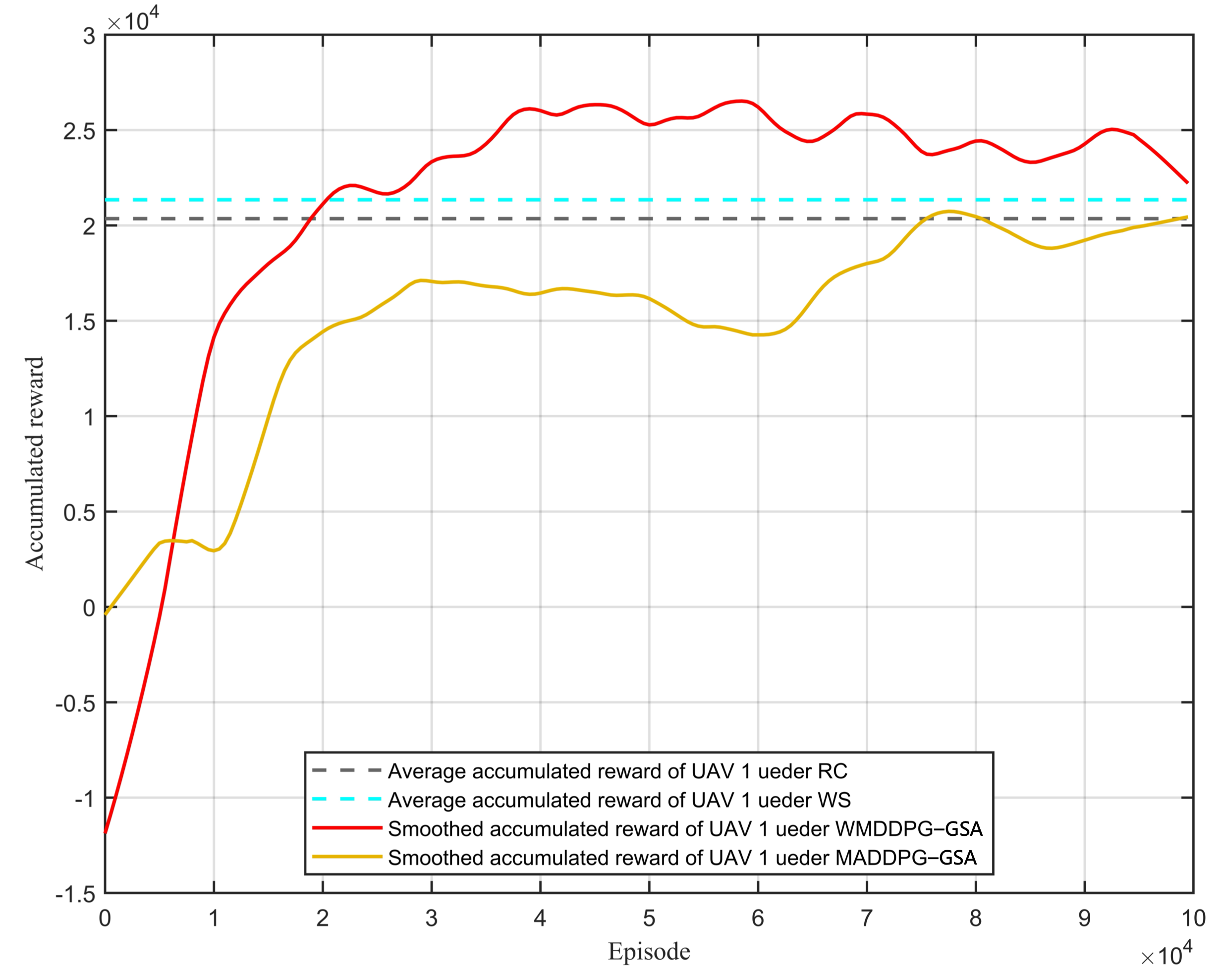
4.2. Learning Stage
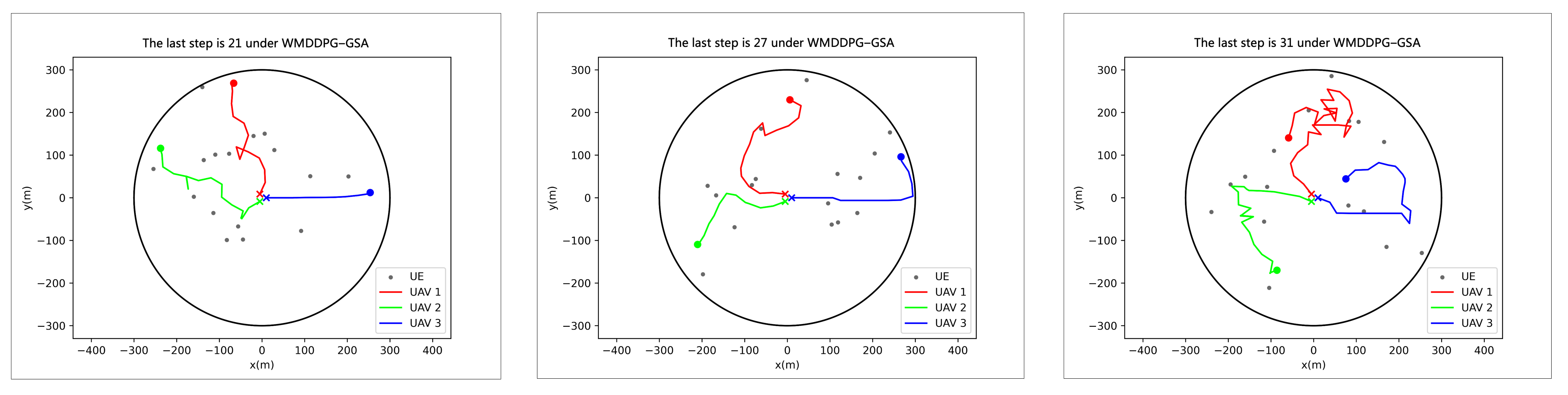
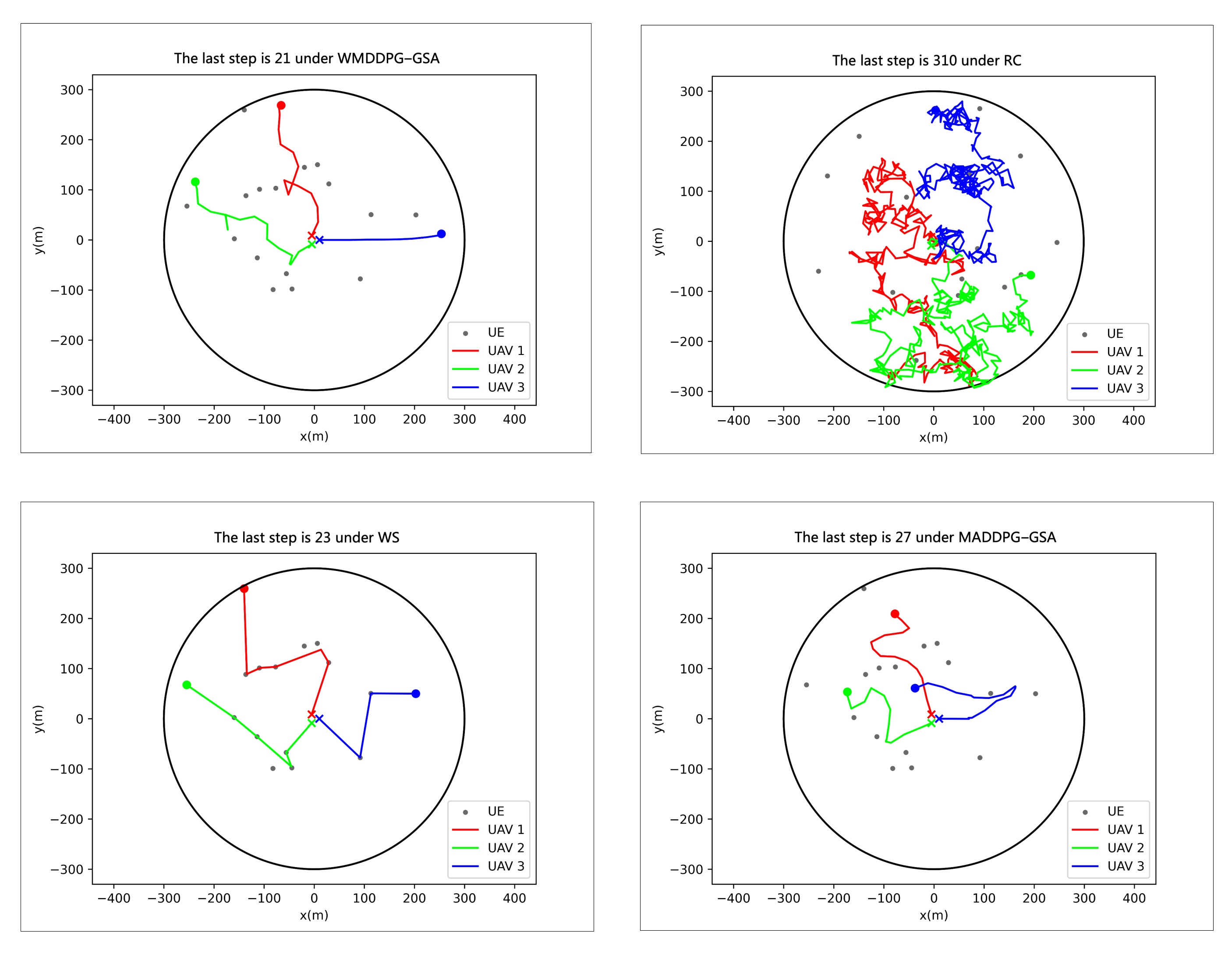
4.3. Testing Phase
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Sun, L.; Wang, J.; Lin, B. Task Allocation Strategy for MEC-Enabled IIoTs via Bayesian Network Based Evolutionary Computation. IEEE Trans. Ind. Inform. 2021, 17, 3441–3449. [Google Scholar] [CrossRef]
- Seng, S.; Yang, G.; Li, X.; Ji, H.; Luo, C. Energy-Efficient Communications in Unmanned Aerial Relaying Systems. IEEE Trans. Netw. Sci. Eng. 2021, 8, 2780–2791. [Google Scholar] [CrossRef]
- Zhou, Y.; Pan, C.; Yeoh, P.L.; Wang, K.; Elkashlan, M.; Vucetic, B.; Li, Y. Secure Communications for UAV-Enabled Mobile Edge Computing Systems. IEEE Trans. Commun. 2020, 68, 376–388. [Google Scholar] [CrossRef]
- Luo, Z.; Qian, X.; Huang, C.; Ding, R.; Xin, N.; Su, D. Unmanned Collaborative Intelligent Edge Computing Task Scheduling. In Proceedings of the 2021 IEEE International Conference on Unmanned Systems (ICUS), Beijing, China, 15–17 October 2021; pp. 309–314. [Google Scholar] [CrossRef]
- Zhan, C.; Zeng, Y. Completion Time Minimization for Multi-UAV-Enabled Data Collection. IEEE Trans. Wirel. Commun. 2019, 18, 4859–4872. [Google Scholar] [CrossRef]
- Belaoura, W.; Ghanem, K.; Shakir, M.Z.; Hasna, M.O. Performance and User Association Optimization for UAV Relay-Assisted mm-Wave Massive MIMO Systems. IEEE Access 2022, 10, 49611–49624. [Google Scholar] [CrossRef]
- Mozaffari, M.; Saad, W.; Bennis, M.; Debbah, M. Unmanned Aerial Vehicle With Underlaid Device-to-Device Communications: Performance and Tradeoffs. IEEE Trans. Wirel. Commun. 2016, 15, 3949–3963. [Google Scholar] [CrossRef]
- Zhou, F.; Hu, R.Q.; Li, Z.; Wang, Y. Mobile Edge Computing in Unmanned Aerial Vehicle Networks. IEEE Wirel. Commun. 2020, 27, 140–146. [Google Scholar] [CrossRef]
- Zhang, T.; Xu, Y.; Loo, J.; Yang, D.; Xiao, L. Joint Computation and Communication Design for UAV-Assisted Mobile Edge Computing in IoT. IEEE Trans. Ind. Inform. 2020, 16, 5505–5516. [Google Scholar] [CrossRef]
- Gan, Y.; He, Y. Trajectory Optimization and Computing Offloading Strategy in UAV-Assisted MEC System. In Proceedings of the 2021 Computing, Communications and IoT Applications (ComComAp), Shenzhen, China, 26–28 November 2021; pp. 132–137. [Google Scholar] [CrossRef]
- Argyriou, A. Passive Angle-Doppler Profile Estimation for Narrowband Digitally Modulated Wireless Signals. In Proceedings of the 2022 IEEE 12th Sensor Array and Multichannel Signal Processing Workshop (SAM), Trondheim, Norway, 20–23 June 2022; pp. 246–250. [Google Scholar] [CrossRef]
- Liao, T.; Meng, Q.; Liu, C.; Zhang, M.; Li, B. Study on Doppler Frequency Offset Estimation Algorithm for High Speed Maglev. In Proceedings of the 2021 International Conference on Communications, Information System and Computer Engineering (CISCE), Beijing, China, 14–16 May 2021; pp. 755–758. [Google Scholar] [CrossRef]
- Kang, E.S.; Hwang, H.; Han, D.S. A fine carrier recovery algorithm robustto doppler shift for OFDM systems. IEEE Trans. Consum. Electron. 2010, 56, 1218–1222. [Google Scholar] [CrossRef]
- Zhang, Q.; Sun, H.; Feng, Z.; Gao, H.; Li, W. Data-Aided Doppler Frequency Shift Estimation and Compensation for UAVs. IEEE Internet Things J. 2020, 7, 400–415. [Google Scholar] [CrossRef]
- Hu, X.; Wong, K.K.; Yang, K.; Zheng, Z. UAV-Assisted Relaying and Edge Computing: Scheduling and Trajectory Optimization. IEEE Trans. Wirel. Commun. 2019, 18, 4738–4752. [Google Scholar] [CrossRef]
- Wang, Y.; Gao, Z. Three-Dimensional Trajectory Design for Multi-User MISO UAV Communications: A Deep Reinforcement Learning Approach. In Proceedings of the 2021 IEEE/CIC International Conference on Communications in China (ICCC), Xiamen, China, 28–30 July 2021; pp. 706–711. [Google Scholar] [CrossRef]
- Zhang, X.; Zhang, H.; Ji, H.; Li, X. Joint Optimization of UAV Trajectory and Relay Ratio in UAV-Aided Mobile Edge Computation Network. In Proceedings of the 2020 IEEE 31st Annual International Symposium on Personal, Indoor and Mobile Radio Communications, London, UK, 31 August–3 September 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Qian, Y.; Wang, F.; Li, J.; Shi, L.; Cai, K.; Shu, F. User Association and Path Planning for UAV-Aided Mobile Edge Computing with Energy Restriction. IEEE Wirel. Commun. Lett. 2019, 8, 1312–1315. [Google Scholar] [CrossRef]
- Ding, R.; Gao, F.; Shen, X.S. 3D UAV Trajectory Design and Frequency Band Allocation for Energy-Efficient and Fair Communication: A Deep Reinforcement Learning Approach. IEEE Trans. Wirel. Commun. 2020, 19, 7796–7809. [Google Scholar] [CrossRef]
- Liu, X.; Liu, Y.; Chen, Y. Reinforcement Learning in Multiple-UAV Networks: Deployment and Movement Design. IEEE Trans. Veh. Technol. 2019, 68, 8036–8049. [Google Scholar] [CrossRef]
- Xiao, H.; Hu, Z.; Yang, K.; Du, Y.; Chen, D. An Energy-Aware Joint Routing and Task Allocation Algorithm in MEC Systems Assisted by Multiple UAVs. In Proceedings of the 2020 International Wireless Communications and Mobile Computing (IWCMC), Limassol, Cyprus, 15–19 June 2020; pp. 1654–1659. [Google Scholar] [CrossRef]
- Lowe, R.; Wu, Y.; Tamar, A.; Harb, J.; Abbeel, P.; Mordatch, I. Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments. arXiv 2020, arXiv:1706.02275. [Google Scholar]
- Foerster, J.; Farquhar, G.; Afouras, T.; Nardelli, N.; Whiteson, S. Counterfactual Multi-Agent Policy Gradients. arXiv 2017, arXiv:1705.08926. [Google Scholar] [CrossRef]
- Wang, L.; Wang, K.; Pan, C.; Xu, W.; Aslam, N.; Hanzo, L. Multi-Agent Deep Reinforcement Learning-Based Trajectory Planning for Multi-UAV Assisted Mobile Edge Computing. IEEE Trans. Cogn. Commun. Netw. 2021, 7, 73–84. [Google Scholar] [CrossRef]
- Wu, D.; Wan, K.; Tang, J.; Gao, X.; Zhai, Y.; Qi, Z. An Improved Method towards Multi-UAV Autonomous Navigation Using Deep Reinforcement Learning. In Proceedings of the 2022 7th International Conference on Control and Robotics Engineering (ICCRE), Beijing, China, 15–17 April 2022; pp. 96–101. [Google Scholar] [CrossRef]
- Xu, W.; Zhang, T.; Yang, L. Joint Computing Offloading and Trajectory for Multi-UAV Enabled MEC Systems. In Proceedings of the 2022 IEEE 22nd International Conference on Communication Technology (ICCT), Nanjing, China, 11–14 November 2022; pp. 510–515. [Google Scholar] [CrossRef]
- Zhang, Y.; Han, X.; Dong, Y.; Xie, J.; Xie, G.; Xu, X. A novel state transition simulated annealing algorithm for the multiple traveling salesmen problem. J. Supercomput. 2021, 77, 11827–11852. [Google Scholar] [CrossRef]
- Choachaicharoenkul, S.; Coit, D.; Wattanapongsakorn, N. Multi-Objective Trip Planning With Solution Ranking Based on User Preference and Restaurant Selection. IEEE Access 2022, 10, 10688–10705. [Google Scholar] [CrossRef]
- Zhu, B.; Bedeer, E.; Nguyen, H.H.; Barton, R.; Gao, Z. UAV Trajectory Planning for AoI-Minimal Data Collection in UAV-Aided IoT Networks by Transformer. IEEE Trans. Wirel. Commun. 2023, 22, 1343–1358. [Google Scholar] [CrossRef]
- Al-Hourani, A.; Kandeepan, S.; Lardner, S. Optimal LAP Altitude for Maximum Coverage. IEEE Wirel. Commun. Lett. 2014, 3, 569–572. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm GSA Algorithm for the Offloading Policy. |
|---|
| 1: Update the distance between all UE and UAVs: . |
| 2: Initialize the sorted list of distance between all UAVs and UE: sorted_lst, and sort it in ascending order. |
| 3: Initialize the list of unassigned UE that can be connected to UAVs: unassigned_users. |
| 4: Initialize the list of UE connected to each UAV as the empty list: link_dict_UAV = , initializes the list of UE connected to UAV in slot K as the empty list already_in = [] |
| 5: for do |
| 6: for i in sorted_lst do |
| 7: if and i not in already_in and the pending data of i-th UE > 0 then |
| 8: add i to the list link_dict_UAV and the list already_in. |
| 9: end if |
| 10: end for |
| 11: end for |
| 12: store link_dict_UAV as the initial solution in best_solution, calculate the distance sum of all UE connected to the UAVs as best_cost, and calculate the total number of connected UE as max_connect_ue. |
| 13: for i in range(200) do |
| 14: update already_in and link_dict_UAV as empty lists. |
| 15: for do |
| 16: for _ in range() do |
| 17: randomly select a -th UE from unassigned_users. |
| 18: remove -th UE from unassigned_users. |
| 19: if and not in already_in then |
| 20: add to the list link_dict_UAV and the list already_in. |
| 21: end if |
| 22: end for |
| 23: end for |
| 24: end for |
| 25: Calculate the distance sum of all the UE connected to the UAVs as new_cost, and calculate the number of connected UE in the link_dict_UAV as new_connect_ue. |
| 26: if new_connect_ue > new_connect_ue then |
| 27: best_solution = link_dict_UAV |
| 28: end if |
| 29: if new_connect_ue new_connect_ue then |
| 30: if new_cost < best_cost then |
| 31: best_solution = link_dict_UAV |
| 32: end if |
| 33: end if |
| Algorithm WS algorithm. |
|---|
| 1: Initialize epsilon = 1.0. |
| 2: if random(0, 1) <= epsilon then |
| 3: Update the distance between all UE and UAVs:. |
| 4: Initialize the sorted list of distance between all UAVs and UE: distance_sort, and sort it in ascending order. |
| 5: Initialize the list of selected UE in time slot k as the empty list: selected_UE= . |
| 6: Initialize the list of each UAV for the time slot k to move towards the UE as the empty list: uav_move = . |
| 7: for do |
| 8: for i in distance_sort do |
| 9: if len(selected_UE 0) and i not in selected_UE and the distance from the previously selected UE 80 then |
| 10: add i to the list selected_UE |
| 11: end if |
| 12: end for |
| 13: end for |
| 14: Initialize the sorted list of distances between the already selected UE and all UAVs: distance_selected_UE, and sort it in ascending order. |
| 15: for do |
| 16: for i in distance_selected_UE do |
| 17: if len(uav_move 0) and i not in uav_move then |
| 18: add i to the list uav_move |
| 19: end if |
| 20: end for |
| 21: end for |
| 22:end if |
| Notation | Physical Meaning | Value |
|---|---|---|
| Coverage area of the UAVs | 100 m | |
| Minimum distance allowed between UAVs | 15 m | |
| Duration of time slots | 1 s | |
| Maximum flight speed | 30 m/s | |
| Number of UE that the DP-UAVs can compute in parallel | 3 | |
| Computing capacity of UAVs | cycle/s | |
| Computing capacity of the UE | cycle/s | |
| B | Bandwidth | Hz |
| Training Parameter | Value |
|---|---|
| Total number of training steps | |
| Learning rate of critic network | |
| Learning rate of actor network | |
| Discount factor | |
| Soft update rate for target networks |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, T.; Yang, Y.; Xu, H.; Song, T. Optimizing Task Completion Time in Disaster-Affected Regions with the WMDDPG-GSA Algorithm for UAV-Assisted MEC Systems. Processes 2023, 11, 3000. https://doi.org/10.3390/pr11103000
Ma T, Yang Y, Xu H, Song T. Optimizing Task Completion Time in Disaster-Affected Regions with the WMDDPG-GSA Algorithm for UAV-Assisted MEC Systems. Processes. 2023; 11(10):3000. https://doi.org/10.3390/pr11103000
Chicago/Turabian StyleMa, Tianhao, Yulu Yang, Han Xu, and Tiecheng Song. 2023. "Optimizing Task Completion Time in Disaster-Affected Regions with the WMDDPG-GSA Algorithm for UAV-Assisted MEC Systems" Processes 11, no. 10: 3000. https://doi.org/10.3390/pr11103000
APA StyleMa, T., Yang, Y., Xu, H., & Song, T. (2023). Optimizing Task Completion Time in Disaster-Affected Regions with the WMDDPG-GSA Algorithm for UAV-Assisted MEC Systems. Processes, 11(10), 3000. https://doi.org/10.3390/pr11103000