5.1. Introduction of the Experimental Data
A benchmark power system is modeled in the MATLAB/Simulink environment [
14,
39,
40] to simulate the normal operating and multiple fault datasets, where Simscape Electrical affords a component library to model electronic, mechatronic, and electrical power systems. The simulated system is widely applied to perform power system studies, which are discussed in the literature [
14,
40]. The simulated power system includes two symmetrical areas that are connected by two 220 km-long transmission lines, where the various fault patterns are simulated and studied at the transmission line.
The power system is simulated under normal running and short-circuit fault conditions on the transmission line. A comprehensive normal and fault dataset is constructed to build the developed ECLSTM-based fault diagnosis model by measuring and collecting the line voltages and currents of the power system. The sampling interval is 0.001 s, and a total of 12,000 samples are generated and labeled for twelve types of operating conditions, which include one normal operating condition and eleven short circuit fault patterns. Thus, each type of operating condition contains 1000 samples. Before the normalization of transmission line datasets, Gaussian noise with a zero mean and 0.01 variance is introduced to the monitored variables for the purpose of simulating the actual measurement noise. As listed in
Table 1, the simulated eleven fault patterns are {AG, BG, CG, AB, BC, AC, ABG, BCG, ACG, ABC, ABCG}, where the symbols A, B, C, and G respectively stand for the phases A, B, C, and ground. These eleven short circuit fault patterns are classified as double lines (LL) fault, line to ground (LG) fault, triple lines (LLL) fault, double lines to ground (LLG) fault, and triple lines to ground (LLLG) fault, where only the LLL and LLLG fault patterns are symmetric faults and the remaining are asymmetric faults.
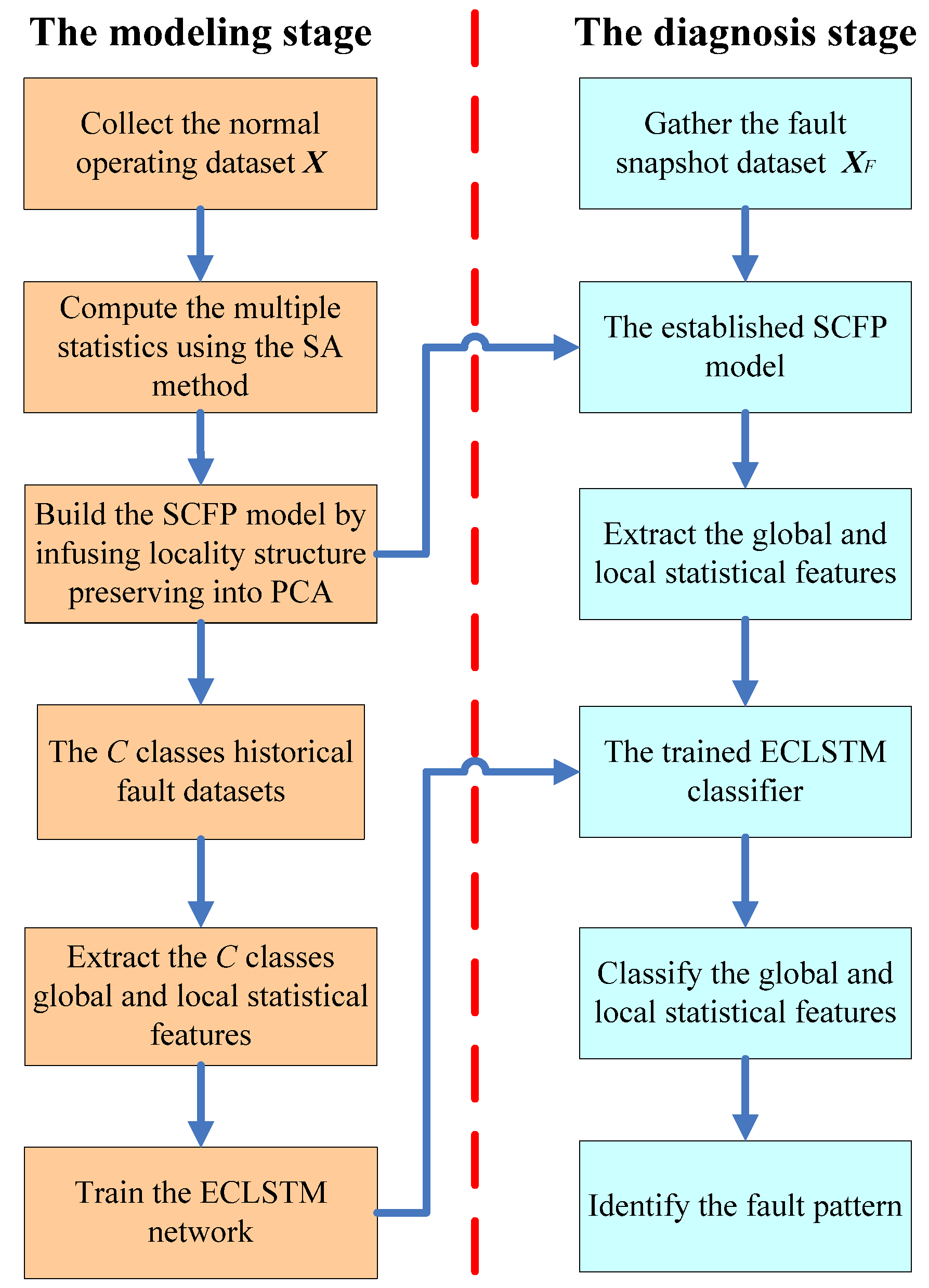
To diagnose the fault pattern of the transmission line, the first 500 collected fault samples are utilized to build the snapshot dataset. And the rest of the 500 fault samples from the same pattern are regarded as the historical fault dataset. The ECLSTM-based fault diagnosis model is first trained by feeding the mined historical fault datasets’ global and local statistical features, which are extracted by the developed SCFP approach, and the snapshot dataset’s global and local statistical features are then extracted and imported into the established ECLSTM-based diagnosis model for the purpose of identifying the pattern of the detected fault.
5.2. Compared Approaches and Effectiveness Evaluation Index
To testify the effectiveness of the proposed ECLSTM-based diagnosis approach, some traditional and closely related fault diagnosis methods, i.e., the support vector machine (SVM), the convolutional neural network (CNN), the deep belief network (DBN), and the long short-term memory (LSTM), are contrasted with the suggested ECLSTM. The global and local statistical features derived by the constructed SCFP are respectively fed to the SVM, CNN, DBN, and ELSTM. And these improved fault diagnosis methods are respectively termed the ESVM, ECNN, EDBN, and ELSTM.
To train the ECLSTM and ELSTM-based diagnosis models, the number of hidden units is set to 300, the batch size is 64, and the 0.001 learning rate is utilized with the help of cross-validation. In addition, the optimal model parameters are determined by the Adam optimizer. The node numbers of the ECNNs three convolution layers are respectively selected as 32, 64, and 128 by trial and error, while the neuron numbers in the EDBNs first, second, and third hidden layers are respectively 500, 300, and 200. Similar to the ECLSTM and ELSTM, the batch size and the learning rate in the ECNN and EDBN are also chosen as 64 and 0.001 for fairness. In the ESVM, the Gaussian kernel function is adopted, and the parameter is set to 600 by the grid search method. In addition, the weight factor of the ESVM is experientially determined at 50.
To assess the performance of the discussed ECLSTM for transmission line fault diagnosis, four performance indices, i.e., the fault diagnosis rate of fault samples in the i-th pattern, the average fault diagnosis rate of fault samples in the total of C patterns, the precision P(i), i = 1, 2, …, C for the i-th pattern, and the average precision, Paverage are employed.
Particularly, the index
is defined as
where
denotes the number of correctly diagnosed fault samples for the i-th pattern.
The index
expressed in Equation (33) indicates the average value of all the acquired fault diagnosis rates for the C fault snapshot datasets.
The precision
for the i-th pattern is defined as
where
represents the number of wrongly identified fault samples in the i-th pattern.
The index average precision
expressed in Equation (35) indicates the average value of all the computed precisions for the C fault snapshot datasets.
5.4. The Comparison of the Fault Diagnosis Results
(1) Fault diagnosis effectiveness verification of the proposed SCFP based feature extraction
In order to prove the improvement of the suggested statistics comprehensive feature preserving (SCFP) technique’s fault diagnosis performance, the SCFP-based feature extraction technique is compared with statistics analysis (SA), principal component analysis (PCA), and locality-preserving-based methods. In our work, the developed SCFP technique is combined with the CLSTM classifier to build the ECLSTM method. Similarly, the SA, PCA, and locality preservation are combined with the CLSTM classifier to respectively build the SCLSTM, GCLSTM, and LCLSTM approaches. In this way, the fault diagnosis capabilities of the SCFP, SA, global feature, and local feature-based exaction approaches can be analyzed.
The fault diagnosis results of the SCLSTM, GCLSTM, LCLSTM, and ECLSTM for the eleven fault patterns are listed in
Table 3 and
Table 4. According to the values of index FDR shown in
Table 3, the index
values for the SCLSTM, GCLSTM, LCLSTM, and ECLSTM are respectively calculated as 88.36%, 84.45%, 86.09%, and 94.45%. Thus, the ECLSTM demonstrates the highest value of the index
for all eleven fault patterns. Anyway, in comparison with the SCLSTM, GCLSTM, and LCLSTM, the ECLSTM also exhibits more remarkable diagnosis performance to discern the eleven fault patterns in terms of the index FDR values. For example, for the fault pattern AC, the values of the index FDR for the SCLSTM, GCLSTM, LCLSTM, and ECLSTM are respectively calculated as 94.80%, 87.20%, 90.60%, and 98.00%, which proves that the ECLSTM owns the highest value of the index FDR among these four fault diagnosis models. Analogously, according to the values of precision P displayed in
Table 4, the ECLSTM also reveals the highest value of the index P
average in comparison with the SCLSTM, GCLSTM, and LCLSTM. Furthermore, the ECLSTM shows much higher values of precision P than the other three methods in terms of identifying the eleven fault patterns. In summary, the above experiments prove the outstanding fault diagnosis performance of the suggested SCFP-based feature extraction techniques.
(2) Fault diagnosis effectiveness verification of the developed ECLSTM based diagnosis model
After the above-introduced eleven fault patterns are detected, the fault diagnosis rates of the ESVM, ECNN, EDBN, ELSTM, and ECLSTM for these eleven fault patterns are figured out and exhibited in
Figure 4 and
Figure 5. Specifically,
Figure 4 gives out the confusion matrixes of these five fault diagnosis approaches. From
Figure 4, the numbers in the dark orange blocks denote the numbers of accurately diagnosed fault samples, while the numbers in the shallow orange blocks stand for the numbers of mistakenly diagnosed fault samples. The orange block is darker, the number of fault samples is more. As displayed in
Figure 4a–d, the numbers in the shallow orange blocks of the sixth rows for the ESVM, ECNN, EDBN, and ELSTM are much greater than those in
Figure 4e of the ECLSTM. This demonstrates that more fault data points pertaining to the fault AC are mistakenly identified by the ESVM, ECNN, EDBN, and ELSTM. Moreover, in comparison with
Figure 4e, much more shallow orange blocks appear in
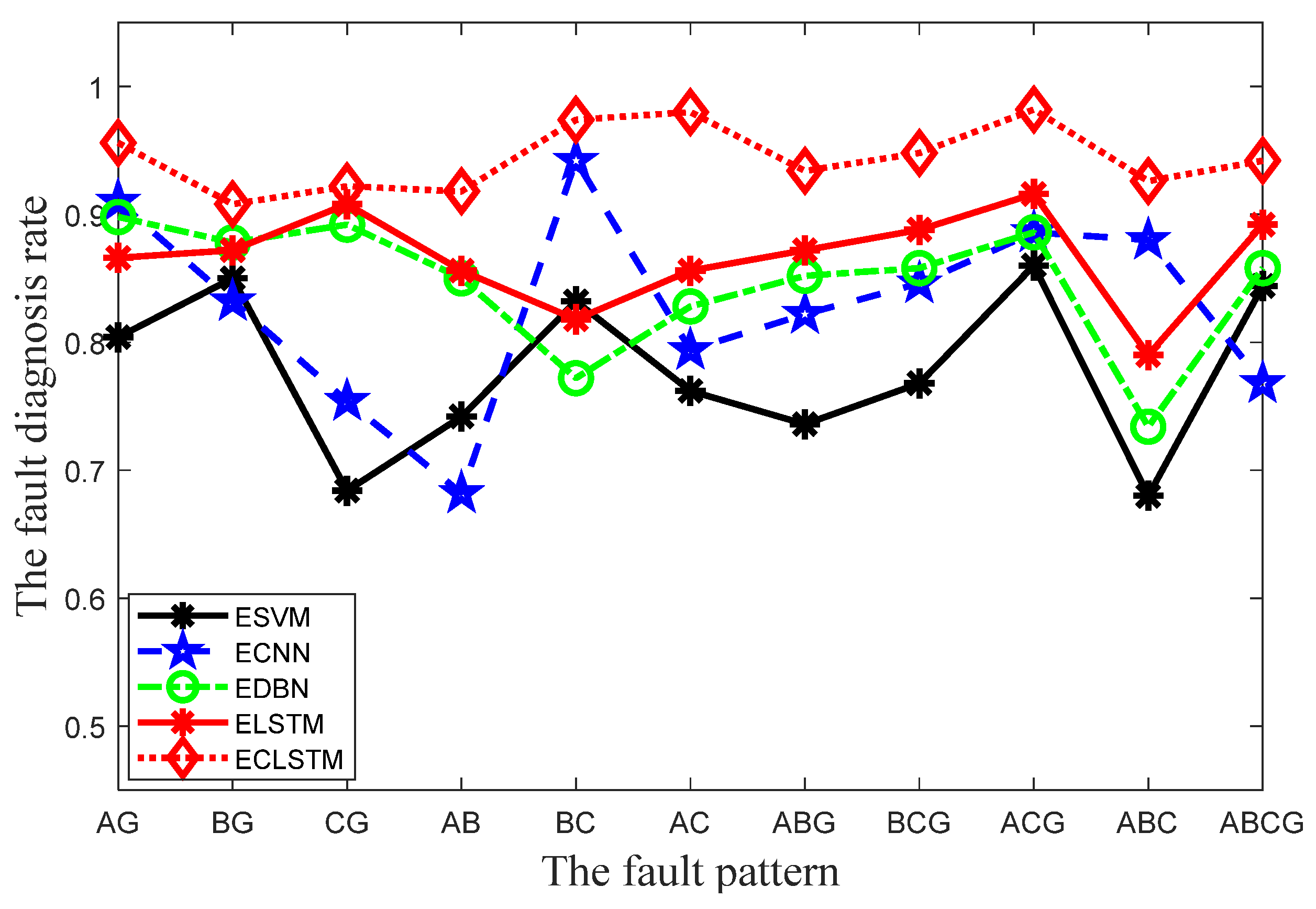
Figure 4a–d. This phenomenon means that the ESVM, ECNN, EDBN, and ELSTM inaccurately discern much more fault data points for these eleven faults than the ECLSTM. To implement more graphical analysis and comparison, the line charts of the fault diagnosis rates for the five approaches under the eleven fault patterns are exhibited in
Figure 5. As revealed in
Figure 5, the fault diagnosis rates of the ECLSTM are significantly improved compared with those of the ESVM, ECNN, EDBN, and ELSTM. To be specific, the ECLSTMs values of the index
FDR for the eleven fault patterns are all above 90.00%, and the fault diagnosis rate even reaches 98.20%. As displayed in
Figure 5, the great differences between the fault diagnosis rates of the five approaches prove the superiority of the ECLSTM for implementing transmission line fault diagnosis.
The fault diagnosis rates of the ESVM, ECNN, EDBN, ELSTM, and ECLSTM for the eleven fault patterns are further quantized in
Table 5. In addition, for the sake of fairness, the values of the index
for the five diagnosis models on the eleven fault patterns are also exhibited in
Table 5. From
Table 5, the values of the index
for the ESVM, ECNN, EDBN, ELSTM, and ECLSTM are respectively computed as 77.84%, 82.87%, 84.60%, 86.67%, and 94.45%. Thus, the ECLSTM-based identification approach demonstrates the largest value of the index
for all eleven fault patterns among the five approaches, which testifies to the superiority of the ECLSTMs overall fault recognition effectiveness. What is more, in comparison with the ESVM, ECNN, EDBN, and ELSTM, the suggested ECLSTM also exhibits more remarkable diagnosis performance to discern the particular fault of the eleven fault patterns. For example, the index
FDRs value for the fault pattern BCG is 94.80% for the ECLSTM, in contrast to only 88.80% for the ELSTM, 85.80% for the EDBN, 84.60% for the ECNN, and 76.80% for the ESVM. Analogously, the value of the index
FDR for the fault pattern AB is 91.80% for the ECLSTM, in comparison with only 85.60% for the ELSTM, 85.00% for the EDBN, 74.20% for the ESVM, and even 68.20% for the ECNN. It can be concluded that the presented ECLSTM approach is excellent for recognizing the short-circuit fault patterns of the transmission line. This is because the global and local statistical features extracted by the ECLSTM promote the improvement of the transmission line’s fault identification task. To facilitate further visualized analysis, the values of the index
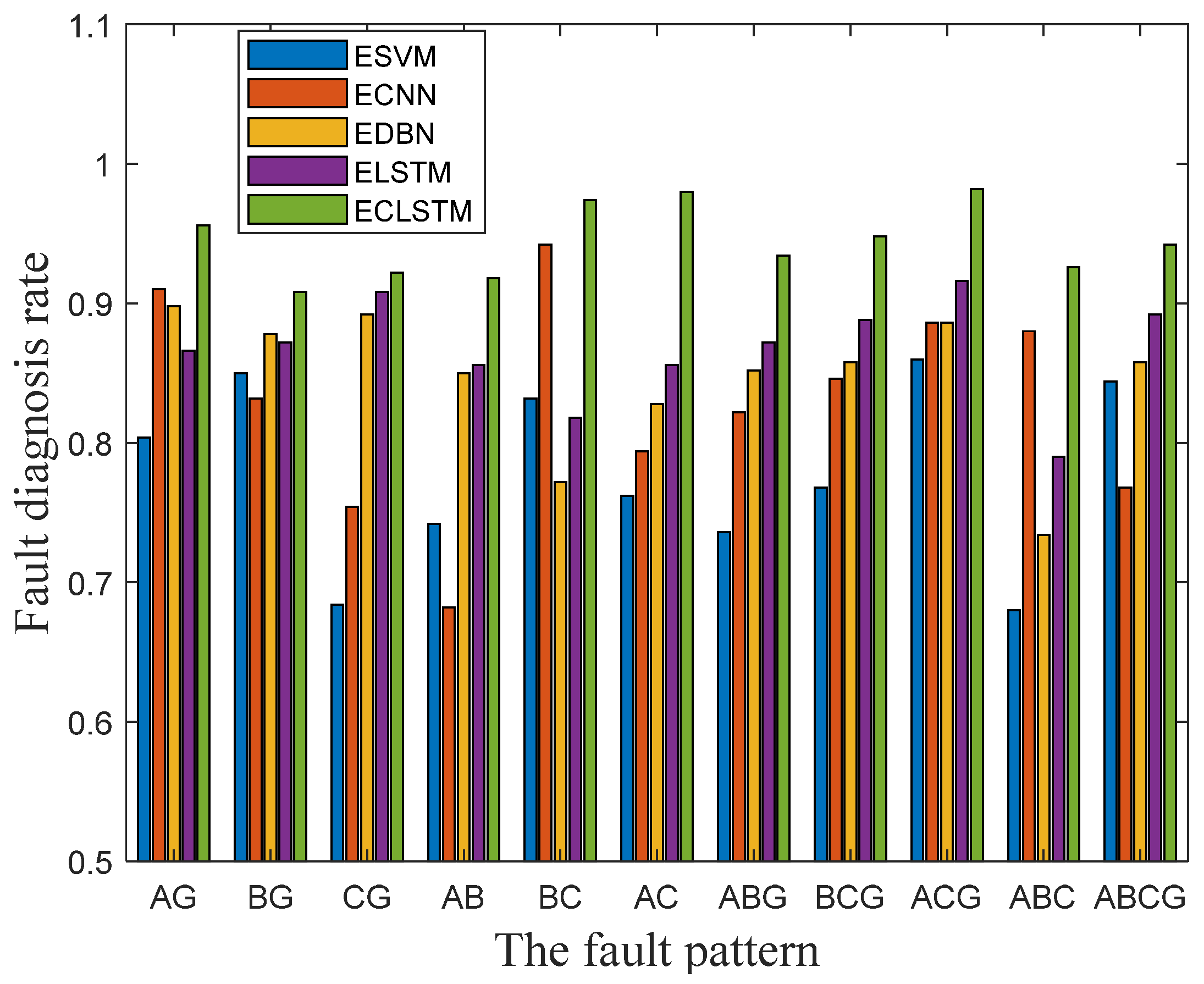
FDR for the five algorithms under the eleven fault patterns are plotted as the histogram in
Figure 6, which also proves the outstanding recognition performance of the ECLSTM over the ESVM, ECNN, EDBN, and ELSTM for discerning all the eleven short circuit faults.
According to the confusion matrices given in
Figure 4, the values of the index precision
P for the ESVM, ECNN, EDBN, ELSTM, and ECLSTM are also listed in
Table 6. Anyway, the values of the index
for the five diagnosis models are also exhibited in
Table 6. From
Table 6, the values of the index
for the ESVM, ECNN, EDBN, ELSTM, and ECLSTM are respectively computed as 78.13%, 82.96%, 84.60%, 86.76%, and 94.47%. Thus, the ECLSTM-based identification approach demonstrates the largest value of the index
for all eleven fault patterns, which testifies the superiority of the ECLSTMs overall fault recognition effectiveness. In comparison with the ESVM, ECNN, EDBN, and ELSTM, the suggested ECLSTM displays more remarkable diagnosis performance to discern the particular fault of the eleven fault patterns. For example, the index precision’s value of the fault pattern CG is 95.64% for the ECLSTM, in contrast to only 89.72% for the ELSTM, 87.07% for the ECNN, 86.94% for the EDBN, and 78.98% for the ESVM. Analogously, the value of the index precision for the fault pattern ABG is 95.50% for the ECLSTM, in comparison with only 86.16% for the ECNN, 85.83% for the ELSTM, 81.30% for the EDBN, and even 76.03% for the ESVM. It can be concluded that the presented ECLSTM approach is excellent for recognizing the short-circuit fault patterns of the transmission line.
(3) Fault diagnosis effects of the proposed ECLSTM under different noise environments
To further verify the fault diagnosis effects of the proposed ECLSTM-based model under different noise environments, Gaussian noise with a zero mean and different variances is introduced to the monitored variables. The specific values of Gaussian noise’s different variances are set to be 0.1, 0.01, 0.001, and 0.0001 by experience. In this way, the ECLSTMs fault diagnosis effects under different noise environments are tested and displayed in
Table 7 and
Table 8.
To be specific,
Table 7 lists the ECLSTMs
FDR and
FDRaverage values, and
Table 8 exhibits the ECLSTMs indices
P and
Paverage values for the eleven fault patterns, with the noise variance varying from 0.1 to 0.0001. When the value of noise variance is 0.1, which is the largest in our experiment, the ECLSTM achieves the worst fault diagnosis performance as the values of the
FDRaverage and
Paverage are both the smallest, i.e., 92.07% and 91.65%, respectively. However, the ECLSTMs values of
FDRaverage and
Paverage at the largest noise variance environment can be acceptable because they are both above 91.00%. With the decrease in noise variance, the ECLSTMs fault diagnosis effect becomes better and better. However, when the noise variance decreases from 0.001 to 0.0001, the diagnosis effectiveness of the ECLSTM improves slightly because the
FDRaverage only varies from 95.71% to 96.25% and the
Paverage only increases from 96.05% to 96.87%.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}