
A Comparative Analysis of Machine Learning Models in Prediction of Mortar Compressive Strength

 ,
,  , and
, and 
Abstract
:1. Introduction
2. Machine Learning Methods
2.1. Linear Regression
2.2. Random Forest Regression
2.3. Support Vector Regression
2.4. AdaBoost Regression
2.5. Multi-Layer Perceptron
- Forward propagation—data propagation begins at the input layer and forwards to the output layer;
- Error calculation—find the error (variation between the estimated and known outcomes) based on the output;
- Backpropagate the error—the derivative based on respective weights in the network is determined, and then the model is updated.
2.6. Gradient Boosting Regression
2.7. Decision Tree Regression
2.8. Hist Gradient Boosting Regression
2.9. XGBoost Regression
3. Problem Description
4. Results and Discussion
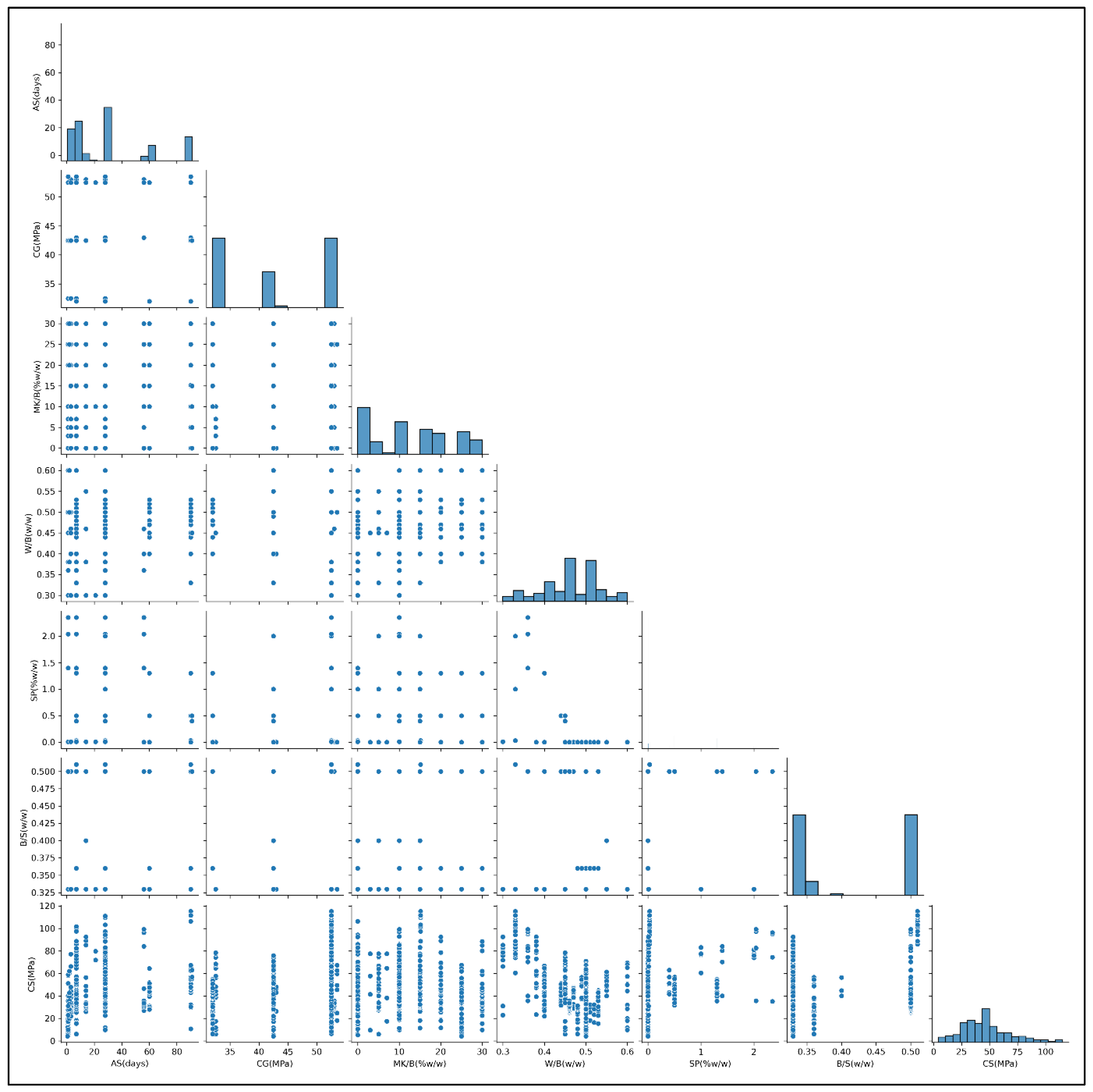
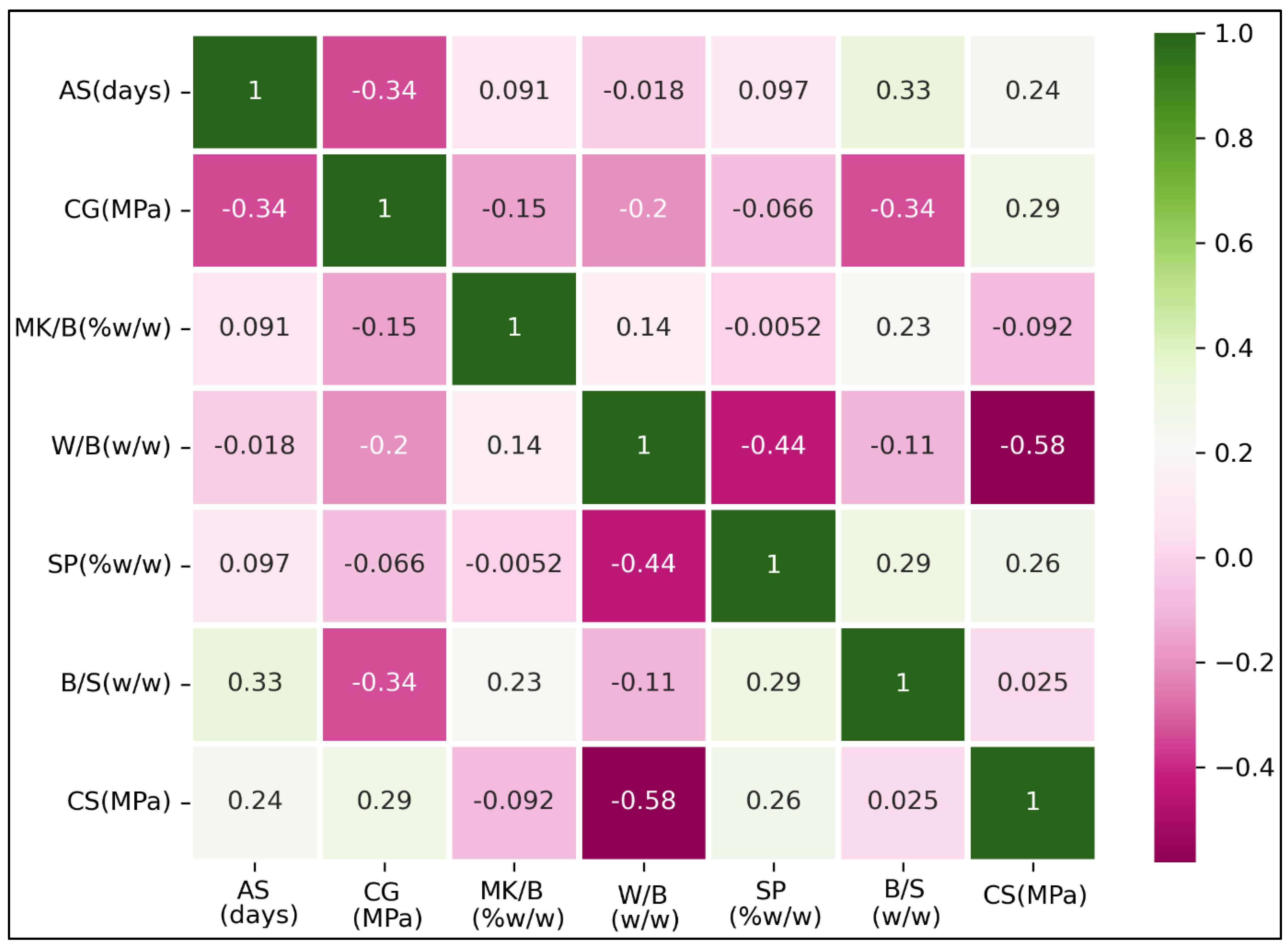
4.1. Characteristics of the Cement-Based Mortars Database
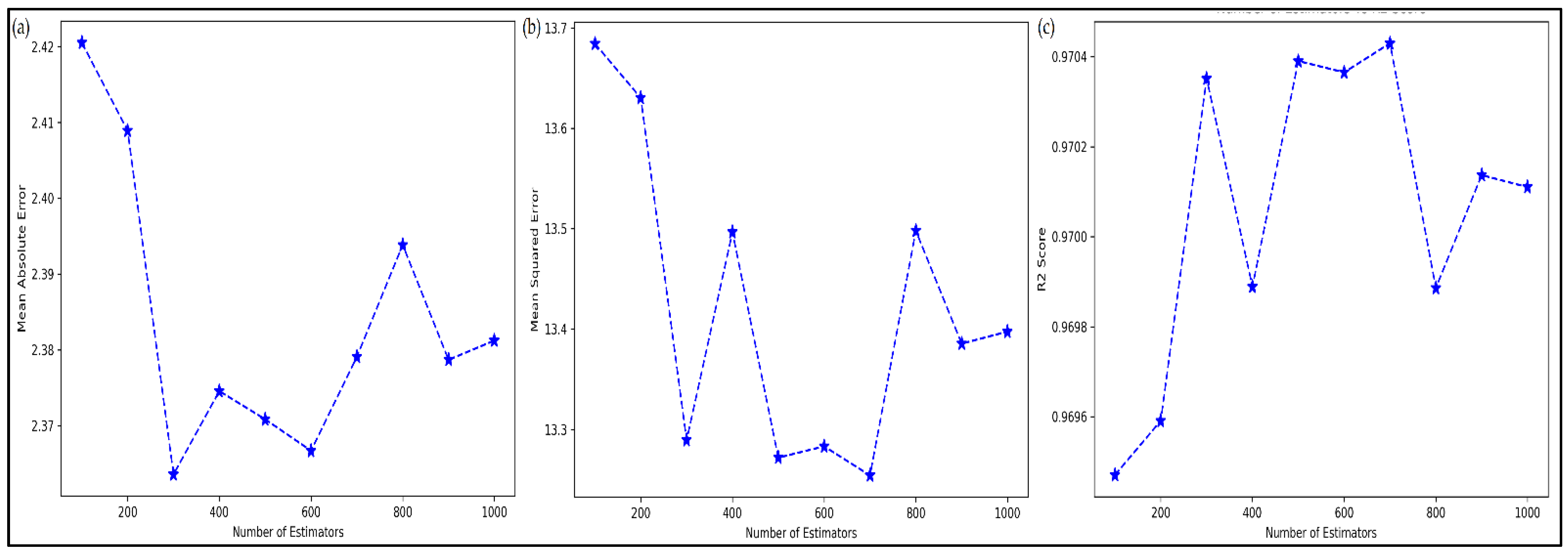
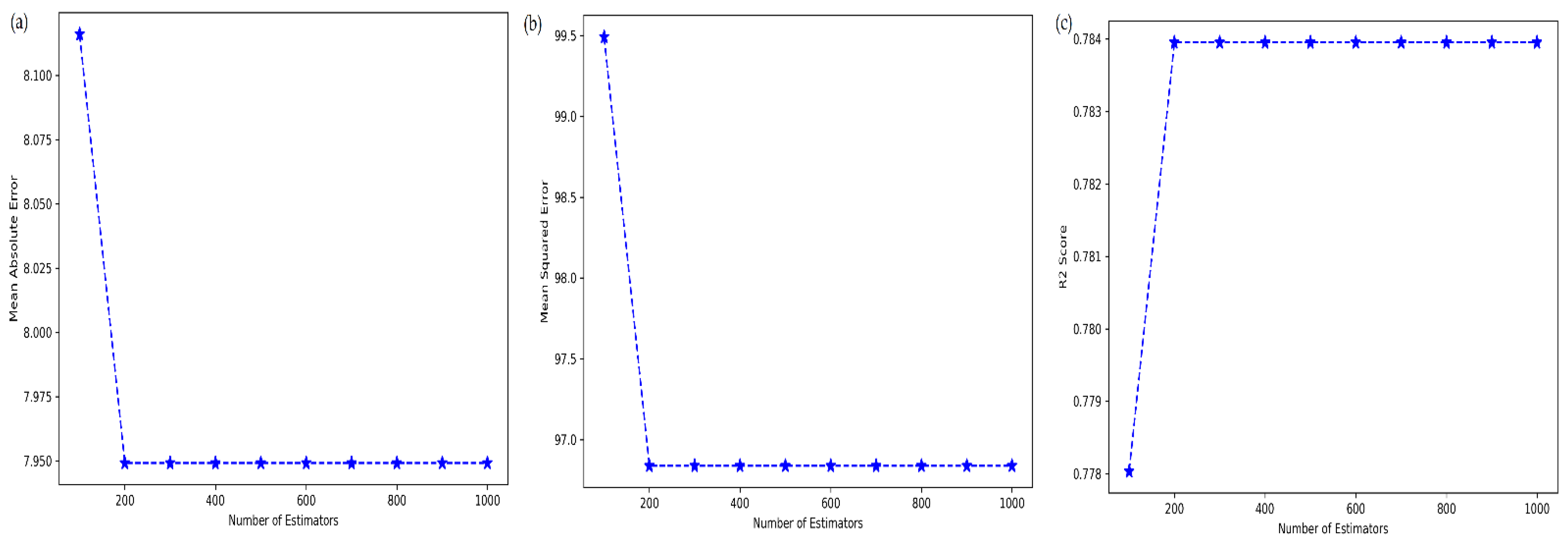
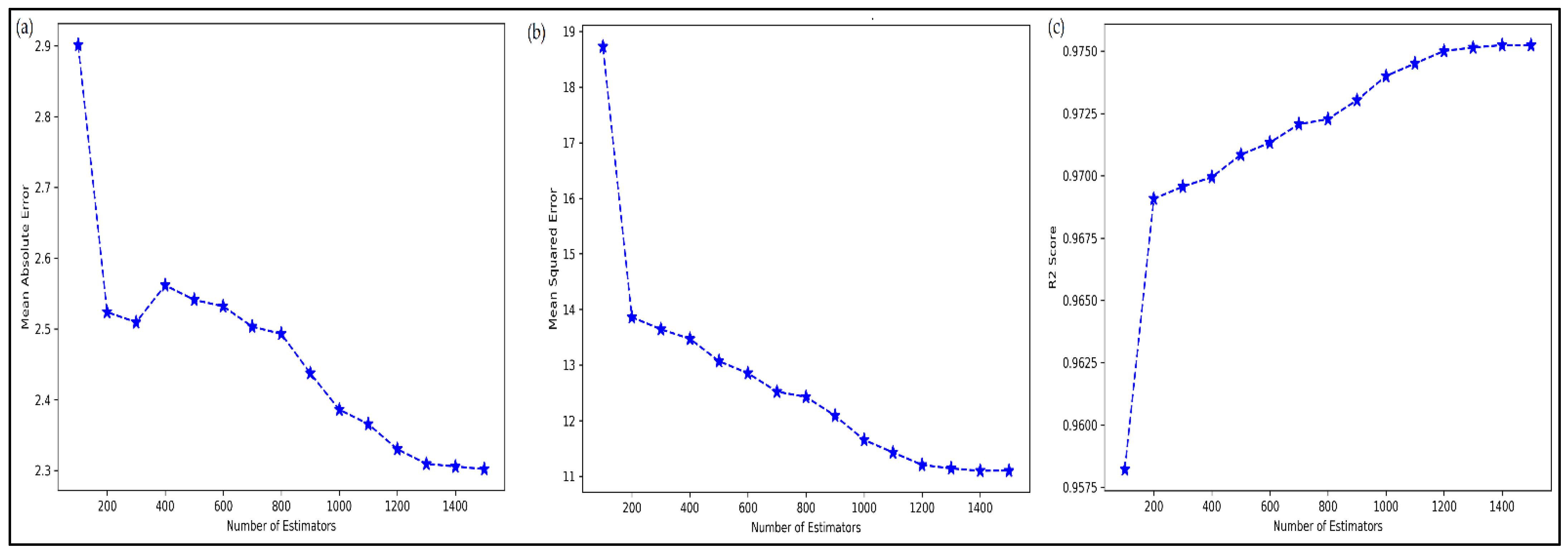
4.2. Tuning of ML Metamodels
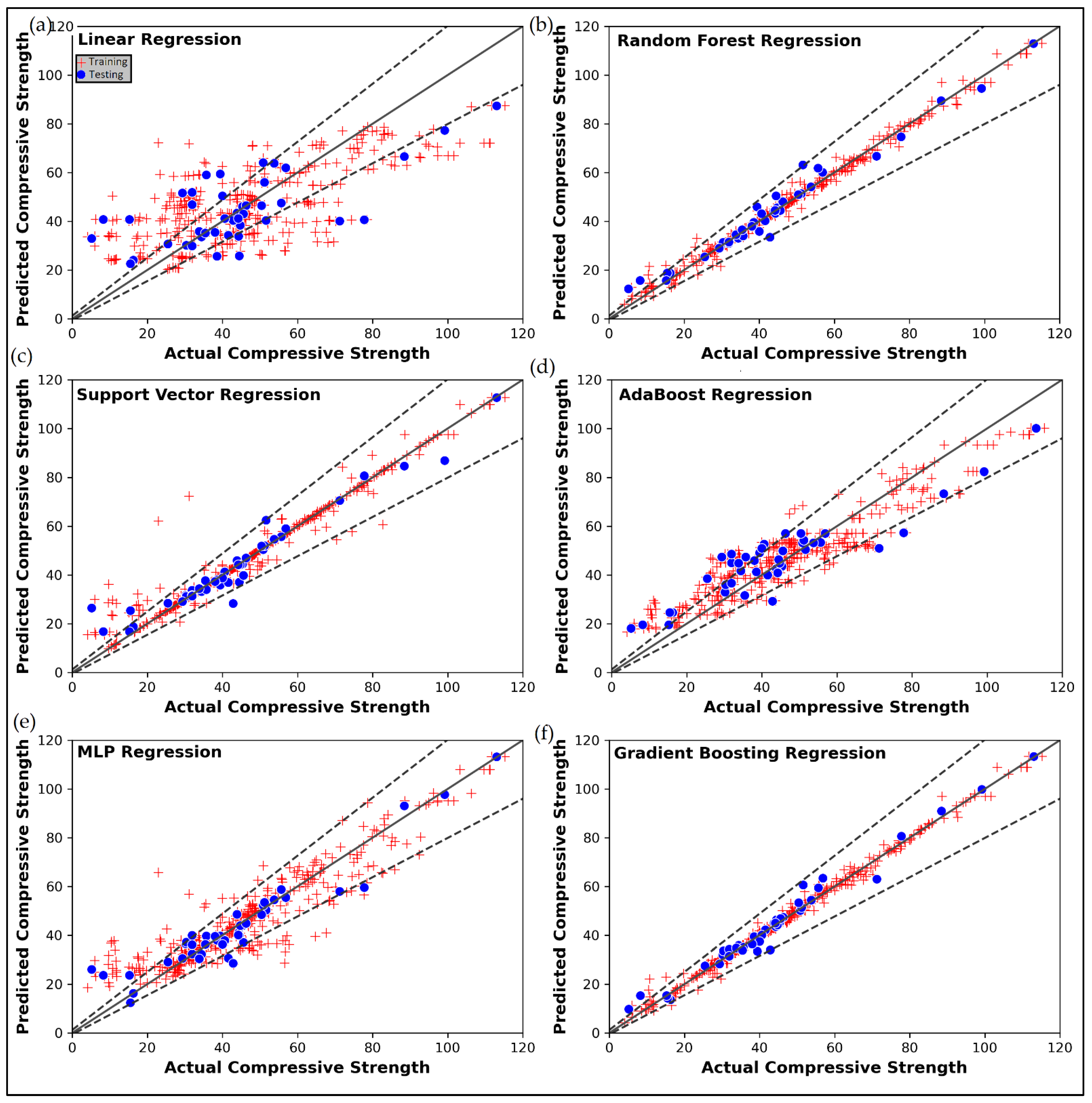
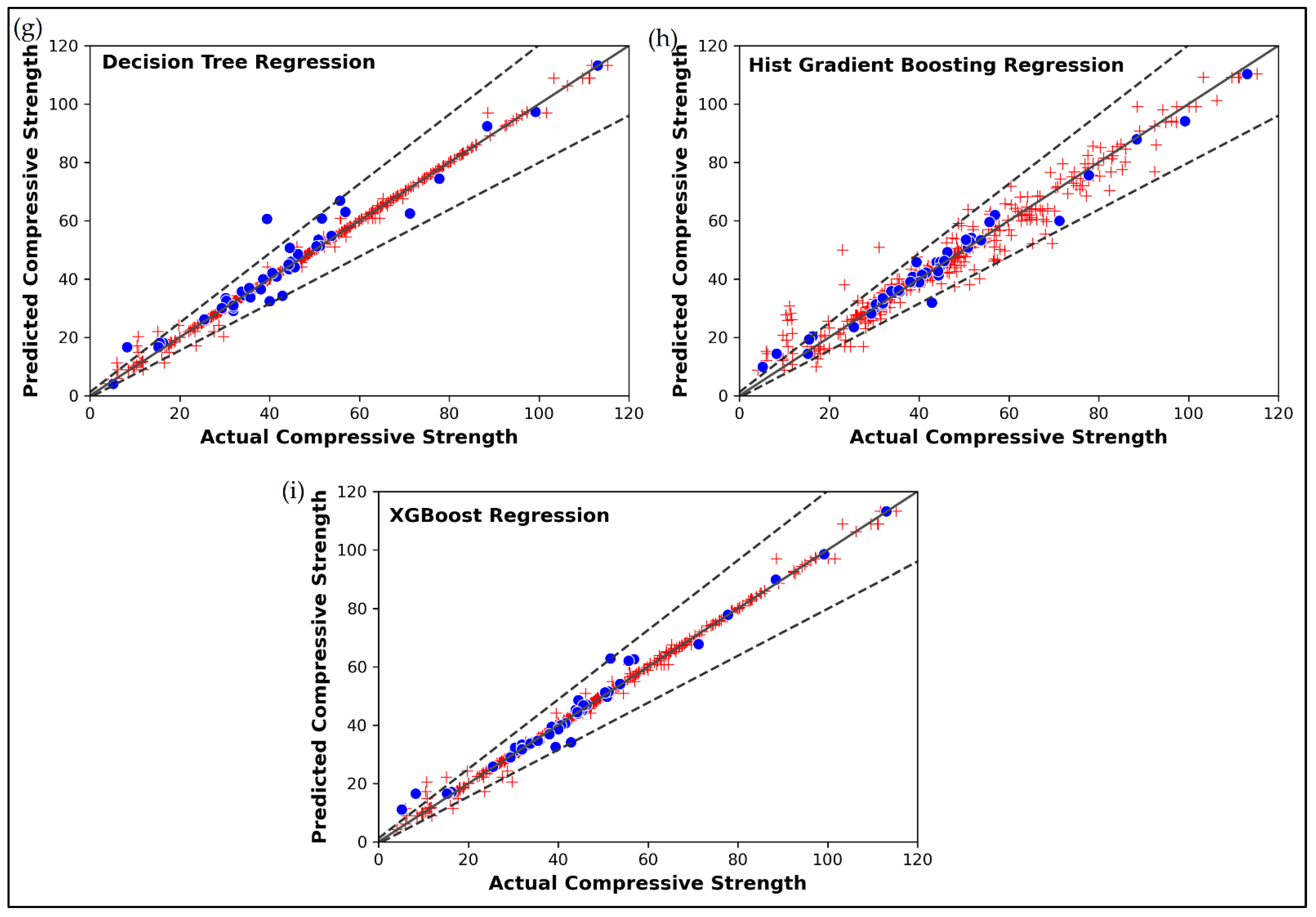
4.3. Prediction of Cement-Based Mortars’ Compressive Strength
4.4. TOPSIS-Based Selection of ML Metamodel
5. Conclusions
- In terms of measured on the testing data, the RFR, SVR, ABR, MLP, GBR, DT, hGBR and XGB metamodels are found to 103%, 95%, 64%, 87%, 104%, 97%, 103% and 104% better than the LR metamodel;
- The RFR, SVR, ABR, MLP, GBR, DT, hGBR and XGB metamodels showed 94%, 87%, 59%, 80%, 95%, 89%, 95% and 95% lower MSE on the testing data as compared to the LR metamodel;
- The improvement in terms of MAE on testing data is seen to be 79%, 72%, 29%, 58%, 80%, 71%, 78% and 82% for RFR, SVR, ABR, MLP, GBR, DT, hGBR and XGB metamodels over the LR metamodel;
- The RFR, SVR, ABR, MLP, GBR, DT, hGBR and XGB metamodels are found to have 69%, 43%, 45%, 44%, 76%, 43%, 70% and 70% lower maximum testing error than the LR metamodel;
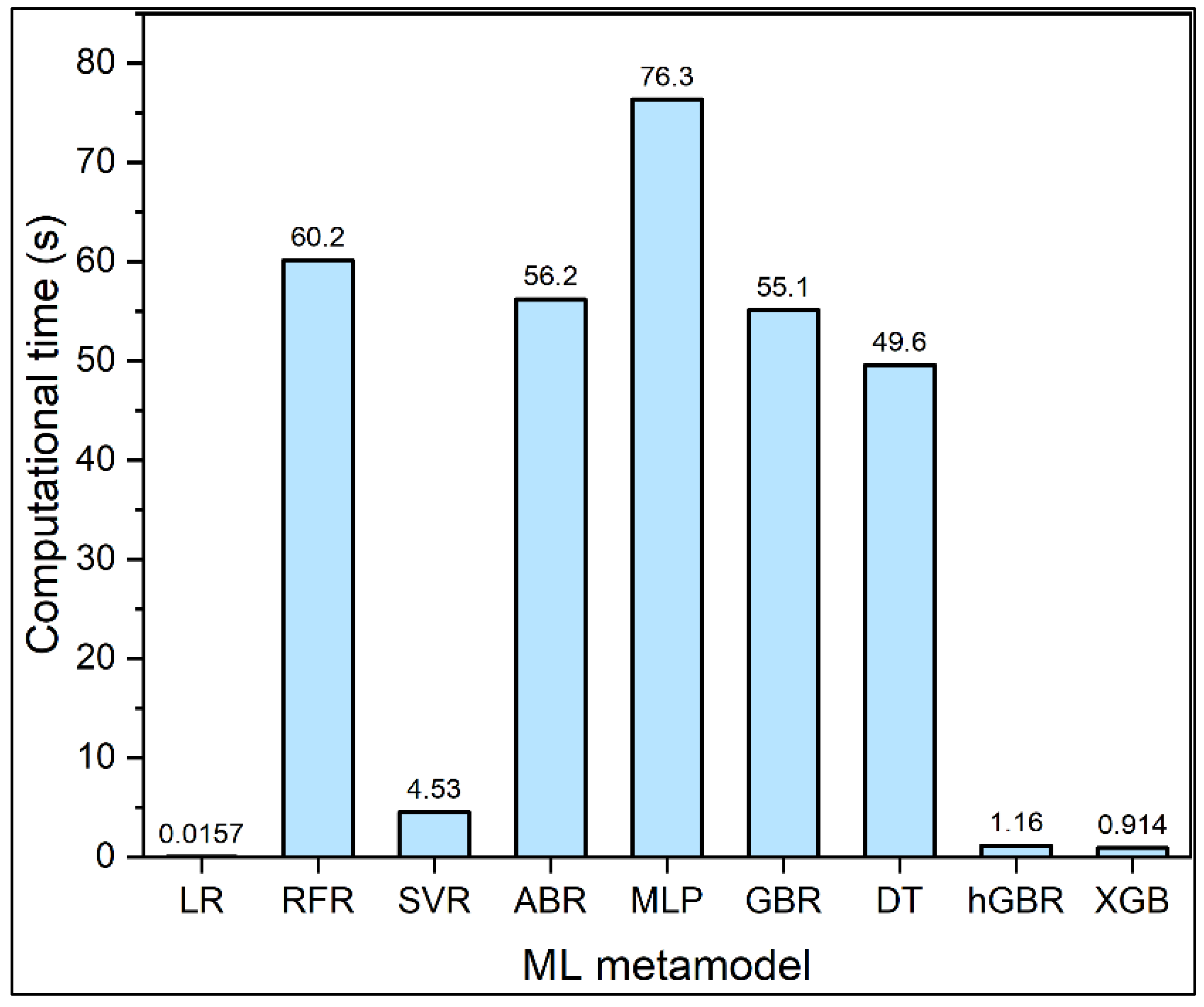
- In terms of computational time, the metamodels can be arranged from most expensive to least expensive as MLP > RFR > ABR > GBR > DT > SVR > hGBR > XGB > LR;
- Using a MADM method called TOPSIS, the metamodels can be ranked from best to worst based on a compromise solution as XGB > hGBR > SVR > GBR > DT > RFR > MLP > ABR > LR.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Pavlikova, M.; Brtník, T.; Keppert, M.; Černỳ, R. Effect of metakaolin as partial Portland-cement replacement on properties of high-performance mortars. Cem. Wapno Beton 2009, 3, 115–122. [Google Scholar]
- Khatib, J.M.; Negim, E.M.; Gjonbalaj, E. High volume metakaolin as cement replacement in mortar. World J. Chem. 2012, 7, 7–10. [Google Scholar] [CrossRef]
- Wianglor, K.; Sinthupinyo, S.; Piyaworapaiboon, M.; Chaipanich, A. Effect of alkali-activated metakaolin cement on compressive strength of mortars. Appl. Clay Sci. 2017, 141, 272–279. [Google Scholar] [CrossRef]
- Yang, C.; Huang, R. A two-phase model for predicting the compressive strength of concrete. Cem. Concr. Res. 1996, 26, 1567–1577. [Google Scholar] [CrossRef]
- Onal, O.; Ozturk, A.U. Artificial neural network application on microstructure-compressive strength relationship of cement mortar. Adv. Eng. Softw. 2010, 41, 165–169. [Google Scholar] [CrossRef]
- Asteris, P.G.; Apostolopoulou, M.; Skentou, A.D.; Moropoulou, A. Application of artificial neural networks for the prediction of the compressive strength of cement-based mortars. Comput. Concr. 2019, 24, 329–345. [Google Scholar] [CrossRef]
- Eskandari-Naddaf, H.; Kazemi, R. ANN prediction of cement mortar compressive strength, influence of cement strength class. Constr. Build. Mater. 2017, 138, 1–11. [Google Scholar] [CrossRef]
- Sharifi, Y.; Hosseinpour, M. A predictive model-based ANN for compressive strength assessment of the mortars containing metakaolin. J. Soft Comput. Civ. Eng. 2020, 4, 1–12. [Google Scholar] [CrossRef]
- Asteris, P.G.; Apostolopoulou, M.; Armaghani, D.J.; Cavaleri, L.; Chountalas, A.T.; Guney, D.; Hajihassani, M.; Hasanipanah, M.; Khandelwal, M.; Karamani, C.; et al. On the Metaheuristic Models for the Prediction of Cement-Metakaolin Mortars Compressive Strength; Techno-Press: Plovdiv, Bulgaria, 2020; Volume 1, p. 063. [Google Scholar] [CrossRef]
- Ly, H.-B.; Nguyen, M.H.; Pham, B.T. Metaheuristic optimization of Levenberg–Marquardt-based artificial neural network using particle swarm optimization for prediction of foamed concrete compressive strength. Neural Comput. Appl. 2021, 33, 17331–17351. [Google Scholar] [CrossRef]
- Zhao, Y.; Hu, H.; Song, C.; Wang, Z. Predicting compressive strength of manufactured-sand concrete using conventional and metaheuristic-tuned artificial neural network. Measurement 2022, 194, 110993. [Google Scholar] [CrossRef]
- Sun, L.; Koopialipoor, M.; Armaghani, D.J.; Tarinejad, R.; Tahir, M.M. Applying a meta-heuristic algorithm to predict and optimize compressive strength of concrete samples. Eng. Comput. 2021, 37, 1133–1145. [Google Scholar] [CrossRef]
- Armaghani, D.J.; Asteris, P.G. A comparative study of ANN and ANFIS models for the prediction of cement-based mortar materials compressive strength. Neural Comput. Appl. 2021, 33, 4501–4532. [Google Scholar] [CrossRef]
- Sevim, U.K.; Bilgic, H.H.; Cansiz, O.F.; Ozturk, M.; Atis, C.D. Compressive strength prediction models for cementitious composites with fly ash using machine learning techniques. Constr. Build. Mater. 2021, 271, 121584. [Google Scholar] [CrossRef]
- Asteris, P.G.; Cavaleri, L.; Ly, H.-B.; Pham, B.T. Surrogate models for the compressive strength mapping of cement mortar materials. Soft Comput. 2021, 25, 6347–6372. [Google Scholar] [CrossRef]
- Dao, D.V.; Adeli, H.; Ly, H.-B.; Le, L.M.; Le, V.M.; Le, T.-T.; Pham, B.T. A Sensitivity and Robustness Analysis of GPR and ANN for High-Performance Concrete Compressive Strength Prediction Using a Monte Carlo Simulation. Sustainability 2020, 12, 830. [Google Scholar] [CrossRef] [Green Version]
- Mohammed, A.; Rafiq, S.; Sihag, P.; Kurda, R.; Mahmood, W.; Ghafor, K.; Sarwar, W. ANN, M5P-tree and nonlinear regression approaches with statistical evaluations to predict the compressive strength of cement-based mortar modified with fly ash. J. Mater. Res. Technol. 2020, 9, 12416–12427. [Google Scholar] [CrossRef]
- Abdalla, A.; Salih, A. Implementation of multi-expression programming (MEP), artificial neural network (ANN), and M5P-tree to forecast the compression strength cement-based mortar modified by calcium hydroxide at different mix proportions and curing ages. Innov. Infrastruct. Solut. 2022, 7, 153. [Google Scholar] [CrossRef]
- Asteris, P.G.; Koopialipoor, M.; Armaghani, D.J.; Kotsonis, E.A.; Lourenço, P.B. Prediction of cement-based mortars compressive strength using machine learning techniques. Neural Comput. Appl. 2021, 33, 13089–13121. [Google Scholar] [CrossRef]
- Çalışkan, A.; Demirhan, S.; Tekin, R. Comparison of different machine learning methods for estimating compressive strength of mortars. Constr. Build. Mater. 2022, 335, 127490. [Google Scholar] [CrossRef]
- Ozcan, G.; Kocak, Y.; Gulbandilar, E. Estimation of compressive strength of BFS and WTRP blended cement mortars with machine learning models. Comput. Concr. 2017, 19, 275–282. [Google Scholar] [CrossRef]
- Montgomery, D.C.; Peck, E.A.; Vining, G.G. Introduction to Linear Regression Analysis; John Wiley & Sons: Hoboken, NJ, USA, 2021. [Google Scholar]
- Biau, G.; Scornet, E. A random forest guided tour. TEST 2016, 25, 197–227. [Google Scholar] [CrossRef] [Green Version]
- Smola, J.; Schölkopf, B. A tutorial on support vector regression. Statistics and computing. Stat. Comput. 2004, 14, 199–222. [Google Scholar] [CrossRef] [Green Version]
- Solomatine, D.P.; Shrestha, D.L. AdaBoost. RT: A boosting algorithm for regression problems. In Proceedings of the 2004 IEEE International Joint Conference on Neural Networks (IEEE Cat. No. 04CH37541), Budapest, Hungary, 25–29 July 2004. [Google Scholar]
- Murtagh, F. Multilayer perceptrons for classification and regression. Neurocomputing 1991, 2, 183–197. [Google Scholar] [CrossRef]
- Friedman, J.H. Stochastic gradient boosting. Comput. Stat. Data Anal. 2002, 38, 367–378. [Google Scholar] [CrossRef]
- Myles, J.; Feudale, R.N.; Liu, Y.; Woody, N.A.; Brown, S.D. An introduction to decision tree modeling. J. Chemom. 2004, 18, 275–285. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016. [Google Scholar]
- Ashok, M.; Parande, A.K.; Jayabalan, P. Strength and durability study on cement mortar containing nano materials. Adv. Nano Res. 2017, 5, 99. [Google Scholar] [CrossRef]
- Batis, G.; Pantazopoulou, P.; Tsivilis, S.; Badogiannis, E. The effect of metakaolin on the corrosion behavior of cement mortars. Cem. Concr. Compos. 2005, 27, 125–130. [Google Scholar] [CrossRef]
- Courard, L.; Darimont, A.; Schouterden, M.; Ferauche, F.; Willem, X.; Degeimbre, R. Durability of mortars modified with metakaolin. Cem. Concr. Res. 2003, 33, 1473–1479. [Google Scholar] [CrossRef]
- Curcio, F.; DeAngelis, B.; Pagliolico, S. Metakaolin as a pozzolanic microfiller for high-performance mortars. Cem. Concr. Res. 1998, 28, 803–809. [Google Scholar] [CrossRef]
- Cyr, M.; Idir, R.; Escadeillas, G.; Julien, A.N.M.S. Stabilization of Industrial By-Products in Mortars Containing Metakaolin; ACI Special Publication, (242 SP); American Concrete Institute: Farmington Hills, MI, USA, 2007; pp. 51–62. [Google Scholar] [CrossRef]
- D’Ayala, D.; Fodde, E. Blended lime-cement mortars for conservation purposes: Microstructure and strength development. In Structural Analysis of Historic Construction: Preserving Safety and Significance; Two Volume Set; CRC Press: Boca Raton, FL, USA, 2008; pp. 1005–1012. [Google Scholar]
- Geng, H.N.; Li, Q. Water Absorption and Hydration Products of Metakaolin Modified Mortar. Key Eng. Mater. 2017, 726, 505–509. [Google Scholar] [CrossRef]
- Al-Chaar, G.; Alkadi, M.; Asteris, P.G. Natural Pozzolan as a Partial Substitute for Cement in Concrete. Open Constr. Build. Technol. J. 2013, 7, 33–42. [Google Scholar] [CrossRef] [Green Version]
- Kadri, E.-H.; Kenai, S.; Ezziane, K.; Siddique, R.; De Schutter, G. Influence of metakaolin and silica fume on the heat of hydration and compressive strength development of mortar. Appl. Clay Sci. 2011, 53, 704–708. [Google Scholar] [CrossRef]
- Khater, H.M. Influence of Metakaolin on Resistivity of Cement Mortar to Magnesium Chloride Solution. J. Mater. Civ. Eng. 2011, 23, 1295–1301. [Google Scholar] [CrossRef]
- Khatib, J.; Wild, S. Sulphate Resistance of Metakaolin Mortar. Cem. Concr. Res. 1998, 28, 83–92. [Google Scholar] [CrossRef]
- Lee, S.; Moon, H.; Hooton, R.D.; Kim, J. Effect of solution concentrations and replacement levels of metakaolin on the resistance of mortars exposed to magnesium sulfate solutions. Cem. Concr. Res. 2005, 35, 1314–1323. [Google Scholar] [CrossRef]
- Mansour, M.S.; Abaldia, T.; Jauberthie, R.; Messaoudenne, I. Metakaolin as a pozzolan for high performance mortar. Cem. Wapno Beton 2012, 2, 102–108. [Google Scholar]
- Mardani-Aghabaglou, A.; Sezer, G.İ.; Ramyar, K. Comparison of fly ash, silica fume and metakaolin from mechanical properties and durability performance of mortar mixtures view point. Constr. Build. Mater. 2014, 70, 17–25. [Google Scholar] [CrossRef]
- Sumasree, C.; Sajja, S. Effect of metakaolin and cerafibermix on mechanical and durability properties of mortars. Int. J. Sci. Eng. Technol. 2016, 4, 501–506. [Google Scholar]
- Vu, D.; Stroeven, P.; Bui, V. Strength and durability aspects of calcined kaolin-blended Portland cement mortar and concrete. Cem. Concr. Compos. 2001, 23, 471–478. [Google Scholar] [CrossRef]
- Parande, A.K.; Babu, B.R.; Karthik, M.A.; Kumaar, K.D.; Palaniswamy, N. Study on strength and corrosion performance for steel embedded in metakaolin blended concrete/mortar. Constr. Build. Mater. 2008, 22, 127–134. [Google Scholar] [CrossRef]
- Potgieter-Vermaak, S.S.; Potgieter, J.H. Metakaolin as an extender in South African cement. J. Mater. Civ. Eng. 2006, 18, 619–623. [Google Scholar] [CrossRef]
- Saidat, F.; Mouret, M.; Cyr, M. Chemical Activation of Metakaolin in Cement-Based Materials. Spec. Publ. 2012, 288, 1–15. [Google Scholar] [CrossRef]
- Kalita, K.; Pal, S.; Haldar, S.; Chakraborty, S. A Hybrid TOPSIS-PR-GWO Approach for Multi-objective Process Parameter Optimization. Process Integr. Optim. Sustain. 2022, 1–16. [Google Scholar] [CrossRef]
- Shinde, D.; Öktem, H.; Kalita, K.; Chakraborty, S.; Gao, X.-Z. Optimization of Process Parameters for Friction Materials Using Multi-Criteria Decision Making: A Comparative Analysis. Processes 2021, 9, 1570. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Statistic | AS (Days) | CG (MPa) | MK/B (w/w) | W/B (w/w) | SP (w/w) | B/S (w/w) | CS (MPa) |
|---|---|---|---|---|---|---|---|
| Count | 424 | 424 | 424 | 424 | 424 | 424 | 424 |
| Mean | 29.80981 | 42.39151 | 12.39811 | 0.457476 | 0.208325 | 0.411132 | 46.42219 |
| Std | 29.28965 | 9.151924 | 10.00436 | 0.069217 | 0.493958 | 0.083049 | 21.79888 |
| Min | 0.67 | 32 | 0 | 0.3 | 0 | 0.33 | 4.1 |
| 25% | 7 | 32 | 0 | 0.4 | 0 | 0.33 | 31.1675 |
| 50% | 28 | 42.5 | 10 | 0.46 | 0 | 0.36 | 44.315 |
| 75% | 28 | 52.5 | 20 | 0.5 | 0.01 | 0.5 | 56.76 |
| Max | 91 | 53.5 | 30 | 0.6 | 2.35 | 0.51 | 115.25 |
| Metamodel | MSE | MAE | Maximum Error | |
|---|---|---|---|---|
| Linear Regression (LR) | 46% | 254.99 | 12.59 | 49.13 |
| Random Forest Regression (RFR) | 99% | 4.60 | 1.35 | 10.72 |
| Support Vector Regression (SVR) | 95% | 26.05 | 1.92 | 41.19 |
| AdaBoost Regression (ABR) | 84% | 77.67 | 7.08 | 21.24 |
| Multi-layer Perceptron (MLP) | 84% | 77.42 | 6.08 | 42.71 |
| Gradient Boosting Regression (GBR) | 99% | 3.48 | 1.13 | 11.40 |
| Decision Tree Regression (DT) | 100% | 2.14 | 0.44 | 9.51 |
| Hist Gradient Boosting Regression (hGBR) | 95% | 23.39 | 3.11 | 26.93 |
| XGBoost Regression (XGB) | 100% | 2.23 | 0.62 | 9.75 |
| Metamodel | MSE | MAE | Maximum Error | |
|---|---|---|---|---|
| Linear Regression (LR) | 48% | 233.53 | 11.27 | 37.10 |
| Random Forest Regression (RFR) | 97% | 13.25 | 2.38 | 11.63 |
| Support Vector Regression (SVR) | 93% | 30.24 | 3.19 | 21.27 |
| AdaBoost Regression (ABR) | 78% | 96.84 | 7.95 | 20.44 |
| Multi-layer Perceptron (MLP) | 90% | 46.82 | 4.69 | 20.84 |
| Gradient Boosting Regression (GBR) | 98% | 11.10 | 2.31 | 9.09 |
| Decision Tree Regression (DT) | 94% | 26.09 | 3.23 | 21.20 |
| Hist Gradient Boosting Regression (hGBR) | 97% | 12.25 | 2.43 | 11.24 |
| XGBoost Regression (XGB) | 97% | 11.25 | 2.00 | 11.30 |
| ML Metamodel | Train MSE | Train MAE | Train Max. Error | Test MSE | Test MAE | Test Max. Error | Time | ||
|---|---|---|---|---|---|---|---|---|---|
| LR | 0.4642 | 254.9905 | 12.5909 | 49.1344 | 0.4790 | 233.5340 | 11.2675 | 37.1014 | 0.0157 |
| RFR | 0.9903 | 4.6019 | 1.3541 | 10.7207 | 0.9704 | 13.2542 | 2.3791 | 11.6316 | 60.1560 |
| SVR | 0.9453 | 26.0509 | 1.9248 | 41.1870 | 0.9325 | 30.2384 | 3.1906 | 21.2661 | 4.5255 |
| ABR | 0.8368 | 77.6693 | 7.0753 | 21.2384 | 0.7840 | 96.8379 | 7.9491 | 20.4384 | 56.1910 |
| MLP | 0.8373 | 77.4222 | 6.0752 | 42.7065 | 0.8955 | 46.8205 | 4.6858 | 20.8425 | 76.3300 |
| GBR | 0.9927 | 3.4802 | 1.1267 | 11.3979 | 0.9752 | 11.0971 | 2.3057 | 9.0895 | 55.1308 |
| DT | 0.9955 | 2.1444 | 0.4435 | 9.5050 | 0.9418 | 26.0865 | 3.2279 | 21.2000 | 49.5710 |
| hGBR | 0.9508 | 23.3947 | 3.1075 | 26.9261 | 0.9727 | 12.2548 | 2.4347 | 11.2410 | 1.1601 |
| XGB | 0.9953 | 2.2291 | 0.6163 | 9.7533 | 0.9749 | 11.2493 | 1.9959 | 11.3029 | 0.9138 |
| Criteria Type | Benefit | Cost | Cost | Cost | Benefit | Cost | Cost | Cost | Cost |
| Weights | 0.05 | 0.05 | 0.05 | 0.05 | 0.15 | 0.15 | 0.15 | 0.15 | 0.2 |
| ML Metamodel | Train MSE | Train MAE | Train Max. Error | Test MSE | Test MAE | Test Max. Error | Time | ||
|---|---|---|---|---|---|---|---|---|---|
| LR | 0.0086 | 0.0456 | 0.0389 | 0.0283 | 0.0268 | 0.1341 | 0.1061 | 0.0927 | 0.0000 |
| RFR | 0.0182 | 0.0008 | 0.0042 | 0.0062 | 0.0543 | 0.0076 | 0.0224 | 0.0291 | 0.0894 |
| SVR | 0.0174 | 0.0047 | 0.0059 | 0.0237 | 0.0522 | 0.0174 | 0.0301 | 0.0531 | 0.0067 |
| ABR | 0.0154 | 0.0139 | 0.0218 | 0.0122 | 0.0438 | 0.0556 | 0.0749 | 0.0511 | 0.0835 |
| MLP | 0.0154 | 0.0138 | 0.0187 | 0.0246 | 0.0501 | 0.0269 | 0.0441 | 0.0521 | 0.1134 |
| GBR | 0.0183 | 0.0006 | 0.0035 | 0.0066 | 0.0545 | 0.0064 | 0.0217 | 0.0227 | 0.0819 |
| DT | 0.0183 | 0.0004 | 0.0014 | 0.0055 | 0.0527 | 0.0150 | 0.0304 | 0.0530 | 0.0736 |
| hGBR | 0.0175 | 0.0042 | 0.0096 | 0.0155 | 0.0544 | 0.0070 | 0.0229 | 0.0281 | 0.0017 |
| XGB | 0.0183 | 0.0004 | 0.0019 | 0.0056 | 0.0545 | 0.0065 | 0.0188 | 0.0282 | 0.0014 |
| PIS | 0.0183 | 0.0004 | 0.0014 | 0.0055 | 0.0545 | 0.0064 | 0.0188 | 0.0227 | 0.0000 |
| NIS | 0.0086 | 0.0456 | 0.0389 | 0.0283 | 0.0268 | 0.1341 | 0.1061 | 0.0927 | 0.1134 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gayathri, R.; Rani, S.U.; Čepová, L.; Rajesh, M.; Kalita, K. A Comparative Analysis of Machine Learning Models in Prediction of Mortar Compressive Strength. Processes 2022, 10, 1387. https://doi.org/10.3390/pr10071387
Gayathri R, Rani SU, Čepová L, Rajesh M, Kalita K. A Comparative Analysis of Machine Learning Models in Prediction of Mortar Compressive Strength. Processes. 2022; 10(7):1387. https://doi.org/10.3390/pr10071387
Chicago/Turabian StyleGayathri, Rajakumaran, Shola Usha Rani, Lenka Čepová, Murugesan Rajesh, and Kanak Kalita. 2022. "A Comparative Analysis of Machine Learning Models in Prediction of Mortar Compressive Strength" Processes 10, no. 7: 1387. https://doi.org/10.3390/pr10071387
APA StyleGayathri, R., Rani, S. U., Čepová, L., Rajesh, M., & Kalita, K. (2022). A Comparative Analysis of Machine Learning Models in Prediction of Mortar Compressive Strength. Processes, 10(7), 1387. https://doi.org/10.3390/pr10071387