
Deep Reinforcement Learning for Integrated Non-Linear Control of Autonomous UAVs


 , ,
, , 
Abstract
:1. Introduction
1.1. Relevant Studies
1.2. Research Contributions
- This study represents one of the pioneering work that applies DRL on controlling a non conventional UAV over its complete trajectory and flight envelope.
- Although a conventional DDPG algorithm lies at the core of current problem solving but it is pertinent to highlight that applied DDPG was modified with regards to its learning architecture through data feeding sequence to the replay buffer. Generated data was fed to the agent in smaller chunks to ensure positive learning through actor policy network. This data feeding distribution also makes it easier for the critic network to follow the policy and to help in positive learning of the agent.
- An optimal reward function was incorporated which primarily focuses on controlling the roll and yaw rates of the platform because of strong coupling between them due to inherent inverted V- tail design of the UAV. Optimal reward function was formulated from initial data collected in Replay Buffer before the formal commencement of agent’s learning.
2. Problem Setup
2.1. Flight Dynamics Modeling
2.2. State and Action Space Characterization
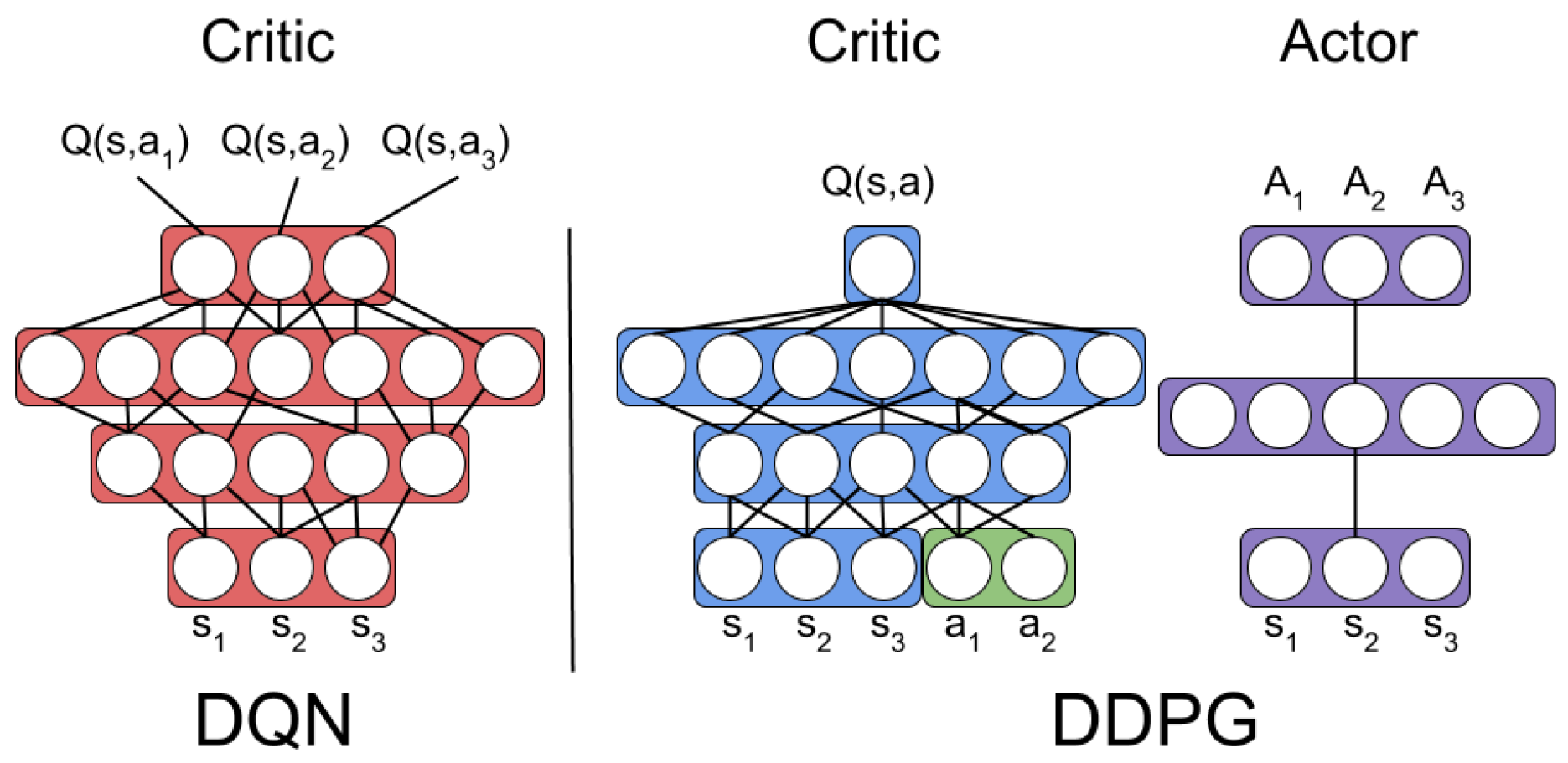
2.3. Drl Algorithms and Appropriate Selection
2.4. Selection of Optimizer Algorithm
3. Results and Discussion
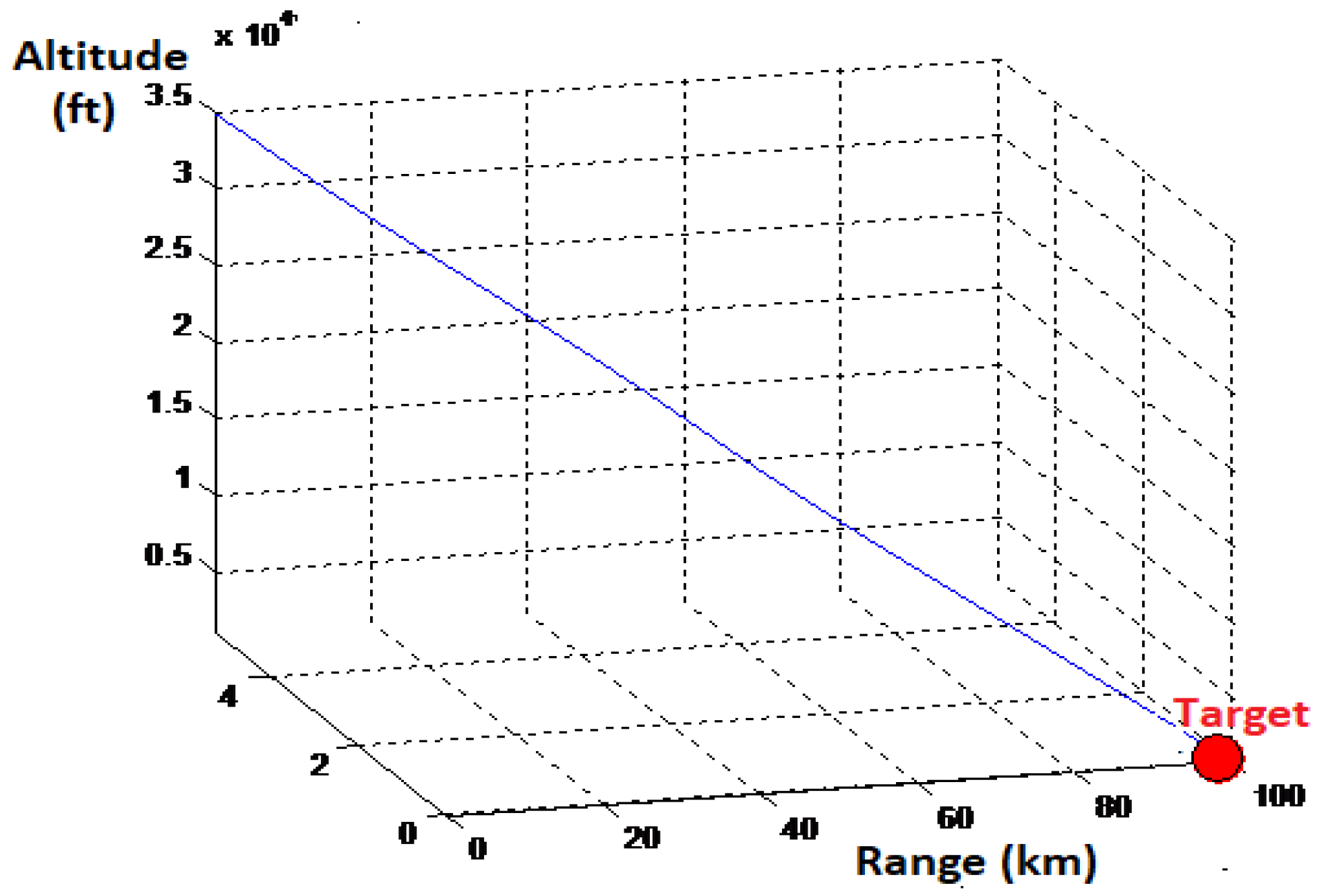
- Launch Condition No. 1 Altitude 35,500 ft, Mach 0.85; Angle of Attach 0
- Launch Condition No. 2 Altitude 35,000 ft, Mach 0.7; Angle of Attach 2
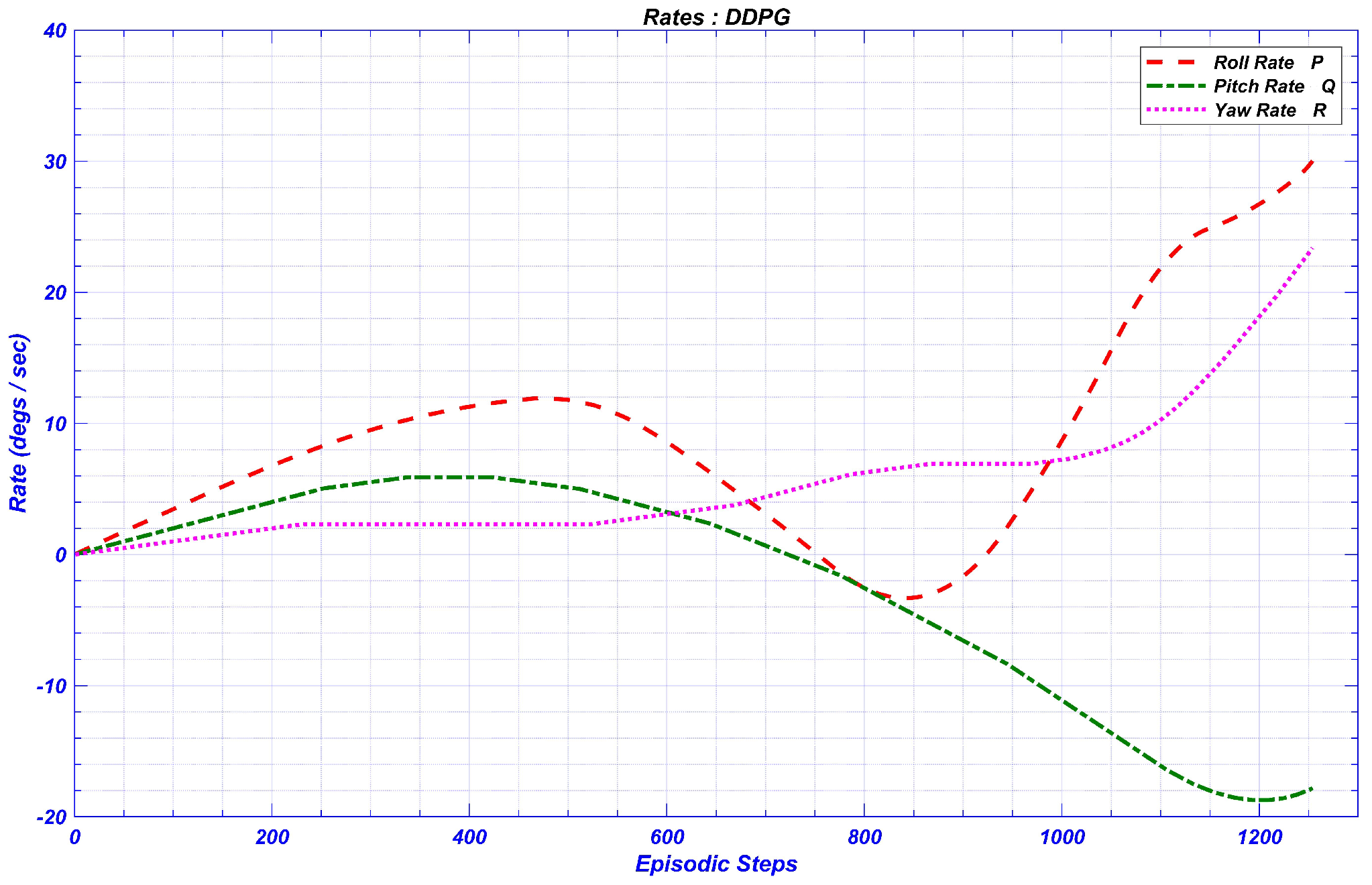
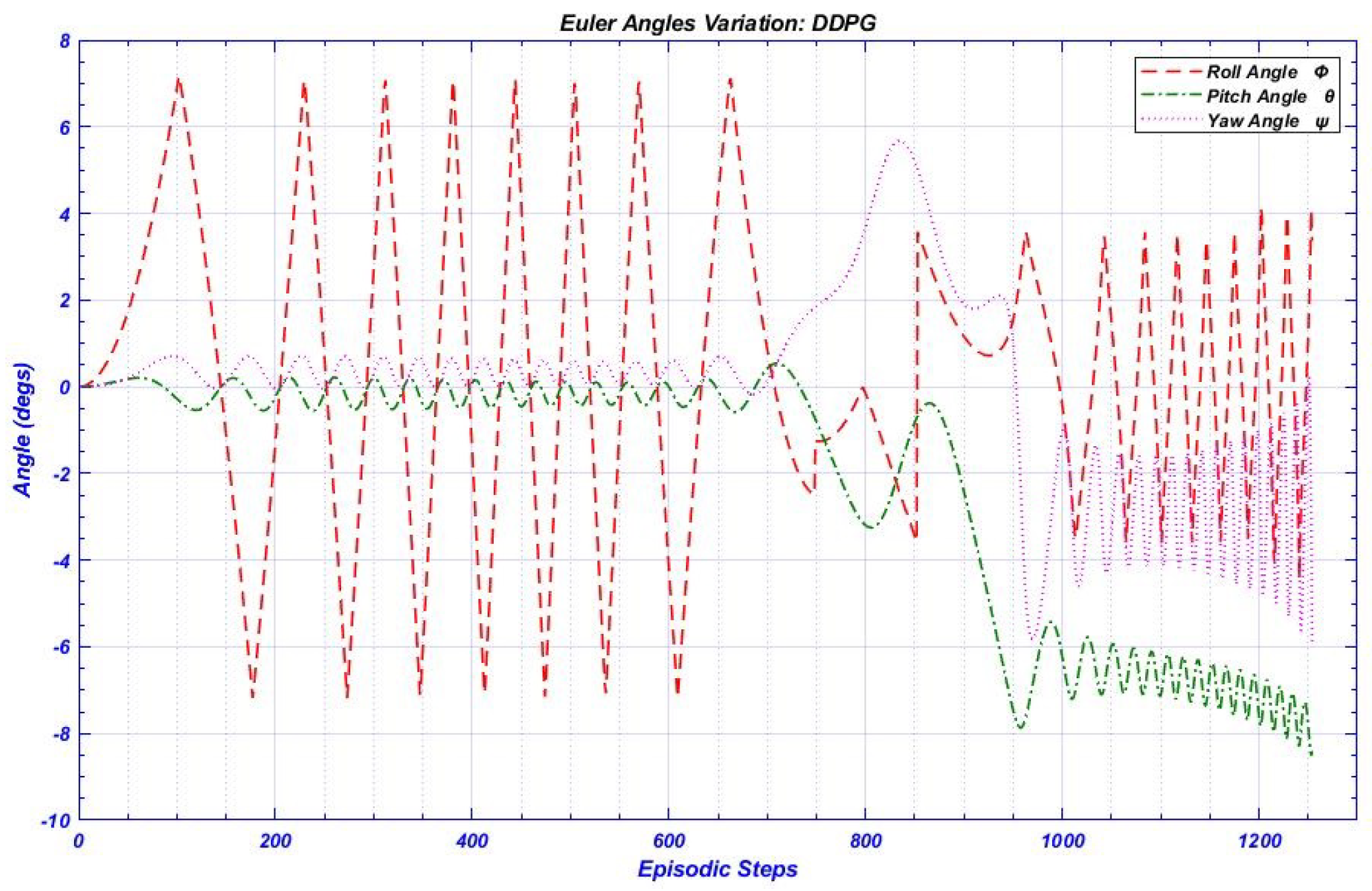
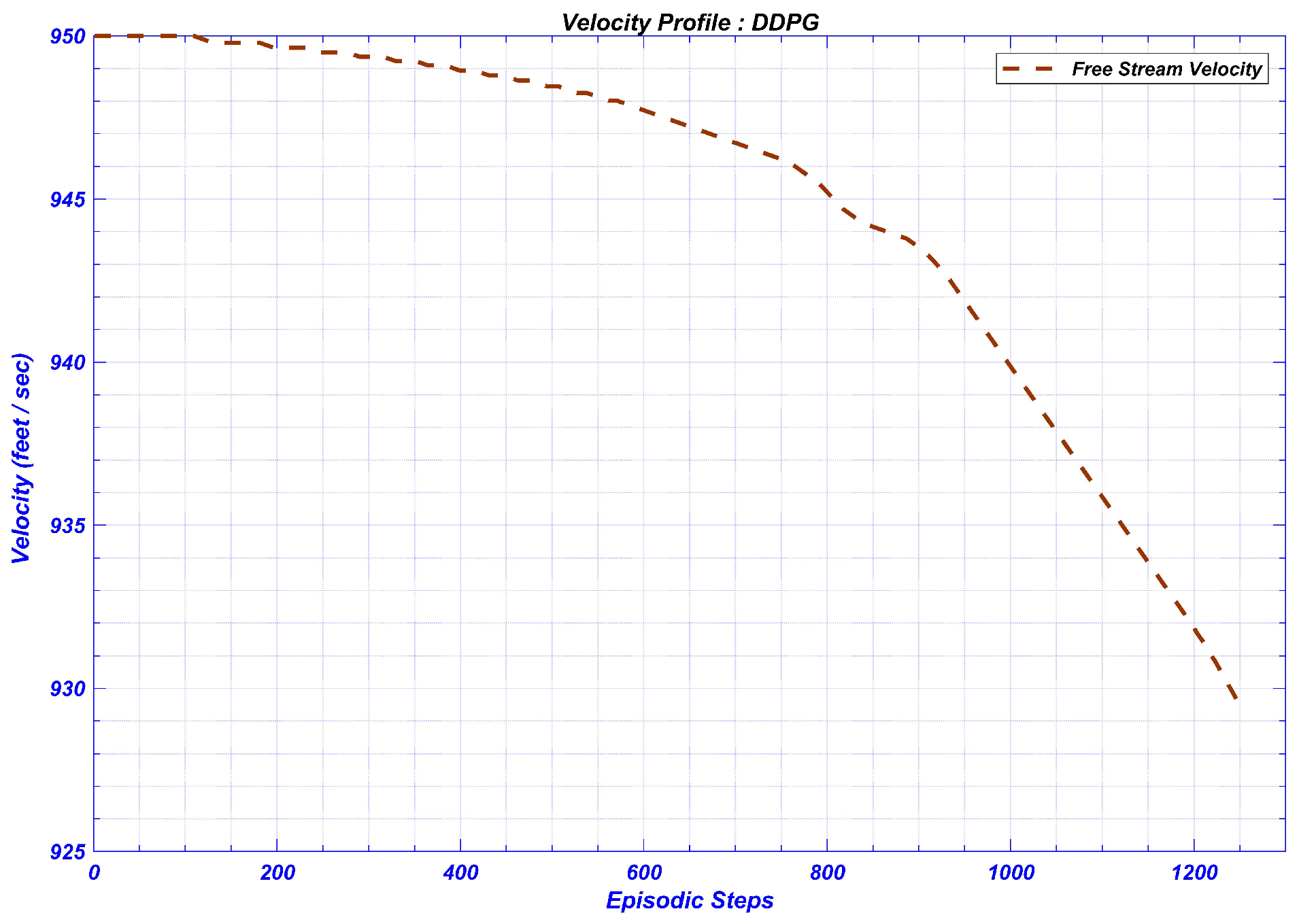
DDPG RL Controller Results
4. Comparison of Proposed Algorithm with Contemporary PID
DDPG vs. LQR Control Architecture
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Din, A.F.U.; Akhtar, S.; Maqsood, A.; Habib, M.; Mir, I. Modified model free dynamic programming: An augmented approach for unmanned aerial vehicle. Appl. Intell. 2022, 1–21. [Google Scholar] [CrossRef]
- Kim, D.; Park, S.; Kim, J.; Bang, J.Y.; Jung, S. Stabilized adaptive sampling control for reliable real-time learning-based surveillance systems. J. Commun. Netw. 2021, 23, 129–137. [Google Scholar] [CrossRef]
- Fatima, S.K.; Abbas, M.; Mir, I.; Gul, F.; Mir, S.; Saeed, N.; Alotaibi, A.A.; Althobaiti, T.; Abualigah, L. Data Driven Model Estimation for Aerial Vehicles: A Perspective Analysis. Processes 2022, 10, 1236. [Google Scholar] [CrossRef]
- Din, A.F.U.; Mir, I.; Gul, F.; Nasar, A.; Rustom, M.; Abualigah, L. Reinforced Learning-Based Robust Control Design for Unmanned Aerial Vehicle. Arab. J. Sci. Eng. 2022, 1–16. [Google Scholar] [CrossRef]
- Mir, I.; Eisa, S.; Taha, H.E.; Gul, F. On the Stability of Dynamic Soaring: Floquet-based Investigation. In Proceedings of the AIAA SCITECH 2022 Forum, San Diego, CA, USA, 3–7 January 2022; p. 0882. [Google Scholar]
- Mir, I.; Eisa, S.; Maqsood, A.; Gul, F. Contraction Analysis of Dynamic Soaring. In Proceedings of the AIAA SCITECH 2022 Forum, San Diego, CA, USA, 3–7 January 2022; p. 0881. [Google Scholar]
- Mir, I.; Taha, H.; Eisa, S.A.; Maqsood, A. A controllability perspective of dynamic soaring. Nonlinear Dyn. 2018, 94, 2347–2362. [Google Scholar] [CrossRef]
- Mir, I.; Maqsood, A.; Akhtar, S. Dynamic modeling & stability analysis of a generic UAV in glide phase. Proc. Matec Web Conf. 2017, 114, 01007. [Google Scholar]
- Mir, I.; Eisa, S.A.; Taha, H.; Maqsood, A.; Akhtar, S.; Islam, T.U. A stability perspective of bioinspired unmanned aerial vehicles performing optimal dynamic soaring. Bioinspiration Biomim. 2021, 16, 066010. [Google Scholar] [CrossRef]
- Huang, H.; Savkin, A.V. An algorithm of reactive collision free 3-D deployment of networked unmanned aerial vehicles for surveillance and monitoring. IEEE Trans. Ind. Inform. 2019, 16, 132–140. [Google Scholar] [CrossRef]
- Nawaratne, R.; Alahakoon, D.; De Silva, D.; Yu, X. Spatiotemporal anomaly detection using deep learning for real-time video surveillance. IEEE Trans. Ind. Inform. 2019, 16, 393–402. [Google Scholar] [CrossRef]
- Gul, F.; Mir, I.; Abualigah, L.; Mir, S.; Altalhi, M. Cooperative multi-function approach: A new strategy for autonomous ground robotics. Future Gener. Comput. Syst. 2022, 134, 361–373. [Google Scholar] [CrossRef]
- Gul, F.; Mir, S.; Mir, I. Coordinated Multi-Robot Exploration: Hybrid Stochastic Optimization Approach. In Proceedings of the AIAA SCITECH 2022 Forum, San Diego, CA, USA, 3–7 January 2022; p. 1414. [Google Scholar]
- Gul, F.; Mir, S.; Mir, I. Multi Robot Space Exploration: A Modified Frequency Whale Optimization Approach. In Proceedings of the AIAA SCITECH 2022 Forum, San Diego, CA, USA, 3–7 January 2022; p. 1416. [Google Scholar]
- Gul, F.; Mir, S.; Mir, I. Reinforced Whale Optimizer for Multi-Robot Application. In Proceedings of the AIAA SCITECH 2022 Forum, San Diego, CA, USA, 3–7 January 2022; p. 1416. [Google Scholar]
- Gul, F.; Mir, I.; Abualigah, L.; Sumari, P. Multi-Robot Space Exploration: An Augmented Arithmetic Approach. IEEE Access 2021, 9, 107738–107750. [Google Scholar] [CrossRef]
- Gul, F.; Rahiman, W.; Alhady, S.N.; Ali, A.; Mir, I.; Jalil, A. Meta-heuristic approach for solving multi-objective path planning for autonomous guided robot using PSO–GWO optimization algorithm with evolutionary programming. J. Ambient. Intell. Humaniz. Comput. 2021, 12, 7873–7890. [Google Scholar] [CrossRef]
- Gul, F.; Mir, I.; Rahiman, W.; Islam, T.U. Novel Implementation of Multi-Robot Space Exploration Utilizing Coordinated Multi-Robot Exploration and Frequency Modified Whale Optimization Algorithm. IEEE Access 2021, 9, 22774–22787. [Google Scholar] [CrossRef]
- Gul, F.; Mir, I.; Abualigah, L.; Sumari, P.; Forestiero, A. A Consolidated Review of Path Planning and Optimization Techniques: Technical Perspectives and Future Directions. Electronics 2021, 10, 2250. [Google Scholar] [CrossRef]
- Martinez, C.; Sampedro, C.; Chauhan, A.; Campoy, P. Towards autonomous detection and tracking of electric towers for aerial power line inspection. In Proceedings of the 2014 International Conference on Unmanned Aircraft Systems (ICUAS), Orlando, FL, USA, 27–30 May 2014; pp. 284–295. [Google Scholar]
- Olivares-Mendez, M.A.; Fu, C.; Ludivig, P.; Bissyandé, T.F.; Kannan, S.; Zurad, M.; Annaiyan, A.; Voos, H.; Campoy, P. Towards an autonomous vision-based unmanned aerial system against wildlife poachers. Sensors 2015, 15, 31362–31391. [Google Scholar] [CrossRef]
- Carrio, A.; Pestana, J.; Sanchez-Lopez, J.L.; Suarez-Fernandez, R.; Campoy, P.; Tendero, R.; García-De-Viedma, M.; González-Rodrigo, B.; Bonatti, J.; Rejas-Ayuga, J.G.; et al. UBRISTES: UAV-based building rehabilitation with visible and thermal infrared remote sensing. In Proceedings of the Robot 2015: Second Iberian Robotics Conference, Lisbon, Portugal, 19–21 November 2015; Springer: Berlin/Heidelberg, Germany, 2016; pp. 245–256. [Google Scholar]
- Li, L.; Fan, Y.; Huang, X.; Tian, L. Real-time UAV weed scout for selective weed control by adaptive robust control and machine learning algorithm. In Proceedings of the 2016 ASABE Annual International Meeting. American Society of Agricultural and Biological Engineers, Orlando, FL, USA, 17–20 July 2016; p. 1. [Google Scholar]
- Arulkumaran, K.; Deisenroth, M.P.; Brundage, M.; Bharath, A.A. Deep reinforcement learning: A brief survey. IEEE Signal Process. Mag. 2017, 34, 26–38. [Google Scholar] [CrossRef] [Green Version]
- Dao, P.N.; Liu, Y.C. Adaptive reinforcement learning strategy with sliding mode control for unknown and disturbed wheeled inverted pendulum. Int. J. Control. Autom. Syst. 2021, 19, 1139–1150. [Google Scholar] [CrossRef]
- Dao, P.N.; Liu, Y.C. Adaptive reinforcement learning in control design for cooperating manipulator systems. Asian J. Control 2022, 24, 1088–1103. [Google Scholar] [CrossRef]
- Vu, V.T.; Pham, T.L.; Dao, P.N. Disturbance observer-based adaptive reinforcement learning for perturbed uncertain surface vessels. ISA Trans. 2022; in press. [Google Scholar]
- Vu, V.T.; Tran, Q.H.; Pham, T.L.; Dao, P.N. Online Actor-critic Reinforcement Learning Control for Uncertain Surface Vessel Systems with External Disturbances. Int. J. Control. Autom. Syst. 2022, 20, 1029–1040. [Google Scholar] [CrossRef]
- Hussain, A.; Hussain, I.; Mir, I.; Afzal, W.; Anjum, U.; Channa, B.A. Target Parameter Estimation in Reduced Dimension STAP for Airborne Phased Array Radar. In Proceedings of the 2020 IEEE 23rd International Multitopic Conference (INMIC), Bahawalpur, Pakistan, 5–7 November 2020; pp. 1–6. [Google Scholar]
- Hussain, A.; Anjum, U.; Channa, B.A.; Afzal, W.; Hussain, I.; Mir, I. Displaced Phase Center Antenna Processing For Airborne Phased Array Radar. In Proceedings of the 2021 International Bhurban Conference on Applied Sciences and Technologies (IBCAST), Islamabad, Pakistan, 12–16 January 2021; pp. 988–992. [Google Scholar]
- Szczepanski, R.; Tarczewski, T.; Grzesiak, L.M. Adaptive state feedback speed controller for PMSM based on Artificial Bee Colony algorithm. Appl. Soft Comput. 2019, 83, 105644. [Google Scholar] [CrossRef]
- Szczepanski, R.; Bereit, A.; Tarczewski, T. Efficient Local Path Planning Algorithm Using Artificial Potential Field Supported by Augmented Reality. Energies 2021, 14, 6642. [Google Scholar] [CrossRef]
- Szczepanski, R.; Tarczewski, T. Global path planning for mobile robot based on Artificial Bee Colony and Dijkstra’s algorithms. In Proceedings of the 2021 IEEE 19th International Power Electronics and Motion Control Conference (PEMC), Gliwice, Poland, 25–29 April 2021; pp. 724–730. [Google Scholar]
- Kim, D.; Oh, G.; Seo, Y.; Kim, Y. Reinforcement learning-based optimal flat spin recovery for unmanned aerial vehicle. J. Guid. Control. Dyn. 2017, 40, 1076–1084. [Google Scholar] [CrossRef]
- Pham, H.X.; La, H.M.; Feil-Seifer, D.; Nguyen, L.V. Autonomous uav navigation using reinforcement learning. arXiv 2018, arXiv:1801.05086. [Google Scholar]
- Mir, I.; Maqsood, A.; Eisa, S.A.; Taha, H.; Akhtar, S. Optimal morphing–augmented dynamic soaring maneuvers for unmanned air vehicle capable of span and sweep morphologies. Aerosp. Sci. Technol. 2018, 79, 17–36. [Google Scholar] [CrossRef]
- Mir, I.; Maqsood, A.; Akhtar, S. Optimization of dynamic soaring maneuvers to enhance endurance of a versatile UAV. In Proceedings of the IOP Conference Series: Materials Science and Engineering, Bangkok, Thailand, 21–23 April 2017; Volume 211, p. 012010. [Google Scholar]
- Mir, I.; Eisa, S.A.; Taha, H.; Maqsood, A.; Akhtar, S.; Islam, T.U. A stability perspective of bio-inspired UAVs performing dynamic soaring optimally. Bioinspiration Biomim. 2021, 16, 066010. [Google Scholar] [CrossRef]
- Mir, I.; Akhtar, S.; Eisa, S.; Maqsood, A. Guidance and control of standoff air-to-surface carrier vehicle. Aeronaut. J. 2019, 123, 283–309. [Google Scholar] [CrossRef]
- Mir, I.; Maqsood, A.; Taha, H.E.; Eisa, S.A. Soaring Energetics for a Nature Inspired Unmanned Aerial Vehicle. In Proceedings of the AIAA Scitech 2019 Forum, San Diego, CA, USA, 7–11 January 2019; p. 1622. [Google Scholar]
- Mir, I.; Eisa, S.A.; Maqsood, A. Review of dynamic soaring: Technical aspects, nonlinear modeling perspectives and future directions. Nonlinear Dyn. 2018, 94, 3117–3144. [Google Scholar] [CrossRef]
- Mir, I.; Maqsood, A.; Akhtar, S. Biologically inspired dynamic soaring maneuvers for an unmanned air vehicle capable of sweep morphing. Int. J. Aeronaut. Space Sci. 2018, 19, 1006–1016. [Google Scholar] [CrossRef]
- Hafner, R.; Riedmiller, M. Reinforcement learning in feedback control. Mach. Learn. 2011, 84, 137–169. [Google Scholar] [CrossRef] [Green Version]
- Laroche, R.; Feraud, R. Reinforcement learning algorithm selection. arXiv 2017, arXiv:1701.08810. [Google Scholar]
- Henderson, P.; Islam, R.; Bachman, P.; Pineau, J.; Precup, D.; Meger, D. Deep reinforcement learning that matters. arXiv 2018, arXiv:1709.06560. [Google Scholar] [CrossRef]
- Schulman, J.; Levine, S.; Abbeel, P.; Jordan, M.; Moritz, P. Trust region policy optimization. In Proceedings of the International Conference on Machine Learning. PMLR, Lille, France, 7–9 July 2015; pp. 1889–1897. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2015, arXiv:1509.02971. [Google Scholar]
- Wu, Y.; Mansimov, E.; Grosse, R.B.; Liao, S.; Ba, J. Scalable trust-region method for deep reinforcement learning using kronecker-factored approximation. Adv. Neural Inf. Process. Syst. 2017, 30, 1–14. [Google Scholar]
- Heess, N.; Hunt, J.J.; Lillicrap, T.P.; Silver, D. Memory-based control with recurrent neural networks. arXiv 2015, arXiv:1512.04455. [Google Scholar]
- Luo, X.; Zhang, Y.; He, Z.; Yang, G.; Ji, Z. A two-step environment-learning-based method for optimal UAV deployment. IEEE Access 2019, 7, 149328–149340. [Google Scholar] [CrossRef]
- Stooke, A.; Abbeel, P. rlpyt: A research code base for deep reinforcement learning in pytorch. arXiv 2019, arXiv:1909.01500. [Google Scholar]
- Werbos, P.J.; Miller, W.; Sutton, R. A menu of designs for reinforcement learning over time. Neural Netw. Control 1990, 3, 67–95. [Google Scholar]
- Silver, D.; Lever, G.; Heess, N.; Degris, T.; Wierstra, D.; Riedmiller, M. Deterministic Policy Gradient Algorithms. 2014. Available online: https://ieeexplore.ieee.org/document/6300641 (accessed on 17 June 2022).
- Chen, J.; Xing, H.; Xiao, Z.; Xu, L.; Tao, T. A DRL agent for jointly optimizing computation offloading and resource allocation in MEC. IEEE Internet Things J. 2021, 8, 17508–17524. [Google Scholar] [CrossRef]
- Pan, J.; Wang, X.; Cheng, Y.; Yu, Q. Multisource transfer double DQN based on actor learning. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 2227–2238. [Google Scholar] [CrossRef]
- Tflearn. 2016. Available online: https://ieeexplore.ieee.org/document/8310951 (accessed on 17 June 2022).
- Tang, Y. TF. Learn: TensorFlow’s high-level module for distributed machine learning. arXiv 2016, arXiv:1612.04251. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Kingma, D.P.; Ba, J. A Method for Stochastic Optimization. arXiv 2015, arXiv:1412.6980. [Google Scholar]
- Zhao, J.; Gao, Z.M.; Chen, H.F. The Simplified Aquila Optimization Algorithm. IEEE Access 2022, 10, 22487–22515. [Google Scholar] [CrossRef]
- Zhang, Y.J.; Yan, Y.X.; Zhao, J.; Gao, Z.M. AOAAO: The hybrid algorithm of arithmetic optimization algorithm with aquila optimizer. IEEE Access 2022, 10, 10907–10933. [Google Scholar] [CrossRef]
- Ruder, S. An overview of gradient descent optimization algorithms. arXiv 2016, arXiv:1609.04747. [Google Scholar]
- CS231n. Convolutional Neural Networks for Visual Recognition. 2017. Available online: https://cs231n.github.io/ (accessed on 17 June 2022).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Nomenclature | Value | No. | Nomenclature | Value |
|---|---|---|---|---|---|
| 1 | Weight | 600 Kg | 6 | Wing Area/Mean Aerodynamic chord/Wing Span | 9.312 0.8783 /4.101 |
| 2 | Angle of incidence of wing | 6 | 7 | Horizontal tail incidence Angle | 0 |
| 3 | cg location | 3.78 | 8 | Vertical location of center of gravity from reference plane (Vcg) | 2.4 |
| 4 | Airfoil of Tail (Vertical) | NACA-6-65A007 | 9 | Wing airfoil | NACA-6-65-210 |
| 5 | Airfoil of Tail (Horizontal) | NACA-6-65A007 | 10 | Moment of Inertia Matrix |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
ud Din, A.F.; Mir, I.; Gul, F.; Mir, S.; Saeed, N.; Althobaiti, T.; Abbas, S.M.; Abualigah, L. Deep Reinforcement Learning for Integrated Non-Linear Control of Autonomous UAVs. Processes 2022, 10, 1307. https://doi.org/10.3390/pr10071307
ud Din AF, Mir I, Gul F, Mir S, Saeed N, Althobaiti T, Abbas SM, Abualigah L. Deep Reinforcement Learning for Integrated Non-Linear Control of Autonomous UAVs. Processes. 2022; 10(7):1307. https://doi.org/10.3390/pr10071307
Chicago/Turabian Styleud Din, Adnan Fayyaz, Imran Mir, Faiza Gul, Suleman Mir, Nasir Saeed, Turke Althobaiti, Syed Manzar Abbas, and Laith Abualigah. 2022. "Deep Reinforcement Learning for Integrated Non-Linear Control of Autonomous UAVs" Processes 10, no. 7: 1307. https://doi.org/10.3390/pr10071307
APA Styleud Din, A. F., Mir, I., Gul, F., Mir, S., Saeed, N., Althobaiti, T., Abbas, S. M., & Abualigah, L. (2022). Deep Reinforcement Learning for Integrated Non-Linear Control of Autonomous UAVs. Processes, 10(7), 1307. https://doi.org/10.3390/pr10071307