
Sensor Fault Detection Combined Data Quality Optimization of Energy System for Energy Saving and Emission Reduction






Abstract
:1. Introduction
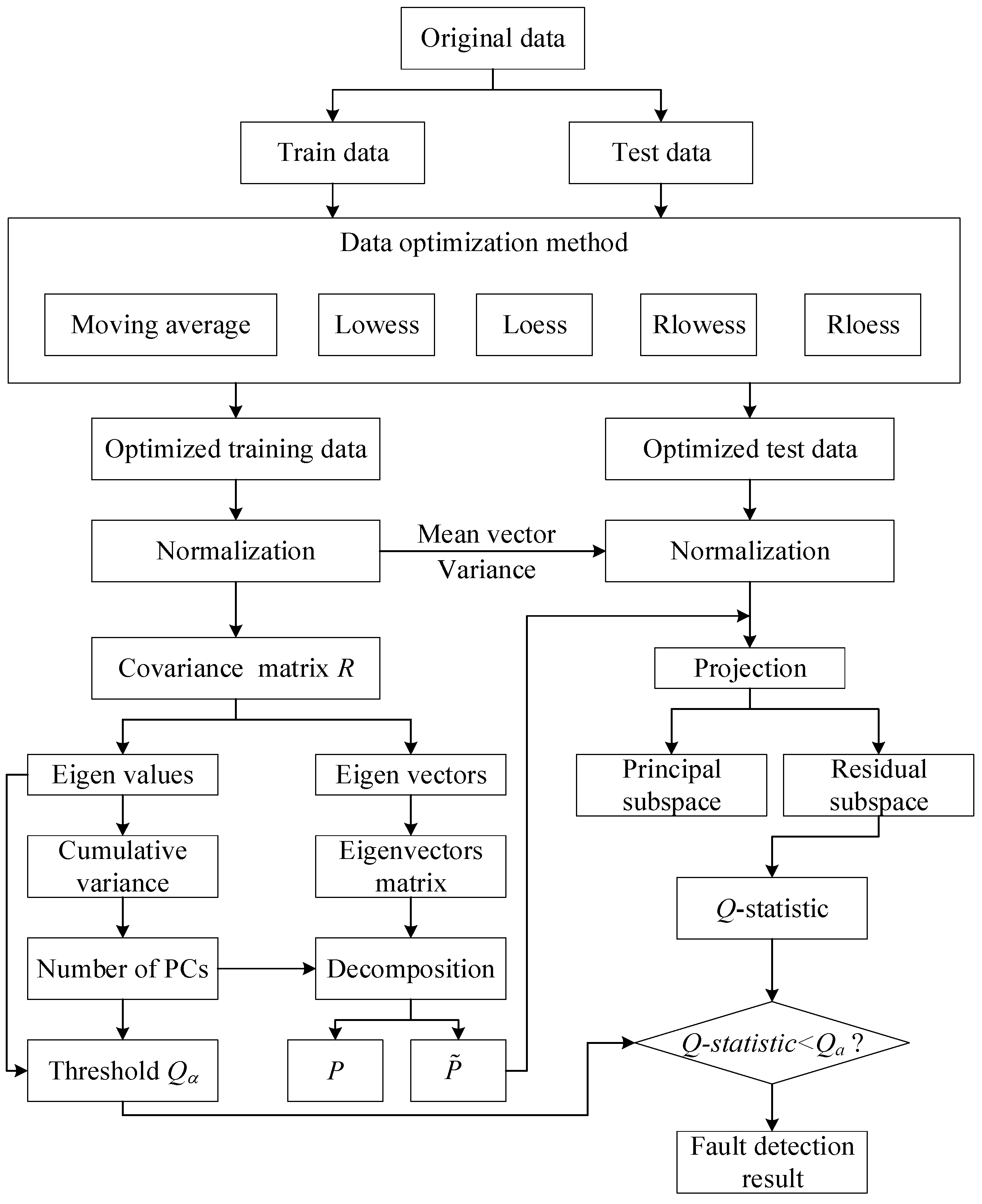
2. Methodology
2.1. Data Optimization Methods
2.1.1. The Moving Average Data Smoothing Method
- (1)
- The window size must be odd.
- (2)
- Data points that need to be smoothed must be centered within the window.
- (3)
- When data points at both ends of the data can’t have the given window size data, the window size is automatically adjusted.
- (4)
- The positions of the endpoints on both sides of the data are not smoothed since the window with data on both sides can’t be constructed.
2.1.2. Local Regression Smoothing Approach
- (a)
- The data points to be smoothed have the largest weight and have the greatest influence on the function fit.
- (b)
- Data points outside the window width have a weight of zero and have no influence on the fit.
2.1.3. Rlowess and Rloess Methods
- (1)
- The residuals are first calculated according to the regression process described in the previous section.
- (2)
- The robust weight of each data point within the window width is calculated. The weight is calculated by the bisquare function, as shown in Equation (4).
- (1)
- The data is smoothed again using robust weights. Local regression weights and robust weights are used to calculate the final smoothed value.
- (2)
- The previous two steps are iterated a total of five times.
2.2. The PCA Method for Sensor Fault Detection
3. Fault Detection Results of Optimized PCA Models
3.1. Data Set Description
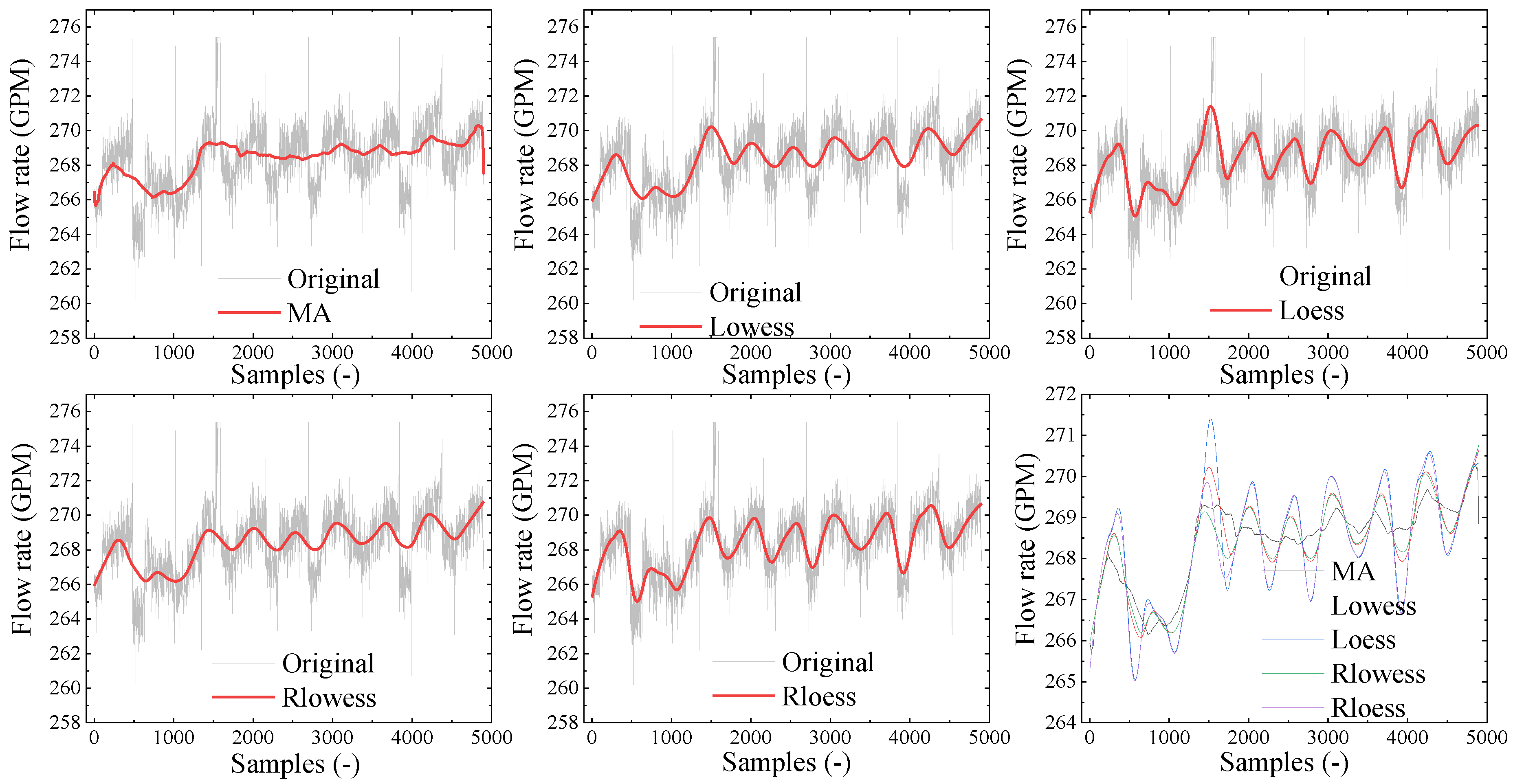
3.2. The Data Optimization Performance
3.3. Fault Detection Results
4. Discussions
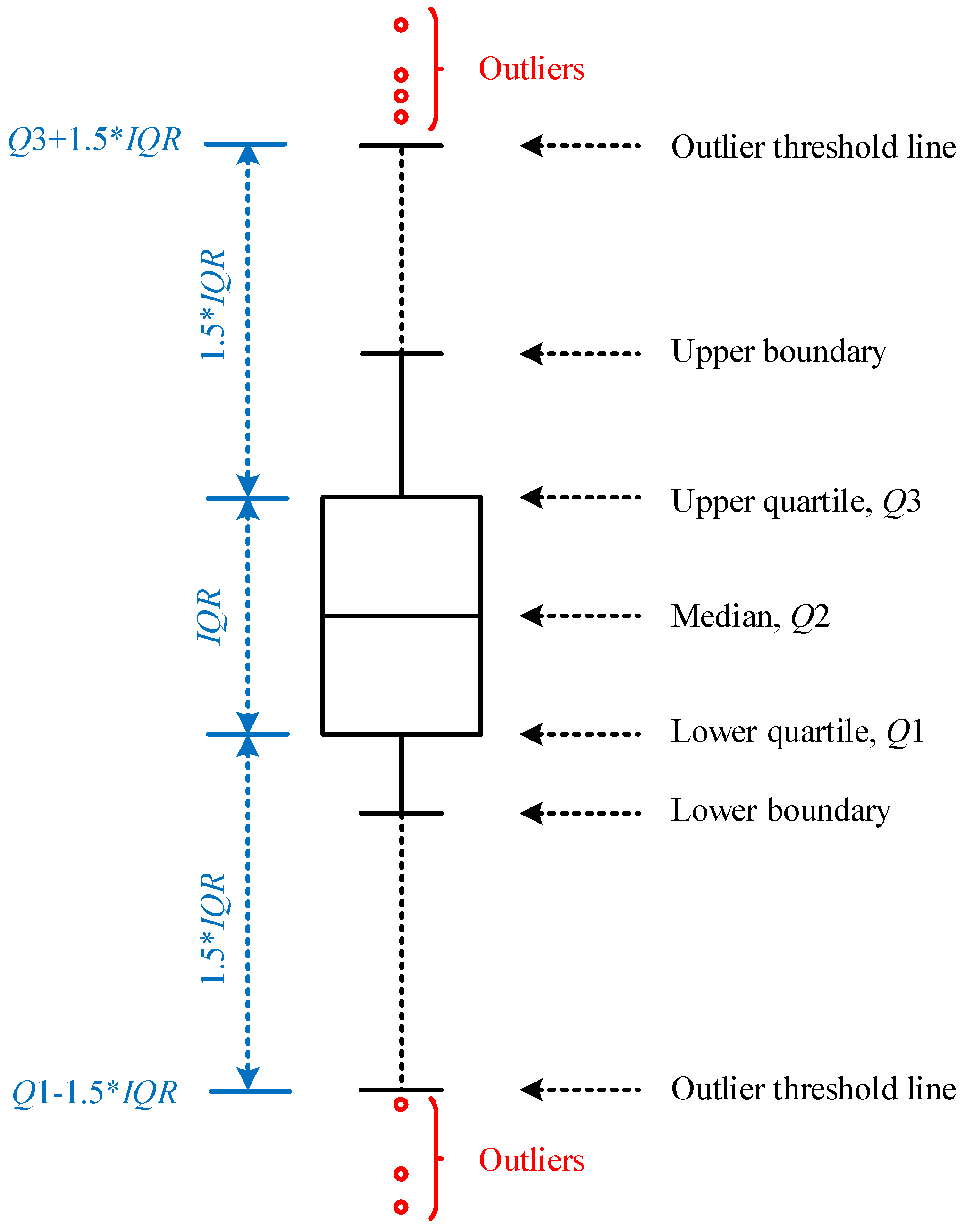
4.1. The Data Outlier Detection and Analysis
4.2. The Parameter Selection of Data Smoothness
5. Conclusions
- (1)
- The five smoothing methods have the effect of optimizing the data. The MA and Lowess methods are better than the other three methods. From the perspective of variability, the MA method has the best optimization performance when the smoothness degree is level 2. The optimized data fluctuation range is controlled within the range of ±1.
- (2)
- From the perspective of fault detection results, the Q-statistic threshold of the optimized PCA model is lower than that of the original model. Fault detection results have improved. Among them, when the evaporation temperature sensor fault is 5 °C deviation, the fault detection accuracy rate of the model optimized based on the MA method is increased from 32.51% to 83.96%, and the performance is significantly improved.
- (3)
- In addition, when the smoothing parameter is set too large, the data will deviate from the original data trend, and the effective information of the original data will be lost. Therefore, the smoothness of the data should not be too large.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Nomenclature
| Cov | covariance matrix | |
| d | distance | |
| HVAC | heating, ventilation and air conditioning | |
| LOF | local outlier factor | |
| Lowess | local regression smoothing with the linear polynomial | |
| Loess | local regression smoothing with the quadratic polynomial | |
| MA | moving average | |
| MAD | median absolute residual | |
| N | the number of data points on both sides of the smoothed data | |
| PCA | principal component analysis | |
| P | load matrix | |
| threshold of the Q-statistic | ||
| r | residual | |
| Rlowess | robust local regression smoothing with the linear polynomial | |
| Rloess | robust local regression smoothing with the quadratic polynomial | |
| x | the predicted value corresponding to the smoothed point | |
| smoothed data | ||
| Greeks | ||
| the coefficient | ||
| the weight | ||
References
- Hong, T.; Koo, C.; Kim, J.; Lee, M.; Jeong, K. A review on sustainable construction management strategies for monitoring, diagnosing, and retrofitting the building’s dynamic energy performance: Focused on the operation and maintenance phase. Appl. Energy 2015, 155, 671–707. [Google Scholar] [CrossRef]
- Yang, L.; Yan, H.; Lam, J.C. Thermal comfort and building energy consumption implications–A review. Appl. Energy 2014, 115, 164–173. [Google Scholar] [CrossRef]
- Yu, X.; Yan, D.; Sun, K.; Hong, T.; Zhu, D. Comparative study of the cooling energy performance of variable refrigerant flow systems and variable air volume systems in office buildings. Appl. Energy 2016, 183, 725–736. [Google Scholar] [CrossRef] [Green Version]
- Guo, Y.; Chen, H. Fault diagnosis of VRF air-conditioning system based on improved Gaussian mixture model with PCA approach. Int. J. Refrig. 2020, 118, 1–11. [Google Scholar] [CrossRef]
- Xu, Y.; Shen, C.; Lu, B.; Luo, C.; Wu, F.; Li, X.; Zhang, L. Study on the effect of NaBr modification on CaO-based sorbent for CO2 capture and SO2 capture. Carbon Cap. Sci. Technol. 2021, 1, 100015. [Google Scholar] [CrossRef]
- Xu, Y.; Zhang, T.; Lu, B.; Luo, C.; Wu, F.; Li, X.; Zhang, L. Glycine tailored effective CaO-based heat carriers for thermochemical energy storage in concentrated solar power plants. Energ. Conver. Manag. 2021, 250, 114886. [Google Scholar] [CrossRef]
- Xu, Y.; Lu, B.; Luo, C.; Wu, F.; Li, X.; Zhang, L. Na2CO3 promoted CaO-based heat carrier for thermochemical energy storage in concentrated solar power plants. Chem. Eng. J. 2022, 435, 134852. [Google Scholar] [CrossRef]
- Lee, S.; Yik, F. A study on the energy penalty of various air-side system faults in buildings. Energy Build. 2010, 42, 2–10. [Google Scholar] [CrossRef]
- Yoon, S.H.; Payne, W.V.; Domanski, P. Residential heat pump heating performance with single faults imposed. Appl. Therm. Eng. 2011, 31, 765–771. [Google Scholar] [CrossRef] [Green Version]
- Hu, Y.; Li, G.; Chen, H.; Li, H.; Liu, J. Sensitivity analysis for PCA-based chiller sensor fault detection. Int. J. Refrig. 2016, 63, 133–143. [Google Scholar] [CrossRef]
- Du, Z.; Chen, L.; Jin, X. Data-driven based reliability evaluation for measurements of sensors in a vapor compression system. Energy 2017, 122, 237–248. [Google Scholar] [CrossRef]
- Han, H.; Gu, B.; Wang, T.; Li, Z. Important sensors for chiller fault detection and diagnosis (FDD) from the perspective of feature selection and machine learning. Int. J. Refrig. 2011, 34, 586–599. [Google Scholar] [CrossRef]
- Elnour, M.; Meskin, N.; Al-Naemi, M. Sensor data validation and fault diagnosis using Auto-Associative Neural Network for HVAC systems. J. Build. Eng. 2019, 27, 100935. [Google Scholar] [CrossRef]
- Guo, Y.; Wang, J.; Chen, H.; Li, G.; Huang, R.; Yuan, Y.; Ahmad, T.; Sun, S. An expert rule-based fault diagnosis strategy for variable refrigerant flow air conditioning systems. Appl. Therm. Eng. 2018, 149, 1223–1235. [Google Scholar] [CrossRef]
- Wang, S.; Xing, J.; Jiang, Z.; Li, J. A decentralized sensor fault detection and self-repair method for HVAC systems. Build. Serv. Eng. Res. Technol. 2018, 39, 667–678. [Google Scholar] [CrossRef]
- Shahnazari, H.; Mhaskar, P.; House, J.M.; Salsbury, T.I. Modeling and fault diagnosis design for HVAC systems using recurrent neural networks. Comput. Chem. Eng. 2019, 126, 189–203. [Google Scholar] [CrossRef]
- Wang, S.; Xing, J.; Jiang, Z.; Dai, Y. A novel sensors fault detection and self-correction method for HVAC systems using decentralized swarm intelligence algorithm. Int. J. Refrig. 2019, 106, 54–65. [Google Scholar] [CrossRef]
- Yan, R.; Ma, Z.; Kokogiannakis, G.; Zhao, Y. A sensor fault detection strategy for air handling units using cluster analysis. Autom. Constr. 2016, 70, 77–88. [Google Scholar] [CrossRef] [Green Version]
- Li, G.; Hu, Y. Improved sensor fault detection, diagnosis and estimation for screw chillers using density-based clustering and principal component analysis. Energy Build. 2018, 173, 502–515. [Google Scholar] [CrossRef]
- Montazeri, A.; Kargar, S.M. Fault detection and diagnosis in air handling using data-driven methods. J. Build. Eng. 2020, 31, 101388. [Google Scholar] [CrossRef]
- Li, G.; Hu, Y.; Chen, H.; Li, H.; Hu, M.; Guo, Y.; Shi, S.; Hu, W. A sensor fault detection and diagnosis strategy for screw chiller system using support vector data description-based D-statistic and DV-contribution plots. Energy Build. 2016, 133, 230–245. [Google Scholar] [CrossRef]
- Xu, X.; Xiao, F.; Wang, S. Enhanced chiller sensor fault detection, diagnosis and estimation using wavelet analysis and principal component analysis methods. Appl. Therm. Eng. 2008, 28, 226–237. [Google Scholar] [CrossRef]
- Du, Z.; Fan, B.; Chi, J.; Jin, X. Sensor fault detection and its efficiency analysis in air handling unit using the combined neural networks. Energy Build. 2014, 72, 157–166. [Google Scholar] [CrossRef]
- Zhao, Y.; Wen, J.; Xiao, F.; Yang, X.; Wang, S. Diagnostic Bayesian networks for diagnosing air handling units faults—Part I: Faults in dampers, fans, filters and sensors. Appl. Therm. Eng. 2017, 111, 1272–1286. [Google Scholar] [CrossRef]
- Guo, Y.; Li, G.; Chen, H.; Hu, Y.; Li, H.; Xing, L.; Hu, W. An enhanced PCA method with Savitzky-Golay method for VRF system sensor fault detection and diagnosis. Energy Build. 2017, 142, 167–178. [Google Scholar] [CrossRef]
- Kocyigit, N. Fault and sensor error diagnostic strategies for a vapor compression refrigeration system by using fuzzy inference systems and artificial neural network. Int. J. Refrig. 2015, 50, 69–79. [Google Scholar] [CrossRef]
- Li, S.; Wen, J. A model-based fault detection and diagnostic methodology based on PCA method and wavelet transform. Energy Build. 2014, 68, 63–71. [Google Scholar] [CrossRef]
- Zhu, Y.; Jin, X.; Du, Z. Fault diagnosis for sensors in air handling unit based on neural network pre-processed by wavelet and fractal. Energy Build. 2012, 44, 7–16. [Google Scholar] [CrossRef]
- Li, G.; Hu, Y. An enhanced PCA-based chiller sensor fault detection method using ensemble empirical mode decomposition based denoising. Energy Build. 2018, 183, 311–324. [Google Scholar] [CrossRef]
- Yalcin, O.F.; Dicleli, M. Effect of the high frequency components of near-fault ground motions on the response of linear and nonlinear SDOF systems: A moving average filtering approach. Soil Dyn. Earthq. Eng. 2020, 129. [Google Scholar] [CrossRef]
- Mariani, M.; Basu, K. Local regression type methods applied to the study of geophysics and high frequency financial data. Phys. A Stat. Mech. Its Appl. 2014, 410, 609–622. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Evaporator Outlet Water Temperature (F) | Condenser Inlet Water Temperature (F) | Cooling Capacity (%) |
|---|---|---|---|
| Setting values | 50 | 85 | 90–100 |
| 45 | 75 | 70–80 | |
| 40 | 70 | 50–60 | |
| 65 | 25–40 | ||
| 62 | 25–35 | ||
| 45–50 | |||
| 70–90 |
| Smoothing Level | Different Approaches | ||||
|---|---|---|---|---|---|
| MA | Lowess | Loess | Rlowess | Rloess | |
| Level 1 | 5 | 5 | 5 | 5 | 5 |
| Level 2 | 9 | 10 | 10 | 10 | 10 |
| Level 3 | 15 | 15 | 15 | 15 | 15 |
| Level 4 | 19 | 20 | 20 | 20 | 20 |
| Fault Sensor | Fault Level | Fault Detection Model | |||||
|---|---|---|---|---|---|---|---|
| Original | MA | Lowess | Loess | Rlowess | Rloess | ||
| Evaporation temperature sensor | −7 °C | 0.9996 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 0.9998 |
| −6 °C | 0.8271 | 1.0000 | 1.0000 | 0.9898 | 1.0000 | 0.9906 | |
| −5 °C | 0.4298 | 0.9549 | 0.9078 | 0.6561 | 0.9259 | 0.6563 | |
| −4 °C | 0.2416 | 0.6600 | 0.5759 | 0.3953 | 0.5910 | 0.3867 | |
| 4 °C | 0.1918 | 0.5100 | 0.4355 | 0.2882 | 0.4453 | 0.2920 | |
| 5 °C | 0.3251 | 0.8396 | 0.7418 | 0.5012 | 0.7696 | 0.5027 | |
| 6 °C | 0.6498 | 1.0000 | 0.9998 | 0.9322 | 1.0000 | 0.9333 | |
| 7 °C | 0.9951 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | |
| Cooling water flow rate sensor | −6% | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 |
| −5% | 0.9961 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | |
| −4% | 0.9914 | 0.9941 | 0.9937 | 0.9933 | 0.9935 | 0.9927 | |
| −3% | 0.9865 | 0.9910 | 0.9900 | 0.9892 | 0.9916 | 0.9898 | |
| −2% | 0.8539 | 0.9902 | 0.9884 | 0.9627 | 0.9910 | 0.9614 | |
| −1% | 0.2847 | 0.5947 | 0.5359 | 0.4090 | 0.5596 | 0.4057 | |
| 1% | 0.2078 | 0.5849 | 0.5224 | 0.3622 | 0.5324 | 0.3547 | |
| 2% | 0.7329 | 0.9824 | 0.9694 | 0.9212 | 0.9753 | 0.9186 | |
| 3% | 0.9871 | 0.9978 | 0.9973 | 0.9969 | 0.9978 | 0.9967 | |
| 4% | 0.9990 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 0.9998 | |
| 5% | 0.9996 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | |
| 6% | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | 1.0000 | |
| Evaporation pressure sensor | −17% | 0.8467 | 1.0000 | 0.9980 | 0.9690 | 0.9986 | 0.9690 |
| −16% | 0.7088 | 0.9955 | 0.9865 | 0.9204 | 0.9884 | 0.9163 | |
| −15% | 0.5688 | 0.9814 | 0.9602 | 0.8208 | 0.9690 | 0.8149 | |
| −14% | 0.4484 | 0.9484 | 0.8935 | 0.6863 | 0.9059 | 0.6755 | |
| −13% | 0.3537 | 0.8590 | 0.7853 | 0.5561 | 0.8090 | 0.5400 | |
| −12% | 0.2884 | 0.7543 | 0.6612 | 0.4573 | 0.6867 | 0.4410 | |
| 12% | 0.2241 | 0.5829 | 0.5045 | 0.3398 | 0.5169 | 0.3384 | |
| 13% | 0.2712 | 0.6949 | 0.6114 | 0.4088 | 0.6286 | 0.4143 | |
| 14% | 0.3388 | 0.8171 | 0.7294 | 0.5165 | 0.7559 | 0.5184 | |
| 15% | 0.4249 | 0.9276 | 0.8627 | 0.6494 | 0.8859 | 0.6512 | |
| 16% | 0.5504 | 0.9941 | 0.9606 | 0.7878 | 0.9745 | 0.7894 | |
| 17% | 0.6914 | 1.0000 | 0.9992 | 0.9141 | 1.0000 | 0.9114 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, Y.; Zhang, Z.; Chen, Y.; Li, H.; Liu, C.; Lu, J.; Li, R. Sensor Fault Detection Combined Data Quality Optimization of Energy System for Energy Saving and Emission Reduction. Processes 2022, 10, 347. https://doi.org/10.3390/pr10020347
Guo Y, Zhang Z, Chen Y, Li H, Liu C, Lu J, Li R. Sensor Fault Detection Combined Data Quality Optimization of Energy System for Energy Saving and Emission Reduction. Processes. 2022; 10(2):347. https://doi.org/10.3390/pr10020347
Chicago/Turabian StyleGuo, Yabin, Zheng Zhang, Yu Chen, Hongxin Li, Changhai Liu, Jifu Lu, and Ruixin Li. 2022. "Sensor Fault Detection Combined Data Quality Optimization of Energy System for Energy Saving and Emission Reduction" Processes 10, no. 2: 347. https://doi.org/10.3390/pr10020347
APA StyleGuo, Y., Zhang, Z., Chen, Y., Li, H., Liu, C., Lu, J., & Li, R. (2022). Sensor Fault Detection Combined Data Quality Optimization of Energy System for Energy Saving and Emission Reduction. Processes, 10(2), 347. https://doi.org/10.3390/pr10020347