1. Introduction
The cyber insurance market is rapidly growing due to the effects of digital transformation in today’s world. Cyber risk, as both an emerging threat and an opportunity, is gaining prominence in the insurance landscape. Traditional insurance policies, such as those for motor vehicles or property, are increasingly incorporating cyber risks. This change is driven by the advent of connected and autonomous vehicles and the adoption of smart homes equipped with devices connected to servers and satellites. A major concern with traditional insurance policies is the undervaluation of cyber risk and ‘silent cyber’, which refers to previously unknown exposures that have neither been underwritten nor billed. Nevertheless, identifying and mitigating the exposure to silent cyber is possible (
Aon 2018).
Cybercrime can manifest in many forms, including ransomware attacks, hacking, phishing, malware, spoofing, purchase fraud, theft of customer data, and tax fraud. This diversity, combined with the short history of available data and a rapidly evolving environment, makes handling cyber insurance claims and developing models significantly more complex than in traditional insurance (see, e.g.,
Dacorogna and Kratz 2022,
2023;
Eling 2020;
Tsohou et al. 2023). When evaluating common cyber risk scenarios, it is important to consider potential reputational damage, loss of confidential information, financial losses, regulatory fines, data privacy violations, data availability and integrity issues, contractual violations, and implications for third parties. After a cyber incident, the recovery time is crucial for mitigating business interruption. For example, the average recovery time for ransomware attacks is approximately 19 days (
Tsohou et al. 2023).
Cyber insurance losses are generally categorized as ‘first party’ and ‘third party’. First-party losses are those that the insured party directly incurs. Third-party liability covers claims made by individuals or entities who allege they have suffered losses as a result of the insured’s actions (
Romanosky et al. 2019;
Tsohou et al. 2023). In the current research, we are focusing on first-party losses.
In today’s interconnected world, the perspective on risks is evolving. New emerging risks, technological advancements, and globalization increase the interdependence among risk parameters within the industry. For example, as demonstrated by COVID-19, a virus originating in one location can quickly escalate into a global pandemic, affecting insurance claims across distant regions. As a result, developing dependent risk models plays a crucial role in achieving better pricing in the insurance industry. However, employing dependent risk models is more complex than using independent models in predictive analytics. In actuarial science, copula functions are frequently used to model such dependencies (see, e.g.,
Constantinescu et al. 2011;
Eling and Jung 2018;
Embrechts et al. 2003;
Lefèvre 2021).
Our goal here is to treat cyber claim amounts as quantum data rather than classical data due to the assumed uncertainty in the number of cyber attacks. In this context, the number of claims does not always correspond to the number of events (cyber attacks), so we analyze the cyber data by assuming that a single cyber claim can result from more than one cyber attack. Quantum methods originate from physics and have since been applied in various fields of application. Much of the theory and applications can be found in the books
Baaquie (
2014);
Chang (
2012);
Griffiths (
2002);
Parthasarathy (
2012). We also mention some recent work related to our subject. Thus, the analysis of quantum data in finance and insurance is studied in
Hao et al. (
2019);
Lefèvre et al. (
2018). Copulas and quantum mechanics are explored in
Al-Adilee and Nanasiova (
2009);
Zhu et al. (
2023). Cyber insurance pricing and modeling with copulas are discussed, e.g., in
Awiszus et al. (
2003);
Eling and Jung (
2018);
Herath and Herath (
2011).
In this paper, we start with a study on quantum theory for non-commutative paths. Next, we analyze synthetic data using a data classification method and risk-error functions. Finally, we use a classical copula function to predict future dependent claims.
2. Quantum Claim Data
Historical claim data from traditional insurance policies can be considered as classical data as there is generally no uncertainty about the number and amounts of claims, except in the cases of fraud and misreporting. Cyber claims, however, differ from traditional insurance claims in several ways, as listed in
Table 1. Therefore, they should be handled from a different perspective.
Cyber damage is often detected much later and may result from multiple cyber attacks originating from diverse sources. According to the Cost of a Data Breach Report
IBM (
2023), the average time taken to identify and contain a data breach in 2022 was 277 days. Thus, we assume that the number of claims was 1 when the damage was noticed after 277 days. However, this damage could have originated from multiple sources at various times during those days.
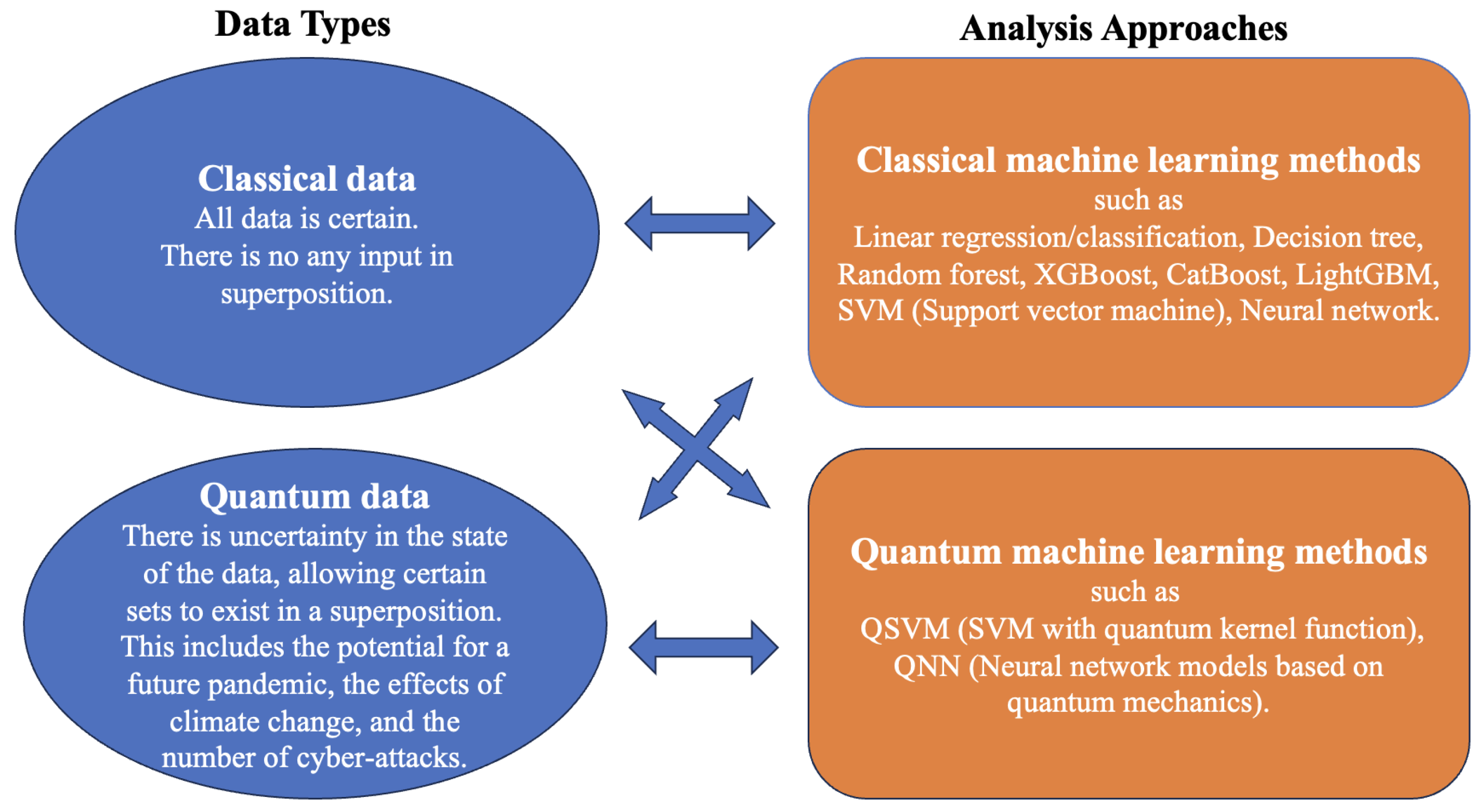
In
Figure 1, the data types and analysis approaches are explained and illustrated (
IBM 2024). While analyzing classical data using deterministic methods is widespread, the use of quantum algorithms—including quantum kernels and quantum neural networks—is becoming increasingly common. As previously noted, cyber insurance claims are considered under the assumption that they originate from several stochastic processes. Therefore, we will treat them as quantum data and examine them by computing likelihood and risk-loss functions within the context of dynamic classification.
3. Quantum for Non-Commutative Event Paths
Event paths and projectors. In a probabilistic setup, an event path
is modeled as a product of indicators as
Such indicators correspond to the projection operators in quantum theory. Recall that an operator
P is called projector if
P is self-adjoint and idempotent (i.e.,
and
). A basic projector is defined via a unit vector
e by
where
and
are, respectively, column and row vectors that describe the quantum state of the system. They correspond to the bra-ket notation, also called Dirac notation. A general projector is then given by
where
denotes an orthonormal basis.
The probability of the system in the ground state
e is measured by the expectation of (
1). This expected value is obtained via a usual trace function
as
where
is a density operator which is a quantum state matrix of the system.
In quantum, a non-commutative version of the event path
is defined as a product of projectors as
Hereafter, the modeling is initiated by considering paths having the following product form
In our context, is an event stating that the genuine customer has the right to exercise a financial claim if any, and the are bounded self-adjoint operators indicating possible obstacles such as computer malfunctions, cyberattacks, criminal activities of a fraudster …
A self-adjoint operator
Q is known to be bounded if it can be expanded as
where
and
are the eigenvectors and eigenvalues of
Q (i.e.,
). The probability of the measurement is extended by linearity of the expectation to
after using (
2).
Note, that the path
is not a projector in general. However, when
and
Q is a projector, then
(provided that
) and it is a projector if and only if
P and
Q are commutative as follows from Halmos’ two projections theorem (see
Bottcher and Spitkovsky 2010).
Quantum Risk Model. Let us first look at a genuine customer model similar to the one introduced in
Lefèvre et al. (
2018). A customer has the right to exercise financial claims. Any claim amount, if requested, is given by a fixed real number
m which corresponds to a small claim for a short period of time. If not requested, the amount is 0.
Recall that an operator
Z is observable if it is self-adjoint (i.e.,
). For this model, the overall observable
H is given by the following sum
This includes the actual amount modeled, with the help of the tensor product, as
in agreement with
Hao et al. (
2019);
Lefèvre et al. (
2018). The exercise right is then described by the state projection
, thus
so that
H becomes
Quantum Risk Model with Obstacles (called (O) model). This time, we hypothesize that the projector may be vulnerable to potential cyberattacks. We model the corresponding event as a path
of the form (
1), using different parameters. Instead of (
5), the
j-th overall capital in this (O) model is then defined by
We now need to determine the overall observable . This will be conducted using the following result.
Lemma 1. A general path σ admits the representation Proof. By definition,
in (
1). Note, that
in (
9) necessarily implies
since
From the decomposition (
4) of
Q, we obtain
where
c is the term
. Thus, a direct computation gives, in obvious notation,
as announced in (
9). □
Returning to the (O) model, we have
for all
j by virtue of (
9). Since
, the formula (
8) of
becomes
From (
10), the observable
is thus given by
For clarity, let us assume that all are equal to the same a. In other words, the obstacle activities are considered here to be homogeneous ((OH) case). From (7) and (11), we have proven the following result.
Proposition 1. More generally, we suppose there is one line of claims for the genuine customer model, yielding the observable , and n separate risk models with homogeneous obstacles, yielding the observables , . This combined claim process is called (CC) model.
Corollary 1. For the (CC) model, the overall observable is modeled by In Section 4, we will consider such a (CC) process with three possible obstacles, i.e., three (O) risk models, which leads to model the data using a sum of three stochastic processes. Before that, we present a few simple examples for illustration. Example 1. Consider two events A and B such that . Let and be the indicators of these events. Suppose that a sequence of events gives the first eight outcomes . In probability, the associated product of indicators isbecause of the commutative property of indicators (see Lefèvre et al. 2017 for classical exchangeable sequences). In quantum, and are replaced by projectors P and Q, respectively. Since projectors do not commute, in general, the associated product of projectors is as follows:So, the order in which they are applied can provide different results. Example 2. For three events, we introduce the qubits . The outcomes then are as follows: A basis for a qubit system is given by the eight statesso that for a ψ system,where the represent amplitudes of the states and satisfy . The probability of can be determined as in (5), viawhere the density matrix ρ is given by , i.e.,Sum of the matrices is an identity matrix . Among them, is a matrix consisting entirely of zeros, except for the third element of the diagonal, which is 1. Using (15), we obtain Example 3. In the continuation of Example 1, consider for P and Q the following Jordan block matriceswhere p and q take non-null values. We observe that and , so they are not projectors. Defining the density ρ bywe then obtain Basically, matrices with eigenvalues 1 cannot be treated as events, as this can lead to nonsensical results. How to deal with non-self-adjoint matrices is an important question; several methods are proposed in quantum modeling.
4. Quantum Approach to Cyber Insurance Claims
The overall compound claim is viewed here as the path resulting from a series of cyber attacks. Specifically, let denote the total cyber insurance claims occurred during successsive small time intervals , over a horizon of length . Each claim is assumed to come from a combination of several stochastic processes, and the corresponding data are treated as quantum data. Let m be the mean of and its frequency rate, so that measures the expected loss amount.
Our approach consists of two main steps: (i) learning patterns from existing data by dividing it into several stochastic processes, and (ii) using copula functions to generate data for estimating future claims. This section addresses point (i), while point (ii) will be discussed in the next section.
For illustration, we examine how to split historical claim data into (at most) three different stochastic processes. Naturally, if security vulnerabilities evolve over time, our current data may become less reliable. However, we can make it usable again by treating data as the result of combined processes and understanding their patterns.
Each claim
is here the sum of the claims generated by three processes and can be expressed as
where given any
, the claims
,
, are i.i.d. random variables with means
, and they occur independently at rates
. This implies that
The total expected claim amount per unit of time is shown in
Table 2 when there are at most three generating processes.
Additionally, let us assume that
is, for example, a combination of at most two claims per unit of time. In this case, (
16) simplifies to
where
is positive but the
’s can be zero. All possible scenarios for the mean claims are listed in
Table 3 in the case
. For example, if
, it is the 6-th scenario which is appropriate because the values in the classes are then in ascending order; if
, this is the 11-th scenario for the same reason.
Moreover,
Table 4 gives the corresponding total claims
,
, and their frequencies
, the probabilities of occurrence being
.
4.1. Hamiltonian Operator
Observable quantities are represented by self-adjoint operators. In the paper
Lefèvre et al. (
2018), we showed how to analyze such data using the quantum spectrum. In quantum mechanics, the spectrum of an operator is precisely the set of eigenvalues which correspond to observables for certain Hermitian operators/self-adjoint matrices.
Consider the model (
17) with three processes and at most two claims per unit of time. We define the corresponding Hamiltonian observable operator by the following tensorial product
where
and
are the operators for one and two claims occurrences which are defined by the
matrices
B is the operator for the claim amount on a jump which is defined by the
matrix
and
is the identity operator of dimension 3 (ln is just applied to diagonal elements of the matrices).
The two terms of claim amounts in (
18) are the diagonal
matrices
Therefore,
H is a self-adjoint
matrix with eigenvalues
so its spectrum has nine distinct eigenvalues
The Hamiltonian operator is given by (
18) when the claim amount
is strictly positive. If
, it is defined as
where
In the following, we assume
and will thus use the Hamiltonian operator (
18).
4.2. Likelihood and Risk Functions
First, we classify the data with respect to the eigenvalues (
19) of the operator (
18) and label them. The order of two successive claims in a unit of time is ignored. The different classes are listed below:
Using the Maxwell–Boltzmann statistics, the associated likelihood function
is given by
where
are the numbers of claims in class
, and
are the normalized frequencies of
Table 4 for the three Poisson processes.
Finally, the risk function
is calculated via the square distance (
), or the Gaussian (squared exponential) distance (
,
). For the square distance kernel, the risk function is here
and for the Gaussian distance kernel,
To minimize such a risk value, we perform optimization on all possible values of
. Additionally, we determine boundaries using the neighborhood approach.
4.3. Illustration
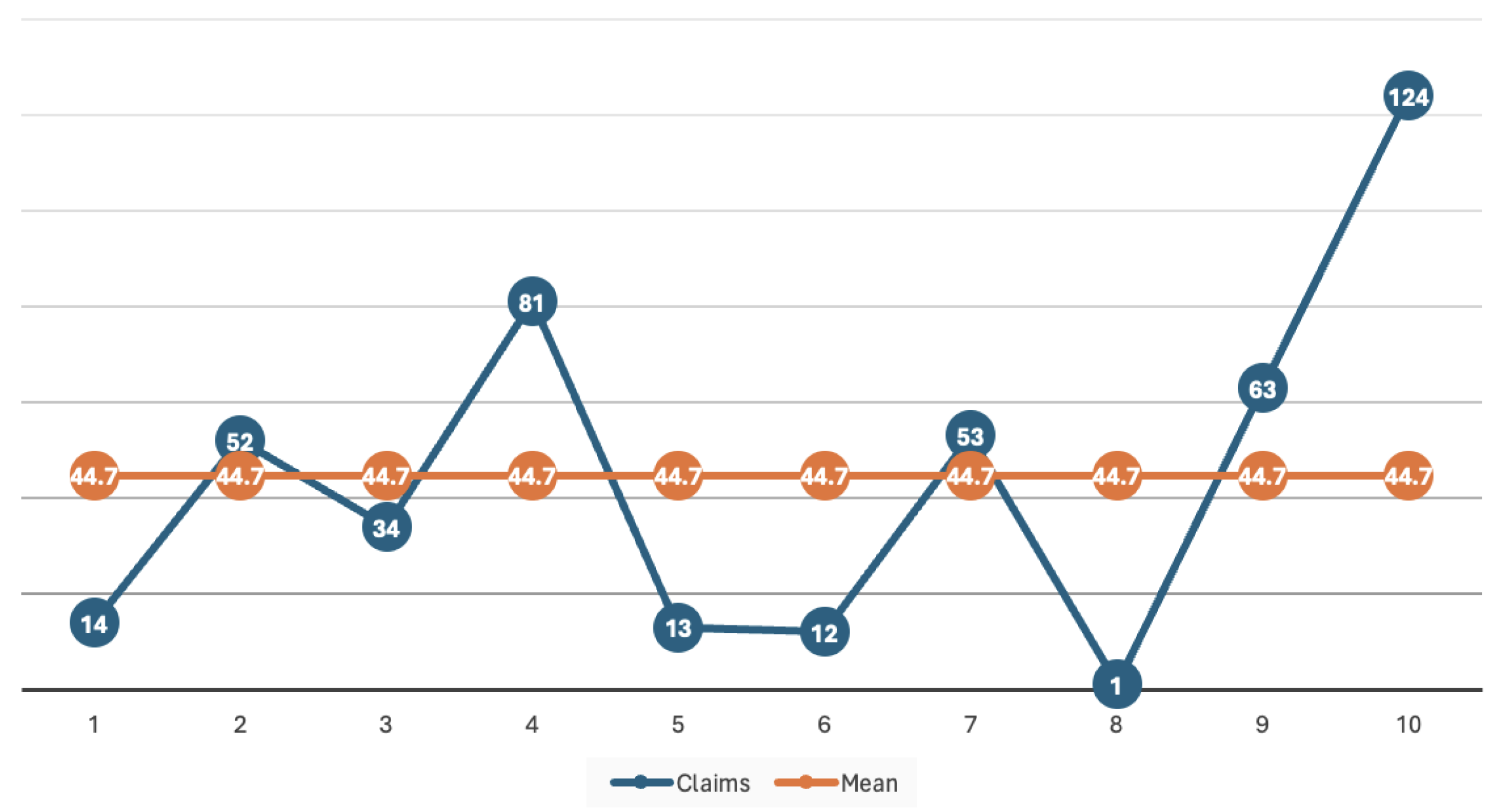
Let us consider the following dataset
The main reason for choosing a small dataset size is only to simplify the demonstration of the example. Our algorithm can of course be applied to large datasets.
Table 5 shows the means
and the rates
for the three processes, obtained using the two previous distance kernels. Neighborhood optimization is conducted here by perturbing the boundaries between classes with
. Of course, it is possible to achieve better results with an advanced optimization technique.
As expected, using different kernels with nearest neighbor approaches influence the results. For the current analysis, we applied the squared distance kernel and thus obtain
,
,
(which corresponds to scenario 6 of
Table 3). In addition, the dataset is distributed in the nine classes according to the distribution indicated in
Table 6. For this classification, midpoint values are used to define class boundaries. Note, that these boundaries are dynamic and change in response to the values of
,
,
.
The classes containing two claims, i.e.,
,
,
,
,
,
, are separated with respect to the weights of
,
,
as follows:
So, the two claims in
of sum 14, for example, yield the amounts 7 and 7. For
, the sum 34 is subdivided into
and
; for
, 63 becomes
and
; for
, 81 yields
and
.
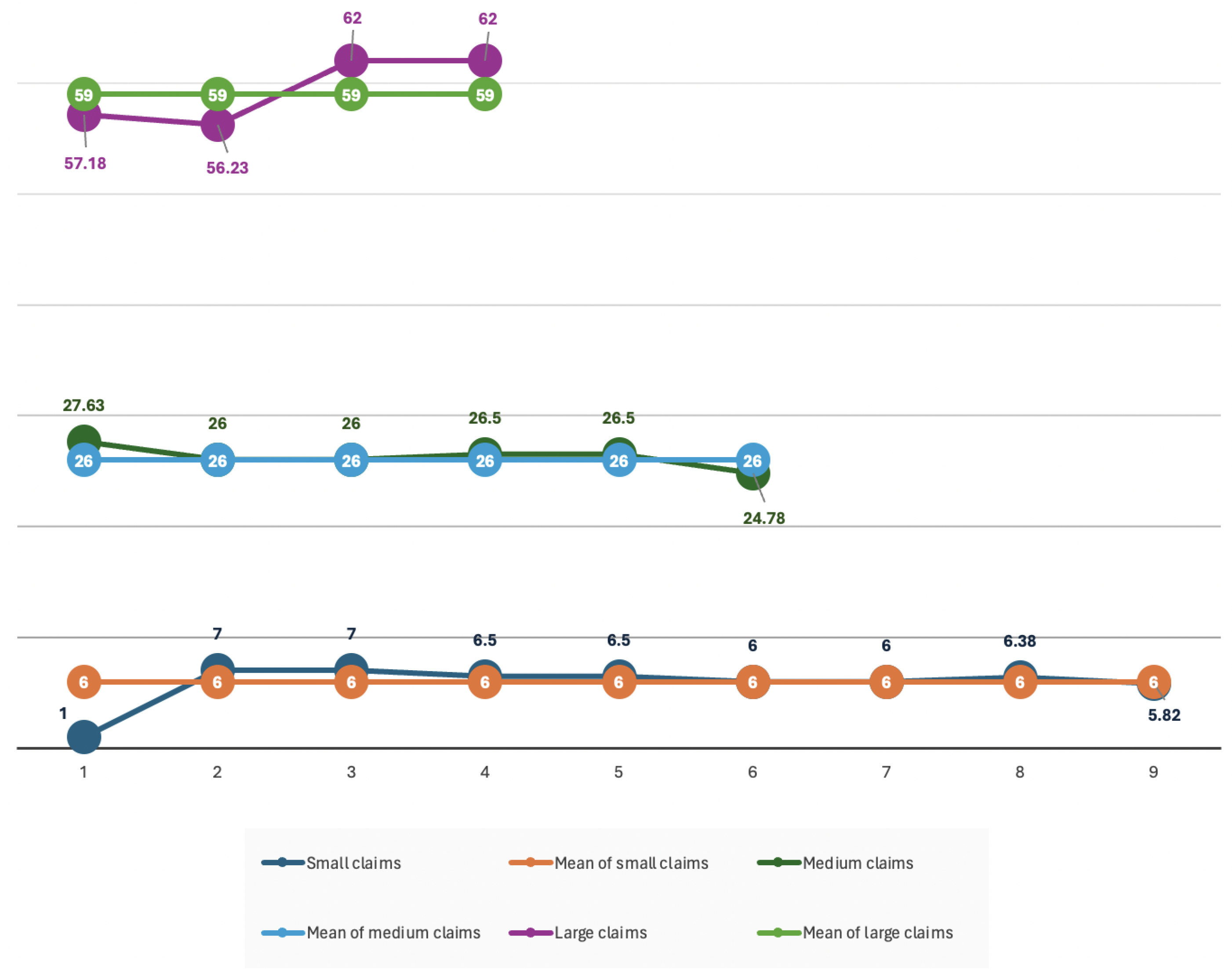
Following this method, the claims in the three processes are listed in
Table 7 and displayed with their means and frequencies in
Figure 2. According to
Table 5, the claim arrival rates for these processes are
,
,
.
As shown in
Figure 3 and
Figure 4, the deviation from the mean in the sub-processes is minimized after the claims splitting and categorization process.
The detailed pseudo-code is provided by the Algorithm 1.
| Algorithm 1: for splitting the main claim process and classifying the cyber data. |
![Risks 12 00083 i001]() |
6. Conclusions
With the advent of new technologies, such as generative AI, quantum computing and metaverse platforms, coupled with challenges such as climate change, pandemics and globalization, humanity has entered a period of exponential change. In such a rapidly evolving environment, relying solely on historical data can lead to incorrect predictions. As a solution, we used a stochastic process based on historical data, dividing it into three distinct sub-processes to better discern patterns. To account for parameter changes and correlated cases, we used Clayton copula, one of the well-known Archimedean copulas, which allows us to predict future claims by updating claims from the subprocesses and considering the magnitude of change. This methodology provides a fairly compelling example of how to turn unreliable historical data into a reliable resource in a rapidly changing environment.
Analyzing cyber insurance data is far more complex than what has been discussed here. In particular, it would be extremely beneficial to process actual cyber data and test the performance of the non-standard approach we are proposing. Nevertheless, in this work, we have demonstrated how cyber data can be considered as quantum data. We also explained how to segment the dataset using various subprocesses and how to make predictions in an uncertain environment.
In the analysis of cyber insurance data and forecasting, working with researchers in an agile environment and updating current models are essential. This necessity arises because hackers are becoming more innovative, and technology is rapidly evolving. In this paper, we have introduced a different approach from a mathematical perspective. We would like to emphasize that this approach is only applicable if the data are distributed across a wide spectrum, exhibiting high bias relative to the mean, in order to yield more accurate estimates. The approach can be used for large datasets. However, from the industrial perspective, the model should be tested and validated by experts using real cyber insurance data.








{kind=link}
{kind=link}
{kind=link}
{kind=link}