
Cyber Risk Contagion



Abstract
:1. Introduction
- Literature on cyber risk measurement: (see, for example, Chande and Yanchus 2019; Eling 2020; Eling and Wirfs 2019; Facchinetti et al. 2020; Florackis et al. 2023; Giudici and Raffinetti 2021; Kure et al. 2021; Mazzoccoli and Naldi 2021; Paté-Cornell et al. 2017; Ruan 2019).Our contribution is a multivariate model that adds to the literature on cyber risk measurement a measure of interdependency between cyber risks.
- Literature on operational risk measurement: (see, for example, Aldasoro et al. 2022; Chernobai et al. 2019; Cohen et al. 2019; Curti et al. 2022).Our contribution is a multivariate model that adds to the literature on operational risks the consideration of multivariate dependence between count data.
- Literature on systemic risk: (see, for example, Agosto et al. 2016, 2020; Aldasoro et al. 2022; Danielsson and Macrae 2019; Escribano and Maggi 2019; Giudici et al. 2019; Lando and Nielsen 2010).Our contribution is a systemic risk model for cyber risks that adds to the literature the employment of generalized autoregressive score models.
2. Materials and Methods
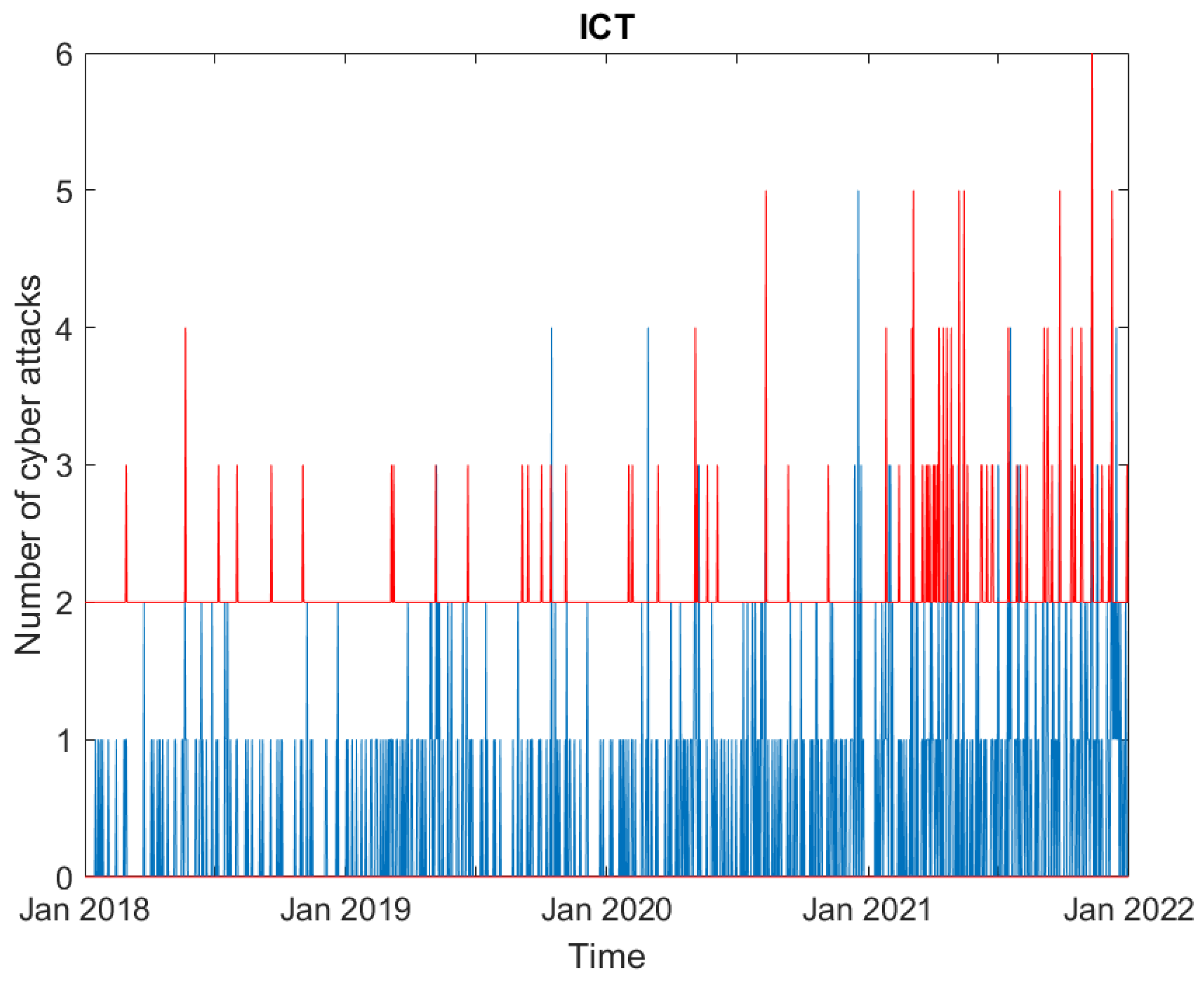
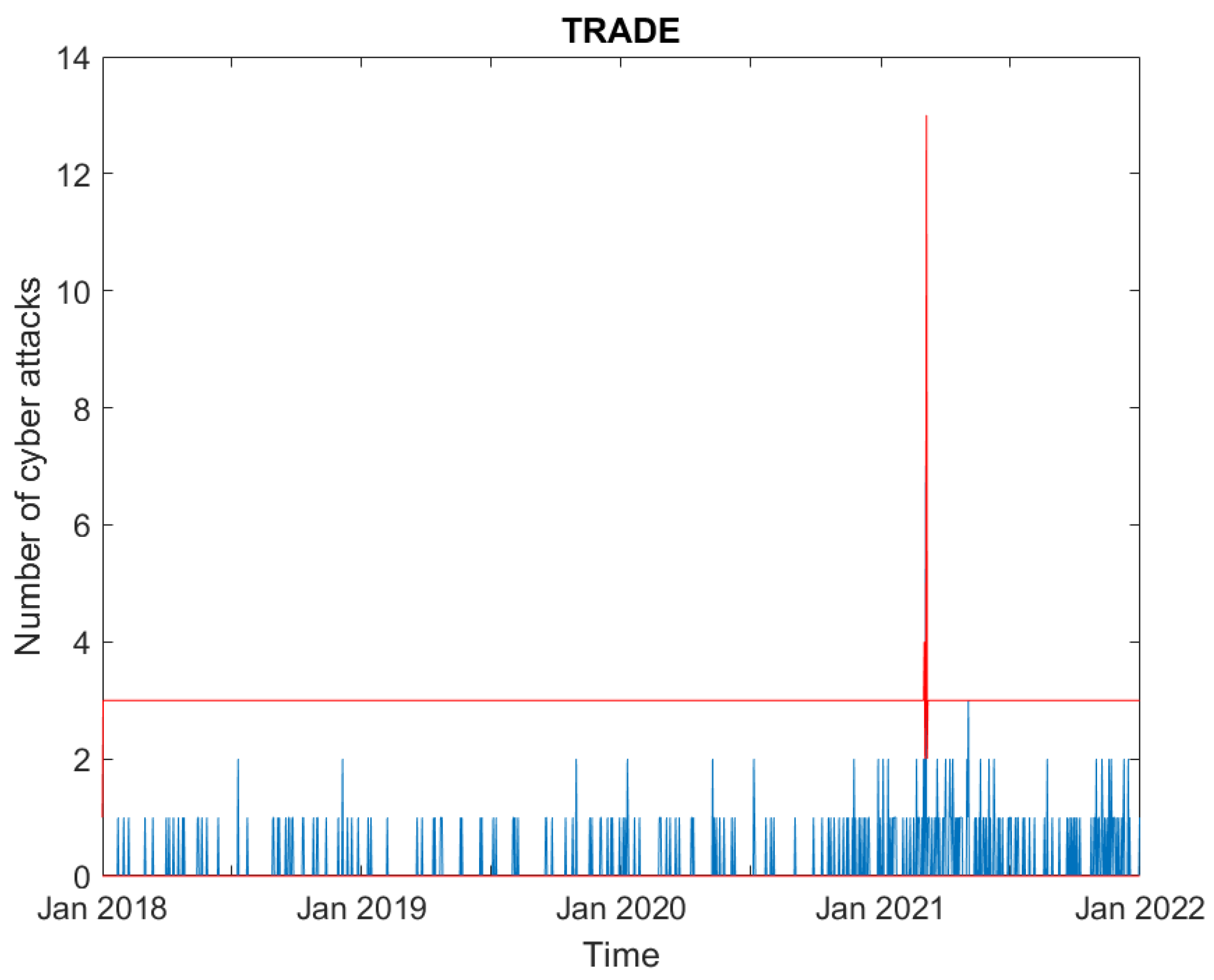
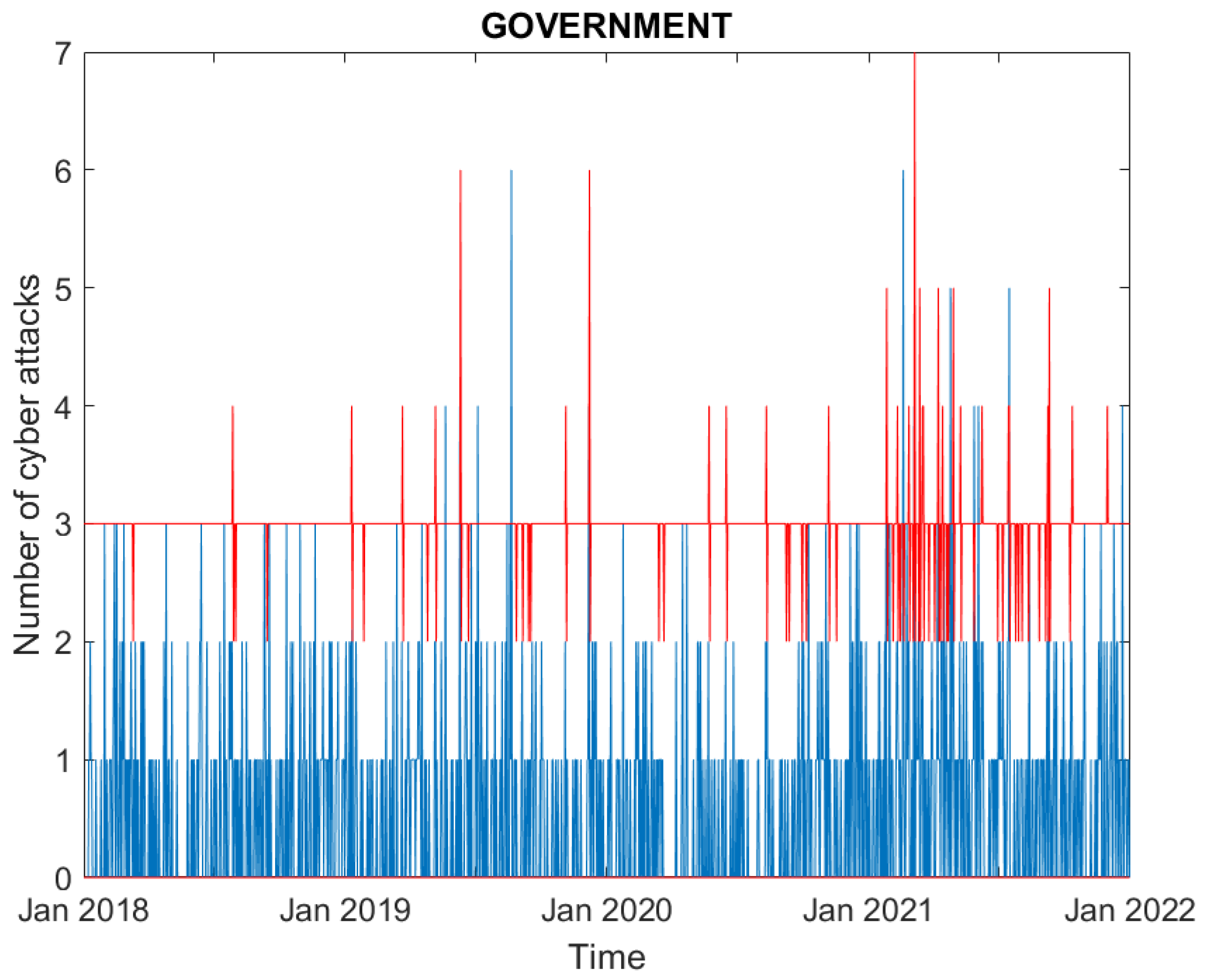
3. Results
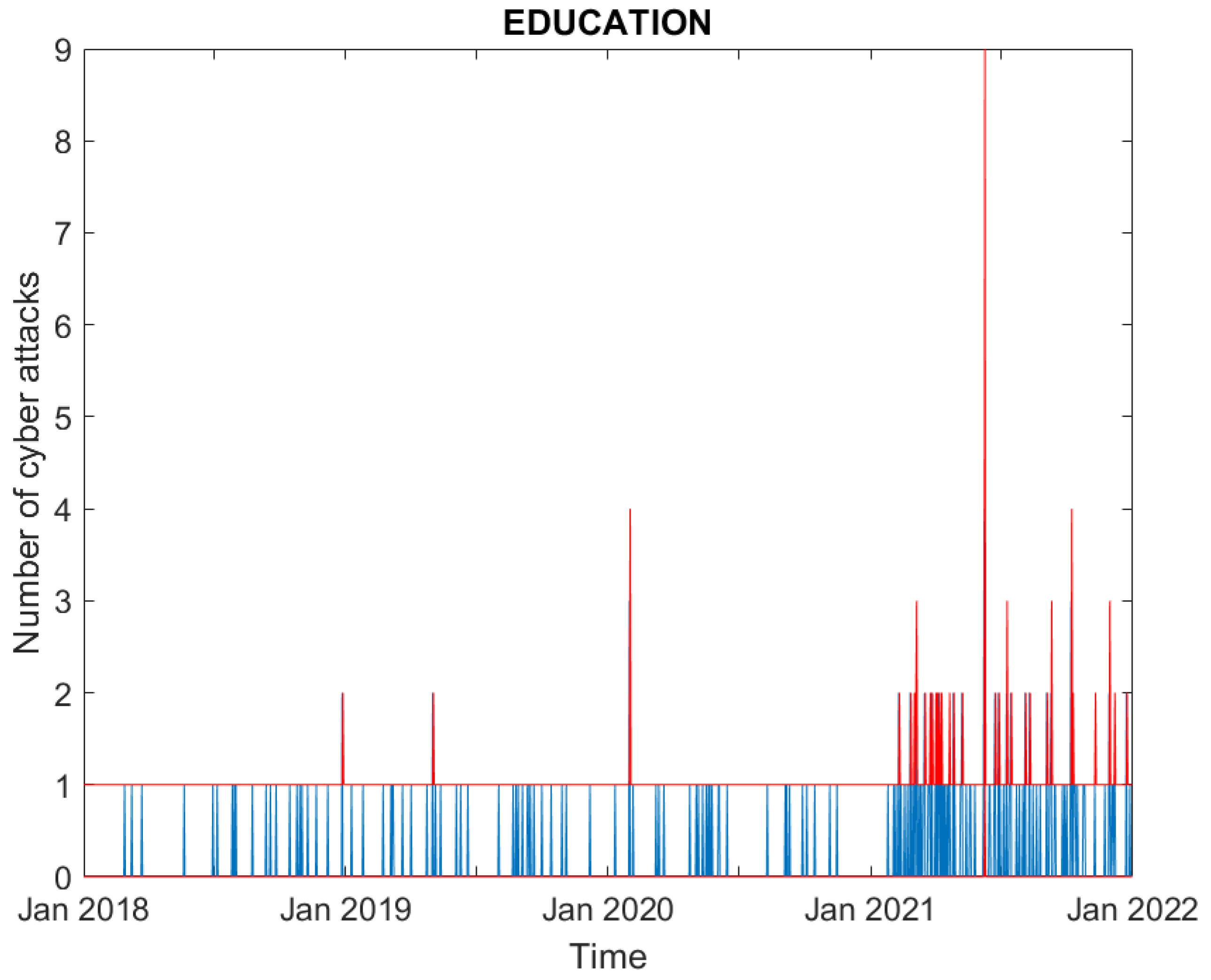
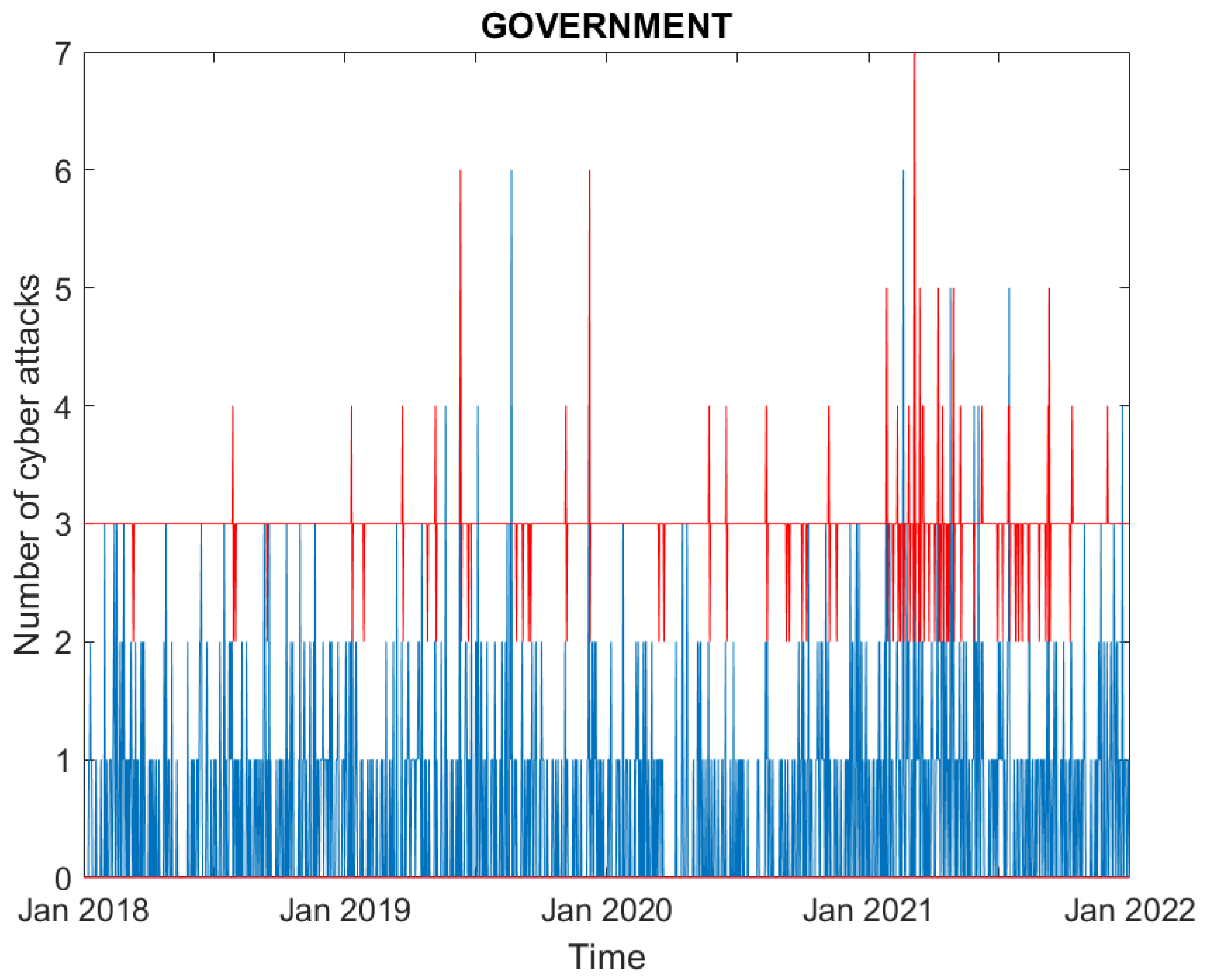
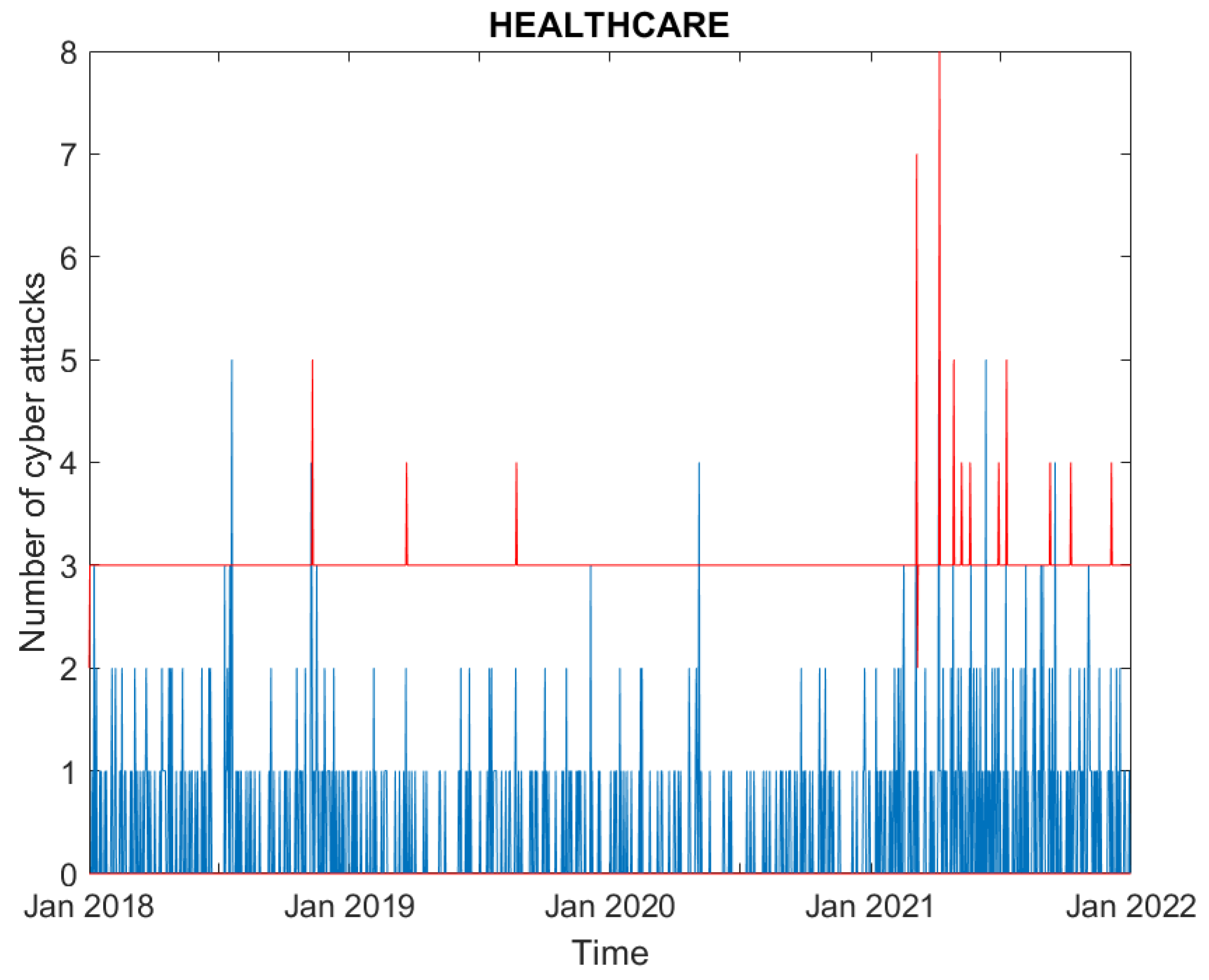
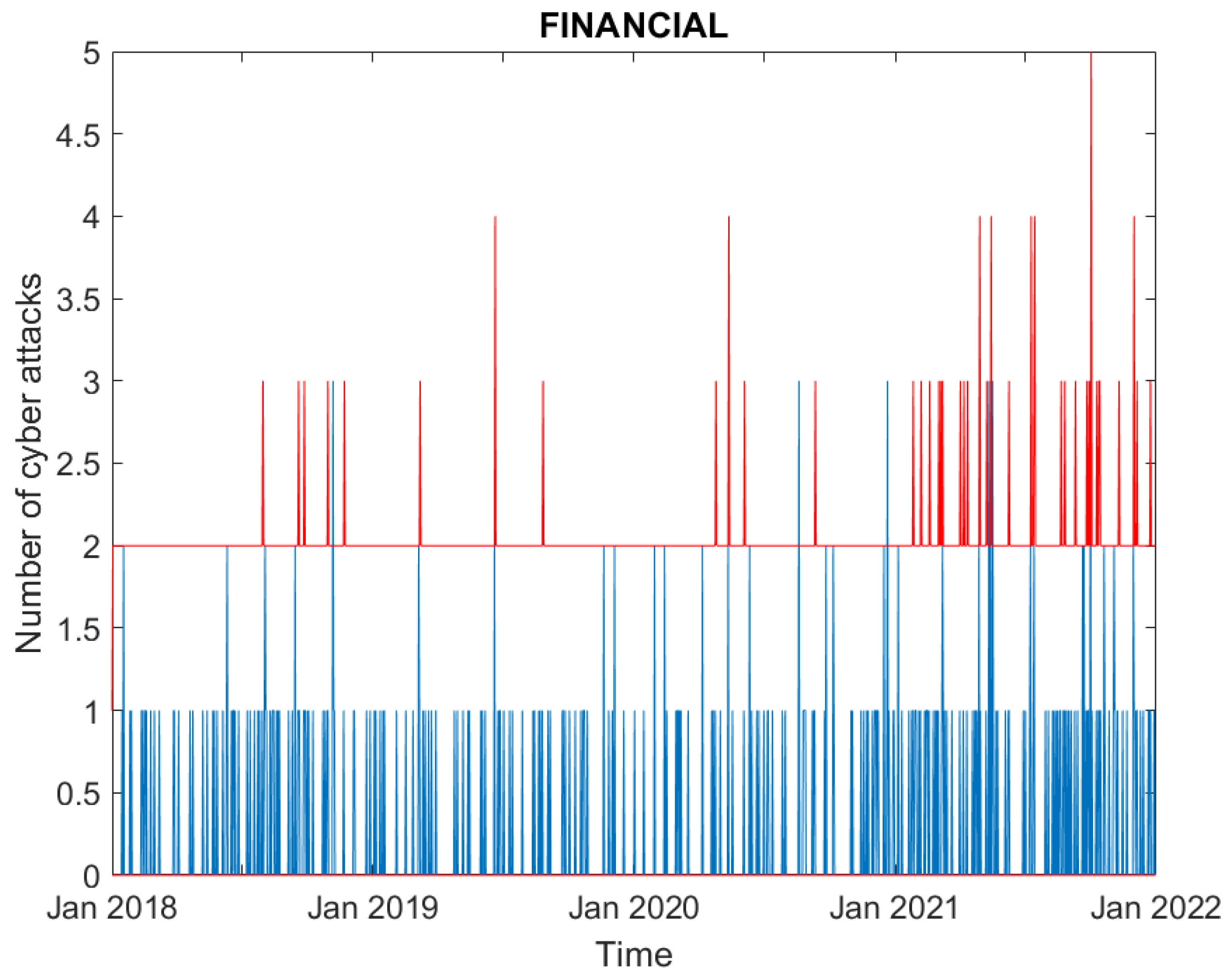
3.1. Data
3.2. Empirical Findings
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Agosto, Arianna. 2022. Multivariate Score-Driven Models for Count Time Series to Assess Financial Contagion. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4119895 (accessed on 1 June 2023).
- Agosto, Arianna, Daniel Felix Ahelegbey, and Paolo Giudici. 2020. Tree Networks to Assess Financial Contagion. Economic Modelling 85: 349–66. [Google Scholar] [CrossRef]
- Agosto, Arianna, Giuseppe Cavaliere, Dennis Kristensen, and Anders Rahbek. 2016. Modeling corporate defaults: Poisson autoregressions with exogenous covariates (parx). Journal of Empirical Finance 38: 640–63. [Google Scholar] [CrossRef]
- Ahelegbey, Daniel Felix, Monica Billio, and Roberto Casarin. 2016. Bayesian graphical models for structural vector autoregressive models. Journal of Applied Econometrics 31: 357–86. [Google Scholar] [CrossRef]
- Aldasoro, Iñaki, Leonardo Gambacorta, Paolo Giudici, and Thomas Leach. 2022. The drivers of cyber risk. Journal of Financial Stability 60: 100989. [Google Scholar] [CrossRef]
- Billio, Monica, Mila Getmansky, Andrew W. Lo, and Loriana Pelizzon. 2012. Econometric measures of connectedness and systemic risk in the finance and insurance sectors. Journal of Financial Economics 104: 535–59. [Google Scholar] [CrossRef]
- Chernobai, Anna, Philippe Jorion, and Fan Yu. 2019. The determinants of operational risk in US financial institutions. Journal of Financial and Quantitative Analysis 46: 1683–725. [Google Scholar] [CrossRef]
- Chande, Nikil, and Dennis Yanchus. 2019. The Cyber Incident Landscape. Bank of Canada Working Paper 32. Ottawa: Bank of Canada. [Google Scholar]
- Cohen, Ruben D., Jonathan Humphries, Sabrina Veau, and Roger Francis. 2019. An investigation of cyber loss data and its links to operational risk. Journal of Operational Risk 14: 1–25. [Google Scholar] [CrossRef]
- Creal, Drew, Siem Jan Koopman, and André Lucas. 2013. Generalized autoregressive score models with applications. Journal of Applied Econometrics 28: 777–95. [Google Scholar] [CrossRef]
- Curti, Filippo, Atanas Mihov, and W. Scott Frame. 2022. Are the Largest Banking Organizations Operationally More Risky? Journal of Money, Credit and Banking 54: 1223–59. [Google Scholar] [CrossRef]
- Danielsson, J., and Robert Macrae. 2019. Systemic Consequences of Outsourcing to the Cloud. VoxEU, CEPR. Available online: https://cepr.org/voxeu/columns/systemic-consequences-outsourcing-cloud (accessed on 5 December 2019).
- Diebold, Francis X., and Kamil Yılmaz. 2014. On the Network Topology of Variance Decompositions: Measuring the Connectedness of Financial Firms. Journal of Econometrics 182: 119–34. [Google Scholar] [CrossRef]
- Eling, Martin. 2020. Cyber risk research in business and actuarial science. European Actuarial Journal 10: 303–33. [Google Scholar] [CrossRef]
- Eling, Martin, and Jan Wirfs. 2019. What are the actual costs of cyber risk events? European Journal of Operational Research 272: 1109–19. [Google Scholar] [CrossRef]
- Escribano, Ana, and Mario Maggi. 2019. Intersectoral default contagion: A multivariate Poisson autoregression analysis. Economic Modelling 82: 376–400. [Google Scholar] [CrossRef]
- Facchinetti, Silvia, Paolo Giudici, and Silvia Angela Osmetti. 2020. Cyber risk measurement with ordinal data. Statistical Methods & Applications 29: 173–85. [Google Scholar]
- Florackis, Chris, Christodoulos Louca, Roni Michaely, and Michael Weber. 2023. Cybersecurity Risk. The Review of Financial Studies 36: 351–407. [Google Scholar] [CrossRef]
- Giudici, Paolo, and Emanuela Raffinetti. 2021. Explainable AI methods in cyber risk management. Quality and Reliability Engineering International 38: 1318–26. [Google Scholar] [CrossRef]
- Giudici, Paolo, Branka Hadji-Misheva, and Alessandro Spelta. 2019. Network based credit risk models. Quality Engineering 32: 199–211. [Google Scholar] [CrossRef]
- Heinen, Andréas, and Erick Rengifo. 2007. Multivariate autoregressive modeling of time series count data using copulas. Journal of Empirical Finance 14: 564–83. [Google Scholar] [CrossRef]
- Harvey, Andrew C. 2013. Dynamic Models for Volatility and Heavy Tails: With Applications to Financial and Economic Time Series. New York: Cambridge University Press. [Google Scholar]
- Kopp, Emanuel, Lincoln Kaffenberger, and Christopher Wilson. 2017. Cyber Risk, Market Failures, and Financial Stability. IMF Working Paper, WP/17/185. Washington, DC: International Monetary Fund. Available online: https://ssrn.com/abstract=3030776 (accessed on 5 December 2019).
- Kure, Halima Ibrahim, Shareeful Islam, Mustansar Ghazanfar, Asad Raza, and Maruf Pasha. 2021. Asset criticality and risk prediction for an effective cybersecurity risk management of cyber-physical systems. Neural Computing and Applications 34: 493–514. [Google Scholar] [CrossRef]
- Lando, David, and Mads Stenbo Nielsen. 2010. Correlation in corporate defaults: Contagion or conditional independence? Journal of Financial Intermediation 19: 355–72. [Google Scholar] [CrossRef]
- Mazzoccoli, Alessandro, and Maurizio Naldi. 2021. Optimal Investment in Cyber-Security under Cyber Insurance for a Multi-Branch. Risks 9: 24. [Google Scholar] [CrossRef]
- Paté-Cornell, M-Elisabeth, Marshall Kuypers, Matthew Smith, and Philip Keller. 2017. Cyber Risk Management for Critical Infrastructure: A Risk Analysis Model and Three Case Studies. Risk Analysis 38: 226–41. [Google Scholar] [CrossRef] [PubMed]
- Ruan, Keyun. 2019. Digital Asset Valuation and Cyber Risk Measurement. New York: Academic Press. [Google Scholar]
- Tobias, Adrian, and Markus K. Brunnermeier. 2016. CoVaR. The American Economic Review 106: 1705–41. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sector | c | b |
|---|---|---|
| Education | −1.9443 *** | 0.1547 *** |
| (0.0639) | (0.0202) | |
| Government | −0.3891 *** | 0.1086 *** |
| (0.0417) | (0.0963) | |
| Healthcare | −0.3833 *** | 0.1086 *** |
| (0.0504) | (0.0619) | |
| Financial | −0.3864 *** | 0.1085 *** |
| (0.0952) | (0.0707) | |
| ICT | −0.3881 *** | 0.1086 *** |
| (−0.0612) | (0.0906) | |
| Trade | −0.3868 *** | 0.1085 *** |
| (0.0345) | (0.0504) |
| Sector | EDU | GOV | HLT | FIN | ICT | TRD |
|---|---|---|---|---|---|---|
| EDU | 0.9548 | 0.0097 | 0.0015 | 0.0067 | 0.0105 | 0.0434 |
| GOV | 0.0039 | 0.3834 | 0.0000 | 0.0034 | 0.0052 | 0.0217 |
| HLT | 0.0061 | 0.0075 | 0.3798 | 0.0052 | 0.0081 | 0.0336 |
| FIN | 0.0123 | 0.0152 | 0.0023 | 0.3910 | 0.0164 | 0.0680 |
| ICT | 0.0000 | 0.0000 | 0.0012 | 0.0000 | 0.3788 | 0.0000 |
| TRD | 0.0016 | 0.0020 | 0.0000 | 0.0014 | 0.0021 | 0.3890 |
| Sector | % of Upper Confidence Interval Violations | Binomial Test p-Value |
|---|---|---|
| EDU | 0.0171 | 0.0272 |
| GOV | 0.0335 | 0.9817 |
| HLT | 0.0144 | 0.0035 |
| FIN | 0.0041 | 0.0000 |
| ICT | 0.0157 | 0.0106 |
| TRD | 0.0014 | 0.0000 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Agosto, A.; Giudici, P. Cyber Risk Contagion. Risks 2023, 11, 165. https://doi.org/10.3390/risks11090165
Agosto A, Giudici P. Cyber Risk Contagion. Risks. 2023; 11(9):165. https://doi.org/10.3390/risks11090165
Chicago/Turabian StyleAgosto, Arianna, and Paolo Giudici. 2023. "Cyber Risk Contagion" Risks 11, no. 9: 165. https://doi.org/10.3390/risks11090165
APA StyleAgosto, A., & Giudici, P. (2023). Cyber Risk Contagion. Risks, 11(9), 165. https://doi.org/10.3390/risks11090165