1. Introduction
Colorectal cancer (CRC) remains one of the leading causes of cancer-related morbidity and mortality worldwide, with early detection and removal of precancerous polyps being the most effective method of reducing incidence and improving outcomes [
1,
2,
3,
4]. While colonoscopy is the gold standard for detection, even experienced endoscopists are dealing with substantial adenoma miss rates (AMRs), which can approach 26% based on a 2019 meta-analysis [
5]. Recent advances in artificial intelligence (AI), particularly in deep learning-based image segmentation, offer a promising solution to enhancing diagnostic accuracy by supporting clinicians during endoscopic procedures [
6,
7,
8,
9].
Deep convolutional neural networks (CNNs) trained on large, diverse datasets have shown encouraging results in polyp detection and segmentation tasks. However, the development of such models is restricted by a bottleneck: the scarcity of annotated medical imaging data. Regulatory, ethical, and logistical constraints often limit access to sufficiently diverse datasets [
10,
11]. To address this challenge, two complementary approaches have gained attention: the generation of (1) synthetic data created from scratch using generative adversarial networks (GANs) or diffusion models [
12,
13,
14] and (2) pseudosynthetic data, which consist of real images augmented via clinically plausible transformations (e.g., flipping, rotation, and contrast adjustment) while preserving a traceable link to the original case [
14].
Our prior research has shown that training CNNs on datasets enriched with synthetic and pseudosynthetic images leads to significant performance gains in polyp segmentation models [
15]. Diffusion-based synthetic images have been observed to offer greater generalization and anatomical realism than those generated via GANs. Meanwhile, pseudosynthetic data offer an advantage—traceability. Because these images are derived from real-world clinical cases, they maintain a direct connection to actual patient data, addressing concerns around privacy, reproducibility, and regulatory approval.
Despite these technical advances, an important aspect remains underexplored: Can human clinicians reliably distinguish between real, synthetic, and pseudosynthetic images? The clinical acceptability of AI-generated data depends not only on algorithmic performance but also on the trust and interpretive ability of its end users—gastroenterologists. If synthetic or pseudosynthetic images are perceptually indistinguishable from real ones, they may serve not only as valid training inputs for AI but also as educational tools and validation resources in medical practice.
In this study, we present a validation experiment designed to investigate gastroenterologists’ ability to discern between real, synthetic (CycleGAN and diffusion-generated), and pseudosynthetic images of colorectal polyps. While prior work demonstrated clear model performance benefits from using these augmented datasets, this work is investigating the perceptual realism of these images from a human point of view. By evaluating classification accuracy, confusion patterns, and differences between experience levels, we aim to assess the feasibility of integrating synthetic and pseudosynthetic datasets into clinical workflows and future doctor training platforms.
2. Materials and Methods
This study involved 32 gastroenterologists from university hospitals, state/public hospitals with no affiliation to a university, and private practices in Romania. The cohort included 14 senior gastroenterologists with an average of 6.1 years of post-residency experience and 18 residents with an average of 2.9 years of gastroenterology training. Inclusion criteria required active endoscopic practice. Participants were invited to fill out a questionnaire on Google Forms (Google LLC, Moutain View, CA, USA) via social media platforms and email and consented voluntarily [
16]. Responses were anonymous, with no personal data collected. This study used publicly available, deidentified datasets.
A total of 24 endoscopic polyp images were used, divided equally into three classification categories: real, pseudosynthetic, and synthetic (8 images each). All images underwent uniform preprocessing—resized to 256 × 256 pixels and normalized to a [0, 1] pixel value range to ensure consistent display. Real images were randomly selected from the Kvasir-SEG [
17] and PolypGen [
18] datasets, containing 1000 and 3762 annotated polyp images, respectively. These represented endoscopic images with no visual modifications beyond preprocessing. Pseudosynthetic images were derived from Kvasir-SEG and PolypGen, with additional transformations applied using Python’s (version 3.11) Albumentations library [
19]. Transformations included spatial alterations (horizontal flips, 90-degree rotations, and 10–20% crops) and color adjustments (10–20% changes in brightness, contrast, and saturation). Images were randomly selected from a pool of augmented images to include varied transformations. Synthetic Images were extracted from the Synth-Colon dataset, generated using CycleGAN [
20], and from a dataset using the diffusion-based polyp synthesis method (Polyp-DDPM [
21,
22]). Four images were randomly selected from each dataset to balance generation methods.
Overall accuracy was calculated for the entire cohort and separately for residents and seniors; Wilson 95% confidence intervals were reported [
19]. Pearson χ
2 test assessed resident versus senior accuracy [
23]. Sensitivity (recall) and precision (positive predictive value or PPV) were computed for each true class, and a binary analysis (“real” versus “synthetic/pseudosynthetic”) supplied sensitivity and specificity for recognizing real images. Confusion matrices of size 3 × 3 were produced for the complete set of ratings and for each training-level subgroup [
24,
25,
26]. We used a Wilcoxon signed-rank test to assess the within-rater difference to compare how clinicians recognized the two polyp synthesis methods [
27,
28]. Within each true class, resident-versus-senior predicted-label distributions were compared with 2 × 3 χ
2 tests. Inter-rater agreement was measured with Fleiss’ κ for all raters and for each subgroup with corresponding 95% confidence intervals [
29]. The significance threshold—alpha—was set at 0.05. Statistical analysis was performed using Python version 3.11 with SciPy version 1.9.3 and Pandas version 1.5.3 libraries, using Google Colab as the environment [
30,
31].
3. Results
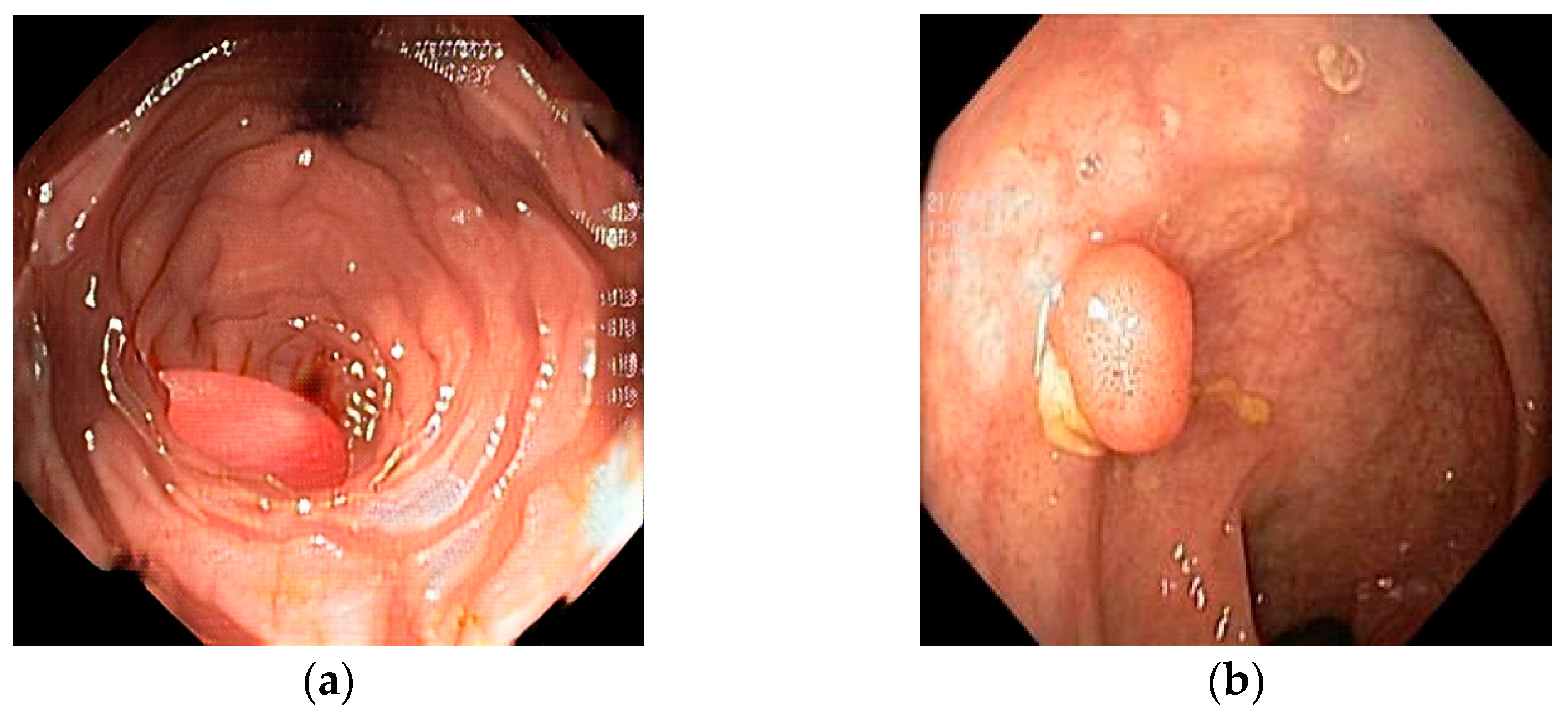
For a better understanding of this study, two polar-opposite images are shown below that represent both ends of the perceptual–realism spectrum of synthetic generation.
Figure 1 depicts a cGAN synthetic image (a), 100% reported by respondents as synthetic, next to a diffusion-based synthetic image (b), which was mislabeled by 26 out of 32 respondents (81.3%). The cGAN-generated image has color patterns and shapes that are easily recognized as synthetic, with the polyp having a “perfect” shape and the mucosa showing unnatural architecture. On the other hand, the diffusion-based image can be easily confused as real, displaying cues such as unnatural lighting and debris and mucosal folds with distortions. These features are not present in the real and augmented images. The real image that was mislabeled most frequently as synthetic or pseudosynthetic (12/32 or 37.5% contained mucosa with a normal vascular pattern with no sudden breaks, as well as normal colors and lighting. It contains a small, sessile colon polyp, showing the fine vascular detail and true texture that sometimes diffusion and almost always GAN models struggle to replicate.
Out of 768 ratings, 470 were correct, giving an overall accuracy of 61.2% (95% CI 57.7–64.6%). Residents provided 432 ratings and were correct on 269 occasions, for an accuracy of 62.3% (95% CI 57.6–66.7%). Seniors gave 336 ratings with 201 correct classifications, corresponding to an accuracy of 59.8% (95% CI 54.5–64.9%). Results are displayed in
Table 1.
Pearson χ2 test shows no statistically significant difference in overall accuracy between residents and senior gastroenterologists (χ2) p = 0.54.
Across all 768 ratings, performance varied by image category. Real polyps were identified most consistently, while synthetic images showed a comparable precision but a slightly lower sensitivity, indicating that nearly four in ten computer-generated frames were mislabeled as either real or augmented. Augmented frames were the least recognizable. Performance metrics are reported in
Table 2.
When the task was collapsed to a binary decision—“real” versus “synthetic/pseudosynthetic”—participants correctly detected genuine endoscopy frames with a sensitivity of 70.7% (181/256). They marked synthetic or pseudosynthetic images as non-real in 78.5% of cases (402/512).
We then computed the overall confusion matrix, with subsequent calculation of confusion matrices per each subset of participants (residents vs. seniors), and the results are displayed below in
Table 3,
Table 4 and
Table 5. Performance is reported in percentages, along with 95% CI.
For each participant, the four CycleGAN images were paired with four diffusion images, creating 128 rater-level comparisons. Correct recognition (labeled synthetic) was perfect for CycleGAN (128/128) but achieved in only 29/128 cases for diffusion images.
Detection rates and 95% confidence intervals for each synthesis method are provided in
Table 6.
We then applied the Wilcoxon signed-rank test, which returned a p-value of <0.001, confirming that CycleGAN frames were markedly easier to identify as synthetic.
The results regarding prediction patterns of residents vs. seniors within each true class are displayed in
Table 7 below. None of the 2 × 3 comparisons reached statistical significance, indicating that residents and seniors distributed their response categories similarly for real, augmented, and synthetic images.
Across all three true classes, the 95% confidence intervals overlap by an appreciable degree, corroborating the statistically non-significant p-values.
Inter-rater agreement for the three-way task was modest. Fleiss κ for the entire group of 32 gastroenterologists was 0.30 (95% CI 0.15–0.43), a level conventionally interpreted as “fair” concordance. Agreement within the resident subgroup was slightly higher, κ = 0.34 (0.18–0.47), whereas seniors reached κ = 0.27 (0.11–0.40); the overlapping confidence intervals indicate no meaningful difference between experience levels.
4. Discussion
In this study, we saw that experience level did not materially shift the distribution of chosen labels, whereas the near-perfect recognition of CycleGAN output indicates obvious artifacts or texture cues that clinicians find easy to spot, whereas diffusion-generated images are far more realistic: more than three-quarters were mistaken for real or augmented. This disparity underscores that diffusion models currently pose the greater challenge for human verification in endoscopic workflows.
In this study, gastroenterologists achieved a moderate overall accuracy when distinguishing real, augmented, and synthetic polyp images, being in the same range as other findings in related domains, where observers usually score in the 55–65% range when tasked with real-vs-non-real image classification in endoscopy, radiology, and dermatology. For example, Yoon et al. conducted a study where four expert endoscopists evaluated GAN-synthesized colonoscopy images containing sessile serrated lesions. The experts’ ability to differentiate between real and synthetic images was limited, highlighting the challenges faced by clinicians in identifying AI-generated content.
Even with capsule endoscopy frames, gastroenterologists as a group performed near chance level (~53% correct) in differentiating real vs. GAN-generated images [
32]. Similarly, radiologists reviewing synthetic versus real scans hover just above chance: for instance, a multi-reader study on high-resolution CT images reported a mean accuracy of 59.4%, only marginally better than the 50% expected by guessing [
33]. In a Turing-style test with melanoma and nevus photos, both real and generated using GAN, 19 dermatologists (seniors and residents) achieved an overall accuracy of 59.3%. These findings show that overall accuracy in human realism discrimination falls in the 55–60% range for most modalities, indicating a substantial challenge in recognizing synthetic or augmented medical images [
34].
Stratifying by experience level revealed no statistically significant difference in performance, suggesting that additional years of post-training endoscopic practice do not confer a clear advantage in perceiving subtle artifacts or anomalies introduced by modern augmentation and synthesis methods. One intuitive hypothesis is that having more years of experience might better detect subtle signs of image altering or synthesis, but studies show minimal benefit of observer experience regarding the type of task. In a CT study, radiologists were stratified by experience (junior residents, senior radiologists, and experts), but their ability to discern real vs. non-real images did not significantly differ (mean accuracies of 58.0%, 60.5%, and 59.8%, respectively;
p = 0.36) [
33].
There are cases where domain experts perform worse than their less-specialized colleagues. In a brain MRI experiment, the two fellowship-trained neuroradiologists achieved only 30% and 55% accuracy, essentially at or below chance, whereas three non-specialist radiologists scored between 64% and 83% [
35]. Overall, the evidence indicates that observer background has a minor influence on detecting synthetic images, and expertise alone cannot overcome the fundamental visual plausibility of modern-era synthetic or augmented medical images.
When the classification experiment is collapsed to a binary (real-vs-non-real) decision, performance corresponds to an area under the curve in the 0.5–0.6 range—far below what would be needed for confident medical discrimination. Moreover, different people often disagree on which images are non-real, as reflected by poor inter-rater κ values in our study and the aforementioned studies.
These findings suggest the need for objective validation of image authenticity (for instance, algorithmic detection methods or metadata checks) if distinguishing real vs. AI-generated images is required, given that human observers alone are inclined to error and disagreement in this domain. The current literature provides a cautionary note: in the context of medical imaging, synthetic data generation techniques have effectively passed the “visual Turing test” in many cases, achieving deception rates that make human recognition unreliable [
32,
33,
34,
35].
The results in this research are in line with other published papers that demonstrate the superiority of diffusion methods over GAN methods in terms of generalization ability and anatomical authenticity. For example, Balla et al. (2023) found that a diffusion model produced synthetic ultrasound images whose pixel intensity distributions closely matched real images, preserving realistic anatomical textures, compared to GAN methods [
36]. Additionally, the work of Saragih et al. from 2024 and Hung et al. (2023) have made similar comparisons between synthetic medical data generation methods and concluded that diffusion methods outperform GANs and the former have great potential regarding conditional medical image generation [
37,
38].
The design of this study is in line with other published papers, such as the work of Korkinof et al. from 2020, which asked participants to judge 10 image pairs (20 images) per reader when assessing GAN-derived mammograms [
39]. We nevertheless acknowledge that broader lesion diversity could further strengthen generalizability, and future work will imply the expansion of an experiment with images from multiple medical institutions and potentially incorporate video sequences, where temporal cues might aid authenticity judgments, better replicating the endoscopy process. Because our cohort consisted only of Romanian gastroenterologists, external validity may be constrained by regional differences in training pathways, quality benchmarks, epidemiology, and technology. In light of these differences, we plan to conduct a similar multi-center study across Europe in the near future to test the validity of our findings.
Because the synthetic images are already indistinguishable from reality for most observers, they represent a viable way of enlarging training datasets—practical in the formation of new generations of doctors. Nevertheless, their use in AI development and clinical workflows must be accompanied by automated origin checks or watermarking to prevent accidental dataset contamination and satisfy emerging regulatory requirements. Future work should then integrate authenticity detectors into the synthetic data pipeline and evaluate whether the resulting augmented models translate into measurable reductions in adenoma-miss rates.
5. Conclusions
This study demonstrates that gastroenterologists exhibit only moderate accuracy (61.2%, 95% CI: 57.7–64.6%) when distinguishing real, augmented, and synthetic colonoscopy images. Accuracy did not differ significantly by training level, suggesting that additional clinical experience does not notably enhance the ability to detect synthetic images. Detection varied markedly by generation method: CycleGAN images, characterized by noticeable artifacts, were easily identified as synthetic, whereas diffusion-generated images—more anatomically realistic—proved challenging for clinicians to recognize. Inter-rater agreement was fair (κ = 0.30, 95% CI: 0.15–0.43), reflecting widespread uncertainty among observers. Taken together, these findings emphasize that human perception alone is insufficient for reliably identifying synthetic endoscopic images, particularly those produced by advanced diffusion techniques. Objective verification methods should, therefore, complement clinician judgment whenever synthetic data are used, and future studies should test whether such provenance-controlled augmentation translates into lower adenoma-miss rates.
Author Contributions
Conceptualization, M.-Ș.M. and A.-C.I.; methodology, A.-M.F. and A.-C.I.; software, A.-C.I. and M.-Ș.M.; validation, M.-Ș.M.; formal analysis, M.-Ș.M.; data curation, A.-M.F. and V.F.P.; writing—original draft preparation, A.-C.I. and A.-M.F.; writing—review and editing, V.F.P.; supervision, M.-Ș.M. and D.-E.D. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Ethical review and approval were waived for this study since this type of study (online survey) is waived from scrutiny in conformity with the UMFST G.E. Palade Internal Code of Conduct.
Informed Consent Statement
Informed consent was obtained from all subjects involved in this study at the time of completion of the online form.
Data Availability Statement
The data presented in this study are available on request from the corresponding author due to privacy reasons.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Morgan, E.; Arnold, M.; Gini, A.; Lorenzoni, V.; Cabasag, C.J.; Laversanne, M.; Vignat, J.; Ferlay, J.; Murphy, N.; Bray, F. Global burden of colorectal cancer in 2020 and 2040: Incidence and mortality estimates from GLOBOCAN. Gut 2023, 72, 338–344. [Google Scholar] [CrossRef] [PubMed]
- Roshandel, G.; Ghasemi-Kebria, F.; Malekzadeh, R. Colorectal Cancer: Epidemiology, Risk Factors, and Prevention. Cancers 2024, 16, 1530. [Google Scholar] [CrossRef] [PubMed]
- Arnold, M.; Sierra, M.S.; Laversanne, M.; Soerjomataram, I.; Jemal, A.; Bray, F. Global patterns and trends in colorectal cancer incidence and mortality. Gut 2017, 66, 683–691. [Google Scholar] [CrossRef] [PubMed]
- Sharma, K.P.; DeGroff, A.; Maxwell, A.E.; Cole, A.M.; Escoffery, N.C.; Hannon, P.A. Evidence-based interventions and colorectal cancer screening rates: The Colorectal Cancer Screening Program, 2015–2017. Am. J. Prev. Med. 2021, 61, 402–409. [Google Scholar] [CrossRef]
- Zhao, S.; Wang, S.; Pan, P.; Xia, T.; Chang, X.; Yang, X.; Guo, L.; Meng, Q.; Yang, F.; Qian, W.; et al. Magnitude, risk factors, and factors associated with adenoma miss rate of tandem colonoscopy: A systematic review and meta-analysis. Gastroenterology 2019, 156, 1661–1674.e11. [Google Scholar] [CrossRef]
- Barua, I.; Vinsard, D.G.; Jodal, H.C.; Løberg, M.; Kalager, M.; Holme, Ø.; Misawa, M.; Bretthauer, M.; Mori, Y. Artificial intelligence for polyp detection during colonoscopy: A systematic review and meta-analysis. Endoscopy 2021, 53, 277–284. [Google Scholar] [CrossRef]
- Shao, L.; Yan, X.; Liu, C.; Guo, C.; Cai, B. Effects of AI-assisted colonoscopy on adenoma miss rate/adenoma detection rate: A protocol for systematic review and meta-analysis. Medicine 2022, 101, e31945. [Google Scholar] [CrossRef]
- Jafar, A.; Abidin, Z.U.; Naqvi, R.A.; Lee, S.-W. Unmasking colorectal cancer: A high-performance semantic network for polyp and surgical instrument segmentation. Eng. Appl. Artif. Intell. 2024, 138, 109292. [Google Scholar] [CrossRef]
- Malik, H.; Naeem, A.; Sadeghi-Niaraki, A.; Naqvi, R.A.; Lee, S.W. Multi-classification deep learning models for detection of ulcerative colitis, polyps, and dyed-lifted polyps using wireless capsule endoscopy images. Complex Intell. Syst. 2024, 10, 2477–2497. [Google Scholar] [CrossRef]
- Ali, S. Where do we stand in AI for endoscopic image analysis? Deciphering gaps and future directions. npj Digit. Med. 2022, 5, 184. [Google Scholar] [CrossRef]
- Williamson, S.M.; Prybutok, V. Balancing privacy and progress: A review of privacy challenges, systemic oversight, and patient perceptions in AI-driven healthcare. Appl. Sci. 2024, 14, 675. [Google Scholar] [CrossRef]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Dorjsembe, Z.; Pao, H.K.; Xiao, F. Polyp-DDPM: Diffusion-based semantic polyp synthesis for enhanced segmentation. In Proceedings of the 46th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC 2024), Orlando, FL, USA, 15–19 July 2024; pp. 1–7. [Google Scholar]
- Ioanovici, A.-C.; Mărușteri, M.-Ș.; Feier, A.M.; Ioanovici, I.; Dobru, D.-E. Using synthetic and pseudosynthetic data to enhance polyp detection in future AI-assisted endoscopy frameworks: Is it the right time? Preprint 2025, 2025011097. [Google Scholar] [CrossRef]
- Google Forms Documentation. Available online: https://www.google.com/forms/about/ (accessed on 29 May 2025).
- Jha, D.; Smedsrud, P.H.; Riegler, M.A.; Halvorsen, P.; De Lange, T.; Johansen, D.; Johansen, H.D. Kvasir-SEG: A segmented polyp dataset. In Proceedings of the 26th International Conference on Multimedia Modeling (MMM 2020), Daejeon, Republic of Korea, 5–8 January 2020; Springer: Cham, Switzerland, 2020; pp. 451–462. [Google Scholar]
- Ali, S.; Jha, D.; Ghatwary, N.; Realdon, S.; Cannizzaro, R.; Salem, O.E.; Lamarque, D.; Daul, C.; Riegler, M.A.; Anonsen, K.V.; et al. A multi-centre polyp detection and segmentation dataset for generalisability assessment. Sci. Data 2023, 10, 75. [Google Scholar] [CrossRef] [PubMed]
- Buslaev, A.; Iglovikov, V.I.; Khvedchenya, E.; Parinov, A.; Druzhinin, M.; Kalinin, A.A. Albumentations: Fast and flexible image augmentations. Information 2020, 11, 125. [Google Scholar] [CrossRef]
- Moreu, E.; McGuinness, K.; O’Connor, N.E. Synthetic data for unsupervised polyp segmentation. arXiv 2022, arXiv:2202.08680. Available online: https://arxiv.org/abs/2202.08680 (accessed on 15 May 2025).
- Ho, J.; Jain, A.; Abbeel, P. Denoising diffusion probabilistic models. Adv. Neural Inf. Process. Syst. 2020, 33, 6840–6851. [Google Scholar]
- Grunau, G.; Linn, S. Detection and diagnostic overall accuracy measures of medical tests. Rambam Maimonides Med. J. 2018, 9, e0027. [Google Scholar] [CrossRef]
- Fisher, M.J.; Marshall, A.P.; Mitchell, M. Testing differences in proportions. Aust. Crit. Care 2011, 24, 133–138. [Google Scholar] [CrossRef]
- Available online: https://en.wikipedia.org/wiki/Precision_and_recall (accessed on 14 May 2025).
- Available online: https://en.wikipedia.org/wiki/Sensitivity_and_specificity (accessed on 14 May 2025).
- Monaghan, T.F.; Rahman, S.N.; Agudelo, C.W.; Wein, A.J.; Lazar, J.M.; Everaert, K.; Dmochowski, R.R. Foundational statistical principles in medical research: Sensitivity, specificity, positive predictive value, and negative predictive value. Medicina 2021, 57, 503. [Google Scholar] [CrossRef]
- Wilcoxon, F. Individual comparisons by ranking methods. Biom. Bull. 1945, 1, 80–83. [Google Scholar] [CrossRef]
- Available online: https://www.statisticssolutions.com/free-resources/directory-of-statistical-analyses/assumptions-of-the-wilcox-sign-test/ (accessed on 15 May 2025).
- McHugh, M.L. Interrater reliability: The kappa statistic. Biochem. Med. 2012, 22, 276–282. [Google Scholar] [CrossRef]
- McKinney, W. Pandas: A Foundational Python Library for Data Analysis and Statistics. Python Sci. Conf. 2010, 9, 1–9. [Google Scholar]
- Bisong, E. Google Colaboratory. In Building Machine Learning and Deep Learning Models on Google Cloud Platform: A Comprehensive Guide for Beginners; Apress: Berkeley, CA, USA, 2019; pp. 59–64. [Google Scholar] [CrossRef]
- Vats, A.; Pedersen, M.; Mohammed, A.; Hovde, Ø. Evaluating clinical diversity and plausibility of synthetic capsule endoscopic images. Sci. Rep. 2023, 13, 10857. [Google Scholar] [CrossRef] [PubMed]
- Park, H.Y.; Bae, H.J.; Hong, G.S.; Kim, M.; Yun, J.; Park, S.; Chung, W.J.; Kim, N. Realistic high-resolution body computed tomography image synthesis by using progressive growing generative adversarial network: Visual Turing test. JMIR Med. Inform. 2021, 9, e23328. [Google Scholar] [CrossRef]
- Cho, S.I.; Navarrete-Dechent, C.; Daneshjou, R.; Cho, H.S.; Chang, S.E.; Kim, S.H.; Na, J.I.; Han, S.S. Generation of a melanoma and nevus data set from unstandardized clinical photographs on the Internet. JAMA Dermatol. 2023, 159, 1223–1231. [Google Scholar] [CrossRef]
- Koshino, K.; Werner, R.A.; Toriumi, F.; Javadi, M.S.; Pomper, M.G.; Solnes, L.B.; Verde, F.; Higuchi, T.; Rowe, S.P. Generative adversarial networks for the creation of realistic artificial brain magnetic resonance images. Tomography 2018, 4, 159–163. [Google Scholar] [CrossRef] [PubMed]
- Balla, B.; Hibi, A.; Tyrrell, P.N. Diffusion-Based Image Synthesis or Traditional Augmentation for Enriching Musculoskeletal Ultrasound Datasets. BioMedInformatics 2024, 4, 1934. [Google Scholar] [CrossRef]
- Saragih, D.G.; Hibi, A.; Tyrrell, P.N. Using diffusion models to generate synthetic labeled data for medical image segmentation. Int. J. Comput. Assist. Radiol. Surg. 2024, 19, 1615–1625. [Google Scholar] [CrossRef]
- Hung, A.L.Y.; Zhao, K.; Zheng, H.; Yan, R.; Raman, S.S.; Terzopoulos, D.; Sung, K. Med-cDiff: Conditional Medical Image Generation with Diffusion Models. Bioengineering 2023, 10, 1258. [Google Scholar] [CrossRef]
- Korkinof, D.; Harvey, H.; Heindl, A.; Karpati, E.; Williams, G.; Rijken, T.; Kecskemethy, P.; Glocker, B. Perceived Realism of High-Resolution Generative Adversarial Network-derived Synthetic Mammograms. Radiol. Artif. Intell. 2020, 3, e190181. [Google Scholar] [CrossRef]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).


 ,
, 

{kind=link}