
Sharing Biomedical Data: Strengthening AI Development in Healthcare

 ,
,  , , , , , , ,
, , , , , , ,  and
and 
{kind=link}
Abstract
:1. Introduction
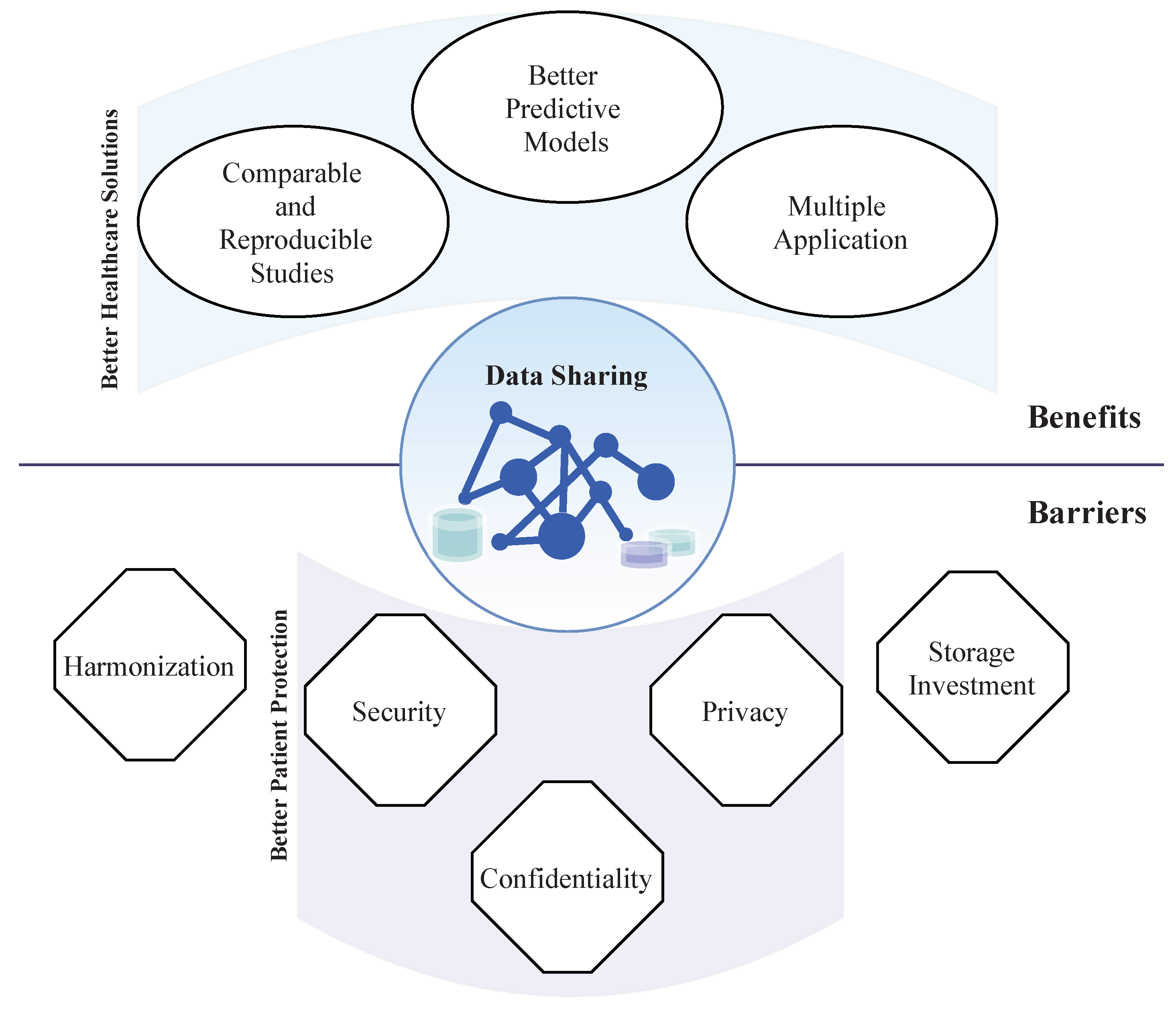
2. Benefits of Data Sharing
3. Barriers to Access
4. Possible Solution Strategies
4.1. Transfer Learning
4.2. Blockchain
4.3. Synthetic Data
4.4. International Strategies
4.5. Research Resource for Medical Imaging
5. Summary
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Makridakis, S. The forthcoming Artificial Intelligence (AI) revolution: Its impact on society and firms. Futures 2017, 90, 46–60. [Google Scholar] [CrossRef]
- Dean, J. The Deep Learning Revolution and Its Implications for Computer Architecture and Chip Design. arXiv 2019, arXiv:1911.05289. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F.-F. ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 25, 1097–1105. [Google Scholar] [CrossRef]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. (IJCV) 2015, 115, 211–252. [Google Scholar] [CrossRef] [Green Version]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar] [CrossRef] [Green Version]
- Alom, M.Z.; Taha, T.M.; Yakopcic, C.; Westberg, S.; Sidike, P.; Nasrin, M.S.; Hasan, M.; Van Essen, B.C.; Awwal, A.A.; Asari, V.K. A state-of-the-art survey on deep learning theory and architectures. Electronics 2019, 8, 292. [Google Scholar] [CrossRef] [Green Version]
- Guidotti, R.; Monreale, A.; Ruggieri, S.; Turini, F.; Giannotti, F.; Pedreschi, D. A survey of methods for explaining black box models. ACM Comput. Surv. 2018, 51, 1–42. [Google Scholar] [CrossRef] [Green Version]
- Urolagin, S.; Prema, K.; Reddy, N.S. Generalization Capability of Artificial Neural Network Incorporated with Pruning Method. In Proceedings of the International Conference on Advanced Computing, Networking and Security, Surathkal, India, 16–18 December 2011; pp. 171–178. [Google Scholar]
- Chung, Y.; Haas, P.J.; Upfal, E.; Kraska, T. Unknown Examples & Machine Learning Model Generalization. arXiv 2018, arXiv:1808.08294. [Google Scholar]
- Mutasa, S.; Sun, S.; Ha, R. Understanding artificial intelligence based radiology studies: What is overfitting? Clin. Imaging 2020, 65, 96–99. [Google Scholar] [CrossRef]
- Ying, X. An Overview of Overfitting and its Solutions. J. Phys. Conf. Ser. 2019, 1168, 022022. [Google Scholar] [CrossRef]
- Hadi, H.J.; Shnain, A.H.; Hadishaheed, S.; Ahmad, A.H. Big Data And Five V’s Characteristics. Int. J. Adv. Electron. Comput. Sci. 2015, 2, 16–23. [Google Scholar]
- Kohli, M.; Summers, R.; Geis, J. Medical Image Data and Datasets in the Era of Machine Learning-Whitepaper from the 2016 C-MIMI Meeting Dataset Session. J. Digit. Imaging 2017, 30, 392–399. [Google Scholar] [CrossRef] [Green Version]
- Lysaght, T.; Lim, H.Y.; Xafis, V.; Ngiam, K.Y. AI-Assisted Decision-making in Healthcare. Asian Bioeth. Rev. 2019, 11, 299–314. [Google Scholar] [CrossRef] [Green Version]
- Tobore, I.; Li, J.; Yuhang, L.; Al-Handarish, Y.; Kandwal, A.; Nie, Z.; Wang, L. Deep Learning Intervention for Health Care Challenges: Some Biomedical Domain Considerations. JMIR mHealth uHealth 2019, 7, e11966. [Google Scholar] [CrossRef]
- Hazarika, I. Artificial intelligence: Opportunities and implications for the health workforce. Int. Health 2020, 12, 241–245. [Google Scholar] [CrossRef]
- Kiani, A.; Uyumazturk, B.; Rajpurkar, P.; Wang, A.; Gao, R.; Jones, E.; Yu, Y.; Langlotz, C.P.; Ball, R.L.; Montine, T.J.; et al. Impact of a deep learning assistant on the histopathologic classification of liver cancer. NPJ Digit. Med. 2020, 3, 23. [Google Scholar] [CrossRef] [Green Version]
- Hulsen, T.; Jamuar, S.S.; Moody, A.R.; Karnes, J.H.; Varga, O.; Hedensted, S.; Spreafico, R.; Hafler, D.A.; McKinney, E.F. From big data to precision medicine. Front. Med. 2019, 6, 34. [Google Scholar] [CrossRef] [Green Version]
- Doi, K. Computer-aided diagnosis in medical imaging: Historical review, current status and future potential. Comput. Med. Imaging Graph. 2007, 31, 198–211. [Google Scholar] [CrossRef] [Green Version]
- Liu, X.; Faes, L.; Kale, A.U.; Wagner, S.K.; Fu, D.J.; Bruynseels, A.; Mahendiran, T.; Moraes, G.; Shamdas, M.; Kern, C.; et al. A comparison of deep learning performance against health-care professionals in detecting diseases from medical imaging: A systematic review and meta-analysis. Lancet Digit. Health 2019, 1, e271–e297. [Google Scholar] [CrossRef]
- Campion, E.W.; Jarcho, J.A. Watched by Apple. N. Engl. J. Med. 2019, 381, 1964–1965. [Google Scholar] [CrossRef]
- Perez, M.V.; Mahaffey, K.W.; Hedlin, H.; Rumsfeld, J.S.; Garcia, A.; Ferris, T.; Balasubramanian, V.; Russo, A.M.; Rajmane, A.; Cheung, L.; et al. Large-Scale Assessment of a Smartwatch to Identify Atrial Fibrillation. N. Engl. J. Med. 2019, 381, 1909–1917. [Google Scholar] [CrossRef]
- Abouelmehdi, K.; Beni-Hessane, A.; Khaloufi, H. Big healthcare data: Preserving security and privacy. J. Big Data 2018, 5, 1. [Google Scholar] [CrossRef]
- Cios, K.J.; William Moore, G. Uniqueness of medical data mining. Artif. Intell. Med. 2002, 26, 1–24. [Google Scholar] [CrossRef]
- ALLEA; EASAC; FEAM. International Sharing of Personal Health Data for Research. The ALLEA, EASAC and FEAM Joint Initiative on Resolving the Barriers of Transferring Public Sector Data Outside the EU/EEA. 2021, p. 63. Available online: www.doi.org/10.26356/IHDT (accessed on 3 March 2021). [CrossRef]
- Moner, D.; Maldonado, J.A.; Bosca, D.; Fernández, J.T.; Angulo, C.; Crespo, P.; Vivancos, P.J.; Robles, M. Archetype-Based Semantic Integration and Standardization of Clinical Data. In Proceedings of the 2006 International Conference of the IEEE Engineering in Medicine and Biology Society, New York, NY, USA, 30 August–3 September 2006; pp. 5141–5144. [Google Scholar]
- Berlanga, R.; Jimenez-Ruiz, E.; Nebot, V.; Manset, D.; Branson, A.; Hauer, T.; McClatchey, R.; Rogulin, D.; Shamdasani, J.; Zillner, S.; et al. Medical Data Integration and the Semantic Annotation of Medical Protocols. In Proceedings of the 2008 21st IEEE International Symposium on Computer-Based Medical Systems, Jyväskylä, Finland, 17–19 June 2008; pp. 644–649. [Google Scholar]
- Cheung, K.H.; Prud’hommeaux, E.; Wang, Y.; Stephens, S. Semantic Web for Health Care and Life Sciences: A review of the state of the art. Brief. Bioinform. 2009, 10, 111–113. [Google Scholar] [CrossRef] [Green Version]
- Sonsilphong, S.; Arch-int, N. Semantic Interoperability for data integration framework using semantic web services and rule-based inference: A case study in healthcare domain. J. Converg. Inf. Technol. (JCIT) 2013, 8, 150–159. [Google Scholar]
- Lenz, R.; Beyer, M.; Kuhn, K.A. Semantic integration in healthcare networks. Int. J. Med. Inform. 2007, 76, 201–207. [Google Scholar] [CrossRef] [PubMed]
- Mortensen, K.; Hughes, T.L. Comparing Amazon’s Mechanical Turk platform to conventional data collection methods in the health and medical research literature. J. Gen. Intern. Med. 2018, 33, 533–538. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bontcheva, K.; Roberts, I.; Derczynski, L.; Rout, D. The GATE Crowdsourcing Plugin: Crowdsourcing Annotated Corpora Made Easy. In Proceedings of the Demonstrations at the 14th Conference of the European Chapter of the Association for Computational Linguistics, Gothenburg, Sweden, 26–30 April 2014; pp. 97–100. [Google Scholar]
- de Herrera, A.G.S.; Foncubierta-Rodrıguez, A.; Markonis, D.; Schaer, R.; Müller, H. Crowdsourcing for medical image classification. In Proceedings of the Annual Congress SGMI; 2014; Volume 2014. Available online: https://hesso.tind.io/record/698 (accessed on 3 May 2021).
- Hannun, A.Y.; Rajpurkar, P.; Haghpanahi, M.; Tison, G.H.; Bourn, C.; Turakhia, M.P.; Ng, A.Y. Cardiologist-level arrhythmia detection and classification in ambulatory electrocardiograms using a deep neural network. Nat. Med. 2019, 25, 65–69. [Google Scholar] [CrossRef] [PubMed]
- Raghu, M.; Zhang, C.; Kleinberg, J.; Bengio, S. Transfusion: Understanding transfer Learning for Medical Imaging. In Proceedings of the Annual Conference on Neural Information Processing Systems 2019, Vancouver, BC, Canada, 8–14 December 2019; pp. 3347–3357. [Google Scholar]
- Kim, H.G.; Choi, Y.; Ro, Y.M. Modality-Bridge Transfer Learning for Medical Image Classification. In Proceedings of the 2017 10th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics, Shanghai, China, 14–16 October 2017. [Google Scholar] [CrossRef] [Green Version]
- Maqsood, M.; Nazir, F.; Khan, U.; Aadil, F.; Jamal, H.; Mehmood, I.; Song, O.Y. Transfer Learning Assisted Classification and Detection of Alzheimer’s Disease Stages Using 3D MRI Scans. Sensors 2019, 19, 2645. [Google Scholar] [CrossRef] [Green Version]
- Drosatos, G.; Kaldoudi, E. Blockchain applications in the biomedical domain: A scoping review. Comput. Struct. Biotechnol. J. 2019, 17, 229–240. [Google Scholar] [CrossRef]
- Justinia, T. Blockchain Technologies: Opportunities for Solving Real-World Problems in Healthcare and Biomedical Sciences. Acta Inform. Medica 2019, 27, 284–291. [Google Scholar] [CrossRef]
- Kuo, T.T.; Kim, H.E.; Ohno-Machado, L. Blockchain distributed ledger technologies for biomedical and health care applications. J. Am. Med. Inform. Assoc. 2017, 24, 1211–1220. [Google Scholar] [CrossRef] [Green Version]
- Finck, M. Blockchains and Data Protection in the European Union. Eur. Data Prot. Law Rev. 2018. [Google Scholar] [CrossRef] [Green Version]
- Radanović, I.; Likić, R. Opportunities for use of blockchain technology in medicine. Appl. Health Econ. Health Policy 2018, 16, 583–590. [Google Scholar] [CrossRef]
- Zhang, P.; White, J.; Schmidt, D.C.; Lenz, G.; Rosenbloom, S.T. FHIRChain: Applying blockchain to securely and scalably share clinical data. Comput. Struct. Biotechnol. J. 2018, 16, 267–278. [Google Scholar] [CrossRef]
- Glicksberg, B.S.; Burns, S.; Currie, R.; Griffin, A.; Wang, Z.J.; Haussler, D.; Goldstein, T.; Collisson, E. Blockchain-Authenticated Sharing of Genomic and Clinical Outcomes Data of Patients With Cancer: A Prospective Cohort Study. J. Med. Internet Res. 2020, 22, e16810. [Google Scholar] [CrossRef]
- Kulemin, N.; Popov, S.; Gorbachev, A. The Zenome Project: Whitepaper blockchain-based genomic ecosystem. Zenome 2017. [Google Scholar] [CrossRef]
- Lata, K.; Dave, M.; Nishanth, K.N. Data Augmentation Using Generative Adversarial Network. SSRN Electron. J. 2019. [Google Scholar] [CrossRef]
- Benaim, A.R.; Almog, R.; Gorelik, Y.; Hochberg, I.; Nassar, L.; Mashiach, T.; Khamaisi, M.; Lurie, Y.; Azzam, Z.S.; Khoury, J.; et al. Analyzing medical research results based on synthetic data and their relation to real data results: Systematic comparison from five observational studies. JMIR Med. Inform. 2020, 8, e16492. [Google Scholar] [CrossRef]
- Rankin, D.; Black, M.; Bond, R.; Wallace, J.; Mulvenna, M.; Epelde, G. Reliability of supervised machine learning using synthetic data in health care: Model to preserve privacy for data sharing. JMIR Med. Inform. 2020, 8, e18910. [Google Scholar] [CrossRef]
- Walonoski, J.; Kramer, M.; Nichols, J.; Quina, A.; Moesel, C.; Hall, D.; Duffett, C.; Dube, K.; Gallagher, T.; McLachlan, S. Synthea: An approach, method, and software mechanism for generating synthetic patients and the synthetic electronic health care record. J. Am. Med. Inform. Assoc. 2018, 25, 230–238. [Google Scholar] [CrossRef] [Green Version]
- Chen, J.; Chun, D.; Patel, M.; Chiang, E.; James, J. The validity of synthetic clinical data: A validation study of a leading synthetic data generator (Synthea) using clinical quality measures. BMC Med. Inform. Decis. Mak. 2019, 19, 44. [Google Scholar] [CrossRef] [Green Version]
- Borji, A. Pros and cons of GAN evaluation measures. Comput. Vis. Image Underst. 2019, 179, 41–65. [Google Scholar] [CrossRef] [Green Version]
- Wilkinson, M.D.; Dumontier, M.; Aalbersberg, I.J.; Appleton, G.; Axton, M.; Baak, A.; Blomberg, N.; Boiten, J.W.; da Silva Santos, L.B.; Bourne, P.E.; et al. The FAIR Guiding Principles for scientific data management and stewardship. Sci. Data 2016, 3, 160018. [Google Scholar] [CrossRef] [Green Version]
- Koehorst, J.J.; van Dam, J.C.; Saccenti, E.; Martins dos Santos, V.A.; Suarez-Diez, M.; Schaap, P.J. SAPP: Functional genome annotation and analysis through a semantic framework using FAIR principles. Bioinformatics 2018, 34, 1401–1403. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cole, C.L.; Sengupta, S.; Rossetti, S.; Vawdrey, D.K.; Halaas, M.; Maddox, T.M.; Gordon, G.; Dave, T.; Payne, P.R.O.; Williams, A.E.; et al. Ten principles for data sharing and commercialization. J. Am. Med. Inform. Assoc. 2020, 28, 646–649. [Google Scholar] [CrossRef] [PubMed]
- European Commission. Managing Health Data; European Commission: Brussels, Belgium, 2019. [Google Scholar]
- European Commission. eHealth: Digital Health and Care; European Commission: Brussels, Belgium, 2020. [Google Scholar]
- European Commission. Digital Single Market; European Commission: Brussels, Belgium, 2019. [Google Scholar]
- Information Commissioner’s Office (ICO). Guide to the General Data Protection Regulation (GDPR); ICO: Wilmslow, UK, 2018. [Google Scholar]
- Mostert, M.; Bredenoord, A.L.; Van Der Slootb, B.; Van Delden, J.J. From privacy to data protection in the EU: Implications for big data health research. Eur. J. Health Law 2017, 25, 43–55. [Google Scholar] [CrossRef] [Green Version]
- Dridi, A.; Sassi, S.; Chbeir, R.; Faiz, S. A Flexible Semantic Integration Framework for Fully-Integrated EHR Based on FHIR Standard. In Proceedings of the 12th International Conference on Agents and Artificial Intelligence (ICAART 2020), Valletta, Malta, 22–24 February 2020. [Google Scholar] [CrossRef]
- Weiler, G.; Schwarz, U.; Rauch, J.; Rohm, K.; Lehr, T.; Theobald, S.; Kiefer, S.; Götz, K.; Och, K.; Pfeifer, N.; et al. XplOit: An ontology-based data integration platform supporting the development of predictive models for personalized medicine. Stud. Health Technol. Inform. 2018. [Google Scholar] [CrossRef]
- Zillner, S.; Neururer, S. Big data in the health sector. In New Horizons for a Data-Driven Economy: A Roadmap for Usage and Exploitation of Big Data in Europe; Springer: Cham, Switzerland, 2016. [Google Scholar] [CrossRef] [Green Version]
- Hong, N.; Wen, A.; Shen, F.; Sohn, S.; Wang, C.; Liu, H.; Jiang, G. Developing a scalable FHIR-based clinical data normalization pipeline for standardizing and integrating unstructured and structured electronic health record data. JAMIA Open 2019, 2, 570–579. [Google Scholar] [CrossRef]
- Wang, Z.; Jensen, M.A.; Zenklusen, J.C. A Practical Guide to the Cancer Genome Atlas (TCGA). In Methods in Molecular Biology; Springer: New York, NY, USA, 2016. [Google Scholar] [CrossRef]
- Clark, K.; Vendt, B.; Smith, K.; Freymann, J.; Kirby, J.; Koppel, P.; Moore, S.; Phillips, S.; Maffitt, D.; Pringle, M.; et al. The cancer imaging archive (TCIA): Maintaining and operating a public information repository. J. Digit. Imaging 2013, 26, 1045–1057. [Google Scholar] [CrossRef] [Green Version]
- Sayers, E.W.; Beck, J.; Bolton, E.E.; Bourexis, D.; Brister, J.R.; Canese, K.; Comeau, D.C.; Funk, K.; Kim, S.; Klimke, W.; et al. Database resources of the National Center for Biotechnology Information. Nucleic Acids Res. 2021, 36, D13–D21. [Google Scholar] [CrossRef]
- Stanford Center for Artificial Intelligence in Medicine and Imaging. Medical ImageNet; Stanford Center for Artificial Intelligence in Medicine and Imaging: Stanford, CA, USA, 2019. [Google Scholar]
- Tang, A.; Tam, R.; Cadrin-Chênevert, A.; Guest, W.; Chong, J.; Barfett, J.; Chepelev, L.; Cairns, R.; Mitchell, J.R.; Cicero, M.D.; et al. Canadian Association of Radiologists White Paper on Artificial Intelligence in Radiology. Can. Assoc. Radiol. J. 2018, 69, 120–135. [Google Scholar] [CrossRef] [Green Version]
- National Institutes of Health—Office of Data Science Strategy. Open-Access Data and Computational Resources to Address COVID-19; National Institutes of Health: Bethesda, MD, USA, 2020. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pereira, T.; Morgado, J.; Silva, F.; Pelter, M.M.; Dias, V.R.; Barros, R.; Freitas, C.; Negrão, E.; Flor de Lima, B.; Correia da Silva, M.; et al. Sharing Biomedical Data: Strengthening AI Development in Healthcare. Healthcare 2021, 9, 827. https://doi.org/10.3390/healthcare9070827
Pereira T, Morgado J, Silva F, Pelter MM, Dias VR, Barros R, Freitas C, Negrão E, Flor de Lima B, Correia da Silva M, et al. Sharing Biomedical Data: Strengthening AI Development in Healthcare. Healthcare. 2021; 9(7):827. https://doi.org/10.3390/healthcare9070827
Chicago/Turabian StylePereira, Tania, Joana Morgado, Francisco Silva, Michele M. Pelter, Vasco Rosa Dias, Rita Barros, Cláudia Freitas, Eduardo Negrão, Beatriz Flor de Lima, Miguel Correia da Silva, and et al. 2021. "Sharing Biomedical Data: Strengthening AI Development in Healthcare" Healthcare 9, no. 7: 827. https://doi.org/10.3390/healthcare9070827
APA StylePereira, T., Morgado, J., Silva, F., Pelter, M. M., Dias, V. R., Barros, R., Freitas, C., Negrão, E., Flor de Lima, B., Correia da Silva, M., Madureira, A. J., Ramos, I., Hespanhol, V., Costa, J. L., Cunha, A., & Oliveira, H. P. (2021). Sharing Biomedical Data: Strengthening AI Development in Healthcare. Healthcare, 9(7), 827. https://doi.org/10.3390/healthcare9070827