Abstract
Background/Objective: This study investigates the implementation and evolution of intelligent medical question-answering (QA) systems in healthcare to enhance service efficiency and quality. Methods: Through an integrated literature review and bibliometric analysis using CiteSpace 6.3.R1(64-bit) Basic software, we systematically evaluated core concepts, frameworks, and applications within medical QA systems, analyzing literature from 2018 to 2025 to identify research trends. Results: Significant applications were revealed across clinical decision support, medical knowledge retrieval, traditional Chinese medicine (TCM) formulation development, medical imaging report analysis, medical record quality control, mental health monitoring, and emotion recognition, demonstrating optimized resource allocation and service efficiency. Persistent challenges include system accuracy limitations, multimodal interaction capabilities, user trust barriers, and privacy protection concerns. Conclusion: Future research should prioritize multimodal diagnostic imaging, TCM-specific AI agents, and virtual-reality-assisted surgical exploration. Contributions: This work consolidates current achievements while establishing theoretical–practical foundations for innovation and large-scale implementation, advancing intelligent healthcare transformation.
1. Introduction
The rapid advancement of artificial intelligence (AI) and digital transformation in healthcare has intensified public demand for accessible medical services. Current expectations extend beyond traditional clinical models to encompass real-time health monitoring and in-depth medical knowledge acquisition. Nevertheless, China’s healthcare system remains under optimization, struggling to fully meet these demands. In this context, intelligent medical question-answering (QA) systems have emerged as a novel human–computer interaction paradigm with significant practical implications [1]. Given constraints in healthcare staffing and scheduling, developing such systems is critical. They effectively alleviate clinicians’ workloads by automating routine queries, enabling professionals to focus on complex medical tasks [2]. This innovation optimizes resource allocation, enhances service efficiency, and elevates care quality. By delivering rapid and accurate consultations, QA systems transcend spatiotemporal barriers, empowering users to access medical advice anytime, anywhere—thereby reducing healthcare burdens. Through continuous knowledge refinement, these systems provide personalized guidance that improves patient education and confidence, ultimately enhancing healthcare experiences.
To address China’s uneven distribution of medical resources, QA systems facilitate equitable access via online consultations, democratizing high-quality care [3]. Currently, AI serves as a pivotal force in governmental and industrial transformation. As a quintessential AI application, medical QA systems advance both technical capabilities and broader AI adoption. Consequently, they play an indispensable role in elevating healthcare quality, reducing costs, and accelerating AI progress.
However, existing research exhibits critical gaps: insufficient systemic analysis of QA frameworks and limited elaboration on healthcare-specific implementation details. To bridge these gaps, this study comprehensively examines the evolution of medical QA systems, analyzing key development aspects—evaluation metrics, data collection, knowledge storage, natural language understanding (NLU) modules, knowledge computation, and dialog management. We further systematize healthcare applications with case studies, aiming to establish theoretical foundations and practical guidelines for system refinement.
The innovation of this study is that it adopts a combination of literature review and bibliometric analysis and uses CiteSpace software to conduct in-depth mining and analysis of a large amount of related literature, so as to more comprehensively and accurately grasp the current research status and development trend of the intelligent medical QA system. In addition, this study will provide a systematic summary and outlook on the construction and application of intelligent medical QA systems from the practical needs of the healthcare field, so as to provide new perspectives and ideas for promoting the technological advancement and wide application of intelligent medical QA systems.
This paper is organized as follows: Firstly, the concept, definition, and framework of the QA system are introduced, then the evolution process of the QA system and its application in the medical field are elaborated in detail. Next, the construction of the QA system is discussed in depth, including relevant evaluation indices, data collection, knowledge storage, natural language understanding module, knowledge computing module, and dialog management and interaction. Then, a systematic summary of the intelligent QA system in the healthcare field is presented, analyzing it with typical cases, as well as a bibliometric analysis of existing studies. Finally, we conclude the whole paper and look forward to the future development trend of the intelligent medical QA system.
2. Question Answering Systems
2.1. Concepts, Definitions, and Frameworks
Question answering (QA) systems constitute a cornerstone of natural language processing (NLP), serving as advanced information retrieval frameworks engineered to deliver precise responses to natural language queries. Emerging during the 1950s within the framework of the Turing test, early systems, including BASEBALL (1961) [4] and ELIZA (1966) [5], established foundational techniques for domain-specific and conversational QA. These systems have evolved from text-limited paradigms toward comprehensive frameworks supporting multimodal interactions (e.g., images, audio, and video) [6,7]. For example, Microsoft Xiao-Ice [8] and Alibaba’s Xiaomei [9] demonstrate multimodal systems that integrate text, images, and video for e-commerce and social applications.
The QA structural framework comprises three core phases (Figure 1): question analysis, information retrieval, and answer extraction. Firstly, features are extracted from the multimodal information input by the user, such as text, image, audio, etc., and fused into a unified representation. Next, relevant data are retrieved and filtered from knowledge bases or document collections. Finally, concise answers are generated through template matching, semantic parsing, or deep learning techniques [10].
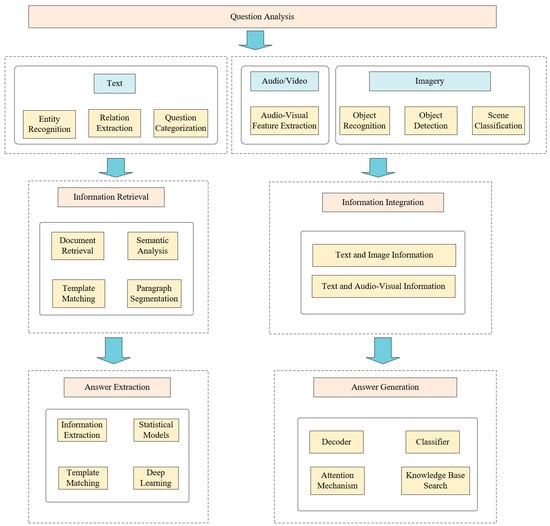
Figure 1.
Processing framework for the QA system.
2.2. Evolution and Medical Applications
The evolution of QA systems is characterized by three distinct phases: The initial phase (1960s–1990s) was defined by rule-based systems, such as LUNAR (Geology) [11] and TREC QA Track [12]. Such systems relied exclusively on expert-defined rules and structured databases. The subsequent phase (2000s–2010s) featured data-driven systems, including START and Siri [13], which utilized open-domain architectures with free-text corpora and community platforms. The current phase (2020–present) is dominated by AI-driven paradigms employing large language models (e.g., ChatGPT [14]) and knowledge graphs to enable context-aware multimodal interactions.
In healthcare, medical QA systems are categorized as semantic-based systems or keyword-matching systems. Semantic-based systems integrate clinical guidelines and PubMed data for query parsing, with AskHERMES [15] being representative. Keyword-matching systems use shallow syntactic analysis but lack semantic depth, as exemplified by MedQA [16].
While systems such as MEANS [17] and AskCuebee [18] address specialized domains (e.g., parasitology), significant challenges persist in handling negation and complex reasoning. ChatGPT shows potential for medical triage but is limited by factual inaccuracies and instability [14]. HestiaQA [19] and Medicine Seekers emphasize disease-specific counseling importance yet exhibit challenges in maintaining answer consistency.
3. Construction of QA System
3.1. Relevant Evaluation Indicators and Data Collection
3.1.1. Relevant Evaluation Indicators
Regarding the evaluation metrics of the QA system, the common metrics are accuracy, F1-score (F1), precision, recall, exact match (EM), mean average precision (MAP), and mean reciprocal rank (MRR).
(Acc) is the ratio of the number of correct responses to the total number of questions, as in Equation (1):
Here, (true positive) denotes the number of samples correctly predicted as positive, (true negative) represents samples correctly predicted as negative, and signifies the total test samples.
-score is a metric that combines precision and recall, as in Equation (2):
Precision is the percentage of correct answers among the answers provided by the QA system, as in Equation (3):
(false positive) indicates samples misclassified as positive.
Recall is the ratio of the number of correct answers returned by the system to the number of all correct answers, as in Equation (4):
(false negative) refers to samples misclassified as negative.
Exact match () is a measure of the perfect match between the predicted answer and the actual facts, which is commonly used in the question and answer task data SQuAD, as in Equation (5):
The mean average precision () is the average of the mean precision of multiple questions, which evaluates the quality of the answer ranking returned by the system, as in Equation (6):
The mean reciprocal rank () is a measure of the quality of the ranking of the retrieval results, as in Equation (7):
In Equation (7), is often used as a metric in multi-result problems, where denotes the total number of queries and is the sequence of queries. is the proportion of correct answers appearing in the first K returned results, as in Equation (8):
In Equation (8), by adjusting the value of K, the performance under different numbers of returns in the QA system can be evaluated.
Bilingual evaluation understudy () is suitable for evaluating the metrics of machine translation quality, which is widely used in the field of QA systems, and a higher value of indicates that the generated answer is more similar to the reference answer, i.e., the quality of the answer is higher, as in Equation (9):
where is the length penalty factor, is the weight for different N-grams, is the corrected precision, N-gram is a segment consisting of n consecutive words inside an utterance, and N is the segment length.
Recall-oriented understudy for gisting evaluation (ROUGE) is mainly based on the calculation of recall and is a measure of how much information from the reference answer is included in the generated answer.
3.1.2. Data Acquisition
Publicly accessible natural language data are available in various forms [20,21]. These data can be transformed into large-scale, high-quality, diverse, and actionable datasets through de-duplication and cleaning processes, thereby establishing foundational databases for medical QA systems. Generic datasets possess rich training data and linguistic diversity, enhancing QA system performance and applicability. In addition, synthetic datasets generated from advanced language models (e.g., ChatGPT) have been utilized for model training. The synthetic data are widely adopted due to their low acquisition cost and high quality [22]. This innovative approach has yielded high-performance language models.
Medical QA systems typically leverage resources, including publicly accessible healthcare platform QA data, doctor–patient dialogs, knowledge bases, open medical datasets, and ChatGPT-generated synthetic data [23]. Table 1 summarizes prevalent biomedical datasets while analyzing their distinct contents and applications.

Table 1.
Common biomedical datasets.
3.2. Knowledge Storage
The knowledge storage module stores extracted triples within a graph database while providing visual knowledge graph representations. Knowledge graph storage centers on triple-based systems, primarily encompassing RDF graph models and attribute-based graph databases, with the latter constituting the current mainstream approach. Related research addresses RDF graph data management [33,34], graph querying [35], and computational frameworks [36,37]. Reference [38] provides a systematic review of data models, query languages, and storage management, establishing theoretical foundations for knowledge storage development.
Three primary storage methods exist: relational databases, RDF-specific triple stores, and native graph databases. Relational databases employ mature strategies—including triple, horizontal, attribute table, and vertical partitioning storage—yet exhibit query performance limitations and significant storage demands. RDF-specific triple stores support SPARQL standards, offering formatting advantages. Native graph databases demonstrate superior storage/query efficiency, particularly for associative queries, with Neo4j representing the industry standard. Each method exhibits distinct tradeoffs, enabling flexible selection—particularly in medical knowledge graphs—of single or hybrid approaches based on application requirements, with critical attention to inter-format synchronization and conversion.
3.3. Natural Language Understanding Module
The natural language understanding module performs named entity recognition and intent recognition on user queries to extract semantic meaning. Early methods primarily utilized rule-based and statistical approaches. Rule-based systems depended on manually crafted grammar and expert knowledge, exhibiting limited scalability and adaptability to linguistic evolution. Subsequently, statistical methods, including N-gram models, emerged, processing linguistic data through word co-occurrence probability calculations. These methods demonstrated partial performance improvements but remained limited in capturing long-range dependencies and complex semantic relationships. In 2013, the Word2vec model was proposed by Mikolov, marking a milestone in natural language understanding. This model employs shallow neural networks to map words into low-dimensional vector space, where semantic relationships are represented through vector distances and orientations. Its two primary architectures—Skip-gram and CBOW (Continuous Bag of Words)—learn word vectors by predicting context words and center words, respectively. With advancing deep learning techniques, recurrent neural network (RNN) was introduced for natural language understanding. Long short-term memory (LSTM) [39] and gated recurrent unit (GRU) [40] mitigate RNN gradient vanishing through gating mechanisms, enabling stable and efficient long-sequence processing. Peters et al. [41] argued that context-aware pretrained vectors should encapsulate rich syntactic and semantic information, leading to the ELMo (Embeddings from Language Models) model development. In 2018, BERT (Bidirectional Encoder Representations from Transformers) was introduced by Devlin et al. [42], representing another breakthrough in natural language understanding. BERT adopts the transformer [43] architecture to capture contextual information through bidirectional training. Masked language modeling and next-sentence prediction tasks are employed during pretraining. Breakthrough results were achieved across multiple natural language understanding benchmarks. The pretraining–finetuning paradigm subsequently became standard for natural language understanding methodologies. Similarly, OpenAI’s GPT series [44] (Generative Pretrained Transformer) has demonstrated powerful language capabilities through large-scale pretraining. Recently, large language models, including ChatGPT [45], Meta’s LLaMA [46], Baidu’s Wenxin Yiyan, and Alibaba’s Tongyi Qianwen [47], have garnered significant attention for their contextual comprehension and text generation capabilities. Advancing natural language technologies are increasingly being deployed in high-risk, high-stakes, and sensitive domains. This trend presents new challenges and opportunities. Consequently, enhancing decision transparency while ensuring prediction credibility has emerged as a critical research focus.
Natural language understanding (NLU) technologies in healthcare have evolved along a generic NLP pathway yet demonstrate a distinct trajectory due to the specialized nature of medical texts. Early rule-based approaches relied on medical ontologies for structuring electronic health records (EHRs) but had poor scalability. N-gram models could mine drug associations but found it difficult to handle long-distance semantics. During the deep learning era, PubMed2vec established medical terminology embeddings, RNN/LSTM improved time-series medical data processing, and BioBERT and ClinicalBERT enhanced clinical decision support via domain-specific finetuning. Contemporary large language models represented by ChatGPT have been successfully adapted to medical data demonstrating efficacy in differential diagnosis and virtual patient consultation. However, stringent regulatory requirements in medical contexts present interpretability challenges, motivating efforts to resolve the “black box” dilemma through techniques like attention visualization.
3.4. Knowledge Computing Module
The knowledge computation module converts natural-language-processed interrogatives into structured queries, which are executed against the knowledge graph to retrieve answers. Knowledge graph technology serves as the core enabler for computable medical knowledge research, with key methodologies focusing on knowledge representation, named entity recognition and entity relationship extraction. Regarding knowledge representation, medical models have been constructed using rule bases, data-driven approaches, semantic triples, and ontologies, as evidenced by Gao et al.’s multilayer model for data compatibility optimization [48], Yang et al.’s EHR-based disease prediction framework enhancing structured knowledge computability [49], Suo’s proposition of semantic triples as fundamental representation units [50], and Patel’s demonstration of ontological efficacy in representing imprecise heterogeneous knowledge [51]. Knowledge representation methodologies evolve along two dimensions: feature-based approaches integrate textual content, attributes, and positional features (e.g., Ye et al.’s “knowledge pattern” framework [52] and Song’s adversarial learning integration of multicenter clinical data [53]); conversely, association-based methods utilize semantic triples and ontologies as foundational units [54]. Semantic ternary and ontology modeling depict inter-knowledge relationships, as demonstrated by Li et al.’s RDF-based clinical big data representation [54] and Zhang’s multimodal feature aggregation network for medical knowledge embedding [55].
Named entity recognition (NER) has evolved from dictionary-rule systems through traditional machine learning to deep learning, with contemporary dominance by LSTM-CRF and BiLSTM-CRF architectures [56,57]. For limited-data scenarios in Chinese clinical guidelines, low-resource NER research concentrates on data augmentation and model transfer techniques. In model structure design, lexicon-matching conflicts are resolved by Ding et al. via multigraph architectures [58], while lexical information integration through transformers enhances recognition efficiency (Li et al. [59]). Regarding data resource optimization, feature capture is enhanced by Sun et al. using AdaBoost [60], whereas lexicon weighting improves model inference (Liu et al. [61]). Entity relationship extraction identifies semantic links via co-occurrence analysis, rule-based systems, and machine/deep learning approaches. Deep learning methods exhibit superior performance: Chen et al.’s BiLSTM-CRF achieved 82.27% F1 on EHR relationships [62], PubMedBERT attained 92% F1 in low-resource biomedical extraction (Milosevic et al. [63]), and Cao et al.’s knowledge base fusion yielded 96.00% F1 for cancer mutation gene–disease relationships [64]. These approaches establish the foundation for structured healthcare knowledge processing and efficient implementation.
3.5. Dialog Management and Interaction
Early dialog management relied on rudimentary text interactions, wherein systems provided single responses post-user queries. This approach exhibited dynamic limitations and struggled with semantic associations due to inadequate contextual modeling for multi-turn reasoning. To enable natural conversational experiences </mark>, <mark> dialog strategies and interaction designs have been enhanced through multidimensional optimizations. For example, deep learning context modeling techniques (e.g., transformer and memory network) are employed to build a state tracking mechanism enabling implicit need identification via extended dialog history support. Reinforcement learning is integrated to optimize dialog policies, with systems trained through physician–patient scenario simulations to proactively disambiguate queries and dynamically adapt responses during multi-turn exchanges, thereby enhancing QA logic and user satisfaction.
Additionally, voice interaction technology is increasingly being implemented in medical QA systems. Speech recognition and synthesis technologies facilitate voice-based querying and response delivery, enhancing interaction naturalness and convenience. Concurrently, multimodal interaction has emerged as a research focus, enabling system integration of graphical inputs (such as uploaded laboratory reports and medication instructions) with voice data. Cross-modal fusion models aim to achieve composite “voice-to-image-to-text” interactions. Furthermore, medical scenario specificity is addressed through precise intent analysis: domain-specific classifiers distinguish diagnostic consultations, medication guidance, health science dissemination, and health information queries. Personalized responses are subsequently generated based on user profiles (e.g., age and medical history).
4. Intelligent Question Answering System in Healthcare
4.1. Intelligent Assisted Medical Decision Support
Medical-assisted decision-making represents a critical application scenario for intelligent medical QA systems. The diagnosis–treatment workflow is optimized through deep analysis of patient data, delivering critical information to clinicians. Accurate support is provided across diverse medical scenarios via intelligent discrimination and model integration within clinical decision support systems. At the data level, key diagnostic insights are generated through analysis of consultation records, electronic health records (EHRs), and medical image data. At the model level, optimal integration pathways between large language models and expert systems are identified to deliver scenario-specific decision support.
Intelligent medical QA systems demonstrate robust predictive and classification capabilities, enabling synthesis of personalized patient profiles with comprehensive medical datasets to generate individualized treatment plans. This customized clinical decision support enhances treatment outcomes for healthcare providers.
4.2. Medical Knowledge QA
Document data are segmented into discrete paragraphs via a paragraph-splitting model, establishing the foundation for subsequent text vectorization. These paragraphs are then vectorized using a text embedding model, with a document vector index library constructed to enable efficient retrieval. Upon query initiation, user inputs are vectorized by the QA system, followed by vector retrieval operations to identify maximally relevant document segments. Matching results are integrated with prompt templates, assembling inputs processed by the large language model to generate final responses. Final outputs are delivered via streaming API to user terminals, enabling rapid and accurate knowledge services. MedGPT, a healthcare-specific large language model, delivers detailed medical condition explanations, treatment plan recommendations, and common health problem resolutions through conversational interactions. Leveraging multi-turn dialog training datasets, it provides accessible health intelligence services.
4.3. Chinese Medicine R&D and Pharmacy Services
Intelligent QA system implementation in pharmaceutical research enhances efficiency, reduces costs, improves accuracy, and enables personalized treatment planning, representing a significant industry trend. In traditional Chinese medicine (TCM) and pharmaceutical services, QA system modules integrate modern pharmacology with TCM principles to analyze herbal constituents in depth, identifying potential herb–drug interactions and safety concerns. Building on Chinese medicine canon and drug interaction research, novel personalized treatment concepts and tools are generated. Computer simulations enable prediction of drug activity profiles, safety parameters, and adverse effects.
QA systems have facilitated breakthrough innovations in cardiovascular and antineoplastic therapeutics. In 2015, two Ebola-inhibitory drug candidates were identified by Atomwise using AI algorithms, reducing discovery timelines by orders of magnitude. Traditional methods may take months or even years to achieve similar results. Therefore, AI-based drug screening demonstrates significantly higher efficiency versus conventional techniques [65]. Multimodal QA systems analyze chemical and biological data during development, predicting compound bioactivity, toxicity, and pharmacokinetic properties. This capability enables discovery of novel drug targets, disease mechanisms, and therapeutic strategies. TCM pharmaceutical services extend QA system capabilities through drug knowledge base integration, enhancing medical query resolution. After receiving questions submitted by users, the service first calls the drug name entity recognition module to extract drug names, then calls the text vectorization model to vectorize the extracted drug names and retrieves the standard drug names from the drug name vector library to obtain the drug primary key. User queries are then converted to semantic vectors, triggering retrieval from drug specification vector libraries and related literature. External knowledge is integrated with queries to assemble prompts, which are processed by the QA system for answer generation.
Retrieval-augmented generation technology integrates semantic search and generative mechanisms, enabling rapid extraction of precise knowledge from pharmaceutical databases and synthesis of clinically accurate responses. These tightly integrated retrieval and generation systems exhibit enhanced accuracy and response speed, revolutionizing pharmaceutical knowledge acquisition and user experiences.
4.4. Medical Imaging Report Analysis for Accurate Diagnosis and Treatment Decision-Making
Diagnostic imaging in medicine can assist doctors in accurately diagnosing and treating patients’ conditions; however, traditional methods are prone to issues, such as highly repetitive work, which is prone to increasing the diagnostic error rate, prolonging diagnostic time, the absence of an auditing doctor for certain medical imaging categories, and a stronger reliance on individual doctors’ experience. The multimodal intelligent QA system can develop an image report analysis service that enables doctors to perform preliminary image screening, conduct quantitative disease analysis, and generate disease analysis reports by incorporating big data analysis and AI deep learning technology. The service automatically analyzes medical images through AI reading, identifies the patient’s lesion area, and generates a detailed image report that includes the lesion’s location, size, and morphological features, as well as an accurate diagnosis based on the analysis results. For follow-up patients with a history of multiple imaging examinations, the system can automatically retrieve the patient’s historical report information for the same anatomical region, conduct detailed comparative analysis of the reports, correlate the relevant diagnostic information, and generate diagnostic imaging conclusions.
The image report analysis service has three specific application scenarios: guided diagnostic conclusions, comparative analysis scenarios, and fully automated generation services. Guided diagnostic conclusions enable the image report analysis service to automatically generate diagnostic conclusions based on the imaging doctor’s textual description of the findings. Doctors can then use the automatically generated content to adjust their references and produce a complete image report. Comparative analysis scenarios allow the system to retrieve historical reports of patients with multiple imaging tests, enabling a comparative analysis of the findings across different reports and generating a diagnosis that reflects both the current imaging results and historical trends. A fully automated generation service streamlines the entire diagnostic process, from AI reading and image description to the final diagnostic conclusion.
4.5. Quality Control Analysis of Medical Record Content
Quality control (QC) of medical records, the core content of hospital quality management, can detect and correct errors and defects in the medical process, ensuring the accuracy, completeness, and reliability of medical information [66].
Currently, most medical institutions have established electronic medical record quality control systems to ensure timeliness and completeness. However, these systems primarily monitor the formal aspects of quality control, with much of the content still relying on manual sampling. Quality control officers need to review numerous medical records, orders, and examination reports, a process that is labor-intensive and inefficient. Moreover, manual sampling can only cover a limited portion of a hospital’s medical records. The intelligent QA system’s medical record content QC analysis applies to multiple medical scenarios, shifting traditional rule- and template-based QC methods toward self-learning models. This enables the system to grasp the complex nuances of QC rules and ensures logical medical record content checking. By finetuning the model, the large language model can better understand human language requests and provide detailed and accurate explanations of the quality control results, instead of merely returning “yes” or “no” to indicate compliance with the quality control rules. According to the type of QC rules, different algorithmic model levels are automatically matched to address automated content QC, self-explanatory content QC, and self-learning feedback mechanisms, enabling the model to better satisfy diverse user needs during self-learning.
4.6. Mental Health Monitoring and Emotion Recognition
Recent advances in AI-driven mental health monitoring have shifted depression detection from subjective assessments toward objective quantification. Facial expression analysis—a core methodology—integrates multimodal data through deep learning models, emerging as a pivotal tool for identifying depression and affective disorders.
Convolutional neural networks (CNNs) now enable precise capture of depression-related micro-expressions. Pretrained models (e.g., VGG-19 and ResNet-152) achieve superior performance via transfer learning on datasets like CK+ and FER2013. Notably, VGG-19 attained 0.98 mean accuracy on CK+, establishing a technical foundation for early depression screening [67]. These models selectively freeze low-level feature extraction layers while finetuning high-level classifiers to detect subtle facial muscle dynamics (e.g., drooping corners of the mouth and periorbital muscle tension). Augmentation techniques (image rotation and brightness adjustment) further enhance robustness against real-world variables like lighting variations and facial occlusions [67].
Multimodal data fusion expands clinical applications. Integrating facial dynamics (expression duration and intensity variation), body posture (shoulder/neck rigidity), and vocal prosody elevates detection accuracy by 15–20% [68]. For instance, DenseNet architectures combining facial landmark trajectories with head-motion features comprehensively capture affective blunting in depression patients, including delayed emotional responses and reduced movement amplitude [68]. Such frameworks are now embedded in telemedicine platforms (e.g., DoctorLINK), enabling real-time emotion monitoring for remote psychological interventions [67].
Currently, the research in this field is developing toward the direction of ‘precision individualization’. On the one hand, the cross-group recognition bias is reduced by transfer learning to adapt facial expression features in different cultural contexts (e.g., more introverted emotional expression in Eastern populations); on the other hand, multimodal fusion models combining physiological signals (e.g., heart rate variability and skin electrical activity) and facial expressions are becoming a new path to resolve the neurophysiological mechanisms of depression [69]. These advances not only promote the automation and objectivity of depression detection but also provide a technological paradigm for achieving the full-cycle mental health management of ‘screening–intervention–follow-up’ by embedding the tele-diagnosis process [67].
5. QA System in Healthcare Field
5.1. Shenglang AI Clinical Intelligent QA System
Leveraging deep learning and natural language processing (NLP) technologies, the Shenglang AI Clinical Intelligent QA System constructs a multisource knowledge base integrating medical literature, clinical guidelines, and real-world cases. Text-based interactions and visual outputs are supported, including symptom analysis reports and treatment pathway diagrams. Diagnostic logic is optimized through patented algorithms, reducing misdiagnosis risk by 37%, as validated using clinical data from over 500 partner institutions, including the 301 hospitals. Dual-user interfaces serve clinicians and patients: patient-facing features enable symptom self-assessment, medication guidance, and triage advice, while clinician tools support diagnostic and therapeutic decision-making with real-time evidence-based recommendations and personalized treatment plans. The technical architecture achieves dynamic clinical data–knowledge graph fusion, demonstrating rare diseases’ characteristic identification in complex case analyses. This capability will be integrated into medical school curricula from 2025, exemplifying AI-enhanced clinical decision-making.
5.2. Zhiyun Health’s Knowledge Graph-Based Medical Intelligent Consultation System
A large-scale knowledge graph encompassing 3000+ diseases, 20,000+ drugs, and 1 billion electronic medical records has been developed by Zhiyun Health. Accurate consultation and prescription compliance verification are enabled through a rule engine and machine learning algorithms, achieving 99.97% accuracy in detecting drug contraindications. The system is differentiated in retail pharmacy and medical institution scenarios: the SaaS platform for 228,000 pharmacies provides real-time early warning of medication risks and improves the safety of medication at the grass-roots level, while the pre-inquiry module at the hospital end improves the efficiency of the outpatient process by 40% and innovatively supports the intelligent analysis of unstructured data, such as TCM symptoms and constitution identification, etc. Integration with the DeepSeek-R1 enhanced model is scheduled for 2025, with deployment in electronic medical records. Following implementation, abnormal indicator identification speed will increase 5-fold in electronic medical records, while chronic condition oversight in primary medical institutions will decrease to 1.2%. These enhancements will establish the system as a critical intelligent support tool within hierarchical diagnosis frameworks.
5.3. MedAI
MedAI focuses on intelligent solutions for the entire pharmaceutical R&D lifecycle. Its core functionalities encompass clinical trial management and medical data standardization. Utilizing natural language understanding (NLU) technology, its medical coding system automatically maps unstructured data to international standard terminologies, such as MedDRA and WHO-DD, with 98.7% accuracy, significantly enhancing clinical trial data processing efficiency. In new drug R&D scenarios, companies such as Hengrui Pharma and WuXi AppTec are assisted in shortening R&D cycles by 15–20% through protocol design optimization and automated CRF generation. Scheduled for launch in 2024, Version 3.0 integrates a real-world data (RWD) analysis module. This module mines drug efficacy signals from electronic medical records and healthcare insurance data, providing data-driven support for post-marketing safety monitoring and indication expansion, thereby establishing it as a key component for pharmaceutical industry innovation.
5.4. Pearl River Hospital DeepSeek Intelligent QA Platform
The Pearl River Hospital DeepSeek platform, based on DeepSeek large model architecture, supports localized deployment and multimodal interaction (voice input and image data parsing). It focuses on enhancing electronic medical record intelligence and improving primary care quality. Technically, its medical record generation module reduces structured documentation time from 2 h to 10 min, achieves 85% accuracy in image report logic verification, and enables automatic TI-RADS grading determination for thyroid nodule ultrasound reports (91% compliance rate). Following deployment in institutions such as the Gansu Linxia Maternal and Child Health Hospital, the platform’s medical record quality control system increased high-risk pregnancy guidance accuracy to 92%, reduced test report interpretation time by 93%, and lowered omission rates from 15% to 6%. Through the domain adaptation optimization of the large model, the platform has demonstrated its comprehensive processing capability for multimodal data in complex clinical scenarios and has become an important technical carrier for promoting the syncing of high-quality medical resources.
5.5. WiNGPT
WiNGPT, a medical-domain-specific large model (7 billion parameters), provides an intelligent service system covering the entire pre-diagnosis, diagnosis, and post-diagnosis process. Core technologies include multi-round consultation logic modeling (98% critical value recognition accuracy), structured medical record generation (efficiency improved by 3–5 times, error rate reduced to 2%), and personalized follow-up plan formulation (diabetic patients’ adherence improved by 27%). A key advantage is its support for integrated Chinese–Western medicine diagnosis. The traditional Chinese medicine (TCM) evidence identification model digitally reconstructs the TCM consultation process (95% accuracy). Additionally, the open-sourced 7B lightweight version (>100,000 downloads) promotes AI-assisted diagnostic tool adoption in primary hospitals. In the pilot studies of the People’s Hospital of Peking University and Zhejiang Provincial Hospital of Traditional Chinese Medicine, the system has shortened the average outpatient consultation time by 22 min, and the standardization rate of medical record writing has increased from 68% to 94%, which has become a benchmark system of medical informatization construction that is both technologically innovative and practical on the ground.
5.6. Comparative Analysis of Healthcare Question-Answering Systems
To systematically profile medical QA systems, we conducted a comparative analysis of five mainstream platforms. As summarized in Table 2, Shenglang AI and Zhiyun Health emerged as the most widely adopted solutions due to their comprehensive coverage of clinical decision-making and primary care demands.
Table 2.
Comparison of mainstream healthcare QA systems.
6. Challenges and Future Trends
6.1. Problems and Challenges
6.1.1. Accuracy and Professionalism
Although the intelligent medical QA system possesses a certain degree of general medical knowledge, it has significant limitations both in terms of specialized medical knowledge reserves and serious medical numerical or intellectual reasoning. As a result, the system may generate inaccurate or even incorrect medical advice during the dialog process [70], which severely limits its application in medical tasks with high difficulty, depth, and real-time requirements.
The essence of large language models (LLMs) lies in generating evidence-based judgments and predictions. Thus, maximizing their potential in healthcare hinges critically on overcoming data bottlenecks. Compared to vertical-domain LLMs, medical data’s specialized, complex, and heterogeneous nature creates unique deployment challenges: low data quality, severe data siloing, impeded data assetization, and stringent demands for multimodal data synergy, standardization, and timeliness.
First, medical data span diverse diseases, patient cohorts, and clinical scenarios. Multimodal sources—text, images, and genomic data—originate from disparate healthcare institutions and information systems, resulting in inconsistent data quality and high integration complexity. Second, the absence of unified data standards and interoperable interfaces compounds these issues. Most hospitals restrict database access to local networks, perpetuating data silos that obstruct LLM training.
Model hallucination constitutes a major safety barrier for medical LLMs. This phenomenon occurs when models generate content based on internal constructs rather than factual data, manifesting as fabricated details or erroneous factual interpretations. As Zheng Haihua (CTO of WeMed) notes, the non-transparent algorithmic processes underlying LLM reasoning raise concerns about explainability and reliability in clinical applications. The Taxonomy of LLM Hallucinations (Tencent AI Lab) classifies hallucinations into three categories:
- Input-conflicting hallucinations: incongruent responses (e.g., describing disease symptoms when queried about treatments).
- Context-conflicting hallucinations: inconsistent outputs across sessions (e.g., diagnosing a cold today versus allergies tomorrow for identical symptoms).
- Fact-conflicting hallucinations: fabrication of pseudo-factual content (e.g., misidentifying metoclopramide as “natural gas ketone” [71]).
Such hallucinations risk propagating misinformation, misdiagnosis, and clinical errors, endangering patient safety. Gartner’s July 2024 report cautions that generative AI in healthcare has entered the “trough of disillusionment”. Ensuring medical LLMs remain both effective and rational—preventing uncontrolled deviations—requires sustained efforts [71].
6.1.2. Multimodal Interactivity
Current intelligent medical QA systems mainly rely on textual dialogs, while users may use multimodal medical data involving, e.g., text, speech, images, videos, and histological data, such as electrocardiograms, imaging reports, wound pictures, and exercise videos, in actual medical scenario dialogs [72]. These data are pivotal for disease diagnosis, precision medicine, and drug development. Yet realizing their full potential necessitates complex multi-stage data governance—a process critically challenged by the heterogeneity and complexity of multimodal healthcare data [73]. Healthcare data governance encompasses data acquisition, standardization, and integration. Data acquisition aggregates voluminous and diverse medical sources, standardization cleanses, transforms, and normalizes heterogeneous multimodal data into consistent formats for downstream processing, and integration consolidates these standardized datasets to create unified views enabling cross-source interoperability.
Existing governance frameworks exhibit limitations in multimodal data handling. Structurally, divergent semantic features across modalities complicate standardization and integration. Analytically, current tools predominantly process unimodal data, failing to leverage multimodal information holistically. Ethically, safeguarding confidentiality, integrity, and availability of sensitive health data while preventing breaches remains a persistent challenge [74].
Medical imaging analysis—spanning lesion detection, segmentation, and classification—faces analogous hurdles. Traditional manual methods are labor-intensive and subjective, increasing misdiagnosis risks. AI models trained on specialized datasets require costly expert annotations and complex feature extraction yet demonstrate poor generalization across institutions and imaging devices [75]. Addressing these issues mandates resolving multimodal data fusion barriers to securely integrate imaging, pathology, genomics, and EHRs, thereby advancing data assetization. Developing medical semantic data cleaning/annotation frameworks will provide high-quality structured training data, facilitating EHR sharing, test result interoperability, and optimized insurance services.
The smart hospital era transforms clinical workflows and operational paradigms. Embedding large models throughout diagnostic–therapeutic processes necessitates enhancing clinicians’ AI interaction skills and investigating foundational theories: personalized learning, multi-agent collaboration, and uncertainty reasoning. Establishing medical LLM training platforms [76], redesigning human–AI collaboration, and implementing adaptive clinician–patient–AI systems are essential to evolve from diagnostic assistance to closed-loop therapeutic decision-making.
6.1.3. User Adherence and Trust Issues
Despite preliminary applications of medical large language models (LLMs) in drug discovery, patient consultation, medical imaging decision support, and health management, fragmented scenario-specific requirements and insufficient domain comprehension perpetuate trust deficits—a primary barrier to widespread adoption [71]. As healthcare constitutes a credence good, users cannot evaluate service quality through experience or cost alone, relying predominantly on trust-based selection. Consequently, patients preferentially rely on clinicians’ expertise over algorithm-generated diagnoses despite continuous LLM performance improvements, explaining limited real-world acceptance [71].
Furthermore, while LLM accuracy advances (e.g., Tencent Health AI’s 87% accuracy in medical note summarization), significant performance gaps persist in core diagnostic tasks compared to experienced physicians. Studies confirm limitations in treatment planning, where even minor errors risk severe consequences—fostering clinician and patient caution toward LLM-driven decisions [71]. In case of intellectual errors or misleading information, patients’ compliance may significantly decrease, and physicians may question their reliability [77]. In addition, there are significant differences in the acceptance of chatbots among users of different regions and age groups: users in developed regions are more likely to accept them due to higher technology penetration, while users in developing regions are relatively conservative, and young users tend to accept technological innovations, while older users have higher thresholds due to technological unfamiliarity and operational complexity [78]. Therefore, improving the credibility and transparency of smart medical QA systems and optimizing their design for different user groups are key challenges to increase their acceptance and long-term application value.
6.1.4. Privacy Protection and Ethical Issues
Intelligent medical QA systems face serious privacy and security risks when processing user data. Despite the gradual maturation of data encryption and anonymization technologies, the possibility of privacy leakage still exists [70]. In addition, errors in medical advice may lead to serious consequences, and the issue of responsibility attribution needs to be clearly defined [79]. Despite data’s established status as the fifth production factor, medical data assetization confronts persistent barriers. Hospitals adopt conservative approaches toward cross-institutional data sharing due to stringent privacy requirements, high misuse risks, ambiguous accountability frameworks, insufficient trusted health data exchange platforms, and inadequate regulatory mechanisms for data circulation. Given that high-quality data constitute the foundation of LLM optimization, these constraints severely impede medical LLM training [71]. Therefore, it is important to develop strict regulatory policies and ethical standards to secure user data and maintain system reliability.
6.2. Future Development Trends
This study’s projections of future trends derive from bibliometric analysis, recent advancements in high-frequency AI technologies, and synthesis of domain-expert literature, encompassing multimodal diagnostic imaging, TCM-oriented intelligent agents, and virtual agents.
6.2.1. Multimodal Image Diagnosis
Exploring diagnostic imaging based on multimodal AI techniques refers to the use of multiple types of medical data (e.g., images, text, sound, etc.) for training and modeling in order to provide accurate diagnosis, prediction, and treatment recommendations for a specific disease or medical scenario [80]. Numerous multimodal datasets integrate imaging studies with diverse data sources (e.g., genomics, clinical records, laboratory tests, and wearable devices). Through self-supervised learning, generic models applicable to multiple data types are generated, revealing relationships between image features, specific genomic signatures, and laboratory findings. Consequently, multimodal AI technology enables exploration of diagnostic imaging applications focused on early cancer biology, including cancer risk assessment and biomarker discovery/validation. By integrating various types of data, such as X-rays, pathology reports, and patient histories, and by using deep learning and machine learning algorithms to identify the type, grade, and prognosis of cancers, the combination of different types of data will provide a more comprehensive understanding of the patient’s condition and health status to provide more reliable support for medical decision-making [81,82,83].
6.2.2. Intelligent Body of Chinese Medicine
Intelligent agents establish a framework enabling healthcare models to make dynamic decisions, thereby enhancing their capacity to address complex tasks and diverse scenarios. This foundation facilitates the transition of healthcare models from language-based systems to real-world applications.
In healthcare, large model-based intelligent agents will serve as collaborative partners across all treatment domains. For doctors, intelligent systems will provide a full range of services in their daily work. For instance, during outpatient encounters, these agents can record conversations in real time, automatically generate clinical documentation, provide updated clinical guidelines, and deliver research evidence to support treatment planning. In addition, they facilitate interdisciplinary expert coordination, optimize complex case management, and enable remote patient communication. During symptom analysis and preliminary diagnosis, patients are guided through appointment scheduling and pre-visit preparation [84,85].
The traditional Chinese medicine (TCM) intelligence agent integrates specialized domain knowledge to ensure delivery of high-quality clinical advice and diagnostic solutions. Enhanced by expert knowledge, this agent applies complex TCM theories with greater accuracy for patient treatment. Through analysis of extensive TCM literature and clinical data, evidence-based diagnostic and therapeutic plans are generated. For example, analysis of Chinese medicine formula efficacy enables optimization of treatment plans based on real-time patient responses. During treatment, medical recommendations are documented while patients receive plan clarification; during rehabilitation, medication management and health guidance are provided, including long-term monitoring for chronic conditions [86]. This all-round support reduces the burden of patients, on the one hand, and ensures the efficiency of the medical process on the other hand, creating a more connected, efficient, and humanized healthcare environment for doctors and patients together.
6.2.3. Virtual Reality Surgery
Virtual reality surgical simulation constructs an operating room environment using patient-specific 3D anatomical models and frame-rendering technology. This enables a VR–environment interaction where instruments can be manipulated as in actual surgery, while patient images, records, and diagnostic data are accessible intraoperatively. However, current platforms exhibit significant limitations requiring enhancement. For example, it has not yet realized a more realistic simulation of the impact of surgical operations on patients’ physiological parameters, as well as failing to simulate the impact of differences in different patients’ conditions and other changes in the physical environment.
AI and large language model advancements will enhance virtual surgery interactivity and decision support. Using large language models and expert knowledge augmentation techniques, these deficiencies can be remedied through more refined data modeling and algorithm design. Specifically, surgical data analysis through machine learning enables generation of complex biomechanical models simulating patient-specific intraoperative physiological responses. Additionally, expert system integration provides real-time feedback for surgical optimization during procedures [87]. Large model-driven NLP technology facilitates real-time medical knowledge base queries, expert advice retrieval, and transformation of complex terminology into actionable surgical guidance. In addition, AI can help generate personalized patient data to better simulate the differences in different patients’ conditions. Real-time analytics enable dynamic intraoperative parameter adjustment. For instance, digital twin technology monitors physiological changes, providing feedback that—when integrated with large model knowledge bases—enhances surgical risk prediction and strategy adaptation. This combination not only improves the realism of virtual surgeries but also enhances their guiding role in actual surgeries. Leveraging large language model knowledge enhancement, global expertise is integrated into virtual platforms. During surgery, doctors can access best practices and expert advice for the current surgical situation in real time. This dynamic knowledge service enhances virtual surgery utility and bridges skill gaps between experienced and novice surgeons.
7. Bibliometric Analysis
The study of intelligent QA systems in healthcare has become a much talked about research topic. Relevant literature on intelligent medical QA systems published in SCI-indexed journals between 1 January 2018 and 31 March 2025 was reviewed and analyzed using CiteSpace software [88]. The literature search employed “healthcare” and “QA system” keywords to ensure comprehensive coverage of field findings.
7.1. Methodology and Data
7.1.1. Methodology
CiteSpace software (Java platform), a powerful bibliometric visualization and document analysis tool, was utilized for in-depth analysis [88]. With robust bibliometric analysis capabilities, CiteSpace visualizes complex literature associations through scientific knowledge graphs, facilitating both historical research evolution tracing and future research direction prediction [88]. Its core capability involves transforming large-scale scientific literature into intuitive visualizations, incorporating efficient analysis modules for pathfinding, clustering, and timeline analysis [89]. Specifically, the pathfinding function identifies the shortest connection paths between nodes, revealing potential research topic associations and clustering groups nodes by similarity to identify academic subfields or research domains, while timeline analysis tracks field development, highlighting seminal milestones and key events [89]. In addition, CiteSpace also provides quantitative indicators, such as the frequency of citations and the intensity of author collaboration, which provide a scientific basis for researchers to assess the importance and influence of each node in the literature network [90].
7.1.2. Data
This study used Web of Science (WOS) to collect literature data on the application of QA systems in healthcare over a period of 8 years (2018–2025). There were 509 records in the WOS core database, excluding review articles. This study selected “healthcare” and “Q&A system” as retrieval keywords based on core research objectives in medical QA systems, combined with high-frequency terms and domain hotspots from existing literature. Preliminary screening of publications validated keyword coverage, ensuring comprehensive representation of applications, technological evolution, and research trends for intelligent QA systems in healthcare.
7.2. Analysis of Results
This study used the CiteSpace tool to synthesize and analyze relevant information from different countries, institutions, journals, and scholars and compare their contributions in the field of medical QA systems. As illustrated in Figure 2, 509 publications related to healthcare QA system applications were identified. From 2018 to 2024, there was a significant increase in the number of related publications, from 36 to 481. The cumulative annual publication count demonstrated a pronounced upward trajectory, indicating growing scholarly attention to healthcare QA system research.
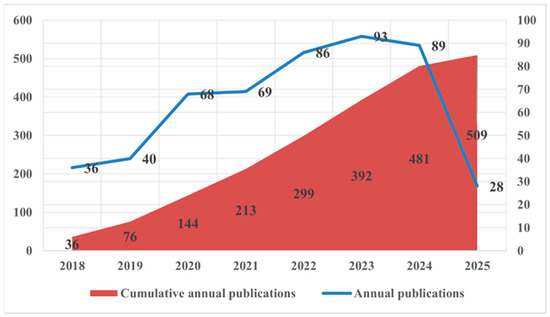
Figure 2.
Annual distribution of the number of publications.
7.2.1. Countries and Publishers
As shown in Figure 3, the countries that have published the most papers on the application of QA systems in healthcare are the United States (152 papers), the United Kingdom (62 papers), Germany (45 papers), Australia (40 papers), and China (39 papers). The United States has the highest number of publications in this area, which is 2.45 times higher than the second-ranked country, the United Kingdom, indicating that the United States attaches the highest importance to the application of QA systems in healthcare. Consistent with the Pareto principle (80/20 rule), the top 10 countries contributed 94.9% (483/509) of publications, indicating that analyzing this dominant cohort efficiently reflects the field’s primary research contributors. We, therefore, focused on these 10 nations for subsequent analysis.
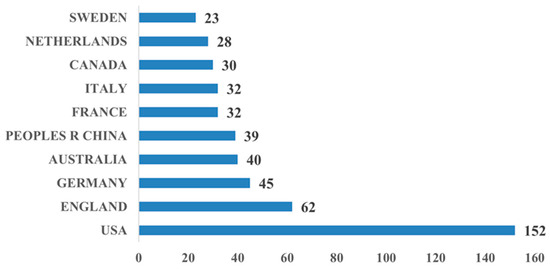
Figure 3.
Bar chart of top 10 countries by number of publications.
As presented in Figure 4, the most prolific institutions publishing on healthcare QA system applications were: Harvard University (14 article), University of London (14 articles), University of California (12 articles), Harvard University Medical Affiliates (11 articles), Institut National de la Sante et de la Recherche Medicale Inserm (11 articles), Monash University (11 articles), University of Pennsylvania (11 articles), University of Toronto (11 articles), Imperial College London (10 articles), and Universite Paris Cite (10 articles). Four of the top seven institutions are located in the United States. This distribution indicates substantial US research engagement in this domain. In addition, it also shows that the US has done a lot of work and extensive efforts in developing medical QA systems compared to other countries.
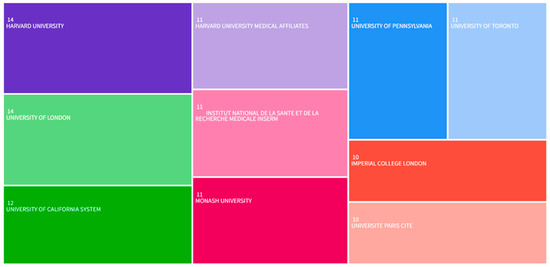
Figure 4.
Tree diagram of the top 10 organizations by number of publications.
7.2.2. Authors
In order to further analyze the research related to the application of QA systems in healthcare, this paper used CiteSpace to statistically summarize the authors of published studies and identify several influential authors in the field, as shown in Figure 5.
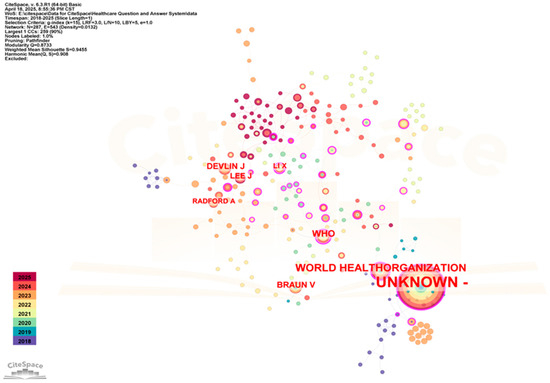
Figure 5.
Co-citation network map of authors in related fields (time span: 2018–2025; slice length = 1; G-index = 15; LRF = 3; LBY = 5; e = 1; N = 287; E = 543).
As depicted in Figure 5, the network comprised 287 nodes and 543 links with a density of 0.0132. Devlin J was cited 18 times, followed by Lee J with 17 citations.
These results indicate that Devlin Jacob is the most influential scholar in medical QA systems, with research focused on deep learning techniques for natural language processing enhancement. The BERT model (Bidirectional Encoder Representations from Transformers), proposed by Devlin et al. [42], has significantly advanced QA system research and development. The second ranked author is Joon Lee, who focuses on data mining of clinical data. The research of these authors represents the prevailing trend in the application of QA systems in healthcare.
7.2.3. Topical Trends
Keyword emergence is defined as a rapid increase in keyword frequency over a short period, reflecting research hotspots that attract significant attention within specific fields and timeframes. In this study, CiteSpace was used to statistically measure topic trends over an eight-year period. Topic trends were assessed through keyword emergence, measured by frequency changes. Emergence intensity, calculated via a statistical formula, quantified this phenomenon, as illustrated in Figure 6.

Figure 6.
Annual thematic trend analysis.
As illustrated in Figure 6, temporal trends in healthcare QA system applications over the past eight years are depicted by the right-hand lines. During 2018–2020, “satisfaction”, “healthcare”, “machine learning”, and “guidelines” emerged as prominent keywords. This reflects the early trend hotspots for research on the application of QA systems in healthcare, with studies during this period discussing the use of big data technologies to improve decision-making and practice in the current state of healthcare. Between 2020 and 2022, “attitude”, “deep learning”, “modeling”, and “mental health” were identified as dominant keywords. This suggests that during this period, researchers were increasingly focusing on new computer technologies and models, and were paying more attention to mental health as a specific healthcare area. During 2022–2025, “artificial intelligence”, “natural language processing”, “models”, “outcomes”, “physician”, “validation”, and “internet” gained prominence, suggesting that when applying QA systems in healthcare, the researchers were placing more emphasis on emerging technologies and models in the field of AI, and that validation of healthcare technologies, data, models, and interventions was increasingly emphasized.
7.2.4. Cited Journals
To identify authoritative journals and understand research dynamics, cited journals in healthcare QA system research were analyzed using CiteSpace. As presented in Figure 7, there were 294 nodes and 392 connections.

Figure 7.
Co-citation network map of cited journals (time span: 2018–2025; slice length = 1; G-index = 17; LRF = 3; Lby = 5; E = 1; N = 294; E = 392).
PLOS One (125 citations) was the most cited journal—an open-access publication spanning life sciences, medicine, engineering, and computer science. The Lancet (111 citations), an internationally recognized premier integrative medicine journal, is dedicated to advancing scientific knowledge for societal benefit. The New England Journal of Medicine (110 citations) is a weekly general medicine journal, which publishes new research, review articles, and editorials on a range of topics of importance to healthcare, including a series of journals focused exclusively on medical informatics and the application of artificial intelligence to medicine. These highly cited journals constitute essential references and have profoundly influenced intelligent healthcare QA system research.
7.2.5. Summary of Research Methods for Medical Question and Answer Systems
Systematic synthesis of retrieved literature revealed prevailing research methodologies for medical question-answering (QA) systems, as cataloged in Table 3. Thematic trend analysis in Figure 6 further confirms deep learning and large language model (LLM) approaches as dominant methodologies through pronounced keyword bursts.
Table 3.
Summary of research methodologies for medical QA systems.
8. Conclusions
This paper systematically reviewed the research progress of medical QA systems. Existing literature provided the foundation for introducing fundamental concepts, definitions, and frameworks—progressing from traditional QA systems to medical QA system construction, with research advances across system modules examined. Secondly, combined with the actual needs of artificial intelligence in healthcare, it outlined the applications of medical QA systems in intelligent assisted diagnosis and treatment decision support, medical knowledge QA, traditional Chinese medicine research and development and pharmacy services, medical image report analysis for accurate diagnosis and treatment decisions, and quality control analysis of medical record content. Representative systems were detailed. In addition, a bibliometric analysis and discussion were presented, revealing the increasing research on the application of QA systems in healthcare.
Advancements in AI—particularly deep learning and NLP—are transforming medical QA systems from text-based to multimodal interaction, enabling more comprehensive and accurate medical information delivery. However, medical QA systems still have some problems and challenges in practical applications, which need to be further optimized and improved by researchers.
Technical evolution has established deep learning and large language models (LLMs) as dominant methodologies in medical QA systems. Domain-specific systems (e.g., WiNGPT with a 250 ms response time) outperform general models in targeted applications but require rigorous clinical validation for safety assurance. Multimodal diagnostics, TCM-oriented intelligent agents, and virtual reality surgery represent three high-potential research domains. However, their advancement hinges on resolving LLM compliance frameworks and adoption barriers in primary care settings.
Current research prioritizes multimodal diagnostic imaging, TCM agents, and VR-assisted surgery. Medical QA systems demonstrate continuous progress toward intelligence, personalization, and efficiency. Technological innovations will amplify their role in enhancing care quality, optimizing resource allocation, and accelerating medical AI integration.
This paper summarized these challenges and analyzed the future development direction of medical QA systems. Multimodal image diagnosis, Chinese medicine intelligence body, and virtual reality surgery are more likely to be favored by researchers in the future.
Medical QA system research is progressively advancing toward intelligent, personalized, and efficient solutions. Through ongoing innovation, these systems will serve increasingly critical roles in enhancing healthcare quality/efficiency, optimizing personalized resource allocation, and advancing medical AI applications.
Due to various factors, in the future, we will further study the research and application trends of question-answering systems in the medical field and further enrich the visual content of the article and strengthen the visual expression of future trend analysis.
Author Contributions
Conceptualization, B.L. and P.Y.; methods, B.L.; software, B.L.; validation, P.Y.; formal analysis, B.L.; investigation, P.Y.; resources, B.L.; data curation, P.Y.; writing—original draft preparation, P.Y.; writing—review and editing, B.L.; visualization, P.Y.; supervision, B.L.; project administration, P.Y. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The original contributions presented in this study are included in the article. Further inquiries can be directed to the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Chen, M.; Liu, R.; Xiong, H. Research on intelligent Q&A system based on medical knowledge graph. Intell. Sci. 2023, 41, 118–126. [Google Scholar] [CrossRef]
- Yi, L.; Dong, C.; Niu, Z.; Liu, S.; Ni, X.; Luo, S. Research and Implementation of Question and Answer System in Intelligent Medical Domain. Inf. Rec. Mater. 2021, 22, 232–234. [Google Scholar] [CrossRef]
- Yu, L. Research and Application of Medical Intelligent Q&A System Based on Deep Learning. Master’s Thesis, Qingdao University of Science and Technology, Qingdao, China, 2023. [Google Scholar] [CrossRef]
- Isah, M.A.; Kim, B.S. Question-answering system powered by knowledge graph and generative pretrained transformer to support risk identification in tunnel projects. J. Constr. Eng. Manag. 2025, 151, 04024193-1–04024193-11. [Google Scholar] [CrossRef]
- Rokhshad, R.; Khoury, Z.H.; Mohammad-Rahimi, H.; Motie, P.; Price, J.B.; Tavares, T.; Jessri, M.; Bavarian, R.; Sciubba, J.J.; Sultan, A.S. Efficacy and empathy of AI chatbots in answering frequently asked questions on oral oncology. Oral Surgery, Oral Med. Oral Pathol. Oral Radiol. 2025, 139, 719–728. [Google Scholar] [CrossRef]
- Zhou, L.; Gao, J.; Li, D.; Shum, H.Y. The Design and Implementation of XiaoIce, an Empathetic Social Chatbot. Comput. Linguist. 2020, 46, 53–93. [Google Scholar] [CrossRef]
- Shi, Z.; Lv, X.; Dong, Y.; Liu, J.; Wang, X. Research on the current status of development of multimodal knowledge graph fusion technology in medical field. Comput. Sci. Explor. 2025, 19, 1729–1746. Available online: http://kns.cnki.net/kcms/detail/11.5602.TP.20250328.1103.006.html (accessed on 16 April 2025).
- Stefanek, G.; Demuth, J. An avatar-based framework using large language models for assessing patient cognitive state. Issues Inf. Syst. 2024, 25, 190–202. [Google Scholar] [CrossRef]
- Wang, H.; Xie, T.; Zhan, C. Negative effects of anthropomorphization of intelligent customer service incarnations in service failure scenarios: A mediating mechanism of aversion. Nankai Manag. Rev. 2021, 24, 194–206. [Google Scholar]
- Hai, J.; Wang, R.; Yuan, L.; Zhang, K.; Deng, W.; Xiao, Y.; Zhou, T.; Chang, K. Exploration and practice of constructing a knowledge quiz system based on retrieval enhancement of Chinese medicine standards. Data Anal. Knowl. Discov. 2025, 1–13. Available online: http://kns.cnki.net/kcms/detail/10.1478.G2.20250120.1024.004.html (accessed on 16 April 2025).
- Wen, S.; Qian, L.; Hu, M.; Chang, Z. A review on the research progress of question and answer technology based on large language model. Data Anal. Knowl. Discov. 2024, 8, 16–29. [Google Scholar]
- Che, W.; Dou, Z.; Feng, Y.; Gui, T.; Han, X.; Hu, B.; Huang, M.; Huang, X.; Liu, K.; Liu, T.; et al. Natural language processing in the era of big models: Challenges, opportunities and development. Sci. China Inf. Sci. 2023, 53, 1645–1687. [Google Scholar]
- Song, H. Construction and Application of Assisted Diagnosis and Treatment Q&A System Based on Knowledge Graph. Master’s Thesis, Xijing Institute, Xi’an, China, 2024. [Google Scholar] [CrossRef]
- Zhou, J.; Ke, P.; Qiu, X.; Huang, M.; Zhang, J. ChatGPT: Potential, prospects, and limitations. Front. Inf. Technol. Electron. Eng. 2024, 25, 6–11. [Google Scholar] [CrossRef]
- Li, J.; Zan, H.; Yan, Y.; Zhang, K. Construction of a quiz system for pediatric diseases and health care. J. Chin. Inf. 2022, 36, 127–134. [Google Scholar]
- Zhu, W.; Lu, W.; Chen, M. Advancing the application of artificial intelligence macromodeling in the medical field. Radiol. Pract. 2025, 1, 5–8. [Google Scholar] [CrossRef]
- Xuan, G. Governance paradoxes and breakthroughs in inference modeling. J. Intell. 2025, 1–9. Available online: http://kns.cnki.net/kcms/detail/61.1167.G3.20250427.1028.002.html (accessed on 29 April 2025).
- Guo, Z.; Tan, Z.; Wang, J.; Ye, Q. Construction of an intelligent Q&A platform for proprietary Chinese medicine based on knowledge graph. Comput. Inf. Technol. 2023, 31, 52–57. [Google Scholar] [CrossRef]
- Shin, X. Research on Question Text Clustering for Intelligent Q&A System in Medical Field. Master’s Thesis, Peking Union Medical College, Beijing, China, 2023. [Google Scholar] [CrossRef]
- Mao, Z.; Liao, S.; Ma, H. Database, knowledge base and big model for biomanufacturing. J. Bioeng. 2025, 41, 901–916. [Google Scholar] [CrossRef]
- Thite, A.; Foster, C.; Leahy, C.; He, H.; Phang, J.; Golding, L.; Gao, L.; Nabeshima, N.; Presser, S. The Pile: An 800GB Dataset of Diverse Text for Language Modeling. 2021. Available online: https://arxiv.org/abs/2101.00027 (accessed on 27 April 2025).
- Trummer, I. Large Language Models: Principles and Practice. In Proceedings of the 2024 IEEE 40th International Conference on Data Engineering (ICDE), Utrecht, The Netherlands, 13–17 May 2024; pp. 5354–5357. [Google Scholar] [CrossRef]
- Ruan, T.; Bian, M.A.; Yu, G.Y.; Xu, J. A review of medical big language modeling research and application. Chin. J. Health Inf. Manag. 2023, 20, 853–861. [Google Scholar]
- Wagholikar, K.B.; Layne, A.; David, Z.; Kira, C.; Michael, M.; Jeffery, K.; Alexander, J.B.; Angela, M.; Rupendra, C.; Michael, O.; et al. I2b2-etl: Python application for importing Electronic Health Data into the Informatics for Integrating Biology and the Bedside Platform. Bioinformatics 2022, 38, 4833–4836. [Google Scholar] [CrossRef]
- Mahmudi, S.A.; Stojanova, J.; Vounzoulaki, E.; Tomlinson, E.; Pizarro, A.B.; Khademioore, S.; Ngeh, E.; Sharifan, A.; Mrema, L.E.; Britten-Jones, A.C. Cochrane Reviews’ authorship has become more gender-diverse but remains geographically concentrated: A meta-research study. J. Clin. Epidemiol. 2025, 181, 111719. [Google Scholar] [CrossRef]
- Singhal, K.; Azizi, S.; Tu, T.; Mahdavi, S.; Wei, J.; Chung, H.W.; Scales, N.; Tanwani, A.; Cole-Lewis, H.; Pfohl, S. Large language models encode clinical knowledge. Nature 2023, 620, 172–180. [Google Scholar] [CrossRef]
- Pal, A.; Umapathi, L.K.; Sankarasubbu, M. MedMCQA: A Large-scale Multi-Subject Multi-Choice Dataset for Medical domain Question Answering. arXiv 2022, arXiv:2203.14371. [Google Scholar] [CrossRef]
- Johnson, A.E.W.; Pollard, T.J.; Shen, L.; Lehman, L.-w.H.; Feng, M.; Ghassemi, M.; Moody, B.; Szolovits, P.; Celi, L.A.; Mark, R.G. MIMIC-III, a freely accessible critical care database. Sci. Data 2016, 3, 160035. [Google Scholar] [CrossRef] [PubMed]
- Tsatsaronis, G.; Balikas, G.; Malakasiotis, P.; Partalas, I.; Zschunke, M.; Alvers, M.R.; Weissenborn, D.; Krithara, A.; Petridis, S.; Polychronopoulos, D. An overview of the BIOASQ large-scale biomedical semantic indexing and question answering competition. BMC Bioinform. 2015, 16, 138. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Peng, Y.; Lu, L.; Lu, Z.; Summers, R.M. TieNet: Text-Image Embedding Network for Common Thorax Disease Classification and Reporting in Chest X-rays. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 9049–9058. [Google Scholar] [CrossRef]
- Rajit, D.; McDonald, S.; Tay, T.C.; Du, L.; Enticott, J.; Helena Teede, H. Assessing the Coverage of PubMed, Embase, OpenAlex and Semantic Scholar for Automated Single Database Searches in Living Guideline Evidence Surveillance: A Case Study of the International PCOS Guidelines 2023. J. Clin. Epidemiol. 2025, 181, 111789. [Google Scholar] [CrossRef]
- Karan, S.; Tao, T.; Juraj, G.; Rory, S.; Ellery, W.; Mohamed, A.; Le, H.; Kevin, C.; Stephen, R.P.; Heather, C.L.; et al. Toward expert-level medical question answering with large language models. Nat. Med. 2025, 31, 943–950. [Google Scholar] [CrossRef]
- Liu, H.; Qu, X.; Shen, Y.; Jiang, Z.; Xie, X.; Zhao, Y.; Zhang, X. Research on the inference of Chinese medicine knowledge map. World Sci. Technol. Mod. Chin. Med. 2025, 27, 601–611. Available online: http://kns.cnki.net/kcms/detail/11.5699.R.20250307.2243.009.html (accessed on 16 April 2025).
- Wu, T.X.; Cao, X.D.; Bi, S.; Chen, Y.; Cai, P.; Sha, H.; Qi, G.; Wang, H. Construction of a major chronic disease health management information system based on a large language model. Comput. Res. Dev. 2025, 62, 1653–1667. Available online: http://kns.cnki.net/kcms/detail/11.1777.TP.20250127.0926.008.html (accessed on 16 April 2025).
- Qiu, T.; Wang, Y.H.; Deng, G.P.; Sun, Y.; Lv, G.; Xia, X. A structured regular path query method for graph data. Comput. Appl. Res. 2023, 40, 3022–3027. [Google Scholar] [CrossRef]
- Liu, Y.; Yang, S.P.; Zhang, Z.G. Fast learning resource recommendation based on knowledge graph under Storm distributed computing framework. J. Nanjing Univ. Posts Telecommun. 2024, 44, 93–99. [Google Scholar] [CrossRef]
- Gaudry, A.; Pagni, M.; Mehl, F.; LuisManuel, Q.G.; Luca, C.; Adriano, R.; Marcel, K.; Laurence, M.; Emerson, F.Q.; Ioset, J.R. A Sample-Centric and Knowledge-Driven Computational Framework for Natural Products Drug Discovery. ACS Cent. Sci. 2024, 10, 494–510. [Google Scholar] [CrossRef] [PubMed]
- Tang, D.Y.; Ding, Y.Z.; Wang, X.; Lai, L.; Yu, J. Current status and research outlook on the application of knowledge graph technology in prediction and health management. Electro. Opt. Control 2024, 31, 1–11. [Google Scholar]
- Jiang, M.; Jiang, Y. Research on accurate communication recommendation of new media based on time-based long and short-term memory network. Autom. Instrum. 2025, 3, 34–37. [Google Scholar] [CrossRef]
- Wu, Y.; Hu, F.; Yue, C.; Sun, S. Residual-time gated recurrent unit. Neurocomputing 2025, 624, 129396. [Google Scholar] [CrossRef]
- Peters, M.E.; Neumann, M.; Iyyer, M.; Gardner, M.; Zettlemoyer, L. Deep contextualized word representations. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, New Orleans, LA, USA, 1–6 June 2018; Volume 1, pp. 2227–2237. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics (NAACL), Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Liu, W.; Xue, H.; Zhang, H. A comparative study of discriminative and generative language models for Chinese medical named entity recognition. Libr. Intell. Work 2025, 69, 107–116. [Google Scholar] [CrossRef]
- Peng, H.; Shen, H.M.; Fang, Y.S. Progress and trend analysis of ChatGPT-based applications. Internet. World 2023, 4, 42–47. [Google Scholar]
- OpenAI. Introducing ChatGPT. OpenAI Blogs. Available online: https://openai.com/blog/chatgpt (accessed on 27 April 2025).
- Touvron, H.; Lavril, T.; Izacard, G.; Xavier, M.; Lachaux, M.A.; Timothée, L.; Baptiste, R.; Naman, G.; Eric, H.; Faisal, A.; et al. LLaMA: Open and efficient foundation language models. arXiv 2023, arXiv:2302.13971. [Google Scholar] [CrossRef]
- Bai, J.; Bai, S.; Chu, Y.; Zeyu, C.; Dang, K.; Deng, X.; Yang, F.; Ge, W.; Han, Y.; Huang, F.; et al. Qwen technical report. arXiv 2023, arXiv:2309.16609. [Google Scholar] [CrossRef]
- Gao, J.S.; Fu, J.W. Research on fine-grained knowledge representation of cultural relic image resources based on knowledge elements. Intell. Sci. 2022, 40, 526–541. [Google Scholar] [CrossRef]
- Yang, X.Y.; Mou, D.M.; Peng, H.; Wang, Y.; Wang, P.; Li, H. Research on data-driven clinical decision-making model of electronic medical record based on data characteristics. Intell. Theory Pract. 2022, 45, 181–188. [Google Scholar] [CrossRef]
- Suo, C.J.; Pai, Y.X. Connotation, methods and strategies of data architecture for digital transformation of libraries. Intell. Theory Pract. 2024, 47, 27–35. [Google Scholar] [CrossRef]
- Patel, A.; Debnath, N.C.; Shukla, P.K. SecureOnt: A Security Ontology for Establishing Data Provenance in Semantic Web. J. Web Eng. 2022, 21, 1347–1370. [Google Scholar] [CrossRef]
- Ye, Y. An overview of qualitative knowledge construction and quantitative knowledge analysis: A discussion of the theoretical foundations of academic benchmarking. Chin. Libr. J. 2022, 48, 38–51. [Google Scholar] [CrossRef]
- Song, X.; Chu, J.; Guo, Z.; Wei, Q.; Wang, Q.; Hu, W.; Wang, L.; Zhao, W.; Zheng, H.; Lu, X. Prognostic prediction of breast cancer patients using machine learning models: A retrospective analysis. Gland. Surg. 2024, 13, 1575–1587. [Google Scholar] [CrossRef]
- Li, H.W.; Yan, W. Research on the design and application of clinical distributed big data-based knowledge graph. China Med. Manag. Sci. 2023, 13, 36–41. [Google Scholar]
- Zhang, Y.; Wu, X.; Fang, Q.; Qian, S.; Xu, C. Knowledge-Enhanced Attributed Multi-Task Learning for Medicine Recommendation. ACM Trans. Inf. Syst. 2022, 41, 1–24. [Google Scholar] [CrossRef]
- Mou, D.M.; Ju, Y.H.; Yu, H.T.; Wang, S. Research on the computational model of diagnosis and treatment specification knowledge from the perspective of computable biomedical knowledge. Mod. Intell. 2023, 43, 73–87. [Google Scholar]
- Peng, Y.F.; Chen, J.H.; He, Z.Q. Comparison and application of South China Sea evidential data extraction algorithms based on machine learning and deep learning. Mod. Intell. 2022, 42, 55–69. [Google Scholar]
- Ding, R.Q.; Zhao, J.F.; Wang, L.Y. Integrating entity semantics and ontology information for entity alignment in multi-source Chinese medical knowledge graph. J. Softw. 2025, 1–19. [Google Scholar] [CrossRef]
- Li, X.; Zhu, C.; Li, L.; Yin, Z.; Sun, T.; Qiu, X. LLatrieval: LLM-Verified Retrieval for Verifiable Generation. arXiv 2023, arXiv:2311.07838. [Google Scholar]
- Sun, X.C.; Lu, F.; Feng, Y.A. Cross-scale pooled embedded image fusion algorithm for long and short range attention synergy. Adv. Lasers Optoelectron. 2025, 62, 366–376. Available online: http://kns.cnki.net/kcms/detail/31.1690.tn.20250103.1344.008.html (accessed on 16 April 2025).
- Liu, Y.; Zhan, Y.L.; Jiang, Z.H.; Li, J.; Yan, Z.; He, C. MWDLS: A multimodal online healthy rumor detection method considering language style features. Data Anal. Knowl. Discov. 2015, 1–16. Available online: http://kns.cnki.net/kcms/detail/10.1478.G2.20250124.1328.002.html (accessed on 18 March 2025).
- Chen, T.; Hu, Y. Entity relation extraction from electronic medical records based on improved annotation rules and BiLSTM-CRF. Ann. Transl. Med. 2021, 9, 1415. [Google Scholar] [CrossRef] [PubMed]
- Milosevic, N.; Thielemann, W. Comparison of biomedical relationship extraction methods and models for knowledge graph creation. J. Web Semant. 2023, 75, 100756. [Google Scholar] [CrossRef]
- Cao, J.; Van Veen, E.M.; Peek, N.; Renehan, A.G.; Ananiadou, S. A Novel Automated Approach to Mutation-Cancer Relation Extraction by Incorporating Heterogeneous Knowledge. J. Biomed. Health Inf. 2023, 27, 1096–1105. [Google Scholar] [CrossRef] [PubMed]
- Xu, Y.P.; Shangguan, L.N.; Xu, Y.L. Influence of public crisis information sources and narratives on public risk perception and protective behaviors—An experimental study based on public health emergencies. Mod. Intell. 2023, 43, 88–100. [Google Scholar]
- Shi, J.Y.; Xu, J.Y. Legal Challenges of Medical Artificial Intelligence Applications and Their Governance. J. Northwestern Univ. 2024, 54, 91–103. [Google Scholar] [CrossRef]
- Kumar, R.; Corvisieri, G.; Fici, T.F.; Hussain, S.I.; Tegolo, D.; Valenti, C. Transfer Learning for Facial Expression Recognition. Information 2025, 16, 320. [Google Scholar] [CrossRef]
- Liu, Y.; Zhang, Y.W.; Wang, Y. Application of deep learning-based image processing in emotion recognition and psychological therapy. Trait. Du Signal 2024, 41, 2923–2933. [Google Scholar] [CrossRef]
- Kumar, R.; Hussain, S.I. A review of the deep convolutional neural networks for the analysis of facial expressions. J. Innov. Technol. 2024, 6, 41–49. [Google Scholar]
- Omiye, J.A.; Gui, H.; Daneshjou, Z.R. Large Language Models in Medicine: The Potentials and Pitfalls: A Narrative Review. Ann. Intern. Med. 2024, 177, 210–220. [Google Scholar] [CrossRef]
- Liu, J.; Wei, J.; Xiao, M. How Big Models Can Help Improve the Quality and Efficiency of Healthcare Services-An Example of Micro Pulse Care AI’s Practice. Tsinghua Manag. Rev. 2025, 3, 100–108. [Google Scholar]
- Alsaad, R.; Abd-Alrazaq, A.; Boughorbel, S.; Ahmed, A.; Renault, M.A.; Damseh, R.; Javaid Sheikh, M.A. Multimodal Large Language Models in Health Care: Applications, Challenges, and Future Outlook. J. Med. Internet Res. 2024, 26, e59505. [Google Scholar] [CrossRef]
- Ruan, T.; Qiu, J.; Zhang, Z.; Ye, Q. Medical data governance: Building the data foundation for intelligent analysis of high quality medical big data. Big Data 2019, 5, 12–24. [Google Scholar]
- Liu, Z. Research on privacy protection and data security techniques for large models of artificial intelligence. Software 2024, 45, 143–145+151. [Google Scholar]
- Teoh, J.R.; Dong, J.; Zuo, X.; Lai, K.W.; Hasikin, K.; Wu, X. Advancing healthcare through multimodal data fusion: A comprehensive review of techniques and applications. Peer J Comput Sci. 2024, 10, e2298. [Google Scholar] [CrossRef] [PubMed]
- Qu, X.; Yang, J.; Chen, T.; Zhang, W. Reflections on the Implications of the Developments in ChatGPT for Changes in Medical Education Models. J. Sichuan Univ. 2023, 54, 937–940. [Google Scholar]
- Clusmann, J.; Kolbinger, F.R.; Muti, H.S.; Carrero, Z.I.; Eckardt, J.N.; Laleh, N.G.; Lavinia Löffler, C.M.; Schwarzkopf, S.C.; Unger, M.; Veldhuizen, G.; et al. The future landscape of large language models in medicine. Commun. Med. 2023, 3, 141. [Google Scholar] [CrossRef]
- Gumilar, K.E.; Indraprasta, B.R.; Hsu, Y.C.; Yu, Z.Y.; Chen, H.; Irawan, B.; Tambunan, Z.; Wibowo, B.M.; Nugroho, H.; Tjokroprawiro, B.A. Disparities in medical recommendations from AI-based chatbots across different countries/regions. Sci. Rep. 2024, 14, 17052. [Google Scholar] [CrossRef]
- Wang, D.; Zhang, S. Large language models in medical and healthcare fields: Applications, advances, and challenges. Artif. Intell. Rev. 2024, 57, 299. [Google Scholar] [CrossRef]
- Meskó, B. The Impact of Multimodal Large Language Models on Health Care’s Future. J. Med. Internet Res. 2023, 25, e52865. [Google Scholar] [CrossRef] [PubMed]
- Nannini, G.; Saitta, S.; Baggiano, A.; Maragna, R.; Mushtaq, S.; Pontone, G.; Redaelli, A. A fully automated deep learning approach for coronary artery segmentation and comprehensive characterization. APL Bioeng. 2024, 8, 016103. [Google Scholar] [CrossRef] [PubMed]
- Jang, J.; Yoon, D.; Yang, S.; Cha, S.; Lee, M.; Logeswaran, L.; Seo, M. Knowledge Unlearning for Mitigating Privacy Risks in Language Models. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics, Toronto, ON, Canada, 9–14 July 2023; pp. 14389–14408. [Google Scholar] [CrossRef]
- Al-Tam, R.M.; Hashim, F.A.; Maqsood, S.; Abualigah, L.; Alwhaibi, R.M. Enhancing Parkinson’s Disease Diagnosis Through Stacking Ensemble-Based Machine Learning Approach. IEEE Access 2024, 12, 79549–79567. [Google Scholar] [CrossRef]
- Lin, H.Y.; Jiang, Y.; Zhang, X.Y.; Cui, H.; Wang, W.; Zhao, C.; Shang, H. Analysis of the research status and application prospect of Chinese medicine clinical auxiliary diagnosis and treatment platform. Chin. J. Tradit. Chin. Med. 2024, 39, 2711–2714. [Google Scholar]
- Su, Y.L.; Hu, X.Y.; Ma, S.J.; Zhang, Y.N.; Abulizi, A.; Abudukelimu, H. Review of Research on Artificial Intelligence in Traditional Chinese Medicine Diagnosis and Treatment. Comput. Eng. Appl. 2024, 60, 1–18. [Google Scholar]
- Ma, Y.; Wang, L.; Luo, J.; Fang, X. A Trusted and Intelligent Service System for the Decoction of Traditional Chinese Medicine. In Proceedings of the 2023 26th International Conference on Computer Supported Cooperative Work in Design (CSCWD), Rio de Janeiro, Brazil, 24–26 May 2023; pp. 666–672. [Google Scholar] [CrossRef]
- Covaciu, F.; Crisan, N.; Vaida, C.; Andras, I.; Pusca, A.; Gherman, B.; Radu, C.; Tucan, P.; Hajjar, N.; Pisla, D. Integration of Virtual Reality in the Control System of an Innovative Medical Robot for Single-Incision Laparoscopic Surgery. Sensors 2023, 23, 5400. [Google Scholar] [CrossRef]
- Zhao, X.; Zhang, S.; Nan, D.; Han, J.; Kim, J.H. Human–Computer Interaction in Healthcare: A Bibliometric Analysis with CiteSpace. Healthcare 2024, 12, 2467. [Google Scholar] [CrossRef]
- Hao, Y.; Yang, L. Hotspots and Trends in Research on Mental Health of the Rural Elderly: A Bibliometric Analysis Using CiteSpace. Healthcare 2025, 13, 209. [Google Scholar] [CrossRef]
- Liu, L.Q. Literature review of social investment theory based on CiteSpace visualization analysis. West. J. 2024, 4, 30–33. [Google Scholar] [CrossRef]







Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).