
Application of Machine Learning Algorithms to Predict Uncontrolled Diabetes Using the All of Us Research Program Data

 and
and 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Materials and Methods
2.1. Source of Data
2.2. Population Characteristics
2.3. Data Processing and Mining
2.4. Model Selection and Rationale
2.5. Model Development and Optimization of Parameters
2.6. Feature Importance
2.7. Performance Metrics
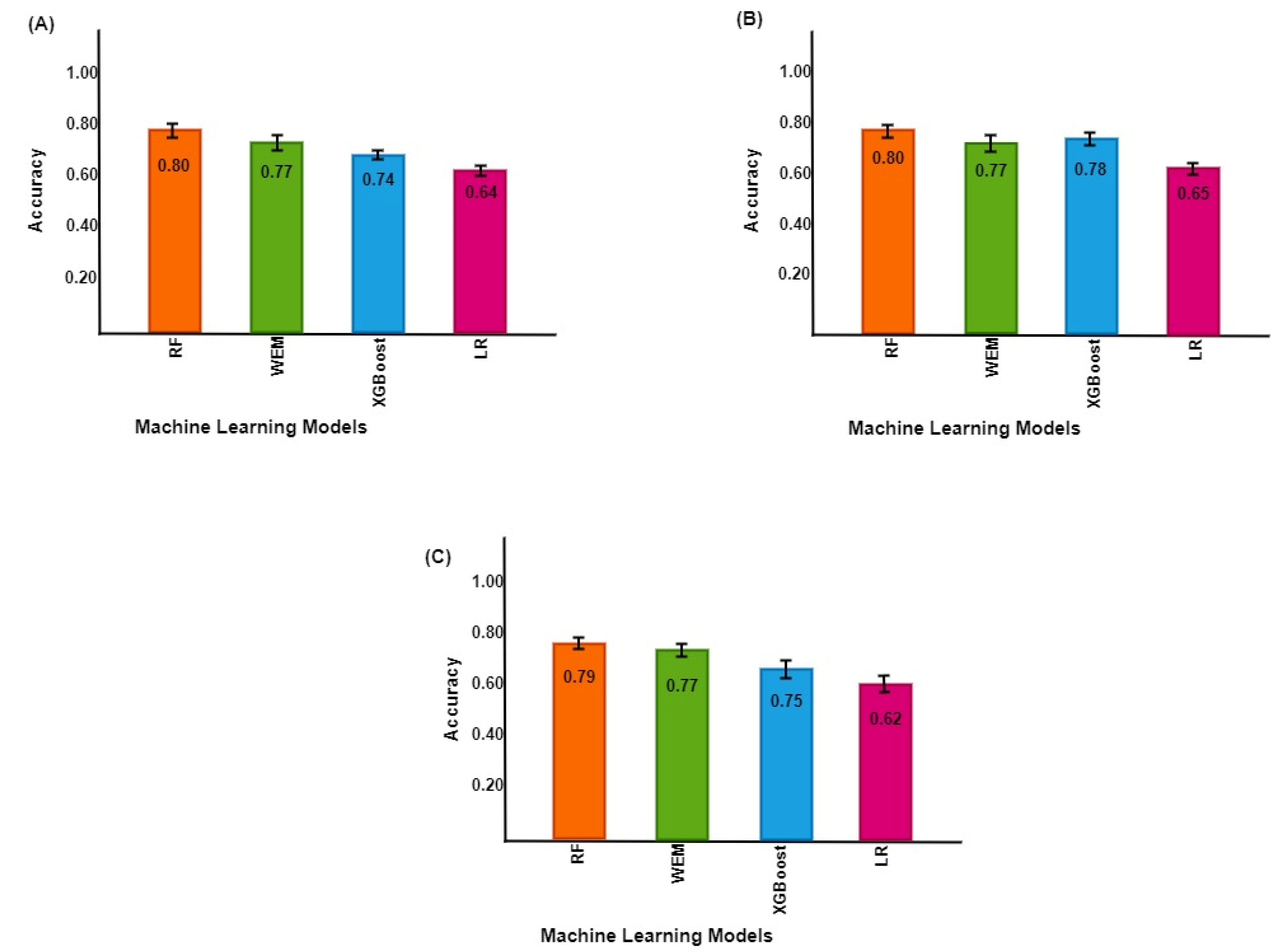
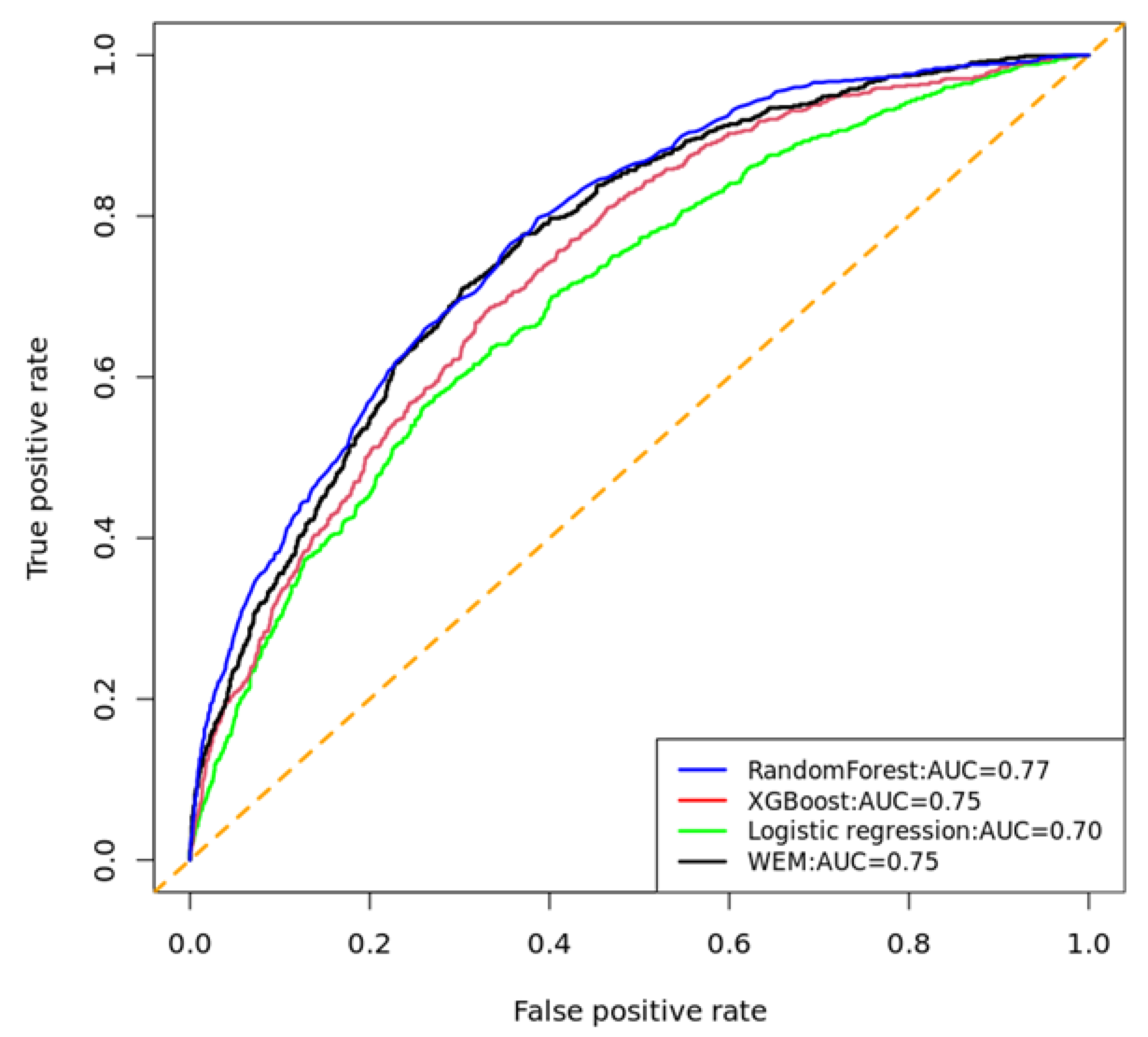
3. Results
3.1. Classification Performance of Models to Predict UDM
3.2. Feature Importance
4. Discussion
Strengths and Limitations of the Study
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ADA | American Diabetes Association |
| ALP | Alkaline phosphatase |
| ALT | Alanine transaminase |
| AST | Aspartate aminotransferase |
| AROC | Area under the receiver operating characteristic curve |
| AoU | All of Us |
| AUC | Area under the curve |
| BMI | Body mass index |
| CDC | Center for Disease Control and Prevention |
| DBP | Diastolic blood pressure |
| DM | Diabetes mellitus |
| HbA1C | Hemoglobin A1C |
| ICD | International classification of disease |
| KATP | ATP-sensitive potassium channel |
| LR | Logistic regression |
| MCH | Mean corpuscular hemoglobin |
| MCHC | Mean corpuscular hemoglobin concentration |
| MCV | Mean corpuscular volume |
| ML | Machine learning |
| OOB | Out-of-bag |
| RAAS | Renin–angiotensin–aldosterone system |
| RF | Random forest |
| ROSE | Random over-sampling examples |
| SBP | Systolic blood pressure |
| T1DM | Type 1 diabetes mellitus |
| T2DM | Type 2 diabetes mellitus |
| UDM | Uncontrolled diabetes mellitus |
| US | United States |
| VIF | Variance inflation factor |
| WEM | Weighted ensemble model |
| XGBoost | Extreme gradient boosting |
References
- American Diabetes Association. Diagnosis and classification of diabetes mellitus. Diabetes Care 2010, 33 (Suppl. S1), S62–S69. [Google Scholar] [CrossRef] [PubMed]
- Centers for Disease Control and Prevention. National Diabetes Statistics Report Website. Available online: https://www.cdc.gov/diabetes/data/statistics-report/index.html (accessed on 4 February 2023).
- American Diabetes Association. Economic Costs of Diabetes in the U.S. in 2017. Diabetes Care 2018, 41, 917–928. [Google Scholar] [CrossRef] [PubMed]
- Moghissi, E.S.; Korytkowski, M.T.; DiNardo, M.; Einhorn, D.; Hellman, R.; Hirsch, I.B.; Inzucchi, S.E.; Ismail-Beigi, F.; Kirkman, M.S.; Umpierrez, G.E. American Association of Clinical Endocrinologists and American Diabetes Association consensus statement on inpatient glycemic control. Diabetes Care 2009, 32, 1119–1131. [Google Scholar] [CrossRef]
- Borgharkar, S.S.; Das, S.S. Real-world evidence of glycemic control among patients with type 2 diabetes mellitus in India: The TIGHT study. BMJ Open Diabetes Res. Care 2019, 7, e000654. [Google Scholar] [CrossRef]
- Fang, M.; Wang, D.; Coresh, J.; Selvin, E. Trends in diabetes treatment and control in US adults, 1999–2018. New Engl. J. Med. 2021, 384, 2219–2228. [Google Scholar] [CrossRef]
- Raveendran, A.V.; Chacko, E.C.; Pappachan, J.M. Non-pharmacological treatment options in the management of diabetes mellitus. Eur. Endocrinol. 2018, 14, 31. [Google Scholar] [CrossRef] [PubMed]
- American Diabetes Association. 9. Pharmacologic approaches to glycemic treatment: Standards of Medical Care in Diabetes—2021. Diabetes Care 2021, 44 (Suppl. S1), S111–S112. [Google Scholar] [CrossRef]
- Garg, S.K.; Grunberger, G.; Weinstock, R.S.; Lawson, M.L.; Hirsch, I.B.; DiMeglio, L.A.; Pop-Busui, R.; Philis-Tsimikas, A.; Kipnes, M.S.; Lilenquist, D.R. Improved Glycemia with Hybrid Closed-Loop (HCL) Versus Continuous Subcutaneous Insulin Infusion (CSII) Therapy: Results from a Randomized Controlled Trial. Diabetes Technol. Ther. 2023, 25, 1–12. [Google Scholar] [CrossRef]
- Phillip, M.; Nimri, R.; Bergenstal, R.M.; Barnard-Kelly, K.; Danne, T.; Hovorka, R.; Kovatchev, B.P.; Messer, L.H.; Parkin, C.G.; Ambler-Osborn, L. Consensus Recommendations for the Use of Automated Insulin Delivery (AID) Technologies in Clinical Practice. Endocr. Rev. 2022, 44, 254–280. [Google Scholar] [CrossRef]
- Battelino, T.; Alexander, C.M.; Amiel, S.A.; Arreaza-Rubin, G.; Beck, R.W.; Bergenstal, R.M.; Buckingham, B.A.; Carroll, J.; Ceriello, A.; Chow, E. Continuous glucose monitoring and metrics for clinical trials: An international consensus statement. Lancet Diabetes Endocrinol. 2022, 11, 42–57. [Google Scholar] [CrossRef]
- Pantalone, K.M.; Misra-Hebert, A.D.; Hobbs, T.M.; Wells, B.J.; Kong, S.X.; Chagin, K.; Dey, T.; Milinovich, A.; Weng, W.; Bauman, J.M. Effect of glycemic control on the Diabetes Complications Severity Index score and development of complications in people with newly diagnosed type 2 diabetes. J. Diabetes 2018, 10, 192–199. [Google Scholar] [CrossRef]
- Pettus, J.H.; Zhou, F.L.; Shepherd, L.; Preblick, R.; Hunt, P.R.; Paranjape, S.; Miller, K.M.; Edelman, S.V. Incidences of severe hypoglycemia and diabetic ketoacidosis and prevalence of microvascular complications stratified by age and glycemic control in US adult patients with type 1 diabetes: A real-world study. Diabetes Care 2019, 42, 2220–2227. [Google Scholar] [CrossRef]
- Basu, S.; Narayanaswamy, R. A prediction model for uncontrolled type 2 diabetes mellitus incorporating area-level social determinants of health. Med. Care 2019, 57, 592–600. [Google Scholar] [CrossRef] [PubMed]
- Chatterjee, R.; Yeh, H.C.; Edelman, D.; Brancati, F. Potassium and risk of Type 2 diabetes. Expert Rev. Endocrinol. Metab. 2011, 6, 665–672. [Google Scholar] [CrossRef] [PubMed]
- Jian, Y.; Pasquier, M.; Sagahyroon, A.; Aloul, F. A Machine Learning Approach to Predicting Diabetes Complications. Healthcare 2021, 9, 1712. [Google Scholar] [CrossRef] [PubMed]
- Dinh, A.; Miertschin, S.; Young, A.; Mohanty, S.D. A data-driven approach to predicting diabetes and cardiovascular disease with machine learning. BMC Med. Inform. Decis. Mak. 2019, 19, 211. [Google Scholar] [CrossRef] [PubMed]
- Zou, Q.; Qu, K.; Luo, Y.; Yin, D.; Ju, Y.; Tang, H. Predicting diabetes mellitus with machine learning techniques. Front. Genet. 2018, 9, 515. [Google Scholar] [CrossRef]
- Yang, L.; Gabriel, N.; Hernandez, I.; Winterstein, A.G.; Guo, J. Using machine learning to identify diabetes patients with canagliflozin prescriptions at high-risk of lower extremity amputation using real-world data. Pharmacoepidemiol. Drug Saf. 2021, 30, 644–651. [Google Scholar] [CrossRef]
- Del Parigi, A.; Tang, W.; Liu, D.; Lee, C.; Pratley, R. Machine learning to identify predictors of glycemic control in type 2 diabetes: An analysis of target HbA1c reduction using empagliflozin/linagliptin data. Pharm. Med. 2019, 33, 209–217. [Google Scholar] [CrossRef]
- Seo, W.; Lee, Y.-B.; Lee, S.; Jin, S.-M.; Park, S.-M. A machine-learning approach to predict postprandial hypoglycemia. BMC Med. Inform. Decis. Mak. 2019, 19, 210. [Google Scholar] [CrossRef]
- Hanson, R.L.; Imperatore, G.; Bennett, P.H.; Knowler, W.C. Components of the “metabolic syndrome” and incidence of type 2 diabetes. Diabetes 2002, 51, 3120–3127. [Google Scholar] [CrossRef] [PubMed]
- Bhutto, A.R.; Abbasi, A.; Abro, A.H. Correlation of hemoglobin A1c with red cell width distribution and other parameters of red blood cells in type II diabetes mellitus. Cureus 2019, 11, e5533. [Google Scholar] [CrossRef] [PubMed]
- All of Us Research Program Investigators. The “All of Us” research program. N. Engl. J. Med. 2019, 381, 668–676. [Google Scholar] [CrossRef]
- All of Us Research Program. National Institutes of Health (NIH). Available online: https://allofus.nih.gov/ (accessed on 8 April 2023).
- Ramirez, A.H.; Sulieman, L.; Schlueter, D.J.; Halvorson, A.; Qian, J.; Ratsimbazafy, F.; Loperena, R.; Mayo, K.; Basford, M.; Deflaux, N. The All of Us Research Program: Data quality, utility, and diversity. Patterns 2022, 3, 100570. [Google Scholar] [CrossRef] [PubMed]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2022; Available online: https://www.R-project.org/ (accessed on 13 April 2023).
- Menardi, G.; Torelli, N. Training and assessing classification rules with imbalanced data. Data Min. Knowl. Discov. 2014, 28, 92–122. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Natekin, A.; Knoll, A. Gradient boosting machines, a tutorial. Front. Neurorobotics 2013, 7, 21. [Google Scholar] [CrossRef]
- Couronné, R.; Probst, P.; Boulesteix, A.-L. Random forest versus logistic regression: A large-scale benchmark experiment. BMC Bioinform. 2018, 19, 270. [Google Scholar] [CrossRef]
- Probst, P.; Wright, M.N.; Boulesteix, A.L. Hyperparameters and tuning strategies for random forest. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2019, 9, e1301. [Google Scholar] [CrossRef]
- Chen, R.-C.; Dewi, C.; Huang, S.-W.; Caraka, R.E. Selecting critical features for data classification based on machine learning methods. J. Big Data 2020, 7, 52. [Google Scholar] [CrossRef]
- Ting, K.M. Precision and Recall. In Encyclopedia of Machine Learning; Sammut, C., Webb, G.I., Eds.; Springer: Boston, MA, USA, 2010; p. 781. [Google Scholar] [CrossRef]
- Baratloo, A.; Hosseini, M.; Negida, A.; El Ashal, G. Part 1: Simple Definition and Calculation of Accuracy, Sensitivity and Specificity. Emerg (Tehran) 2015, 3, 48–49. [Google Scholar] [PubMed]
- Fan, Y.; Long, E.; Cai, L.; Cao, Q.; Wu, X.; Tong, R. Machine learning approaches to predict risks of diabetic complications and poor glycemic control in nonadherent type 2 diabetes. Front. Pharmacol. 2021, 12, 1485. [Google Scholar] [CrossRef] [PubMed]
- Motaib, I.; Aitlahbib, F.; Fadil, A.; Tlemcani, F.Z.R.; Elamari, S.; Laidi, S.; Chadli, A. Predicting poor glycemic control during Ramadan among non-fasting patients with diabetes using artificial intelligence based machine learning models. Diabetes Res. Clin. Pract. 2022, 190, 109982. [Google Scholar] [CrossRef] [PubMed]
- Tao, X.; Jiang, M.; Liu, Y.; Hu, Q.; Zhu, B.; Hu, J.; Guo, W.; Wu, X.; Xiong, Y.; Shi, X. Predicting three-month fasting blood glucose and glycated hemoglobin of patients with type 2 diabetes based on multiple machine learning algorithms. Research Square. 2022. [Google Scholar] [CrossRef]
- Coregliano-Ring, L.; Goia-Nishide, K.; Rangel, É.B. Hypokalemia in Diabetes Mellitus Setting. Medicina 2022, 58, 431. [Google Scholar] [CrossRef] [PubMed]
- Luther, J.M.; Brown, N.J. The renin–angiotensin–aldosterone system and glucose homeostasis. Trends Pharmacol. Sci. 2011, 32, 734–739. [Google Scholar] [CrossRef] [PubMed]
- Ferrannini, E.; Galvan, A.Q.; Santoro, D.; Natali, A. Potassium as a link between insulin and the renin-angiotensin-aldosterone system. J. Hypertens. 1992, 10, S11. [Google Scholar] [CrossRef]
- Chatterjee, R.; Davenport, C.A.; Svetkey, L.P.; Batch, B.C.; Lin, P.-H.; Ramachandran, V.S.; Fox, E.R.; Harman, J.; Yeh, H.-C.; Selvin, E. Serum potassium is a predictor of incident diabetes in African Americans with normal aldosterone: The Jackson Heart Study. Am. J. Clin. Nutr. 2017, 105, 442–449. [Google Scholar] [CrossRef]
- Watanabe, R. Hyperkalemia in chronic kidney disease. Rev. Assoc. Médica Bras. 2020, 66, s31–s36. [Google Scholar] [CrossRef]
- Weiss, J.N.; Qu, Z.; Shivkumar, K. Electrophysiology of hypokalemia and hyperkalemia. Circ. Arrhythmia Electrophysiol. 2017, 10, e004667. [Google Scholar] [CrossRef]
- Palmer, B.F. Regulation of potassium homeostasis. Clin. J. Am. Soc. Nephrol. 2015, 10, 1050–1060. [Google Scholar] [CrossRef]
- Harada, N.; Inagaki, N. Role of sodium-glucose transporters in glucose uptake of the intestine and kidney. J. Diabetes Investig. 2012, 3, 352. [Google Scholar] [CrossRef]
- Goia-Nishide, K.; Coregliano-Ring, L.; Rangel, É.B. Hyperkalemia in Diabetes Mellitus Setting. Diseases 2022, 10, 20. [Google Scholar] [CrossRef]
- Wade, A.N.; Hambleton, I.R.; Hennis, A.J.; Howitt, C.; Jeyaseelan, S.M.; Ojeh, N.O.; Rose, A.M.; Unwin, N. Anthropometric cut-offs to identify hyperglycemia in an Afro-Caribbean population: A cross-sectional population-based study from Barbados. BMJ Open Diabetes Res. Care 2021, 9, e002246. [Google Scholar] [CrossRef]
- Abolhasani, M.; Maghbouli, N.; Sazgara, F.; Saleh, S.K.; Tahmasebi, M.; Ashraf, H. Evaluation of Several Anthropometric and Metabolic Indices as Correlates of Hyperglycemia in Overweight/Obese Adults. Diabetes Metab. Syndr. Obes. Targets Ther. 2020, 13, 2327. [Google Scholar] [CrossRef]
- Grundy, S.M.; Brewer, H.B., Jr.; Cleeman, J.I.; Smith, S.C., Jr.; Lenfant, C. Definition of metabolic syndrome: Report of the National Heart, Lung, and Blood Institute/American Heart Association conference on scientific issues related to definition. Circulation 2004, 109, 433–438. [Google Scholar] [CrossRef]
- Verkouter, I.; Noordam, R.; le Cessie, S.; van Dam, R.M.; Lamb, H.J.; Rosendaal, F.R.; van Heemst, D.; de Mutsert, R. The association between adult weight gain and insulin resistance at middle age: Mediation by visceral fat and liver fat. J. Clin. Med. 2019, 8, 1559. [Google Scholar] [CrossRef] [PubMed]
- Hardy, O.T.; Czech, M.P.; Corvera, S. What causes the insulin resistance underlying obesity? Curr. Opin. Endocrinol. Diabetes Obes. 2012, 19, 81. [Google Scholar] [CrossRef] [PubMed]
- Otto-Ślusarczyk, D.; Graboń, W.; Mielczarek-Puta, M. Aspartate aminotransferase--key enzyme in the human systemic metabolism. Postep. Hig. I Med. Dosw. (Online) 2016, 70, 219–230. [Google Scholar] [CrossRef] [PubMed]
- Huang, X.-J.; Choi, Y.-K.; Im, H.-S.; Yarimaga, O.; Yoon, E.; Kim, H.-S. Aspartate aminotransferase (AST/GOT) and alanine aminotransferase (ALT/GPT) detection techniques. Sensors 2006, 6, 756–782. [Google Scholar] [CrossRef]
- Jeon, C.Y.; Roberts, C.K.; Crespi, C.M.; Zhang, Z.-F. Elevated liver enzymes in individuals with undiagnosed diabetes in the US. J. Diabetes Its Complicat. 2013, 27, 333–339. [Google Scholar] [CrossRef]
- Sheng, X.; Che, H.; Ji, Q.; Yang, F.; Lv, J.; Wang, Y.; Xian, H.; Wang, L. The relationship between liver enzymes and insulin resistance in type 2 diabetes patients with nonalcoholic fatty liver disease. Horm. Metab. Res. 2018, 50, 397–402. [Google Scholar] [CrossRef] [PubMed]
- Ahn, H.-R.; Shin, M.-H.; Nam, H.-S.; Park, K.-S.; Lee, Y.-H.; Jeong, S.-K.; Choi, J.-S.; Kweon, S.-S. The association between liver enzymes and risk of type 2 diabetes: The Namwon study. Diabetol. Metab. Syndr. 2014, 6, 14. [Google Scholar] [CrossRef] [PubMed]
- Esteghamati, A.; Noshad, S.; Khalilzadeh, O.; Khalili, M.; Zandieh, A.; Nakhjavani, M. Insulin resistance is independently associated with liver aminotransferases in diabetic patients without ultrasound signs of nonalcoholic fatty liver disease. Metab. Syndr. Relat. Disord. 2011, 9, 111–117. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Yang, P.; Yan, Z.; Liu, Z.; Ma, Q.; Zhang, Z.; Wang, Y.; Su, Y. The relationship between erythrocytes and diabetes mellitus. J. Diabetes Res. 2021, 2021, 6656062. [Google Scholar] [CrossRef]
- Arkew, M.; Asmerom, H.; Tesfa, T.; Tsegaye, S.; Gemechu, K.; Bete, T.; Haile, K. Red Blood Cell Parameters and Their Correlation with Glycemic Control Among Type 2 Diabetic Adult Patients in Eastern Ethiopia: A Comparative Cross-Sectional Study. Diabetes Metab. Syndr. Obes. Targets Ther. 2022, 15, 3499–3507. [Google Scholar] [CrossRef]
- Rashed, E.; Alkout, T.; Eltomy, S.; Etekbali, O.R.; Alkout, A.M. The effects of red blood cells parameters on HbA1c and random blood sugar levels in diabetics diagnosis. Int. J. Diabetes Clin. Res 2020, 7, 1–7. [Google Scholar]
- Zhao, Q.; Zhu, J.; Shen, X.; Lin, C.; Zhang, Y.; Liang, Y.; Cao, B.; Li, J.; Liu, X.; Rao, W. Chinese diabetes datasets for data-driven machine learning. Sci. Data 2023, 10, 35. [Google Scholar] [CrossRef]
- Tejedor, M.; Woldaregay, A.Z.; Godtliebsen, F. Reinforcement learning application in diabetes blood glucose control: A systematic review. Artif. Intell. Med. 2020, 104, 101836. [Google Scholar] [CrossRef]




Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abegaz, T.M.; Ahmed, M.; Sherbeny, F.; Diaby, V.; Chi, H.; Ali, A.A. Application of Machine Learning Algorithms to Predict Uncontrolled Diabetes Using the All of Us Research Program Data. Healthcare 2023, 11, 1138. https://doi.org/10.3390/healthcare11081138
Abegaz TM, Ahmed M, Sherbeny F, Diaby V, Chi H, Ali AA. Application of Machine Learning Algorithms to Predict Uncontrolled Diabetes Using the All of Us Research Program Data. Healthcare. 2023; 11(8):1138. https://doi.org/10.3390/healthcare11081138
Chicago/Turabian StyleAbegaz, Tadesse M., Muktar Ahmed, Fatimah Sherbeny, Vakaramoko Diaby, Hongmei Chi, and Askal Ayalew Ali. 2023. "Application of Machine Learning Algorithms to Predict Uncontrolled Diabetes Using the All of Us Research Program Data" Healthcare 11, no. 8: 1138. https://doi.org/10.3390/healthcare11081138
APA StyleAbegaz, T. M., Ahmed, M., Sherbeny, F., Diaby, V., Chi, H., & Ali, A. A. (2023). Application of Machine Learning Algorithms to Predict Uncontrolled Diabetes Using the All of Us Research Program Data. Healthcare, 11(8), 1138. https://doi.org/10.3390/healthcare11081138