
Development of a Nurse Turnover Prediction Model in Korea Using Machine Learning
 , , and
, , and
Abstract
:1. Introduction
2. Materials and Methods
2.1. Design and Subjects
2.2. Construction of the Prediction Model
2.2.1. Data Collection
2.2.2. Structure of the Nurse Turnover Prediction Model
2.2.3. Data Preprocessing
2.2.4. Construction of Training Data, Validation Data, and Data Set
2.2.5. Proposal for the Predictive Model
Decision Tree
Logistic Regression
Random Forest
2.3. Evaluation of the Prediction Model
3. Results
3.1. Sociodemographic Characteristics of the Participants
3.2. Data Preprocessing and Learning Data Assignment
3.3. Confusion Matrix of Nurse Turnover Prediction
3.4. Performance of Nurse Turnover Prediction Model
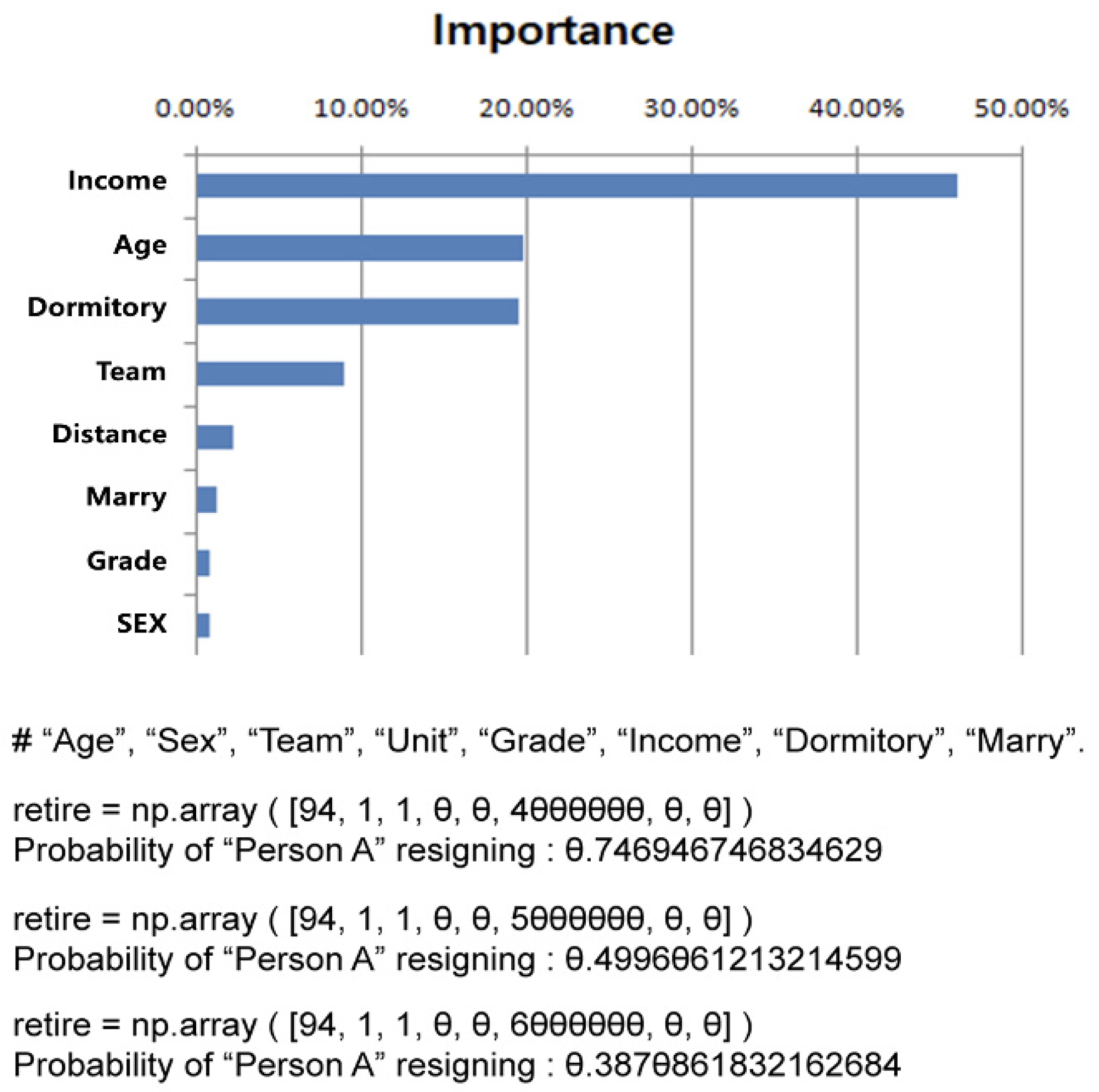
3.5. Variable Importance in the Prediction Model
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Korean Statistical Information Service. Status of Medical Personnel by Type of Medical Institution; Korean Statistical Information Service: Daejeon, Republic of Korea, 2022; Available online: https://kosis.kr/statHtml/statHtml.do?orgId=354&tblId=DT_HIRA4A (accessed on 16 December 2022).
- Lee, Y.; Kang, J. Related Factors of Turnover Intention among Korean Hospital Nurses: A Systematic Review and Meta-Analysis. Korean J. Adult Nurs. 2018, 30, 1–17. [Google Scholar] [CrossRef]
- Korean Hospital Nurses Association. Hospital Nurses Staffing State Survey. Korean: Seoul Hospital Nurses Association, 2022. Available online: http://khna.or.kr (accessed on 19 December 2022).
- Dewanto, A.; Wardhani, V. Nurse turnover and perceived causes and consequences: A preliminary study at private hospitals in Indonesia. BMC Nurs. 2018, 17 (Suppl. S2), 52. [Google Scholar] [CrossRef] [PubMed]
- Sim, Y.S.; Shim, G.S.; Sim, B.H.; Sung, J.H. Effects of Meaning of Work, Job Embeddedness, and Workplace Bullying on Turnover Intention of Nurses in a University Hospital. J. Korean Acad. Nurs. Adm. 2021, 27, 227–235. [Google Scholar] [CrossRef]
- Mobley, W.H.; Horner, S.O.; Hollingsworth, A.T. An evaluation of precursors of hospital employee turnover. J. Appl. Psychol. 1978, 63, 408–414. [Google Scholar] [CrossRef] [PubMed]
- Falatah, R. The Impact of the Coronavirus Disease (COVID-19) Pandemic on Nurses’ Turnover Intention: An Integrative Review. Nurs. Rep. 2021, 11, 787–810. [Google Scholar] [CrossRef] [PubMed]
- Gao, X.; Wen, J.; Zhang, C. An Improved Random Forest Algorithm for Predicting Employee Turnover. Math. Probl. Eng. 2019, 2019, 1–12. [Google Scholar] [CrossRef]
- Price, J.L. The Study of Turnover; Iowa State University Press: Ames, IA, USA, 1977. [Google Scholar]
- Lee, E.; Choi, H.; Song, Y.S. An Exploratory Study on determinants predicting university graduate newcomers’ early turn over. J. Corp. Educ. Talent. Res. 2020, 22, 163–193. [Google Scholar] [CrossRef]
- Lee, Y.; Kim, J.L.; Kim, S.H.; Chae, J. Effect of an Age-Stratified Working Environment and Hospital Characteristics on Nurse Turnover. HIRA Policy Brief 2022, 2, 106–119. [Google Scholar] [CrossRef]
- Park, J.H. A Study on the Reasons of Nurse’s Turnover and Factors Affecting Turnover. Master’s Thesis, Yeonsei University, Seoul, Republic of Korea, 2019; pp. 1–47. [Google Scholar]
- Choi, J.H.; Park, H.K.; Park, J.E.; Lee, C.M.; Choi, B.G. Artificial intelligence to forecast new nurse turnover rates in hospital. J. Korea Converg. Soc. 2018, 9, 431–440. [Google Scholar] [CrossRef]
- Janiesch, C.; Zschech, P.; Heinrich, K. Machine learning and deep learning. Electron. Mark. 2021, 31, 685–695. [Google Scholar] [CrossRef]
- De Caigny, A.; Coussement, K.; De Bock, K.W. A new hybrid classification algorithm for customer churn prediction based on logistic regression and decision trees. Eur. J. Oper. Res. 2018, 269, 760–772. [Google Scholar] [CrossRef]
- Naghibi, S.A.; Ahmadi, K.; Daneshi, A. Application of Support Vector Machine, Random Forest, and Genetic Algorithm Optimized Random Forest Models in Groundwater Potential Mapping. Water Resour. Manag. 2017, 31, 2761–2775. [Google Scholar] [CrossRef]
- Song, S.G.; Kang, S.H.; Choi, Y.H.; Sim, E.K.; Lee, J.W.; Park, J.H.; Choi, B.K. Study on development of graphic user interface for Tensorflow based on artificial intelligence. J. Digit Converg. 2018, 16, 221–229. [Google Scholar] [CrossRef]
- Chakraborty, R.; Mridha, K.; Shaw, R.N.; Ghosh, A. Study and Prediction Analysis of the Employee Turnover using Machine Learning Approaches. In Proceedings of the 2021 IEEE 4th International Conference on Computing, Power and Communication Technologies (GUCON), Kuala Lumpur, Malaysia, 24–26 September 2021; IEEE: Piscataway Township, NJ, USA; pp. 1–6. [Google Scholar] [CrossRef]
- Ganthi, L.S.; Nallapaneni, Y.; Perumalsamy, D.; Mahalingam, K. Employee Attrition Prediction Using Machine Learning Algorithms. Data Sci. Appl. 2022, 288, 577–596. [Google Scholar] [CrossRef]
- Kim, J.; Ha, S.; Park, Y.W.; Kim, Y.H.; Kwon, H.J. Nurse wage structure and its determinants in hospital industry. J. Korean Clin. Nurs. Res. 2019, 25, 294–302. [Google Scholar] [CrossRef]
- Kim, J.H.; Ha, S.K.; Park, Y.W.; Kim, Y.H.; Yi, S.M.; Kwon, H.J. Nursing salary guideline for Korean hospitals. J. Korean Clin. Nurs. Res. 2020, 26, 75–85. [Google Scholar] [CrossRef]
- Bakker, A.B.; Killmer, C.H.; Siegrist, J.; Schaufeli, W.B. Effort-reward imbalance and burnout among nurses. J. Adv. Nurs. 2000, 31, 884–891. [Google Scholar] [CrossRef] [PubMed]
- Korean Hospital Nurses Association. Analysis of Trends in the 2010–2019 Hospital Nursing Staff Placement and Working Conditions Survey; Korean Hospital Nurses Association: Seoul, Republic of Korea, 2022. [Google Scholar]
- Statistics Korea. Additional Survey Results of the Economically Active Population Survey of the Elderly in May 2022. Dajeon. Statistics Korea, 2022. Available online: https://kostat.go.kr/portal/korea/kor_nw/1/1/index.board?bmode=read&aSeq=419453&pageNo=&rowNum=10&amSeq=&sTarget=&sTxt= (accessed on 10 January 2023).
- Kim, K.K.; Kim, G.Y.; Kim, B.K. New Nurses’ Experience of Turnover: A Qualitative Meta-Synthesis. J. Korean Acad. Nurs. Adm. 2020, 26, 84–99. [Google Scholar] [CrossRef]
- Hayes, L.J.; O’brien-Pallas, L.; Duffield, C.; Shamian, J.; Buchan, J.; Hughes, F.; Laschinger, H.K.S.; North, N. Nurse turnover: A literature review—An update. Int. J. Nurs. Stud. 2012, 49, 887–905. [Google Scholar] [CrossRef] [PubMed]
- Lee, J.H.; Song, Y. Predictive factors of turnover intention among intensive care unit nurses. J. Korean Clin. Nurs. Res. 2018, 24, 347–355. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| True Class | Performance Metrics | |||
|---|---|---|---|---|
| Positive (1) | Negative (0) | |||
| Predicted class | Positive (1) | TP (True positive) | FP (False positive) | Accuracy: ((TP + TN)/(TP + FN + FP + TN)) Precision: (TP/(TP + FP)) Recall/Sensitivity: (TP/(TP + FN)) F1-score: (2× (Precision×Recall)/(Precision + Recall)) |
| Negative (0) | FN (False negative) | TN (True negative) | ||
| Variables | Categories | Resignees (N = 629) | Employees (N = 777) | ||
|---|---|---|---|---|---|
| N (%) | Mean ± SD | N (%) | Mean ± SD | ||
| Age (yr) | 20s | 250 (39.7) | 33.06 ± 6.13 | 475 (61.1) | 30.95 ± 7.37 |
| 30s | 305 (48.5) | 192 (24.7) | |||
| 40s | 67 (10.7) | 97 (12.5) | |||
| 50s | 5 (0.8) | 13 (1.7) | |||
| 60s | 2 (0.3) | 0 (0.0) | |||
| Sex | Female | 577 (91.7) | 718 (92.4) | ||
| Male | 52 (8.3) | 59 (7.6) | |||
| Team | Outpatient | 186 (29.6) | 164 (21.1) | ||
| ICU | 163 (25.9) | 213 (27.4) | |||
| Ward | 299 (47.5) | 399 (51.4) | |||
| Nursing department | 1 (0.2) | 1 (0.1) | |||
| Grade | Nurse | 614 (97.6) | 712 (91.6) | ||
| Nurse practitioner | 15 (2.4) | 65 (8.4) | |||
| Income | Unit: 10 million won | 4.19 ± 0.83 | 5.11 ± 0.93 | ||
| Dormitory | Resident | 442 (70.3) | 151 (19.4) | ||
| Non-resident | 187 (29.7) | 626 (80.6) | |||
| Married | Yes | 116 (18.4) | 161 (20.7) | ||
| No | 513 (81.6) | 616 (79.3) | |||
| Distance from home to workplace | Near | 542 (86.2) | 715 (92.0) | ||
| Far | 87 (13.8) | 62 (8.0) | |||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, S.-K.; Kim, E.-J.; Kim, H.-K.; Song, S.-S.; Park, B.-N.; Jo, K.-W. Development of a Nurse Turnover Prediction Model in Korea Using Machine Learning. Healthcare 2023, 11, 1583. https://doi.org/10.3390/healthcare11111583
Kim S-K, Kim E-J, Kim H-K, Song S-S, Park B-N, Jo K-W. Development of a Nurse Turnover Prediction Model in Korea Using Machine Learning. Healthcare. 2023; 11(11):1583. https://doi.org/10.3390/healthcare11111583
Chicago/Turabian StyleKim, Seong-Kwang, Eun-Joo Kim, Hye-Kyeong Kim, Sung-Sook Song, Bit-Na Park, and Kyoung-Won Jo. 2023. "Development of a Nurse Turnover Prediction Model in Korea Using Machine Learning" Healthcare 11, no. 11: 1583. https://doi.org/10.3390/healthcare11111583
APA StyleKim, S.-K., Kim, E.-J., Kim, H.-K., Song, S.-S., Park, B.-N., & Jo, K.-W. (2023). Development of a Nurse Turnover Prediction Model in Korea Using Machine Learning. Healthcare, 11(11), 1583. https://doi.org/10.3390/healthcare11111583