
Automatic Recognition of Ragged Red Fibers in Muscle Biopsy from Patients with Mitochondrial Disorders

 , and
, and
Abstract
:1. Introduction
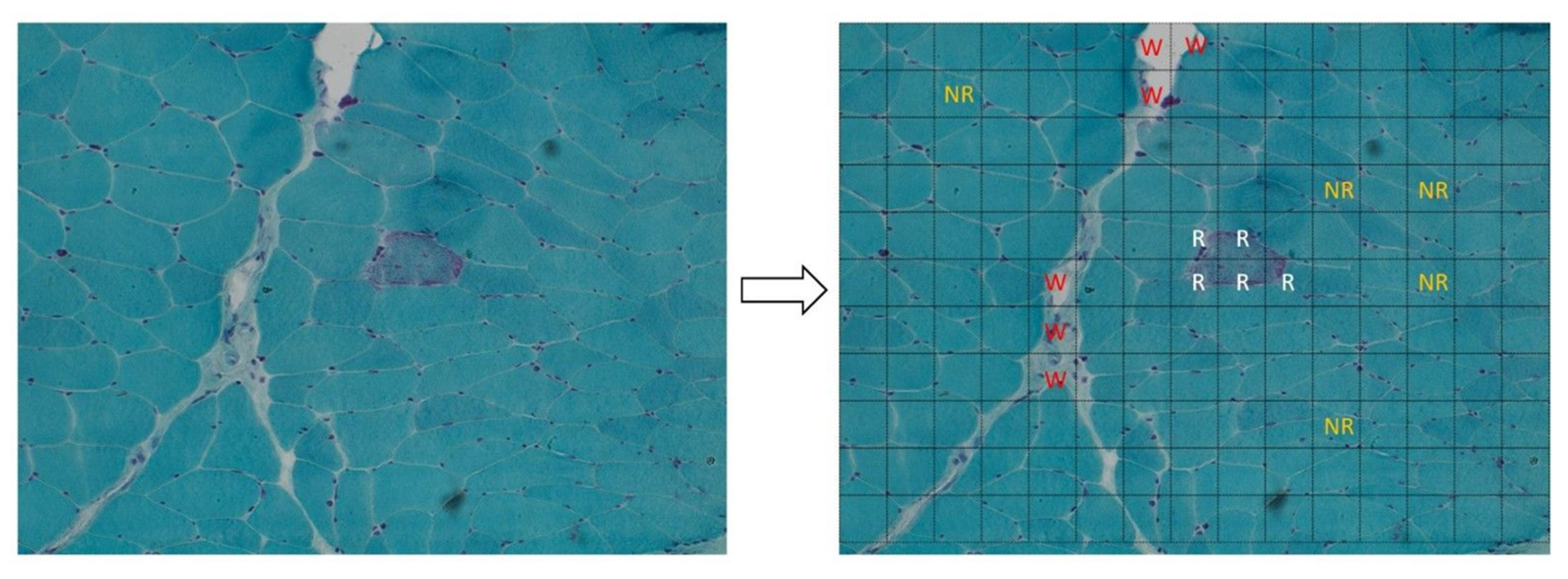
2. Materials and Methods
- There were artifacts (bubbles, slice folding, staining artifacts, etc.) that did not allow a clear view;
- The percentage of the connective tissue was higher than in the muscle tissue.
- The grey-level co-occurrence matrix (GLCM) of size Ng × Ng is defined as P(i,j|δ,θ). The (i,j) element of this matrix represents the number of times. The combination of levels i and j occurs in two pixels in the image, which are separated by a distance of δ pixels along angle θ [11].Twenty-one second-order GLCM features were calculated.
- The grey-level run length matrix (GLRLM) quantifies gray-level runs, which are defined as the length in the number of pixels, of consecutive pixels that have the same gray-level value. In a gray-level run length matrix P(i,j|θ), the (i,j)th element describes the number of runs with gray level i and length j occur in the image along angle θ [12].Eleven second-order GLRLM features were calculated.
- The grey-level size zone matrix (GLSZM) quantifies gray-level zones in an image. A gray level zone is defined as the number of connected pixels that share the same gray level intensity. A pixel is considered connected, if the distance is 1, according to the infinity norm (8-connected region in two dimensions). In the gray-level size zone matrix P(i,j), the (i,j)th element equals the number of zones with gray level i and size j appears in the image. Contrary to the GLCM and the GLRLM, the GLSZM is rotation-independent, with only one matrix calculated for all directions in the image [13].Eleven second-order GLSZM features were calculated.
- Random forest (RF): This is a widely used shallow machine-learning method that combines decision tree predictors following the bagging technique [14,15]. In this model, the class that receives the majority of votes from trees in the forest is considered the output result. This protocol relies on creating the number of models (n) and averaging predictions of all models for a finale prediction.
- Gradient boosting machine (GBM): This is an ensemble algorithm of decision trees [16,17]. The ensemble works by combining a set of weaker machine-learning algorithms to get an improved machine-learning algorithm in overall. The main difference between GBM and RF is the way of sampling. RF is based on uniform sampling with return. Instead, GBM gives higher weights to the wrongly predicted samples in the current weaker leaner, and then these samples will be paid more attention to when training the next weaker leaner.
- Support vector machine (SVM): This system divides the training set into two parts by constructing a hyper-plane in the feature space. Features in non-linear separation may be changed into linear separation, using kernel functions to map the original data to a feature space with a higher dimension [18,19].
3. Results
- The wasted zones in Gomori’s trichrome-stained muscle images;
- RRFs in a field of normal muscular fibers.
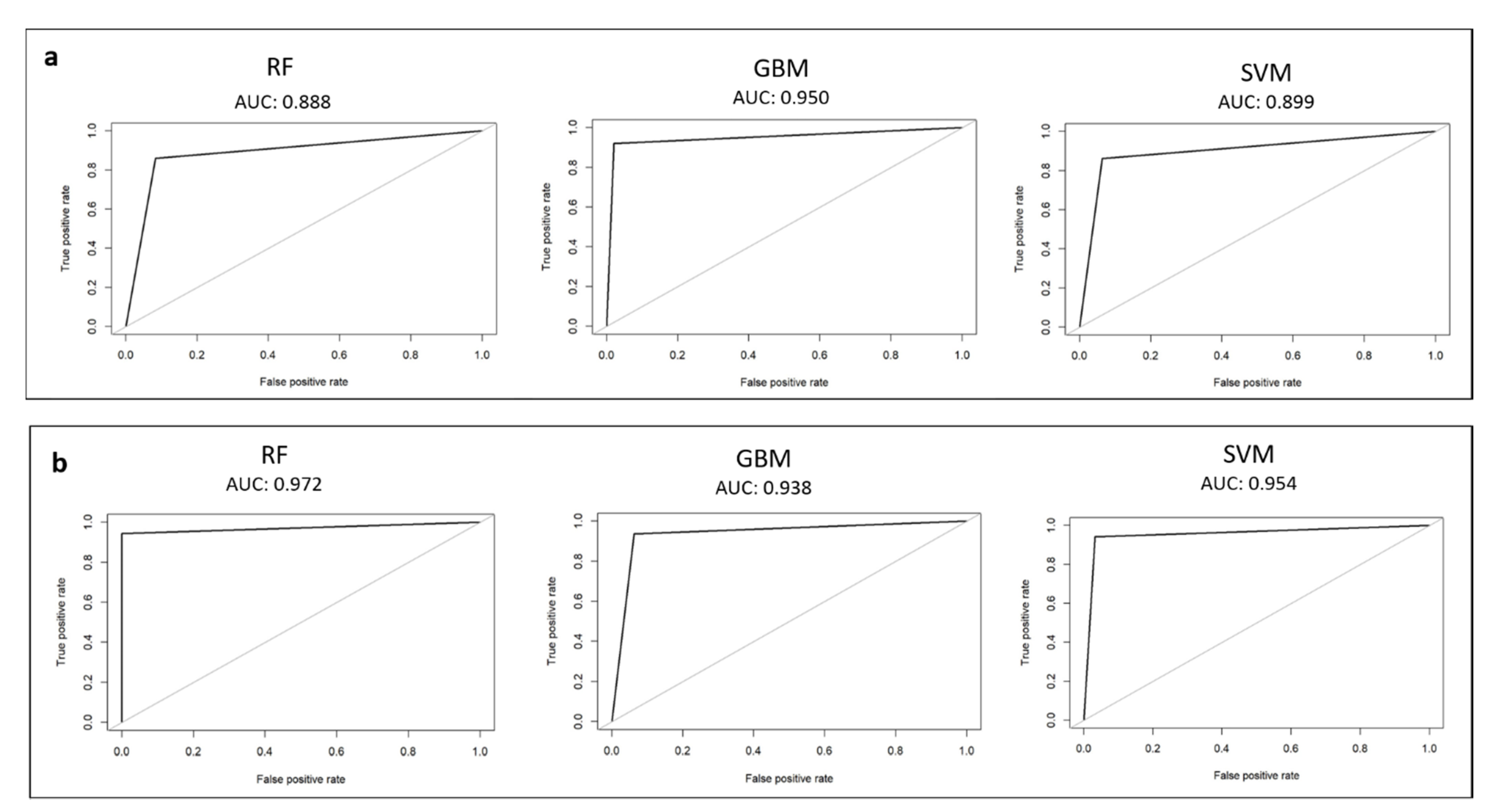
3.1. Waste-Tissue Classification
3.2. Ragged–Not Ragged Classification
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- McFarland, R.; Taylor, R.W.; Turnbull, D.M. A neurological perspective on mitochondrial disease. Lancet Neurol. 2010, 9, 829–840. [Google Scholar] [CrossRef]
- Calvo, S.E.; Mootha, V.K. The mitochondrial proteome and human disease. Annu. Rev. Genom. Hum. Genet. 2010, 11, 25–44. [Google Scholar] [CrossRef] [Green Version]
- Wortmann, S.B.; Koolen, D.A.; Smeitink, J.A.; van den Heuvel, L.; Rodenburg, R.J. Whole exome sequencing of suspected mitochondrial patients in clinical practice. J. Inherit. Metab. Dis. 2015, 38, 437–443. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Neveling, K.; Feenstra, I.; Gilissen, C.; Hoefsloot, L.H.; Kamsteeg, E.-J.; Mensenkamp, A.; Rodenburg, R.; Yntema, H.G.; Spruijt, L.; Vermeer, S.; et al. A post-hoc comparison of the utility of sanger sequencing and exome sequencing for the diagnosis of heterogeneous diseases. Hum. Mutat. 2013, 34, 1721–1726. [Google Scholar] [CrossRef] [PubMed]
- Haack, T.B.; Haberberger, B.; Frisch, E.M.; Wieland, T.; Iuso, A.; Gorza, M.; Strecker, V.; Graf, E.; Mayr, J.A.; Herberg, U.; et al. Molecular diagnosis in mitochondrial complex I deficiency using exome sequencing. J. Med. Genet. 2012, 49, 277–283. [Google Scholar] [CrossRef] [Green Version]
- Kohda, M.; Tokuzawa, Y.; Kishita, Y.; Nyuzuki, H.; Moriyama, Y.; Mizuno, Y.; Hirata, T.; Yatsuka, Y.; Yamashita-Sugahara, Y.; Nakachi, Y.; et al. A comprehensive genomic analysis reveals the genetic landscape of mitochondrial respiratory chain complex deficiencies. PLoS Genet. 2016, 12, e1005679. [Google Scholar] [CrossRef]
- Lek, M.; Karczewski, K.J.; Minikel, E.V.; Samocha, K.E.; Banks, E.; Fennell, T.; O’Donnell-Luria, A.H.; Ware, J.S.; Hill, A.J.; Cummings, B.B.; et al. Analysis of protein-coding genetic variation in 60,706 humans. Nature 2016, 536, 285–291. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wortmann, S.B.; Mayr, J.; Nuoffer, J.M.; Prokisch, H.; Sperl, W. A Guideline for the Diagnosis of Pediatric Mitochondrial Disease: The Value of Muscle and Skin Biopsies in the Genetics Era. Neuropediatrics 2017, 48, 309–314. [Google Scholar] [CrossRef]
- Martel, A.L.; Hosseinzadeh, D.; Senaras, C.; Zhou, Y.; Yazdanpanah, A.; Shojaii, R.; Patterson, E.S.; Madabhushi, A.; Gurcan, M.N. An image analysis resource for cancer research: PIIP-pathology image informatics platform for visualization, analysis, and management. Cancer Res. 2017, 77, e83–e86. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gutman, D.; Cobb, J.; Somanna, D.; Park, Y.; Wang, F.; Kurc, T.; Saltz, J.H.; Brat, D.J.; Cooper, L.A.D.; Kong, J. Cancer digital slide archive: An informatics resource to support integrated in silico analysis of TCGA pathology data. J. Am. Med. Inform. Assoc. 2013, 20, 1091–1098. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Haralick, R.; Shanmugan, K.; Dinstein, I. Textural features for image classification. IEEE Trans. Syst. Man Cybern. 1973, 3, 610–621. [Google Scholar] [CrossRef] [Green Version]
- Galloway, M.M. Texture analysis using gray level run lengths. Comput. Graph. Image Processing 1975, 4, 172–179. [Google Scholar] [CrossRef]
- Thibault, G.; Fertil, B.; Navarro, C.; Pereira, S.; Cau, P.; Levy, N.; Sequeira, J.; Mari, J. Texture Indexes and Gray Level Size Zone Matrix. Application to Cell Nuclei Classification. In Proceedings of the Pattern Recognition and Information Processing (PRIP), Minsk, Belarus, 19–21 May 2009; pp. 140–145. [Google Scholar]
- Xiao, Y.; Wu, J.; Lin, Z.; Zhao, X. A deep learning-based multi-model ensemble method for cancer prediction. Comput. Methods Programs Biomed. 2018, 153, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Li, Y. Study of cardiovascular disease prediction model based on random forest in eastern China. Sci. Rep. 2020, 10, 5245. [Google Scholar] [CrossRef] [Green Version]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; ACM: San Francisco, CA, USA, 2016; pp. 785–794. [Google Scholar]
- Derara, D.R. Diagnosis of Diabetes Mellitus Using Gradient Boosting Machine (LightGBM). Diagnostics 2021, 11, 1714. [Google Scholar] [CrossRef]
- Duda, R.O.; Peter, E.H.; David, G.S. Pattern Classification; Wiley-Interscience: Hoboken, NJ, USA, 2012. [Google Scholar]
- Huang, S. Applications of Support Vector Machine (SVM) Learning in Cancer Genomics. Cancer Genom. Proteom. 2018, 15, 41–51. [Google Scholar] [CrossRef] [Green Version]
- Chen, J.H.; Asch, S.M. Machine learning and prediction in medicine-beyond the peak of inflated expectations. N. Engl. J. Med. 2017, 376, 2507–2509. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cabitza, F.; Rasoini, R.; Gensini, G.F. Unintended consequences of machine learning in medicine. JAMA 2017, 318, 517–518. [Google Scholar] [CrossRef] [PubMed]
- Fuchs, T.J.; Wild, P.J.; Moch, H.; Buhmann, J.M. Computational pathology analysis of tissue microarrays predicts survivalof renal clear cell carcinoma patients. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, New York, NY, USA, 6–10 September 2008; Springer: Berlin/Heidelberg, Germany, 2008; pp. 1–8. [Google Scholar]
- Yu, K.-H.; Zhang, C.; Berry, G.J.; Altman, R.; Ré, C.; Rubin, D.L.; Snyder, M. Predicting non-small cell lung cancer prognosis by fully automated microscopic pathology image features. Nat. Commun. 2016, 7, 12474. [Google Scholar] [CrossRef] [Green Version]
- Ertosun, M.G.; Rubin, D.L. Automated grading of gliomas using deep learning in digital pathology images: A modular approach with ensemble of convolutional neural networks. AMIA Annu. Symp. Proc. 2015, 2015, 1899–1908. [Google Scholar]
- Poostchi, M.; Silamut, K.; Maude, R.J.; Jaeger, S.; Thoma, G. Image analysis and machine learning for detecting malaria. Transl. Res. 2018, 194, 36–55. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Encarnacion-Rivera, L.; Foltz, S.; Hartzell, H.C.; Choo, H. Myosoft: An automated muscle histology analysis tool using machine learning algorithm utilizing FIJI/ImageJ software. PLoS ONE 2020, 15, e0229041. [Google Scholar] [CrossRef] [PubMed]
- Kastenschmidt, J.M.; Ellefsen, K.L.; Mannaa, A.H.; Giebel, J.J.; Yahia, R.; Ayer, R.E.; Pham, P.; Rios, R.; Vetrone, S.A.; Mozaffar, T.; et al. QuantiMus: A Machine Learning-Based Approach for High Precision Analysis of Skeletal Muscle Morphology. Front. Physiol. 2019, 10, 2019. [Google Scholar] [CrossRef] [PubMed]
- Kabeya, Y.; Okubo, M.; Yonezawa, S.; Nakano, H.; Inoue, M.; Ogasawara, M.; Saito, Y.; Tanboon, J.; Indrawati, L.A.; Kumutpongpanich, T.; et al. Deep convolutional neural network-based algorithm for muscle biopsy diagnosis. Lab Investig. 2021, 102, 220–226. [Google Scholar] [CrossRef]
- Xie, Y.; Liu, F.; Xing, F.; Yang, L. Deep Learning for Muscle Pathology Image Analysis. In Deep Learning and Convolutional Neural Networks for Medical Imaging and Clinical Informatics. Advances in Computer Vision and Pattern Recognition; Lu, L., Wang, X., Carneiro, G., Yang, L., Eds.; Springer: Cham, Switzerland, 2019. [Google Scholar] [CrossRef]
- Sarvamangala, D.R.; Kulkarni, R.V. Convolutional neural networks in medical image understanding: A survey. Evol. Intell. 2021, 3, 1–22. [Google Scholar] [CrossRef] [PubMed]
- Fischer, A.H.; Jacobson, K.A.; Rose, J.; Zeller, R. Hematoxylin and eosin staining of tissue and cell sections. Cold Spring Harb. Protoc. 2008, 2008, pdb-prot4986. [Google Scholar] [CrossRef]
- Madabhushi, A.; Lee, G. Image analysis and machine learning in digital pathology: Challenges and opportunities. Med. Image Anal. 2016, 33, 170–175. [Google Scholar] [CrossRef] [Green Version]

{kind=link}
{kind=link}
| a | F1 measure | Accuracy | True positive rate | True negative rate | False positive rate | False negative rate | Positive predicted values | Negative predicted values |
|---|---|---|---|---|---|---|---|---|
| Random forest (RF) | 0.872 | 0.872 | 0.869 | 0.873 | 0.127 | 0.131 | 0.882 | 0.862 |
| Gradient boosting machine (GBM) | 0.908 | 0.911 | 0.892 | 0.924 | 0.076 | 0.108 | 0.929 | 0.895 |
| Support vector machine (SVM) | 0.891 | 0.900 | 0.883 | 0.922 | 0.078 | 0.117 | 0.920 | 0.887 |
| b | F1 measure | Accuracy | True positive rate | True negative rate | False positive rate | False negative rate | Positive predicted values | Negative predicted values |
| RF | 0.965 | 0.963 | 0.943 | 0.990 | 0.010 | 0.057 | 0.989 | 0.928 |
| GBM | 0.951 | 0.953 | 0.941 | 0.971 | 0.029 | 0.059 | 0.969 | 0.928 |
| SVM | 0.949 | 0.942 | 0.972 | 0.909 | 0.091 | 0.028 | 0.930 | 0.963 |
| a | RF Confusion Matrix | GBM Confusion Matrix | SVM Confusion Matrix | ||||||
| waste | tissue | Waste | Tissue | Waste | Tissue | ||||
| Waste | 44 | 4 | Waste | 47 | 1 | Waste | 44 | 3 | |
| Tissue | 7 | 43 | Tissue | 4 | 46 | Tissue | 7 | 44 | |
| b | RF Confusion Matrix | GBM Confusion Matrix | SVM Confusion Matrix | ||||||
| Not ragged | Ragged | Not Ragged | Ragged | Not ragged | Ragged | ||||
| Not Ragged | 30 | 0 | Not Ragged | 30 | 2 | Not Ragged | 30 | 1 | |
| Ragged | 1 | 17 | Ragged | 1 | 15 | Ragged | 1 | 16 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Baldacci, J.; Calderisi, M.; Fiorillo, C.; Santorelli, F.M.; Rubegni, A. Automatic Recognition of Ragged Red Fibers in Muscle Biopsy from Patients with Mitochondrial Disorders. Healthcare 2022, 10, 574. https://doi.org/10.3390/healthcare10030574
Baldacci J, Calderisi M, Fiorillo C, Santorelli FM, Rubegni A. Automatic Recognition of Ragged Red Fibers in Muscle Biopsy from Patients with Mitochondrial Disorders. Healthcare. 2022; 10(3):574. https://doi.org/10.3390/healthcare10030574
Chicago/Turabian StyleBaldacci, Jacopo, Marco Calderisi, Chiara Fiorillo, Filippo Maria Santorelli, and Anna Rubegni. 2022. "Automatic Recognition of Ragged Red Fibers in Muscle Biopsy from Patients with Mitochondrial Disorders" Healthcare 10, no. 3: 574. https://doi.org/10.3390/healthcare10030574
APA StyleBaldacci, J., Calderisi, M., Fiorillo, C., Santorelli, F. M., & Rubegni, A. (2022). Automatic Recognition of Ragged Red Fibers in Muscle Biopsy from Patients with Mitochondrial Disorders. Healthcare, 10(3), 574. https://doi.org/10.3390/healthcare10030574