
A Tooth Segmentation Method Based on Multiple Geometric Feature Learning



Abstract
:1. Introduction
2. Related Works
2.1. Traditional Tooth Segmentation Methods
2.2. Tooth Segmentation Methods Based on Deep Learning
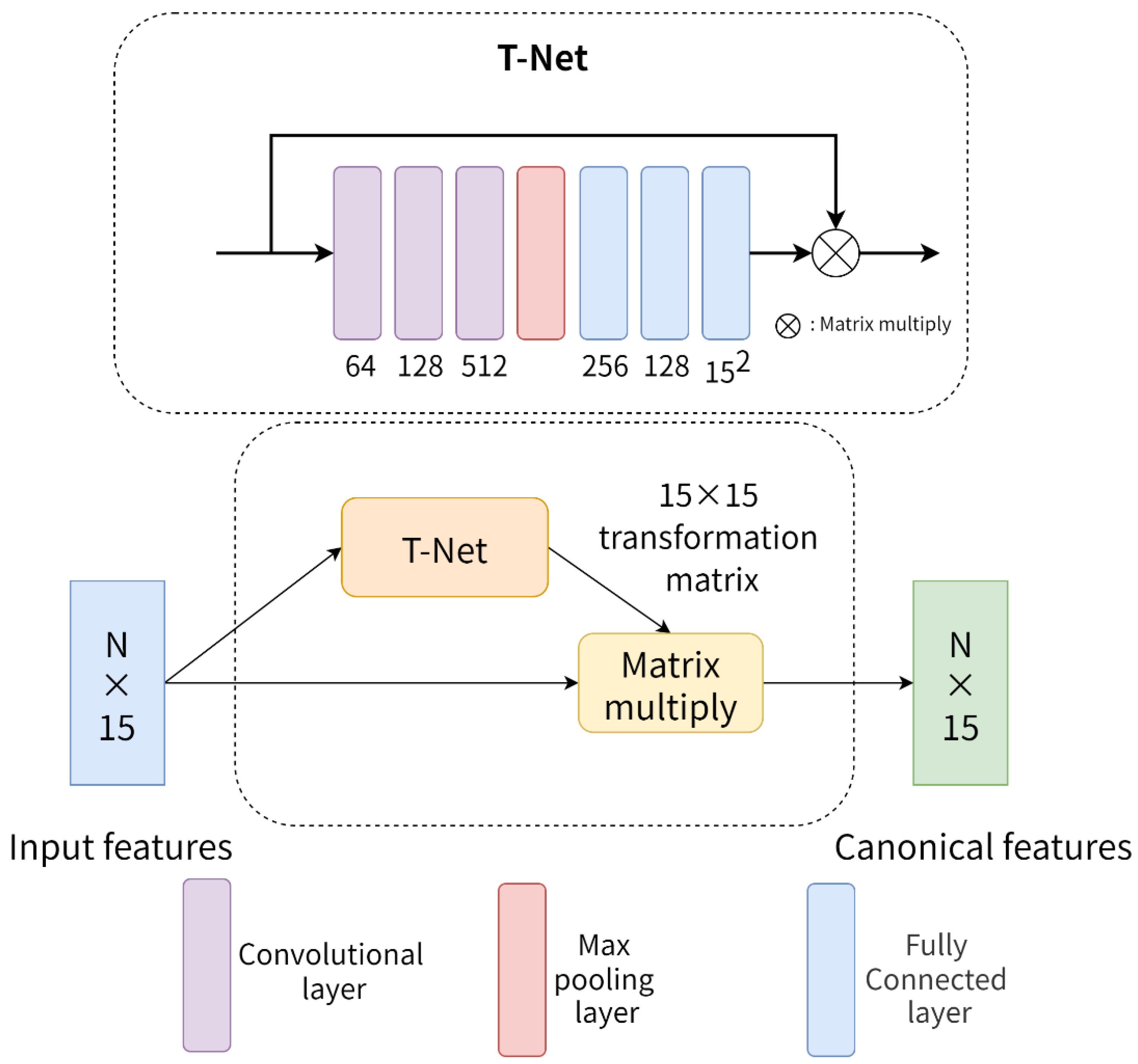
3. Method
- (1)
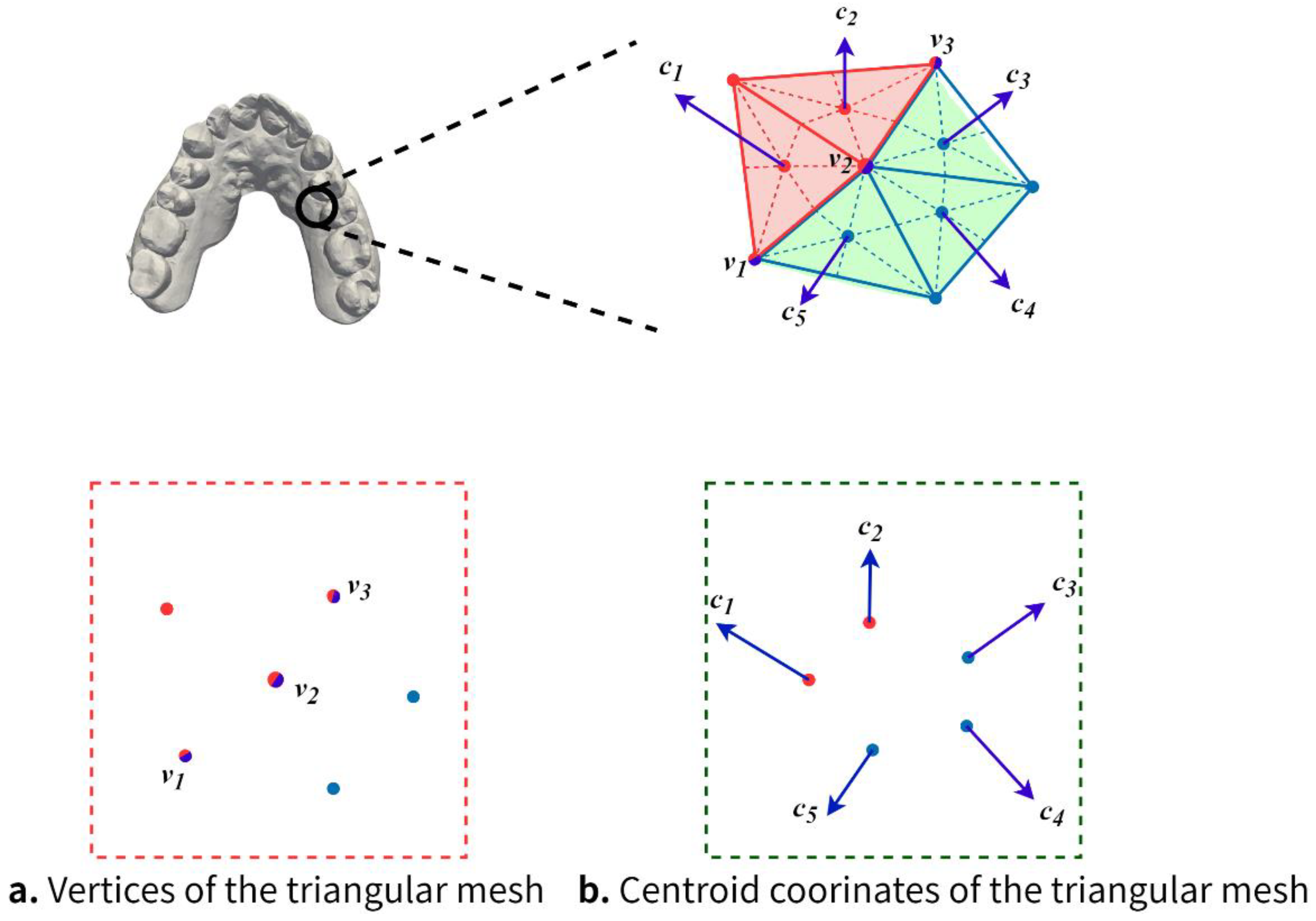
- Creation and preprocessing of dental model datasets. As shown in Figure 1, it includes downsampling of the dental model, labeling of the dental model, data augmentation, and extraction of each triangular mesh centroids;
- (2)
- Construction of a tooth segmentation network based on multiple geometric feature learning.
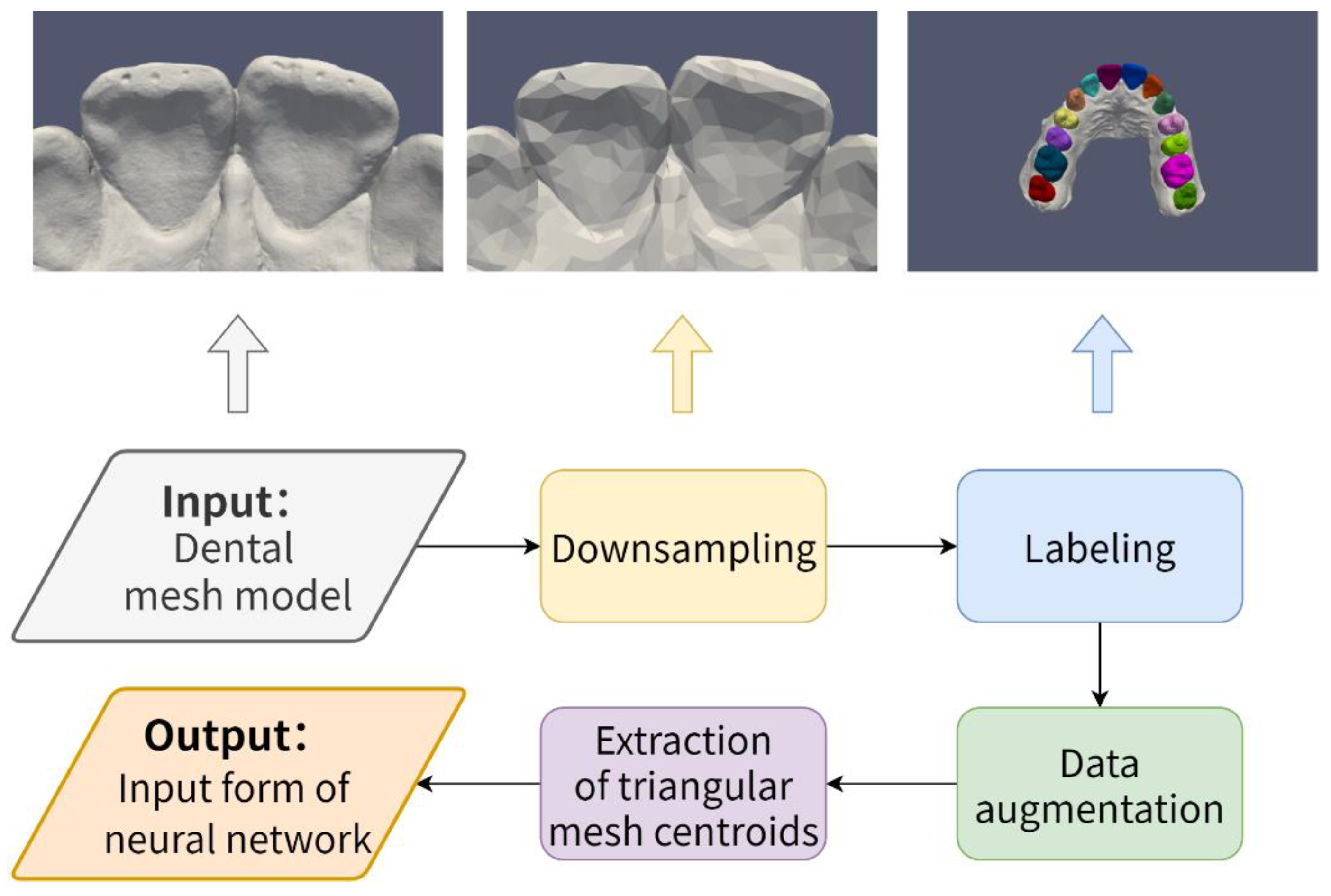
3.1. Creation and Preprocessing of Dental Model Datasets
- Random translation. Along any coordinate axis in three-dimensional space, the dental model undergoes a small translation;
- Construction of a tooth segmentation network based on multiple geometric feature learning;
- Random rescaling. The dental model is zoomed in or out randomly and appropriately;
- Randomly removal. Some triangular meshes are randomly removed from the dental models during training.
3.2. Network Architecture Design
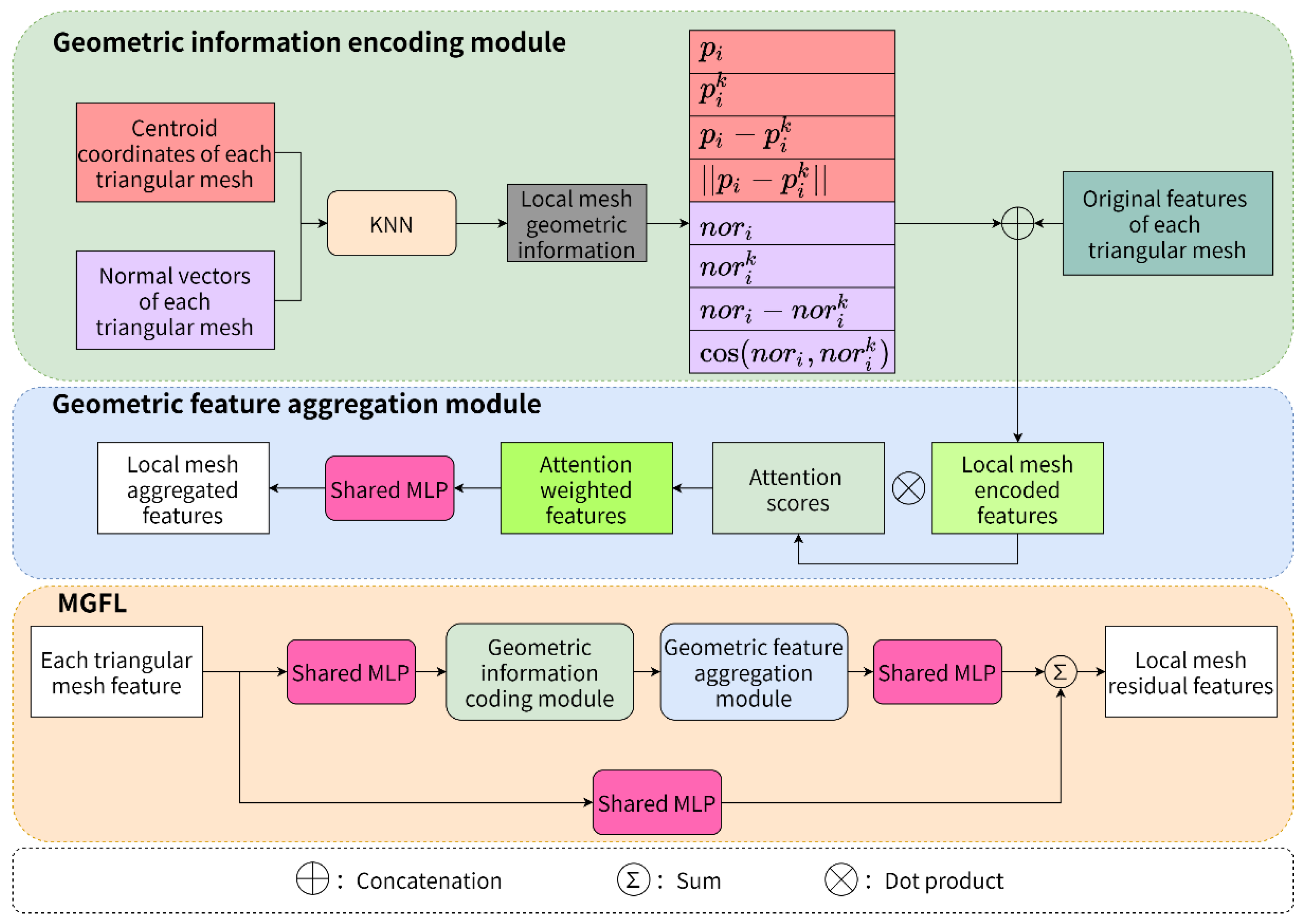
3.2.1. Multiple Geometric Feature Learning Module
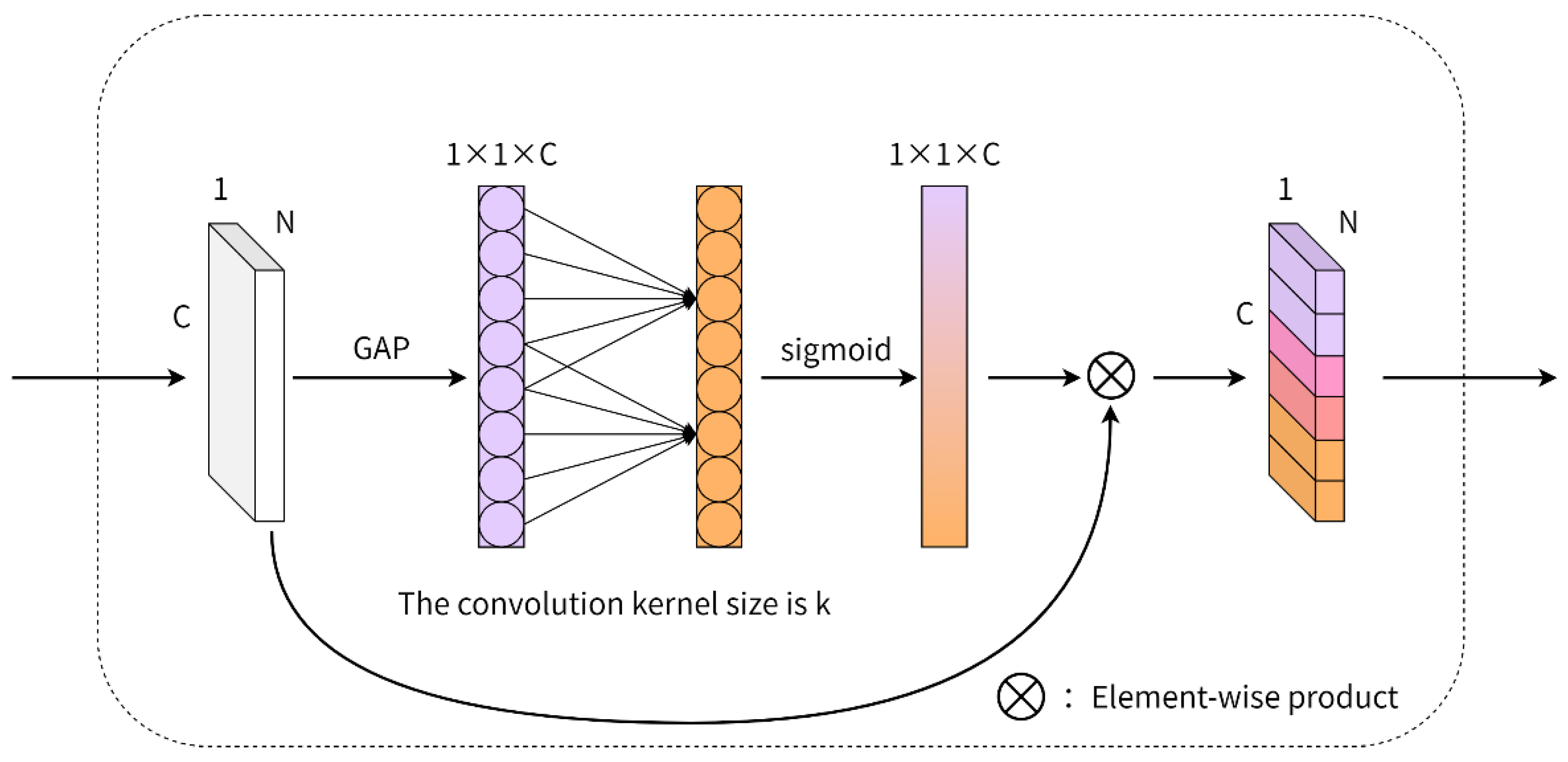
3.2.2. Global Feature Channel Optimization
3.2.3. More Network Details
4. Experiments
4.1. Evaluation Metrics
4.2. Results
4.3. Ablation Study
4.3.1. Effectiveness of Geometric Information Encoding Module
4.3.2. Effectiveness of the Double Branch MGFL
4.3.3. Effectiveness of Global Feature Channel Optimization
4.3.4. Effect of Different Input Triangular Mesh Numbers on Tooth Segmentation Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wu, T.-H.; Lian, C.; Piers, C.; Pastewait, M.; Wang, L.; Shen, D.; Ko, C.-C. Machine (Deep) Learning for Orthodontic CAD/CAM Technologies. In Machine Learning in Dentistry; Springer: Berlin/Heidelberg, Germany, 2021; pp. 117–129. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 77–85. [Google Scholar] [CrossRef] [Green Version]
- Qi, C.R.; Yi, L.; Su, H.; Guibas, L.J. PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; pp. 5099–5108. [Google Scholar]
- Wang, L.; Huang, Y.; Hou, Y.; Zhang, S.; Shan, J. Graph Attention Convolution for Point Cloud Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, 16–20 June 2019; pp. 10296–10305. [Google Scholar]
- Hu, Q.; Yang, B.; Xie, L.; Rosa, S.; Guo, Y.; Wang, Z.; Trigoni, N.; Markham, A. RandLA-Net: Efficient Semantic Segmentation of Large-Scale Point Clouds. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, WA, USA, 13–19 June 2020; pp. 11105–11114. [Google Scholar]
- Lei, T.; Jia, X.; Zhang, Y.; Liu, S.; Meng, H.; Nandi, A.K. Superpixel-Based Fast Fuzzy C-Means Clustering for Color Image Segmentation. IEEE Trans. Fuzzy Syst. 2018, 27, 1753–1766. [Google Scholar] [CrossRef] [Green Version]
- Tang, Y.; Ren, F.; Pedrycz, W. Fuzzy C-Means Clustering through SSIM and Patch for Image Segmentation. Appl. Soft Comput. 2020, 87, 105928. [Google Scholar] [CrossRef]
- Xu, X.; Liu, C.; Zheng, Y. 3D Tooth Segmentation and Labeling Using Deep Convolutional Neural Networks. IEEE Trans. Vis. Comput. Graph. 2018, 25, 2336–2348. [Google Scholar] [CrossRef] [PubMed]
- Lian, C.; Wang, L.; Wu, T.-H.; Liu, M.; Durán, F.; Ko, C.-C.; Shen, D. MeshSNet: Deep Multi-Scale Mesh Feature Learning for End-to-End Tooth Labeling on 3D Dental Surfaces. In Proceedings of the Medical Image Computing and Computer Assisted Intervention—MICCAI 2019—22nd International Conference, Shenzhen, China, 13–17 October 2019; Proceedings, Part VI. pp. 837–845. [Google Scholar] [CrossRef]
- Lian, C.; Wang, L.; Wu, T.-H.; Wang, F.; Yap, P.-T.; Ko, C.-C.; Shen, D. Deep Multi-Scale Mesh Feature Learning for Automated Labeling of Raw Dental Surfaces From 3D Intraoral Scanners. IEEE Trans. Med. Imaging 2020, 39, 2440–2450. [Google Scholar] [CrossRef]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, WA, USA, 13–19 June 2020; pp. 11531–11539. [Google Scholar]
- Kondo, T.; Ong, S.H.; Foong, K.W.C. Tooth Segmentation of Dental Study Models Using Range Images. IEEE Trans. Med. Imaging 2004, 23, 350–362. [Google Scholar] [CrossRef] [PubMed]
- Hao, G.; Cheng, X.; Dai, N.; Yu, Q. The Morphology-based Interactive Segmentation of Dental Models. Mach. Des. Manuf. Eng. 2008, 37, 36–39. [Google Scholar]
- Yuan, T.; Liao, W.; Dai, N.; Cheng, X.; Yu, Q. Single-Tooth Modeling for 3D Dental Model. Int. J. Biomed. Imaging 2010, 2010, 535329. [Google Scholar] [CrossRef] [Green Version]
- Kronfeld, T.; Brunner, D.; Brunnett, G. Snake-Based Segmentation of Teeth from Virtual Dental Casts. Comput.-Aided Des. Appl. 2010, 7, 221–233. [Google Scholar] [CrossRef] [Green Version]
- Wu, K.; Chen, L.; Li, J.; Zhou, Y. Tooth Segmentation on Dental Meshes Using Morphologic Skeleton. Comput. Graph. 2014, 38, 199–211. [Google Scholar] [CrossRef]
- Zou, B.; Liu, S.; Liao, S.; Ding, X.; Liang, Y. Interactive Tooth Partition of Dental Mesh Base on Tooth-Target Harmonic Field. Comput. Biol. Med. 2015, 56, 132–144. [Google Scholar] [CrossRef]
- Mangan, A.P.; Whitaker, R.T. Partitioning 3D Surface Meshes Using Watershed Segmentation. IEEE Trans. Vis. Comput. Graph. 1999, 5, 308–321. [Google Scholar] [CrossRef] [Green Version]
- Li, Z.; Ning, X.; Wang, Z. A Fast Segmentation Method for STL Teeth Model. In Proceedings of the 2007 IEEE/ICME International Conference on Complex Medical Engineering, Beijing, China, 23–27 May 2007; pp. 163–166. [Google Scholar] [CrossRef]
- Kumar, Y.; Janardan, R.; Larson, B.; Moon, J. Improved Segmentation of Teeth in Dental Models. Comput.-Aided Des. Appl. 2011, 8, 211–224. [Google Scholar] [CrossRef] [Green Version]
- Li, Z.; Sun, Z.; Li, H.; Liu, T. Automatic selection of tooth seed point by graph convolutional network. J. Image Graph. 2020, 25, 1481–1489. [Google Scholar]
- Verma, N.; Boyer, E.; Verbeek, J. FeaStNet: Feature-Steered Graph Convolutions for 3D Shape Analysis. In Proceedings of the 2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2598–2606. [Google Scholar]
- Tian, S.; Dai, N.; Yuan, L.; Zhang, B.; Yu, Q.; Cheng, X. Tooth Segmentation and Recognition on Dental Models Based on Multi-Level Hierarchical 3D Convolutional Neural Networks. J. Comput.-Aided Des. Comput. Graph. 2020, 32, 1218–1227. [Google Scholar]
- Zhang, Y.; Yu, Z.; He, B. Semantic Segmentation of 3D Tooth Model Based on GCNN for CBCT Simulated Mouth Scan Point Cloud Data. J. Comput.-Aided Des. Comput. Graph. 2020, 32, 1162–1170. [Google Scholar]
- Wang, Z.; Qin, P.; Chai, R.; Wu, F.; Cheng, Y.; Shi, Y. Automatic Identification Method of Tooth Impaction Based on Deep Learning. Comput. Eng. 2022, 48, 307–313. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015—18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III. pp. 234–241. [Google Scholar] [CrossRef] [Green Version]
- Thomas, H.; Qi, C.R.; Deschaud, J.-E.; Marcotegui, B.; Goulette, F.; Guibas, L.J. KPConv: Flexible and Deformable Convolution for Point Clouds. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, ICCV 2019, Seoul, Korea, 2 November–27 October 2019; pp. 6410–6419. [Google Scholar] [CrossRef] [Green Version]
- Zanjani, F.G.; Pourtaherian, A.; Zinger, S.; Moin, D.A.; Claessen, F.; Cherici, T.; Parinussa, S.; de With, P.H.N. Mask-MCNet: Tooth Instance Segmentation in 3D Point Clouds of Intra-Oral Scans. Neurocomputing 2021, 453, 286–298. [Google Scholar] [CrossRef]
- Li, Y.; Bu, R.; Sun, M.; Wu, W.; Di, X.; Chen, B. PointCNN: Convolution On X-Transformed Points. In Proceedings of the Advances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems 2018, NeurIPS 2018, Montréal, QC, Canada, 3–8 December 2018; pp. 828–838. [Google Scholar]
- Cui, Z.; Li, C.; Chen, N.; Wei, G.; Chen, R.; Zhou, Y.; Shen, D.; Wang, W. TSegNet: An Efficient and Accurate Tooth Segmentation Network on 3D Dental Model. Med. Image Anal. 2021, 69, 101949. [Google Scholar] [CrossRef] [PubMed]
- Zhang, L.; Zhao, Y.; Meng, D.; Cui, Z.; Gao, C.; Gao, X.; Lian, C.; Shen, D. TSGCNet: Discriminative Geometric Feature Learning With Two-Stream Graph Convolutional Network for 3D Dental Model Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, virtual. Nashville, TN, USA, 19–25 June 2021; pp. 6699–6708. [Google Scholar]
- Guan, B.; Zhou, F.; Lin, S.; Luo, X. Boundary-Aware Point Based Deep Neural Network for Shape Segmentation. J. Comput.-Aided Des. Comput. Graph. 2020, 32, 147–155. [Google Scholar]
- Sudre, C.H.; Li, W.; Vercauteren, T.; Ourselin, S.; Jorge Cardoso, M. Generalised Dice Overlap as a Deep Learning Loss Function for Highly Unbalanced Segmentations. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer International Publishing: Cham, Switzerland, 2017; pp. 240–248. [Google Scholar]
- Yu, Z.; Sohail, A.; Jamil, M.; Beg, O.A.; Tavares, J.M.R.S. Hybrid Algorithm for the Classification of Fractal Designs and Images. Fractals 2022. [Google Scholar] [CrossRef]
- Yu, Z.; Sohail, A.; Arif, R.; Nutini, A.; Nofal, T.A.; Tunc, S. Modeling the Crossover Behavior of the Bacterial Infection with the COVID-19 Epidemics. Results Phys. 2022, 39, 105774. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | OA | mIoU |
|---|---|---|
| PointNet | 95.9 | 89.3 |
| RandLA-Net | 92.2 | 81.4 |
| MeshSegNet | 97.3 | 92.9 |
| Ours | 98.4 | 96.3 |
| Method | Training (s/Epoch) | Prediction (s/Dental) |
|---|---|---|
| PointNet | 20.83 | 0.24 |
| RandLA-Net | 56.15 | 0.34 |
| MeshSegNet | 929.97 | 3.20 |
| Ours | 86.55 | 0.48 |
| Structure | OA | mIoU |
|---|---|---|
| 96.0 | 90.6 | |
| 97.4 | 94.1 | |
| both include | 98.4 | 96.3 |
| Structure | OA | mIoU |
|---|---|---|
| MGFL-S | 96.2 | 90.7 |
| MGFL-L | 97.6 | 95.1 |
| both include | 98.4 | 96.3 |
| Structure | OA | mIoU |
|---|---|---|
| without ECA | 97.9 | 94.7 |
| with ECA | 98.4 | 96.3 |
| Input Number of Triangular Meshes | OA | mIoU |
|---|---|---|
| 6000 | 87.7 | 80.5 |
| 7000 | 95.1 | 91.1 |
| 8000 | 97.1 | 93.7 |
| 9000 | 98.4 | 96.3 |
| 10,000 | 98.1 | 95.4 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, T.; Yang, Y.; Zhai, J.; Yang, J.; Zhang, J. A Tooth Segmentation Method Based on Multiple Geometric Feature Learning. Healthcare 2022, 10, 2089. https://doi.org/10.3390/healthcare10102089
Ma T, Yang Y, Zhai J, Yang J, Zhang J. A Tooth Segmentation Method Based on Multiple Geometric Feature Learning. Healthcare. 2022; 10(10):2089. https://doi.org/10.3390/healthcare10102089
Chicago/Turabian StyleMa, Tian, Yizhou Yang, Jiechen Zhai, Jiayi Yang, and Jiehui Zhang. 2022. "A Tooth Segmentation Method Based on Multiple Geometric Feature Learning" Healthcare 10, no. 10: 2089. https://doi.org/10.3390/healthcare10102089
APA StyleMa, T., Yang, Y., Zhai, J., Yang, J., & Zhang, J. (2022). A Tooth Segmentation Method Based on Multiple Geometric Feature Learning. Healthcare, 10(10), 2089. https://doi.org/10.3390/healthcare10102089