
The Relationship between Mustard Import and COVID-19 Deaths: A Workflow with Cross-Country Text Mining




Abstract
:1. Introduction
2. Methods
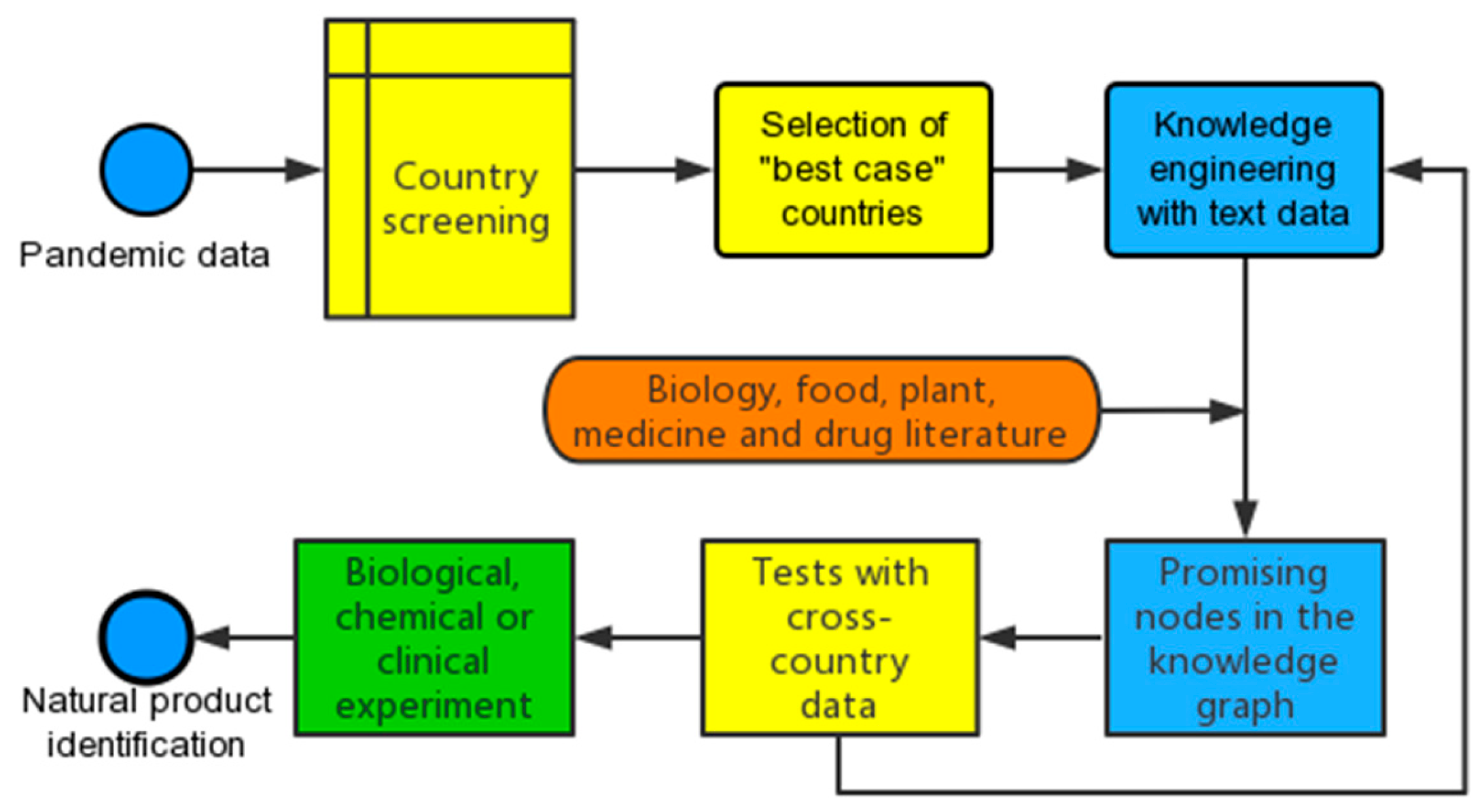
2.1. A Workflow with NPN Approach
2.2. Data Analysis
3. Results
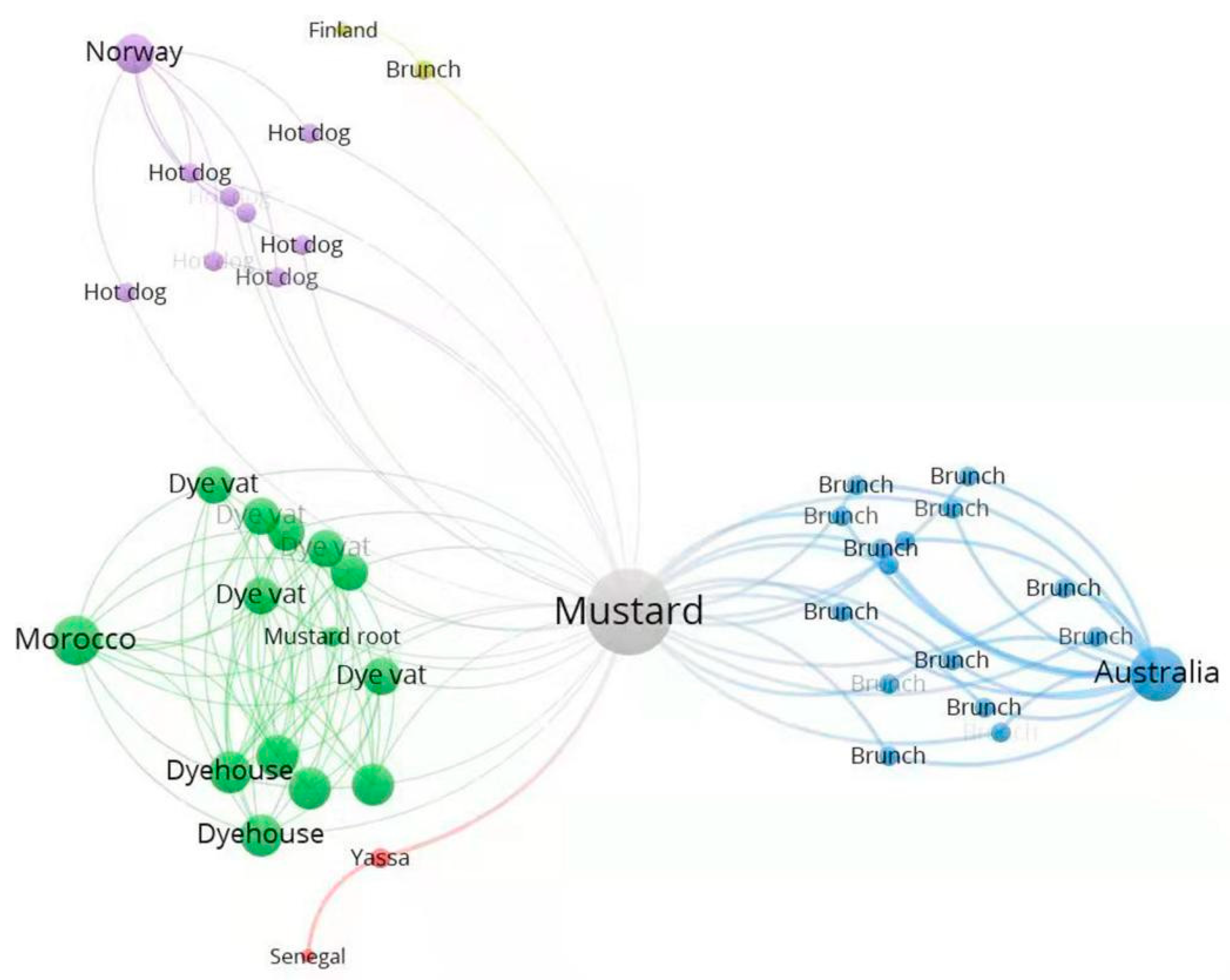
3.1. Corpus Development and Knowledge Engineering
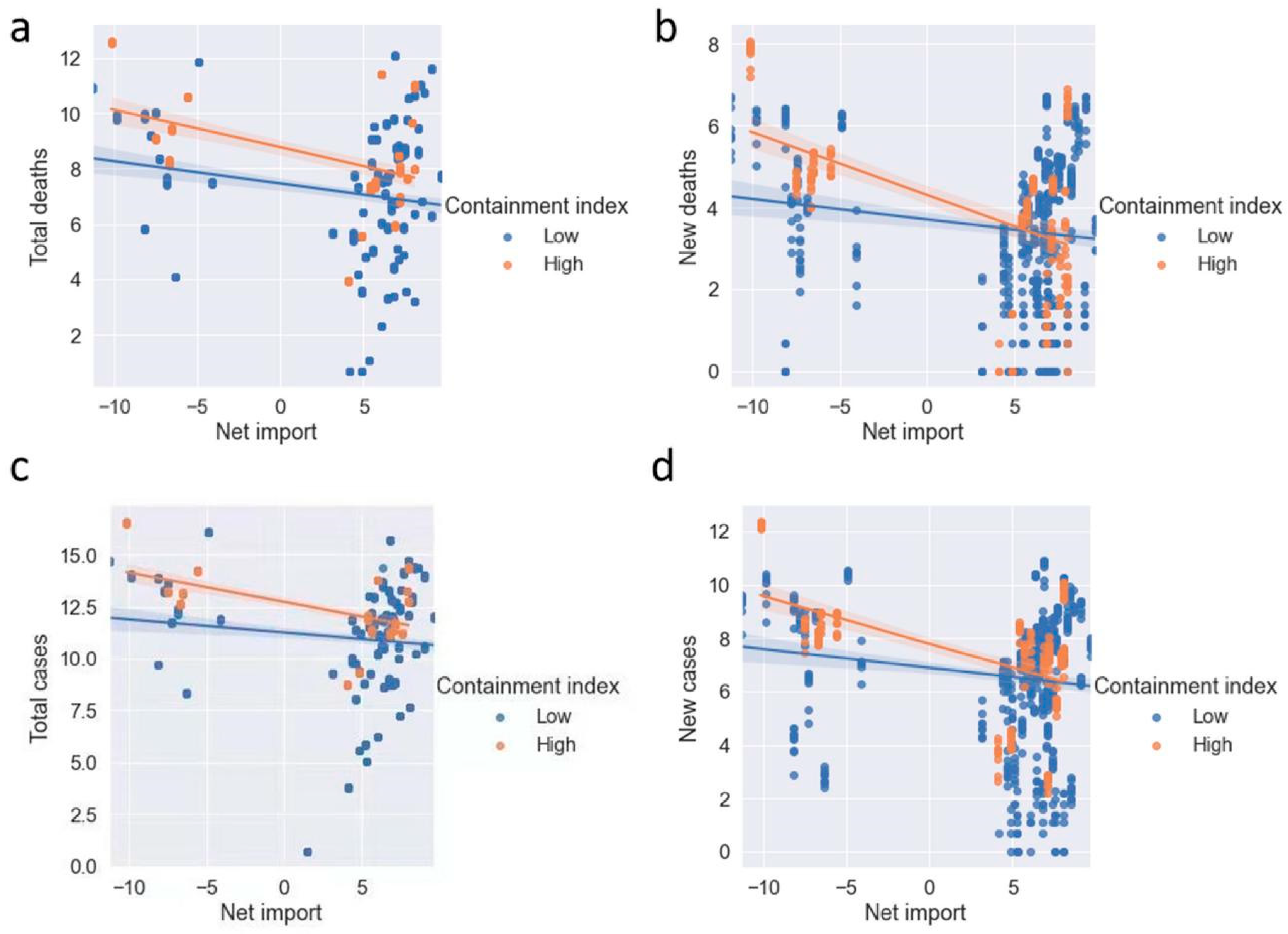
3.2. Hypothesis Testing
3.3. Sensitivity Analysis for Additional COVID-19 Outcomes
4. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Boum, I.Y.; Ouattara, A.; Torreele, E.; Okonta, C. How to ensure a needs-driven and community-centred vaccination strategy for COVID-19 in Africa. BMJ Glob. Health. 2021, 6, e005306. [Google Scholar] [CrossRef] [PubMed]
- Garcia-Beltran, W.F.; Lam, E.C.; St Denis, K.; Nitido, A.D.; Garcia, Z.H.; Hauser, B.M.; Feldman, J.; Pavlovic, M.N.; Gregory, D.J.; Poznansky, M.C.; et al. Multiple SARS-CoV-2 variants escape neutralization by vaccine-induced humoral immunity. Cell 2021, 184, 2372–2383.e9. [Google Scholar] [CrossRef] [PubMed]
- Zhou, D.; Dejnirattisai, W.; Supasa, P.; Liu, C.; Mentzer, A.J.; Ginn, H.M.; Zhao, Y.; Duyvesteyn, H.M.E.; Tuekprakhon, A.; Nutalai, R.; et al. Evidence of escape of SARS-CoV-2 variant B.1.351 from natural and vaccine-induced sera. Cell 2021, 184, 2348–2361.e6. [Google Scholar] [CrossRef] [PubMed]
- Lopez Bernal, J.; Andrews, N.; Gower, C.; Gallagher, E.; Simmons, R.; Thelwall, S.; Stowe, J.; Tessier, E.; Groves, N.; Dabrera, G.; et al. Effectiveness of Covid-19 vaccines against the B.1.617.2 (Delta) variant. N. Engl. J. Med. 2021, 385, 585–594. [Google Scholar] [CrossRef]
- Gaziano, L.; Giambartolomei, C.; Pereira, A.C.; Gaulton, A.; Posner, D.C.; Swanson, S.A.; Ho, Y.-L.; Iyengar, S.K.; Kosik, N.M.; Vujkovic, M.; et al. Actionable druggable genome-wide Mendelian randomization identifies repurposing opportunities for COVID-19. Nat. Med. 2021, 27, 668–676. [Google Scholar] [CrossRef]
- Guy, R.K.; DiPaola, R.S.; Romanelli, F.; Dutch, R.E. Rapid repurposing of drugs for COVID-19. Science 2020, 368, 829–830. [Google Scholar] [CrossRef]
- Shyr, Y.; Berry, L.D.; Hsu, C.Y. Scientific rigor in the age of COVID-19. JAMA Oncol. 2021, 7, 171–172. [Google Scholar] [CrossRef]
- Doroghazi, J.R.; Albright, J.C.; Goering, A.W.; Ju, K.S.; Haines, R.R.; Tchalukov, K.A.; Labeda, D.P.; Kellehe, N.L.; Metcalf, W.W. A roadmap for natural product discovery based on large-scale genomics and metabolomics. Nat. Chem. Biol. 2014, 10, 963–968. [Google Scholar] [CrossRef]
- Kersten, R.D.; Yang, Y.L.; Xu, Y.; Cimermancic, P.; Nam, S.J.; Fenical, W.; Fischbach, M.A.; Moore, B.S.; Dorrestein, P.C. A mass spectrometry–guided genome mining approach for natural product peptidogenomics. Nat. Chem. Biol. 2011, 7, 794–802. [Google Scholar] [CrossRef] [Green Version]
- Elbattah, M.; Arnaud, É.; Gignon, M.; Dequen, G. The role of text analytics in Healthcare: A review of recent developments and applications. In Proceedings of the 14th International Joint Conference on Biomedical Engineering Systems and Technologies, Vienna, Austria, 11–13 February 2021; pp. 825–832. [Google Scholar] [CrossRef]
- Ong, S.-Q.; Pauzi, M.B.M.; Gan, K.H. Text mining and determinants of sentiments towards the COVID-19 vaccine booster of twitter users in Malaysia. Healthcare 2022, 10, 994. [Google Scholar] [CrossRef]
- Xu, H.; Zeng, J.; Tai, Z.; Hao, H. Public attention and sentiment toward intimate partner violence based on Weibo in China: A text mining approach. Healthcare 2022, 10, 198. [Google Scholar] [CrossRef]
- Nagashima, T.; Shirakawa, H.; Nakagawa, T.; Kaneko, S. Prevention of antipsychotic-induced hyperglycaemia by vitamin D: A data mining prediction followed by experimental exploration of the molecular mechanism. Sci. Rep. 2016, 6, 26375. [Google Scholar] [CrossRef] [Green Version]
- Sarangdhar, M.; Tabar, S.; Schmidt, C.; Kushwaha, A.; Shah, K.; Dahlquist, J.E.; Jegga, A.G.; Aronow, B.J. Data mining differential clinical outcomes associated with drug regimens using adverse event reporting data. Nat. Biotechnol. 2016, 34, 697–700. [Google Scholar] [CrossRef]
- Michel, F.; Gandon, F.; Ah-Kane, V.; Bobasheva, A.; Cabrio, E.; Corby, O.; Gazzotti, R.; Giboin, A.; Marro, S.; Mayer, T.; et al. Covid-on-the-Web: Knowledge graph and services to advance COVID-19 research. In Proceedings of the International Semantic Web Conference, Athens, Greece, 1–6 November 2020; pp. 294–310. [Google Scholar]
- Steenwinckel, B.; Vandewiele, G.; Rausch, I.; Heyvaert, P.; Taelman, R.; Colpaert, P.; Simoens, P.; Dimou, A.; De Turck, F.; Ongenae, F. Facilitating the analysis of COVID-19 literature through a knowledge graph. In Proceedings of the International Semantic Web Conference, Athens, Greece, 1–6 November 2020; pp. 344–357. [Google Scholar]
- Tsai, C.-T.S. Memorable tourist experiences and place attachment when consuming local food. Int. J. Tour. Res. 2016, 18, 536–548. [Google Scholar] [CrossRef]
- Kim, S.; Choe, J.Y.; King, B.; Oh, M.; Otoo, F.E. Tourist perceptions of local food: A mapping of cultural values. Int. J. Tour. Res. 2021; in print. [Google Scholar] [CrossRef]
- Brauner, J.M.; Mindermann, S.; Sharma, M.; Johnston, D.; Salvatier, J.; Gavenčiak, T.; Stephenson, A.B.; Leech, G.; Altman, G.; Mikulik, V.; et al. Inferring the effectiveness of government interventions against COVID-19. Science 2021, 371, eabd9338. [Google Scholar] [CrossRef]
- Hsiang, S.; Allen, D.; Annan-Phan, S.; Bell, K.; Bolliger, I.; Chong, T.; Druckenmiller, H.; Huang, L.Y.; Hultgren, A.; Krasovich, E.; et al. The effect of large-scale anti-contagion policies on the COVID-19 pandemic. Nature 2020, 584, 262–267. [Google Scholar] [CrossRef]
- Liang, L.L.; Tseng, C.H.; Ho, H.J.; Wu, C.Y. Covid-19 mortality is negatively associated with test number and government effectiveness. Sci. Rep. 2020, 10, 12567. [Google Scholar] [CrossRef]
- Coronavirus Resource Center, Data Notes by Regions, by Johns Hopkins University & Medicine. Available online: https://coronavirus.jhu.edu/region (accessed on 5 August 2021).
- Shi, Z. Intelligence Science: Leading the Age of Intelligence; Tsinghua University Press: Beijing, China, 2021; pp. 1–31. [Google Scholar]
- Cernile, G.; Heritage, T.; Sebire, N.J.; Gordon, B.; Schwering, T.; Kazemlou, S.; Borecki, Y. Network graph representation of COVID-19 scientific publications to aid knowledge discovery. BMJ Health Care Inform. 2021, 28, e100254. [Google Scholar] [CrossRef]
- Van Eck, N.J.; Waltman, L. Software survey: VOSviewer, a computer program for bibliometric mapping. Scientometrics 2010, 84, 523–538. [Google Scholar] [CrossRef] [Green Version]
- Van Eck, N.J.; Waltman, L. Text mining and visualization using VOSviewer. arXiv 2011, arXiv:1109.2058. [Google Scholar]
- Feuerstein, S. Do coffee roasters benefit from high prices of green coffee? Int. J. Indus. Org. 2002, 20, 89–118. [Google Scholar] [CrossRef]
- Michael, S.W. Application of a dynamic panel data estimator to cross-country coffee demand: A tale of two eras. J. Econ. Dev. 2009, 34, 1–17. [Google Scholar] [CrossRef]
- Cameron, A.C.; Gelbach, J.B.; Miller, D.L. Robust inference with multiway clustering. J. Bus. Econ. Stat. 2011, 29, 238–249. [Google Scholar] [CrossRef] [Green Version]
- Ellis, P.D. The Essential Guide to Effect Sizes: Statistical Power, Meta-Analysis, and the Interpretation of Research Results; Cambridge University Press: Cambridge, UK, 2010. [Google Scholar]
- Gaye, B.; Khoury, S.; Cene, C.W.; Kingue, S.; N’Guetta, R.; Lassale, C.; Baldé, D.; Diop, I.B.; Dowd, J.B.; Mills, M.C.; et al. Socio-demographic and epidemiological consideration of Africa’s COVID-19 response: What is the possible pandemic course? Nat. Med. 2020, 26, 996–999. [Google Scholar] [CrossRef] [PubMed]
- Sharma, A.; Borah, S.B.; Moses, A.C. Responses to COVID-19: The role of governance, healthcare infrastructure, and learning from past pandemics. J. Bus. Res. 2021, 122, 597–607. [Google Scholar] [CrossRef] [PubMed]
- Haider, N.; Osman, A.Y.; Gadzekpo, A.; Akipede, G.O.; Asogun, D.; Ansumana, R.; Lessells, R.J.; Khan, P.; Hamid, M.M.A.; Yeboah-Manu, D.; et al. Lockdown measures in response to COVID-19 in nine sub-Saharan African countries. BMJ Glob. Health 2020, 5, e003319. [Google Scholar] [CrossRef] [PubMed]
- Le, B.; Anh, P.T.N.; Yang, S.H. Enhancement of the anti-inflammatory effect of mustard kimchi on RAW 264.7 macrophages by the Lactobacillus plantarum fermentation-mediated generation of phenolic compound derivatives. Foods 2020, 9, 181. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Guijarro-Real, C.; Plazas, M.; Rodríguez-Burruezo, A.; Prohens, J.; Fita, A. Potential in vitro inhibition of selected plant extracts against SARS-CoV-2 chymotripsin-like protease (3CLPro) activity. Foods 2021, 10, 1503. [Google Scholar] [CrossRef]
- Rahman, M.; Nowakowski, S.; Agrawal, R.; Naik, A.; Sharafkhaneh, A.; Razjouyan, J. Validation of a natural language processing algorithm for the extraction of the sleep parameters from the polysomnography reports. Healthcare 2022, 10, 1837. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
| Country Name | Containment Index | Total Cases/M | Country Name | Containment Index | Total Cases/M |
|---|---|---|---|---|---|
| Nicaragua | 12.50 | 881 | Somalia | 38.69 | 280 |
| Tanzania | 16.37 | 9 | Finland | 44.94 | 4595 |
| Burundi | 17.26 | 58 | Denmark | 48.21 | 14,238 |
| Yemen Rep. | 18.45 | 70 | Norway | 50.60 | 6750 |
| Afghanistan | 23.81 | 1195 | United Arab Emirates | 52.62 | 17,203 |
| Central African Rep. | 24.40 | 1018 | Netherlands | 52.98 | 31,289 |
| Congo Dem. Rep. | 24.70 | 144 | Singapore | 52.98 | 9953 |
| Sudan | 26.19 | 416 | South Africa | 55.36 | 13,359 |
| Mauritius | 26.79 | 397 | Sweden | 57.14 | 25,819 |
| Niger | 27.08 | 66 | Australia | 57.14 | 1095 |
| Mauritania | 28.57 | 1873 | Korea Rep. | 58.63 | 686 |
| Burkina Faso | 28.57 | 140 | Bahrain | 59.52 | 51,209 |
| New Zealand | 32.14 | 427 | Belgium | 60.71 | 49,977 |
| Syria | 33.04 | 456 | Lithuania | 61.31 | 22,963 |
| Congo Rep. | 35.71 | 1046 | Germany | 61.31 | 13,065 |
| Eswatini | 36.90 | 5553 | Qatar | 61.90 | 48,246 |
| Tajikistan | 36.90 | 1282 | Morocco | 62.20 | 9749 |
| Senegal | 36.90 | 962 | United Kingdom | 63.10 | 24,265 |
| Madagascar | 36.90 | 626 | Luxembourg | 63.10 | 56,119 |
| Haiti | 38.10 | 815 | Spain | 63.69 | 35,428 |
| Potatoes | Cucumbers and Gherkins | Fruits of the Genus Capsicum or of the Genus Pimenta | |
|---|---|---|---|
| 70,190 | 70,700 | 70,960 | |
| N = 14,757 | N = 12,300 | N = 14,621 | |
| Total cases | 0.0864 | −0.0672 | −0.0302 |
| New cases | 0.0946 | −0.0694 | −0.0465 |
| Total deaths | 0.1272 | −0.106 | −0.05 |
| New deaths | 0.0735 | −0.0729 | −0.0459 |
| mushrooms and truffles | coconuts | almonds | |
| 71,230 | 80,110 | 80,212 | |
| N = 14,191 | N = 14,378 | N = 14,312 | |
| Total cases | −0.0294 | −0.0201 | 0.231 |
| New cases | 0.0636 | −0.0801 | 0.1922 |
| Total deaths | −0.0426 | −0.0628 | 0.3168 |
| New deaths | −0.0023 | −0.1166 | 0.2081 |
| pineapples | oranges | citrus fruit | |
| 80,430 | 80,510 | 80,590 | |
| N = 13,420 | N = 14,534 | N = 10,325 | |
| Total cases | 0.2359 | −0.014 | −0.0767 |
| New cases | 0.1707 | −0.0022 | −0.0579 |
| Total deaths | 0.2916 | −0.0838 | −0.0662 |
| New deaths | 0.1785 | −0.074 | −0.0522 |
| grapes | papaws | plums and sloes | |
| 80,620 | 80,720 | 80,940 | |
| N = 13,837 | N = 8381 | N = 12,994 | |
| Total cases | 0.2066 | 0.1354 | 0.0083 |
| New cases | 0.227 | 0.1258 | 0.0238 |
| Total deaths | 0.2766 | 0.1708 | 0.0039 |
| New deaths | 0.2479 | 0.1062 | 0.0275 |
| apples | |||
| 81,330 | |||
| N = 11,232 | |||
| Total cases | 0.1649 | ||
| New cases | 0.1726 | ||
| Total deaths | 0.2379 | ||
| New deaths | 0.1767 |
| Total Deaths (Model 1) | New Deaths (Model 2) | |||||||
|---|---|---|---|---|---|---|---|---|
| Coef. | SE | t | p > t | Coef. | SE | t | p > t | |
| Net import | −0.011 | 0.005 | −2.37 | 0.020 | −0.011 | 0.005 | −2.17 | 0.034 |
| Containment index | 0.010 | 0.011 | 0.90 | 0.371 | 0.014 | 0.010 | 1.48 | 0.144 |
| Log(population) | 1.051 | 0.088 | 11.91 | 0.000 | 0.692 | 0.067 | 10.32 | 0.000 |
| Life expectancy | −0.146 | 0.063 | −2.33 | 0.023 | −0.173 | 0.036 | −4.74 | 0.000 |
| Log(GDP per capita) | 1.181 | 0.357 | 3.31 | 0.001 | 0.315 | 0.227 | 1.39 | 0.169 |
| Cardiovasc death rate | −0.002 | 0.001 | −1.70 | 0.094 | −0.003 | 0.001 | −3.69 | 0.000 |
| Diabetes prevalence | −0.053 | 0.040 | −1.33 | 0.189 | −0.032 | 0.033 | −0.96 | 0.340 |
| Aged 70 | 0.097 | 0.051 | 1.90 | 0.062 | 0.089 | 0.032 | 2.78 | 0.007 |
| Log (population density) | 0.008 | 0.129 | 0.06 | 0.953 | −0.115 | 0.093 | −1.24 | 0.220 |
| Hospital beds (1000) | −0.144 | 0.059 | −2.46 | 0.016 | −0.140 | 0.039 | −3.55 | 0.001 |
| Electricity | 0.054 | 0.019 | 2.81 | 0.006 | 0.082 | 0.015 | 5.62 | 0.000 |
| Mobile subscriptions | −0.023 | 0.008 | −3.07 | 0.003 | −0.008 | 0.004 | −1.83 | 0.072 |
| Total Cases (Model 3) | New Cases (Model 4) | |||||||
|---|---|---|---|---|---|---|---|---|
| Coef. | SE | t | p > t | Coef. | SE | t | p > t | |
| Net import | −0.010 | 0.005 | −2.030 | 0.046 | −0.017 | 0.008 | −2.120 | 0.037 |
| Containment index | 0.012 | 0.010 | 1.210 | 0.228 | 0.007 | 0.018 | 0.370 | 0.710 |
| Log(population) | 0.942 | 0.079 | 11.900 | 0.000 | 0.763 | 0.141 | 5.420 | 0.000 |
| Life expectancy | −0.047 | 0.069 | −0.680 | 0.502 | −0.159 | 0.072 | −2.210 | 0.030 |
| Log(GDP per capita) | 1.502 | 0.348 | 4.310 | 0.000 | 1.383 | 0.417 | 3.310 | 0.001 |
| Cardiovasc death rate | 0.000 | 0.001 | 0.240 | 0.813 | −0.001 | 0.001 | −0.390 | 0.701 |
| Diabetes prevalence | −0.020 | 0.041 | −0.490 | 0.627 | −0.028 | 0.052 | −0.540 | 0.593 |
| Aged 70 | −0.002 | 0.046 | −0.050 | 0.963 | 0.011 | 0.058 | 0.190 | 0.848 |
| Log(population density) | 0.008 | 0.081 | 0.100 | 0.920 | −0.009 | 0.119 | −0.080 | 0.940 |
| Hospital beds (1000) | −0.074 | 0.054 | −1.380 | 0.172 | −0.088 | 0.067 | −1.320 | 0.192 |
| Electricity | 0.011 | 0.019 | 0.600 | 0.553 | 0.039 | 0.020 | 1.990 | 0.050 |
| Mobile subscriptions | −0.014 | 0.006 | −2.130 | 0.036 | −0.014 | 0.009 | −1.500 | 0.137 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhan, G.; Yang, F.; Zhang, L.; Wang, H. The Relationship between Mustard Import and COVID-19 Deaths: A Workflow with Cross-Country Text Mining. Healthcare 2022, 10, 2071. https://doi.org/10.3390/healthcare10102071
Zhan G, Yang F, Zhang L, Wang H. The Relationship between Mustard Import and COVID-19 Deaths: A Workflow with Cross-Country Text Mining. Healthcare. 2022; 10(10):2071. https://doi.org/10.3390/healthcare10102071
Chicago/Turabian StyleZhan, Ge, Fuming Yang, Liangbo Zhang, and Hanfeng Wang. 2022. "The Relationship between Mustard Import and COVID-19 Deaths: A Workflow with Cross-Country Text Mining" Healthcare 10, no. 10: 2071. https://doi.org/10.3390/healthcare10102071
APA StyleZhan, G., Yang, F., Zhang, L., & Wang, H. (2022). The Relationship between Mustard Import and COVID-19 Deaths: A Workflow with Cross-Country Text Mining. Healthcare, 10(10), 2071. https://doi.org/10.3390/healthcare10102071